Lecture on Modeling Tools for Clustering & Regression
|
|
|
- Domenic Jackson
- 5 years ago
- Views:
Transcription



1 Lecture on Modeling Tools for Clustering & Regression CS Analysis and Modeling of Brain Networks Department of Computer Science University of Crete
2 Data Clustering Overview Organizing data into sensible groupings is critical for understanding and learning. Cluster analysis: methods/algorithms for grouping objects according to measured or perceived intrinsic characteristics or similarity. Cluster analysis does not use category labels that tag objects with prior identifiers, i.e., class labels. The absence of category labels distinguishes data clustering (unsupervised learning) from classification (supervised learning). Clustering aims to find structure in data and is therefore exploratory in nature.
3 Clustering has a long rich history in various scientific fields. K-means (1955): One of the most popular simple clustering algorithms. Still widely-used! The design of a general purpose clustering algorithm is a difficult task.
4 Clustering
5 Clustering objectives
6
7 The centroid of a cluster can be computed as a point with coordinates the mean of the coordinates of each point. Other metrics based on similarity (e.g., cosine) could be also employed.
8 k-means: simplest unsupervised learning algorithm Iterative greedy algorithm (K): 1. Place K points into the space represented by the objects that are being clustered These points represent initial group centroids (e.g., start by randomly selecting K centroids) 2. Assign each object to the group that has the closest centroid (e.g., Euclidian distance) 3. When all objects have been assigned, recalculate the positions of the K centroids Repeat Steps 2 and 3 until the centroids no longer move. It converges but does not guarantee optimal solutions. It is heuristic!
9 Example 1 Well-defined clusters
10 Example 1 Well-defined clusters (cont d)
11 Example 2 Not so well-defined clusters The initial data points before clustering.
12 Example 2 Not so well-defined clusters The initial data points before clustering.
13 Example 2 Not so well-defined clusters The initial data points before clustering. Random selection of centroids (circled points).
14 Example 2 (cont d) After the grouping of the points (in the first iteration), the True centroid of each group has been computed. Note that it is different from the initially randomly selected centroid. The process continues until the centroids do not change
15 Criteria for Assessing a Clustering Internal criterion analyzes intrinsic characteristics of a clustering External criterion analyzes how close is a clustering to a reference Relative criterion analyzes the sensitivity of internal criterion during clustering generation The measured quality of a clustering depends on both the object representation & the similarity measure used
16 Properties of a good clustering according to the internal criterion High intra-class (intra-cluster) similarity Cluster cohesion: measures how closely related are objects in a cluster Low inter-class similarity Cluster separation: measures how well-separated a cluster is from other clusters The measured quality depends on the object representation & the similarity measure used
17
18 Silhouette Coefficient x x x x x x x x x x x x x
19 Silhouette Measures Cohesion Compared to Separation How similar an object is to its own cluster (cohesion) compared to other clusters (separation) Ranges in [ 1, 1]: a high value indicates that the object is well matched to its own cluster & poorly matched to neighboring clusters If most objects have a high value, then the clustering configuration is appropriate If many points have a low or negative value, then the clustering configuration may have too many or too few clusters α(i) average dissimilarity of i with all other data within the same cluster. b(i): lowest average dissimilarity of i to any other cluster, of which i is not a member
20 External criteria for clustering quality External criteria: analyze how close is a clustering to a reference Quality measured by its ability to discover some or all of the hidden patterns or latent classes in gold standard data Assesses a clustering with respect to ground truth requires labeled data Assume items with C gold standard classes, while our clustering algorithms produce K clusters, ω 1, ω 2,, ω K with n i members.
21 External Evaluation of Cluster Quality (cont d) Assume items with C gold standard classes, while our clustering produces K clusters, ω 1, ω 2,, ω K with n i members. Purity: the ratio between the dominant class in the cluster π i & the size of cluster ω i 1 Purity ( i) max j ( nij ) j C ni Biased because having n clusters maximizes purity Entropy of classes in clusters Mutual information between classes and clusters
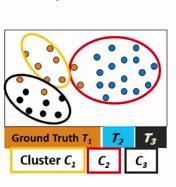
22 Purity example Cluster I Cluster II Cluster III Cluster I: Purity = 1/6 (max(5, 1, 0)) = 5/6 Cluster II: Purity = 1/6 (max(1, 4, 1)) = 4/6 Cluster III: Purity = 1/5 (max(2, 0, 3)) = 3/5
23
24 Entropy-based Measure of the Quality of Clustering
25 Mutual-information based Measure of Quality of Clustering
26
27
28
29
30 Example Clustering of neurons at positions A, B and C in the conditional STTC (A, B C) 1 st cluster: neurons with approximately equal participation at each position 2 nd cluster: neurons with high presence in the position B
31
32

33

34
35 Linear Regression for Predictive Modeling Suppose a set of observations & a set of explanatory variables (i.e., predictors) We build a linear model where each predictor are the coefficients of given as a weighted sum of the predictors, with the weights being the coefficients
36 Why using linear regression? Strength of the relationship between y and a variable x i - Assess the impact of each predictor x i on y through the magnitude of β i - Identify subsets of X that contain redundant information about y
37 Simple linear regression Suppose that we have obtained the dataset and we want to model these as a linear function of To determine which is the optimal β R n, we solve the least squares problem: where is the β that minimizes the Sum of Squared Errors (SSE)
38 An intercept term β 0 captures the noise not caught by predictor variable Again we estimate using least squares without intercept term with intercept term
39 Example 2 The intercept term improves the accuracy of the model Predicted Y Squared Error SSE = 3.55 Predicted Y Squared Error SSE =

40 Multiple linear regression Models the relationship between two or more predictors & the target where are the optimal coefficients β 1, β 2,..., β p of predictors x 1, x 2,..., x p respectively, that minimize the sum of squared errors
41 Regularization Process of introducing additional information in order to prevent overfitting Loss function λ controls the importance of the regularization
42 Regularization Bias Error from erroneous assumptions about the training data high bias: underfitting Variance Error from sensitivity to small fluctuations (noise) in the training data high variance: overfitting Shrinks the magnitude of coefficients Increasing λ
43 Regularization Bias: error from erroneous assumptions about the training data Miss relevant relations between predictors & target (underfitting) Variance: error from sensitivity to small fluctuations in the training data noise, not the intended output (overfitting) Bias variance tradeoff: Ignore small details to get a more general big picture
44 Ridge regression Given a vector with observations & a predictor matrix the ridge regression coefficients are defined as: Not only minimizing the squared error but also the size of the coefficients!
