Video Mining with Frequent Itemset Configurations
|
|
|
- Ethan Neal
- 6 years ago
- Views:
Transcription
1 Video Mining with Frequent Itemset Configurations Till Quack 1, Vittorio Ferrari 2, and Luc Van Gool 1 1 ETH Zurich 2 LEAR - INRIA Grenoble Abstract. We present a method for mining frequently occurring objects and scenes from videos. Object candidates are detected by finding recurring spatial arrangements of affine covariant regions. Our mining method is based on the class of frequent itemset mining algorithms, which have proven their efficiency in other domains, but have not been applied to video mining before. In this work we show how to express vectorquantized features and their spatial relations as itemsets. Furthermore, a fast motion segmentation method is introduced as an attention filter for the mining algorithm. Results are shown on real world data consisting of music video clips. 1 Introduction The goal of this work is to mine interesting objects and scenes from video data. In other words, to detect frequently occurring objects automatically. Mining such representative objects, actors, and scenes in video data is useful for many applications. For instance, they can serve as entry points for retrieval and browsing, or they can provide a basis for video summarization. Our approach to video data mining is based on the detection of recurring spatial arrangements of local features. These features are represented in quantized codebooks, which has been a recently popular and successful technique in object recognition, retrieval [14] and classification [10]. On top of this representation, we introduce a method to detect frequently re-occurring spatial configurations of codebook entries. Whereas isolated features still show weak links with semantic content, their co-occurrence has far greater meaning. Our approach relies on frequent itemset mining algorithms, which have been successfully applied to several other, large-scale data mining problems such as market basket analysis or query log analysis [1, 2]. In our context, the concept of an item corresponds to a codebook entry. The input to the mining algorithm consists of subsets of feature-codebook entries for each video frame, encoded into transactions, as they are known in the data mining literature [1]. We demonstrate how to incorporate spatial arrangement information in transactions and how to select the neighborhood defining the subset of image features included in a transaction. For scenes with significant motion, we define this neighborhood via motion segmentation. To this end, we also introduce a simple and very fast technique for motion segmentation on feature codebooks.
2 II Few works have dealt with the problem of mining objects composed of local features from video data. In this respect, the closest work to ours is by Sivic and Zisserman [5]. However, there are considerable differences. [5] starts by selecting subsets of quantized features. The neighborhoods for mining are always of fixed size (e.g. the 20 nearest neighbors). Each such neighborhood is expressed as a simple, orderless bag-of-words, represented as a sparse binary indicator vector. The actual mining proceeds by computing the dot-product between all pairs of neighborhoods and setting a threshold on the resulting number of codebook terms they have in common. While this definition of a neighborhood is similar in spirit to our transactions, we also include information about the localization of the feature within its neighborhood. Furthermore, the neighborhood itself is not of fixed size. For scenes containing significant motion, we can exploit our fast motion segmentation to restrict the neighborhood to features with similar motions, and hence more likely to belong to a single object. As another important difference, unlike [5] our approach does not require pairwise matching of bagof-words indicator vectors, but it relies instead on a frequent itemset mining algorithm, which is a well studied technique in data mining. This brings the additional benefit of knowing which regions are common between neighborhoods, versus the dot-product technique only reporting how many they are. It also opens the doors to a large body of research on the efficient detection of frequent itemsets and many deduced mining methods. To the best of our knowledge, no work has been published on frequent itemset mining of video data, and very little is reported on static image data. In [3] an extended association rule mining algorithm was used to mine spatial associations between five classes of texture-tiles in aerial images (forest, urban etc.). In [4] association rules were used to create a classifier for breast cancer detection from mammogram-images. Each mammogram was first cropped to contain the same fraction of the breast, and then described by photometric moments. Compared to our method, both works were only applied to static image data containing rather small variations. The remainder of this paper is organized as follows. First the pre-processing steps (i.e. video shot detection, local feature extraction and clustering into appearance codebooks) are described in section 2. Section 3 introduces the concepts of our mining method. Section 4 describes the application of the mining method to video sequences. Finally, results are shown in section 5. 2 Shot detection, features and appearance codebooks The main processing stages of our system (next sections) rely on the prior subdivision of the video into shots. We apply the shot partitioning algorithm [6], and pick four keyframes per second within each shot. As in [5], this results in a denser and more uniform sampling than when using the keyframes selected by [6]. In each keyframe we extract two types of affine covariant features (regions): Hessian-Affine [7] and MSER [8]. Affine covariant features are preferred over simpler scale-invariant ones, as they provide robustness against viewpoint
3 III changes. Each normalized region is described with a SIFT-descriptor [9]. Next, a quantized codebook [10] (also called visual vocabulary [5]) is constructed by clustering the SIFT descriptors with the hierarchical-agglomerative technique described in [10]. In a typical video, this results in about 8000 appearance clusters for each feature type. We apply the stop-list method known from text-retrieval and [5] as a final polishing: very frequent and very rare visual words are removed from the codebook (the 5% most and 5% least frequent). Note that the following processing stages use only the spatial location of features and their assigned appearancecodebook id s. The appearance descriptors are no longer needed. 3 Our mining approach Our goal is to find frequent spatial configurations of visual words in video scenes. For the time being, let us consider a configuration to be just an unordered set of visual words. We add spatial relationships later, in section 3.2. For a codebook of size d there are 2 d possible subsets of visual words. For each of our two feature types we have a codebook with about 8000 words, which means d is typically > 10000, resulting in an immense search space. Hence we need a mining method capable of dealing with such a large dataset and to return frequently occurring word combinations. Frequent itemset mining methods are a good choice, as they have solved analogous problems in market basket like data [1, 2]. Here we briefly summarize the terminology and methodology of frequent itemset mining. 3.1 Frequent itemset mining Let I = {i 1... i p } be a set of p items. Let A be a subset of I with l items,i.e. A I, A = l. Then we call A a l-itemset. A transaction is an itemset T I with a transaction identifier tid(t ). A transaction database D is a set of transactions with unique identifiers D = {T 1... T n }. We say that a transaction T supports an itemset A, if A T. We can now define the support of an itemset in the transactions-database D as follows: Definition 1. The support of an itemset A D is support(a) = {T D A T } D [0, 1] (1) An itemset A is called frequent in D if support(a) s where s is a threshold for the minimal support defined by the user. Frequent itemsets are subject to the monotonicity property: all l-subsets of frequent (l+1)-sets are also frequent. The well known APriori algorithm [1] takes advantage of the monotonicity property and allows us to find frequent itemsets very quickly.
4 IV 3.2 Incorporating spatial information In our context, the items correspond to visual words. In the simplest case, a transaction would be created for each visual word, and would consist of an orderless bag of all other words within some image neighborhood. In order to include also spatial information (i.e. locations of visual words) in the mining process, we further adapt the concept of an item to our problem. The key idea is to encode spatial information directly in the items. In each image we create transactions from the neighborhood around a limited subset of selected words {v c }. These words must appear in at least f min and at most in f max frames. This is motivated by the notion that neighbourhoods containing a very infrequent word would create infrequent transactions, neighbourhoods around extremely frequent word have a high probability of being part of clutter. Each v c must also have a matching word in the previous frame, if both frames are from the same shot. Typically, with these restrictions, about 1/4 of the regions in a frame are selected. For each v c we create a transaction which contains the surrounding k nearest words together with their rough spatial arrangement. The neighbourhood around v c is divided into B sections. In all experiments we use B = 4 sections. Each section covers 90 plus an overlap o = 5 with its neighboring sections, to be robust against small rotations. We label the sections {tl, tr, bl, br} (for top-left, top-right, etc.), and append to each visual word the label of the section it lies in. In the example in figure 1, the transaction created for v c is T = {tl55, tl9, tr923, br79, br23, bl23, bl9}. In the following, we refer to the selected words {v c } as central words. Although the approach only accomodates for small rotations, in most videos objects rarely appear in substantially different orientations. Rotations of the neighborhood stemming from perspective transformations are safely accomodated by the overlap o. Although augmenting the Fig. 1. Creating transaction from a neighborhood. The area around a central visual word v c is divided into sections. Each section is labeled (tl, tr, bl, br) and the label is appended to the visual word ids. items in this fashion increases their total number by a factor B, no changes to the frequent itemset mining algorithm itself are necessary. Besides, thanks to the careful selection of the central visual words v c, we reduce the number of transactions and thus the runtime of the algorithm.
