Deep Learning Cook Book
|
|
|
- Derek Burke
- 5 years ago
- Views:
Transcription
1 Deep Learning Cook Book Robert Haschke (CITEC)
2 Overview Input Representation Output Layer + Cost Function Hidden Layer Units Initialization Regularization

3 Input representation Choose an input representation that captures / preserves as much structure as possible e.g. images have a grid-like neighbourhood structure preserve that structure instead of flattening the image into a vector changes smoothly with small semantic changes for orientations, use cos/sin expressions instead of angular values
4 Input Normalization Mean subtraction: X -= np.mean(x, axis=0) Normalization: X /= np.std(x, axis=0) Karpathy 2015
5 Input Normalization: Whitening / PCA Decorrelate feature dimensions with PCA X -= np.mean(x, axis=0) # zero-center cov = np.dot(x.t, X) / X.shape[0] # covariance U,S,V = np.linalg.svd(cov) Xwhite = np.dot(x, U) / np.sqrt(s) Karpathy 2015
6 Input Normalization Each input feature gets zero mean unit variance Decorrelated across whole training data set Only compute normalization on training data set. Apply calculated transformation to test + validation set.
7 Output Units and Cost Functions How to choose a suitable output layer and cost function for a given task? Output layer encodes result Cost function defines learning task avoid saturation = vanishing gradient
8 Maximum Likelihood Optimization
9 L1 vs. L2 norm
10 Linear Outputs + MSE / MAE
11 Binary Classification Task Task: classify between two classes (0,1) Approach: Predict p(y x) with Bernoulli distribution p(y=1 x) = p σ(w x+b) Single output suffices! p(y=0 x) = 1-p sigmoid σ( ) ensures constraint p [0,1] min -log σ( ) reverts squashing
12 Binary Classification Task Task: classify between two classes (0,1) Approach: Predict p(y x) with Bernoulli distribution p(y=1 x) = p σ(w x+b) Single output suffices! p(y=0 x) = 1-p sigmoid σ( ) ensures constraint p [0,1] min -log σ( ) reverts squashing soft-plus function: soft version of x+ = max(0,x)
13 Binary Classification Task for binary classification use (single) sigmoid output binary cross-entropy as cost because target y {0,1} Gradient gets small only if classification is correct.
14 Binary Classification Task for binary classification use (single) sigmoid output binary cross-entropy as cost because target y {0,1} Gradient gets small only if classification is correct.
15 Kullback-Leibler divergence
16 Asymmetry of KL divergence Deep Learning book
17 Cross-Entropy Minimizing KL-divergence DKL(P Q) w.r.t. Q is equivalent to minimizing the cross-entropy H(P Q): binary cross-entropy (of Bernoulli distributions)
18 From 2-Class to Multi-Class Classification Multi-Class classification should output a probability distribution over all N classes: yi = P(y = i x) with constraints yi [0,1] Σ i yi = 1 Soft-Max on z = W h + b ensures these constraints: Minimizing cross-entropy again reverts the exponential
19 Minimizing Cross-Entropy
20 Gradient of Cross-Entropy + Soft-Max
21 Gradient of Cross-Entropy + Soft-Max
22 Gradient of Cross-Entropy + Soft-Max
23 Gradient of Cross-Entropy + Soft-Max
24 Gradient of Cross-Entropy + Soft-Max
25 Gradient of Cross-Entropy + Soft-Max
26 Multi-Class Classification Use soft-max output layer Use cross-entropy cost Use one-hot encoding for target values y α: y α = (0,, 0, 1, 0,, 0)t Ensures equal distance of all class prototypes on hyper cube
27 Hinge Loss Optimizing inequalities



28 Hinge Loss Calculation Example cat car frog loss
29 Hidden Units h = g(z = W x + b) default non-linearity g: Rectified Linear Unit (ReLu) g(z) = max (0, z) ReLu units do not learn if activation becomes zero initially avoid saturation (z < 0) use small positive b 0.1
30 Generalizations of ReLu Leaky ReLu g(z) = max (0, z) + α min (0, z) with α 0.01 Absolute Value Rectification g(z) = max (0, z) min (0, z) Parametric ReLu g(z) = max (0, z) + α min (0, z) with trainable α Soft-Plus ζ(z) = log(1+exp(z))
31 Linear Hidden Units Composing linear functions yields a linear function again. Usually, it s not useful to stack linear layers. They could be squashed into one: W = U V Exception: encoder U V: (p + q) n parameters W: p q parameters U V p n q
32 Parameter Initialization Gradient descent strongly depends on initial params Converging at all? Converging how fast? Converging to small training / generalization error?
33 Parameter Initialization Gradient descent strongly depends on initial params Converging at all? Converging how fast? Converging to small training / generalization error? main concern: breaking symmetry Identically initialized units receiving identical inputs will evolve identically. random initialization
34 Random Weight Initialization Gaussian or Uniform Distribution mean zero main paramater: scale large weights + better break symmetry + avoid losing forward signal - risk exploding forward signal - take long to be corrected clip initial weights to 2σ
35 Xavier Initialization Heuristic goal: same activation or gradient variance Keras Initializers Different authors suggest different scale s and n Glorot & Bengio 2010: s=2, n=fanin + fanout He 2015: s=2, n=fanin
36 Weight Scaling - Motivation
37 Weight Scaling - Motivation
38 Bias Initialization b=0 b = 0.1 to ensure initial activation of ReLu units For output units in classification tasks bias towards a-priori distribution p(y) soft-max(b) = p(y)
39 Recap: Machine Learning Theory Minimize expected costs on a data distribution p(x,y)! Learning can only optimize w.r.t. a finite training set {xα,yα} which yields training error Estimate generalization error on an independent test set
40 Training vs. Testing Error training error is optimized by learning algorithm testing error is usually larger testing error usually increases after excessive learning Early Stopping
41 Recap: Model Capacity model framework uncertainty: insufficiency of model estimation uncertainty: insufficiency of data to estimate available model parameters estimation uncertainty can be reduced with more training data
42 Bias Variance Dilemma Consider data-generating model f(x, θ*) θ* is true underlying parameter set Learner estimates parameter θ, probably a different one each time What happens on average? How large is the bias, i.e. estimation error θ-θ*? How large is the variance of estimation? Both should be small!
43 Bias Variance Dilemma Let s consider the expected quadratic estimation error We cannot reduce both, variance and bias! model complexity: bias, variance
44 Example: Model Capacity Example: Polynomial Function Fitting Model Capacity = Degree of Polynomial too small capacity: under-fitting too high capacity: over-fitting
45 Regularization Deep Networks have high capacity (many parameters) Regularization counteracts over-fitting enforcing a simpler model if possible
46 Regularization Deep Networks have high capacity (many parameters) Regularization counteracts over-fitting enforcing a simpler model if possible Occam s Razor (13th century): If multiple models explain our observations, prefer the simplest theory.
47 Regularization Deep Networks have high capacity (many parameters) Regularization counteracts over-fitting enforcing a simpler model if possible Occam s Razor (13th century): If multiple models explain our observations, prefer the simplest theory. Regularization usually increases the training error, but should decrease the generalization error.
