The Hilbert Problems of Computer Vision. Jitendra Malik UC Berkeley & Google, Inc.
|
|
|
- Theodore Barnett
- 6 years ago
- Views:
Transcription

1 The Hilbert Problems of Computer Vision Jitendra Malik UC Berkeley & Google, Inc.
2 This talk The computational power of the human brain Research is the art of the soluble Hilbert problems, circa 2004 Hilbert problems, circa 2015
3 Moravec s argument(1998) ROBOT: Mere Machine To Transcendent Mind 1 neuron = 1000 instructions/sec 1 synapse = 1 byte of information Human brain then processes 10^14 IPS and has 10^14 bytes of storage In 2000, we have 10^9 IPS and 10^9 bytes on a desktop machine Assuming Moore s law we obtain human level computing power in 2025, or with a cluster of 100 nodes in 2015.
4
5 Neural network architectures Getting Deeper All The Time Alexnet: Krizhevsky, Sutskever & Hinton (2012) Zeiler & Fergus (2013) VGG: Simonyan and Zisserman(2014) Googlenet: Szegedy et al (2014) ResNet: He et al (2015) My talk will focus on a higher level of abstraction


6 Research is the Art of the Soluble
7 The Hilbert Problems of Computer Vision Jitendra Malik Jitendra Malik Presented at Bay Area Vision Meeting, UC Santa Cruz, 2004
8 Forty years of computer vision s: Beginnings in artificial intelligence, image processing and pattern recognition 1970s: Foundational work on image formation: Horn, Koenderink, Longuet-Higgins 1980s: Vision as applied mathematics: geometry, multi-scale analysis, control theory, optimization 1990s: Geometric analysis largely completed Probabilistic/Learning approaches in full swing Successful applications in graphics, biometrics, HCI
9 And now Back to basics: the classic problem of understanding the scene from its image/s Central question: Interplay of bottom-up and top-down information
10 Early Vision What can we learn from image statistics that we didn't know already? How far can bottom-up image segmentation go? How do we make inferences from shading and texture patterns in natural images?
11 Static Scene Understanding What is the interaction between segmentation and recognition? What is the interaction between scenes, objects, and parts? What is the role of design vs. learning in recognition systems?
12 Dynamic Scene Understanding What is the role of high-level knowledge in long range motion correspondence? How do we find and track articulated structures? How do we represent "movemes" and actions?
13 With the benefit of hindsight
14 Early Vision What can we learn from image statistics that we didn't know already? Training a deep multi layer neural network on a supervised learning task develops general representations How far can bottom-up image segmentation go? Can produce a small set of object proposals which can then be assigned labels by a classifier. Sliding windows no longer necessary How do we make inferences from shading and texture patterns in natural images? Instead of trying to model inverse optics, we can use learning. If there is a sparsityof data, one needs to use priors with few parameters, given enough data one can use nonparametric techniques like neural networks
15 Static Scene Understanding What is the interaction between segmentation and recognition? Bidirectional Information Flow What is the interaction between scenes, objects, and parts? Still Open. Context has not yet lived up to its promise. What is the role of design vs. learning in recognition systems? Learn as much as you can from data. Don t design features. Design architectures.
16 The Three R s of Vision Recognition Reconstruction Reorganization Each of the 6 directed arcs in this diagram is a useful direction of information flow



 We")


17 Simultaneous Detection & Segmentation Hariharan, Arbelaez, Girshick & Malik (2014,2015) We mark the pixels corresponding to an object instance, not just its bounding box.
18 Dynamic Scene Understanding What is the role of high-level knowledge in long range motion correspondence? How to find good correspondences can be learnt. An extreme case is Flownet (Brox), which shows how even optical flow computation can be learnt. How do we find and track articulated structures? Great progress in finding human keypoints How do we represent "movemes" and actions? Still open. We don t understand the hierarchical structure of activity and events
19 Human Pose Estimation with Iterative Error Feedback Joao Carreira Pulkit Agrawal Katerina Fragkiadaki Jitendra Malik

