3D Shape Segmentation with Projective Convolutional Networks
|
|
|
- Jennifer Kelley
- 6 years ago
- Views:
Transcription


1 3D Shape Segmentation with Projective Convolutional Networks Evangelos Kalogerakis 1 Melinos Averkiou 2 Subhransu Maji 1 Siddhartha Chaudhuri 3 1 University of Massachusetts Amherst 2 University of Cyprus 3 IIT Bombay
2 Goal: learn to segment & label parts in 3D shapes 3D Geometric representation
3 Goal: learn to segment & label parts in 3D shapes ShapePFCN 3D Geometric representation
4 Goal: learn to segment & label parts in 3D shapes ShapePFCN 3D Geometric representation Labeled 3D shape back seat base armrest











5 Goal: learn to segment & label parts in 3D shapes ShapePFCN 3D Geometric representation Training Dataset... Labeled 3D shape back seat base armrest





6 Motivation: Parsing RGBD data... back seat base armrest RGBD data from A Large Dataset of Object Scans Choi, Zhou, Miller, Koltun 2016 Our result









7 Motivation: 3D Modeling & Animation Ear Head Torso Back Upper arm Lower arm Hand Upper leg Lower leg Foot Tail Animation Texturing 3D Models Kalogerakis, Hertzmann, Singh, SIGGRAPH 2010 Simari, Nowrouzezahrai, Kalogerakis, Singh, SGP 2009
8 Related Work Train classifiers on hand engineered descriptors e.g., Kalogerakis et al. 2010, Guo et al curvature shape contexts geodesic dist.
9 Related Work Train classifiers on hand engineered descriptors e.g., Kalogerakis et al. 2010, Guo et al Concurrent approaches: Volumetric / octree based methods: Riegler et al (OctNet), Wang et al (O CNN), Klokov et al (kd net) Point based networks: Qi et al (PointNet / PointNet++) Graph based / spectral networks: Yi et al (SyncSpecCNN) Surface embedding networks: Maron et al curvature shape contexts geodesic dist.
, Wang et al. 2017 (O CNN), Klokov et al. 2017 (kd net) Point based networks: Qi et al. 2017 (PointNet / PointNet++) Graph based / spectral networks: Yi et al.")
10 Related Work Train classifiers on hand engineered descriptors e.g., Kalogerakis et al. 2010, Guo et al Concurrent approaches: Volumetric / octree based methods: Riegler et al (OctNet), Wang et al (O CNN), Klokov et al (kd net) Point based networks: Qi et al (PointNet / PointNet++) Graph based / spectral networks: Yi et al (SyncSpecCNN) Surface embedding networks: Maron et al curvature shape contexts geodesic dist. Our method: view based network

11 Key Observations 3D models are often designed for viewing.


12 Key Observations 3D models are often designed for viewing.


13 Key Observations 3D models are often designed for viewing. Empty inside!
14 3D scans capture the surface. Key Observations + noise, missing regions etc


15 Key Observations 3D models are often designed for viewing. Parts do not touch! (not easily noticeable to the viewer, yet geometric implications on topology, connectedness...)
 Image based network Chair! Airplane!")

16 Key Observations Shape renderings can be treated as photos of objects (without texture) Image based network Chair! Airplane! Shape renderings can be processed by powerful image based architectures through transfer learning from massive image datasets. (Su, Maji, Kalogerakis, Learned Miller, ICCV 2015)
17 Key Idea Deep architecture that combines view based convnets for part reasoning on rendered shape images & prob. graphical models for surface processing.
18 Key Idea Deep architecture that combines view based convnets for part reasoning on rendered shape images & prob. graphical models for surface processing. Key challenges: Select views to avoid surface information loss & deal with occlusions
19 Key Idea Deep architecture that combines view based convnets for part reasoning on rendered shape images & prob. graphical models for surface processing. Key challenges: Select views to avoid surface information loss & deal with occlusions Promote invariance under 3D shape rotations
20 Key Idea Deep architecture that combines view based convnets for part reasoning on rendered shape images & prob. graphical models for surface processing. Key challenges: Select views to avoid surface information loss & deal with occlusions Promote invariance under 3D shape rotations Joint reasoning about parts across multiple views +surface
21 Pipeline View selection ShapePFCN fuselage wing vert. stabilizer horiz. stabilizer
22 Pipeline View selection ShapePFCN fuselage wing vert. stabilizer horiz. stabilizer
23 Input: shape as a collection of rendered views For each input shape, infer a set of viewpoints that maximally cover its surface across multiple distances.
24 Input: shape as a collection of rendered views Render shaded images (normal dot view vector) encoding surface normals. Shaded images
25 Input: shape as a collection of rendered views Render also depth images encoding surface position relative to the camera. Shaded images Depth images




26 Input: shape as a collection of rendered views Perform in plane camera rotations for rotational invariance. 0 o,90 o, 180 o, 270 o rotations Shaded images Depth images
27 Projective convnet architecture Each pair of depth & shaded images is processed by a FCN. Views are not ordered (no view correspondence across shapes). [Long, Shelhamer, and Darrell 2015] FCN FCN Surface confidence maps Shaded images Depth images FCN
28 Projective convnet architecture Each pair of depth & shaded images is processed by a FCN. Views are not ordered (no view correspondence across shapes). [Long, Shelhamer, and Darrell 2015] FCN FCN Surface confidence maps Shaded images Depth images FCN shared filters

29 Projective convnet architecture The output of each FCN branch is a view based confidence map per part label. hor. stabilizer FCN FCN Surface confidence maps Shaded images Depth images FCN shared filters View based map
30 Projective convnet architecture The output of each FCN branch is a view based confidence map per part label. wing FCN FCN Shaded images Depth images FCN shared filters View based map
31 Projective convnet architecture Aggregate & project the image confidence maps from all views on the surface. FCN FCN Surface based map Shaded images Depth images FCN shared filters View based map
32 Image2Surface projection layer For each surface element (triangle), find all pixels that include it in all views. Surface confidence: use max of these pixel confidences per label. FCN FCN max Surface based map Shaded images Depth images FCN shared filters View based map
33 Image2Surface projection layer For each surface element (triangle), find all pixels that include it in all views. Surface confidence: use max of these pixel confidences per label. FCN FCN max Surface based map Shaded images Depth images FCN shared filters View based map
34 Image2Surface projection layer For each surface element (triangle), find all pixels that include it in all views. Surface confidence: use max of these pixel confidences per label. FCN FCN max Surface based map Shaded images Depth images FCN shared filters View based map

