CS 572: Information Retrieval
|
|
|
- Aubrie Anthony
- 5 years ago
- Views:
Transcription
1 CS 7: Information Retrieval Recommender Systems : Implementation and Applications Acknowledgements Many slides in this lecture are adapted from Xavier Amatriain (Netflix), Yehuda Koren (Yahoo), and Dietmar Jannach (TU Dortmund), Jimmy Lin, Foster Provost
2 Recap of Recommendation Approaches Collaborative Content-based Knowledge-based Pros No knowledge-engineering effort, serendipity of results, learns market segments No community required, comparison between items possible Deterministic recommendations, assured quality, no cold-start, can resemble sales dialogue Cons Requires some form of rating feedback, cold start for new users and new items Content descriptions necessary, cold start for new users, no surprises Knowledge engineering effort to bootstrap, basically static, does not react to short-term trends /6/06 CS 7: Information Retrieval. Spring 06
3 Recap: What works (in real world ) /6/06 CS 7: Information Retrieval. Spring 06
4 Today: Applications Products: Netflix challenge Information: News recommendation Social: Who to follow Human issues (how recommendations are used) /6/06 CS 7: Information Retrieval. Spring 06

5 Netflix Challenge /6/06 CS 7: Information Retrieval. Spring 06
6 Movie rating data Training data Test data user movie score user movie score 6? 96? 7?? 768 7? 76?? 68 8? 9? 7? ? ? /6/06 CS 7: Information Retrieval. Spring 06 6
7 Netflix Prize Training data 00 million ratings 80,000 users 7,770 movies 6 years of data: Test data Last few ratings of each user (.8 million) Evaluation criterion: root mean squared error (RMSE) Netflix Cinematch RMSE: 0.9 Competition 700+ teams $ million grand prize for 0% improvement on Cinematch result $0, progress prize for 8.% improvement /6/06 CS 7: Information Retrieval. Spring 06 7

8 Overall rating distribution Third of ratings are s Average rating is.68 From TimelyDevelopment.com /6/06 CS 7: Information Retrieval. Spring 06 8

9 #ratings per movie Avg #ratings/movie: 67 /6/06 CS 7: Information Retrieval. Spring 06 9

10 #ratings per user Avg #ratings/user: 08 /6/06 CS 7: Information Retrieval. Spring 06 0
11 Average movie rating by movie count More ratings to better movies From TimelyDevelopment.com /6/06 CS 7: Information Retrieval. Spring 06
12 Most loved movies Title The Shawshank Redemption Lord of the Rings: The Return of the King The Green Mile Lord of the Rings: The Two Towers Finding Nemo Raiders of the Lost Ark Forrest Gump Lord of the Rings: The Fellowship of the ring The Sixth Sense Indiana Jones and the Last Crusade Avg rating Count CS 7: Information Retrieval. Spring 06 /6/06
13 Important RMSEs Global average:.96 erroneous User average:.06 Personalization Movie average:.0 Cinematch: 0.9; baseline BellKor: 0.869; 8.6% improvement Grand Prize: 0.86; 0% improvement Inherent noise:???? accurate /6/06 CS 7: Information Retrieval. Spring 06

14 Challenges Size of data Scalability Keeping data in memory Missing data 99 percent missing Very imbalanced Avoiding overfitting Test and training data differ significantly movie #6 /6/06 CS 7: Information Retrieval. Spring 06
15 The Rules Improve RMSE metric by 0% RMSE= square root of the averaged squared difference between each prediction and the actual rating amplifies the contributions of egregious errors, both false positives ("trust busters") and false negatives ("missed opportunities"). 00 million training ratings provided User, Rating, Movie name, date /6/06 CS 7: Information Retrieval. Spring 06

16 /6/06 CS 7: Information Retrieval. Spring 06 6

17 /6/06 CS 7: Information Retrieval. Spring 06 7


 movie #868")

18 Lessons from the Netflix Prize Yehuda Koren The BellKor team (with Robert Bell & Chris Volinsky) movie #868 movie #76 movie #0 /6/06 CS 7: Information Retrieval. Spring 06 8
19 The BellKor recommender system Use an ensemble of complementing predictors Two, half tuned models worth more than a single, fully tuned model /6/06 CS 7: Information Retrieval. Spring 06 9
20 Effect of ensemble size Error - RMSE #Predictors /6/06 CS 7: Information Retrieval. Spring 06 0
21 The BellKor recommender system Use an ensemble of complementing predictors Two, half tuned models worth more than a single, fully tuned model But: Many seemingly different models expose similar characteristics of the data, and won t mix well Concentrate efforts along three axes... /6/06 CS 7: Information Retrieval. Spring 06

22 The three dimensions of the BellKor system The first axis: Multi-scale modeling of the data Combine top level, regional modeling of the data, with a refined, local view: k-nn: Extracting local patterns Factorization: Addressing regional effects Global effects Factorization k-nn /6/06 CS 7: Information Retrieval. Spring 06
23 Multi-scale modeling st tier Global effects: Mean rating:.7 stars The Sixth Sense is 0. stars above avg Joe rates 0. stars below avg Baseline estimation: Joe will rate The Sixth Sense stars /6/06 CS 7: Information Retrieval. Spring 06

24 Multi-scale modeling nd tier Factors model: Both The Sixth Sense and Joe are placed high on the Supernatural Thrillers scale Adjusted estimate: Joe will rate The Sixth Sense. stars /6/06 CS 7: Information Retrieval. Spring 06


25 Multi-scale modeling rd tier Neighborhood model: Joe didn t like related movie Signs Final estimate: Joe will rate The Sixth Sense. stars /6/06 CS 7: Information Retrieval. Spring 06
26 The three dimensions of the BellKor system The second axis: Quality of modeling Make the best out of a model Strive for: Fundamental derivation Simplicity Avoid overfitting Robustness against #iterations, parameter setting, etc. Optimizing is good, but don t overdo it! global local quality /6/06 CS 7: Information Retrieval. Spring 06 6
27 The three dimensions of the BellKor system The third dimension will be discussed later... Next: Moving the multi-scale view along the quality axis global local??? quality /6/06 CS 7: Information Retrieval. Spring 06 7
 A parallel user-user flavor: rely on ratings of like-minded users (not in this talk) /6/06 CS 7: Information Retrieval.")
28 Local modeling through k-nn Earliest and most popular collaborative filtering method Derive unknown ratings from those of similar items (movie-movie variant) A parallel user-user flavor: rely on ratings of like-minded users (not in this talk) /6/06 CS 7: Information Retrieval. Spring 06 8
29 k-nn users movies - unknown rating - rating between to /6/06 CS 7: Information Retrieval. Spring 06 9
30 k-nn ? 6 users movies - estimate rating of movie by user /6/06 CS 7: Information Retrieval. Spring 06 0
31 k-nn ? 6 users Neighbor selection: Identify movies similar to, rated by user movies /6/06 CS 7: Information Retrieval. Spring 06
32 k-nn ? 6 users Compute similarity weights: s =0., s 6 =0. movies /6/06 CS 7: Information Retrieval. Spring 06
33 k-nn users Predict by taking weighted average: (0.*+0.*)/(0.+0.)=.6 movies /6/06 CS 7: Information Retrieval. Spring 06

34 Properties of k-nn Intuitive No substantial preprocessing is required Easy to explain reasoning behind a recommendation Accurate? /6/06 CS 7: Information Retrieval. Spring 06
35 k-nn on the RMSE scale Global average:.96 erroneous User average:.06 Movie average:.0 k-nn Cinematch: 0.9 BellKor: Grand Prize: 0.86 Inherent noise:???? accurate /6/06 CS 7: Information Retrieval. Spring 06
36 k-nn - Common practice. Define a similarity measure between items: s ij. Select neighbors -- N(i;u): items most similar to i, that were rated by u. Estimate unknown rating, r ui, as the weighted average: s r b ij uj uj r ui b ui j N ( i; u) j N ( i; u) s ij baseline estimate for r ui /6/06 CS 7: Information Retrieval. Spring 06 6
37 k-nn - Common practice. Define a similarity measure between items: s ij. Select neighbors -- N(i;u): items similar to i, rated by u. Estimate unknown rating, r ui, as the weighted average: Problems: r ui b ui j N ( i; u). Similarity measures are arbitrary; no fundamental justification. Pairwise similarities isolate each neighbor; neglect interdependencies among neighbors. Taking a weighted average is restricting; e.g., when neighborhood information is limited s r b ij uj uj j N ( i; u) s ij /6/06 CS 7: Information Retrieval. Spring 06 7
38 Interpolation weights Use a weighted sum rather than a weighted average: r b w r b ui ui j N ( i; u) ij uj uj (We allow w ) j N ( i; u) ij Model relationships between item i and its neighbors Can be learnt through a least squares problem from all other users that rated i: r b w r b Min w v u vi vi j N ( i; u) ij vj vj /6/06 CS 7: Information Retrieval. Spring 06 8
39 Interpolation weights r b w r b Min w v u vi vi j N ( i; u) ij vj vj Interpolation weights derived based on their role; no use of an arbitrary similarity measure Explicitly account for interrelationships among the neighbors Mostly unknown Challenges: Deal with missing values Avoid overfitting Efficient implementation Estimate inner-products among movie ratings /6/06 CS 7: Information Retrieval. Spring 06 9




