Performance and Power Impact of Issuewidth in Chip-Multiprocessor Cores
|
|
|
- Branden Bond
- 5 years ago
- Views:
Transcription
1 Performance and Power Impact of Issuewidth in Chip-Multiprocessor Cores Magnus Ekman Per Stenstrom Department of Computer Engineering, Department of Computer Engineering,
2 Outline Problem statement Assumptions and studied system Methodology Results Conclusion
3 Problem What is the best trade-off between the number of cores and their complexity in a CMP? Wide design space ranging from very few very complex superscalar processors to lots of very simple single-issue cores.
4 Assumptions Chip-area requirements are constant in all designs Clock frequency is constant in all designs Parallel applications
5 Assumptions & Disclamers Chip-area requirements are constant in all designs Very rough area estimates Clock frequency is constant in all designs Perhaps more realistic with faster clock for simpler designs Parallel applications The world is not entirely parallel
6 Four basic systems studied 2 cores, 8-issue 4 cores, 4-issue 8 cores, dual-issue 16 cores, single-issue
7 Things that we study Total execution time of the same task on all systems How does applications exploit ILP vs. TLP? Power consumption for the different systems Gives hints about hot-spots in the designs Total energy consumption of executing the same task on all systems How efficient is the system?
8 Simulation methodology (complexity effective?) Multiprocessor version of SimWattch [1] SimWattch is based on Simics [2] and Wattch [3] (which is based on SimpleScalar [4] and Cacti [5]). [1] SimWattch, 2003 IEEE International Symposium on Performance Analysis of Systems and Software [2] [3] ISCA 2000 [4] [5] research.compaq.com/wrl/people/jouppi/cacti.html
9 How it works Simics generates traces dynamically Traces are fed into the detailed processor simulators, which tell Simics if they can handle more instructions or if they should stall. Activity counters are used in order to get an estimation of energy consumption
10 Simulation parameters all systems SimpleScalar pipeline Snoop-based MOESI protocol Shared bus, with contention modeled Shared L2-Cache: L1-latency: L2-latency: Mem-latency: 2M, 8-way 1 cycle 12 cycles+bus-arb. 128 cycles
11 Simulation parameters 8-issue core Issue-width: 8 Window and ROB-size: 128 Load/Store-queue: 64 G-Share BP: 16K-entries Branch Target Buffer: 4K-entries Return Address Stack: 8 entries L1I-Cache 64K, 2-way L1D-Cache 64K, 4-way
12 Scaling methodology Everything except return address stack is scaled linearly. Tend to favor systems with many cores.
13 Benchmarks Parallel applications from Splash-2 Cholesky Raytrace FFT Radix Water-sp
14 Execution time
15 Instructions per cycle
16 Executed instructions 1IPC system Baseline system
17 IPC with perfect memory
18 Execution time with longer memory latency (3x) Increased execution time Cholesky: 114% Radix: 112% FFT: 103% Water: 61% Raytrace: 94%
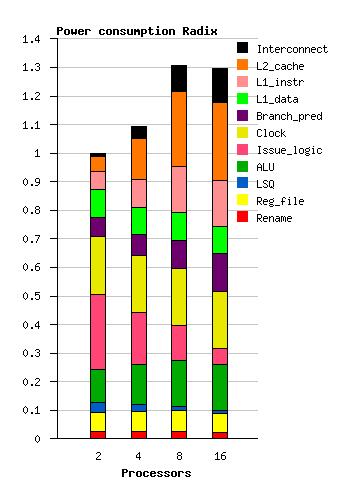
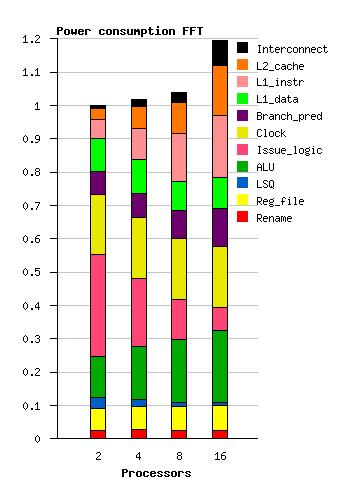
19 Power consumption Radix FFT Water-sp

20 Energy consumption Radix FFT Water-sp
21 Conclusions Four 4-issue cores seem to yield almost as good performance as more cores for these multi-threaded applications. Considering power and energy, four or eight cores seem beneficial. Choose four cores in order to achieve good single-thread performance!
Outline EEL 5764 Graduate Computer Architecture. Chapter 3 Limits to ILP and Simultaneous Multithreading. Overcoming Limits - What do we need??
 Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
CS 654 Computer Architecture Summary. Peter Kemper
 CS 654 Computer Architecture Summary Peter Kemper Chapters in Hennessy & Patterson Ch 1: Fundamentals Ch 2: Instruction Level Parallelism Ch 3: Limits on ILP Ch 4: Multiprocessors & TLP Ap A: Pipelining
CS 654 Computer Architecture Summary Peter Kemper Chapters in Hennessy & Patterson Ch 1: Fundamentals Ch 2: Instruction Level Parallelism Ch 3: Limits on ILP Ch 4: Multiprocessors & TLP Ap A: Pipelining
Beyond ILP II: SMT and variants. 1 Simultaneous MT: D. Tullsen, S. Eggers, and H. Levy
 EE482: Advanced Computer Organization Lecture #13 Processor Architecture Stanford University Handout Date??? Beyond ILP II: SMT and variants Lecture #13: Wednesday, 10 May 2000 Lecturer: Anamaya Sullery
EE482: Advanced Computer Organization Lecture #13 Processor Architecture Stanford University Handout Date??? Beyond ILP II: SMT and variants Lecture #13: Wednesday, 10 May 2000 Lecturer: Anamaya Sullery
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading)
") CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
Advanced issues in pipelining
 Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Hardware-based Speculation
 Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
Lecture-13 (ROB and Multi-threading) CS422-Spring
 CS422-Spring") Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects
 Announcements UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects Inf3 Computer Architecture - 2017-2018 1 Last time: Tomasulo s Algorithm Inf3 Computer
Announcements UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects Inf3 Computer Architecture - 2017-2018 1 Last time: Tomasulo s Algorithm Inf3 Computer
CPI < 1? How? What if dynamic branch prediction is wrong? Multiple issue processors: Speculative Tomasulo Processor
 1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
CPI IPC. 1 - One At Best 1 - One At best. Multiple issue processors: VLIW (Very Long Instruction Word) Speculative Tomasulo Processor
 Speculative Tomasulo Processor") Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Instruction Level Parallelism
 Instruction Level Parallelism Software View of Computer Architecture COMP2 Godfrey van der Linden 200-0-0 Introduction Definition of Instruction Level Parallelism(ILP) Pipelining Hazards & Solutions Dynamic
Instruction Level Parallelism Software View of Computer Architecture COMP2 Godfrey van der Linden 200-0-0 Introduction Definition of Instruction Level Parallelism(ILP) Pipelining Hazards & Solutions Dynamic
Hyperthreading Technology
 Hyperthreading Technology Aleksandar Milenkovic Electrical and Computer Engineering Department University of Alabama in Huntsville milenka@ece.uah.edu www.ece.uah.edu/~milenka/ Outline What is hyperthreading?
Hyperthreading Technology Aleksandar Milenkovic Electrical and Computer Engineering Department University of Alabama in Huntsville milenka@ece.uah.edu www.ece.uah.edu/~milenka/ Outline What is hyperthreading?
CS / ECE 6810 Midterm Exam - Oct 21st 2008
 Name and ID: CS / ECE 6810 Midterm Exam - Oct 21st 2008 Notes: This is an open notes and open book exam. If necessary, make reasonable assumptions and clearly state them. The only clarifications you may
Name and ID: CS / ECE 6810 Midterm Exam - Oct 21st 2008 Notes: This is an open notes and open book exam. If necessary, make reasonable assumptions and clearly state them. The only clarifications you may
 Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
250P: Computer Systems Architecture. Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019
 Anton Burtsev February, 2019") 250P: Computer Systems Architecture Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction and instr
250P: Computer Systems Architecture Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction and instr
Simultaneous Multithreading on Pentium 4
 Hyper-Threading: Simultaneous Multithreading on Pentium 4 Presented by: Thomas Repantis trep@cs.ucr.edu CS203B-Advanced Computer Architecture, Spring 2004 p.1/32 Overview Multiple threads executing on
Hyper-Threading: Simultaneous Multithreading on Pentium 4 Presented by: Thomas Repantis trep@cs.ucr.edu CS203B-Advanced Computer Architecture, Spring 2004 p.1/32 Overview Multiple threads executing on
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction)
") EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
Exploitation of instruction level parallelism
 Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
EECC551 - Shaaban. 1 GHz? to???? GHz CPI > (?)
") Evolution of Processor Performance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static
Evolution of Processor Performance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static
Multithreaded Processors. Department of Electrical Engineering Stanford University
 Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Efficient Runahead Threads Tanausú Ramírez Alex Pajuelo Oliverio J. Santana Onur Mutlu Mateo Valero
 Efficient Runahead Threads Tanausú Ramírez Alex Pajuelo Oliverio J. Santana Onur Mutlu Mateo Valero The Nineteenth International Conference on Parallel Architectures and Compilation Techniques (PACT) 11-15
Efficient Runahead Threads Tanausú Ramírez Alex Pajuelo Oliverio J. Santana Onur Mutlu Mateo Valero The Nineteenth International Conference on Parallel Architectures and Compilation Techniques (PACT) 11-15
Multi-threaded processors. Hung-Wei Tseng x Dean Tullsen
 Multi-threaded processors Hung-Wei Tseng x Dean Tullsen OoO SuperScalar Processor Fetch instructions in the instruction window Register renaming to eliminate false dependencies edule an instruction to
Multi-threaded processors Hung-Wei Tseng x Dean Tullsen OoO SuperScalar Processor Fetch instructions in the instruction window Register renaming to eliminate false dependencies edule an instruction to
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Assuming ideal conditions (perfect pipelining and no hazards), how much time would it take to execute the same program in: b) A 5-stage pipeline?
