Social Data Exploration
|
|
|
- Douglas West
- 5 years ago
- Views:
Transcription
1 Social Data Exploration Sihem Amer-Yahia DR LIG Sihem.Amer-Yahia@imag.fr Big Data & Optimization Workshop 12ème Séminaire POC LIP6 Dec 5 th, 2014
 Item")


2 Collaborative data model User space (with attributes) Item space (with attributes) user1 boolean, rating, tag, sentiment Item 1 Item 2 user3 user2 Item 3 Item 4 user4 user5 Item 5 Item 6 Item 7 User6 2
3 MovieLens instances ID Title Genre Director Name Gender Location Rating 1 Titanic Drama James Cameron 2 Schindler s List Drama Steven Speilberg Amy Female New York 8.5 John Male New York 7.0 ID Title Genre Director Name Gender Location Tags 1 Titanic Drama James Cameron 2 Schindler s List Drama Steven Speilberg Amy Female New York love, Oscar John Male New York history, Oscar 3
4 More on MovieLens datasets 4
5 Social Data Exploration Rating exploration q Meaningful Interpretations of Collaborative Ratings Tag exploration q Who Tags What? An Analysis Framework Perspectives 5
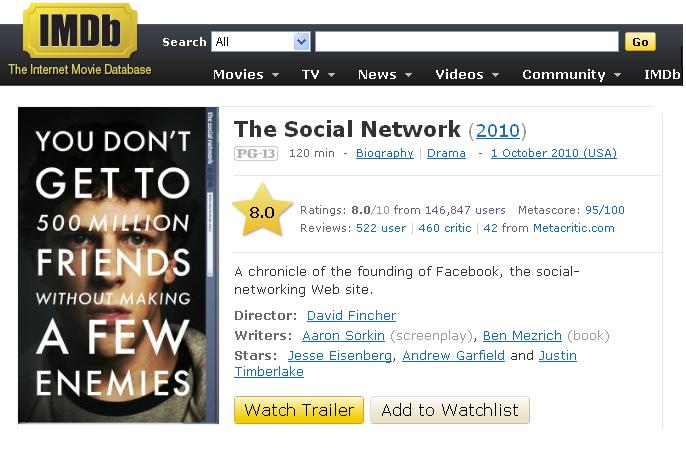
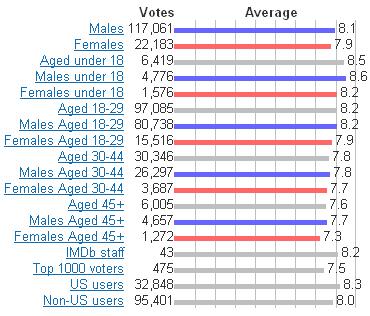
6 Meaningful Interpretations of Collaborative Ratings 6
7 Data Model Collaborative rating site: Set of Items, Set of Users, Ratings q Rating tuple: <item attributes, user attributes, rating> ID Title Genre Director Name Gender Location Rating 1 Titanic Drama James Cameron Amy Female New York Schindler s List Drama Steven Speilberg John Male New York 7.0 Group: Set of ratings describable by a set of attribute values Notion of group based on data cube q OLAP literature for mining multidimensional data 7
8 Exploration Space Each node/cuboid in lattice is a group A = Gender: Male B = Age: Young C = Location: CA D = Occupation: Student Task Quickly identify good groups in the lattice that help analysts understand ratings effectively Partial Rating Lattice for a Movie (M:Male, Y:Young, CA:California, S:Student) 8
9 DEM: Meaningful Description Mining For an input item covering R I ratings, return set C of groups, such that: description error is minimized, subject to: C k; coverage α Description Error Measures how well a group average rating approximates each individual rating belonging to it Coverage: measures percentage of ratings covered by returned groups DEM is NP-Hard: proof details in [1] [1] MRI: Meaningful Interpretations of Collaborative Ratings, S. Amer-Yahia, Mahashweta Das, Gautam Das and Cong Yu. In the Proceedings of the International Conference on Very Large Databases (PVLDB),

10 DEM: Meaningful Description Mining q Identify groups of reviewers who consistently share similar ratings on items 10

11 DEM: Meaningful Description Mining To verify NP-completeness, we reduce the Exact 3-Set Cover problem (EC3) to the decision version of our problem. EC3 is the problem of finding an exact cover for a finite set U, where each of the subsets available for use contain exactly 3 elements. The EC3 problem is proved to be NP-Complete by a reduction from the Three Dimensional Matching problem in computational complexity theory 11
12 DEM Algorithms Exact Algorithm (E-DEM) q Brute-force enumerating all possible combinations of cuboids in lattice to return the exact (i.e., optimal) set as rating descriptions Random Restart Hill Climbing Algorithm q Often fails to satisfy Coverage constraint; Large number of restarts required q Need an algorithm that optimizes both Coverage and Description Error constraints simultaneously Randomized Hill Exploration Algorithm (RHE-DEM) 12
13 RHE-DEM Algorithm Satisfy Coverage Minimize Error C= {Male, Student} {California, Student} 13
14 RHE-DEM Algorithm Satisfy Coverage Minimize Error C= {Male, Student} {California, Student} Say, C does not satisfy Coverage Constraint 14
15 RHE-DEM Algorithm Satisfy Coverage Minimize Error C= {Male, Student} {California, Student} C= {Male} {California,Student} C= {Student} {California,Student} 15
16 RHE-DEM Algorithm Satisfy Coverage Minimize Error C= {Male} {California, Student} Say, C satisfies Coverage Constraint 16
17 RHE-DEM Algorithm Satisfy Coverage Minimize Error C= {Male} {California, Student} 17
18 RHE-DEM Algorithm Satisfy Coverage Minimize Error C= {Male} {California, Student} 18

19 RHE-DEM Algorithm Satisfy Coverage Minimize Error C= {Male} {Student} 19
20 DIM: Meaningful Difference Mining For an input item covering R I + R I - ratings, return set C of cuboids, such that: q difference balance is minimized, subject to: C k; α α 20
21 DIM: Meaningful Difference Mining Difference Balance Measures whether the positive and negative ratings are mingled together" (high balance) or separated apart" (low balance) Coverage Measures the percentage of +/- ratings covered by returned groups DIM is NP-Hard: proof details in [1] [1] S. Amer-Yahia, Mahashweta Das, Gautam Das, Cong Yu: MRI: Meaningful Interpretations of Collaborative Ratings,. In PVLDB

22 DIM: Meaningful Difference Mining q Identify groups of reviewers who consistently disagree on item ratings 22
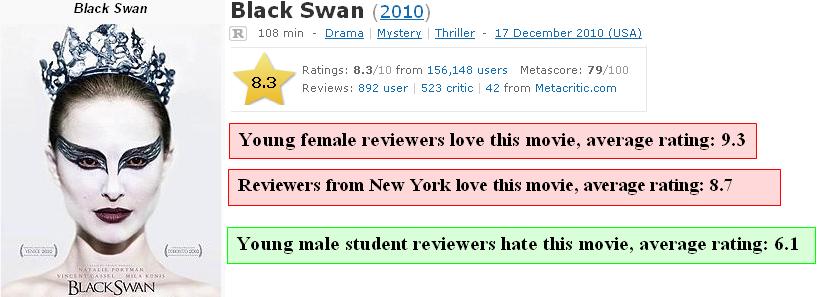
23
24 DIM: Meaningful Difference Mining NP-Completeness: reduction of the Exact 3-Set Cover problem (EC3). 24
25 DIM Algorithms Exact Algorithm (E-DIM) Randomized Hill Exploration Algorithm (RHE-DIM) q Unlike DEM error, DIM balance computation is expensive Quadratic computation scanning all possible positive and negative ratings for each set of cuboids q Introduce the concept of fundamental regions to aid faster balance computation Each rating tuple is a k-bit vector where a bit is 1 if the tuple is covered by a group A fundamental region is the set of rating tuples that share the same signature Partition space of all ratings and aggregate rating tuples in each region 25
26 DIM Algorithms: Fundamental Region C 1 = {Male, Student} C 2 = {California, Student} set of k=2 cuboids having 75 ratings (46+, 33-) balance = 26
27 Summary of Rating Exploration DEM and DIM are hard problems q q Leverage the lattice structure to improve coverage Exploit properties of rating function for faster error computation Explore other rating aggregation functions Explore other constraints: e.g., group size Explore other optimization dimensions: group diversity 27
28 Social Data Exploration Rating exploration q MRI: Meaningful Interpretations of Collaborative Ratings Tag exploration q Who Tags What? An Analysis Framework Perspectives 28
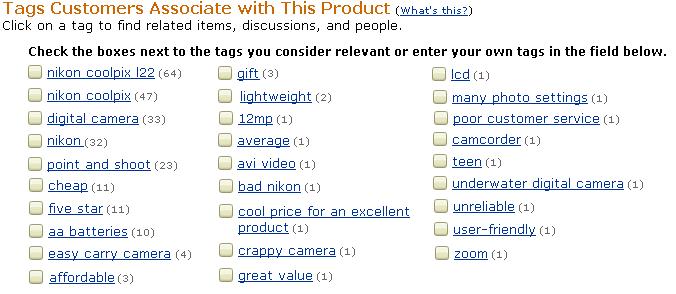
29 Collaborative Tagging Site (Amazon) 29
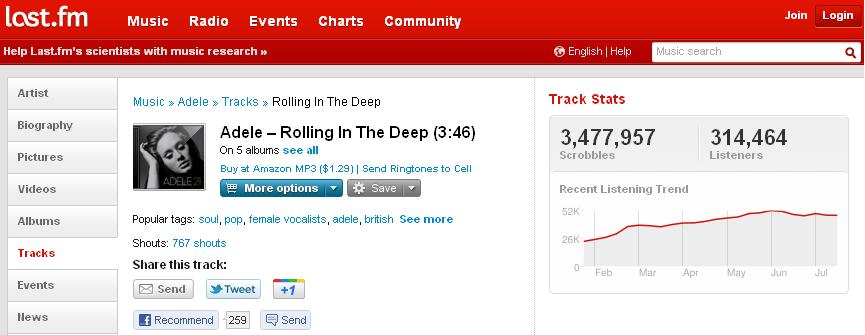
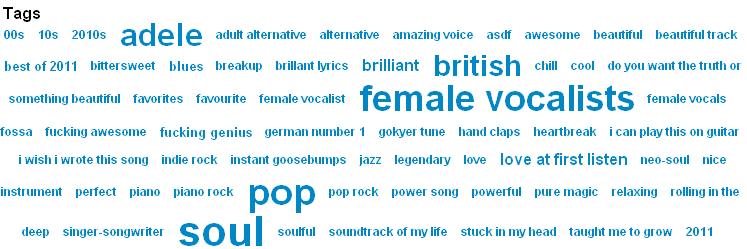
30 Collaborative Tagging Site (LastFM) 30



31 Exploring Collaborative Tagging in MovieLens Tag Signature for all Users Tag Signature for all CA Users 31
32 Exploring Collaborative Tagging Exploration considers three dimensions q User, Item, Tag and two alternative measures q Similarity, Diversity 32