20
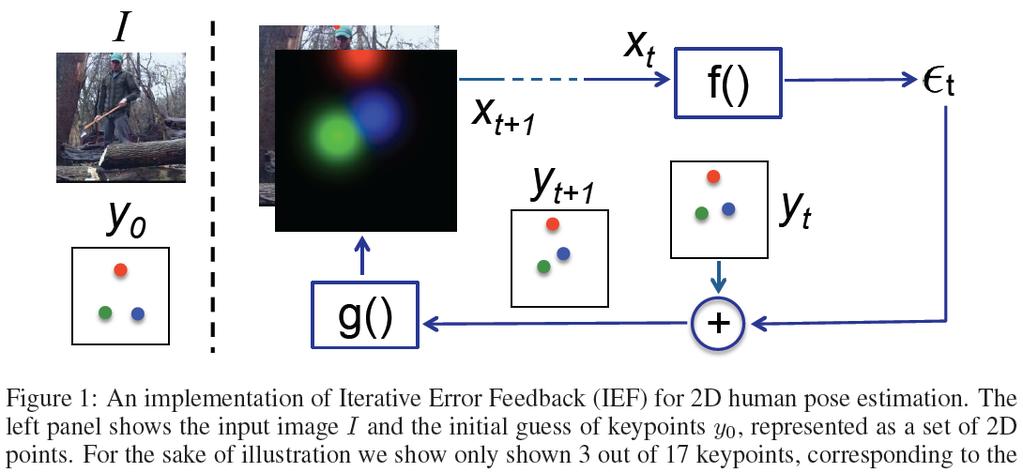
21

22
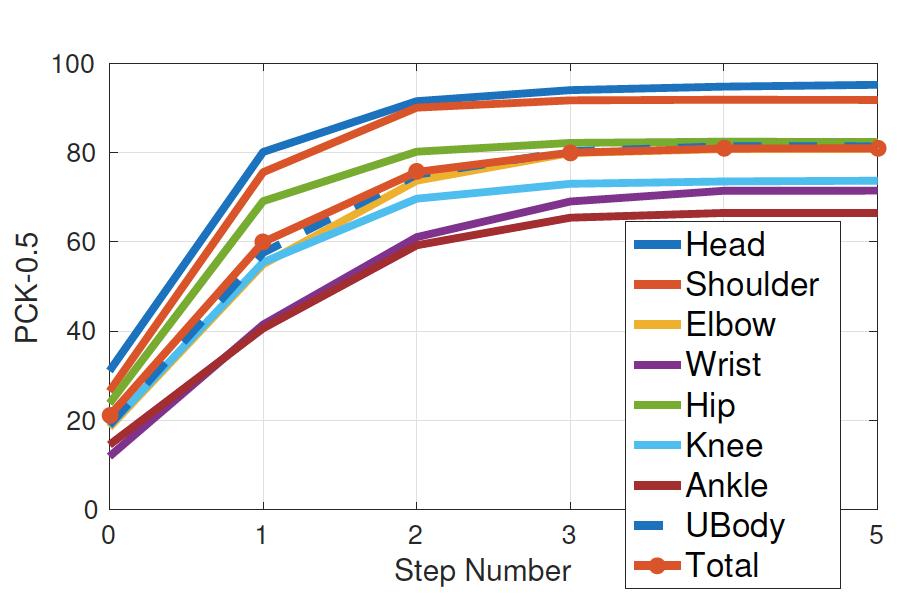
23
24 Results on MPI dataset assuming person scale is known (upper) or unknown(lower)
25 The (new) Hilbert Problems of Computer Vision Jitendra Malik Jitendra Malik Workshop, Santiago, 2015
26 People, Places and Things Model every place in the world Model every object category Model humans and develop algorithms for social perception




27 Reconstructing the world Over the past 10 years, 3D modeling from images has made huge advances in scale, quality, and generality. We can reconstruct scenes automatically from huge collections of photos downloaded from the Internet Snavely, Seitz, Szeliski. Reconstructing the World from Internet Photo Collections.

28 Reconstructing the world Over the past 10 years, 3D modeling from images has made huge advances in scale, quality, and generality. We can reconstruct scenes that vary over time Matzen & Snavely. Scene Chronology. ECCV 2014

29 Reconstructing the world Over the past 10 years, 3D modeling from images has made huge advances in scale, quality, and generality. We can reconstruct scenes that vary over time Matzen & Snavely. Scene Chronology. ECCV 2014 Martin-Brualla, Gallup, Seitz. Time-lapse Mining from Internet Photos.


30 Reconstructing the great indoors using Semantic Reconstruction of Rooms and Objects rendering 3D mesh point cloud using Depth Cameras Choi, Zhou, Koltun. Robust Reconstruction of Indoor Scenes. CVPR 2015 Ikehata, Yan, Furukawa. Structured Indoor Modeling. ICCV 2015

31 ShapeNet (Stanford & Princeton)





32 Image 3D Reconstruction from a Single Image Kar, Tulsiani, Carreira & Malik (2015) R-CNN, SDS Object Detection and Instance Segmentation Girshick et al., Hariharan et al. CVPR 2014 CVPR 2015 Viewpoints and Keypoints Tulsiani Viewpoint & Malik, Estimation CVPR 2015 car car Deformable 3D model High Frequency Depth Map Category Specific 3D Reconstruction

33 Basis Shape Models
34 Social Perception Computers today have pitifully low social intelligence We need to understand the internal state of humans as they interact with each other and the external world Examples: emotional state, body language, current goals.
35 Towards Human-Level AI First let s look at the evidence from Child Development
36 The Development of Embodied Cognition: Six Lessons from Babies Linda Smith & Michael Gasser
37 The Six Lessons Be multi-modal Be incremental Be physical Explore Be social Use language An example: Learning to see by moving, P. Agrawal, J. Carreira, J. Malik (ICCV 2015)
38 Towards Human-Level AI Perceptual Robotics Visual Grounding of Language Acquire Visual Commonsense from Observation and Interaction
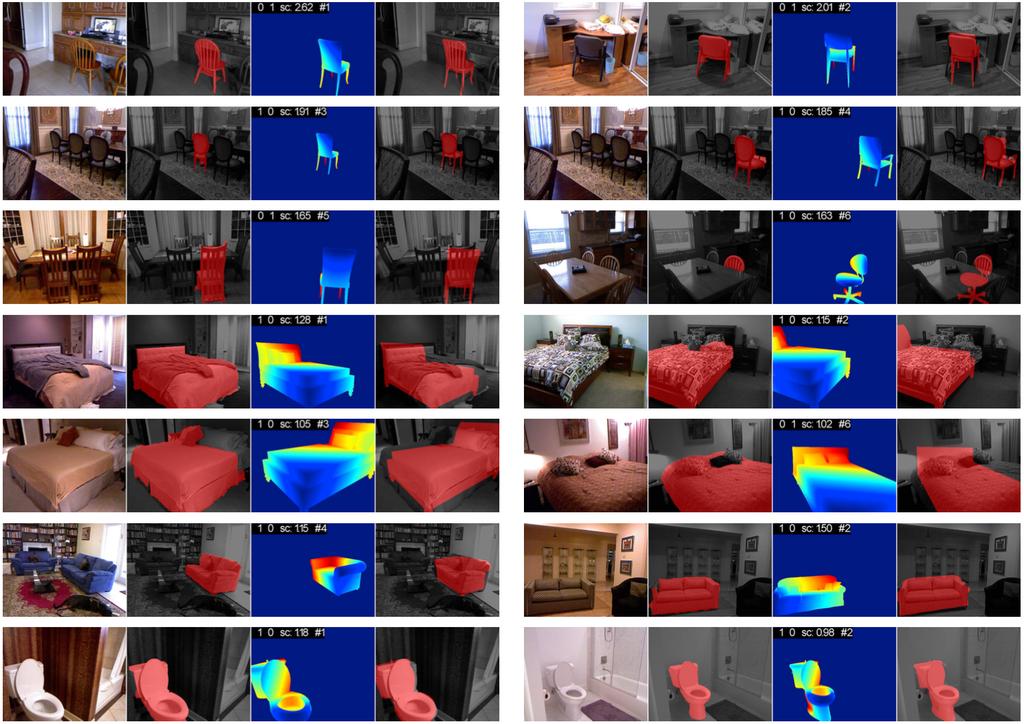
39 Scene Understanding from RGB-D Images Object Detection, Instance Segmentation & Pose Estimation Saurabh Gupta, Ross Girshick, Pablo Arbeláez, Jitendra Malik UC Berkeley






