MapReduce for Graph Algorithms
|
|
|
- Christina Morrison
- 6 years ago
- Views:
Transcription

1 Seminar: Massive-Scale Graph Analysis Summer Semester 2015 MapReduce for Graph Algorithms Modeling & Approach Ankur Sharma May 8, 2015
2 Agenda 1 Map-Reduce Framework Big Data MapReduce Graph Algorithms Graphs Graph Algorithms Design pattern Summary & Conclusion
 & 5B (Bing) b Big Data Market will account $50 Billion by 2017")
3 Big Data: Definition 2 Sources? : Web pages, social network, tweets, messages and many more How Big? : Google s Index is larger than 100 Peta Bytes and consumed over 1M computing hours to build a Number of webpages indexed: 48B (Google) & 5B (Bing) b Big Data Market will account $50 Billion by 2017 c a b c

4 Big Data: Processing 3 Figure: Comic from Socmedsean 1 1 Source:
5 Big Data: Processing 4 Quick and efficient analysis of Big Data requires extreme parallelism. A lot of systems were developed in late 1990s for parallel data processing such as SRB a These systems were efficient but lacked nice wrapper for average developer. In 2004, Jeffrey Dean and Sanjay Ghemawat from Google introduced MapReduce b which is a part of company s proprietary infrastructure. Similar open source infrastructure Hadoop c was developed in late 2005 by Doug Cutting & Mike Cafarella. a Wan et. al. The SDSC storage resource broker, CASCON 98 b Ghemawat et. al. MapReduce: Simplified data processing on large clusters, OSDI 14 c
6 MapReduce: Framework 5 Introduction MapReduce motivates from LISP s map and reduce operations (map square ( )) ( ) (reduce + ( )) (15) Framework provides automatic parallelism, fault-tolerance, I/O scheduling and monitoring for data processing
7 MapReduce: Framework 5 Introduction MapReduce motivates from LISP s map and reduce operations (map square ( )) ( ) (reduce + ( )) (15) Framework provides automatic parallelism, fault-tolerance, I/O scheduling and monitoring for data processing MapReduce: Programming Model Input / Output are a set of key value pairs User only needs to provide simple functions map(), reduce() and combine() a map(in_k, in_v) list(out_k, imt_v) combine(in_k, list(in_v)) list(out_k, imt_v) reduce(out_k, list(imt_v)) list(out_v) a optional
8 MapReduce: Execution Model 6 Figure: Overview: Map-Reduce execution model 2 2 Source: Ghemawat et. al. MapReduce: Simplified data processing on large clusters, OSDI 14
9 MapReduce: Example Word Count 7 Map function M(in_k, in_v) for each word in in_v: emit(word, 1) end function
10 MapReduce: Example Word Count 7 Map function M(in_k, in_v) for each word in in_v: emit(word, 1) end function Combine/Reduce function C_R(out_k, list{imt_v}) emit(word, imt_v) end function
 end function Combine/Reduce function C_R(out_k, list{imt_v}) emit(word, imt_v) end")
11 MapReduce: Example Word Count 7 Map function M(in_k, in_v) for each word in in_v: emit(word, 1) end function Combine/Reduce function C_R(out_k, list{imt_v}) emit(word, imt_v) end function
12 Graphs 8 Graph are everywhere: social graphs representing connections or citation graphs representing hierarchy in scientific research Due to massive scale, it is impractical to use conventional techniques for graph storage and in-memory analysis These constraints had driven the development of scalable systems such as distributed file systems like Google File System a and Hadoop File System b MapReduce provides a good way to partition and analyze graphs as suggested by Cohen et. al. c a Ghemawat et. al. The Google File System, SOSP 03 b c Jonathan Cohen, Graph twiddling in a MapReduce world, Computing in Science & Engineering 2009
13 Augmenting edge with vertex degree 9 Input: All edges as Key Value Pair <-,e ij > : edge connecting v i & v j MapReduce Job I map(<-,e ij >) list[<v i, e ij >, <v j, e ij >] reduce(v k, list[e pk, e qk...]>) [<e pk, deg(v k )>, <e qk, deg(v k )>,...] where deg(v k ) = size of the list in the parameter Input: Output of Job I MapReduce Job II map() is an identity function: does no modification to input reduce(<e ij, list[deg(v i ), deg(v j )]>) <e ij, deg(v i ), deg(v j )>
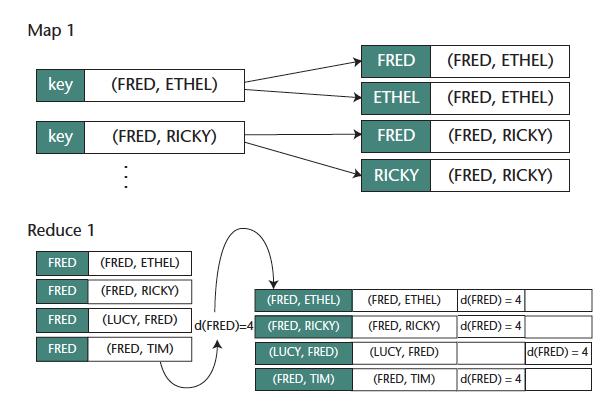
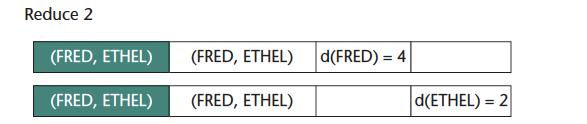
14 Augmenting edge... contd Example 10
, deg(v j )>) output: deg(v i ) < deg(v j )?")