48 Hyper-Parameters Hyper-Parameters are model parameters that are not directly optimized by the learning algorithm model capacity polynomial degree network structure, number of units CNNs: filter size + number initialization parameters layer parameters dropout parameter p CNNs: stride, pooling size,...
49 Hyper-Parameters Hyper-Parameters are model parameters that are not directly optimized by the learning algorithm Optimize with Meta-Optimization Grid Search Random Search Do not use test set for hyper-parameter optimization! Test set is used for independent estimation of test error Split data set into training set validation set test set
50 Cross-Validation Splitting into training, validation, and test set requires huge amounts of data for reasonable statistics If only few data is available, use k-fold cross validation Partition data into k sub sets k
51 Cross-Validation Splitting into training, validation, and test set requires huge amounts of data for reasonable statistics If only few data is available, use k-fold cross validation Partition data into k sub sets k k-fold learning, using each sub set for testing once Average all test errors
52 Cross-Validation Splitting into training, validation, and test set requires huge amounts of data for reasonable statistics If only few data is available, use k-fold cross validation Partition data into k sub sets k k-fold learning, using each sub set for testing once Average all test errors
53 Cross-Validation Splitting into training, validation, and test set requires huge amounts of data for reasonable statistics If only few data is available, use k-fold cross validation Partition data into k sub sets k k-fold learning, using each sub set for testing once Average all test errors
54 Cross-Validation Splitting into training, validation, and test set requires huge amounts of data for reasonable statistics If only few data is available, use k-fold cross validation Partition data into k sub sets k k-fold learning, using each sub set for testing once Average all test errors
55 Cross-Validation Splitting into training, validation, and test set requires huge amounts of data for reasonable statistics If only few data is available, use k-fold cross validation Partition data into k sub sets k k-fold learning, using each sub set for testing once Average all test errors
56 Cross-Validation Splitting into training, validation, and test set requires huge amounts of data for reasonable statistics If only few data is available, use k-fold cross validation Partition data into k sub sets k k-fold learning, using each sub set for testing once Average all test errors
57 Regularization Methods for Neural Networks Weight Norm Penalties: L2, L1 Weight Constraints Early Stopping Representational Sparsity Data Augmentation + Input Noise Representational Robustness: Dropout
58 L2, L1 regularization Prefer smaller (multiplicative) weights Not used for bias b (z = W x + b) Approach: extra cost term
59 L2 regularization
60 L2 regularization
61 L2 regularization
62 L1 regularization
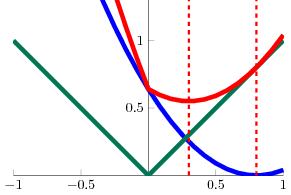
63 L1 regularization
64 L2, L1 regularization
65 Weight Clipping L2, L1 regularization smoothly forces weights into unit ball around origin Alternatively, explicitly constrain weights: Take (arbitrary) gradient step λ 3-4 Project w back onto constraint, e.g. renormalizing Allows high learning rate, while avoiding weight explosion In practice: constraint norm for each unit separately, i.e. row-wise in Wx+b Keras constraints
66 Early Stopping Monitor validation error (estimating the test error) Stop, when it doesn t decrease for several steps (and return stored optimal parameters) Restricts weight trajectory to stay close to initial values Similar effect as L2 / L1 regularization no extra cost
67 Representational Sparsity L1 regularization enforced sparse weights To enforce sparse representations (in hidden layers) use an L1 regularization for hidden layer activations h:
68 Data Augmentation Training on more data always improves generalization Artificially augment your training set Adding Gaussian noise to the input or hidden layers Prefers robust minima Apply invariant transformations (for classification tasks) shift, rotate, scale, lighten/darken,... images distort / warp speech signals Be careful not to change class semantics: 6 9 Noise in output layer is not useful
69 Label Smoothing: Noise on class labels Classification is trained with soft-max output, cross-entropy cost, and one-hot target vectors (0,1,0 0)t Soft-max can never exactly reach zero / one Training increases weights forever Use smoothed one-hot targets:
70 Ensemble Methods Averaging over multiple learners reduces expected variance
71 Ensemble Methods Averaging over multiple learners reduces expected variance Bagging same model trained on different datasets same neural network converges to different params due to random initialization, random mini-batching, dropout, computational costs increase linearly with ensemble size
72 Dropout during training: zero the activity of randomly selected (prob. p) hidden units (or inputs) within a mini batch p 0.5 hidden units p 0.8 input units during inference: scale down dropout weights by factor p expected total input pw x + b of a unit will be similar as in training W px + b Srivastava + Hinton 2014
73 Effects of Dropout dropped units do not contribute to output other units need to compensate enforce redundant, distributed representation avoid complex co-adaptations of neurons, each neuron needs to learn a strong feature on its own reduces effective capacity of the network increase layer size increases number of epochs by 1/p
74 Dropout as Ensemble Averaging each dropout randomization is new instance of network trained on a mini-batch sharing weights between all ensemble instances full network averages across ensemble
75 Batch Normalization gradient updates can result in strong output changes This is due to all layers updated in parallel, while assuming their constness when computing gradients. Result: strong change of hidden layer distributions
76 Batch Normalization How to avoid internal covariate shift between updates? Naive Approach: Explicit Whitening in mini-batch B counteracts progress of gradient descent
77 Batch Normalization New in BN: propagate gradient through normalization Ignore gradient components that merely change mean or variance Focus on important changes Restricting mean and variance, restricts model s capacity Preserve capacity by where γ and β are component-wise trainable parameters Ioffe + Szegedy, 2015
78 Batch Normalization Improves convergence speed Allows for higher learning rates Regularizing effect, reduces need for dropout for L2 regularization Apply before nonlinearity, i.e. on W x + b
79 Transfer Learning Avoid Learning from scratch Start from existing network on a similar task Deep Features are often universal, i.e. transfer to different tasks
80 Transfer Learning With Convnets Find pretrained network FC 1000 FC 4096 FC 4096 Max Pool Small dataset. Fix all weights (use convnet as feature extractor) Train only the classifier layer Conv 256 Conv 384 Conv 384 Max Pool FC N FC 4096 FC 4096 Max Pool Conv 256 Swap the softmax layer at the end, replace with appropriate number of classes N Conv 384 Conv 384 Max Pool Medium-sized or larger dataset. Fine-tune the network. Use pre-trained net as an initialization. Train the full network, or just some of the last layers. Retrain a bigger portion of the network, or even all of it FC N FC 4096 FC 4096 Max Pool Conv 256 Conv 384 Conv 384 Max Pool LRN LRN LRN Conv 256 Conv 256 Conv 256 Max Pool Max Pool LRN LRN Conv 96 Conv 96 Use only ~1/10th of the original learning rate when fine-tuning the top-most layers and ~1/100th for other layers Max Pool LRN Conv 96
81 A Two-stage Approach to Fine-tuning First, train only the new classifier layer to convergence, without modifying the other network weights FC N FC 4096 FC 4096 Conv 256 FC 4096 FC 4096 Max Pool Max Pool Conv 384 Prevents the pretrained network from being subjected to noisy updates from the randomly initialized classifier layer Then, train more of the network, or even all of it (with reduced learning rate) FC N Fine-tuning can proceed from a good starting point Conv 256 Conv 384 Conv 384 Conv 384 Max Pool Max Pool LRN LRN Conv 256 Conv 256 Max Pool Max Pool LRN LRN Conv 96 Conv 96
82 specific From the Source to Other Tasks FC 1000 FC 4096 compared with the source, the target dataset is a... FC 4096 very similar dataset very different dataset very little data Learn linear classifier on features from top layer(s) You re in trouble try a linear classifier on different layers lots of data Finetune a few layers Finetune more layers Max Pool Conv 256 Conv 384 Conv 384 Max Pool generic LRN Conv 256 Max Pool LRN Conv 96 the target dataset has...
