Introduction to CUDA (1 of n*)
|
|
|
- Jayson Newman
- 6 years ago
- Views:
Transcription

1 Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS Spring 2011 * Where n is 2 or 3 Acknowledgements Many slides are from Kayvon Fatahalian's From Shader Code to a Teraflop: How GPU Shader Cores Work: fatahalian_gpuarchteraflop_bps_siggraph201 0.pdf David Kirk and Wen-mei Hwu s UIUC course: GPU Architecture Review GPUs are: Parallel Multithreaded Many-core GPUs have: Tremendous computational horsepower High memory bandwidth GPU Architecture Review GPUs are specialized for Compute-intensive, highly parallel computation Graphics! Transistors are devoted to: Processing Not: Data caching Flow control GPU Architecture Review Transistor Usage Image from:


2 Slide from: Slide from: Slide from: Slide from: Slide from: Slide from:

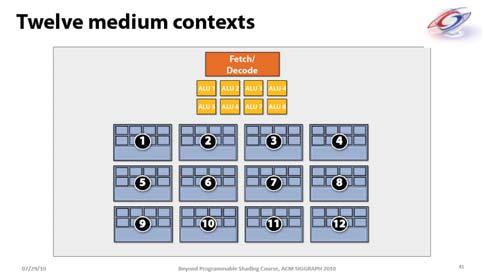
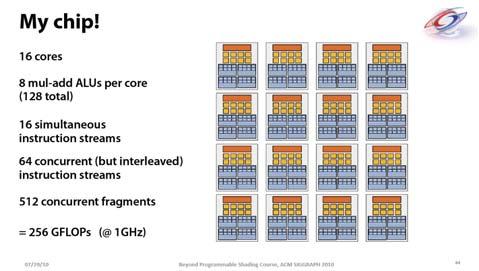
3 Slide from: Slide from: Slide from: Slide from: ing Hardware in G80 Slide from:

4 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 3D 3D API: API: 3D API Commands 3D 3D OpenGL OpenGL or or Application Application Direct3D Direct3D Or Or Game Game GPU Command & Data Stream GPU GPU Front Front End End Pre-transformed Vertices Vertex Index Stream Primitive Primitive Assembly Assembly Programmable Programmable Vertex Vertex Processor Processor Assembled Primitives Transformed Vertices Rasterization and Interpolation Pre-transformed Fragments Fixed-function pipeline CPU-GPU Boundary (AGP/PCIe) Pixel Location Stream Programmable Programmable Fragment Fragment Processor Processor Raster Operations Pixel Updates Transformed Fragments Frame Frame Buffer Buffer 3D 3D API: API: 3D API Commands 3D 3D OpenGL OpenGL or or Application Application Direct3D Direct3D Or Or Game Game GPU Command & Data Stream GPU GPU Front Front End End Vertex Index Stream Primitive Primitive Assembly Assembly Assembled Primitives CPU-GPU Boundary (AGP/PCIe) Rasterization and Interpolation Pixel Location Stream Programmable pipeline Raster Operations Pixel Updates Frame Frame Buffer Buffer 3D 3D API: API: 3D API Commands 3D 3D OpenGL OpenGL or or Application Application Direct3D Direct3D Or Or Game Game GPU Command & Data Stream GPU GPU Front Front End End Vertex Index Stream Primitive Primitive Assembly Assembly Assembled Primitives Rasterization and Interpolation Pixel Location Stream Unified Programmable pipeline CPU-GPU Boundary (AGP/PCIe) Raster Operations Pixel Updates Frame Frame Buffer Buffer Pre-transformed Vertices Programmable Programmable Vertex Vertex Processor Processor Transformed Vertices Pre-transformed Fragments Programmable Programmable Fragment Fragment Processor Processor Transformed Fragments Pre-transformed Vertices Transformed Vertices Pre-transformed Fragments Unified Unified Vertex, Vertex, Fragment, Fragment, Geometry Geometry Processor Processor Transformed Fragments General Diagram (6800/NV40) Turbo Uses PCI-Express bandwidth to render directly to system memory Card needs less memory Performance boost while lowering cost Turbo Manager dynamically allocates from main memory Local memory used to cache data and to deliver peak performance when needed
 passed on to fragment units An NV40 vertex")



 General Diagram")
5 NV40 Vertex Processor NV40 Fragment Processors Early termination from mini z buffer and z buffer checks; resulting sets of 4 pixels (quads) passed on to fragment units An NV40 vertex processor is able to execute one vector operation (up to four FP32 components), one scalar FP32 operation, and make one access to the texture per clock cycle Why NV40 series was better Massive parallelism Scalability Lower end products have fewer pixel pipes and fewer vertex shader units Computation Power 222 million transistors First to comply with Microsoft s DirectX 9 spec Dynamic Branching in pixel shaders Dynamic Branching Helps detect if pixel needs shading Instruction flow handled in groups of pixels Specify branch granularity (the number of consecutive pixels that take the same branch) Better distribution of blocks of pixels between the different quad engines General Diagram (7800/G70) General Diagram (7800/G70) General Diagram (6800/NV40)




6 GeForce Go 7800 Power Issues Power consumption and package are the same as the 6800 Ultra chip, meaning notebook designers do not have to change very much about their thermal designs Dynamic clock scaling can run as slow as 16 MHz This is true for the engine, memory, and pixel clocks Heavier use of clock gating than the desktop version Runs at voltages lower than any other mobile performance part Regardless, you won t get much battery-based runtime for a 3D game GeForce 7800 GTX Parallelism Z-Cull Triangle Setup/Raster Shader Instruction Dispatch 8 Vertex Engines 24 Pixel Shaders G80 Graphics Mode The future of GPUs is programmable processing Host So build the architecture around the Input Assembler Setup / Rstr / ZCull processor Vtx Issue Geom Issue Pixel Issue Fragment Crossbar 16 Raster Operation Pipelines L1 L1 L1 L1 L1 L1 L1 L1 Processor L2 L2 L2 L2 L2 L2 Partition Partition Partition Partition G80 CUDA mode A Example Processors execute computing threads New operating mode/hw interface for Host computing Input Assembler Execution Manager Why Use the GPU for Computing? The GPU has evolved into a very flexible and powerful processor: It s programmable using high-level languages It supports 32-bit floating point precision It offers lots of GFLOPS: Parallel Data Parallel Data Parallel Data Parallel Data Parallel Data Parallel Data Parallel Data Parallel Data Texture Texture Texture Texture Texture Texture Texture Texture Load/store Load/store Load/store Load/store Load/store Load/store Global GFLOPS GPU in every PC and workstation G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce 6800 Ultra NV35 = GeForce FX 5950 Ultra NV30 = GeForce FX 5800
 So, more transistors can be devoted to data processing rather than data")
7 What is Behind such an Evolution? The GPU is specialized for compute-intensive, highly data parallel computation (exactly what graphics rendering is about) So, more transistors can be devoted to data processing rather than data caching and flow control ALU Control ALU CPU DRAM ALU ALU DRAM GPU The fast-growing video game industry exerts What is (Historical) GPGPU? General Purpose computation using GPU and graphics API in applications other than 3D graphics GPU accelerates critical path of application Data parallel algorithms leverage GPU attributes Large data arrays, streaming throughput Fine-grain SIMD parallelism Low-latency floating point (FP) computation Applications see //GPGPU.org Game effects (FX) physics image processing Previous GPGPU Constraints Dealing with graphics API Working with the corner cases of the graphics API Addressing modes Limited texture size/dimension Shader capabilities Limited outputs Instruction sets Lack of Integer & bit ops Communication limited Between pixels Scatter a[i] = p Input Fragment Program Output Texture Constants per thread per Shader per Context Temp An Example of Physical Reality Behind CUDA CPU (host) GPU w/ local DRAM (device) Arrays of Parallel s A CUDA kernel is executed by an array of threads All threads run the same code (MD) Each thread has an ID that it uses to compute memory addresses and make control decisions threadid float x = input[threadid]; float y = func(x); output[threadid] = y; s: Scalable Cooperation Divide monolithic thread array into multiple blocks s within a block cooperate via shared memory, atomic operations and barrier synchronization s 0in different blocks 0 cannot cooperate N threadid float x = input[threadid]; float y = func(x); output[threadid] = y; float x = input[threadid]; float y = func(x); output[threadid] = y; float x = input[threadid]; float y = func(x); output[threadid] = y;
8 Batching: Grids and s A kernel is executed as a grid of thread blocks All threads share data memory space A thread block is a batch of threads that can cooperate with each other by: Synchronizing their execution For hazard-free shared memory accesses Efficiently sharing data through a low latency shared memory Two threads from two different blocks cannot cooperate Host Kernel 1 Kernel 2 (1, 1) (0, 0) (0, 1) (0, 2) (1, 0) (1, 1) (1, 2) Grid 1 (0, 0) (0, 1) Grid 2 (2, 0) (2, 1) (2, 2) (1, 0) (1, 1) (3, 0) (3, 1) (3, 2) Courtesy: NDVIA (4, 0) (4, 1) (4, 2) (2, 0) (2, 1) and IDs s and blocks have IDs So each thread can decide what data to work on ID: 1D or 2D ID: 1D, 2D, or 3D Simplifies memory addressing when processing multidimensional data Image processing Solving PDEs on volumes (1, 1) (0, 0) (0, 1) (0, 2) (1, 0) (1, 1) (1, 2) Grid 1 (0, 0) (0, 1) (2, 0) (2, 1) (2, 2) (1, 0) (1, 1) (3, 0) (3, 1) (3, 2) (4, 0) (4, 1) (4, 2) Courtesy: NDVIA (2, 0) (2, 1) CUDA Space Overview Each thread can: R/W per-thread registers R/W per-thread local memory R/W per-block shared memory R/W per-grid global memory Read only per-grid constant memory Read only per-grid texture memory The host can R/W global, constant, and texture memories Host () Grid (0, 0) Local Global Constant Texture Shared (0, 0) (1, 0) Local (1, 0) Local Shared (0, 0) (1, 0) Local Global, Constant, and Texture Memories (Long Latency Accesses) () Grid Global memory Main means of (0, 0) communicating R/W Shared Data between host and device Contents visible to all (0, 0) (1, 0) threads Texture and Constant Local Local Local Memories Constants initialized by host Contents visible to all threads Host Global Constant Texture (1, 0) Shared (0, 0) Courtesy: NDVIA (1, 0) Local IDs and IDs Each thread uses IDs to decide what data to work on ID: 1D or 2D ID: 1D, 2D, or 3D Simplifies memory addressing when processing multidimensional data Image processing Solving PDEs on Host Kernel 1 Grid 1 Grid 2 (0, 0) (0, 1) (1, 0) (1, 1) Kernel 2 (1, 1) (0,0,1) (1,0,1) (2,0,1) (3,0,1) (0,0,0) (1,0,0) (2,0,0) (3,0,0) (0,1,0) (1,1,0) (2,1,0) (3,1,0) Courtesy: NDVIA CUDA Model Overview Global memory Main means of communicating R/W Data between host and device Contents visible to all threads Long latency access We will focus on global memory for now Host Grid (0, 0) Shared (0, 0) Global (1, 0) (1, 0) Shared (0, 0) (1, 0)
