Balanced COD-CLARANS: A Constrained Clustering Algorithm to Optimize Logistics Distribution Network
|
|
|
- Robyn Wilkerson
- 5 years ago
- Views:
Transcription

1 Advances in Intelligent Systems Research, volume 133 2nd International Conference on Artificial Intelligence and Industrial Engineering (AIIE2016) Balanced COD-CLARANS: A Constrained Clustering Algorithm to Optimize Logistics Distribution Network Tong Zhang1, Dong Wang2 and Haonan Chen2 1 Shanghai Jiao Tong University, China Shanghai Jiao Tong University, China 2 Abstract In this paper, we focus on the problem of the siting of distribution stations, which is of key importance during designing a logistics distribution network. This problem includes dealing with physical obstacles in real world, making the orders as close as possible to their respective stations and making the workload of each station as balanced as possible. To solve this problem, we use a dataset of the geographical coordinates of all orders of a certain express company per day in Shanghai, and propose an algorithm called Balanced COD-CLARANS, which is a constrained clustering algorithm capable of handling physical obstacles and balance factor and outputting a set of clusters for decision-making. Besides, we design the experiment to prove that Keywords-data mining; constrained clustering; distribution network; balance-driven; obstacle I. logistics BACKGROUND AND PROBLEM STATEMENT With e-commerce develops rapidly in recent years, more and more people have already accepted and get used to go shopping online. Meanwhile, people also expect more convenient shopping experience, such as receiving goods as early as possible and so on. All these requirements cannot be satisfied without logistics distribution network, so it has been one of the main bottlenecks preventing enterprises and shops from further expanding their markets. Therefore, the optimization of logistics distribution network is of great importance and necessity. For the purpose of the optimization of logistics distribution network, we focus on the problem of the siting of distribution stations, which is of key importance during designing a logistics distribution network. At present, express companies often decide the initial locations of distribution stations according to experience. As the situation changes, a station may be divided into several ones for overload, or merge with another because of underload. This process has no theory support and lacks replicability. Thus, it may cause waste of labor, material and money. Data mining is a hot topic in recent years. If an express company has a certain amount of geographical coordinates of orders and plans to change the stations' locations, or a online ecommerce platform having numerous geographical coordinates of orders wants to design its own logistics distribution network, both of them can mine useful knowledge through data mining to provide theories and references for the siting of distribution stations. Based on this idea, we obtain a dataset of the geographical coordinates of all orders of a certain express company per day in Shanghai and use clustering to get a set of stations' locations. We take the obstacles in real world into account and aim at not only making the orders as close as possible to their respective stations but also making the workload of each station as balanced as possible. The remainder of this paper is organized as follows. In Session 2, we summarize some related work. In Session 3, we introduce the algorithm called Balanced COD-CLARANS to optimize the logistics distribution network. Experimental results are analyzed in Section 4. Conclusions are given in Section 5. II. RELATED WORK Users often have background knowledge that they want to integrate into cluster analysis, and ignoring this knowledge may cause some unexpected results. Such information can be modeled as clustering constraints, and constrained clustering is proposed to take these constraints into account. The following are the constraints related to this paper: physical obstacles and balance. FIGURE I. THE DISTRIBUTION OF THE ORDERS IN SHANGHAI. There are many researches on physical obstacles. Tung et al. proposed COD-CLARANS[1], which first introduced obstacle Copyright 2016, the Authors. Published by Atlantis Press. This is an open access article under the CC BY-NC license ( 141
![distance into CLARANS[2]. The concept of visible space is introduced into DBCluC[3] which is based on DBSCAN[4].](/docs-images/88/115120109/images/2-1.jpg "DBRS+[5] extending the density-based clustering method DBRS[6] can handle any combination of intersecting obstacles.")
![AUTOCLUST+[7] using Delaunay diagram not only detects clusters of arbitrary shapes, but also clusters of different densities.](/docs-images/88/115120109/images/2-2.jpg "In balanced clustering, most researches focus on how to obtain an equal number of objects in each cluster.")
2 distance into CLARANS[2]. The concept of visible space is introduced into DBCluC[3] which is based on DBSCAN[4]. DBRS+[5] extending the density-based clustering method DBRS[6] can handle any combination of intersecting obstacles. AUTOCLUST+[7] using Delaunay diagram not only detects clusters of arbitrary shapes, but also clusters of different densities. In balanced clustering, most researches focus on how to obtain an equal number of objects in each cluster. In general, it is a 2-objective optimization problem in which two aims contradict each other: to minimize MSE and to balance cluster sizes. In balance-constrained clustering, cluster size balance is a mandatory requirement. Constrained k-means[8], Balanced k- means[9], etc, belong to this category. On the other hand, balance is an aim but not mandatory in balance-driven clustering. FSCL[10], SRcut[11], etc, belong to this category. In this paper, we don't focus on an equal number of objects but a balanced workload in each cluster. The workload of a cluster is a value computed more complicatedly, so the methods mentioned above no longer work. Besides, we take physical obstacles and balance into consideration at the same time. These are the challenges we meet. III. BALANCED COD-CLARANS A. Algorithm Framework We choose the k-medoids method as our algorithm framework. The k-medoids method pick actual objects as 'medoids' to represent the clusters, using one representative object per cluster. This ensures that the medoids don't fall into some obstacle. Then it aims to partition n objects into k clusters in which each object belongs to the cluster with the nearest medoid, which results in a partitioning of the data space into Voronoi cells. This guarantees that the responsible regions of any pair of stations don't overlap. Moreover, there are two elements in the k-medoids method we can modify to solve our problem: the dissimilarity between two objects and the objective function which is used to judge the quality of the clusters. In general, we use Euclidean distance to measure the dissimilarity, and the objective function is defined as the sum of the dissimilarities between each object p and its corresponding representative object: dissimilarity and the objective function in the general k- medoids method to deal with our problem. B. Obstacles There are many obstacles in real world, such as rivers, lakes and mountains, and if you do not consider these obstacles, the results will fail to meet your expectation. For example, the two objects on both sides of the river may be partitioned in the same cluster. Although the Euclidean distance between these two objects is very close, in fact the actual distance between them may be "far" because the bridge across the river is very far from them. The solution to physical obstacles is basically the same as that proposed by Tung et al.