45 Ridge regression as regularization If the β j are unconstrained, they can explode and hence are susceptible to very high variance! To control variance, we regularize the coefficients i.e., control how large they can grow
46 Example 3 Underfitting Overfitting Increasing size of λ
47 Variable selection Problem of selecting the most relevant predictors from a larger set of predictors In linear modeling, this means estimating some coefficients to be exactly zero This can be very important for the purposes of model interpretation Ridge regression cannot perform variable selection - Does not set coefficients exactly to zero, unless λ =
48 Example 4 Suppose that we study the level of prostate-specific antigen (PSA), which is often elevated in men with prostate cancer. We examine n = 97 men with prostate cancer & p = 8 clinical measurements. Interested in identifying a small number of predictors, say 2 or 3, that impact PSA. We perform ridge regression over a wide range of λ
49 Lasso regression The Lasso coefficients are defined as: The only difference between Lasso vs. ridge regression is the penalty term - Ridge uses l 2 penalty - Lasso uses l 1 penalty

50 Lasso regression λ 0 is a tuning parameter for controlling the strength of the penalty The nature of the l 1 penalty causes some coefficients to be shrunken to zero exactly As λ increases, more coefficients are set to zero less predictors are selected Can perform variable selection
51
52
53 Example 5: Ridge vs. Lasso lcp, age & gleason: the least important predictors set to zero
54 Example 6: Ridge (left) vs. Lasso (right)
55 Constrained form of lasso & ridge For any λ and corresponding solution in the penalized form, there is a value of t such that the above constrained form has this same solution. The imposed constraints constrict the coefficient vector to lie in some geometric shape centered around the origin Type of shape (i.e., type of constraint) really matters!
56 The elliptical contour represents sum of square error term The coefficient β 1 is 0 The diamond shape indicates the constraint region
57 Coefficients β 1 & β 2 0
58
59 Why lasso sets coefficients to zero? The elliptical contour plot represents sum of square error term The diamond shape in the middle indicates the constraint region Optimal point: intersection between ellipse & circle - Corner of the diamond region, where the coefficient is zero Instead with ridge:
60 Regularization penalizes hypothesis complexity L2 regularization leads to small weights L1 regularization leads to many zero weights (sparsity) Feature selection aims to discard irrelevant features
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Linear Methods for Regression and Shrinkage Methods
 Linear Methods for Regression and Shrinkage Methods Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer 1 Linear Regression Models Least Squares Input vectors
Linear Methods for Regression and Shrinkage Methods Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer 1 Linear Regression Models Least Squares Input vectors
Using Machine Learning to Optimize Storage Systems
 Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Artificial Intelligence. Programming Styles
 Artificial Intelligence Intro to Machine Learning Programming Styles Standard CS: Explicitly program computer to do something Early AI: Derive a problem description (state) and use general algorithms to
Artificial Intelligence Intro to Machine Learning Programming Styles Standard CS: Explicitly program computer to do something Early AI: Derive a problem description (state) and use general algorithms to
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING Clustering Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu November 7, 2017 Learnt Clustering Methods Vector Data Set Data Sequence Data Text
CS145: INTRODUCTION TO DATA MINING Clustering Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu November 7, 2017 Learnt Clustering Methods Vector Data Set Data Sequence Data Text
Clustering (Basic concepts and Algorithms) Entscheidungsunterstützungssysteme
 Entscheidungsunterstützungssysteme") Clustering (Basic concepts and Algorithms) Entscheidungsunterstützungssysteme Why do we need to find similarity? Similarity underlies many data science methods and solutions to business problems. Some
Clustering (Basic concepts and Algorithms) Entscheidungsunterstützungssysteme Why do we need to find similarity? Similarity underlies many data science methods and solutions to business problems. Some
Performance Estimation and Regularization. Kasthuri Kannan, PhD. Machine Learning, Spring 2018
 Performance Estimation and Regularization Kasthuri Kannan, PhD. Machine Learning, Spring 2018 Bias- Variance Tradeoff Fundamental to machine learning approaches Bias- Variance Tradeoff Error due to Bias:
Performance Estimation and Regularization Kasthuri Kannan, PhD. Machine Learning, Spring 2018 Bias- Variance Tradeoff Fundamental to machine learning approaches Bias- Variance Tradeoff Error due to Bias:
CSE Data Mining Concepts and Techniques STATISTICAL METHODS (REGRESSION) Professor- Anita Wasilewska. Team 13
 Professor- Anita Wasilewska. Team 13") CSE 634 - Data Mining Concepts and Techniques STATISTICAL METHODS Professor- Anita Wasilewska (REGRESSION) Team 13 Contents Linear Regression Logistic Regression Bias and Variance in Regression Model Fit
CSE 634 - Data Mining Concepts and Techniques STATISTICAL METHODS Professor- Anita Wasilewska (REGRESSION) Team 13 Contents Linear Regression Logistic Regression Bias and Variance in Regression Model Fit
Last time... Coryn Bailer-Jones. check and if appropriate remove outliers, errors etc. linear regression
