Learning to Estimate 3D Human Pose and Shape from a Single Color Image Supplementary material
|
|
|
- Trevor Norton
- 5 years ago
- Views:
Transcription
1 Learning to Estimate 3D Human Pose and Shape from a Single Color Image Supplementary material Georgios Pavlakos 1, Luyang Zhu 2, Xiaowei Zhou 3, Kostas Daniilidis 1 1 University of Pennsylvania 2 Peking University 3 State Key Lab of CAD&CG, Zhejiang University This supplementary material provides itional details for our approach that were not included in the main manuscript due to space constraints. Sections 1 to 6 present itional qualitative results of our approach. Section 7 demonstrates a qualitative evaluation of the proposed pervertex loss. Section 8 includes the exact description of the different architectures employed in our experiments. Section 9 provides further details regarding our implementation. Section 10 includes details relevant to our training procedure. Finally, Section 11 focuses on extensive qualitative evaluation and provides itional examples of the proposed approach on images from the selected datasets. 1. Individual benefit for shape/pose Most of the results from the main manuscript focus on joint evaluation of pose and shape. To provide more insight into which component is influenced more from our proposed losses, we analyze further the results of Table 1 of the main manuscript. Focusing on the outputs using parameter loss and our proposed per-vertex loss, we provide further evaluations, using a) the predicted pose parameters and ground truth shape parameters, and b) the predicted shape parameters and ground truth pose parameters. The detailed results are presented in Table 1. From these results we can easily infer that the benefit comes primarily from predicting a more accurate pose. On the other hand, the shape influence in the final error is rather small and shape prediction is only marginally improved when we adopt the per-vertex loss. This demonstrates that 3D pose prediction is a very challenging problem and one that is properly ressed with the introduction of our per-vertex loss. 2. Additional ablatives for decision choices To clarify and motivate some of our decision choices, we provide here the results of itional ablative experiments. Focusing on the setting of Table 1 of the main manuscript, we do further exploration by: training without parameter loss and keeping only the per-vertex loss active. ignoring the keypoint detection confidences of Human2D, and not using them as input to the PosePrior network, as we currently do. Pred GT shape GT pose Parameter loss (rot matrix) Per-vertex loss Table 1: Effect of the proposed per-vertex loss on pose and shape prediction individually. Most of the benefit comes from better pose prediction, while the shape has only small improvement. The numbers are mean per-vertex errors (mm). The results are reported using UP-3D and correspond to the setting of Table 1 of the main manuscript. Alternative models Avg Error Our model no parameter loss no keypoint confidence combined Pose/ShapePrior GT 2D input 79.9 Table 2: Additional ablative studies motivating some of our decision choices. The numbers are mean per-vertex errors (mm). The results are reported using UP-3D and correspond to the setting of Table 1 of the main manuscript. using a single network for pose and shape prediction, where the input is the channel-wise concatenation of the heatmaps and the masks from Human2D. using ground truth 2D keypoints and masks as input to the Priors networks. The complete results for these experiments are presented in Table 2. The results of the first three cases justify some of our design choices, while the last experiment demonstrates the potential upper bound for our approach. 3. Detailed results on SURREAL In Table 3 we provide the results for all the actions of the Human3.6M part of the SURREAL dataset [10]. This is the extended version of Table 3 of the main manuscript. Our approach outperforms the other baselines across the majority of actions and on average. 1
![Direct. Discuss Eating Greet Phone Photo Pose Purch. Sitting SitingD Smoke Wait WalkD Walk WalkT Avg Lassner et al. [5] (GT shape) 145.4 118.1 166.0 152.9 175.2 213.8 150.1 288.7 271.2 446.9 194.](/docs-images/90/101638620/images/2-1.jpg "7 172.1 267.9 154.4 171.1 200.5 Bogo et al. [2] (GT shape) 129.0 103.1 148.3 137.8 153.8 191.8 140.0 251.2 237.9 392.4 176.2 154.6 238.3 134.1 137.7 177.2 Ours (GT shape) 120.9 111.1 132.1 138.1 137.8 154.")
2 Direct. Discuss Eating Greet Phone Photo Pose Purch. Sitting SitingD Smoke Wait WalkD Walk WalkT Avg Lassner et al. [5] (GT shape) Bogo et al. [2] (GT shape) Ours (GT shape) Bogo et al. [2] Ours Table 3: Detailed results on the Human3.6M part of SURREAL [10]. Numbers are mean per vertex errors (mm). For the first three rows, the shape coefficients are known, for the last two rows they are predicted. 4. Detailed results on Human3.6M In Table 4 we provide the results for all the actions of Human3.6M dataset [3]. This is the extended version of Table 4 of the main manuscript. Our approach outperforms the other baselines across the majority of actions and on average. 5. Boosting SMPLify The motivation for Section 5.5 of the main manuscript, was to demonstrate the benefit of using our direct predictions as an initialization and an anchor of iterative optimization methods to accelerate them and improve their results. Here, we provide more details on this aspect, by evaluating the performance of our anchor itself, and exploring using another direct prediction approach as an optimization anchor. For our experiments, we employed the direct prediction approach of Lassner et al. [5]. Using this anchor lead to slightly worse, yet comparable results with out approach. However, the optimization became 10% slower, compared to using our anchor, which indicates that our anchor was more accurate to begin with. Indeed, by evaluating the anchors themselves on the same task of person and part segmentation, we achieve significantly better performance with our anchor. The results of our direct prediction are worse than the ones obtained by SMPLify, since SMPLify explicitly optimizes for the 2D-3D consistency. However, this sometimes comes in the expense of obtaining a non-coherent 3D pose (check also sample reconstructions of Figure 10). 6. Keypoint localization Following the evaluation of the previous section, focusing on the 2D aspect of our predictions, we also evaluate our predictions on the task of the 2D keypoint localization on the UP-3D dataset [5]. The complete results expressed in PCKh are presented in Table 6. The comparison includes the accuracy of our keypoint predictions from Human2D, as well as the 2D keypoints resulting from projecting the 3D joints of the body model on the 2D plane. Although the projection of the 3D joints is quite accurate, we observe that it still falls slightly behind the network trained exclusively for 2D keypoint localization. This observation is consistent with other approaches that are trained for 3D pose consistency in expense of highly accurate keypoint localization (e.g. [9]). We also observed that the reprojections of the 3D joints can perform more accurate 2D localization when we train longer Front Back Figure 1: Qualitative evaluation of the benefit of the pervertex loss. A human body model is visualized, where the color of each vertex corresponds to the improvement of the mean error of that vertex, after using a per-vertex loss for training (compared to using only a vanilla parameter loss). For the evaluation, we used all test examples of UP-3D. The numbers are expressed in mm. using the reprojection losses, but typically this can start having a negative effect on the 3D reconstruction itself. 7. Qualitative benefit of per-vertex loss For a qualitative evaluation of the proposed per-vertex loss in comparison to simply using a loss only on the parameters, we visualize the parts of the human body that are mostly influenced by this improvement. Starting with the parameter loss as a baseline, in Figure 1 we visualize a human body model such that the color of each vertex represents the improvement of the mean error for this vertex after we impose our per-vertex loss for training. For this evaluation, we used all test examples of UP-3D. From the visualization, we infer that the per-vertex loss has benefited mostly the extremities of the human body (arms, legs, head), and in particular the lower arms, where the decrease of the mean error can even exceed the 50mm. 8. Architecture The individual components of our architecture (i.e., Human2D, PosePrior, ShapePrior), are designed following best practices from the literature, as we described in the main manuscript. For completeness, here we present all the details concerning the exact architectures used in our experiments. In Figure 2, we present the basic architecture for 2
3 Direct. Discuss Eating Greet Phone Photo Pose Purch. Sitting SitingD Smoke Wait WalkD Walk WalkT Avg Akhter & Black [1]* Ramakrishna et al. [8]* Zhou et al. [12]* Bogo et al. [2] Lassner et al. [5] (direct) 93.9 Lassner et al. [5] (optimization) 80.7 Ours Table 4: Detailed results on Human3.6M [3]. Numbers are reconstruction errors (mm). The numbers are taken from the respective papers, except for (*), which were obtained from [2]. FB Seg. Part Seg. acc. f1 acc. f1 SMPLify on GT SMPLify SMPLify + Lassner et al. anchor [5] SMPLify + our anchor Lassner et al. [5] anchor Our anchor Table 5: Accuracy and f1 scores for foreground-background and six-part segmentation on LSP test set for different versions of SMPLify, the direct prediction of Lassner et al. [5], and our direct prediction. The numbers for the first, second and fifth rows are taken from [5]. Our approach performs better than the direct prediction method of Lassner et al. [5] and leads to faster convergence of the iterative optimization when the two are employed as anchors for SMPLify. 64x64 32x32 16x16 8x8 4x4 4x4 8x8 16x16 32x32 64x64 PCKh Human2D D joints projection 89.5 Table 6: Evaluation of 2D keypoint localization on the test set of UP-3D. The numbers are PCKh scores. Since the Human2D network has been explicitly trained for the keypoint detection, it performs better on this task, compared to projecting the 3D joint predictions on the 2D plane. the hourglass module [7], while in Figure 3 we present Human2D, an adaptation of the stacked hourglass network, that predicts both heatmaps for the joints and silhouette segmentation. Regarding the Priors networks, Figure 4 illustrates our PosePrior network, which was used for the prediction of the pose parameters and includes two bilinear modules [6]. The ShapePrior network for shape parameter estimation is presented in Figure 5 and consists of five convolutional layers and one bilinear module in the end. Figure 2: Schematic representation of the hourglass component. Each column corresponds to three consecutive residual modules. The convolutions are implemented with 3 3 kernels, and the number of channels remains equal to 256 across the hourglass. ReLU is the activation function, while batch normalization is also used. The numbers at the bottom of each column indicate the spatial resolution of each level of the hourglass. At the encoding part of the hourglass, max pooling is used to decrease the resolution, while at the decoding part, nearest neighbor upsampling is used to increase the resolution. The skip connections also contain residual modules, and their output is ed element-wise to the feature map of the decoding part after the nearest neighbor upsampling procedure. 9. Implementation details Regarding the transition from the Human2D network to the PosePrior component, we need to transform the N heatmaps (where N = 16) to the input vector of 3N values. To get the pixel position of the joints, we use an argsoftmax operation [11] on the heatmaps. Then, we shift the joint coordinates, such that the root joint (pelvis) is on the location 3
4 max pool N 256 N Figure 3: The complete architecture for Human2D, including the hourglass components. The orange columns are convolutional layers, the red column corresponds to the input image, while the blue columns indicate the outputs (intermediate and final) for heatmaps (corresponding to the N joints) and silhouettes (body and background channels). The green modules correspond to the hourglass design from Figure 2. The numbers at the bottom of the columns indicate the number of channels for each feature map. ReLU is the activation function, while batch normalization is also used. All layers are implemented as residual modules with kernels of size 3 3. The only exception is the first layer, which is a 7 7 convolution, and the layers that produce and post-process the outputs, which implement 1 1 convolutions. The spatial resolution starts at , drops at after the first layer (which uses stride equal to two), and then drops again to after the second module with a max pooling operation. This resolution remains constant until the end of the network (with the exception of the interiors of the hourglasses). Input 3N Output Figure 4: Detailed architecture for the PosePrior component. The input is a vector of size 3N, containing the coordinates of the 2D joint locations and the confidences of the detections (realized by the maximum values of the heatmaps). Then a fully connected layer brings the dimensionality to. After that, two bilinear modules [6] follow. The architecture of each bilinear module includes two fully connected (linear) layers of size with a skip residual connection from the input to the output of the module. Finally, an itional fully connected layer brings the dimensionality to 72, which is the output of the PosePrior component. After each fully connected layer of size, we use batch normalization, ReLU, and Dropout. 72 (0, 0), and we scale them by dividing with the max absolute value across all the x-y coordinates, such that the coordinates are in the [ 1, 1] interval. The max value of each heatmap (which realizes an evidence for the confidence of the detection) is also concatenated to these 2N values. Concerning the differentiable rendering, we use a perspective projection model. For the supervision based on 2D annotations from in-the-wild images (described in Section 4.3 of the main manuscript), the focal length is typically not known and it is hard to be precisely estimated. For our implementation, we use a standard value f = During training, for a predicted 3D shape, we use this value to estimate the global translation vector (camera extrinsics) which asserts that our projected 3D shape will have the same vertical extend as the annotated silhouette. Provided with these parameters (focal length, global translation, 3D shape), the renderer can handle the rest of the projection procedure. 10. Training details For the training of the Priors networks, it is crucial to augment the training with noisy inputs, to anticipate noisy 2D predictions from the Human2D network. This is a form of data augmentation, which is typically used in the form 4
5 8 64x64 32x32 16x16 8x8 4x Figure 5: Detailed architecture of the ShapePrior component. Initially, the body segmentation is filtered with five convolutional layers which are implemented as residual modules. The kernels are of size 3 3. The activation is ReLU, while batch normalization is also used. Max pooling is used after every module to reduce the spatial resolution. The numbers at the bottom of each module indicate the number of channels for the feature maps, while the numbers at the top indicate the spatial resolution. After the last convolutional layer, a fully connected layer brings the dimensionality to 512. Consequently, one bilinear module [6] follows. The bilinear module includes two fully connected layers with size 512 and a skip connection from the input to the output. A final fully connected layer brings the dimensionality to 10, which is the output of the ShapePrior component. After each fully connected layer of size 512, we use batch normalization, ReLU, and Dropout. of pixel-wise noise when training CovNets with images as input. For the PosePrior component we noise to each coordinate (after centering and rescaling in [ 1, 1]), sampling from a Gaussian with µ = 0 and σ = Given the distance of each noisy keypoint from its original position, we scale the input confidence value as well (where we assign conf = 1 if the distance is 0, conf = 0 if the distance is 0.4 or greater, and we use linear scaling to assign confidences for distance values within this interval). For the ShapePrior network we the more traditional pixelwise noise to the input silhouette. 11. Qualitative evaluation Because of space constraints, the main manuscript included only a small sample of reconstruction examples for our approach. Here we provide a more detailed qualitative evaluation on the various datasets. Figure 6 collects successful reconstructions of our approach on UP-3D [5] (effectively extending Figure 3 of the main manuscript). In Figure 7, we compare the results of our approach with output meshes from the direct prediction approach of Lassner et al. [5] on the same dataset (extending Figure 4 of the main manuscript). Concluding the evaluation on UP-3D, in Figure 8 we present some erroneous reconstructions made by our network, which summarize the failure modes of our approach. Regarding the Human3.6M part of SURREAL [10], we have collected a variety of outputs in Figure 9. The first seven rows consist of successful reconstructions, while the last row includes some error cases. In general, the low lighting and the challenging backgrounds are the cause of the most common failures for this dataset. For Human3.6M [3], we have collected in Figure 10 a subset of the failure cases for the iterative optimization approach of Bogo et al. [2] and compare it with our predictions for the same input images. In the majority of these examples, the projected 2D pose for [2] is correct, so the errors occur at the reconstruction step (optimization). In contrast, our direct approach which is discriminatively trained, predicts more faithful reconstructions, which even if they do not match exactly with the image evidence, are in accordance with the 3D pose of the person. Finally, in Figure 11, we provide itional examples for the scenario (Section 5.5 of the main manuscript) that our direct predictions are used as an initialization and an anchor for the iterative optimization approach of Bogo et al. [2] (SMPLify), leading to more accurate pose and shape reconstructions (extending Figure 5 of the main manuscript). References [1] I. Akhter and M. J. Black. Pose-conditioned joint angle limits for 3D human pose reconstruction. In CVPR, [2] F. Bogo, A. Kanazawa, C. Lassner, P. Gehler, J. Romero, and M. J. Black. Keep it SMPL: Automatic estimation of 3D human pose and shape from a single image. In ECCV, , 3, 5, 8 [3] C. Ionescu, D. Papava, V. Olaru, and C. Sminchisescu. Human3.6M: Large scale datasets and predictive methods for 3D human sensing in natural environments. PAMI, 36(7): , , 3, 5, 8 [4] S. Johnson and M. Everingham. Clustered pose and nonlinear appearance models for human pose estimation. In BMVC, [5] C. Lassner, J. Romero, M. Kiefel, F. Bogo, M. J. Black, and P. V. Gehler. Unite the people: Closing the loop between 3D and 2D human representations. In CVPR, , 3, 5, 6 [6] J. Martinez, R. Hossain, J. Romero, and J. J. Little. A simple yet effective baseline for 3D human pose estimation. In ICCV, , 4, 5 [7] A. Newell, K. Yang, and J. Deng. Stacked hourglass networks for human pose estimation. In ECCV, [8] V. Ramakrishna, T. Kanade, and Y. Sheikh. Reconstructing 3D human pose from 2D image landmarks. In ECCV, [9] X. Sun, J. Shang, S. Liang, and Y. Wei. Compositional human pose regression. In ICCV, [10] G. Varol, J. Romero, X. Martin, N. Mahmood, M. Black, I. Laptev, and C. Schmid. Learning from synthetic humans. In CVPR, , 2, 5, 7 [11] K. M. Yi, E. Trulls, V. Lepetit, and P. Fua. LIFT: Learned invariant feature transform. In ECCV, [12] X. Zhou, M. Zhu, S. Leonardos, and K. Daniilidis. Sparse representation for 3D shape estimation: A convex relaxation approach. PAMI,