[1]. In this solution, the length of the shortest path between two objects in the visibility graph, called obstacle distance, is proposed to replace Euclidean distance and is used to measure the dissimilarity. A visibility graph is the graph, VG= (V,E), such that each obstacle vertex and each object in the data set has a corresponding node in V, and two nodes, v 1 and v 2, in V are joined by an edge in E if and only if the corresponding obstacle vertices or objects they represent are visible to each other. Please note that we use node to represent obstacle vertices and objects in this session. If two objects are visible to each other, the obstacle distance is equal to the Euclidean distance. Otherwise, the obstacle distance between them can consist of several Euclidean distances. Let us denote the set containing all the obstacle vertices visible to node x as vis (x), the Euclidean distance between node x and node y as d(x, y), and whether x and y are visible to each other as visible(x, y). Then the obstacle distance between node x and node y is defined recursively as: where E is the sum of the dissimilarities for all objects p in the data set, and o i is the representative object of C i. And the k- medoids method groups n objects into k clusters by minimizing this objective function. Since the volume of our data sets after processed is nearly We choose CLARANS as our algorithm framework. It is based on PAM algorithm, and use random search to have lower algorithm complexity and deal with larger data sets than PAM. Next, we modify the method used to measure the FIGURE II. THIS IS A VISIBILITY GRAPH. POLYGON O1, O2 AND O3 IN THIS GRAPH REPRESENT THREE OBSTACLES, AND X, Y AND Z REPRESENT THREE OBJECTS. SINCE X AND Z ARE VISIBLE TO EACH OTHER, THE OBSTACLE DISTANCE IS EQUAL TO THE EUCLIDEAN DISTANCE. MEANWHILE, X AND Y ARE NOT VISIBLE TO EACH OTHER. THEIR OBSTACLE DISTANCE CAN BE COMPOSED OF THE EUCLIDEAN DISTANCE BETWEEN X AND SOME OBSTACLE VERTEX U VISIBLE TO X, THE EUCLIDEAN DISTANCE BETWEEN Y AND SOME OBSTACLE VERTEX V VISIBLE TO Y, AND THE OBSTACLE DISTANCE BETWEEN U AND V. 142
3 To reduce the cost of distance computation between any two pairs of objects, we precompute the obstacle distance between any two pairs of obstacle vertex and vis(x) for every node x. Every time we compute the obstacle distance between two objects invisible to each other, we just enumerate all possibilities of (2), and take the minimum value as the result. So how to compute vis(x) for a node x? The problem can be solved by a data structure called BSP tree[12], which can efficiently determine whether two node are visible to each other. No unnecessary details are given here. Since the Euclidean distance is replaced by the obstacle distance, the possibility that two objects invisible to each other are partitioned into the same cluster effectively declines. C. Balanced Workload As mentioned in Session 1, we aim at not only making the orders as close as possible to their respective stations but also making the workload of each station as balanced as possible. Thus the clustering algorithm we proposed is balance-driven. Since CLARANS partitions n objects into k clusters by minimizing the objective function, we modify the objective function and introduce the balance factor into it. The new objective function is defined as: where E' is the linear combination of the mean of dissimilarities for all objects p in the data set and the standard deviation of workloads for all clusters, W c is the workload for cluster c, C is the set of all clusters, of which size is k, and λ is the ratio to control the effect of balance on the result. CLARANS iteratively decrease the value of this objective function, and this means that in each iteration the objects are more close to their respective medoids and the workload of each cluster is more balanced. We also note that if we set λ to 1, the new objective function degenerates to the original one multiplied by 1/k and if we set λ to 0, the new objective only focuses on the balance factor. In (3), the workload of a cluster is a value. And this increases the flexibility of the algorithm, which means that we can refine the final result by improving the method of calculating the workload, and even we can use the new objective function in any balance-driven clustering problem where the factor required to be balanced can be measured by a value. Since in real world the workload of delivering a lot of orders in a small region may be equal to the workload of delivering several orders in a large region, the workload of a cluster should be a value not only related to the number of objects in this cluster. Thus we define the workload of a cluster c as: where W c is the sum of the costs for all objects p in the cluster c. The cost of an object is the delivery cost of the order which this object represents. In this paper, we simply define the cost of an object p as: where cost p is the obstacle distance between p and its medoid. In the future work, this can be improved to obtain a more appropriate result which is used to optimize the logistics distribution network. D. Conclusion So far, a new algorithm called Balanced COD-CLARANS to optimize the logistics distribution network is proposed. Besides the input dataset, this algorithm has four input parameters three of which are the same as those of CLARANS: the number of clusters, the maximum number of neighbors examined, the number of local minima obtained and the ratio to control the effect of balance on the result. Although our proposed Balanced COD-CLARANS is similar to CLARANS due to its framework based on CLARANS, there are three key points that are different from CLARANS: In the initialization phase Balanced COD-CLARANS applies the strategy of k-means++ so that it can avoid the initial centers getting together and reduce the number of iterations for convergence. Since Balanced COD-CLARANS introduces balanced workload in each cluster, the objective function is modified to guide the clusters to having balanced workload. Balanced COD-CLARANS calculates the obstacle distance between two objects instead the Euclidean distance in consideration of physical obstacles. IV. EXPERIMENT A. Experimental Design There are three data sets used in the contrast experiment: the dataset of the geographical coordinates of all orders of a certain express company per day in Shanghai, the dataset of the physical obstacles in Shanghai, most of which are the Huangpu River and the waters of Shanghai, and the dataset of the locations and responsible regions of the existing stations decided by this express company. The first dataset is extracted from the order information table provided by the express company. The geographical coordinates of the obstacle vertices in the second dataset is obtained from the electronic map manually. The third dataset is crawled from the official website of the company website. There are four groups set up for the contrast experiment. In group 1, all the orders are partitioned into the corresponding responsible regions of the existing stations. And each station and the orders it is responsible for are treated as one cluster. In group 2, we use CLARANS to partition the orders, without regard to physical obstacles and balanced workload. In group 3, CLARANS is used to partition the orders, without regard to 143
4 physical obstacles but balanced workload. In group 4, we use Balanced COD-CLARANS to partition the orders. Among all of the above groups, the input is the same, and the method of calculating the workload which use the obstacle distance is the same. Thus, the difference among the algorithms is the only factor that leads to different results. B. Experimental Results In Figure III to VI, green bars represent the workload of a cluster, and purple dots represent the number of the objects in a cluster. These figures show that in a cluster there is no direct correlation between the workload and the number of the objects, which is in accord with our thinking in Session 3. In this paper, since the workload of a cluster is defined as the sum of the obstacle distance between the medoid and every object p within the cluster, we can use it to measure the closeness of the objects to their respective medoids. In Figure VII, green bars represent the average of workloads for all the clusters, which means the closeness of the objects to their respective medoids. Purple bars represent the standard deviation of workloads for all clusters, which means the balance degree among the workloads of the clusters. The statistical results of the four groups are ordered by the sequence number of the group and arranged from left to right. Figure III is the result of group 1. It shows that the workloads of most clusters are below the average, and there are some clusters with very high