 Machine learning, pattern recognition and statistical data modelling Lecture 3. Linear Methods (part 1) Coryn Bailer-Jones Last time... curse of dimensionality local methods quickly become nonlocal as
Machine learning, pattern recognition and statistical data modelling Lecture 3. Linear Methods (part 1) Coryn Bailer-Jones Last time... curse of dimensionality local methods quickly become nonlocal as
CSC 411: Lecture 02: Linear Regression
 CSC 411: Lecture 02: Linear Regression Raquel Urtasun & Rich Zemel University of Toronto Sep 16, 2015 Urtasun & Zemel (UofT) CSC 411: 02-Regression Sep 16, 2015 1 / 16 Today Linear regression problem continuous
CSC 411: Lecture 02: Linear Regression Raquel Urtasun & Rich Zemel University of Toronto Sep 16, 2015 Urtasun & Zemel (UofT) CSC 411: 02-Regression Sep 16, 2015 1 / 16 Today Linear regression problem continuous
FMA901F: Machine Learning Lecture 3: Linear Models for Regression. Cristian Sminchisescu
 FMA901F: Machine Learning Lecture 3: Linear Models for Regression Cristian Sminchisescu Machine Learning: Frequentist vs. Bayesian In the frequentist setting, we seek a fixed parameter (vector), with value(s)
FMA901F: Machine Learning Lecture 3: Linear Models for Regression Cristian Sminchisescu Machine Learning: Frequentist vs. Bayesian In the frequentist setting, we seek a fixed parameter (vector), with value(s)
SOCIAL MEDIA MINING. Data Mining Essentials
 SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
CS490W. Text Clustering. Luo Si. Department of Computer Science Purdue University
 CS490W Text Clustering Luo Si Department of Computer Science Purdue University [Borrows slides from Chris Manning, Ray Mooney and Soumen Chakrabarti] Clustering Document clustering Motivations Document
CS490W Text Clustering Luo Si Department of Computer Science Purdue University [Borrows slides from Chris Manning, Ray Mooney and Soumen Chakrabarti] Clustering Document clustering Motivations Document
COMPUTATIONAL INTELLIGENCE SEW (INTRODUCTION TO MACHINE LEARNING) SS18. Lecture 6: k-nn Cross-validation Regularization
 SS18. Lecture 6: k-nn Cross-validation Regularization") COMPUTATIONAL INTELLIGENCE SEW (INTRODUCTION TO MACHINE LEARNING) SS18 Lecture 6: k-nn Cross-validation Regularization LEARNING METHODS Lazy vs eager learning Eager learning generalizes training data before
COMPUTATIONAL INTELLIGENCE SEW (INTRODUCTION TO MACHINE LEARNING) SS18 Lecture 6: k-nn Cross-validation Regularization LEARNING METHODS Lazy vs eager learning Eager learning generalizes training data before
CSE446: Linear Regression. Spring 2017
 CSE446: Linear Regression Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin and Luke Zettlemoyer Prediction of continuous variables Billionaire says: Wait, that s not what I meant! You say: Chill
CSE446: Linear Regression Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin and Luke Zettlemoyer Prediction of continuous variables Billionaire says: Wait, that s not what I meant! You say: Chill
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Leveling Up as a Data Scientist. ds/2014/10/level-up-ds.jpg
 Model Optimization Leveling Up as a Data Scientist http://shorelinechurch.org/wp-content/uploa ds/2014/10/level-up-ds.jpg Bias and Variance Error = (expected loss of accuracy) 2 + flexibility of model
Model Optimization Leveling Up as a Data Scientist http://shorelinechurch.org/wp-content/uploa ds/2014/10/level-up-ds.jpg Bias and Variance Error = (expected loss of accuracy) 2 + flexibility of model
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
Variable Selection 6.783, Biomedical Decision Support
 6.783, Biomedical Decision Support (lrosasco@mit.edu) Department of Brain and Cognitive Science- MIT November 2, 2009 About this class Why selecting variables Approaches to variable selection Sparsity-based
6.783, Biomedical Decision Support (lrosasco@mit.edu) Department of Brain and Cognitive Science- MIT November 2, 2009 About this class Why selecting variables Approaches to variable selection Sparsity-based
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 6: Flat Clustering Wiltrud Kessler & Hinrich Schütze Institute for Natural Language Processing, University of Stuttgart 0-- / 83
Introduction to Information Retrieval http://informationretrieval.org IIR 6: Flat Clustering Wiltrud Kessler & Hinrich Schütze Institute for Natural Language Processing, University of Stuttgart 0-- / 83
Assignment 4 (Sol.) Introduction to Data Analytics Prof. Nandan Sudarsanam & Prof. B. Ravindran
 Introduction to Data Analytics Prof. Nandan Sudarsanam & Prof. B. Ravindran") Assignment 4 (Sol.) Introduction to Data Analytics Prof. andan Sudarsanam & Prof. B. Ravindran 1. Which among the following techniques can be used to aid decision making when those decisions depend upon
Assignment 4 (Sol.) Introduction to Data Analytics Prof. andan Sudarsanam & Prof. B. Ravindran 1. Which among the following techniques can be used to aid decision making when those decisions depend upon
Model selection and validation 1: Cross-validation
 Model selection and validation 1: Cross-validation Ryan Tibshirani Data Mining: 36-462/36-662 March 26 2013 Optional reading: ISL 2.2, 5.1, ESL 7.4, 7.10 1 Reminder: modern regression techniques Over the
Model selection and validation 1: Cross-validation Ryan Tibshirani Data Mining: 36-462/36-662 March 26 2013 Optional reading: ISL 2.2, 5.1, ESL 7.4, 7.10 1 Reminder: modern regression techniques Over the
Unsupervised Learning. Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi
 Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Expectation Maximization!