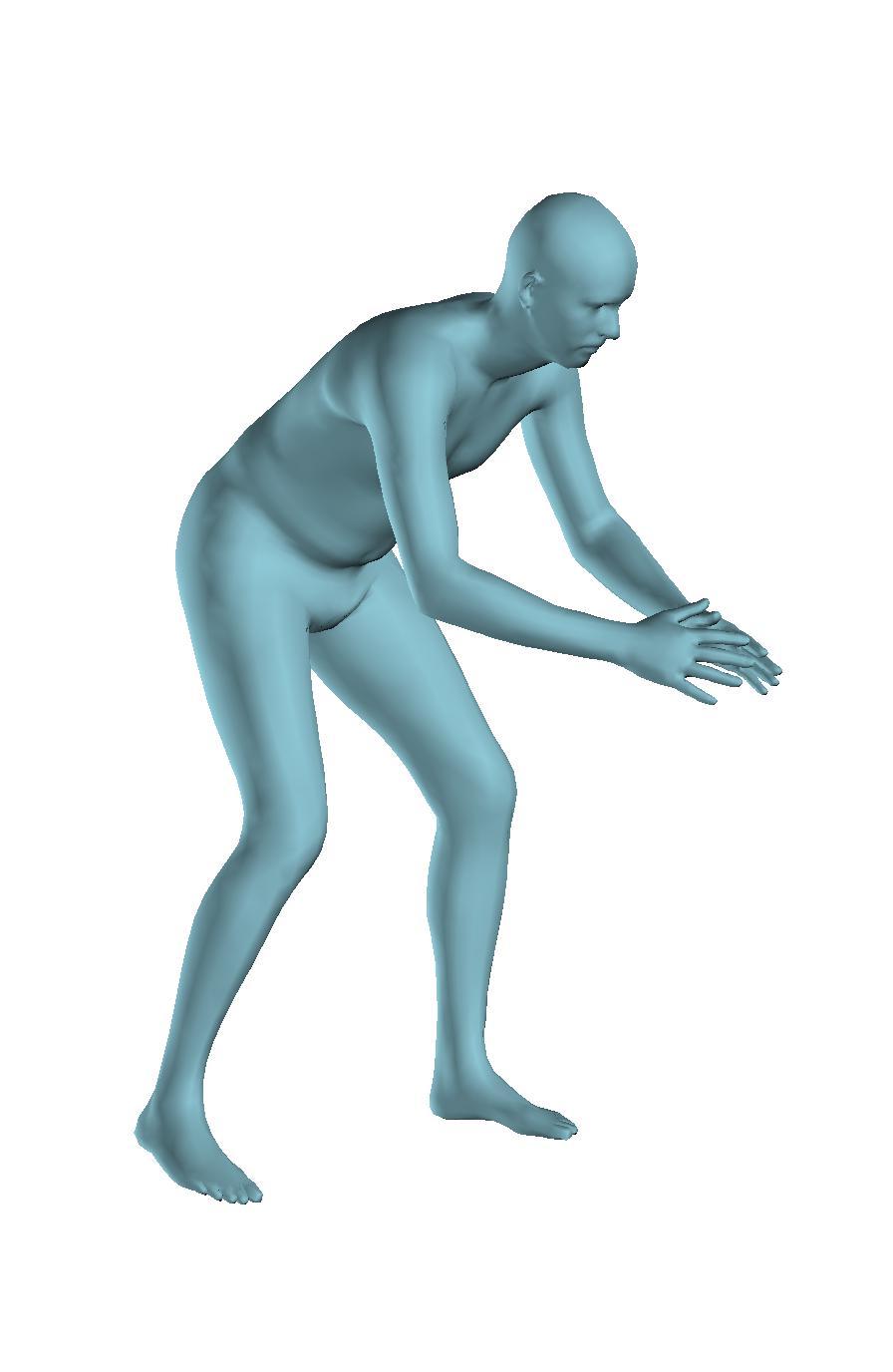

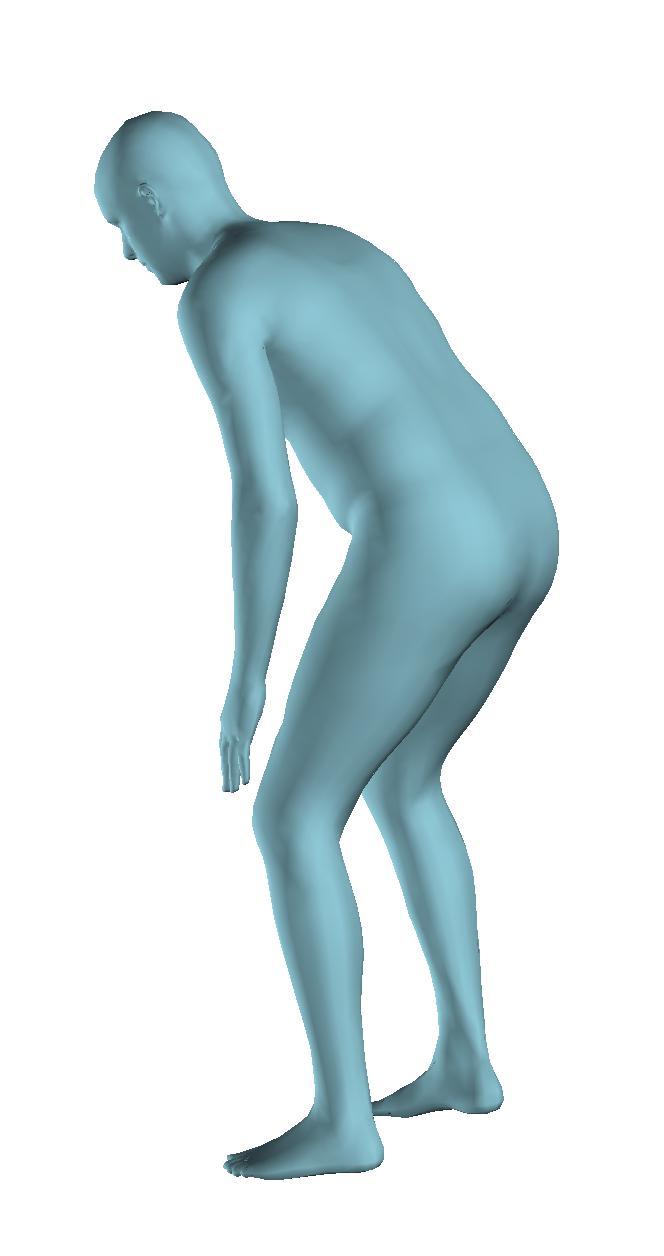




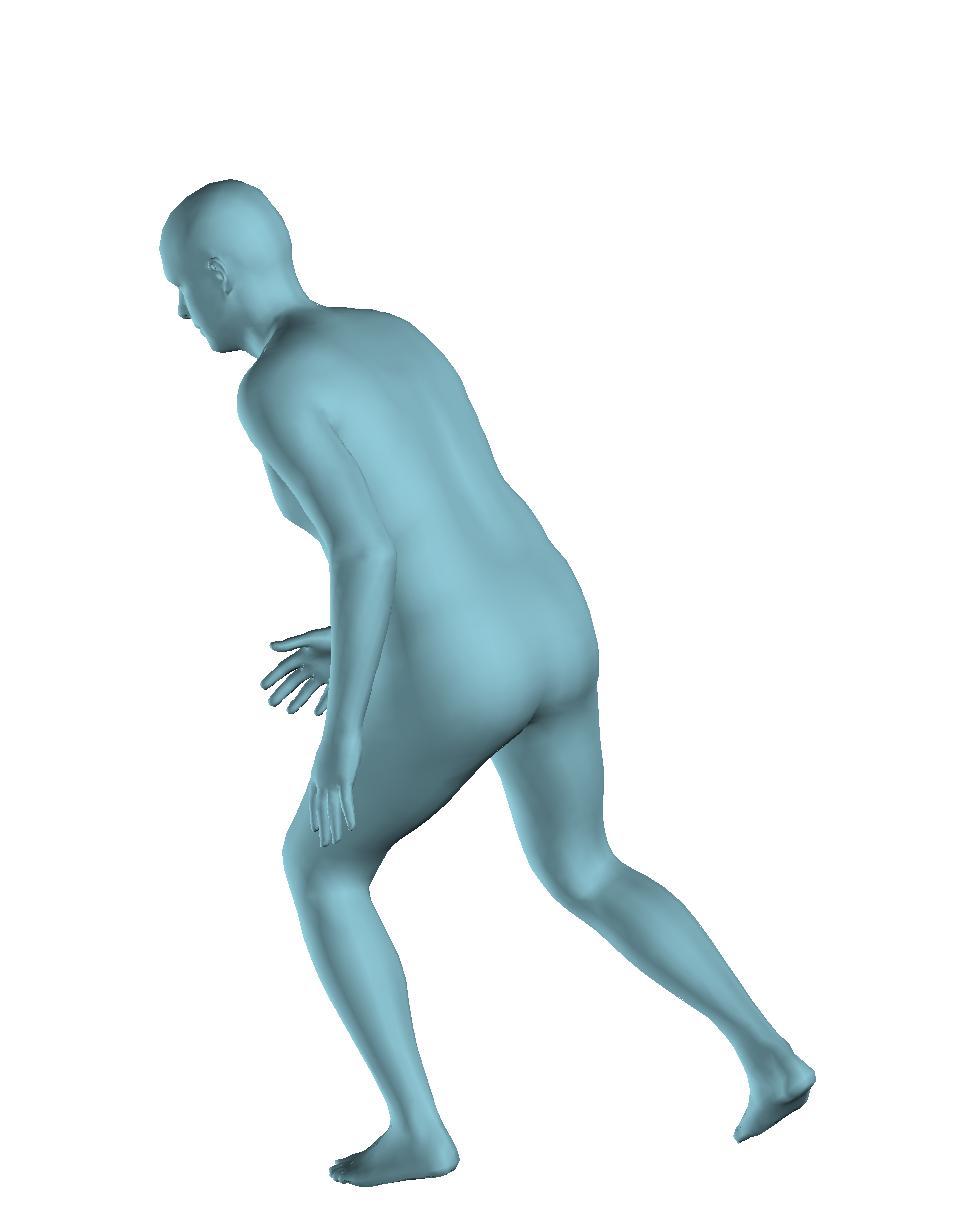
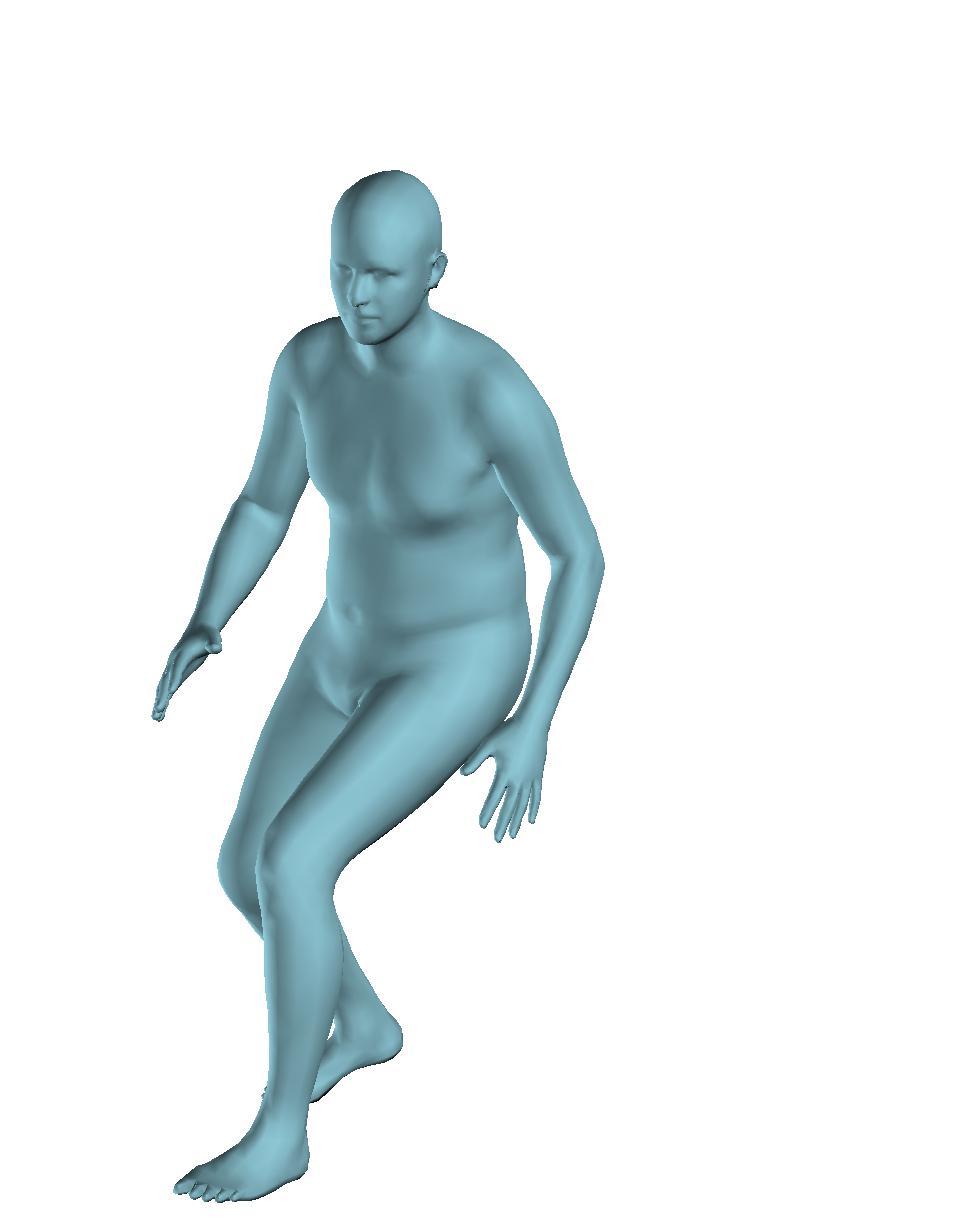