workload and ones with very low workload. Meanwhile, the average and the standard deviation of group 1 are the biggest among the four groups. This means that the workloads of the existing stations are not balanced to some extent, indicating that the siting of the stations is required to be optimized, and also showing that the work of this paper is valuable. Figure IV is the result of group 2. We can see from the figure that the result has improved compared to the one of group 1, but the maximal workload of group 2 is higher than the one of group 1. The cause of this is that group 2 is without regard to physical obstacles. Compared to group 2, although the standard deviation doesn't decrease significantly, the average decreases by 36%, which optimizes the total workload of all the clusters. Figure V is the result of group 3. It shows that the result is more balanced compared to the one of group 2, but there are a few clusters with workload 5 times higher than the average. The cause of this is also that group 3 is without regard to physical obstacles. Besides, we can see that the average of group 3 is higher than the one of group2, because group 2 takes balance into account and sacrifices some closeness of the objects to their respective medoids. Figure VI is the result of group 4. The workload distribution of all the clusters in this group is the most balanced one among all the groups, which can be from the fact that the maximal workload is the smallest one in the four groups. Meanwhile, we can see that the maximum value of the Y-axis in figure VI is only one-tenth of the ones in figure III, IV and V. Besides, the average and the standard deviation of group 4 are the smallest among the four groups. Especially, the standard deviation is 14% of the one of group1, 16% of the one of group2, and 22% of the one of group3, which means that V. CONCLUSIONS In this paper, we study the optimization problem of the siting of distribution stations. To solve this problem, we propose algorithm called Balanced COD-CLARANS, which is a constrained clustering algorithm capable of handling physical obstacles and balance factor and outputting a set of clusters for decision-making. And we design the experiment to prove that REFERENCES [1] Tung, A. K., Hou, J., & Han, J. (2001). Spatial clustering in the presence of obstacles. In Data Engineering, Proceedings. 17th International Conference on (pp ). IEEE. [2] Ng, R. T., & Han, J. (2002). CLARANS: A method for clustering objects for spatial data mining. IEEE transactions on knowledge and data engineering, 14(5), [3] Zaïane, O. R., & Lee, C. H. (2002). Clustering spatial data when facing physical constraints. In Data Mining, ICDM Proceedings IEEE International Conference on (pp ). IEEE. [4] Ester, M., Kriegel, H. P., Sander, J., & Xu, X. (1996, August). A density-based algorithm for discovering clusters in large spatial databases with noise. In Kdd (Vol. 96, No. 34, pp ). [5] Wang, X., Rostoker, C., & Hamilton, H. J. (2004, September). Densitybased spatial clustering in the presence of obstacles and facilitators. In European Conference on Principles of Data Mining and Knowledge Discovery (pp ). Springer Berlin Heidelberg. [6] Wang, X., & Hamilton, H. J. (2003, April). DBRS: a density-based spatial clustering method with random sampling. In Pacific-Asia Conference on Knowledge Discovery and Data Mining (pp ). Springer Berlin Heidelberg. [7] Estivill-Castro, V., & Lee, I. (2001). Autoclust+: Automatic clustering of point-data sets in the presence of obstacles. In Temporal, Spatial, and Spatio-Temporal Data Mining (pp ). Springer Berlin Heidelberg. [8] Bradley, P. S., Bennett, K. P., & Demiriz, A. (2000). Constrained k- means clustering. Microsoft Research, Redmond, 1-8. [9] Malinen, M. I., & Fränti, P. (2014, August). Balanced k-means for clustering. In Joint IAPR International Workshops on Statistical Techniques in Pattern Recognition (SPR) and Structural and Syntactic Pattern Recognition (SSPR) (pp ). Springer Berlin Heidelberg. [10] Banerjee, A., & Ghosh, J. (2004). Frequency-sensitive competitive learning for scalable balanced clustering on high-dimensional hyperspheres. IEEE Transactions on Neural Networks, 15(3), [11] Burkhard, R., Dell Amico, M., & Martello, S. (2012). Assignment Problems (Revised reprint). [12] Fuchs, H., Kedem, Z. M., & Naylor, B. F. (1980, July). On visible surface generation by a priori tree structures. In ACM Siggraph Computer Graphics(Vol. 14, No. 3, pp ). ACM. 144




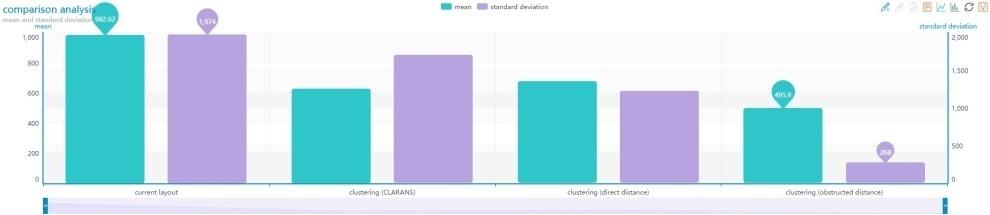
5 Advances in Intelligent Systems Research, volume 133 FIGURE III. THIS IS THE WORKLOAD DISTRIBUTION OF GROUP 1. FIGURE IV. THIS IS THE WORKLOAD DISTRIBUTION OF GROUP 2. FIGURE V. THIS IS THE WORKLOAD DISTRIBUTION OF GROUP 3. FIGURE VI. THIS IS THE WORKLOAD DISTRIBUTION OF GROUP 4. FIGURE VII. THIS IS THE AVERAGE AND THE STANDARD DEVIATION OF THE WORKLOAD FOR THE FOUR GROUPS. 145
Clustering Spatial Data in the Presence of Obstacles
 Clustering Spatial Data in the Presence of Obstacles Abstract. Clustering is a form of unsupervised machine learning. In this paper, we proposed the method to identify clusters in the presence of intersected
Clustering Spatial Data in the Presence of Obstacles Abstract. Clustering is a form of unsupervised machine learning. In this paper, we proposed the method to identify clusters in the presence of intersected
Efficient and Effective Clustering Methods for Spatial Data Mining. Raymond T. Ng, Jiawei Han
 Efficient and Effective Clustering Methods for Spatial Data Mining Raymond T. Ng, Jiawei Han 1 Overview Spatial Data Mining Clustering techniques CLARANS Spatial and Non-Spatial dominant CLARANS Observations
Efficient and Effective Clustering Methods for Spatial Data Mining Raymond T. Ng, Jiawei Han 1 Overview Spatial Data Mining Clustering techniques CLARANS Spatial and Non-Spatial dominant CLARANS Observations
DENSITY BASED AND PARTITION BASED CLUSTERING OF UNCERTAIN DATA BASED ON KL-DIVERGENCE SIMILARITY MEASURE
 DENSITY BASED AND PARTITION BASED CLUSTERING OF UNCERTAIN DATA BASED ON KL-DIVERGENCE SIMILARITY MEASURE Sinu T S 1, Mr.Joseph George 1,2 Computer Science and Engineering, Adi Shankara Institute of Engineering
DENSITY BASED AND PARTITION BASED CLUSTERING OF UNCERTAIN DATA BASED ON KL-DIVERGENCE SIMILARITY MEASURE Sinu T S 1, Mr.Joseph George 1,2 Computer Science and Engineering, Adi Shankara Institute of Engineering
S p a t i a l D a t a M i n i n g. Spatial Clustering in the Presence of Obstacles
 S p a t i a l D a t a M i n i n g Spatial Clustering in the Presence of Obstacles Milan Magdics Spring, 2007 I n t r o d u c t i o n Clustering in spatial data mining is to group similar objects based
S p a t i a l D a t a M i n i n g Spatial Clustering in the Presence of Obstacles Milan Magdics Spring, 2007 I n t r o d u c t i o n Clustering in spatial data mining is to group similar objects based
Outlier Detection Using Unsupervised and Semi-Supervised Technique on High Dimensional Data
 Outlier Detection Using Unsupervised and Semi-Supervised Technique on High Dimensional Data Ms. Gayatri Attarde 1, Prof. Aarti Deshpande 2 M. E Student, Department of Computer Engineering, GHRCCEM, University
Outlier Detection Using Unsupervised and Semi-Supervised Technique on High Dimensional Data Ms. Gayatri Attarde 1, Prof. Aarti Deshpande 2 M. E Student, Department of Computer Engineering, GHRCCEM, University
Effect of Physical Constraints on Spatial Connectivity in Urban Areas
 Effect of Physical Constraints on Spatial Connectivity in Urban Areas Yoav Vered and Sagi Filin Department of Transportation and Geo-Information Technion Israel Institute of Technology Motivation Wide
Effect of Physical Constraints on Spatial Connectivity in Urban Areas Yoav Vered and Sagi Filin Department of Transportation and Geo-Information Technion Israel Institute of Technology Motivation Wide
CS412 Homework #3 Answer Set
 CS41 Homework #3 Answer Set December 1, 006 Q1. (6 points) (1) (3 points) Suppose that a transaction datase DB is partitioned into DB 1,..., DB p. The outline of a distributed algorithm is as follows.
CS41 Homework #3 Answer Set December 1, 006 Q1. (6 points) (1) (3 points) Suppose that a transaction datase DB is partitioned into DB 1,..., DB p. The outline of a distributed algorithm is as follows.
