Multimedia Database Systems
|
|
|
- Melina Sherman
- 6 years ago
- Views:
Transcription
1 Department of Informatics Aristotle University of Thessaloniki Fall Multimedia Database Systems Indexing Part A Multidimensional Indexing Techniques
2 Outline Motivation Multidimensional indexing R-tree R*-tree X-tree Pyramid technique Processing Nearest-Neighbor queries Conclusions
3 Motivation In many real-life applications objects are represented as multidimensional points: Spatial databases (e.g., points in 2D or 3D space) Multidimensional databases (each record is considered a point in n-d space) Multimedia databases (e.g., feature vectors are extracted from images, audio files)

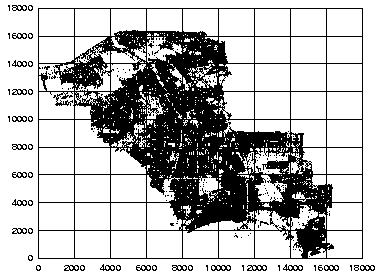
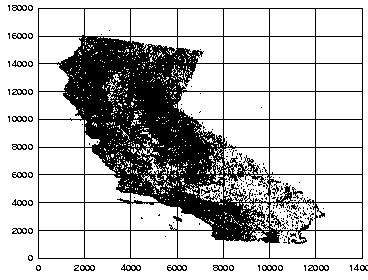
4 Examples of 2D Data Sets
5 Requirements Indexing scheme are needed to speed up query processing. We need disk-based techniques, since we do not want to be constrained by the memory capacity. The methods should handle insertions/deletions of objects (i.e., they should work in a dynamic environment).
6 The R-tree A. Guttman: R-tree: A Dynamic Index Structure for Spatial Searching, ACM SIGMOD Conference, 1984
7 R-tree Index Structure An R-tree is a height-balanced tree similar to a B-tree. Index records in its leaf nodes containing pointers to data objects. Nodes correspond to disk pages if the index is disk-resident. The index is completely dynamic. Leaf node structure (r, objectid) r: minimum bounding rectangle of object objectid: the identifier of the corresponding object Nonleaf node structure (R, childptr) R: covers all rectangles in the lower node childptr: the address of a lower node in the R-tree
8 Properties of the R-treeR M: maximum number of entries that will fit in one node m: minimum number of entries in a node, m M/2 Every leaf node contains between b and M index records unless it is the root. For each index record (r, objectid) in a leaf node, r is the smallest rectangle (Minimum Bounding Rectangle (MBR)) that spatially contains the data object. Every non-leaf node has between m and M children, unless it is the root. For each entry (R, childptr) in a non-leaf node, R is the smallest rectangle that spatially contains the rectangles in the child node. The root node has at least 2 children unless it is a leaf. All leaves appear at the same level.
9 R-Tree Example R3 B A D R4 E R1 F R2 G R5 I K H R6 L M : maximum number of entries m : minimum number of entries ( M/2) (1) Every leaf node contains between m and M index records unless it is the root. (2) Each leaf node has the smallest rectangle that spatially contains the n-dimensional data objects. (3) Every non-leaf node has between m and M children unless it is the root. (4) Each non-leaf node has the smallest rectangle that spatially contains the rectangles in the child node. (5) The root node has at least two children unless it is a leaf. (6) All leaves appear on the same level. R1 R2 <MBR, Pointer to a child node> R3 R4 R5 R6 <MBR, Pointer or ID> A B D E F G H I K L 9
10 R-tree Search Algorithm Given an R-tree whose root is T, find all index records whose rectangles overlap a search rectangle S. Algorithm Search [Search subtrees] If T is not a leaf, check each entry E to determine whether E.R overlaps S. For all overlapping entries, invoke Search on the tree whose root is pointed to by E.childPTR. [Search leaf node] If T is a leaf, check all entries E to determine whether E.r overlaps S. If so, E is a qualifying record.
11 R-Tree Search Example (1/7) R3 B A D R4 E R1 F R2 G R5 I K H R6 L Find all objects whose rectangles are overlapped with a search rectangle S R1 R2 R3 R4 R5 R6 A B D E F G H I K L 11
12 R-Tree Search Example (2/7) R3 B A D R4 E R1 F R2 G R5 I K H R6 L R1 R2 R3 R4 R5 R6 A B D E F G H I K L 12
13 R-Tree Search Example (3/7) R3 B A D R4 E R1 F R2 G R5 I K H R6 L R1 R2 R3 R4 R5 R6 A B D E F G H I K L 13
14 R-Tree Search Example (4/7) R3 B A D R4 E R1 F R2 G R5 I K H R6 L R1 R2 R3 R4 R5 R6 A B D E F G H I K L 14
15 R-Tree Search Example (5/7) R3 B A D R4 E R1 F R2 G R5 I K H R6 L R1 R2 R3 R4 R5 R6 A B D E F G H I K L 15
16 R-Tree Search Example (6/7) R3 B A D R4 E R1 F R2 G R5 I K H R6 L R1 R2 R3 R4 R5 R6 A B D E F G H I K L 16
17 R-Tree Search Example (7/7) R3 B A D R4 E R1 F R3 R4 R1 R2 R5 R6 B and D overlapped objects with S A B D E F G H I K L 17
18 R-tree Insertion Algorithm Insert // Insert a new index entry E into an R-tree. [Find position for new record] Invoke ChooseLeaf to select a leaf node L in which to place E. [Add record to leaf node] If L has room for another entry, install E. Otherwise invoke SplitNode to obtain L and LL containing E and all the old entries of L. [Propagate changes upward] Invoke AdjustTree on L, also passing LL if a split was performed [Grow tree taller] If node split propagation caused the root to split, create a new root whose children are the 2 resulting nodes.
19 Algorithm ChooseLeaf // Select a leaf node in which to place a new index entry E. [Initialize] Set N to be the root node. [Leaf check]* If N is not a leaf, return N. [Choose subtree] If N is not a leaf, let F be the entry in N whose rectangle F.I needs least enlargement to include E.I. Resolve ties by choosing the entry with the rectangle of smallest area. [Descend until a leaf is reached] Set N to be the child node pointed to by F.p. Repeat from *.
20 Algorithm AdjustTree // Ascend from a leaf node L to the root, adjusting covering rectangles and propagating node splits as necessary. [Initialize] Set N=L. If L was split previously, set NN to be the resulting second node. [Check if done]* If N is the root, stop. [Adjust covering rectangle in parent entry] Let P be the parent node of N, and let E n be N s entry in P. Adjust E n.i so that it tightly encloses all entry rectangles in N. [Propagate node split upward] If N has a partner NN resulting from an earlier split, create a new entry E NN with E NN.p pointing to NN and E NN.I enclosing all rectangles in NN. Add E NN to P if there is room. Otherwise, invoke SplitNode to produce P and PP containing E NN and all P s old entries. [Move up to next level] Set N = P and set NN = PP if a split occurred. Repeat from *.
21 R-tree Deletion Algorithm Delete // Remove index record E from an R-tree. [Find node containing record] Invoke FindLeaf to locate the leaf node L containing E. Stop if the record was not found. [Delete record] Remove E from L. [Propagate changes] Invoke CondenseTree, passing L. [Shorten tree] If the root node has only one child after the tree has been adjusted, make the child the new root. Algorithm FindLeaf // Find the leaf node containing the entry E in an R-tree with root T. [Search subtrees] If T is not a leaf, check each entry F in T to determine if F.I overlaps E.I. For each such entry invoke FindLeaf on the tree whose root is pointed to by F.p until E is found or all entries have been checked. [Search leaf node for record] If T is a leaf, check each entry to see if it matches E. If E is found return T.
22 Algorithm CondenseTree // Given a leaf node L from which an entry has been deleted, eliminate the node if it // has too few entries and relocate its entries. // Propagate node elimination upward as necessary. // Adjust all covering rectangles on the path to the root. [Initialize] Set N=L. Set Q, the set of eliminated nodes, to be empty. [Find parent entry]* If N is the root, go to +. Otherwise, let P be the parent of N, and let E n be N s entry in P. [Eliminate under-full node] If N has fewer than m entries, delete E n from P and add N to set Q. [Adjust covering rectangle] If N has not been eliminated, adjust E n.i to tightly contain all entries in N. [Move up one level in tree] Set N=P and repeat from *. [Re-insert orphaned entries]+ Re-insert all entries of nodes in set Q. Entries from eliminated leaf nodes are re-inserted in tree leaves as described in Insert, but entries from higher-level nodes must be placed higher in the tree, so that leaves of their dependent subtrees will be on the same level as leaves of the main tree.
23 Node Splitting The total area of the 2 covering rectangles after a split should be minimized. The same criterion was used in ChooseLeaf to decide a new index entry: at each level in the tree, the subtree chosen was the one whose covering rectangle would have to be enlarged least. bad split good split
24 Node Split Algorithms Exhaustive Algorithm To generate all possible groupings and choose the best. The number of possible splits is very large. Quadratic-Cost Algorithm Attempts to find a small-area split, but is not guaranteed to find one with the smallest area possible. Quadratic in M (node capacity) and linear in dimensionality Picks two of the M+1 entries to be the first elements of the 2 new groups by choosing the pair that would waste the most area if both were put in the same group, i.e., the area of a rectangle covering both entries would be greatest. The remaining entries are then assigned to groups one at a time. At each step the area expansion required to add each remaining entry to each group is calculated, and the entry assigned is the one showing the greatest difference between the 2 groups.
