Detecting and Parsing of Visual Objects: Humans and Animals. Alan Yuille (UCLA)
|
|
|
- Eleanor Hodge
- 5 years ago
- Views:
Transcription
1 Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA)
2 Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of object parts encoding spatial relations between them. We use deep convolutional neural networks (DCNNs) to make proposals for detecting the object parts. We use graphical models to encode spatial relationships between object parts and AND/OR graphs to share object parts between different, but similar, objects (e.g., cow torso and horse torso). We also describe AND/OR graphs for parsing humans.
3 Compositional Strategy Deep Convolutional Neural Networks (DCNNs) have been extremely successful for many visual tasks such as object detection. But DCNNs are complicated black boxes and it is hard to understand what they are doing. They do not have explicit representations of object parts and the spatial relationships between them. Our strategy is to represent objects in terms of compositions of object parts. DCNNs are trained to detect parts. Then we use explicit graphical models including AND/OR graphs to encode spatial relations and to enable part sharing.
4 Organization Three Parts Part (I). Parsing Humans joint detection. Xianjie Chen and Alan Yuille (NIPS 2014, CVPR 2015). Part (II). Parsing Animals -- Semantic Segmentation. Peng Wang, Xiaohui Shen, Zhe Lin, Scott Cohen, Brian Price, Alan Yuille (ICCV 2015). Note: Shen, Lin, Cohen, Price are at Adobe Research. Part (III). Parsing Humans Semantic Segmentation. Fangting Xia, Jun Zhu, Peng Wang, Alan Yuille (arxiv).

5 Part I: Parsing Human Joint Detection In this project, the parts are joints (e.g., elbows, wrists, shoulders, ). Graphical models are used to represent spatial relationships between the parts. Part sharing is used to enable efficient inference when the human is occluded. X. Chen and A.L. Yuille (NIPS 2014, CVPR 2015).

6 NUTS!

7 NUTS!!

8 NUTSIII

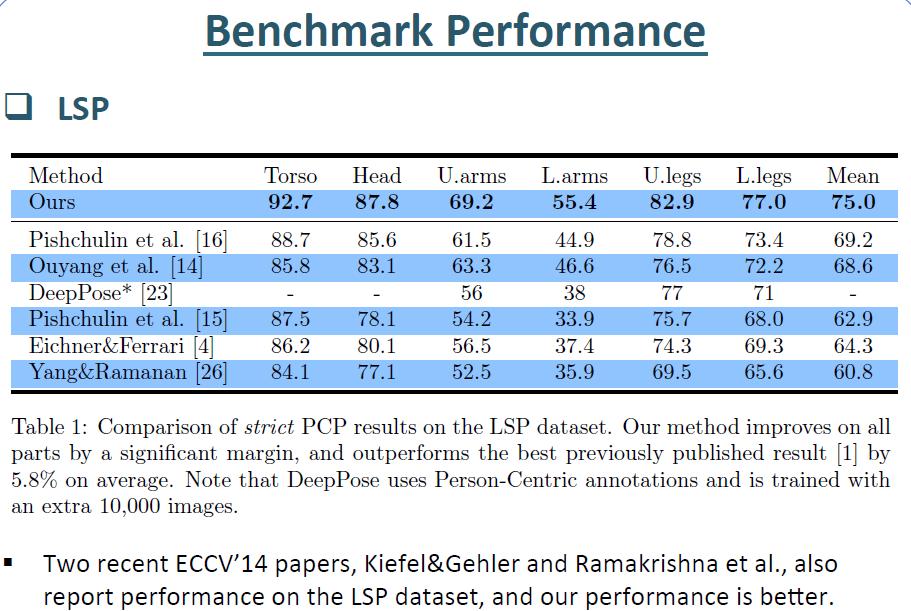
9 Performance Summary
10
11
12

13
14
15
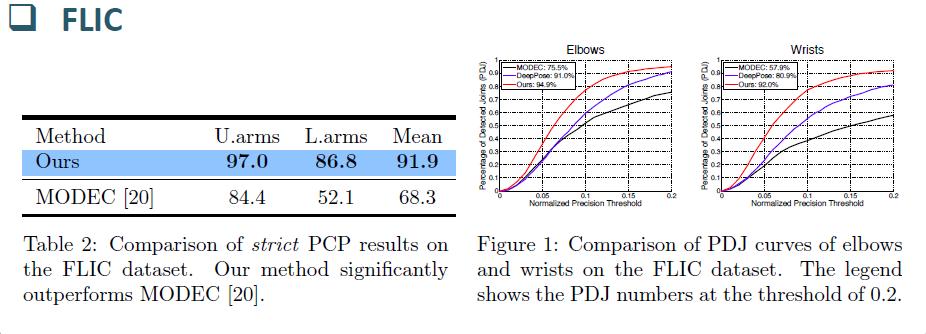
16

17
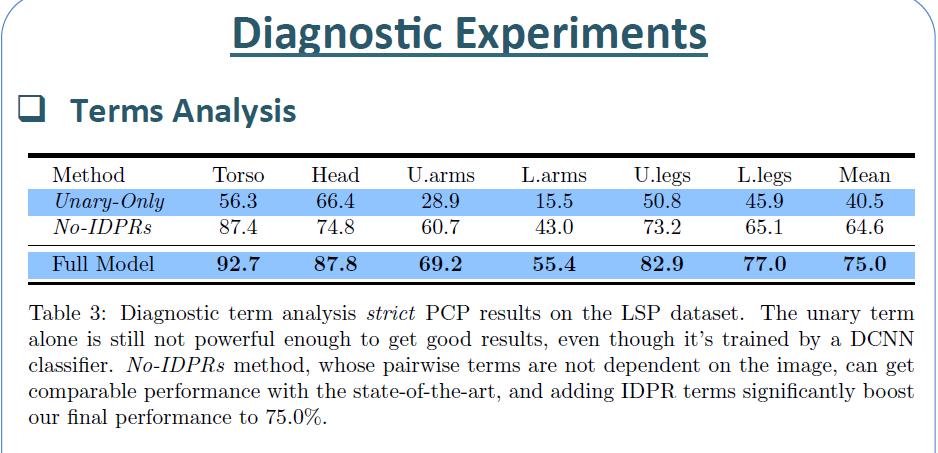
18
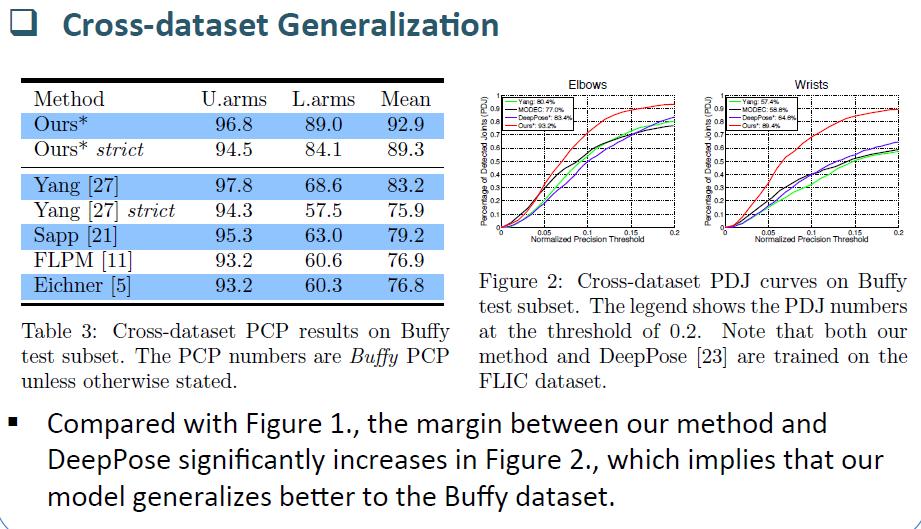
19
20 Parsing People by Flexible Compositions. (Chen and Yuille CVPR 2015). In realistic images many object parts are occluded. Previous graphical model are robust to only a few occlusions. Prior observed nodes of graphical model are often connected. Strategy: extend the method used in NIPS 2014 to deal with occlusion.
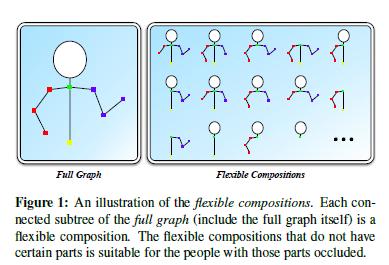
21

22

23
24 Model Base Model: as before. Introduce decoupling terms Penalties for missing terms
25 Inference There are many different models no. of connected subtrees of the graph. But inference is efficient because of part-sharing. Inference is only twice the complexity of the base model:

26 Evaluation We Are Family (WAF) Dataset 525 images, six people per image on average. (350/175 train/test).
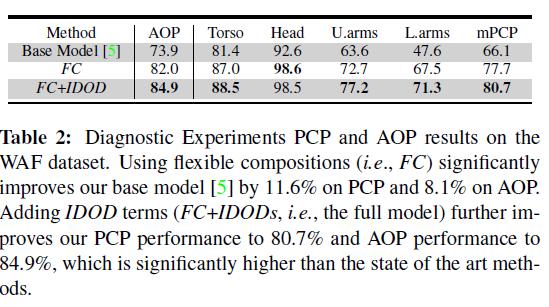
27 Diagnostics

28
, action recognition (C. Wang et al, 2013, 2014).")
29 From 2D to 3D. Pose detection with and with occlusion. Prior connected parts for occlusion (validated on WAF) Efficient inference despite occlusion due to part sharing. Note: detection of pose is important for many applications. E.g., estimating of 3D structure (C. Wang et al. 2014), action recognition (C. Wang et al, 2013, 2014). Collaboration with Peking University.
30 Summary of Part I: Parsing Humans -- Joints Detection of object parts (joints) in presence of occlusion. DCNNs for detecting parts, graphical models to impose spatial relations, efficient inference using dynamic programming. The detected parts can be used to estimate 3D structure of humans from a single image and enable action recognition. Limitations. Objects are represented in terms of joints only. This becomes problematic in some human configurations.
31 Part II Parsing Animals Semantic Segmentation Detecting and Parsing of Animals. Semantic Segmentation. The parts are heads, arms, torsos, legs, tails. The parts are shared between different animals. We perform semantic segmentation i.e. labeling the pixels of each part. P. Wang, X. Shen, Z. Lin, S. Cohen, B. Price, A. Yuille. ICCV 2015.

32 The Task Original image Object mask Part mask Detect and Parse Animals: Jointly infer the object segmentation and part segments
33 Motivation Detecting parts can improve object detection: Strongly supervised DPM [Azizpour et.al ECCV 2012] Detect what you can [X. Chen et.al CVPR 2014]... The same intuitions apply to segmentation, Parts need less context and can provide finer boundaries Object needs long range context, but miss details. Parsing and segmenting objects in term of parts give rich descriptions suitable for many visual tasks.

34 The Framework Our method is performed using two stages: Object and Part potentials -- make proposals for parts. Fully connected CRF spatial relations and part sharing.
35 Part Sharing: Semantic compositional parts (SCP) We use part sharing to reduce the amount of computation. l op {horse-head, horse-body, horse-leg, horse-tail, cow-head, cow-leg, cow-body, cow-tail}

36 SCP segments proposal Parts are detected despite the difficulty of the data.

37 Joint FCRF: representing spatial relations Two layer neural network, with features from Context potential Relative spatial position Geodesic and Euclidean distance
38 Experiments Data (3 Dataset derived from our PASCAL part [X. Chen et. al CVPR 2014]) Horse-Cow Data The Quadrupeds Data Pascal part benchmark Comparison Semantic part segmentation (SPS) [J. Wang and A.L. Yuille CVPR 2015] Hypercolumn [Hariharan et.al CVPR 2015] FCN for object segmentation [Long et. al CVPR 2015]

39 Horse-Cow Data Data from SPS, segment horse and cow parts given bounding box.

40 The Quadrupeds Data 5 animal classes from PASCAL

41 Pascal part benchmark Quadrupeds part segments from Pascal test set

42 Qualitative results
43 Summary Part 2: Animal Parsing, Semantic Segmentation Detect and semantically segment object parts. Limitations: Occlusions, Small Ambiguous Parts (e.g., Tails).
44 Part III: Parsing Humans Semantic Segmentation. Pose-Guided Human Body Parsing with Deep-Learned Features Fangting Xia, Jun Zhu, Peng Wang and Alan Yuille
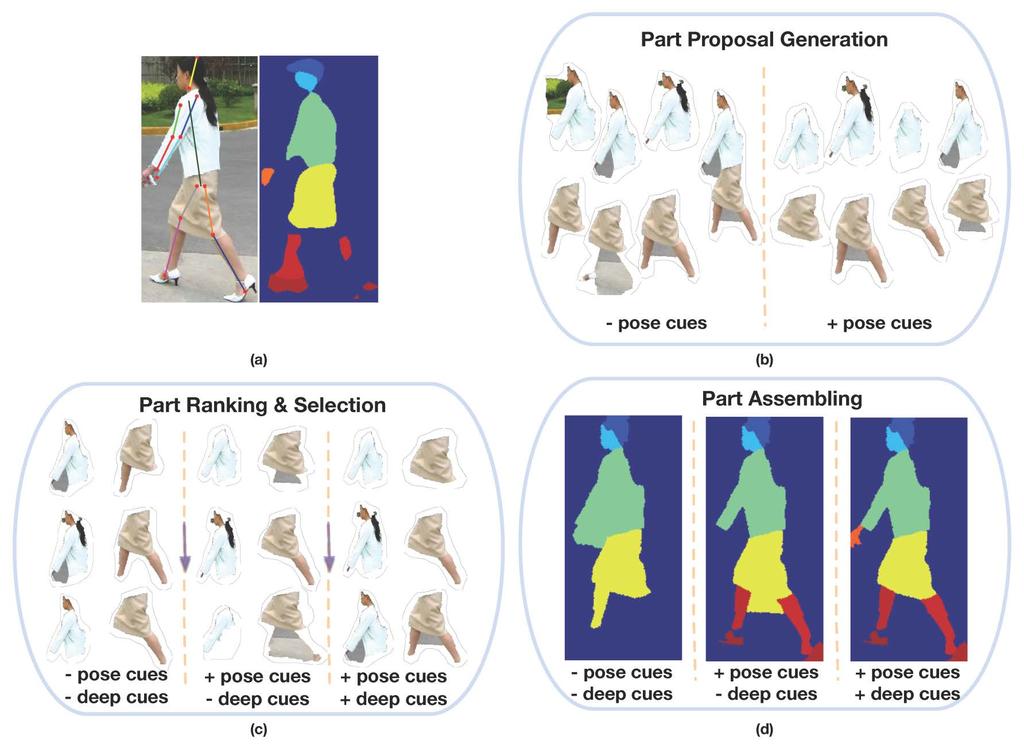
45 Motivation
46 The Human Parsing Pipeline Pose Context Feature

47 The AOG model for part assembling
48 The AOG Model leaf vertex non-leaf vertex

49 The Pose Context Feature

50 The Unary Part Prototypes Learned from Pose Context Feature

51 The Pairwise Part Prototypes Learned Fromm Pose Context Feature
52 The Effect of Pose Cues for Part Segment Proposal Generation The Recall and Average IoU of Our Segment Proposals
 for Part Proposal Ranking and Selection PCF PCF Top-1 (upper row) and top-10")
53 The Effect of Various Features (Comb.) for Part Proposal Ranking and Selection PCF PCF Top-1 (upper row) and top-10 (lower row) AOI scores of part ranking models

54 Investigating The Effect of AOG for Part Assembling Naive assembling: using only the unary terms and basic geometric common sense constraints (e.g. upper-clothes and lower-clothes must be adjacent). Basic AOG: using only the unary terms and the parent-child pairwise terms, without the side-way pairwise terms between parts. Ours: using all potentials together (including the unary terms, the parent-child pairwise terms, and the side-way pairwise terms). Ours (w/o pruning): the results of our model without greedy pruning. The pruning only brings ignorable decrease in performance while it reduces the inference time from 2 min. to 1 sec. per image.

55 Comparison to The State of The Art Comparison of our approach with other state-of-the-art algorithms over the Penn-Fudan dataset. The Avg means the average without shoes class since it did not included in other algorithms.

