Clustering Tips and Tricks in 45 minutes (maybe more :)
|
|
|
- Beatrice O’Brien’
- 5 years ago
- Views:
Transcription
1 Clustering Tips and Tricks in 45 minutes (maybe more :) Olfa Nasraoui, University of Louisville Tutorial for the Data Science for Social Good Fellowship 2015 cohort of Chicago Acknowledgment: many sources collected throughout years of teaching from textbook slides, etc, in particular Tan et al
2 Roadmap Problem Definition and Examples (2 min) Major Families of Algorithms (2 min) Recipe Book (15 min) Types of inputs, Nature of data, Desired outputs Algorithm choice (5 min) Nature of data Distance / Similarity measure choice (5 min) Validation (5 min) Presentation Interpretation (5 min) Challenges (10 min) o Expanding on 1 number of clusters, outliers, large data, high dimensional data, sparse data, mixed /heterogeneous data types, nestedness, domain knowledge: a few labels/constraints Python Info (10 min)
3 Definition of Clustering Finding groups of objects such that: the objects in a group will be similar (or related) to one another and the objects in a group will be different from (or unrelated to) the objects in other groups Intra-cluster distances are minimized Inter-cluster distances are maximized
4 Application Examples Marketing: Discover groups of customers with similar purchase patterns or similar demographics Land use: Find areas of similar land use in an earth observation database City-planning: Identify groups of houses according to their house type, value, and geographical location Web Usage Profiling: find groups of users with similar usage or interests on a website Document Organization: find groups of documents about similar topics Summarization or Data Reduction: Reduce size of large data sets can be better than random sampling 1) Cluster into large # of clusters 2) then use cluster centroids Discretize Numerical attributes: 1) Cluster numerical attribute into partitions 2) Then consider each partition (group) 1 categorical value Imputate Missing Values : Cluster attribute values Replace missing value with cluster center
5 Clustering Steps

6 What is your input?
 Example: Kernel matrix (for kernel")

7 Input Data Types for Clustering Data matrix (two modes) Dissimilarity matrix (one mode) Example: Kernel matrix (for kernel clustering algorithms) Adjacency or relationship matrix in social graph Or you can compute the distance matrix from every pair of data points 7


8 What is Your Desired Output? C. Rojas 8






9 A Few Specialty Algorithms Depending on the Data Numerical data k-means, DBSCAN, etc. Categorical data k-modes, ROCK, CACTUS, etc. Transactional or text data spherical k-means, Bisecting K-means Graph data KMETIS, spectral clustering, etc. 9
10 Types of Clustering Partitional Clustering A division of data objects into non-overlapping subsets (clusters) This division is called a partition Can also be overlapping (soft clusters) Fuzzy clustering Most probabilstic/ model-based clustering Hierarchical clustering A set of nested clusters organized as a hierarchical tree, Tree is called dendogram Density-based clustering A cluster is a dense region of points, which is separated by low-density regions, from other regions of high density. Used when the clusters are irregular or intertwined, and when noise and outliers are present.

11 Partitional Clustering Original Points A Partitional Clustering


12 Hierarchical Clustering Traditional Hierarchical Clustering Traditional Dendogram Non-traditional Hierarchical Clustering Non-traditional Dendogram
13 6 Density Based Clusters
14 K-means Clustering Partitional clustering approach Each cluster is associated with a centroid (center point) Each point is assigned to the cluster with the closest centroid Number of clusters, K, must be specified The basic algorithm is very simple x x
15 Bisecting K-means Bisecting K-means algorithm Variant of K-means that can produce a partitional or a hierarchical clustering // and remove it from list of clusters // repeat several trial bisections to find the best // i.e. split it in 2
16 Hierarchical Clustering Two main types of hierarchical clustering Agglomerative: Start with the points as individual clusters At each step, merge the closest pair of clusters until only one cluster (or k clusters) left Divisive: Start with one, all-inclusive cluster At each step, split a cluster until each cluster contains a point (or there are k clusters) Traditional hierarchical algorithms use a similarity or distance matrix Merge or split one cluster at a time
17 Agglomerative Clustering Algorithm Most popular hierarchical clustering technique Basic algorithm is straightforward Compute the proximity matrix Let each data point be a cluster Repeat Merge the two closest clusters Update the proximity matrix Until only a single cluster remains Key operation is the computation of the proximity of two clusters Different approaches to defining the distance between clusters distinguish the different algorithms
18 How to Define Inter-Cluster Similarity p1 Similarity? p2 p3 p4 p5 p1 p2 p3 p4 MIN MAX Group Average Distance Between Centroids Other methods driven by an objective function Ward s Method uses squared error p5... Proximity Matrix...
19 How to Define Inter-Cluster Similarity p1 p2 p3 p4 p5 p1 p2 p3 p4 MIN MAX Group Average Distance Between Centroids Other methods driven by an objective function Ward s Method uses squared error p5... Proximity Matrix...