Unsupervised learning on Color Images
 Unsupervised learning on Color Images Sindhuja Vakkalagadda 1, Prasanthi Dhavala 2 1 Computer Science and Systems Engineering, Andhra University, AP, India 2 Computer Science and Systems Engineering, Andhra
Unsupervised learning on Color Images Sindhuja Vakkalagadda 1, Prasanthi Dhavala 2 1 Computer Science and Systems Engineering, Andhra University, AP, India 2 Computer Science and Systems Engineering, Andhra
COMPARISON OF DENSITY-BASED CLUSTERING ALGORITHMS
 COMPARISON OF DENSITY-BASED CLUSTERING ALGORITHMS Mariam Rehman Lahore College for Women University Lahore, Pakistan mariam.rehman321@gmail.com Syed Atif Mehdi University of Management and Technology Lahore,
COMPARISON OF DENSITY-BASED CLUSTERING ALGORITHMS Mariam Rehman Lahore College for Women University Lahore, Pakistan mariam.rehman321@gmail.com Syed Atif Mehdi University of Management and Technology Lahore,
Clustering Algorithms In Data Mining
 2017 5th International Conference on Computer, Automation and Power Electronics (CAPE 2017) Clustering Algorithms In Data Mining Xiaosong Chen 1, a 1 Deparment of Computer Science, University of Vermont,
2017 5th International Conference on Computer, Automation and Power Electronics (CAPE 2017) Clustering Algorithms In Data Mining Xiaosong Chen 1, a 1 Deparment of Computer Science, University of Vermont,
CHAPTER 7. PAPER 3: EFFICIENT HIERARCHICAL CLUSTERING OF LARGE DATA SETS USING P-TREES
 CHAPTER 7. PAPER 3: EFFICIENT HIERARCHICAL CLUSTERING OF LARGE DATA SETS USING P-TREES 7.1. Abstract Hierarchical clustering methods have attracted much attention by giving the user a maximum amount of
CHAPTER 7. PAPER 3: EFFICIENT HIERARCHICAL CLUSTERING OF LARGE DATA SETS USING P-TREES 7.1. Abstract Hierarchical clustering methods have attracted much attention by giving the user a maximum amount of
C-NBC: Neighborhood-Based Clustering with Constraints
 C-NBC: Neighborhood-Based Clustering with Constraints Piotr Lasek Chair of Computer Science, University of Rzeszów ul. Prof. St. Pigonia 1, 35-310 Rzeszów, Poland lasek@ur.edu.pl Abstract. Clustering is
C-NBC: Neighborhood-Based Clustering with Constraints Piotr Lasek Chair of Computer Science, University of Rzeszów ul. Prof. St. Pigonia 1, 35-310 Rzeszów, Poland lasek@ur.edu.pl Abstract. Clustering is
A Data Classification Algorithm of Internet of Things Based on Neural Network
 A Data Classification Algorithm of Internet of Things Based on Neural Network https://doi.org/10.3991/ijoe.v13i09.7587 Zhenjun Li Hunan Radio and TV University, Hunan, China 278060389@qq.com Abstract To
A Data Classification Algorithm of Internet of Things Based on Neural Network https://doi.org/10.3991/ijoe.v13i09.7587 Zhenjun Li Hunan Radio and TV University, Hunan, China 278060389@qq.com Abstract To
Analysis and Extensions of Popular Clustering Algorithms
 Analysis and Extensions of Popular Clustering Algorithms Renáta Iváncsy, Attila Babos, Csaba Legány Department of Automation and Applied Informatics and HAS-BUTE Control Research Group Budapest University
Analysis and Extensions of Popular Clustering Algorithms Renáta Iváncsy, Attila Babos, Csaba Legány Department of Automation and Applied Informatics and HAS-BUTE Control Research Group Budapest University
Text clustering based on a divide and merge strategy
 Available online at www.sciencedirect.com ScienceDirect Procedia Computer Science 55 (2015 ) 825 832 Information Technology and Quantitative Management (ITQM 2015) Text clustering based on a divide and
Available online at www.sciencedirect.com ScienceDirect Procedia Computer Science 55 (2015 ) 825 832 Information Technology and Quantitative Management (ITQM 2015) Text clustering based on a divide and
Data Mining: Concepts and Techniques. Chapter March 8, 2007 Data Mining: Concepts and Techniques 1
 Data Mining: Concepts and Techniques Chapter 7.1-4 March 8, 2007 Data Mining: Concepts and Techniques 1 1. What is Cluster Analysis? 2. Types of Data in Cluster Analysis Chapter 7 Cluster Analysis 3. A
Data Mining: Concepts and Techniques Chapter 7.1-4 March 8, 2007 Data Mining: Concepts and Techniques 1 1. What is Cluster Analysis? 2. Types of Data in Cluster Analysis Chapter 7 Cluster Analysis 3. A
Clustering in Ratemaking: Applications in Territories Clustering
 Clustering in Ratemaking: Applications in Territories Clustering Ji Yao, PhD FIA ASTIN 13th-16th July 2008 INTRODUCTION Structure of talk Quickly introduce clustering and its application in insurance ratemaking
Clustering in Ratemaking: Applications in Territories Clustering Ji Yao, PhD FIA ASTIN 13th-16th July 2008 INTRODUCTION Structure of talk Quickly introduce clustering and its application in insurance ratemaking
Clustering part II 1
 Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
CLUSTERING. CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16
 CLUSTERING CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16 1. K-medoids: REFERENCES https://www.coursera.org/learn/cluster-analysis/lecture/nj0sb/3-4-the-k-medoids-clustering-method https://anuradhasrinivas.files.wordpress.com/2013/04/lesson8-clustering.pdf
CLUSTERING CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16 1. K-medoids: REFERENCES https://www.coursera.org/learn/cluster-analysis/lecture/nj0sb/3-4-the-k-medoids-clustering-method https://anuradhasrinivas.files.wordpress.com/2013/04/lesson8-clustering.pdf
I. INTRODUCTION II. RELATED WORK.
 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: A New Hybridized K-Means Clustering Based Outlier Detection Technique
ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: A New Hybridized K-Means Clustering Based Outlier Detection Technique
Course Content. What is Classification? Chapter 6 Objectives
 Principles of Knowledge Discovery in Data Fall 007 Chapter 6: Data Clustering Dr. Osmar R. Zaïane University of Alberta Course Content Introduction to Data Mining Association Analysis Sequential Pattern
Principles of Knowledge Discovery in Data Fall 007 Chapter 6: Data Clustering Dr. Osmar R. Zaïane University of Alberta Course Content Introduction to Data Mining Association Analysis Sequential Pattern
A Parallel Community Detection Algorithm for Big Social Networks
 A Parallel Community Detection Algorithm for Big Social Networks Yathrib AlQahtani College of Computer and Information Sciences King Saud University Collage of Computing and Informatics Saudi Electronic
A Parallel Community Detection Algorithm for Big Social Networks Yathrib AlQahtani College of Computer and Information Sciences King Saud University Collage of Computing and Informatics Saudi Electronic
Kapitel 4: Clustering
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
Datasets Size: Effect on Clustering Results
 1 Datasets Size: Effect on Clustering Results Adeleke Ajiboye 1, Ruzaini Abdullah Arshah 2, Hongwu Qin 3 Faculty of Computer Systems and Software Engineering Universiti Malaysia Pahang 1 {ajibraheem@live.com}
1 Datasets Size: Effect on Clustering Results Adeleke Ajiboye 1, Ruzaini Abdullah Arshah 2, Hongwu Qin 3 Faculty of Computer Systems and Software Engineering Universiti Malaysia Pahang 1 {ajibraheem@live.com}
Course Content. Classification = Learning a Model. What is Classification?