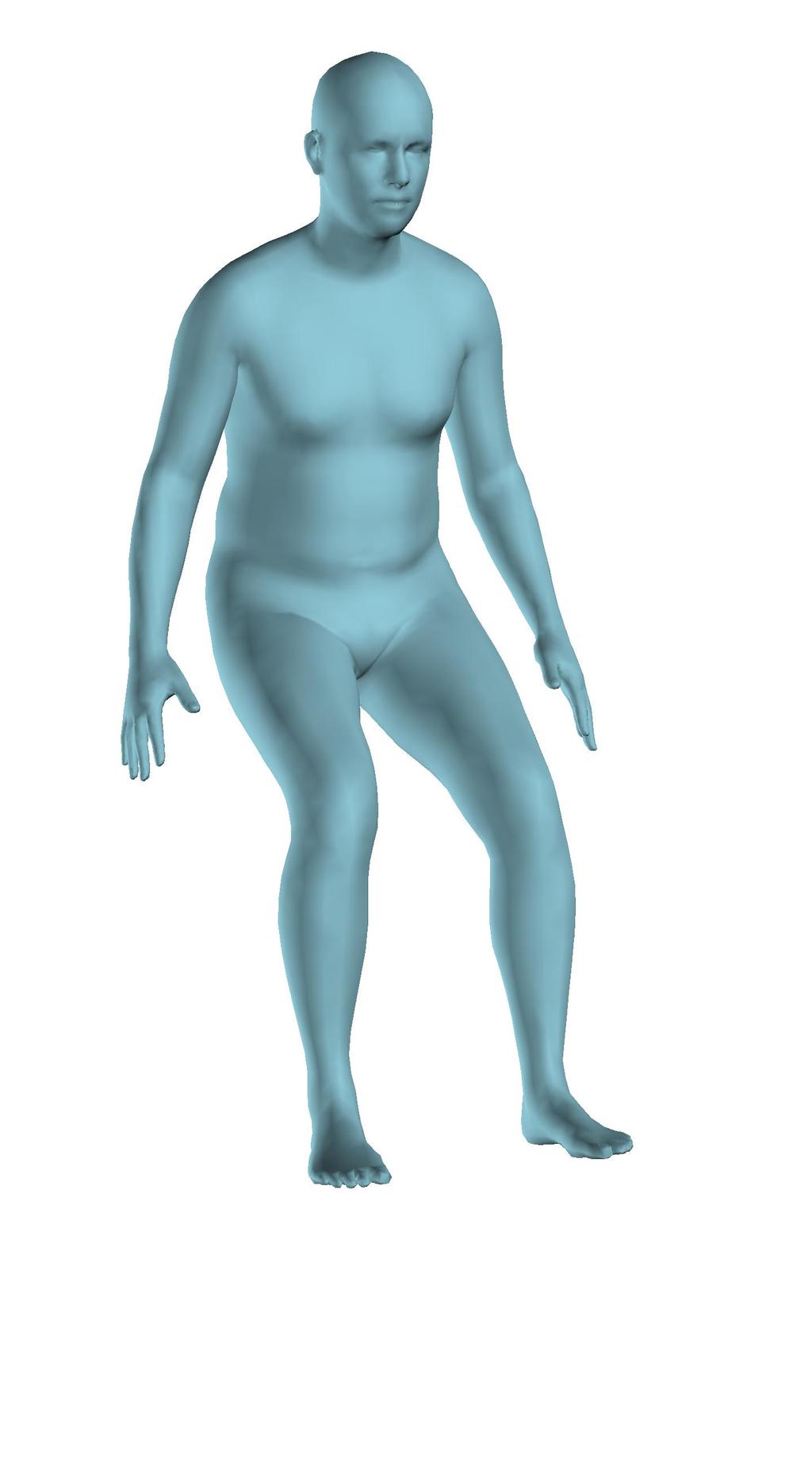
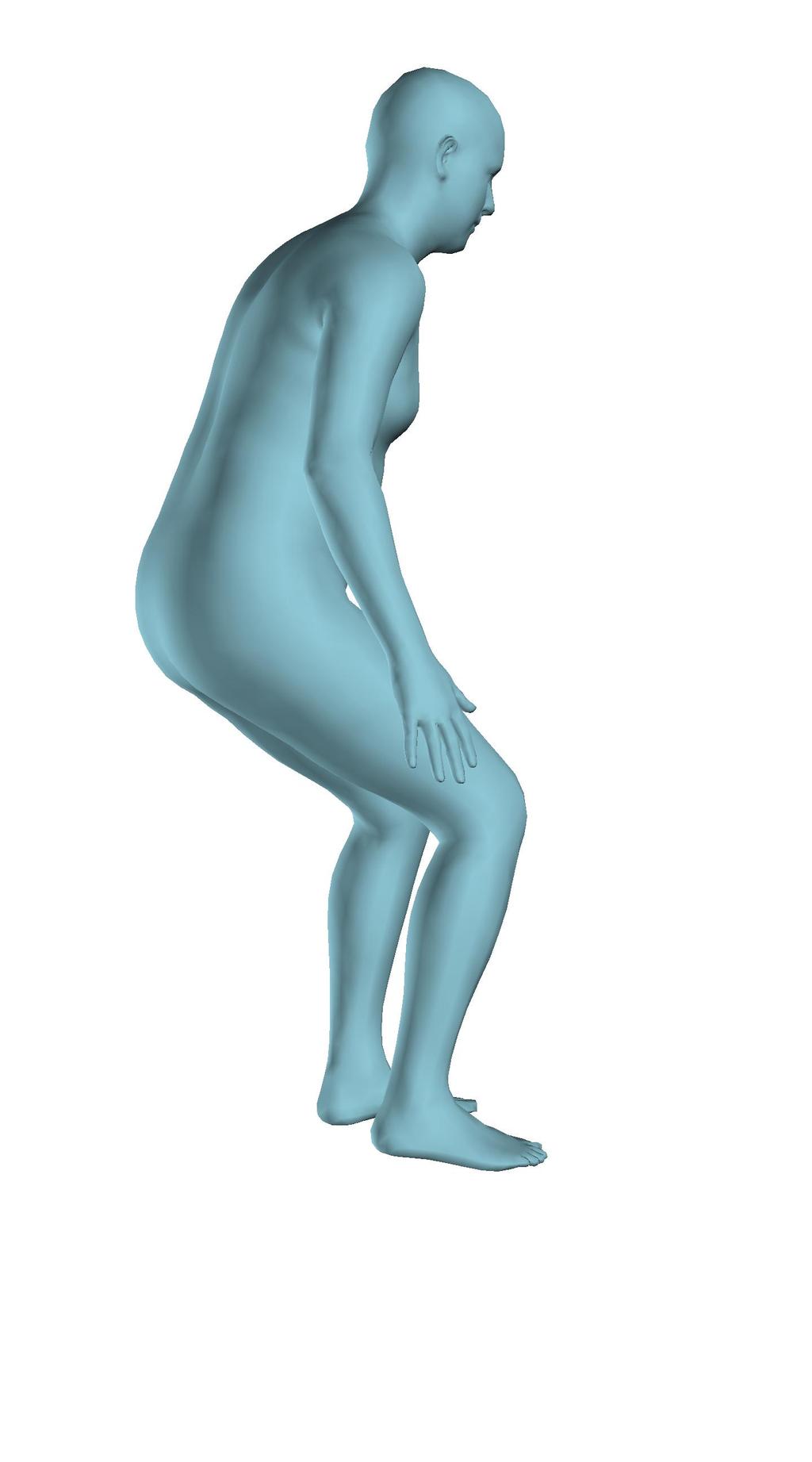