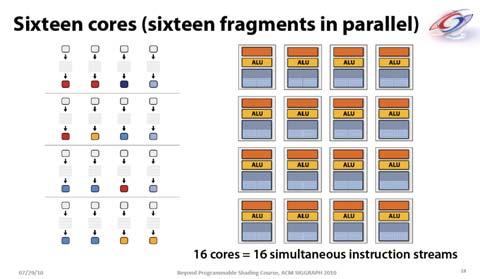
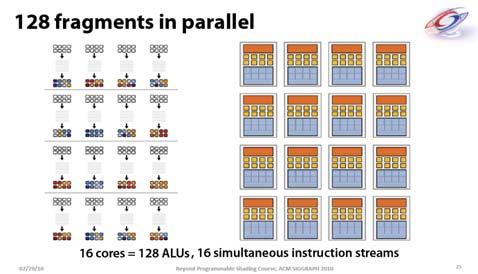
9 Parallel Computing on a GPU 8-series GPUs deliver 25 to 200+ GFLOPS on compiled parallel C applications Available in laptops, desktops, and clusters GPU parallelism is doubling every year Programming model scales transparently Programmable in C with CUDA tools Tesla D870 GeForce 8800 Tesla S870 Single-Program Multiple-Data (MD) CUDA integrated CPU + GPU application C program Serial C code executes on CPU Parallel Kernel C code executes on GPU CPU Serial Code thread blocks GPU Parallel Kernel KernelA<<< nblk, ntid >>>(args); CPU Serial Code GPU Parallel Kernel KernelB<<< nblk, ntid >>>(args); Grid 0 Grid 1 Grids and s A kernel is executed as a grid of thread blocks All threads share global memory space A thread block is a batch of threads that can cooperate with each other by: Synchronizing their execution using barrier Efficiently sharing data through a low latency shared memory Two threads from two different blocks cannot Host Grid 1 Kernel 1 (0, 0) (1, 0) (0, 1) (1, 1) Grid 2 Kernel 2 (1, 1) (0,0,1) (1,0,1) (2,0,1) (3,0,1) (0,0,0) (1,0,0) (2,0,0) (3,0,0) (0,1,0) (1,1,0) (2,1,0) (3,1,0) Courtesy: NDVIA CUDA Programmer declares () : size 1 to 512 concurrent threads CUDA shape 1D, 2D, or 3D Id #: m dimensions in threads All threads in a execute the same thread program s share data and synchronize while doing their share of the work s have thread id numbers within program Courtesy: John Nickolls, NVIDIA GeForce-8 Series HW Overview Streaming Processor Array TPC TPC TPC TPC TPC TPC Texture Processor Cluster Streaming Multiprocessor Instruction L1 Data L1 SM Instruction Fetch/Dispatch Shared TEX SM SFU SFU CUDA Processor Terminology A Streaming Processor Array (variable across GeForce 8-series, 8 in GeForce8800) TPC Texture Processor Cluster (2 SM + TEX) SM Streaming Multiprocessor (8 ) Multi-threaded processor core Fundamental processing unit for CUDA thread block Streaming Processor Scalar ALU for a single CUDA thread
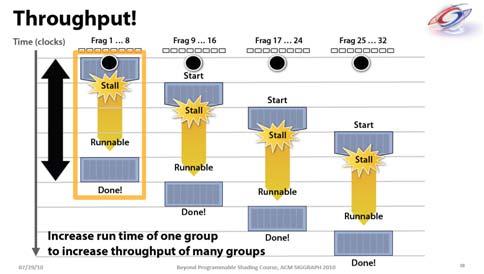
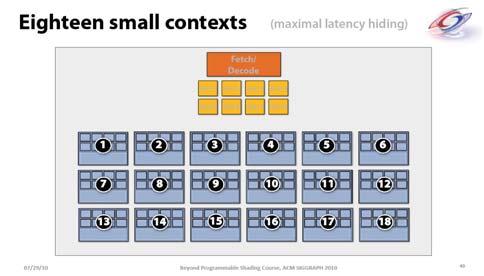
10 Streaming Multiprocessor (SM) Streaming Multiprocessor (SM) 8 Streaming Processors () 2 Super Function Units (SFU) Multi-threaded instruction dispatch 1 to 512 threads active Shared instruction fetch per 32 threads Cover latency of texture/memory loads 20+ GFLOPS 16 KB shared memory texture and global memory access Streaming Multiprocessor Instruction L1 Data L1 Instruction Fetch/Dispatch Shared SFU SFU G80 Computing Pipeline The Processors future of execute GPUs is computing programmable threads processing Alternative operating mode specifically for Host Generates So computing build the architecture grids based on around the Input Input Assembler kernel calls Setup / Rstr / ZCull processor Execution Manager Vtx Issue Geom Issue Pixel Issue Parallel Data Parallel Data Parallel Data Parallel Data Parallel Data Parallel Data Parallel Data Parallel Data Texture L1 Texture L1 Texture L1 Texture L1 Texture L1 Texture L1 Texture L1 Texture L1 Load/store L2 Load/storeL2 Load/store L2 Load/store L2 Load/store L2 Load/store L2 Global Processor Life Cycle Host in HW Grid is launched on the A s are serially distributed to all the SM s Potentially >1 per SM Each SM launches Warps of s 2 levels of parallelism SM schedules and executes Warps that are ready to run As Warps and s complete, Kernel 1 Kernel 2 (1, 1) (0, 0) (0, 1) (0, 2) (1, 0) (1, 1) (1, 2) Grid 1 (0, 0) (0, 1) Grid 2 (2, 0) (2, 1) (2, 2) (1, 0) (1, 1) (3, 0) (3, 1) (3, 2) (4, 0) (4, 1) (4, 2) (2, 0) (2, 1) SM Executes s t0 t1 t2 tm s SM 0 SM 1 MT IU Shared MT IU Shared Texture L1 L2 t0 t1 t2 tm s s are assigned to SMs in granularity Up to 8 s to each SM as resource allows SM in G80 can take up to 768 threads Could be 256 (threads/block) * 3 blocks Or 128 (threads/block) * 6 blocks, etc. s run concurrently Scheduling/Execution Each s is divided in 32-thread Warps This is an implementation decision, not part of the CUDA programming model Warps are scheduling units in SM If 