 Lecture 6 Week 0 (May ) and Week (May 9) 459-0 Principles of Knowledge Discovery in Data Clustering Analysis: Agglomerative,, and other approaches Lecture by: Dr. Osmar R. Zaïane Course Content Introduction
Lecture 6 Week 0 (May ) and Week (May 9) 459-0 Principles of Knowledge Discovery in Data Clustering Analysis: Agglomerative,, and other approaches Lecture by: Dr. Osmar R. Zaïane Course Content Introduction
Clustering in Data Mining
 Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
FACET SHIFT ALGORITHM BASED ON MINIMAL DISTANCE IN SIMPLIFICATION OF BUILDINGS WITH PARALLEL STRUCTURE
 FACET SHIFT ALGORITHM BASED ON MINIMAL DISTANCE IN SIMPLIFICATION OF BUILDINGS WITH PARALLEL STRUCTURE GE Lei, WU Fang, QIAN Haizhong, ZHAI Renjian Institute of Surveying and Mapping Information Engineering
FACET SHIFT ALGORITHM BASED ON MINIMAL DISTANCE IN SIMPLIFICATION OF BUILDINGS WITH PARALLEL STRUCTURE GE Lei, WU Fang, QIAN Haizhong, ZHAI Renjian Institute of Surveying and Mapping Information Engineering
Enhancing Clustering Results In Hierarchical Approach By Mvs Measures
 International Journal of Engineering Research and Development e-issn: 2278-067X, p-issn: 2278-800X, www.ijerd.com Volume 10, Issue 6 (June 2014), PP.25-30 Enhancing Clustering Results In Hierarchical Approach
International Journal of Engineering Research and Development e-issn: 2278-067X, p-issn: 2278-800X, www.ijerd.com Volume 10, Issue 6 (June 2014), PP.25-30 Enhancing Clustering Results In Hierarchical Approach
Clustering. Chapter 10 in Introduction to statistical learning
 Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
TOWARDS NEW ESTIMATING INCREMENTAL DIMENSIONAL ALGORITHM (EIDA)
") TOWARDS NEW ESTIMATING INCREMENTAL DIMENSIONAL ALGORITHM (EIDA) 1 S. ADAEKALAVAN, 2 DR. C. CHANDRASEKAR 1 Assistant Professor, Department of Information Technology, J.J. College of Arts and Science, Pudukkottai,
TOWARDS NEW ESTIMATING INCREMENTAL DIMENSIONAL ALGORITHM (EIDA) 1 S. ADAEKALAVAN, 2 DR. C. CHANDRASEKAR 1 Assistant Professor, Department of Information Technology, J.J. College of Arts and Science, Pudukkottai,
6. Concluding Remarks
 [8] K. J. Supowit, The relative neighborhood graph with an application to minimum spanning trees, Tech. Rept., Department of Computer Science, University of Illinois, Urbana-Champaign, August 1980, also
[8] K. J. Supowit, The relative neighborhood graph with an application to minimum spanning trees, Tech. Rept., Department of Computer Science, University of Illinois, Urbana-Champaign, August 1980, also
An Efficient Density Based Incremental Clustering Algorithm in Data Warehousing Environment
 An Efficient Density Based Incremental Clustering Algorithm in Data Warehousing Environment Navneet Goyal, Poonam Goyal, K Venkatramaiah, Deepak P C, and Sanoop P S Department of Computer Science & Information
An Efficient Density Based Incremental Clustering Algorithm in Data Warehousing Environment Navneet Goyal, Poonam Goyal, K Venkatramaiah, Deepak P C, and Sanoop P S Department of Computer Science & Information
High Capacity Reversible Watermarking Scheme for 2D Vector Maps
 Scheme for 2D Vector Maps 1 Information Management Department, China National Petroleum Corporation, Beijing, 100007, China E-mail: jxw@petrochina.com.cn Mei Feng Research Institute of Petroleum Exploration
Scheme for 2D Vector Maps 1 Information Management Department, China National Petroleum Corporation, Beijing, 100007, China E-mail: jxw@petrochina.com.cn Mei Feng Research Institute of Petroleum Exploration
Analyzing Outlier Detection Techniques with Hybrid Method
 Analyzing Outlier Detection Techniques with Hybrid Method Shruti Aggarwal Assistant Professor Department of Computer Science and Engineering Sri Guru Granth Sahib World University. (SGGSWU) Fatehgarh Sahib,
Analyzing Outlier Detection Techniques with Hybrid Method Shruti Aggarwal Assistant Professor Department of Computer Science and Engineering Sri Guru Granth Sahib World University. (SGGSWU) Fatehgarh Sahib,
A GENETIC ALGORITHM FOR CLUSTERING ON VERY LARGE DATA SETS
 A GENETIC ALGORITHM FOR CLUSTERING ON VERY LARGE DATA SETS Jim Gasvoda and Qin Ding Department of Computer Science, Pennsylvania State University at Harrisburg, Middletown, PA 17057, USA {jmg289, qding}@psu.edu
A GENETIC ALGORITHM FOR CLUSTERING ON VERY LARGE DATA SETS Jim Gasvoda and Qin Ding Department of Computer Science, Pennsylvania State University at Harrisburg, Middletown, PA 17057, USA {jmg289, qding}@psu.edu
APPLICATION OF MULTIPLE RANDOM CENTROID (MRC) BASED K-MEANS CLUSTERING ALGORITHM IN INSURANCE A REVIEW ARTICLE
 BASED K-MEANS CLUSTERING ALGORITHM IN INSURANCE A REVIEW ARTICLE") APPLICATION OF MULTIPLE RANDOM CENTROID (MRC) BASED K-MEANS CLUSTERING ALGORITHM IN INSURANCE A REVIEW ARTICLE Sundari NallamReddy, Samarandra Behera, Sanjeev Karadagi, Dr. Anantha Desik ABSTRACT: Tata
APPLICATION OF MULTIPLE RANDOM CENTROID (MRC) BASED K-MEANS CLUSTERING ALGORITHM IN INSURANCE A REVIEW ARTICLE Sundari NallamReddy, Samarandra Behera, Sanjeev Karadagi, Dr. Anantha Desik ABSTRACT: Tata
A Review on Cluster Based Approach in Data Mining
 A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
A New Clustering Algorithm On Nominal Data Sets
 A New Clustering Algorithm On Nominal Data Sets Bin Wang Abstract This paper presents a new clustering technique named as the Olary algorithm, which is suitable to cluster nominal data sets. This algorithm
A New Clustering Algorithm On Nominal Data Sets Bin Wang Abstract This paper presents a new clustering technique named as the Olary algorithm, which is suitable to cluster nominal data sets. This algorithm
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
SOMSN: An Effective Self Organizing Map for Clustering of Social Networks
 SOMSN: An Effective Self Organizing Map for Clustering of Social Networks Fatemeh Ghaemmaghami Research Scholar, CSE and IT Dept. Shiraz University, Shiraz, Iran Reza Manouchehri Sarhadi Research Scholar,
SOMSN: An Effective Self Organizing Map for Clustering of Social Networks Fatemeh Ghaemmaghami Research Scholar, CSE and IT Dept. Shiraz University, Shiraz, Iran Reza Manouchehri Sarhadi Research Scholar,
AN APPROACH FOR LOAD BALANCING FOR SIMULATION IN HETEROGENEOUS DISTRIBUTED SYSTEMS USING SIMULATION DATA MINING
 AN APPROACH FOR LOAD BALANCING FOR SIMULATION IN HETEROGENEOUS DISTRIBUTED SYSTEMS USING SIMULATION DATA MINING Irina Bernst, Patrick Bouillon, Jörg Frochte *, Christof Kaufmann Dept. of Electrical Engineering
AN APPROACH FOR LOAD BALANCING FOR SIMULATION IN HETEROGENEOUS DISTRIBUTED SYSTEMS USING SIMULATION DATA MINING Irina Bernst, Patrick Bouillon, Jörg Frochte *, Christof Kaufmann Dept. of Electrical Engineering
Unsupervised Learning Partitioning Methods
 Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
Density-based clustering algorithms DBSCAN and SNN
 Density-based clustering algorithms DBSCAN and SNN Version 1.0, 25.07.2005 Adriano Moreira, Maribel Y. Santos and Sofia Carneiro {adriano, maribel, sofia}@dsi.uminho.pt University of Minho - Portugal 1.
Density-based clustering algorithms DBSCAN and SNN Version 1.0, 25.07.2005 Adriano Moreira, Maribel Y. Santos and Sofia Carneiro {adriano, maribel, sofia}@dsi.uminho.pt University of Minho - Portugal 1.
