PS Web IE. End hand-ins Wednesday, April 27, 2005
|
|
|
- Gavin Carr
- 6 years ago
- Views:
Transcription

1 PS Web IE End hand-ins Wednesday, April 27,
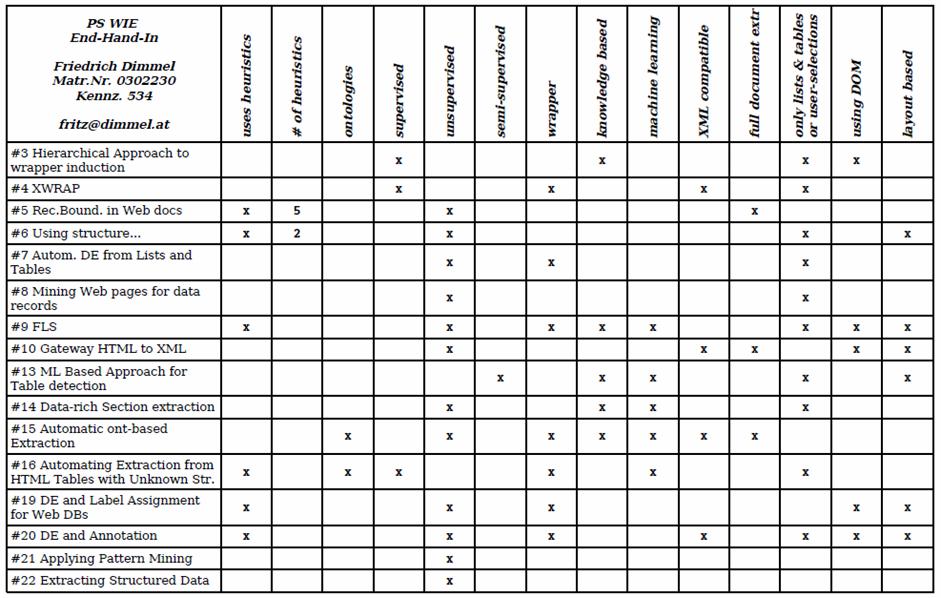
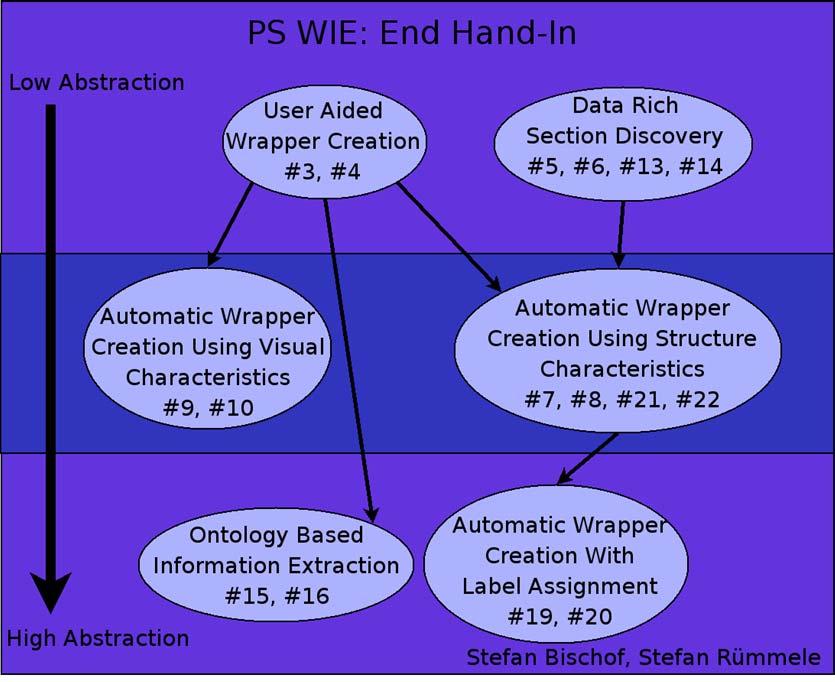
2 summary: web information extraction C h. V e i g e l v s. R e n é C. K i e s l e r, S u m m e r Method\ Paper R1 R2 R3 needs userinteraction X X X X X X X X domain dependent X X X uses training examples X X X X X X X X X uses special input structure X X X X X depends on html-tags X X X X X X X X X X X X X uses DOM/ T-DOM X X X uses hierarchy X X X X X ontologybased X X X handles non-cont. data X X uses templatefinding X X X X X finds slots/ data sections X X X X X X X X X X X X finds datatables X X X X X X X X generates tag/ token-tree X X X X X X extracts records X X X X X X X X X X X X extracts columns X X X X X X X X annotates data (XML) X X X X X X content partition / aggreg. X X X X gernerates schema X X infers grammar X generates wrapper/rules X X X X X X X X X uses 3 rd -party tools X X X X X X c o m p l e t e e x t r a c t i o n i n d b w r a p p e r ( x m l, e t c. ) t r a n s f o r - m a t i o n ( t e x t, h t m l, e t c. ) r e c o r d s o r e x t r a c t - r u l e s r e c o r d b o u n d a r i e s g a i n e d r e s u l t X #4, R2 X #3, R3 n e e d s t o b e g u i d e d ( r e g i o n s + o n t o l o g y ) X #15 X #16 l e v e l o f a u t o m a t i o n d e p e n d s u p o n o n t o l o g y X #7, #9, #10, #19, #20, #21, R1 X #6, #8, #13, #14, #22 f u l l y a u t o m a t i c X #5 a u t o m a t e d, b u t e v e n b e t t e r r e s u l t s t h r o u g h u s e r - i n p u t 03: Stefan Schönig vs. Stalker 04: Marco Schönig vs. Xwrap 05: René C. Kiesler vs. Record Boundary Discovery 06: Christoph Veigel vs. Automated Segmentation 07: Marian Schedenig vs. Automatic Data Extraction 08: Paul Bohunsky vs. Mining Web Pages 09: Sunil Pilani vs. Flexible Learning 10: Friedrich Diemmel vs. Gateway HTML -> XML 13: Gregor Pridun vs. Table Detection 14: Max Arends vs. Data-rich Section Extraction 15: Stefan Bischof vs. Automatic Knowledge Extraction 16: Stefan Rümmele vs. HTML Table extraction 19: Leopold Redlingshofer vs. Data Extraction with Labels 20: Edvin Seferovic vs. Data Extraction and Annotation 21: Jeremy Solarz vs. Applying Pattern Mining 22: Tobias Doenz vs. Extracting Structured Data R1: Martin Zeilinger vs. Newswrapper for Brokers R2: Taoir Hassan vs. Intelligent Text Extraction R3: Rainer Dobiasch vs. MOMIS Schema-Merging
3 Paper wrapper DOM-based equivalence classes pat trie HTML-based non-continguos records multi-page records ontology heuristic regexp supervised template discovery precision implementation # # % - #4 + + * ** - # # *** # **** %-85% - # # #22 opt % - # ***** # # # # % - # % + Web Information Extraction Comparison Matrix Paul Bohunsky ( ) Marian Schedenig ( ) * ) unsupervised derivative exists ** ) user *** ) optional **** ) Hidden Markov Model ***** ) SVM
4 2
5 #3 #4 X #5 #6 #3 #4 #5 #6 #7 #8 #9 #10 #13 #14 #15 #16 #19 #20 #21 #22 #7 X X X #8 X X #9 X X X X #10 X X X X X #13 X #14 X X X #15 X #16 X X X X #19 X X X X #20 X X X X X X X X X X #21 X X X X X X X X #22 X X X X X X X X X X X X Legende: X...Ähnlichkeit in Sachgebiet ist gegeben Max Arends Gregor Pridun
6 1
7 REDLINGSHOFER Leopold, SEFEROVIC Edvin, Paper number Supervised Unsupervised Human Interaction (Token) Suffix Tree Pattern Tree DOM/Tag Tree Wrapper Generation CSP Probalistic methods Knowledge Based System Heuristics #3 #4 #5 #6 #7 #8 #9 #10 #13 #14 #15 #16 #19 #20 #21 #22 Data Annotation Machine Learning Depth First Algorithm String Matching Algorithm WL 2 -Algorithm Normalisation of content Ontology Output: Record Boundary Output: CSV Output: Text Output: Flat Table Output: Data Rich Section Output: XML #3 Stefan Schoenig: Ion Muslea, Steve Minton, Craig Knoblock. A Hierarchical Approach to Wrapper Induction. Proceedings of the Third International Conference on Autonomous Agents (Agents'99), Seattle, WA. #4 Marco Schoenig: Ling Liu, Calton Pu, Wei Han.XWRAP: An XML-enabled Wrapper Construction System for Web Information Sources. International Conference on Data Engineering (ICDE), pages , #5 René Kiesler: D. W. Embley, Y. Jiang, Y.-K. Ng. Record-Boundary Discovery in Web Documents. Proceedings of the 1999 ACM SIGMOD international conference on Management of data, Philadelphia, Pennsylvania, #6 Christoph Veigl: Kristina Lerman, Lise Getoor, Steven Minton, Craig Knoblock. Using the Structure of Web Sites for Automatic Segmentation of Tables. Proceedings of the 2004 ACM SIGMOD international conference on Management of data, Paris, France. #7 Marian Schedenig: Kristina Lerman, Craig Knoblock, Steven Minton. Automatic Data Extraction from Lists and Tables in Web Sources. In Proceedings of the workshop on Advances in Text Extraction and Mining, IJCAI #8 Paul Bohunsky: Bing Liu, R. Grossman, Yanhong Zhai. Mining Web Pages for Data Records. Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining, Washington, D.C., #9 Sunil Pilani: William W. Cohen, Matthew Hurst, Lee S. Jensen. A Flexible Learning System for Wrapping Tables and Lists in HTML Documents. In The Eleventh International World Wide Web Conference WWW-2002, #10 Friedrich Dimmel: Tao Fu, Mengchi Liu. A Gateway From HTML to XML. IDEAS 2004: #13 Gregor Pridun: Yalin Wang, Jianying Hu. A Machine Learning Based Approach for Table Detection on The Web. Proceedings of the eleventh international conference on World Wide Web, Honolulu, Hawaii, USA, #14 Max Arends: Jiying Wang, Fred H. Lochovsky. Data-rich Section Extraction from HTML pages. Proceedings of the 3rd International Conference on Web Information Systems Engineering, Pages: , #15 Stefan Bischof: Harith Alani, Sanghee Kim, David E. Millard, Mark J. Weal, Wendy Hall, Paul H. Lewis, Nigel R. Shadbolt. Automatic Ontology-Based Extraction from Web Documents. IEEE Intelligent Systems, Volume 18, Issue 1, January #16 Stefan Rümmele: David W. Embley, Cui Tao, Stephen W. Liddle. Automating the Extraction of Data from HTML Tables with Unknown Structure. Submitted, May 2003, (source: #19 Leopold Redlingshofer: Jiying Wang, Frederick H. Lochovsky. Data Extraction and Label Assignment for Web Databases. Proceedings of the twelfth international conference on World Wide Web, Budapest, Hungary, #20 Edvin Seferovic: Hui Song, Suraj Giri, Fanyuan Ma. Data Extraction and Annotation for Dynamic Web Pages IEEE International Conference on e-technology, e-commerce and e-service (EEE'04) March 28-31, 2004 Taipei, Taiwan. #21 Jeremy Solarz: Chia-Hui Chang, Shao-Chen Lui, Yen-Chin Wu, Applying Pattern Mining to Web Information Extraction. Proceedings of the 5th Pacific-Asia Conference on Knowledge Discovery and Data Mining, #22 Tobias Dönz: Arvind Arasu, Hector Garcia-Molina. Extracting Structured Data from Web Pages. Proceedings of the 2003 ACM SIGMOD international conference on Management of data, San Diego, California.