20 How to Define Inter-Cluster Similarity p1 p2 p3 p4 p5 p1 p2 p3 p4 MIN MAX Group Average Distance Between Centroids Other methods driven by an objective function Ward s Method uses squared error p5... Proximity Matrix...
21 How to Define Inter-Cluster Similarity p1 p2 p3 p4 p5 p1 p2 p3 p4 MIN MAX Group Average Distance Between Centroids Other methods driven by an objective function Ward s Method uses squared error p5... Proximity Matrix...
22 How to Define Inter-Cluster Similarity p1 p2 p3 p4 p5 p1 p2 p3 p4 MIN MAX Group Average Distance Between Centroids Other methods driven by an objective function Ward s Method uses squared error p5... Proximity Matrix...
23 Strength of MIN Original Points Two Clusters Can handle non-elliptical shapes
24 Limitations of MIN Original Points Two Clusters Sensitive to noise and outliers
25 MST: Divisive Hierarchical Clustering (2 steps) STEP 1: Build MST (Minimum Spanning Tree) Start with a tree that consists of any point In successive steps, look for the closest pair of points (p, q) such that one point (p) is in the current tree but the other (q) is not in tree Add q to the tree and put an edge between p and q
26 MST: Divisive Hierarchical Clustering STEP 2: Build Hierarchy: Use MST for constructing hierarchy of clusters: starts with MST from STEP 1, then gradually removes one edge (the one with highest distance) at a time (thus dividing clusters) to obtain a hierarchy
27 Density-based Clustering: DBSCAN DBSCAN is a density-based algorithm. Density = number of points within a specified radius (Eps) A point is a core point if it has more than a specified Minimum number of points (MinPts) within Eps These are points that are at the interior of a cluster A border point has fewer than MinPts within Eps, but is in the neighborhood of a core point i.e.: Not a CORE pt, but close to a CORE pt A noise point is any point that is not a core point and not a border point.
28 DBSCAN: Core, Border, and Noise Points
29 DBSCAN Algorithm Label all pts as CORE, BORDER, or NOISE Eliminate noise points Perform clustering on the remaining points Put an edge between all CORE pts within Eps of each other Make each group of connected CORE pts into a separate cluster (i.e. give them a cluster label) Assign each BORDER pt to one of the clusters of its associated CORE pts
30 DBSCAN: Core, Border and Noise Points Original Points Point types: core, border and noise Eps = 10, MinPts = 4
31 When DBSCAN Works Well Original Points Clusters Resistant to Noise Can handle clusters of different shapes and sizes
32 DBSCAN: Determining EPS and MinPts Idea is that for points in a cluster, their kth nearest neighbors are at roughly the same distance Noise points have the kth nearest neighbor at farther distance So, plot sorted distance of every point to its kth nearest neighbor, choose dist where max jump occurs (the knee)
33
34
35
36
37 Distance and Similarity Measures
38 Distance functions Key to clustering. similarity and dissimilarity can also commonly used terms. There are numerous distance functions for Different types of data Numeric data Nominal data Different specific applications 38
39 Distance functions for numeric attributes Most commonly used functions are Euclidean distance and Manhattan (city block) distance We denote distance with: dist(xi, xj), where xi and xj are data points (vectors) They are special cases of Minkowski distance. h is positive integer. 39
40 Euclidean distance and Manhattan distance If h = 2, it is the Euclidean distance If h = 1, it is the Manhattan distance Weighted Euclidean distance 40
41 Squared distance and Chebychev distance Squared Euclidean distance: to place progressively greater weight on data points that are further apart. Chebychev distance: one wants to define two data points as "different" if they are different on any one of the attributes. 41
42 Distance functions for binary and nominal attributes Binary attribute: has two values or states but no ordering relationships, e.g., Gender: male and female. We use a confusion matrix to introduce the distance functions/measures. Let the ith and jth data points be xi and xj (vectors) 42
43 Contingency matrix 43

44 Symmetric binary attributes A binary attribute is symmetric if both of its states (0 and 1) have equal importance, and carry the same weights, e.g., male and female of the attribute Gender Distance function: Simple Matching Coefficient, proportion of mismatches of their values 44
45 Symmetric binary attributes: example 45

46 Asymmetric binary attributes (this is the most important attribute for TEXT, Transactions, Web sessions, etc) Asymmetric: if one of the states is more important or more valuable than the other. By convention, state 1 represents the more important state, which is typically the rare or infrequent state. Jaccard coefficient is a popular measure We can have some variations, adding weights, etc 46

47 Nominal attributes Nominal attributes: with more than two states or values. the commonly used distance measure is also based on the simple matching method. Given two data points xi and xj, let the number of attributes be r, and the number of values that match in xi and xj be q. 47
48 Distance function for text documents A text document consists of a sequence of sentences and each sentence consists of a sequence of words. To simplify: a document is usually considered a bag of words in document clustering. Sequence and position of words are ignored. A document is represented with a vector just like a normal data point. TF-IDF (or simple binary), remember to eliminate rare and overly-frequent terms It is common to use similarity to compare two documents rather than distance. The most commonly used similarity function is the cosine similarity. 48
49 Mutual Neighbor Distance With NN(x, y) the neighbor number of x with respect to y. MND is not symmetric (it is not a metric)
50 Cluster Validation
51 Measures of Cluster Validity Numerical measures that are applied to judge various aspects of cluster validity, are classified into the following three types. External Index: Used to measure the extent to which cluster labels match externally supplied class labels. Entropy Internal Index: Used to measure the goodness of a clustering structure without external information. E.g. Sum of Squared Error (SSE) Relative Index: Used to compare two different clusterings or clusters. Often an external or internal index is used for this function, e.g., SSE or entropy
52 Measuring Cluster Validity Via Correlation Two matrices Proximity Matrix (P(i,j) = similarity or distance between pt i and pt j) Incidence Matrix ( I(i,j) =1 if in same cluster) Compute the correlation between the two matrices P and I One row and one column for each data point An entry is 1 if the associated pair of points belong to the same cluster An entry is 0 if the associated pair of points belongs to different clusters Since the matrices are symmetric, only the correlation between n(n-1) / 2 entries needs to be calculated. High correlation indicates that points that belong to the same cluster are close to each other. Not a good measure for some density or contiguity based clusters.