40 Latent factor models serious The Color Purple Amadeus Braveheart Geared towards females Sense and Sensibility Ocean s Lethal Weapon Geared towards males Dave The Princess Diaries The Lion King Independence Day Dumb and Dumber Gus escapist /6/06 CS 7: Information Retrieval. Spring 06 0
41 Latent factor models users items ~ users ~ items A rank- SVD approximation /6/06 CS 7: Information Retrieval. Spring 06
42 Estimate unknown ratings as inner-products of factors: users items? ~ users ~ items A rank- SVD approximation /6/06 CS 7: Information Retrieval. Spring 06
43 Estimate unknown ratings as inner-products of factors: users items? ~ users ~ items A rank- SVD approximation /6/06 CS 7: Information Retrieval. Spring 06
44 Estimate unknown ratings as inner-products of factors: users items. ~ users ~ items A rank- SVD approximation /6/06 CS 7: Information Retrieval. Spring 06
45 Latent factor models. -.. ~ Properties: SVD isn t defined when entries are unknown use specialized methods Very powerful model can easily overfit, sensitive to regularization Probably most popular model among contestants //006: Simon Funk describes an SVD based method /9/006: Free implementation at timelydevelopment.com /6/06 CS 7: Information Retrieval. Spring 06
46 Factorization on the RMSE scale Global average:.96 User average:.06 Movie average:.0 factorization Cinematch: 0.9 BellKor: Grand Prize: 0.86 Inherent noise:???? /6/06 CS 7: Information Retrieval. Spring 06 6
47 BellKore Approach User factors: Model a user u as a vector p u ~ N k (, ) Movie factors: Model a movie i as a vector q i ~ N k (γ, Λ) Ratings: Measure agreement between u and i: r ui ~ N(p ut q i, ε ) Maximize model s likelihood: Alternate between recomputing user-factors, moviefactors and model parameters Special cases: Alternating Ridge regression Nonnegative matrix factorization /6/06 CS 7: Information Retrieval. Spring 06 7
48 Combining multi-scale views Residual fitting global effects factorization Weighted average regional effects k-nn local effects A unified model factorization k-nn /6/06 CS 7: Information Retrieval. Spring 06 8
49 Localized factorization model Standard factorization: User u is a linear function parameterized by p u r ui = p ut q i Allow user factors p u to depend on the item being predicted r ui = p u (i) T q i Vector p u (i) models behavior of u on items like i /6/06 CS 7: Information Retrieval. Spring 06 9
50 Results on Netflix Probe set RMSE vs. #Factors RMSE Factorization Localized factorization More accurate #Factors /6/06 CS 7: Information Retrieval. Spring 06 0
51 The third dimension of the BellKor system A powerful source of information: Characterize users by which movies they rated, rather than how they rated A binary representation of the data users movies users movies /6/06 CS 7: Information Retrieval. Spring 06


52 The third dimension of the BellKor system Great news to recommender systems: Works even better on real life datasets (?) Improve accuracy by exploiting implicit feedback Implicit behavior is abundant and easy to collect: Rental history Search patterns Browsing history... Implicit feedback allows predicting personalized ratings for users that never rated! movie #770 /6/06 CS 7: Information Retrieval. Spring 06
53
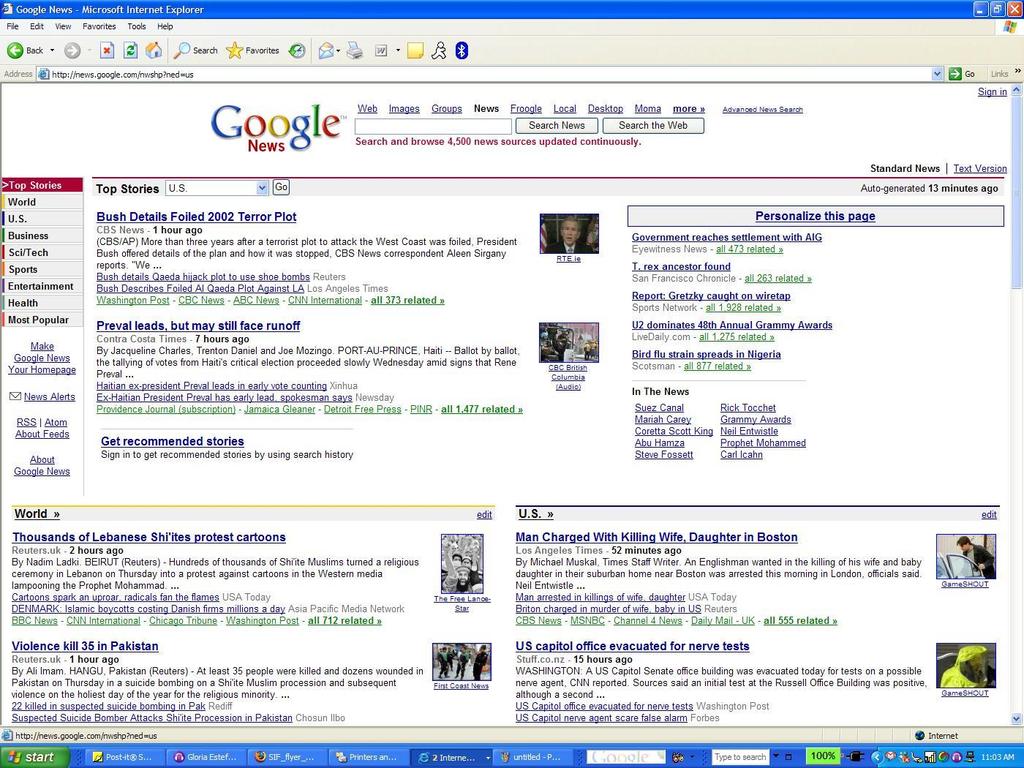

