3D ADI Method for Fluid Simulation on Multiple GPUs. Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA
|
|
|
- Frederick Manning
- 6 years ago
- Views:
Transcription


1 3D ADI Method for Fluid Simulation on Multiple GPUs Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA
2 Introduction Fluid simulation using direct numerical methods Gives the most accurate result Requires lots of memory and computational power GPUs are very suitable for direct methods Have great instruction throughput and high memory bandwidth How will it scale on multiple GPUs?
3 cmc-fluid-solver Open source project on Google Code Started at CMC faculty of MSU, Russia CPU: OpenMP, GPU: CUDA 3D fluid simulation using ADI solver Key people: MSU: Vilen Paskonov, Sergey Berezin NVIDIA: Nikolay Sakharnykh, Nikolay Markovskiy
4 Outline Fluid Simulation in 3D domain Problem statement, applications ADI numerical method GPU implementation details, optimizations Performance analysis Multi-GPU implementation
5 Problem Statement Viscid incompressible fluid in 3D domain Arbitrary closed geometry for boundaries no-slip free injection Euler coordinates: velocity and temperature



6 Applications Sea and ocean simulation Additional parameters: salinity, etc. Low-speed gas flow Inside 3D channel Around objects
7 Definitions Density Velocity Temperature Pressure Equation of state Describe relation between and Example: gas constant for air

8 Governing equations Continuity equation For incompressible fluids: Navier-Stokes equations: Dimensionless form, use equation of state Reynolds number (= inertia/viscosity ratio)

9 Governing equations Energy equation: Dimensionless form, use equation of state heat capacity ratio Prandtl number dissipative function

10 ADI numerical method X Y Z Fixed Y, Z Fixed X, Z Fixed X, Y X Y Z
11 ADI numerical method Benefits Doesn t have hard requirements on time step Domain decomposition each step can be well parallelized Many applications Computational Fluid Dynamics Computational Finance Linear 3D PDE

12 ADI method iterations Use global iterations for the whole system of equations previous time step Solve X-dir equations Solve Y-dir equations global iterations Solve Z-dir equations Updating all variables next time step Some equations are not linear: Use local iterations to approximate the non-linear term

13 Discretization Use regular grid, implicit finite difference scheme Second order in space First order in time Leads to a tridiagonal system for Independent system for each fixed pair (j, k)
14 Tridiagonal systems Need to solve lots of tridiagonal systems Sizes of systems may vary across the grid system 1 system 2 system 3 Outside cell Boundary cell Inside cell
15 Implementation details <for each direction X, Y, Z> { <for each local iteration> { <for each equation u, v, w, T> { build tridiagonal matrices and rhs solve tridiagonal systems } update non-linear terms } }
16 GPU implementation Store all data arrays entirely in GPU memory Reduce number of PCI-E transfers to minimum Map 3D arrays to linear memory (X, Y, Z) Main kernel Build matrix coefficients Solve tridiagonal systems Z + Y * dimz + X * dimy * dimz Z fastest-changing dimension
17 Building matrices Input data: Previous/non-linear 3D layers Each thread computes: Coefficients of a tridiagonal matrix Right-hand side vector a b c d Use C++ templates for direction and equation

18 Tesla C2050 (SP) Building matrices performance 2.0 sec Total time Build kernels X dir Y dir Dir Requests per warp L1 global load hit % IPC X Z dir Y Build Build + Solve Z Poor Z direction performance compared to X/Y Threads access contiguous memory region Memory access is uncoalesced, lots of cache misses


19 Building matrices optimization Run Z phase in transposed XZY space Better locality for memory accesses Additional overhead on transpose X local iterations Y local iterations Z local iterations XYZ Transpose input arrays Transpose output arrays XYZ XZY Y local iterations XZY
20 Tesla C2050 (SP) Building matrices - optimization sec Total time 2.5x Transpose Build + Solve Z dir Build kernels Requests per warp L1 global load hit % IPC Original Transposed X dir Y dir Z dir Z dir OPT Tridiagonal solver time dominates over transpose Transpose will takes less % with more local iterations
21 Solving tridiagonal systems Number of tridiagonal systems ~ grid size squared Sweep algorithm is the most efficient in this case 1 thread solves 1 system for( int p = 1; p < end; p++ ) { //.. compute tridiagonal coefficients a_val, b_val, c_val, d_val.. get(c,p) = c_val / (b_val - a_val * get(c,p-1)); get(d,p) = (d_val - get(d,p-1) * a_val) / (b_val - a_val * get(c,p-1)); } for( int i = end-1; i >= 0; i-- ) get(x,i) = get(d,i) - get(c,i) * get(x, i+1);
22 Thread 1 Thread 2 Thread 3 Solving tridiagonal systems Matrix layout is crucial for performance Interleaved layout a0 a0 a0 a0 a1 a1 a1 a1 similar as ELLPACK for sparse matrices Sweep friendly X, Y directions matrices are interleaved by default Z is interleaved as well if doing in transposed space
23 Solving tridiagonal systems L1/L2 effect on performance Using 48K L1 instead of 16K gives 10-15% speed-up Turning L1 off reduces performance by 10% Really help on misaligned accesses and spatial reuse Occupancy >= 50% Running 128 threads per block registers per thread (different for u, v, w, T) No shared memory
24 Performance benchmark CPU configuration: Intel Core i7-3930k 3.2 GHz, 12 cores Use OpenMP for CPU parallelization Mostly memory bandwidth bound Some parts achieves ~4x speed-up vs 1 core GPU configuration: NVIDIA Tesla C2070

25 Test cases Box Pipe X Y Y 1 X L 1 Z Simple geometry Systems of the same size Need to compute in all rectangular grid points

26 Test cases White Sea X Y Complex geometry Big divergence for system sizes Need to compute only inside the area