33 Data Model q Tagging action tuple: <user attributes, item attributes, tags> ID Title Genre Director Name Gender Location Tags 1 Titanic Drama James Cameron Amy Female New York love, Oscar 2 Schindler s List Drama Steven Speilberg John Male New York history, Oscar 33
34 Tagging Behavior Dual Mining Problem (TagDM) 34
35 Tagging Behavior Dual mining Problem Instance 35


36 Problem: Tagging Behavior Dual Mining (TagDM) Identify similar groups of reviewers who share similar tagging behavior for diverse set of items Male Young comedy, drama, friendship drama, friendship 36
37 Tagging Behavior Dual Mining Instance 37

38 Tagging Behavior Dual Mining Instance Identify diverse groups of reviewers who share diverse tagging behavior for similar items Male Teen gun, special effects Female Teen violence, gory 38
![TagDM is NP-Hard (proof details in [2]) [2] Mahashweta Das, Saravanan Thirumuruganathan,](/docs-images/93/113895975/images/39-0.jpg "Sihem AmerYahia, Gautam Das, Cong Yu: Who Tags What? An Analysis Framework, In PVLDB 2012.")
39 TagDM is NP-Hard (proof details in [2]) [2] Mahashweta Das, Saravanan Thirumuruganathan, Sihem AmerYahia, Gautam Das, Cong Yu: Who Tags What? An Analysis Framework, In PVLDB
40 Two algorithms LSH (Locality Sensitive Hashing) based algorithm to handle TagDM problem instances optimizing similarity FDP (Facility Dispersion Problem) based algorithm handles TagDM problem instances optimizing diversity Both rely on computing tag signatures for groups q q Latent Dirichlet Allocation to aggregate tags Comparison between signatures based on cosine 40
41 Algorithm: LSH Based LSH (Locality Sensitive Hashing) based algorithm handles TagDM problem instances optimizing similarity LSH is popular to solve nearest neighbor search problems in high dimensions LSH hashes similar input items into same bucket with high probability q We hash group tag signature vectors into buckets, and then rank the buckets based on the strength of their (tag) similarity SM-LSH q Returns a set of groups, k having maximum similarity in tagging behavior, measured by comparing distances between group tag signature vectors SM-LSH-Fi: Handles hard constraints by Filtering result of SM-LSH SM-LSH-Fo: Handles hard constraints by Folding them to SM-LSH 41
42 Algorithm: LSH Based Hashing function for SM-LSH q We use LSH scheme in [3] that employs a family of hashing functions based on cosine similarity where Trep(g) is the tag signature vector for group g q Probability of finding the optimal result set by SM-LSH is bounded by: (proof details in paper) q where d is the dimensionality of hash signatures (buckets) We employ iterative relaxation to tune d in each iteration (Monte Carlo randomized algorithm) so that post-processing of hash tables yields nonnull result set [3]: M. Charikar. Similarity estimation techniques from rounding algorithms. In STOC,
43 Algorithm: LSH Based SM-LSH-Fi: Dealing with constraints by Filtering q For each hash table, check for satisfiability of hard constraints in each bucket, and then rank filtered buckets on tagging similarity Often yields null results SM-LSH-Fo: Dealing with constraints by Folding q Fold hard constraints maximizing similarity as soft constraints into SM-LSH q Hash similar input tagging action groups (similar with respect to group tag signature vector and user and/or item attributes) into the same bucket with high probability However, it is non-obvious how LSH hash functions may be inversed to account for dissimilarity while preserving LSH properties 43
44 Algorithm: FDP Based FDP (Facility Dispersion Problem) based algorithm handles TagDM problem instances optimizing diversity FDP problem locates facilities on a network in order to maximize distance between facilities q We find tagging groups maximizing diversity (distance) betweeen tag signature vectors We intialize a pair of facilities with maximum weight, and then add nodes with maximum distance to those selected, in each subsequent iteration [4] [4]: S. S. Ravi, D. J. Rosenkrantz, and G. K. Tayi. Facility dispersion problems: Heuristics and special cases. In WADS,
45 Algorithm: FDP Based DV-FDP q Returns a set of groups, k having maximum diversity in tagging behavior, measured by maximizing average pairwise distance between group tag signature vectors q If G opt and G app represent the set of k ( k 2) tagging action groups returned by optimal and our approximate DV-FDP algorithm, and tag signature vectors satisfy triangular inequality: (Proof details in paper) DV-FDP-Fi q Handles hard constraints by Filtering result of DV-FDP DV-FDP-Fo q Handles hard constraints by Folding them to DV-FDP 45
 and 6 (find similar user sub-populations who disagree most on their tagging behavior for a similar set of items),")
46 Some anecdotal evidence on analysts prefs Users prefer TagDM Problems 2 (find similar user sub-populations who agree most on their tagging behavior for a diverse set of items), 3 (find diverse user subpopulations who agree most on their tagging behavior for a similar set of items) and 6 (find similar user sub-populations who disagree most on their tagging behavior for a similar set of items), having diversity as the measure for exactly one of the tagging component: item, user and tag respectively. 46
47 Summary and Perspectives The notion of group is central to social data exploration q q Because it is meaningful to analysts: groups are describable Because group relationships can be explored for efficient space exploration 47
48 Perspective 1 Rating exploration q q A single dimension was optimized at a time (error or balance) We could formulate a problem that seeks k most uniform (minimize error) and most diverse groups (least overlapping) 48

49 Perspective 2 There is a total of 112 concrete problem instances that our TagDM framework captures! And those optimize the tagging dimensions only 49
50 Perspective 3 Social data exploration over time 50
New Perspectives in Social Data Management
 New Perspectives in Social Data Management Sihem Amer-Yahia Research Director CNRS @ LIG Sihem.Amer-Yahia@imag.fr TSUKUBA University May 20 th, 2014 Traditional data management stack High-level specification
New Perspectives in Social Data Management Sihem Amer-Yahia Research Director CNRS @ LIG Sihem.Amer-Yahia@imag.fr TSUKUBA University May 20 th, 2014 Traditional data management stack High-level specification
arxiv: v1 [cs.db] 1 Aug 2012
![arxiv: v1 [cs.db] 1 Aug 2012](/thumbs/81/82776602.jpg "arxiv: v1 [cs.db] 1 Aug 2012") Who Tags What? An Analysis Framework Mahashweta Das, Saravanan Thirumuruganathan, Sihem Amer-Yahia, Gautam Das,, Cong Yu University of Texas at Arlington; Qatar Computing Research Institute; Google Research
Who Tags What? An Analysis Framework Mahashweta Das, Saravanan Thirumuruganathan, Sihem Amer-Yahia, Gautam Das,, Cong Yu University of Texas at Arlington; Qatar Computing Research Institute; Google Research
EXPLORATORY MINING OF COLLABORATIVE SOCIAL CONTENT MAHASHWETA DAS. Presented to the Faculty of the Graduate School of
 EXPLORATORY MINING OF COLLABORATIVE SOCIAL CONTENT by MAHASHWETA DAS Presented to the Faculty of the Graduate School of The University of Texas at Arlington in Partial Fulfillment of the Requirements for
EXPLORATORY MINING OF COLLABORATIVE SOCIAL CONTENT by MAHASHWETA DAS Presented to the Faculty of the Graduate School of The University of Texas at Arlington in Partial Fulfillment of the Requirements for
Big Data Analytics Influx of data pertaining to the 4Vs, i.e. Volume, Veracity, Velocity and Variety
 Holistic Analysis of Multi-Source, Multi- Feature Data: Modeling and Computation Challenges Big Data Analytics Influx of data pertaining to the 4Vs, i.e. Volume, Veracity, Velocity and Variety Abhishek
Holistic Analysis of Multi-Source, Multi- Feature Data: Modeling and Computation Challenges Big Data Analytics Influx of data pertaining to the 4Vs, i.e. Volume, Veracity, Velocity and Variety Abhishek
Holistic Analysis of Multi-Source, Multi- Feature Data: Modeling and Computation Challenges
 Holistic Analysis of Multi-Source, Multi- Feature Data: Modeling and Computation Challenges Abhishek Santra 1 and Sanjukta Bhowmick 2 1 Information Technology Laboratory, CSE Department, University of
Holistic Analysis of Multi-Source, Multi- Feature Data: Modeling and Computation Challenges Abhishek Santra 1 and Sanjukta Bhowmick 2 1 Information Technology Laboratory, CSE Department, University of
Graph Cube: On Warehousing and OLAP Multidimensional Networks
 Graph Cube: On Warehousing and OLAP Multidimensional Networks Peixiang Zhao, Xiaolei Li, Dong Xin, Jiawei Han Department of Computer Science, UIUC Groupon Inc. Google Cooperation pzhao4@illinois.edu, hanj@cs.illinois.edu
Graph Cube: On Warehousing and OLAP Multidimensional Networks Peixiang Zhao, Xiaolei Li, Dong Xin, Jiawei Han Department of Computer Science, UIUC Groupon Inc. Google Cooperation pzhao4@illinois.edu, hanj@cs.illinois.edu
Exploiting Group Recommendation Functions for Flexible Preferences
 Exploiting Group Recommendation Functions for Flexible Preferences Senjuti Basu Roy, Saravanan Thirumuruganathan #, Sihem Amer-Yahia +, Gautam Das #, Cong Yu University of Washington Tacoma # University
Exploiting Group Recommendation Functions for Flexible Preferences Senjuti Basu Roy, Saravanan Thirumuruganathan #, Sihem Amer-Yahia +, Gautam Das #, Cong Yu University of Washington Tacoma # University
CS249: ADVANCED DATA MINING
 CS249: ADVANCED DATA MINING Recommender Systems II Instructor: Yizhou Sun yzsun@cs.ucla.edu May 31, 2017 Recommender Systems Recommendation via Information Network Analysis Hybrid Collaborative Filtering
CS249: ADVANCED DATA MINING Recommender Systems II Instructor: Yizhou Sun yzsun@cs.ucla.edu May 31, 2017 Recommender Systems Recommendation via Information Network Analysis Hybrid Collaborative Filtering
Interactive Summarization and Exploration of Top Aggregate Query Answers
 Interactive Summarization and Exploration of Top Aggregate Query Answers Yuhao Wen, Xiaodan Zhu, Sudeepa Roy, Jun Yang Department of Computer Science, Duke University {ywen, xdzhu, sudeepa, junyang}@cs.duke.edu
Interactive Summarization and Exploration of Top Aggregate Query Answers Yuhao Wen, Xiaodan Zhu, Sudeepa Roy, Jun Yang Department of Computer Science, Duke University {ywen, xdzhu, sudeepa, junyang}@cs.duke.edu
Using Data Mining to Determine User-Specific Movie Ratings
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320 088X IMPACT FACTOR: 6.017 IJCSMC,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320 088X IMPACT FACTOR: 6.017 IJCSMC,
COSC160: Data Structures Hashing Structures. Jeremy Bolton, PhD Assistant Teaching Professor
 COSC160: Data Structures Hashing Structures Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Hashing Structures I. Motivation and Review II. Hash Functions III. HashTables I. Implementations
COSC160: Data Structures Hashing Structures Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Hashing Structures I. Motivation and Review II. Hash Functions III. HashTables I. Implementations
3 No-Wait Job Shops with Variable Processing Times
 3 No-Wait Job Shops with Variable Processing Times In this chapter we assume that, on top of the classical no-wait job shop setting, we are given a set of processing times for each operation. We may select
3 No-Wait Job Shops with Variable Processing Times In this chapter we assume that, on top of the classical no-wait job shop setting, we are given a set of processing times for each operation. We may select
Data Preprocessing. Why Data Preprocessing? MIT-652 Data Mining Applications. Chapter 3: Data Preprocessing. Multi-Dimensional Measure of Data Quality
 Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate data e.g., occupation = noisy: containing
Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate data e.g., occupation = noisy: containing
Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University Infinite data. Filtering data streams
 /9/7 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them
/9/7 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them
Personalized Entity Recommendation: A Heterogeneous Information Network Approach
 Personalized Entity Recommendation: A Heterogeneous Information Network Approach Xiao Yu, Xiang Ren, Yizhou Sun, Quanquan Gu, Bradley Sturt, Urvashi Khandelwal, Brandon Norick, Jiawei Han University of
Personalized Entity Recommendation: A Heterogeneous Information Network Approach Xiao Yu, Xiang Ren, Yizhou Sun, Quanquan Gu, Bradley Sturt, Urvashi Khandelwal, Brandon Norick, Jiawei Han University of
Security Control Methods for Statistical Database
 Security Control Methods for Statistical Database Li Xiong CS573 Data Privacy and Security Statistical Database A statistical database is a database which provides statistics on subsets of records OLAP
Security Control Methods for Statistical Database Li Xiong CS573 Data Privacy and Security Statistical Database A statistical database is a database which provides statistics on subsets of records OLAP
Theorem 2.9: nearest addition algorithm
 There are severe limits on our ability to compute near-optimal tours It is NP-complete to decide whether a given undirected =(,)has a Hamiltonian cycle An approximation algorithm for the TSP can be used
There are severe limits on our ability to compute near-optimal tours It is NP-complete to decide whether a given undirected =(,)has a Hamiltonian cycle An approximation algorithm for the TSP can be used
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu Customer X Buys Metalica CD Buys Megadeth CD Customer Y Does search on Metalica Recommender system suggests Megadeth
CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu Customer X Buys Metalica CD Buys Megadeth CD Customer Y Does search on Metalica Recommender system suggests Megadeth
Algorithms for Nearest Neighbors
 Algorithms for Nearest Neighbors Classic Ideas, New Ideas Yury Lifshits Steklov Institute of Mathematics at St.Petersburg http://logic.pdmi.ras.ru/~yura University of Toronto, July 2007 1 / 39 Outline
Algorithms for Nearest Neighbors Classic Ideas, New Ideas Yury Lifshits Steklov Institute of Mathematics at St.Petersburg http://logic.pdmi.ras.ru/~yura University of Toronto, July 2007 1 / 39 Outline
Understanding Clustering Supervising the unsupervised
 Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Thanks to Jure Leskovec, Anand Rajaraman, Jeff Ullman
 Thanks to Jure Leskovec, Anand Rajaraman, Jeff Ullman http://www.mmds.org Overview of Recommender Systems Content-based Systems Collaborative Filtering J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive
Thanks to Jure Leskovec, Anand Rajaraman, Jeff Ullman http://www.mmds.org Overview of Recommender Systems Content-based Systems Collaborative Filtering J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive
Near Neighbor Search in High Dimensional Data (1) Dr. Anwar Alhenshiri
 Dr. Anwar Alhenshiri") Near Neighbor Search in High Dimensional Data (1) Dr. Anwar Alhenshiri Scene Completion Problem The Bare Data Approach High Dimensional Data Many real-world problems Web Search and Text Mining Billions
Near Neighbor Search in High Dimensional Data (1) Dr. Anwar Alhenshiri Scene Completion Problem The Bare Data Approach High Dimensional Data Many real-world problems Web Search and Text Mining Billions
Locality- Sensitive Hashing Random Projections for NN Search
 Case Study 2: Document Retrieval Locality- Sensitive Hashing Random Projections for NN Search Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 18, 2017 Sham Kakade
Case Study 2: Document Retrieval Locality- Sensitive Hashing Random Projections for NN Search Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 18, 2017 Sham Kakade
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu /2/8 Jure Leskovec, Stanford CS246: Mining Massive Datasets 2 Task: Given a large number (N in the millions or
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu /2/8 Jure Leskovec, Stanford CS246: Mining Massive Datasets 2 Task: Given a large number (N in the millions or
Fast Contextual Preference Scoring of Database Tuples
 Fast Contextual Preference Scoring of Database Tuples Kostas Stefanidis Department of Computer Science, University of Ioannina, Greece Joint work with Evaggelia Pitoura http://dmod.cs.uoi.gr 2 Motivation
Fast Contextual Preference Scoring of Database Tuples Kostas Stefanidis Department of Computer Science, University of Ioannina, Greece Joint work with Evaggelia Pitoura http://dmod.cs.uoi.gr 2 Motivation
A Hybrid Peer-to-Peer Recommendation System Architecture Based on Locality-Sensitive Hashing
 A Hybrid Peer-to-Peer Recommendation System Architecture Based on Locality-Sensitive Hashing Alexander Smirnov, Andrew Ponomarev St. Petersburg Institute for Informatics and Automation of the Russian Academy
A Hybrid Peer-to-Peer Recommendation System Architecture Based on Locality-Sensitive Hashing Alexander Smirnov, Andrew Ponomarev St. Petersburg Institute for Informatics and Automation of the Russian Academy
A PROPOSED HYBRID BOOK RECOMMENDER SYSTEM
 A PROPOSED HYBRID BOOK RECOMMENDER SYSTEM SUHAS PATIL [M.Tech Scholar, Department Of Computer Science &Engineering, RKDF IST, Bhopal, RGPV University, India] Dr.Varsha Namdeo [Assistant Professor, Department
A PROPOSED HYBRID BOOK RECOMMENDER SYSTEM SUHAS PATIL [M.Tech Scholar, Department Of Computer Science &Engineering, RKDF IST, Bhopal, RGPV University, India] Dr.Varsha Namdeo [Assistant Professor, Department
Towards a hybrid approach to Netflix Challenge
 Towards a hybrid approach to Netflix Challenge Abhishek Gupta, Abhijeet Mohapatra, Tejaswi Tenneti March 12, 2009 1 Introduction Today Recommendation systems [3] have become indispensible because of the
Towards a hybrid approach to Netflix Challenge Abhishek Gupta, Abhijeet Mohapatra, Tejaswi Tenneti March 12, 2009 1 Introduction Today Recommendation systems [3] have become indispensible because of the
Machine Learning for Software Engineering
 Machine Learning for Software Engineering Introduction and Motivation Prof. Dr.-Ing. Norbert Siegmund Intelligent Software Systems 1 2 Organizational Stuff Lectures: Tuesday 11:00 12:30 in room SR015 Cover
Machine Learning for Software Engineering Introduction and Motivation Prof. Dr.-Ing. Norbert Siegmund Intelligent Software Systems 1 2 Organizational Stuff Lectures: Tuesday 11:00 12:30 in room SR015 Cover
Geometric data structures:
 Geometric data structures: Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade Sham Kakade 2017 1 Announcements: HW3 posted Today: Review: LSH for Euclidean distance Other
Geometric data structures: Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade Sham Kakade 2017 1 Announcements: HW3 posted Today: Review: LSH for Euclidean distance Other
Mining di Dati Web. Lezione 3 - Clustering and Classification
 Mining di Dati Web Lezione 3 - Clustering and Classification Introduction Clustering and classification are both learning techniques They learn functions describing data Clustering is also known as Unsupervised
Mining di Dati Web Lezione 3 - Clustering and Classification Introduction Clustering and classification are both learning techniques They learn functions describing data Clustering is also known as Unsupervised
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS46: Mining Massive Datasets Jure Leskovec, Stanford University http://cs46.stanford.edu /7/ Jure Leskovec, Stanford C46: Mining Massive Datasets Many real-world problems Web Search and Text Mining Billions
CS46: Mining Massive Datasets Jure Leskovec, Stanford University http://cs46.stanford.edu /7/ Jure Leskovec, Stanford C46: Mining Massive Datasets Many real-world problems Web Search and Text Mining Billions
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu //8 Jure Leskovec, Stanford CS6: Mining Massive Datasets High dim. data Graph data Infinite data Machine learning
CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu //8 Jure Leskovec, Stanford CS6: Mining Massive Datasets High dim. data Graph data Infinite data Machine learning
Ranking Clustered Data with Pairwise Comparisons
 Ranking Clustered Data with Pairwise Comparisons Alisa Maas ajmaas@cs.wisc.edu 1. INTRODUCTION 1.1 Background Machine learning often relies heavily on being able to rank the relative fitness of instances
Ranking Clustered Data with Pairwise Comparisons Alisa Maas ajmaas@cs.wisc.edu 1. INTRODUCTION 1.1 Background Machine learning often relies heavily on being able to rank the relative fitness of instances