, how much time would it take to execute the same program in: b) A 5-stage pipeline?") 1. Imagine we have a non-pipelined processor running at 1MHz and want to run a program with 1000 instructions. a) How much time would it take to execute the program? 1 instruction per cycle. 1MHz clock
1. Imagine we have a non-pipelined processor running at 1MHz and want to run a program with 1000 instructions. a) How much time would it take to execute the program? 1 instruction per cycle. 1MHz clock
Module 18: "TLP on Chip: HT/SMT and CMP" Lecture 39: "Simultaneous Multithreading and Chip-multiprocessing" TLP on Chip: HT/SMT and CMP SMT
 TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
DDM-CMP: Data-Driven Multithreading on a Chip Multiprocessor
 DDM-CMP: Data-Driven Multithreading on a Chip Multiprocessor Kyriakos Stavrou, Paraskevas Evripidou, and Pedro Trancoso Department of Computer Science, University of Cyprus, 75 Kallipoleos Ave., P.O.Box
DDM-CMP: Data-Driven Multithreading on a Chip Multiprocessor Kyriakos Stavrou, Paraskevas Evripidou, and Pedro Trancoso Department of Computer Science, University of Cyprus, 75 Kallipoleos Ave., P.O.Box
Speculative Lock Elision: Enabling Highly Concurrent Multithreaded Execution
 Speculative Lock Elision: Enabling Highly Concurrent Multithreaded Execution Ravi Rajwar and Jim Goodman University of Wisconsin-Madison International Symposium on Microarchitecture, Dec. 2001 Funding
Speculative Lock Elision: Enabling Highly Concurrent Multithreaded Execution Ravi Rajwar and Jim Goodman University of Wisconsin-Madison International Symposium on Microarchitecture, Dec. 2001 Funding
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Simultaneous Multithreading Architecture
 Simultaneous Multithreading Architecture Virendra Singh Indian Institute of Science Bangalore Lecture-32 SE-273: Processor Design For most apps, most execution units lie idle For an 8-way superscalar.
Simultaneous Multithreading Architecture Virendra Singh Indian Institute of Science Bangalore Lecture-32 SE-273: Processor Design For most apps, most execution units lie idle For an 8-way superscalar.
Respin: Rethinking Near- Threshold Multiprocessor Design with Non-Volatile Memory
 Respin: Rethinking Near- Threshold Multiprocessor Design with Non-Volatile Memory Computer Architecture Research Lab h"p://arch.cse.ohio-state.edu Universal Demand for Low Power Mobility Ba"ery life Performance
Respin: Rethinking Near- Threshold Multiprocessor Design with Non-Volatile Memory Computer Architecture Research Lab h"p://arch.cse.ohio-state.edu Universal Demand for Low Power Mobility Ba"ery life Performance
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1)
") Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
EECS 470. Lecture 18. Simultaneous Multithreading. Fall 2018 Jon Beaumont
 Lecture 18 Simultaneous Multithreading Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Slides developed in part by Profs. Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi,
Lecture 18 Simultaneous Multithreading Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Slides developed in part by Profs. Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi,
Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University
 Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University Moore s Law Moore, Cramming more components onto integrated circuits, Electronics, 1965. 2 3 Multi-Core Idea:
Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University Moore s Law Moore, Cramming more components onto integrated circuits, Electronics, 1965. 2 3 Multi-Core Idea:
Dual-Core Execution: Building A Highly Scalable Single-Thread Instruction Window
 Dual-Core Execution: Building A Highly Scalable Single-Thread Instruction Window Huiyang Zhou School of Computer Science University of Central Florida New Challenges in Billion-Transistor Processor Era
Dual-Core Execution: Building A Highly Scalable Single-Thread Instruction Window Huiyang Zhou School of Computer Science University of Central Florida New Challenges in Billion-Transistor Processor Era
Kaisen Lin and Michael Conley
 Kaisen Lin and Michael Conley Simultaneous Multithreading Instructions from multiple threads run simultaneously on superscalar processor More instruction fetching and register state Commercialized! DEC
Kaisen Lin and Michael Conley Simultaneous Multithreading Instructions from multiple threads run simultaneously on superscalar processor More instruction fetching and register state Commercialized! DEC
Simultaneous Multithreading and the Case for Chip Multiprocessing
 Simultaneous Multithreading and the Case for Chip Multiprocessing John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 522 Lecture 2 10 January 2019 Microprocessor Architecture
Simultaneous Multithreading and the Case for Chip Multiprocessing John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 522 Lecture 2 10 January 2019 Microprocessor Architecture
(big idea): starting with a multi-core design, we're going to blur the line between multi-threaded and multi-core processing.