53 Measuring Cluster Validity Via Correlation Correlation of incidence and proximity matrices for the K-means clusterings of the following two data sets. (close to Corr = (close to -1 because distance instead of similarity was used as proximity) Corr = (closer to 0)
54 Using Similarity Matrix for Cluster Validation Order the similarity matrix with respect to cluster labels and inspect visually. you see clusters/blocks in matrix

55 Using Similarity Matrix for Cluster Validation Clusters in random data are not so crisp DBSCAN
56 Using Similarity Matrix for Cluster Validation Clusters in random data are not so crisp K-means
57 Using Similarity Matrix for Cluster Validation Clusters in random data are not so crisp Complete Link
58 Using Similarity Matrix for Cluster Validation DBSCAN
59 Internal Measures: SSE Clusters in more complicated figures aren t well separated Internal Index: Used to measure the goodness of a clustering structure without respect to external information SSE SSE is good for comparing two clusterings or two clusters (average SSE). Can also be used to estimate the number of clusters (but with reservations since SSE is biased by K!!!)
60 Internal Measures: SSE SSE curve for a more complicated data set SSE of clusters found using K-means
61 Cluster Presentation & Interpretation Dendogram (hierarchy) Cluster Summary Centroid Size of cluster Cluster representative (medoid) Frequent words Frequent categories Pie charts histograms of attributes Parallel Coordinates Discriminating Rules
62 Using classification model All the data points in a cluster are regarded to have the same class label, e.g., the cluster ID. run a supervised learning algorithm on the data to find a classification model. 62
63 Use frequent values to represent cluster This method is mainly for clustering of categorical data (e.g., k-modes clustering). Main method used in text clustering, where a small set of frequent words in each cluster is selected to represent the cluster. 63

64

65 Clustering Dolphins: Pie charts of the relative frequencies of specific events within the cluster categories and hierarchical Cluster Analysis of the Behaviours set a/
66
67 Critical Issues Initialization! How to determine the number of clusters? How to handle outliers? How to handle large data sets? How to handle high dimensional data? Includes sparse data How to handle Mixed /heterogeneous data types? Nested Attributes are related in a concept hierarchy Domain knowledge: a few labels/constraints (semi-supervised clustering) Cluster must have min size (constrained K-means) Need Reliable Clustering? Clustering Ensembles
68 Solutions to Initial Centroids Problem Multiple runs Helps, but probability is not on your side if too much data + high dimensionality Sample data Then use hierarchical clustering to determine initial centroids Select more than K initial centroids and then select among these initial centroids in the end Select most widely separated Ensemble Clustering Produce many different clustering results Combine into consensus Bisecting K-means Not as susceptible to initialization issues Global Optimization Simulated Annealing; Genetic algorithms
69 How many clusters? How many clusters? 6 Clusters 2 Clusters 4 Clusters
70 Cluster Stability Algorithm: Choose k with most stable cluster results
71 Gap Statistic
72 Python Specific Info Each clustering algorithm comes in two variants: 1. a class, that implements the fit method to learn the clusters on train data, and 2. a function, that, given train data, returns an array of integer labels corresponding to the different clusters. For the class, the labels over the training data can be found in the labels_ attribute.