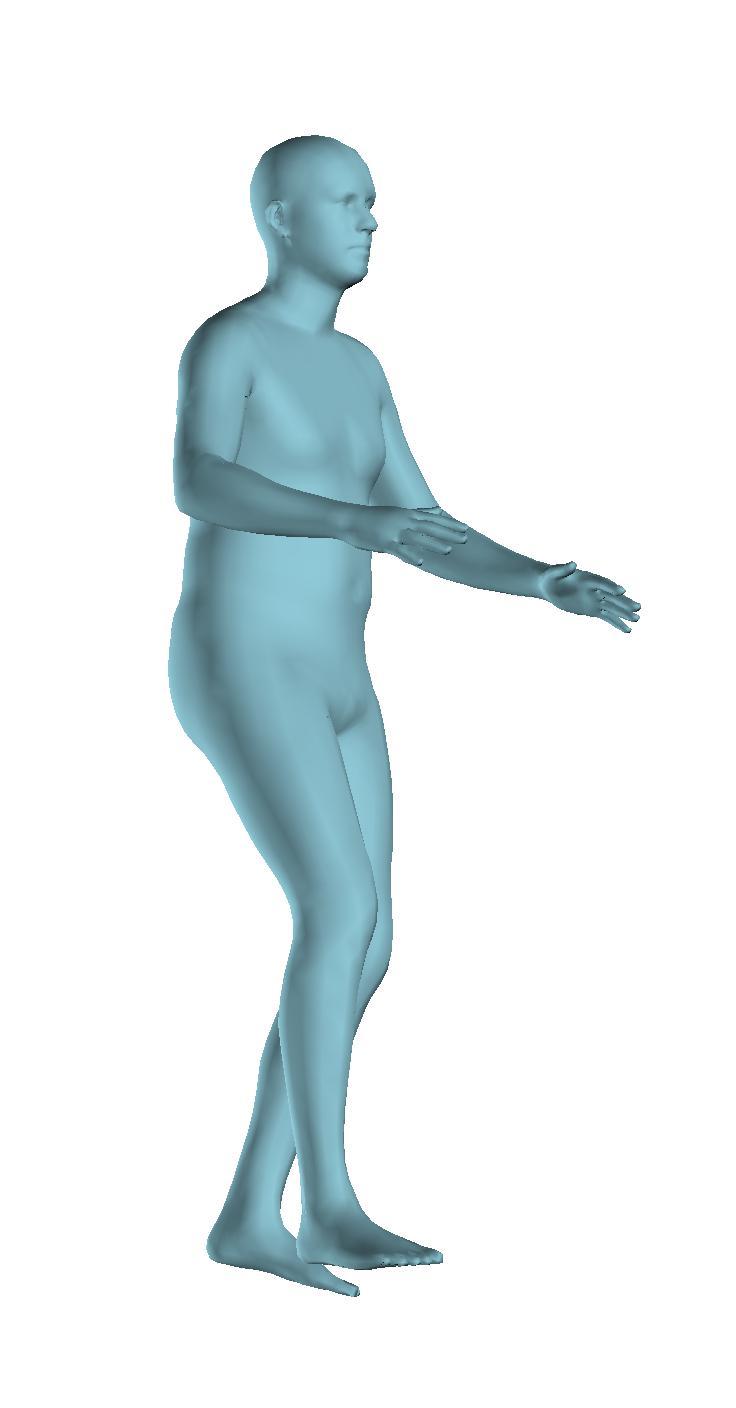





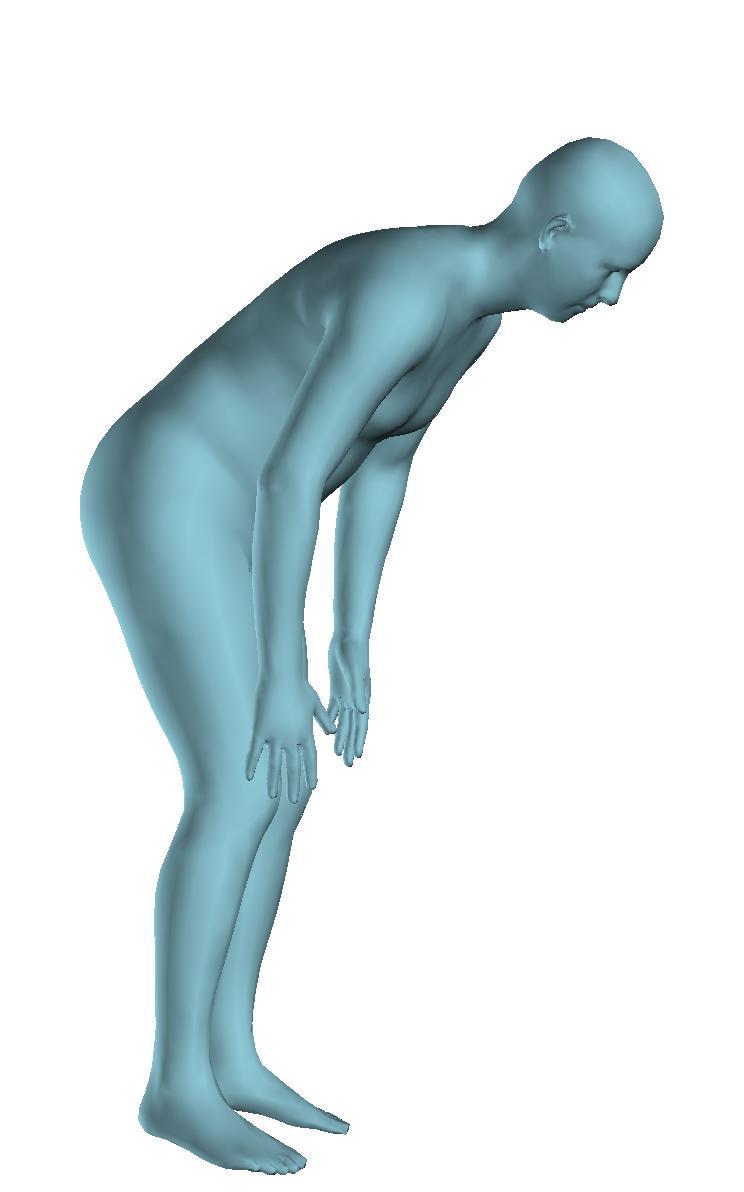
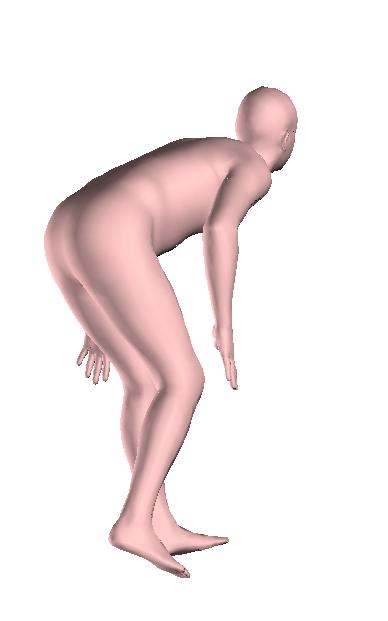
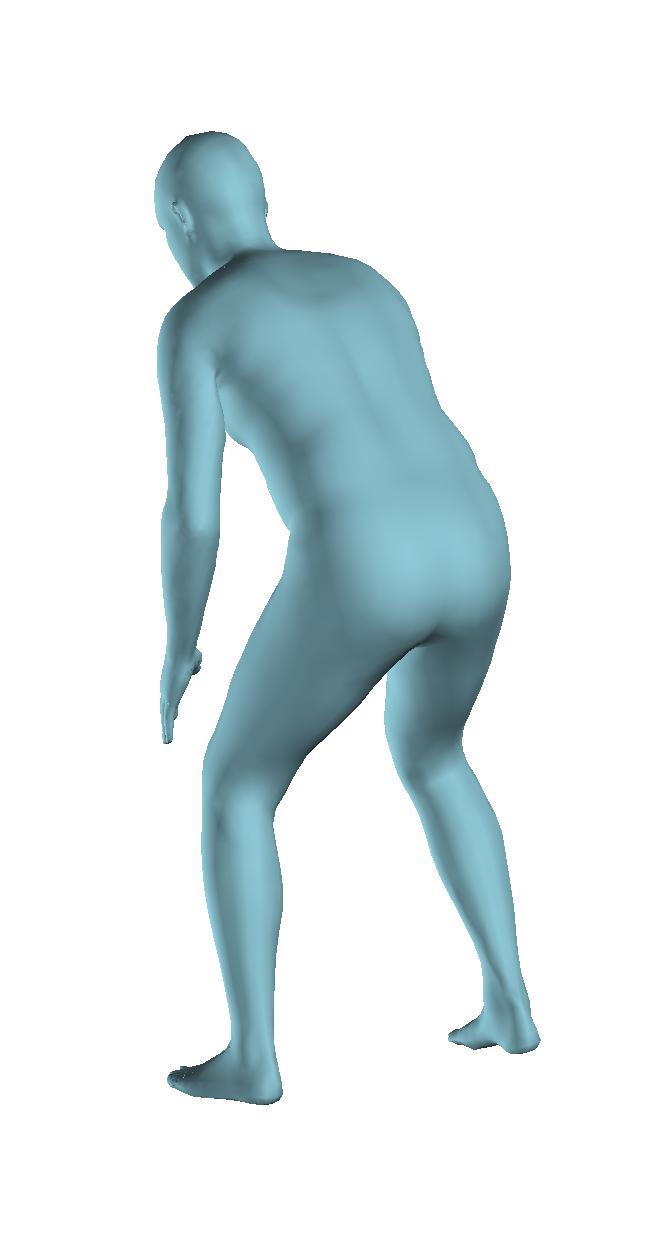


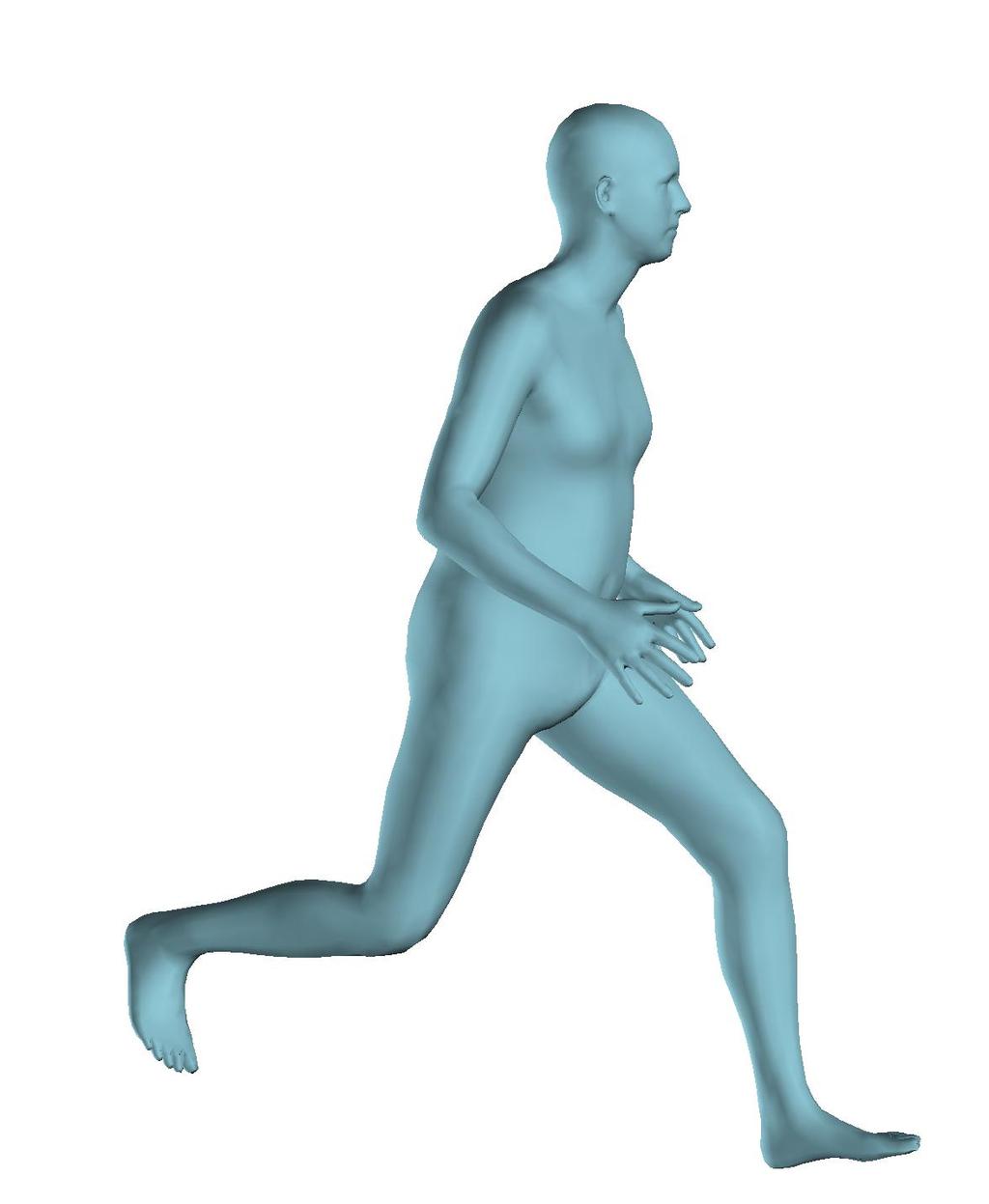
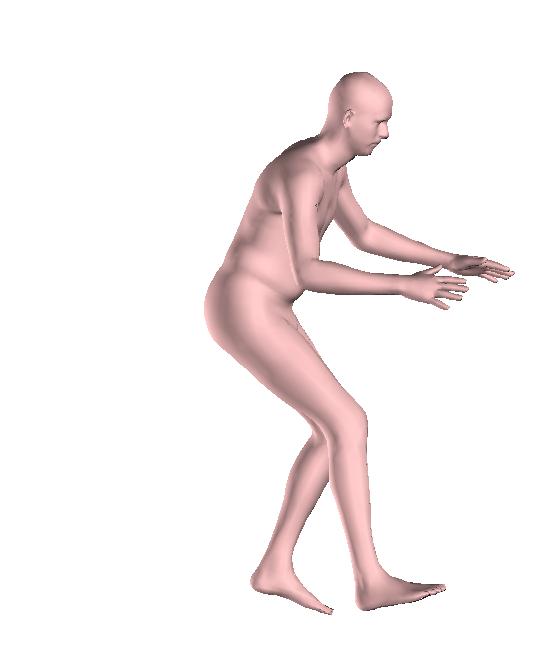