35 CRF layer for spatially coherent labeling Last layer performs inference in a probabilistic model defined on the surface. R 1 R 2 R 3 R 4 R 1, R 2, R 3, R 4 random variables taking values: fuselage wing vert. stabilizer horiz. stabilizer
36 CRF layer for spatially coherent labeling Conditional Random Field: unary factors based on surface based confidences R 1 R 2 R 3 R 4 1 P( R, R, R, R... shape) P( R views) P( R, R surface) f f f ' Z f 1.. n f, f ' Unary factors (FCN confidences)
37 Projective convnet architecture: CRF layer Pairwise terms favor same label for triangles with: (a) similar surface normals (b) small geodesic distance R 2 R 1 R 3 R 4 1 P( R, R, R, R... shape) P( R views) P( R, R surface) f f f ' Z f 1.. n f, f ' Pairwise factors (geodesic+normal distance)
 max 1 P(")
 P( R views) P( R, R surface) f f f 1 2 3 4 ' Z f 1.")
38 Projective convnet architecture: CRF layer Infer most likely joint assignment to all surface random variables (mean field) max 1 P( R, R, R, R... shape) P( R views) P( R, R surface) f f f ' Z f 1.. n f, f ' MAP assignment (mean field inference) R 2 R 1 R 3 R 4
39 Forward pass inference (convnet+crf) CRF FCN
40 Training The architecture is trained end to end with analytic gradients. CRF FCN Backpropagation / joint training (convnet+crf)
41 Training The architecture is trained end to end with analytic gradients. Training starts from a pretrained image based net (VGG16), then fine tune. CRF FCN Pre trained Backpropagation / joint training (convnet+crf)

42 Dataset used in experiments Evaluation on ShapeNet + LPSB + COSEG (46 classes of shapes) 50% used for training / 50% used for test split per Shapenet category Max 250 shapes for training. No assumption on shape orientation. [Yi et al. 2016]

43 Dataset used in experiments Evaluation on ShapeNet + LPSB + COSEG (46 classes of shapes) 50% used for training / 50% used for test split per Shapenet category Max 250 shapes for training. No assumption on shape orientation. [Yi et al. 2016]
44 Results Labeling accuracy on ShapeNet test dataset: ShapeBoost Guo et al. ShapePFCN
45 Results Ignore easy classes (2 or 3 part labels) Labeling accuracy on ShapeNet test dataset: ShapeBoost Guo et al. ShapePFCN % improvement in labeling accuracy for complex categories (vehicles, furniture)
46 Results Ignore easy classes (2 or 3 part labels) Labeling accuracy on ShapeNet test dataset: ShapeBoost Guo et al. ShapePFCN % improvement in labeling accuracy for complex categories (vehicles, furniture) Labeling accuracy on LPSB+COSEG test dataset: ShapeBoost Guo et al. ShapePFCN

47 ground-truth ShapeBoost ShapePFCN


48 ShapeBoost ShapePFCN Object scans from A Large Dataset of Object Scans Choi et al. 2016
49 Summary Deep architecture combining view based FCN & surface based CRF Multi scale view selection to avoid loss of surface information Transfer learning from massive image datasets Robust to geometric representation artifacts Acknowledgements: NSF (CHS , CHS , IIS ) Experiments were performed in the UMass GPU cluster (400 GPUs!) obtained under a grant by the MassTech Collaborative




50 Project page:
51 Auxiliary slides




52 What are the filters doing? Activated in the presence of certain patterns of surface patches conv4 conv5 fc6
53 What are the filters doing? Activated in the presence of certain patterns of surface patches conv4 conv5 fc6
54 What are the filters doing? Activated in the presence of certain patterns of surface patches conv4 conv5 fc6
55 Input: shape as a collection of rendered views For each input shape, infer a set of viewpoints that maximally cover its surface across multiple distances.
56 Input: shape as a collection of rendered views For each input shape, infer a set of viewpoints that maximally cover its surface across multiple distances.
57 Input: shape as a collection of rendered views For each input shape, infer a set of viewpoints that maximally cover its surface across multiple distances.


58 Input: shape as a collection of rendered views For each input shape, infer a set of viewpoints that maximally cover its surface across multiple distances.


59 Input: shape as a collection of rendered views For each input shape, infer a set of viewpoints that maximally cover its surface across multiple distances.
60 Input: shape as a collection of rendered views For each input shape, infer a set of viewpoints that maximally cover its surface across multiple distances.




61 FCN FCN max Surface based map Shaded images Depth images FCN shared filters View based map
62 Training The architecture is trained end to end with analytic gradients. CRF FCN Backpropagation / joint training (convnet+crf)
63 Challenges 3D models have missing or non photorealistic texture



64 Challenges 3D models have missing or non photorealistic texture (focus on shape instead)

65 ShapeNetCore: 8% improvement in labeling accuracy for complex categories (vehicles, furniture etc)
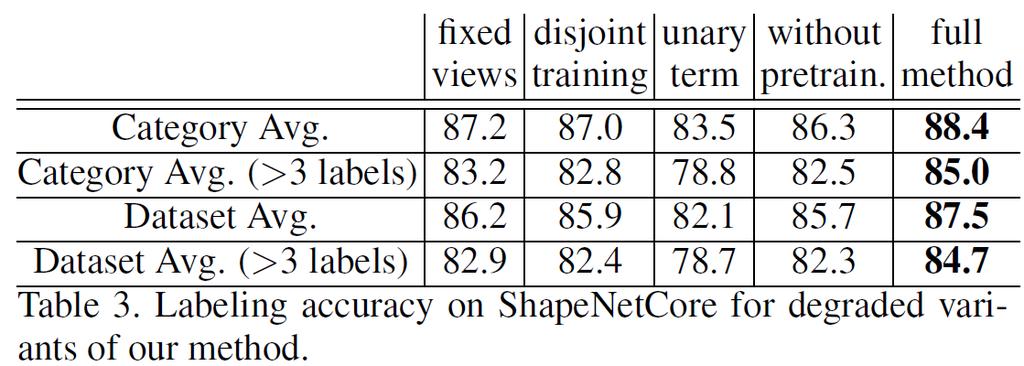
66