8 low #5 #6 Paper characteristics matrix Supervised Nr. Annotation Unsupervised Approach uses ML #3 finite automate * Content structure type table list compl. uses heuristics #4 tag(1) tree #21 #5 tag tree #22 #6 CSP HMM abstraction level #3 #4 #7 #9 #13 #8 #10 #7 #8 #9 #10 #13 token sequence tag tree string - match. wrapper learning DOM tree ML #14 #14 data-rich sections #15 ontolog. #19 #20 #16 ontolog. #19 suffix pattern high #16 #15 #20 #21 #22 tag tree comp. PAT Tree LFEQ dtoken #22 Tobias Dönz ( ) #21 Jeremy Solarz ( ) * ML algorithm and/or training set (1) to #3, #4: extraction rules : teilweise : eher nicht
EXTRACTION AND ALIGNMENT OF DATA FROM WEB PAGES
 EXTRACTION AND ALIGNMENT OF DATA FROM WEB PAGES Praveen Kumar Malapati 1, M. Harathi 2, Shaik Garib Nawaz 2 1 M.Tech, Computer Science Engineering, 2 M.Tech, Associate Professor, Computer Science Engineering,
EXTRACTION AND ALIGNMENT OF DATA FROM WEB PAGES Praveen Kumar Malapati 1, M. Harathi 2, Shaik Garib Nawaz 2 1 M.Tech, Computer Science Engineering, 2 M.Tech, Associate Professor, Computer Science Engineering,
EXTRACTION INFORMATION ADAPTIVE WEB. The Amorphic system works to extract Web information for use in business intelligence applications.
 By Dawn G. Gregg and Steven Walczak ADAPTIVE WEB INFORMATION EXTRACTION The Amorphic system works to extract Web information for use in business intelligence applications. Web mining has the potential
By Dawn G. Gregg and Steven Walczak ADAPTIVE WEB INFORMATION EXTRACTION The Amorphic system works to extract Web information for use in business intelligence applications. Web mining has the potential
A survey: Web mining via Tag and Value
 A survey: Web mining via Tag and Value Khirade Rajratna Rajaram. Information Technology Department SGGS IE&T, Nanded, India Balaji Shetty Information Technology Department SGGS IE&T, Nanded, India Abstract
A survey: Web mining via Tag and Value Khirade Rajratna Rajaram. Information Technology Department SGGS IE&T, Nanded, India Balaji Shetty Information Technology Department SGGS IE&T, Nanded, India Abstract
An Efficient Technique for Tag Extraction and Content Retrieval from Web Pages
 An Efficient Technique for Tag Extraction and Content Retrieval from Web Pages S.Sathya M.Sc 1, Dr. B.Srinivasan M.C.A., M.Phil, M.B.A., Ph.D., 2 1 Mphil Scholar, Department of Computer Science, Gobi Arts
An Efficient Technique for Tag Extraction and Content Retrieval from Web Pages S.Sathya M.Sc 1, Dr. B.Srinivasan M.C.A., M.Phil, M.B.A., Ph.D., 2 1 Mphil Scholar, Department of Computer Science, Gobi Arts
DataRover: A Taxonomy Based Crawler for Automated Data Extraction from Data-Intensive Websites
 DataRover: A Taxonomy Based Crawler for Automated Data Extraction from Data-Intensive Websites H. Davulcu, S. Koduri, S. Nagarajan Department of Computer Science and Engineering Arizona State University,
DataRover: A Taxonomy Based Crawler for Automated Data Extraction from Data-Intensive Websites H. Davulcu, S. Koduri, S. Nagarajan Department of Computer Science and Engineering Arizona State University,
WEB DATA EXTRACTION METHOD BASED ON FEATURED TERNARY TREE
 WEB DATA EXTRACTION METHOD BASED ON FEATURED TERNARY TREE *Vidya.V.L, **Aarathy Gandhi *PG Scholar, Department of Computer Science, Mohandas College of Engineering and Technology, Anad **Assistant Professor,
WEB DATA EXTRACTION METHOD BASED ON FEATURED TERNARY TREE *Vidya.V.L, **Aarathy Gandhi *PG Scholar, Department of Computer Science, Mohandas College of Engineering and Technology, Anad **Assistant Professor,
Extraction of Flat and Nested Data Records from Web Pages
 Proc. Fifth Australasian Data Mining Conference (AusDM2006) Extraction of Flat and Nested Data Records from Web Pages Siddu P Algur 1 and P S Hiremath 2 1 Dept. of Info. Sc. & Engg., SDM College of Engg
Proc. Fifth Australasian Data Mining Conference (AusDM2006) Extraction of Flat and Nested Data Records from Web Pages Siddu P Algur 1 and P S Hiremath 2 1 Dept. of Info. Sc. & Engg., SDM College of Engg
Automatic Generation of Wrapper for Data Extraction from the Web
 Automatic Generation of Wrapper for Data Extraction from the Web 2 Suzhi Zhang 1, 2 and Zhengding Lu 1 1 College of Computer science and Technology, Huazhong University of Science and technology, Wuhan,
Automatic Generation of Wrapper for Data Extraction from the Web 2 Suzhi Zhang 1, 2 and Zhengding Lu 1 1 College of Computer science and Technology, Huazhong University of Science and technology, Wuhan,
ISSN: (Online) Volume 3, Issue 6, June 2015 International Journal of Advance Research in Computer Science and Management Studies
 Volume 3, Issue 6, June 2015 International Journal of Advance Research in Computer Science and Management Studies") ISSN: 2321-7782 (Online) Volume 3, Issue 6, June 2015 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
ISSN: 2321-7782 (Online) Volume 3, Issue 6, June 2015 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
Much information on the Web is presented in regularly structured objects. A list
 Mining Web Pages for Data Records Bing Liu, Robert Grossman, and Yanhong Zhai, University of Illinois at Chicago Much information on the Web is presented in regularly suctured objects. A list of such objects
Mining Web Pages for Data Records Bing Liu, Robert Grossman, and Yanhong Zhai, University of Illinois at Chicago Much information on the Web is presented in regularly suctured objects. A list of such objects
Keywords Data alignment, Data annotation, Web database, Search Result Record
 Volume 5, Issue 8, August 2015 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Annotating Web
Volume 5, Issue 8, August 2015 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Annotating Web
A Hybrid Unsupervised Web Data Extraction using Trinity and NLP
 IJIRST International Journal for Innovative Research in Science & Technology Volume 2 Issue 02 July 2015 ISSN (online): 2349-6010 A Hybrid Unsupervised Web Data Extraction using Trinity and NLP Anju R
IJIRST International Journal for Innovative Research in Science & Technology Volume 2 Issue 02 July 2015 ISSN (online): 2349-6010 A Hybrid Unsupervised Web Data Extraction using Trinity and NLP Anju R
Improving A Page Classifier with Anchor Extraction and Link Analysis
 Improving A Page Classifier with Anchor Extraction and Link Analysis William W. Cohen Center for Automated Learning and Discovery, CMU 5000 Forbes Ave, Pittsburgh, PA 15213 william@wcohen.com Abstract
Improving A Page Classifier with Anchor Extraction and Link Analysis William W. Cohen Center for Automated Learning and Discovery, CMU 5000 Forbes Ave, Pittsburgh, PA 15213 william@wcohen.com Abstract
A Flexible Learning System for Wrapping Tables and Lists
 A Flexible Learning System for Wrapping Tables and Lists or How to Write a Really Complicated Learning Algorithm Without Driving Yourself Mad William W. Cohen Matthew Hurst Lee S. Jensen WhizBang Labs
A Flexible Learning System for Wrapping Tables and Lists or How to Write a Really Complicated Learning Algorithm Without Driving Yourself Mad William W. Cohen Matthew Hurst Lee S. Jensen WhizBang Labs
Mining Data Records in Web Pages
 Mining Data Records in Web Pages Bing Liu Department of Computer Science University of Illinois at Chicago 851 S. Morgan Street Chicago, IL 60607-7053 liub@cs.uic.edu Robert Grossman Dept. of Mathematics,
Mining Data Records in Web Pages Bing Liu Department of Computer Science University of Illinois at Chicago 851 S. Morgan Street Chicago, IL 60607-7053 liub@cs.uic.edu Robert Grossman Dept. of Mathematics,
Reconfigurable Web Wrapper Agents for Web Information Integration
 Reconfigurable Web Wrapper Agents for Web Information Integration Chun-Nan Hsu y, Chia-Hui Chang z, Harianto Siek y, Jiann-Jyh Lu y, Jen-Jie Chiou \ y Institute of Information Science, Academia Sinica,
Reconfigurable Web Wrapper Agents for Web Information Integration Chun-Nan Hsu y, Chia-Hui Chang z, Harianto Siek y, Jiann-Jyh Lu y, Jen-Jie Chiou \ y Institute of Information Science, Academia Sinica,
A Survey on Unsupervised Extraction of Product Information from Semi-Structured Sources
 A Survey on Unsupervised Extraction of Product Information from Semi-Structured Sources Abhilasha Bhagat, ME Computer Engineering, G.H.R.I.E.T., Savitribai Phule University, pune PUNE, India Vanita Raut
A Survey on Unsupervised Extraction of Product Information from Semi-Structured Sources Abhilasha Bhagat, ME Computer Engineering, G.H.R.I.E.T., Savitribai Phule University, pune PUNE, India Vanita Raut
ISSN: (Online) Volume 2, Issue 3, March 2014 International Journal of Advance Research in Computer Science and Management Studies
 Volume 2, Issue 3, March 2014 International Journal of Advance Research in Computer Science and Management Studies") ISSN: 2321-7782 (Online) Volume 2, Issue 3, March 2014 International Journal of Advance Research in Computer Science and Management Studies Research Article / Paper / Case Study Available online at: www.ijarcsms.com
ISSN: 2321-7782 (Online) Volume 2, Issue 3, March 2014 International Journal of Advance Research in Computer Science and Management Studies Research Article / Paper / Case Study Available online at: www.ijarcsms.com
Te Whare Wananga o te Upoko o te Ika a Maui. Computer Science
 VICTORIA UNIVERSITY OF WELLINGTON Te Whare Wananga o te Upoko o te Ika a Maui School of Mathematical and Computing Sciences Computer Science Approximately Repetitive Structure Detection for Wrapper Induction
VICTORIA UNIVERSITY OF WELLINGTON Te Whare Wananga o te Upoko o te Ika a Maui School of Mathematical and Computing Sciences Computer Science Approximately Repetitive Structure Detection for Wrapper Induction
Visual Resemblance Based Content Descent for Multiset Query Records using Novel Segmentation Algorithm
 Visual Resemblance Based Content Descent for Multiset Query Records using Novel Segmentation Algorithm S. Ishwarya 1, S. Grace Mary 2 Department of Computer Science and Engineering, Shivani Engineering
Visual Resemblance Based Content Descent for Multiset Query Records using Novel Segmentation Algorithm S. Ishwarya 1, S. Grace Mary 2 Department of Computer Science and Engineering, Shivani Engineering
Web Scraping Framework based on Combining Tag and Value Similarity
 www.ijcsi.org 118 Web Scraping Framework based on Combining Tag and Value Similarity Shridevi Swami 1, Pujashree Vidap 2 1 Department of Computer Engineering, Pune Institute of Computer Technology, University
www.ijcsi.org 118 Web Scraping Framework based on Combining Tag and Value Similarity Shridevi Swami 1, Pujashree Vidap 2 1 Department of Computer Engineering, Pune Institute of Computer Technology, University
Extraction of Automatic Search Result Records Using Content Density Algorithm Based on Node Similarity
 Extraction of Automatic Search Result Records Using Content Density Algorithm Based on Node Similarity Yasar Gozudeli*, Oktay Yildiz*, Hacer Karacan*, Muhammed R. Baker*, Ali Minnet**, Murat Kalender**,
Extraction of Automatic Search Result Records Using Content Density Algorithm Based on Node Similarity Yasar Gozudeli*, Oktay Yildiz*, Hacer Karacan*, Muhammed R. Baker*, Ali Minnet**, Murat Kalender**,
USER PERSONALIZATION IN BIG DATA
 USER PERSONALIZATION IN BIG DATA Santhi nisha.e 1, Dr.P.S.K.Patra 2 1 Department of computer science, Agni college of technology, Thalambur, Chennai-603 103 2 Department of computer science, Agni college
USER PERSONALIZATION IN BIG DATA Santhi nisha.e 1, Dr.P.S.K.Patra 2 1 Department of computer science, Agni college of technology, Thalambur, Chennai-603 103 2 Department of computer science, Agni college
Extraction of Automatic Search Result Records Using Content Density Algorithm Based on Node Similarity
 Extraction of Automatic Search Result Records Using Content Density Algorithm Based on Node Similarity Yasar Gozudeli*, Oktay Yildiz*, Hacer Karacan*, Mohammed R. Baker*, Ali Minnet**, Murat Kalender**,
Extraction of Automatic Search Result Records Using Content Density Algorithm Based on Node Similarity Yasar Gozudeli*, Oktay Yildiz*, Hacer Karacan*, Mohammed R. Baker*, Ali Minnet**, Murat Kalender**,
Information Discovery, Extraction and Integration for the Hidden Web
 Information Discovery, Extraction and Integration for the Hidden Web Jiying Wang Department of Computer Science University of Science and Technology Clear Water Bay, Kowloon Hong Kong cswangjy@cs.ust.hk
Information Discovery, Extraction and Integration for the Hidden Web Jiying Wang Department of Computer Science University of Science and Technology Clear Water Bay, Kowloon Hong Kong cswangjy@cs.ust.hk
Deepec: An Approach For Deep Web Content Extraction And Cataloguing
 Association for Information Systems AIS Electronic Library (AISeL) ECIS 2013 Completed Research ECIS 2013 Proceedings 7-1-2013 Deepec: An Approach For Deep Web Content Extraction And Cataloguing Augusto
Association for Information Systems AIS Electronic Library (AISeL) ECIS 2013 Completed Research ECIS 2013 Proceedings 7-1-2013 Deepec: An Approach For Deep Web Content Extraction And Cataloguing Augusto
Web Database Integration
 In Proceedings of the Ph.D Workshop in conjunction with VLDB 06 (VLDB-PhD2006), Seoul, Korea, September 11, 2006 Web Database Integration Wei Liu School of Information Renmin University of China Beijing,
In Proceedings of the Ph.D Workshop in conjunction with VLDB 06 (VLDB-PhD2006), Seoul, Korea, September 11, 2006 Web Database Integration Wei Liu School of Information Renmin University of China Beijing,
Web Data Extraction Using Tree Structure Algorithms A Comparison
 Web Data Extraction Using Tree Structure Algorithms A Comparison Seema Kolkur, K.Jayamalini Abstract Nowadays, Web pages provide a large amount of structured data, which is required by many advanced applications.
Web Data Extraction Using Tree Structure Algorithms A Comparison Seema Kolkur, K.Jayamalini Abstract Nowadays, Web pages provide a large amount of structured data, which is required by many advanced applications.
Object Extraction. Output Tagging. A Generated Wrapper
 Wrapping Data into XML Wei Han, David Buttler, Calton Pu Georgia Institute of Technology College of Computing Atlanta, Georgia 30332-0280 USA fweihan, buttler, calton g@cc.gatech.edu Abstract The vast
Wrapping Data into XML Wei Han, David Buttler, Calton Pu Georgia Institute of Technology College of Computing Atlanta, Georgia 30332-0280 USA fweihan, buttler, calton g@cc.gatech.edu Abstract The vast
Reverse method for labeling the information from semi-structured web pages
 Reverse method for labeling the information from semi-structured web pages Z. Akbar and L.T. Handoko Group for Theoretical and Computational Physics, Research Center for Physics, Indonesian Institute of
Reverse method for labeling the information from semi-structured web pages Z. Akbar and L.T. Handoko Group for Theoretical and Computational Physics, Research Center for Physics, Indonesian Institute of
RecipeCrawler: Collecting Recipe Data from WWW Incrementally
 RecipeCrawler: Collecting Recipe Data from WWW Incrementally Yu Li 1, Xiaofeng Meng 1, Liping Wang 2, and Qing Li 2 1 {liyu17, xfmeng}@ruc.edu.cn School of Information, Renmin Univ. of China, China 2 50095373@student.cityu.edu.hk
RecipeCrawler: Collecting Recipe Data from WWW Incrementally Yu Li 1, Xiaofeng Meng 1, Liping Wang 2, and Qing Li 2 1 {liyu17, xfmeng}@ruc.edu.cn School of Information, Renmin Univ. of China, China 2 50095373@student.cityu.edu.hk
ISSN (Online) ISSN (Print)
 ISSN (Print)") Accurate Alignment of Search Result Records from Web Data Base 1Soumya Snigdha Mohapatra, 2 M.Kalyan Ram 1,2 Dept. of CSE, Aditya Engineering College, Surampalem, East Godavari, AP, India Abstract: Most
Accurate Alignment of Search Result Records from Web Data Base 1Soumya Snigdha Mohapatra, 2 M.Kalyan Ram 1,2 Dept. of CSE, Aditya Engineering College, Surampalem, East Godavari, AP, India Abstract: Most
Exploring Information Extraction Resilience
 Journal of Universal Computer Science, vol. 14, no. 11 (2008), 1911-1920 submitted: 30/9/07, accepted: 25/1/08, appeared: 1/6/08 J.UCS Exploring Information Extraction Resilience Dawn G. Gregg (University
Journal of Universal Computer Science, vol. 14, no. 11 (2008), 1911-1920 submitted: 30/9/07, accepted: 25/1/08, appeared: 1/6/08 J.UCS Exploring Information Extraction Resilience Dawn G. Gregg (University
Content Based Cross-Site Mining Web Data Records
 Content Based Cross-Site Mining Web Data Records Jebeh Kawah, Faisal Razzaq, Enzhou Wang Mentor: Shui-Lung Chuang Project #7 Data Record Extraction 1. Introduction Current web data record extraction methods
Content Based Cross-Site Mining Web Data Records Jebeh Kawah, Faisal Razzaq, Enzhou Wang Mentor: Shui-Lung Chuang Project #7 Data Record Extraction 1. Introduction Current web data record extraction methods
The Wargo System: Semi-Automatic Wrapper Generation in Presence of Complex Data Access Modes
 The Wargo System: Semi-Automatic Wrapper Generation in Presence of Complex Data Access Modes J. Raposo, A. Pan, M. Álvarez, Justo Hidalgo, A. Viña Denodo Technologies {apan, jhidalgo,@denodo.com University
The Wargo System: Semi-Automatic Wrapper Generation in Presence of Complex Data Access Modes J. Raposo, A. Pan, M. Álvarez, Justo Hidalgo, A. Viña Denodo Technologies {apan, jhidalgo,@denodo.com University
The Syllabus Based Web Content Extractor (SBWCE)
") The Syllabus Based Web Content Extractor (SBWCE) Saba Hilal DAV Institute of Management Haryana, India saba21hilal@yahoo.com S. A. M. Rizvi Department of Computer Science Jamia Millia Islamia New Delhi,
The Syllabus Based Web Content Extractor (SBWCE) Saba Hilal DAV Institute of Management Haryana, India saba21hilal@yahoo.com S. A. M. Rizvi Department of Computer Science Jamia Millia Islamia New Delhi,
Using Protégé for Automatic Ontology Instantiation
 Using Protégé for Automatic Ontology Instantiation Harith Alani, Sanghee Kim, David Millard, Mark Weal, Paul Lewis, Wendy Hall, Nigel Shadbolt 7 th International Protégé Conference ArtEquAKT Aims: Use
Using Protégé for Automatic Ontology Instantiation Harith Alani, Sanghee Kim, David Millard, Mark Weal, Paul Lewis, Wendy Hall, Nigel Shadbolt 7 th International Protégé Conference ArtEquAKT Aims: Use
Manual Wrapper Generation. Automatic Wrapper Generation. Grammar Induction Approach. Overview. Limitations. Website Structure-based Approach
 Automatic Wrapper Generation Kristina Lerman University of Southern California Manual Wrapper Generation Manual wrapper generation requires user to Specify the schema of the information source Single tuple
Automatic Wrapper Generation Kristina Lerman University of Southern California Manual Wrapper Generation Manual wrapper generation requires user to Specify the schema of the information source Single tuple
AN APPROACH FOR EXTRACTING INFORMATION FROM NARRATIVE WEB INFORMATION SOURCES
 AN APPROACH FOR EXTRACTING INFORMATION FROM NARRATIVE WEB INFORMATION SOURCES A. Vashishta Computer Science & Software Engineering Department University of Wisconsin - Platteville Platteville, WI 53818,
AN APPROACH FOR EXTRACTING INFORMATION FROM NARRATIVE WEB INFORMATION SOURCES A. Vashishta Computer Science & Software Engineering Department University of Wisconsin - Platteville Platteville, WI 53818,
Ontology Extraction from Tables on the Web
 Ontology Extraction from Tables on the Web Masahiro Tanaka and Toru Ishida Department of Social Informatics, Kyoto University. Kyoto 606-8501, JAPAN mtanaka@kuis.kyoto-u.ac.jp, ishida@i.kyoto-u.ac.jp Abstract
Ontology Extraction from Tables on the Web Masahiro Tanaka and Toru Ishida Department of Social Informatics, Kyoto University. Kyoto 606-8501, JAPAN mtanaka@kuis.kyoto-u.ac.jp, ishida@i.kyoto-u.ac.jp Abstract
Automatic Extraction of Informative Blocks from Webpages
 2005 ACM Symposium on Applied Computing Automatic Extraction Informative Blocks from Webpages Sandip Debnath, Prasenjit Mitra, C. Lee Giles, Department Computer Sciences and Engineering The Pennsylvania
2005 ACM Symposium on Applied Computing Automatic Extraction Informative Blocks from Webpages Sandip Debnath, Prasenjit Mitra, C. Lee Giles, Department Computer Sciences and Engineering The Pennsylvania
Web Data Extraction. Craig Knoblock University of Southern California. This presentation is based on slides prepared by Ion Muslea and Kristina Lerman
 Web Data Extraction Craig Knoblock University of Southern California This presentation is based on slides prepared by Ion Muslea and Kristina Lerman Extracting Data from Semistructured Sources NAME Casablanca
Web Data Extraction Craig Knoblock University of Southern California This presentation is based on slides prepared by Ion Muslea and Kristina Lerman Extracting Data from Semistructured Sources NAME Casablanca
Agglomerative clustering on vertically partitioned data
 Agglomerative clustering on vertically partitioned data R.Senkamalavalli Research Scholar, Department of Computer Science and Engg., SCSVMV University, Enathur, Kanchipuram 631 561 sengu_cool@yahoo.com
Agglomerative clustering on vertically partitioned data R.Senkamalavalli Research Scholar, Department of Computer Science and Engg., SCSVMV University, Enathur, Kanchipuram 631 561 sengu_cool@yahoo.com
DATA SEARCH ENGINE INTRODUCTION
 D DATA SEARCH ENGINE INTRODUCTION The World Wide Web was first developed by Tim Berners- Lee and his colleagues in 1990. In just over a decade, it has become the largest information source in human history.
D DATA SEARCH ENGINE INTRODUCTION The World Wide Web was first developed by Tim Berners- Lee and his colleagues in 1990. In just over a decade, it has become the largest information source in human history.
Providing Robust Access to Data in Web Pages
 Providing Robust Access to Data in Web Pages Jerome Robinson Department of Computer Science, University of Essex, Colchester, Essex, U.K. robij@essex.ac.uk Abstract. Much useful e-commerce information
Providing Robust Access to Data in Web Pages Jerome Robinson Department of Computer Science, University of Essex, Colchester, Essex, U.K. robij@essex.ac.uk Abstract. Much useful e-commerce information
Annotating Multiple Web Databases Using Svm
 Annotating Multiple Web Databases Using Svm M.Yazhmozhi 1, M. Lavanya 2, Dr. N. Rajkumar 3 PG Scholar, Department of Software Engineering, Sri Ramakrishna Engineering College, Coimbatore, India 1, 3 Head
Annotating Multiple Web Databases Using Svm M.Yazhmozhi 1, M. Lavanya 2, Dr. N. Rajkumar 3 PG Scholar, Department of Software Engineering, Sri Ramakrishna Engineering College, Coimbatore, India 1, 3 Head
Mining Structured Objects (Data Records) Based on Maximum Region Detection by Text Content Comparison From Website
 Based on Maximum Region Detection by Text Content Comparison From Website") International Journal of Electrical & Computer Sciences IJECS-IJENS Vol:10 No:02 21 Mining Structured Objects (Data Records) Based on Maximum Region Detection by Text Content Comparison From Website G.M.
International Journal of Electrical & Computer Sciences IJECS-IJENS Vol:10 No:02 21 Mining Structured Objects (Data Records) Based on Maximum Region Detection by Text Content Comparison From Website G.M.
A New Method Based on Tree Simplification and Schema Matching for Automatic Web Result Extraction and Matching
 A New Method Based on Tree Simplification and Schema Matching for Automatic Web Result Extraction and Matching Yasar Gozudeli, Hacer Karacan, Oktay Yildiz, Mohammed R. Baker, Ali Minnet, Murat Kaler, Ozcan
A New Method Based on Tree Simplification and Schema Matching for Automatic Web Result Extraction and Matching Yasar Gozudeli, Hacer Karacan, Oktay Yildiz, Mohammed R. Baker, Ali Minnet, Murat Kaler, Ozcan
Web Data Extraction and Alignment Tools: A Survey Pranali Nikam 1 Yogita Gote 2 Vidhya Ghogare 3 Jyothi Rapalli 4
 IJSRD - International Journal for Scientific Research & Development Vol. 3, Issue 01, 2015 ISSN (online): 2321-0613 Web Data Extraction and Alignment Tools: A Survey Pranali Nikam 1 Yogita Gote 2 Vidhya
IJSRD - International Journal for Scientific Research & Development Vol. 3, Issue 01, 2015 ISSN (online): 2321-0613 Web Data Extraction and Alignment Tools: A Survey Pranali Nikam 1 Yogita Gote 2 Vidhya
Hidden Web Data Extraction Using Dynamic Rule Generation
 Hidden Web Data Extraction Using Dynamic Rule Generation Anuradha Computer Engg. Department YMCA University of Sc. & Technology Faridabad, India anuangra@yahoo.com A.K Sharma Computer Engg. Department
Hidden Web Data Extraction Using Dynamic Rule Generation Anuradha Computer Engg. Department YMCA University of Sc. & Technology Faridabad, India anuangra@yahoo.com A.K Sharma Computer Engg. Department
Object-Level Ranking: Bringing Order to Web Objects
 Object-Level Ranking: Bringing Order to Web Objects Zaiqing Nie 1 Yuanzhi Zhang 2 Ji-Rong Wen 1 Wei-Ying Ma 1 1 Microsoft Research Asia 2 Peking University Beijing, P. R. China Beijing, P. R. China {t-znie,jrwen,wyma}@microsoft.com
Object-Level Ranking: Bringing Order to Web Objects Zaiqing Nie 1 Yuanzhi Zhang 2 Ji-Rong Wen 1 Wei-Ying Ma 1 1 Microsoft Research Asia 2 Peking University Beijing, P. R. China Beijing, P. R. China {t-znie,jrwen,wyma}@microsoft.com
Multi-Modal Data Fusion: A Description
 Multi-Modal Data Fusion: A Description Sarah Coppock and Lawrence J. Mazlack ECECS Department University of Cincinnati Cincinnati, Ohio 45221-0030 USA {coppocs,mazlack}@uc.edu Abstract. Clustering groups
Multi-Modal Data Fusion: A Description Sarah Coppock and Lawrence J. Mazlack ECECS Department University of Cincinnati Cincinnati, Ohio 45221-0030 USA {coppocs,mazlack}@uc.edu Abstract. Clustering groups
Integrating the World: The WorldInfo Assistant
 Integrating the World: The WorldInfo Assistant Craig A. Knoblock, Jose Luis Ambite, Steven Minton, Cyrus Shahabi, Mohammad Kolahdouzan, Maria Muslea, Jean Oh, and Snehal Thakkar University of Southern
Integrating the World: The WorldInfo Assistant Craig A. Knoblock, Jose Luis Ambite, Steven Minton, Cyrus Shahabi, Mohammad Kolahdouzan, Maria Muslea, Jean Oh, and Snehal Thakkar University of Southern
Automatic Hidden-Web Table Interpretation by Sibling Page Comparison
 Automatic Hidden-Web Table Interpretation by Sibling Page Comparison Cui Tao and David W. Embley Brigham Young University, Provo, Utah 84602, U.S.A. {ctao, embley}@cs.byu.edu Abstract. The longstanding
Automatic Hidden-Web Table Interpretation by Sibling Page Comparison Cui Tao and David W. Embley Brigham Young University, Provo, Utah 84602, U.S.A. {ctao, embley}@cs.byu.edu Abstract. The longstanding
Information Extraction from Tree Documents by Learning Subtree Delimiters
 Information Extraction from Tree Documents by Learning Subtree Delimiters Boris Chidlovskii Xerox Research Centre Europe, France 6, chemin de Maupertuis, F 38240 Meylan, chidlovskii@xrce.xerox.com Abstract
Information Extraction from Tree Documents by Learning Subtree Delimiters Boris Chidlovskii Xerox Research Centre Europe, France 6, chemin de Maupertuis, F 38240 Meylan, chidlovskii@xrce.xerox.com Abstract
An Efficient Density Based Incremental Clustering Algorithm in Data Warehousing Environment
 An Efficient Density Based Incremental Clustering Algorithm in Data Warehousing Environment Navneet Goyal, Poonam Goyal, K Venkatramaiah, Deepak P C, and Sanoop P S Department of Computer Science & Information
An Efficient Density Based Incremental Clustering Algorithm in Data Warehousing Environment Navneet Goyal, Poonam Goyal, K Venkatramaiah, Deepak P C, and Sanoop P S Department of Computer Science & Information
Wrapper Induction for End-User Semantic Content Development
 Wrapper Induction for End-User Semantic Content Development ndrew Hogue MIT CSIL Cambridge, M 02139 ahogue@csail.mit.edu David Karger MIT CSIL Cambridge, M 02139 karger@csail.mit.edu STRCT The transition
Wrapper Induction for End-User Semantic Content Development ndrew Hogue MIT CSIL Cambridge, M 02139 ahogue@csail.mit.edu David Karger MIT CSIL Cambridge, M 02139 karger@csail.mit.edu STRCT The transition
Incremental Knowledge Acquisition Approach for Information Extraction on both Semi-structured and Unstructured Text from the Open Domain Web
 Incremental Knowledge Acquisition Approach for Information Extraction on both Semi-structured and Unstructured Text from the Open Domain Web Maria Myung Hee Kim Defence Science Technology Group Edinburgh,
Incremental Knowledge Acquisition Approach for Information Extraction on both Semi-structured and Unstructured Text from the Open Domain Web Maria Myung Hee Kim Defence Science Technology Group Edinburgh,
A Probabilistic Approach for Adapting Information Extraction Wrappers and Discovering New Attributes
 A Probabilistic Approach for Adapting Information Extraction Wrappers and Discovering New Attributes Tak-Lam Wong and Wai Lam Department of Systems Engineering and Engineering Management The Chinese University
A Probabilistic Approach for Adapting Information Extraction Wrappers and Discovering New Attributes Tak-Lam Wong and Wai Lam Department of Systems Engineering and Engineering Management The Chinese University
F(Vi)DE: A Fusion Approach for Deep Web Data Extraction
DE: A Fusion Approach for Deep Web Data Extraction") F(Vi)DE: A Fusion Approach for Deep Web Data Extraction Saranya V Assistant Professor Department of Computer Science and Engineering Sri Vidya College of Engineering and Technology, Virudhunagar, Tamilnadu,
F(Vi)DE: A Fusion Approach for Deep Web Data Extraction Saranya V Assistant Professor Department of Computer Science and Engineering Sri Vidya College of Engineering and Technology, Virudhunagar, Tamilnadu,
Extracting Product Data from E-Shops
 V. Kůrková et al. (Eds.): ITAT 2014 with selected papers from Znalosti 2014, CEUR Workshop Proceedings Vol. 1214, pp. 40 45 http://ceur-ws.org/vol-1214, Series ISSN 1613-0073, c 2014 P. Gurský, V. Chabal,
V. Kůrková et al. (Eds.): ITAT 2014 with selected papers from Znalosti 2014, CEUR Workshop Proceedings Vol. 1214, pp. 40 45 http://ceur-ws.org/vol-1214, Series ISSN 1613-0073, c 2014 P. Gurský, V. Chabal,
Source Modeling. Kristina Lerman University of Southern California. Based on slides by Mark Carman, Craig Knoblock and Jose Luis Ambite
 Source Modeling Kristina Lerman University of Southern California Based on slides by Mark Carman, Craig Knoblock and Jose Luis Ambite Source Modeling vs. Schema Matching Schema Matching Align schemas between
Source Modeling Kristina Lerman University of Southern California Based on slides by Mark Carman, Craig Knoblock and Jose Luis Ambite Source Modeling vs. Schema Matching Schema Matching Align schemas between
An Approach To Web Content Mining
 An Approach To Web Content Mining Nita Patil, Chhaya Das, Shreya Patanakar, Kshitija Pol Department of Computer Engg. Datta Meghe College of Engineering, Airoli, Navi Mumbai Abstract-With the research
An Approach To Web Content Mining Nita Patil, Chhaya Das, Shreya Patanakar, Kshitija Pol Department of Computer Engg. Datta Meghe College of Engineering, Airoli, Navi Mumbai Abstract-With the research
AAAI 2018 Tutorial Building Knowledge Graphs. Craig Knoblock University of Southern California
 AAAI 2018 Tutorial Building Knowledge Graphs Craig Knoblock University of Southern California Wrappers for Web Data Extraction Extracting Data from Semistructured Sources NAME Casablanca Restaurant STREET
AAAI 2018 Tutorial Building Knowledge Graphs Craig Knoblock University of Southern California Wrappers for Web Data Extraction Extracting Data from Semistructured Sources NAME Casablanca Restaurant STREET
Development of an Ontology-Based Portal for Digital Archive Services
 Development of an Ontology-Based Portal for Digital Archive Services Ching-Long Yeh Department of Computer Science and Engineering Tatung University 40 Chungshan N. Rd. 3rd Sec. Taipei, 104, Taiwan chingyeh@cse.ttu.edu.tw
Development of an Ontology-Based Portal for Digital Archive Services Ching-Long Yeh Department of Computer Science and Engineering Tatung University 40 Chungshan N. Rd. 3rd Sec. Taipei, 104, Taiwan chingyeh@cse.ttu.edu.tw
Master s Thesis Defense. Matthew Jeremy Michelson University of Southern California June 15, 2005
 Master s Thesis Defense Matthew Jeremy Michelson University of Southern California June 15, 2005 Building Queryable Datasets from Ungrammatical and Unstructured Sources Matthew Jeremy Michelson University
Master s Thesis Defense Matthew Jeremy Michelson University of Southern California June 15, 2005 Building Queryable Datasets from Ungrammatical and Unstructured Sources Matthew Jeremy Michelson University
Recognising Informative Web Page Blocks Using Visual Segmentation for Efficient Information Extraction
 Journal of Universal Computer Science, vol. 14, no. 11 (2008), 1893-1910 submitted: 30/9/07, accepted: 25/1/08, appeared: 1/6/08 J.UCS Recognising Informative Web Page Blocks Using Visual Segmentation
Journal of Universal Computer Science, vol. 14, no. 11 (2008), 1893-1910 submitted: 30/9/07, accepted: 25/1/08, appeared: 1/6/08 J.UCS Recognising Informative Web Page Blocks Using Visual Segmentation
Handling Irregularities in ROADRUNNER
 Handling Irregularities in ROADRUNNER Valter Crescenzi Universistà Roma Tre Italy crescenz@dia.uniroma3.it Giansalvatore Mecca Universistà della Basilicata Italy mecca@unibas.it Paolo Merialdo Universistà
Handling Irregularities in ROADRUNNER Valter Crescenzi Universistà Roma Tre Italy crescenz@dia.uniroma3.it Giansalvatore Mecca Universistà della Basilicata Italy mecca@unibas.it Paolo Merialdo Universistà
A Web Page Segmentation Method by using Headlines to Web Contents as Separators and its Evaluations
 IJCSNS International Journal of Computer Science and Network Security, VOL.13 No.1, January 2013 1 A Web Page Segmentation Method by using Headlines to Web Contents as Separators and its Evaluations Hiroyuki
IJCSNS International Journal of Computer Science and Network Security, VOL.13 No.1, January 2013 1 A Web Page Segmentation Method by using Headlines to Web Contents as Separators and its Evaluations Hiroyuki
EXTRACT THE TARGET LIST WITH HIGH ACCURACY FROM TOP-K WEB PAGES
 EXTRACT THE TARGET LIST WITH HIGH ACCURACY FROM TOP-K WEB PAGES B. GEETHA KUMARI M. Tech (CSE) Email-id: Geetha.bapr07@gmail.com JAGETI PADMAVTHI M. Tech (CSE) Email-id: jageti.padmavathi4@gmail.com ABSTRACT:
EXTRACT THE TARGET LIST WITH HIGH ACCURACY FROM TOP-K WEB PAGES B. GEETHA KUMARI M. Tech (CSE) Email-id: Geetha.bapr07@gmail.com JAGETI PADMAVTHI M. Tech (CSE) Email-id: jageti.padmavathi4@gmail.com ABSTRACT:
Template Extraction from Heterogeneous Web Pages
 Template Extraction from Heterogeneous Web Pages 1 Mrs. Harshal H. Kulkarni, 2 Mrs. Manasi k. Kulkarni Asst. Professor, Pune University, (PESMCOE, Pune), Pune, India Abstract: Templates are used by many
Template Extraction from Heterogeneous Web Pages 1 Mrs. Harshal H. Kulkarni, 2 Mrs. Manasi k. Kulkarni Asst. Professor, Pune University, (PESMCOE, Pune), Pune, India Abstract: Templates are used by many
Similarity-based web clip matching
 Control and Cybernetics vol. 40 (2011) No. 3 Similarity-based web clip matching by Małgorzata Baczkiewicz, Danuta Łuczak and Maciej Zakrzewicz Poznań University of Technology, Institute of Computing Science
Control and Cybernetics vol. 40 (2011) No. 3 Similarity-based web clip matching by Małgorzata Baczkiewicz, Danuta Łuczak and Maciej Zakrzewicz Poznań University of Technology, Institute of Computing Science
A Two-Phase Rule Generation and Optimization Approach for Wrapper Generation
 A Two-Phase Rule Generation and Optimization Approach for Wrapper Generation Yanan Hao Yanchun Zhang School of Computer Science and Mathematics Victoria University Melbourne, VIC, Australia haoyn@csm.vu.edu.au
A Two-Phase Rule Generation and Optimization Approach for Wrapper Generation Yanan Hao Yanchun Zhang School of Computer Science and Mathematics Victoria University Melbourne, VIC, Australia haoyn@csm.vu.edu.au
Gestão e Tratamento da Informação
 Gestão e Tratamento da Informação Web Data Extraction: Automatic Wrapper Generation Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2010/2011 Outline Automatic Wrapper Generation
Gestão e Tratamento da Informação Web Data Extraction: Automatic Wrapper Generation Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2010/2011 Outline Automatic Wrapper Generation
Schema-Guided Wrapper Maintenance for Web-Data Extraction
 Schema-Guided Wrapper Maintenance for Web-Data Extraction Xiaofeng Meng, Dongdong Hu, Haiyan Wang School of Information, Renmin University of China, Beijing 100872, China xfmeng@mail.ruc.edu.cn Abstract
Schema-Guided Wrapper Maintenance for Web-Data Extraction Xiaofeng Meng, Dongdong Hu, Haiyan Wang School of Information, Renmin University of China, Beijing 100872, China xfmeng@mail.ruc.edu.cn Abstract
Mining Multiple Web Sources Using Non- Deterministic Finite State Automata
 University of Windsor Scholarship at UWindsor Electronic Theses and Dissertations 2012 Mining Multiple Web Sources Using Non- Deterministic Finite State Automata Mohammad Harun-Or-Rashid Follow this and
University of Windsor Scholarship at UWindsor Electronic Theses and Dissertations 2012 Mining Multiple Web Sources Using Non- Deterministic Finite State Automata Mohammad Harun-Or-Rashid Follow this and
CUM : An Efficient Framework for Mining Concept Units
 COMAD 2008 CUM : An Efficient Framework for Mining Concept Units By Mrs. Santhi Thilagam Department of Computer Engineering NITK - Surathkal Outline Introduction Problem statement Design and solution methodology
COMAD 2008 CUM : An Efficient Framework for Mining Concept Units By Mrs. Santhi Thilagam Department of Computer Engineering NITK - Surathkal Outline Introduction Problem statement Design and solution methodology
An UML-XML-RDB Model Mapping Solution for Facilitating Information Standardization and Sharing in Construction Industry
 An UML-XML-RDB Model Mapping Solution for Facilitating Information Standardization and Sharing in Construction Industry I-Chen Wu 1 and Shang-Hsien Hsieh 2 Department of Civil Engineering, National Taiwan
An UML-XML-RDB Model Mapping Solution for Facilitating Information Standardization and Sharing in Construction Industry I-Chen Wu 1 and Shang-Hsien Hsieh 2 Department of Civil Engineering, National Taiwan
A New Mode of Browsing Web Tables on Small Screens
 A New Mode of Browsing Web Tables on Small Screens Wenchang Xu, Xin Yang, Yuanchun Shi Department of Computer Science and Technology, Tsinghua University, Beijing, P.R. China stefanie8806@gmail.com; yang-x02@mails.tsinghua.edu.cn;
A New Mode of Browsing Web Tables on Small Screens Wenchang Xu, Xin Yang, Yuanchun Shi Department of Computer Science and Technology, Tsinghua University, Beijing, P.R. China stefanie8806@gmail.com; yang-x02@mails.tsinghua.edu.cn;
A NEW CLUSTER MERGING ALGORITHM OF SUFFIX TREE CLUSTERING
 A NEW CLUSTER MERGING ALGORITHM OF SUFFIX TREE CLUSTERING Jianhua Wang, Ruixu Li Computer Science Department, Yantai University, Yantai, Shandong, China Abstract: Key words: Document clustering methods
A NEW CLUSTER MERGING ALGORITHM OF SUFFIX TREE CLUSTERING Jianhua Wang, Ruixu Li Computer Science Department, Yantai University, Yantai, Shandong, China Abstract: Key words: Document clustering methods
International Journal of Research in Computer and Communication Technology, Vol 3, Issue 11, November
 Annotation Wrapper for Annotating The Search Result Records Retrieved From Any Given Web Database 1G.LavaRaju, 2Darapu Uma 1,2Dept. of CSE, PYDAH College of Engineering, Patavala, Kakinada, AP, India ABSTRACT:
Annotation Wrapper for Annotating The Search Result Records Retrieved From Any Given Web Database 1G.LavaRaju, 2Darapu Uma 1,2Dept. of CSE, PYDAH College of Engineering, Patavala, Kakinada, AP, India ABSTRACT:
DEVELOPMENT OF ONTOLOGY-BASED INTELLIGENT SYSTEM FOR SOFTWARE TESTING
 Abstract DEVELOPMENT OF ONTOLOGY-BASED INTELLIGENT SYSTEM FOR SOFTWARE TESTING A. Anandaraj 1 P. Kalaivani 2 V. Rameshkumar 3 1 &2 Department of Computer Science and Engineering, Narasu s Sarathy Institute
Abstract DEVELOPMENT OF ONTOLOGY-BASED INTELLIGENT SYSTEM FOR SOFTWARE TESTING A. Anandaraj 1 P. Kalaivani 2 V. Rameshkumar 3 1 &2 Department of Computer Science and Engineering, Narasu s Sarathy Institute
A Few Things to Know about Machine Learning for Web Search
 AIRS 2012 Tianjin, China Dec. 19, 2012 A Few Things to Know about Machine Learning for Web Search Hang Li Noah s Ark Lab Huawei Technologies Talk Outline My projects at MSRA Some conclusions from our research
AIRS 2012 Tianjin, China Dec. 19, 2012 A Few Things to Know about Machine Learning for Web Search Hang Li Noah s Ark Lab Huawei Technologies Talk Outline My projects at MSRA Some conclusions from our research
Indexing in Search Engines based on Pipelining Architecture using Single Link HAC
 Indexing in Search Engines based on Pipelining Architecture using Single Link HAC Anuradha Tyagi S. V. Subharti University Haridwar Bypass Road NH-58, Meerut, India ABSTRACT Search on the web is a daily
Indexing in Search Engines based on Pipelining Architecture using Single Link HAC Anuradha Tyagi S. V. Subharti University Haridwar Bypass Road NH-58, Meerut, India ABSTRACT Search on the web is a daily
ISSN: (Online) Volume 2, Issue 3, March 2014 International Journal of Advance Research in Computer Science and Management Studies
 Volume 2, Issue 3, March 2014 International Journal of Advance Research in Computer Science and Management Studies") ISSN: 2321-7782 (Online) Volume 2, Issue 3, March 2014 International Journal of Advance Research in Computer Science and Management Studies Research Article / Paper / Case Study Available online at: www.ijarcsms.com
ISSN: 2321-7782 (Online) Volume 2, Issue 3, March 2014 International Journal of Advance Research in Computer Science and Management Studies Research Article / Paper / Case Study Available online at: www.ijarcsms.com
SEMI-AUTOMATIC WRAPPER GENERATION AND ADAPTION Living with heterogeneity in a market environment
 SEMI-AUTOMATIC WRAPPER GENERATION AND ADAPTION Living with heterogeneity in a market environment Michael Christoffel, Bethina Schmitt, Jürgen Schneider Institute for Program Structures and Data Organization,
SEMI-AUTOMATIC WRAPPER GENERATION AND ADAPTION Living with heterogeneity in a market environment Michael Christoffel, Bethina Schmitt, Jürgen Schneider Institute for Program Structures and Data Organization,
Heading-Based Sectional Hierarchy Identification for HTML Documents
 Heading-Based Sectional Hierarchy Identification for HTML Documents 1 Dept. of Computer Engineering, Boğaziçi University, Bebek, İstanbul, 34342, Turkey F. Canan Pembe 1,2 and Tunga Güngör 1 2 Dept. of
Heading-Based Sectional Hierarchy Identification for HTML Documents 1 Dept. of Computer Engineering, Boğaziçi University, Bebek, İstanbul, 34342, Turkey F. Canan Pembe 1,2 and Tunga Güngör 1 2 Dept. of
An Automatic Extraction of Educational Digital Objects and Metadata from institutional Websites
 An Automatic Extraction of Educational Digital Objects and Metadata from institutional Websites Kajal K. Nandeshwar 1, Praful B. Sambhare 2 1M.E. IInd year, Dept. of Computer Science, P. R. Pote College
An Automatic Extraction of Educational Digital Objects and Metadata from institutional Websites Kajal K. Nandeshwar 1, Praful B. Sambhare 2 1M.E. IInd year, Dept. of Computer Science, P. R. Pote College
HTML Extraction Algorithm Based on Property and Data Cell
 IOP Conference Series: Materials Science and Engineering OPEN ACCESS HTML Extraction Algorithm Based on Property and Data Cell To cite this article: Detty Purnamasari et al 2013 IOP Conf. Ser.: Mater.
IOP Conference Series: Materials Science and Engineering OPEN ACCESS HTML Extraction Algorithm Based on Property and Data Cell To cite this article: Detty Purnamasari et al 2013 IOP Conf. Ser.: Mater.
Information Integration for the Masses
 Information Integration for the Masses Jim Blythe Dipsy Kapoor Craig A. Knoblock Kristina Lerman USC Information Sciences Institute 4676 Admiralty Way, Marina del Rey, CA 90292 Steven Minton Fetch Technologies
Information Integration for the Masses Jim Blythe Dipsy Kapoor Craig A. Knoblock Kristina Lerman USC Information Sciences Institute 4676 Admiralty Way, Marina del Rey, CA 90292 Steven Minton Fetch Technologies
Distributed Data Anonymization with Hiding Sensitive Node Labels
 Distributed Data Anonymization with Hiding Sensitive Node Labels C.EMELDA Research Scholar, PG and Research Department of Computer Science, Nehru Memorial College, Putthanampatti, Bharathidasan University,Trichy
Distributed Data Anonymization with Hiding Sensitive Node Labels C.EMELDA Research Scholar, PG and Research Department of Computer Science, Nehru Memorial College, Putthanampatti, Bharathidasan University,Trichy
A Hierarchical Document Clustering Approach with Frequent Itemsets
 A Hierarchical Document Clustering Approach with Frequent Itemsets Cheng-Jhe Lee, Chiun-Chieh Hsu, and Da-Ren Chen Abstract In order to effectively retrieve required information from the large amount of
A Hierarchical Document Clustering Approach with Frequent Itemsets Cheng-Jhe Lee, Chiun-Chieh Hsu, and Da-Ren Chen Abstract In order to effectively retrieve required information from the large amount of
An Approach to Resolve Data Model Heterogeneities in Multiple Data Sources
 Edith Cowan University Research Online ECU Publications Pre. 2011 2006 An Approach to Resolve Data Model Heterogeneities in Multiple Data Sources Chaiyaporn Chirathamjaree Edith Cowan University 10.1109/TENCON.2006.343819
Edith Cowan University Research Online ECU Publications Pre. 2011 2006 An Approach to Resolve Data Model Heterogeneities in Multiple Data Sources Chaiyaporn Chirathamjaree Edith Cowan University 10.1109/TENCON.2006.343819
Data Extraction and Alignment in Web Databases
 Data Extraction and Alignment in Web Databases Mrs K.R.Karthika M.Phil Scholar Department of Computer Science Dr N.G.P arts and science college Coimbatore,India Mr K.Kumaravel Ph.D Scholar Department of
Data Extraction and Alignment in Web Databases Mrs K.R.Karthika M.Phil Scholar Department of Computer Science Dr N.G.P arts and science college Coimbatore,India Mr K.Kumaravel Ph.D Scholar Department of
MetaNews: An Information Agent for Gathering News Articles On the Web
 MetaNews: An Information Agent for Gathering News Articles On the Web Dae-Ki Kang 1 and Joongmin Choi 2 1 Department of Computer Science Iowa State University Ames, IA 50011, USA dkkang@cs.iastate.edu
MetaNews: An Information Agent for Gathering News Articles On the Web Dae-Ki Kang 1 and Joongmin Choi 2 1 Department of Computer Science Iowa State University Ames, IA 50011, USA dkkang@cs.iastate.edu
THE STUDY OF WEB MINING - A SURVEY
 THE STUDY OF WEB MINING - A SURVEY Ashish Gupta, Anil Khandekar Abstract over the year s web mining is the very fast growing research field. Web mining contains two research areas: Data mining and World
THE STUDY OF WEB MINING - A SURVEY Ashish Gupta, Anil Khandekar Abstract over the year s web mining is the very fast growing research field. Web mining contains two research areas: Data mining and World
Exploiting Background Knowledge to Build Reference Sets for Information Extraction
 Exploiting Background Knowledge to Build Reference Sets for Information Extraction Matthew Michelson & Craig A. Knoblock Fetch Technologies* USC Information Sciences Institute * Work done while at USC
Exploiting Background Knowledge to Build Reference Sets for Information Extraction Matthew Michelson & Craig A. Knoblock Fetch Technologies* USC Information Sciences Institute * Work done while at USC
Leopold Franzens University Innsbruck. Ontology Learning. Institute of Computer Science STI - Innsbruck. Seminar Paper
 Leopold Franzens University Innsbruck Institute of Computer Science STI - Innsbruck Ontology Learning Seminar Paper Applied Ontology Engineering (WS 2010) Supervisor: Dr. Katharina Siorpaes Michael Rogger
Leopold Franzens University Innsbruck Institute of Computer Science STI - Innsbruck Ontology Learning Seminar Paper Applied Ontology Engineering (WS 2010) Supervisor: Dr. Katharina Siorpaes Michael Rogger
RoadRunner for Heterogeneous Web Pages Using Extended MinHash
 RoadRunner for Heterogeneous Web Pages Using Extended MinHash A Suresh Babu 1, P. Premchand 2 and A. Govardhan 3 1 Department of Computer Science and Engineering, JNTUACE Pulivendula, India asureshjntu@gmail.com
RoadRunner for Heterogeneous Web Pages Using Extended MinHash A Suresh Babu 1, P. Premchand 2 and A. Govardhan 3 1 Department of Computer Science and Engineering, JNTUACE Pulivendula, India asureshjntu@gmail.com
Trends for Web Information Processing over World Wide Web
 Trends for Web Information Processing over World Wide Web Dr. Harmunish Taneja M.M. Engineering College, M.M. University, Mullana, Ambala Dr. Kavita Taneja M.M.I.C.T. & B.M. M.M. University, Mullana, Ambala
Trends for Web Information Processing over World Wide Web Dr. Harmunish Taneja M.M. Engineering College, M.M. University, Mullana, Ambala Dr. Kavita Taneja M.M.I.C.T. & B.M. M.M. University, Mullana, Ambala