: starting with a multi-core design, we're going to blur the line between multi-threaded and multi-core processing.") (big idea): starting with a multi-core design, we're going to blur the line between multi-threaded and multi-core processing. Intro: CMP with MT cores e.g. POWER5, Niagara 1 & 2, Nehalem Off-chip miss
(big idea): starting with a multi-core design, we're going to blur the line between multi-threaded and multi-core processing. Intro: CMP with MT cores e.g. POWER5, Niagara 1 & 2, Nehalem Off-chip miss
Multiprocessors and Thread-Level Parallelism. Department of Electrical & Electronics Engineering, Amrita School of Engineering
 Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Multi-core Architectures. Dr. Yingwu Zhu
 Multi-core Architectures Dr. Yingwu Zhu Outline Parallel computing? Multi-core architectures Memory hierarchy Vs. SMT Cache coherence What is parallel computing? Using multiple processors in parallel to
Multi-core Architectures Dr. Yingwu Zhu Outline Parallel computing? Multi-core architectures Memory hierarchy Vs. SMT Cache coherence What is parallel computing? Using multiple processors in parallel to
TDT 4260 lecture 7 spring semester 2015
 1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
Multithreading: Exploiting Thread-Level Parallelism within a Processor
 Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Limitations of Scalar Pipelines
 Limitations of Scalar Pipelines Superscalar Organization Modern Processor Design: Fundamentals of Superscalar Processors Scalar upper bound on throughput IPC = 1 Inefficient unified pipeline
Limitations of Scalar Pipelines Superscalar Organization Modern Processor Design: Fundamentals of Superscalar Processors Scalar upper bound on throughput IPC = 1 Inefficient unified pipeline
Multi-core Programming Evolution
 Multi-core Programming Evolution Based on slides from Intel Software ollege and Multi-ore Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts, Evolution
Multi-core Programming Evolution Based on slides from Intel Software ollege and Multi-ore Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts, Evolution
Software-Controlled Multithreading Using Informing Memory Operations
 Software-Controlled Multithreading Using Informing Memory Operations Todd C. Mowry Computer Science Department University Sherwyn R. Ramkissoon Department of Electrical & Computer Engineering University
Software-Controlled Multithreading Using Informing Memory Operations Todd C. Mowry Computer Science Department University Sherwyn R. Ramkissoon Department of Electrical & Computer Engineering University
Techniques for Efficient Processing in Runahead Execution Engines
 Techniques for Efficient Processing in Runahead Execution Engines Onur Mutlu Hyesoon Kim Yale N. Patt Depment of Electrical and Computer Engineering University of Texas at Austin {onur,hyesoon,patt}@ece.utexas.edu
Techniques for Efficient Processing in Runahead Execution Engines Onur Mutlu Hyesoon Kim Yale N. Patt Depment of Electrical and Computer Engineering University of Texas at Austin {onur,hyesoon,patt}@ece.utexas.edu
CSE502 Graduate Computer Architecture. Lec 22 Goodbye to Computer Architecture and Review
 CSE502 Graduate Computer Architecture Lec 22 Goodbye to Computer Architecture and Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
CSE502 Graduate Computer Architecture Lec 22 Goodbye to Computer Architecture and Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism. In-Cheol Park Dept. of EE, KAIST
 Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
h Coherence Controllers
 High-Throughput h Coherence Controllers Anthony-Trung Nguyen Microprocessor Research Labs Intel Corporation 9/30/03 Motivations Coherence Controller (CC) throughput is bottleneck of scalable systems. CCs
High-Throughput h Coherence Controllers Anthony-Trung Nguyen Microprocessor Research Labs Intel Corporation 9/30/03 Motivations Coherence Controller (CC) throughput is bottleneck of scalable systems. CCs
Transactional Memory Coherence and Consistency
 Transactional emory Coherence and Consistency all transactions, all the time Lance Hammond, Vicky Wong, ike Chen, rian D. Carlstrom, ohn D. Davis, en Hertzberg, anohar K. Prabhu, Honggo Wijaya, Christos
Transactional emory Coherence and Consistency all transactions, all the time Lance Hammond, Vicky Wong, ike Chen, rian D. Carlstrom, ohn D. Davis, en Hertzberg, anohar K. Prabhu, Honggo Wijaya, Christos
A Key Theme of CIS 371: Parallelism. CIS 371 Computer Organization and Design. Readings. This Unit: (In-Order) Superscalar Pipelines
 Superscalar Pipelines") A Key Theme of CIS 371: arallelism CIS 371 Computer Organization and Design Unit 10: Superscalar ipelines reviously: pipeline-level parallelism Work on execute of one instruction in parallel with decode