40 Input Re-organization Recognition Detailed 3D Understanding Contour Detection Semantic Segm. Color and Depth Image Pair Region Proposal Generation Object Detection Instance Segm. Pose Estimation 40





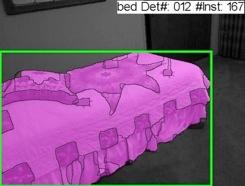















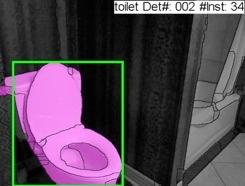

41 Instance Segmentation
42

43

44

45 What we would like to infer Will person B put some money into Person C s tip bag?


46
")
47 Labeling Gupta & Malik (2015)
48 Events e.g. A meal at a restaurant Classical AI/Cognitive Science Solution Schemas (frames, scripts etc.) To have a robust, visually grounded solution we need to learn the equivalent from video + Knowledge Graph like structures Perhaps best tackled in particular domains e.g. team sports, instructional videos etc.
49 Core problems in vision Relationship between parts, objects and scenes The hierarchical structure of human behaviormovement, goals, actions and events ACTION = MOVEMENT + GOAL
50 Core problems in learning Should learning be done end-to-end for specific tasks (no semantics for intermediate layers) or do we want intermediate representations to emerge driven by the need to solve multiple tasks? Why are neural network solutions so remarkably replicable? Why do we not get stuck in bad local minima? What is a taxonomy of learning problems that is aligned with what we know from child development?
51 The best is yet to come.. Let s meet again in 2025
ECCV Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016
 ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
Multi-view stereo. Many slides adapted from S. Seitz
 Multi-view stereo Many slides adapted from S. Seitz Beyond two-view stereo The third eye can be used for verification Multiple-baseline stereo Pick a reference image, and slide the corresponding window
Multi-view stereo Many slides adapted from S. Seitz Beyond two-view stereo The third eye can be used for verification Multiple-baseline stereo Pick a reference image, and slide the corresponding window
Fuzzy Set Theory in Computer Vision: Example 3
 Fuzzy Set Theory in Computer Vision: Example 3 Derek T. Anderson and James M. Keller FUZZ-IEEE, July 2017 Overview Purpose of these slides are to make you aware of a few of the different CNN architectures
Fuzzy Set Theory in Computer Vision: Example 3 Derek T. Anderson and James M. Keller FUZZ-IEEE, July 2017 Overview Purpose of these slides are to make you aware of a few of the different CNN architectures
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Computer Vision Lecture 16
 Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Deep learning for dense per-pixel prediction. Chunhua Shen The University of Adelaide, Australia
 Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
3D Shape Analysis with Multi-view Convolutional Networks. Evangelos Kalogerakis
 3D Shape Analysis with Multi-view Convolutional Networks Evangelos Kalogerakis 3D model repositories [3D Warehouse - video] 3D geometry acquisition [KinectFusion - video] 3D shapes come in various flavors
3D Shape Analysis with Multi-view Convolutional Networks Evangelos Kalogerakis 3D model repositories [3D Warehouse - video] 3D geometry acquisition [KinectFusion - video] 3D shapes come in various flavors
LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS
 LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS Alexey Dosovitskiy, Jost Tobias Springenberg and Thomas Brox University of Freiburg Presented by: Shreyansh Daftry Visual Learning and Recognition
LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS Alexey Dosovitskiy, Jost Tobias Springenberg and Thomas Brox University of Freiburg Presented by: Shreyansh Daftry Visual Learning and Recognition
Introduction to Computer Vision. Srikumar Ramalingam School of Computing University of Utah
 Introduction to Computer Vision Srikumar Ramalingam School of Computing University of Utah srikumar@cs.utah.edu Course Website http://www.eng.utah.edu/~cs6320/ What is computer vision? Light source 3D
Introduction to Computer Vision Srikumar Ramalingam School of Computing University of Utah srikumar@cs.utah.edu Course Website http://www.eng.utah.edu/~cs6320/ What is computer vision? Light source 3D
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
An Exploration of Computer Vision Techniques for Bird Species Classification
 An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
The most cited papers in Computer Vision
 COMPUTER VISION, PUBLICATION The most cited papers in Computer Vision In Computer Vision, Paper Talk on February 10, 2012 at 11:10 pm by gooly (Li Yang Ku) Although it s not always the case that a paper
COMPUTER VISION, PUBLICATION The most cited papers in Computer Vision In Computer Vision, Paper Talk on February 10, 2012 at 11:10 pm by gooly (Li Yang Ku) Although it s not always the case that a paper
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Deformable Part Models
 CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
EECS 442 Computer Vision fall 2011
 EECS 442 Computer Vision fall 2011 Instructor Silvio Savarese silvio@eecs.umich.edu Office: ECE Building, room: 4435 Office hour: Tues 4:30-5:30pm or under appoint. (after conversation hour) GSIs: Mohit
EECS 442 Computer Vision fall 2011 Instructor Silvio Savarese silvio@eecs.umich.edu Office: ECE Building, room: 4435 Office hour: Tues 4:30-5:30pm or under appoint. (after conversation hour) GSIs: Mohit
Large Scale 3D Reconstruction by Structure from Motion
 Large Scale 3D Reconstruction by Structure from Motion Devin Guillory Ziang Xie CS 331B 7 October 2013 Overview Rome wasn t built in a day Overview of SfM Building Rome in a Day Building Rome on a Cloudless
Large Scale 3D Reconstruction by Structure from Motion Devin Guillory Ziang Xie CS 331B 7 October 2013 Overview Rome wasn t built in a day Overview of SfM Building Rome in a Day Building Rome on a Cloudless