25 Algorithm Quadratic Split // Divide a set of M+1 index entries into 2 groups. [Pick first entry for each group] Apply algorithm PickSeeds to choose 2 entries to be the first elements of the groups. Assign each to a group. [Check if done]* If all entries have been assigned, stop. If one group has so few entries that all the rest must be assigned to it in order for it to have the minimum number m, assign them and stop. [Select entry to assign] Invoke algorithm PickNext to choose the next entry to assign. Add it to the group whose covering rectangle will have to be enlarged least to accommodate it. Resolve ties by adding the entry to the group with smaller entry, then to the one with fewer entries, then to either. Repeat from *.
26 Algorithms PickSeeds & PickNext Algorithm PickSeeds // Select 2 entries to be the first elements of the groups. [Calculate inefficiency of grouping entries together] For each pair of entries E 1 and E 2, compose a rectangle J including E 1.I and E 2.I. Calculate d = area(j) area(e 1.I) area(e 2.I). [Choose the most wasteful pair.] Choose the pair with the largest d. Algorithm PickNext // Select one remaining entry for classification in a group. [Determine cost of putting each entry in each group] For each entry E not yet in a group, -Calculate d 1 = the area increase required in the covering rectangle of Group 1 to include E.I. -Calculate d 2 similarly for Group 2. [Find entry with greatest preference for one group] Choose any entry with the maximum difference between d 1 & d 2.
27 A Linear-Cost Algorithm Linear in M and in dimensionality Linear Split is identical to Quadratic Split but uses a different PickSeeds. PickNext simply chooses any of the remaining entries. Algorithm LinearPickSeeds // Select 2 entries to be the first elements of the groups. [Find extreme rectangles along all dimensions] Along each dimension, find the entry whose rectangle has the highest low side, and the one with the lowest high side. Record the separation. [Adjust for shape of the rectangle cluster] Normalize the separations by dividing by the width of the entire set along the corresponding dimension. [Select the most extreme pair] Choose the pair with the greatest normalized separation along any dimension.
28 Performance (Insert/Delete/Search)
29 Performance (Search/Space)
30 Conclusions The R-tree structure has been shown to be useful for indexing spatial data objects of non-zero size. The linear node-split algorithm proved to be as good as more expensive techniques. It was fast, and the slightly worse quality of the splits did not affect search performance noticeably.
31 The R*-tree N. Bechmann, H.-P. Kriegel, R. Schneider, B. Seeger: The R*-tree: An Efficient and Robust Access Methods for Points and Rectangles, ACM SIGMOD Conference, 1990.
32 Introduction R-tree Tries to minimize the area of the enclosing rectangle (minimum bounding rectangle: MBR) in each inner node. [Note] SAMs are based on the approximation of a complex spatial object by MBR. R*-tree Tries to minimize the area, margin and overlap of each enclosing rectangle in the directory and to increase storage utilization. It clearly outperforms the R-tree.
33 Parameters for Retrieval Performance The area covered by a directory rectangle should be minimized. The dead space should be minimized. The overlap between directory rectangles should be minimized. The margin of a directory rectangle should be minimized. Storage utilization should be maximized. Overlap of an entry E 1,, E p are the entries in a node. overlap( E k ) p = area(rec tan gle( E i= 1, i k k ) rec tan gle( E )), i i k p
34 Trade-offs in Performance Parameters Keeping the area, overlap, and margin of a directory rectangle small will be paid with lower storage utilization. Since more quadratic directory rectangles support packing better, it will be easier to maintain high storage utilization. The performance for queries with large query rectangles will be affected more by the storage utilization.
35 Split of the R*-tree
36 Algorithm ChooseSubtree Set N to be the root. If N is a leaf, return N. * Else If the child_pointers in N point to leaves // Determine the minimum overlap cost // Choose the entry in N whose rectangle needs least overlap enlargement to include the new data rectangle. Resolve ties by choosing the entry whose rectangle needs least area enlargement, then the entry with the rectangle of smallest area. Else // Determine the minimum area cost // Choose the entry in N whose rectangle needs least area enlargement to include the new data rectangle. Resolve ties by choosing the entry with the rectangle of smallest area. Set N to be the child_node pointed to by the child_pointer of the chosen entry and repeat from *.
37 Split of the R*-tree Finding good splits Along each axis, the entries are first sorted by the lower value, then sorted by the upper value of their rectangles. For each sort M-2m+2 distributions of the M+1 entries into 2 groups are determined, where the k-th distribution (k = 1,, M-2m+2) is described as follows: The 1 st group contains the 1 st (m-1)+k entries, The 2 nd group contains the remaining entries. 1, 2, 3,,, m, m+1,,, M-m+1, M M-m+2, M,, M+1 m entries possible M-2m+2 splits m entries For each distribution, goodness values are determined. Depending on these goodness values the final distribution of the entries is determined. Three different goodness values and different approaches of using them in different combinations are tested experimentally.
38 Three Goodness Values Area-value area[bb(1 st group)] + area[bb(2 nd group)] Margin-value margin[bb(1 st group)] + margin[bb(2 nd group)] Overlap-value area[bb(1 st group)] area[bb(2 nd group)] where bb: bounding box of a set of rectangles
39 The Split Process Algorithm Split Invoke ChooseSplitAxis to determine the axis, perpendicular to which the split is performed. Invoke ChooseSplitIndex to determine the best distribution into 2 groups along that axis. Distribute the entries into 2 groups. Algorithm ChooseSplitAxis For each axis Sort the entries by the lower then by the upper value of their rectangles and determine all distributions as described above. Compute S, the sum of all margin-values of the different distributions. Choose the axis with the minimum S as split axis. Algorithm ChooseSplitIndex Along the chosen split axis, choose the distribution with the minimum overlapvalue. Resolve ties by choosing the distribution with minimum area-value.
40 Forced Reinsert Data rectangles inserted during the early growth of the index may have introduced directory rectangles not suitable to the current situation. This problem would be maintained or even worsened if underfilled nodes would be merged under the old parent. R-tree Deletes the node and reinserts the orphaned entries in the corresponding level. Distributing entries into different nodes. R*-tree Forces entries to be reinserted during the insertion routine.
41 Insertion Algorithm Insert Invoke ChooseSubtree, with the level as a parameter, to find an appropriate node N, in which to place the new entry E. If N has less than M entries, accommodate E in N. If N has M entries, invoke OverflowTreatment with the level of N as a parameter [for reinsertion or split]. If OverflowTreatment was called and a split was performed, propagate OverflowTreatment upwards if necessary. If OverflowTreatment caused a split of the root, create a new root. Adjust all covering rectangles in the insertion path s.t. they are minimum bounding boxes enclosing their children rectangles. Algorithm OverflowTreatment If the level is not the root level and this is the 1 st call of OverflowTreatment in the given level during the insertion of one data rectangle, then invoke ReInsert. Else Invoke Split.
42 Reinsert Algorithm ReInsert 1. For all M+1 entries of a node N, compute the distance between the centers of their rectangles and the center of the bounding rectangle of N. 2. Sort the entries in decreasing order of their distances computed in Remove the first p entries from N and adjust the bounding rectangle of N. 4. In the sort, defined in 2, starting with the maximum distance (= far reinsert) or minimum distance (= close reinsert), invoke Insert to reinsert the entries. The parameter p can be varied independently as part of performance tuning. Experiments showed that p = 30% of M yields the best performance.
43 Performance Comparison
44 Conclusions Forced reinsert changes entries between neighboring nodes and thus decreases the overlap. As a side effect, storage utilization is improved. Due to more restructuring, less splits occur. Since the outer rectangles of a node are reinserted, the shape of the directory rectangles will be more quadratic. As discussed above, this is a desirable property.
45 The X-tree S. Berchtold, D.A. Keim, and H.-P. Kriegel: The X-tree: An Index Structure for High-Dimensional Data, VLDB Conference, 1996.
46 Motivation The R*-tree is not adequate for indexing highdimensional datasets. Major problem of R-tree-based indexing methods The overlap of the bounding boxes in the directory which increases with growing dimension. X-tree Uses a split algorithm that minimizes overlap. Uses the concept of supernodes. Outperforms the R*-tree and the TV-tree by up to 2 orders of magnitude.
47 Introduction Some observations in high-dimensional datasets Real data in high-dimensional space are highly correlated and clustered. The data occupy only some subspace. In most high-dimensional datasets, a small number of dimensions bears most of the information. Transforms data objects into some lower dimensional space Traditional index structures may be used. Problems of Dimensionality Reduction The datasets still have a quite large dimensionality. It s a static method. X-tree Avoids overlap of bounding boxes in the directory by using a new organization of directory supernode Avoids splits which would result in a high degree of overlap in the directory. Instead of allowing splits that introduce high overlaps, directory nodes are extended over the usual block size, resulting in supernodes.
48 Problems of R-tree-based Index Structures The performance of the R*-tree deteriorates rapidly when going to higher dimensions The overlap in the directory is increasing very rapidly with growing dimensionality of data.
49 Overlap of R*-tree Directory Nodes
50 Definition of Overlap The overlap of an R-tree node is the percentage of space covered by more than one hyper-rectangle. The weighted overlap of an R-tree node is the percentage of data objects that fall in the overlapping portion of the space.
51 Multi-overlap of an R-tree Node The sum of overlapping volumes multiplied by the number of overlapping hyper-rectangles relative to the overall volume of the considered space.