56 Qualitative Results

57 Qualitative Result Comparison Between Our Method and FCNN
, ground truth, and our parsing result are")
58 Some Failure Cases of Our Method Failure cases of our algorithm on Penn-Fudan dataset. For each case, the original image (with pose prediction), ground truth, and our parsing result are displayed from left to right.
59 Summary of Part III: Human parsing semantic segmentation Parsing humans is more difficult than parsing animals because human s wear clothes, and there are many choices of clothes. Our approach uses deep networks for joints (X. Chen and A.L. Yuille), pose-context features, appearance cues (including deep networks for large parts). AND/OR graph is used to allow us to model the large number of possibly configurations of humans.
60 Summary This talk illustrated a research program where we represent objects as compositions of object parts. We use deep convolutional neural networks (DCNNs) to make proposals for the parts. The parts can either be human joint (e.g., elbows) or animal parts (e.g., head and torso). Graphical model are used to capture spatial relations between object parts and to enable part sharing (e.g., horse torso and cow torso). This approach gives state of the art results on benchmarked datasets.
61 Papers Cited. X. Chen and A.L. Yuille. Articulated Pose Estimation with Image-Dependent Preference on Pairwise Relations. NIPS X. Chen and A.L. Yuille. Parsing Occluded People by Flexible Compositions. CVPR P. Wang, P. Wang, X. Shen, Z. Lin, S. Cohen, B. Price, A. Yuille. Joint Object and Part Segmentation using Deep Learned Potentials.ICCV Z. Xia, J. Zhu, P. Wang, A.L. Yuille. Pose-Guided Human Body Parsing with Deep-Learned Features. Arxiv C. Wang, Y. Wang, Z. Lin, A.L. Yuille, and W. Gao.Robust Estimation of 3D Human Poses from Single Images. CVPR
Joint Multi-Person Pose Estimation and Semantic Part Segmentation
 Joint Multi-Person Pose Estimation and Semantic Part Segmentation Fangting Xia 1 Peng Wang 1 Xianjie Chen 1 Alan Yuille 2 sukixia@gmail.com pengwangpku2012@gmail.com cxj@ucla.edu alan.yuille@jhu.edu 1
Joint Multi-Person Pose Estimation and Semantic Part Segmentation Fangting Xia 1 Peng Wang 1 Xianjie Chen 1 Alan Yuille 2 sukixia@gmail.com pengwangpku2012@gmail.com cxj@ucla.edu alan.yuille@jhu.edu 1
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network
 Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network Anurag Arnab and Philip H.S. Torr University of Oxford {anurag.arnab, philip.torr}@eng.ox.ac.uk 1. Introduction
Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network Anurag Arnab and Philip H.S. Torr University of Oxford {anurag.arnab, philip.torr}@eng.ox.ac.uk 1. Introduction
Learning Deep Structured Models for Semantic Segmentation. Guosheng Lin
 Learning Deep Structured Models for Semantic Segmentation Guosheng Lin Semantic Segmentation Outline Exploring Context with Deep Structured Models Guosheng Lin, Chunhua Shen, Ian Reid, Anton van dan Hengel;
Learning Deep Structured Models for Semantic Segmentation Guosheng Lin Semantic Segmentation Outline Exploring Context with Deep Structured Models Guosheng Lin, Chunhua Shen, Ian Reid, Anton van dan Hengel;
Object Detection by 3D Aspectlets and Occlusion Reasoning
 Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan Silvio Savarese Stanford University In the 4th International IEEE Workshop on 3D Representation and Recognition
Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan Silvio Savarese Stanford University In the 4th International IEEE Workshop on 3D Representation and Recognition
3D Shape Analysis with Multi-view Convolutional Networks. Evangelos Kalogerakis
 3D Shape Analysis with Multi-view Convolutional Networks Evangelos Kalogerakis 3D model repositories [3D Warehouse - video] 3D geometry acquisition [KinectFusion - video] 3D shapes come in various flavors
3D Shape Analysis with Multi-view Convolutional Networks Evangelos Kalogerakis 3D model repositories [3D Warehouse - video] 3D geometry acquisition [KinectFusion - video] 3D shapes come in various flavors
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
3D Shape Segmentation with Projective Convolutional Networks
 3D Shape Segmentation with Projective Convolutional Networks Evangelos Kalogerakis 1 Melinos Averkiou 2 Subhransu Maji 1 Siddhartha Chaudhuri 3 1 University of Massachusetts Amherst 2 University of Cyprus
3D Shape Segmentation with Projective Convolutional Networks Evangelos Kalogerakis 1 Melinos Averkiou 2 Subhransu Maji 1 Siddhartha Chaudhuri 3 1 University of Massachusetts Amherst 2 University of Cyprus
ECE 6554:Advanced Computer Vision Pose Estimation
 ECE 6554:Advanced Computer Vision Pose Estimation Sujay Yadawadkar, Virginia Tech, Agenda: Pose Estimation: Part Based Models for Pose Estimation Pose Estimation with Convolutional Neural Networks (Deep
ECE 6554:Advanced Computer Vision Pose Estimation Sujay Yadawadkar, Virginia Tech, Agenda: Pose Estimation: Part Based Models for Pose Estimation Pose Estimation with Convolutional Neural Networks (Deep
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs
 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
 Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields Authors: Zhe Cao, Tomas Simon, Shih-En Wei, Yaser Sheikh Presented by: Suraj Kesavan, Priscilla Jennifer ECS 289G: Visual Recognition
Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields Authors: Zhe Cao, Tomas Simon, Shih-En Wei, Yaser Sheikh Presented by: Suraj Kesavan, Priscilla Jennifer ECS 289G: Visual Recognition
Separating Objects and Clutter in Indoor Scenes
 Separating Objects and Clutter in Indoor Scenes Salman H. Khan School of Computer Science & Software Engineering, The University of Western Australia Co-authors: Xuming He, Mohammed Bennamoun, Ferdous
Separating Objects and Clutter in Indoor Scenes Salman H. Khan School of Computer Science & Software Engineering, The University of Western Australia Co-authors: Xuming He, Mohammed Bennamoun, Ferdous
Combining PGMs and Discriminative Models for Upper Body Pose Detection
 Combining PGMs and Discriminative Models for Upper Body Pose Detection Gedas Bertasius May 30, 2014 1 Introduction In this project, I utilized probabilistic graphical models together with discriminative
Combining PGMs and Discriminative Models for Upper Body Pose Detection Gedas Bertasius May 30, 2014 1 Introduction In this project, I utilized probabilistic graphical models together with discriminative
arxiv: v1 [cs.cv] 11 May 2018
![arxiv: v1 [cs.cv] 11 May 2018](/thumbs/88/115835402.jpg "arxiv: v1 [cs.cv] 11 May 2018") Weakly and Semi Supervised Human Body Part Parsing via Pose-Guided Knowledge Transfer Hao-Shu Fang 1, Guansong Lu 1, Xiaolin Fang 2, Jianwen Xie 3, Yu-Wing Tai 4, Cewu Lu 1 1 Shanghai Jiao Tong University,
Weakly and Semi Supervised Human Body Part Parsing via Pose-Guided Knowledge Transfer Hao-Shu Fang 1, Guansong Lu 1, Xiaolin Fang 2, Jianwen Xie 3, Yu-Wing Tai 4, Cewu Lu 1 1 Shanghai Jiao Tong University,
Supplementary Material: Decision Tree Fields