27 Performance results Box Pipe segments/ms SINGLE segments/ms DOUBLE x CPU x CPU 1000 GPU 1000 GPU Solve X Solve Y Solve Z Total Grid 128x128x128 0 Solve X Solve Y Solve Z Total
28 Performance results White Sea segments/ms SINGLE segments/ms DOUBLE x CPU GPU x CPU GPU Solve X Solve Y Solve Z Total Grid 256x192x160 0 Solve X Solve Y Solve Z Total
29 Outline Fluid Simulation in 3D domain Multi-GPU implementation General splitting algorithm Running computations using CUDA Benchmarking and performance analysis Improving weak scaling
30 Multi-GPU motivation Limited available amount of memory 3D arrays: grid, temporary arrays, matrices Max size of grid that can fit into Tesla M2050 ~ Distribute the computations between multiple GPUs and multiple nodes Can compute large grids Speed-up computations
31 Main Idea of mgpu Systems along Y/Z are solved independently in parallel on each GPU No data transfer Along X data must be synchronized Y X Computing alternating directions: Z X Y Z GPU 0 GPU 1 GPU 2
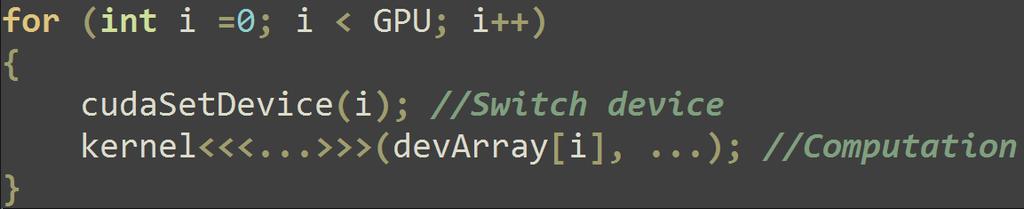
32 CUDA - parallelization Split the grid along X (the longest stride) Z + Y * dimz + X * dimy * dimz Launch kernels on several GPUs from one host thread for (int i = 0; i < numdev; i++) { cudasetdevice(i); //Switch device kernel<<< >>>(devarray[i],..); //Computation } CUDA 4.x Data transfer Async P2P through PCI-E (cudamemcpypeerasync)
33 Synchronization of Nonlinear Layer for (int i = 0; i < numdev-1; i++) cudamemcpypeerrasync(dhaloleft[i+1], i+1, ddataright[i], i, num_bytes, devstream[i]); // might need multidev synchronization here for (int i = 1; i < numdev; i++) cudamemcpypeerasync(dhaloright[i-1], i-1, ddataleft[i], i, num_bytes, devstream[i]); High aggregate throughput on 8 GPU system Communication impact Is not significant
34 Solve X (tridiagonal solver) GPU 0 GPU 1 GPU 1 bound partially bound unbound halo
35 Solve X (tridiagonal solver) Process bound segments without intercommunication Interleave segments for better memory access one segment per thread Align to the left Gauss elimination Communicate Forward Backward
36 Y Solve X X Split the grid ( long X ) Array[i*dimz*dimy+ ] Allocation of layers in mgpu 3D segment analysis Z
37 Y Solve X X Split the grid ( long X ) Array[i*dimz*dimy+ ] Allocation of layers in mgpu Forward sweep along X Z Active GPU
38 Y Solve X X Split the grid ( long X ) Array[i*dimz*dimy+ ] Allocation of layers in mgpu Forward sweep along X Z Active GPU
39 Y Solve X X Split the grid ( long X ) Array[i*dimz*dimy+ ] Allocation of layers in mgpu Back sweep along X Z Active GPU
40 Y Solve X X Split the grid ( long X ) Array[i*dimz*dimy+ ] Allocation of layers in mgpu Back sweep along X Z Active GPU
41 Y Solve X X Split the grid ( long X ) Array[i*dimz*dimy+ ] Allocation of layers in mgpu Back sweep along X Result: No speedup along X Z Active GPU
42 Benchmarks Multiple GPU: 8 Tesla M2050 with P2P Multiple Nodes: 4 InfiniBand MPI nodes, 1 Tesla M2090 each Sample tests: Y Box Pipe 1 X L 1 Z White Sea
43 Millions points per sec Millions points per sec Results: 8 GPU, 1 MPI node Box Pipe x2.9 x White Sea x1.35 x Total 0 Total Grid Tesla M2050
44 Points / ms Points / ms 1 GPU Efficiency Box Pipe Grid size White Sea Grid size Estimate amount of work per GPU in 8xGPU system using single GPU: /8 = Box Pipe enough work for single GPU White Sea takes about 5% of volume of the grid. Grid size of is not enough. Tesla M2090

45 Millions points per sec Millions points per sec Results: 1 GPU, 4 MPI nodes Box Pipe Total x White Sea Total x Tesla M2090
46 Segments Load Balancing X splitting criteria: Equal volumes Equal number of segments Performance benefit observed: up to 15.5% Y(x) + Z(X) + X(x)dX x Tesla M2090

47 Time, ms Time, ms Time, ms Load Balancing. White Sea (288x320x320) Even X SweepX SweepY SweepZ Transpose GPU 0 GPU 1 GPU 2 GPU 3 t total = 47.3 Even Segments GPU 0 GPU 1 GPU 2 SweepX SweepY SweepZ Transpose GPU 3 Even Volumes GPU 0 SweepX SweepY SweepZ Transpose Tesla M2090 t total = 44.3 GPU 1 GPU 2 GPU 3 t total = 44.4
48 Analysis All parts of the solver but one (Gauss elimination along X) are fully parallel Communication (using P2P + InfiniBand) is not a big issue for given problem size Bad weak scaling Use blocks to hide latency for X sweeps
49 Y Improved Solve X GPU0 GPU1 GPU2 X Split the grid ( long X ) Array[i*dimz*dimy+ ] Allocation of layers in mgpu 3D segment analysis Z
50 Improved Solve X Y B 0 B 1 GPU0 GPU1 GPU2 X Splitting the grid to XY blocks along Z direction Segments sorting Sweep through all scalar fields at once B 2 B 3 B 4 Z
51 Improved Solve X Y B 0 B 1 B 2 X Splitting the grid to XY blocks along Z direction Segments sorting Sweep through all scalar fields at once Forward sweep along X, Async halo send forward B 3 B 4 Z
52 Improved Solve X Y B 0 B 1 B 2 B 3 X Splitting the grid to XY blocks along Z direction Segments sorting Sweep through all scalar fields at once Forward sweep along X, Async halo send forward Move to the next block group B 4 Z
53 Improved Solve X Y B 0 B 1 B 2 B 3 X Splitting the grid to XY blocks along Z direction Segments sorting Sweep through all scalar fields at once Forward sweep along X, Async halo send forward Move to the next block group Backward sweep along X, Async halo send backward B 4 Z
54 Improved Solve X Y B 0 B 1 B 2 B 3 X Splitting the grid to XY blocks along Z direction Segments sorting Sweep through all scalar fields at once Forward sweep along X, Async halo send forward Move to the next block group Backward sweep along X, Async halo send backward B 4 Z
55 Improved Solve X Y B 0 B 1 B 2 B 3 X Splitting the grid to XY blocks along Z direction Segments sorting Sweep through all scalar fields at once Forward sweep along X, Async halo send forward Move to the next block group Backward sweep along X, Async halo send backward B 4 Z Equal work per node!