52 X-tree (extended node tree) The X-tree avoids overlap whenever possible without allowing the tree to degenerate. Otherwise, the X-tree uses extended variable size directory nodes, called supernodes. The X-tree may be seen as a hybrid of a linear array-like and a hierarchical R-tree-like directory. In low dimensions a hierarchical organization would be most efficient. For very high dimensionality a linear organization is more efficient. For medium dimensionality Partially hierarchical and partially linear organization may be efficient.
53 Structure of the X-tree The X-tree consists of 3 kinds of nodes Data nodes Normal directory nodes Supernodes: large directory nodes of variable size To avoid splits in directory nodes
54 X-tree shapes in different dimensions The number and size of superndoes increases with the dimension.
55 X-tree Insertion
56 Split Algorithm
57 Supernodes If the number of MBRs in one of the partitions is below a given threshold, the split algorithm terminates without providing a split. In this case, the current node is extended to become a supernode of twice the standard block size. If the same case occurs for an already existing supernode, the supernode is extended by one additional block. If a supernode is created or extended, there may be not enough contiguous space on disk to sequentially store the supernode. In this case, the disk manager has to perform a local reorganization.
58 Determining the Overlap-Minimal (Overlap-Free) Split
59 Split History For finding an overlap-free split, we have to determine a dimension according to which all MBRs of S have been split previously. The split history provides the necessary information: - split dimensions and new MBRs created by split. - It may be represented by a binary tree, called the split tree.
60 Performance Evaluation (1/2)
61 Performance Evaluation (2/2)
62 The Pyramid-Technique S.Berchtold, C. Bohm, H.-P. Kriegel The Pyramid-Technique: Towards Breaking the Curse of Dimensionality ACM SIGMOD Conference, 1998.
63 Contents Introduction Analysis of Balanced Splits The Pyramid-Technique Query Processing Analysis of the Pyramid-Technique The Extended Pyramid-Technique Experimental Evaluation
64 Introduction A variety of new DB applications has been developed Data warehousing Require a multidimensional view on the data Multimedia Using some kind of feature vectors Has to support query processing on large amounts of high-dimensional data
65 Analysis of Balanced Splits Performance degeneration 1 Data space cannot be split in each dimension To a uniformly distributed data set 1-dimenstion data space 2 1 = 2 data pages 20-dimension data space ,000,000 data pages Similar property holds for range query q = d s q = 0.63, d = 20, selectivity s = 0.01% = q for d = 20 d=1: q = d=2: q = 0.01 d=3: q = d=20: q = Dim ensions
66 Analysis of Balanced Splits Expected value of data page access E balanced( d, q, N ) = C N ( d) eff 0.5 min(1, 1 q log 2 ( C eff N ) ( d ) ) 10
67 The Pyramid-Technique Basic idea Transform d-dimesional point into 1-dimensional value Store and access the values using B + -tree Store d-dimensional points plus 1-dimensional key
68 Data Space Partitioning Pyramid-Technique Split the data space into 2d pyramids top: center point (0.5, 0.5,, 0.5) base: (d-1)-dimensional surface each of pyramids is divided into several partitions d-1 dimensional 4 pyramids partition Center Point (0.5, 0.5) 2-dimension
69 Data Space Partitioning Definition 1: (Pyramid of a point v) i = ( j j max j max max + d) if ( v if ( v j j max max < 0.5) 0.5) = ( j ( k,0 ( j, k) < d, j k : 0.5 v j 0.5 vk )) d 1 (0.8, 0.5) p 0 p p 20 p 1 (0.6, 0.2) d v v v 0 j max = 0 v jmax = 0.2<0.5 i = 1 v is in p 1 v 0.5-v 0 v 2 (0.6, 0.2) 0.5-v v 1 = j max = 0 v jmax = i=j max +d= 0+2=2 v 2 is in p 2
70 Data Space Partitioning Definition 2: (Height of a point v) h = 0.5 v v i MOD d h v = =0.3 (0.6, 0.2) Definition 3: (Pyramid value of a point v) pv = ( i + h ) v v v Pyramid p 1 d 1 p 0 p 3 p 2 Def 1: i = 1 Def 2: h v = 0.3 Def 3: pv v = = 1.3 p 1 (0.6, 0.2) d 0
71 Index Creation Insert Determine the pyramid value of a point v Insert into B + -tree using pv v as a key M=3 Store the d-dimensional point v and pv v In the according data page of the B + -tree Update and delete can be done analogously Resulting data pages of the B + -tree Belong to same pyramid Interval given by the min and max value partition min max (0.6,0.2)
72 Query Processing Point query Compute the pyramid value pv q of q Query the B + -tree using pv q Obtain a set of points sharing pv q Determine whether the set contains q M=3 1.2 (0.2, 0.7) q=(0.2,0.3) pv q =0.3 q (0.2,0.7)
73 Query Processing Range query i=0 i=1 i=2 i=3 h low =0.2 h high =0.4 Point_Set PyrTree::range_query(range q) { Point_Set res; for (i=0; i<2d; i++) { if (intersect(p[i], q) { Lemma 1 determine_range(p[i], q, h low, h high ); Lemma 2 cs = btree_query(i+h low, i+h high ); for (c=cs.first; cs.end; cs.next) if (inside(q, c)) res.add(c); } } return res; } Q M=3 [0.1, 0.6][0.1, 0.3] (0.1, 0.3) (0.5, 0.3) (0.3, 0.2) (0.5, 0.1) (0.3,0.4) (0.2,0.7) (0.1,0.3) (0.1, 0.5)
74 Query Processing Lemma 1: (Intersection of a Pyramid and a Rectangle) j 0 j < d, j i : qˆ MIN( qˆ min, i j ) Only use i<d MIN( r) 0 = min( rmin, r max ) if r min 0 r otherwise max d 1 p 0 p 1 d 0 [0.4, 0.9][0.1, 0.3] [-0.1, 0.4][-0.4, -0.2] i=0: q imin =-0.1 -MIN(q j )= > -0.2 false i=1: q imin =-0.4 -MIN(q j )=0-0.4 < 0 true
75 Query Processing Lemma 2: (Interval of Intersection of Query and Pyramid) Case 1: h Case 2: (otherwise) hlow = min 0 j< d, j i) ( q jmin low ( j,0 j < d : ( qˆ j 0 qˆ )) min jmax ) = 0, hhigh = MAX ( qi ) ) ( ), hhigh = MAX ( qi ) ) ) max( MIN( qi ), MIN( q j )) q j min = ) MIN( qi ) i=0: h low =0.2 h high =0.4 i=1: h low =0.2 h high =0.3 MIN(q i ) d 1 ) if MAX ( q i=0: h low =0 h high =0.3 i=1: h low =0 h high =0.1 j ) ) MIN( q ) otherwise d 0 i d 1 MIN(q j ) = MIN(q i ) Only use i<d d 0
76 Analysis of the Pyramid-Technique Required number of accesses pages for 2d pyramids d + 1 2d + N (1 (2q 1) ) Epyrimidtree ( d, q, N) = 2C ( d) ( d + 1) (1 q) eff Does not reveal any performance degeneration
77 The Extended Pyramid-Technique Basic idea (0.1, 0.y) (0.5, 0.5) Conditions (0.x, 0.1) ti 0) = 0, ti(1) = 1, ti( mpi ) = 0.5, ti 1 log ( ) 2 mpi ti( x) = x r r t i( x) = x, ti( mpi ) = 0. 5 = mpi ( :[0,1] [0,1]
78 The Extended Pyramid-Technique Performance Speed up : about 10 ~ 40% Loss of performance not too high Compare to high speed-up factors over other index structures
79 Experimental Evaluation Using Synthetic Data Performance behavior over database size (16- dimension) Performance behavior over data space dimension 1,000,000 objects
80 Experimental Evaluation Using Real Data Sets Query processing on text data (16-dimension) Query processing on warehousing data (13 attributes)
81 Conclusions For almost hypercube shaped queries Outperforms any competitive technique Including linear scan Holds even for skewed, clustered and categorical data For queries having a bad selectivity Outperforms competitive index structures However, a linear scan is faster <For 1-dimensional queries> pyramid T.: 2.6 Sequ. Scan: 2.48 Fin.
82 Nearest Neighbor Queries N. Roussopoulos, S. Kelly, and F. Vincent: Nearest Neighbor Queries, ACM SIGMOD Conference, 1995.
83 Introduction A frequently encountered type of query in MMDB and GIS is to find the k nearest neighbor objects (k NNs) to a given point in space. Efficient branch-and-bound R-tree traversal algorithm to find k NNs to a point is presented.
84 Introduction Example k-nn queries Find k images most similar to a query image Find k nearest hotels from this point Efficient processing of k-nn queries requires spatial data structures which capitalize on the proximity of the objects to focus the search of potential neighbors only. An efficient branch-and-bound search algorithm for processing exact k-nn queries for the R-trees.
85 k-nn Search Using R-trees R-tree example Minimum bounding rectangle (MBR)
86 Metrics for k-nn Search Fan-out (branching factor) The maximum number of entries that a node can have Performance of an R-tree search is measured by the number of disk accesses (reads) necessary to find (or not found) the desired objects in the database. Two metrics for ordering the k-nn search Given a query point P and an object O enclosed in its MBR 1. The minimum distance (MINDIST) of the object O from P 2. The minimum of the maximum possible distance (MINMAXDIST) from P to a face (or vertex) of the MBR containing O. Offer a lower and an upper bound on the actual distance of O from P respectively. Used to order and efficiently prune the paths of the search space in an R-tree.
87 Minimum Distance (MINDIST) - 1/2 Def. 1. A Rectangle R in Euclidean space E(n) of dimension n, is defined by the 2 endpoints S and T of its major diagonal: R = (S, T) where S = {s 1, s 2,, s n } and T = {t 1, t 2,, t n } and s i t i for 1 i n Def. 2. MINDIST(P, R) The distance of a point P in E(n) from a rectangle R in the same space, denoted MINDIST(P,R), is: MINDIST ( P,R) = n i= 1 p i r i 2, where s i if p i < s i r i = t i if p i > s i otherwise p i If the point is inside the rectangle, the distance between them is 0. If the point is outside, we use the square of the Euclidean distance between the point and the nearest edge of the rectangle.
88 Minimum Distance (MINDIST) - 2/2 Lemma 1. The distance of Def. 2 is equal to the square of the minimal Euclidean distance from P to any point on the perimeter of R. Def. 2. The minimum distance of a point P from a spatial object o, denoted by (P,o) is: 2 ( P,o) = min ( pi xi, X = [ x1,...,x i= 1 Theorem 1. Given a point P and an MBR R enclosing a set of objects O = {o i, 1 i m}, the following is true: o O, MINDIST(P,R) (P,o) Lemma 2. The MBR Face Property n ] O) Every face (i.e., edge in dimension 2, rectangle in dimension 3 and hyperspace in higher dimensions) of any MBR (at any level of the R-tree) contains at least one point of some spatial object in the DB (See Figs. 3 and 4). n
89 MBR Face Property
90 Minimax Distance (MINMAXDIST) - 1/2 Upper bound (MINMAXDIST) of the NN distance to any object inside an MBR Minimum value of all the maximum distances between the query point and points on the each of the n axes Allows to prune MBRs that have MINDIST upper bound Guarantees there is an object within the distance(mbr) MINMAXDIST.
91 MINMAXDIST 2/2 Theorem 2. Given a point P and an MBR R enclosing a set of objects O = {o i, 1 i m}, the following property holds: O, (P, o) MINMAXDIST(P,R) Guarantees the presence of an object O in R whose distance from P is within this distance.
92 MINDIST and MINMAXDIST Search Ordering MINDIST ordering is the optimistic choice. MINMAXDIST metric is the pessimistic one. MINDIST metric ordering is not always the best choice.
93 Strategies for Search Pruning 1. An MBR M with MINDIST(P,M) greater than the MINMAXDIST(P,M') of another MBR M' is discarded because it cannot contain the NN. 2. An actual distance from P to a given object O which is greater than the MINMAXDIST(P,M) for an MBR M can be discarded because M contains an object O' which is nearer to P. 3. Every MBR M with MINDIST(P,M) greater than the actual distance from P to a given object O is discarded because it cannot enclose an object nearer than O.
94 Nearest Neighbor Search Algorithm (1/2) Ordered depth first traversal 1. Begins with the R-tree root node and proceeds down the tree. 2. During the descending phase, at each newly visited nonleaf node, computes the ordering metric bounds (MINDIST/MAXDIST) for all its MBRs and sorts them into an Active Branch List. 3. Applies pruning strategies to the ABL to remove unnecessary branches. 4. The algorithm iterates on this ABL until the ABL empty: For each iteration, the algorithm selects the next branch in the list and applies itself recursively to the node corresponding to the MBR of this branch. 5. At a leaf node (DB objects level), the algorithm calls a type specific distance function for each object and selects the smaller distance between current value of Nearest and each computed value and updates Nearest appropriately. 6. At the return from the recursion, we take this new estimate of the NN and apply pruning strategy 3 to remove all branches with MINDIST(P,M) > Nearest for all MBRs M in the ABL.
95 Nearest Neighbor Search Algorithm (2/2)
96 Generalization: Finding k NNs The differences from 1-NN algorithm are: A sorted buffer of at most k current NNs is needed. The MBRs pruning is done according to the distance of the farthest NN in this buffer.
97 Experimental Results (1/2) TIGER data files for Long Brach and Montgomery.
98 Experimental Results (2/2)
99 Synopsis We have discussed: The R-tree and R*-tree The X-tree The Pyramid technique An algorithm for k-nn search There are other methods such as: TV-tree, SS-tree, SR-tree, VA-File.
100 Bibliography +++
Introduction to Indexing R-trees. Hong Kong University of Science and Technology
 Introduction to Indexing R-trees Dimitris Papadias Hong Kong University of Science and Technology 1 Introduction to Indexing 1. Assume that you work in a government office, and you maintain the records
Introduction to Indexing R-trees Dimitris Papadias Hong Kong University of Science and Technology 1 Introduction to Indexing 1. Assume that you work in a government office, and you maintain the records
Spatial Queries. Nearest Neighbor Queries
 Spatial Queries Nearest Neighbor Queries Spatial Queries Given a collection of geometric objects (points, lines, polygons,...) organize them on disk, to answer efficiently point queries range queries k-nn
Spatial Queries Nearest Neighbor Queries Spatial Queries Given a collection of geometric objects (points, lines, polygons,...) organize them on disk, to answer efficiently point queries range queries k-nn
Query Processing and Advanced Queries. Advanced Queries (2): R-TreeR
: R-TreeR") Query Processing and Advanced Queries Advanced Queries (2): R-TreeR Review: PAM Given a point set and a rectangular query, find the points enclosed in the query We allow insertions/deletions online Query
Query Processing and Advanced Queries Advanced Queries (2): R-TreeR Review: PAM Given a point set and a rectangular query, find the points enclosed in the query We allow insertions/deletions online Query
X-tree. Daniel Keim a, Benjamin Bustos b, Stefan Berchtold c, and Hans-Peter Kriegel d. SYNONYMS Extended node tree
 X-tree Daniel Keim a, Benjamin Bustos b, Stefan Berchtold c, and Hans-Peter Kriegel d a Department of Computer and Information Science, University of Konstanz b Department of Computer Science, University
X-tree Daniel Keim a, Benjamin Bustos b, Stefan Berchtold c, and Hans-Peter Kriegel d a Department of Computer and Information Science, University of Konstanz b Department of Computer Science, University
So, we want to perform the following query:
 Abstract This paper has two parts. The first part presents the join indexes.it covers the most two join indexing, which are foreign column join index and multitable join index. The second part introduces
Abstract This paper has two parts. The first part presents the join indexes.it covers the most two join indexing, which are foreign column join index and multitable join index. The second part introduces
Advances in Data Management Principles of Database Systems - 2 A.Poulovassilis
 1 Advances in Data Management Principles of Database Systems - 2 A.Poulovassilis 1 Storing data on disk The traditional storage hierarchy for DBMSs is: 1. main memory (primary storage) for data currently
1 Advances in Data Management Principles of Database Systems - 2 A.Poulovassilis 1 Storing data on disk The traditional storage hierarchy for DBMSs is: 1. main memory (primary storage) for data currently
Spatial Data Management
 Spatial Data Management [R&G] Chapter 28 CS432 1 Types of Spatial Data Point Data Points in a multidimensional space E.g., Raster data such as satellite imagery, where each pixel stores a measured value
Spatial Data Management [R&G] Chapter 28 CS432 1 Types of Spatial Data Point Data Points in a multidimensional space E.g., Raster data such as satellite imagery, where each pixel stores a measured value
Datenbanksysteme II: Multidimensional Index Structures 2. Ulf Leser
 Datenbanksysteme II: Multidimensional Index Structures 2 Ulf Leser Content of this Lecture Introduction Partitioned Hashing Grid Files kdb Trees kd Tree kdb Tree R Trees Example: Nearest neighbor image
Datenbanksysteme II: Multidimensional Index Structures 2 Ulf Leser Content of this Lecture Introduction Partitioned Hashing Grid Files kdb Trees kd Tree kdb Tree R Trees Example: Nearest neighbor image
Striped Grid Files: An Alternative for Highdimensional
 Striped Grid Files: An Alternative for Highdimensional Indexing Thanet Praneenararat 1, Vorapong Suppakitpaisarn 2, Sunchai Pitakchonlasap 1, and Jaruloj Chongstitvatana 1 Department of Mathematics 1,
Striped Grid Files: An Alternative for Highdimensional Indexing Thanet Praneenararat 1, Vorapong Suppakitpaisarn 2, Sunchai Pitakchonlasap 1, and Jaruloj Chongstitvatana 1 Department of Mathematics 1,
Spatial Data Management
 Spatial Data Management Chapter 28 Database management Systems, 3ed, R. Ramakrishnan and J. Gehrke 1 Types of Spatial Data Point Data Points in a multidimensional space E.g., Raster data such as satellite
Spatial Data Management Chapter 28 Database management Systems, 3ed, R. Ramakrishnan and J. Gehrke 1 Types of Spatial Data Point Data Points in a multidimensional space E.g., Raster data such as satellite
Summary. 4. Indexes. 4.0 Indexes. 4.1 Tree Based Indexes. 4.0 Indexes. 19-Nov-10. Last week: This week:
 Summary Data Warehousing & Data Mining Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de Last week: Logical Model: Cubes,
Summary Data Warehousing & Data Mining Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de Last week: Logical Model: Cubes,
Chap4: Spatial Storage and Indexing. 4.1 Storage:Disk and Files 4.2 Spatial Indexing 4.3 Trends 4.4 Summary
 Chap4: Spatial Storage and Indexing 4.1 Storage:Disk and Files 4.2 Spatial Indexing 4.3 Trends 4.4 Summary Learning Objectives Learning Objectives (LO) LO1: Understand concept of a physical data model
Chap4: Spatial Storage and Indexing 4.1 Storage:Disk and Files 4.2 Spatial Indexing 4.3 Trends 4.4 Summary Learning Objectives Learning Objectives (LO) LO1: Understand concept of a physical data model
Chapter 11: Indexing and Hashing
 Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
Chapter 12: Indexing and Hashing. Basic Concepts
 Chapter 12: Indexing and Hashing! Basic Concepts! Ordered Indices! B+-Tree Index Files! B-Tree Index Files! Static Hashing! Dynamic Hashing! Comparison of Ordered Indexing and Hashing! Index Definition
Chapter 12: Indexing and Hashing! Basic Concepts! Ordered Indices! B+-Tree Index Files! B-Tree Index Files! Static Hashing! Dynamic Hashing! Comparison of Ordered Indexing and Hashing! Index Definition
Nearest Neighbor Queries
 Nearest Neighbor Queries Nick Roussopoulos Stephen Kelley Frederic Vincent University of Maryland May 1995 Problem / Motivation Given a point in space, find the k NN classic NN queries (find the nearest
Nearest Neighbor Queries Nick Roussopoulos Stephen Kelley Frederic Vincent University of Maryland May 1995 Problem / Motivation Given a point in space, find the k NN classic NN queries (find the nearest
Chapter 12: Indexing and Hashing
 Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
Multidimensional Indexing The R Tree
 Multidimensional Indexing The R Tree Module 7, Lecture 1 Database Management Systems, R. Ramakrishnan 1 Single-Dimensional Indexes B+ trees are fundamentally single-dimensional indexes. When we create
Multidimensional Indexing The R Tree Module 7, Lecture 1 Database Management Systems, R. Ramakrishnan 1 Single-Dimensional Indexes B+ trees are fundamentally single-dimensional indexes. When we create
Spatiotemporal Access to Moving Objects. Hao LIU, Xu GENG 17/04/2018
 Spatiotemporal Access to Moving Objects Hao LIU, Xu GENG 17/04/2018 Contents Overview & applications Spatiotemporal queries Movingobjects modeling Sampled locations Linear function of time Indexing structure
Spatiotemporal Access to Moving Objects Hao LIU, Xu GENG 17/04/2018 Contents Overview & applications Spatiotemporal queries Movingobjects modeling Sampled locations Linear function of time Indexing structure
R-Trees. Accessing Spatial Data
 R-Trees Accessing Spatial Data In the beginning The B-Tree provided a foundation for R- Trees. But what s a B-Tree? A data structure for storing sorted data with amortized run times for insertion and deletion
R-Trees Accessing Spatial Data In the beginning The B-Tree provided a foundation for R- Trees. But what s a B-Tree? A data structure for storing sorted data with amortized run times for insertion and deletion
Chapter 11: Indexing and Hashing
 Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Intro to DB CHAPTER 12 INDEXING & HASHING
 Intro to DB CHAPTER 12 INDEXING & HASHING Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing
Intro to DB CHAPTER 12 INDEXING & HASHING Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing
Search Space Reductions for Nearest-Neighbor Queries
 Search Space Reductions for Nearest-Neighbor Queries Micah Adler 1 and Brent Heeringa 2 1 Department of Computer Science, University of Massachusetts, Amherst 140 Governors Drive Amherst, MA 01003 2 Department
Search Space Reductions for Nearest-Neighbor Queries Micah Adler 1 and Brent Heeringa 2 1 Department of Computer Science, University of Massachusetts, Amherst 140 Governors Drive Amherst, MA 01003 2 Department
Indexing Techniques 3 rd Part
 Indexing Techniques 3 rd Part Presented by: Tarik Ben Touhami Supervised by: Dr. Hachim Haddouti CSC 5301 Spring 2003 Outline! Join indexes "Foreign column join index "Multitable join index! Indexing techniques
Indexing Techniques 3 rd Part Presented by: Tarik Ben Touhami Supervised by: Dr. Hachim Haddouti CSC 5301 Spring 2003 Outline! Join indexes "Foreign column join index "Multitable join index! Indexing techniques
Database System Concepts, 6 th Ed. Silberschatz, Korth and Sudarshan See for conditions on re-use
 Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files Static
Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files Static
Multidimensional Indexes [14]
![Multidimensional Indexes [14]](/thumbs/88/117268268.jpg "Multidimensional Indexes [14]") CMSC 661, Principles of Database Systems Multidimensional Indexes [14] Dr. Kalpakis http://www.csee.umbc.edu/~kalpakis/courses/661 Motivation Examined indexes when search keys are in 1-D space Many interesting
CMSC 661, Principles of Database Systems Multidimensional Indexes [14] Dr. Kalpakis http://www.csee.umbc.edu/~kalpakis/courses/661 Motivation Examined indexes when search keys are in 1-D space Many interesting
Principles of Data Management. Lecture #14 (Spatial Data Management)
") Principles of Data Management Lecture #14 (Spatial Data Management) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s Notable News v Project
Principles of Data Management Lecture #14 (Spatial Data Management) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s Notable News v Project
Chapter 11: Indexing and Hashing
 Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Using Natural Clusters Information to Build Fuzzy Indexing Structure
 Using Natural Clusters Information to Build Fuzzy Indexing Structure H.Y. Yue, I. King and K.S. Leung Department of Computer Science and Engineering The Chinese University of Hong Kong Shatin, New Territories,
Using Natural Clusters Information to Build Fuzzy Indexing Structure H.Y. Yue, I. King and K.S. Leung Department of Computer Science and Engineering The Chinese University of Hong Kong Shatin, New Territories,
Extending High-Dimensional Indexing Techniques Pyramid and iminmax(θ) : Lessons Learned
 : Lessons Learned") Extending High-Dimensional Indexing Techniques Pyramid and iminmax(θ) : Lessons Learned Karthik Ganesan Pillai, Liessman Sturlaugson, Juan M. Banda, and Rafal A. Angryk Montana State University, Bozeman,
Extending High-Dimensional Indexing Techniques Pyramid and iminmax(θ) : Lessons Learned Karthik Ganesan Pillai, Liessman Sturlaugson, Juan M. Banda, and Rafal A. Angryk Montana State University, Bozeman,
Data Warehousing & Data Mining
 Data Warehousing & Data Mining Wolf-Tilo Balke Kinda El Maarry Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de Summary Last week: Logical Model: Cubes,
Data Warehousing & Data Mining Wolf-Tilo Balke Kinda El Maarry Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de Summary Last week: Logical Model: Cubes,
R-Tree Based Indexing of Now-Relative Bitemporal Data
 36 R-Tree Based Indexing of Now-Relative Bitemporal Data Rasa Bliujūtė, Christian S. Jensen, Simonas Šaltenis, and Giedrius Slivinskas The databases of a wide range of applications, e.g., in data warehousing,
36 R-Tree Based Indexing of Now-Relative Bitemporal Data Rasa Bliujūtė, Christian S. Jensen, Simonas Šaltenis, and Giedrius Slivinskas The databases of a wide range of applications, e.g., in data warehousing,
Chapter 11: Indexing and Hashing" Chapter 11: Indexing and Hashing"
 Chapter 11: Indexing and Hashing" Database System Concepts, 6 th Ed.! Silberschatz, Korth and Sudarshan See www.db-book.com for conditions on re-use " Chapter 11: Indexing and Hashing" Basic Concepts!
Chapter 11: Indexing and Hashing" Database System Concepts, 6 th Ed.! Silberschatz, Korth and Sudarshan See www.db-book.com for conditions on re-use " Chapter 11: Indexing and Hashing" Basic Concepts!
CSE 530A. B+ Trees. Washington University Fall 2013
 CSE 530A B+ Trees Washington University Fall 2013 B Trees A B tree is an ordered (non-binary) tree where the internal nodes can have a varying number of child nodes (within some range) B Trees When a key
CSE 530A B+ Trees Washington University Fall 2013 B Trees A B tree is an ordered (non-binary) tree where the internal nodes can have a varying number of child nodes (within some range) B Trees When a key
Chapter 12: Indexing and Hashing
 Chapter 12: Indexing and Hashing Database System Concepts, 5th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 12: Indexing and Hashing Database System Concepts, 5th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Clustering Billions of Images with Large Scale Nearest Neighbor Search
 Clustering Billions of Images with Large Scale Nearest Neighbor Search Ting Liu, Charles Rosenberg, Henry A. Rowley IEEE Workshop on Applications of Computer Vision February 2007 Presented by Dafna Bitton
Clustering Billions of Images with Large Scale Nearest Neighbor Search Ting Liu, Charles Rosenberg, Henry A. Rowley IEEE Workshop on Applications of Computer Vision February 2007 Presented by Dafna Bitton
Pivoting M-tree: A Metric Access Method for Efficient Similarity Search
 Pivoting M-tree: A Metric Access Method for Efficient Similarity Search Tomáš Skopal Department of Computer Science, VŠB Technical University of Ostrava, tř. 17. listopadu 15, Ostrava, Czech Republic tomas.skopal@vsb.cz
Pivoting M-tree: A Metric Access Method for Efficient Similarity Search Tomáš Skopal Department of Computer Science, VŠB Technical University of Ostrava, tř. 17. listopadu 15, Ostrava, Czech Republic tomas.skopal@vsb.cz
Physical Level of Databases: B+-Trees
 Physical Level of Databases: B+-Trees Adnan YAZICI Computer Engineering Department METU (Fall 2005) 1 B + -Tree Index Files l Disadvantage of indexed-sequential files: performance degrades as file grows,
Physical Level of Databases: B+-Trees Adnan YAZICI Computer Engineering Department METU (Fall 2005) 1 B + -Tree Index Files l Disadvantage of indexed-sequential files: performance degrades as file grows,
Improving the Query Performance of High-Dimensional Index Structures by Bulk Load Operations
 Improving the Query Performance of High-Dimensional Index Structures by Bulk Load Operations Stefan Berchtold, Christian Böhm 2, and Hans-Peter Kriegel 2 AT&T Labs Research, 8 Park Avenue, Florham Park,
Improving the Query Performance of High-Dimensional Index Structures by Bulk Load Operations Stefan Berchtold, Christian Böhm 2, and Hans-Peter Kriegel 2 AT&T Labs Research, 8 Park Avenue, Florham Park,
CS 310 B-trees, Page 1. Motives. Large-scale databases are stored in disks/hard drives.
 CS 310 B-trees, Page 1 Motives Large-scale databases are stored in disks/hard drives. Disks are quite different from main memory. Data in a disk are accessed through a read-write head. To read a piece
CS 310 B-trees, Page 1 Motives Large-scale databases are stored in disks/hard drives. Disks are quite different from main memory. Data in a disk are accessed through a read-write head. To read a piece
Evaluation of R-trees for Nearest Neighbor Search
 Evaluation of R-trees for Nearest Neighbor Search A Thesis Presented to The Faculty of the Department of Computer Science University of Houston In Partial Fulfillment Of the Requirements for the Degree
Evaluation of R-trees for Nearest Neighbor Search A Thesis Presented to The Faculty of the Department of Computer Science University of Houston In Partial Fulfillment Of the Requirements for the Degree
Local Dimensionality Reduction: A New Approach to Indexing High Dimensional Spaces
 Local Dimensionality Reduction: A New Approach to Indexing High Dimensional Spaces Kaushik Chakrabarti Department of Computer Science University of Illinois Urbana, IL 61801 kaushikc@cs.uiuc.edu Sharad
Local Dimensionality Reduction: A New Approach to Indexing High Dimensional Spaces Kaushik Chakrabarti Department of Computer Science University of Illinois Urbana, IL 61801 kaushikc@cs.uiuc.edu Sharad
I/O-Algorithms Lars Arge Aarhus University
 I/O-Algorithms Aarhus University April 10, 2008 I/O-Model Block I/O D Parameters N = # elements in problem instance B = # elements that fits in disk block M = # elements that fits in main memory M T =
I/O-Algorithms Aarhus University April 10, 2008 I/O-Model Block I/O D Parameters N = # elements in problem instance B = # elements that fits in disk block M = # elements that fits in main memory M T =
In-Memory Searching. Linear Search. Binary Search. Binary Search Tree. k-d Tree. Hashing. Hash Collisions. Collision Strategies.
 In-Memory Searching Linear Search Binary Search Binary Search Tree k-d Tree Hashing Hash Collisions Collision Strategies Chapter 4 Searching A second fundamental operation in Computer Science We review
In-Memory Searching Linear Search Binary Search Binary Search Tree k-d Tree Hashing Hash Collisions Collision Strategies Chapter 4 Searching A second fundamental operation in Computer Science We review
2. Dynamic Versions of R-trees
 2. Dynamic Versions of R-trees The survey by Gaede and Guenther [69] annotates a vast list of citations related to multi-dimensional access methods and, in particular, refers to R-trees to a significant
2. Dynamic Versions of R-trees The survey by Gaede and Guenther [69] annotates a vast list of citations related to multi-dimensional access methods and, in particular, refers to R-trees to a significant
Question Bank Subject: Advanced Data Structures Class: SE Computer
 Question Bank Subject: Advanced Data Structures Class: SE Computer Question1: Write a non recursive pseudo code for post order traversal of binary tree Answer: Pseudo Code: 1. Push root into Stack_One.
Question Bank Subject: Advanced Data Structures Class: SE Computer Question1: Write a non recursive pseudo code for post order traversal of binary tree Answer: Pseudo Code: 1. Push root into Stack_One.
Chapter 12: Indexing and Hashing (Cnt(
 Chapter 12: Indexing and Hashing (Cnt( Cnt.) Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition
Chapter 12: Indexing and Hashing (Cnt( Cnt.) Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition
What we have covered?
 What we have covered? Indexing and Hashing Data warehouse and OLAP Data Mining Information Retrieval and Web Mining XML and XQuery Spatial Databases Transaction Management 1 Lecture 6: Spatial Data Management
What we have covered? Indexing and Hashing Data warehouse and OLAP Data Mining Information Retrieval and Web Mining XML and XQuery Spatial Databases Transaction Management 1 Lecture 6: Spatial Data Management
Database System Concepts, 5th Ed. Silberschatz, Korth and Sudarshan See for conditions on re-use
 Chapter 12: Indexing and Hashing Database System Concepts, 5th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 12: Indexing and Hashing Database System Concepts, 5th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
CMSC 754 Computational Geometry 1
 CMSC 754 Computational Geometry 1 David M. Mount Department of Computer Science University of Maryland Fall 2005 1 Copyright, David M. Mount, 2005, Dept. of Computer Science, University of Maryland, College
CMSC 754 Computational Geometry 1 David M. Mount Department of Computer Science University of Maryland Fall 2005 1 Copyright, David M. Mount, 2005, Dept. of Computer Science, University of Maryland, College
CSE 544 Principles of Database Management Systems. Magdalena Balazinska Winter 2009 Lecture 6 - Storage and Indexing
 CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2009 Lecture 6 - Storage and Indexing References Generalized Search Trees for Database Systems. J. M. Hellerstein, J. F. Naughton
CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2009 Lecture 6 - Storage and Indexing References Generalized Search Trees for Database Systems. J. M. Hellerstein, J. F. Naughton
Chapter 2: The Game Core. (part 2)
") Ludwig Maximilians Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture Notes for Managing and Mining Multiplayer Online Games for the Summer Semester 2017
Ludwig Maximilians Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture Notes for Managing and Mining Multiplayer Online Games for the Summer Semester 2017
Algorithms for GIS:! Quadtrees
 Algorithms for GIS: Quadtrees Quadtree A data structure that corresponds to a hierarchical subdivision of the plane Start with a square (containing inside input data) Divide into 4 equal squares (quadrants)
Algorithms for GIS: Quadtrees Quadtree A data structure that corresponds to a hierarchical subdivision of the plane Start with a square (containing inside input data) Divide into 4 equal squares (quadrants)
Introduction to Spatial Database Systems
 Introduction to Spatial Database Systems by Cyrus Shahabi from Ralf Hart Hartmut Guting s VLDB Journal v3, n4, October 1994 Data Structures & Algorithms 1. Implementation of spatial algebra in an integrated
Introduction to Spatial Database Systems by Cyrus Shahabi from Ralf Hart Hartmut Guting s VLDB Journal v3, n4, October 1994 Data Structures & Algorithms 1. Implementation of spatial algebra in an integrated
9/23/2009 CONFERENCES CONTINUOUS NEAREST NEIGHBOR SEARCH INTRODUCTION OVERVIEW PRELIMINARY -- POINT NN QUERIES
 CONFERENCES Short Name SIGMOD Full Name Special Interest Group on Management Of Data CONTINUOUS NEAREST NEIGHBOR SEARCH Yufei Tao, Dimitris Papadias, Qiongmao Shen Hong Kong University of Science and Technology
CONFERENCES Short Name SIGMOD Full Name Special Interest Group on Management Of Data CONTINUOUS NEAREST NEIGHBOR SEARCH Yufei Tao, Dimitris Papadias, Qiongmao Shen Hong Kong University of Science and Technology
Kathleen Durant PhD Northeastern University CS Indexes
 Kathleen Durant PhD Northeastern University CS 3200 Indexes Outline for the day Index definition Types of indexes B+ trees ISAM Hash index Choosing indexed fields Indexes in InnoDB 2 Indexes A typical
Kathleen Durant PhD Northeastern University CS 3200 Indexes Outline for the day Index definition Types of indexes B+ trees ISAM Hash index Choosing indexed fields Indexes in InnoDB 2 Indexes A typical
Database index structures
 Database index structures From: Database System Concepts, 6th edijon Avi Silberschatz, Henry Korth, S. Sudarshan McGraw- Hill Architectures for Massive DM D&K / UPSay 2015-2016 Ioana Manolescu 1 Chapter
Database index structures From: Database System Concepts, 6th edijon Avi Silberschatz, Henry Korth, S. Sudarshan McGraw- Hill Architectures for Massive DM D&K / UPSay 2015-2016 Ioana Manolescu 1 Chapter
CSIT5300: Advanced Database Systems
 CSIT5300: Advanced Database Systems L08: B + -trees and Dynamic Hashing Dr. Kenneth LEUNG Department of Computer Science and Engineering The Hong Kong University of Science and Technology Hong Kong SAR,
CSIT5300: Advanced Database Systems L08: B + -trees and Dynamic Hashing Dr. Kenneth LEUNG Department of Computer Science and Engineering The Hong Kong University of Science and Technology Hong Kong SAR,
6. Algorithm Design Techniques
 6. Algorithm Design Techniques 6. Algorithm Design Techniques 6.1 Greedy algorithms 6.2 Divide and conquer 6.3 Dynamic Programming 6.4 Randomized Algorithms 6.5 Backtracking Algorithms Malek Mouhoub, CS340
6. Algorithm Design Techniques 6. Algorithm Design Techniques 6.1 Greedy algorithms 6.2 Divide and conquer 6.3 Dynamic Programming 6.4 Randomized Algorithms 6.5 Backtracking Algorithms Malek Mouhoub, CS340
Unsupervised Learning Hierarchical Methods
 Unsupervised Learning Hierarchical Methods Road Map. Basic Concepts 2. BIRCH 3. ROCK The Principle Group data objects into a tree of clusters Hierarchical methods can be Agglomerative: bottom-up approach
Unsupervised Learning Hierarchical Methods Road Map. Basic Concepts 2. BIRCH 3. ROCK The Principle Group data objects into a tree of clusters Hierarchical methods can be Agglomerative: bottom-up approach
Quadrant-Based MBR-Tree Indexing Technique for Range Query Over HBase
 Quadrant-Based MBR-Tree Indexing Technique for Range Query Over HBase Bumjoon Jo and Sungwon Jung (&) Department of Computer Science and Engineering, Sogang University, 35 Baekbeom-ro, Mapo-gu, Seoul 04107,
Quadrant-Based MBR-Tree Indexing Technique for Range Query Over HBase Bumjoon Jo and Sungwon Jung (&) Department of Computer Science and Engineering, Sogang University, 35 Baekbeom-ro, Mapo-gu, Seoul 04107,
Course Content. Objectives of Lecture? CMPUT 391: Spatial Data Management Dr. Jörg Sander & Dr. Osmar R. Zaïane. University of Alberta
 Database Management Systems Winter 2002 CMPUT 39: Spatial Data Management Dr. Jörg Sander & Dr. Osmar. Zaïane University of Alberta Chapter 26 of Textbook Course Content Introduction Database Design Theory
Database Management Systems Winter 2002 CMPUT 39: Spatial Data Management Dr. Jörg Sander & Dr. Osmar. Zaïane University of Alberta Chapter 26 of Textbook Course Content Introduction Database Design Theory
Tree-Structured Indexes
 Introduction Tree-Structured Indexes Chapter 10 As for any index, 3 alternatives for data entries k*: Data record with key value k
Introduction Tree-Structured Indexes Chapter 10 As for any index, 3 alternatives for data entries k*: Data record with key value k
Using the Holey Brick Tree for Spatial Data. in General Purpose DBMSs. Northeastern University
 Using the Holey Brick Tree for Spatial Data in General Purpose DBMSs Georgios Evangelidis Betty Salzberg College of Computer Science Northeastern University Boston, MA 02115-5096 1 Introduction There is
Using the Holey Brick Tree for Spatial Data in General Purpose DBMSs Georgios Evangelidis Betty Salzberg College of Computer Science Northeastern University Boston, MA 02115-5096 1 Introduction There is
We assume uniform hashing (UH):
:") We assume uniform hashing (UH): the probe sequence of each key is equally likely to be any of the! permutations of 0,1,, 1 UH generalizes the notion of SUH that produces not just a single number, but a
We assume uniform hashing (UH): the probe sequence of each key is equally likely to be any of the! permutations of 0,1,, 1 UH generalizes the notion of SUH that produces not just a single number, but a
Indexing High-Dimensional Data for Content-Based Retrieval in Large Databases
 Indexing High-Dimensional Data for Content-Based Retrieval in Large Databases Manuel J. Fonseca, Joaquim A. Jorge Department of Information Systems and Computer Science INESC-ID/IST/Technical University
Indexing High-Dimensional Data for Content-Based Retrieval in Large Databases Manuel J. Fonseca, Joaquim A. Jorge Department of Information Systems and Computer Science INESC-ID/IST/Technical University
Chapter 17 Indexing Structures for Files and Physical Database Design
 Chapter 17 Indexing Structures for Files and Physical Database Design We assume that a file already exists with some primary organization unordered, ordered or hash. The index provides alternate ways to
Chapter 17 Indexing Structures for Files and Physical Database Design We assume that a file already exists with some primary organization unordered, ordered or hash. The index provides alternate ways to
Chapter 12: Query Processing. Chapter 12: Query Processing
 Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 12: Query Processing Overview Measures of Query Cost Selection Operation Sorting Join
Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 12: Query Processing Overview Measures of Query Cost Selection Operation Sorting Join
Module 4: Tree-Structured Indexing
 Module 4: Tree-Structured Indexing Module Outline 4.1 B + trees 4.2 Structure of B + trees 4.3 Operations on B + trees 4.4 Extensions 4.5 Generalized Access Path 4.6 ORACLE Clusters Web Forms Transaction
Module 4: Tree-Structured Indexing Module Outline 4.1 B + trees 4.2 Structure of B + trees 4.3 Operations on B + trees 4.4 Extensions 4.5 Generalized Access Path 4.6 ORACLE Clusters Web Forms Transaction
CS127: B-Trees. B-Trees
 CS127: B-Trees B-Trees 1 Data Layout on Disk Track: one ring Sector: one pie-shaped piece. Block: intersection of a track and a sector. Disk Based Dictionary Structures Use a disk-based method when the
CS127: B-Trees B-Trees 1 Data Layout on Disk Track: one ring Sector: one pie-shaped piece. Block: intersection of a track and a sector. Disk Based Dictionary Structures Use a disk-based method when the
R-Tree Based Indexing of Now-Relative Bitemporal Data
 R-Tree Based Indexing of Now-Relative Bitemporal Data Rasa Bliujūtė Christian S. Jensen Simonas Šaltenis Giedrius Slivinskas Department of Computer Science Aalborg University, Denmark rasa, csj, simas,
R-Tree Based Indexing of Now-Relative Bitemporal Data Rasa Bliujūtė Christian S. Jensen Simonas Šaltenis Giedrius Slivinskas Department of Computer Science Aalborg University, Denmark rasa, csj, simas,
The Effects of Dimensionality Curse in High Dimensional knn Search
 The Effects of Dimensionality Curse in High Dimensional knn Search Nikolaos Kouiroukidis, Georgios Evangelidis Department of Applied Informatics University of Macedonia Thessaloniki, Greece Email: {kouiruki,
The Effects of Dimensionality Curse in High Dimensional knn Search Nikolaos Kouiroukidis, Georgios Evangelidis Department of Applied Informatics University of Macedonia Thessaloniki, Greece Email: {kouiruki,
Organizing Spatial Data
 Organizing Spatial Data Spatial data records include a sense of location as an attribute. Typically location is represented by coordinate data (in 2D or 3D). 1 If we are to search spatial data using the
Organizing Spatial Data Spatial data records include a sense of location as an attribute. Typically location is represented by coordinate data (in 2D or 3D). 1 If we are to search spatial data using the
CS Fall 2010 B-trees Carola Wenk
 CS 3343 -- Fall 2010 B-trees Carola Wenk 10/19/10 CS 3343 Analysis of Algorithms 1 External memory dictionary Task: Given a large amount of data that does not fit into main memory, process it into a dictionary
CS 3343 -- Fall 2010 B-trees Carola Wenk 10/19/10 CS 3343 Analysis of Algorithms 1 External memory dictionary Task: Given a large amount of data that does not fit into main memory, process it into a dictionary
What is a Multi-way tree?
 B-Tree Motivation for studying Multi-way and B-trees A disk access is very expensive compared to a typical computer instruction (mechanical limitations) -One disk access is worth about 200,000 instructions.
B-Tree Motivation for studying Multi-way and B-trees A disk access is very expensive compared to a typical computer instruction (mechanical limitations) -One disk access is worth about 200,000 instructions.
Deletion Techniques for the ND-tree in Non-ordered Discrete Data Spaces
 Deletion Techniques for the ND-tree in Non-ordered Discrete Data Spaces Hyun Jeong Seok Qiang Zhu Gang Qian Department of Computer and Information Science Department of Computer Science The University
Deletion Techniques for the ND-tree in Non-ordered Discrete Data Spaces Hyun Jeong Seok Qiang Zhu Gang Qian Department of Computer and Information Science Department of Computer Science The University
Progressive Skyline Computation in Database Systems
 Progressive Skyline Computation in Database Systems DIMITRIS PAPADIAS Hong Kong University of Science and Technology YUFEI TAO City University of Hong Kong GREG FU JP Morgan Chase and BERNHARD SEEGER Philipps
Progressive Skyline Computation in Database Systems DIMITRIS PAPADIAS Hong Kong University of Science and Technology YUFEI TAO City University of Hong Kong GREG FU JP Morgan Chase and BERNHARD SEEGER Philipps
Lesson 05. Mid Phase. Collision Detection
 Lesson 05 Mid Phase Collision Detection Lecture 05 Outline Problem definition and motivations Generic Bounding Volume Hierarchy (BVH) BVH construction, fitting, overlapping Metrics and Tandem traversal
Lesson 05 Mid Phase Collision Detection Lecture 05 Outline Problem definition and motivations Generic Bounding Volume Hierarchy (BVH) BVH construction, fitting, overlapping Metrics and Tandem traversal
9/29/2016. Chapter 4 Trees. Introduction. Terminology. Terminology. Terminology. Terminology
 Introduction Chapter 4 Trees for large input, even linear access time may be prohibitive we need data structures that exhibit average running times closer to O(log N) binary search tree 2 Terminology recursive
Introduction Chapter 4 Trees for large input, even linear access time may be prohibitive we need data structures that exhibit average running times closer to O(log N) binary search tree 2 Terminology recursive
Tree-Structured Indexes
 Tree-Structured Indexes Chapter 9 Database Management Systems, R. Ramakrishnan and J. Gehrke 1 Introduction As for any index, 3 alternatives for data entries k*: ➀ Data record with key value k ➁
Tree-Structured Indexes Chapter 9 Database Management Systems, R. Ramakrishnan and J. Gehrke 1 Introduction As for any index, 3 alternatives for data entries k*: ➀ Data record with key value k ➁
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2014/15
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2014/15 Lecture II: Indexing Part I of this course Indexing 3 Database File Organization and Indexing Remember: Database tables
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2014/15 Lecture II: Indexing Part I of this course Indexing 3 Database File Organization and Indexing Remember: Database tables
Problem. Indexing with B-trees. Indexing. Primary Key Indexing. B-trees: Example. B-trees. primary key indexing
 15-82 Advanced Topics in Database Systems Performance Problem Given a large collection of records, Indexing with B-trees find similar/interesting things, i.e., allow fast, approximate queries 2 Indexing
15-82 Advanced Topics in Database Systems Performance Problem Given a large collection of records, Indexing with B-trees find similar/interesting things, i.e., allow fast, approximate queries 2 Indexing
Ranking Spatial Data by Quality Preferences
 International Journal of Engineering Research and Development e-issn: 2278-067X, p-issn: 2278-800X, www.ijerd.com Volume 10, Issue 7 (July 2014), PP.68-75 Ranking Spatial Data by Quality Preferences Satyanarayana
International Journal of Engineering Research and Development e-issn: 2278-067X, p-issn: 2278-800X, www.ijerd.com Volume 10, Issue 7 (July 2014), PP.68-75 Ranking Spatial Data by Quality Preferences Satyanarayana
Lecture 8 Index (B+-Tree and Hash)
") CompSci 516 Data Intensive Computing Systems Lecture 8 Index (B+-Tree and Hash) Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 HW1 due tomorrow: Announcements Due on 09/21 (Thurs),
CompSci 516 Data Intensive Computing Systems Lecture 8 Index (B+-Tree and Hash) Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 HW1 due tomorrow: Announcements Due on 09/21 (Thurs),
UNIT III BALANCED SEARCH TREES AND INDEXING
 UNIT III BALANCED SEARCH TREES AND INDEXING OBJECTIVE The implementation of hash tables is frequently called hashing. Hashing is a technique used for performing insertions, deletions and finds in constant
UNIT III BALANCED SEARCH TREES AND INDEXING OBJECTIVE The implementation of hash tables is frequently called hashing. Hashing is a technique used for performing insertions, deletions and finds in constant
Chapter 12: Query Processing
 Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Overview Chapter 12: Query Processing Measures of Query Cost Selection Operation Sorting Join
Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Overview Chapter 12: Query Processing Measures of Query Cost Selection Operation Sorting Join
Lesson 3. Prof. Enza Messina
 Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Data Structures and Algorithms
 Data Structures and Algorithms CS245-2008S-19 B-Trees David Galles Department of Computer Science University of San Francisco 19-0: Indexing Operations: Add an element Remove an element Find an element,
Data Structures and Algorithms CS245-2008S-19 B-Trees David Galles Department of Computer Science University of San Francisco 19-0: Indexing Operations: Add an element Remove an element Find an element,
Fast Similarity Search for High-Dimensional Dataset
 Fast Similarity Search for High-Dimensional Dataset Quan Wang and Suya You Computer Science Department University of Southern California {quanwang,suyay}@graphics.usc.edu Abstract This paper addresses
Fast Similarity Search for High-Dimensional Dataset Quan Wang and Suya You Computer Science Department University of Southern California {quanwang,suyay}@graphics.usc.edu Abstract This paper addresses
A Note on Scheduling Parallel Unit Jobs on Hypercubes
 A Note on Scheduling Parallel Unit Jobs on Hypercubes Ondřej Zajíček Abstract We study the problem of scheduling independent unit-time parallel jobs on hypercubes. A parallel job has to be scheduled between
A Note on Scheduling Parallel Unit Jobs on Hypercubes Ondřej Zajíček Abstract We study the problem of scheduling independent unit-time parallel jobs on hypercubes. A parallel job has to be scheduled between
Module 4: Index Structures Lecture 13: Index structure. The Lecture Contains: Index structure. Binary search tree (BST) B-tree. B+-tree.
 B-tree. B+-tree.") The Lecture Contains: Index structure Binary search tree (BST) B-tree B+-tree Order file:///c /Documents%20and%20Settings/iitkrana1/My%20Documents/Google%20Talk%20Received%20Files/ist_data/lecture13/13_1.htm[6/14/2012
The Lecture Contains: Index structure Binary search tree (BST) B-tree B+-tree Order file:///c /Documents%20and%20Settings/iitkrana1/My%20Documents/Google%20Talk%20Received%20Files/ist_data/lecture13/13_1.htm[6/14/2012
Search and Optimization
 Search and Optimization Search, Optimization and Game-Playing The goal is to find one or more optimal or sub-optimal solutions in a given search space. We can either be interested in finding any one solution
Search and Optimization Search, Optimization and Game-Playing The goal is to find one or more optimal or sub-optimal solutions in a given search space. We can either be interested in finding any one solution
An AVL tree with N nodes is an excellent data. The Big-Oh analysis shows that most operations finish within O(log N) time
 time") B + -TREES MOTIVATION An AVL tree with N nodes is an excellent data structure for searching, indexing, etc. The Big-Oh analysis shows that most operations finish within O(log N) time The theoretical conclusion
B + -TREES MOTIVATION An AVL tree with N nodes is an excellent data structure for searching, indexing, etc. The Big-Oh analysis shows that most operations finish within O(log N) time The theoretical conclusion
High Dimensional Indexing by Clustering
 Yufei Tao ITEE University of Queensland Recall that, our discussion so far has assumed that the dimensionality d is moderately high, such that it can be regarded as a constant. This means that d should
Yufei Tao ITEE University of Queensland Recall that, our discussion so far has assumed that the dimensionality d is moderately high, such that it can be regarded as a constant. This means that d should
PCR*-Tree: PCM-aware R*-Tree
 JOURNAL OF INFORMATION SCIENCE AND ENGINEERING 32, XXXX-XXXX (2016) PCR*-Tree: PCM-aware R*-Tree ELKHAN JABAROV AND MYONG-SOON PARK 1 Department of Computer and Radio Communications Engineering Korea University,
JOURNAL OF INFORMATION SCIENCE AND ENGINEERING 32, XXXX-XXXX (2016) PCR*-Tree: PCM-aware R*-Tree ELKHAN JABAROV AND MYONG-SOON PARK 1 Department of Computer and Radio Communications Engineering Korea University,
Mining Data Streams. Outline [Garofalakis, Gehrke & Rastogi 2002] Introduction. Summarization Methods. Clustering Data Streams
![Mining Data Streams. Outline [Garofalakis, Gehrke & Rastogi 2002] Introduction. Summarization Methods. Clustering Data Streams](/thumbs/85/93020188.jpg "Mining Data Streams. Outline [Garofalakis, Gehrke & Rastogi 2002] Introduction. Summarization Methods. Clustering Data Streams") Mining Data Streams Outline [Garofalakis, Gehrke & Rastogi 2002] Introduction Summarization Methods Clustering Data Streams Data Stream Classification Temporal Models CMPT 843, SFU, Martin Ester, 1-06
Mining Data Streams Outline [Garofalakis, Gehrke & Rastogi 2002] Introduction Summarization Methods Clustering Data Streams Data Stream Classification Temporal Models CMPT 843, SFU, Martin Ester, 1-06
Chapter 13: Query Processing
 Chapter 13: Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 13.1 Basic Steps in Query Processing 1. Parsing
Chapter 13: Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 13.1 Basic Steps in Query Processing 1. Parsing
Introduction. for large input, even access time may be prohibitive we need data structures that exhibit times closer to O(log N) binary search tree
 binary search tree") Chapter 4 Trees 2 Introduction for large input, even access time may be prohibitive we need data structures that exhibit running times closer to O(log N) binary search tree 3 Terminology recursive definition
Chapter 4 Trees 2 Introduction for large input, even access time may be prohibitive we need data structures that exhibit running times closer to O(log N) binary search tree 3 Terminology recursive definition
B-Trees. Based on materials by D. Frey and T. Anastasio
 B-Trees Based on materials by D. Frey and T. Anastasio 1 Large Trees n Tailored toward applications where tree doesn t fit in memory q operations much faster than disk accesses q want to limit levels of
B-Trees Based on materials by D. Frey and T. Anastasio 1 Large Trees n Tailored toward applications where tree doesn t fit in memory q operations much faster than disk accesses q want to limit levels of
An index structure for efficient reverse nearest neighbor queries
 An index structure for efficient reverse nearest neighbor queries Congjun Yang Division of Computer Science, Department of Mathematical Sciences The University of Memphis, Memphis, TN 38152, USA yangc@msci.memphis.edu
An index structure for efficient reverse nearest neighbor queries Congjun Yang Division of Computer Science, Department of Mathematical Sciences The University of Memphis, Memphis, TN 38152, USA yangc@msci.memphis.edu
9/24/ Hash functions
 11.3 Hash functions A good hash function satis es (approximately) the assumption of SUH: each key is equally likely to hash to any of the slots, independently of the other keys We typically have no way
11.3 Hash functions A good hash function satis es (approximately) the assumption of SUH: each key is equally likely to hash to any of the slots, independently of the other keys We typically have no way