 Supplementary Material: Decision Tree Fields Note, the supplementary material is not needed to understand the main paper. Sebastian Nowozin Sebastian.Nowozin@microsoft.com Toby Sharp toby.sharp@microsoft.com
Supplementary Material: Decision Tree Fields Note, the supplementary material is not needed to understand the main paper. Sebastian Nowozin Sebastian.Nowozin@microsoft.com Toby Sharp toby.sharp@microsoft.com
Shape-based Pedestrian Parsing
 Shape-based Pedestrian Parsing Yihang Bo School of Computer and Information Technology Beijing Jiaotong University, China yihang.bo@gmail.com Charless C. Fowlkes Department of Computer Science University
Shape-based Pedestrian Parsing Yihang Bo School of Computer and Information Technology Beijing Jiaotong University, China yihang.bo@gmail.com Charless C. Fowlkes Department of Computer Science University
Articulated Pose Estimation by a Graphical Model with Image Dependent Pairwise Relations
 Articulated Pose Estimation by a Graphical Model with Image Dependent Pairwise Relations Xianjie Chen University of California, Los Angeles Los Angeles, CA 90024 cxj@ucla.edu Alan Yuille University of
Articulated Pose Estimation by a Graphical Model with Image Dependent Pairwise Relations Xianjie Chen University of California, Los Angeles Los Angeles, CA 90024 cxj@ucla.edu Alan Yuille University of
Encoder-Decoder Networks for Semantic Segmentation. Sachin Mehta
 Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Semantic Object Parsing with Local-Global Long Short-Term Memory
 Semantic Object Parsing with Local-Global Long Short-Term Memory Xiaodan Liang 1,3, Xiaohui Shen 4, Donglai Xiang 3, Jiashi Feng 3 Liang Lin 1, Shuicheng Yan 2,3 1 Sun Yat-sen University 2 360 AI Institute
Semantic Object Parsing with Local-Global Long Short-Term Memory Xiaodan Liang 1,3, Xiaohui Shen 4, Donglai Xiang 3, Jiashi Feng 3 Liang Lin 1, Shuicheng Yan 2,3 1 Sun Yat-sen University 2 360 AI Institute
Gradient of the lower bound
 Weakly Supervised with Latent PhD advisor: Dr. Ambedkar Dukkipati Department of Computer Science and Automation gaurav.pandey@csa.iisc.ernet.in Objective Given a training set that comprises image and image-level
Weakly Supervised with Latent PhD advisor: Dr. Ambedkar Dukkipati Department of Computer Science and Automation gaurav.pandey@csa.iisc.ernet.in Objective Given a training set that comprises image and image-level
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS. Zhao Chen Machine Learning Intern, NVIDIA
 JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Efficient Segmentation-Aided Text Detection For Intelligent Robots
 Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Estimating Human Pose in Images. Navraj Singh December 11, 2009
 Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Learning from 3D Data
 Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Deep learning for dense per-pixel prediction. Chunhua Shen The University of Adelaide, Australia
 Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
End-to-End Learning of Deformable Mixture of Parts and Deep Convolutional Neural Networks for Human Pose Estimation
 End-to-End Learning of Deformable Mixture of Parts and Deep Convolutional Neural Networks for Human Pose Estimation Wei Yang Wanli Ouyang Hongsheng Li Xiaogang Wang Department of Electronic Engineering,
End-to-End Learning of Deformable Mixture of Parts and Deep Convolutional Neural Networks for Human Pose Estimation Wei Yang Wanli Ouyang Hongsheng Li Xiaogang Wang Department of Electronic Engineering,
Semantic Segmentation without Annotating Segments
 Chapter 3 Semantic Segmentation without Annotating Segments Numerous existing object segmentation frameworks commonly utilize the object bounding box as a prior. In this chapter, we address semantic segmentation
Chapter 3 Semantic Segmentation without Annotating Segments Numerous existing object segmentation frameworks commonly utilize the object bounding box as a prior. In this chapter, we address semantic segmentation
Flow-Based Video Recognition
 Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
arxiv: v1 [cs.cv] 16 Nov 2015
![arxiv: v1 [cs.cv] 16 Nov 2015](/thumbs/85/92600288.jpg "arxiv: v1 [cs.cv] 16 Nov 2015") Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model
 Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model Johnson Hsieh (johnsonhsieh@gmail.com), Alexander Chia (alexchia@stanford.edu) Abstract -- Object occlusion presents a major
Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model Johnson Hsieh (johnsonhsieh@gmail.com), Alexander Chia (alexchia@stanford.edu) Abstract -- Object occlusion presents a major
Regionlet Object Detector with Hand-crafted and CNN Feature
 Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
3D Pose Estimation using Synthetic Data over Monocular Depth Images
 3D Pose Estimation using Synthetic Data over Monocular Depth Images Wei Chen cwind@stanford.edu Xiaoshi Wang xiaoshiw@stanford.edu Abstract We proposed an approach for human pose estimation over monocular
3D Pose Estimation using Synthetic Data over Monocular Depth Images Wei Chen cwind@stanford.edu Xiaoshi Wang xiaoshiw@stanford.edu Abstract We proposed an approach for human pose estimation over monocular
A Hierarchical Compositional System for Rapid Object Detection
 A Hierarchical Compositional System for Rapid Object Detection Long Zhu and Alan Yuille Department of Statistics University of California at Los Angeles Los Angeles, CA 90095 {lzhu,yuille}@stat.ucla.edu
A Hierarchical Compositional System for Rapid Object Detection Long Zhu and Alan Yuille Department of Statistics University of California at Los Angeles Los Angeles, CA 90095 {lzhu,yuille}@stat.ucla.edu
Perceiving the 3D World from Images and Videos. Yu Xiang Postdoctoral Researcher University of Washington
 Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Deformable Part Models
 CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
Amodal and Panoptic Segmentation. Stephanie Liu, Andrew Zhou
 Amodal and Panoptic Segmentation Stephanie Liu, Andrew Zhou This lecture: 1. 2. 3. 4. Semantic Amodal Segmentation Cityscapes Dataset ADE20K Dataset Panoptic Segmentation Semantic Amodal Segmentation Yan
Amodal and Panoptic Segmentation Stephanie Liu, Andrew Zhou This lecture: 1. 2. 3. 4. Semantic Amodal Segmentation Cityscapes Dataset ADE20K Dataset Panoptic Segmentation Semantic Amodal Segmentation Yan
Proposal-free Network for Instance-level Object Segmentation
 IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. XX, NO. X, X 20XX 1 Proposal-free Network for Instance-level Object Segmentation Xiaodan Liang, Yunchao Wei, Xiaohui Shen, Jianchao
IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. XX, NO. X, X 20XX 1 Proposal-free Network for Instance-level Object Segmentation Xiaodan Liang, Yunchao Wei, Xiaohui Shen, Jianchao
HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION
 HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION Chien-Yao Wang, Jyun-Hong Li, Seksan Mathulaprangsan, Chin-Chin Chiang, and Jia-Ching Wang Department of Computer Science and Information
HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION Chien-Yao Wang, Jyun-Hong Li, Seksan Mathulaprangsan, Chin-Chin Chiang, and Jia-Ching Wang Department of Computer Science and Information
Lecture 5: Object Detection
 Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Scene Text Recognition for Augmented Reality. Sagar G V Adviser: Prof. Bharadwaj Amrutur Indian Institute Of Science
 Scene Text Recognition for Augmented Reality Sagar G V Adviser: Prof. Bharadwaj Amrutur Indian Institute Of Science Outline Research area and motivation Finding text in natural scenes Prior art Improving
Scene Text Recognition for Augmented Reality Sagar G V Adviser: Prof. Bharadwaj Amrutur Indian Institute Of Science Outline Research area and motivation Finding text in natural scenes Prior art Improving
Data driven 3D shape analysis and synthesis
 Data driven 3D shape analysis and synthesis Head Neck Torso Leg Tail Ear Evangelos Kalogerakis UMass Amherst 3D shapes for computer aided design Architecture Interior design 3D shapes for information visualization
Data driven 3D shape analysis and synthesis Head Neck Torso Leg Tail Ear Evangelos Kalogerakis UMass Amherst 3D shapes for computer aided design Architecture Interior design 3D shapes for information visualization
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus
 Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
arxiv: v2 [cs.cv] 18 Jul 2017
![arxiv: v2 [cs.cv] 18 Jul 2017](/thumbs/72/67294650.jpg "arxiv: v2 [cs.cv] 18 Jul 2017") PHAM, ITO, KOZAKAYA: BISEG 1 arxiv:1706.02135v2 [cs.cv] 18 Jul 2017 BiSeg: Simultaneous Instance Segmentation and Semantic Segmentation with Fully Convolutional Networks Viet-Quoc Pham quocviet.pham@toshiba.co.jp
PHAM, ITO, KOZAKAYA: BISEG 1 arxiv:1706.02135v2 [cs.cv] 18 Jul 2017 BiSeg: Simultaneous Instance Segmentation and Semantic Segmentation with Fully Convolutional Networks Viet-Quoc Pham quocviet.pham@toshiba.co.jp
Object detection with CNNs
 Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Xiaowei Hu* Lei Zhu* Chi-Wing Fu Jing Qin Pheng-Ann Heng
 Direction-aware Spatial Context Features for Shadow Detection Xiaowei Hu* Lei Zhu* Chi-Wing Fu Jing Qin Pheng-Ann Heng The Chinese University of Hong Kong The Hong Kong Polytechnic University Shenzhen
Direction-aware Spatial Context Features for Shadow Detection Xiaowei Hu* Lei Zhu* Chi-Wing Fu Jing Qin Pheng-Ann Heng The Chinese University of Hong Kong The Hong Kong Polytechnic University Shenzhen
Semantic Object Parsing with Graph LSTM
 Semantic Object Parsing with Graph LSTM Xiaodan Liang 1 Xiaohui Shen 4 Jiashi Feng 3 Liang Lin 1 Shuicheng Yan 2,3 1 Sun Yat-sen University 2 360 AI Institue 3 National University of Singapore 4 Adobe
Semantic Object Parsing with Graph LSTM Xiaodan Liang 1 Xiaohui Shen 4 Jiashi Feng 3 Liang Lin 1 Shuicheng Yan 2,3 1 Sun Yat-sen University 2 360 AI Institue 3 National University of Singapore 4 Adobe
Hierarchical Learning for Object Detection. Long Zhu, Yuanhao Chen, William Freeman, Alan Yuille, Antonio Torralba MIT and UCLA, 2010
 Hierarchical Learning for Object Detection Long Zhu, Yuanhao Chen, William Freeman, Alan Yuille, Antonio Torralba MIT and UCLA, 2010 Background I: Our prior work Our work for the Pascal Challenge is based
Hierarchical Learning for Object Detection Long Zhu, Yuanhao Chen, William Freeman, Alan Yuille, Antonio Torralba MIT and UCLA, 2010 Background I: Our prior work Our work for the Pascal Challenge is based
Yiqi Yan. May 10, 2017
 Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
Human Upper Body Pose Estimation in Static Images
 1. Research Team Human Upper Body Pose Estimation in Static Images Project Leader: Graduate Students: Prof. Isaac Cohen, Computer Science Mun Wai Lee 2. Statement of Project Goals This goal of this project
1. Research Team Human Upper Body Pose Estimation in Static Images Project Leader: Graduate Students: Prof. Isaac Cohen, Computer Science Mun Wai Lee 2. Statement of Project Goals This goal of this project
Multi-Scale Structure-Aware Network for Human Pose Estimation
 Multi-Scale Structure-Aware Network for Human Pose Estimation Lipeng Ke 1, Ming-Ching Chang 2, Honggang Qi 1, and Siwei Lyu 2 1 University of Chinese Academy of Sciences, Beijing, China 2 University at
Multi-Scale Structure-Aware Network for Human Pose Estimation Lipeng Ke 1, Ming-Ching Chang 2, Honggang Qi 1, and Siwei Lyu 2 1 University of Chinese Academy of Sciences, Beijing, China 2 University at
3D Object Recognition and Scene Understanding from RGB-D Videos. Yu Xiang Postdoctoral Researcher University of Washington
 3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
Learning and Inferring Depth from Monocular Images. Jiyan Pan April 1, 2009
 Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Depth from Stereo. Dominic Cheng February 7, 2018
 Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Multi-Scale Structure-Aware Network for Human Pose Estimation
 Multi-Scale Structure-Aware Network for Human Pose Estimation Lipeng Ke 1, Ming-Ching Chang 2, Honggang Qi 1, Siwei Lyu 2 1 University of Chinese Academy of Sciences, Beijing, China 2 University at Albany,
Multi-Scale Structure-Aware Network for Human Pose Estimation Lipeng Ke 1, Ming-Ching Chang 2, Honggang Qi 1, Siwei Lyu 2 1 University of Chinese Academy of Sciences, Beijing, China 2 University at Albany,
Analysis: TextonBoost and Semantic Texton Forests. Daniel Munoz Februrary 9, 2009
 Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Human Pose Estimation with Deep Learning. Wei Yang
 Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
arxiv: v1 [cs.cv] 8 Mar 2017
![arxiv: v1 [cs.cv] 8 Mar 2017](/thumbs/76/73394967.jpg "arxiv: v1 [cs.cv] 8 Mar 2017") Interpretable Structure-Evolving LSTM Xiaodan Liang 1 Liang Lin 2 Xiaohui Shen 4 Jiashi Feng 3 Shuicheng Yan 3 Eric P. Xing 1 1 Carnegie Mellon University 2 Sun Yat-sen University 3 National University
Interpretable Structure-Evolving LSTM Xiaodan Liang 1 Liang Lin 2 Xiaohui Shen 4 Jiashi Feng 3 Shuicheng Yan 3 Eric P. Xing 1 1 Carnegie Mellon University 2 Sun Yat-sen University 3 National University
Team G-RMI: Google Research & Machine Intelligence
 Team G-RMI: Google Research & Machine Intelligence Alireza Fathi (alirezafathi@google.com) Nori Kanazawa, Kai Yang, George Papandreou, Tyler Zhu, Jonathan Huang, Vivek Rathod, Chen Sun, Kevin Murphy, et
Team G-RMI: Google Research & Machine Intelligence Alireza Fathi (alirezafathi@google.com) Nori Kanazawa, Kai Yang, George Papandreou, Tyler Zhu, Jonathan Huang, Vivek Rathod, Chen Sun, Kevin Murphy, et
Presentation Outline. Semantic Segmentation. Overview. Presentation Outline CNN. Learning Deconvolution Network for Semantic Segmentation 6/6/16
 6/6/16 Learning Deconvolution Network for Semantic Segmentation Hyeonwoo Noh, Seunghoon Hong,Bohyung Han Department of Computer Science and Engineering, POSTECH, Korea Shai Rozenberg 6/6/2016 1 2 Semantic
6/6/16 Learning Deconvolution Network for Semantic Segmentation Hyeonwoo Noh, Seunghoon Hong,Bohyung Han Department of Computer Science and Engineering, POSTECH, Korea Shai Rozenberg 6/6/2016 1 2 Semantic
DETAILS OF SST-SWAPTREE ALGORITHM