 Expectation Maximization! adapted from: Doug Downey and Bryan Pardo, Northwestern University and http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Steps in Clustering Select Features
Expectation Maximization! adapted from: Doug Downey and Bryan Pardo, Northwestern University and http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Steps in Clustering Select Features
10601 Machine Learning. Model and feature selection
 10601 Machine Learning Model and feature selection Model selection issues We have seen some of this before Selecting features (or basis functions) Logistic regression SVMs Selecting parameter value Prior
10601 Machine Learning Model and feature selection Model selection issues We have seen some of this before Selecting features (or basis functions) Logistic regression SVMs Selecting parameter value Prior
CSE 7/5337: Information Retrieval and Web Search Document clustering I (IIR 16)
") CSE 7/5337: Information Retrieval and Web Search Document clustering I (IIR 16) Michael Hahsler Southern Methodist University These slides are largely based on the slides by Hinrich Schütze Institute for
CSE 7/5337: Information Retrieval and Web Search Document clustering I (IIR 16) Michael Hahsler Southern Methodist University These slides are largely based on the slides by Hinrich Schütze Institute for
Flat Clustering. Slides are mostly from Hinrich Schütze. March 27, 2017
 Flat Clustering Slides are mostly from Hinrich Schütze March 7, 07 / 79 Overview Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? / 79 Outline Recap Clustering:
Flat Clustering Slides are mostly from Hinrich Schütze March 7, 07 / 79 Overview Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? / 79 Outline Recap Clustering:
Evaluation Measures. Sebastian Pölsterl. April 28, Computer Aided Medical Procedures Technische Universität München
 Evaluation Measures Sebastian Pölsterl Computer Aided Medical Procedures Technische Universität München April 28, 2015 Outline 1 Classification 1. Confusion Matrix 2. Receiver operating characteristics
Evaluation Measures Sebastian Pölsterl Computer Aided Medical Procedures Technische Universität München April 28, 2015 Outline 1 Classification 1. Confusion Matrix 2. Receiver operating characteristics
Random Forest A. Fornaser
 Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
LECTURE 12: LINEAR MODEL SELECTION PT. 3. October 23, 2017 SDS 293: Machine Learning
 LECTURE 12: LINEAR MODEL SELECTION PT. 3 October 23, 2017 SDS 293: Machine Learning Announcements 1/2 Presentation of the CS Major & Minors TODAY @ lunch Ford 240 FREE FOOD! Announcements 2/2 CS Internship
LECTURE 12: LINEAR MODEL SELECTION PT. 3 October 23, 2017 SDS 293: Machine Learning Announcements 1/2 Presentation of the CS Major & Minors TODAY @ lunch Ford 240 FREE FOOD! Announcements 2/2 CS Internship
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Machine Learning: An Applied Econometric Approach Online Appendix
 Machine Learning: An Applied Econometric Approach Online Appendix Sendhil Mullainathan mullain@fas.harvard.edu Jann Spiess jspiess@fas.harvard.edu April 2017 A How We Predict In this section, we detail
Machine Learning: An Applied Econometric Approach Online Appendix Sendhil Mullainathan mullain@fas.harvard.edu Jann Spiess jspiess@fas.harvard.edu April 2017 A How We Predict In this section, we detail
Clustering and Visualisation of Data
 Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Supervised vs unsupervised clustering
 Classification Supervised vs unsupervised clustering Cluster analysis: Classes are not known a- priori. Classification: Classes are defined a-priori Sometimes called supervised clustering Extract useful
Classification Supervised vs unsupervised clustering Cluster analysis: Classes are not known a- priori. Classification: Classes are defined a-priori Sometimes called supervised clustering Extract useful
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Solution Sketches Midterm Exam COSC 6342 Machine Learning March 20, 2013
 Your Name: Your student id: Solution Sketches Midterm Exam COSC 6342 Machine Learning March 20, 2013 Problem 1 [5+?]: Hypothesis Classes Problem 2 [8]: Losses and Risks Problem 3 [11]: Model Generation
Your Name: Your student id: Solution Sketches Midterm Exam COSC 6342 Machine Learning March 20, 2013 Problem 1 [5+?]: Hypothesis Classes Problem 2 [8]: Losses and Risks Problem 3 [11]: Model Generation
CS Introduction to Data Mining Instructor: Abdullah Mueen
 CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
Lecture 13: Model selection and regularization
 Lecture 13: Model selection and regularization Reading: Sections 6.1-6.2.1 STATS 202: Data mining and analysis October 23, 2017 1 / 17 What do we know so far In linear regression, adding predictors always