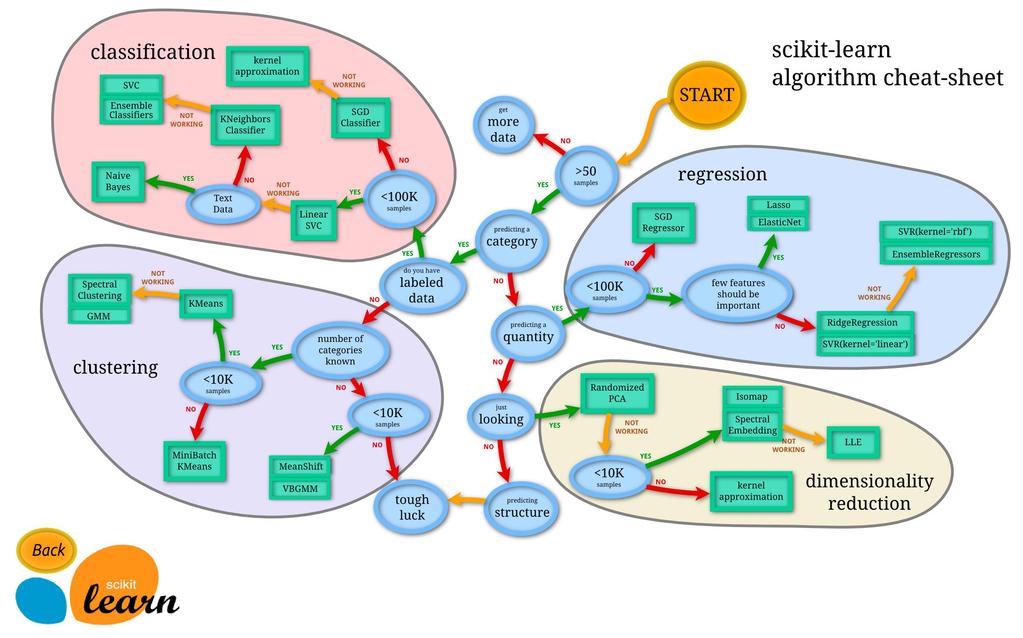
73
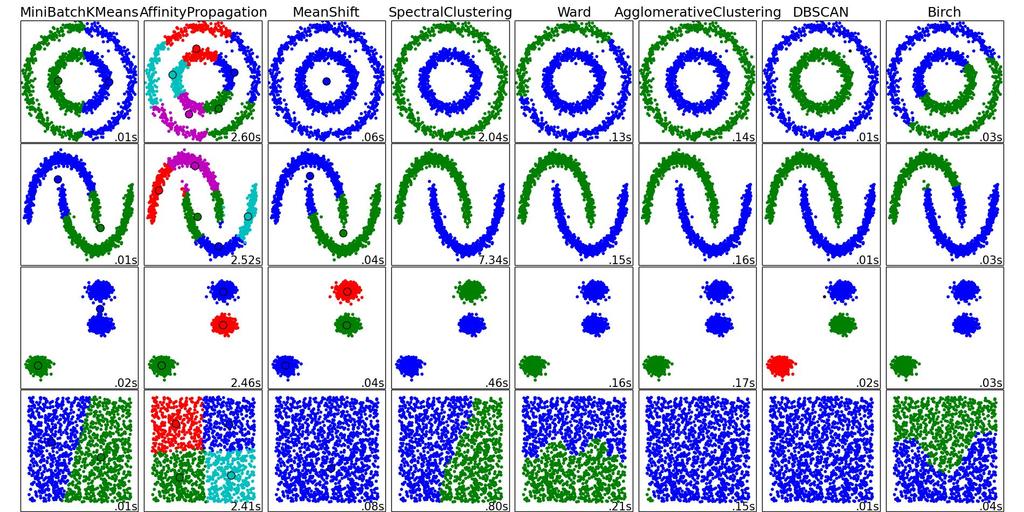
74 Scikit-learn
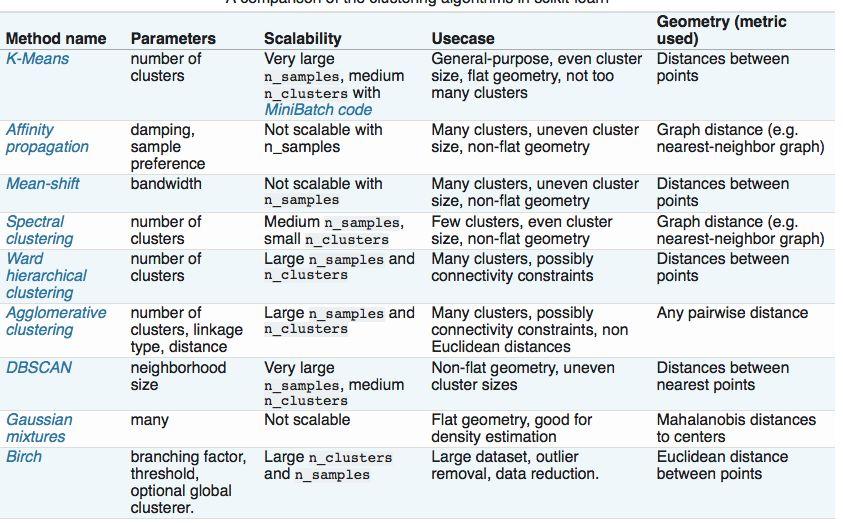
75 Scikit-learn
76 Initializing K-means K-means can converge to a local minimum, depending on the initialization of the centroids. As a result, the computation is often done several times, with different initializations of the centroids. k-means++ initialization scheme: method to help address this issue implemented in scikit-learn use the init='kmeans++' parameter. This initializes the centroids to be (generally) distant from each other, leading to provably better results than random initialization, as shown in the reference. k-means++: The advantages of careful seeding Arthur, David, and Sergei Vassilvitskii, Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms, Society for Industrial and Applied Mathematics (2007)
77 Mini Batch K-Means The MiniBatchKMeans is a variant of the KMeans algorithm which uses mini-batches to reduce the computation time while still attempting to optimize the same objective function. Mini-batches = subsets of the input data, randomly sampled in each training iteration For each sample in the mini-batch, the assigned centroid is updated by taking the streaming average of the sample and all previous samples assigned to that centroid. converges faster than KMeans, but the quality of the results is reduced.