A Key Theme of CIS 371: arallelism CIS 371 Computer Organization and Design Unit 10: Superscalar ipelines reviously: pipeline-level parallelism Work on execute of one instruction in parallel with decode
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Multi-{Socket,,Thread} Getting More Performance Keep pushing IPC and/or frequenecy Design complexity (time to market) Cooling (cost) Power delivery (cost) Possible, but too
CSE 502: Computer Architecture Multi-{Socket,,Thread} Getting More Performance Keep pushing IPC and/or frequenecy Design complexity (time to market) Cooling (cost) Power delivery (cost) Possible, but too
Outline Review: Basic Pipeline Scheduling and Loop Unrolling Multiple Issue: Superscalar, VLIW. CPE 631 Session 19 Exploiting ILP with SW Approaches
 Session xploiting ILP with SW Approaches lectrical and Computer ngineering University of Alabama in Huntsville Outline Review: Basic Pipeline Scheduling and Loop Unrolling Multiple Issue: Superscalar,
Session xploiting ILP with SW Approaches lectrical and Computer ngineering University of Alabama in Huntsville Outline Review: Basic Pipeline Scheduling and Loop Unrolling Multiple Issue: Superscalar,
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Chapter 03. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 03 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 3.3 Comparison of 2-bit predictors. A noncorrelating predictor for 4096 bits is first, followed
Chapter 03 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 3.3 Comparison of 2-bit predictors. A noncorrelating predictor for 4096 bits is first, followed
Lecture 11: SMT and Caching Basics. Today: SMT, cache access basics (Sections 3.5, 5.1)
") Lecture 11: SMT and Caching Basics Today: SMT, cache access basics (Sections 3.5, 5.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized for most of the time by doubling
Lecture 11: SMT and Caching Basics Today: SMT, cache access basics (Sections 3.5, 5.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized for most of the time by doubling
Unit 8: Superscalar Pipelines
 A Key Theme: arallelism reviously: pipeline-level parallelism Work on execute of one instruction in parallel with decode of next CIS 501: Computer Architecture Unit 8: Superscalar ipelines Slides'developed'by'Milo'Mar0n'&'Amir'Roth'at'the'University'of'ennsylvania'
A Key Theme: arallelism reviously: pipeline-level parallelism Work on execute of one instruction in parallel with decode of next CIS 501: Computer Architecture Unit 8: Superscalar ipelines Slides'developed'by'Milo'Mar0n'&'Amir'Roth'at'the'University'of'ennsylvania'
Banked Multiported Register Files for High-Frequency Superscalar Microprocessors
 Banked Multiported Register Files for High-Frequency Superscalar Microprocessors Jessica H. T seng and Krste Asanoviü MIT Laboratory for Computer Science, Cambridge, MA 02139, USA ISCA2003 1 Motivation
Banked Multiported Register Files for High-Frequency Superscalar Microprocessors Jessica H. T seng and Krste Asanoviü MIT Laboratory for Computer Science, Cambridge, MA 02139, USA ISCA2003 1 Motivation
CS533: Speculative Parallelization (Thread-Level Speculation)
") CS533: Speculative Parallelization (Thread-Level Speculation) Josep Torrellas University of Illinois in Urbana-Champaign March 5, 2015 Josep Torrellas (UIUC) CS533: Lecture 14 March 5, 2015 1 / 21 Concepts
CS533: Speculative Parallelization (Thread-Level Speculation) Josep Torrellas University of Illinois in Urbana-Champaign March 5, 2015 Josep Torrellas (UIUC) CS533: Lecture 14 March 5, 2015 1 / 21 Concepts
EITF20: Computer Architecture Part3.2.1: Pipeline - 3
 EITF20: Computer Architecture Part3.2.1: Pipeline - 3 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Dynamic scheduling - Tomasulo Superscalar, VLIW Speculation ILP limitations What we have done
EITF20: Computer Architecture Part3.2.1: Pipeline - 3 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Dynamic scheduling - Tomasulo Superscalar, VLIW Speculation ILP limitations What we have done
In-order vs. Out-of-order Execution. In-order vs. Out-of-order Execution
 In-order vs. Out-of-order Execution In-order instruction execution instructions are fetched, executed & committed in compilergenerated order if one instruction stalls, all instructions behind it stall
In-order vs. Out-of-order Execution In-order instruction execution instructions are fetched, executed & committed in compilergenerated order if one instruction stalls, all instructions behind it stall
Execution-based Prediction Using Speculative Slices
 Execution-based Prediction Using Speculative Slices Craig Zilles and Guri Sohi University of Wisconsin - Madison International Symposium on Computer Architecture July, 2001 The Problem Two major barriers
Execution-based Prediction Using Speculative Slices Craig Zilles and Guri Sohi University of Wisconsin - Madison International Symposium on Computer Architecture July, 2001 The Problem Two major barriers
Lecture 3: Snooping Protocols. Topics: snooping-based cache coherence implementations
 Lecture 3: Snooping Protocols Topics: snooping-based cache coherence implementations 1 Design Issues, Optimizations When does memory get updated? demotion from modified to shared? move from modified in
Lecture 3: Snooping Protocols Topics: snooping-based cache coherence implementations 1 Design Issues, Optimizations When does memory get updated? demotion from modified to shared? move from modified in
Advanced d Processor Architecture. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
Advanced d Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
Dynamic Memory Dependence Predication
 Dynamic Memory Dependence Predication Zhaoxiang Jin and Soner Önder ISCA-2018, Los Angeles Background 1. Store instructions do not update the cache until they are retired (too late). 2. Store queue is
Dynamic Memory Dependence Predication Zhaoxiang Jin and Soner Önder ISCA-2018, Los Angeles Background 1. Store instructions do not update the cache until they are retired (too late). 2. Store queue is
High Performance SMIPS Processor
 High Performance SMIPS Processor Jonathan Eastep 6.884 Final Project Report May 11, 2005 1 Introduction 1.1 Description This project will focus on producing a high-performance, single-issue, in-order,
High Performance SMIPS Processor Jonathan Eastep 6.884 Final Project Report May 11, 2005 1 Introduction 1.1 Description This project will focus on producing a high-performance, single-issue, in-order,
Limits of Data-Level Parallelism
 Limits of Data-Level Parallelism Sreepathi Pai, R. Govindarajan, M. J. Thazhuthaveetil Supercomputer Education and Research Centre, Indian Institute of Science, Bangalore, India. Email: {sree@hpc.serc,govind@serc,mjt@serc}.iisc.ernet.in
Limits of Data-Level Parallelism Sreepathi Pai, R. Govindarajan, M. J. Thazhuthaveetil Supercomputer Education and Research Centre, Indian Institute of Science, Bangalore, India. Email: {sree@hpc.serc,govind@serc,mjt@serc}.iisc.ernet.in
Chapter 7. Digital Design and Computer Architecture, 2 nd Edition. David Money Harris and Sarah L. Harris. Chapter 7 <1>
 Chapter 7 Digital Design and Computer Architecture, 2 nd Edition David Money Harris and Sarah L. Harris Chapter 7 Chapter 7 :: Topics Introduction (done) Performance Analysis (done) Single-Cycle Processor
Chapter 7 Digital Design and Computer Architecture, 2 nd Edition David Money Harris and Sarah L. Harris Chapter 7 Chapter 7 :: Topics Introduction (done) Performance Analysis (done) Single-Cycle Processor
Several Common Compiler Strategies. Instruction scheduling Loop unrolling Static Branch Prediction Software Pipelining
 Several Common Compiler Strategies Instruction scheduling Loop unrolling Static Branch Prediction Software Pipelining Basic Instruction Scheduling Reschedule the order of the instructions to reduce the
Several Common Compiler Strategies Instruction scheduling Loop unrolling Static Branch Prediction Software Pipelining Basic Instruction Scheduling Reschedule the order of the instructions to reduce the
CS377P Programming for Performance Multicore Performance Multithreading
 CS377P Programming for Performance Multicore Performance Multithreading Sreepathi Pai UTCS October 14, 2015 Outline 1 Multiprocessor Systems 2 Programming Models for Multicore 3 Multithreading and POSIX
CS377P Programming for Performance Multicore Performance Multithreading Sreepathi Pai UTCS October 14, 2015 Outline 1 Multiprocessor Systems 2 Programming Models for Multicore 3 Multithreading and POSIX
Phastlane: A Rapid Transit Optical Routing Network
 Phastlane: A Rapid Transit Optical Routing Network Mark Cianchetti, Joseph Kerekes, and David Albonesi Computer Systems Laboratory Cornell University The Interconnect Bottleneck Future processors: tens
Phastlane: A Rapid Transit Optical Routing Network Mark Cianchetti, Joseph Kerekes, and David Albonesi Computer Systems Laboratory Cornell University The Interconnect Bottleneck Future processors: tens
One-Level Cache Memory Design for Scalable SMT Architectures
 One-Level Cache Design for Scalable SMT Architectures Muhamed F. Mudawar and John R. Wani Computer Science Department The American University in Cairo mudawwar@aucegypt.edu rubena@aucegypt.edu Abstract
One-Level Cache Design for Scalable SMT Architectures Muhamed F. Mudawar and John R. Wani Computer Science Department The American University in Cairo mudawwar@aucegypt.edu rubena@aucegypt.edu Abstract
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design
 ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
Towards a More Efficient Trace Cache