67 Key Observations 3D models have arbitrary orientation in the wild. Consistent shape orientation only in specific, well engineered datasets (often with manual intervention, no perfect alignment algorithm)
68 Comparisons pitfalls Method A assumes consistent shape alignment (or upright orientation), method B doesn t. Well, you may get much better numbers for B by changing its input! Convnet A has orders of magnitude more parameters than Convnet B. It might also be easy to get better numbers for B, if you increase its number of filters! Convnet A has an architectural trick that Convnet B could also have (e.g., U net, ensemble). Why not apply the same trick to B? Methods are largely tested on training data because of duplicate or near duplicate shapes. The more you overfit, the better! Ouch! 3DShapeNet has many identical models, or models with tiny differences (e.g., same airplane with different rockets)...
3D Shape Analysis with Multi-view Convolutional Networks. Evangelos Kalogerakis
 3D Shape Analysis with Multi-view Convolutional Networks Evangelos Kalogerakis 3D model repositories [3D Warehouse - video] 3D geometry acquisition [KinectFusion - video] 3D shapes come in various flavors
3D Shape Analysis with Multi-view Convolutional Networks Evangelos Kalogerakis 3D model repositories [3D Warehouse - video] 3D geometry acquisition [KinectFusion - video] 3D shapes come in various flavors
Data driven 3D shape analysis and synthesis
 Data driven 3D shape analysis and synthesis Head Neck Torso Leg Tail Ear Evangelos Kalogerakis UMass Amherst 3D shapes for computer aided design Architecture Interior design 3D shapes for information visualization
Data driven 3D shape analysis and synthesis Head Neck Torso Leg Tail Ear Evangelos Kalogerakis UMass Amherst 3D shapes for computer aided design Architecture Interior design 3D shapes for information visualization
Analysis and Synthesis of 3D Shape Families via Deep Learned Generative Models of Surfaces
 Analysis and Synthesis of 3D Shape Families via Deep Learned Generative Models of Surfaces Haibin Huang, Evangelos Kalogerakis, Benjamin Marlin University of Massachusetts Amherst Given an input 3D shape
Analysis and Synthesis of 3D Shape Families via Deep Learned Generative Models of Surfaces Haibin Huang, Evangelos Kalogerakis, Benjamin Marlin University of Massachusetts Amherst Given an input 3D shape
arxiv: v3 [cs.cv] 13 Nov 2017
![arxiv: v3 [cs.cv] 13 Nov 2017](/thumbs/79/78897270.jpg "arxiv: v3 [cs.cv] 13 Nov 2017") 3D Shape Segmentation with Projective Convolutional Networks Evangelos Kalogerakis 1 Melinos Averkiou 2 Subhransu Maji 1 Siddhartha Chaudhuri 3 1 University of Massachusetts Amherst 2 University of Cyprus
3D Shape Segmentation with Projective Convolutional Networks Evangelos Kalogerakis 1 Melinos Averkiou 2 Subhransu Maji 1 Siddhartha Chaudhuri 3 1 University of Massachusetts Amherst 2 University of Cyprus
Machine Learning for Shape Analysis and Processing. Evangelos Kalogerakis
 Machine Learning for Shape Analysis and Processing Evangelos Kalogerakis 3D shapes for computer aided design Architecture Interior design 3D shapes for information visualization Geo visualization Scientific
Machine Learning for Shape Analysis and Processing Evangelos Kalogerakis 3D shapes for computer aided design Architecture Interior design 3D shapes for information visualization Geo visualization Scientific
3D Shape Segmentation with Projective Convolutional Networks
 3D Shape Segmentation with Projective Convolutional Networks Evangelos Kalogerakis 1 Melinos Averkiou 2 Subhransu Maji 1 Siddhartha Chaudhuri 3 1 University of Massachusetts Amherst 2 University of Cyprus
3D Shape Segmentation with Projective Convolutional Networks Evangelos Kalogerakis 1 Melinos Averkiou 2 Subhransu Maji 1 Siddhartha Chaudhuri 3 1 University of Massachusetts Amherst 2 University of Cyprus
CS468: 3D Deep Learning on Point Cloud Data. class label part label. Hao Su. image. May 10, 2017
 CS468: 3D Deep Learning on Point Cloud Data class label part label Hao Su image. May 10, 2017 Agenda Point cloud generation Point cloud analysis CVPR 17, Point Set Generation Pipeline render CVPR 17, Point
CS468: 3D Deep Learning on Point Cloud Data class label part label Hao Su image. May 10, 2017 Agenda Point cloud generation Point cloud analysis CVPR 17, Point Set Generation Pipeline render CVPR 17, Point
Detecting and Parsing of Visual Objects: Humans and Animals. Alan Yuille (UCLA)
") Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
ECCV Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016
 ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
Learning to generate 3D shapes
 Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
Learning from 3D Data
 Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Encoder-Decoder Networks for Semantic Segmentation. Sachin Mehta
 Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Su et al. Shape Descriptors - III
 Su et al. Shape Descriptors - III Siddhartha Chaudhuri http://www.cse.iitb.ac.in/~cs749 Funkhouser; Feng, Liu, Gong Recap Global A shape descriptor is a set of numbers that describes a shape in a way that
Su et al. Shape Descriptors - III Siddhartha Chaudhuri http://www.cse.iitb.ac.in/~cs749 Funkhouser; Feng, Liu, Gong Recap Global A shape descriptor is a set of numbers that describes a shape in a way that
3D Deep Learning on Geometric Forms. Hao Su
 3D Deep Learning on Geometric Forms Hao Su Many 3D representations are available Candidates: multi-view images depth map volumetric polygonal mesh point cloud primitive-based CAD models 3D representation
3D Deep Learning on Geometric Forms Hao Su Many 3D representations are available Candidates: multi-view images depth map volumetric polygonal mesh point cloud primitive-based CAD models 3D representation
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material
 Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
Seeing the unseen. Data-driven 3D Understanding from Single Images. Hao Su
 Seeing the unseen Data-driven 3D Understanding from Single Images Hao Su Image world Shape world 3D perception from a single image Monocular vision a typical prey a typical predator Cited from https://en.wikipedia.org/wiki/binocular_vision
Seeing the unseen Data-driven 3D Understanding from Single Images Hao Su Image world Shape world 3D perception from a single image Monocular vision a typical prey a typical predator Cited from https://en.wikipedia.org/wiki/binocular_vision
... arxiv: v2 [cs.cv] 5 Sep Learning local shape descriptors from part correspondences with multi-view convolutional networks