54


55 Recommended Stories Signed in, search history enab
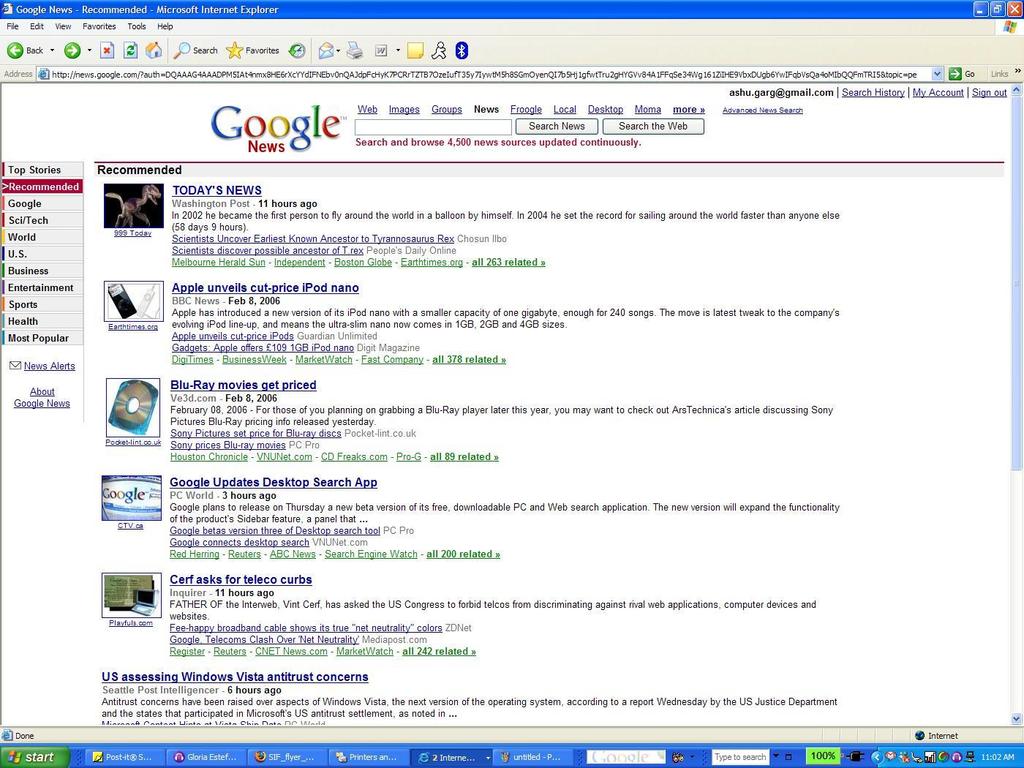
56
57 Challenges Scale Number of unique visitors in last months: several millions Number of stories within last months: several millions Item Churn News stories change every 0- mins Recency of stories is important Cannot build models ever so often Noisy ratings Clicks treated as noisy positive vote
58 Approach Content-based vs. Collaborative filtering Collaborative filtering based on co-visitation Content agnostic: Can be applied to other application domains, languages, countries Google s key strength: Huge user base and their data. Could have used content based filtering Focus on algorithms that are scalable
59 Algorithm Overview Obtain a list of candidate stories For each story: Obtain scores (y, y, y ) Final score = w i *y i User clustering algorithms (Minhash (y ), PLSI (y )) Score ~ number of times this story was clicked by other users in your cluster Story-story co-visitation (y ) Score ~ number of times this story was co-clicked with other stories in your recent click history
60 Algorithm Overview User clustering done offline as batch process Can be run every day or - times a week Cluster-story counts maintained in real time New users May not be clustered Rely on co-visitation to generate recommendations
61 Architecture Bigtables Read Stats StoryTable (cluster +covisit counts) Personalization Servers Update Stats User clustering (Offline) (Mapreduce) Rank Request Rank Reply Click Notify Read user profile UserTable (user clusters, click hist) Update profile News Frontend Webserver
62 User clustering - Minhash Input: User and his clicked stories u u Su { s, s,..., s u m } User similarity = Su S / u S u S u Output: User clusters. Similar users belong to same cluster
63 Minhash Randomly permute the universe of clicked stories { s MH ( u), s,..., s } { s ', s ',..., s ' m m min( s j u min defined by permutation P{ MH ( u Pseudo-random permutation Compute hash for each story and treat hash-value as permutation index Treat MinHash value as ClusterId Probabilistic clustering ) ) MH ( u )} S S u u } S S u u
64 MinHash as Mapreduce Map phase: Input: key = userid, value = storyid Compute hash for each story (parallelizable across all data) Output: key = userid value = storyhash Reduce phase: Input: key = userid value = <list of storyhash values> Compute min over the story hash-values (parallelizable across users)
65 PLSI Framework u s u z s u z u Users s Latent Classes Stories P(s u) = z P(s z)*p(z u)
66 Clustering - PLSI Algorithm Learning (done offline) ML estimation Learn model parameters that maximize the likelihood of the sample data Ouput = P[z j u] s P[s z j ] s P[z j u] s lead to a soft clustering of users Runtime: we only use P[z j u] s and ignore P[s z j ] s u z s P[z u] P[s z]
67 PLSI (EM estimation) as Mapreduce E step: (Map phase) q*(z; u,s,ø) = p(s z)p(z u)/( z p(s z)p(z u)) M step: (Reduce phase) p(s z) = u q*(z; u,s,ø)/( s u q*(z; u,s,ø)) p(z u) = s q*(z; u,s,ø)/( z s q*(z; u,s,ø)) Cannot load the entire model from prev iteration in a single machine during map phase Trick: Partition users and stories. Each partition loads the stats pertinent to it
68 PLSI as Mapreduce
69 Covisitation For each story s i store the covisitation counts with other stories c(s i, s j ) Candidate story: s k User history: s,, s n score (s i, s j ) = c(s i, s j )/ m c(s i, s m ) total_score(s k ) = n score(s k, s n )
70 Experimental results
71 Live traffic clickthrough evaluation
72 Summary Most effective approaches are often hybrid between collaborative and content-based filtering c.f. Netflix, Google News recommendations Lots of data available, but algorithm scalability critical (use Map/Reduce, Hadoop) Suggested rules-of-thumb (take w/ grain of salt): If have moderate amounts of rating data for each user, use collaborative filtering with knn (reasonable baseline) When little data available, use content (model-) based recommendations /6/06 CS 7: Information Retrieval. Spring 06 7

73 /6/06 CS 7: Information Retrieval. Spring 06 7

74 /6/06 CS 7: Information Retrieval. Spring 06 7

75 /6/06 CS 7: Information Retrieval. Spring 06 7

76 /6/06 CS 7: Information Retrieval. Spring 06 76

77 /6/06 CS 7: Information Retrieval. Spring 06 77

78 /6/06 CS 7: Information Retrieval. Spring 06 78
79 EXPLAINING RECOMMENDATIONS /6/06 CS 7: Information Retrieval. Spring 06 79
80 Explanation is Critical /6/06 CS 7: Information Retrieval. Spring 06 80


81 Explanations in recommender systems Additional information to explain the system s output following some objectives
82 Objectives of explanations Transparency Validity Trustworthiness Persuasiveness Effectiveness Efficiency Satisfaction Relevance Comprehensibility Education


83 Explanations in general How? and Why? explanations in expert systems Form of abductive reasoning Given: KB RS i (item i is recommended by method RS) Find KB KB s.t. KB RS i Principle of succinctness Find smallest subset of KB KB s.t. KB RS i i.e. for all KB KB holds KB RS i But additional filtering Some parts relevant for deduction, might be obvious for humans [Friedrich & Zanker, AI Magazine, 0]

84 Taxonomy for generating explanations in RS Major design dimensions of current explanation components: Category of reasoning model for generating explanations White box Black box RS paradigm for generating explanations Determines the exploitable semantic relations Information categories
 Matrix factorization (b) Introduces additional factors as proxies for determining")
85 RS paradigms and their ontologies Classes of objects Users Items Properties N-ary relations between them Collaborative filtering Neighborhood based CF (a) Matrix factorization (b) Introduces additional factors as proxies for determining similarities


86 RS paradigms and their ontologies Content-based Properties characterizing items TF*IDF model Knowledge based Properties of items Properties of user model Additional mediating domain concepts


 Tag")
87 Similarity between items Similarity between users Tags Tag relevance (for item) Tag preference (of user)

88 Results from testing the explanation feature Explanation +* + ** sign. < %, * sign. < % Perceived Utility Trust +** +** +** +** Positive Usage exp. Recommend others Intention to repeated usage Knowledgeable explanations significantly increase the users perceived utility Perceived utility strongly correlates with usage intention etc.