 For each pair of edge connected by v i, emit <e 1, e 2 > with key as <v p, v q>, where v p and v q represent the open end of triad The order")
15 Enumerating Triangles 11 The main idea behind enumerating the triangles is to find triad and an edge joining the open ends together Input: Augmented edges with vertex valency MapReduce Job 1 map(<e ij, deg(v i ), deg(v j )>) output: deg(v i ) < deg(v j )? <v i, e ij > : <v j, e ij > If deg(v i ) == deg(v j ), we can break the tie by any consistent method such as using vertex names reduce(<v i, list[edges connecting v i ]>) For each pair of edge connected by v i, emit <e 1, e 2 > with key as <v p, v q>, where v p and v q represent the open end of triad The order of v p and v q is decided using some consistent technique like vertex names
 if R is")
 if R is a record from MR Job I and hence a triad, change key to <v i, v j > such that")
![deg(v i ) < deg(v j ), where v i & v j are vertices of open ends reduce(<[v i, v j ],](/docs-images/72/66903677/images/16-5.jpg "list[containing a triad, edge] a >) If there is a record corresponding to an edge and a")
16 Enumerating Triangles...contd 12 Input: Augmented edge set and output of Job I MapReduce Job 2 map(<r>) if R is a record from Augmented Edge Set, change key to <v i, v j > such that deg(v i ) < deg(v j ) if R is a record from MR Job I and hence a triad, change key to <v i, v j > such that deg(v i ) < deg(v j ), where v i & v j are vertices of open ends reduce(<[v i, v j ], list[containing a triad, edge] a >) If there is a record corresponding to an edge and a triad with same key, emit a triangle <e ij, e jk, e ki > a may or may not be there
17 Enumerating Rectangles 13 Idea: Two triads joining with a common edge can be merged to form a rectangle 4! = 24 different orderings. Since symmetry group(s 4 ) on 4 elements has S 4 = 8, we have 24 8 = 3 distinct orderings
18 Enumerating Rectangles 13 Idea: Two triads joining with a common edge can be merged to form a rectangle 4! = 24 different orderings. Since symmetry group(s 4 ) on 4 elements has S 4 = 8, we have 24 8 = 3 distinct orderings MapReduce Job I map(<e ij, deg(v i ), deg(v j )>) [<v i, H, e ij >, <v j, L, e ij >] reduce(<v k, list[edges incident on v k ]>) emit a triad for L-L & H-L record if we express deg(v) = deg L (v) + deg H (v), each vertex appears in O(deg 2 L (v)) low triads and O(deg L(v)deg H (v)) mixed triads
 on 4 elements has S 4 = 8, we have 24 8 = 3 distinct orderings MapReduce Job I map(<e ij, deg(v i ), deg(v j )>) [<v i, H, e ij >, <v j, L, e ij >] reduce(<v k, list[edges")
19 Enumerating Rectangles 13 Idea: Two triads joining with a common edge can be merged to form a rectangle 4! = 24 different orderings. Since symmetry group(s 4 ) on 4 elements has S 4 = 8, we have 24 8 = 3 distinct orderings MapReduce Job I map(<e ij, deg(v i ), deg(v j )>) [<v i, H, e ij >, <v j, L, e ij >] reduce(<v k, list[edges incident on v k ]>) emit a triad for L-L & H-L record if we express deg(v) = deg L (v) + deg H (v), each vertex appears in O(deg 2 L (v)) low triads and O(deg L(v)deg H (v)) mixed triads MapReduce Job II map(<v k, list[triads]>) list[<key: edge joining open ends, value: triad>] reduce(<e ij, list[triads open at same end]>) emit rectangle: [e ij, e jk, e kl, & e li ]
 if (e ij triangle i ) : <e ij,1> reduce(<e ij, list[1,1...,1]>) if ( list i ) k : emit e ij All edges emitted by map-reduce job belongs to the k-truss")
20 Finding k-truss 14 Definition: A k-truss is a sub-graph in which each edge is a part of atleast k-2 triangles MapReduce Job Input: Augmented edge set & enumerated triangles of the graph map(<e ij, triangle i >) if (e ij triangle i ) : <e ij,1> reduce(<e ij, list[1,1...,1]>) if ( list i ) k : emit e ij All edges emitted by map-reduce job belongs to the k-truss
21 Barycentric Clustering 15 Clusters are sub-graphs that partitions graph without loosing the co-relevant information. Barycentric Clustering is a highly scalable approach of finding tighly connected sub-graphs. w ij : weight of edge e ij and d i = w ij : weighted degree of vertex v i If x = (x 1, x 2,.., x n) T denotes the position of n vertices, then x = Mx modifies the vertex position by the average of its old position and position of its neighborhood. The process is repeated and literature 3 suggests that 5 repetitions are adequate. If the length of edge > threshold, it can be cut 1/(d 1 + 1) w 12 1/(d 1 + 1) w 1n 1/(d 1 + 1) w 21 1/(d 2 + 1) 1/(d 2 + 1) w 2n 1/(d 2 + 1) M = w n1 1/(d n + 1) w n2 1/(d n + 1) 1/(d n + 1) 3 Cohen et. at. Barycentric Graph Clustering, 2008
22 Barycentric Clustering... contd 16 MapReduce Job I map(<e ij >) [<v i, e ij >, <v j, e ij >] reduce(<v i, list[e ij, e ik,...]>) [<e ij, P(v i )>, <e ik, P(v i )>,...], where P(v) denotes the position vector of vertex v.
23 Barycentric Clustering... contd 16 MapReduce Job I map(<e ij >) [<v i, e ij >, <v j, e ij >] reduce(<v i, list[e ij, e ik,...]>) [<e ij, P(v i )>, <e ik, P(v i )>,...], where P(v) denotes the position vector of vertex v. MapReduce Job II map : (identity) reduce(<e ij, list[p(v i ), P(v j )]>) <e ij, P(v i ), P(v j )>
24 Barycentric Clustering... contd 16 MapReduce Job I map(<e ij >) [<v i, e ij >, <v j, e ij >] reduce(<v i, list[e ij, e ik,...]>) [<e ij, P(v i )>, <e ik, P(v i )>,...], where P(v) denotes the position vector of vertex v. MapReduce Job II map : (identity) reduce(<e ij, list[p(v i ), P(v j )]>) <e ij, P(v i ), P(v j )> Now we execute 5 iterations of next two map reduce jobs MapReduce Job III map(<e ij, P(v i ), P(v j )>) [<v i, e ij, P(v i ), P(v j )>, <v j, e ij, P(v i ), P(v j )>] reduce(<v i, list[<e ij, P(v i ), P(v j )>, <e ik, P(v i ), P(v k )>...]>) calculates modified P (v i ) = M*P (v i )and emits [<e ij, P (v i ), P(v j )>, <e ik, P (v i ), P(v k )>,...]
25 Barycentric Clustering... contd 17 MapReduce Job IV map: (identity) reduce(<e ij, list[<e ij, P (v i ), P(v j )>, <e ij, P(v i ), P (v j )>]>) <e ij, P (v i ), P (v j )>
26 Barycentric Clustering... contd 17 MapReduce Job IV map: (identity) reduce(<e ij, list[<e ij, P (v i ), P(v j )>, <e ij, P(v i ), P (v j )>]>) <e ij, P (v i ), P (v j )> MapReduce Job V map(e ij, list[p 1, P 2,..., P r ]) [<v i, AVG(P i ), AVG(P j )>, <v j, AVG(P j )>] reduce(<v i, list[<e ij, P j >, <e ik, P k >..]>) [<e ij, >, <e ik, P j, P k,...>...], P j, P k,..., a ij = Pj, P k,... represents the weight of edge e ij.
27 Barycentric Clustering... contd 17 MapReduce Job IV map: (identity) reduce(<e ij, list[<e ij, P (v i ), P(v j )>, <e ij, P(v i ), P (v j )>]>) <e ij, P (v i ), P (v j )> MapReduce Job V map(e ij, list[p 1, P 2,..., P r ]) [<v i, AVG(P i ), AVG(P j )>, <v j, AVG(P j )>] reduce(<v i, list[<e ij, P j >, <e ik, P k >..]>) [<e ij, >, <e ik, P j, P k,...>...], P j, P k,..., a ij = Pj, P k,... represents the weight of edge e ij. MapReduce Job VI map : (identity) reduce(<e ij, list[weights emitted by previous map reduce job]>) : computes ā ij, if ā ij > a ij, emit the edge k N a jk + i k N a jk a ij j a ij = N i + N j 1 where N k represents the set of vertices in the neighborhood of v k


28 Finding Components 18 Algorithm using MapReduce Step 1 consists of two MapReduce Jobs focussing on translating the vertex-vertex information into zone zone information MapReduce 1 assigns edges with zones, producing 1 record for each vertex in edge and then translating this information to assign 1 zone to both the vertices MapReduce 2 merges the result of Job 1. If distinct zones are connected by an edge, then the zone with lower zone_id captures the other Step 2 consists of one MapReduce Job MapReduce 1 It record any updates to zone information for each vertex Step 1 and 2 alternate until step 1 produces no new record, which marks the completion of zone assignment Figure: Graph with three components
29 Design Patterns Strategies for Efficient MapReduce Implementation 19 Lin et. al a suggested following design patterns for efficiently implementing graph algorithms using MapReduce. Local aggregation done using combiners reduce the amount intermediate data. It is effective only in case of high duplication factor of intermediate key-value pair. In-Mapper Combining performs better than than regular combiner. Combiner often have to create and destroy objects and perform object serialization and de-serialization which is often costly. Schimmy Pattern divides the graph into n partitions each sorted by vertex id. Number of reducers are then set to n and it is guaranteed that reducer R i processes same vertex ids as in partition P i in sorted manner. Hence reducing the cost of shuffle and sort. Range Partitioning proposes to maximize intra-block connectivity and minimize inter-block connectivity. Dividing a graph into blocks with such a property helps reducing the amount of communication over network. a Jimmy Lin, Michael Schatz, Design patterns for efficient graph algorithms in MapReduce, MLG 10

30 Design Patterns... contd Performance Comparison 20 Figure: Performance comparison for PageRank using suggested strategies. 4 4 Jimmy Lin, Michael Schatz, Design patterns for efficient graph algorithms in MapReduce, MLG 10
31 Summary & Conclusion 21 In general, it is a good contribution to attract MapReduce community to develop distributed systems for graph processing. Author focused on breaking down smaller problems in map-reduce jobs and merging them together to solve bigger problem. The contribution provides no information about the performance of the implementation. No comparison to standard approach. Most of the algorithms need complete re-transformation for implementation using MR framework. Some may become easy and some like finding component becomes complex. Lin et. al. introduced some really good strategies for efficient MapReduce implementation which can be used even for non-graph algorithms.
32 Thank You Questions?
The MapReduce Abstraction
 The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
Relationship collections are well expressed
 C LOUD C OMPUTING Graph Twiddling in a MapReduce World The easily distributed sorting primitives that constitute MapReduce jobs have shown great value in processing large data volumes If useful graph operations
C LOUD C OMPUTING Graph Twiddling in a MapReduce World The easily distributed sorting primitives that constitute MapReduce jobs have shown great value in processing large data volumes If useful graph operations
Principles of Data Management. Lecture #16 (MapReduce & DFS for Big Data)
") Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Fall 2018: Introduction to Data Science GIRI NARASIMHAN, SCIS, FIU
 Fall 2018: Introduction to Data Science GIRI NARASIMHAN, SCIS, FIU !2 MapReduce Overview! Sometimes a single computer cannot process data or takes too long traditional serial programming is not always
Fall 2018: Introduction to Data Science GIRI NARASIMHAN, SCIS, FIU !2 MapReduce Overview! Sometimes a single computer cannot process data or takes too long traditional serial programming is not always
Frequent Item Set using Apriori and Map Reduce algorithm: An Application in Inventory Management
 Frequent Item Set using Apriori and Map Reduce algorithm: An Application in Inventory Management Kranti Patil 1, Jayashree Fegade 2, Diksha Chiramade 3, Srujan Patil 4, Pradnya A. Vikhar 5 1,2,3,4,5 KCES
Frequent Item Set using Apriori and Map Reduce algorithm: An Application in Inventory Management Kranti Patil 1, Jayashree Fegade 2, Diksha Chiramade 3, Srujan Patil 4, Pradnya A. Vikhar 5 1,2,3,4,5 KCES
Announcements. Parallel Data Processing in the 20 th Century. Parallel Join Illustration. Introduction to Database Systems CSE 414
 Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
MapReduce: Algorithm Design for Relational Operations
 MapReduce: Algorithm Design for Relational Operations Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec Projection π Projection in MapReduce Easy Map over tuples, emit
MapReduce: Algorithm Design for Relational Operations Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec Projection π Projection in MapReduce Easy Map over tuples, emit
Parallel Nested Loops
 Parallel Nested Loops For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on (S 1,T 1 ), (S 1,T 2 ),
Parallel Nested Loops For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on (S 1,T 1 ), (S 1,T 2 ),
Parallel Partition-Based. Parallel Nested Loops. Median. More Join Thoughts. Parallel Office Tools 9/15/2011
 Parallel Nested Loops Parallel Partition-Based For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on
Parallel Nested Loops Parallel Partition-Based For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on
Graph Algorithms using Map-Reduce. Graphs are ubiquitous in modern society. Some examples: The hyperlink structure of the web
 Graph Algorithms using Map-Reduce Graphs are ubiquitous in modern society. Some examples: The hyperlink structure of the web Graph Algorithms using Map-Reduce Graphs are ubiquitous in modern society. Some
Graph Algorithms using Map-Reduce Graphs are ubiquitous in modern society. Some examples: The hyperlink structure of the web Graph Algorithms using Map-Reduce Graphs are ubiquitous in modern society. Some
Data Partitioning and MapReduce
 Data Partitioning and MapReduce Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Intelligent Decision Support Systems Master studies,
Data Partitioning and MapReduce Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Intelligent Decision Support Systems Master studies,
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
MapReduce & Resilient Distributed Datasets. Yiqing Hua, Mengqi(Mandy) Xia
 Xia") MapReduce & Resilient Distributed Datasets Yiqing Hua, Mengqi(Mandy) Xia Outline - MapReduce: - - Resilient Distributed Datasets (RDD) - - Motivation Examples The Design and How it Works Performance Motivation
MapReduce & Resilient Distributed Datasets Yiqing Hua, Mengqi(Mandy) Xia Outline - MapReduce: - - Resilient Distributed Datasets (RDD) - - Motivation Examples The Design and How it Works Performance Motivation
MapReduce Design Patterns
 MapReduce Design Patterns MapReduce Restrictions Any algorithm that needs to be implemented using MapReduce must be expressed in terms of a small number of rigidly defined components that must fit together
MapReduce Design Patterns MapReduce Restrictions Any algorithm that needs to be implemented using MapReduce must be expressed in terms of a small number of rigidly defined components that must fit together
CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University](/thumbs/90/104368640.jpg "CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
Jeffrey D. Ullman Stanford University
 Jeffrey D. Ullman Stanford University for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for third-party components of this work must
Jeffrey D. Ullman Stanford University for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for third-party components of this work must
Map Reduce Group Meeting
 Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
Databases 2 (VU) ( / )
 ( / )") Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
CSE 544 Principles of Database Management Systems. Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
PSON: A Parallelized SON Algorithm with MapReduce for Mining Frequent Sets
 2011 Fourth International Symposium on Parallel Architectures, Algorithms and Programming PSON: A Parallelized SON Algorithm with MapReduce for Mining Frequent Sets Tao Xiao Chunfeng Yuan Yihua Huang Department
2011 Fourth International Symposium on Parallel Architectures, Algorithms and Programming PSON: A Parallelized SON Algorithm with MapReduce for Mining Frequent Sets Tao Xiao Chunfeng Yuan Yihua Huang Department
Graphs (Part II) Shannon Quinn
 Shannon Quinn") Graphs (Part II) Shannon Quinn (with thanks to William Cohen and Aapo Kyrola of CMU, and J. Leskovec, A. Rajaraman, and J. Ullman of Stanford University) Parallel Graph Computation Distributed computation
Graphs (Part II) Shannon Quinn (with thanks to William Cohen and Aapo Kyrola of CMU, and J. Leskovec, A. Rajaraman, and J. Ullman of Stanford University) Parallel Graph Computation Distributed computation
A computational model for MapReduce job flow
 A computational model for MapReduce job flow Tommaso Di Noia, Marina Mongiello, Eugenio Di Sciascio Dipartimento di Ingegneria Elettrica e Dell informazione Politecnico di Bari Via E. Orabona, 4 70125
A computational model for MapReduce job flow Tommaso Di Noia, Marina Mongiello, Eugenio Di Sciascio Dipartimento di Ingegneria Elettrica e Dell informazione Politecnico di Bari Via E. Orabona, 4 70125
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
MapReduce: Simplified Data Processing on Large Clusters
 MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat OSDI 2004 Presented by Zachary Bischof Winter '10 EECS 345 Distributed Systems 1 Motivation Summary Example Implementation
MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat OSDI 2004 Presented by Zachary Bischof Winter '10 EECS 345 Distributed Systems 1 Motivation Summary Example Implementation
MapReduce Algorithms
 Large-scale data processing on the Cloud Lecture 3 MapReduce Algorithms Satish Srirama Some material adapted from slides by Jimmy Lin, 2008 (licensed under Creation Commons Attribution 3.0 License) Outline
Large-scale data processing on the Cloud Lecture 3 MapReduce Algorithms Satish Srirama Some material adapted from slides by Jimmy Lin, 2008 (licensed under Creation Commons Attribution 3.0 License) Outline
MapReduce in Erlang. Tom Van Cutsem
 MapReduce in Erlang Tom Van Cutsem 1 Context Masters course on Multicore Programming Focus on concurrent, parallel and... functional programming Didactic implementation of Google s MapReduce algorithm
MapReduce in Erlang Tom Van Cutsem 1 Context Masters course on Multicore Programming Focus on concurrent, parallel and... functional programming Didactic implementation of Google s MapReduce algorithm
1. Introduction to MapReduce
 Processing of massive data: MapReduce 1. Introduction to MapReduce 1 Origins: the Problem Google faced the problem of analyzing huge sets of data (order of petabytes) E.g. pagerank, web access logs, etc.
Processing of massive data: MapReduce 1. Introduction to MapReduce 1 Origins: the Problem Google faced the problem of analyzing huge sets of data (order of petabytes) E.g. pagerank, web access logs, etc.
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Part A: MapReduce. Introduction Model Implementation issues
 Part A: Massive Parallelism li with MapReduce Introduction Model Implementation issues Acknowledgements Map-Reduce The material is largely based on material from the Stanford cources CS246, CS345A and
Part A: Massive Parallelism li with MapReduce Introduction Model Implementation issues Acknowledgements Map-Reduce The material is largely based on material from the Stanford cources CS246, CS345A and
MapReduce. Kiril Valev LMU Kiril Valev (LMU) MapReduce / 35
 MapReduce / 35") MapReduce Kiril Valev LMU valevk@cip.ifi.lmu.de 23.11.2013 Kiril Valev (LMU) MapReduce 23.11.2013 1 / 35 Agenda 1 MapReduce Motivation Definition Example Why MapReduce? Distributed Environment Fault Tolerance
MapReduce Kiril Valev LMU valevk@cip.ifi.lmu.de 23.11.2013 Kiril Valev (LMU) MapReduce 23.11.2013 1 / 35 Agenda 1 MapReduce Motivation Definition Example Why MapReduce? Distributed Environment Fault Tolerance
Introduction to MapReduce Algorithms and Analysis
 Introduction to MapReduce Algorithms and Analysis Jeff M. Phillips October 25, 2013 Trade-Offs Massive parallelism that is very easy to program. Cheaper than HPC style (uses top of the line everything)
Introduction to MapReduce Algorithms and Analysis Jeff M. Phillips October 25, 2013 Trade-Offs Massive parallelism that is very easy to program. Cheaper than HPC style (uses top of the line everything)
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Cloud, Big Data & Linear Algebra
 Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
MapReduce: Recap. Juliana Freire & Cláudio Silva. Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec
 MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
B490 Mining the Big Data. 5. Models for Big Data
 B490 Mining the Big Data 5. Models for Big Data Qin Zhang 1-1 2-1 MapReduce MapReduce The MapReduce model (Dean & Ghemawat 2004) Input Output Goal Map Shuffle Reduce Standard model in industry for massive
B490 Mining the Big Data 5. Models for Big Data Qin Zhang 1-1 2-1 MapReduce MapReduce The MapReduce model (Dean & Ghemawat 2004) Input Output Goal Map Shuffle Reduce Standard model in industry for massive
The MapReduce Framework
 The MapReduce Framework In Partial fulfilment of the requirements for course CMPT 816 Presented by: Ahmed Abdel Moamen Agents Lab Overview MapReduce was firstly introduced by Google on 2004. MapReduce
The MapReduce Framework In Partial fulfilment of the requirements for course CMPT 816 Presented by: Ahmed Abdel Moamen Agents Lab Overview MapReduce was firstly introduced by Google on 2004. MapReduce
Introduction to MapReduce
 732A54 Big Data Analytics Introduction to MapReduce Christoph Kessler IDA, Linköping University Towards Parallel Processing of Big-Data Big Data too large to be read+processed in reasonable time by 1 server
732A54 Big Data Analytics Introduction to MapReduce Christoph Kessler IDA, Linköping University Towards Parallel Processing of Big-Data Big Data too large to be read+processed in reasonable time by 1 server
Big Data Analytics. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Lecture Map-Reduce. Algorithms. By Marina Barsky Winter 2017, University of Toronto
 Lecture 04.02 Map-Reduce Algorithms By Marina Barsky Winter 2017, University of Toronto Example 1: Language Model Statistical machine translation: Need to count number of times every 5-word sequence occurs
Lecture 04.02 Map-Reduce Algorithms By Marina Barsky Winter 2017, University of Toronto Example 1: Language Model Statistical machine translation: Need to count number of times every 5-word sequence occurs
Improving the MapReduce Big Data Processing Framework
 Improving the MapReduce Big Data Processing Framework Gistau, Reza Akbarinia, Patrick Valduriez INRIA & LIRMM, Montpellier, France In collaboration with Divyakant Agrawal, UCSB Esther Pacitti, UM2, LIRMM
Improving the MapReduce Big Data Processing Framework Gistau, Reza Akbarinia, Patrick Valduriez INRIA & LIRMM, Montpellier, France In collaboration with Divyakant Agrawal, UCSB Esther Pacitti, UM2, LIRMM
Parallel Computing: MapReduce Jin, Hai
 Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Hadoop Map Reduce 10/17/2018 1
 Hadoop Map Reduce 10/17/2018 1 MapReduce 2-in-1 A programming paradigm A query execution engine A kind of functional programming We focus on the MapReduce execution engine of Hadoop through YARN 10/17/2018
Hadoop Map Reduce 10/17/2018 1 MapReduce 2-in-1 A programming paradigm A query execution engine A kind of functional programming We focus on the MapReduce execution engine of Hadoop through YARN 10/17/2018
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 2: MapReduce Algorithm Design (2/2) January 12, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 2: MapReduce Algorithm Design (2/2) January 12, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Data-Intensive Computing with MapReduce
 Data-Intensive Computing with MapReduce Session 5: Graph Processing Jimmy Lin University of Maryland Thursday, February 21, 2013 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Data-Intensive Computing with MapReduce Session 5: Graph Processing Jimmy Lin University of Maryland Thursday, February 21, 2013 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
L22: SC Report, Map Reduce
 L22: SC Report, Map Reduce November 23, 2010 Map Reduce What is MapReduce? Example computing environment How it works Fault Tolerance Debugging Performance Google version = Map Reduce; Hadoop = Open source
L22: SC Report, Map Reduce November 23, 2010 Map Reduce What is MapReduce? Example computing environment How it works Fault Tolerance Debugging Performance Google version = Map Reduce; Hadoop = Open source
Survey Paper on Traditional Hadoop and Pipelined Map Reduce
 International Journal of Computational Engineering Research Vol, 03 Issue, 12 Survey Paper on Traditional Hadoop and Pipelined Map Reduce Dhole Poonam B 1, Gunjal Baisa L 2 1 M.E.ComputerAVCOE, Sangamner,
International Journal of Computational Engineering Research Vol, 03 Issue, 12 Survey Paper on Traditional Hadoop and Pipelined Map Reduce Dhole Poonam B 1, Gunjal Baisa L 2 1 M.E.ComputerAVCOE, Sangamner,
Mitigating Data Skew Using Map Reduce Application
 Ms. Archana P.M Mitigating Data Skew Using Map Reduce Application Mr. Malathesh S.H 4 th sem, M.Tech (C.S.E) Associate Professor C.S.E Dept. M.S.E.C, V.T.U Bangalore, India archanaanil062@gmail.com M.S.E.C,
Ms. Archana P.M Mitigating Data Skew Using Map Reduce Application Mr. Malathesh S.H 4 th sem, M.Tech (C.S.E) Associate Professor C.S.E Dept. M.S.E.C, V.T.U Bangalore, India archanaanil062@gmail.com M.S.E.C,
PREGEL: A SYSTEM FOR LARGE- SCALE GRAPH PROCESSING
 PREGEL: A SYSTEM FOR LARGE- SCALE GRAPH PROCESSING G. Malewicz, M. Austern, A. Bik, J. Dehnert, I. Horn, N. Leiser, G. Czajkowski Google, Inc. SIGMOD 2010 Presented by Ke Hong (some figures borrowed from
PREGEL: A SYSTEM FOR LARGE- SCALE GRAPH PROCESSING G. Malewicz, M. Austern, A. Bik, J. Dehnert, I. Horn, N. Leiser, G. Czajkowski Google, Inc. SIGMOD 2010 Presented by Ke Hong (some figures borrowed from
Similarity Joins in MapReduce
 Similarity Joins in MapReduce Benjamin Coors, Kristian Hunt, and Alain Kaeslin KTH Royal Institute of Technology {coors,khunt,kaeslin}@kth.se Abstract. This paper studies how similarity joins can be implemented
Similarity Joins in MapReduce Benjamin Coors, Kristian Hunt, and Alain Kaeslin KTH Royal Institute of Technology {coors,khunt,kaeslin}@kth.se Abstract. This paper studies how similarity joins can be implemented
Global Journal of Engineering Science and Research Management
 A FUNDAMENTAL CONCEPT OF MAPREDUCE WITH MASSIVE FILES DATASET IN BIG DATA USING HADOOP PSEUDO-DISTRIBUTION MODE K. Srikanth*, P. Venkateswarlu, Ashok Suragala * Department of Information Technology, JNTUK-UCEV
A FUNDAMENTAL CONCEPT OF MAPREDUCE WITH MASSIVE FILES DATASET IN BIG DATA USING HADOOP PSEUDO-DISTRIBUTION MODE K. Srikanth*, P. Venkateswarlu, Ashok Suragala * Department of Information Technology, JNTUK-UCEV
Hadoop and Map-reduce computing
 Hadoop and Map-reduce computing 1 Introduction This activity contains a great deal of background information and detailed instructions so that you can refer to it later for further activities and homework.
Hadoop and Map-reduce computing 1 Introduction This activity contains a great deal of background information and detailed instructions so that you can refer to it later for further activities and homework.
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
Document Clustering with Map Reduce using Hadoop Framework
 Document Clustering with Map Reduce using Hadoop Framework Satish Muppidi* Department of IT, GMRIT, Rajam, AP, India msatishmtech@gmail.com M. Ramakrishna Murty Department of CSE GMRIT, Rajam, AP, India
Document Clustering with Map Reduce using Hadoop Framework Satish Muppidi* Department of IT, GMRIT, Rajam, AP, India msatishmtech@gmail.com M. Ramakrishna Murty Department of CSE GMRIT, Rajam, AP, India
Massively Parallel Graph Algorithms with MapReduce
 Massively Parallel Graph Algorithms with MapReduce Alexander Reinefeld, Thorsten Schütt, Robert Maier Zuse Institute Berlin AEI Cluster Day, 5 April 2011 Zuse Institute Berlin Research institute for applied
Massively Parallel Graph Algorithms with MapReduce Alexander Reinefeld, Thorsten Schütt, Robert Maier Zuse Institute Berlin AEI Cluster Day, 5 April 2011 Zuse Institute Berlin Research institute for applied
CS 61C: Great Ideas in Computer Architecture. MapReduce
 CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Fall 2016 1 HW8 is out Last assignment! Get Amazon credits now (see instructions) Spark with Hadoop Due next wed CSE 344 - Fall 2016
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Fall 2016 1 HW8 is out Last assignment! Get Amazon credits now (see instructions) Spark with Hadoop Due next wed CSE 344 - Fall 2016
Keywords Hadoop, Map Reduce, K-Means, Data Analysis, Storage, Clusters.
 Volume 6, Issue 3, March 2016 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Special Issue
Volume 6, Issue 3, March 2016 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Special Issue
Putting it together. Data-Parallel Computation. Ex: Word count using partial aggregation. Big Data Processing. COS 418: Distributed Systems Lecture 21
 Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Lessons Learned While Building Infrastructure Software at Google
 Lessons Learned While Building Infrastructure Software at Google Jeff Dean jeff@google.com Google Circa 1997 (google.stanford.edu) Corkboards (1999) Google Data Center (2000) Google Data Center (2000)
Lessons Learned While Building Infrastructure Software at Google Jeff Dean jeff@google.com Google Circa 1997 (google.stanford.edu) Corkboards (1999) Google Data Center (2000) Google Data Center (2000)
CS6030 Cloud Computing. Acknowledgements. Today s Topics. Intro to Cloud Computing 10/20/15. Ajay Gupta, WMU-CS. WiSe Lab
 CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 2: MapReduce Algorithm Design (2/2) January 14, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 2: MapReduce Algorithm Design (2/2) January 14, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
How to Implement MapReduce Using. Presented By Jamie Pitts
 How to Implement MapReduce Using Presented By Jamie Pitts A Problem Seeking A Solution Given a corpus of html-stripped financial filings: Identify and count unique subjects. Possible Solutions: 1. Use
How to Implement MapReduce Using Presented By Jamie Pitts A Problem Seeking A Solution Given a corpus of html-stripped financial filings: Identify and count unique subjects. Possible Solutions: 1. Use
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Department of Computer Science San Marcos, TX Report Number TXSTATE-CS-TR Clustering in the Cloud. Xuan Wang
 Department of Computer Science San Marcos, TX 78666 Report Number TXSTATE-CS-TR-2010-24 Clustering in the Cloud Xuan Wang 2010-05-05 !"#$%&'()*+()+%,&+!"-#. + /+!"#$%&'()*+0"*-'(%,1$+0.23%(-)+%-+42.--3+52367&.#8&+9'21&:-';
Department of Computer Science San Marcos, TX 78666 Report Number TXSTATE-CS-TR-2010-24 Clustering in the Cloud Xuan Wang 2010-05-05 !"#$%&'()*+()+%,&+!"-#. + /+!"#$%&'()*+0"*-'(%,1$+0.23%(-)+%-+42.--3+52367&.#8&+9'21&:-';
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
MapReduce for Data Intensive Scientific Analyses
 apreduce for Data Intensive Scientific Analyses Jaliya Ekanayake Shrideep Pallickara Geoffrey Fox Department of Computer Science Indiana University Bloomington, IN, 47405 5/11/2009 Jaliya Ekanayake 1 Presentation
apreduce for Data Intensive Scientific Analyses Jaliya Ekanayake Shrideep Pallickara Geoffrey Fox Department of Computer Science Indiana University Bloomington, IN, 47405 5/11/2009 Jaliya Ekanayake 1 Presentation
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
ECE5610/CSC6220 Introduction to Parallel and Distribution Computing. Lecture 6: MapReduce in Parallel Computing
 ECE5610/CSC6220 Introduction to Parallel and Distribution Computing Lecture 6: MapReduce in Parallel Computing 1 MapReduce: Simplified Data Processing Motivation Large-Scale Data Processing on Large Clusters
ECE5610/CSC6220 Introduction to Parallel and Distribution Computing Lecture 6: MapReduce in Parallel Computing 1 MapReduce: Simplified Data Processing Motivation Large-Scale Data Processing on Large Clusters
CS-2510 COMPUTER OPERATING SYSTEMS
 CS-2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application Functional
CS-2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application Functional
CSE Lecture 11: Map/Reduce 7 October Nate Nystrom UTA
 CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
Introduction to MapReduce
 Introduction to MapReduce April 19, 2012 Jinoh Kim, Ph.D. Computer Science Department Lock Haven University of Pennsylvania Research Areas Datacenter Energy Management Exa-scale Computing Network Performance
Introduction to MapReduce April 19, 2012 Jinoh Kim, Ph.D. Computer Science Department Lock Haven University of Pennsylvania Research Areas Datacenter Energy Management Exa-scale Computing Network Performance
CS MapReduce. Vitaly Shmatikov
 CS 5450 MapReduce Vitaly Shmatikov BackRub (Google), 1997 slide 2 NEC Earth Simulator, 2002 slide 3 Conventional HPC Machine ucompute nodes High-end processors Lots of RAM unetwork Specialized Very high
CS 5450 MapReduce Vitaly Shmatikov BackRub (Google), 1997 slide 2 NEC Earth Simulator, 2002 slide 3 Conventional HPC Machine ucompute nodes High-end processors Lots of RAM unetwork Specialized Very high
Batch Processing Basic architecture
 Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Database System Architectures Parallel DBs, MapReduce, ColumnStores
 Database System Architectures Parallel DBs, MapReduce, ColumnStores CMPSCI 445 Fall 2010 Some slides courtesy of Yanlei Diao, Christophe Bisciglia, Aaron Kimball, & Sierra Michels- Slettvet Motivation:
Database System Architectures Parallel DBs, MapReduce, ColumnStores CMPSCI 445 Fall 2010 Some slides courtesy of Yanlei Diao, Christophe Bisciglia, Aaron Kimball, & Sierra Michels- Slettvet Motivation:
An improved MapReduce Design of Kmeans for clustering very large datasets
 An improved MapReduce Design of Kmeans for clustering very large datasets Amira Boukhdhir Laboratoire SOlE Higher Institute of management Tunis Tunis, Tunisia Boukhdhir _ amira@yahoo.fr Oussama Lachiheb
An improved MapReduce Design of Kmeans for clustering very large datasets Amira Boukhdhir Laboratoire SOlE Higher Institute of management Tunis Tunis, Tunisia Boukhdhir _ amira@yahoo.fr Oussama Lachiheb
Parallel HITS Algorithm Implemented Using HADOOP GIRAPH Framework to resolve Big Data Problem
 I J C T A, 9(41) 2016, pp. 1235-1239 International Science Press Parallel HITS Algorithm Implemented Using HADOOP GIRAPH Framework to resolve Big Data Problem Hema Dubey *, Nilay Khare *, Alind Khare **
I J C T A, 9(41) 2016, pp. 1235-1239 International Science Press Parallel HITS Algorithm Implemented Using HADOOP GIRAPH Framework to resolve Big Data Problem Hema Dubey *, Nilay Khare *, Alind Khare **
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
Distributed Systems. 18. MapReduce. Paul Krzyzanowski. Rutgers University. Fall 2015
 Distributed Systems 18. MapReduce Paul Krzyzanowski Rutgers University Fall 2015 November 21, 2016 2014-2016 Paul Krzyzanowski 1 Credit Much of this information is from Google: Google Code University [no
Distributed Systems 18. MapReduce Paul Krzyzanowski Rutgers University Fall 2015 November 21, 2016 2014-2016 Paul Krzyzanowski 1 Credit Much of this information is from Google: Google Code University [no
Parallel Programming Concepts
 Parallel Programming Concepts MapReduce Frank Feinbube Source: MapReduce: Simplied Data Processing on Large Clusters; Dean et. Al. Examples for Parallel Programming Support 2 MapReduce 3 Programming model
Parallel Programming Concepts MapReduce Frank Feinbube Source: MapReduce: Simplied Data Processing on Large Clusters; Dean et. Al. Examples for Parallel Programming Support 2 MapReduce 3 Programming model
Announcements. Optional Reading. Distributed File System (DFS) MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm
 MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm") Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
index construct Overview Overview Recap How to construct index? Introduction Index construction Introduction to Recap
 to to Information Retrieval Index Construct Ruixuan Li Huazhong University of Science and Technology http://idc.hust.edu.cn/~rxli/ October, 2012 1 2 How to construct index? Computerese term document docid
to to Information Retrieval Index Construct Ruixuan Li Huazhong University of Science and Technology http://idc.hust.edu.cn/~rxli/ October, 2012 1 2 How to construct index? Computerese term document docid
ABSTRACT I. INTRODUCTION
 International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 3 ISS: 2456-3307 Hadoop Periodic Jobs Using Data Blocks to Achieve
International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 3 ISS: 2456-3307 Hadoop Periodic Jobs Using Data Blocks to Achieve
MapReduce and Hadoop
 Università degli Studi di Roma Tor Vergata MapReduce and Hadoop Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference Big Data stack High-level Interfaces Data Processing
Università degli Studi di Roma Tor Vergata MapReduce and Hadoop Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference Big Data stack High-level Interfaces Data Processing
CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin. Presented by: Suhua Wei Yong Yu
 CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin Presented by: Suhua Wei Yong Yu Papers: MapReduce: Simplified Data Processing on Large Clusters 1 --Jeffrey Dean
CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin Presented by: Suhua Wei Yong Yu Papers: MapReduce: Simplified Data Processing on Large Clusters 1 --Jeffrey Dean
Database Systems CSE 414
 Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Systems research enables application development by defining and implementing abstractions:
 61A Lecture 36 Announcements Unix Computer Systems Systems research enables application development by defining and implementing abstractions: Operating systems provide a stable, consistent interface to
61A Lecture 36 Announcements Unix Computer Systems Systems research enables application development by defining and implementing abstractions: Operating systems provide a stable, consistent interface to
Motivation. Map in Lisp (Scheme) Map/Reduce. MapReduce: Simplified Data Processing on Large Clusters
 Map/Reduce. MapReduce: Simplified Data Processing on Large Clusters") Motivation MapReduce: Simplified Data Processing on Large Clusters These are slides from Dan Weld s class at U. Washington (who in turn made his slides based on those by Jeff Dean, Sanjay Ghemawat, Google,
Motivation MapReduce: Simplified Data Processing on Large Clusters These are slides from Dan Weld s class at U. Washington (who in turn made his slides based on those by Jeff Dean, Sanjay Ghemawat, Google,
Embedded Technosolutions
 Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Advanced Data Management Technologies
 ADMT 2017/18 Unit 16 J. Gamper 1/53 Advanced Data Management Technologies Unit 16 MapReduce J. Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Acknowledgements: Much of the information
ADMT 2017/18 Unit 16 J. Gamper 1/53 Advanced Data Management Technologies Unit 16 MapReduce J. Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Acknowledgements: Much of the information
Anurag Sharma (IIT Bombay) 1 / 13
 1 / 13") 0 Map Reduce Algorithm Design Anurag Sharma (IIT Bombay) 1 / 13 Relational Joins Anurag Sharma Fundamental Research Group IIT Bombay Anurag Sharma (IIT Bombay) 1 / 13 Secondary Sorting Required if we need
0 Map Reduce Algorithm Design Anurag Sharma (IIT Bombay) 1 / 13 Relational Joins Anurag Sharma Fundamental Research Group IIT Bombay Anurag Sharma (IIT Bombay) 1 / 13 Secondary Sorting Required if we need
Why do we need graph processing?
 Why do we need graph processing? Community detection: suggest followers? Determine what products people will like Count how many people are in different communities (polling?) Graphs are Everywhere Group
Why do we need graph processing? Community detection: suggest followers? Determine what products people will like Count how many people are in different communities (polling?) Graphs are Everywhere Group
Developing MapReduce Programs
 Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2017/18 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2017/18 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Complexity Measures for Map-Reduce, and Comparison to Parallel Computing
 Complexity Measures for Map-Reduce, and Comparison to Parallel Computing Ashish Goel Stanford University and Twitter Kamesh Munagala Duke University and Twitter November 11, 2012 The programming paradigm
Complexity Measures for Map-Reduce, and Comparison to Parallel Computing Ashish Goel Stanford University and Twitter Kamesh Munagala Duke University and Twitter November 11, 2012 The programming paradigm
Lecture 7: MapReduce design patterns! Claudia Hauff (Web Information Systems)!
!") Big Data Processing, 2014/15 Lecture 7: MapReduce design patterns!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm
Big Data Processing, 2014/15 Lecture 7: MapReduce design patterns!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second