Representation of 2D objects with a topology preserving network
 Representation of 2D objects with a topology preserving network Francisco Flórez, Juan Manuel García, José García, Antonio Hernández, Departamento de Tecnología Informática y Computación. Universidad de
Representation of 2D objects with a topology preserving network Francisco Flórez, Juan Manuel García, José García, Antonio Hernández, Departamento de Tecnología Informática y Computación. Universidad de
An Improved KNN Classification Algorithm based on Sampling
 International Conference on Advances in Materials, Machinery, Electrical Engineering (AMMEE 017) An Improved KNN Classification Algorithm based on Sampling Zhiwei Cheng1, a, Caisen Chen1, b, Xuehuan Qiu1,
International Conference on Advances in Materials, Machinery, Electrical Engineering (AMMEE 017) An Improved KNN Classification Algorithm based on Sampling Zhiwei Cheng1, a, Caisen Chen1, b, Xuehuan Qiu1,
Study on Delaunay Triangulation with the Islets Constraints
 Intelligent Information Management, 2010, 2, 375-379 doi:10.4236/iim.2010.26045 Published Online June 2010 (http://www.scirp.org/journal/iim) Study on Delaunay Triangulation with the Islets Constraints
Intelligent Information Management, 2010, 2, 375-379 doi:10.4236/iim.2010.26045 Published Online June 2010 (http://www.scirp.org/journal/iim) Study on Delaunay Triangulation with the Islets Constraints
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING 09: Vector Data: Clustering Basics Instructor: Yizhou Sun yzsun@cs.ucla.edu October 27, 2017 Methods to Learn Vector Data Set Data Sequence Data Text Data Classification
CS145: INTRODUCTION TO DATA MINING 09: Vector Data: Clustering Basics Instructor: Yizhou Sun yzsun@cs.ucla.edu October 27, 2017 Methods to Learn Vector Data Set Data Sequence Data Text Data Classification
Heterogeneous Density Based Spatial Clustering of Application with Noise
 210 Heterogeneous Density Based Spatial Clustering of Application with Noise J. Hencil Peter and A.Antonysamy, Research Scholar St. Xavier s College, Palayamkottai Tamil Nadu, India Principal St. Xavier
210 Heterogeneous Density Based Spatial Clustering of Application with Noise J. Hencil Peter and A.Antonysamy, Research Scholar St. Xavier s College, Palayamkottai Tamil Nadu, India Principal St. Xavier
An Optimization Algorithm of Selecting Initial Clustering Center in K means
 2nd International Conference on Machinery, Electronics and Control Simulation (MECS 2017) An Optimization Algorithm of Selecting Initial Clustering Center in K means Tianhan Gao1, a, Xue Kong2, b,* 1 School
2nd International Conference on Machinery, Electronics and Control Simulation (MECS 2017) An Optimization Algorithm of Selecting Initial Clustering Center in K means Tianhan Gao1, a, Xue Kong2, b,* 1 School
Enhancing K-means Clustering Algorithm with Improved Initial Center
 Enhancing K-means Clustering Algorithm with Improved Initial Center Madhu Yedla #1, Srinivasa Rao Pathakota #2, T M Srinivasa #3 # Department of Computer Science and Engineering, National Institute of
Enhancing K-means Clustering Algorithm with Improved Initial Center Madhu Yedla #1, Srinivasa Rao Pathakota #2, T M Srinivasa #3 # Department of Computer Science and Engineering, National Institute of
CHAPTER VII INDEXED K TWIN NEIGHBOUR CLUSTERING ALGORITHM 7.1 INTRODUCTION
 CHAPTER VII INDEXED K TWIN NEIGHBOUR CLUSTERING ALGORITHM 7.1 INTRODUCTION Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called cluster)
CHAPTER VII INDEXED K TWIN NEIGHBOUR CLUSTERING ALGORITHM 7.1 INTRODUCTION Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called cluster)
Clustering-Based Distributed Precomputation for Quality-of-Service Routing*
 Clustering-Based Distributed Precomputation for Quality-of-Service Routing* Yong Cui and Jianping Wu Department of Computer Science, Tsinghua University, Beijing, P.R.China, 100084 cy@csnet1.cs.tsinghua.edu.cn,
Clustering-Based Distributed Precomputation for Quality-of-Service Routing* Yong Cui and Jianping Wu Department of Computer Science, Tsinghua University, Beijing, P.R.China, 100084 cy@csnet1.cs.tsinghua.edu.cn,
Unsupervised Learning
 Networks for Pattern Recognition, 2014 Networks for Single Linkage K-Means Soft DBSCAN PCA Networks for Kohonen Maps Linear Vector Quantization Networks for Problems/Approaches in Machine Learning Supervised
Networks for Pattern Recognition, 2014 Networks for Single Linkage K-Means Soft DBSCAN PCA Networks for Kohonen Maps Linear Vector Quantization Networks for Problems/Approaches in Machine Learning Supervised
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
PAM algorithm. Types of Data in Cluster Analysis. A Categorization of Major Clustering Methods. Partitioning i Methods. Hierarchical Methods
 Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Clustering Algorithms for Data Stream
 Clustering Algorithms for Data Stream Karishma Nadhe 1, Prof. P. M. Chawan 2 1Student, Dept of CS & IT, VJTI Mumbai, Maharashtra, India 2Professor, Dept of CS & IT, VJTI Mumbai, Maharashtra, India Abstract:
Clustering Algorithms for Data Stream Karishma Nadhe 1, Prof. P. M. Chawan 2 1Student, Dept of CS & IT, VJTI Mumbai, Maharashtra, India 2Professor, Dept of CS & IT, VJTI Mumbai, Maharashtra, India Abstract:
Data Clustering With Leaders and Subleaders Algorithm
 IOSR Journal of Engineering (IOSRJEN) e-issn: 2250-3021, p-issn: 2278-8719, Volume 2, Issue 11 (November2012), PP 01-07 Data Clustering With Leaders and Subleaders Algorithm Srinivasulu M 1,Kotilingswara
IOSR Journal of Engineering (IOSRJEN) e-issn: 2250-3021, p-issn: 2278-8719, Volume 2, Issue 11 (November2012), PP 01-07 Data Clustering With Leaders and Subleaders Algorithm Srinivasulu M 1,Kotilingswara
Research on Applications of Data Mining in Electronic Commerce. Xiuping YANG 1, a
 International Conference on Education Technology, Management and Humanities Science (ETMHS 2015) Research on Applications of Data Mining in Electronic Commerce Xiuping YANG 1, a 1 Computer Science Department,
International Conference on Education Technology, Management and Humanities Science (ETMHS 2015) Research on Applications of Data Mining in Electronic Commerce Xiuping YANG 1, a 1 Computer Science Department,
Constrained Clustering with Interactive Similarity Learning
 SCIS & ISIS 2010, Dec. 8-12, 2010, Okayama Convention Center, Okayama, Japan Constrained Clustering with Interactive Similarity Learning Masayuki Okabe Toyohashi University of Technology Tenpaku 1-1, Toyohashi,
SCIS & ISIS 2010, Dec. 8-12, 2010, Okayama Convention Center, Okayama, Japan Constrained Clustering with Interactive Similarity Learning Masayuki Okabe Toyohashi University of Technology Tenpaku 1-1, Toyohashi,
CS570: Introduction to Data Mining
 CS570: Introduction to Data Mining Cluster Analysis Reading: Chapter 10.4, 10.6, 11.1.3 Han, Chapter 8.4,8.5,9.2.2, 9.3 Tan Anca Doloc-Mihu, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber &
CS570: Introduction to Data Mining Cluster Analysis Reading: Chapter 10.4, 10.6, 11.1.3 Han, Chapter 8.4,8.5,9.2.2, 9.3 Tan Anca Doloc-Mihu, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber &
Graph-based High Level Motion Segmentation using Normalized Cuts
 Graph-based High Level Motion Segmentation using Normalized Cuts Sungju Yun, Anjin Park and Keechul Jung Abstract Motion capture devices have been utilized in producing several contents, such as movies
Graph-based High Level Motion Segmentation using Normalized Cuts Sungju Yun, Anjin Park and Keechul Jung Abstract Motion capture devices have been utilized in producing several contents, such as movies
Database and Knowledge-Base Systems: Data Mining. Martin Ester
 Database and Knowledge-Base Systems: Data Mining Martin Ester Simon Fraser University School of Computing Science Graduate Course Spring 2006 CMPT 843, SFU, Martin Ester, 1-06 1 Introduction [Fayyad, Piatetsky-Shapiro
Database and Knowledge-Base Systems: Data Mining Martin Ester Simon Fraser University School of Computing Science Graduate Course Spring 2006 CMPT 843, SFU, Martin Ester, 1-06 1 Introduction [Fayyad, Piatetsky-Shapiro
Density Based Clustering using Modified PSO based Neighbor Selection
 Density Based Clustering using Modified PSO based Neighbor Selection K. Nafees Ahmed Research Scholar, Dept of Computer Science Jamal Mohamed College (Autonomous), Tiruchirappalli, India nafeesjmc@gmail.com
Density Based Clustering using Modified PSO based Neighbor Selection K. Nafees Ahmed Research Scholar, Dept of Computer Science Jamal Mohamed College (Autonomous), Tiruchirappalli, India nafeesjmc@gmail.com
Visual Representations for Machine Learning
 Visual Representations for Machine Learning Spectral Clustering and Channel Representations Lecture 1 Spectral Clustering: introduction and confusion Michael Felsberg Klas Nordberg The Spectral Clustering
Visual Representations for Machine Learning Spectral Clustering and Channel Representations Lecture 1 Spectral Clustering: introduction and confusion Michael Felsberg Klas Nordberg The Spectral Clustering
Top-k Keyword Search Over Graphs Based On Backward Search
 Top-k Keyword Search Over Graphs Based On Backward Search Jia-Hui Zeng, Jiu-Ming Huang, Shu-Qiang Yang 1College of Computer National University of Defense Technology, Changsha, China 2College of Computer
Top-k Keyword Search Over Graphs Based On Backward Search Jia-Hui Zeng, Jiu-Ming Huang, Shu-Qiang Yang 1College of Computer National University of Defense Technology, Changsha, China 2College of Computer
DBSCAN. Presented by: Garrett Poppe
 DBSCAN Presented by: Garrett Poppe A density-based algorithm for discovering clusters in large spatial databases with noise by Martin Ester, Hans-peter Kriegel, Jörg S, Xiaowei Xu Slides adapted from resources
DBSCAN Presented by: Garrett Poppe A density-based algorithm for discovering clusters in large spatial databases with noise by Martin Ester, Hans-peter Kriegel, Jörg S, Xiaowei Xu Slides adapted from resources
AN IMPROVED DENSITY BASED k-means ALGORITHM
 AN IMPROVED DENSITY BASED k-means ALGORITHM Kabiru Dalhatu 1 and Alex Tze Hiang Sim 2 1 Department of Computer Science, Faculty of Computing and Mathematical Science, Kano University of Science and Technology
AN IMPROVED DENSITY BASED k-means ALGORITHM Kabiru Dalhatu 1 and Alex Tze Hiang Sim 2 1 Department of Computer Science, Faculty of Computing and Mathematical Science, Kano University of Science and Technology
Clustering Part 4 DBSCAN
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
A New Fast Clustering Algorithm Based on Reference and Density
 A New Fast Clustering Algorithm Based on Reference and Density Shuai Ma 1, TengJiao Wang 1, ShiWei Tang 1,2, DongQing Yang 1, and Jun Gao 1 1 Department of Computer Science, Peking University, Beijing
A New Fast Clustering Algorithm Based on Reference and Density Shuai Ma 1, TengJiao Wang 1, ShiWei Tang 1,2, DongQing Yang 1, and Jun Gao 1 1 Department of Computer Science, Peking University, Beijing
Data Mining. Clustering. Hamid Beigy. Sharif University of Technology. Fall 1394
 Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
Learning the Three Factors of a Non-overlapping Multi-camera Network Topology
 Learning the Three Factors of a Non-overlapping Multi-camera Network Topology Xiaotang Chen, Kaiqi Huang, and Tieniu Tan National Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy
Learning the Three Factors of a Non-overlapping Multi-camera Network Topology Xiaotang Chen, Kaiqi Huang, and Tieniu Tan National Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy
Keywords Clustering, Goals of clustering, clustering techniques, clustering algorithms.
 Volume 3, Issue 5, May 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com A Survey of Clustering
Volume 3, Issue 5, May 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com A Survey of Clustering
Detect tracking behavior among trajectory data
 Detect tracking behavior among trajectory data Jianqiu Xu, Jiangang Zhou Nanjing University of Aeronautics and Astronautics, China, jianqiu@nuaa.edu.cn, jiangangzhou@nuaa.edu.cn Abstract. Due to the continuing
Detect tracking behavior among trajectory data Jianqiu Xu, Jiangang Zhou Nanjing University of Aeronautics and Astronautics, China, jianqiu@nuaa.edu.cn, jiangangzhou@nuaa.edu.cn Abstract. Due to the continuing
Course Content. Objectives of Lecture? CMPUT 391: Spatial Data Management Dr. Jörg Sander & Dr. Osmar R. Zaïane. University of Alberta
 Database Management Systems Winter 2002 CMPUT 39: Spatial Data Management Dr. Jörg Sander & Dr. Osmar. Zaïane University of Alberta Chapter 26 of Textbook Course Content Introduction Database Design Theory
Database Management Systems Winter 2002 CMPUT 39: Spatial Data Management Dr. Jörg Sander & Dr. Osmar. Zaïane University of Alberta Chapter 26 of Textbook Course Content Introduction Database Design Theory
Fast Approximate Minimum Spanning Tree Algorithm Based on K-Means
 Fast Approximate Minimum Spanning Tree Algorithm Based on K-Means Caiming Zhong 1,2,3, Mikko Malinen 2, Duoqian Miao 1,andPasiFränti 2 1 Department of Computer Science and Technology, Tongji University,
Fast Approximate Minimum Spanning Tree Algorithm Based on K-Means Caiming Zhong 1,2,3, Mikko Malinen 2, Duoqian Miao 1,andPasiFränti 2 1 Department of Computer Science and Technology, Tongji University,
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Ranking Web Pages by Associating Keywords with Locations
 Ranking Web Pages by Associating Keywords with Locations Peiquan Jin, Xiaoxiang Zhang, Qingqing Zhang, Sheng Lin, and Lihua Yue University of Science and Technology of China, 230027, Hefei, China jpq@ustc.edu.cn
Ranking Web Pages by Associating Keywords with Locations Peiquan Jin, Xiaoxiang Zhang, Qingqing Zhang, Sheng Lin, and Lihua Yue University of Science and Technology of China, 230027, Hefei, China jpq@ustc.edu.cn
Research on Data Mining Technology Based on Business Intelligence. Yang WANG
 2018 International Conference on Mechanical, Electronic and Information Technology (ICMEIT 2018) ISBN: 978-1-60595-548-3 Research on Data Mining Technology Based on Business Intelligence Yang WANG Communication
2018 International Conference on Mechanical, Electronic and Information Technology (ICMEIT 2018) ISBN: 978-1-60595-548-3 Research on Data Mining Technology Based on Business Intelligence Yang WANG Communication
Improving K-Means by Outlier Removal
 Improving K-Means by Outlier Removal Ville Hautamäki, Svetlana Cherednichenko, Ismo Kärkkäinen, Tomi Kinnunen, and Pasi Fränti Speech and Image Processing Unit, Department of Computer Science, University
Improving K-Means by Outlier Removal Ville Hautamäki, Svetlana Cherednichenko, Ismo Kärkkäinen, Tomi Kinnunen, and Pasi Fränti Speech and Image Processing Unit, Department of Computer Science, University
New Approach for K-mean and K-medoids Algorithm
 New Approach for K-mean and K-medoids Algorithm Abhishek Patel Department of Information & Technology, Parul Institute of Engineering & Technology, Vadodara, Gujarat, India Purnima Singh Department of
New Approach for K-mean and K-medoids Algorithm Abhishek Patel Department of Information & Technology, Parul Institute of Engineering & Technology, Vadodara, Gujarat, India Purnima Singh Department of
Mining Quantitative Association Rules on Overlapped Intervals
 Mining Quantitative Association Rules on Overlapped Intervals Qiang Tong 1,3, Baoping Yan 2, and Yuanchun Zhou 1,3 1 Institute of Computing Technology, Chinese Academy of Sciences, Beijing, China {tongqiang,
Mining Quantitative Association Rules on Overlapped Intervals Qiang Tong 1,3, Baoping Yan 2, and Yuanchun Zhou 1,3 1 Institute of Computing Technology, Chinese Academy of Sciences, Beijing, China {tongqiang,
Comparative Study of Subspace Clustering Algorithms
 Comparative Study of Subspace Clustering Algorithms S.Chitra Nayagam, Asst Prof., Dept of Computer Applications, Don Bosco College, Panjim, Goa. Abstract-A cluster is a collection of data objects that
Comparative Study of Subspace Clustering Algorithms S.Chitra Nayagam, Asst Prof., Dept of Computer Applications, Don Bosco College, Panjim, Goa. Abstract-A cluster is a collection of data objects that
Available online at ScienceDirect. Procedia Computer Science 89 (2016 )
") Available online at www.sciencedirect.com ScienceDirect Procedia Computer Science 89 (2016 ) 341 348 Twelfth International Multi-Conference on Information Processing-2016 (IMCIP-2016) Parallel Approach
Available online at www.sciencedirect.com ScienceDirect Procedia Computer Science 89 (2016 ) 341 348 Twelfth International Multi-Conference on Information Processing-2016 (IMCIP-2016) Parallel Approach
Clustering & Dimensionality Reduction. 273A Intro Machine Learning
 Clustering & Dimensionality Reduction 273A Intro Machine Learning What is Unsupervised Learning? In supervised learning we were given attributes & targets (e.g. class labels). In unsupervised learning
Clustering & Dimensionality Reduction 273A Intro Machine Learning What is Unsupervised Learning? In supervised learning we were given attributes & targets (e.g. class labels). In unsupervised learning
Image Segmentation Based on Watershed and Edge Detection Techniques
 0 The International Arab Journal of Information Technology, Vol., No., April 00 Image Segmentation Based on Watershed and Edge Detection Techniques Nassir Salman Computer Science Department, Zarqa Private
0 The International Arab Journal of Information Technology, Vol., No., April 00 Image Segmentation Based on Watershed and Edge Detection Techniques Nassir Salman Computer Science Department, Zarqa Private
A Survey on DBSCAN Algorithm To Detect Cluster With Varied Density.