89 Probabilistic View (Foster Provost) /6/06 CS 7: Information Retrieval. Spring 06 89

90 Example /6/06 CS 7: Information Retrieval. Spring 06 90

91 Consumers Increasingly Concerned About Inferences Made About Them /6/06 CS 7: Information Retrieval. Spring 06 9

92 Example Result /6/06 CS 7: Information Retrieval. Spring 06 9

93 Critical Eveidence ( Counter-factural ) Models can be viewed as evidencecombining systems For a specific decision, can ask: What is a minimal set of evidence such that if it were not present, the decision would not have been made? /6/06 CS 7: Information Retrieval. Spring 06 9
94 Removing Evidence: Cloacking /6/06 CS 7: Information Retrieval. Spring 06 9
95 How Many Likes Have to Remove? /6/06 CS 7: Information Retrieval. Spring 06 9
96 Explanations in recommender systems: Summary There are many types of explanations and various goals that an explanation can achieve Which type of explanation can be generated depends greatly on the recommender approach applied Explanations may be used to shape the wishes and desires of customers but are a double-edged sword On the one hand, explanations can help the customer to make wise buying decisions; On the other hand, explanations can be abused to push a customer in a direction which is advantageous solely for the seller As a result a deep understanding of explanations and their effects on customers is of great interest.
97 Resources Recommender Systems Survey: Koren et al. on winning the NetFlix challenge: m-netflix-prize-methods.html /6/06 CS 7: Information Retrieval. Spring 06 97
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu /6/01 Jure Leskovec, Stanford C6: Mining Massive Datasets Training data 100 million ratings, 80,000 users, 17,770
CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu /6/01 Jure Leskovec, Stanford C6: Mining Massive Datasets Training data 100 million ratings, 80,000 users, 17,770
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu Training data 00 million ratings, 80,000 users, 7,770 movies 6 years of data: 000 00 Test data Last few ratings of
CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu Training data 00 million ratings, 80,000 users, 7,770 movies 6 years of data: 000 00 Test data Last few ratings of
COMP 465: Data Mining Recommender Systems
 //0 movies COMP 6: Data Mining Recommender Systems Slides Adapted From: www.mmds.org (Mining Massive Datasets) movies Compare predictions with known ratings (test set T)????? Test Data Set Root-mean-square
//0 movies COMP 6: Data Mining Recommender Systems Slides Adapted From: www.mmds.org (Mining Massive Datasets) movies Compare predictions with known ratings (test set T)????? Test Data Set Root-mean-square
Data Mining Techniques
 Data Mining Techniques CS 60 - Section - Fall 06 Lecture Jan-Willem van de Meent (credit: Andrew Ng, Alex Smola, Yehuda Koren, Stanford CS6) Recommender Systems The Long Tail (from: https://www.wired.com/00/0/tail/)
Data Mining Techniques CS 60 - Section - Fall 06 Lecture Jan-Willem van de Meent (credit: Andrew Ng, Alex Smola, Yehuda Koren, Stanford CS6) Recommender Systems The Long Tail (from: https://www.wired.com/00/0/tail/)
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu //8 Jure Leskovec, Stanford CS6: Mining Massive Datasets Training data 00 million ratings, 80,000 users, 7,770 movies
CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu //8 Jure Leskovec, Stanford CS6: Mining Massive Datasets Training data 00 million ratings, 80,000 users, 7,770 movies
Data Mining Techniques
 Data Mining Techniques CS 6 - Section - Spring 7 Lecture Jan-Willem van de Meent (credit: Andrew Ng, Alex Smola, Yehuda Koren, Stanford CS6) Project Project Deadlines Feb: Form teams of - people 7 Feb:
Data Mining Techniques CS 6 - Section - Spring 7 Lecture Jan-Willem van de Meent (credit: Andrew Ng, Alex Smola, Yehuda Koren, Stanford CS6) Project Project Deadlines Feb: Form teams of - people 7 Feb:
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu Customer X Buys Metalica CD Buys Megadeth CD Customer Y Does search on Metalica Recommender system suggests Megadeth
CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu Customer X Buys Metalica CD Buys Megadeth CD Customer Y Does search on Metalica Recommender system suggests Megadeth
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 We need your help with our research on human interpretable machine learning. Please complete a survey at http://stanford.io/1wpokco. It should be fun and take about 1min to complete. Thanks a lot for your
We need your help with our research on human interpretable machine learning. Please complete a survey at http://stanford.io/1wpokco. It should be fun and take about 1min to complete. Thanks a lot for your
Recommendation Systems
 Recommendation Systems CS 534: Machine Learning Slides adapted from Alex Smola, Jure Leskovec, Anand Rajaraman, Jeff Ullman, Lester Mackey, Dietmar Jannach, and Gerhard Friedrich Recommender Systems (RecSys)
Recommendation Systems CS 534: Machine Learning Slides adapted from Alex Smola, Jure Leskovec, Anand Rajaraman, Jeff Ullman, Lester Mackey, Dietmar Jannach, and Gerhard Friedrich Recommender Systems (RecSys)
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu //8 Jure Leskovec, Stanford CS6: Mining Massive Datasets High dim. data Graph data Infinite data Machine learning
CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu //8 Jure Leskovec, Stanford CS6: Mining Massive Datasets High dim. data Graph data Infinite data Machine learning
CS 124/LINGUIST 180 From Languages to Information
 CS /LINGUIST 80 From Languages to Information Dan Jurafsky Stanford University Recommender Systems & Collaborative Filtering Slides adapted from Jure Leskovec Recommender Systems Customer X Buys Metallica
CS /LINGUIST 80 From Languages to Information Dan Jurafsky Stanford University Recommender Systems & Collaborative Filtering Slides adapted from Jure Leskovec Recommender Systems Customer X Buys Metallica
Recommender Systems New Approaches with Netflix Dataset
 Recommender Systems New Approaches with Netflix Dataset Robert Bell Yehuda Koren AT&T Labs ICDM 2007 Presented by Matt Rodriguez Outline Overview of Recommender System Approaches which are Content based
Recommender Systems New Approaches with Netflix Dataset Robert Bell Yehuda Koren AT&T Labs ICDM 2007 Presented by Matt Rodriguez Outline Overview of Recommender System Approaches which are Content based
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu /7/0 Jure Leskovec, Stanford CS6: Mining Massive Datasets, http://cs6.stanford.edu High dim. data Graph data Infinite
CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu /7/0 Jure Leskovec, Stanford CS6: Mining Massive Datasets, http://cs6.stanford.edu High dim. data Graph data Infinite
Machine Learning and Data Mining. Collaborative Filtering & Recommender Systems. Kalev Kask
 Machine Learning and Data Mining Collaborative Filtering & Recommender Systems Kalev Kask Recommender systems Automated recommendations Inputs User information Situation context, demographics, preferences,
Machine Learning and Data Mining Collaborative Filtering & Recommender Systems Kalev Kask Recommender systems Automated recommendations Inputs User information Situation context, demographics, preferences,
Recommender Systems Collabora2ve Filtering and Matrix Factoriza2on
 Recommender Systems Collaborave Filtering and Matrix Factorizaon Narges Razavian Thanks to lecture slides from Alex Smola@CMU Yahuda Koren@Yahoo labs and Bing Liu@UIC We Know What You Ought To Be Watching
Recommender Systems Collaborave Filtering and Matrix Factorizaon Narges Razavian Thanks to lecture slides from Alex Smola@CMU Yahuda Koren@Yahoo labs and Bing Liu@UIC We Know What You Ought To Be Watching
Recommender Systems: Practical Aspects, Case Studies. Radek Pelánek
 Recommender Systems: Practical Aspects, Case Studies Radek Pelánek 2017 This Lecture practical aspects : attacks, context, shared accounts,... case studies, illustrations of application illustration of
Recommender Systems: Practical Aspects, Case Studies Radek Pelánek 2017 This Lecture practical aspects : attacks, context, shared accounts,... case studies, illustrations of application illustration of
CSE 258 Lecture 8. Web Mining and Recommender Systems. Extensions of latent-factor models, (and more on the Netflix prize)
") CSE 258 Lecture 8 Web Mining and Recommender Systems Extensions of latent-factor models, (and more on the Netflix prize) Summary so far Recap 1. Measuring similarity between users/items for binary prediction
CSE 258 Lecture 8 Web Mining and Recommender Systems Extensions of latent-factor models, (and more on the Netflix prize) Summary so far Recap 1. Measuring similarity between users/items for binary prediction
CSE 158 Lecture 8. Web Mining and Recommender Systems. Extensions of latent-factor models, (and more on the Netflix prize)
") CSE 158 Lecture 8 Web Mining and Recommender Systems Extensions of latent-factor models, (and more on the Netflix prize) Summary so far Recap 1. Measuring similarity between users/items for binary prediction
CSE 158 Lecture 8 Web Mining and Recommender Systems Extensions of latent-factor models, (and more on the Netflix prize) Summary so far Recap 1. Measuring similarity between users/items for binary prediction
Real-time Recommendations on Spark. Jan Neumann, Sridhar Alla (Comcast Labs) DC Spark Interactive Meetup East May
 DC Spark Interactive Meetup East May") Real-time Recommendations on Spark Jan Neumann, Sridhar Alla (Comcast Labs) DC Spark Interactive Meetup East May 19 2015 Who am I? Jan Neumann, Lead of Big Data and Content Analysis Research Teams This
Real-time Recommendations on Spark Jan Neumann, Sridhar Alla (Comcast Labs) DC Spark Interactive Meetup East May 19 2015 Who am I? Jan Neumann, Lead of Big Data and Content Analysis Research Teams This
Recommender Systems (RSs)
") Recommender Systems Recommender Systems (RSs) RSs are software tools providing suggestions for items to be of use to users, such as what items to buy, what music to listen to, or what online news to read
Recommender Systems Recommender Systems (RSs) RSs are software tools providing suggestions for items to be of use to users, such as what items to buy, what music to listen to, or what online news to read
By Atul S. Kulkarni Graduate Student, University of Minnesota Duluth. Under The Guidance of Dr. Richard Maclin
 By Atul S. Kulkarni Graduate Student, University of Minnesota Duluth Under The Guidance of Dr. Richard Maclin Outline Problem Statement Background Proposed Solution Experiments & Results Related Work Future
By Atul S. Kulkarni Graduate Student, University of Minnesota Duluth Under The Guidance of Dr. Richard Maclin Outline Problem Statement Background Proposed Solution Experiments & Results Related Work Future
Recommendation and Advertising. Shannon Quinn (with thanks to J. Leskovec, A. Rajaraman, and J. Ullman of Stanford University)
") Recommendation and Advertising Shannon Quinn (with thanks to J. Leskovec, A. Rajaraman, and J. Ullman of Stanford University) Lecture breakdown Part : Advertising Bipartite Matching AdWords Part : Recommendation
Recommendation and Advertising Shannon Quinn (with thanks to J. Leskovec, A. Rajaraman, and J. Ullman of Stanford University) Lecture breakdown Part : Advertising Bipartite Matching AdWords Part : Recommendation
An Empirical Comparison of Collaborative Filtering Approaches on Netflix Data
 An Empirical Comparison of Collaborative Filtering Approaches on Netflix Data Nicola Barbieri, Massimo Guarascio, Ettore Ritacco ICAR-CNR Via Pietro Bucci 41/c, Rende, Italy {barbieri,guarascio,ritacco}@icar.cnr.it
An Empirical Comparison of Collaborative Filtering Approaches on Netflix Data Nicola Barbieri, Massimo Guarascio, Ettore Ritacco ICAR-CNR Via Pietro Bucci 41/c, Rende, Italy {barbieri,guarascio,ritacco}@icar.cnr.it
Weighted Alternating Least Squares (WALS) for Movie Recommendations) Drew Hodun SCPD. Abstract
 for Movie Recommendations) Drew Hodun SCPD. Abstract") Weighted Alternating Least Squares (WALS) for Movie Recommendations) Drew Hodun SCPD Abstract There are two common main approaches to ML recommender systems, feedback-based systems and content-based systems.
Weighted Alternating Least Squares (WALS) for Movie Recommendations) Drew Hodun SCPD Abstract There are two common main approaches to ML recommender systems, feedback-based systems and content-based systems.
Music Recommendation with Implicit Feedback and Side Information
 Music Recommendation with Implicit Feedback and Side Information Shengbo Guo Yahoo! Labs shengbo@yahoo-inc.com Behrouz Behmardi Criteo b.behmardi@criteo.com Gary Chen Vobile gary.chen@vobileinc.com Abstract
Music Recommendation with Implicit Feedback and Side Information Shengbo Guo Yahoo! Labs shengbo@yahoo-inc.com Behrouz Behmardi Criteo b.behmardi@criteo.com Gary Chen Vobile gary.chen@vobileinc.com Abstract
Performance Comparison of Algorithms for Movie Rating Estimation
 Performance Comparison of Algorithms for Movie Rating Estimation Alper Köse, Can Kanbak, Noyan Evirgen Research Laboratory of Electronics, Massachusetts Institute of Technology Department of Electrical
Performance Comparison of Algorithms for Movie Rating Estimation Alper Köse, Can Kanbak, Noyan Evirgen Research Laboratory of Electronics, Massachusetts Institute of Technology Department of Electrical
Reddit Recommendation System Daniel Poon, Yu Wu, David (Qifan) Zhang CS229, Stanford University December 11 th, 2011
 Zhang CS229, Stanford University December 11 th, 2011") Reddit Recommendation System Daniel Poon, Yu Wu, David (Qifan) Zhang CS229, Stanford University December 11 th, 2011 1. Introduction Reddit is one of the most popular online social news websites with millions
Reddit Recommendation System Daniel Poon, Yu Wu, David (Qifan) Zhang CS229, Stanford University December 11 th, 2011 1. Introduction Reddit is one of the most popular online social news websites with millions
Property1 Property2. by Elvir Sabic. Recommender Systems Seminar Prof. Dr. Ulf Brefeld TU Darmstadt, WS 2013/14
 Property1 Property2 by Recommender Systems Seminar Prof. Dr. Ulf Brefeld TU Darmstadt, WS 2013/14 Content-Based Introduction Pros and cons Introduction Concept 1/30 Property1 Property2 2/30 Based on item
Property1 Property2 by Recommender Systems Seminar Prof. Dr. Ulf Brefeld TU Darmstadt, WS 2013/14 Content-Based Introduction Pros and cons Introduction Concept 1/30 Property1 Property2 2/30 Based on item
CS224W Project: Recommendation System Models in Product Rating Predictions
 CS224W Project: Recommendation System Models in Product Rating Predictions Xiaoye Liu xiaoye@stanford.edu Abstract A product recommender system based on product-review information and metadata history
CS224W Project: Recommendation System Models in Product Rating Predictions Xiaoye Liu xiaoye@stanford.edu Abstract A product recommender system based on product-review information and metadata history
Introduction to Data Mining
 Introduction to Data Mining Lecture #7: Recommendation Content based & Collaborative Filtering Seoul National University In This Lecture Understand the motivation and the problem of recommendation Compare
Introduction to Data Mining Lecture #7: Recommendation Content based & Collaborative Filtering Seoul National University In This Lecture Understand the motivation and the problem of recommendation Compare
CS 124/LINGUIST 180 From Languages to Information
 CS /LINGUIST 80 From Languages to Information Dan Jurafsky Stanford University Recommender Systems & Collaborative Filtering Slides adapted from Jure Leskovec Recommender Systems Customer X Buys CD of
CS /LINGUIST 80 From Languages to Information Dan Jurafsky Stanford University Recommender Systems & Collaborative Filtering Slides adapted from Jure Leskovec Recommender Systems Customer X Buys CD of
Unsupervised Learning
 Networks for Pattern Recognition, 2014 Networks for Single Linkage K-Means Soft DBSCAN PCA Networks for Kohonen Maps Linear Vector Quantization Networks for Problems/Approaches in Machine Learning Supervised
Networks for Pattern Recognition, 2014 Networks for Single Linkage K-Means Soft DBSCAN PCA Networks for Kohonen Maps Linear Vector Quantization Networks for Problems/Approaches in Machine Learning Supervised
CS 5614: (Big) Data Management Systems. B. Aditya Prakash Lecture #16: Recommenda2on Systems
 Data Management Systems. B. Aditya Prakash Lecture #16: Recommenda2on Systems") CS 6: (Big) Data Management Systems B. Aditya Prakash Lecture #6: Recommendaon Systems Example: Recommender Systems Customer X Buys Metallica CD Buys Megadeth CD Customer Y Does search on Metallica Recommender
CS 6: (Big) Data Management Systems B. Aditya Prakash Lecture #6: Recommendaon Systems Example: Recommender Systems Customer X Buys Metallica CD Buys Megadeth CD Customer Y Does search on Metallica Recommender
Using Machine Learning to Optimize Storage Systems
 Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
CS 124/LINGUIST 180 From Languages to Information
 CS /LINGUIST 80 From Languages to Information Dan Jurafsky Stanford University Recommender Systems & Collaborative Filtering Slides adapted from Jure Leskovec Recommender Systems Customer X Buys CD of
CS /LINGUIST 80 From Languages to Information Dan Jurafsky Stanford University Recommender Systems & Collaborative Filtering Slides adapted from Jure Leskovec Recommender Systems Customer X Buys CD of
Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University Infinite data. Filtering data streams
 /9/7 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them
/9/7 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them
Author(s): Rahul Sami, 2009
: Rahul Sami, 2009") Author(s): Rahul Sami, 2009 License: Unless otherwise noted, this material is made available under the terms of the Creative Commons Attribution Noncommercial Share Alike 3.0 License: http://creativecommons.org/licenses/by-nc-sa/3.0/
Author(s): Rahul Sami, 2009 License: Unless otherwise noted, this material is made available under the terms of the Creative Commons Attribution Noncommercial Share Alike 3.0 License: http://creativecommons.org/licenses/by-nc-sa/3.0/
Progress Report: Collaborative Filtering Using Bregman Co-clustering
 Progress Report: Collaborative Filtering Using Bregman Co-clustering Wei Tang, Srivatsan Ramanujam, and Andrew Dreher April 4, 2008 1 Introduction Analytics are becoming increasingly important for business
Progress Report: Collaborative Filtering Using Bregman Co-clustering Wei Tang, Srivatsan Ramanujam, and Andrew Dreher April 4, 2008 1 Introduction Analytics are becoming increasingly important for business
Additive Regression Applied to a Large-Scale Collaborative Filtering Problem
 Additive Regression Applied to a Large-Scale Collaborative Filtering Problem Eibe Frank 1 and Mark Hall 2 1 Department of Computer Science, University of Waikato, Hamilton, New Zealand eibe@cs.waikato.ac.nz
Additive Regression Applied to a Large-Scale Collaborative Filtering Problem Eibe Frank 1 and Mark Hall 2 1 Department of Computer Science, University of Waikato, Hamilton, New Zealand eibe@cs.waikato.ac.nz
KDD 10 Tutorial: Recommender Problems for Web Applications. Deepak Agarwal and Bee-Chung Chen Yahoo! Research
 KDD 10 Tutorial: Recommender Problems for Web Applications Deepak Agarwal and Bee-Chung Chen Yahoo! Research Agenda Focus: Recommender problems for dynamic, time-sensitive applications Content Optimization
KDD 10 Tutorial: Recommender Problems for Web Applications Deepak Agarwal and Bee-Chung Chen Yahoo! Research Agenda Focus: Recommender problems for dynamic, time-sensitive applications Content Optimization
Use of KNN for the Netflix Prize Ted Hong, Dimitris Tsamis Stanford University
 Use of KNN for the Netflix Prize Ted Hong, Dimitris Tsamis Stanford University {tedhong, dtsamis}@stanford.edu Abstract This paper analyzes the performance of various KNNs techniques as applied to the
Use of KNN for the Netflix Prize Ted Hong, Dimitris Tsamis Stanford University {tedhong, dtsamis}@stanford.edu Abstract This paper analyzes the performance of various KNNs techniques as applied to the
Web Personalisation and Recommender Systems
 Web Personalisation and Recommender Systems Shlomo Berkovsky and Jill Freyne DIGITAL PRODUCTIVITY FLAGSHIP Outline Part 1: Information Overload and User Modelling Part 2: Web Personalisation and Recommender
Web Personalisation and Recommender Systems Shlomo Berkovsky and Jill Freyne DIGITAL PRODUCTIVITY FLAGSHIP Outline Part 1: Information Overload and User Modelling Part 2: Web Personalisation and Recommender
K Nearest Neighbor Wrap Up K- Means Clustering. Slides adapted from Prof. Carpuat
 K Nearest Neighbor Wrap Up K- Means Clustering Slides adapted from Prof. Carpuat K Nearest Neighbor classification Classification is based on Test instance with Training Data K: number of neighbors that
K Nearest Neighbor Wrap Up K- Means Clustering Slides adapted from Prof. Carpuat K Nearest Neighbor classification Classification is based on Test instance with Training Data K: number of neighbors that
Thanks to Jure Leskovec, Anand Rajaraman, Jeff Ullman
 Thanks to Jure Leskovec, Anand Rajaraman, Jeff Ullman http://www.mmds.org Overview of Recommender Systems Content-based Systems Collaborative Filtering J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive
Thanks to Jure Leskovec, Anand Rajaraman, Jeff Ullman http://www.mmds.org Overview of Recommender Systems Content-based Systems Collaborative Filtering J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive
General Instructions. Questions
 CS246: Mining Massive Data Sets Winter 2018 Problem Set 2 Due 11:59pm February 8, 2018 Only one late period is allowed for this homework (11:59pm 2/13). General Instructions Submission instructions: These
CS246: Mining Massive Data Sets Winter 2018 Problem Set 2 Due 11:59pm February 8, 2018 Only one late period is allowed for this homework (11:59pm 2/13). General Instructions Submission instructions: These
CptS 570 Machine Learning Project: Netflix Competition. Parisa Rashidi Vikramaditya Jakkula. Team: MLSurvivors. Wednesday, December 12, 2007
 CptS 570 Machine Learning Project: Netflix Competition Team: MLSurvivors Parisa Rashidi Vikramaditya Jakkula Wednesday, December 12, 2007 Introduction In current report, we describe our efforts put forth
CptS 570 Machine Learning Project: Netflix Competition Team: MLSurvivors Parisa Rashidi Vikramaditya Jakkula Wednesday, December 12, 2007 Introduction In current report, we describe our efforts put forth
Lecture 8: The EM algorithm
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 8: The EM algorithm Lecturer: Manuela M. Veloso, Eric P. Xing Scribes: Huiting Liu, Yifan Yang 1 Introduction Previous lecture discusses
10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 8: The EM algorithm Lecturer: Manuela M. Veloso, Eric P. Xing Scribes: Huiting Liu, Yifan Yang 1 Introduction Previous lecture discusses
CSE255 Assignment 1 Improved image-based recommendations for what not to wear dataset
 CSE255 Assignment 1 Improved image-based recommendations for what not to wear dataset Prabhav Agrawal and Soham Shah 23 February 2015 1 Introduction We are interested in modeling the human perception of
CSE255 Assignment 1 Improved image-based recommendations for what not to wear dataset Prabhav Agrawal and Soham Shah 23 February 2015 1 Introduction We are interested in modeling the human perception of
Assignment 5: Collaborative Filtering
 Assignment 5: Collaborative Filtering Arash Vahdat Fall 2015 Readings You are highly recommended to check the following readings before/while doing this assignment: Slope One Algorithm: https://en.wikipedia.org/wiki/slope_one.
Assignment 5: Collaborative Filtering Arash Vahdat Fall 2015 Readings You are highly recommended to check the following readings before/while doing this assignment: Slope One Algorithm: https://en.wikipedia.org/wiki/slope_one.
Deep Learning for Recommender Systems
 join at Slido.com with #bigdata2018 Deep Learning for Recommender Systems Oliver Gindele @tinyoli oliver.gindele@datatonic.com Big Data Conference Vilnius 28.11.2018 Who is Oliver? + Head of Machine Learning
join at Slido.com with #bigdata2018 Deep Learning for Recommender Systems Oliver Gindele @tinyoli oliver.gindele@datatonic.com Big Data Conference Vilnius 28.11.2018 Who is Oliver? + Head of Machine Learning
Allstate Insurance Claims Severity: A Machine Learning Approach
 Allstate Insurance Claims Severity: A Machine Learning Approach Rajeeva Gaur SUNet ID: rajeevag Jeff Pickelman SUNet ID: pattern Hongyi Wang SUNet ID: hongyiw I. INTRODUCTION The insurance industry has
Allstate Insurance Claims Severity: A Machine Learning Approach Rajeeva Gaur SUNet ID: rajeevag Jeff Pickelman SUNet ID: pattern Hongyi Wang SUNet ID: hongyiw I. INTRODUCTION The insurance industry has
CSE 573: Artificial Intelligence Autumn 2010
 CSE 573: Artificial Intelligence Autumn 2010 Lecture 16: Machine Learning Topics 12/7/2010 Luke Zettlemoyer Most slides over the course adapted from Dan Klein. 1 Announcements Syllabus revised Machine
CSE 573: Artificial Intelligence Autumn 2010 Lecture 16: Machine Learning Topics 12/7/2010 Luke Zettlemoyer Most slides over the course adapted from Dan Klein. 1 Announcements Syllabus revised Machine
CS535 Big Data Fall 2017 Colorado State University 10/10/2017 Sangmi Lee Pallickara Week 8- A.
 CS535 Big Data - Fall 2017 Week 8-A-1 CS535 BIG DATA FAQs Term project proposal New deadline: Tomorrow PA1 demo PART 1. BATCH COMPUTING MODELS FOR BIG DATA ANALYTICS 5. ADVANCED DATA ANALYTICS WITH APACHE
CS535 Big Data - Fall 2017 Week 8-A-1 CS535 BIG DATA FAQs Term project proposal New deadline: Tomorrow PA1 demo PART 1. BATCH COMPUTING MODELS FOR BIG DATA ANALYTICS 5. ADVANCED DATA ANALYTICS WITH APACHE
CS570: Introduction to Data Mining
 CS570: Introduction to Data Mining Classification Advanced Reading: Chapter 8 & 9 Han, Chapters 4 & 5 Tan Anca Doloc-Mihu, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei. Data Mining.
CS570: Introduction to Data Mining Classification Advanced Reading: Chapter 8 & 9 Han, Chapters 4 & 5 Tan Anca Doloc-Mihu, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei. Data Mining.
MIT Samberg Center Cambridge, MA, USA. May 30 th June 2 nd, by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA
 Exploratory Machine Learning studies for disruption prediction on DIII-D by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA Presented at the 2 nd IAEA Technical Meeting on
Exploratory Machine Learning studies for disruption prediction on DIII-D by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA Presented at the 2 nd IAEA Technical Meeting on
COSC6376 Cloud Computing Homework 1 Tutorial
 COSC6376 Cloud Computing Homework 1 Tutorial Instructor: Weidong Shi (Larry), PhD Computer Science Department University of Houston Outline Homework1 Tutorial based on Netflix dataset Homework 1 K-means
COSC6376 Cloud Computing Homework 1 Tutorial Instructor: Weidong Shi (Larry), PhD Computer Science Department University of Houston Outline Homework1 Tutorial based on Netflix dataset Homework 1 K-means