56 Y Algorithm block 0 node 0 i node N nodes X N Z N blocks cudastream 2 2(N nodes i node 1) receive X inode +1 i block Z receive X inode 1 i block i node cudastream 1
57 Y Algorithm block 0 node 0 i node N nodes X N Z N blocks Backward cudastream 2 2(N nodes i node 1) Forward cudastream 1 i block i block i node Z
58 Y Algorithm block 0 node 0 i node N nodes X N Z N blocks send X inode cudastream 2 2(N nodes i node 1) cudastream 1 i block Z i block i node send X inode
59 Improved Solve XY Y B 0 X Separate buffer for Y sweeps B 1 Y blocks B 2 B 3 Block Y sweeps are performed independently in separate cudastreams Helps with data transfer/compute overlap B 4 Z
60 Time, ms Weak Scaling Average time for Solve XYZ Box Pipe Grids: 224 3, 288 3, 352 3, Number of GPUs Tesla M2050
61 Time, ms Big Systems Limit Average time for Solve XYZ Number of blocks Consider on scalar field: no physics, more available RAM 8 M2050 GPUs Grid: With larger grid sizes, curve minimum shifts down/right
62 Conclusions GPU outperforms multi-core CPU over 10x factor GPU works well with complex input domains Performance and scaling factors heavily depend on input geometry and size of grid Efficient work distribution methods are essential for performance Using block-splitting for ADI improves scaling factor by hiding dependency of sweep processing
63 Future work Test on large scale systems Potentially on Lomonosov supercomputer at MSU GPU part with peak performance of 863 TFlops Memory usage optimizations Explore different tridiagonal approaches
64 Questions? Thank You!
65
66
Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation
 Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation Nikolai Sakharnykh - NVIDIA San Jose Convention Center, San Jose, CA September 21, 2010 Introduction Tridiagonal solvers very popular
Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation Nikolai Sakharnykh - NVIDIA San Jose Convention Center, San Jose, CA September 21, 2010 Introduction Tridiagonal solvers very popular
Software and Performance Engineering for numerical codes on GPU clusters
 Software and Performance Engineering for numerical codes on GPU clusters H. Köstler International Workshop of GPU Solutions to Multiscale Problems in Science and Engineering Harbin, China 28.7.2010 2 3
Software and Performance Engineering for numerical codes on GPU clusters H. Köstler International Workshop of GPU Solutions to Multiscale Problems in Science and Engineering Harbin, China 28.7.2010 2 3
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC. Guest Lecturer: Sukhyun Song (original slides by Alan Sussman)
") CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
Two-Phase flows on massively parallel multi-gpu clusters
 Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES. Cliff Woolley, NVIDIA
 HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES Cliff Woolley, NVIDIA PREFACE This talk presents a case study of extracting parallelism in the UMT2013 benchmark for 3D unstructured-mesh
HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES Cliff Woolley, NVIDIA PREFACE This talk presents a case study of extracting parallelism in the UMT2013 benchmark for 3D unstructured-mesh
AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015
 AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015 Agenda Introduction to AmgX Current Capabilities Scaling V2.0 Roadmap for the future 2 AmgX Fast, scalable linear solvers, emphasis on iterative
AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015 Agenda Introduction to AmgX Current Capabilities Scaling V2.0 Roadmap for the future 2 AmgX Fast, scalable linear solvers, emphasis on iterative
CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0. Julien Demouth, NVIDIA
 CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0 Julien Demouth, NVIDIA What Will You Learn? An iterative method to optimize your GPU code A way to conduct that method with Nsight VSE APOD
CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0 Julien Demouth, NVIDIA What Will You Learn? An iterative method to optimize your GPU code A way to conduct that method with Nsight VSE APOD
Hybrid OpenMP-MPI Turbulent boundary Layer code over 32k cores
 Hybrid OpenMP-MPI Turbulent boundary Layer code over 32k cores T/NT INTERFACE y/ x/ z/ 99 99 Juan A. Sillero, Guillem Borrell, Javier Jiménez (Universidad Politécnica de Madrid) and Robert D. Moser (U.
Hybrid OpenMP-MPI Turbulent boundary Layer code over 32k cores T/NT INTERFACE y/ x/ z/ 99 99 Juan A. Sillero, Guillem Borrell, Javier Jiménez (Universidad Politécnica de Madrid) and Robert D. Moser (U.