 A DETAILS OF SST-SWAPTREE ALGORITHM Our tree construction algorithm begins with an arbitrary tree structure and seeks to iteratively improve it by making moves within the space of tree structures. We consider
A DETAILS OF SST-SWAPTREE ALGORITHM Our tree construction algorithm begins with an arbitrary tree structure and seeks to iteratively improve it by making moves within the space of tree structures. We consider
Accurate 3D Face and Body Modeling from a Single Fixed Kinect
 Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
Label Propagation in RGB-D Video
 Label Propagation in RGB-D Video Md. Alimoor Reza, Hui Zheng, Georgios Georgakis, Jana Košecká Abstract We propose a new method for the propagation of semantic labels in RGB-D video of indoor scenes given
Label Propagation in RGB-D Video Md. Alimoor Reza, Hui Zheng, Georgios Georgakis, Jana Košecká Abstract We propose a new method for the propagation of semantic labels in RGB-D video of indoor scenes given
Learning to Match. Jun Xu, Zhengdong Lu, Tianqi Chen, Hang Li
 Learning to Match Jun Xu, Zhengdong Lu, Tianqi Chen, Hang Li 1. Introduction The main tasks in many applications can be formalized as matching between heterogeneous objects, including search, recommendation,
Learning to Match Jun Xu, Zhengdong Lu, Tianqi Chen, Hang Li 1. Introduction The main tasks in many applications can be formalized as matching between heterogeneous objects, including search, recommendation,
Segmenting Objects in Weakly Labeled Videos
 Segmenting Objects in Weakly Labeled Videos Mrigank Rochan, Shafin Rahman, Neil D.B. Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, Canada {mrochan, shafin12, bruce, ywang}@cs.umanitoba.ca
Segmenting Objects in Weakly Labeled Videos Mrigank Rochan, Shafin Rahman, Neil D.B. Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, Canada {mrochan, shafin12, bruce, ywang}@cs.umanitoba.ca
Photo OCR ( )
") Photo OCR (2017-2018) Xiang Bai Huazhong University of Science and Technology Outline VALSE2018, DaLian Xiang Bai 2 Deep Direct Regression for Multi-Oriented Scene Text Detection [He et al., ICCV, 2017.]
Photo OCR (2017-2018) Xiang Bai Huazhong University of Science and Technology Outline VALSE2018, DaLian Xiang Bai 2 Deep Direct Regression for Multi-Oriented Scene Text Detection [He et al., ICCV, 2017.]
Learning to Estimate 3D Human Pose and Shape from a Single Color Image Supplementary material
 Learning to Estimate 3D Human Pose and Shape from a Single Color Image Supplementary material Georgios Pavlakos 1, Luyang Zhu 2, Xiaowei Zhou 3, Kostas Daniilidis 1 1 University of Pennsylvania 2 Peking
Learning to Estimate 3D Human Pose and Shape from a Single Color Image Supplementary material Georgios Pavlakos 1, Luyang Zhu 2, Xiaowei Zhou 3, Kostas Daniilidis 1 1 University of Pennsylvania 2 Peking
DEEP STRUCTURED OUTPUT LEARNING FOR UNCONSTRAINED TEXT RECOGNITION
 DEEP STRUCTURED OUTPUT LEARNING FOR UNCONSTRAINED TEXT RECOGNITION Max Jaderberg, Karen Simonyan, Andrea Vedaldi, Andrew Zisserman Visual Geometry Group, Department Engineering Science, University of Oxford,
DEEP STRUCTURED OUTPUT LEARNING FOR UNCONSTRAINED TEXT RECOGNITION Max Jaderberg, Karen Simonyan, Andrea Vedaldi, Andrew Zisserman Visual Geometry Group, Department Engineering Science, University of Oxford,
Learning and Recognizing Visual Object Categories Without First Detecting Features
 Learning and Recognizing Visual Object Categories Without First Detecting Features Daniel Huttenlocher 2007 Joint work with D. Crandall and P. Felzenszwalb Object Category Recognition Generic classes rather
Learning and Recognizing Visual Object Categories Without First Detecting Features Daniel Huttenlocher 2007 Joint work with D. Crandall and P. Felzenszwalb Object Category Recognition Generic classes rather
Web-Scale Image Search and Their Applications
 Web-Scale Image Search and Their Applications Sung-Eui Yoon KAIST http://sglab.kaist.ac.kr Project Guidelines: Project Topics Any topics related to the course theme are okay You can find topics by browsing
Web-Scale Image Search and Their Applications Sung-Eui Yoon KAIST http://sglab.kaist.ac.kr Project Guidelines: Project Topics Any topics related to the course theme are okay You can find topics by browsing
Deep Learning on Graphs
 Deep Learning on Graphs with Graph Convolutional Networks Hidden layer Hidden layer Input Output ReLU ReLU, 22 March 2017 joint work with Max Welling (University of Amsterdam) BDL Workshop @ NIPS 2016
Deep Learning on Graphs with Graph Convolutional Networks Hidden layer Hidden layer Input Output ReLU ReLU, 22 March 2017 joint work with Max Welling (University of Amsterdam) BDL Workshop @ NIPS 2016
Decomposing a Scene into Geometric and Semantically Consistent Regions
 Decomposing a Scene into Geometric and Semantically Consistent Regions Stephen Gould sgould@stanford.edu Richard Fulton rafulton@cs.stanford.edu Daphne Koller koller@cs.stanford.edu IEEE International
Decomposing a Scene into Geometric and Semantically Consistent Regions Stephen Gould sgould@stanford.edu Richard Fulton rafulton@cs.stanford.edu Daphne Koller koller@cs.stanford.edu IEEE International
LSTM and its variants for visual recognition. Xiaodan Liang Sun Yat-sen University
 LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab.
 [ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
[ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform. Xintao Wang Ke Yu Chao Dong Chen Change Loy
 Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform Xintao Wang Ke Yu Chao Dong Chen Change Loy Problem enlarge 4 times Low-resolution image High-resolution image Previous
Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform Xintao Wang Ke Yu Chao Dong Chen Change Loy Problem enlarge 4 times Low-resolution image High-resolution image Previous
Tracking People. Tracking People: Context
 Tracking People A presentation of Deva Ramanan s Finding and Tracking People from the Bottom Up and Strike a Pose: Tracking People by Finding Stylized Poses Tracking People: Context Motion Capture Surveillance
Tracking People A presentation of Deva Ramanan s Finding and Tracking People from the Bottom Up and Strike a Pose: Tracking People by Finding Stylized Poses Tracking People: Context Motion Capture Surveillance
Learning to parse images of articulated bodies
 Learning to parse images of articulated bodies Deva Ramanan Toyota Technological Institute at Chicago Chicago, IL 60637 ramanan@tti-c.org Abstract We consider the machine vision task of pose estimation
Learning to parse images of articulated bodies Deva Ramanan Toyota Technological Institute at Chicago Chicago, IL 60637 ramanan@tti-c.org Abstract We consider the machine vision task of pose estimation
Using k-poselets for detecting people and localizing their keypoints
 Using k-poselets for detecting people and localizing their keypoints Georgia Gkioxari, Bharath Hariharan, Ross Girshick and itendra Malik University of California, Berkeley - Berkeley, CA 94720 {gkioxari,bharath2,rbg,malik}@berkeley.edu
Using k-poselets for detecting people and localizing their keypoints Georgia Gkioxari, Bharath Hariharan, Ross Girshick and itendra Malik University of California, Berkeley - Berkeley, CA 94720 {gkioxari,bharath2,rbg,malik}@berkeley.edu