5 V 3.3 Exploiting motion Shots containing significant motion 1 allow us to further increase the degree of specificity of transactions: if we had a rough segmentation of the scene into object candidates, we could restrict the neighborhood for a transaction to the segmented area for each candidate, hence dramatically simplifying the task of the mining algorithm. In this case, as the central visual words v c we pick the two closest regions to the center of the segmented image area. All other words inside the segmented area are included in the transaction (figure 3). In this section, we propose a simple and very fast motion segmentation algorithm to find such object candidates. The assumption is that interesting objects move independently from each other within a shot. More precisely, we can identify groups of visual words which translate consistently from frame to frame. The grouping method consists of two steps: Step 1. Matching words. A pair of words from two frames f(t), f(t + n) at times t and t + n is deemed matched if they have the same codebook ids (i.e. they are in the same appearance cluster), and if the translation is below a maximum translation threshold t max. This matching step is extremely fast, since we rely only on cluster id correspondences. In our experiments we typically use t max = 40 pixels and n = 6 since we operate on four keyframes per second. Step 2. Translation clustering. At each timestep t, the pairs of regions matched between frames f(t) and f(t+n) are grouped according to their translation using k-means clustering. In order to determine the initial number of motion groups k, k-means is initialized with a leader initialization [12], on the translation between the first two frames. For each remaining timestep, we run k-means three times with different values for k, specifically k(t) {k(t 1) 1, k(t 1), k(t 1) + 1} (2) where k(t 1) is the number of motion groups in the previous timestep. k(t) is constrained to be in [2...6]. This prevents the number of motion groups from changing abruptly from frame to frame. To further improve stability, we run the algorithm twice for each k with different random initializations. From the resulting different clusterings, we keep the one with the best mean silhouette value [13]. We improve the quality of the motion groups with the following filter. For each motion group, we estimate a series of bounding-boxes, containing from 80% progressively up to all regions closest to the spatial median of the group. We retain as bounding-box for the group the one with the maximal density number of regions bounding box area. This procedure removes from the motion groups regions located far from most of the others. These are most often mismatches which accidentally translate similar to the group. The closest two visual words to the bounding box center are now selected as the central visual word v c for the motion group. Figure 2 shows detected motion groups for a scene of a music videoclip. 1 Since shot partitioning [6] returns a single keyframe for static shots and several keyframes for moving shots, we can easily detect shots with significant motion.

 shots with considerable motion: a motion group is the basis for a transaction, thus the number of items in a transaction is not fixed but given by the size of the motion group.")
.")

6 VI Fig. 2. First row: motion groups (only region centers shown) with bounding boxes. Second row: motion groups in translation space. Note: colors do not necessarily correspond along a row, since groups are not tracked along time. Fig. 3. Creating transactions: (a) static shots: transactions are formed around each v c from the k-neighborhood. (b) shots with considerable motion: a motion group is the basis for a transaction, thus the number of items in a transaction is not fixed but given by the size of the motion group. With (b) in general fewer transactions are generated. 4 Mining the entire video We quickly summarize the processing stages from the previous sections. A video is first partitioned into shots. For rather static shots we create transactions from a fixed neighborhood around each central word (subsection 3.2). For shots with considerable motion, we use as central words the two words closest to the spatial center of the motion group, and create two transactions covering only visual words within it. For frequent itemset mining itself we use an implementation of APriori from [11]. We mine so called maximal frequent itemsets. An itemset is called maximal if no superset is frequent. Only sets with four or more items are kept. Note how frequent itemset mining returns sparse but discriminative descriptions of neighborhoods. As opposed to the dot-product of binary indicator vectors used in [5], the frequent itemsets show which visual words cooccur in the mined transactions. Such a sparse description might also be helpful for efficiently indexing mined objects.
7 VII 4.1 Choosing a support threshold The choice of a good minimal support threshold s in frequent itemset mining is not easy, especially in our untraditional setting where items and itemsets are constructed without supervision. If the threshold is too high, no frequent itemsets are mined. If it is too low, too many (possibly millions) are mined. Thus, rather than defining a fixed threshold, we run the algorithm with several thresholds, until the number of frequent itemsets falls within a reasonable range. We achieve this with a binary split search strategy. Two extremal support thresholds are defined, s low and s high. The number of itemsets is desired to be between n min and n max. Let n be the number of itemsets mined in the current step of the search, and s be the corresponding support threshold. If the number of itemsets is not in the desired range, we update s by the following rule and rerun the miner: { s (t+1) s = (t) + (s high s (t) ) 2, s low = s (t) if n > n max s (t) (s(t) s low ) 2, s high = s (t) if n < n min Since the mining algorithm is very fast, we can afford to run it several times (runtimes reported in the result section). 4.2 Finding interesting itemsets The output of the APriori algorithm is usually a rather large set of frequent itemsets, depending on the minimal support threshold. Finding interesting item sets (and association rules) is a much discussed topic in the data mining literature [16]. There are several approaches which define interestingness with purely statistical measures. For instance, itemsets whose items appear statistically dependent are interesting. A measure for independence can be defined as follows. Assuming independence, the expected value for the support of an itemset is computed from the product of the supports of the individual items. The ratio of actual and expected support of an itemset is computed and its difference to 1 serves as an interestingness measure (i.e. difference to perfect independence). Only itemsets for which this difference is above a given threshold are retained as interesting. This was suggested in [11] and had in general a positive effect on the quality of our mining results. Another strategy is to rely on domain-specific knowledge. In our domain, itemsets which describe a spatial configuration stretching across multiple sections tl, tr, bl, br are interesting. These itemsets are less likely to appear by coincidence and also make the most of our spatial encoding scheme, in that these configurations respect stronger spatial constraints. The number of sections that an itemset has to cover in order to be selected depends on a threshold n sec {1... 4}. Selecting interesting itemsets with this criteria is easily implemented and reduces the number of itemsets drastically (typically by a factor 10 to 100). 4.3 Itemset clustering Since the frequent itemset mining typically returns spatially and temporally overlapping itemsets, we merge them with a final clustering stage. Pairs of item-
8 VIII sets which jointly appear in more than F frames and share more than R regions are merged. Merging starts from the pair with the highest sum R + F. If any of the two itemsets in a pair is already part of a cluster, the other itemset is also added to that cluster. Otherwise, a new cluster is created. 5 Results and conclusion We present results on two music videos from Kylie Minogue [17, 18]. In particular the clip [17] makes an interesting test case for mining, because the singer passes by the same locations three times, and it even appears replicated several times in some frames. (figure 4, bottom row). Hence, we can test whether the miner picks up the reappearing objects. Furthermore, the scene gets more and more crowded with time, hence allowing to test the system s robustness to clutter. A few of the objects mined from the 1500 keyframes long clip [17] are shown in figure 4. The full miner was used, including motion grouping and itemset filtering with n sec = 2. The building in the first row is mined in spite of viewpoint changes, thereby showing this ability of our approach. The street scene in the second row is mined in spite of partial occlusion. Finally, in the third row the singer is mined, based on her shirt. The second video frame of this row is particularly interesting, since the singer appears in three copies and all of them were mined. Figure 5 shows typical results for mining with a fixed 40-neighborhood, i.e. without motion segmentation, akin to what proposed by [5]. As can be seen in subfigures 5a and 5b, only smaller parts of the large objects from figure 4 are mined. More examples of objects mined at the 40-neighborhood scale are shown in the other subfigures. Comparing these results to those in figure 4 highlights the benefits of defining the neighborhood for mining based on motion segmentation. Thanks to it, objects can be mined at their actual size (number of regions), which can vary widely from object to object, instead than being confined to a fixed, predefined size. Additionally, the singer was not mined when motion segmentation was turned off. The last row of 4 shows example objects mined from the clip [18] with a 40-neighbourhood. Our algorithm is naturally challenged by sparsely textured, non-rigid objects. As an example one could mention the legs of the main character. There are few features to begin with and the walking motion strongly changes the configuration of those, thus not the whole body is detected as object. In table 1 we compare quantitatively mining with motion segmentation, and with a fixed 40-neighborhood for the clip [17]. Note that there are only 8056 transactions when using motion segmentation, compared to more than half a million when using a fixed 40-neighborhood. While the runtime is very short for both cases, the method is faster for the 40-neighborhood case, because transactions are shorter and only shorter itemsets were frequent. Additionally, in the 40-NN case, the support threshold to mine even a small set of only 285 frequent itemsets has to be set more than a factor 10 lower. The mean time for performing motion segmentation matching + k-means clustering) was typically about 0.4s per frame, but obviously depends on the number of features detected per frame.







![[18]. Fig.](/docs-images/71/66142822/images/9-7.jpg "5.")







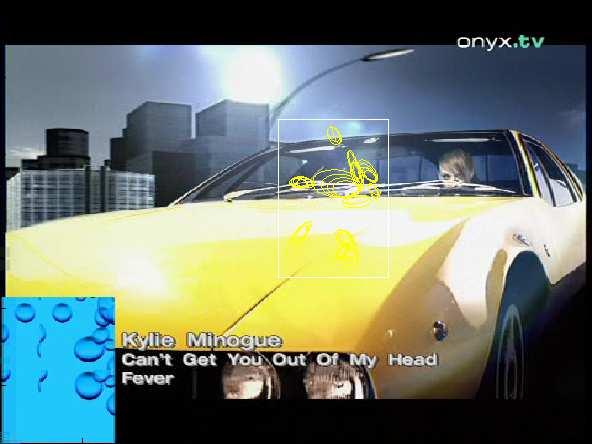





9 IX Fig. 4. Top three rows: results for clip [17]. Each row shows instances from one itemset cluster. Bottom row: results for clip [18]. Fig. 5. Examples for clip [17] mined at a fixed 40 neighborhood.