 Towards a More Efficient Trace Cache Rajnish Kumar, Amit Kumar Saha, Jerry T. Yen Department of Computer Science and Electrical Engineering George R. Brown School of Engineering, Rice University {rajnish,
Towards a More Efficient Trace Cache Rajnish Kumar, Amit Kumar Saha, Jerry T. Yen Department of Computer Science and Electrical Engineering George R. Brown School of Engineering, Rice University {rajnish,
Donn Morrison Department of Computer Science. TDT4255 Memory hierarchies
 TDT4255 Lecture 10: Memory hierarchies Donn Morrison Department of Computer Science 2 Outline Chapter 5 - Memory hierarchies (5.1-5.5) Temporal and spacial locality Hits and misses Direct-mapped, set associative,
TDT4255 Lecture 10: Memory hierarchies Donn Morrison Department of Computer Science 2 Outline Chapter 5 - Memory hierarchies (5.1-5.5) Temporal and spacial locality Hits and misses Direct-mapped, set associative,
The University of Texas at Austin
 EE382 (20): Computer Architecture - Parallelism and Locality Lecture 4 Parallelism in Hardware Mattan Erez The University of Texas at Austin EE38(20) (c) Mattan Erez 1 Outline 2 Principles of parallel
EE382 (20): Computer Architecture - Parallelism and Locality Lecture 4 Parallelism in Hardware Mattan Erez The University of Texas at Austin EE38(20) (c) Mattan Erez 1 Outline 2 Principles of parallel
Multicast Snooping: A Multicast Address Network. A New Coherence Method Using. With sponsorship and/or participation from. Mark Hill & David Wood
 Multicast Snooping: A New Coherence Method Using A Multicast Address Ender Bilir, Ross Dickson, Ying Hu, Manoj Plakal, Daniel Sorin, Mark Hill & David Wood Computer Sciences Department University of Wisconsin
Multicast Snooping: A New Coherence Method Using A Multicast Address Ender Bilir, Ross Dickson, Ying Hu, Manoj Plakal, Daniel Sorin, Mark Hill & David Wood Computer Sciences Department University of Wisconsin
Multiple Instruction Issue. Superscalars
 Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Datapoint 2200 IA-32. main memory. components. implemented by Intel in the Nicholas FitzRoy-Dale
 Datapoint 2200 IA-32 Nicholas FitzRoy-Dale At the forefront of the computer revolution - Intel Difficult to explain and impossible to love - Hennessy and Patterson! Released 1970! 2K shift register main
Datapoint 2200 IA-32 Nicholas FitzRoy-Dale At the forefront of the computer revolution - Intel Difficult to explain and impossible to love - Hennessy and Patterson! Released 1970! 2K shift register main
Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13
 Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13 Moore s Law Moore, Cramming more components onto integrated circuits, Electronics,
Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13 Moore s Law Moore, Cramming more components onto integrated circuits, Electronics,
Power-Efficient Approaches to Reliability. Abstract
 Power-Efficient Approaches to Reliability Niti Madan, Rajeev Balasubramonian UUCS-05-010 School of Computing University of Utah Salt Lake City, UT 84112 USA December 2, 2005 Abstract Radiation-induced
Power-Efficient Approaches to Reliability Niti Madan, Rajeev Balasubramonian UUCS-05-010 School of Computing University of Utah Salt Lake City, UT 84112 USA December 2, 2005 Abstract Radiation-induced
Hardware Speculation Support
 Hardware Speculation Support Conditional instructions Most common form is conditional move BNEZ R1, L ;if MOV R2, R3 ;then CMOVZ R2,R3, R1 L: ;else Other variants conditional loads and stores nullification
Hardware Speculation Support Conditional instructions Most common form is conditional move BNEZ R1, L ;if MOV R2, R3 ;then CMOVZ R2,R3, R1 L: ;else Other variants conditional loads and stores nullification
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
LogTM: Log-Based Transactional Memory
 LogTM: Log-Based Transactional Memory Kevin E. Moore, Jayaram Bobba, Michelle J. Moravan, Mark D. Hill, & David A. Wood 12th International Symposium on High Performance Computer Architecture () 26 Mulitfacet
LogTM: Log-Based Transactional Memory Kevin E. Moore, Jayaram Bobba, Michelle J. Moravan, Mark D. Hill, & David A. Wood 12th International Symposium on High Performance Computer Architecture () 26 Mulitfacet
Superscalar SMIPS Processor
 Superscalar SMIPS Processor Group 2 Qian (Vicky) Liu Cliff Frey 1 Introduction Our project is the implementation of a superscalar processor that implements the SMIPS specification. Our primary goal is
Superscalar SMIPS Processor Group 2 Qian (Vicky) Liu Cliff Frey 1 Introduction Our project is the implementation of a superscalar processor that implements the SMIPS specification. Our primary goal is
Dynamic Hardware Prediction. Basic Branch Prediction Buffers. N-bit Branch Prediction Buffers