arxiv: v2 [cs.cv] 4 Dec 2017
![arxiv: v2 [cs.cv] 4 Dec 2017](/thumbs/73/69442417.jpg "arxiv: v2 [cs.cv] 4 Dec 2017") Objects as context for detecting their semantic parts Abel Gonzalez-Garcia Davide Modolo Vittorio Ferrari a.gonzalez-garcia@sms.ed.ac.uk davide.modolo@gmail.com vferrari@staffmail.ed.ac.uk University of
Objects as context for detecting their semantic parts Abel Gonzalez-Garcia Davide Modolo Vittorio Ferrari a.gonzalez-garcia@sms.ed.ac.uk davide.modolo@gmail.com vferrari@staffmail.ed.ac.uk University of
arxiv: v1 [cs.cv] 20 Nov 2015
![arxiv: v1 [cs.cv] 20 Nov 2015](/thumbs/88/115969830.jpg "arxiv: v1 [cs.cv] 20 Nov 2015") eepcut: Joint Subset Partition and Labeling for Multi Person Pose Estimation Leonid Pishchulin, Eldar Insafutdinov, Siyu Tang, Bjoern Andres, Mykhaylo Andriluka,, Peter Gehler, and Bernt Schiele arxiv:.0v
eepcut: Joint Subset Partition and Labeling for Multi Person Pose Estimation Leonid Pishchulin, Eldar Insafutdinov, Siyu Tang, Bjoern Andres, Mykhaylo Andriluka,, Peter Gehler, and Bernt Schiele arxiv:.0v
SSD: Single Shot MultiBox Detector. Author: Wei Liu et al. Presenter: Siyu Jiang
 SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
Detection III: Analyzing and Debugging Detection Methods
 CS 1699: Intro to Computer Vision Detection III: Analyzing and Debugging Detection Methods Prof. Adriana Kovashka University of Pittsburgh November 17, 2015 Today Review: Deformable part models How can
CS 1699: Intro to Computer Vision Detection III: Analyzing and Debugging Detection Methods Prof. Adriana Kovashka University of Pittsburgh November 17, 2015 Today Review: Deformable part models How can
Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet.
 Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet 7D Labs VINNOVA https://7dlabs.com Photo-realistic image synthesis
Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet 7D Labs VINNOVA https://7dlabs.com Photo-realistic image synthesis
Multi-instance Object Segmentation with Occlusion Handling
 Multi-instance Object Segmentation with Occlusion Handling Yi-Ting Chen 1 Xiaokai Liu 1,2 Ming-Hsuan Yang 1 University of California at Merced 1 Dalian University of Technology 2 Abstract We present a
Multi-instance Object Segmentation with Occlusion Handling Yi-Ting Chen 1 Xiaokai Liu 1,2 Ming-Hsuan Yang 1 University of California at Merced 1 Dalian University of Technology 2 Abstract We present a
EE-559 Deep learning Networks for semantic segmentation
 EE-559 Deep learning 7.4. Networks for semantic segmentation François Fleuret https://fleuret.org/ee559/ Mon Feb 8 3:35:5 UTC 209 ÉCOLE POLYTECHNIQUE FÉDÉRALE DE LAUSANNE The historical approach to image
EE-559 Deep learning 7.4. Networks for semantic segmentation François Fleuret https://fleuret.org/ee559/ Mon Feb 8 3:35:5 UTC 209 ÉCOLE POLYTECHNIQUE FÉDÉRALE DE LAUSANNE The historical approach to image
Object Detection Based on Deep Learning
 Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling
 [DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
[DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
arxiv: v2 [cs.cv] 26 Apr 2016
![arxiv: v2 [cs.cv] 26 Apr 2016](/thumbs/75/72294067.jpg "arxiv: v2 [cs.cv] 26 Apr 2016") eepcut: Joint Subset Partition and Labeling for Multi Person Pose Estimation Leonid Pishchulin, Eldar Insafutdinov, Siyu Tang, Bjoern Andres, Mykhaylo Andriluka,, Peter Gehler, and Bernt Schiele arxiv:.0v
eepcut: Joint Subset Partition and Labeling for Multi Person Pose Estimation Leonid Pishchulin, Eldar Insafutdinov, Siyu Tang, Bjoern Andres, Mykhaylo Andriluka,, Peter Gehler, and Bernt Schiele arxiv:.0v
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Fast Online Upper Body Pose Estimation from Video
 CHANG et al.: FAST ONLINE UPPER BODY POSE ESTIMATION FROM VIDEO 1 Fast Online Upper Body Pose Estimation from Video Ming-Ching Chang 1,2 changm@ge.com Honggang Qi 1,3 hgqi@ucas.ac.cn Xin Wang 1 xwang26@albany.edu
CHANG et al.: FAST ONLINE UPPER BODY POSE ESTIMATION FROM VIDEO 1 Fast Online Upper Body Pose Estimation from Video Ming-Ching Chang 1,2 changm@ge.com Honggang Qi 1,3 hgqi@ucas.ac.cn Xin Wang 1 xwang26@albany.edu
OCCLUSION BOUNDARIES ESTIMATION FROM A HIGH-RESOLUTION SAR IMAGE
 OCCLUSION BOUNDARIES ESTIMATION FROM A HIGH-RESOLUTION SAR IMAGE Wenju He, Marc Jäger, and Olaf Hellwich Berlin University of Technology FR3-1, Franklinstr. 28, 10587 Berlin, Germany {wenjuhe, jaeger,
OCCLUSION BOUNDARIES ESTIMATION FROM A HIGH-RESOLUTION SAR IMAGE Wenju He, Marc Jäger, and Olaf Hellwich Berlin University of Technology FR3-1, Franklinstr. 28, 10587 Berlin, Germany {wenjuhe, jaeger,
LEARNING BOUNDARIES WITH COLOR AND DEPTH. Zhaoyin Jia, Andrew Gallagher, Tsuhan Chen
 LEARNING BOUNDARIES WITH COLOR AND DEPTH Zhaoyin Jia, Andrew Gallagher, Tsuhan Chen School of Electrical and Computer Engineering, Cornell University ABSTRACT To enable high-level understanding of a scene,
LEARNING BOUNDARIES WITH COLOR AND DEPTH Zhaoyin Jia, Andrew Gallagher, Tsuhan Chen School of Electrical and Computer Engineering, Cornell University ABSTRACT To enable high-level understanding of a scene,
Fashion Analytics and Systems
 Learning and Vision Group, NUS (NUS-LV) Fashion Analytics and Systems Shuicheng YAN eleyans@nus.edu.sg National University of Singapore [ Special thanks to Luoqi LIU, Xiaodan LIANG, Si LIU, Jianshu LI]
Learning and Vision Group, NUS (NUS-LV) Fashion Analytics and Systems Shuicheng YAN eleyans@nus.edu.sg National University of Singapore [ Special thanks to Luoqi LIU, Xiaodan LIANG, Si LIU, Jianshu LI]
Interpretable Structure-Evolving LSTM
 Interpretable Structure-Evolving LSTM Xiaodan Liang 1,2 Liang Lin 2,5 Xiaohui Shen 4 Jiashi Feng 3 Shuicheng Yan 3 Eric P. Xing 1 1 Carnegie Mellon University 2 Sun Yat-sen University 3 National University
Interpretable Structure-Evolving LSTM Xiaodan Liang 1,2 Liang Lin 2,5 Xiaohui Shen 4 Jiashi Feng 3 Shuicheng Yan 3 Eric P. Xing 1 1 Carnegie Mellon University 2 Sun Yat-sen University 3 National University
Deep Learning for Face Recognition. Xiaogang Wang Department of Electronic Engineering, The Chinese University of Hong Kong
 Deep Learning for Face Recognition Xiaogang Wang Department of Electronic Engineering, The Chinese University of Hong Kong Deep Learning Results on LFW Method Accuracy (%) # points # training images Huang
Deep Learning for Face Recognition Xiaogang Wang Department of Electronic Engineering, The Chinese University of Hong Kong Deep Learning Results on LFW Method Accuracy (%) # points # training images Huang
arxiv: v1 [cs.cv] 11 Apr 2018
![arxiv: v1 [cs.cv] 11 Apr 2018](/thumbs/89/99253021.jpg "arxiv: v1 [cs.cv] 11 Apr 2018") arxiv:1804.03821v1 [cs.cv] 11 Apr 2018 ExFuse: Enhancing Feature Fusion for Semantic Segmentation Zhenli Zhang 1, Xiangyu Zhang 2, Chao Peng 2, Dazhi Cheng 3, Jian Sun 2 1 Fudan University, 2 Megvii Inc.
arxiv:1804.03821v1 [cs.cv] 11 Apr 2018 ExFuse: Enhancing Feature Fusion for Semantic Segmentation Zhenli Zhang 1, Xiangyu Zhang 2, Chao Peng 2, Dazhi Cheng 3, Jian Sun 2 1 Fudan University, 2 Megvii Inc.