3 blocks are assigned to an SM and each has 256 threads, how many Warps are there in an SM? Each is divided into 256/32 = 8 Warps There are 8 * 3 = 24 Warps 1 Warps t0 t1 t2 t31 SFU 2 Warps t0 t1 t2 t31 Streaming Multiprocessor Instruction L1 Data L1 Instruction Fetch/Dispatch Shared SFU time SM Warp Scheduling SM multithreaded Warp scheduler warp 8 instruction 11 warp 1 instruction 42 warp 3 instruction 95. warp 8 instruction 12 warp 3 instruction 96 SM hardware implements zero-overhead Warp scheduling Warps whose next instruction has its operands ready for consumption are eligible for execution Eligible Warps are selected for execution on a prioritized scheduling policy All threads in a Warp execute the same instruction when selected 4 clock cycles needed to
11 SM Instruction Buffer Warp Scheduling Fetch one warp instruction/cycle from instruction L1 cache into any instruction buffer slot Issue one ready-to-go warp instruction/cycle from any warp - instruction buffer slot operand scoreboarding used to prevent hazards Issue selection based on roundrobin/age of warp SM broadcasts the same instruction I$ L1 Multithreaded Instruction Buffer R C$ Shared F L1 Mem Operand Select MAD SFU Scoreboarding All register operands of all instructions in the Instruction Buffer are scoreboarded Instruction becomes ready after the needed values are deposited prevents hazards cleared instructions are eligible for issue Decoupled /Processor pipelines any thread can continue to issue instructions until scoreboarding prevents issue allows /Processor ops to proceed in shadow of other waiting /Processor ops Granularity Considerations For Matrix Multiplication, should I use 4X4, 8X8, 16X16 or 32X32 tiles? For 4X4, we have 16 threads per block, Since each SM can take up to 768 threads, the thread capacity allows 48 blocks. However, each SM can only take up to 8 blocks, thus there will be only 128 threads in each SM! There are 8 warps but each warp is only half full. Hardware in G80 For 8X8, we have 64 threads per. Since each SM can take up to 768 threads, it could take up to 12 s. However, each SM can only take up to 8 s, only 512 threads will go into each SM! There are 16 warps available for scheduling in each SM Each warp spans four slices in the y dimension For 16X16, we have 256 threads per. Since each SM can take up to 768 threads, it can take up to 3 s and achieve full capacity unless other resource considerations overrule. There are 24 warps available for scheduling in each SM Each warp spans two slices in the y dimension CUDA Space: Review Each thread can: R/W per-thread registers R/W per-thread local memory R/W per-block shared memory R/W per-grid global memory Read only per-grid constant Host R/W memory global, constant, Read only and per-grid texture memory The host can texture memories () Grid (0, 0) Local Global Constant Texture Shared (0, 0) (1, 0) Local (1, 0) Local Shared (0, 0) (1, 0) Local Parallel Sharing Grid 0 Grid 1 Local Shared Local : perthread Private per thread Auto variables, register spill Shared : per- Shared by threads of the same block Inter-thread communication Global Sequential Global : Gridsper- application in Time Shared by all threads Inter-Grid communication
12 SM Architecture t0 t1 t2 tm s SM 0 SM 1 MT IU Shared Courtesy: John Nicols, NVIDIA MT IU Shared Texture L1 L2 t0 t1 t2 tm s s in a block share data & results In and Shared Synchronize at barrier instruction Per- Shared Allocation Keeps data close to processor SM Register File Register File (RF) 32 KB (8K entries) for each SM in G80 TEX pipe can also read/write RF 2 SMs share 1 TEX Load/Store pipe can also read/write RF I$ L1 Multithreaded Instruction Buffer R C$ Shared F L1 Mem Operand Select MAD SFU Programmer View of Register File 4 blocks 3 blocks There are 8192 registers in each SM in G80 This is an implementation decision, not part of CUDA are dynamically partitioned across all blocks assigned to the SM Once assigned to a Matrix Multiplication Example If each has 16X16 threads and each thread uses 10 registers, how many thread can run on each SM? Each block requires 10*256 = 2560 registers 8192 = 3 * change So, three blocks can run on an SM as far as registers are concerned How about if each thread increases the use of registers by 1? Each now requires 11*256 = 2816 registers 8192 < 2816 *3 More on Dynamic Partitioning Dynamic partitioning gives more flexibility to compilers/programmers One can run a smaller number of threads that require many registers each or a large number of threads that require few registers each This allows for finer grain threading than traditional CPU threading models. The compiler can tradeoff between instruction-level parallelism and thread level parallelism Let s program this thing!


13 GPU Computing History 2001/2002 researchers see GPU as dataparallel coprocessor The GPGPU field is born 2007 NVIDIA releases CUDA CUDA Compute Uniform Architecture GPGPU shifts to GPU Computing 2008 Khronos releases OpenCL specification CUDA Abstractions A hierarchy of thread groups Shared memories Barrier synchronization CUDA Terminology Host typically the CPU Code written in ANSI C typically the GPU (data-parallel) Code written in extended ANSI C Host and device have separate memories CUDA Program Contains both host and device code CUDA Terminology Kernel data-parallel function Invoking a kernel creates lightweight threads on the device s are generated and scheduled with hardware Does a kernel remind you of a shader in OpenGL? CUDA Kernels CUDA Program Execution Executed N times in parallel by N different CUDA threads Declaration Specifier ID Execution Configuration Image from:

14 Hierarchies Hierarchies Grid one or more thread blocks 1D or 2D array of threads 1D, 2D, or 3D Each block in a grid has the same number of threads Each thread in a block can Synchronize Access shared memory Image from: Hierarchies 1D, 2D, or 3D Example: Index into vector, matrix, volume Hierarchies ID: Scalar thread identifier Index: threadidx 1D: ID == Index 2D with size (D x, D y ) ID of index (x, y) == x + y D y 3D with size (D x, D y, D z ) ID of index (x, y, z) == x + y D y + z D x D y Hierarchies Hierarchies 2D Index Group of threads G80 and GT200: Up to 512 threads Fermi: Up to 1024 threads Reside on same processor core Share memory of that core 1 2D

15 Hierarchies Group of threads G80 and GT200: Up to 512 threads Fermi: Up to 1024 threads Reside on same processor core Share memory of that core Hierarchies Index: blockidx Dimension: blockdim 1D or 2D Image from: Hierarchies Hierarchies 16x16 s per block Example: N = 32 16x16 threads per block (independent of N) threadidx ([0, 15], [0, 15]) 2x2 thread blocks in grid blockidx ([0, 1], [0, 1]) blockdim = 16 2D i = [0, 1] * 16 + [0, 15] Hierarchies Hierarchies blocks execute independently In any order: parallel or series Scheduled in any order by any number of cores Allows code to scale with core count Image from:

16 Hierarchies CUDA Transfers s in a block Share (limited) low-latency memory Synchronize execution To coordinate memory accesses syncs() Barrier threads in block wait until all threads reach this Lightweight Image from: Image from: CUDA Transfers Host can transfer to/from device Global memory Constant memory CUDA Transfers cudamalloc() Allocate global memory on device cudafree() Frees memory Image from: Image from: CUDA Transfers CUDA Transfers Pointer to device memory
17 CUDA Transfers CUDA Transfers cudamemcpy() Size in bytes transfer Host to host Host to device to host to device Hos t Global Does this remind you of VBOs in OpenGL? CUDA Transfers CUDA Transfers cudamemcpy() cudamemcpy() transfer Host to host Host to device to host to device Hos t Global transfer Host to host Host to device to host to device Hos t Global CUDA Transfers CUDA Transfers cudamemcpy() cudamemcpy() transfer Host to host Host to device to host to device Hos t Global transfer Host to host Host to device to host to device Hos t Global All transfers are asynchronous

18 CUDA Transfers CUDA Transfers Host to device Destination (device) Source (host) Hos t Global Hos t Global CUDA Transfers Matrix Multiply P = M * N Assume M and N are square for simplicity Is this data-parallel? Hos t Global Image from: Matrix Multiply 1,000 x 1,000 matrix 1,000,000 dot products Each 1,000 multiples and 1,000 adds Matrix Multiply: CPU Implementation void MatrixMulOnHost(float* M, float* N, float* P, int width) { for (int i = 0; i < width; ++i) for (int j = 0; j < width; ++j) { float sum = 0; for (int k = 0; k < width; ++k) { float a = M[i * width + k]; float b = N[k * width + j]; sum += a * b; } P[i * width + j] = sum; } } Code from:
19 Matrix Multiply: CUDA Skeleton Matrix Multiply: CUDA Skeleton Matrix Multiply: CUDA Skeleton Matrix Multiply Step 1 Add CUDA memory transfers to the skeleton Matrix Multiply: Data Transfer Matrix Multiply: Data Transfer Allocate input Allocate output

20 Matrix Multiply: Data Transfer Matrix Multiply: Data Transfer Read back from device Matrix Multiply: Data Transfer Matrix Multiply Step 2 Implement the kernel in CUDA C Does this remind you of GPGPU with GLSL? Matrix Multiply: CUDA Kernel Matrix Multiply: CUDA Kernel Accessing a matrix, so using a 2D block Each kernel computes one output

21 Matrix Multiply: CUDA Kernel Matrix Multiply: CUDA Kernel Where did the two outer for loops in the CPU implementation go? No locks or synchronization, why? Matrix Multiply Step 3 Invoke the kernel in CUDA C Matrix Multiply: Invoke Kernel One block with width by width threads Matrix Multiply One of threads compute matrix Pd Each thread computes one element of Pd Each thread Loads a row of matrix Md Loads a column of matrix Nd Perform one multiply and addition for each pair of Md and Nd elements Compute to off-chip memory access ratio close to 1:1 (not very high) Size of matrix limited by the number of threads allowed in a thread block Md Pd David Kirk/NVIDIA and Wen-mei W. Hwu, ECE 498AL Spring 2010, University of Illinois, Urbana-Champaign 125 Slide from: Grid 1 1 (2, 2) WIDTH Nd Matrix Multiply What is the major performance problem with our implementation? What is the major limitation?
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
Introduction to CUDA (1 of n*)
") Administrivia Introduction to CUDA (1 of n*) Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Paper presentation due Wednesday, 02/23 Topics first come, first serve Assignment 4 handed today
Administrivia Introduction to CUDA (1 of n*) Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Paper presentation due Wednesday, 02/23 Topics first come, first serve Assignment 4 handed today
Mattan Erez. The University of Texas at Austin
 EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
EE382N (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III)
: Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III)") EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III) Mattan Erez The University of Texas at Austin EE382: Principles of Computer Architecture, Fall 2011 -- Lecture
EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III) Mattan Erez The University of Texas at Austin EE382: Principles of Computer Architecture, Fall 2011 -- Lecture
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
CIS 665: GPU Programming. Lecture 2: The CUDA Programming Model
 CIS 665: GPU Programming Lecture 2: The CUDA Programming Model 1 Slides References Nvidia (Kitchen) David Kirk + Wen-Mei Hwu (UIUC) Gary Katz and Joe Kider 2 3D 3D API: API: OpenGL OpenGL or or Direct3D
CIS 665: GPU Programming Lecture 2: The CUDA Programming Model 1 Slides References Nvidia (Kitchen) David Kirk + Wen-Mei Hwu (UIUC) Gary Katz and Joe Kider 2 3D 3D API: API: OpenGL OpenGL or or Direct3D
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
General Purpose GPU programming (GP-GPU) with Nvidia CUDA. Libby Shoop
 with Nvidia CUDA. Libby Shoop") General Purpose GPU programming (GP-GPU) with Nvidia CUDA Libby Shoop 3 What is (Historical) GPGPU? General Purpose computation using GPU and graphics API in applications other than 3D graphics GPU accelerates
General Purpose GPU programming (GP-GPU) with Nvidia CUDA Libby Shoop 3 What is (Historical) GPGPU? General Purpose computation using GPU and graphics API in applications other than 3D graphics GPU accelerates
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin") EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
CUDA programming model. N. Cardoso & P. Bicudo. Física Computacional (FC5)
") CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CS8803SC Software and Hardware Cooperative Computing GPGPU. Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology
 CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
Intro to GPU s for Parallel Computing
 Intro to GPU s for Parallel Computing Goals for Rest of Course Learn how to program massively parallel processors and achieve high performance functionality and maintainability scalability across future
Intro to GPU s for Parallel Computing Goals for Rest of Course Learn how to program massively parallel processors and achieve high performance functionality and maintainability scalability across future
Master Informatics Eng.
 Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
ME964 High Performance Computing for Engineering Applications
 ME964 High Performance Computing for Engineering Applications Memory Issues in CUDA Execution Scheduling in CUDA February 23, 2012 Dan Negrut, 2012 ME964 UW-Madison Computers are useless. They can only
ME964 High Performance Computing for Engineering Applications Memory Issues in CUDA Execution Scheduling in CUDA February 23, 2012 Dan Negrut, 2012 ME964 UW-Madison Computers are useless. They can only
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
GPU Programming. Lecture 2: CUDA C Basics. Miaoqing Huang University of Arkansas 1 / 34
 1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
The NVIDIA GeForce 8800 GPU
 The NVIDIA GeForce 8800 GPU August 2007 Erik Lindholm / Stuart Oberman Outline GeForce 8800 Architecture Overview Streaming Processor Array Streaming Multiprocessor Texture ROP: Raster Operation Pipeline
The NVIDIA GeForce 8800 GPU August 2007 Erik Lindholm / Stuart Oberman Outline GeForce 8800 Architecture Overview Streaming Processor Array Streaming Multiprocessor Texture ROP: Raster Operation Pipeline
Data Parallel Execution Model
 CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
GPU Computation CSCI 4239/5239 Advanced Computer Graphics Spring 2014
 GPU Computation CSCI 4239/5239 Advanced Computer Graphics Spring 2014 Solutions to Parallel Processing Message Passing (distributed) MPI (library) Threads (shared memory) pthreads (library) OpenMP (compiler)
GPU Computation CSCI 4239/5239 Advanced Computer Graphics Spring 2014 Solutions to Parallel Processing Message Passing (distributed) MPI (library) Threads (shared memory) pthreads (library) OpenMP (compiler)
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
Programming in CUDA. Malik M Khan
 Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC.
 David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
Parallel Computing. Lecture 19: CUDA - I
 CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
CS GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8. Markus Hadwiger, KAUST
 CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
CSE 160 Lecture 24. Graphical Processing Units
 CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
Module 2: Introduction to CUDA C
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
Core/Many-Core Architectures and Programming. Prof. Huiyang Zhou
 ST: CDA 6938 Multi-Core/Many Core/Many-Core Architectures and Programming http://csl.cs.ucf.edu/courses/cda6938/ Prof. Huiyang Zhou School of Electrical Engineering and Computer Science University of Central
ST: CDA 6938 Multi-Core/Many Core/Many-Core Architectures and Programming http://csl.cs.ucf.edu/courses/cda6938/ Prof. Huiyang Zhou School of Electrical Engineering and Computer Science University of Central
Lecture 3: Introduction to CUDA
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Spring Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim 2 Warp is the basic unit of execution A group of threads (e.g. 32 threads for the Tesla GPU architecture) Warp Execution Inst 1 Inst 2 Inst 3 Sources ready T T T T One warp
Spring 2011 Prof. Hyesoon Kim 2 Warp is the basic unit of execution A group of threads (e.g. 32 threads for the Tesla GPU architecture) Warp Execution Inst 1 Inst 2 Inst 3 Sources ready T T T T One warp
Spring 2009 Prof. Hyesoon Kim
 Spring 2009 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
Spring 2009 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
An Example of Physical Reality Behind CUDA. GeForce Speedup of Applications Why Massively Parallel Processor.
 Fall 007 Illinois ECE 498AL1 Programming Massively Parallel Processors Why Massively Parallel Processor A quiet revolution and potential build-up Calculation: 367 GFLOPS vs. 3 GFLOPS Bandwidth: 86.4 GB/s
Fall 007 Illinois ECE 498AL1 Programming Massively Parallel Processors Why Massively Parallel Processor A quiet revolution and potential build-up Calculation: 367 GFLOPS vs. 3 GFLOPS Bandwidth: 86.4 GB/s
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Spring 2011 Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
Spring 2011 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
Lecture 1: Introduction and Computational Thinking
 PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
GRAPHICS PROCESSING UNITS
 GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
HPC COMPUTING WITH CUDA AND TESLA HARDWARE. Timothy Lanfear, NVIDIA
 HPC COMPUTING WITH CUDA AND TESLA HARDWARE Timothy Lanfear, NVIDIA WHAT IS GPU COMPUTING? What is GPU Computing? x86 PCIe bus GPU Computing with CPU + GPU Heterogeneous Computing Low Latency or High Throughput?
HPC COMPUTING WITH CUDA AND TESLA HARDWARE Timothy Lanfear, NVIDIA WHAT IS GPU COMPUTING? What is GPU Computing? x86 PCIe bus GPU Computing with CPU + GPU Heterogeneous Computing Low Latency or High Throughput?
CUDA (Compute Unified Device Architecture)
") CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
ME964 High Performance Computing for Engineering Applications
 ME964 High Performance Computing for Engineering Applications Execution Scheduling in CUDA Revisiting Memory Issues in CUDA February 17, 2011 Dan Negrut, 2011 ME964 UW-Madison Computers are useless. They
ME964 High Performance Computing for Engineering Applications Execution Scheduling in CUDA Revisiting Memory Issues in CUDA February 17, 2011 Dan Negrut, 2011 ME964 UW-Madison Computers are useless. They
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
GPGPU. Lecture 2: CUDA
 GPGPU Lecture 2: CUDA GPU is fast Previous GPGPU Constraints Dealing with graphics API Working with the corner cases of the graphics API Addressing modes Limited texture size/dimension Shader capabilities
GPGPU Lecture 2: CUDA GPU is fast Previous GPGPU Constraints Dealing with graphics API Working with the corner cases of the graphics API Addressing modes Limited texture size/dimension Shader capabilities
Lecture 2: Introduction to CUDA C
 CS/EE 217 GPU Architecture and Programming Lecture 2: Introduction to CUDA C David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2013 1 CUDA /OpenCL Execution Model Integrated host+device app C program Serial or
CS/EE 217 GPU Architecture and Programming Lecture 2: Introduction to CUDA C David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2013 1 CUDA /OpenCL Execution Model Integrated host+device app C program Serial or
CUDA PROGRAMMING MODEL. Carlo Nardone Sr. Solution Architect, NVIDIA EMEA
 CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CS179 GPU Programming Introduction to CUDA. Lecture originally by Luke Durant and Tamas Szalay
 Introduction to CUDA Lecture originally by Luke Durant and Tamas Szalay Today CUDA - Why CUDA? - Overview of CUDA architecture - Dense matrix multiplication with CUDA 2 Shader GPGPU - Before current generation,
Introduction to CUDA Lecture originally by Luke Durant and Tamas Szalay Today CUDA - Why CUDA? - Overview of CUDA architecture - Dense matrix multiplication with CUDA 2 Shader GPGPU - Before current generation,
ECE 574 Cluster Computing Lecture 15
 ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
Module 2: Introduction to CUDA C. Objective
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
CSCI-GA Graphics Processing Units (GPUs): Architecture and Programming Lecture 2: Hardware Perspective of GPUs
: Architecture and Programming Lecture 2: Hardware Perspective of GPUs") CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 2: Hardware Perspective of GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com History of GPUs
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 2: Hardware Perspective of GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com History of GPUs
CE 431 Parallel Computer Architecture Spring Graphics Processor Units (GPU) Architecture
 Architecture") CE 431 Parallel Computer Architecture Spring 2017 Graphics Processor Units (GPU) Architecture Nikos Bellas Computer and Communications Engineering Department University of Thessaly Some slides borrowed
CE 431 Parallel Computer Architecture Spring 2017 Graphics Processor Units (GPU) Architecture Nikos Bellas Computer and Communications Engineering Department University of Thessaly Some slides borrowed
From Brook to CUDA. GPU Technology Conference
 From Brook to CUDA GPU Technology Conference A 50 Second Tutorial on GPU Programming by Ian Buck Adding two vectors in C is pretty easy for (i=0; i
From Brook to CUDA GPU Technology Conference A 50 Second Tutorial on GPU Programming by Ian Buck Adding two vectors in C is pretty easy for (i=0; i
Introduction to CUDA
 Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Nvidia G80 Architecture and CUDA Programming
 Nvidia G80 Architecture and CUDA Programming School of Electrical Engineering and Computer Science CUDA Programming Model: A Highly Multithreaded Coprocessor The GPU is viewed as a compute device that:
Nvidia G80 Architecture and CUDA Programming School of Electrical Engineering and Computer Science CUDA Programming Model: A Highly Multithreaded Coprocessor The GPU is viewed as a compute device that:
Using The CUDA Programming Model
 Using The CUDA Programming Model Leveraging GPUs for Application Acceleration Dan Ernst, Brandon Holt University of Wisconsin Eau Claire 1 What is (Historical) GPGPU? General Purpose computation using
Using The CUDA Programming Model Leveraging GPUs for Application Acceleration Dan Ernst, Brandon Holt University of Wisconsin Eau Claire 1 What is (Historical) GPGPU? General Purpose computation using
1/26/09. Administrative. L4: Hardware Execution Model and Overview. Recall Execution Model. Outline. First assignment out, due Friday at 5PM
 Administrative L4: Hardware Execution Model and Overview January 26, 2009 First assignment out, due Friday at 5PM Any questions? New mailing list: cs6963-discussion@list.eng.utah.edu Please use for all
Administrative L4: Hardware Execution Model and Overview January 26, 2009 First assignment out, due Friday at 5PM Any questions? New mailing list: cs6963-discussion@list.eng.utah.edu Please use for all
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Windowing System on a 3D Pipeline. February 2005
 Windowing System on a 3D Pipeline February 2005 Agenda 1.Overview of the 3D pipeline 2.NVIDIA software overview 3.Strengths and challenges with using the 3D pipeline GeForce 6800 220M Transistors April
Windowing System on a 3D Pipeline February 2005 Agenda 1.Overview of the 3D pipeline 2.NVIDIA software overview 3.Strengths and challenges with using the 3D pipeline GeForce 6800 220M Transistors April
1/19/11. Administrative. L2: Hardware Execution Model and Overview. What is an Execution Model? Parallel programming model. Outline.
 L2: Hardware Execution Model and Overview January 19, 2011 Administrative First assignment out, due Friday at 5PM Use handin on CADE machines to submit handin cs6963 lab1 The file
L2: Hardware Execution Model and Overview January 19, 2011 Administrative First assignment out, due Friday at 5PM Use handin on CADE machines to submit handin cs6963 lab1 The file
ECE 574 Cluster Computing Lecture 17
 ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
Lecture 5. Performance programming for stencil methods Vectorization Computing with GPUs
 Lecture 5 Performance programming for stencil methods Vectorization Computing with GPUs Announcements Forge accounts: set up ssh public key, tcsh Turnin was enabled for Programming Lab #1: due at 9pm today,
Lecture 5 Performance programming for stencil methods Vectorization Computing with GPUs Announcements Forge accounts: set up ssh public key, tcsh Turnin was enabled for Programming Lab #1: due at 9pm today,
Introduction to Multicore architecture. Tao Zhang Oct. 21, 2010
 Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
B. Tech. Project Second Stage Report on
 B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC.
 David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
Massively Parallel Architectures
 Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
COMP 322: Fundamentals of Parallel Programming. Flynn s Taxonomy for Parallel Computers
 COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture
 COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
Introduction to CELL B.E. and GPU Programming. Agenda
 Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
CUDA C Programming Mark Harris NVIDIA Corporation
 CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
Today s Content. Lecture 7. Trends. Factors contributed to the growth of Beowulf class computers. Introduction. CUDA Programming CUDA (I)
") Today s Content Lecture 7 CUDA (I) Introduction Trends in HPC GPGPU CUDA Programming 1 Trends Trends in High-Performance Computing HPC is never a commodity until 199 In 1990 s Performances of PCs are getting
Today s Content Lecture 7 CUDA (I) Introduction Trends in HPC GPGPU CUDA Programming 1 Trends Trends in High-Performance Computing HPC is never a commodity until 199 In 1990 s Performances of PCs are getting
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes.
 HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
GPU programming. Dr. Bernhard Kainz
 GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
Challenges for GPU Architecture. Michael Doggett Graphics Architecture Group April 2, 2008
 Michael Doggett Graphics Architecture Group April 2, 2008 Graphics Processing Unit Architecture CPUs vsgpus AMD s ATI RADEON 2900 Programming Brook+, CAL, ShaderAnalyzer Architecture Challenges Accelerated
Michael Doggett Graphics Architecture Group April 2, 2008 Graphics Processing Unit Architecture CPUs vsgpus AMD s ATI RADEON 2900 Programming Brook+, CAL, ShaderAnalyzer Architecture Challenges Accelerated
GPUs and GPGPUs. Greg Blanton John T. Lubia
 GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Parallel Systems Course: Chapter IV. GPU Programming. Jan Lemeire Dept. ETRO November 6th 2008
 Parallel Systems Course: Chapter IV GPU Programming Jan Lemeire Dept. ETRO November 6th 2008 GPU Message-passing Programming with Parallel CUDAMessagepassing Parallel Processing Processing Overview 1.
Parallel Systems Course: Chapter IV GPU Programming Jan Lemeire Dept. ETRO November 6th 2008 GPU Message-passing Programming with Parallel CUDAMessagepassing Parallel Processing Processing Overview 1.
Current Trends in Computer Graphics Hardware
 Current Trends in Computer Graphics Hardware Dirk Reiners University of Louisiana Lafayette, LA Quick Introduction Assistant Professor in Computer Science at University of Louisiana, Lafayette (since 2006)
Current Trends in Computer Graphics Hardware Dirk Reiners University of Louisiana Lafayette, LA Quick Introduction Assistant Professor in Computer Science at University of Louisiana, Lafayette (since 2006)
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Mattan Erez. The University of Texas at Austin
 EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 11 The Graphics Processing Unit Mattan Erez The University of Texas at Austin Outline What is a GPU? Why should
EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 11 The Graphics Processing Unit Mattan Erez The University of Texas at Austin Outline What is a GPU? Why should
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
GeForce4. John Montrym Henry Moreton
 GeForce4 John Montrym Henry Moreton 1 Architectural Drivers Programmability Parallelism Memory bandwidth 2 Recent History: GeForce 1&2 First integrated geometry engine & 4 pixels/clk Fixed-function transform,
GeForce4 John Montrym Henry Moreton 1 Architectural Drivers Programmability Parallelism Memory bandwidth 2 Recent History: GeForce 1&2 First integrated geometry engine & 4 pixels/clk Fixed-function transform,
Computer Architecture
 Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Graphics Hardware. Graphics Processing Unit (GPU) is a Subsidiary hardware. With massively multi-threaded many-core. Dedicated to 2D and 3D graphics
 is a Subsidiary hardware. With massively multi-threaded many-core. Dedicated to 2D and 3D graphics") Why GPU? Chapter 1 Graphics Hardware Graphics Processing Unit (GPU) is a Subsidiary hardware With massively multi-threaded many-core Dedicated to 2D and 3D graphics Special purpose low functionality, high
Why GPU? Chapter 1 Graphics Hardware Graphics Processing Unit (GPU) is a Subsidiary hardware With massively multi-threaded many-core Dedicated to 2D and 3D graphics Special purpose low functionality, high
GPGPU/CUDA/C Workshop 2012
 GPGPU/CUDA/C Workshop 2012 Day-2: Intro to CUDA/C Programming Presenter(s): Abu Asaduzzaman Chok Yip Wichita State University July 11, 2012 GPGPU/CUDA/C Workshop 2012 Outline Review: Day-1 Brief history
GPGPU/CUDA/C Workshop 2012 Day-2: Intro to CUDA/C Programming Presenter(s): Abu Asaduzzaman Chok Yip Wichita State University July 11, 2012 GPGPU/CUDA/C Workshop 2012 Outline Review: Day-1 Brief history
ECE 8823: GPU Architectures. Objectives
 ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
Lecture 1: Introduction
 ECE 498AL Applied Parallel Programming Lecture 1: Introduction 1 Course Goals Learn how to program massively parallel processors and achieve high performance functionality and maintainability scalability
ECE 498AL Applied Parallel Programming Lecture 1: Introduction 1 Course Goals Learn how to program massively parallel processors and achieve high performance functionality and maintainability scalability
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
GPU Architecture. Michael Doggett Department of Computer Science Lund university
 GPU Architecture Michael Doggett Department of Computer Science Lund university GPUs from my time at ATI R200 Xbox360 GPU R630 R610 R770 Let s start at the beginning... Graphics Hardware before GPUs 1970s
GPU Architecture Michael Doggett Department of Computer Science Lund university GPUs from my time at ATI R200 Xbox360 GPU R630 R610 R770 Let s start at the beginning... Graphics Hardware before GPUs 1970s
Matrix Multiplication in CUDA. A case study
 Matrix Multiplication in CUDA A case study 1 Matrix Multiplication: A Case Study Matrix multiplication illustrates many of the basic features of memory and thread management in CUDA Usage of thread/block
Matrix Multiplication in CUDA A case study 1 Matrix Multiplication: A Case Study Matrix multiplication illustrates many of the basic features of memory and thread management in CUDA Usage of thread/block