10 X Method Regions #T t FIMI s # FI # FI filt (n sec ) Clusters (F,R) Motion Seg s (2) 11 (2,2) 40-NN s (0) 55 (2,2) Table 1. Mining methods compared. Regions: number of regions in the entire video. #T : number of transactions. t FIMI : runtime of the frequent itemset mining. s: support threshold. #FI : number of frequent itemsets. FI filt: number of FI after filtering step with n sec sections. Clusters: number of clusters for itemset clustering with parameters F,R. In conclusion, we showed that our mining approach based on frequent itemsets is a suitable and efficient tool for video mining. Restricting the neighborhood by motion grouping has proven to be useful for detecting objects of different sizes at the same time. Future works include testing on larger datasets (e.g. TRECVID), defining more interestingness measures, and stronger customization of itemset mining algorithms to video data. References [1] Agrawal, R., Imielinski, T., Swami, A.: Mining Association Rules between Sets of Items in Large Databases. Proceedings of the 1993 ACM SIGMOD (1993) (26 28) [2] Mobasher, B., et al.: Effective personalization based on association rule discovery from web usage data. Web Information and Data Management 2001 (9-15) [3] Tešić, J., Newsam, S., Manjunath, B.S.: Mining Image Datasets using Perceptual Association Rules. In Proc. SIAM Sixth Workshop on Mining Scientific and Engineering Datasets in conjunction with SDM [4] Antonie, M., Zaïane, O., Coman, A.: Associative Classifiers for Medical Images. Lecture Notes in A.I. 2797, Mining Multimedia and Complex Data (2003) (68 83) [5] Sivic, J., Zisserman, A.: Video Data Mining Using Configurations of Viewpoint Invariant Regions. IEEE CVPR (2004), VOL 1, ( ) [6] Osian M., Van Gool L.: Video shot characterization. Mach. Vision Appl. 15: ( ) [7] Mikolajczyk, K., Schmid, C.: Scale and Affine invariant interest point detectors. IJCV 1(60) 2004 (63 86) [8] Matas, J., Chum, O., Urban, M., Pajdla, T.: Robust wide baseline stereo from maximally stable extremal regions. BMVC 2002 ( ). [9] Lowe, D.: Distinctive image features from scale invariant keypoints. IJCV 2(60) 2004 (91 110). [10] Leibe, B., Schiele, B.: Interleaved Object Categorization and Segmentation. In Proc. British Machine Vision Conference (BMVC 03). [11] Borgelt, C.: APriori. borgelt/apriori.html [12] Webb,A.: Statistical Pattern Recognition. Wiley, [13] Kaufman, L., Rousseeuw, P.: Finding Groups in Data: An Introduction to Cluster Analysis. Wiley, [14] Sivic, J., Zisserman, A.: Video Google: A text retrieval approach to object matching in videos. In Proc. ICCV, [15] Hand, D., Mannila, H., Smyth, P.: Principles of Data Mining. MIT Press [16] Tan, P., Kumar, V., Srivastava, J.: Selecting the right interestingness measure for association patterns. In Proc. ACM SIGKD [17] Minogue, K., Gondry, M.: Come Into My World. EMI [18] Minogue, K., Shadforth, D.: Can t Get You Out Of My Head. EMI 2001.
SEARCH BY MOBILE IMAGE BASED ON VISUAL AND SPATIAL CONSISTENCY. Xianglong Liu, Yihua Lou, Adams Wei Yu, Bo Lang
 SEARCH BY MOBILE IMAGE BASED ON VISUAL AND SPATIAL CONSISTENCY Xianglong Liu, Yihua Lou, Adams Wei Yu, Bo Lang State Key Laboratory of Software Development Environment Beihang University, Beijing 100191,
SEARCH BY MOBILE IMAGE BASED ON VISUAL AND SPATIAL CONSISTENCY Xianglong Liu, Yihua Lou, Adams Wei Yu, Bo Lang State Key Laboratory of Software Development Environment Beihang University, Beijing 100191,
Video Google: A Text Retrieval Approach to Object Matching in Videos
 Video Google: A Text Retrieval Approach to Object Matching in Videos Josef Sivic, Frederik Schaffalitzky, Andrew Zisserman Visual Geometry Group University of Oxford The vision Enable video, e.g. a feature
Video Google: A Text Retrieval Approach to Object Matching in Videos Josef Sivic, Frederik Schaffalitzky, Andrew Zisserman Visual Geometry Group University of Oxford The vision Enable video, e.g. a feature
Patch Descriptors. EE/CSE 576 Linda Shapiro
 Patch Descriptors EE/CSE 576 Linda Shapiro 1 How can we find corresponding points? How can we find correspondences? How do we describe an image patch? How do we describe an image patch? Patches with similar
Patch Descriptors EE/CSE 576 Linda Shapiro 1 How can we find corresponding points? How can we find correspondences? How do we describe an image patch? How do we describe an image patch? Patches with similar
Bundling Features for Large Scale Partial-Duplicate Web Image Search
 Bundling Features for Large Scale Partial-Duplicate Web Image Search Zhong Wu, Qifa Ke, Michael Isard, and Jian Sun Microsoft Research Abstract In state-of-the-art image retrieval systems, an image is
Bundling Features for Large Scale Partial-Duplicate Web Image Search Zhong Wu, Qifa Ke, Michael Isard, and Jian Sun Microsoft Research Abstract In state-of-the-art image retrieval systems, an image is
Specular 3D Object Tracking by View Generative Learning
 Specular 3D Object Tracking by View Generative Learning Yukiko Shinozuka, Francois de Sorbier and Hideo Saito Keio University 3-14-1 Hiyoshi, Kohoku-ku 223-8522 Yokohama, Japan shinozuka@hvrl.ics.keio.ac.jp
Specular 3D Object Tracking by View Generative Learning Yukiko Shinozuka, Francois de Sorbier and Hideo Saito Keio University 3-14-1 Hiyoshi, Kohoku-ku 223-8522 Yokohama, Japan shinozuka@hvrl.ics.keio.ac.jp
Evaluation and comparison of interest points/regions
 Introduction Evaluation and comparison of interest points/regions Quantitative evaluation of interest point/region detectors points / regions at the same relative location and area Repeatability rate :
Introduction Evaluation and comparison of interest points/regions Quantitative evaluation of interest point/region detectors points / regions at the same relative location and area Repeatability rate :
Discovering Visual Hierarchy through Unsupervised Learning Haider Razvi
 Discovering Visual Hierarchy through Unsupervised Learning Haider Razvi hrazvi@stanford.edu 1 Introduction: We present a method for discovering visual hierarchy in a set of images. Automatically grouping
Discovering Visual Hierarchy through Unsupervised Learning Haider Razvi hrazvi@stanford.edu 1 Introduction: We present a method for discovering visual hierarchy in a set of images. Automatically grouping
Detecting Printed and Handwritten Partial Copies of Line Drawings Embedded in Complex Backgrounds
 9 1th International Conference on Document Analysis and Recognition Detecting Printed and Handwritten Partial Copies of Line Drawings Embedded in Complex Backgrounds Weihan Sun, Koichi Kise Graduate School
9 1th International Conference on Document Analysis and Recognition Detecting Printed and Handwritten Partial Copies of Line Drawings Embedded in Complex Backgrounds Weihan Sun, Koichi Kise Graduate School
Patch Descriptors. CSE 455 Linda Shapiro
 Patch Descriptors CSE 455 Linda Shapiro How can we find corresponding points? How can we find correspondences? How do we describe an image patch? How do we describe an image patch? Patches with similar
Patch Descriptors CSE 455 Linda Shapiro How can we find corresponding points? How can we find correspondences? How do we describe an image patch? How do we describe an image patch? Patches with similar
Large Scale Image Retrieval
 Large Scale Image Retrieval Ondřej Chum and Jiří Matas Center for Machine Perception Czech Technical University in Prague Features Affine invariant features Efficient descriptors Corresponding regions
Large Scale Image Retrieval Ondřej Chum and Jiří Matas Center for Machine Perception Czech Technical University in Prague Features Affine invariant features Efficient descriptors Corresponding regions
An Evaluation of Volumetric Interest Points
 An Evaluation of Volumetric Interest Points Tsz-Ho YU Oliver WOODFORD Roberto CIPOLLA Machine Intelligence Lab Department of Engineering, University of Cambridge About this project We conducted the first
An Evaluation of Volumetric Interest Points Tsz-Ho YU Oliver WOODFORD Roberto CIPOLLA Machine Intelligence Lab Department of Engineering, University of Cambridge About this project We conducted the first
Beyond Bags of features Spatial information & Shape models
 Beyond Bags of features Spatial information & Shape models Jana Kosecka Many slides adapted from S. Lazebnik, FeiFei Li, Rob Fergus, and Antonio Torralba Detection, recognition (so far )! Bags of features
Beyond Bags of features Spatial information & Shape models Jana Kosecka Many slides adapted from S. Lazebnik, FeiFei Li, Rob Fergus, and Antonio Torralba Detection, recognition (so far )! Bags of features
Previously. Part-based and local feature models for generic object recognition. Bag-of-words model 4/20/2011
 Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Object of interest discovery in video sequences
 Object of interest discovery in video sequences A Design Project Report Presented to Engineering Division of the Graduate School Of Cornell University In Partial Fulfillment of the Requirements for the
Object of interest discovery in video sequences A Design Project Report Presented to Engineering Division of the Graduate School Of Cornell University In Partial Fulfillment of the Requirements for the
Instance-level recognition II.