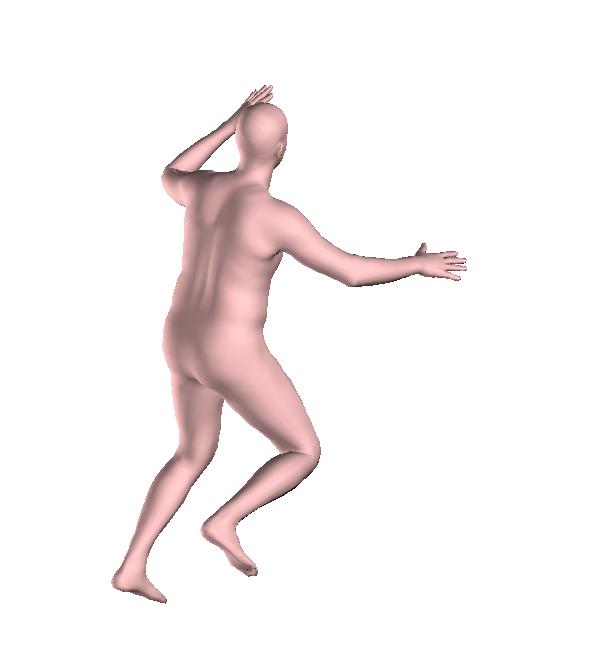

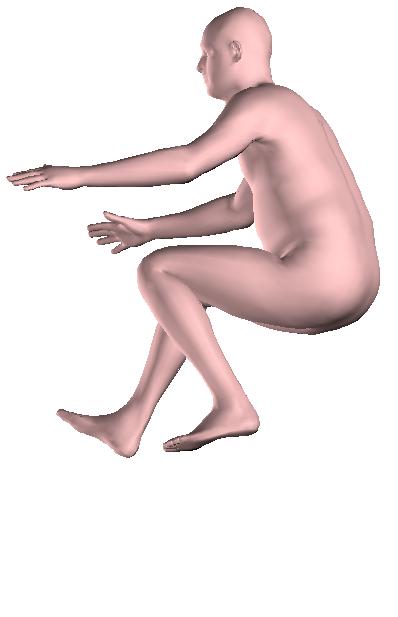
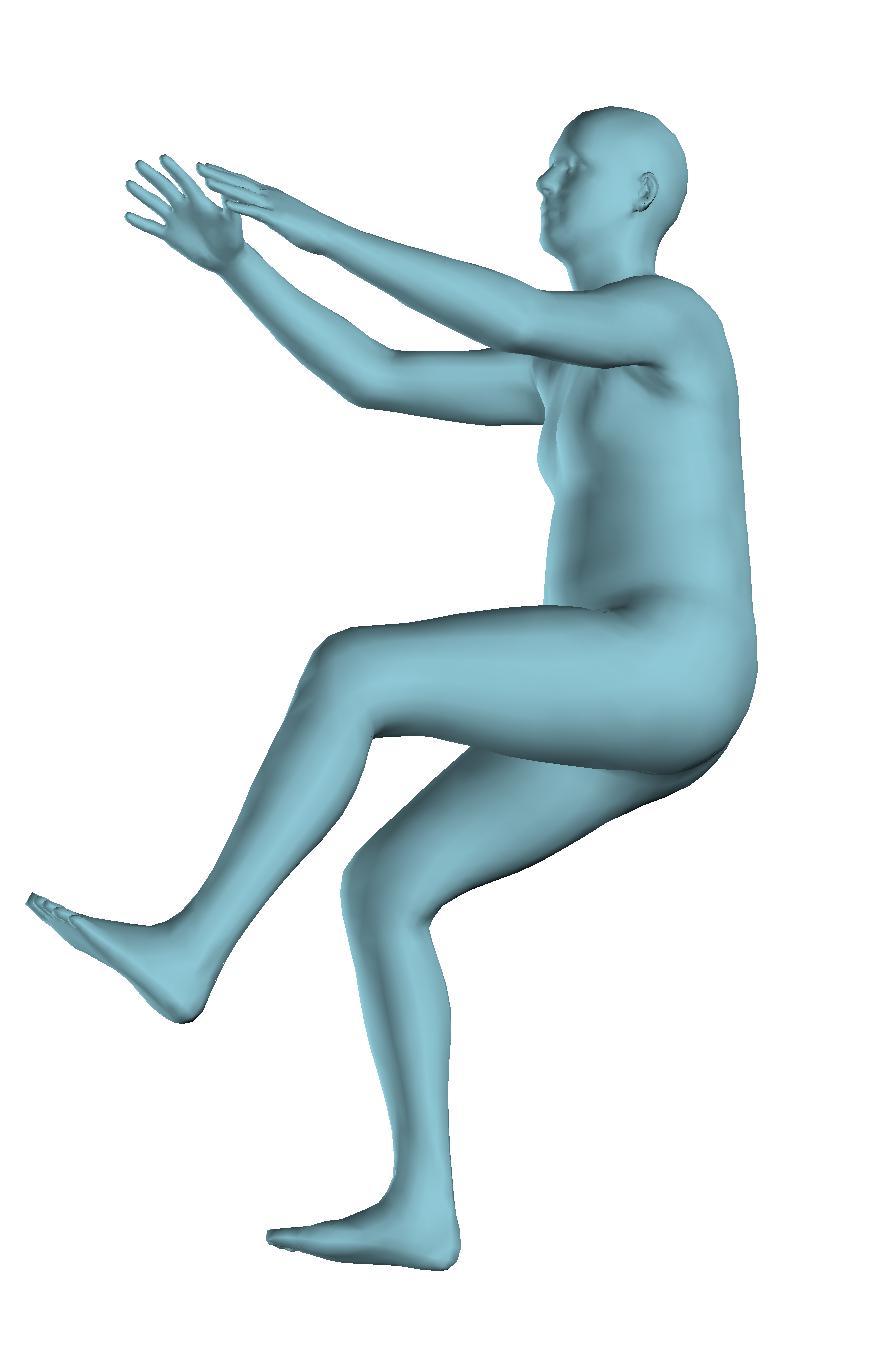
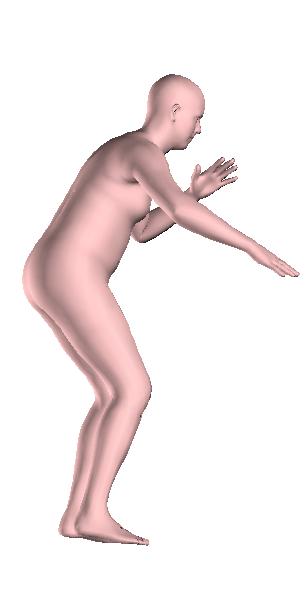


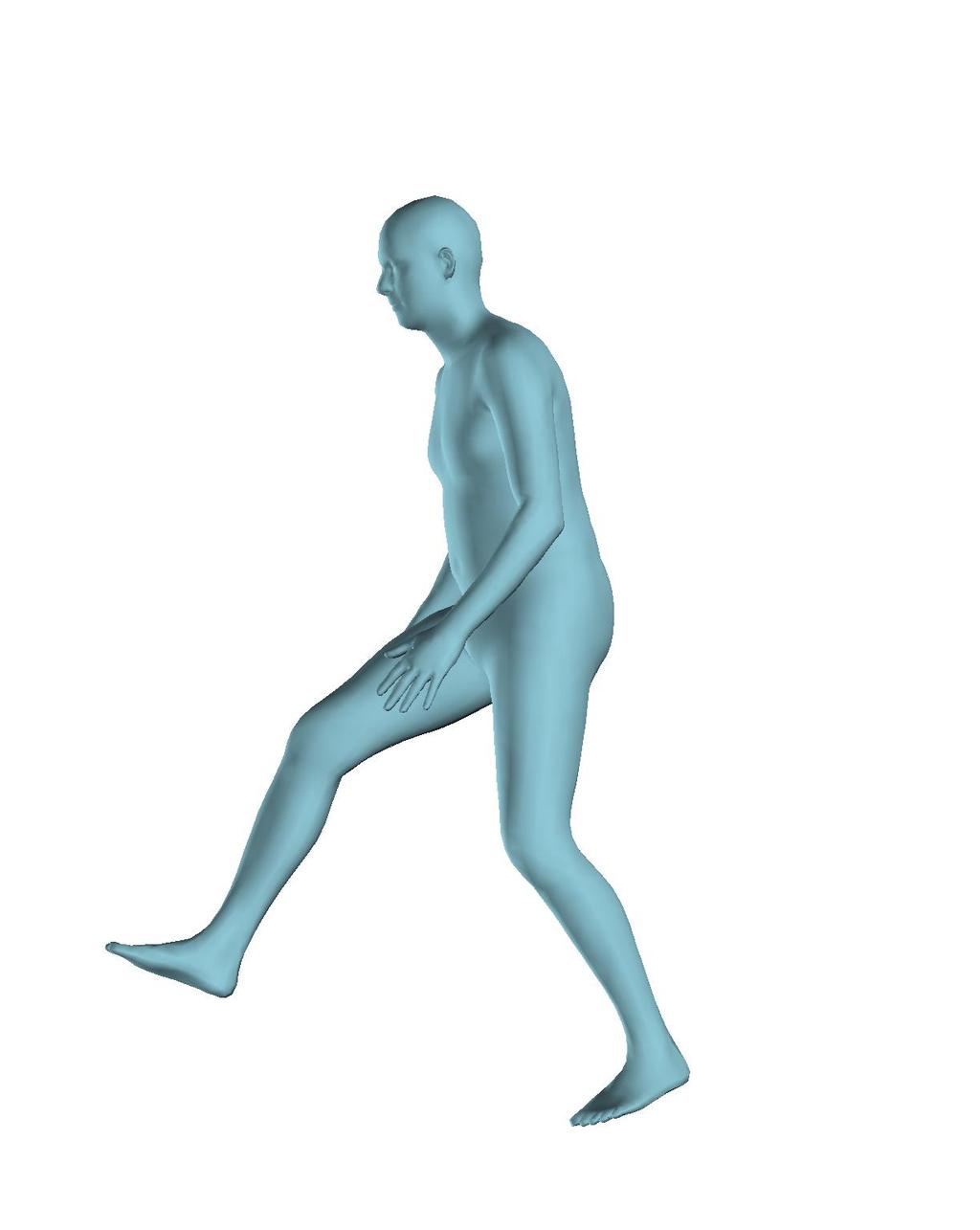


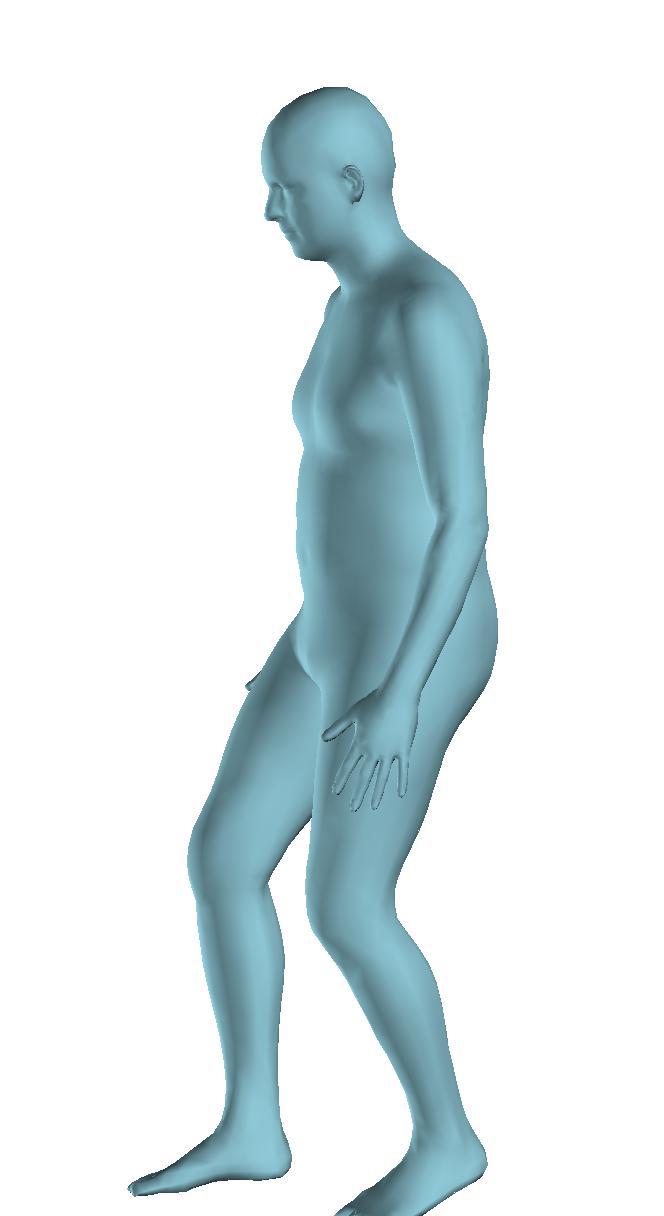







6 Figure 6: Successful reconstructions of our aproach on UP-3D [5] (extension of Figure 3 of the main manuscript). Figure 7: Reconstructions on UP-3D [5] using our approach (blue) and the direct prediction approach of [5] (pink). Our approach typically leads to more accurate and faithful reconstructions (extension of Figure 4 of the main manuscript). Figure 8: A set of typical failure cases on UP-3D [5] for our approach. Reconstructions that do not match exactly to the 2D image evidence, retrieval of a more regular pose, ignoring small scale details, errors in the global rotation, and failures because of particularly challenging poses (e.g., with self-occlusions), are the main sources of error for our approach. 6

























7 Figure 9: Reconstructions of our approach on the Human3.6M part of SURREAL [10]. The last row corresponds to failure cases, which are usually attributed to the low lighting conditions and challenging backgrounds. 7