Lecture 13: Model selection and regularization Reading: Sections 6.1-6.2.1 STATS 202: Data mining and analysis October 23, 2017 1 / 17 What do we know so far In linear regression, adding predictors always
model order p weights The solution to this optimization problem is obtained by solving the linear system
 CS 189 Introduction to Machine Learning Fall 2017 Note 3 1 Regression and hyperparameters Recall the supervised regression setting in which we attempt to learn a mapping f : R d R from labeled examples
CS 189 Introduction to Machine Learning Fall 2017 Note 3 1 Regression and hyperparameters Recall the supervised regression setting in which we attempt to learn a mapping f : R d R from labeled examples
Predictive Analytics: Demystifying Current and Emerging Methodologies. Tom Kolde, FCAS, MAAA Linda Brobeck, FCAS, MAAA
 Predictive Analytics: Demystifying Current and Emerging Methodologies Tom Kolde, FCAS, MAAA Linda Brobeck, FCAS, MAAA May 18, 2017 About the Presenters Tom Kolde, FCAS, MAAA Consulting Actuary Chicago,
Predictive Analytics: Demystifying Current and Emerging Methodologies Tom Kolde, FCAS, MAAA Linda Brobeck, FCAS, MAAA May 18, 2017 About the Presenters Tom Kolde, FCAS, MAAA Consulting Actuary Chicago,
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
PV211: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv211
 PV: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv IIR 6: Flat Clustering Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University, Brno Center
PV: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv IIR 6: Flat Clustering Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University, Brno Center
Machine Learning. Unsupervised Learning. Manfred Huber
 Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Lasso. November 14, 2017
 Lasso November 14, 2017 Contents 1 Case Study: Least Absolute Shrinkage and Selection Operator (LASSO) 1 1.1 The Lasso Estimator.................................... 1 1.2 Computation of the Lasso Solution............................
Lasso November 14, 2017 Contents 1 Case Study: Least Absolute Shrinkage and Selection Operator (LASSO) 1 1.1 The Lasso Estimator.................................... 1 1.2 Computation of the Lasso Solution............................
EE 511 Linear Regression
 EE 511 Linear Regression Instructor: Hanna Hajishirzi hannaneh@washington.edu Slides adapted from Ali Farhadi, Mari Ostendorf, Pedro Domingos, Carlos Guestrin, and Luke Zettelmoyer, Announcements Hw1 due
EE 511 Linear Regression Instructor: Hanna Hajishirzi hannaneh@washington.edu Slides adapted from Ali Farhadi, Mari Ostendorf, Pedro Domingos, Carlos Guestrin, and Luke Zettelmoyer, Announcements Hw1 due
Information Retrieval and Organisation
 Information Retrieval and Organisation Chapter 16 Flat Clustering Dell Zhang Birkbeck, University of London What Is Text Clustering? Text Clustering = Grouping a set of documents into classes of similar
Information Retrieval and Organisation Chapter 16 Flat Clustering Dell Zhang Birkbeck, University of London What Is Text Clustering? Text Clustering = Grouping a set of documents into classes of similar
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Cluster Evaluation and Expectation Maximization! adapted from: Doug Downey and Bryan Pardo, Northwestern University
 Cluster Evaluation and Expectation Maximization! adapted from: Doug Downey and Bryan Pardo, Northwestern University Kinds of Clustering Sequential Fast Cost Optimization Fixed number of clusters Hierarchical
Cluster Evaluation and Expectation Maximization! adapted from: Doug Downey and Bryan Pardo, Northwestern University Kinds of Clustering Sequential Fast Cost Optimization Fixed number of clusters Hierarchical
Problems 1 and 5 were graded by Amin Sorkhei, Problems 2 and 3 by Johannes Verwijnen and Problem 4 by Jyrki Kivinen. Entropy(D) = Gini(D) = 1
 = Gini(D) = 1") Problems and were graded by Amin Sorkhei, Problems and 3 by Johannes Verwijnen and Problem by Jyrki Kivinen.. [ points] (a) Gini index and Entropy are impurity measures which can be used in order to measure
Problems and were graded by Amin Sorkhei, Problems and 3 by Johannes Verwijnen and Problem by Jyrki Kivinen.. [ points] (a) Gini index and Entropy are impurity measures which can be used in order to measure
Lecture 16: High-dimensional regression, non-linear regression
 Lecture 16: High-dimensional regression, non-linear regression Reading: Sections 6.4, 7.1 STATS 202: Data mining and analysis November 3, 2017 1 / 17 High-dimensional regression Most of the methods we
Lecture 16: High-dimensional regression, non-linear regression Reading: Sections 6.4, 7.1 STATS 202: Data mining and analysis November 3, 2017 1 / 17 High-dimensional regression Most of the methods we