83 Further Reading Stanford lecture on Convolutional Networks Caffe-in-a-day Tutorial
Perceptron: This is convolution!
 Perceptron: This is convolution! v v v Shared weights v Filter = local perceptron. Also called kernel. By pooling responses at different locations, we gain robustness to the exact spatial location of image
Perceptron: This is convolution! v v v Shared weights v Filter = local perceptron. Also called kernel. By pooling responses at different locations, we gain robustness to the exact spatial location of image
Neural Network Optimization and Tuning / Spring 2018 / Recitation 3
 Neural Network Optimization and Tuning 11-785 / Spring 2018 / Recitation 3 1 Logistics You will work through a Jupyter notebook that contains sample and starter code with explanations and comments throughout.
Neural Network Optimization and Tuning 11-785 / Spring 2018 / Recitation 3 1 Logistics You will work through a Jupyter notebook that contains sample and starter code with explanations and comments throughout.
Deep Learning for Computer Vision II
 IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
COMP 551 Applied Machine Learning Lecture 16: Deep Learning
 COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
CS 6501: Deep Learning for Computer Graphics. Training Neural Networks II. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Training Neural Networks II Connelly Barnes Overview Preprocessing Initialization Vanishing/exploding gradients problem Batch normalization Dropout Additional
CS 6501: Deep Learning for Computer Graphics Training Neural Networks II Connelly Barnes Overview Preprocessing Initialization Vanishing/exploding gradients problem Batch normalization Dropout Additional
Machine Learning. Deep Learning. Eric Xing (and Pengtao Xie) , Fall Lecture 8, October 6, Eric CMU,
 , Fall Lecture 8, October 6, Eric CMU,") Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Lecture 20: Neural Networks for NLP. Zubin Pahuja
 Lecture 20: Neural Networks for NLP Zubin Pahuja zpahuja2@illinois.edu courses.engr.illinois.edu/cs447 CS447: Natural Language Processing 1 Today s Lecture Feed-forward neural networks as classifiers simple
Lecture 20: Neural Networks for NLP Zubin Pahuja zpahuja2@illinois.edu courses.engr.illinois.edu/cs447 CS447: Natural Language Processing 1 Today s Lecture Feed-forward neural networks as classifiers simple
Lecture 37: ConvNets (Cont d) and Training
 and Training") Lecture 37: ConvNets (Cont d) and Training CS 4670/5670 Sean Bell [http://bbabenko.tumblr.com/post/83319141207/convolutional-learnings-things-i-learned-by] (Unrelated) Dog vs Food [Karen Zack, @teenybiscuit]
Lecture 37: ConvNets (Cont d) and Training CS 4670/5670 Sean Bell [http://bbabenko.tumblr.com/post/83319141207/convolutional-learnings-things-i-learned-by] (Unrelated) Dog vs Food [Karen Zack, @teenybiscuit]
CS489/698: Intro to ML
 CS489/698: Intro to ML Lecture 14: Training of Deep NNs Instructor: Sun Sun 1 Outline Activation functions Regularization Gradient-based optimization 2 Examples of activation functions 3 5/28/18 Sun Sun
CS489/698: Intro to ML Lecture 14: Training of Deep NNs Instructor: Sun Sun 1 Outline Activation functions Regularization Gradient-based optimization 2 Examples of activation functions 3 5/28/18 Sun Sun
Deep Learning. Vladimir Golkov Technical University of Munich Computer Vision Group
 Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
CMU Lecture 18: Deep learning and Vision: Convolutional neural networks. Teacher: Gianni A. Di Caro
 CMU 15-781 Lecture 18: Deep learning and Vision: Convolutional neural networks Teacher: Gianni A. Di Caro DEEP, SHALLOW, CONNECTED, SPARSE? Fully connected multi-layer feed-forward perceptrons: More powerful
CMU 15-781 Lecture 18: Deep learning and Vision: Convolutional neural networks Teacher: Gianni A. Di Caro DEEP, SHALLOW, CONNECTED, SPARSE? Fully connected multi-layer feed-forward perceptrons: More powerful
Deep Learning with Tensorflow AlexNet
 Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
CS 2750: Machine Learning. Neural Networks. Prof. Adriana Kovashka University of Pittsburgh April 13, 2016
 CS 2750: Machine Learning Neural Networks Prof. Adriana Kovashka University of Pittsburgh April 13, 2016 Plan for today Neural network definition and examples Training neural networks (backprop) Convolutional
CS 2750: Machine Learning Neural Networks Prof. Adriana Kovashka University of Pittsburgh April 13, 2016 Plan for today Neural network definition and examples Training neural networks (backprop) Convolutional
Deep Learning for Computer Vision
 Deep Learning for Computer Vision Lecture 7: Universal Approximation Theorem, More Hidden Units, Multi-Class Classifiers, Softmax, and Regularization Peter Belhumeur Computer Science Columbia University
Deep Learning for Computer Vision Lecture 7: Universal Approximation Theorem, More Hidden Units, Multi-Class Classifiers, Softmax, and Regularization Peter Belhumeur Computer Science Columbia University
Natural Language Processing CS 6320 Lecture 6 Neural Language Models. Instructor: Sanda Harabagiu
 Natural Language Processing CS 6320 Lecture 6 Neural Language Models Instructor: Sanda Harabagiu In this lecture We shall cover: Deep Neural Models for Natural Language Processing Introduce Feed Forward
Natural Language Processing CS 6320 Lecture 6 Neural Language Models Instructor: Sanda Harabagiu In this lecture We shall cover: Deep Neural Models for Natural Language Processing Introduce Feed Forward
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Deep Learning and Its Applications
 Convolutional Neural Network and Its Application in Image Recognition Oct 28, 2016 Outline 1 A Motivating Example 2 The Convolutional Neural Network (CNN) Model 3 Training the CNN Model 4 Issues and Recent
Convolutional Neural Network and Its Application in Image Recognition Oct 28, 2016 Outline 1 A Motivating Example 2 The Convolutional Neural Network (CNN) Model 3 Training the CNN Model 4 Issues and Recent
Introduction to Neural Networks
 Introduction to Neural Networks Jakob Verbeek 2017-2018 Biological motivation Neuron is basic computational unit of the brain about 10^11 neurons in human brain Simplified neuron model as linear threshold
Introduction to Neural Networks Jakob Verbeek 2017-2018 Biological motivation Neuron is basic computational unit of the brain about 10^11 neurons in human brain Simplified neuron model as linear threshold
Lecture : Neural net: initialization, activations, normalizations and other practical details Anne Solberg March 10, 2017
 INF 5860 Machine learning for image classification Lecture : Neural net: initialization, activations, normalizations and other practical details Anne Solberg March 0, 207 Mandatory exercise Available tonight,