 Dynamic Hardware Prediction Importance of control dependences Branches and jumps are frequent Limiting factor as ILP increases (Amdahl s law) Schemes to attack control dependences Static Basic (stall the
Dynamic Hardware Prediction Importance of control dependences Branches and jumps are frequent Limiting factor as ILP increases (Amdahl s law) Schemes to attack control dependences Static Basic (stall the
Synthetic Traffic Generation: a Tool for Dynamic Interconnect Evaluation
 Synthetic Traffic Generation: a Tool for Dynamic Interconnect Evaluation W. Heirman, J. Dambre, J. Van Campenhout ELIS Department, Ghent University, Belgium Sponsored by IAP-V PHOTON & IAP-VI photonics@be,
Synthetic Traffic Generation: a Tool for Dynamic Interconnect Evaluation W. Heirman, J. Dambre, J. Van Campenhout ELIS Department, Ghent University, Belgium Sponsored by IAP-V PHOTON & IAP-VI photonics@be,
Chapter 3 (Cont III): Exploiting ILP with Software Approaches. Copyright Josep Torrellas 1999, 2001, 2002,
: Exploiting ILP with Software Approaches. Copyright Josep Torrellas 1999, 2001, 2002,") Chapter 3 (Cont III): Exploiting ILP with Software Approaches Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Exposing ILP (3.2) Want to find sequences of unrelated instructions that can be overlapped
Chapter 3 (Cont III): Exploiting ILP with Software Approaches Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Exposing ILP (3.2) Want to find sequences of unrelated instructions that can be overlapped
Computer Architecture 计算机体系结构. Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II. Chao Li, PhD. 李超博士
 Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
Beyond ILP. Hemanth M Bharathan Balaji. Hemanth M & Bharathan Balaji
 Beyond ILP Hemanth M Bharathan Balaji Multiscalar Processors Gurindar S Sohi Scott E Breach T N Vijaykumar Control Flow Graph (CFG) Each node is a basic block in graph CFG divided into a collection of
Beyond ILP Hemanth M Bharathan Balaji Multiscalar Processors Gurindar S Sohi Scott E Breach T N Vijaykumar Control Flow Graph (CFG) Each node is a basic block in graph CFG divided into a collection of
IBM's POWER5 Micro Processor Design and Methodology
 IBM's POWER5 Micro Processor Design and Methodology Ron Kalla IBM Systems Group Outline POWER5 Overview Design Process Power POWER Server Roadmap 2001 POWER4 2002-3 POWER4+ 2004* POWER5 2005* POWER5+ 2006*
IBM's POWER5 Micro Processor Design and Methodology Ron Kalla IBM Systems Group Outline POWER5 Overview Design Process Power POWER Server Roadmap 2001 POWER4 2002-3 POWER4+ 2004* POWER5 2005* POWER5+ 2006*
45-year CPU Evolution: 1 Law -2 Equations
 4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Computer Architecture: Multithreading (I) Prof. Onur Mutlu Carnegie Mellon University
 Prof. Onur Mutlu Carnegie Mellon University") Computer Architecture: Multithreading (I) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-742 Fall 2012, Parallel Computer Architecture, Lecture 9: Multithreading
Computer Architecture: Multithreading (I) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-742 Fall 2012, Parallel Computer Architecture, Lecture 9: Multithreading
Advanced Instruction-Level Parallelism
 Advanced Instruction-Level Parallelism Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu
Advanced Instruction-Level Parallelism Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu
ECE/CS 757: Homework 1
 ECE/CS 757: Homework 1 Cores and Multithreading 1. A CPU designer has to decide whether or not to add a new micoarchitecture enhancement to improve performance (ignoring power costs) of a block (coarse-grain)
ECE/CS 757: Homework 1 Cores and Multithreading 1. A CPU designer has to decide whether or not to add a new micoarchitecture enhancement to improve performance (ignoring power costs) of a block (coarse-grain)
COSC 6385 Computer Architecture - Memory Hierarchy Design (III)
") COSC 6385 Computer Architecture - Memory Hierarchy Design (III) Fall 2006 Reducing cache miss penalty Five techniques Multilevel caches Critical word first and early restart Giving priority to read misses
COSC 6385 Computer Architecture - Memory Hierarchy Design (III) Fall 2006 Reducing cache miss penalty Five techniques Multilevel caches Critical word first and early restart Giving priority to read misses
Cache Performance, System Performance, and Off-Chip Bandwidth... Pick any Two
 Cache Performance, System Performance, and Off-Chip Bandwidth... Pick any Two Bushra Ahsan and Mohamed Zahran Dept. of Electrical Engineering City University of New York ahsan bushra@yahoo.com mzahran@ccny.cuny.edu
Cache Performance, System Performance, and Off-Chip Bandwidth... Pick any Two Bushra Ahsan and Mohamed Zahran Dept. of Electrical Engineering City University of New York ahsan bushra@yahoo.com mzahran@ccny.cuny.edu