![... arxiv: v2 [cs.cv] 5 Sep Learning local shape descriptors from part correspondences with multi-view convolutional networks](/thumbs/75/72009962.jpg "... arxiv: v2 [cs.cv] 5 Sep Learning local shape descriptors from part correspondences with multi-view convolutional networks") Learning local shape descriptors from part correspondences with multi-view convolutional networks HAIBIN HUANG, University of Massachusetts Amherst EVANGELOS KALOGERAKIS, University of Massachusetts Amherst
Learning local shape descriptors from part correspondences with multi-view convolutional networks HAIBIN HUANG, University of Massachusetts Amherst EVANGELOS KALOGERAKIS, University of Massachusetts Amherst
Multiresolution Tree Networks for 3D Point Cloud Processing
 Multiresolution Tree Networks for 3D Point Cloud Processing Matheus Gadelha, Rui Wang and Subhransu Maji College of Information and Computer Sciences, University of Massachusetts - Amherst {mgadelha, ruiwang,
Multiresolution Tree Networks for 3D Point Cloud Processing Matheus Gadelha, Rui Wang and Subhransu Maji College of Information and Computer Sciences, University of Massachusetts - Amherst {mgadelha, ruiwang,
3D Object Classification via Spherical Projections
 3D Object Classification via Spherical Projections Zhangjie Cao 1,QixingHuang 2,andRamaniKarthik 3 1 School of Software Tsinghua University, China 2 Department of Computer Science University of Texas at
3D Object Classification via Spherical Projections Zhangjie Cao 1,QixingHuang 2,andRamaniKarthik 3 1 School of Software Tsinghua University, China 2 Department of Computer Science University of Texas at
LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS
 LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS Alexey Dosovitskiy, Jost Tobias Springenberg and Thomas Brox University of Freiburg Presented by: Shreyansh Daftry Visual Learning and Recognition
LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS Alexey Dosovitskiy, Jost Tobias Springenberg and Thomas Brox University of Freiburg Presented by: Shreyansh Daftry Visual Learning and Recognition
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS. Zhao Chen Machine Learning Intern, NVIDIA
 JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
Pixels to Voxels: Modeling Visual Representation in the Human Brain
 Pixels to Voxels: Modeling Visual Representation in the Human Brain Authors: Pulkit Agrawal, Dustin Stansbury, Jitendra Malik, Jack L. Gallant Presenters: JunYoung Gwak, Kuan Fang Outlines Background Motivation
Pixels to Voxels: Modeling Visual Representation in the Human Brain Authors: Pulkit Agrawal, Dustin Stansbury, Jitendra Malik, Jack L. Gallant Presenters: JunYoung Gwak, Kuan Fang Outlines Background Motivation
Deep Learning For Video Classification. Presented by Natalie Carlebach & Gil Sharon
 Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
Deep Models for 3D Reconstruction
 Deep Models for 3D Reconstruction Andreas Geiger Autonomous Vision Group, MPI for Intelligent Systems, Tübingen Computer Vision and Geometry Group, ETH Zürich October 12, 2017 Max Planck Institute for
Deep Models for 3D Reconstruction Andreas Geiger Autonomous Vision Group, MPI for Intelligent Systems, Tübingen Computer Vision and Geometry Group, ETH Zürich October 12, 2017 Max Planck Institute for
Separating Objects and Clutter in Indoor Scenes
 Separating Objects and Clutter in Indoor Scenes Salman H. Khan School of Computer Science & Software Engineering, The University of Western Australia Co-authors: Xuming He, Mohammed Bennamoun, Ferdous
Separating Objects and Clutter in Indoor Scenes Salman H. Khan School of Computer Science & Software Engineering, The University of Western Australia Co-authors: Xuming He, Mohammed Bennamoun, Ferdous
Machine Learning Techniques for Geometric Modeling. Evangelos Kalogerakis
 Machine Learning Techniques for Geometric Modeling Evangelos Kalogerakis 3D models for digital entertainment Limit Theory 3D models for printing MakerBot Industries 3D models for architecture Architect:
Machine Learning Techniques for Geometric Modeling Evangelos Kalogerakis 3D models for digital entertainment Limit Theory 3D models for printing MakerBot Industries 3D models for architecture Architect:
Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning
 Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
POINT CLOUD DEEP LEARNING
 POINT CLOUD DEEP LEARNING Innfarn Yoo, 3/29/28 / 57 Introduction AGENDA Previous Work Method Result Conclusion 2 / 57 INTRODUCTION 3 / 57 2D OBJECT CLASSIFICATION Deep Learning for 2D Object Classification
POINT CLOUD DEEP LEARNING Innfarn Yoo, 3/29/28 / 57 Introduction AGENDA Previous Work Method Result Conclusion 2 / 57 INTRODUCTION 3 / 57 2D OBJECT CLASSIFICATION Deep Learning for 2D Object Classification
Learning 3D Part Detection from Sparsely Labeled Data: Supplemental Material
 Learning 3D Part Detection from Sparsely Labeled Data: Supplemental Material Ameesh Makadia Google New York, NY 10011 makadia@google.com Mehmet Ersin Yumer Carnegie Mellon University Pittsburgh, PA 15213
Learning 3D Part Detection from Sparsely Labeled Data: Supplemental Material Ameesh Makadia Google New York, NY 10011 makadia@google.com Mehmet Ersin Yumer Carnegie Mellon University Pittsburgh, PA 15213
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
3D Deep Learning
 3D Deep Learning Tutorial@CVPR2017 Hao Su (UCSD) Leonidas Guibas (Stanford) Michael Bronstein (Università della Svizzera Italiana) Evangelos Kalogerakis (UMass) Jimei Yang (Adobe Research) Charles Qi (Stanford)
3D Deep Learning Tutorial@CVPR2017 Hao Su (UCSD) Leonidas Guibas (Stanford) Michael Bronstein (Università della Svizzera Italiana) Evangelos Kalogerakis (UMass) Jimei Yang (Adobe Research) Charles Qi (Stanford)
3D Semantic Segmentation with Submanifold Sparse Convolutional Networks
 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks Benjamin Graham Facebook AI Research benjamingraham@fb.com Martin Engelcke University of Oxford martin@robots.ox.ac.uk Laurens van
3D Semantic Segmentation with Submanifold Sparse Convolutional Networks Benjamin Graham Facebook AI Research benjamingraham@fb.com Martin Engelcke University of Oxford martin@robots.ox.ac.uk Laurens van
Photo-realistic Renderings for Machines Seong-heum Kim
 Photo-realistic Renderings for Machines 20105034 Seong-heum Kim CS580 Student Presentations 2016.04.28 Photo-realistic Renderings for Machines Scene radiances Model descriptions (Light, Shape, Material,