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK
 TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
Martian lava field, NASA, Wikipedia
 Martian lava field, NASA, Wikipedia Old Man of the Mountain, Franconia, New Hampshire Pareidolia http://smrt.ccel.ca/203/2/6/pareidolia/ Reddit for more : ) https://www.reddit.com/r/pareidolia/top/ Pareidolia
Martian lava field, NASA, Wikipedia Old Man of the Mountain, Franconia, New Hampshire Pareidolia http://smrt.ccel.ca/203/2/6/pareidolia/ Reddit for more : ) https://www.reddit.com/r/pareidolia/top/ Pareidolia
Visual features detection based on deep neural network in autonomous driving tasks
 430 Fomin I., Gromoshinskii D., Stepanov D. Visual features detection based on deep neural network in autonomous driving tasks Ivan Fomin, Dmitrii Gromoshinskii, Dmitry Stepanov Computer vision lab Russian
430 Fomin I., Gromoshinskii D., Stepanov D. Visual features detection based on deep neural network in autonomous driving tasks Ivan Fomin, Dmitrii Gromoshinskii, Dmitry Stepanov Computer vision lab Russian
Seeing the unseen. Data-driven 3D Understanding from Single Images. Hao Su
 Seeing the unseen Data-driven 3D Understanding from Single Images Hao Su Image world Shape world 3D perception from a single image Monocular vision a typical prey a typical predator Cited from https://en.wikipedia.org/wiki/binocular_vision
Seeing the unseen Data-driven 3D Understanding from Single Images Hao Su Image world Shape world 3D perception from a single image Monocular vision a typical prey a typical predator Cited from https://en.wikipedia.org/wiki/binocular_vision
Seeing 3D chairs: Exemplar part-based 2D-3D alignment using a large dataset of CAD models
 Seeing 3D chairs: Exemplar part-based 2D-3D alignment using a large dataset of CAD models Mathieu Aubry (INRIA) Daniel Maturana (CMU) Alexei Efros (UC Berkeley) Bryan Russell (Intel) Josef Sivic (INRIA)
Seeing 3D chairs: Exemplar part-based 2D-3D alignment using a large dataset of CAD models Mathieu Aubry (INRIA) Daniel Maturana (CMU) Alexei Efros (UC Berkeley) Bryan Russell (Intel) Josef Sivic (INRIA)
Computer vision: teaching computers to see
 Computer vision: teaching computers to see Mats Sjöberg Department of Computer Science Aalto University mats.sjoberg@aalto.fi Turku.AI meetup June 5, 2018 Computer vision Giving computers the ability to
Computer vision: teaching computers to see Mats Sjöberg Department of Computer Science Aalto University mats.sjoberg@aalto.fi Turku.AI meetup June 5, 2018 Computer vision Giving computers the ability to
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS. Zhao Chen Machine Learning Intern, NVIDIA
 JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
CS 395T Numerical Optimization for Graphics and AI (3D Vision) Qixing Huang August 29 th 2018
 Qixing Huang August 29 th 2018") CS 395T Numerical Optimization for Graphics and AI (3D Vision) Qixing Huang August 29 th 2018 3D Vision Understanding geometric relations between images and the 3D world between images Obtaining 3D information
CS 395T Numerical Optimization for Graphics and AI (3D Vision) Qixing Huang August 29 th 2018 3D Vision Understanding geometric relations between images and the 3D world between images Obtaining 3D information
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
Miniature faking. In close-up photo, the depth of field is limited.
 Miniature faking In close-up photo, the depth of field is limited. http://en.wikipedia.org/wiki/file:jodhpur_tilt_shift.jpg Miniature faking Miniature faking http://en.wikipedia.org/wiki/file:oregon_state_beavers_tilt-shift_miniature_greg_keene.jpg
Miniature faking In close-up photo, the depth of field is limited. http://en.wikipedia.org/wiki/file:jodhpur_tilt_shift.jpg Miniature faking Miniature faking http://en.wikipedia.org/wiki/file:oregon_state_beavers_tilt-shift_miniature_greg_keene.jpg
Deep Learning for Virtual Shopping. Dr. Jürgen Sturm Group Leader RGB-D
 Deep Learning for Virtual Shopping Dr. Jürgen Sturm Group Leader RGB-D metaio GmbH Augmented Reality with the Metaio SDK: IKEA Catalogue App Metaio: Augmented Reality Metaio SDK for ios, Android and Windows
Deep Learning for Virtual Shopping Dr. Jürgen Sturm Group Leader RGB-D metaio GmbH Augmented Reality with the Metaio SDK: IKEA Catalogue App Metaio: Augmented Reality Metaio SDK for ios, Android and Windows
INTRODUCTION TO DEEP LEARNING
 INTRODUCTION TO DEEP LEARNING CONTENTS Introduction to deep learning Contents 1. Examples 2. Machine learning 3. Neural networks 4. Deep learning 5. Convolutional neural networks 6. Conclusion 7. Additional
INTRODUCTION TO DEEP LEARNING CONTENTS Introduction to deep learning Contents 1. Examples 2. Machine learning 3. Neural networks 4. Deep learning 5. Convolutional neural networks 6. Conclusion 7. Additional
Learning with Side Information through Modality Hallucination
 Master Seminar Report for Recent Trends in 3D Computer Vision Learning with Side Information through Modality Hallucination Judy Hoffman, Saurabh Gupta, Trevor Darrell. CVPR 2016 Nan Yang Supervisor: Benjamin
Master Seminar Report for Recent Trends in 3D Computer Vision Learning with Side Information through Modality Hallucination Judy Hoffman, Saurabh Gupta, Trevor Darrell. CVPR 2016 Nan Yang Supervisor: Benjamin
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Spontaneously Emerging Object Part Segmentation
 Spontaneously Emerging Object Part Segmentation Yijie Wang Machine Learning Department Carnegie Mellon University yijiewang@cmu.edu Katerina Fragkiadaki Machine Learning Department Carnegie Mellon University
Spontaneously Emerging Object Part Segmentation Yijie Wang Machine Learning Department Carnegie Mellon University yijiewang@cmu.edu Katerina Fragkiadaki Machine Learning Department Carnegie Mellon University