INF 5860 Machine learning for image classification Lecture : Neural net: initialization, activations, normalizations and other practical details Anne Solberg March 0, 207 Mandatory exercise Available tonight,
CPSC 340: Machine Learning and Data Mining. Deep Learning Fall 2016
 CPSC 340: Machine Learning and Data Mining Deep Learning Fall 2016 Assignment 5: Due Friday. Assignment 6: Due next Friday. Final: Admin December 12 (8:30am HEBB 100) Covers Assignments 1-6. Final from
CPSC 340: Machine Learning and Data Mining Deep Learning Fall 2016 Assignment 5: Due Friday. Assignment 6: Due next Friday. Final: Admin December 12 (8:30am HEBB 100) Covers Assignments 1-6. Final from
Fuzzy Set Theory in Computer Vision: Example 3, Part II
 Fuzzy Set Theory in Computer Vision: Example 3, Part II Derek T. Anderson and James M. Keller FUZZ-IEEE, July 2017 Overview Resource; CS231n: Convolutional Neural Networks for Visual Recognition https://github.com/tuanavu/stanford-
Fuzzy Set Theory in Computer Vision: Example 3, Part II Derek T. Anderson and James M. Keller FUZZ-IEEE, July 2017 Overview Resource; CS231n: Convolutional Neural Networks for Visual Recognition https://github.com/tuanavu/stanford-
Dropout. Sargur N. Srihari This is part of lecture slides on Deep Learning:
 Dropout Sargur N. srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Regularization Strategies 1. Parameter Norm Penalties 2. Norm Penalties
Dropout Sargur N. srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Regularization Strategies 1. Parameter Norm Penalties 2. Norm Penalties
11. Neural Network Regularization
 11. Neural Network Regularization CS 519 Deep Learning, Winter 2016 Fuxin Li With materials from Andrej Karpathy, Zsolt Kira Preventing overfitting Approach 1: Get more data! Always best if possible! If
11. Neural Network Regularization CS 519 Deep Learning, Winter 2016 Fuxin Li With materials from Andrej Karpathy, Zsolt Kira Preventing overfitting Approach 1: Get more data! Always best if possible! If
Deep Learning for Embedded Security Evaluation
 Deep Learning for Embedded Security Evaluation Emmanuel Prouff 1 1 Laboratoire de Sécurité des Composants, ANSSI, France April 2018, CISCO April 2018, CISCO E. Prouff 1/22 Contents 1. Context and Motivation
Deep Learning for Embedded Security Evaluation Emmanuel Prouff 1 1 Laboratoire de Sécurité des Composants, ANSSI, France April 2018, CISCO April 2018, CISCO E. Prouff 1/22 Contents 1. Context and Motivation
Machine Learning With Python. Bin Chen Nov. 7, 2017 Research Computing Center
 Machine Learning With Python Bin Chen Nov. 7, 2017 Research Computing Center Outline Introduction to Machine Learning (ML) Introduction to Neural Network (NN) Introduction to Deep Learning NN Introduction
Machine Learning With Python Bin Chen Nov. 7, 2017 Research Computing Center Outline Introduction to Machine Learning (ML) Introduction to Neural Network (NN) Introduction to Deep Learning NN Introduction
All You Want To Know About CNNs. Yukun Zhu
 All You Want To Know About CNNs Yukun Zhu Deep Learning Deep Learning Image from http://imgur.com/ Deep Learning Image from http://imgur.com/ Deep Learning Image from http://imgur.com/ Deep Learning Image
All You Want To Know About CNNs Yukun Zhu Deep Learning Deep Learning Image from http://imgur.com/ Deep Learning Image from http://imgur.com/ Deep Learning Image from http://imgur.com/ Deep Learning Image
Lecture 5: Training Neural Networks, Part I
 Lecture 5: Training Neural Networks, Part I Thursday February 2, 2017 comp150dl 1 Announcements! - HW1 due today! - Because of website typo, will accept homework 1 until Saturday with no late penalty.
Lecture 5: Training Neural Networks, Part I Thursday February 2, 2017 comp150dl 1 Announcements! - HW1 due today! - Because of website typo, will accept homework 1 until Saturday with no late penalty.
Deep neural networks II
 Deep neural networks II May 31 st, 2018 Yong Jae Lee UC Davis Many slides from Rob Fergus, Svetlana Lazebnik, Jia-Bin Huang, Derek Hoiem, Adriana Kovashka, Why (convolutional) neural networks? State of
Deep neural networks II May 31 st, 2018 Yong Jae Lee UC Davis Many slides from Rob Fergus, Svetlana Lazebnik, Jia-Bin Huang, Derek Hoiem, Adriana Kovashka, Why (convolutional) neural networks? State of
Neural Network Neurons
 Neural Networks Neural Network Neurons 1 Receives n inputs (plus a bias term) Multiplies each input by its weight Applies activation function to the sum of results Outputs result Activation Functions Given
Neural Networks Neural Network Neurons 1 Receives n inputs (plus a bias term) Multiplies each input by its weight Applies activation function to the sum of results Outputs result Activation Functions Given
Machine Learning. The Breadth of ML Neural Networks & Deep Learning. Marc Toussaint. Duy Nguyen-Tuong. University of Stuttgart
 Machine Learning The Breadth of ML Neural Networks & Deep Learning Marc Toussaint University of Stuttgart Duy Nguyen-Tuong Bosch Center for Artificial Intelligence Summer 2017 Neural Networks Consider
Machine Learning The Breadth of ML Neural Networks & Deep Learning Marc Toussaint University of Stuttgart Duy Nguyen-Tuong Bosch Center for Artificial Intelligence Summer 2017 Neural Networks Consider
Vulnerability of machine learning models to adversarial examples
 Vulnerability of machine learning models to adversarial examples Petra Vidnerová Institute of Computer Science The Czech Academy of Sciences Hora Informaticae 1 Outline Introduction Works on adversarial
Vulnerability of machine learning models to adversarial examples Petra Vidnerová Institute of Computer Science The Czech Academy of Sciences Hora Informaticae 1 Outline Introduction Works on adversarial
Improving the way neural networks learn Srikumar Ramalingam School of Computing University of Utah
 Improving the way neural networks learn Srikumar Ramalingam School of Computing University of Utah Reference Most of the slides are taken from the third chapter of the online book by Michael Nielson: neuralnetworksanddeeplearning.com
Improving the way neural networks learn Srikumar Ramalingam School of Computing University of Utah Reference Most of the slides are taken from the third chapter of the online book by Michael Nielson: neuralnetworksanddeeplearning.com
COMP9444 Neural Networks and Deep Learning 7. Image Processing. COMP9444 c Alan Blair, 2017
 COMP9444 Neural Networks and Deep Learning 7. Image Processing COMP9444 17s2 Image Processing 1 Outline Image Datasets and Tasks Convolution in Detail AlexNet Weight Initialization Batch Normalization
COMP9444 Neural Networks and Deep Learning 7. Image Processing COMP9444 17s2 Image Processing 1 Outline Image Datasets and Tasks Convolution in Detail AlexNet Weight Initialization Batch Normalization
The exam is closed book, closed notes except your one-page cheat sheet.
 CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
Index. Umberto Michelucci 2018 U. Michelucci, Applied Deep Learning,
 A Acquisition function, 298, 301 Adam optimizer, 175 178 Anaconda navigator conda command, 3 Create button, 5 download and install, 1 installing packages, 8 Jupyter Notebook, 11 13 left navigation pane,
A Acquisition function, 298, 301 Adam optimizer, 175 178 Anaconda navigator conda command, 3 Create button, 5 download and install, 1 installing packages, 8 Jupyter Notebook, 11 13 left navigation pane,
The exam is closed book, closed notes except your one-page (two-sided) cheat sheet.
 cheat sheet.") CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
SEMANTIC COMPUTING. Lecture 8: Introduction to Deep Learning. TU Dresden, 7 December Dagmar Gromann International Center For Computational Logic
 SEMANTIC COMPUTING Lecture 8: Introduction to Deep Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 7 December 2018 Overview Introduction Deep Learning General Neural Networks
SEMANTIC COMPUTING Lecture 8: Introduction to Deep Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 7 December 2018 Overview Introduction Deep Learning General Neural Networks
Convolutional Neural Networks
 NPFL114, Lecture 4 Convolutional Neural Networks Milan Straka March 25, 2019 Charles University in Prague Faculty of Mathematics and Physics Institute of Formal and Applied Linguistics unless otherwise
NPFL114, Lecture 4 Convolutional Neural Networks Milan Straka March 25, 2019 Charles University in Prague Faculty of Mathematics and Physics Institute of Formal and Applied Linguistics unless otherwise
Deep Learning. Deep Learning provided breakthrough results in speech recognition and image classification. Why?
 Data Mining Deep Learning Deep Learning provided breakthrough results in speech recognition and image classification. Why? Because Speech recognition and image classification are two basic examples of
Data Mining Deep Learning Deep Learning provided breakthrough results in speech recognition and image classification. Why? Because Speech recognition and image classification are two basic examples of
Application of Convolutional Neural Network for Image Classification on Pascal VOC Challenge 2012 dataset
 Application of Convolutional Neural Network for Image Classification on Pascal VOC Challenge 2012 dataset Suyash Shetty Manipal Institute of Technology suyash.shashikant@learner.manipal.edu Abstract In
Application of Convolutional Neural Network for Image Classification on Pascal VOC Challenge 2012 dataset Suyash Shetty Manipal Institute of Technology suyash.shashikant@learner.manipal.edu Abstract In
CS 1674: Intro to Computer Vision. Neural Networks. Prof. Adriana Kovashka University of Pittsburgh November 16, 2016
 CS 1674: Intro to Computer Vision Neural Networks Prof. Adriana Kovashka University of Pittsburgh November 16, 2016 Announcements Please watch the videos I sent you, if you haven t yet (that s your reading)
CS 1674: Intro to Computer Vision Neural Networks Prof. Adriana Kovashka University of Pittsburgh November 16, 2016 Announcements Please watch the videos I sent you, if you haven t yet (that s your reading)
Practical Tips for using Backpropagation
 Practical Tips for using Backpropagation Keith L. Downing August 31, 2017 1 Introduction In practice, backpropagation is as much an art as a science. The user typically needs to try many combinations of
Practical Tips for using Backpropagation Keith L. Downing August 31, 2017 1 Introduction In practice, backpropagation is as much an art as a science. The user typically needs to try many combinations of
Machine Learning 13. week
 Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Neural Networks. CE-725: Statistical Pattern Recognition Sharif University of Technology Spring Soleymani
 Neural Networks CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Biological and artificial neural networks Feed-forward neural networks Single layer
Neural Networks CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Biological and artificial neural networks Feed-forward neural networks Single layer
Study of Residual Networks for Image Recognition
 Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
Alternatives to Direct Supervision
 CreativeAI: Deep Learning for Graphics Alternatives to Direct Supervision Niloy Mitra Iasonas Kokkinos Paul Guerrero Nils Thuerey Tobias Ritschel UCL UCL UCL TUM UCL Timetable Theory and Basics State of
CreativeAI: Deep Learning for Graphics Alternatives to Direct Supervision Niloy Mitra Iasonas Kokkinos Paul Guerrero Nils Thuerey Tobias Ritschel UCL UCL UCL TUM UCL Timetable Theory and Basics State of
Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift. Amit Patel Sambit Pradhan
 Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift Amit Patel Sambit Pradhan Introduction Internal Covariate Shift Batch Normalization Computational Graph of Batch
Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift Amit Patel Sambit Pradhan Introduction Internal Covariate Shift Batch Normalization Computational Graph of Batch
Dynamic Routing Between Capsules
 Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Deep Learning For Video Classification. Presented by Natalie Carlebach & Gil Sharon
 Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
Semantic Segmentation. Zhongang Qi
 Semantic Segmentation Zhongang Qi qiz@oregonstate.edu Semantic Segmentation "Two men riding on a bike in front of a building on the road. And there is a car." Idea: recognizing, understanding what's in
Semantic Segmentation Zhongang Qi qiz@oregonstate.edu Semantic Segmentation "Two men riding on a bike in front of a building on the road. And there is a car." Idea: recognizing, understanding what's in
Deep Learning. Volker Tresp Summer 2014
 Deep Learning Volker Tresp Summer 2014 1 Neural Network Winter and Revival While Machine Learning was flourishing, there was a Neural Network winter (late 1990 s until late 2000 s) Around 2010 there
Deep Learning Volker Tresp Summer 2014 1 Neural Network Winter and Revival While Machine Learning was flourishing, there was a Neural Network winter (late 1990 s until late 2000 s) Around 2010 there
Neural Network and Deep Learning. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Neural Network and Deep Learning Early history of deep learning Deep learning dates back to 1940s: known as cybernetics in the 1940s-60s, connectionism in the 1980s-90s, and under the current name starting
Neural Network and Deep Learning Early history of deep learning Deep learning dates back to 1940s: known as cybernetics in the 1940s-60s, connectionism in the 1980s-90s, and under the current name starting
Facial Expression Classification with Random Filters Feature Extraction
 Facial Expression Classification with Random Filters Feature Extraction Mengye Ren Facial Monkey mren@cs.toronto.edu Zhi Hao Luo It s Me lzh@cs.toronto.edu I. ABSTRACT In our work, we attempted to tackle