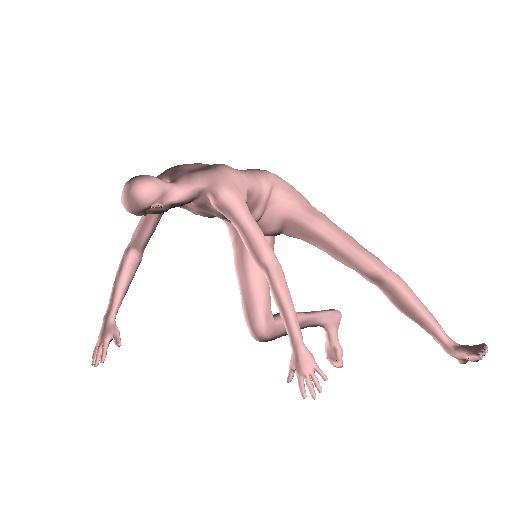









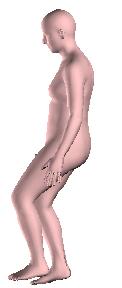

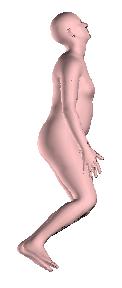






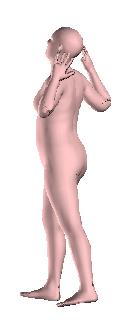







8 Figure 10: Reconstructions on Human3.6M [3] for our approach (blue) and the iterative optimization approach of Bogo et al. [2] (pink). The optimization solution relies heavily on the 2D detections. Even small errors for the detected 2D locations can lead to erroneous reconstructions (including flipping, interpenetration, failures because of depth ambiguity, etc). In these cases our approach typically provides more reasonable results, even if they are not completely faithful to the image evidence. Figure 11: Reconstruction on the test set of LSP [4] using vanilla SMPLify [2] (left of each image), and our anchored version of the same algorithm (right of each image). Using our direct prediction as initialization and as anchor can help to get reasonable 3D reconstructions and avoid unsatisfying failures (extension of Figure 5 of the main manuscript). 8
Supplementary: Cross-modal Deep Variational Hand Pose Estimation
 Supplementary: Cross-modal Deep Variational Hand Pose Estimation Adrian Spurr, Jie Song, Seonwook Park, Otmar Hilliges ETH Zurich {spurra,jsong,spark,otmarh}@inf.ethz.ch Encoder/Decoder Linear(512) Table
Supplementary: Cross-modal Deep Variational Hand Pose Estimation Adrian Spurr, Jie Song, Seonwook Park, Otmar Hilliges ETH Zurich {spurra,jsong,spark,otmarh}@inf.ethz.ch Encoder/Decoder Linear(512) Table
Human Pose Estimation using Global and Local Normalization. Ke Sun, Cuiling Lan, Junliang Xing, Wenjun Zeng, Dong Liu, Jingdong Wang
 Human Pose Estimation using Global and Local Normalization Ke Sun, Cuiling Lan, Junliang Xing, Wenjun Zeng, Dong Liu, Jingdong Wang Overview of the supplementary material In this supplementary material,
Human Pose Estimation using Global and Local Normalization Ke Sun, Cuiling Lan, Junliang Xing, Wenjun Zeng, Dong Liu, Jingdong Wang Overview of the supplementary material In this supplementary material,
arxiv: v4 [cs.cv] 12 Sep 2018
![arxiv: v4 [cs.cv] 12 Sep 2018](/thumbs/94/118550082.jpg "arxiv: v4 [cs.cv] 12 Sep 2018") arxiv:1711.08585v4 [cs.cv] 12 Sep 2018 Exploiting temporal information for 3D human pose estimation Mir Rayat Imtiaz Hossain, James J. Little Department of Computer Science, University of British Columbia
arxiv:1711.08585v4 [cs.cv] 12 Sep 2018 Exploiting temporal information for 3D human pose estimation Mir Rayat Imtiaz Hossain, James J. Little Department of Computer Science, University of British Columbia
Exploiting temporal information for 3D human pose estimation
 Exploiting temporal information for 3D human pose estimation Mir Rayat Imtiaz Hossain, James J. Little Department of Computer Science, University of British Columbia {rayat137,little}@cs.ubc.ca Abstract.
Exploiting temporal information for 3D human pose estimation Mir Rayat Imtiaz Hossain, James J. Little Department of Computer Science, University of British Columbia {rayat137,little}@cs.ubc.ca Abstract.
Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach
 Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach Xingyi Zhou, Qixing Huang, Xiao Sun, Xiangyang Xue, Yichen Wei UT Austin & MSRA & Fudan Human Pose Estimation Pose representation
Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach Xingyi Zhou, Qixing Huang, Xiao Sun, Xiangyang Xue, Yichen Wei UT Austin & MSRA & Fudan Human Pose Estimation Pose representation
Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs Supplementary Material
 Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs Supplementary Material Peak memory usage, GB 10 1 0.1 0.01 OGN Quadratic Dense Cubic Iteration time, s 10
Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs Supplementary Material Peak memory usage, GB 10 1 0.1 0.01 OGN Quadratic Dense Cubic Iteration time, s 10
3D Pose Estimation using Synthetic Data over Monocular Depth Images
 3D Pose Estimation using Synthetic Data over Monocular Depth Images Wei Chen cwind@stanford.edu Xiaoshi Wang xiaoshiw@stanford.edu Abstract We proposed an approach for human pose estimation over monocular
3D Pose Estimation using Synthetic Data over Monocular Depth Images Wei Chen cwind@stanford.edu Xiaoshi Wang xiaoshiw@stanford.edu Abstract We proposed an approach for human pose estimation over monocular
Stereo Human Keypoint Estimation
 Stereo Human Keypoint Estimation Kyle Brown Stanford University Stanford Intelligent Systems Laboratory kjbrown7@stanford.edu Abstract The goal of this project is to accurately estimate human keypoint
Stereo Human Keypoint Estimation Kyle Brown Stanford University Stanford Intelligent Systems Laboratory kjbrown7@stanford.edu Abstract The goal of this project is to accurately estimate human keypoint
Human Shape from Silhouettes using Generative HKS Descriptors and Cross-Modal Neural Networks
 Human Shape from Silhouettes using Generative HKS Descriptors and Cross-Modal Neural Networks Endri Dibra 1, Himanshu Jain 1, Cengiz Öztireli 1, Remo Ziegler 2, Markus Gross 1 1 Department of Computer
Human Shape from Silhouettes using Generative HKS Descriptors and Cross-Modal Neural Networks Endri Dibra 1, Himanshu Jain 1, Cengiz Öztireli 1, Remo Ziegler 2, Markus Gross 1 1 Department of Computer
arxiv: v1 [cs.cv] 29 Sep 2016
![arxiv: v1 [cs.cv] 29 Sep 2016](/thumbs/76/73787064.jpg "arxiv: v1 [cs.cv] 29 Sep 2016") arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
arxiv: v2 [cs.cv] 11 Apr 2017
![arxiv: v2 [cs.cv] 11 Apr 2017](/thumbs/79/80229724.jpg "arxiv: v2 [cs.cv] 11 Apr 2017") 3D Human Pose Estimation = 2D Pose Estimation + Matching Ching-Hang Chen Carnegie Mellon University chinghac@andrew.cmu.edu Deva Ramanan Carnegie Mellon University deva@cs.cmu.edu arxiv:1612.06524v2 [cs.cv]
3D Human Pose Estimation = 2D Pose Estimation + Matching Ching-Hang Chen Carnegie Mellon University chinghac@andrew.cmu.edu Deva Ramanan Carnegie Mellon University deva@cs.cmu.edu arxiv:1612.06524v2 [cs.cv]
Human Pose Estimation with Deep Learning. Wei Yang
 Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
A Dual-Source Approach for 3D Human Pose Estimation from Single Images
 1 Computer Vision and Image Understanding journal homepage: www.elsevier.com A Dual-Source Approach for 3D Human Pose Estimation from Single Images Umar Iqbal a,, Andreas Doering a, Hashim Yasin b, Björn
1 Computer Vision and Image Understanding journal homepage: www.elsevier.com A Dual-Source Approach for 3D Human Pose Estimation from Single Images Umar Iqbal a,, Andreas Doering a, Hashim Yasin b, Björn
Articulated Pose Estimation with Flexible Mixtures-of-Parts
 Articulated Pose Estimation with Flexible Mixtures-of-Parts PRESENTATION: JESSE DAVIS CS 3710 VISUAL RECOGNITION Outline Modeling Special Cases Inferences Learning Experiments Problem and Relevance Problem:
Articulated Pose Estimation with Flexible Mixtures-of-Parts PRESENTATION: JESSE DAVIS CS 3710 VISUAL RECOGNITION Outline Modeling Special Cases Inferences Learning Experiments Problem and Relevance Problem:
Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose
 Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose Georgios Pavlakos 1, Xiaowei Zhou 1, Konstantinos G. Derpanis 2, Kostas Daniilidis 1 1 University of Pennsylvania 2 Ryerson University
Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose Georgios Pavlakos 1, Xiaowei Zhou 1, Konstantinos G. Derpanis 2, Kostas Daniilidis 1 1 University of Pennsylvania 2 Ryerson University
Ordinal Depth Supervision for 3D Human Pose Estimation
 Ordinal Depth Supervision for 3D Human Pose Estimation Georgios Pavlakos 1, Xiaowei Zhou 2, Kostas Daniilidis 1 1 University of Pennsylvania 2 State Key Lab of CAD&CG, Zhejiang University Abstract Our
Ordinal Depth Supervision for 3D Human Pose Estimation Georgios Pavlakos 1, Xiaowei Zhou 2, Kostas Daniilidis 1 1 University of Pennsylvania 2 State Key Lab of CAD&CG, Zhejiang University Abstract Our
arxiv: v1 [cs.cv] 18 Dec 2017
![arxiv: v1 [cs.cv] 18 Dec 2017](/thumbs/78/78715631.jpg "arxiv: v1 [cs.cv] 18 Dec 2017") End-to-end Recovery of Human Shape and Pose arxiv:1712.06584v1 [cs.cv] 18 Dec 2017 Angjoo Kanazawa1,3, Michael J. Black2, David W. Jacobs3, Jitendra Malik1 1 University of California, Berkeley 2 MPI for
End-to-end Recovery of Human Shape and Pose arxiv:1712.06584v1 [cs.cv] 18 Dec 2017 Angjoo Kanazawa1,3, Michael J. Black2, David W. Jacobs3, Jitendra Malik1 1 University of California, Berkeley 2 MPI for
arxiv: v2 [cs.cv] 23 Jun 2018
![arxiv: v2 [cs.cv] 23 Jun 2018](/thumbs/85/92598818.jpg "arxiv: v2 [cs.cv] 23 Jun 2018") End-to-end Recovery of Human Shape and Pose arxiv:1712.06584v2 [cs.cv] 23 Jun 2018 Angjoo Kanazawa1, Michael J. Black2, David W. Jacobs3, Jitendra Malik1 1 University of California, Berkeley 2 MPI for
End-to-end Recovery of Human Shape and Pose arxiv:1712.06584v2 [cs.cv] 23 Jun 2018 Angjoo Kanazawa1, Michael J. Black2, David W. Jacobs3, Jitendra Malik1 1 University of California, Berkeley 2 MPI for
arxiv: v1 [cs.cv] 31 Jan 2017
![arxiv: v1 [cs.cv] 31 Jan 2017](/thumbs/75/71971098.jpg "arxiv: v1 [cs.cv] 31 Jan 2017") Deep Multitask Architecture for Integrated 2D and 3D Human Sensing Alin-Ionut Popa 2, Mihai Zanfir 2, Cristian Sminchisescu 1,2 alin.popa@imar.ro, mihai.zanfir@imar.ro cristian.sminchisescu@math.lth.se
Deep Multitask Architecture for Integrated 2D and 3D Human Sensing Alin-Ionut Popa 2, Mihai Zanfir 2, Cristian Sminchisescu 1,2 alin.popa@imar.ro, mihai.zanfir@imar.ro cristian.sminchisescu@math.lth.se
3D Human Pose Estimation from a Single Image via Distance Matrix Regression
 3D Human Pose Estimation from a Single Image via Distance Matrix Regression Francesc Moreno-Noguer Institut de Robòtica i Informàtica Industrial (CSIC-UPC), 08028, Barcelona, Spain Abstract This paper
3D Human Pose Estimation from a Single Image via Distance Matrix Regression Francesc Moreno-Noguer Institut de Robòtica i Informàtica Industrial (CSIC-UPC), 08028, Barcelona, Spain Abstract This paper
Detecting and Parsing of Visual Objects: Humans and Animals. Alan Yuille (UCLA)
") Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
arxiv: v1 [cs.cv] 17 May 2016
![arxiv: v1 [cs.cv] 17 May 2016](/thumbs/74/69966525.jpg "arxiv: v1 [cs.cv] 17 May 2016") arxiv:1605.05180v1 [cs.cv] 17 May 2016 TEKIN ET AL.: STRUCTURED PREDICTION OF 3D HUMAN POSE 1 Structured Prediction of 3D Human Pose with Deep Neural Networks Bugra Tekin 1 bugra.tekin@epfl.ch Isinsu Katircioglu
arxiv:1605.05180v1 [cs.cv] 17 May 2016 TEKIN ET AL.: STRUCTURED PREDICTION OF 3D HUMAN POSE 1 Structured Prediction of 3D Human Pose with Deep Neural Networks Bugra Tekin 1 bugra.tekin@epfl.ch Isinsu Katircioglu
Structured Light II. Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov
 Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
Neural Body Fitting: Unifying Deep Learning and Model Based Human Pose and Shape Estimation
 Neural Body Fitting: Unifying Deep Learning and Model Based Human Pose and Shape Estimation Mohamed Omran 1 Christoph Lassner 2 Gerard Pons-Moll 1 Peter V. Gehler 2 Bernt Schiele 1 1 Max Planck Institute
Neural Body Fitting: Unifying Deep Learning and Model Based Human Pose and Shape Estimation Mohamed Omran 1 Christoph Lassner 2 Gerard Pons-Moll 1 Peter V. Gehler 2 Bernt Schiele 1 1 Max Planck Institute
Uncertainty-Driven 6D Pose Estimation of Objects and Scenes from a Single RGB Image - Supplementary Material -
 Uncertainty-Driven 6D Pose Estimation of s and Scenes from a Single RGB Image - Supplementary Material - Eric Brachmann*, Frank Michel, Alexander Krull, Michael Ying Yang, Stefan Gumhold, Carsten Rother
Uncertainty-Driven 6D Pose Estimation of s and Scenes from a Single RGB Image - Supplementary Material - Eric Brachmann*, Frank Michel, Alexander Krull, Michael Ying Yang, Stefan Gumhold, Carsten Rother
End-to-end Recovery of Human Shape and Pose
 End-to-end Recovery of Human Shape and Pose Angjoo Kanazawa1, Michael J. Black2, David W. Jacobs3, Jitendra Malik1 1 University of California, Berkeley 2 MPI for Intelligent Systems, Tu bingen, Germany,
End-to-end Recovery of Human Shape and Pose Angjoo Kanazawa1, Michael J. Black2, David W. Jacobs3, Jitendra Malik1 1 University of California, Berkeley 2 MPI for Intelligent Systems, Tu bingen, Germany,
arxiv: v3 [cs.cv] 20 Mar 2018
![arxiv: v3 [cs.cv] 20 Mar 2018](/thumbs/77/75966172.jpg "arxiv: v3 [cs.cv] 20 Mar 2018") arxiv:1711.08229v3 [cs.cv] 20 Mar 2018 Integral Human Pose Regression Xiao Sun 1, Bin Xiao 1, Fangyin Wei 2, Shuang Liang 3, Yichen Wei 1 1 Microsoft Research, 2 Peking University, 3 Tongji University
arxiv:1711.08229v3 [cs.cv] 20 Mar 2018 Integral Human Pose Regression Xiao Sun 1, Bin Xiao 1, Fangyin Wei 2, Shuang Liang 3, Yichen Wei 1 1 Microsoft Research, 2 Peking University, 3 Tongji University
One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models
 One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models [Supplemental Materials] 1. Network Architecture b ref b ref +1 We now describe the architecture of the networks
One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models [Supplemental Materials] 1. Network Architecture b ref b ref +1 We now describe the architecture of the networks
3D Computer Vision. Structured Light II. Prof. Didier Stricker. Kaiserlautern University.
 3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
arxiv:submit/ [cs.cv] 14 Apr 2017