High performance 2D Discrete Fourier Transform on Heterogeneous Platforms. Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli
 High performance 2D Discrete Fourier Transform on Heterogeneous Platforms Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli Motivation Fourier Transform widely used in Physics, Astronomy, Engineering
High performance 2D Discrete Fourier Transform on Heterogeneous Platforms Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli Motivation Fourier Transform widely used in Physics, Astronomy, Engineering
Numerical Algorithms on Multi-GPU Architectures
 Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
Efficient AMG on Hybrid GPU Clusters. ScicomP Jiri Kraus, Malte Förster, Thomas Brandes, Thomas Soddemann. Fraunhofer SCAI
 Efficient AMG on Hybrid GPU Clusters ScicomP 2012 Jiri Kraus, Malte Förster, Thomas Brandes, Thomas Soddemann Fraunhofer SCAI Illustration: Darin McInnis Motivation Sparse iterative solvers benefit from
Efficient AMG on Hybrid GPU Clusters ScicomP 2012 Jiri Kraus, Malte Förster, Thomas Brandes, Thomas Soddemann Fraunhofer SCAI Illustration: Darin McInnis Motivation Sparse iterative solvers benefit from
CUDA. Fluid simulation Lattice Boltzmann Models Cellular Automata
 CUDA Fluid simulation Lattice Boltzmann Models Cellular Automata Please excuse my layout of slides for the remaining part of the talk! Fluid Simulation Navier Stokes equations for incompressible fluids
CUDA Fluid simulation Lattice Boltzmann Models Cellular Automata Please excuse my layout of slides for the remaining part of the talk! Fluid Simulation Navier Stokes equations for incompressible fluids
Asynchronous OpenCL/MPI numerical simulations of conservation laws
 Asynchronous OpenCL/MPI numerical simulations of conservation laws Philippe HELLUY 1,3, Thomas STRUB 2. 1 IRMA, Université de Strasbourg, 2 AxesSim, 3 Inria Tonus, France IWOCL 2015, Stanford Conservation
Asynchronous OpenCL/MPI numerical simulations of conservation laws Philippe HELLUY 1,3, Thomas STRUB 2. 1 IRMA, Université de Strasbourg, 2 AxesSim, 3 Inria Tonus, France IWOCL 2015, Stanford Conservation
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
S4289: Efficient solution of multiple scalar and block-tridiagonal equations
 S4289: Efficient solution of multiple scalar and block-tridiagonal equations Endre László endre.laszlo [at] oerc.ox.ac.uk Oxford e-research Centre, University of Oxford, UK Pázmány Péter Catholic University,
S4289: Efficient solution of multiple scalar and block-tridiagonal equations Endre László endre.laszlo [at] oerc.ox.ac.uk Oxford e-research Centre, University of Oxford, UK Pázmány Péter Catholic University,
Fast Tridiagonal Solvers on GPU
 Fast Tridiagonal Solvers on GPU Yao Zhang John Owens UC Davis Jonathan Cohen NVIDIA GPU Technology Conference 2009 Outline Introduction Algorithms Design algorithms for GPU architecture Performance Bottleneck-based
Fast Tridiagonal Solvers on GPU Yao Zhang John Owens UC Davis Jonathan Cohen NVIDIA GPU Technology Conference 2009 Outline Introduction Algorithms Design algorithms for GPU architecture Performance Bottleneck-based
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs
 High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs Gordon Erlebacher Department of Scientific Computing Sept. 28, 2012 with Dimitri Komatitsch (Pau,France) David Michea
High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs Gordon Erlebacher Department of Scientific Computing Sept. 28, 2012 with Dimitri Komatitsch (Pau,France) David Michea
Optimising the Mantevo benchmark suite for multi- and many-core architectures
 Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Study and implementation of computational methods for Differential Equations in heterogeneous systems. Asimina Vouronikoy - Eleni Zisiou
 Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Advanced CUDA Optimizations. Umar Arshad ArrayFire
 Advanced CUDA Optimizations Umar Arshad (@arshad_umar) ArrayFire (@arrayfire) ArrayFire World s leading GPU experts In the industry since 2007 NVIDIA Partner Deep experience working with thousands of customers
Advanced CUDA Optimizations Umar Arshad (@arshad_umar) ArrayFire (@arrayfire) ArrayFire World s leading GPU experts In the industry since 2007 NVIDIA Partner Deep experience working with thousands of customers
From Notebooks to Supercomputers: Tap the Full Potential of Your CUDA Resources with LibGeoDecomp
 From Notebooks to Supercomputers: Tap the Full Potential of Your CUDA Resources with andreas.schaefer@cs.fau.de Friedrich-Alexander-Universität Erlangen-Nürnberg GPU Technology Conference 2013, San José,
From Notebooks to Supercomputers: Tap the Full Potential of Your CUDA Resources with andreas.schaefer@cs.fau.de Friedrich-Alexander-Universität Erlangen-Nürnberg GPU Technology Conference 2013, San José,
DAG-Scheduled Linear Algebra Using Template-Based Building Blocks
 DAG-Scheduled Linear Algebra Using Template-Based Building Blocks Jonathan Hogg STFC Rutherford Appleton Laboratory 1 / 20 19 March 2015 GPU Technology Conference San Jose, California * Thanks also to
DAG-Scheduled Linear Algebra Using Template-Based Building Blocks Jonathan Hogg STFC Rutherford Appleton Laboratory 1 / 20 19 March 2015 GPU Technology Conference San Jose, California * Thanks also to
Convolution Soup: A case study in CUDA optimization. The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam
 Convolution Soup: A case study in CUDA optimization The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam Optimization GPUs are very fast BUT Naïve programming can result in disappointing performance
Convolution Soup: A case study in CUDA optimization The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam Optimization GPUs are very fast BUT Naïve programming can result in disappointing performance
Double-Precision Matrix Multiply on CUDA