 Reconnaissance d objets et vision artificielle 2010 Instance-level recognition II. Josef Sivic http://www.di.ens.fr/~josef INRIA, WILLOW, ENS/INRIA/CNRS UMR 8548 Laboratoire d Informatique, Ecole Normale
Reconnaissance d objets et vision artificielle 2010 Instance-level recognition II. Josef Sivic http://www.di.ens.fr/~josef INRIA, WILLOW, ENS/INRIA/CNRS UMR 8548 Laboratoire d Informatique, Ecole Normale
Beyond Bags of Features
 : for Recognizing Natural Scene Categories Matching and Modeling Seminar Instructed by Prof. Haim J. Wolfson School of Computer Science Tel Aviv University December 9 th, 2015
: for Recognizing Natural Scene Categories Matching and Modeling Seminar Instructed by Prof. Haim J. Wolfson School of Computer Science Tel Aviv University December 9 th, 2015
VK Multimedia Information Systems
 VK Multimedia Information Systems Mathias Lux, mlux@itec.uni-klu.ac.at Dienstags, 16.oo Uhr This work is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Agenda Evaluations
VK Multimedia Information Systems Mathias Lux, mlux@itec.uni-klu.ac.at Dienstags, 16.oo Uhr This work is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Agenda Evaluations
Beyond bags of features: Adding spatial information. Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba
 Beyond bags of features: Adding spatial information Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba Adding spatial information Forming vocabularies from pairs of nearby features doublets
Beyond bags of features: Adding spatial information Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba Adding spatial information Forming vocabularies from pairs of nearby features doublets
Visual Object Recognition
 Perceptual and Sensory Augmented Computing Visual Object Recognition Tutorial Visual Object Recognition Bastian Leibe Computer Vision Laboratory ETH Zurich Chicago, 14.07.2008 & Kristen Grauman Department
Perceptual and Sensory Augmented Computing Visual Object Recognition Tutorial Visual Object Recognition Bastian Leibe Computer Vision Laboratory ETH Zurich Chicago, 14.07.2008 & Kristen Grauman Department
Requirements for region detection
 Region detectors Requirements for region detection For region detection invariance transformations that should be considered are illumination changes, translation, rotation, scale and full affine transform
Region detectors Requirements for region detection For region detection invariance transformations that should be considered are illumination changes, translation, rotation, scale and full affine transform
Patch-based Object Recognition. Basic Idea
 Patch-based Object Recognition 1! Basic Idea Determine interest points in image Determine local image properties around interest points Use local image properties for object classification Example: Interest
Patch-based Object Recognition 1! Basic Idea Determine interest points in image Determine local image properties around interest points Use local image properties for object classification Example: Interest
III. VERVIEW OF THE METHODS
 An Analytical Study of SIFT and SURF in Image Registration Vivek Kumar Gupta, Kanchan Cecil Department of Electronics & Telecommunication, Jabalpur engineering college, Jabalpur, India comparing the distance
An Analytical Study of SIFT and SURF in Image Registration Vivek Kumar Gupta, Kanchan Cecil Department of Electronics & Telecommunication, Jabalpur engineering college, Jabalpur, India comparing the distance
Instance-level recognition part 2
 Visual Recognition and Machine Learning Summer School Paris 2011 Instance-level recognition part 2 Josef Sivic http://www.di.ens.fr/~josef INRIA, WILLOW, ENS/INRIA/CNRS UMR 8548 Laboratoire d Informatique,
Visual Recognition and Machine Learning Summer School Paris 2011 Instance-level recognition part 2 Josef Sivic http://www.di.ens.fr/~josef INRIA, WILLOW, ENS/INRIA/CNRS UMR 8548 Laboratoire d Informatique,
By Suren Manvelyan,
 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan,
By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan,
String distance for automatic image classification
 String distance for automatic image classification Nguyen Hong Thinh*, Le Vu Ha*, Barat Cecile** and Ducottet Christophe** *University of Engineering and Technology, Vietnam National University of HaNoi,
String distance for automatic image classification Nguyen Hong Thinh*, Le Vu Ha*, Barat Cecile** and Ducottet Christophe** *University of Engineering and Technology, Vietnam National University of HaNoi,
Improving Recognition through Object Sub-categorization
 Improving Recognition through Object Sub-categorization Al Mansur and Yoshinori Kuno Graduate School of Science and Engineering, Saitama University, 255 Shimo-Okubo, Sakura-ku, Saitama-shi, Saitama 338-8570,
Improving Recognition through Object Sub-categorization Al Mansur and Yoshinori Kuno Graduate School of Science and Engineering, Saitama University, 255 Shimo-Okubo, Sakura-ku, Saitama-shi, Saitama 338-8570,
Fuzzy based Multiple Dictionary Bag of Words for Image Classification
 Available online at www.sciencedirect.com Procedia Engineering 38 (2012 ) 2196 2206 International Conference on Modeling Optimisation and Computing Fuzzy based Multiple Dictionary Bag of Words for Image
Available online at www.sciencedirect.com Procedia Engineering 38 (2012 ) 2196 2206 International Conference on Modeling Optimisation and Computing Fuzzy based Multiple Dictionary Bag of Words for Image
Binary SIFT: Towards Efficient Feature Matching Verification for Image Search
 Binary SIFT: Towards Efficient Feature Matching Verification for Image Search Wengang Zhou 1, Houqiang Li 2, Meng Wang 3, Yijuan Lu 4, Qi Tian 1 Dept. of Computer Science, University of Texas at San Antonio
Binary SIFT: Towards Efficient Feature Matching Verification for Image Search Wengang Zhou 1, Houqiang Li 2, Meng Wang 3, Yijuan Lu 4, Qi Tian 1 Dept. of Computer Science, University of Texas at San Antonio
CS6670: Computer Vision
 CS6670: Computer Vision Noah Snavely Lecture 16: Bag-of-words models Object Bag of words Announcements Project 3: Eigenfaces due Wednesday, November 11 at 11:59pm solo project Final project presentations:
CS6670: Computer Vision Noah Snavely Lecture 16: Bag-of-words models Object Bag of words Announcements Project 3: Eigenfaces due Wednesday, November 11 at 11:59pm solo project Final project presentations:
Determinant of homography-matrix-based multiple-object recognition
 Determinant of homography-matrix-based multiple-object recognition 1 Nagachetan Bangalore, Madhu Kiran, Anil Suryaprakash Visio Ingenii Limited F2-F3 Maxet House Liverpool Road Luton, LU1 1RS United Kingdom
Determinant of homography-matrix-based multiple-object recognition 1 Nagachetan Bangalore, Madhu Kiran, Anil Suryaprakash Visio Ingenii Limited F2-F3 Maxet House Liverpool Road Luton, LU1 1RS United Kingdom
Content-Based Image Classification: A Non-Parametric Approach
 1 Content-Based Image Classification: A Non-Parametric Approach Paulo M. Ferreira, Mário A.T. Figueiredo, Pedro M. Q. Aguiar Abstract The rise of the amount imagery on the Internet, as well as in multimedia
1 Content-Based Image Classification: A Non-Parametric Approach Paulo M. Ferreira, Mário A.T. Figueiredo, Pedro M. Q. Aguiar Abstract The rise of the amount imagery on the Internet, as well as in multimedia
Robust Online Object Learning and Recognition by MSER Tracking
 Computer Vision Winter Workshop 28, Janez Perš (ed.) Moravske Toplice, Slovenia, February 4 6 Slovenian Pattern Recognition Society, Ljubljana, Slovenia Robust Online Object Learning and Recognition by
Computer Vision Winter Workshop 28, Janez Perš (ed.) Moravske Toplice, Slovenia, February 4 6 Slovenian Pattern Recognition Society, Ljubljana, Slovenia Robust Online Object Learning and Recognition by
Global localization from a single feature correspondence
 Global localization from a single feature correspondence Friedrich Fraundorfer and Horst Bischof Institute for Computer Graphics and Vision Graz University of Technology {fraunfri,bischof}@icg.tu-graz.ac.at
Global localization from a single feature correspondence Friedrich Fraundorfer and Horst Bischof Institute for Computer Graphics and Vision Graz University of Technology {fraunfri,bischof}@icg.tu-graz.ac.at
Speeding up the Detection of Line Drawings Using a Hash Table
 Speeding up the Detection of Line Drawings Using a Hash Table Weihan Sun, Koichi Kise 2 Graduate School of Engineering, Osaka Prefecture University, Japan sunweihan@m.cs.osakafu-u.ac.jp, 2 kise@cs.osakafu-u.ac.jp
Speeding up the Detection of Line Drawings Using a Hash Table Weihan Sun, Koichi Kise 2 Graduate School of Engineering, Osaka Prefecture University, Japan sunweihan@m.cs.osakafu-u.ac.jp, 2 kise@cs.osakafu-u.ac.jp
Local invariant features
 Local invariant features Tuesday, Oct 28 Kristen Grauman UT-Austin Today Some more Pset 2 results Pset 2 returned, pick up solutions Pset 3 is posted, due 11/11 Local invariant features Detection of interest
Local invariant features Tuesday, Oct 28 Kristen Grauman UT-Austin Today Some more Pset 2 results Pset 2 returned, pick up solutions Pset 3 is posted, due 11/11 Local invariant features Detection of interest
SIFT: SCALE INVARIANT FEATURE TRANSFORM SURF: SPEEDED UP ROBUST FEATURES BASHAR ALSADIK EOS DEPT. TOPMAP M13 3D GEOINFORMATION FROM IMAGES 2014
 SIFT: SCALE INVARIANT FEATURE TRANSFORM SURF: SPEEDED UP ROBUST FEATURES BASHAR ALSADIK EOS DEPT. TOPMAP M13 3D GEOINFORMATION FROM IMAGES 2014 SIFT SIFT: Scale Invariant Feature Transform; transform image
SIFT: SCALE INVARIANT FEATURE TRANSFORM SURF: SPEEDED UP ROBUST FEATURES BASHAR ALSADIK EOS DEPT. TOPMAP M13 3D GEOINFORMATION FROM IMAGES 2014 SIFT SIFT: Scale Invariant Feature Transform; transform image
Part-based and local feature models for generic object recognition
 Part-based and local feature models for generic object recognition May 28 th, 2015 Yong Jae Lee UC Davis Announcements PS2 grades up on SmartSite PS2 stats: Mean: 80.15 Standard Dev: 22.77 Vote on piazza
Part-based and local feature models for generic object recognition May 28 th, 2015 Yong Jae Lee UC Davis Announcements PS2 grades up on SmartSite PS2 stats: Mean: 80.15 Standard Dev: 22.77 Vote on piazza
Preliminary Local Feature Selection by Support Vector Machine for Bag of Features
 Preliminary Local Feature Selection by Support Vector Machine for Bag of Features Tetsu Matsukawa Koji Suzuki Takio Kurita :University of Tsukuba :National Institute of Advanced Industrial Science and
Preliminary Local Feature Selection by Support Vector Machine for Bag of Features Tetsu Matsukawa Koji Suzuki Takio Kurita :University of Tsukuba :National Institute of Advanced Industrial Science and
A Framework for Multiple Radar and Multiple 2D/3D Camera Fusion
 A Framework for Multiple Radar and Multiple 2D/3D Camera Fusion Marek Schikora 1 and Benedikt Romba 2 1 FGAN-FKIE, Germany 2 Bonn University, Germany schikora@fgan.de, romba@uni-bonn.de Abstract: In this
A Framework for Multiple Radar and Multiple 2D/3D Camera Fusion Marek Schikora 1 and Benedikt Romba 2 1 FGAN-FKIE, Germany 2 Bonn University, Germany schikora@fgan.de, romba@uni-bonn.de Abstract: In this
SUMMARY: DISTINCTIVE IMAGE FEATURES FROM SCALE- INVARIANT KEYPOINTS
 SUMMARY: DISTINCTIVE IMAGE FEATURES FROM SCALE- INVARIANT KEYPOINTS Cognitive Robotics Original: David G. Lowe, 004 Summary: Coen van Leeuwen, s1460919 Abstract: This article presents a method to extract
SUMMARY: DISTINCTIVE IMAGE FEATURES FROM SCALE- INVARIANT KEYPOINTS Cognitive Robotics Original: David G. Lowe, 004 Summary: Coen van Leeuwen, s1460919 Abstract: This article presents a method to extract
Evaluation of GIST descriptors for web scale image search
 Evaluation of GIST descriptors for web scale image search Matthijs Douze Hervé Jégou, Harsimrat Sandhawalia, Laurent Amsaleg and Cordelia Schmid INRIA Grenoble, France July 9, 2009 Evaluation of GIST for
Evaluation of GIST descriptors for web scale image search Matthijs Douze Hervé Jégou, Harsimrat Sandhawalia, Laurent Amsaleg and Cordelia Schmid INRIA Grenoble, France July 9, 2009 Evaluation of GIST for
Multiple-Choice Questionnaire Group C
 Family name: Vision and Machine-Learning Given name: 1/28/2011 Multiple-Choice naire Group C No documents authorized. There can be several right answers to a question. Marking-scheme: 2 points if all right
Family name: Vision and Machine-Learning Given name: 1/28/2011 Multiple-Choice naire Group C No documents authorized. There can be several right answers to a question. Marking-scheme: 2 points if all right
Similar Fragment Retrieval of Animations by a Bag-of-features Approach
 Similar Fragment Retrieval of Animations by a Bag-of-features Approach Weihan Sun, Koichi Kise Dept. Computer Science and Intelligent Systems Osaka Prefecture University Osaka, Japan sunweihan@m.cs.osakafu-u.ac.jp,
Similar Fragment Retrieval of Animations by a Bag-of-features Approach Weihan Sun, Koichi Kise Dept. Computer Science and Intelligent Systems Osaka Prefecture University Osaka, Japan sunweihan@m.cs.osakafu-u.ac.jp,
Salient Visual Features to Help Close the Loop in 6D SLAM
 Visual Features to Help Close the Loop in 6D SLAM Lars Kunze, Kai Lingemann, Andreas Nüchter, and Joachim Hertzberg University of Osnabrück, Institute of Computer Science Knowledge Based Systems Research
Visual Features to Help Close the Loop in 6D SLAM Lars Kunze, Kai Lingemann, Andreas Nüchter, and Joachim Hertzberg University of Osnabrück, Institute of Computer Science Knowledge Based Systems Research
Image Retrieval (Matching at Large Scale)
") Image Retrieval (Matching at Large Scale) Image Retrieval (matching at large scale) At a large scale the problem of matching between similar images translates into the problem of retrieving similar images
Image Retrieval (Matching at Large Scale) Image Retrieval (matching at large scale) At a large scale the problem of matching between similar images translates into the problem of retrieving similar images
IMAGE RETRIEVAL USING VLAD WITH MULTIPLE FEATURES
 IMAGE RETRIEVAL USING VLAD WITH MULTIPLE FEATURES Pin-Syuan Huang, Jing-Yi Tsai, Yu-Fang Wang, and Chun-Yi Tsai Department of Computer Science and Information Engineering, National Taitung University,
IMAGE RETRIEVAL USING VLAD WITH MULTIPLE FEATURES Pin-Syuan Huang, Jing-Yi Tsai, Yu-Fang Wang, and Chun-Yi Tsai Department of Computer Science and Information Engineering, National Taitung University,
Large scale object/scene recognition
 Large scale object/scene recognition Image dataset: > 1 million images query Image search system ranked image list Each image described by approximately 2000 descriptors 2 10 9 descriptors to index! Database
Large scale object/scene recognition Image dataset: > 1 million images query Image search system ranked image list Each image described by approximately 2000 descriptors 2 10 9 descriptors to index! Database
Structure of Association Rule Classifiers: a Review
 Structure of Association Rule Classifiers: a Review Koen Vanhoof Benoît Depaire Transportation Research Institute (IMOB), University Hasselt 3590 Diepenbeek, Belgium koen.vanhoof@uhasselt.be benoit.depaire@uhasselt.be
Structure of Association Rule Classifiers: a Review Koen Vanhoof Benoît Depaire Transportation Research Institute (IMOB), University Hasselt 3590 Diepenbeek, Belgium koen.vanhoof@uhasselt.be benoit.depaire@uhasselt.be
Selection of Scale-Invariant Parts for Object Class Recognition
 Selection of Scale-Invariant Parts for Object Class Recognition Gy. Dorkó and C. Schmid INRIA Rhône-Alpes, GRAVIR-CNRS 655, av. de l Europe, 3833 Montbonnot, France fdorko,schmidg@inrialpes.fr Abstract
Selection of Scale-Invariant Parts for Object Class Recognition Gy. Dorkó and C. Schmid INRIA Rhône-Alpes, GRAVIR-CNRS 655, av. de l Europe, 3833 Montbonnot, France fdorko,schmidg@inrialpes.fr Abstract
Bridging the Gap Between Local and Global Approaches for 3D Object Recognition. Isma Hadji G. N. DeSouza
 Bridging the Gap Between Local and Global Approaches for 3D Object Recognition Isma Hadji G. N. DeSouza Outline Introduction Motivation Proposed Methods: 1. LEFT keypoint Detector 2. LGS Feature Descriptor
Bridging the Gap Between Local and Global Approaches for 3D Object Recognition Isma Hadji G. N. DeSouza Outline Introduction Motivation Proposed Methods: 1. LEFT keypoint Detector 2. LGS Feature Descriptor
Image Retrieval with a Visual Thesaurus
 2010 Digital Image Computing: Techniques and Applications Image Retrieval with a Visual Thesaurus Yanzhi Chen, Anthony Dick and Anton van den Hengel School of Computer Science The University of Adelaide
2010 Digital Image Computing: Techniques and Applications Image Retrieval with a Visual Thesaurus Yanzhi Chen, Anthony Dick and Anton van den Hengel School of Computer Science The University of Adelaide
CS229: Action Recognition in Tennis
 CS229: Action Recognition in Tennis Aman Sikka Stanford University Stanford, CA 94305 Rajbir Kataria Stanford University Stanford, CA 94305 asikka@stanford.edu rkataria@stanford.edu 1. Motivation As active
CS229: Action Recognition in Tennis Aman Sikka Stanford University Stanford, CA 94305 Rajbir Kataria Stanford University Stanford, CA 94305 asikka@stanford.edu rkataria@stanford.edu 1. Motivation As active
Computer Vision for HCI. Topics of This Lecture
 Computer Vision for HCI Interest Points Topics of This Lecture Local Invariant Features Motivation Requirements, Invariances Keypoint Localization Features from Accelerated Segment Test (FAST) Harris Shi-Tomasi
Computer Vision for HCI Interest Points Topics of This Lecture Local Invariant Features Motivation Requirements, Invariances Keypoint Localization Features from Accelerated Segment Test (FAST) Harris Shi-Tomasi
Image Feature Evaluation for Contents-based Image Retrieval
 Image Feature Evaluation for Contents-based Image Retrieval Adam Kuffner and Antonio Robles-Kelly, Department of Theoretical Physics, Australian National University, Canberra, Australia Vision Science,
Image Feature Evaluation for Contents-based Image Retrieval Adam Kuffner and Antonio Robles-Kelly, Department of Theoretical Physics, Australian National University, Canberra, Australia Vision Science,
From Structure-from-Motion Point Clouds to Fast Location Recognition
 From Structure-from-Motion Point Clouds to Fast Location Recognition Arnold Irschara1;2, Christopher Zach2, Jan-Michael Frahm2, Horst Bischof1 1Graz University of Technology firschara, bischofg@icg.tugraz.at
From Structure-from-Motion Point Clouds to Fast Location Recognition Arnold Irschara1;2, Christopher Zach2, Jan-Michael Frahm2, Horst Bischof1 1Graz University of Technology firschara, bischofg@icg.tugraz.at
Mining Quantitative Maximal Hyperclique Patterns: A Summary of Results
 Mining Quantitative Maximal Hyperclique Patterns: A Summary of Results Yaochun Huang, Hui Xiong, Weili Wu, and Sam Y. Sung 3 Computer Science Department, University of Texas - Dallas, USA, {yxh03800,wxw0000}@utdallas.edu
Mining Quantitative Maximal Hyperclique Patterns: A Summary of Results Yaochun Huang, Hui Xiong, Weili Wu, and Sam Y. Sung 3 Computer Science Department, University of Texas - Dallas, USA, {yxh03800,wxw0000}@utdallas.edu
Local Image Features
 Local Image Features Ali Borji UWM Many slides from James Hayes, Derek Hoiem and Grauman&Leibe 2008 AAAI Tutorial Overview of Keypoint Matching 1. Find a set of distinctive key- points A 1 A 2 A 3 B 3
Local Image Features Ali Borji UWM Many slides from James Hayes, Derek Hoiem and Grauman&Leibe 2008 AAAI Tutorial Overview of Keypoint Matching 1. Find a set of distinctive key- points A 1 A 2 A 3 B 3
Sampling Strategies for Object Classifica6on. Gautam Muralidhar
 Sampling Strategies for Object Classifica6on Gautam Muralidhar Reference papers The Pyramid Match Kernel Grauman and Darrell Approximated Correspondences in High Dimensions Grauman and Darrell Video Google
Sampling Strategies for Object Classifica6on Gautam Muralidhar Reference papers The Pyramid Match Kernel Grauman and Darrell Approximated Correspondences in High Dimensions Grauman and Darrell Video Google
 5*4%),-
5*4%),- Video Google faces. Josef Sivic, Mark Everingham, Andrew Zisserman. Visual Geometry Group University of Oxford
 Video Google faces Josef Sivic, Mark Everingham, Andrew Zisserman Visual Geometry Group University of Oxford The objective Retrieve all shots in a video, e.g. a feature length film, containing a particular
Video Google faces Josef Sivic, Mark Everingham, Andrew Zisserman Visual Geometry Group University of Oxford The objective Retrieve all shots in a video, e.g. a feature length film, containing a particular
Classifying Images with Visual/Textual Cues. By Steven Kappes and Yan Cao
 Classifying Images with Visual/Textual Cues By Steven Kappes and Yan Cao Motivation Image search Building large sets of classified images Robotics Background Object recognition is unsolved Deformable shaped
Classifying Images with Visual/Textual Cues By Steven Kappes and Yan Cao Motivation Image search Building large sets of classified images Robotics Background Object recognition is unsolved Deformable shaped
Visuelle Perzeption für Mensch- Maschine Schnittstellen
 Visuelle Perzeption für Mensch- Maschine Schnittstellen Vorlesung, WS 2009 Prof. Dr. Rainer Stiefelhagen Dr. Edgar Seemann Institut für Anthropomatik Universität Karlsruhe (TH) http://cvhci.ira.uka.de
Visuelle Perzeption für Mensch- Maschine Schnittstellen Vorlesung, WS 2009 Prof. Dr. Rainer Stiefelhagen Dr. Edgar Seemann Institut für Anthropomatik Universität Karlsruhe (TH) http://cvhci.ira.uka.de
Hamming embedding and weak geometric consistency for large scale image search
 Hamming embedding and weak geometric consistency for large scale image search Herve Jegou, Matthijs Douze, and Cordelia Schmid INRIA Grenoble, LEAR, LJK firstname.lastname@inria.fr Abstract. This paper
Hamming embedding and weak geometric consistency for large scale image search Herve Jegou, Matthijs Douze, and Cordelia Schmid INRIA Grenoble, LEAR, LJK firstname.lastname@inria.fr Abstract. This paper
UNSUPERVISED OBJECT MATCHING AND CATEGORIZATION VIA AGGLOMERATIVE CORRESPONDENCE CLUSTERING
 UNSUPERVISED OBJECT MATCHING AND CATEGORIZATION VIA AGGLOMERATIVE CORRESPONDENCE CLUSTERING Md. Shafayat Hossain, Ahmedullah Aziz and Mohammad Wahidur Rahman Department of Electrical and Electronic Engineering,
UNSUPERVISED OBJECT MATCHING AND CATEGORIZATION VIA AGGLOMERATIVE CORRESPONDENCE CLUSTERING Md. Shafayat Hossain, Ahmedullah Aziz and Mohammad Wahidur Rahman Department of Electrical and Electronic Engineering,
A NEW FEATURE BASED IMAGE REGISTRATION ALGORITHM INTRODUCTION
 A NEW FEATURE BASED IMAGE REGISTRATION ALGORITHM Karthik Krish Stuart Heinrich Wesley E. Snyder Halil Cakir Siamak Khorram North Carolina State University Raleigh, 27695 kkrish@ncsu.edu sbheinri@ncsu.edu
A NEW FEATURE BASED IMAGE REGISTRATION ALGORITHM Karthik Krish Stuart Heinrich Wesley E. Snyder Halil Cakir Siamak Khorram North Carolina State University Raleigh, 27695 kkrish@ncsu.edu sbheinri@ncsu.edu
Lecture 12 Recognition
 Institute of Informatics Institute of Neuroinformatics Lecture 12 Recognition Davide Scaramuzza 1 Lab exercise today replaced by Deep Learning Tutorial Room ETH HG E 1.1 from 13:15 to 15:00 Optional lab
Institute of Informatics Institute of Neuroinformatics Lecture 12 Recognition Davide Scaramuzza 1 Lab exercise today replaced by Deep Learning Tutorial Room ETH HG E 1.1 from 13:15 to 15:00 Optional lab
INRIA-LEAR S VIDEO COPY DETECTION SYSTEM. INRIA LEAR, LJK Grenoble, France 1 Copyright detection task 2 High-level feature extraction task
 INRIA-LEAR S VIDEO COPY DETECTION SYSTEM Matthijs Douze, Adrien Gaidon 2, Herve Jegou, Marcin Marszałek 2 and Cordelia Schmid,2 INRIA LEAR, LJK Grenoble, France Copyright detection task 2 High-level feature
INRIA-LEAR S VIDEO COPY DETECTION SYSTEM Matthijs Douze, Adrien Gaidon 2, Herve Jegou, Marcin Marszałek 2 and Cordelia Schmid,2 INRIA LEAR, LJK Grenoble, France Copyright detection task 2 High-level feature
Large-scale visual recognition The bag-of-words representation
 Large-scale visual recognition The bag-of-words representation Florent Perronnin, XRCE Hervé Jégou, INRIA CVPR tutorial June 16, 2012 Outline Bag-of-words Large or small vocabularies? Extensions for instance-level
Large-scale visual recognition The bag-of-words representation Florent Perronnin, XRCE Hervé Jégou, INRIA CVPR tutorial June 16, 2012 Outline Bag-of-words Large or small vocabularies? Extensions for instance-level
Introduction. Introduction. Related Research. SIFT method. SIFT method. Distinctive Image Features from Scale-Invariant. Scale.
 Distinctive Image Features from Scale-Invariant Keypoints David G. Lowe presented by, Sudheendra Invariance Intensity Scale Rotation Affine View point Introduction Introduction SIFT (Scale Invariant Feature
Distinctive Image Features from Scale-Invariant Keypoints David G. Lowe presented by, Sudheendra Invariance Intensity Scale Rotation Affine View point Introduction Introduction SIFT (Scale Invariant Feature
Generalized RANSAC framework for relaxed correspondence problems
 Generalized RANSAC framework for relaxed correspondence problems Wei Zhang and Jana Košecká Department of Computer Science George Mason University Fairfax, VA 22030 {wzhang2,kosecka}@cs.gmu.edu Abstract
Generalized RANSAC framework for relaxed correspondence problems Wei Zhang and Jana Košecká Department of Computer Science George Mason University Fairfax, VA 22030 {wzhang2,kosecka}@cs.gmu.edu Abstract
Local features and image matching. Prof. Xin Yang HUST
 Local features and image matching Prof. Xin Yang HUST Last time RANSAC for robust geometric transformation estimation Translation, Affine, Homography Image warping Given a 2D transformation T and a source
Local features and image matching Prof. Xin Yang HUST Last time RANSAC for robust geometric transformation estimation Translation, Affine, Homography Image warping Given a 2D transformation T and a source
Scale Invariant Feature Transform
 Scale Invariant Feature Transform Why do we care about matching features? Camera calibration Stereo Tracking/SFM Image moiaicing Object/activity Recognition Objection representation and recognition Image
Scale Invariant Feature Transform Why do we care about matching features? Camera calibration Stereo Tracking/SFM Image moiaicing Object/activity Recognition Objection representation and recognition Image
The SIFT (Scale Invariant Feature
 The SIFT (Scale Invariant Feature Transform) Detector and Descriptor developed by David Lowe University of British Columbia Initial paper ICCV 1999 Newer journal paper IJCV 2004 Review: Matt Brown s Canonical
The SIFT (Scale Invariant Feature Transform) Detector and Descriptor developed by David Lowe University of British Columbia Initial paper ICCV 1999 Newer journal paper IJCV 2004 Review: Matt Brown s Canonical
Perception IV: Place Recognition, Line Extraction
 Perception IV: Place Recognition, Line Extraction Davide Scaramuzza University of Zurich Margarita Chli, Paul Furgale, Marco Hutter, Roland Siegwart 1 Outline of Today s lecture Place recognition using
Perception IV: Place Recognition, Line Extraction Davide Scaramuzza University of Zurich Margarita Chli, Paul Furgale, Marco Hutter, Roland Siegwart 1 Outline of Today s lecture Place recognition using
Part based models for recognition. Kristen Grauman
 Part based models for recognition Kristen Grauman UT Austin Limitations of window-based models Not all objects are box-shaped Assuming specific 2d view of object Local components themselves do not necessarily
Part based models for recognition Kristen Grauman UT Austin Limitations of window-based models Not all objects are box-shaped Assuming specific 2d view of object Local components themselves do not necessarily
State-of-the-Art: Transformation Invariant Descriptors. Asha S, Sreeraj M
 International Journal of Scientific & Engineering Research, Volume 4, Issue ş, 2013 1994 State-of-the-Art: Transformation Invariant Descriptors Asha S, Sreeraj M Abstract As the popularity of digital videos
International Journal of Scientific & Engineering Research, Volume 4, Issue ş, 2013 1994 State-of-the-Art: Transformation Invariant Descriptors Asha S, Sreeraj M Abstract As the popularity of digital videos
Large-scale Image Search and location recognition Geometric Min-Hashing. Jonathan Bidwell
 Large-scale Image Search and location recognition Geometric Min-Hashing Jonathan Bidwell Nov 3rd 2009 UNC Chapel Hill Large scale + Location Short story... Finding similar photos See: Microsoft PhotoSynth
Large-scale Image Search and location recognition Geometric Min-Hashing Jonathan Bidwell Nov 3rd 2009 UNC Chapel Hill Large scale + Location Short story... Finding similar photos See: Microsoft PhotoSynth
Region Graphs for Organizing Image Collections
 Region Graphs for Organizing Image Collections Alexander Ladikos 1, Edmond Boyer 2, Nassir Navab 1, and Slobodan Ilic 1 1 Chair for Computer Aided Medical Procedures, Technische Universität München 2 Perception
Region Graphs for Organizing Image Collections Alexander Ladikos 1, Edmond Boyer 2, Nassir Navab 1, and Slobodan Ilic 1 1 Chair for Computer Aided Medical Procedures, Technische Universität München 2 Perception
Combining Selective Search Segmentation and Random Forest for Image Classification
 Combining Selective Search Segmentation and Random Forest for Image Classification Gediminas Bertasius November 24, 2013 1 Problem Statement Random Forest algorithm have been successfully used in many
Combining Selective Search Segmentation and Random Forest for Image Classification Gediminas Bertasius November 24, 2013 1 Problem Statement Random Forest algorithm have been successfully used in many
Frequent Inner-Class Approach: A Semi-supervised Learning Technique for One-shot Learning
 Frequent Inner-Class Approach: A Semi-supervised Learning Technique for One-shot Learning Izumi Suzuki, Koich Yamada, Muneyuki Unehara Nagaoka University of Technology, 1603-1, Kamitomioka Nagaoka, Niigata
Frequent Inner-Class Approach: A Semi-supervised Learning Technique for One-shot Learning Izumi Suzuki, Koich Yamada, Muneyuki Unehara Nagaoka University of Technology, 1603-1, Kamitomioka Nagaoka, Niigata
3D model search and pose estimation from single images using VIP features
 3D model search and pose estimation from single images using VIP features Changchang Wu 2, Friedrich Fraundorfer 1, 1 Department of Computer Science ETH Zurich, Switzerland {fraundorfer, marc.pollefeys}@inf.ethz.ch
3D model search and pose estimation from single images using VIP features Changchang Wu 2, Friedrich Fraundorfer 1, 1 Department of Computer Science ETH Zurich, Switzerland {fraundorfer, marc.pollefeys}@inf.ethz.ch
Vision and Image Processing Lab., CRV Tutorial day- May 30, 2010 Ottawa, Canada
 Spatio-Temporal Salient Features Amir H. Shabani Vision and Image Processing Lab., University of Waterloo, ON CRV Tutorial day- May 30, 2010 Ottawa, Canada 1 Applications Automated surveillance for scene
Spatio-Temporal Salient Features Amir H. Shabani Vision and Image Processing Lab., University of Waterloo, ON CRV Tutorial day- May 30, 2010 Ottawa, Canada 1 Applications Automated surveillance for scene
Tensor Decomposition of Dense SIFT Descriptors in Object Recognition
 Tensor Decomposition of Dense SIFT Descriptors in Object Recognition Tan Vo 1 and Dat Tran 1 and Wanli Ma 1 1- Faculty of Education, Science, Technology and Mathematics University of Canberra, Australia
Tensor Decomposition of Dense SIFT Descriptors in Object Recognition Tan Vo 1 and Dat Tran 1 and Wanli Ma 1 1- Faculty of Education, Science, Technology and Mathematics University of Canberra, Australia
CAP 5415 Computer Vision Fall 2012
 CAP 5415 Computer Vision Fall 01 Dr. Mubarak Shah Univ. of Central Florida Office 47-F HEC Lecture-5 SIFT: David Lowe, UBC SIFT - Key Point Extraction Stands for scale invariant feature transform Patented
CAP 5415 Computer Vision Fall 01 Dr. Mubarak Shah Univ. of Central Florida Office 47-F HEC Lecture-5 SIFT: David Lowe, UBC SIFT - Key Point Extraction Stands for scale invariant feature transform Patented
Signboard Optical Character Recognition
 1 Signboard Optical Character Recognition Isaac Wu and Hsiao-Chen Chang isaacwu@stanford.edu, hcchang7@stanford.edu Abstract A text recognition scheme specifically for signboard recognition is presented.
1 Signboard Optical Character Recognition Isaac Wu and Hsiao-Chen Chang isaacwu@stanford.edu, hcchang7@stanford.edu Abstract A text recognition scheme specifically for signboard recognition is presented.
IMPROVING SPATIO-TEMPORAL FEATURE EXTRACTION TECHNIQUES AND THEIR APPLICATIONS IN ACTION CLASSIFICATION. Maral Mesmakhosroshahi, Joohee Kim
 IMPROVING SPATIO-TEMPORAL FEATURE EXTRACTION TECHNIQUES AND THEIR APPLICATIONS IN ACTION CLASSIFICATION Maral Mesmakhosroshahi, Joohee Kim Department of Electrical and Computer Engineering Illinois Institute
IMPROVING SPATIO-TEMPORAL FEATURE EXTRACTION TECHNIQUES AND THEIR APPLICATIONS IN ACTION CLASSIFICATION Maral Mesmakhosroshahi, Joohee Kim Department of Electrical and Computer Engineering Illinois Institute
Web Page Classification using FP Growth Algorithm Akansha Garg,Computer Science Department Swami Vivekanad Subharti University,Meerut, India
 Web Page Classification using FP Growth Algorithm Akansha Garg,Computer Science Department Swami Vivekanad Subharti University,Meerut, India Abstract - The primary goal of the web site is to provide the
Web Page Classification using FP Growth Algorithm Akansha Garg,Computer Science Department Swami Vivekanad Subharti University,Meerut, India Abstract - The primary goal of the web site is to provide the
TEXTURE CLASSIFICATION METHODS: A REVIEW
 TEXTURE CLASSIFICATION METHODS: A REVIEW Ms. Sonal B. Bhandare Prof. Dr. S. M. Kamalapur M.E. Student Associate Professor Deparment of Computer Engineering, Deparment of Computer Engineering, K. K. Wagh
TEXTURE CLASSIFICATION METHODS: A REVIEW Ms. Sonal B. Bhandare Prof. Dr. S. M. Kamalapur M.E. Student Associate Professor Deparment of Computer Engineering, Deparment of Computer Engineering, K. K. Wagh
Lecture 12 Recognition. Davide Scaramuzza
 Lecture 12 Recognition Davide Scaramuzza Oral exam dates UZH January 19-20 ETH 30.01 to 9.02 2017 (schedule handled by ETH) Exam location Davide Scaramuzza s office: Andreasstrasse 15, 2.10, 8050 Zurich
Lecture 12 Recognition Davide Scaramuzza Oral exam dates UZH January 19-20 ETH 30.01 to 9.02 2017 (schedule handled by ETH) Exam location Davide Scaramuzza s office: Andreasstrasse 15, 2.10, 8050 Zurich
Scale Invariant Feature Transform
 Why do we care about matching features? Scale Invariant Feature Transform Camera calibration Stereo Tracking/SFM Image moiaicing Object/activity Recognition Objection representation and recognition Automatic
Why do we care about matching features? Scale Invariant Feature Transform Camera calibration Stereo Tracking/SFM Image moiaicing Object/activity Recognition Objection representation and recognition Automatic
Content Based Image Retrieval (CBIR) Using Segmentation Process
 Using Segmentation Process") Content Based Image Retrieval (CBIR) Using Segmentation Process R.Gnanaraja 1, B. Jagadishkumar 2, S.T. Premkumar 3, B. Sunil kumar 4 1, 2, 3, 4 PG Scholar, Department of Computer Science and Engineering,
Content Based Image Retrieval (CBIR) Using Segmentation Process R.Gnanaraja 1, B. Jagadishkumar 2, S.T. Premkumar 3, B. Sunil kumar 4 1, 2, 3, 4 PG Scholar, Department of Computer Science and Engineering,
Aggregated Color Descriptors for Land Use Classification
 Aggregated Color Descriptors for Land Use Classification Vedran Jovanović and Vladimir Risojević Abstract In this paper we propose and evaluate aggregated color descriptors for land use classification
Aggregated Color Descriptors for Land Use Classification Vedran Jovanović and Vladimir Risojević Abstract In this paper we propose and evaluate aggregated color descriptors for land use classification
Research on Recognition and Classification of Moving Objects in Mixed Traffic Based on Video Detection
 Hu, Qu, Li and Wang 1 Research on Recognition and Classification of Moving Objects in Mixed Traffic Based on Video Detection Hongyu Hu (corresponding author) College of Transportation, Jilin University,
Hu, Qu, Li and Wang 1 Research on Recognition and Classification of Moving Objects in Mixed Traffic Based on Video Detection Hongyu Hu (corresponding author) College of Transportation, Jilin University,
Image Features: Detection, Description, and Matching and their Applications
 Image Features: Detection, Description, and Matching and their Applications Image Representation: Global Versus Local Features Features/ keypoints/ interset points are interesting locations in the image.
Image Features: Detection, Description, and Matching and their Applications Image Representation: Global Versus Local Features Features/ keypoints/ interset points are interesting locations in the image.
Recognition of Animal Skin Texture Attributes in the Wild. Amey Dharwadker (aap2174) Kai Zhang (kz2213)
 Kai Zhang (kz2213)") Recognition of Animal Skin Texture Attributes in the Wild Amey Dharwadker (aap2174) Kai Zhang (kz2213) Motivation Patterns and textures are have an important role in object description and understanding
Recognition of Animal Skin Texture Attributes in the Wild Amey Dharwadker (aap2174) Kai Zhang (kz2213) Motivation Patterns and textures are have an important role in object description and understanding
Detecting and Segmenting Humans in Crowded Scenes
 Detecting and Segmenting Humans in Crowded Scenes Mikel D. Rodriguez University of Central Florida 4000 Central Florida Blvd Orlando, Florida, 32816 mikel@cs.ucf.edu Mubarak Shah University of Central
Detecting and Segmenting Humans in Crowded Scenes Mikel D. Rodriguez University of Central Florida 4000 Central Florida Blvd Orlando, Florida, 32816 mikel@cs.ucf.edu Mubarak Shah University of Central
Motion illusion, rotating snakes
 Motion illusion, rotating snakes Local features: main components 1) Detection: Find a set of distinctive key points. 2) Description: Extract feature descriptor around each interest point as vector. x 1
Motion illusion, rotating snakes Local features: main components 1) Detection: Find a set of distinctive key points. 2) Description: Extract feature descriptor around each interest point as vector. x 1
Object Recognition with Invariant Features
 Object Recognition with Invariant Features Definition: Identify objects or scenes and determine their pose and model parameters Applications Industrial automation and inspection Mobile robots, toys, user
Object Recognition with Invariant Features Definition: Identify objects or scenes and determine their pose and model parameters Applications Industrial automation and inspection Mobile robots, toys, user
Feature Detection. Raul Queiroz Feitosa. 3/30/2017 Feature Detection 1
 Feature Detection Raul Queiroz Feitosa 3/30/2017 Feature Detection 1 Objetive This chapter discusses the correspondence problem and presents approaches to solve it. 3/30/2017 Feature Detection 2 Outline
Feature Detection Raul Queiroz Feitosa 3/30/2017 Feature Detection 1 Objetive This chapter discusses the correspondence problem and presents approaches to solve it. 3/30/2017 Feature Detection 2 Outline
Motion Estimation and Optical Flow Tracking
 Image Matching Image Retrieval Object Recognition Motion Estimation and Optical Flow Tracking Example: Mosiacing (Panorama) M. Brown and D. G. Lowe. Recognising Panoramas. ICCV 2003 Example 3D Reconstruction
Image Matching Image Retrieval Object Recognition Motion Estimation and Optical Flow Tracking Example: Mosiacing (Panorama) M. Brown and D. G. Lowe. Recognising Panoramas. ICCV 2003 Example 3D Reconstruction