 A Survey on DBSCAN Algorithm To Detect Cluster With Varied Density. Amey K. Redkar, Prof. S.R. Todmal Abstract Density -based clustering methods are one of the important category of clustering methods
A Survey on DBSCAN Algorithm To Detect Cluster With Varied Density. Amey K. Redkar, Prof. S.R. Todmal Abstract Density -based clustering methods are one of the important category of clustering methods
Image Mining: frameworks and techniques
 Image Mining: frameworks and techniques Madhumathi.k 1, Dr.Antony Selvadoss Thanamani 2 M.Phil, Department of computer science, NGM College, Pollachi, Coimbatore, India 1 HOD Department of Computer Science,
Image Mining: frameworks and techniques Madhumathi.k 1, Dr.Antony Selvadoss Thanamani 2 M.Phil, Department of computer science, NGM College, Pollachi, Coimbatore, India 1 HOD Department of Computer Science,
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest)
") Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Intelligent management of on-line video learning resources supported by Web-mining technology based on the practical application of VOD
 World Transactions on Engineering and Technology Education Vol.13, No.3, 2015 2015 WIETE Intelligent management of on-line video learning resources supported by Web-mining technology based on the practical
World Transactions on Engineering and Technology Education Vol.13, No.3, 2015 2015 WIETE Intelligent management of on-line video learning resources supported by Web-mining technology based on the practical
Automatic Group-Outlier Detection
 Automatic Group-Outlier Detection Amine Chaibi and Mustapha Lebbah and Hanane Azzag LIPN-UMR 7030 Université Paris 13 - CNRS 99, av. J-B Clément - F-93430 Villetaneuse {firstname.secondname}@lipn.univ-paris13.fr
Automatic Group-Outlier Detection Amine Chaibi and Mustapha Lebbah and Hanane Azzag LIPN-UMR 7030 Université Paris 13 - CNRS 99, av. J-B Clément - F-93430 Villetaneuse {firstname.secondname}@lipn.univ-paris13.fr
APPENDIX: DETAILS ABOUT THE DISTANCE TRANSFORM
 APPENDIX: DETAILS ABOUT THE DISTANCE TRANSFORM To speed up the closest-point distance computation, 3D Euclidean Distance Transform (DT) can be used in the proposed method. A DT is a uniform discretization
APPENDIX: DETAILS ABOUT THE DISTANCE TRANSFORM To speed up the closest-point distance computation, 3D Euclidean Distance Transform (DT) can be used in the proposed method. A DT is a uniform discretization
City, University of London Institutional Repository
 City Research Online City, University of London Institutional Repository Citation: Andrienko, N., Andrienko, G., Fuchs, G., Rinzivillo, S. & Betz, H-D. (2015). Real Time Detection and Tracking of Spatial
City Research Online City, University of London Institutional Repository Citation: Andrienko, N., Andrienko, G., Fuchs, G., Rinzivillo, S. & Betz, H-D. (2015). Real Time Detection and Tracking of Spatial
Data Mining 4. Cluster Analysis
 Data Mining 4. Cluster Analysis 4.5 Spring 2010 Instructor: Dr. Masoud Yaghini Introduction DBSCAN Algorithm OPTICS Algorithm DENCLUE Algorithm References Outline Introduction Introduction Density-based
Data Mining 4. Cluster Analysis 4.5 Spring 2010 Instructor: Dr. Masoud Yaghini Introduction DBSCAN Algorithm OPTICS Algorithm DENCLUE Algorithm References Outline Introduction Introduction Density-based
An Enhanced Density Clustering Algorithm for Datasets with Complex Structures
 An Enhanced Density Clustering Algorithm for Datasets with Complex Structures Jieming Yang, Qilong Wu, Zhaoyang Qu, and Zhiying Liu Abstract There are several limitations of DBSCAN: 1) parameters have
An Enhanced Density Clustering Algorithm for Datasets with Complex Structures Jieming Yang, Qilong Wu, Zhaoyang Qu, and Zhiying Liu Abstract There are several limitations of DBSCAN: 1) parameters have
Data Mining Algorithms
 for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
Nearest Neighbor Search by Branch and Bound
 Nearest Neighbor Search by Branch and Bound Algorithmic Problems Around the Web #2 Yury Lifshits http://yury.name CalTech, Fall 07, CS101.2, http://yury.name/algoweb.html 1 / 30 Outline 1 Short Intro to
Nearest Neighbor Search by Branch and Bound Algorithmic Problems Around the Web #2 Yury Lifshits http://yury.name CalTech, Fall 07, CS101.2, http://yury.name/algoweb.html 1 / 30 Outline 1 Short Intro to
MOSAIC: A Proximity Graph Approach for Agglomerative Clustering 1
 MOSAIC: A Proximity Graph Approach for Agglomerative Clustering Jiyeon Choo, Rachsuda Jiamthapthaksin, Chun-sheng Chen, Oner Ulvi Celepcikay, Christian Giusti, and Christoph F. Eick Computer Science Department,
MOSAIC: A Proximity Graph Approach for Agglomerative Clustering Jiyeon Choo, Rachsuda Jiamthapthaksin, Chun-sheng Chen, Oner Ulvi Celepcikay, Christian Giusti, and Christoph F. Eick Computer Science Department,
Distances, Clustering! Rafael Irizarry!
 Distances, Clustering! Rafael Irizarry! Heatmaps! Distance! Clustering organizes things that are close into groups! What does it mean for two genes to be close?! What does it mean for two samples to
Distances, Clustering! Rafael Irizarry! Heatmaps! Distance! Clustering organizes things that are close into groups! What does it mean for two genes to be close?! What does it mean for two samples to