 Double-Precision Matrix Multiply on CUDA Parallel Computation (CSE 60), Assignment Andrew Conegliano (A5055) Matthias Springer (A995007) GID G--665 February, 0 Assumptions All matrices are square matrices
Double-Precision Matrix Multiply on CUDA Parallel Computation (CSE 60), Assignment Andrew Conegliano (A5055) Matthias Springer (A995007) GID G--665 February, 0 Assumptions All matrices are square matrices
Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation
 Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation 1 Cheng-Han Du* I-Hsin Chung** Weichung Wang* * I n s t i t u t e o f A p p l i e d M
Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation 1 Cheng-Han Du* I-Hsin Chung** Weichung Wang* * I n s t i t u t e o f A p p l i e d M
B. Tech. Project Second Stage Report on
 B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
2006: Short-Range Molecular Dynamics on GPU. San Jose, CA September 22, 2010 Peng Wang, NVIDIA
 2006: Short-Range Molecular Dynamics on GPU San Jose, CA September 22, 2010 Peng Wang, NVIDIA Overview The LAMMPS molecular dynamics (MD) code Cell-list generation and force calculation Algorithm & performance
2006: Short-Range Molecular Dynamics on GPU San Jose, CA September 22, 2010 Peng Wang, NVIDIA Overview The LAMMPS molecular dynamics (MD) code Cell-list generation and force calculation Algorithm & performance
CUDA OPTIMIZATIONS ISC 2011 Tutorial
 CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
S0432 NEW IDEAS FOR MASSIVELY PARALLEL PRECONDITIONERS
 S0432 NEW IDEAS FOR MASSIVELY PARALLEL PRECONDITIONERS John R Appleyard Jeremy D Appleyard Polyhedron Software with acknowledgements to Mark A Wakefield Garf Bowen Schlumberger Outline of Talk Reservoir
S0432 NEW IDEAS FOR MASSIVELY PARALLEL PRECONDITIONERS John R Appleyard Jeremy D Appleyard Polyhedron Software with acknowledgements to Mark A Wakefield Garf Bowen Schlumberger Outline of Talk Reservoir
Available online at ScienceDirect. Parallel Computational Fluid Dynamics Conference (ParCFD2013)
") Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 61 ( 2013 ) 81 86 Parallel Computational Fluid Dynamics Conference (ParCFD2013) An OpenCL-based parallel CFD code for simulations
Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 61 ( 2013 ) 81 86 Parallel Computational Fluid Dynamics Conference (ParCFD2013) An OpenCL-based parallel CFD code for simulations
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
International Supercomputing Conference 2009
 International Supercomputing Conference 2009 Implementation of a Lattice-Boltzmann-Method for Numerical Fluid Mechanics Using the nvidia CUDA Technology E. Riegel, T. Indinger, N.A. Adams Technische Universität
International Supercomputing Conference 2009 Implementation of a Lattice-Boltzmann-Method for Numerical Fluid Mechanics Using the nvidia CUDA Technology E. Riegel, T. Indinger, N.A. Adams Technische Universität
3D Helmholtz Krylov Solver Preconditioned by a Shifted Laplace Multigrid Method on Multi-GPUs
 3D Helmholtz Krylov Solver Preconditioned by a Shifted Laplace Multigrid Method on Multi-GPUs H. Knibbe, C. W. Oosterlee, C. Vuik Abstract We are focusing on an iterative solver for the three-dimensional
3D Helmholtz Krylov Solver Preconditioned by a Shifted Laplace Multigrid Method on Multi-GPUs H. Knibbe, C. W. Oosterlee, C. Vuik Abstract We are focusing on an iterative solver for the three-dimensional
Speedup Altair RADIOSS Solvers Using NVIDIA GPU
 Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
Exploiting GPU Caches in Sparse Matrix Vector Multiplication. Yusuke Nagasaka Tokyo Institute of Technology
 Exploiting GPU Caches in Sparse Matrix Vector Multiplication Yusuke Nagasaka Tokyo Institute of Technology Sparse Matrix Generated by FEM, being as the graph data Often require solving sparse linear equation
Exploiting GPU Caches in Sparse Matrix Vector Multiplication Yusuke Nagasaka Tokyo Institute of Technology Sparse Matrix Generated by FEM, being as the graph data Often require solving sparse linear equation
Numerical Methods for PDEs. SSC Workgroup Meetings Juan J. Alonso October 8, SSC Working Group Meetings, JJA 1
 Numerical Methods for PDEs SSC Workgroup Meetings Juan J. Alonso October 8, 2001 SSC Working Group Meetings, JJA 1 Overview These notes are meant to be an overview of the various memory access patterns
Numerical Methods for PDEs SSC Workgroup Meetings Juan J. Alonso October 8, 2001 SSC Working Group Meetings, JJA 1 Overview These notes are meant to be an overview of the various memory access patterns
How to Optimize Geometric Multigrid Methods on GPUs
 How to Optimize Geometric Multigrid Methods on GPUs Markus Stürmer, Harald Köstler, Ulrich Rüde System Simulation Group University Erlangen March 31st 2011 at Copper Schedule motivation imaging in gradient
How to Optimize Geometric Multigrid Methods on GPUs Markus Stürmer, Harald Köstler, Ulrich Rüde System Simulation Group University Erlangen March 31st 2011 at Copper Schedule motivation imaging in gradient
Convolution Soup: A case study in CUDA optimization. The Fairmont San Jose Joe Stam
 Convolution Soup: A case study in CUDA optimization The Fairmont San Jose Joe Stam Optimization GPUs are very fast BUT Poor programming can lead to disappointing performance Squeaking out the most speed
Convolution Soup: A case study in CUDA optimization The Fairmont San Jose Joe Stam Optimization GPUs are very fast BUT Poor programming can lead to disappointing performance Squeaking out the most speed
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
S WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS. Jakob Progsch, Mathias Wagner GTC 2018
 S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA
 Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Advanced CUDA Optimizing to Get 20x Performance. Brent Oster
 Advanced CUDA Optimizing to Get 20x Performance Brent Oster Outline Motivation for optimizing in CUDA Demo performance increases Tesla 10-series architecture details Optimization case studies Particle