78 Clustering text documents using k-means A good example: ustering.html#example-text-document-clustering-py 2 feature extraction methods can be used in this example: TfidfVectorizer HashingVectorizer Word count vectors are then normalized to each have L2-norm =1 projected to the Euclidean unit-ball => Spherical K-Means 2 algorithms are demoed: ordinary k-means and more scalable minibatch k-means. Several runs with independent random initialization might be necessary to get a good convergence. Or use kmeans++
79 Clustering text documents using k-means (Feature extraction & transformation details) TfidfVectorizer uses a in-memory vocabulary (a python dict) to map the most frequent words to features indices hence compute a word occurrence frequency (sparse) matrix. IDF: The word frequencies are then reweighted using the Inverse Document Frequency (IDF) vector collected feature-wise over the corpus. reduces weight of words that are very common (occur in many documents) They are not helpful to discriminate between clusters or classes HashingVectorizer hashes word occurrences to a fixed dimensional space, possibly with collisions. HashingVectorizer does not provide IDF weighting. IDF weighting: If needed, add it by pipelining its output to a TfidfTransformer instance. SVD reduces dimensionality captures semantics (related words)
80 Validation ng.html#clustering-evaluation Several cluster validation metrics including RAND index, Silhouette, Mutual Information Scores, Homogeneity, Compactness, V-Measure Gap statistic also available
81 Density based (also good for spatial) clustering DBSCAN: ted/sklearn.cluster.dbscan.html#sklearn.clus ter.dbscan
82 Large Data Sets that can t fit in memory: BIRCH Birch builds a tree called the Characteristic Feature Tree (CFT) for the given data. The data is essentially lossy compressed to a set of Characteristic Feature nodes (CF Nodes). The CF Nodes have a number of CF subclusters CF Subclusters located in the non-terminal CF Nodes can have CF Nodes as children. The CF Subclusters hold the necessary information for clustering which prevents the need to hold the entire input data in memory: Number of samples in a subcluster. Linear Sum - A n-dimensional vector holding the sum of all samples Squared Sum - Sum of the squared L2 norm of all samples. Centroids - To avoid recalculation linear sum / n_samples. Squared norm of the centroids.
83 Birch or MiniBatchKMeans? Birch does not scale very well to high dimensional data. As a rule of thumb if n_features > 20 use MiniBatchKMeans. Birch is more useful than MiniBatchKMeans: If # data instances needs to be reduced, or need a large number of subclusters either as a preprocessing step or otherwise
84 Unfinished Recipe for Clustering Next slide :)
85 A Recipe for Clustering Clustering Recipe To be continued. Olfa Nasraoui
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
DATA MINING LECTURE 7. Hierarchical Clustering, DBSCAN The EM Algorithm
 DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/4 What
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/4 What
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/004 What
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/004 What
University of Florida CISE department Gator Engineering. Clustering Part 5
 Clustering Part 5 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville SNN Approach to Clustering Ordinary distance measures have problems Euclidean
Clustering Part 5 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville SNN Approach to Clustering Ordinary distance measures have problems Euclidean
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/09/2018)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
Cluster analysis. Agnieszka Nowak - Brzezinska
 Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
DATA MINING - 1DL105, 1Dl111. An introductory class in data mining
 1 DATA MINING - 1DL105, 1Dl111 Fall 007 An introductory class in data mining http://user.it.uu.se/~udbl/dm-ht007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
1 DATA MINING - 1DL105, 1Dl111 Fall 007 An introductory class in data mining http://user.it.uu.se/~udbl/dm-ht007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
CSE 347/447: DATA MINING
 CSE 347/447: DATA MINING Lecture 6: Clustering II W. Teal Lehigh University CSE 347/447, Fall 2016 Hierarchical Clustering Definition Produces a set of nested clusters organized as a hierarchical tree
CSE 347/447: DATA MINING Lecture 6: Clustering II W. Teal Lehigh University CSE 347/447, Fall 2016 Hierarchical Clustering Definition Produces a set of nested clusters organized as a hierarchical tree
Road map. Basic concepts
 Clustering Basic concepts Road map K-means algorithm Representation of clusters Hierarchical clustering Distance functions Data standardization Handling mixed attributes Which clustering algorithm to use?
Clustering Basic concepts Road map K-means algorithm Representation of clusters Hierarchical clustering Distance functions Data standardization Handling mixed attributes Which clustering algorithm to use?
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
University of Florida CISE department Gator Engineering. Clustering Part 4
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning. Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi
 Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
Clustering Part 4 DBSCAN
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/10/2017)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar (modified by Predrag Radivojac, 07) Old Faithful Geyser Data
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar (modified by Predrag Radivojac, 07) Old Faithful Geyser Data
Unsupervised Learning. Supervised learning vs. unsupervised learning. What is Cluster Analysis? Applications of Cluster Analysis
 7 Supervised learning vs unsupervised learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These patterns are then
7 Supervised learning vs unsupervised learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These patterns are then
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Clustering. Chapter 10 in Introduction to statistical learning
 Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Slides From Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Cluster Analysis: Basic Concepts and Algorithms
 Cluster Analysis: Basic Concepts and Algorithms Data Warehousing and Mining Lecture 10 by Hossen Asiful Mustafa What is Cluster Analysis? Finding groups of objects such that the objects in a group will
Cluster Analysis: Basic Concepts and Algorithms Data Warehousing and Mining Lecture 10 by Hossen Asiful Mustafa What is Cluster Analysis? Finding groups of objects such that the objects in a group will
Introduction to Clustering
 Introduction to Clustering Ref: Chengkai Li, Department of Computer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) What is Cluster Analysis? Finding groups of
Introduction to Clustering Ref: Chengkai Li, Department of Computer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) What is Cluster Analysis? Finding groups of
What is Cluster Analysis?
 Cluster Analysis What is Cluster Analysis? Finding groups of objects (data points) such that the objects in a group will be similar (or related) to one another and different from (or unrelated to) the
Cluster Analysis What is Cluster Analysis? Finding groups of objects (data points) such that the objects in a group will be similar (or related) to one another and different from (or unrelated to) the
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Hierarchical Clustering
 Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
数据挖掘 Introduction to Data Mining
 数据挖掘 Introduction to Data Mining Philippe Fournier-Viger Full professor School of Natural Sciences and Humanities philfv8@yahoo.com Spring 2019 S8700113C 1 Introduction Last week: Association Analysis
数据挖掘 Introduction to Data Mining Philippe Fournier-Viger Full professor School of Natural Sciences and Humanities philfv8@yahoo.com Spring 2019 S8700113C 1 Introduction Last week: Association Analysis
University of Florida CISE department Gator Engineering. Clustering Part 2
 Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest)
") Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
CS7267 MACHINE LEARNING
 S7267 MAHINE LEARNING HIERARHIAL LUSTERING Ref: hengkai Li, Department of omputer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) Mingon Kang, Ph.D. omputer Science,
S7267 MAHINE LEARNING HIERARHIAL LUSTERING Ref: hengkai Li, Department of omputer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) Mingon Kang, Ph.D. omputer Science,
Lecture Notes for Chapter 7. Introduction to Data Mining, 2 nd Edition. by Tan, Steinbach, Karpatne, Kumar
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Hierarchical Clustering Produces a set
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Hierarchical Clustering Produces a set
Data Mining Concepts & Techniques
 Data Mining Concepts & Techniques Lecture No 08 Cluster Analysis Naeem Ahmed Email: naeemmahoto@gmailcom Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro Outline
Data Mining Concepts & Techniques Lecture No 08 Cluster Analysis Naeem Ahmed Email: naeemmahoto@gmailcom Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro Outline
Clustering in Data Mining
 Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering Lecture 4: Density-based Methods
 Clustering Lecture 4: Density-based Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering Lecture 4: Density-based Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering Part 3. Hierarchical Clustering
 Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
Clustering Lecture 3: Hierarchical Methods
 Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Knowledge Discovery in Databases
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture notes Knowledge Discovery in Databases Summer Semester 2012 Lecture 8: Clustering
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture notes Knowledge Discovery in Databases Summer Semester 2012 Lecture 8: Clustering
Clustering Basic Concepts and Algorithms 1
 Clustering Basic Concepts and Algorithms 1 Jeff Howbert Introduction to Machine Learning Winter 014 1 Machine learning tasks Supervised Classification Regression Recommender systems Reinforcement learning
Clustering Basic Concepts and Algorithms 1 Jeff Howbert Introduction to Machine Learning Winter 014 1 Machine learning tasks Supervised Classification Regression Recommender systems Reinforcement learning
Data Mining. Clustering. Hamid Beigy. Sharif University of Technology. Fall 1394
 Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A
 MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
Unsupervised Data Mining: Clustering. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Lecture Notes for Chapter 7. Introduction to Data Mining, 2 nd Edition. by Tan, Steinbach, Karpatne, Kumar
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, nd Edition by Tan, Steinbach, Karpatne, Kumar What is Cluster Analysis? Finding groups
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, nd Edition by Tan, Steinbach, Karpatne, Kumar What is Cluster Analysis? Finding groups
Chapter 4: Text Clustering
 4.1 Introduction to Text Clustering Clustering is an unsupervised method of grouping texts / documents in such a way that in spite of having little knowledge about the content of the documents, we can
4.1 Introduction to Text Clustering Clustering is an unsupervised method of grouping texts / documents in such a way that in spite of having little knowledge about the content of the documents, we can
5/15/16. Computational Methods for Data Analysis. Massimo Poesio UNSUPERVISED LEARNING. Clustering. Unsupervised learning introduction
 Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
CS 1675 Introduction to Machine Learning Lecture 18. Clustering. Clustering. Groups together similar instances in the data sample
 CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
Chapter DM:II. II. Cluster Analysis
 Chapter DM:II II. Cluster Analysis Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained Cluster Analysis DM:II-1
Chapter DM:II II. Cluster Analysis Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained Cluster Analysis DM:II-1
Unsupervised Learning. Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team
 Unsupervised Learning Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team Table of Contents 1)Clustering: Introduction and Basic Concepts 2)An Overview of Popular Clustering Methods 3)Other Unsupervised
Unsupervised Learning Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team Table of Contents 1)Clustering: Introduction and Basic Concepts 2)An Overview of Popular Clustering Methods 3)Other Unsupervised
Data Mining: Concepts and Techniques. Chapter March 8, 2007 Data Mining: Concepts and Techniques 1
 Data Mining: Concepts and Techniques Chapter 7.1-4 March 8, 2007 Data Mining: Concepts and Techniques 1 1. What is Cluster Analysis? 2. Types of Data in Cluster Analysis Chapter 7 Cluster Analysis 3. A
Data Mining: Concepts and Techniques Chapter 7.1-4 March 8, 2007 Data Mining: Concepts and Techniques 1 1. What is Cluster Analysis? 2. Types of Data in Cluster Analysis Chapter 7 Cluster Analysis 3. A
CS570: Introduction to Data Mining
 CS570: Introduction to Data Mining Scalable Clustering Methods: BIRCH and Others Reading: Chapter 10.3 Han, Chapter 9.5 Tan Cengiz Gunay, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei.
CS570: Introduction to Data Mining Scalable Clustering Methods: BIRCH and Others Reading: Chapter 10.3 Han, Chapter 9.5 Tan Cengiz Gunay, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei.
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis. Angela Montanari and Laura Anderlucci
 Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Contents. Preface to the Second Edition
 Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
Workload Characterization Techniques
 Workload Characterization Techniques Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 Jain@cse.wustl.edu These slides are available on-line at: http://www.cse.wustl.edu/~jain/cse567-08/
Workload Characterization Techniques Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 Jain@cse.wustl.edu These slides are available on-line at: http://www.cse.wustl.edu/~jain/cse567-08/
Cluster Analysis. CSE634 Data Mining
 Cluster Analysis CSE634 Data Mining Agenda Introduction Clustering Requirements Data Representation Partitioning Methods K-Means Clustering K-Medoids Clustering Constrained K-Means clustering Introduction
Cluster Analysis CSE634 Data Mining Agenda Introduction Clustering Requirements Data Representation Partitioning Methods K-Means Clustering K-Medoids Clustering Constrained K-Means clustering Introduction
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Olmo S. Zavala Romero. Clustering Hierarchical Distance Group Dist. K-means. Center of Atmospheric Sciences, UNAM.
 Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
COMP 465: Data Mining Still More on Clustering
 3/4/015 Exercise COMP 465: Data Mining Still More on Clustering Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Describe each of the following
3/4/015 Exercise COMP 465: Data Mining Still More on Clustering Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Describe each of the following
MSA220 - Statistical Learning for Big Data
 MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
Understanding Clustering Supervising the unsupervised
 Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
What to come. There will be a few more topics we will cover on supervised learning
 Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
DS504/CS586: Big Data Analytics Big Data Clustering II
 Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: AK 232 Fall 2016 More Discussions, Limitations v Center based clustering K-means BFR algorithm
Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: AK 232 Fall 2016 More Discussions, Limitations v Center based clustering K-means BFR algorithm
Clustering part II 1
 Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Clustering fundamentals
 Elena Baralis, Tania Cerquitelli Politecnico di Torino What is Cluster Analsis? Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from
Elena Baralis, Tania Cerquitelli Politecnico di Torino What is Cluster Analsis? Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from
Data Mining Algorithms
 for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
DS504/CS586: Big Data Analytics Big Data Clustering II
 Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: KH 116 Fall 2017 Updates: v Progress Presentation: Week 15: 11/30 v Next Week Office hours
Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: KH 116 Fall 2017 Updates: v Progress Presentation: Week 15: 11/30 v Next Week Office hours
Cluster Analysis: Basic Concepts and Algorithms
 7 Cluster Analysis: Basic Concepts and Algorithms Cluster analysis divides data into groups (clusters) that are meaningful, useful, or both. If meaningful groups are the goal, then the clusters should
7 Cluster Analysis: Basic Concepts and Algorithms Cluster analysis divides data into groups (clusters) that are meaningful, useful, or both. If meaningful groups are the goal, then the clusters should
Hierarchical Clustering
 Hierarchical Clustering Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree-like diagram that records the sequences of merges
Hierarchical Clustering Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree-like diagram that records the sequences of merges
Statistics 202: Data Mining. c Jonathan Taylor. Week 8 Based in part on slides from textbook, slides of Susan Holmes. December 2, / 1
 Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Contents. List of Figures. List of Tables. List of Algorithms. I Clustering, Data, and Similarity Measures 1
 Contents List of Figures List of Tables List of Algorithms Preface xiii xv xvii xix I Clustering, Data, and Similarity Measures 1 1 Data Clustering 3 1.1 Definition of Data Clustering... 3 1.2 The Vocabulary
Contents List of Figures List of Tables List of Algorithms Preface xiii xv xvii xix I Clustering, Data, and Similarity Measures 1 1 Data Clustering 3 1.1 Definition of Data Clustering... 3 1.2 The Vocabulary
Lesson 3. Prof. Enza Messina
 Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Unsupervised Learning Partitioning Methods
 Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
DATA MINING II - 1DL460
 DATA MINING II - 1DL460 Spring 2017 A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt17 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
DATA MINING II - 1DL460 Spring 2017 A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt17 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Statistics 202: Data Mining. c Jonathan Taylor. Clustering Based in part on slides from textbook, slides of Susan Holmes.
 Clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group will be similar (or
Clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group will be similar (or
Clustering. Shishir K. Shah
 Clustering Shishir K. Shah Acknowledgement: Notes by Profs. M. Pollefeys, R. Jin, B. Liu, Y. Ukrainitz, B. Sarel, D. Forsyth, M. Shah, K. Grauman, and S. K. Shah Clustering l Clustering is a technique
Clustering Shishir K. Shah Acknowledgement: Notes by Profs. M. Pollefeys, R. Jin, B. Liu, Y. Ukrainitz, B. Sarel, D. Forsyth, M. Shah, K. Grauman, and S. K. Shah Clustering l Clustering is a technique
Table Of Contents: xix Foreword to Second Edition
 Data Mining : Concepts and Techniques Table Of Contents: Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments xxxi About the Authors xxxv Chapter 1 Introduction 1 (38) 1.1 Why Data
Data Mining : Concepts and Techniques Table Of Contents: Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments xxxi About the Authors xxxv Chapter 1 Introduction 1 (38) 1.1 Why Data
Forestry Applied Multivariate Statistics. Cluster Analysis
 1 Forestry 531 -- Applied Multivariate Statistics Cluster Analysis Purpose: To group similar entities together based on their attributes. Entities can be variables or observations. [illustration in Class]
1 Forestry 531 -- Applied Multivariate Statistics Cluster Analysis Purpose: To group similar entities together based on their attributes. Entities can be variables or observations. [illustration in Class]
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining /8/ What is Cluster
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining /8/ What is Cluster
Clustering Documentation
 Clustering Documentation Release 0.3.0 Dahua Lin and contributors Dec 09, 2017 Contents 1 Overview 3 1.1 Inputs................................................... 3 1.2 Common Options.............................................
Clustering Documentation Release 0.3.0 Dahua Lin and contributors Dec 09, 2017 Contents 1 Overview 3 1.1 Inputs................................................... 3 1.2 Common Options.............................................
Hierarchical clustering
 Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
Clustering and Dissimilarity Measures. Clustering. Dissimilarity Measures. Cluster Analysis. Perceptually-Inspired Measures
 Clustering and Dissimilarity Measures Clustering APR Course, Delft, The Netherlands Marco Loog May 19, 2008 1 What salient structures exist in the data? How many clusters? May 19, 2008 2 Cluster Analysis
Clustering and Dissimilarity Measures Clustering APR Course, Delft, The Netherlands Marco Loog May 19, 2008 1 What salient structures exist in the data? How many clusters? May 19, 2008 2 Cluster Analysis
Distance-based Methods: Drawbacks
 Distance-based Methods: Drawbacks Hard to find clusters with irregular shapes Hard to specify the number of clusters Heuristic: a cluster must be dense Jian Pei: CMPT 459/741 Clustering (3) 1 How to Find
Distance-based Methods: Drawbacks Hard to find clusters with irregular shapes Hard to specify the number of clusters Heuristic: a cluster must be dense Jian Pei: CMPT 459/741 Clustering (3) 1 How to Find
An Unsupervised Technique for Statistical Data Analysis Using Data Mining
 International Journal of Information Sciences and Application. ISSN 0974-2255 Volume 5, Number 1 (2013), pp. 11-20 International Research Publication House http://www.irphouse.com An Unsupervised Technique
International Journal of Information Sciences and Application. ISSN 0974-2255 Volume 5, Number 1 (2013), pp. 11-20 International Research Publication House http://www.irphouse.com An Unsupervised Technique
A Review on Cluster Based Approach in Data Mining
 A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
Tan,Steinbach, Kumar Introduction to Data Mining 4/18/ Tan,Steinbach, Kumar Introduction to Data Mining 4/18/
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
Clustering and Visualisation of Data
 Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Tan,Steinbach, Kumar Introduction to Data Mining 4/18/ Tan,Steinbach, Kumar Introduction to Data Mining 4/18/
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the