CS249: ADVANCED DATA MINING
 CS249: ADVANCED DATA MINING Classification Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu April 24, 2017 Homework 2 out Announcements Due May 3 rd (11:59pm) Course project proposal
CS249: ADVANCED DATA MINING Classification Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu April 24, 2017 Homework 2 out Announcements Due May 3 rd (11:59pm) Course project proposal
Part 11: Collaborative Filtering. Francesco Ricci
 Part : Collaborative Filtering Francesco Ricci Content An example of a Collaborative Filtering system: MovieLens The collaborative filtering method n Similarity of users n Methods for building the rating
Part : Collaborative Filtering Francesco Ricci Content An example of a Collaborative Filtering system: MovieLens The collaborative filtering method n Similarity of users n Methods for building the rating
CS 229 Midterm Review
 CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
Data Mining. Lecture 03: Nearest Neighbor Learning
 Data Mining Lecture 03: Nearest Neighbor Learning Theses slides are based on the slides by Tan, Steinbach and Kumar (textbook authors) Prof. R. Mooney (UT Austin) Prof E. Keogh (UCR), Prof. F. Provost
Data Mining Lecture 03: Nearest Neighbor Learning Theses slides are based on the slides by Tan, Steinbach and Kumar (textbook authors) Prof. R. Mooney (UT Austin) Prof E. Keogh (UCR), Prof. F. Provost
Lecture on Modeling Tools for Clustering & Regression
 Lecture on Modeling Tools for Clustering & Regression CS 590.21 Analysis and Modeling of Brain Networks Department of Computer Science University of Crete Data Clustering Overview Organizing data into
Lecture on Modeling Tools for Clustering & Regression CS 590.21 Analysis and Modeling of Brain Networks Department of Computer Science University of Crete Data Clustering Overview Organizing data into
Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model
 Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model Yehuda Koren AT&T Labs Research 180 Park Ave, Florham Park, NJ 07932 yehuda@research.att.com ABSTRACT Recommender systems
Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model Yehuda Koren AT&T Labs Research 180 Park Ave, Florham Park, NJ 07932 yehuda@research.att.com ABSTRACT Recommender systems
Clustering. Bruno Martins. 1 st Semester 2012/2013
 Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2012/2013 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 Motivation Basic Concepts
Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2012/2013 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 Motivation Basic Concepts
The Principle and Improvement of the Algorithm of Matrix Factorization Model based on ALS
 of the Algorithm of Matrix Factorization Model based on ALS 12 Yunnan University, Kunming, 65000, China E-mail: shaw.xuan820@gmail.com Chao Yi 3 Yunnan University, Kunming, 65000, China E-mail: yichao@ynu.edu.cn
of the Algorithm of Matrix Factorization Model based on ALS 12 Yunnan University, Kunming, 65000, China E-mail: shaw.xuan820@gmail.com Chao Yi 3 Yunnan University, Kunming, 65000, China E-mail: yichao@ynu.edu.cn
Recommender System Optimization through Collaborative Filtering
 Recommender System Optimization through Collaborative Filtering L.W. Hoogenboom Econometric Institute of Erasmus University Rotterdam Bachelor Thesis Business Analytics and Quantitative Marketing July
Recommender System Optimization through Collaborative Filtering L.W. Hoogenboom Econometric Institute of Erasmus University Rotterdam Bachelor Thesis Business Analytics and Quantitative Marketing July
Recommender Systems. Collaborative Filtering & Content-Based Recommending
 Recommender Systems Collaborative Filtering & Content-Based Recommending 1 Recommender Systems Systems for recommending items (e.g. books, movies, CD s, web pages, newsgroup messages) to users based on
Recommender Systems Collaborative Filtering & Content-Based Recommending 1 Recommender Systems Systems for recommending items (e.g. books, movies, CD s, web pages, newsgroup messages) to users based on
Recommender Systems: User Experience and System Issues
 Recommender Systems: User Experience and System ssues Joseph A. Konstan University of Minnesota konstan@cs.umn.edu http://www.grouplens.org Summer 2005 1 About me Professor of Computer Science & Engineering,
Recommender Systems: User Experience and System ssues Joseph A. Konstan University of Minnesota konstan@cs.umn.edu http://www.grouplens.org Summer 2005 1 About me Professor of Computer Science & Engineering,
Announcements. CS 188: Artificial Intelligence Spring Classification: Feature Vectors. Classification: Weights. Learning: Binary Perceptron
 CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/20/2010 Announcements W7 due Thursday [that s your last written for the semester!] Project 5 out Thursday Contest running
CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/20/2010 Announcements W7 due Thursday [that s your last written for the semester!] Project 5 out Thursday Contest running
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
COMP6237 Data Mining Making Recommendations. Jonathon Hare
 COMP6237 Data Mining Making Recommendations Jonathon Hare jsh2@ecs.soton.ac.uk Introduction Recommender systems 101 Taxonomy of recommender systems Collaborative Filtering Collecting user preferences as
COMP6237 Data Mining Making Recommendations Jonathon Hare jsh2@ecs.soton.ac.uk Introduction Recommender systems 101 Taxonomy of recommender systems Collaborative Filtering Collecting user preferences as
CS249: ADVANCED DATA MINING
 CS249: ADVANCED DATA MINING Recommender Systems II Instructor: Yizhou Sun yzsun@cs.ucla.edu May 31, 2017 Recommender Systems Recommendation via Information Network Analysis Hybrid Collaborative Filtering
CS249: ADVANCED DATA MINING Recommender Systems II Instructor: Yizhou Sun yzsun@cs.ucla.edu May 31, 2017 Recommender Systems Recommendation via Information Network Analysis Hybrid Collaborative Filtering
Bayesian Personalized Ranking for Las Vegas Restaurant Recommendation
 Bayesian Personalized Ranking for Las Vegas Restaurant Recommendation Kiran Kannar A53089098 kkannar@eng.ucsd.edu Saicharan Duppati A53221873 sduppati@eng.ucsd.edu Akanksha Grover A53205632 a2grover@eng.ucsd.edu
Bayesian Personalized Ranking for Las Vegas Restaurant Recommendation Kiran Kannar A53089098 kkannar@eng.ucsd.edu Saicharan Duppati A53221873 sduppati@eng.ucsd.edu Akanksha Grover A53205632 a2grover@eng.ucsd.edu
CPSC 340: Machine Learning and Data Mining. Recommender Systems Fall 2017
 CPSC 340: Machine Learning and Data Mining Recommender Systems Fall 2017 Assignment 4: Admin Due tonight, 1 late day for Monday, 2 late days for Wednesday. Assignment 5: Posted, due Monday of last week
CPSC 340: Machine Learning and Data Mining Recommender Systems Fall 2017 Assignment 4: Admin Due tonight, 1 late day for Monday, 2 late days for Wednesday. Assignment 5: Posted, due Monday of last week
Factor in the Neighbors: Scalable and Accurate Collaborative Filtering
 1 Factor in the Neighbors: Scalable and Accurate Collaborative Filtering YEHUDA KOREN Yahoo! Research Recommender systems provide users with personalized suggestions for products or services. These systems
1 Factor in the Neighbors: Scalable and Accurate Collaborative Filtering YEHUDA KOREN Yahoo! Research Recommender systems provide users with personalized suggestions for products or services. These systems
Collaborative Filtering for Netflix
 Collaborative Filtering for Netflix Michael Percy Dec 10, 2009 Abstract The Netflix movie-recommendation problem was investigated and the incremental Singular Value Decomposition (SVD) algorithm was implemented
Collaborative Filtering for Netflix Michael Percy Dec 10, 2009 Abstract The Netflix movie-recommendation problem was investigated and the incremental Singular Value Decomposition (SVD) algorithm was implemented
Machine Learning using MapReduce
 Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Yelp Recommendation System
 Yelp Recommendation System Jason Ting, Swaroop Indra Ramaswamy Institute for Computational and Mathematical Engineering Abstract We apply principles and techniques of recommendation systems to develop
Yelp Recommendation System Jason Ting, Swaroop Indra Ramaswamy Institute for Computational and Mathematical Engineering Abstract We apply principles and techniques of recommendation systems to develop
CSC 411 Lecture 4: Ensembles I
 CSC 411 Lecture 4: Ensembles I Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 04-Ensembles I 1 / 22 Overview We ve seen two particular classification algorithms:
CSC 411 Lecture 4: Ensembles I Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 04-Ensembles I 1 / 22 Overview We ve seen two particular classification algorithms:
CSE 6242 A / CS 4803 DVA. Feb 12, Dimension Reduction. Guest Lecturer: Jaegul Choo
 CSE 6242 A / CS 4803 DVA Feb 12, 2013 Dimension Reduction Guest Lecturer: Jaegul Choo CSE 6242 A / CS 4803 DVA Feb 12, 2013 Dimension Reduction Guest Lecturer: Jaegul Choo Data is Too Big To Do Something..