Nonparametric Methods Recap
 Nonparametric Methods Recap Aarti Singh Machine Learning 10-701/15-781 Oct 4, 2010 Nonparametric Methods Kernel Density estimate (also Histogram) Weighted frequency Classification - K-NN Classifier Majority
Nonparametric Methods Recap Aarti Singh Machine Learning 10-701/15-781 Oct 4, 2010 Nonparametric Methods Kernel Density estimate (also Histogram) Weighted frequency Classification - K-NN Classifier Majority
Clustering algorithms and autoencoders for anomaly detection
 Clustering algorithms and autoencoders for anomaly detection Alessia Saggio Lunch Seminars and Journal Clubs Université catholique de Louvain, Belgium 3rd March 2017 a Outline Introduction Clustering algorithms
Clustering algorithms and autoencoders for anomaly detection Alessia Saggio Lunch Seminars and Journal Clubs Université catholique de Louvain, Belgium 3rd March 2017 a Outline Introduction Clustering algorithms
Machine Learning in Python. Rohith Mohan GradQuant Spring 2018
 Machine Learning in Python Rohith Mohan GradQuant Spring 2018 What is Machine Learning? https://twitter.com/myusuf3/status/995425049170489344 Traditional Programming Data Computer Program Output Getting
Machine Learning in Python Rohith Mohan GradQuant Spring 2018 What is Machine Learning? https://twitter.com/myusuf3/status/995425049170489344 Traditional Programming Data Computer Program Output Getting
Understanding Clustering Supervising the unsupervised
 Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
INTRODUCTION TO MACHINE LEARNING. Measuring model performance or error
 INTRODUCTION TO MACHINE LEARNING Measuring model performance or error Is our model any good? Context of task Accuracy Computation time Interpretability 3 types of tasks Classification Regression Clustering
INTRODUCTION TO MACHINE LEARNING Measuring model performance or error Is our model any good? Context of task Accuracy Computation time Interpretability 3 types of tasks Classification Regression Clustering
Unsupervised Data Mining: Clustering. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Preface to the Second Edition. Preface to the First Edition. 1 Introduction 1
 Preface to the Second Edition Preface to the First Edition vii xi 1 Introduction 1 2 Overview of Supervised Learning 9 2.1 Introduction... 9 2.2 Variable Types and Terminology... 9 2.3 Two Simple Approaches
Preface to the Second Edition Preface to the First Edition vii xi 1 Introduction 1 2 Overview of Supervised Learning 9 2.1 Introduction... 9 2.2 Variable Types and Terminology... 9 2.3 Two Simple Approaches
CS 229 Midterm Review
 CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 16: Flat Clustering Hinrich Schütze Institute for Natural Language Processing, Universität Stuttgart 2009.06.16 1/ 64 Overview
Introduction to Information Retrieval http://informationretrieval.org IIR 16: Flat Clustering Hinrich Schütze Institute for Natural Language Processing, Universität Stuttgart 2009.06.16 1/ 64 Overview
Information Driven Healthcare:
 Information Driven Healthcare: Machine Learning course Lecture: Feature selection I --- Concepts Centre for Doctoral Training in Healthcare Innovation Dr. Athanasios Tsanas ( Thanasis ), Wellcome Trust
Information Driven Healthcare: Machine Learning course Lecture: Feature selection I --- Concepts Centre for Doctoral Training in Healthcare Innovation Dr. Athanasios Tsanas ( Thanasis ), Wellcome Trust
STA 4273H: Sta-s-cal Machine Learning
 STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! h0p://www.cs.toronto.edu/~rsalakhu/ Lecture 3 Parametric Distribu>ons We want model the probability
STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! h0p://www.cs.toronto.edu/~rsalakhu/ Lecture 3 Parametric Distribu>ons We want model the probability
Chapter 7: Numerical Prediction
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases SS 2016 Chapter 7: Numerical Prediction Lecture: Prof. Dr.
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases SS 2016 Chapter 7: Numerical Prediction Lecture: Prof. Dr.
2017 ITRON EFG Meeting. Abdul Razack. Specialist, Load Forecasting NV Energy
 2017 ITRON EFG Meeting Abdul Razack Specialist, Load Forecasting NV Energy Topics 1. Concepts 2. Model (Variable) Selection Methods 3. Cross- Validation 4. Cross-Validation: Time Series 5. Example 1 6.
2017 ITRON EFG Meeting Abdul Razack Specialist, Load Forecasting NV Energy Topics 1. Concepts 2. Model (Variable) Selection Methods 3. Cross- Validation 4. Cross-Validation: Time Series 5. Example 1 6.
COSC 6339 Big Data Analytics. Fuzzy Clustering. Some slides based on a lecture by Prof. Shishir Shah. Edgar Gabriel Spring 2017.
 COSC 6339 Big Data Analytics Fuzzy Clustering Some slides based on a lecture by Prof. Shishir Shah Edgar Gabriel Spring 217 Clustering Clustering is a technique for finding similarity groups in data, called
COSC 6339 Big Data Analytics Fuzzy Clustering Some slides based on a lecture by Prof. Shishir Shah Edgar Gabriel Spring 217 Clustering Clustering is a technique for finding similarity groups in data, called
COMP 551 Applied Machine Learning Lecture 16: Deep Learning
 COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
Linear Model Selection and Regularization. especially usefull in high dimensions p>>100.
 Linear Model Selection and Regularization especially usefull in high dimensions p>>100. 1 Why Linear Model Regularization? Linear models are simple, BUT consider p>>n, we have more features than data records
Linear Model Selection and Regularization especially usefull in high dimensions p>>100. 1 Why Linear Model Regularization? Linear models are simple, BUT consider p>>n, we have more features than data records
Applying Supervised Learning
 Applying Supervised Learning When to Consider Supervised Learning A supervised learning algorithm takes a known set of input data (the training set) and known responses to the data (output), and trains
Applying Supervised Learning When to Consider Supervised Learning A supervised learning algorithm takes a known set of input data (the training set) and known responses to the data (output), and trains
Contents Machine Learning concepts 4 Learning Algorithm 4 Predictive Model (Model) 4 Model, Classification 4 Model, Regression 4 Representation
 4 Model, Classification 4 Model, Regression 4 Representation") Contents Machine Learning concepts 4 Learning Algorithm 4 Predictive Model (Model) 4 Model, Classification 4 Model, Regression 4 Representation Learning 4 Supervised Learning 4 Unsupervised Learning 4
Contents Machine Learning concepts 4 Learning Algorithm 4 Predictive Model (Model) 4 Model, Classification 4 Model, Regression 4 Representation Learning 4 Supervised Learning 4 Unsupervised Learning 4
Lasso Regression: Regularization for feature selection
 Lasso Regression: Regularization for feature selection CSE 416: Machine Learning Emily Fox University of Washington April 12, 2018 Symptom of overfitting 2 Often, overfitting associated with very large
Lasso Regression: Regularization for feature selection CSE 416: Machine Learning Emily Fox University of Washington April 12, 2018 Symptom of overfitting 2 Often, overfitting associated with very large
Decision Trees Dr. G. Bharadwaja Kumar VIT Chennai
 Decision Trees Decision Tree Decision Trees (DTs) are a nonparametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target
Decision Trees Decision Tree Decision Trees (DTs) are a nonparametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target
DS Machine Learning and Data Mining I. Alina Oprea Associate Professor, CCIS Northeastern University
 DS 4400 Machine Learning and Data Mining I Alina Oprea Associate Professor, CCIS Northeastern University September 20 2018 Review Solution for multiple linear regression can be computed in closed form
DS 4400 Machine Learning and Data Mining I Alina Oprea Associate Professor, CCIS Northeastern University September 20 2018 Review Solution for multiple linear regression can be computed in closed form
Chapter 9. Classification and Clustering
 Chapter 9 Classification and Clustering Classification and Clustering Classification and clustering are classical pattern recognition and machine learning problems Classification, also referred to as categorization
Chapter 9 Classification and Clustering Classification and Clustering Classification and clustering are classical pattern recognition and machine learning problems Classification, also referred to as categorization
3 Nonlinear Regression
 CSC 4 / CSC D / CSC C 3 Sometimes linear models are not sufficient to capture the real-world phenomena, and thus nonlinear models are necessary. In regression, all such models will have the same basic
CSC 4 / CSC D / CSC C 3 Sometimes linear models are not sufficient to capture the real-world phenomena, and thus nonlinear models are necessary. In regression, all such models will have the same basic
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 10: Decision Trees
 University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 10: Decision Trees colour=green? size>20cm? colour=red? watermelon size>5cm? size>5cm? colour=yellow? apple
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 10: Decision Trees colour=green? size>20cm? colour=red? watermelon size>5cm? size>5cm? colour=yellow? apple
5 Learning hypothesis classes (16 points)
") 5 Learning hypothesis classes (16 points) Consider a classification problem with two real valued inputs. For each of the following algorithms, specify all of the separators below that it could have generated
5 Learning hypothesis classes (16 points) Consider a classification problem with two real valued inputs. For each of the following algorithms, specify all of the separators below that it could have generated
Big Data Methods. Chapter 5: Machine learning. Big Data Methods, Chapter 5, Slide 1
 Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
Big Data Analytics! Special Topics for Computer Science CSE CSE Feb 9
 Big Data Analytics! Special Topics for Computer Science CSE 4095-001 CSE 5095-005! Feb 9 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Clustering I What
Big Data Analytics! Special Topics for Computer Science CSE 4095-001 CSE 5095-005! Feb 9 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Clustering I What
COSC 6397 Big Data Analytics. Fuzzy Clustering. Some slides based on a lecture by Prof. Shishir Shah. Edgar Gabriel Spring 2015.
 COSC 6397 Big Data Analytics Fuzzy Clustering Some slides based on a lecture by Prof. Shishir Shah Edgar Gabriel Spring 215 Clustering Clustering is a technique for finding similarity groups in data, called
COSC 6397 Big Data Analytics Fuzzy Clustering Some slides based on a lecture by Prof. Shishir Shah Edgar Gabriel Spring 215 Clustering Clustering is a technique for finding similarity groups in data, called
Unsupervised Learning. Supervised learning vs. unsupervised learning. What is Cluster Analysis? Applications of Cluster Analysis
 7 Supervised learning vs unsupervised learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These patterns are then
7 Supervised learning vs unsupervised learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These patterns are then
CLUSTERING. CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16
 CLUSTERING CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16 1. K-medoids: REFERENCES https://www.coursera.org/learn/cluster-analysis/lecture/nj0sb/3-4-the-k-medoids-clustering-method https://anuradhasrinivas.files.wordpress.com/2013/04/lesson8-clustering.pdf
CLUSTERING CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16 1. K-medoids: REFERENCES https://www.coursera.org/learn/cluster-analysis/lecture/nj0sb/3-4-the-k-medoids-clustering-method https://anuradhasrinivas.files.wordpress.com/2013/04/lesson8-clustering.pdf
Introduction to Computer Science
 DM534 Introduction to Computer Science Clustering and Feature Spaces Richard Roettger: About Me Computer Science (Technical University of Munich and thesis at the ICSI at the University of California at
DM534 Introduction to Computer Science Clustering and Feature Spaces Richard Roettger: About Me Computer Science (Technical University of Munich and thesis at the ICSI at the University of California at
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Administrative. Machine learning code. Supervised learning (e.g. classification) Machine learning: Unsupervised learning" BANANAS APPLES
 Machine learning: Unsupervised learning BANANAS APPLES") Administrative Machine learning: Unsupervised learning" Assignment 5 out soon David Kauchak cs311 Spring 2013 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Machine
Administrative Machine learning: Unsupervised learning" Assignment 5 out soon David Kauchak cs311 Spring 2013 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Machine
CS294-1 Assignment 2 Report
 CS294-1 Assignment 2 Report Keling Chen and Huasha Zhao February 24, 2012 1 Introduction The goal of this homework is to predict a users numeric rating for a book from the text of the user s review. The
CS294-1 Assignment 2 Report Keling Chen and Huasha Zhao February 24, 2012 1 Introduction The goal of this homework is to predict a users numeric rating for a book from the text of the user s review. The
Classification. Vladimir Curic. Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University
 Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
I How does the formulation (5) serve the purpose of the composite parameterization
 serve the purpose of the composite parameterization") Supplemental Material to Identifying Alzheimer s Disease-Related Brain Regions from Multi-Modality Neuroimaging Data using Sparse Composite Linear Discrimination Analysis I How does the formulation (5)
Supplemental Material to Identifying Alzheimer s Disease-Related Brain Regions from Multi-Modality Neuroimaging Data using Sparse Composite Linear Discrimination Analysis I How does the formulation (5)
10701 Machine Learning. Clustering
 171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 10: Decision Trees
 University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 10: Decision Trees colour=green? size>20cm? colour=red? watermelon size>5cm? size>5cm? colour=yellow? apple
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 10: Decision Trees colour=green? size>20cm? colour=red? watermelon size>5cm? size>5cm? colour=yellow? apple
CS6375: Machine Learning Gautam Kunapuli. Mid-Term Review
 Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest)
") Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Cluster analysis. Agnieszka Nowak - Brzezinska
 Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Data Informatics. Seon Ho Kim, Ph.D.
 Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu Clustering Overview Supervised vs. Unsupervised Learning Supervised learning (classification) Supervision: The training data (observations, measurements,
Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu Clustering Overview Supervised vs. Unsupervised Learning Supervised learning (classification) Supervision: The training data (observations, measurements,
Data Clustering. Danushka Bollegala
 Data Clustering Danushka Bollegala Outline Why cluster data? Clustering as unsupervised learning Clustering algorithms k-means, k-medoids agglomerative clustering Brown s clustering Spectral clustering
Data Clustering Danushka Bollegala Outline Why cluster data? Clustering as unsupervised learning Clustering algorithms k-means, k-medoids agglomerative clustering Brown s clustering Spectral clustering
Dimensionality Reduction, including by Feature Selection.
 Dimensionality Reduction, including by Feature Selection www.cs.wisc.edu/~dpage/cs760 Goals for the lecture you should understand the following concepts filtering-based feature selection information gain
Dimensionality Reduction, including by Feature Selection www.cs.wisc.edu/~dpage/cs760 Goals for the lecture you should understand the following concepts filtering-based feature selection information gain
Overfitting. Machine Learning CSE546 Carlos Guestrin University of Washington. October 2, Bias-Variance Tradeoff
 Overfitting Machine Learning CSE546 Carlos Guestrin University of Washington October 2, 2013 1 Bias-Variance Tradeoff Choice of hypothesis class introduces learning bias More complex class less bias More
Overfitting Machine Learning CSE546 Carlos Guestrin University of Washington October 2, 2013 1 Bias-Variance Tradeoff Choice of hypothesis class introduces learning bias More complex class less bias More
Ensemble methods in machine learning. Example. Neural networks. Neural networks
 Ensemble methods in machine learning Bootstrap aggregating (bagging) train an ensemble of models based on randomly resampled versions of the training set, then take a majority vote Example What if you
Ensemble methods in machine learning Bootstrap aggregating (bagging) train an ensemble of models based on randomly resampled versions of the training set, then take a majority vote Example What if you