Facial Expression Classification with Random Filters Feature Extraction Mengye Ren Facial Monkey mren@cs.toronto.edu Zhi Hao Luo It s Me lzh@cs.toronto.edu I. ABSTRACT In our work, we attempted to tackle
DECISION TREES & RANDOM FORESTS X CONVOLUTIONAL NEURAL NETWORKS
 DECISION TREES & RANDOM FORESTS X CONVOLUTIONAL NEURAL NETWORKS Deep Neural Decision Forests Microsoft Research Cambridge UK, ICCV 2015 Decision Forests, Convolutional Networks and the Models in-between
DECISION TREES & RANDOM FORESTS X CONVOLUTIONAL NEURAL NETWORKS Deep Neural Decision Forests Microsoft Research Cambridge UK, ICCV 2015 Decision Forests, Convolutional Networks and the Models in-between
Machine Learning. MGS Lecture 3: Deep Learning
 Dr Michel F. Valstar http://cs.nott.ac.uk/~mfv/ Machine Learning MGS Lecture 3: Deep Learning Dr Michel F. Valstar http://cs.nott.ac.uk/~mfv/ WHAT IS DEEP LEARNING? Shallow network: Only one hidden layer
Dr Michel F. Valstar http://cs.nott.ac.uk/~mfv/ Machine Learning MGS Lecture 3: Deep Learning Dr Michel F. Valstar http://cs.nott.ac.uk/~mfv/ WHAT IS DEEP LEARNING? Shallow network: Only one hidden layer
Ensemble methods in machine learning. Example. Neural networks. Neural networks
 Ensemble methods in machine learning Bootstrap aggregating (bagging) train an ensemble of models based on randomly resampled versions of the training set, then take a majority vote Example What if you
Ensemble methods in machine learning Bootstrap aggregating (bagging) train an ensemble of models based on randomly resampled versions of the training set, then take a majority vote Example What if you
Tutorial on Machine Learning Tools
 Tutorial on Machine Learning Tools Yanbing Xue Milos Hauskrecht Why do we need these tools? Widely deployed classical models No need to code from scratch Easy-to-use GUI Outline Matlab Apps Weka 3 UI TensorFlow
Tutorial on Machine Learning Tools Yanbing Xue Milos Hauskrecht Why do we need these tools? Widely deployed classical models No need to code from scratch Easy-to-use GUI Outline Matlab Apps Weka 3 UI TensorFlow
Unsupervised Learning
 Deep Learning for Graphics Unsupervised Learning Niloy Mitra Iasonas Kokkinos Paul Guerrero Vladimir Kim Kostas Rematas Tobias Ritschel UCL UCL/Facebook UCL Adobe Research U Washington UCL Timetable Niloy
Deep Learning for Graphics Unsupervised Learning Niloy Mitra Iasonas Kokkinos Paul Guerrero Vladimir Kim Kostas Rematas Tobias Ritschel UCL UCL/Facebook UCL Adobe Research U Washington UCL Timetable Niloy
Neural Networks for Machine Learning. Lecture 15a From Principal Components Analysis to Autoencoders
 Neural Networks for Machine Learning Lecture 15a From Principal Components Analysis to Autoencoders Geoffrey Hinton Nitish Srivastava, Kevin Swersky Tijmen Tieleman Abdel-rahman Mohamed Principal Components
Neural Networks for Machine Learning Lecture 15a From Principal Components Analysis to Autoencoders Geoffrey Hinton Nitish Srivastava, Kevin Swersky Tijmen Tieleman Abdel-rahman Mohamed Principal Components
Natural Language Processing with Deep Learning CS224N/Ling284. Christopher Manning Lecture 4: Backpropagation and computation graphs
 Natural Language Processing with Deep Learning CS4N/Ling84 Christopher Manning Lecture 4: Backpropagation and computation graphs Lecture Plan Lecture 4: Backpropagation and computation graphs 1. Matrix
Natural Language Processing with Deep Learning CS4N/Ling84 Christopher Manning Lecture 4: Backpropagation and computation graphs Lecture Plan Lecture 4: Backpropagation and computation graphs 1. Matrix
Inception Network Overview. David White CS793
 Inception Network Overview David White CS793 So, Leonardo DiCaprio dreams about dreaming... https://m.media-amazon.com/images/m/mv5bmjaxmzy3njcxnf5bml5banbnxkftztcwnti5otm0mw@@._v1_sy1000_cr0,0,675,1 000_AL_.jpg
Inception Network Overview David White CS793 So, Leonardo DiCaprio dreams about dreaming... https://m.media-amazon.com/images/m/mv5bmjaxmzy3njcxnf5bml5banbnxkftztcwnti5otm0mw@@._v1_sy1000_cr0,0,675,1 000_AL_.jpg
Research on Pruning Convolutional Neural Network, Autoencoder and Capsule Network
 Research on Pruning Convolutional Neural Network, Autoencoder and Capsule Network Tianyu Wang Australia National University, Colledge of Engineering and Computer Science u@anu.edu.au Abstract. Some tasks,
Research on Pruning Convolutional Neural Network, Autoencoder and Capsule Network Tianyu Wang Australia National University, Colledge of Engineering and Computer Science u@anu.edu.au Abstract. Some tasks,
Deep Neural Networks Optimization
 Deep Neural Networks Optimization Creative Commons (cc) by Akritasa http://arxiv.org/pdf/1406.2572.pdf Slides from Geoffrey Hinton CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy
Deep Neural Networks Optimization Creative Commons (cc) by Akritasa http://arxiv.org/pdf/1406.2572.pdf Slides from Geoffrey Hinton CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy
Simple Model Selection Cross Validation Regularization Neural Networks
 Neural Nets: Many possible refs e.g., Mitchell Chapter 4 Simple Model Selection Cross Validation Regularization Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February
Neural Nets: Many possible refs e.g., Mitchell Chapter 4 Simple Model Selection Cross Validation Regularization Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February
Plankton Classification Using ConvNets
 Plankton Classification Using ConvNets Abhinav Rastogi Stanford University Stanford, CA arastogi@stanford.edu Haichuan Yu Stanford University Stanford, CA haichuan@stanford.edu Abstract We present the
Plankton Classification Using ConvNets Abhinav Rastogi Stanford University Stanford, CA arastogi@stanford.edu Haichuan Yu Stanford University Stanford, CA haichuan@stanford.edu Abstract We present the
Accelerating Convolutional Neural Nets. Yunming Zhang
 Accelerating Convolutional Neural Nets Yunming Zhang Focus Convolutional Neural Nets is the state of the art in classifying the images The models take days to train Difficult for the programmers to tune
Accelerating Convolutional Neural Nets Yunming Zhang Focus Convolutional Neural Nets is the state of the art in classifying the images The models take days to train Difficult for the programmers to tune
Keras: Handwritten Digit Recognition using MNIST Dataset
 Keras: Handwritten Digit Recognition using MNIST Dataset IIT PATNA January 31, 2018 1 / 30 OUTLINE 1 Keras: Introduction 2 Installing Keras 3 Keras: Building, Testing, Improving A Simple Network 2 / 30
Keras: Handwritten Digit Recognition using MNIST Dataset IIT PATNA January 31, 2018 1 / 30 OUTLINE 1 Keras: Introduction 2 Installing Keras 3 Keras: Building, Testing, Improving A Simple Network 2 / 30
Autoencoders. Stephen Scott. Introduction. Basic Idea. Stacked AE. Denoising AE. Sparse AE. Contractive AE. Variational AE GAN.