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Convolutional Neural Networks + Neural Style Transfer. Justin Johnson 2/1/2017
 Convolutional Neural Networks + Neural Style Transfer Justin Johnson 2/1/2017 Outline Convolutional Neural Networks Convolution Pooling Feature Visualization Neural Style Transfer Feature Inversion Texture
Convolutional Neural Networks + Neural Style Transfer Justin Johnson 2/1/2017 Outline Convolutional Neural Networks Convolution Pooling Feature Visualization Neural Style Transfer Feature Inversion Texture
Computer Vision: Making machines see
 Computer Vision: Making machines see Roberto Cipolla Department of Engineering http://www.eng.cam.ac.uk/~cipolla/people.html http://www.toshiba.eu/eu/cambridge-research- Laboratory/ Vision: what is where
Computer Vision: Making machines see Roberto Cipolla Department of Engineering http://www.eng.cam.ac.uk/~cipolla/people.html http://www.toshiba.eu/eu/cambridge-research- Laboratory/ Vision: what is where
Part-Based Models for Object Class Recognition Part 3
 High Level Computer Vision! Part-Based Models for Object Class Recognition Part 3 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de! http://www.d2.mpi-inf.mpg.de/cv ! State-of-the-Art
High Level Computer Vision! Part-Based Models for Object Class Recognition Part 3 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de! http://www.d2.mpi-inf.mpg.de/cv ! State-of-the-Art
Image-Based Modeling and Rendering
 Image-Based Modeling and Rendering Richard Szeliski Microsoft Research IPAM Graduate Summer School: Computer Vision July 26, 2013 How far have we come? Light Fields / Lumigraph - 1996 Richard Szeliski
Image-Based Modeling and Rendering Richard Szeliski Microsoft Research IPAM Graduate Summer School: Computer Vision July 26, 2013 How far have we come? Light Fields / Lumigraph - 1996 Richard Szeliski
Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet.
 Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet 7D Labs VINNOVA https://7dlabs.com Photo-realistic image synthesis
Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet 7D Labs VINNOVA https://7dlabs.com Photo-realistic image synthesis
Lecture 12 Recognition
 Institute of Informatics Institute of Neuroinformatics Lecture 12 Recognition Davide Scaramuzza 1 Lab exercise today replaced by Deep Learning Tutorial Room ETH HG E 1.1 from 13:15 to 15:00 Optional lab
Institute of Informatics Institute of Neuroinformatics Lecture 12 Recognition Davide Scaramuzza 1 Lab exercise today replaced by Deep Learning Tutorial Room ETH HG E 1.1 from 13:15 to 15:00 Optional lab
Perceiving the 3D World from Images and Videos. Yu Xiang Postdoctoral Researcher University of Washington
 Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task
 Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task Kyunghee Kim Stanford University 353 Serra Mall Stanford, CA 94305 kyunghee.kim@stanford.edu Abstract We use a
Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task Kyunghee Kim Stanford University 353 Serra Mall Stanford, CA 94305 kyunghee.kim@stanford.edu Abstract We use a
Bilinear Models for Fine-Grained Visual Recognition
 Bilinear Models for Fine-Grained Visual Recognition Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst Fine-grained visual recognition Example: distinguish
Bilinear Models for Fine-Grained Visual Recognition Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst Fine-grained visual recognition Example: distinguish
Study of Residual Networks for Image Recognition
 Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
Deep Incremental Scene Understanding. Federico Tombari & Christian Rupprecht Technical University of Munich, Germany
 Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Fully Convolutional Network for Depth Estimation and Semantic Segmentation
 Fully Convolutional Network for Depth Estimation and Semantic Segmentation Yokila Arora ICME Stanford University yarora@stanford.edu Ishan Patil Department of Electrical Engineering Stanford University
Fully Convolutional Network for Depth Estimation and Semantic Segmentation Yokila Arora ICME Stanford University yarora@stanford.edu Ishan Patil Department of Electrical Engineering Stanford University
Photo-realistic Renderings for Machines Seong-heum Kim
 Photo-realistic Renderings for Machines 20105034 Seong-heum Kim CS580 Student Presentations 2016.04.28 Photo-realistic Renderings for Machines Scene radiances Model descriptions (Light, Shape, Material,
Photo-realistic Renderings for Machines 20105034 Seong-heum Kim CS580 Student Presentations 2016.04.28 Photo-realistic Renderings for Machines Scene radiances Model descriptions (Light, Shape, Material,
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Su et al. Shape Descriptors - III
 Su et al. Shape Descriptors - III Siddhartha Chaudhuri http://www.cse.iitb.ac.in/~cs749 Funkhouser; Feng, Liu, Gong Recap Global A shape descriptor is a set of numbers that describes a shape in a way that
Su et al. Shape Descriptors - III Siddhartha Chaudhuri http://www.cse.iitb.ac.in/~cs749 Funkhouser; Feng, Liu, Gong Recap Global A shape descriptor is a set of numbers that describes a shape in a way that
Deep Learning in Image Processing
 Deep Learning in Image Processing Roland Memisevic University of Montreal & TwentyBN ICISP 2016 Roland Memisevic Deep Learning in Image Processing ICISP 2016 f 2? cathedral high-rise f 1 It s the features,
Deep Learning in Image Processing Roland Memisevic University of Montreal & TwentyBN ICISP 2016 Roland Memisevic Deep Learning in Image Processing ICISP 2016 f 2? cathedral high-rise f 1 It s the features,
Photo Tourism: Exploring Photo Collections in 3D
 Photo Tourism: Exploring Photo Collections in 3D SIGGRAPH 2006 Noah Snavely Steven M. Seitz University of Washington Richard Szeliski Microsoft Research 2006 2006 Noah Snavely Noah Snavely Reproduced with