Photo-realistic Renderings for Machines 20105034 Seong-heum Kim CS580 Student Presentations 2016.04.28 Photo-realistic Renderings for Machines Scene radiances Model descriptions (Light, Shape, Material,
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs
 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
CMU Lecture 18: Deep learning and Vision: Convolutional neural networks. Teacher: Gianni A. Di Caro
 CMU 15-781 Lecture 18: Deep learning and Vision: Convolutional neural networks Teacher: Gianni A. Di Caro DEEP, SHALLOW, CONNECTED, SPARSE? Fully connected multi-layer feed-forward perceptrons: More powerful
CMU 15-781 Lecture 18: Deep learning and Vision: Convolutional neural networks Teacher: Gianni A. Di Caro DEEP, SHALLOW, CONNECTED, SPARSE? Fully connected multi-layer feed-forward perceptrons: More powerful
arxiv: v1 [cs.cv] 13 Feb 2018
![arxiv: v1 [cs.cv] 13 Feb 2018](/thumbs/85/92549074.jpg "arxiv: v1 [cs.cv] 13 Feb 2018") Recurrent Slice Networks for 3D Segmentation on Point Clouds Qiangui Huang Weiyue Wang Ulrich Neumann University of Southern California Los Angeles, California {qianguih,weiyuewa,uneumann}@uscedu arxiv:180204402v1
Recurrent Slice Networks for 3D Segmentation on Point Clouds Qiangui Huang Weiyue Wang Ulrich Neumann University of Southern California Los Angeles, California {qianguih,weiyuewa,uneumann}@uscedu arxiv:180204402v1
Semantic Segmentation
 Semantic Segmentation UCLA:https://goo.gl/images/I0VTi2 OUTLINE Semantic Segmentation Why? Paper to talk about: Fully Convolutional Networks for Semantic Segmentation. J. Long, E. Shelhamer, and T. Darrell,
Semantic Segmentation UCLA:https://goo.gl/images/I0VTi2 OUTLINE Semantic Segmentation Why? Paper to talk about: Fully Convolutional Networks for Semantic Segmentation. J. Long, E. Shelhamer, and T. Darrell,
An Empirical Study of Generative Adversarial Networks for Computer Vision Tasks
 An Empirical Study of Generative Adversarial Networks for Computer Vision Tasks Report for Undergraduate Project - CS396A Vinayak Tantia (Roll No: 14805) Guide: Prof Gaurav Sharma CSE, IIT Kanpur, India
An Empirical Study of Generative Adversarial Networks for Computer Vision Tasks Report for Undergraduate Project - CS396A Vinayak Tantia (Roll No: 14805) Guide: Prof Gaurav Sharma CSE, IIT Kanpur, India
Supplementary A. Overview. C. Time and Space Complexity. B. Shape Retrieval. D. Permutation Invariant SOM. B.1. Dataset
 Supplementary A. Overview This supplementary document provides more technical details and experimental results to the main paper. Shape retrieval experiments are demonstrated with ShapeNet Core55 dataset
Supplementary A. Overview This supplementary document provides more technical details and experimental results to the main paper. Shape retrieval experiments are demonstrated with ShapeNet Core55 dataset
Machine Learning. Deep Learning. Eric Xing (and Pengtao Xie) , Fall Lecture 8, October 6, Eric CMU,
 , Fall Lecture 8, October 6, Eric CMU,") Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
arxiv: v1 [cs.cv] 28 Nov 2018
![arxiv: v1 [cs.cv] 28 Nov 2018](/thumbs/91/104803963.jpg "arxiv: v1 [cs.cv] 28 Nov 2018") MeshNet: Mesh Neural Network for 3D Shape Representation Yutong Feng, 1 Yifan Feng, 2 Haoxuan You, 1 Xibin Zhao 1, Yue Gao 1 1 BNRist, KLISS, School of Software, Tsinghua University, China. 2 School of
MeshNet: Mesh Neural Network for 3D Shape Representation Yutong Feng, 1 Yifan Feng, 2 Haoxuan You, 1 Xibin Zhao 1, Yue Gao 1 1 BNRist, KLISS, School of Software, Tsinghua University, China. 2 School of
A Deeper Look at 3D Shape Classifiers
 A Deeper Look at 3D Shape Classifiers Jong-Chyi Su, Matheus Gadelha, Rui Wang, Subhransu Maji University of Massachusetts, Amherst {jcsu,mgadelha,ruiwang,smaji}@cs.umass.edu Abstract. We investigate the
A Deeper Look at 3D Shape Classifiers Jong-Chyi Su, Matheus Gadelha, Rui Wang, Subhransu Maji University of Massachusetts, Amherst {jcsu,mgadelha,ruiwang,smaji}@cs.umass.edu Abstract. We investigate the
Shape Co-analysis. Daniel Cohen-Or. Tel-Aviv University
 Shape Co-analysis Daniel Cohen-Or Tel-Aviv University 1 High-level Shape analysis [Fu et al. 08] Upright orientation [Mehra et al. 08] Shape abstraction [Kalograkis et al. 10] Learning segmentation [Mitra
Shape Co-analysis Daniel Cohen-Or Tel-Aviv University 1 High-level Shape analysis [Fu et al. 08] Upright orientation [Mehra et al. 08] Shape abstraction [Kalograkis et al. 10] Learning segmentation [Mitra
Learning and Inferring Depth from Monocular Images. Jiyan Pan April 1, 2009
 Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren Kaiming He Ross Girshick Jian Sun Present by: Yixin Yang Mingdong Wang 1 Object Detection 2 1 Applications Basic
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren Kaiming He Ross Girshick Jian Sun Present by: Yixin Yang Mingdong Wang 1 Object Detection 2 1 Applications Basic
Analysis: TextonBoost and Semantic Texton Forests. Daniel Munoz Februrary 9, 2009
 Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Multi-view Stereo. Ivo Boyadzhiev CS7670: September 13, 2011
 Multi-view Stereo Ivo Boyadzhiev CS7670: September 13, 2011 What is stereo vision? Generic problem formulation: given several images of the same object or scene, compute a representation of its 3D shape
Multi-view Stereo Ivo Boyadzhiev CS7670: September 13, 2011 What is stereo vision? Generic problem formulation: given several images of the same object or scene, compute a representation of its 3D shape
Know your data - many types of networks
 Architectures Know your data - many types of networks Fixed length representation Variable length representation Online video sequences, or samples of different sizes Images Specific architectures for
Architectures Know your data - many types of networks Fixed length representation Variable length representation Online video sequences, or samples of different sizes Images Specific architectures for
PARTIAL STYLE TRANSFER USING WEAKLY SUPERVISED SEMANTIC SEGMENTATION. Shin Matsuo Wataru Shimoda Keiji Yanai
 PARTIAL STYLE TRANSFER USING WEAKLY SUPERVISED SEMANTIC SEGMENTATION Shin Matsuo Wataru Shimoda Keiji Yanai Department of Informatics, The University of Electro-Communications, Tokyo 1-5-1 Chofugaoka,
PARTIAL STYLE TRANSFER USING WEAKLY SUPERVISED SEMANTIC SEGMENTATION Shin Matsuo Wataru Shimoda Keiji Yanai Department of Informatics, The University of Electro-Communications, Tokyo 1-5-1 Chofugaoka,
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas
 PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas Big Data + Deep Representation Learning Robot Perception Augmented Reality