Advanced CUDA Optimizing to Get 20x Performance Brent Oster Outline Motivation for optimizing in CUDA Demo performance increases Tesla 10-series architecture details Optimization case studies Particle
DIFFERENTIAL. Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka
 USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
HPC Algorithms and Applications
 HPC Algorithms and Applications Dwarf #5 Structured Grids Michael Bader Winter 2012/2013 Dwarf #5 Structured Grids, Winter 2012/2013 1 Dwarf #5 Structured Grids 1. dense linear algebra 2. sparse linear
HPC Algorithms and Applications Dwarf #5 Structured Grids Michael Bader Winter 2012/2013 Dwarf #5 Structured Grids, Winter 2012/2013 1 Dwarf #5 Structured Grids 1. dense linear algebra 2. sparse linear
Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs
 Presented at the 2014 ANSYS Regional Conference- Detroit, June 5, 2014 Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs Bhushan Desam, Ph.D. NVIDIA Corporation 1 NVIDIA Enterprise
Presented at the 2014 ANSYS Regional Conference- Detroit, June 5, 2014 Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs Bhushan Desam, Ph.D. NVIDIA Corporation 1 NVIDIA Enterprise
GPU-accelerated data expansion for the Marching Cubes algorithm
 GPU-accelerated data expansion for the Marching Cubes algorithm San Jose (CA) September 23rd, 2010 Christopher Dyken, SINTEF Norway Gernot Ziegler, NVIDIA UK Agenda Motivation & Background Data Compaction
GPU-accelerated data expansion for the Marching Cubes algorithm San Jose (CA) September 23rd, 2010 Christopher Dyken, SINTEF Norway Gernot Ziegler, NVIDIA UK Agenda Motivation & Background Data Compaction
HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER PROF. BRYANT PROF. KAYVON 15618: PARALLEL COMPUTER ARCHITECTURE
 HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER AVISHA DHISLE PRERIT RODNEY ADHISLE PRODNEY 15618: PARALLEL COMPUTER ARCHITECTURE PROF. BRYANT PROF. KAYVON LET S
HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER AVISHA DHISLE PRERIT RODNEY ADHISLE PRODNEY 15618: PARALLEL COMPUTER ARCHITECTURE PROF. BRYANT PROF. KAYVON LET S
GPGPU LAB. Case study: Finite-Difference Time- Domain Method on CUDA
 GPGPU LAB Case study: Finite-Difference Time- Domain Method on CUDA Ana Balevic IPVS 1 Finite-Difference Time-Domain Method Numerical computation of solutions to partial differential equations Explicit
GPGPU LAB Case study: Finite-Difference Time- Domain Method on CUDA Ana Balevic IPVS 1 Finite-Difference Time-Domain Method Numerical computation of solutions to partial differential equations Explicit
Automated Finite Element Computations in the FEniCS Framework using GPUs
 Automated Finite Element Computations in the FEniCS Framework using GPUs Florian Rathgeber (f.rathgeber10@imperial.ac.uk) Advanced Modelling and Computation Group (AMCG) Department of Earth Science & Engineering
Automated Finite Element Computations in the FEniCS Framework using GPUs Florian Rathgeber (f.rathgeber10@imperial.ac.uk) Advanced Modelling and Computation Group (AMCG) Department of Earth Science & Engineering
Optimisation Myths and Facts as Seen in Statistical Physics
 Optimisation Myths and Facts as Seen in Statistical Physics Massimo Bernaschi Institute for Applied Computing National Research Council & Computer Science Department University La Sapienza Rome - ITALY
Optimisation Myths and Facts as Seen in Statistical Physics Massimo Bernaschi Institute for Applied Computing National Research Council & Computer Science Department University La Sapienza Rome - ITALY
OpenACC programming for GPGPUs: Rotor wake simulation
 DLR.de Chart 1 OpenACC programming for GPGPUs: Rotor wake simulation Melven Röhrig-Zöllner, Achim Basermann Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU) GPU computing
DLR.de Chart 1 OpenACC programming for GPGPUs: Rotor wake simulation Melven Röhrig-Zöllner, Achim Basermann Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU) GPU computing
Applications of Berkeley s Dwarfs on Nvidia GPUs
 Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
Adaptive-Mesh-Refinement Hydrodynamic GPU Computation in Astrophysics
 Adaptive-Mesh-Refinement Hydrodynamic GPU Computation in Astrophysics H. Y. Schive ( 薛熙于 ) Graduate Institute of Physics, National Taiwan University Leung Center for Cosmology and Particle Astrophysics
Adaptive-Mesh-Refinement Hydrodynamic GPU Computation in Astrophysics H. Y. Schive ( 薛熙于 ) Graduate Institute of Physics, National Taiwan University Leung Center for Cosmology and Particle Astrophysics
CS/EE 217 Midterm. Question Possible Points Points Scored Total 100
 CS/EE 217 Midterm ANSWER ALL QUESTIONS TIME ALLOWED 60 MINUTES Question Possible Points Points Scored 1 24 2 32 3 20 4 24 Total 100 Question 1] [24 Points] Given a GPGPU with 14 streaming multiprocessor
CS/EE 217 Midterm ANSWER ALL QUESTIONS TIME ALLOWED 60 MINUTES Question Possible Points Points Scored 1 24 2 32 3 20 4 24 Total 100 Question 1] [24 Points] Given a GPGPU with 14 streaming multiprocessor
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation
 ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
Fast Segmented Sort on GPUs
 Fast Segmented Sort on GPUs Kaixi Hou, Weifeng Liu, Hao Wang, Wu-chun Feng {kaixihou, hwang121, wfeng}@vt.edu weifeng.liu@nbi.ku.dk Segmented Sort (SegSort) Perform a segment-by-segment sort on a given
Fast Segmented Sort on GPUs Kaixi Hou, Weifeng Liu, Hao Wang, Wu-chun Feng {kaixihou, hwang121, wfeng}@vt.edu weifeng.liu@nbi.ku.dk Segmented Sort (SegSort) Perform a segment-by-segment sort on a given
Splotch: High Performance Visualization using MPI, OpenMP and CUDA
 Splotch: High Performance Visualization using MPI, OpenMP and CUDA Klaus Dolag (Munich University Observatory) Martin Reinecke (MPA, Garching) Claudio Gheller (CSCS, Switzerland), Marzia Rivi (CINECA,