![arxiv:submit/ [cs.cv] 14 Apr 2017](/thumbs/74/70798537.jpg "arxiv:submit/ [cs.cv] 14 Apr 2017") Harvesting Multiple Views for Marker-less 3D Human Pose Annotations Georgios Pavlakos 1, Xiaowei Zhou 1, Konstantinos G. Derpanis 2, Kostas Daniilidis 1 1 University of Pennsylvania 2 Ryerson University
Harvesting Multiple Views for Marker-less 3D Human Pose Annotations Georgios Pavlakos 1, Xiaowei Zhou 1, Konstantinos G. Derpanis 2, Kostas Daniilidis 1 1 University of Pennsylvania 2 Ryerson University
Coherent Motion Segmentation in Moving Camera Videos using Optical Flow Orientations - Supplementary material
 Coherent Motion Segmentation in Moving Camera Videos using Optical Flow Orientations - Supplementary material Manjunath Narayana narayana@cs.umass.edu Allen Hanson hanson@cs.umass.edu University of Massachusetts,
Coherent Motion Segmentation in Moving Camera Videos using Optical Flow Orientations - Supplementary material Manjunath Narayana narayana@cs.umass.edu Allen Hanson hanson@cs.umass.edu University of Massachusetts,
Propagating LSTM: 3D Pose Estimation based on Joint Interdependency
 Propagating LSTM: 3D Pose Estimation based on Joint Interdependency Kyoungoh Lee, Inwoong Lee, and Sanghoon Lee ( ) Department of Electrical Electronic Engineering, Yonsei University {kasinamooth, mayddb100,
Propagating LSTM: 3D Pose Estimation based on Joint Interdependency Kyoungoh Lee, Inwoong Lee, and Sanghoon Lee ( ) Department of Electrical Electronic Engineering, Yonsei University {kasinamooth, mayddb100,
Nonrigid Surface Modelling. and Fast Recovery. Department of Computer Science and Engineering. Committee: Prof. Leo J. Jia and Prof. K. H.
 Nonrigid Surface Modelling and Fast Recovery Zhu Jianke Supervisor: Prof. Michael R. Lyu Committee: Prof. Leo J. Jia and Prof. K. H. Wong Department of Computer Science and Engineering May 11, 2007 1 2
Nonrigid Surface Modelling and Fast Recovery Zhu Jianke Supervisor: Prof. Michael R. Lyu Committee: Prof. Leo J. Jia and Prof. K. H. Wong Department of Computer Science and Engineering May 11, 2007 1 2
Deep Network for the Integrated 3D Sensing of Multiple People in Natural Images
 Deep Network for the Integrated 3D Sensing of Multiple People in Natural Images Andrei Zanfir 2 Elisabeta Marinoiu 2 Mihai Zanfir 2 Alin-Ionut Popa 2 Cristian Sminchisescu 1,2 {andrei.zanfir, elisabeta.marinoiu,
Deep Network for the Integrated 3D Sensing of Multiple People in Natural Images Andrei Zanfir 2 Elisabeta Marinoiu 2 Mihai Zanfir 2 Alin-Ionut Popa 2 Cristian Sminchisescu 1,2 {andrei.zanfir, elisabeta.marinoiu,
VNect: Real-time 3D Human Pose Estimation with a Single RGB Camera
 VNect: Real-time 3D Human Pose Estimation with a Single RGB Camera By Dushyant Mehta, Srinath Sridhar, Oleksandr Sotnychenko, Helge Rhodin, Mohammad Shafiei, Hans-Peter Seidel, Weipeng Xu, Dan Casas, Christian
VNect: Real-time 3D Human Pose Estimation with a Single RGB Camera By Dushyant Mehta, Srinath Sridhar, Oleksandr Sotnychenko, Helge Rhodin, Mohammad Shafiei, Hans-Peter Seidel, Weipeng Xu, Dan Casas, Christian
Estimating Human Pose in Images. Navraj Singh December 11, 2009
 Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Linear combinations of simple classifiers for the PASCAL challenge
 Linear combinations of simple classifiers for the PASCAL challenge Nik A. Melchior and David Lee 16 721 Advanced Perception The Robotics Institute Carnegie Mellon University Email: melchior@cmu.edu, dlee1@andrew.cmu.edu
Linear combinations of simple classifiers for the PASCAL challenge Nik A. Melchior and David Lee 16 721 Advanced Perception The Robotics Institute Carnegie Mellon University Email: melchior@cmu.edu, dlee1@andrew.cmu.edu
arxiv: v1 [cs.cv] 28 Sep 2018
![arxiv: v1 [cs.cv] 28 Sep 2018](/thumbs/93/113542646.jpg "arxiv: v1 [cs.cv] 28 Sep 2018") Camera Pose Estimation from Sequence of Calibrated Images arxiv:1809.11066v1 [cs.cv] 28 Sep 2018 Jacek Komorowski 1 and Przemyslaw Rokita 2 1 Maria Curie-Sklodowska University, Institute of Computer Science,
Camera Pose Estimation from Sequence of Calibrated Images arxiv:1809.11066v1 [cs.cv] 28 Sep 2018 Jacek Komorowski 1 and Przemyslaw Rokita 2 1 Maria Curie-Sklodowska University, Institute of Computer Science,
arxiv: v1 [cs.cv] 14 Jan 2019
![arxiv: v1 [cs.cv] 14 Jan 2019](/thumbs/93/114117280.jpg "arxiv: v1 [cs.cv] 14 Jan 2019") Fast and Robust Multi-Person 3D Pose Estimation from Multiple Views arxiv:1901.04111v1 [cs.cv] 14 Jan 2019 Junting Dong Zhejiang University jtdong@zju.edu.cn Abstract Hujun Bao Zhejiang University bao@cad.zju.edu.cn
Fast and Robust Multi-Person 3D Pose Estimation from Multiple Views arxiv:1901.04111v1 [cs.cv] 14 Jan 2019 Junting Dong Zhejiang University jtdong@zju.edu.cn Abstract Hujun Bao Zhejiang University bao@cad.zju.edu.cn
Integral Human Pose Regression
 Integral Human Pose Regression Xiao Sun 1, Bin Xiao 1, Fangyin Wei 2, Shuang Liang 3, and Yichen Wei 1 1 Microsoft Research, Beijing, China {xias, Bin.Xiao, yichenw}@microsoft.com 2 Peking University,
Integral Human Pose Regression Xiao Sun 1, Bin Xiao 1, Fangyin Wei 2, Shuang Liang 3, and Yichen Wei 1 1 Microsoft Research, Beijing, China {xias, Bin.Xiao, yichenw}@microsoft.com 2 Peking University,
CAP 6412 Advanced Computer Vision
 CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
DeMoN: Depth and Motion Network for Learning Monocular Stereo Supplementary Material
 Learning rate : Depth and Motion Network for Learning Monocular Stereo Supplementary Material A. Network Architecture Details Our network is a chain of encoder-decoder networks. Figures 15 and 16 explain
Learning rate : Depth and Motion Network for Learning Monocular Stereo Supplementary Material A. Network Architecture Details Our network is a chain of encoder-decoder networks. Figures 15 and 16 explain
arxiv: v3 [cs.cv] 28 Aug 2018
![arxiv: v3 [cs.cv] 28 Aug 2018](/thumbs/86/94638636.jpg "arxiv: v3 [cs.cv] 28 Aug 2018") Single-Shot Multi-Person 3D Pose Estimation From Monocular RGB Dushyant Mehta [1,2], Oleksandr Sotnychenko [1,2], Franziska Mueller [1,2], Weipeng Xu [1,2], Srinath Sridhar [3], Gerard Pons-Moll [1,2],
Single-Shot Multi-Person 3D Pose Estimation From Monocular RGB Dushyant Mehta [1,2], Oleksandr Sotnychenko [1,2], Franziska Mueller [1,2], Weipeng Xu [1,2], Srinath Sridhar [3], Gerard Pons-Moll [1,2],
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation
 AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth
SSD: Single Shot MultiBox Detector. Author: Wei Liu et al. Presenter: Siyu Jiang
 SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
Real-time Hand Tracking under Occlusion from an Egocentric RGB-D Sensor Supplemental Document
 Real-time Hand Tracking under Occlusion from an Egocentric RGB-D Sensor Supplemental Document Franziska Mueller 1,2 Dushyant Mehta 1,2 Oleksandr Sotnychenko 1 Srinath Sridhar 1 Dan Casas 3 Christian Theobalt
Real-time Hand Tracking under Occlusion from an Egocentric RGB-D Sensor Supplemental Document Franziska Mueller 1,2 Dushyant Mehta 1,2 Oleksandr Sotnychenko 1 Srinath Sridhar 1 Dan Casas 3 Christian Theobalt
Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning
 Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
Colored Point Cloud Registration Revisited Supplementary Material
 Colored Point Cloud Registration Revisited Supplementary Material Jaesik Park Qian-Yi Zhou Vladlen Koltun Intel Labs A. RGB-D Image Alignment Section introduced a joint photometric and geometric objective
Colored Point Cloud Registration Revisited Supplementary Material Jaesik Park Qian-Yi Zhou Vladlen Koltun Intel Labs A. RGB-D Image Alignment Section introduced a joint photometric and geometric objective
Analysis: TextonBoost and Semantic Texton Forests. Daniel Munoz Februrary 9, 2009
 Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Keep it SMPL: Automatic Estimation of 3D Human Pose and Shape from a Single Image
 Keep it SMPL: Automatic Estimation of 3D Human Pose and Shape from a Single Image Federica Bogo 2,, Angjoo Kanazawa 3,, Christoph Lassner 1,4, Peter Gehler 1,4, Javier Romero 1, Michael J. Black 1 1 Max
Keep it SMPL: Automatic Estimation of 3D Human Pose and Shape from a Single Image Federica Bogo 2,, Angjoo Kanazawa 3,, Christoph Lassner 1,4, Peter Gehler 1,4, Javier Romero 1, Michael J. Black 1 1 Max
Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos
 Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos Kihyuk Sohn 1 Sifei Liu 2 Guangyu Zhong 3 Xiang Yu 1 Ming-Hsuan Yang 2 Manmohan Chandraker 1,4 1 NEC Labs
Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos Kihyuk Sohn 1 Sifei Liu 2 Guangyu Zhong 3 Xiang Yu 1 Ming-Hsuan Yang 2 Manmohan Chandraker 1,4 1 NEC Labs
Final Exam Study Guide
 Final Exam Study Guide Exam Window: 28th April, 12:00am EST to 30th April, 11:59pm EST Description As indicated in class the goal of the exam is to encourage you to review the material from the course.
Final Exam Study Guide Exam Window: 28th April, 12:00am EST to 30th April, 11:59pm EST Description As indicated in class the goal of the exam is to encourage you to review the material from the course.
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling
 [DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
[DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
CS229: Action Recognition in Tennis
 CS229: Action Recognition in Tennis Aman Sikka Stanford University Stanford, CA 94305 Rajbir Kataria Stanford University Stanford, CA 94305 asikka@stanford.edu rkataria@stanford.edu 1. Motivation As active
CS229: Action Recognition in Tennis Aman Sikka Stanford University Stanford, CA 94305 Rajbir Kataria Stanford University Stanford, CA 94305 asikka@stanford.edu rkataria@stanford.edu 1. Motivation As active
08 An Introduction to Dense Continuous Robotic Mapping
 NAVARCH/EECS 568, ROB 530 - Winter 2018 08 An Introduction to Dense Continuous Robotic Mapping Maani Ghaffari March 14, 2018 Previously: Occupancy Grid Maps Pose SLAM graph and its associated dense occupancy
NAVARCH/EECS 568, ROB 530 - Winter 2018 08 An Introduction to Dense Continuous Robotic Mapping Maani Ghaffari March 14, 2018 Previously: Occupancy Grid Maps Pose SLAM graph and its associated dense occupancy
RSRN: Rich Side-output Residual Network for Medial Axis Detection
 RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model
 Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model Johnson Hsieh (johnsonhsieh@gmail.com), Alexander Chia (alexchia@stanford.edu) Abstract -- Object occlusion presents a major
Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model Johnson Hsieh (johnsonhsieh@gmail.com), Alexander Chia (alexchia@stanford.edu) Abstract -- Object occlusion presents a major
Generating Multiple Hypotheses for 3D Human Pose Estimation with Mixture Density Network
 Generating Multiple Hpotheses for 3D Human Pose Estimation with Miture Densit Network Chen Li Gim Hee Lee Department of Computer Science, National Universit of Singapore {lic, gimhee.lee}@comp.nus.edu.sg
Generating Multiple Hpotheses for 3D Human Pose Estimation with Miture Densit Network Chen Li Gim Hee Lee Department of Computer Science, National Universit of Singapore {lic, gimhee.lee}@comp.nus.edu.sg
3D Human Pose Estimation in the Wild by Adversarial Learning
 3D Human Pose Estimation in the Wild by Adversarial Learning Wei Yang 1 Wanli Ouyang 2 Xiaolong Wang 3 Jimmy Ren 4 Hongsheng Li 1 Xiaogang Wang 1 1 CUHK-SenseTime Joint Lab, The Chinese University of Hong
3D Human Pose Estimation in the Wild by Adversarial Learning Wei Yang 1 Wanli Ouyang 2 Xiaolong Wang 3 Jimmy Ren 4 Hongsheng Li 1 Xiaogang Wang 1 1 CUHK-SenseTime Joint Lab, The Chinese University of Hong
SurfNet: Generating 3D shape surfaces using deep residual networks-supplementary Material
 SurfNet: Generating 3D shape surfaces using deep residual networks-supplementary Material Ayan Sinha MIT Asim Unmesh IIT Kanpur Qixing Huang UT Austin Karthik Ramani Purdue sinhayan@mit.edu a.unmesh@gmail.com
SurfNet: Generating 3D shape surfaces using deep residual networks-supplementary Material Ayan Sinha MIT Asim Unmesh IIT Kanpur Qixing Huang UT Austin Karthik Ramani Purdue sinhayan@mit.edu a.unmesh@gmail.com
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Multi-View 3D Object Detection Network for Autonomous Driving
 Multi-View 3D Object Detection Network for Autonomous Driving Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, Tian Xia CVPR 2017 (Spotlight) Presented By: Jason Ku Overview Motivation Dataset Network Architecture
Multi-View 3D Object Detection Network for Autonomous Driving Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, Tian Xia CVPR 2017 (Spotlight) Presented By: Jason Ku Overview Motivation Dataset Network Architecture
arxiv: v3 [cs.cv] 2 Aug 2017
![arxiv: v3 [cs.cv] 2 Aug 2017](/thumbs/75/72344857.jpg "arxiv: v3 [cs.cv] 2 Aug 2017") Compositional Human Pose Regression Xiao Sun 1, Jiaxiang Shang 1, Shuang Liang 2, Yichen Wei 1 1 Microsoft Research, 2 Tongji University {xias, yichenw}@microsoft.com, jiaxiang.shang@gmail.com, shuangliang@tongji.edu.cn
Compositional Human Pose Regression Xiao Sun 1, Jiaxiang Shang 1, Shuang Liang 2, Yichen Wei 1 1 Microsoft Research, 2 Tongji University {xias, yichenw}@microsoft.com, jiaxiang.shang@gmail.com, shuangliang@tongji.edu.cn
Is 2D Information Enough For Viewpoint Estimation? Amir Ghodrati, Marco Pedersoli, Tinne Tuytelaars BMVC 2014
 Is 2D Information Enough For Viewpoint Estimation? Amir Ghodrati, Marco Pedersoli, Tinne Tuytelaars BMVC 2014 Problem Definition Viewpoint estimation: Given an image, predicting viewpoint for object of
Is 2D Information Enough For Viewpoint Estimation? Amir Ghodrati, Marco Pedersoli, Tinne Tuytelaars BMVC 2014 Problem Definition Viewpoint estimation: Given an image, predicting viewpoint for object of
DensePose: Dense Human Pose Estimation In The Wild
 DensePose: Dense Human Pose Estimation In The Wild Rıza Alp Güler INRIA-CentraleSupélec riza.guler@inria.fr Natalia Neverova Facebook AI Research nneverova@fb.com Iasonas Kokkinos Facebook AI Research
DensePose: Dense Human Pose Estimation In The Wild Rıza Alp Güler INRIA-CentraleSupélec riza.guler@inria.fr Natalia Neverova Facebook AI Research nneverova@fb.com Iasonas Kokkinos Facebook AI Research
CIS680: Vision & Learning Assignment 2.b: RPN, Faster R-CNN and Mask R-CNN Due: Nov. 21, 2018 at 11:59 pm
 CIS680: Vision & Learning Assignment 2.b: RPN, Faster R-CNN and Mask R-CNN Due: Nov. 21, 2018 at 11:59 pm Instructions This is an individual assignment. Individual means each student must hand in their
CIS680: Vision & Learning Assignment 2.b: RPN, Faster R-CNN and Mask R-CNN Due: Nov. 21, 2018 at 11:59 pm Instructions This is an individual assignment. Individual means each student must hand in their
Computer Vision Lecture 16
 Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
CENG 783. Special topics in. Deep Learning. AlchemyAPI. Week 11. Sinan Kalkan
 CENG 783 Special topics in Deep Learning AlchemyAPI Week 11 Sinan Kalkan TRAINING A CNN Fig: http://www.robots.ox.ac.uk/~vgg/practicals/cnn/ Feed-forward pass Note that this is written in terms of the
CENG 783 Special topics in Deep Learning AlchemyAPI Week 11 Sinan Kalkan TRAINING A CNN Fig: http://www.robots.ox.ac.uk/~vgg/practicals/cnn/ Feed-forward pass Note that this is written in terms of the
Depth from Stereo. Dominic Cheng February 7, 2018
 Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
arxiv: v1 [cs.cv] 17 Sep 2016
![arxiv: v1 [cs.cv] 17 Sep 2016](/thumbs/90/104468396.jpg "arxiv: v1 [cs.cv] 17 Sep 2016") arxiv:1609.05317v1 [cs.cv] 17 Sep 2016 Deep Kinematic Pose Regression Xingyi Zhou 1, Xiao Sun 2, Wei Zhang 1, Shuang Liang 3, Yichen Wei 2 1 Shanghai Key Laboratory of Intelligent Information Processing
arxiv:1609.05317v1 [cs.cv] 17 Sep 2016 Deep Kinematic Pose Regression Xingyi Zhou 1, Xiao Sun 2, Wei Zhang 1, Shuang Liang 3, Yichen Wei 2 1 Shanghai Key Laboratory of Intelligent Information Processing
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Augmented Reality VU. Computer Vision 3D Registration (2) Prof. Vincent Lepetit
 Prof. Vincent Lepetit") Augmented Reality VU Computer Vision 3D Registration (2) Prof. Vincent Lepetit Feature Point-Based 3D Tracking Feature Points for 3D Tracking Much less ambiguous than edges; Point-to-point reprojection
Augmented Reality VU Computer Vision 3D Registration (2) Prof. Vincent Lepetit Feature Point-Based 3D Tracking Feature Points for 3D Tracking Much less ambiguous than edges; Point-to-point reprojection
Deep Learning. Vladimir Golkov Technical University of Munich Computer Vision Group
 Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
Supplementary A. Overview. C. Time and Space Complexity. B. Shape Retrieval. D. Permutation Invariant SOM. B.1. Dataset
 Supplementary A. Overview This supplementary document provides more technical details and experimental results to the main paper. Shape retrieval experiments are demonstrated with ShapeNet Core55 dataset
Supplementary A. Overview This supplementary document provides more technical details and experimental results to the main paper. Shape retrieval experiments are demonstrated with ShapeNet Core55 dataset
3 Object Detection. BVM 2018 Tutorial: Advanced Deep Learning Methods. Paul F. Jaeger, Division of Medical Image Computing
 3 Object Detection BVM 2018 Tutorial: Advanced Deep Learning Methods Paul F. Jaeger, of Medical Image Computing What is object detection? classification segmentation obj. detection (1 label per pixel)
3 Object Detection BVM 2018 Tutorial: Advanced Deep Learning Methods Paul F. Jaeger, of Medical Image Computing What is object detection? classification segmentation obj. detection (1 label per pixel)
Metric learning approaches! for image annotation! and face recognition!
 Metric learning approaches! for image annotation! and face recognition! Jakob Verbeek" LEAR Team, INRIA Grenoble, France! Joint work with :"!Matthieu Guillaumin"!!Thomas Mensink"!!!Cordelia Schmid! 1 2
Metric learning approaches! for image annotation! and face recognition! Jakob Verbeek" LEAR Team, INRIA Grenoble, France! Joint work with :"!Matthieu Guillaumin"!!Thomas Mensink"!!!Cordelia Schmid! 1 2
Dynamic Routing Between Capsules
 Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
CS 231A Computer Vision (Winter 2014) Problem Set 3
 Problem Set 3") CS 231A Computer Vision (Winter 2014) Problem Set 3 Due: Feb. 18 th, 2015 (11:59pm) 1 Single Object Recognition Via SIFT (45 points) In his 2004 SIFT paper, David Lowe demonstrates impressive object recognition
CS 231A Computer Vision (Winter 2014) Problem Set 3 Due: Feb. 18 th, 2015 (11:59pm) 1 Single Object Recognition Via SIFT (45 points) In his 2004 SIFT paper, David Lowe demonstrates impressive object recognition
Extracting Spatio-temporal Local Features Considering Consecutiveness of Motions
 Extracting Spatio-temporal Local Features Considering Consecutiveness of Motions Akitsugu Noguchi and Keiji Yanai Department of Computer Science, The University of Electro-Communications, 1-5-1 Chofugaoka,
Extracting Spatio-temporal Local Features Considering Consecutiveness of Motions Akitsugu Noguchi and Keiji Yanai Department of Computer Science, The University of Electro-Communications, 1-5-1 Chofugaoka,
Recurrent 3D Pose Sequence Machines
 Recurrent D Pose Sequence Machines Mude Lin, Liang Lin, Xiaodan Liang, Keze Wang, Hui Cheng School of Data and Computer Science, Sun Yat-sen University linmude@foxmail.com, linliang@ieee.org, xiaodanl@cs.cmu.edu,
Recurrent D Pose Sequence Machines Mude Lin, Liang Lin, Xiaodan Liang, Keze Wang, Hui Cheng School of Data and Computer Science, Sun Yat-sen University linmude@foxmail.com, linliang@ieee.org, xiaodanl@cs.cmu.edu,
COSC160: Detection and Classification. Jeremy Bolton, PhD Assistant Teaching Professor
 COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality
COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality
Object Category Detection. Slides mostly from Derek Hoiem
 Object Category Detection Slides mostly from Derek Hoiem Today s class: Object Category Detection Overview of object category detection Statistical template matching with sliding window Part-based Models
Object Category Detection Slides mostly from Derek Hoiem Today s class: Object Category Detection Overview of object category detection Statistical template matching with sliding window Part-based Models
Single-Shot Multi-Person 3D Pose Estimation From Monocular RGB
 Single-Shot Multi-Person 3D Pose Estimation From Monocular RGB Dushyant Mehta [1,2],OleksandrSotnychenko [1,2],FranziskaMueller [1,2], Weipeng Xu [1,2],SrinathSridhar [3],GerardPons-Moll [1,2], Christian
Single-Shot Multi-Person 3D Pose Estimation From Monocular RGB Dushyant Mehta [1,2],OleksandrSotnychenko [1,2],FranziskaMueller [1,2], Weipeng Xu [1,2],SrinathSridhar [3],GerardPons-Moll [1,2], Christian
Multi-View Image Coding in 3-D Space Based on 3-D Reconstruction
 Multi-View Image Coding in 3-D Space Based on 3-D Reconstruction Yongying Gao and Hayder Radha Department of Electrical and Computer Engineering, Michigan State University, East Lansing, MI 48823 email:
Multi-View Image Coding in 3-D Space Based on 3-D Reconstruction Yongying Gao and Hayder Radha Department of Electrical and Computer Engineering, Michigan State University, East Lansing, MI 48823 email:
Deep Learning For Video Classification. Presented by Natalie Carlebach & Gil Sharon
 Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
Guided Image Super-Resolution: A New Technique for Photogeometric Super-Resolution in Hybrid 3-D Range Imaging
 Guided Image Super-Resolution: A New Technique for Photogeometric Super-Resolution in Hybrid 3-D Range Imaging Florin C. Ghesu 1, Thomas Köhler 1,2, Sven Haase 1, Joachim Hornegger 1,2 04.09.2014 1 Pattern
Guided Image Super-Resolution: A New Technique for Photogeometric Super-Resolution in Hybrid 3-D Range Imaging Florin C. Ghesu 1, Thomas Köhler 1,2, Sven Haase 1, Joachim Hornegger 1,2 04.09.2014 1 Pattern
Specular 3D Object Tracking by View Generative Learning
 Specular 3D Object Tracking by View Generative Learning Yukiko Shinozuka, Francois de Sorbier and Hideo Saito Keio University 3-14-1 Hiyoshi, Kohoku-ku 223-8522 Yokohama, Japan shinozuka@hvrl.ics.keio.ac.jp
Specular 3D Object Tracking by View Generative Learning Yukiko Shinozuka, Francois de Sorbier and Hideo Saito Keio University 3-14-1 Hiyoshi, Kohoku-ku 223-8522 Yokohama, Japan shinozuka@hvrl.ics.keio.ac.jp
A Low Power, High Throughput, Fully Event-Based Stereo System: Supplementary Documentation
 A Low Power, High Throughput, Fully Event-Based Stereo System: Supplementary Documentation Alexander Andreopoulos, Hirak J. Kashyap, Tapan K. Nayak, Arnon Amir, Myron D. Flickner IBM Research March 25,
A Low Power, High Throughput, Fully Event-Based Stereo System: Supplementary Documentation Alexander Andreopoulos, Hirak J. Kashyap, Tapan K. Nayak, Arnon Amir, Myron D. Flickner IBM Research March 25,
Learning from Synthetic Humans
 Learning from Synthetic Humans Gül Varol, Javier Romero, Xavier Martin, Naureen Mahmood, Michael Black, Ivan Laptev, Cordelia Schmid To cite this version: Gül Varol, Javier Romero, Xavier Martin, Naureen
Learning from Synthetic Humans Gül Varol, Javier Romero, Xavier Martin, Naureen Mahmood, Michael Black, Ivan Laptev, Cordelia Schmid To cite this version: Gül Varol, Javier Romero, Xavier Martin, Naureen
What was Monet seeing while painting? Translating artworks to photo-realistic images M. Tomei, L. Baraldi, M. Cornia, R. Cucchiara
 What was Monet seeing while painting? Translating artworks to photo-realistic images M. Tomei, L. Baraldi, M. Cornia, R. Cucchiara COMPUTER VISION IN THE ARTISTIC DOMAIN The effectiveness of Computer Vision
What was Monet seeing while painting? Translating artworks to photo-realistic images M. Tomei, L. Baraldi, M. Cornia, R. Cucchiara COMPUTER VISION IN THE ARTISTIC DOMAIN The effectiveness of Computer Vision
Learning visual odometry with a convolutional network
 Learning visual odometry with a convolutional network Kishore Konda 1, Roland Memisevic 2 1 Goethe University Frankfurt 2 University of Montreal konda.kishorereddy@gmail.com, roland.memisevic@gmail.com
Learning visual odometry with a convolutional network Kishore Konda 1, Roland Memisevic 2 1 Goethe University Frankfurt 2 University of Montreal konda.kishorereddy@gmail.com, roland.memisevic@gmail.com
Three things everyone should know to improve object retrieval. Relja Arandjelović and Andrew Zisserman (CVPR 2012)
") Three things everyone should know to improve object retrieval Relja Arandjelović and Andrew Zisserman (CVPR 2012) University of Oxford 2 nd April 2012 Large scale object retrieval Find all instances of
Three things everyone should know to improve object retrieval Relja Arandjelović and Andrew Zisserman (CVPR 2012) University of Oxford 2 nd April 2012 Large scale object retrieval Find all instances of
Multi-view Facial Expression Recognition Analysis with Generic Sparse Coding Feature
 0/19.. Multi-view Facial Expression Recognition Analysis with Generic Sparse Coding Feature Usman Tariq, Jianchao Yang, Thomas S. Huang Department of Electrical and Computer Engineering Beckman Institute
0/19.. Multi-view Facial Expression Recognition Analysis with Generic Sparse Coding Feature Usman Tariq, Jianchao Yang, Thomas S. Huang Department of Electrical and Computer Engineering Beckman Institute
Applying Synthetic Images to Learning Grasping Orientation from Single Monocular Images
 Applying Synthetic Images to Learning Grasping Orientation from Single Monocular Images 1 Introduction - Steve Chuang and Eric Shan - Determining object orientation in images is a well-established topic
Applying Synthetic Images to Learning Grasping Orientation from Single Monocular Images 1 Introduction - Steve Chuang and Eric Shan - Determining object orientation in images is a well-established topic
ECE 6554:Advanced Computer Vision Pose Estimation
 ECE 6554:Advanced Computer Vision Pose Estimation Sujay Yadawadkar, Virginia Tech, Agenda: Pose Estimation: Part Based Models for Pose Estimation Pose Estimation with Convolutional Neural Networks (Deep
ECE 6554:Advanced Computer Vision Pose Estimation Sujay Yadawadkar, Virginia Tech, Agenda: Pose Estimation: Part Based Models for Pose Estimation Pose Estimation with Convolutional Neural Networks (Deep
MonoCap: Monocular Human Motion Capture using a CNN Coupled with a Geometric Prior
 TO APPEAR IN IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, 2018 1 MonoCap: Monocular Human Motion Capture using a CNN Coupled with a Geometric Prior Xiaowei Zhou, Menglong Zhu, Georgios
TO APPEAR IN IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, 2018 1 MonoCap: Monocular Human Motion Capture using a CNN Coupled with a Geometric Prior Xiaowei Zhou, Menglong Zhu, Georgios