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas Big Data + Deep Representation Learning Robot Perception Augmented Reality
arxiv: v1 [cs.cv] 28 Nov 2017
![arxiv: v1 [cs.cv] 28 Nov 2017](/thumbs/81/83356256.jpg "arxiv: v1 [cs.cv] 28 Nov 2017") 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks arxiv:1711.10275v1 [cs.cv] 28 Nov 2017 Abstract Benjamin Graham, Martin Engelcke, Laurens van der Maaten Convolutional networks are
3D Semantic Segmentation with Submanifold Sparse Convolutional Networks arxiv:1711.10275v1 [cs.cv] 28 Nov 2017 Abstract Benjamin Graham, Martin Engelcke, Laurens van der Maaten Convolutional networks are
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus
 Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
Conditional Random Fields as Recurrent Neural Networks
 BIL722 - Deep Learning for Computer Vision Conditional Random Fields as Recurrent Neural Networks S. Zheng, S. Jayasumana, B. Romera-Paredes V. Vineet, Z. Su, D. Du, C. Huang, P.H.S. Torr Introduction
BIL722 - Deep Learning for Computer Vision Conditional Random Fields as Recurrent Neural Networks S. Zheng, S. Jayasumana, B. Romera-Paredes V. Vineet, Z. Su, D. Du, C. Huang, P.H.S. Torr Introduction
Bilinear Models for Fine-Grained Visual Recognition
 Bilinear Models for Fine-Grained Visual Recognition Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst Fine-grained visual recognition Example: distinguish
Bilinear Models for Fine-Grained Visual Recognition Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst Fine-grained visual recognition Example: distinguish
Accurate 3D Face and Body Modeling from a Single Fixed Kinect
 Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
CS395T paper review. Indoor Segmentation and Support Inference from RGBD Images. Chao Jia Sep
 CS395T paper review Indoor Segmentation and Support Inference from RGBD Images Chao Jia Sep 28 2012 Introduction What do we want -- Indoor scene parsing Segmentation and labeling Support relationships
CS395T paper review Indoor Segmentation and Support Inference from RGBD Images Chao Jia Sep 28 2012 Introduction What do we want -- Indoor scene parsing Segmentation and labeling Support relationships
Three-Dimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients
 ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
SPLATNet: Sparse Lattice Networks for Point Cloud Processing
 SPLATNet: Sparse Lattice Networks for Point Cloud Processing Hang Su UMass Amherst Varun Jampani NVIDIA Evangelos Kalogerakis UMass Amherst Deqing Sun NVIDIA Ming-Hsuan Yang UC Merced Subhransu Maji UMass
SPLATNet: Sparse Lattice Networks for Point Cloud Processing Hang Su UMass Amherst Varun Jampani NVIDIA Evangelos Kalogerakis UMass Amherst Deqing Sun NVIDIA Ming-Hsuan Yang UC Merced Subhransu Maji UMass
COMP 551 Applied Machine Learning Lecture 16: Deep Learning
 COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
Exploring Collections of 3D Models using Fuzzy Correspondences
 Exploring Collections of 3D Models using Fuzzy Correspondences Vladimir G. Kim Wilmot Li Niloy J. Mitra Princeton University Adobe UCL Stephen DiVerdi Adobe Thomas Funkhouser Princeton University Motivating
Exploring Collections of 3D Models using Fuzzy Correspondences Vladimir G. Kim Wilmot Li Niloy J. Mitra Princeton University Adobe UCL Stephen DiVerdi Adobe Thomas Funkhouser Princeton University Motivating
3D Scanning. Qixing Huang Feb. 9 th Slide Credit: Yasutaka Furukawa
 3D Scanning Qixing Huang Feb. 9 th 2017 Slide Credit: Yasutaka Furukawa Geometry Reconstruction Pipeline This Lecture Depth Sensing ICP for Pair-wise Alignment Next Lecture Global Alignment Pairwise Multiple
3D Scanning Qixing Huang Feb. 9 th 2017 Slide Credit: Yasutaka Furukawa Geometry Reconstruction Pipeline This Lecture Depth Sensing ICP for Pair-wise Alignment Next Lecture Global Alignment Pairwise Multiple
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
3D Object Classification using Shape Distributions and Deep Learning
 3D Object Classification using Shape Distributions and Deep Learning Melvin Low Stanford University mwlow@cs.stanford.edu Abstract This paper shows that the Absolute Angle shape distribution (AAD) feature
3D Object Classification using Shape Distributions and Deep Learning Melvin Low Stanford University mwlow@cs.stanford.edu Abstract This paper shows that the Absolute Angle shape distribution (AAD) feature
arxiv: v1 [cs.cv] 30 Sep 2018
![arxiv: v1 [cs.cv] 30 Sep 2018](/thumbs/89/99613806.jpg "arxiv: v1 [cs.cv] 30 Sep 2018") 3D-PSRNet: Part Segmented 3D Point Cloud Reconstruction From a Single Image Priyanka Mandikal, Navaneet K L, and R. Venkatesh Babu arxiv:1810.00461v1 [cs.cv] 30 Sep 2018 Indian Institute of Science, Bangalore,
3D-PSRNet: Part Segmented 3D Point Cloud Reconstruction From a Single Image Priyanka Mandikal, Navaneet K L, and R. Venkatesh Babu arxiv:1810.00461v1 [cs.cv] 30 Sep 2018 Indian Institute of Science, Bangalore,
3D model classification using convolutional neural network
 3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
Real-Time Depth Estimation from 2D Images
 Real-Time Depth Estimation from 2D Images Jack Zhu Ralph Ma jackzhu@stanford.edu ralphma@stanford.edu. Abstract ages. We explore the differences in training on an untrained network, and on a network pre-trained
Real-Time Depth Estimation from 2D Images Jack Zhu Ralph Ma jackzhu@stanford.edu ralphma@stanford.edu. Abstract ages. We explore the differences in training on an untrained network, and on a network pre-trained
The SIFT (Scale Invariant Feature
 The SIFT (Scale Invariant Feature Transform) Detector and Descriptor developed by David Lowe University of British Columbia Initial paper ICCV 1999 Newer journal paper IJCV 2004 Review: Matt Brown s Canonical
The SIFT (Scale Invariant Feature Transform) Detector and Descriptor developed by David Lowe University of British Columbia Initial paper ICCV 1999 Newer journal paper IJCV 2004 Review: Matt Brown s Canonical
3D CONVOLUTIONAL NEURAL NETWORKS BY MODAL FUSION
 3D CONVOLUTIONAL NEURAL NETWORKS BY MODAL FUSION Yusuke Yoshiyasu, Eiichi Yoshida AIST Soeren Pirk, Leonidas Guibas Stanford University ABSTRACT We propose multi-view and volumetric convolutional neural
3D CONVOLUTIONAL NEURAL NETWORKS BY MODAL FUSION Yusuke Yoshiyasu, Eiichi Yoshida AIST Soeren Pirk, Leonidas Guibas Stanford University ABSTRACT We propose multi-view and volumetric convolutional neural
An Exploration of Computer Vision Techniques for Bird Species Classification
 An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
Applications: Sampling/Reconstruction. Sampling and Reconstruction of Visual Appearance. Motivation. Monte Carlo Path Tracing.
 Sampling and Reconstruction of Visual Appearance CSE 274 [Fall 2018], Lecture 5 Ravi Ramamoorthi http://www.cs.ucsd.edu/~ravir Applications: Sampling/Reconstruction Monte Carlo Rendering (biggest application)
Sampling and Reconstruction of Visual Appearance CSE 274 [Fall 2018], Lecture 5 Ravi Ramamoorthi http://www.cs.ucsd.edu/~ravir Applications: Sampling/Reconstruction Monte Carlo Rendering (biggest application)
Using Machine Learning for Classification of Cancer Cells
 Using Machine Learning for Classification of Cancer Cells Camille Biscarrat University of California, Berkeley I Introduction Cell screening is a commonly used technique in the development of new drugs.
Using Machine Learning for Classification of Cancer Cells Camille Biscarrat University of California, Berkeley I Introduction Cell screening is a commonly used technique in the development of new drugs.
Modeling and Analyzing 3D Shapes using Clues from 2D Images. Minglun Gong Dept. of CS, Memorial Univ.
 Modeling and Analyzing 3D Shapes using Clues from 2D Images Minglun Gong Dept. of CS, Memorial Univ. Modeling Flowers from Images Reconstructing 3D flower petal shapes from a single image is difficult
Modeling and Analyzing 3D Shapes using Clues from 2D Images Minglun Gong Dept. of CS, Memorial Univ. Modeling Flowers from Images Reconstructing 3D flower petal shapes from a single image is difficult
Dynamic Routing Between Capsules
 Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Detecting Object Instances Without Discriminative Features
 Detecting Object Instances Without Discriminative Features Edward Hsiao June 19, 2013 Thesis Committee: Martial Hebert, Chair Alexei Efros Takeo Kanade Andrew Zisserman, University of Oxford 1 Object Instance
Detecting Object Instances Without Discriminative Features Edward Hsiao June 19, 2013 Thesis Committee: Martial Hebert, Chair Alexei Efros Takeo Kanade Andrew Zisserman, University of Oxford 1 Object Instance
Unsupervised Deep Learning. James Hays slides from Carl Doersch and Richard Zhang
 Unsupervised Deep Learning James Hays slides from Carl Doersch and Richard Zhang Recap from Previous Lecture We saw two strategies to get structured output while using deep learning With object detection,
Unsupervised Deep Learning James Hays slides from Carl Doersch and Richard Zhang Recap from Previous Lecture We saw two strategies to get structured output while using deep learning With object detection,
CRF Based Point Cloud Segmentation Jonathan Nation
 CRF Based Point Cloud Segmentation Jonathan Nation jsnation@stanford.edu 1. INTRODUCTION The goal of the project is to use the recently proposed fully connected conditional random field (CRF) model to
CRF Based Point Cloud Segmentation Jonathan Nation jsnation@stanford.edu 1. INTRODUCTION The goal of the project is to use the recently proposed fully connected conditional random field (CRF) model to
arxiv: v4 [cs.cv] 29 Mar 2019
![arxiv: v4 [cs.cv] 29 Mar 2019](/thumbs/96/128038877.jpg "arxiv: v4 [cs.cv] 29 Mar 2019") PartNet: A Recursive Part Decomposition Network for Fine-grained and Hierarchical Shape Segmentation Fenggen Yu 1 Kun Liu 1 * Yan Zhang 1 Chenyang Zhu 2 Kai Xu 2 1 Nanjing University 2 National University
PartNet: A Recursive Part Decomposition Network for Fine-grained and Hierarchical Shape Segmentation Fenggen Yu 1 Kun Liu 1 * Yan Zhang 1 Chenyang Zhu 2 Kai Xu 2 1 Nanjing University 2 National University
Transfer Learning. Style Transfer in Deep Learning
 Transfer Learning & Style Transfer in Deep Learning 4-DEC-2016 Gal Barzilai, Ram Machlev Deep Learning Seminar School of Electrical Engineering Tel Aviv University Part 1: Transfer Learning in Deep Learning
Transfer Learning & Style Transfer in Deep Learning 4-DEC-2016 Gal Barzilai, Ram Machlev Deep Learning Seminar School of Electrical Engineering Tel Aviv University Part 1: Transfer Learning in Deep Learning
Learning Material-Aware Local Descriptors for 3D Shapes
 Learning Material-Aware Local Descriptors for 3D Shapes Hubert Lin 1 Melinos Averkiou 2 Evangelos Kalogerakis 3 Balazs Kovacs 4 Siddhant Ranade 5 Vladimir G. Kim 6 Siddhartha Chaudhuri 6,7 Kavita Bala
Learning Material-Aware Local Descriptors for 3D Shapes Hubert Lin 1 Melinos Averkiou 2 Evangelos Kalogerakis 3 Balazs Kovacs 4 Siddhant Ranade 5 Vladimir G. Kim 6 Siddhartha Chaudhuri 6,7 Kavita Bala
INF 5860 Machine learning for image classification. Lecture 11: Visualization Anne Solberg April 4, 2018
 INF 5860 Machine learning for image classification Lecture 11: Visualization Anne Solberg April 4, 2018 Reading material The lecture is based on papers: Deep Dream: https://research.googleblog.com/2015/06/inceptionism-goingdeeper-into-neural.html
INF 5860 Machine learning for image classification Lecture 11: Visualization Anne Solberg April 4, 2018 Reading material The lecture is based on papers: Deep Dream: https://research.googleblog.com/2015/06/inceptionism-goingdeeper-into-neural.html
Deep Learning in Image and Face Intrinsics
 Deep Learning in Image and Face Intrinsics Theo Gevers Professor in Computer Vision: University of Amsterdam Co-founder: Sightcorp 3DUniversum Scanm WIC, Eindhoven, February 24th, 2018 Amsterdam A.I. -
Deep Learning in Image and Face Intrinsics Theo Gevers Professor in Computer Vision: University of Amsterdam Co-founder: Sightcorp 3DUniversum Scanm WIC, Eindhoven, February 24th, 2018 Amsterdam A.I. -
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Lecture 13 Segmentation and Scene Understanding Chris Choy, Ph.D. candidate Stanford Vision and Learning Lab (SVL)
") Lecture 13 Segmentation and Scene Understanding Chris Choy, Ph.D. candidate Stanford Vision and Learning Lab (SVL) http://chrischoy.org Stanford CS231A 1 Understanding a Scene Objects Chairs, Cups, Tables,
Lecture 13 Segmentation and Scene Understanding Chris Choy, Ph.D. candidate Stanford Vision and Learning Lab (SVL) http://chrischoy.org Stanford CS231A 1 Understanding a Scene Objects Chairs, Cups, Tables,
Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform. Xintao Wang Ke Yu Chao Dong Chen Change Loy
 Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform Xintao Wang Ke Yu Chao Dong Chen Change Loy Problem enlarge 4 times Low-resolution image High-resolution image Previous
Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform Xintao Wang Ke Yu Chao Dong Chen Change Loy Problem enlarge 4 times Low-resolution image High-resolution image Previous
arxiv: v1 [cs.gr] 13 Sep 2018
![arxiv: v1 [cs.gr] 13 Sep 2018](/thumbs/95/125866381.jpg "arxiv: v1 [cs.gr] 13 Sep 2018") Learning to Group and Label Fine-Grained Shape Components XIAOGANG WANG, Beihang University BIN ZHOU, Beihang University HAIYUE FANG, Beihang University XIAOWU CHEN, Beihang University QINPING ZHAO, Beihang
Learning to Group and Label Fine-Grained Shape Components XIAOGANG WANG, Beihang University BIN ZHOU, Beihang University HAIYUE FANG, Beihang University XIAOWU CHEN, Beihang University QINPING ZHAO, Beihang
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting
 Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting R. Maier 1,2, K. Kim 1, D. Cremers 2, J. Kautz 1, M. Nießner 2,3 Fusion Ours 1
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting R. Maier 1,2, K. Kim 1, D. Cremers 2, J. Kautz 1, M. Nießner 2,3 Fusion Ours 1
Shape Constancy and Shape Recovery: wherein Human and Computer Vision Meet
 Shape Constancy and Shape Recovery: wherein Human and Computer Vision Meet Zygmunt Pizlo Purdue University, U.S.A. Acknowledgments: Y. Li, T. Sawada, R.M. Steinman Support: NSF, US Department of Energy,
Shape Constancy and Shape Recovery: wherein Human and Computer Vision Meet Zygmunt Pizlo Purdue University, U.S.A. Acknowledgments: Y. Li, T. Sawada, R.M. Steinman Support: NSF, US Department of Energy,
CS 112 The Rendering Pipeline. Slide 1
 CS 112 The Rendering Pipeline Slide 1 Rendering Pipeline n Input 3D Object/Scene Representation n Output An image of the input object/scene n Stages (for POLYGON pipeline) n Model view Transformation n
CS 112 The Rendering Pipeline Slide 1 Rendering Pipeline n Input 3D Object/Scene Representation n Output An image of the input object/scene n Stages (for POLYGON pipeline) n Model view Transformation n
Alternatives to Direct Supervision
 CreativeAI: Deep Learning for Graphics Alternatives to Direct Supervision Niloy Mitra Iasonas Kokkinos Paul Guerrero Nils Thuerey Tobias Ritschel UCL UCL UCL TUM UCL Timetable Theory and Basics State of
CreativeAI: Deep Learning for Graphics Alternatives to Direct Supervision Niloy Mitra Iasonas Kokkinos Paul Guerrero Nils Thuerey Tobias Ritschel UCL UCL UCL TUM UCL Timetable Theory and Basics State of
Structure-oriented Networks of Shape Collections
 Structure-oriented Networks of Shape Collections Noa Fish 1 Oliver van Kaick 2 Amit Bermano 3 Daniel Cohen-Or 1 1 Tel Aviv University 2 Carleton University 3 Princeton University 1 pplementary material
Structure-oriented Networks of Shape Collections Noa Fish 1 Oliver van Kaick 2 Amit Bermano 3 Daniel Cohen-Or 1 1 Tel Aviv University 2 Carleton University 3 Princeton University 1 pplementary material
arxiv: v1 [cs.cv] 19 Sep 2018
![arxiv: v1 [cs.cv] 19 Sep 2018](/thumbs/95/124342713.jpg "arxiv: v1 [cs.cv] 19 Sep 2018") Deep Part Induction from Articulated Object Pairs LI YI, Stanford University HAIBIN HUANG, Megvii (Face++) Research DIFAN LIU, University of Massachusetts Amherst EVANGELOS KALOGERAKIS, University of Massachusetts
Deep Part Induction from Articulated Object Pairs LI YI, Stanford University HAIBIN HUANG, Megvii (Face++) Research DIFAN LIU, University of Massachusetts Amherst EVANGELOS KALOGERAKIS, University of Massachusetts
Multi-view 3D Models from Single Images with a Convolutional Network
 Multi-view 3D Models from Single Images with a Convolutional Network Maxim Tatarchenko University of Freiburg Skoltech - 2nd Christmas Colloquium on Computer Vision Humans have prior knowledge about 3D
Multi-view 3D Models from Single Images with a Convolutional Network Maxim Tatarchenko University of Freiburg Skoltech - 2nd Christmas Colloquium on Computer Vision Humans have prior knowledge about 3D
Bus Detection and recognition for visually impaired people
 Bus Detection and recognition for visually impaired people Hangrong Pan, Chucai Yi, and Yingli Tian The City College of New York The Graduate Center The City University of New York MAP4VIP Outline Motivation
Bus Detection and recognition for visually impaired people Hangrong Pan, Chucai Yi, and Yingli Tian The City College of New York The Graduate Center The City University of New York MAP4VIP Outline Motivation
Machine Learning for Medical Image Analysis. A. Criminisi
 Machine Learning for Medical Image Analysis A. Criminisi Overview Introduction to machine learning Decision forests Applications in medical image analysis Anatomy localization in CT Scans Spine Detection
Machine Learning for Medical Image Analysis A. Criminisi Overview Introduction to machine learning Decision forests Applications in medical image analysis Anatomy localization in CT Scans Spine Detection
Deep Face Recognition. Nathan Sun
 Deep Face Recognition Nathan Sun Why Facial Recognition? Picture ID or video tracking Higher Security for Facial Recognition Software Immensely useful to police in tracking suspects Your face will be an
Deep Face Recognition Nathan Sun Why Facial Recognition? Picture ID or video tracking Higher Security for Facial Recognition Software Immensely useful to police in tracking suspects Your face will be an
Semantic Segmentation. Zhongang Qi
 Semantic Segmentation Zhongang Qi qiz@oregonstate.edu Semantic Segmentation "Two men riding on a bike in front of a building on the road. And there is a car." Idea: recognizing, understanding what's in
Semantic Segmentation Zhongang Qi qiz@oregonstate.edu Semantic Segmentation "Two men riding on a bike in front of a building on the road. And there is a car." Idea: recognizing, understanding what's in
arxiv: v1 [cs.cv] 2 Nov 2018
![arxiv: v1 [cs.cv] 2 Nov 2018](/thumbs/89/100782143.jpg "arxiv: v1 [cs.cv] 2 Nov 2018") 3D Pick & Mix: Object Part Blending in Joint Shape and Image Manifolds Adrian Penate-Sanchez 1,2[0000 0003 2876 3301] Lourdes Agapito 1[0000 0002 6947 1092] arxiv:1811.01068v1 [cs.cv] 2 Nov 2018 1 University
3D Pick & Mix: Object Part Blending in Joint Shape and Image Manifolds Adrian Penate-Sanchez 1,2[0000 0003 2876 3301] Lourdes Agapito 1[0000 0002 6947 1092] arxiv:1811.01068v1 [cs.cv] 2 Nov 2018 1 University
Computer Vision: Summary and Discussion
 12/05/2011 Computer Vision: Summary and Discussion Computer Vision CS 143, Brown James Hays Many slides from Derek Hoiem Announcements Today is last day of regular class Second quiz on Wednesday (Dec 7
12/05/2011 Computer Vision: Summary and Discussion Computer Vision CS 143, Brown James Hays Many slides from Derek Hoiem Announcements Today is last day of regular class Second quiz on Wednesday (Dec 7