International Journal of Computer Engineering and Applications, Volume IX, Issue X, Oct. 15 ISSN
 DIVERSIFIED DATASET EXPLORATION BASED ON USEFULNESS SCORE Geetanjali Mohite 1, Prof. Gauri Rao 2 1 Student, Department of Computer Engineering, B.V.D.U.C.O.E, Pune, Maharashtra, India 2 Associate Professor,
DIVERSIFIED DATASET EXPLORATION BASED ON USEFULNESS SCORE Geetanjali Mohite 1, Prof. Gauri Rao 2 1 Student, Department of Computer Engineering, B.V.D.U.C.O.E, Pune, Maharashtra, India 2 Associate Professor,
Part 12: Advanced Topics in Collaborative Filtering. Francesco Ricci
 Part 12: Advanced Topics in Collaborative Filtering Francesco Ricci Content Generating recommendations in CF using frequency of ratings Role of neighborhood size Comparison of CF with association rules
Part 12: Advanced Topics in Collaborative Filtering Francesco Ricci Content Generating recommendations in CF using frequency of ratings Role of neighborhood size Comparison of CF with association rules
Finding Similar Sets. Applications Shingling Minhashing Locality-Sensitive Hashing
 Finding Similar Sets Applications Shingling Minhashing Locality-Sensitive Hashing Goals Many Web-mining problems can be expressed as finding similar sets:. Pages with similar words, e.g., for classification
Finding Similar Sets Applications Shingling Minhashing Locality-Sensitive Hashing Goals Many Web-mining problems can be expressed as finding similar sets:. Pages with similar words, e.g., for classification
Overview of Clustering
 based on Loïc Cerfs slides (UFMG) April 2017 UCBL LIRIS DM2L Example of applicative problem Student profiles Given the marks received by students for different courses, how to group the students so that
based on Loïc Cerfs slides (UFMG) April 2017 UCBL LIRIS DM2L Example of applicative problem Student profiles Given the marks received by students for different courses, how to group the students so that
Understanding policy intent and misconfigurations from implementations: consistency and convergence
 Understanding policy intent and misconfigurations from implementations: consistency and convergence Prasad Naldurg 1, Ranjita Bhagwan 1, and Tathagata Das 2 1 Microsoft Research India, prasadn@microsoft.com,
Understanding policy intent and misconfigurations from implementations: consistency and convergence Prasad Naldurg 1, Ranjita Bhagwan 1, and Tathagata Das 2 1 Microsoft Research India, prasadn@microsoft.com,
CS435 Introduction to Big Data Spring 2018 Colorado State University. 3/21/2018 Week 10-B Sangmi Lee Pallickara. FAQs. Collaborative filtering
 W10.B.0.0 CS435 Introduction to Big Data W10.B.1 FAQs Term project 5:00PM March 29, 2018 PA2 Recitation: Friday PART 1. LARGE SCALE DATA AALYTICS 4. RECOMMEDATIO SYSTEMS 5. EVALUATIO AD VALIDATIO TECHIQUES
W10.B.0.0 CS435 Introduction to Big Data W10.B.1 FAQs Term project 5:00PM March 29, 2018 PA2 Recitation: Friday PART 1. LARGE SCALE DATA AALYTICS 4. RECOMMEDATIO SYSTEMS 5. EVALUATIO AD VALIDATIO TECHIQUES
The complement of PATH is in NL
 340 The complement of PATH is in NL Let c be the number of nodes in graph G that are reachable from s We assume that c is provided as an input to M Given G, s, t, and c the machine M operates as follows:
340 The complement of PATH is in NL Let c be the number of nodes in graph G that are reachable from s We assume that c is provided as an input to M Given G, s, t, and c the machine M operates as follows:
Implementation of a High-Performance Distributed Web Crawler and Big Data Applications with Husky
 Implementation of a High-Performance Distributed Web Crawler and Big Data Applications with Husky The Chinese University of Hong Kong Abstract Husky is a distributed computing system, achieving outstanding
Implementation of a High-Performance Distributed Web Crawler and Big Data Applications with Husky The Chinese University of Hong Kong Abstract Husky is a distributed computing system, achieving outstanding
Clustering Aggregation
 Clustering Aggregation ARISTIDES GIONIS Yahoo! Research Labs, Barcelona HEIKKI MANNILA University of Helsinki and Helsinki University of Technology and PANAYIOTIS TSAPARAS Microsoft Search Labs We consider
Clustering Aggregation ARISTIDES GIONIS Yahoo! Research Labs, Barcelona HEIKKI MANNILA University of Helsinki and Helsinki University of Technology and PANAYIOTIS TSAPARAS Microsoft Search Labs We consider
Genetic Algorithm for Circuit Partitioning
 Genetic Algorithm for Circuit Partitioning ZOLTAN BARUCH, OCTAVIAN CREŢ, KALMAN PUSZTAI Computer Science Department, Technical University of Cluj-Napoca, 26, Bariţiu St., 3400 Cluj-Napoca, Romania {Zoltan.Baruch,
Genetic Algorithm for Circuit Partitioning ZOLTAN BARUCH, OCTAVIAN CREŢ, KALMAN PUSZTAI Computer Science Department, Technical University of Cluj-Napoca, 26, Bariţiu St., 3400 Cluj-Napoca, Romania {Zoltan.Baruch,
Clustering. SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic
 Clustering SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic Clustering is one of the fundamental and ubiquitous tasks in exploratory data analysis a first intuition about the
Clustering SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic Clustering is one of the fundamental and ubiquitous tasks in exploratory data analysis a first intuition about the
Advanced Data Management Technologies Written Exam
 Advanced Data Management Technologies Written Exam 02.02.2016 First name Student number Last name Signature Instructions for Students Write your name, student number, and signature on the exam sheet. This
Advanced Data Management Technologies Written Exam 02.02.2016 First name Student number Last name Signature Instructions for Students Write your name, student number, and signature on the exam sheet. This
Recommendation with Differential Context Weighting
 Recommendation with Differential Context Weighting Yong Zheng Robin Burke Bamshad Mobasher Center for Web Intelligence DePaul University Chicago, IL USA Conference on UMAP June 12, 2013 Overview Introduction
Recommendation with Differential Context Weighting Yong Zheng Robin Burke Bamshad Mobasher Center for Web Intelligence DePaul University Chicago, IL USA Conference on UMAP June 12, 2013 Overview Introduction
A Study on Reverse Top-K Queries Using Monochromatic and Bichromatic Methods
 A Study on Reverse Top-K Queries Using Monochromatic and Bichromatic Methods S.Anusuya 1, M.Balaganesh 2 P.G. Student, Department of Computer Science and Engineering, Sembodai Rukmani Varatharajan Engineering
A Study on Reverse Top-K Queries Using Monochromatic and Bichromatic Methods S.Anusuya 1, M.Balaganesh 2 P.G. Student, Department of Computer Science and Engineering, Sembodai Rukmani Varatharajan Engineering
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Finding Similar Items:Nearest Neighbor Search
 Finding Similar Items:Nearest Neighbor Search Barna Saha February 23, 2016 Finding Similar Items A fundamental data mining task Finding Similar Items A fundamental data mining task May want to find whether
Finding Similar Items:Nearest Neighbor Search Barna Saha February 23, 2016 Finding Similar Items A fundamental data mining task Finding Similar Items A fundamental data mining task May want to find whether
Leveraging Set Relations in Exact Set Similarity Join
 Leveraging Set Relations in Exact Set Similarity Join Xubo Wang, Lu Qin, Xuemin Lin, Ying Zhang, and Lijun Chang University of New South Wales, Australia University of Technology Sydney, Australia {xwang,lxue,ljchang}@cse.unsw.edu.au,
Leveraging Set Relations in Exact Set Similarity Join Xubo Wang, Lu Qin, Xuemin Lin, Ying Zhang, and Lijun Chang University of New South Wales, Australia University of Technology Sydney, Australia {xwang,lxue,ljchang}@cse.unsw.edu.au,
An Unsupervised Technique for Statistical Data Analysis Using Data Mining
 International Journal of Information Sciences and Application. ISSN 0974-2255 Volume 5, Number 1 (2013), pp. 11-20 International Research Publication House http://www.irphouse.com An Unsupervised Technique
International Journal of Information Sciences and Application. ISSN 0974-2255 Volume 5, Number 1 (2013), pp. 11-20 International Research Publication House http://www.irphouse.com An Unsupervised Technique
Clustering. (Part 2)
") Clustering (Part 2) 1 k-means clustering 2 General Observations on k-means clustering In essence, k-means clustering aims at minimizing cluster variance. It is typically used in Euclidean spaces and works
Clustering (Part 2) 1 k-means clustering 2 General Observations on k-means clustering In essence, k-means clustering aims at minimizing cluster variance. It is typically used in Euclidean spaces and works
Preprocessing Short Lecture Notes cse352. Professor Anita Wasilewska
 Preprocessing Short Lecture Notes cse352 Professor Anita Wasilewska Data Preprocessing Why preprocess the data? Data cleaning Data integration and transformation Data reduction Discretization and concept
Preprocessing Short Lecture Notes cse352 Professor Anita Wasilewska Data Preprocessing Why preprocess the data? Data cleaning Data integration and transformation Data reduction Discretization and concept
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 9: Data Mining (3/4) March 8, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 9: Data Mining (3/4) March 8, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides
Summary of Last Chapter. Course Content. Chapter 3 Objectives. Chapter 3: Data Preprocessing. Dr. Osmar R. Zaïane. University of Alberta 4
 Principles of Knowledge Discovery in Data Fall 2004 Chapter 3: Data Preprocessing Dr. Osmar R. Zaïane University of Alberta Summary of Last Chapter What is a data warehouse and what is it for? What is
Principles of Knowledge Discovery in Data Fall 2004 Chapter 3: Data Preprocessing Dr. Osmar R. Zaïane University of Alberta Summary of Last Chapter What is a data warehouse and what is it for? What is
Joint Entity Resolution
 Joint Entity Resolution Steven Euijong Whang, Hector Garcia-Molina Computer Science Department, Stanford University 353 Serra Mall, Stanford, CA 94305, USA {swhang, hector}@cs.stanford.edu No Institute
Joint Entity Resolution Steven Euijong Whang, Hector Garcia-Molina Computer Science Department, Stanford University 353 Serra Mall, Stanford, CA 94305, USA {swhang, hector}@cs.stanford.edu No Institute
Community-Based Recommendations: a Solution to the Cold Start Problem
 Community-Based Recommendations: a Solution to the Cold Start Problem Shaghayegh Sahebi Intelligent Systems Program University of Pittsburgh sahebi@cs.pitt.edu William W. Cohen Machine Learning Department
Community-Based Recommendations: a Solution to the Cold Start Problem Shaghayegh Sahebi Intelligent Systems Program University of Pittsburgh sahebi@cs.pitt.edu William W. Cohen Machine Learning Department
Efficient integration of data mining techniques in DBMSs
 Efficient integration of data mining techniques in DBMSs Fadila Bentayeb Jérôme Darmont Cédric Udréa ERIC, University of Lyon 2 5 avenue Pierre Mendès-France 69676 Bron Cedex, FRANCE {bentayeb jdarmont
Efficient integration of data mining techniques in DBMSs Fadila Bentayeb Jérôme Darmont Cédric Udréa ERIC, University of Lyon 2 5 avenue Pierre Mendès-France 69676 Bron Cedex, FRANCE {bentayeb jdarmont
Proposed System. Start. Search parameter definition. User search criteria (input) usefulness score > 0.5. Retrieve results
 usefulness score > 0.5. Retrieve results") , Impact Factor- 5.343 Hybrid Approach For Efficient Diversification on Cloud Stored Large Dataset Geetanjali Mohite 1, Prof. Gauri Rao 2 1 Student, Department of Computer Engineering, B.V.D.U.C.O.E, Pune,
, Impact Factor- 5.343 Hybrid Approach For Efficient Diversification on Cloud Stored Large Dataset Geetanjali Mohite 1, Prof. Gauri Rao 2 1 Student, Department of Computer Engineering, B.V.D.U.C.O.E, Pune,
ECLT 5810 Data Preprocessing. Prof. Wai Lam
 ECLT 5810 Data Preprocessing Prof. Wai Lam Why Data Preprocessing? Data in the real world is imperfect incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate
ECLT 5810 Data Preprocessing Prof. Wai Lam Why Data Preprocessing? Data in the real world is imperfect incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate
Viral Marketing and Outbreak Detection. Fang Jin Yao Zhang
 Viral Marketing and Outbreak Detection Fang Jin Yao Zhang Paper 1: Maximizing the Spread of Influence through a Social Network Authors: David Kempe, Jon Kleinberg, Éva Tardos KDD 2003 Outline Problem Statement
Viral Marketing and Outbreak Detection Fang Jin Yao Zhang Paper 1: Maximizing the Spread of Influence through a Social Network Authors: David Kempe, Jon Kleinberg, Éva Tardos KDD 2003 Outline Problem Statement
Instructor: Dr. Mehmet Aktaş. Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University
 Instructor: Dr. Mehmet Aktaş Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
Instructor: Dr. Mehmet Aktaş Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Complexity Results on Graphs with Few Cliques
 Discrete Mathematics and Theoretical Computer Science DMTCS vol. 9, 2007, 127 136 Complexity Results on Graphs with Few Cliques Bill Rosgen 1 and Lorna Stewart 2 1 Institute for Quantum Computing and School
Discrete Mathematics and Theoretical Computer Science DMTCS vol. 9, 2007, 127 136 Complexity Results on Graphs with Few Cliques Bill Rosgen 1 and Lorna Stewart 2 1 Institute for Quantum Computing and School
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Queries on streams
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Queries on streams
val(y, I) α (9.0.2) α (9.0.3)
 α (9.0.2) α (9.0.3)") CS787: Advanced Algorithms Lecture 9: Approximation Algorithms In this lecture we will discuss some NP-complete optimization problems and give algorithms for solving them that produce a nearly optimal,
CS787: Advanced Algorithms Lecture 9: Approximation Algorithms In this lecture we will discuss some NP-complete optimization problems and give algorithms for solving them that produce a nearly optimal,
Semi-Supervised Clustering with Partial Background Information
 Semi-Supervised Clustering with Partial Background Information Jing Gao Pang-Ning Tan Haibin Cheng Abstract Incorporating background knowledge into unsupervised clustering algorithms has been the subject
Semi-Supervised Clustering with Partial Background Information Jing Gao Pang-Ning Tan Haibin Cheng Abstract Incorporating background knowledge into unsupervised clustering algorithms has been the subject
Polynomial-Time Approximation Algorithms
 6.854 Advanced Algorithms Lecture 20: 10/27/2006 Lecturer: David Karger Scribes: Matt Doherty, John Nham, Sergiy Sidenko, David Schultz Polynomial-Time Approximation Algorithms NP-hard problems are a vast
6.854 Advanced Algorithms Lecture 20: 10/27/2006 Lecturer: David Karger Scribes: Matt Doherty, John Nham, Sergiy Sidenko, David Schultz Polynomial-Time Approximation Algorithms NP-hard problems are a vast
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 9: Data Mining (3/4) March 7, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 9: Data Mining (3/4) March 7, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides
Learning independent, diverse binary hash functions: pruning and locality
 Learning independent, diverse binary hash functions: pruning and locality Ramin Raziperchikolaei and Miguel Á. Carreira-Perpiñán Electrical Engineering and Computer Science University of California, Merced
Learning independent, diverse binary hash functions: pruning and locality Ramin Raziperchikolaei and Miguel Á. Carreira-Perpiñán Electrical Engineering and Computer Science University of California, Merced
Hybrid Recommendation System Using Clustering and Collaborative Filtering
 Hybrid Recommendation System Using Clustering and Collaborative Filtering Roshni Padate Assistant Professor roshni@frcrce.ac.in Priyanka Bane B.E. Student priyankabane56@gmail.com Jayesh Kudase B.E. Student
Hybrid Recommendation System Using Clustering and Collaborative Filtering Roshni Padate Assistant Professor roshni@frcrce.ac.in Priyanka Bane B.E. Student priyankabane56@gmail.com Jayesh Kudase B.E. Student
Content-based Dimensionality Reduction for Recommender Systems
 Content-based Dimensionality Reduction for Recommender Systems Panagiotis Symeonidis Aristotle University, Department of Informatics, Thessaloniki 54124, Greece symeon@csd.auth.gr Abstract. Recommender
Content-based Dimensionality Reduction for Recommender Systems Panagiotis Symeonidis Aristotle University, Department of Informatics, Thessaloniki 54124, Greece symeon@csd.auth.gr Abstract. Recommender
Introduction to Approximation Algorithms
 Introduction to Approximation Algorithms Dr. Gautam K. Das Departmet of Mathematics Indian Institute of Technology Guwahati, India gkd@iitg.ernet.in February 19, 2016 Outline of the lecture Background
Introduction to Approximation Algorithms Dr. Gautam K. Das Departmet of Mathematics Indian Institute of Technology Guwahati, India gkd@iitg.ernet.in February 19, 2016 Outline of the lecture Background
How to explore big networks? Question: Perform a random walk on G. What is the average node degree among visited nodes, if avg degree in G is 200?
 How to explore big networks? Question: Perform a random walk on G. What is the average node degree among visited nodes, if avg degree in G is 200? Questions from last time Avg. FB degree is 200 (suppose).
How to explore big networks? Question: Perform a random walk on G. What is the average node degree among visited nodes, if avg degree in G is 200? Questions from last time Avg. FB degree is 200 (suppose).
Solving a Challenging Quadratic 3D Assignment Problem
 Solving a Challenging Quadratic 3D Assignment Problem Hans Mittelmann Arizona State University Domenico Salvagnin DEI - University of Padova Quadratic 3D Assignment Problem Quadratic 3D Assignment Problem
Solving a Challenging Quadratic 3D Assignment Problem Hans Mittelmann Arizona State University Domenico Salvagnin DEI - University of Padova Quadratic 3D Assignment Problem Quadratic 3D Assignment Problem
Introduction to Spatial Database Systems
 Introduction to Spatial Database Systems by Cyrus Shahabi from Ralf Hart Hartmut Guting s VLDB Journal v3, n4, October 1994 Data Structures & Algorithms 1. Implementation of spatial algebra in an integrated
Introduction to Spatial Database Systems by Cyrus Shahabi from Ralf Hart Hartmut Guting s VLDB Journal v3, n4, October 1994 Data Structures & Algorithms 1. Implementation of spatial algebra in an integrated
Horizontal Aggregations in SQL to Prepare Data Sets Using PIVOT Operator
 Horizontal Aggregations in SQL to Prepare Data Sets Using PIVOT Operator R.Saravanan 1, J.Sivapriya 2, M.Shahidha 3 1 Assisstant Professor, Department of IT,SMVEC, Puducherry, India 2,3 UG student, Department
Horizontal Aggregations in SQL to Prepare Data Sets Using PIVOT Operator R.Saravanan 1, J.Sivapriya 2, M.Shahidha 3 1 Assisstant Professor, Department of IT,SMVEC, Puducherry, India 2,3 UG student, Department
UML CS Algorithms Qualifying Exam Fall, 2003 ALGORITHMS QUALIFYING EXAM
 NAME: This exam is open: - books - notes and closed: - neighbors - calculators ALGORITHMS QUALIFYING EXAM The upper bound on exam time is 3 hours. Please put all your work on the exam paper. (Partial credit
NAME: This exam is open: - books - notes and closed: - neighbors - calculators ALGORITHMS QUALIFYING EXAM The upper bound on exam time is 3 hours. Please put all your work on the exam paper. (Partial credit
Propagate the Right Thing: How Preferences Can Speed-Up Constraint Solving
 Propagate the Right Thing: How Preferences Can Speed-Up Constraint Solving Christian Bessiere Anais Fabre* LIRMM-CNRS (UMR 5506) 161, rue Ada F-34392 Montpellier Cedex 5 (bessiere,fabre}@lirmm.fr Ulrich
Propagate the Right Thing: How Preferences Can Speed-Up Constraint Solving Christian Bessiere Anais Fabre* LIRMM-CNRS (UMR 5506) 161, rue Ada F-34392 Montpellier Cedex 5 (bessiere,fabre}@lirmm.fr Ulrich
Assignment 5: Collaborative Filtering
 Assignment 5: Collaborative Filtering Arash Vahdat Fall 2015 Readings You are highly recommended to check the following readings before/while doing this assignment: Slope One Algorithm: https://en.wikipedia.org/wiki/slope_one.
Assignment 5: Collaborative Filtering Arash Vahdat Fall 2015 Readings You are highly recommended to check the following readings before/while doing this assignment: Slope One Algorithm: https://en.wikipedia.org/wiki/slope_one.
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 22, 2016 Course Information Website: http://www.stat.ucdavis.edu/~chohsieh/teaching/ ECS289G_Fall2016/main.html My office: Mathematical Sciences
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 22, 2016 Course Information Website: http://www.stat.ucdavis.edu/~chohsieh/teaching/ ECS289G_Fall2016/main.html My office: Mathematical Sciences
Movie Recommender System - Hybrid Filtering Approach
 Chapter 7 Movie Recommender System - Hybrid Filtering Approach Recommender System can be built using approaches like: (i) Collaborative Filtering (ii) Content Based Filtering and (iii) Hybrid Filtering.
Chapter 7 Movie Recommender System - Hybrid Filtering Approach Recommender System can be built using approaches like: (i) Collaborative Filtering (ii) Content Based Filtering and (iii) Hybrid Filtering.
COMP6237 Data Mining Making Recommendations. Jonathon Hare
 COMP6237 Data Mining Making Recommendations Jonathon Hare jsh2@ecs.soton.ac.uk Introduction Recommender systems 101 Taxonomy of recommender systems Collaborative Filtering Collecting user preferences as
COMP6237 Data Mining Making Recommendations Jonathon Hare jsh2@ecs.soton.ac.uk Introduction Recommender systems 101 Taxonomy of recommender systems Collaborative Filtering Collecting user preferences as
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Multidimensional Indexing The R Tree
 Multidimensional Indexing The R Tree Module 7, Lecture 1 Database Management Systems, R. Ramakrishnan 1 Single-Dimensional Indexes B+ trees are fundamentally single-dimensional indexes. When we create
Multidimensional Indexing The R Tree Module 7, Lecture 1 Database Management Systems, R. Ramakrishnan 1 Single-Dimensional Indexes B+ trees are fundamentally single-dimensional indexes. When we create
University of Florida CISE department Gator Engineering. Clustering Part 2
 Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Spatial Data Management
 Spatial Data Management [R&G] Chapter 28 CS432 1 Types of Spatial Data Point Data Points in a multidimensional space E.g., Raster data such as satellite imagery, where each pixel stores a measured value
Spatial Data Management [R&G] Chapter 28 CS432 1 Types of Spatial Data Point Data Points in a multidimensional space E.g., Raster data such as satellite imagery, where each pixel stores a measured value
Efficient Top-K Count Queries over Imprecise Duplicates
 Efficient Top-K Count Queries over Imprecise Duplicates Sunita Sarawagi IIT Bombay sunita@iitb.ac.in Vinay S Deshpande IIT Bombay vinaysd@cse.iitb.ac.in Sourabh Kasliwal IIT Bombay sourabh@cse.iitb.ac.in
Efficient Top-K Count Queries over Imprecise Duplicates Sunita Sarawagi IIT Bombay sunita@iitb.ac.in Vinay S Deshpande IIT Bombay vinaysd@cse.iitb.ac.in Sourabh Kasliwal IIT Bombay sourabh@cse.iitb.ac.in
SOCIAL MEDIA MINING. Data Mining Essentials
 SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
Data Preprocessing. Slides by: Shree Jaswal
 Data Preprocessing Slides by: Shree Jaswal Topics to be covered Why Preprocessing? Data Cleaning; Data Integration; Data Reduction: Attribute subset selection, Histograms, Clustering and Sampling; Data
Data Preprocessing Slides by: Shree Jaswal Topics to be covered Why Preprocessing? Data Cleaning; Data Integration; Data Reduction: Attribute subset selection, Histograms, Clustering and Sampling; Data
On the Max Coloring Problem
 On the Max Coloring Problem Leah Epstein Asaf Levin May 22, 2010 Abstract We consider max coloring on hereditary graph classes. The problem is defined as follows. Given a graph G = (V, E) and positive
On the Max Coloring Problem Leah Epstein Asaf Levin May 22, 2010 Abstract We consider max coloring on hereditary graph classes. The problem is defined as follows. Given a graph G = (V, E) and positive
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Unit # 2 Sajjad Haider Spring 2010 1 Structured vs. Non-Structured Data Most business databases contain structured data consisting of well-defined fields with numeric
Knowledge Discovery and Data Mining Unit # 2 Sajjad Haider Spring 2010 1 Structured vs. Non-Structured Data Most business databases contain structured data consisting of well-defined fields with numeric
ECT7110. Data Preprocessing. Prof. Wai Lam. ECT7110 Data Preprocessing 1
 ECT7110 Data Preprocessing Prof. Wai Lam ECT7110 Data Preprocessing 1 Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking certain attributes of interest,
ECT7110 Data Preprocessing Prof. Wai Lam ECT7110 Data Preprocessing 1 Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking certain attributes of interest,
Measures of Clustering Quality: A Working Set of Axioms for Clustering
 Measures of Clustering Quality: A Working Set of Axioms for Clustering Margareta Ackerman and Shai Ben-David School of Computer Science University of Waterloo, Canada Abstract Aiming towards the development
Measures of Clustering Quality: A Working Set of Axioms for Clustering Margareta Ackerman and Shai Ben-David School of Computer Science University of Waterloo, Canada Abstract Aiming towards the development
Multidimensional Data and Modelling - DBMS
 Multidimensional Data and Modelling - DBMS 1 DBMS-centric approach Summary: l Spatial data is considered as another type of data beside conventional data in a DBMS. l Enabling advantages of DBMS (data
Multidimensional Data and Modelling - DBMS 1 DBMS-centric approach Summary: l Spatial data is considered as another type of data beside conventional data in a DBMS. l Enabling advantages of DBMS (data
CHAPTER 4 K-MEANS AND UCAM CLUSTERING ALGORITHM
 CHAPTER 4 K-MEANS AND UCAM CLUSTERING 4.1 Introduction ALGORITHM Clustering has been used in a number of applications such as engineering, biology, medicine and data mining. The most popular clustering
CHAPTER 4 K-MEANS AND UCAM CLUSTERING 4.1 Introduction ALGORITHM Clustering has been used in a number of applications such as engineering, biology, medicine and data mining. The most popular clustering
High Dimensional Clustering
 Distributed Computing High Dimensional Clustering Bachelor Thesis Alain Ryser aryser@ethz.ch Distributed Computing Group Computer Engineering and Networks Laboratory ETH Zürich Supervisors: Zeta Avarikioti,
Distributed Computing High Dimensional Clustering Bachelor Thesis Alain Ryser aryser@ethz.ch Distributed Computing Group Computer Engineering and Networks Laboratory ETH Zürich Supervisors: Zeta Avarikioti,
Spatial Data Management
 Spatial Data Management Chapter 28 Database management Systems, 3ed, R. Ramakrishnan and J. Gehrke 1 Types of Spatial Data Point Data Points in a multidimensional space E.g., Raster data such as satellite
Spatial Data Management Chapter 28 Database management Systems, 3ed, R. Ramakrishnan and J. Gehrke 1 Types of Spatial Data Point Data Points in a multidimensional space E.g., Raster data such as satellite
Edge-exchangeable graphs and sparsity
 Edge-exchangeable graphs and sparsity Tamara Broderick Department of EECS Massachusetts Institute of Technology tbroderick@csail.mit.edu Diana Cai Department of Statistics University of Chicago dcai@uchicago.edu
Edge-exchangeable graphs and sparsity Tamara Broderick Department of EECS Massachusetts Institute of Technology tbroderick@csail.mit.edu Diana Cai Department of Statistics University of Chicago dcai@uchicago.edu