CSE 6242 A / CS 4803 DVA Feb 12, 2013 Dimension Reduction Guest Lecturer: Jaegul Choo CSE 6242 A / CS 4803 DVA Feb 12, 2013 Dimension Reduction Guest Lecturer: Jaegul Choo Data is Too Big To Do Something..
Prowess Improvement of Accuracy for Moving Rating Recommendation System
 2017 IJSRST Volume 3 Issue 1 Print ISSN: 2395-6011 Online ISSN: 2395-602X Themed Section: Scienceand Technology Prowess Improvement of Accuracy for Moving Rating Recommendation System P. Damodharan *1,
2017 IJSRST Volume 3 Issue 1 Print ISSN: 2395-6011 Online ISSN: 2395-602X Themed Section: Scienceand Technology Prowess Improvement of Accuracy for Moving Rating Recommendation System P. Damodharan *1,
AI Dining Suggestion App. CS 297 Report Bao Pham ( ) Advisor: Dr. Chris Pollett
 Advisor: Dr. Chris Pollett") AI Dining Suggestion App CS 297 Report Bao Pham (009621001) Advisor: Dr. Chris Pollett Abstract Trying to decide what to eat can be challenging and time-consuming. Google or Yelp are two popular search
AI Dining Suggestion App CS 297 Report Bao Pham (009621001) Advisor: Dr. Chris Pollett Abstract Trying to decide what to eat can be challenging and time-consuming. Google or Yelp are two popular search
Orange3 Data Fusion Documentation. Biolab
 Biolab Mar 07, 2018 Widgets 1 IMDb Actors 1 2 Chaining 5 3 Completion Scoring 9 4 Fusion Graph 13 5 Latent Factors 17 6 Matrix Sampler 21 7 Mean Fuser 25 8 Movie Genres 29 9 Movie Ratings 33 10 Table
Biolab Mar 07, 2018 Widgets 1 IMDb Actors 1 2 Chaining 5 3 Completion Scoring 9 4 Fusion Graph 13 5 Latent Factors 17 6 Matrix Sampler 21 7 Mean Fuser 25 8 Movie Genres 29 9 Movie Ratings 33 10 Table
Opportunities and challenges in personalization of online hotel search
 Opportunities and challenges in personalization of online hotel search David Zibriczky Data Science & Analytics Lead, User Profiling Introduction 2 Introduction About Mission: Helping the travelers to
Opportunities and challenges in personalization of online hotel search David Zibriczky Data Science & Analytics Lead, User Profiling Introduction 2 Introduction About Mission: Helping the travelers to
On hybrid modular recommendation systems for video streaming
 On hybrid modular recommendation systems for video streaming Evripides Tzamousis Maria Papadopouli arxiv:1901.01418v1 [cs.ir] 5 Jan 2019 Abstract The technological advances in networking, mobile computing,
On hybrid modular recommendation systems for video streaming Evripides Tzamousis Maria Papadopouli arxiv:1901.01418v1 [cs.ir] 5 Jan 2019 Abstract The technological advances in networking, mobile computing,
Slides for Data Mining by I. H. Witten and E. Frank
 Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Multi-label classification using rule-based classifier systems
 Multi-label classification using rule-based classifier systems Shabnam Nazmi (PhD candidate) Department of electrical and computer engineering North Carolina A&T state university Advisor: Dr. A. Homaifar
Multi-label classification using rule-based classifier systems Shabnam Nazmi (PhD candidate) Department of electrical and computer engineering North Carolina A&T state university Advisor: Dr. A. Homaifar
Developing MapReduce Programs
 Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2017/18 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2017/18 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
CS178: Machine Learning and Data Mining. Complexity & Nearest Neighbor Methods
 + CS78: Machine Learning and Data Mining Complexity & Nearest Neighbor Methods Prof. Erik Sudderth Some materials courtesy Alex Ihler & Sameer Singh Machine Learning Complexity and Overfitting Nearest
+ CS78: Machine Learning and Data Mining Complexity & Nearest Neighbor Methods Prof. Erik Sudderth Some materials courtesy Alex Ihler & Sameer Singh Machine Learning Complexity and Overfitting Nearest
Non-negative Matrix Factorization for Multimodal Image Retrieval
 Non-negative Matrix Factorization for Multimodal Image Retrieval Fabio A. González PhD Machine Learning 2015-II Universidad Nacional de Colombia F. González NMF for MM IR ML 2015-II 1 / 54 Outline 1 The
Non-negative Matrix Factorization for Multimodal Image Retrieval Fabio A. González PhD Machine Learning 2015-II Universidad Nacional de Colombia F. González NMF for MM IR ML 2015-II 1 / 54 Outline 1 The
Jeff Howbert Introduction to Machine Learning Winter
 Collaborative Filtering Nearest es Neighbor Approach Jeff Howbert Introduction to Machine Learning Winter 2012 1 Bad news Netflix Prize data no longer available to public. Just after contest t ended d
Collaborative Filtering Nearest es Neighbor Approach Jeff Howbert Introduction to Machine Learning Winter 2012 1 Bad news Netflix Prize data no longer available to public. Just after contest t ended d
Classification: Feature Vectors
 Classification: Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free YOUR_NAME MISSPELLED FROM_FRIEND... : : : : 2 0 2 0 PIXEL 7,12
Classification: Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free YOUR_NAME MISSPELLED FROM_FRIEND... : : : : 2 0 2 0 PIXEL 7,12
Computational Intelligence Meets the NetFlix Prize
 Computational Intelligence Meets the NetFlix Prize Ryan J. Meuth, Paul Robinette, Donald C. Wunsch II Abstract The NetFlix Prize is a research contest that will award $1 Million to the first group to improve
Computational Intelligence Meets the NetFlix Prize Ryan J. Meuth, Paul Robinette, Donald C. Wunsch II Abstract The NetFlix Prize is a research contest that will award $1 Million to the first group to improve
CS473: Course Review CS-473. Luo Si Department of Computer Science Purdue University
 CS473: CS-473 Course Review Luo Si Department of Computer Science Purdue University Basic Concepts of IR: Outline Basic Concepts of Information Retrieval: Task definition of Ad-hoc IR Terminologies and
CS473: CS-473 Course Review Luo Si Department of Computer Science Purdue University Basic Concepts of IR: Outline Basic Concepts of Information Retrieval: Task definition of Ad-hoc IR Terminologies and
ECG782: Multidimensional Digital Signal Processing
 ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
Clustering: Classic Methods and Modern Views
 Clustering: Classic Methods and Modern Views Marina Meilă University of Washington mmp@stat.washington.edu June 22, 2015 Lorentz Center Workshop on Clusters, Games and Axioms Outline Paradigms for clustering
Clustering: Classic Methods and Modern Views Marina Meilă University of Washington mmp@stat.washington.edu June 22, 2015 Lorentz Center Workshop on Clusters, Games and Axioms Outline Paradigms for clustering
Feature selection. LING 572 Fei Xia
 Feature selection LING 572 Fei Xia 1 Creating attribute-value table x 1 x 2 f 1 f 2 f K y Choose features: Define feature templates Instantiate the feature templates Dimensionality reduction: feature selection
Feature selection LING 572 Fei Xia 1 Creating attribute-value table x 1 x 2 f 1 f 2 f K y Choose features: Define feature templates Instantiate the feature templates Dimensionality reduction: feature selection
CSC411 Fall 2014 Machine Learning & Data Mining. Ensemble Methods. Slides by Rich Zemel
 CSC411 Fall 2014 Machine Learning & Data Mining Ensemble Methods Slides by Rich Zemel Ensemble methods Typical application: classi.ication Ensemble of classi.iers is a set of classi.iers whose individual
CSC411 Fall 2014 Machine Learning & Data Mining Ensemble Methods Slides by Rich Zemel Ensemble methods Typical application: classi.ication Ensemble of classi.iers is a set of classi.iers whose individual
Announcements. CS 188: Artificial Intelligence Spring Generative vs. Discriminative. Classification: Feature Vectors. Project 4: due Friday.
 CS 188: Artificial Intelligence Spring 2011 Lecture 21: Perceptrons 4/13/2010 Announcements Project 4: due Friday. Final Contest: up and running! Project 5 out! Pieter Abbeel UC Berkeley Many slides adapted
CS 188: Artificial Intelligence Spring 2011 Lecture 21: Perceptrons 4/13/2010 Announcements Project 4: due Friday. Final Contest: up and running! Project 5 out! Pieter Abbeel UC Berkeley Many slides adapted
Applying Supervised Learning
 Applying Supervised Learning When to Consider Supervised Learning A supervised learning algorithm takes a known set of input data (the training set) and known responses to the data (output), and trains
Applying Supervised Learning When to Consider Supervised Learning A supervised learning algorithm takes a known set of input data (the training set) and known responses to the data (output), and trains
Recommender Systems 6CCS3WSN-7CCSMWAL
 Recommender Systems 6CCS3WSN-7CCSMWAL http://insidebigdata.com/wp-content/uploads/2014/06/humorrecommender.jpg Some basic methods of recommendation Recommend popular items Collaborative Filtering Item-to-Item:
Recommender Systems 6CCS3WSN-7CCSMWAL http://insidebigdata.com/wp-content/uploads/2014/06/humorrecommender.jpg Some basic methods of recommendation Recommend popular items Collaborative Filtering Item-to-Item: