Clustering Gene Expression Data: Acknowledgement: Elizabeth Garrett-Mayer; Shirley Liu; Robert Tibshirani; Guenther Walther; Trevor Hastie
|
|
|
- Jane Moody
- 6 years ago
- Views:
Transcription
1 Clustering Gene Expression Data: Acknowledgement: Elizabeth Garrett-Mayer; Shirley Liu; Robert Tibshirani; Guenther Walther; Trevor Hastie
2 Data from Garber et al. PNAS (98), 2001.
3 Clustering Clustering is an exploratory tool for looking at associations within gene expression data Hierarchical clustering dendrogramsd allow us to visualize gene expression data. These methods allow us to hypothesize about relationships between genes and classes. We should use these methods for visualization, hypothesis generation, selection of genes for further consideration You can cluster without having a probability model. In fact most methods are model-less. There is no measure of strength of evidence or strength of clustering structure provided. It is difficult to judge if one clustering result is better than another, or how similar two clustering results are Hierarchical clustering specifically: we are provided with a picture from which we can make many/any conclusions.
4 Cluster analysis arranges objects into groups based on their values in multiple characteristics. In an extreme example, suppose we have observation on only one gene, gene X, in a collection of samples. It seems that the samples form two clusters: one with relatively low expression level (aroud 7) and another with relatively high expression level (around 8) for gene X. Mathematically how do we formulate what our eyes have done Mathematically how do we formulate what our eyes have done intuitively?
5 What if we have two genes? It seems now we see 5 clusters of samples: Groups of GeneX1 GeneX2 samples 1 Low Low 2 Low High 3 High Low 4 High Medium 5 High High Again how did we group the samples? What does it mean Again, how did we group the samples? What does it mean mathematically that some points are close to each other?
6 pictures can be misleading How we stretched the picture how each dimension is weighted in How we stretched the picture how each dimension is weighted in determining distance.
7 Distance and Similarity Every clustering method is based solely on the measure of distance or similarity. E.g. correlation: measures linear association between two samples or genes. What if data are not properly transformed? What if there are outliers? What if there are saturation effects? Even with large number of samples, bad measure of distance or similarity will not be helped.
8 Distance versus similarity Distance Non-negativity d(x,y)>=0 Symmetry d(x,y)=d(y,x) Identification mark d(x,x)=0 Definiteness d(x,y)=0 iff x=y Triangle inequality D(x,y)+d(y,z)>=d(x,z) Similarity Non-negativity s(x,y)>=0 Symmetry s(x,y)=s(y,x) Higher when x,y are more similar
9 Cluster analysis arranges samples and genes into groups based on their expression levels. This arrangement is determined purely by the measured distance or similarity between samples and genes. Popular Distances: Euclidian distance Manhattan distance 1- correlation coefficient
10 Pearson Correlation vs. Euclidean distance Exercise: When the data are standardized (with mean 0 and sd 1), there is a simple linear relationship between the Pearson correlation coefficient r and the squared Euclidean distance
11 Correlation based distance Pearson correlation distance 1-r(x,y) Spearman correlation distance 1-r ( rank(x), rank(y)) More robust, less sensitive
12 Sometimes we consider abs(r) Strong positive correlation often suggest closeness or similarity In some cases, strong negative correlation is also interesting, especially between genes: both inhibition and induction are common
13 Mahalanobis distance If a pair of vectors, x and y, are generated from multivariate distribution with mean and variancecovariance matrix ( x y)' 1 ( x When each element has sd 1, this reduces to squared Euclidean distance When the elements (dimension) are independent, is a diagonal matrix, and we are simply standardizing. This is the same as first standardizing each dimension, and then compute Euclidean distance When the elements are dependent, this accounts for the similarity between the elements. y)
14 Mahalanobis distance between genes For a pair of genes measured over N experiments, x and y are vector of length N. is N x N, representing the variance-covariance of the samples. Typically y after normalization, the samples have the same distribution. Thus the mean and sd of the sample is the same. So if the samples are independent, the mahalanobis distance works the same as Euclidean distance What if there is correlation between experiments? nested design technical replicates and biological replicates


15 A: Consider two biological conditions with 5 independent biological samples B: Consider two biological experiments with 5 technical replicates each The technical replicates are correlated Consider 100 genes that are unrelated
16 Sigma[1:5,1:5]=.7 Sigma[6:10,6:10]=.7 diag(sigma)=1 image2=function(x) ## to visualize as the matrix shows image(t(x)[ncol(x):1,],axes=f) image2(sigma) set.seed(123) x0=mvrnorm(100,mu=rep(0,10),diag(10)) x1=mvrnorm(100,mu=rep(0,10),sigma) rho0=cor(t(x0)) rho1=cor(t(x1)) hist(rho0,xlim=c(-1,1)) hist(rho1,add=t,border=2)
17 It is much more likely to see strong correlation between genes when the experiments are not independent d
18 This is even worse when there is some differential expression Consider two biological experiments with 5 technical replicates each The technical replicates are correlated If there is differential expression between the two experiments: Average expression (0,0,0,0,0,,,,, ) set.seed(123) par(mfrow=c(3,3)) sapply(0:8*.2,function(delta){ # for different levels of DE x2=mvrnorm(100,mu=c(rep(0,5),rep(delta,5)),sigma) rho2=cor(t(x2)) hist(rho2,main=paste("delta=",delta)) })
19
20 Mahalanobis distance between samples For a pair of samples including G genes, x and y are vector of length G. is G x G, representing the variancecovariance of the genes. The genes may have different variances. If the genes are independent ( x y)' 1 ( x is the same as standardizing the genes first, then compute Euclidean distance But we know the genes are not independent And many genes may not be of interest at all we ll get back to this again y)
21 Suppose we settled the issue of distance between subjects. How do we cluster? Maximize inter-cluster distance Minimize intra-cluster distance Linkage: Average linkage: average distance between any pair of elements in different clusters Complete linkage: longest distance between two elements in different clusters Single linkage: shortest distance between two elements in different clusters
22 Average linkage s D(r,B) = T ab / ( N a * N b ) Where Trs is the sum of all pairwise distances between cluster A and cluster B. Na and Nb are the sizes of the clusters A and B respectively r
23 Complete Linkage s r D(r,s) =Max{d(i d(i,j) : Where object i is in cluster r and object j is cluster s }
24 Single linkage s r D( ) Mi { d(i j) Wh bj t i i i l t d D(r,s) = Min { d(i,j) : Where object i is in cluster r and object j is cluster s }
25 Single linkage can lead to string-like clusters in high dimensions Complete linkage tends to find more compact spherical clusters Average linkage produces something intermediate
26 Hierarchical Clustering Divisive Hierarchical Clustering Top down Start from one cluster and split into smaller clusters Maximize inter cluster distance in each split Agglomerative Hierarchical Clustering Bottom up Start from singletons and merge into larger clusters Join closest clusters at each stage More common than Divisive i i approach
27 Example: hierarchical clustering
28 Partitional clustering K-means Minimize j is the centroid of each cluster. other distances can be used as well. Choose cluster size k first Initial centroids can be random Update clustering by assigning elements to closest centroid Re-define centroids by current clustering Iterate till clusters stablize
29 More detailed Kmeans algorithm 1. Choose K centroids at random 2. Make initial partition of objects into k clusters by assigning objects to closest centroid 3. Calculate the centroid (mean) of each of the k clusters. 4. a. For object i, calculate its distance to each of the centroids. b. Allocate object i to cluster with closest centroid. c. If object was reallocated, recalculate centroids based on new clusters. 4. Repeat 3 for object i = 1,.N. 5. Repeat 3 and 4 until no reallocations occur. 6. Assess cluster structure for fit and stability
30 Kmeans Random centroids Each point is assigned to the closest centroid Update centroids location based on current clustering Update clustering again with new centroids
31 How Kmeans work in a movie htt // i l t ti ti /2014/02/18/k
32 Kmeans can stuck in local optimum set.seed(123) x1=c(rnorm(13,1,.1),rnorm(20,5,.1),rnorm(13,1,.1),rnorm(20,5,.1)) x2=c(rnorm(13,5,.1),rnorm(10,6,.1),rnorm(15,7,.1),rnorm( ,5,.1)) dat1=cbind(x1,x2) ####################################################### par(mfrow=c(2,2));set.seed(111) cluster1=kmeans(dat1,5) cluster1$tot.withinss plot(dat1,col=cluster1$cluster) cluster1=kmeans(dat1,5);cluster1$tot.withinss plot(dat1,col=cluster1$cluster) cluster1=kmeans(dat1,5);cluster1$tot.withinss plot(dat1,col=cluster1$cluster) cluster1=kmeans(dat1,5);cluster1$tot.withinss plot(dat1,col=cluster1$cluster) This appears trivial but in higher dimension our eyes pp g y cannot check the result easily.
33 Partitioning around medoids Use one representative point rather than average as centroid for each cluster Often more robust than k-means
34 From partitions from hierarchical clustering
35 How to determine the number of clusters W(k): () total sum of squares within clusters B(k): sum of squares between clusters Calinski & Harabasz Hartigan: Stop when H(k)<10
36
37 Silhouettes Silhouette of gene i is defined as: s ( i ) b i a max( a, b) i i i a i = average distance of gene i to other genes in same cluster b i = average distance of gene i to genes in its nearest neighbor cluster
38
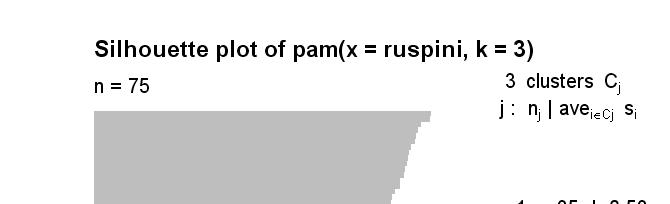



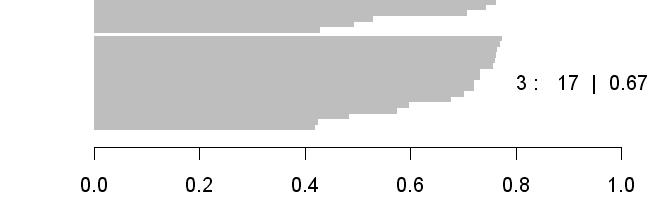





39
40 Within-Cluster Sum of Squares D r i C r j C r x i x j 2 x j x i
41 Within-Cluster Sum of Squares D r i C r j C r 2n r i C r x i x i x x j 2 2 W k 1 r 1 2nn k D r r Measure of compactness of clusters
42 Gap statistic If K is the true number of clusters: The within cluster sum of squares W(k) decrease faster when k<k, and slower when k>k Pick K with largest drop in w(k) Some helpful R code can be found here
43 Using W k to determine # clusters Idea of L-Curve Method: use the k corresponding to the elbow (the most significant increase in goodness-of-fit)
44 Clustering gene expression Cluster Genes with similar expression profile over different samples or conditions Cluster samples with similar expression profile over all the genes
45 More specifically. Cluster analysis arranges samples and genes into groups based on their expression levels. This arrangement is determined purely by the measured distance or similarity between samples and genes. Arrangements are sensitive to choice of distance Outliers Distance mis-specification In hierarchical clustering, the VISUALIZTION of the arrangement (the dendrogram) is not unique! Just because two samples are situated next to each other does not mean that they are similar. Closer scrutiny is needed to interpret dendrogram than is usually given
46 Distance and Similarity Every clustering method is based solely on the measure of distance or similarity. E.g. correlation: measures linear association between two samples or genes. What if data are not properly transformed? What if there are outliers? What if there are saturation effects? Even with large number of samples, bad measure of distance or similarity will not be helped.
47 The similarity/distance matrices G 1 2.N G G DATA MATRIX GENE SIMILARITY MATRIX
48 The similarity/distance matrices G 1 2.N N 1 2..N SAMPLE SIMILARITY MATRIX DATA MATRIX
49 How to make a hierarchical clustering 1. Choose samples and genes to include in cluster analysis 2. Choose similarity/distance metric 3. Choose clustering direction (top-down or bottom-up) 4. Choose linkage method (if bottom-up) 5. Calculate dendrogram 6. Choose height/number of clusters for interpretation 7. Assess cluster fit and stability 8. Interpret resulting cluster structure
50 1. Choose samples and genes to include Important step! Do you want housekeeping genes included? What to do about replicates from the same individual/tumor? Genes that contribute noise will affect your results. Including cud all genes: es dendrogram d can t all be seen at the same time. Perhaps screen the genes?
51 Simulated Data with 4 clusters: 1-10, 11-20, 21-30, A: 450 relevant genes plus 450 noise genes. B: 450 relevant genes.
52 2. Choose similarity/distance matrix Think hard about this step! Remember: garbage in garbage out The metric that you pick should be a valid measure of the distance/similarity of genes. Examples: Applying correlation to highly skewed data will provide misleading results. Applying Euclidean distance to data measured on categorical scale will be invalid. Not just wrong, but which makes most sense
53 Some correlations to choose from Pearson Correlation: s ( x, x ) 1 2 K k 1 K k 1 ( x x )( x x ) 1k 1 2k 2 K 2 ( x x ) ( x x ) 1k 1 k 1 2k 2 2 Uncentered Correlation: sx (, x) 1 2 Absolute Value of Correlation: K k 1 x x 1 k 2 k K K 2 2 x1 k x2k k 1 k 1 sx (, x) 1 2 K K k 1 ( x x )( x x ) 1k 1 2k 2 K 2 2 2k 2 k 1 ( x1k x1 ) ( x x ) k 1
54 The difference is that, if you have two vectors X and Y with identical shape, but which are offset relative to each other by a fixed value, they will have a standard Pearson correlation (centered correlation) of 1 but will not have an uncentered correlation of 1.
55 3. Choose clustering direction (top-down or bottom-up) Agglomerative clustering (bottom-up) Starts with as each gene in its own cluster Joins the two most similar clusters Then, joins next two most similar clusters Continues until all genes are in one cluster Divisive clustering (top-down) Starts with all genes in one cluster Choose split so that genes in the two clusters are most similar (maximize distance between clusters) Find next split in same manner Continue until all genes are in single gene clusters
56 Which to use? Both are only step-wise optimal: at each step the optimal split or merge is performed This does not imply that t the final cluster structure t is optimal! Agglomerative/Bottom-Up Computationally simpler, and more available. More precision at bottom of tree When looking for small clusters and/or many clusters, use agglomerative Divisive/Top-Down More precision at top of tree. When looking for large and/or few clusters, use divisive In gene expression applications, divisive makes more sense. Results ARE sensitive to choice!
57
58 4. Choose linkage method (if bottom-up) Single Linkage: join clusters whose distance between closest genes is smallest (elliptical) Complete Linkage: join clusters whose distance between furthest genes is smallest (spherical) Average Linkage: k join clusters whose average distance is the smallest.
59 5. Calculate dendrogram 6Ch 6. Choose height/number hih/ of clusters for interpretation i In gene expression, we don t see rule-based approach to choosing cutoff very often. Tend to look for what makes a good story. There are more rigorous methods. (more later) Homogeneity and Separation of clusters can be considered. (Chen et al. Statistica Sinica, 2002) Other methods for assessing cluster fit can help determine a reasonable way to cut your tree.
60 7. Assess cluster fit and stability Most often ignored. Cluster structure is treated as reliable and precise Usually the structure is rather unstable, at least at the bottom. Can be VERY sensitive to noise and to outliers Homogeneity and Separation Cluster Silhouettes and Silhouette coefficient: how similar genes within a cluster are to genes in other clusters (composite separation and homogeneity) (more later with K-medoids) (Rousseeuw Journal of Computation and Applied Mathematics, 1987) One approach is to try different approaches and see how tree differs. Use average instead of complete linkage Use divisive instead of agglomerative Use Euclidean distance instead of correlation
61 Assess cluster fit and stability (FYI) WADP: Weighted Average Discrepant Pairs Bittner et al. Nature, 2000 Fit cluster analysis using a dataset Add random noise to the original dataset Fit cluster analysis to the noise-added dataset Repeat many times. Compare the clusters across the noise-added datasets. Consensus Trees Zhang and Zhao Functional and Integrative Genomics, Use parametric bootstrap approach to sample new data using original dataset Proceed similarly to WADP. Look for nodes that are in a majority of the bootstrapped trees. More not mentioned..


62 WADP: Weighted Average Discrepancy Pairs Add perturbations to original i data Calculate the number of paired samples that cluster together th in the original cluster that didn t in the perturbed Repeat for every cutoff (i.e. for each k) Do iteratively Estimate t for each k the proportion of discrepant pairs.
63 WADP Different levels of noise have been added d By Bittner s recommendation, 1.0 is appropriate for our dataset But, not well-justified. External information would help determine level of noise for perturbation We look for largest k before WADP gets big.
64 Some Take-Home Points Clustering can be a useful exploratory tool Cluster results are very sensitive to noise in the data It is crucial to assess cluster structure to see how stable your result is Different clustering approaches can give quite different results For hierarchical clustering, interpretation is almost always subjective There is model based clustering too but we will discuss it separately
65 Extra references Cluster analysis and display of genome-wide expression patterns Eisen et al, 1998, PNAS 95(25): How does gene expression clustering work? D'haeseleer (2005) Nature Biotechnology 23, A systematic comparison and evaluation of biclustering methods for gene expression data Prelic et al (2006) Bioinformatics 22 (9):
Distances, Clustering! Rafael Irizarry!
 Distances, Clustering! Rafael Irizarry! Heatmaps! Distance! Clustering organizes things that are close into groups! What does it mean for two genes to be close?! What does it mean for two samples to
Distances, Clustering! Rafael Irizarry! Heatmaps! Distance! Clustering organizes things that are close into groups! What does it mean for two genes to be close?! What does it mean for two samples to
Clustering. Lecture 6, 1/24/03 ECS289A
 Clustering Lecture 6, 1/24/03 What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
Clustering Lecture 6, 1/24/03 What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
Hierarchical Clustering
 What is clustering Partitioning of a data set into subsets. A cluster is a group of relatively homogeneous cases or observations Hierarchical Clustering Mikhail Dozmorov Fall 2016 2/61 What is clustering
What is clustering Partitioning of a data set into subsets. A cluster is a group of relatively homogeneous cases or observations Hierarchical Clustering Mikhail Dozmorov Fall 2016 2/61 What is clustering
Cluster Analysis for Microarray Data
 Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
MSA220 - Statistical Learning for Big Data
 MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
ECS 234: Data Analysis: Clustering ECS 234
 : Data Analysis: Clustering What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
: Data Analysis: Clustering What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
Clustering Part 3. Hierarchical Clustering
 Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
Multivariate Analysis
 Multivariate Analysis Cluster Analysis Prof. Dr. Anselmo E de Oliveira anselmo.quimica.ufg.br anselmo.disciplinas@gmail.com Unsupervised Learning Cluster Analysis Natural grouping Patterns in the data
Multivariate Analysis Cluster Analysis Prof. Dr. Anselmo E de Oliveira anselmo.quimica.ufg.br anselmo.disciplinas@gmail.com Unsupervised Learning Cluster Analysis Natural grouping Patterns in the data
Understanding Clustering Supervising the unsupervised
 Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Cluster Analysis. Angela Montanari and Laura Anderlucci
 Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Measure of Distance. We wish to define the distance between two objects Distance metric between points:
 Measure of Distance We wish to define the distance between two objects Distance metric between points: Euclidean distance (EUC) Manhattan distance (MAN) Pearson sample correlation (COR) Angle distance
Measure of Distance We wish to define the distance between two objects Distance metric between points: Euclidean distance (EUC) Manhattan distance (MAN) Pearson sample correlation (COR) Angle distance
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
10701 Machine Learning. Clustering
 171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
9/29/13. Outline Data mining tasks. Clustering algorithms. Applications of clustering in biology
 9/9/ I9 Introduction to Bioinformatics, Clustering algorithms Yuzhen Ye (yye@indiana.edu) School of Informatics & Computing, IUB Outline Data mining tasks Predictive tasks vs descriptive tasks Example
9/9/ I9 Introduction to Bioinformatics, Clustering algorithms Yuzhen Ye (yye@indiana.edu) School of Informatics & Computing, IUB Outline Data mining tasks Predictive tasks vs descriptive tasks Example
Clustering. Chapter 10 in Introduction to statistical learning
 Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Hierarchical Clustering
 Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Exploratory data analysis for microarrays
 Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Hierarchical Clustering
 Hierarchical Clustering Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree-like diagram that records the sequences of merges
Hierarchical Clustering Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree-like diagram that records the sequences of merges
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Lesson 3. Prof. Enza Messina
 Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Slides From Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
SYDE Winter 2011 Introduction to Pattern Recognition. Clustering
 SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
Clustering. Robert M. Haralick. Computer Science, Graduate Center City University of New York
 Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Clustering Lecture 3: Hierarchical Methods
 Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
EECS730: Introduction to Bioinformatics
 EECS730: Introduction to Bioinformatics Lecture 15: Microarray clustering http://compbio.pbworks.com/f/wood2.gif Some slides were adapted from Dr. Shaojie Zhang (University of Central Florida) Microarray
EECS730: Introduction to Bioinformatics Lecture 15: Microarray clustering http://compbio.pbworks.com/f/wood2.gif Some slides were adapted from Dr. Shaojie Zhang (University of Central Florida) Microarray
Hierarchical Clustering 4/5/17
 Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
DATA MINING LECTURE 7. Hierarchical Clustering, DBSCAN The EM Algorithm
 DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
CS7267 MACHINE LEARNING
 S7267 MAHINE LEARNING HIERARHIAL LUSTERING Ref: hengkai Li, Department of omputer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) Mingon Kang, Ph.D. omputer Science,
S7267 MAHINE LEARNING HIERARHIAL LUSTERING Ref: hengkai Li, Department of omputer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) Mingon Kang, Ph.D. omputer Science,
Cluster analysis. Agnieszka Nowak - Brzezinska
 Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Lecture Notes for Chapter 7. Introduction to Data Mining, 2 nd Edition. by Tan, Steinbach, Karpatne, Kumar
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Hierarchical Clustering Produces a set
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Hierarchical Clustering Produces a set
Cluster Analysis. Summer School on Geocomputation. 27 June July 2011 Vysoké Pole
 Cluster Analysis Summer School on Geocomputation 27 June 2011 2 July 2011 Vysoké Pole Lecture delivered by: doc. Mgr. Radoslav Harman, PhD. Faculty of Mathematics, Physics and Informatics Comenius University,
Cluster Analysis Summer School on Geocomputation 27 June 2011 2 July 2011 Vysoké Pole Lecture delivered by: doc. Mgr. Radoslav Harman, PhD. Faculty of Mathematics, Physics and Informatics Comenius University,
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Statistics 202: Data Mining. c Jonathan Taylor. Week 8 Based in part on slides from textbook, slides of Susan Holmes. December 2, / 1
 Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CS 1675 Introduction to Machine Learning Lecture 18. Clustering. Clustering. Groups together similar instances in the data sample
 CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
Unsupervised Learning. Supervised learning vs. unsupervised learning. What is Cluster Analysis? Applications of Cluster Analysis
 7 Supervised learning vs unsupervised learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These patterns are then
7 Supervised learning vs unsupervised learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These patterns are then
5/15/16. Computational Methods for Data Analysis. Massimo Poesio UNSUPERVISED LEARNING. Clustering. Unsupervised learning introduction
 Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
University of Florida CISE department Gator Engineering. Clustering Part 2
 Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering part II 1
 Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Hard clustering. Each object is assigned to one and only one cluster. Hierarchical clustering is usually hard. Soft (fuzzy) clustering
 clustering") An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
PAM algorithm. Types of Data in Cluster Analysis. A Categorization of Major Clustering Methods. Partitioning i Methods. Hierarchical Methods
 Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Chapter 6 Continued: Partitioning Methods
 Chapter 6 Continued: Partitioning Methods Partitioning methods fix the number of clusters k and seek the best possible partition for that k. The goal is to choose the partition which gives the optimal
Chapter 6 Continued: Partitioning Methods Partitioning methods fix the number of clusters k and seek the best possible partition for that k. The goal is to choose the partition which gives the optimal
3. Cluster analysis Overview
 Université Laval Multivariate analysis - February 2006 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
Université Laval Multivariate analysis - February 2006 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
Hierarchical clustering
 Hierarchical clustering Rebecca C. Steorts, Duke University STA 325, Chapter 10 ISL 1 / 63 Agenda K-means versus Hierarchical clustering Agglomerative vs divisive clustering Dendogram (tree) Hierarchical
Hierarchical clustering Rebecca C. Steorts, Duke University STA 325, Chapter 10 ISL 1 / 63 Agenda K-means versus Hierarchical clustering Agglomerative vs divisive clustering Dendogram (tree) Hierarchical
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Data Mining Concepts & Techniques
 Data Mining Concepts & Techniques Lecture No 08 Cluster Analysis Naeem Ahmed Email: naeemmahoto@gmailcom Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro Outline
Data Mining Concepts & Techniques Lecture No 08 Cluster Analysis Naeem Ahmed Email: naeemmahoto@gmailcom Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro Outline
Multivariate analyses in ecology. Cluster (part 2) Ordination (part 1 & 2)
 Ordination (part 1 & 2)") Multivariate analyses in ecology Cluster (part 2) Ordination (part 1 & 2) 1 Exercise 9B - solut 2 Exercise 9B - solut 3 Exercise 9B - solut 4 Exercise 9B - solut 5 Multivariate analyses in ecology Cluster
Multivariate analyses in ecology Cluster (part 2) Ordination (part 1 & 2) 1 Exercise 9B - solut 2 Exercise 9B - solut 3 Exercise 9B - solut 4 Exercise 9B - solut 5 Multivariate analyses in ecology Cluster
3. Cluster analysis Overview
 Université Laval Analyse multivariable - mars-avril 2008 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
Université Laval Analyse multivariable - mars-avril 2008 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
An Unsupervised Technique for Statistical Data Analysis Using Data Mining
 International Journal of Information Sciences and Application. ISSN 0974-2255 Volume 5, Number 1 (2013), pp. 11-20 International Research Publication House http://www.irphouse.com An Unsupervised Technique
International Journal of Information Sciences and Application. ISSN 0974-2255 Volume 5, Number 1 (2013), pp. 11-20 International Research Publication House http://www.irphouse.com An Unsupervised Technique
Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering (Basic concepts and Algorithms) Entscheidungsunterstützungssysteme
 Entscheidungsunterstützungssysteme") Clustering (Basic concepts and Algorithms) Entscheidungsunterstützungssysteme Why do we need to find similarity? Similarity underlies many data science methods and solutions to business problems. Some
Clustering (Basic concepts and Algorithms) Entscheidungsunterstützungssysteme Why do we need to find similarity? Similarity underlies many data science methods and solutions to business problems. Some
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Foundations of Machine Learning CentraleSupélec Fall Clustering Chloé-Agathe Azencot
 Foundations of Machine Learning CentraleSupélec Fall 2017 12. Clustering Chloé-Agathe Azencot Centre for Computational Biology, Mines ParisTech chloe-agathe.azencott@mines-paristech.fr Learning objectives
Foundations of Machine Learning CentraleSupélec Fall 2017 12. Clustering Chloé-Agathe Azencot Centre for Computational Biology, Mines ParisTech chloe-agathe.azencott@mines-paristech.fr Learning objectives
Clustering. Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering, cont. Genome 373 Genomic Informatics Elhanan Borenstein. Some slides adapted from Jacques van Helden
 Clustering, cont Genome 373 Genomic Informatics Elhanan Borenstein Some slides adapted from Jacques van Helden Improving the search heuristic: Multiple starting points Simulated annealing Genetic algorithms
Clustering, cont Genome 373 Genomic Informatics Elhanan Borenstein Some slides adapted from Jacques van Helden Improving the search heuristic: Multiple starting points Simulated annealing Genetic algorithms
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
2. Find the smallest element of the dissimilarity matrix. If this is D lm then fuse groups l and m.
 Cluster Analysis The main aim of cluster analysis is to find a group structure for all the cases in a sample of data such that all those which are in a particular group (cluster) are relatively similar
Cluster Analysis The main aim of cluster analysis is to find a group structure for all the cases in a sample of data such that all those which are in a particular group (cluster) are relatively similar
Hierarchical clustering
 Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
University of Florida CISE department Gator Engineering. Clustering Part 5
 Clustering Part 5 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville SNN Approach to Clustering Ordinary distance measures have problems Euclidean
Clustering Part 5 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville SNN Approach to Clustering Ordinary distance measures have problems Euclidean
Cluster Analysis. Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX April 2008 April 2010
 Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Part I. Hierarchical clustering. Hierarchical Clustering. Hierarchical clustering. Produces a set of nested clusters organized as a
 Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Clustering. Content. Typical Applications. Clustering: Unsupervised data mining technique
 Content Clustering Examples Cluster analysis Partitional: K-Means clustering method Hierarchical clustering methods Data preparation in clustering Interpreting clusters Cluster validation Clustering: Unsupervised
Content Clustering Examples Cluster analysis Partitional: K-Means clustering method Hierarchical clustering methods Data preparation in clustering Interpreting clusters Cluster validation Clustering: Unsupervised
University of California, Berkeley
 University of California, Berkeley U.C. Berkeley Division of Biostatistics Working Paper Series Year 2002 Paper 105 A New Partitioning Around Medoids Algorithm Mark J. van der Laan Katherine S. Pollard
University of California, Berkeley U.C. Berkeley Division of Biostatistics Working Paper Series Year 2002 Paper 105 A New Partitioning Around Medoids Algorithm Mark J. van der Laan Katherine S. Pollard
Multivariate Methods
 Multivariate Methods Cluster Analysis http://www.isrec.isb-sib.ch/~darlene/embnet/ Classification Historically, objects are classified into groups periodic table of the elements (chemistry) taxonomy (zoology,
Multivariate Methods Cluster Analysis http://www.isrec.isb-sib.ch/~darlene/embnet/ Classification Historically, objects are classified into groups periodic table of the elements (chemistry) taxonomy (zoology,
CS570: Introduction to Data Mining
 CS570: Introduction to Data Mining Scalable Clustering Methods: BIRCH and Others Reading: Chapter 10.3 Han, Chapter 9.5 Tan Cengiz Gunay, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei.
CS570: Introduction to Data Mining Scalable Clustering Methods: BIRCH and Others Reading: Chapter 10.3 Han, Chapter 9.5 Tan Cengiz Gunay, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei.
Objective of clustering
 Objective of clustering Discover structures and patterns in high-dimensional data. Group data with similar patterns together. This reduces the complexity and facilitates interpretation. Expression level
Objective of clustering Discover structures and patterns in high-dimensional data. Group data with similar patterns together. This reduces the complexity and facilitates interpretation. Expression level
Clustering. CS294 Practical Machine Learning Junming Yin 10/09/06
 Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Tree Models of Similarity and Association. Clustering and Classification Lecture 5
 Tree Models of Similarity and Association Clustering and Lecture 5 Today s Class Tree models. Hierarchical clustering methods. Fun with ultrametrics. 2 Preliminaries Today s lecture is based on the monograph
Tree Models of Similarity and Association Clustering and Lecture 5 Today s Class Tree models. Hierarchical clustering methods. Fun with ultrametrics. 2 Preliminaries Today s lecture is based on the monograph
Clustering. Informal goal. General types of clustering. Applications: Clustering in information search and analysis. Example applications in search
 Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Olmo S. Zavala Romero. Clustering Hierarchical Distance Group Dist. K-means. Center of Atmospheric Sciences, UNAM.
 Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Unsupervised Learning
 Unsupervised Learning Fabio G. Cozman - fgcozman@usp.br November 16, 2018 What can we do? We just have a dataset with features (no labels, no response). We want to understand the data... no easy to define
Unsupervised Learning Fabio G. Cozman - fgcozman@usp.br November 16, 2018 What can we do? We just have a dataset with features (no labels, no response). We want to understand the data... no easy to define
Clustering analysis of gene expression data
 Clustering analysis of gene expression data Chapter 11 in Jonathan Pevsner, Bioinformatics and Functional Genomics, 3 rd edition (Chapter 9 in 2 nd edition) Human T cell expression data The matrix contains
Clustering analysis of gene expression data Chapter 11 in Jonathan Pevsner, Bioinformatics and Functional Genomics, 3 rd edition (Chapter 9 in 2 nd edition) Human T cell expression data The matrix contains
Unsupervised Learning
 Unsupervised Learning A review of clustering and other exploratory data analysis methods HST.951J: Medical Decision Support Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision
Unsupervised Learning A review of clustering and other exploratory data analysis methods HST.951J: Medical Decision Support Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision
Data Exploration with PCA and Unsupervised Learning with Clustering Paul Rodriguez, PhD PACE SDSC
 Data Exploration with PCA and Unsupervised Learning with Clustering Paul Rodriguez, PhD PACE SDSC Clustering Idea Given a set of data can we find a natural grouping? Essential R commands: D =rnorm(12,0,1)
Data Exploration with PCA and Unsupervised Learning with Clustering Paul Rodriguez, PhD PACE SDSC Clustering Idea Given a set of data can we find a natural grouping? Essential R commands: D =rnorm(12,0,1)
4. Ad-hoc I: Hierarchical clustering
 4. Ad-hoc I: Hierarchical clustering Hierarchical versus Flat Flat methods generate a single partition into k clusters. The number k of clusters has to be determined by the user ahead of time. Hierarchical
4. Ad-hoc I: Hierarchical clustering Hierarchical versus Flat Flat methods generate a single partition into k clusters. The number k of clusters has to be determined by the user ahead of time. Hierarchical
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/09/2018)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University
 Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
High throughput Data Analysis 2. Cluster Analysis
 High throughput Data Analysis 2 Cluster Analysis Overview Why clustering? Hierarchical clustering K means clustering Issues with above two Other methods Quality of clustering results Introduction WHY DO
High throughput Data Analysis 2 Cluster Analysis Overview Why clustering? Hierarchical clustering K means clustering Issues with above two Other methods Quality of clustering results Introduction WHY DO
What is Unsupervised Learning?
 Clustering What is Unsupervised Learning? Unlike in supervised learning, in unsupervised learning, there are no labels We simply a search for patterns in the data Examples Clustering Density Estimation
Clustering What is Unsupervised Learning? Unlike in supervised learning, in unsupervised learning, there are no labels We simply a search for patterns in the data Examples Clustering Density Estimation
MATH5745 Multivariate Methods Lecture 13
 MATH5745 Multivariate Methods Lecture 13 April 24, 2018 MATH5745 Multivariate Methods Lecture 13 April 24, 2018 1 / 33 Cluster analysis. Example: Fisher iris data Fisher (1936) 1 iris data consists of
MATH5745 Multivariate Methods Lecture 13 April 24, 2018 MATH5745 Multivariate Methods Lecture 13 April 24, 2018 1 / 33 Cluster analysis. Example: Fisher iris data Fisher (1936) 1 iris data consists of
10601 Machine Learning. Hierarchical clustering. Reading: Bishop: 9-9.2
 161 Machine Learning Hierarchical clustering Reading: Bishop: 9-9.2 Second half: Overview Clustering - Hierarchical, semi-supervised learning Graphical models - Bayesian networks, HMMs, Reasoning under
161 Machine Learning Hierarchical clustering Reading: Bishop: 9-9.2 Second half: Overview Clustering - Hierarchical, semi-supervised learning Graphical models - Bayesian networks, HMMs, Reasoning under
Types of general clustering methods. Clustering Algorithms for general similarity measures. Similarity between clusters
 Types of general clustering methods Clustering Algorithms for general similarity measures agglomerative versus divisive algorithms agglomerative = bottom-up build up clusters from single objects divisive
Types of general clustering methods Clustering Algorithms for general similarity measures agglomerative versus divisive algorithms agglomerative = bottom-up build up clusters from single objects divisive
Clustering Algorithms for general similarity measures
 Types of general clustering methods Clustering Algorithms for general similarity measures general similarity measure: specified by object X object similarity matrix 1 constructive algorithms agglomerative
Types of general clustering methods Clustering Algorithms for general similarity measures general similarity measure: specified by object X object similarity matrix 1 constructive algorithms agglomerative