Splotch: High Performance Visualization using MPI, OpenMP and CUDA Klaus Dolag (Munich University Observatory) Martin Reinecke (MPA, Garching) Claudio Gheller (CSCS, Switzerland), Marzia Rivi (CINECA,
Leveraging Matrix Block Structure In Sparse Matrix-Vector Multiplication. Steve Rennich Nvidia Developer Technology - Compute
 Leveraging Matrix Block Structure In Sparse Matrix-Vector Multiplication Steve Rennich Nvidia Developer Technology - Compute Block Sparse Matrix Vector Multiplication Sparse Matrix-Vector Multiplication
Leveraging Matrix Block Structure In Sparse Matrix-Vector Multiplication Steve Rennich Nvidia Developer Technology - Compute Block Sparse Matrix Vector Multiplication Sparse Matrix-Vector Multiplication
CUDA Performance Optimization. Patrick Legresley
 CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC
 DLR.de Chart 1 Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC Melven Röhrig-Zöllner DLR, Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU)
DLR.de Chart 1 Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC Melven Röhrig-Zöllner DLR, Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU)
J. Blair Perot. Ali Khajeh-Saeed. Software Engineer CD-adapco. Mechanical Engineering UMASS, Amherst
 Ali Khajeh-Saeed Software Engineer CD-adapco J. Blair Perot Mechanical Engineering UMASS, Amherst Supercomputers Optimization Stream Benchmark Stag++ (3D Incompressible Flow Code) Matrix Multiply Function
Ali Khajeh-Saeed Software Engineer CD-adapco J. Blair Perot Mechanical Engineering UMASS, Amherst Supercomputers Optimization Stream Benchmark Stag++ (3D Incompressible Flow Code) Matrix Multiply Function
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
Large scale Imaging on Current Many- Core Platforms
 Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS
 ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS Ferdinando Alessi Annalisa Massini Roberto Basili INGV Introduction The simulation of wave propagation
ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS Ferdinando Alessi Annalisa Massini Roberto Basili INGV Introduction The simulation of wave propagation
Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s)
") Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s) Islam Harb 08/21/2015 Agenda Motivation Research Challenges Contributions & Approach Results Conclusion Future Work 2
Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s) Islam Harb 08/21/2015 Agenda Motivation Research Challenges Contributions & Approach Results Conclusion Future Work 2
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM
 Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM Alexander Monakov, amonakov@ispras.ru Institute for System Programming of Russian Academy of Sciences March 20, 2013 1 / 17 Problem Statement In OpenFOAM,
Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM Alexander Monakov, amonakov@ispras.ru Institute for System Programming of Russian Academy of Sciences March 20, 2013 1 / 17 Problem Statement In OpenFOAM,
Identifying Performance Limiters Paulius Micikevicius NVIDIA August 23, 2011
 Identifying Performance Limiters Paulius Micikevicius NVIDIA August 23, 2011 Performance Optimization Process Use appropriate performance metric for each kernel For example, Gflops/s don t make sense for
Identifying Performance Limiters Paulius Micikevicius NVIDIA August 23, 2011 Performance Optimization Process Use appropriate performance metric for each kernel For example, Gflops/s don t make sense for
Parallel FFT Program Optimizations on Heterogeneous Computers
 Parallel FFT Program Optimizations on Heterogeneous Computers Shuo Chen, Xiaoming Li Department of Electrical and Computer Engineering University of Delaware, Newark, DE 19716 Outline Part I: A Hybrid
Parallel FFT Program Optimizations on Heterogeneous Computers Shuo Chen, Xiaoming Li Department of Electrical and Computer Engineering University of Delaware, Newark, DE 19716 Outline Part I: A Hybrid
Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters
 Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
GREAT PERFORMANCE FOR TINY PROBLEMS: BATCHED PRODUCTS OF SMALL MATRICES. Nikolay Markovskiy Peter Messmer
 GREAT PERFORMANCE FOR TINY PROBLEMS: BATCHED PRODUCTS OF SMALL MATRICES Nikolay Markovskiy Peter Messmer ABOUT CP2K Atomistic and molecular simulations of solid state From ab initio DFT and Hartree-Fock
GREAT PERFORMANCE FOR TINY PROBLEMS: BATCHED PRODUCTS OF SMALL MATRICES Nikolay Markovskiy Peter Messmer ABOUT CP2K Atomistic and molecular simulations of solid state From ab initio DFT and Hartree-Fock
Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies
 Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies John C. Linford John Michalakes Manish Vachharajani Adrian Sandu IMAGe TOY 2009 Workshop 2 Virginia
Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies John C. Linford John Michalakes Manish Vachharajani Adrian Sandu IMAGe TOY 2009 Workshop 2 Virginia
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016
 ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers
 Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Parallel Poisson Solver in Fortran
 Parallel Poisson Solver in Fortran Nilas Mandrup Hansen, Ask Hjorth Larsen January 19, 1 1 Introduction In this assignment the D Poisson problem (Eq.1) is to be solved in either C/C++ or FORTRAN, first
Parallel Poisson Solver in Fortran Nilas Mandrup Hansen, Ask Hjorth Larsen January 19, 1 1 Introduction In this assignment the D Poisson problem (Eq.1) is to be solved in either C/C++ or FORTRAN, first
Outline. Single GPU Implementation. Multi-GPU Implementation. 2-pass and 1-pass approaches Performance evaluation. Scalability on clusters
 Implementing 3D Finite Difference Codes on the GPU Paulius Micikevicius NVIDIA Outline Single GPU Implementation 2-pass and 1-pass approaches Performance evaluation Multi-GPU Implementation Scalability