 Stacked Denoising Sparse Variational (Adapted from Paul Quint and Ian Goodfellow) Stacked Denoising Sparse Variational Autoencoding is training a network to replicate its input to its output Applications:
Stacked Denoising Sparse Variational (Adapted from Paul Quint and Ian Goodfellow) Stacked Denoising Sparse Variational Autoencoding is training a network to replicate its input to its output Applications:
Akarsh Pokkunuru EECS Department Contractive Auto-Encoders: Explicit Invariance During Feature Extraction
 Akarsh Pokkunuru EECS Department 03-16-2017 Contractive Auto-Encoders: Explicit Invariance During Feature Extraction 1 AGENDA Introduction to Auto-encoders Types of Auto-encoders Analysis of different
Akarsh Pokkunuru EECS Department 03-16-2017 Contractive Auto-Encoders: Explicit Invariance During Feature Extraction 1 AGENDA Introduction to Auto-encoders Types of Auto-encoders Analysis of different
3D model classification using convolutional neural network
 3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
EE 511 Neural Networks
 Slides adapted from Ali Farhadi, Mari Ostendorf, Pedro Domingos, Carlos Guestrin, and Luke Zettelmoyer, Andrei Karpathy EE 511 Neural Networks Instructor: Hanna Hajishirzi hannaneh@washington.edu Computational
Slides adapted from Ali Farhadi, Mari Ostendorf, Pedro Domingos, Carlos Guestrin, and Luke Zettelmoyer, Andrei Karpathy EE 511 Neural Networks Instructor: Hanna Hajishirzi hannaneh@washington.edu Computational
Machine Learning. Chao Lan
 Machine Learning Chao Lan Machine Learning Prediction Models Regression Model - linear regression (least square, ridge regression, Lasso) Classification Model - naive Bayes, logistic regression, Gaussian
Machine Learning Chao Lan Machine Learning Prediction Models Regression Model - linear regression (least square, ridge regression, Lasso) Classification Model - naive Bayes, logistic regression, Gaussian
Machine Learning / Jan 27, 2010
 Revisiting Logistic Regression & Naïve Bayes Aarti Singh Machine Learning 10-701/15-781 Jan 27, 2010 Generative and Discriminative Classifiers Training classifiers involves learning a mapping f: X -> Y,
Revisiting Logistic Regression & Naïve Bayes Aarti Singh Machine Learning 10-701/15-781 Jan 27, 2010 Generative and Discriminative Classifiers Training classifiers involves learning a mapping f: X -> Y,
Restricted Boltzmann Machines. Shallow vs. deep networks. Stacked RBMs. Boltzmann Machine learning: Unsupervised version
 Shallow vs. deep networks Restricted Boltzmann Machines Shallow: one hidden layer Features can be learned more-or-less independently Arbitrary function approximator (with enough hidden units) Deep: two
Shallow vs. deep networks Restricted Boltzmann Machines Shallow: one hidden layer Features can be learned more-or-less independently Arbitrary function approximator (with enough hidden units) Deep: two
CNNS FROM THE BASICS TO RECENT ADVANCES. Dmytro Mishkin Center for Machine Perception Czech Technical University in Prague
 CNNS FROM THE BASICS TO RECENT ADVANCES Dmytro Mishkin Center for Machine Perception Czech Technical University in Prague ducha.aiki@gmail.com OUTLINE Short review of the CNN design Architecture progress
CNNS FROM THE BASICS TO RECENT ADVANCES Dmytro Mishkin Center for Machine Perception Czech Technical University in Prague ducha.aiki@gmail.com OUTLINE Short review of the CNN design Architecture progress
The exam is closed book, closed notes except your one-page (two-sided) cheat sheet.
 cheat sheet.") CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
A Sparse and Locally Shift Invariant Feature Extractor Applied to Document Images
 A Sparse and Locally Shift Invariant Feature Extractor Applied to Document Images Marc Aurelio Ranzato Yann LeCun Courant Institute of Mathematical Sciences New York University - New York, NY 10003 Abstract
A Sparse and Locally Shift Invariant Feature Extractor Applied to Document Images Marc Aurelio Ranzato Yann LeCun Courant Institute of Mathematical Sciences New York University - New York, NY 10003 Abstract
Machine Learning and Algorithms for Data Mining Practical 2: Neural Networks
 CST Part III/MPhil in Advanced Computer Science 2016-2017 Machine Learning and Algorithms for Data Mining Practical 2: Neural Networks Demonstrators: Petar Veličković, Duo Wang Lecturers: Mateja Jamnik,
CST Part III/MPhil in Advanced Computer Science 2016-2017 Machine Learning and Algorithms for Data Mining Practical 2: Neural Networks Demonstrators: Petar Veličković, Duo Wang Lecturers: Mateja Jamnik,
Deep Learning. Architecture Design for. Sargur N. Srihari
 Architecture Design for Deep Learning Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation
Architecture Design for Deep Learning Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation
Como funciona o Deep Learning
 Como funciona o Deep Learning Moacir Ponti (com ajuda de Gabriel Paranhos da Costa) ICMC, Universidade de São Paulo Contact: www.icmc.usp.br/~moacir moacir@icmc.usp.br Uberlandia-MG/Brazil October, 2017
Como funciona o Deep Learning Moacir Ponti (com ajuda de Gabriel Paranhos da Costa) ICMC, Universidade de São Paulo Contact: www.icmc.usp.br/~moacir moacir@icmc.usp.br Uberlandia-MG/Brazil October, 2017
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
Lecture : Training a neural net part I Initialization, activations, normalizations and other practical details Anne Solberg February 28, 2018
 INF 5860 Machine learning for image classification Lecture : Training a neural net part I Initialization, activations, normalizations and other practical details Anne Solberg February 28, 2018 Reading
INF 5860 Machine learning for image classification Lecture : Training a neural net part I Initialization, activations, normalizations and other practical details Anne Solberg February 28, 2018 Reading
Deep Learning. Visualizing and Understanding Convolutional Networks. Christopher Funk. Pennsylvania State University.
 Visualizing and Understanding Convolutional Networks Christopher Pennsylvania State University February 23, 2015 Some Slide Information taken from Pierre Sermanet (Google) presentation on and Computer
Visualizing and Understanding Convolutional Networks Christopher Pennsylvania State University February 23, 2015 Some Slide Information taken from Pierre Sermanet (Google) presentation on and Computer
Convolution Neural Network for Traditional Chinese Calligraphy Recognition
 Convolution Neural Network for Traditional Chinese Calligraphy Recognition Boqi Li Mechanical Engineering Stanford University boqili@stanford.edu Abstract script. Fig. 1 shows examples of the same TCC
Convolution Neural Network for Traditional Chinese Calligraphy Recognition Boqi Li Mechanical Engineering Stanford University boqili@stanford.edu Abstract script. Fig. 1 shows examples of the same TCC
Survey of Convolutional Neural Network
 Survey of Convolutional Neural Network Chenyou Fan Indiana University Bloomington, IN fan6@indiana.edu Abstract Convolutional Neural Network (CNN) was firstly introduced in Computer Vision for image recognition
Survey of Convolutional Neural Network Chenyou Fan Indiana University Bloomington, IN fan6@indiana.edu Abstract Convolutional Neural Network (CNN) was firstly introduced in Computer Vision for image recognition
CIS680: Vision & Learning Assignment 2.b: RPN, Faster R-CNN and Mask R-CNN Due: Nov. 21, 2018 at 11:59 pm
 CIS680: Vision & Learning Assignment 2.b: RPN, Faster R-CNN and Mask R-CNN Due: Nov. 21, 2018 at 11:59 pm Instructions This is an individual assignment. Individual means each student must hand in their
CIS680: Vision & Learning Assignment 2.b: RPN, Faster R-CNN and Mask R-CNN Due: Nov. 21, 2018 at 11:59 pm Instructions This is an individual assignment. Individual means each student must hand in their
COMP9444 Neural Networks and Deep Learning 5. Geometry of Hidden Units
 COMP9 8s Geometry of Hidden Units COMP9 Neural Networks and Deep Learning 5. Geometry of Hidden Units Outline Geometry of Hidden Unit Activations Limitations of -layer networks Alternative transfer functions
COMP9 8s Geometry of Hidden Units COMP9 Neural Networks and Deep Learning 5. Geometry of Hidden Units Outline Geometry of Hidden Unit Activations Limitations of -layer networks Alternative transfer functions
Tutorial on Keras CAP ADVANCED COMPUTER VISION SPRING 2018 KISHAN S ATHREY
 Tutorial on Keras CAP 6412 - ADVANCED COMPUTER VISION SPRING 2018 KISHAN S ATHREY Deep learning packages TensorFlow Google PyTorch Facebook AI research Keras Francois Chollet (now at Google) Chainer Company
Tutorial on Keras CAP 6412 - ADVANCED COMPUTER VISION SPRING 2018 KISHAN S ATHREY Deep learning packages TensorFlow Google PyTorch Facebook AI research Keras Francois Chollet (now at Google) Chainer Company
A Quick Guide on Training a neural network using Keras.
 A Quick Guide on Training a neural network using Keras. TensorFlow and Keras Keras Open source High level, less flexible Easy to learn Perfect for quick implementations Starts by François Chollet from
A Quick Guide on Training a neural network using Keras. TensorFlow and Keras Keras Open source High level, less flexible Easy to learn Perfect for quick implementations Starts by François Chollet from
Deep Learning Basic Lecture - Complex Systems & Artificial Intelligence 2017/18 (VO) Asan Agibetov, PhD.
 Asan Agibetov, PhD.") Deep Learning 861.061 Basic Lecture - Complex Systems & Artificial Intelligence 2017/18 (VO) Asan Agibetov, PhD asan.agibetov@meduniwien.ac.at Medical University of Vienna Center for Medical Statistics,
Deep Learning 861.061 Basic Lecture - Complex Systems & Artificial Intelligence 2017/18 (VO) Asan Agibetov, PhD asan.agibetov@meduniwien.ac.at Medical University of Vienna Center for Medical Statistics,
CPSC 340: Machine Learning and Data Mining. Deep Learning Fall 2018
 CPSC 340: Machine Learning and Data Mining Deep Learning Fall 2018 Last Time: Multi-Dimensional Scaling Multi-dimensional scaling (MDS): Non-parametric visualization: directly optimize the z i locations.
CPSC 340: Machine Learning and Data Mining Deep Learning Fall 2018 Last Time: Multi-Dimensional Scaling Multi-dimensional scaling (MDS): Non-parametric visualization: directly optimize the z i locations.
Deep Learning Applications
 October 20, 2017 Overview Supervised Learning Feedforward neural network Convolution neural network Recurrent neural network Recursive neural network (Recursive neural tensor network) Unsupervised Learning
October 20, 2017 Overview Supervised Learning Feedforward neural network Convolution neural network Recurrent neural network Recursive neural network (Recursive neural tensor network) Unsupervised Learning
Model Generalization and the Bias-Variance Trade-Off
 Charu C. Aggarwal IBM T J Watson Research Center Yorktown Heights, NY Model Generalization and the Bias-Variance Trade-Off Neural Networks and Deep Learning, Springer, 2018 Chapter 4, Section 4.1-4.2 What
Charu C. Aggarwal IBM T J Watson Research Center Yorktown Heights, NY Model Generalization and the Bias-Variance Trade-Off Neural Networks and Deep Learning, Springer, 2018 Chapter 4, Section 4.1-4.2 What
INTRODUCTION TO DEEP LEARNING
 INTRODUCTION TO DEEP LEARNING CONTENTS Introduction to deep learning Contents 1. Examples 2. Machine learning 3. Neural networks 4. Deep learning 5. Convolutional neural networks 6. Conclusion 7. Additional
INTRODUCTION TO DEEP LEARNING CONTENTS Introduction to deep learning Contents 1. Examples 2. Machine learning 3. Neural networks 4. Deep learning 5. Convolutional neural networks 6. Conclusion 7. Additional
Generative Modeling with Convolutional Neural Networks. Denis Dus Data Scientist at InData Labs
 Generative Modeling with Convolutional Neural Networks Denis Dus Data Scientist at InData Labs What we will discuss 1. 2. 3. 4. Discriminative vs Generative modeling Convolutional Neural Networks How to
Generative Modeling with Convolutional Neural Networks Denis Dus Data Scientist at InData Labs What we will discuss 1. 2. 3. 4. Discriminative vs Generative modeling Convolutional Neural Networks How to
Residual Networks And Attention Models. cs273b Recitation 11/11/2016. Anna Shcherbina
 Residual Networks And Attention Models cs273b Recitation 11/11/2016 Anna Shcherbina Introduction to ResNets Introduced in 2015 by Microsoft Research Deep Residual Learning for Image Recognition (He, Zhang,
Residual Networks And Attention Models cs273b Recitation 11/11/2016 Anna Shcherbina Introduction to ResNets Introduced in 2015 by Microsoft Research Deep Residual Learning for Image Recognition (He, Zhang,
Global Optimality in Neural Network Training
 Global Optimality in Neural Network Training Benjamin D. Haeffele and René Vidal Johns Hopkins University, Center for Imaging Science. Baltimore, USA Questions in Deep Learning Architecture Design Optimization
Global Optimality in Neural Network Training Benjamin D. Haeffele and René Vidal Johns Hopkins University, Center for Imaging Science. Baltimore, USA Questions in Deep Learning Architecture Design Optimization
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Machine Learning for Physicists Lecture 6. Summer 2017 University of Erlangen-Nuremberg Florian Marquardt
 Machine Learning for Physicists Lecture 6 Summer 2017 University of Erlangen-Nuremberg Florian Marquardt Channels MxM image MxM image K K 3 channels conv 6 channels in any output channel, each pixel receives
Machine Learning for Physicists Lecture 6 Summer 2017 University of Erlangen-Nuremberg Florian Marquardt Channels MxM image MxM image K K 3 channels conv 6 channels in any output channel, each pixel receives