Photo Tourism: Exploring Photo Collections in 3D SIGGRAPH 2006 Noah Snavely Steven M. Seitz University of Washington Richard Szeliski Microsoft Research 2006 2006 Noah Snavely Noah Snavely Reproduced with
3D Computer Vision. Structured Light II. Prof. Didier Stricker. Kaiserlautern University.
 3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
Augmenting Reality, Naturally:
 Augmenting Reality, Naturally: Scene Modelling, Recognition and Tracking with Invariant Image Features by Iryna Gordon in collaboration with David G. Lowe Laboratory for Computational Intelligence Department
Augmenting Reality, Naturally: Scene Modelling, Recognition and Tracking with Invariant Image Features by Iryna Gordon in collaboration with David G. Lowe Laboratory for Computational Intelligence Department
Notes 9: Optical Flow
 Course 049064: Variational Methods in Image Processing Notes 9: Optical Flow Guy Gilboa 1 Basic Model 1.1 Background Optical flow is a fundamental problem in computer vision. The general goal is to find
Course 049064: Variational Methods in Image Processing Notes 9: Optical Flow Guy Gilboa 1 Basic Model 1.1 Background Optical flow is a fundamental problem in computer vision. The general goal is to find
What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today?
 Introduction What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today? What are we trying to achieve? Example from Scott Satkin 3D interpretation
Introduction What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today? What are we trying to achieve? Example from Scott Satkin 3D interpretation
Dense 3D Reconstruction. Christiano Gava
 Dense 3D Reconstruction Christiano Gava christiano.gava@dfki.de Outline Previous lecture: structure and motion II Structure and motion loop Triangulation Today: dense 3D reconstruction The matching problem
Dense 3D Reconstruction Christiano Gava christiano.gava@dfki.de Outline Previous lecture: structure and motion II Structure and motion loop Triangulation Today: dense 3D reconstruction The matching problem
Computer Vision. From traditional approaches to deep neural networks. Stanislav Frolov München,
 Computer Vision From traditional approaches to deep neural networks Stanislav Frolov München, 27.02.2018 Outline of this talk What we are going to talk about Computer vision Human vision Traditional approaches
Computer Vision From traditional approaches to deep neural networks Stanislav Frolov München, 27.02.2018 Outline of this talk What we are going to talk about Computer vision Human vision Traditional approaches
3D Object Recognition and Scene Understanding from RGB-D Videos. Yu Xiang Postdoctoral Researcher University of Washington
 3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
Learning from 3D Data
 Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Learning Semantic Environment Perception for Cognitive Robots
 Learning Semantic Environment Perception for Cognitive Robots Sven Behnke University of Bonn, Germany Computer Science Institute VI Autonomous Intelligent Systems Some of Our Cognitive Robots Equipped
Learning Semantic Environment Perception for Cognitive Robots Sven Behnke University of Bonn, Germany Computer Science Institute VI Autonomous Intelligent Systems Some of Our Cognitive Robots Equipped
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting
 Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting R. Maier 1,2, K. Kim 1, D. Cremers 2, J. Kautz 1, M. Nießner 2,3 Fusion Ours 1
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting R. Maier 1,2, K. Kim 1, D. Cremers 2, J. Kautz 1, M. Nießner 2,3 Fusion Ours 1
Object detection with CNNs
 Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Training models for road scene understanding with automated ground truth Dan Levi
 Training models for road scene understanding with automated ground truth Dan Levi With: Noa Garnett, Ethan Fetaya, Shai Silberstein, Rafi Cohen, Shaul Oron, Uri Verner, Ariel Ayash, Kobi Horn, Vlad Golder,
Training models for road scene understanding with automated ground truth Dan Levi With: Noa Garnett, Ethan Fetaya, Shai Silberstein, Rafi Cohen, Shaul Oron, Uri Verner, Ariel Ayash, Kobi Horn, Vlad Golder,
Does the Brain do Inverse Graphics?
 Does the Brain do Inverse Graphics? Geoffrey Hinton, Alex Krizhevsky, Navdeep Jaitly, Tijmen Tieleman & Yichuan Tang Department of Computer Science University of Toronto The representation used by the
Does the Brain do Inverse Graphics? Geoffrey Hinton, Alex Krizhevsky, Navdeep Jaitly, Tijmen Tieleman & Yichuan Tang Department of Computer Science University of Toronto The representation used by the
Deep Learning in Visual Recognition. Thanks Da Zhang for the slides
 Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Visual Computing TUM
 Visual Computing Group @ TUM Visual Computing Group @ TUM BundleFusion Real-time 3D Reconstruction Scalable scene representation Global alignment and re-localization TOG 17 [Dai et al.]: BundleFusion Real-time
Visual Computing Group @ TUM Visual Computing Group @ TUM BundleFusion Real-time 3D Reconstruction Scalable scene representation Global alignment and re-localization TOG 17 [Dai et al.]: BundleFusion Real-time
VISION FOR AUTOMOTIVE DRIVING
 VISION FOR AUTOMOTIVE DRIVING French Japanese Workshop on Deep Learning & AI, Paris, October 25th, 2017 Quoc Cuong PHAM, PhD Vision and Content Engineering Lab AI & MACHINE LEARNING FOR ADAS AND SELF-DRIVING
VISION FOR AUTOMOTIVE DRIVING French Japanese Workshop on Deep Learning & AI, Paris, October 25th, 2017 Quoc Cuong PHAM, PhD Vision and Content Engineering Lab AI & MACHINE LEARNING FOR ADAS AND SELF-DRIVING
Yiqi Yan. May 10, 2017
 Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
Flow-Based Video Recognition
 Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
Unsupervised Deep Learning. James Hays slides from Carl Doersch and Richard Zhang
 Unsupervised Deep Learning James Hays slides from Carl Doersch and Richard Zhang Recap from Previous Lecture We saw two strategies to get structured output while using deep learning With object detection,
Unsupervised Deep Learning James Hays slides from Carl Doersch and Richard Zhang Recap from Previous Lecture We saw two strategies to get structured output while using deep learning With object detection,
CS 4758: Automated Semantic Mapping of Environment
 CS 4758: Automated Semantic Mapping of Environment Dongsu Lee, ECE, M.Eng., dl624@cornell.edu Aperahama Parangi, CS, 2013, alp75@cornell.edu Abstract The purpose of this project is to program an Erratic
CS 4758: Automated Semantic Mapping of Environment Dongsu Lee, ECE, M.Eng., dl624@cornell.edu Aperahama Parangi, CS, 2013, alp75@cornell.edu Abstract The purpose of this project is to program an Erratic
Part Localization by Exploiting Deep Convolutional Networks
 Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Why equivariance is better than premature invariance
 1 Why equivariance is better than premature invariance Geoffrey Hinton Canadian Institute for Advanced Research & Department of Computer Science University of Toronto with contributions from Sida Wang
1 Why equivariance is better than premature invariance Geoffrey Hinton Canadian Institute for Advanced Research & Department of Computer Science University of Toronto with contributions from Sida Wang
Part-Based Models for Object Class Recognition Part 2
 High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
Part-Based Models for Object Class Recognition Part 2
 High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
Lecture 12 Recognition. Davide Scaramuzza
 Lecture 12 Recognition Davide Scaramuzza Oral exam dates UZH January 19-20 ETH 30.01 to 9.02 2017 (schedule handled by ETH) Exam location Davide Scaramuzza s office: Andreasstrasse 15, 2.10, 8050 Zurich
Lecture 12 Recognition Davide Scaramuzza Oral exam dates UZH January 19-20 ETH 30.01 to 9.02 2017 (schedule handled by ETH) Exam location Davide Scaramuzza s office: Andreasstrasse 15, 2.10, 8050 Zurich
Learning Photographic Image Synthesis With Cascaded Refinement Networks. Jonathan Louie Huy Doan Siavash Motalebi
 Learning Photographic Image Synthesis With Cascaded Refinement Networks Jonathan Louie Huy Doan Siavash Motalebi Introduction and Background Intro We are researching and re-implementing Photographic Image
Learning Photographic Image Synthesis With Cascaded Refinement Networks Jonathan Louie Huy Doan Siavash Motalebi Introduction and Background Intro We are researching and re-implementing Photographic Image
Lecture 5: Object Detection
 Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Dense 3D Reconstruction. Christiano Gava
 Dense 3D Reconstruction Christiano Gava christiano.gava@dfki.de Outline Previous lecture: structure and motion II Structure and motion loop Triangulation Wide baseline matching (SIFT) Today: dense 3D reconstruction
Dense 3D Reconstruction Christiano Gava christiano.gava@dfki.de Outline Previous lecture: structure and motion II Structure and motion loop Triangulation Wide baseline matching (SIFT) Today: dense 3D reconstruction
Real Time Monitoring of CCTV Camera Images Using Object Detectors and Scene Classification for Retail and Surveillance Applications
 Real Time Monitoring of CCTV Camera Images Using Object Detectors and Scene Classification for Retail and Surveillance Applications Anand Joshi CS229-Machine Learning, Computer Science, Stanford University,
Real Time Monitoring of CCTV Camera Images Using Object Detectors and Scene Classification for Retail and Surveillance Applications Anand Joshi CS229-Machine Learning, Computer Science, Stanford University,
Smart Parking System using Deep Learning. Sheece Gardezi Supervised By: Anoop Cherian Peter Strazdins
 Smart Parking System using Deep Learning Sheece Gardezi Supervised By: Anoop Cherian Peter Strazdins Content Labeling tool Neural Networks Visual Road Map Labeling tool Data set Vgg16 Resnet50 Inception_v3
Smart Parking System using Deep Learning Sheece Gardezi Supervised By: Anoop Cherian Peter Strazdins Content Labeling tool Neural Networks Visual Road Map Labeling tool Data set Vgg16 Resnet50 Inception_v3
Local-Level 3D Deep Learning. Andy Zeng
 Local-Level 3D Deep Learning Andy Zeng 1 Matching 3D Data Image Credits: Song and Xiao, Tevs et al. 2 Matching 3D Data Reconstruction Image Credits: Song and Xiao, Tevs et al. 3 Matching 3D Data Reconstruction
Local-Level 3D Deep Learning Andy Zeng 1 Matching 3D Data Image Credits: Song and Xiao, Tevs et al. 2 Matching 3D Data Reconstruction Image Credits: Song and Xiao, Tevs et al. 3 Matching 3D Data Reconstruction
Does the Brain do Inverse Graphics?
 Does the Brain do Inverse Graphics? Geoffrey Hinton, Alex Krizhevsky, Navdeep Jaitly, Tijmen Tieleman & Yichuan Tang Department of Computer Science University of Toronto How to learn many layers of features
Does the Brain do Inverse Graphics? Geoffrey Hinton, Alex Krizhevsky, Navdeep Jaitly, Tijmen Tieleman & Yichuan Tang Department of Computer Science University of Toronto How to learn many layers of features
Dynamic Routing Between Capsules
 Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Reconstructive Sparse Code Transfer for Contour Detection and Semantic Labeling
 Reconstructive Sparse Code Transfer for Contour Detection and Semantic Labeling Michael Maire 1,2 Stella X. Yu 3 Pietro Perona 2 1 TTI Chicago 2 California Institute of Technology 3 University of California
Reconstructive Sparse Code Transfer for Contour Detection and Semantic Labeling Michael Maire 1,2 Stella X. Yu 3 Pietro Perona 2 1 TTI Chicago 2 California Institute of Technology 3 University of California
Topics to be Covered in the Rest of the Semester. CSci 4968 and 6270 Computational Vision Lecture 15 Overview of Remainder of the Semester
 Topics to be Covered in the Rest of the Semester CSci 4968 and 6270 Computational Vision Lecture 15 Overview of Remainder of the Semester Charles Stewart Department of Computer Science Rensselaer Polytechnic
Topics to be Covered in the Rest of the Semester CSci 4968 and 6270 Computational Vision Lecture 15 Overview of Remainder of the Semester Charles Stewart Department of Computer Science Rensselaer Polytechnic
Towards Real-Time Automatic Number Plate. Detection: Dots in the Search Space
 Towards Real-Time Automatic Number Plate Detection: Dots in the Search Space Chi Zhang Department of Computer Science and Technology, Zhejiang University wellyzhangc@zju.edu.cn Abstract Automatic Number
Towards Real-Time Automatic Number Plate Detection: Dots in the Search Space Chi Zhang Department of Computer Science and Technology, Zhejiang University wellyzhangc@zju.edu.cn Abstract Automatic Number
Encoder-Decoder Networks for Semantic Segmentation. Sachin Mehta
 Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
When Big Datasets are Not Enough: The need for visual virtual worlds.
 When Big Datasets are Not Enough: The need for visual virtual worlds. Alan Yuille Bloomberg Distinguished Professor Departments of Cognitive Science and Computer Science Johns Hopkins University Computational
When Big Datasets are Not Enough: The need for visual virtual worlds. Alan Yuille Bloomberg Distinguished Professor Departments of Cognitive Science and Computer Science Johns Hopkins University Computational
Where s Waldo? A Deep Learning approach to Template Matching
 Where s Waldo? A Deep Learning approach to Template Matching Thomas Hossler Department of Geological Sciences Stanford University thossler@stanford.edu Abstract We propose a new approach to Template Matching
Where s Waldo? A Deep Learning approach to Template Matching Thomas Hossler Department of Geological Sciences Stanford University thossler@stanford.edu Abstract We propose a new approach to Template Matching
Actions and Attributes from Wholes and Parts
 Actions and Attributes from Wholes and Parts Georgia Gkioxari UC Berkeley gkioxari@berkeley.edu Ross Girshick Microsoft Research rbg@microsoft.com Jitendra Malik UC Berkeley malik@berkeley.edu Abstract
Actions and Attributes from Wholes and Parts Georgia Gkioxari UC Berkeley gkioxari@berkeley.edu Ross Girshick Microsoft Research rbg@microsoft.com Jitendra Malik UC Berkeley malik@berkeley.edu Abstract
Storyline Reconstruction for Unordered Images
 Introduction: Storyline Reconstruction for Unordered Images Final Paper Sameedha Bairagi, Arpit Khandelwal, Venkatesh Raizaday Storyline reconstruction is a relatively new topic and has not been researched
Introduction: Storyline Reconstruction for Unordered Images Final Paper Sameedha Bairagi, Arpit Khandelwal, Venkatesh Raizaday Storyline reconstruction is a relatively new topic and has not been researched
Computer Vision and Remote Sensing. Lessons Learned
 Computer Vision and Remote Sensing Lessons Learned 1 Department of Photogrammetry Institute for Geodesy and Geoinformation Universtity Bonn Outline Photogrammetry and its relatives Remote Sensing: the
Computer Vision and Remote Sensing Lessons Learned 1 Department of Photogrammetry Institute for Geodesy and Geoinformation Universtity Bonn Outline Photogrammetry and its relatives Remote Sensing: the
Data-driven Depth Inference from a Single Still Image
 Data-driven Depth Inference from a Single Still Image Kyunghee Kim Computer Science Department Stanford University kyunghee.kim@stanford.edu Abstract Given an indoor image, how to recover its depth information
Data-driven Depth Inference from a Single Still Image Kyunghee Kim Computer Science Department Stanford University kyunghee.kim@stanford.edu Abstract Given an indoor image, how to recover its depth information
Colored Point Cloud Registration Revisited Supplementary Material
 Colored Point Cloud Registration Revisited Supplementary Material Jaesik Park Qian-Yi Zhou Vladlen Koltun Intel Labs A. RGB-D Image Alignment Section introduced a joint photometric and geometric objective
Colored Point Cloud Registration Revisited Supplementary Material Jaesik Park Qian-Yi Zhou Vladlen Koltun Intel Labs A. RGB-D Image Alignment Section introduced a joint photometric and geometric objective
12/3/2009. What is Computer Vision? Applications. Application: Assisted driving Pedestrian and car detection. Application: Improving online search
 Introduction to Artificial Intelligence V22.0472-001 Fall 2009 Lecture 26: Computer Vision Rob Fergus Dept of Computer Science, Courant Institute, NYU Slides from Andrew Zisserman What is Computer Vision?
Introduction to Artificial Intelligence V22.0472-001 Fall 2009 Lecture 26: Computer Vision Rob Fergus Dept of Computer Science, Courant Institute, NYU Slides from Andrew Zisserman What is Computer Vision?
The Three R s of Vision
 The Three R s of Vision Recognition Reconstruction Reorganization Jitendra Malik UC Berkeley Recognition, Reconstruction & Reorganization Recognition Reconstruction Reorganization Fifty years of computer
The Three R s of Vision Recognition Reconstruction Reorganization Jitendra Malik UC Berkeley Recognition, Reconstruction & Reorganization Recognition Reconstruction Reorganization Fifty years of computer
Detection and Fine 3D Pose Estimation of Texture-less Objects in RGB-D Images
 Detection and Pose Estimation of Texture-less Objects in RGB-D Images Tomáš Hodaň1, Xenophon Zabulis2, Manolis Lourakis2, Šťěpán Obdržálek1, Jiří Matas1 1 Center for Machine Perception, CTU in Prague,
Detection and Pose Estimation of Texture-less Objects in RGB-D Images Tomáš Hodaň1, Xenophon Zabulis2, Manolis Lourakis2, Šťěpán Obdržálek1, Jiří Matas1 1 Center for Machine Perception, CTU in Prague,