Implementing 3D Finite Difference Codes on the GPU Paulius Micikevicius NVIDIA Outline Single GPU Implementation 2-pass and 1-pass approaches Performance evaluation Multi-GPU Implementation Scalability
Accelerating Leukocyte Tracking Using CUDA: A Case Study in Leveraging Manycore Coprocessors
 Accelerating Leukocyte Tracking Using CUDA: A Case Study in Leveraging Manycore Coprocessors Michael Boyer, David Tarjan, Scott T. Acton, and Kevin Skadron University of Virginia IPDPS 2009 Outline Leukocyte
Accelerating Leukocyte Tracking Using CUDA: A Case Study in Leveraging Manycore Coprocessors Michael Boyer, David Tarjan, Scott T. Acton, and Kevin Skadron University of Virginia IPDPS 2009 Outline Leukocyte
Algorithms, System and Data Centre Optimisation for Energy Efficient HPC
 2015-09-14 Algorithms, System and Data Centre Optimisation for Energy Efficient HPC Vincent Heuveline URZ Computing Centre of Heidelberg University EMCL Engineering Mathematics and Computing Lab 1 Energy
2015-09-14 Algorithms, System and Data Centre Optimisation for Energy Efficient HPC Vincent Heuveline URZ Computing Centre of Heidelberg University EMCL Engineering Mathematics and Computing Lab 1 Energy
Advanced CUDA Optimizing to Get 20x Performance
 Advanced CUDA Optimizing to Get 20x Performance Brent Oster Outline Motivation for optimizing in CUDA Demo performance increases Tesla 10-series architecture details Optimization case studies Particle
Advanced CUDA Optimizing to Get 20x Performance Brent Oster Outline Motivation for optimizing in CUDA Demo performance increases Tesla 10-series architecture details Optimization case studies Particle
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE)
") GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
Fundamental Optimizations
 Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010
 Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
CPU/GPU COMPUTING FOR AN IMPLICIT MULTI-BLOCK COMPRESSIBLE NAVIER-STOKES SOLVER ON HETEROGENEOUS PLATFORM
 Sixth International Symposium on Physics of Fluids (ISPF6) International Journal of Modern Physics: Conference Series Vol. 42 (2016) 1660163 (14 pages) The Author(s) DOI: 10.1142/S2010194516601630 CPU/GPU
Sixth International Symposium on Physics of Fluids (ISPF6) International Journal of Modern Physics: Conference Series Vol. 42 (2016) 1660163 (14 pages) The Author(s) DOI: 10.1142/S2010194516601630 CPU/GPU
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
Multigrid Solvers in CFD. David Emerson. Scientific Computing Department STFC Daresbury Laboratory Daresbury, Warrington, WA4 4AD, UK
 Multigrid Solvers in CFD David Emerson Scientific Computing Department STFC Daresbury Laboratory Daresbury, Warrington, WA4 4AD, UK david.emerson@stfc.ac.uk 1 Outline Multigrid: general comments Incompressible
Multigrid Solvers in CFD David Emerson Scientific Computing Department STFC Daresbury Laboratory Daresbury, Warrington, WA4 4AD, UK david.emerson@stfc.ac.uk 1 Outline Multigrid: general comments Incompressible
Scalable Multi Agent Simulation on the GPU. Avi Bleiweiss NVIDIA Corporation San Jose, 2009
 Scalable Multi Agent Simulation on the GPU Avi Bleiweiss NVIDIA Corporation San Jose, 2009 Reasoning Explicit State machine, serial Implicit Compute intensive Fits SIMT well Collision avoidance Motivation
Scalable Multi Agent Simulation on the GPU Avi Bleiweiss NVIDIA Corporation San Jose, 2009 Reasoning Explicit State machine, serial Implicit Compute intensive Fits SIMT well Collision avoidance Motivation
A Scalable GPU-Based Compressible Fluid Flow Solver for Unstructured Grids
 A Scalable GPU-Based Compressible Fluid Flow Solver for Unstructured Grids Patrice Castonguay and Antony Jameson Aerospace Computing Lab, Stanford University GTC Asia, Beijing, China December 15 th, 2011
A Scalable GPU-Based Compressible Fluid Flow Solver for Unstructured Grids Patrice Castonguay and Antony Jameson Aerospace Computing Lab, Stanford University GTC Asia, Beijing, China December 15 th, 2011
Optimizing Data Locality for Iterative Matrix Solvers on CUDA
 Optimizing Data Locality for Iterative Matrix Solvers on CUDA Raymond Flagg, Jason Monk, Yifeng Zhu PhD., Bruce Segee PhD. Department of Electrical and Computer Engineering, University of Maine, Orono,
Optimizing Data Locality for Iterative Matrix Solvers on CUDA Raymond Flagg, Jason Monk, Yifeng Zhu PhD., Bruce Segee PhD. Department of Electrical and Computer Engineering, University of Maine, Orono,
CUDA OPTIMIZATION WITH NVIDIA NSIGHT VISUAL STUDIO EDITION
 April 4-7, 2016 Silicon Valley CUDA OPTIMIZATION WITH NVIDIA NSIGHT VISUAL STUDIO EDITION CHRISTOPH ANGERER, NVIDIA JAKOB PROGSCH, NVIDIA 1 WHAT YOU WILL LEARN An iterative method to optimize your GPU
April 4-7, 2016 Silicon Valley CUDA OPTIMIZATION WITH NVIDIA NSIGHT VISUAL STUDIO EDITION CHRISTOPH ANGERER, NVIDIA JAKOB PROGSCH, NVIDIA 1 WHAT YOU WILL LEARN An iterative method to optimize your GPU
CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer
 CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer Outline We ll be focussing on optimizing global memory throughput on Fermi-class GPUs
CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer Outline We ll be focussing on optimizing global memory throughput on Fermi-class GPUs
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices
 Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
Driven Cavity Example
 BMAppendixI.qxd 11/14/12 6:55 PM Page I-1 I CFD Driven Cavity Example I.1 Problem One of the classic benchmarks in CFD is the driven cavity problem. Consider steady, incompressible, viscous flow in a square
BMAppendixI.qxd 11/14/12 6:55 PM Page I-1 I CFD Driven Cavity Example I.1 Problem One of the classic benchmarks in CFD is the driven cavity problem. Consider steady, incompressible, viscous flow in a square
Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow
 Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization