Pose-Invariant Face Alignment with a Single CNN
|
|
|
- Valerie Hill
- 6 years ago
- Views:
Transcription



1 Pose-Invariant Face Alignment with a Single CNN Amin Jourabloo 1, Mao Ye 2, Xiaoming Liu 1, and Liu Ren 2 1 Department of Computer Science and Engineering, Michigan State University, MI 2 Bosch Research North America, Palo Alto, CA 1,2 {jourablo, liuxm}@msu.edu, {mao.ye2, liu.ren}@us.bosch.com Abstract Face alignment has witnessed substantial progress in the last decade. One of the recent focuses has been aligning a dense 3D face shape to face images with large head poses. The dominant technology used is based on the cascade of regressors, e.g., CNNs, which has shown promising results. Nonetheless, the cascade of CNNs suffers from several drawbacks, e.g., lack of end-to-end training, handcrafted features and slow training speed. To address these issues, we propose a new layer, named visualization layer, which can be integrated into the CNN architecture and enables joint optimization with different loss functions. Extensive evaluation of the proposed method on multiple datasets demonstrates state-of-the-art accuracy, while reducing the training time by more than half compared to the typical cascade of CNNs. In addition, we compare across multiple CNN architectures, all with the visualization layer, to further demonstrate the advantage of its utilization. 1. Introduction Face alignment, also known as face landmark detection, is an essential process for many facial analysis tasks, such as face recognition [36], expression estimation [1] and 3D face reconstruction [20, 30]. During the last decade, face alignment technologies have been substantially improved [8 10, 32, 41]. One recent advancement in this area is to tackle challenging cases with large face poses, e.g., profile views with±90 yaw angles [18, 19, 23, 24, 47, 50]. The dominant technology for large-pose face alignment (LPFA) utilizes a cascade of regressors which combines different types of regression designs [23, 49, 50] with feature extraction methods [18]. At each stage of this procedure, the target, e.g., the 2D landmarks or the head pose, as well as the 3D face shape, are refined by regress- This work was performed mostly during the first author s internship at Bosch Research North America, Palo Alto, CA. (a) Figure 1. For the purpose of learning an end-to-end face alignment model, our novel visualization layer reconstructs the 3D face shape (a) from the estimated inside the CNN and synthesizes a 2D image (b) via the surface normal vectors of visible vertexes. ing an update of these. Due to the proven power of Convolutional Neural Network (CNN) in vision tasks, it is also adopted as the regressor in this framework and has achieved the state-of-the-art performance on face alignment [18, 23, 34, 50]. Despite the recent success, the cascade of CNNs, when applied to LPFA, still suffers from the following drawbacks. Lack of end-to-end training: It is a consensus that endto-end training is desired for CNN [6, 14]. However, in the existing methods, the CNNs are typically trained independently at each cascade stage. Sometimes even multiple CNNs are applied independently at each stage. For example, locations of different landmark sets are estimated by various CNNs and combined via a separate fusing module [33]. Therefore, these CNNs can not be jointly optimized and might lead to a sub-optimal solution. Hand-crafted feature extraction: Since the CNNs are trained independently, feature extraction is required to utilize the result of a previous CNN and provide input to the current CNN. Simple feature extraction methods are used, e.g., extracting patches based on2d or3d face shapes without considering other factors including pose and expression [33, 45]. Normally, the cascade of CNNs is a collection of shallow CNNs where each one has less than five layers. Hence, this framework can not extract deep features by building upon the extracted features of early-stage CNNs. Slow training speed: Training a cascade of CNNs is (b) 1
2 usually time-consuming for two reasons. Firstly, the CNNs are trained sequentially, one after another. Secondly, feature extraction is required between two consecutive CNNs. To address these issues, we introduce a novel layer, as shown in Figure 1. Our CNN architecture consists of several blocks, which are called visualization blocks. This architecture can be considered as a cascade of shallow CNNs. The new layer visualizes the alignment result of a previous visualization block and utilizes it in a later visualization block. It is designed based on several guidelines. Firstly, it is derived from the surface normals of the underlying 3D face model and encodes the relative pose between the face and camera, partially inspired by the success of using surface normals for 3D face recognition [25]. Secondly, the visualization layer is differentiable, which allows the gradient to be computed analytically and enables end-to-end training. Lastly, a mask is utilized to differentiate between pixels in the middle and contour areas of a face. Benefiting from the design of the visualization layer, our method has the following advantages and contributions: The proposed method allows a block in the CNN to utilize the extracted features from previous blocks and extract deeper features. Therefore, extraction of hand-crafted features is no longer necessary. The visualization layer is differentiable, allowing for backpropagation of an error from a later block to an earlier one. To the best of our knowledge, this is the first method for large-pose face alignment, that utilizes only one single CNN and allows end-to-end training. The proposed method converges faster during the training phase compared to the cascade of CNNs. Therefore, the training time is dramatically reduced.. 2. Prior Work In this section, we review related work in three topics: cascade of regressors for face alignment, convolutional recurrent neural network and visualization in deep learning. Cascade of Regressors for Face Alignment Cascade of Regressors is a classic approach in not only conventional face alignment [44, 51], but also the large-pose face alignment [13, 17, 39, 49]. To handle large poses, many approaches go beyond 2D landmarks and also estimate 3D landmarks and 3D face shapes [18, 50]. Zhu et al. [49] use a set of local regressors to estimate the 2D shape update, and fuse their results with another regressor. The occlusioninvariant approach of RCPR [5] is applicable to large poses since self-occlusion is one type of occlusions. An iterative probabilistic method is utilized in [11, 15] for registering 3D shape to the pre-computed 2D landmarks. Tulyakov et al. [35] also use a cascade of regressors to estimate3d landmark updates directly from a single image. Some even use The source code of the proposed method with the trained model are released here. two regressors at each cascade stage. Wu et al. [39] use one regressor to estimate the2d shape update and the other to estimate the visibility of each landmark. Similarly, Liu et al. [23] employ one regressor for 2D shape update and the other uses the2d shape to estimate the3d face shape. Among methods with cascade of regressors, CNN is a popular choice of regressor due to its strong learning ability. These methods typically extract hand-crafted features between consecutive regressors. TCDCN [46] uses one CNN to estimate five landmarks, with yaw angles within ±60. A cascade of stacked autoencoder (SAE) progressively estimates 2D landmark updates from extracted patches [45]. Similarly, cascades of CNNs with global or local patches are combined at each stage, and their results are fused via averaging [33, 48]. The methods in [18, 19, 50] combine cascade of CNNs with3d feature extraction to estimate the dense 3D face shape. All aforementioned methods lack the ability to end-to-end train the network, which is our novel contribution to large-pose face alignment. Convolutional Recurrent Neural Network (CRNN) Methods based on CRNNs [34, 37, 40] are the first attempts to combine cascade of regressors with joint optimization, for aligning mostly frontal faces. Their convolutional part extracts features from the whole image [40] or from the patches at the landmark locations [34]. The recurrent part facilitates the joint optimization by sharing information among all regressors. The main differences between the proposed method and CRNNs are: 1) existing CRNN methods are designed for near-frontal face alignment, while ours is for LPFA; 2) the CRNN methods share the same CNN at all stages, while our CNN of each block is different which might be more suitable for estimating the coarse-tofine mappings during the course of alignment; 3) due to our new differentiable visualization layer, our method has one additional flow of the gradient back-propagation (note the two blue arrows between consectutive blocks in Figure 2). in Deep Learning techniques have been used in deep learning to assist in making a relative comparison among the input data and focusing on the region of interest. One category of these methods exploits the deconvolutional and upsampling layers to either expand response maps [22, 28] or represent estimated [43]. Alternatively, various types of feature maps, e.g., heatmaps and Z-Buffering, can represent the current estimation of landmarks and. In [4, 26, 38], 2D landmark heatmaps represent the landmarks locations. [4] proposes a two step large pose alignment based on heatmaps to make more precise estimations. The heatmaps suffer from three drawbacks: 1) lack of the capability to represent objects in details; 2) requirement of one heatmap per landmark due to its weak representation power. 3) they cannot estimate visibility of landmarks. The Z-Buffer rendered using the estimated 3D face is also used to convey the re-

![Please refer to Figure 3 for the details of the visualization block. sults of a previous CNN to the next one [50].](/docs-images/74/69642180/images/3-1.jpg "However, the Z-Buffer representation is not differentiable, preventing end-to-end training.")


3 , Estimated, Layer Layer Layer Figure 2. The proposed CNN architecture. We use green, orange, and purple to represent the visualization layer, convolutional layer, and fully connected layer, respectively. Please refer to Figure 3 for the details of the visualization block. sults of a previous CNN to the next one [50]. However, the Z-Buffer representation is not differentiable, preventing end-to-end training. In contrast, our visualization layer is differentiable and encodes the face geometry details via surface normals. It guides the CNN to focus on the face area that incorporates both the pose and expression information. 3. Proposed Method Given a single face image with an arbitrary pose, our goal is to estimate the 2D landmarks with their visibility labels by fitting a3d face model. Towards this end, we propose a CNN architecture with end-to-end training for model fitting, as shown in Figure 2. In this section, we will first describe the underlying 3D face model used in this work, followed by our CNN architecture and the visualization layer D and 2D Face Shapes We use the 3D Morphable Model (3DMM) to represent the 3D shape of a face S p as a linear combination of mean shape S 0, identity bases S I and expression bases S E : N I N E S p = S 0 + p I ks I k + p E k S E k. (1) k We use vector p = [p I, p E ] to indicate the3d shape, where p I = [p I 0,,p I N I ] are the identity and p E = [p E 0,,p E N E ] are the expression. We use the Basel 3D face model [27], which has 199 bases, as our identity bases and the face wearhouse model [7] with29 bases as our expression bases. Each 3D face shape consists of a set of Q 3D vertexes: S p = k x p 1 x p 2... x p Q y p 1 y p 2... y p Q z p 1 z p 2... z p Q. (2) The 2D face shapes are the projection of 3D shapes. In this work, we use the weak perspective projection model with 6 degrees of freedoms, i.e., one for scale, three for rotation angles and two for translations, which projects the 3D face shape S p onto2d images to obtain the2d shape U: U = f(p) = M ( Sp (:, b) 1 ), (3) where and M = [ ] m1 m 2 m 3 m 4, (4) m 5 m 6 m 7 m 8 U = ( x t 1 x t 2... x t N y t 1 y t 2... y t N ). (5) Here U is a set of N 2D landmarks, M is the camera projection matrix. With misuse of notation, we define the target P = {M, p}. The N-dim vector b includes 3D vertex indexes which are semantically corresponding to 2D landmarks. We denote m 1 = [m 1 m 2 m 3 ] and m 2 = [m 5 m 6 m 7 ] as the first two rows of the scaled rotation component, whilem 4 and m 8 are the translations. Equation 3 establishs the relationship, or equivalency, between 2D landmarks U and P, i.e., 3D shape p and the camera projection matrix M. Given that almost all the training images for face alignment have only 2D labels, i.e., U, we preform a data augmentation step similar to [18] to compute their corresponding P. Given an input image, our goal is to estimate the parameter P, based on which the 2D landmarks and their visibilities can be naturally derived Proposed CNN Architecture Our CNN architecture resembles the cascade of CNNs, while each shallow CNN is defined as a visualization block. Inside each block, a visualization layer based on the latest parameter estimation serves as a bridge between consecutive blocks. This design enables us to address the drawbacks of typical cascade of CNNs in Section 1. We now describe the visualization block and CNN architecture, and dive into the details of the visualization layer in Section 3.3. Figure 3 shows the structure of our visualization block. The visualization layer generates a feature map based on the latest parameter P (details in Section 3.3). Each convolutional layer is followed by a batch normalization (BN) layer and a ReLU layer. It extracts deeper features based on the features provided by the previous visualization block and the visualization layer output. Between the two fully connected layers, the first one is followed by a ReLU layer and a dropout layer, while the
4 Type equation here. input features current 2 convolutional, BN, ReLU layers deeper features updated visualization layer 2 fully connected, ReLU, dropout layers Figure 3. A visualization block consists of a visualization layer, two convolutional layers and two fully connected layers. second one simultaneously estimates the update of M and p, denoted P. The outputs of the visualization block are deeper features and the new estimation of the ( P+P). As shown in Figure 3, the top part of the visualization block focuses on learning deeper features, while the bottom part utilizes those features to estimate the in a ResNet-like structure [12]. During the backward pass of the training phase, the visualization block backpropagates the loss through both of its inputs to adjust the convolutional and the fully connected layers in previous blocks. This allows the block to extract better features for the next block and improve the overall parameter estimation. CNN Architecture The proposed architecture consists of several connected visualization blocks as shown in Figure 2. The inputs include an image and an initial estimation of the parameter P 0. The outputs is the final estimation of the parameter. Due to the joint optimization of all visualization blocks through backpropagation, the proposed architecture is able to converge with substantially fewer epochs during training, compared to the typical cascade of CNNs. Loss Functions Two types of loss functions are employed in our CNN architecture. The first one is an Euclidean loss between the estimation and the target of the parameter update, with each parameter weighted separately: E i P = ( P i P i ) T W( P i P i ), (6) where E i P is the loss, P i is the estimation and P i is the target (or ground truth) at the i-th visualization block. The diagonal matrix W contains the weights. For each element of the shape parameter p, its weight is the inverse of the standard deviation that was obtained from the data used in 3DMM training. To compensate the relative scale among the of M, we compute the ratio r between the average of scaled rotation and average of translation in the training data. We set the weights of the scaled rotation of M to 1 r and the weights of the translation of M to 1. The second type of loss function is the Euclidean loss on the resultant2d landmarks: E i S = f(p i + P i ) Ū 2, (7) where Ū is the ground truth2d landmarks, and P i is the input parameter to thei-th block, i.e., the output of thei 1-th block. f( ) computes2d landmark locations using the currently updated via Equation 3. For backpropagation of this loss function to the parameter P, we use the chain rule to compute the gradient. Figure 4. The frontal and side views of the mask a that has positive values in the middle and negative values in the contour area. E i S P i = Ei S f f P i. For the first three visualization blocks, the Euclidean loss on the parameter updates (Equation 6) is used, while the Euclidean loss on2d landmarks (Equation 7) is applied to the last three blocks. The first three blocks estimate to roughly align3d shape to the face image and the last three blocks leverage the good initialization to estimate the and the2d landmark locations more precisely Layer Several visualization techniques have been explored for facial analysis. In particular, Z-Buffering, which is widely used in prior works [2, 3], is a simple and fast 2D representation of the 3D shape. However, this representation is not differentiable. In contrast, our visualization is based on surface normals of the 3D face, which describes surface s orientation in a local neighbourhoods. It has been successfully utilized for different facial analysis tasks, e.g., 3D face reconstruction [30] and3d face recognition [25]. In this work, we use the z coordinate of surface normals of each vertex, transformed with the pose. It is an indicator of frontability of a vertex, i.e., the amount that the surface normal is pointing towards the camera. This quantity is used to assign an intensity value at its projected 2D location to construct the visualization image. The frontability measure g, a Q dimensional vector, can be computed as, g = max ( 0, (m 1 m 2 ) m 1 m 2 N 0 ), (8) where is the cross product, and. denotes the L 2 norm. The 3 Q matrix N 0 is the surface normal vectors of a 3D face shape. To avoid the high computational cost of calculating the surface normals after each shape update, we approximate N 0 with the surface normals of the mean3d face. Note that both the face shape and pose are still continuously updated across visualization blocks, and are used to determine the projected 2D location. Hence, this approximation would only slightly affect the intensity values. To transform the surface normal based on the pose, we apply the estimation of the scaled rotation matrix (m 1 and m 2 ) to the surface normals computed from the mean face. The value is then truncated with the lower bound of0(equation 8).
 t, (9) where D(u,v) is the set of indexes of vertexes whose 2D projected locations are within the local neighborhood of the pixel (u,v).")
 and the projected location (x t q,yq), t w(u,v,x t q,y t q) = exp ( (u xt q) 2 +(v y t q) 2 2σ 2 ).")
 p 2 +(z n zq) p 2, 2σ 2 n (11) where (x n,y n,z n ) is the vertex coordinate of the nose tip. a is pre-computed and normalized for zero-mean and unit standard deviation.")
5 The pixel intensity of a visualized image V(u,v) is computed as the weighted average of the frontability measures within a local neighbourhood: q D(u,v) V(u,v) = g(q)a(q)w(u,v,xt q,yq) t q D(u,v) w(u,v,xt q,yq) t, (9) where D(u,v) is the set of indexes of vertexes whose 2D projected locations are within the local neighborhood of the pixel (u,v). (x t q,yq) t is the 2D projected location of q-th 3D vertex. The weightw is the distance metric between the pixel(u,v) and the projected location (x t q,yq), t w(u,v,x t q,y t q) = exp ( (u xt q) 2 +(v y t q) 2 2σ 2 ). (10) The Q-dim vector a is a mask with positive values for vertexes in the middle area of the face and negative values for vertexes around ( the contour area of the face: ) a(q) = exp (xn x p q) 2 +(y n yq) p 2 +(z n zq) p 2, 2σ 2 n (11) where (x n,y n,z n ) is the vertex coordinate of the nose tip. a is pre-computed and normalized for zero-mean and unit standard deviation. The mask is utilized to discriminate between the middle and contour areas of the face. A visualization of the mask is provided in Figure 4. Since the human face is a 3D object, visualizing it at an arbitrary view angle requires the estimation of the visibility of each 3D vertex. To avoid the computationally expensive visibility test via rendering, we adopt two strategies for approximation. Firstly, we prune the vertexes whose frontability measures g equal 0, i.e., the vertexes pointing against the camera. Secondly, if multiple vertexes projects to a same image pixel, we keep only the one with the smallest depth values. An illustration is provided in Figure 5. Backpropagation To allow backpropagation of the loss functions through the visualization layers, we compute the derivative of V with respect to the elements of the M and p. Firstly, we compute the partial derivatives, g m k, w(u,v,xt i,yt i ) m k and w(u,v,xt i,yt i ) p j. Then the derivatives of V m k and V p j can be computed based on Equation Experimental Results We evaluate our method on two challenging LPFA datasets, AFLW and AFW, both qualitatively and quantitatively, as well as the near-frontal face dataset of 300W. Furthermore, we conduct experiments on different CNN architectures to validate our visualization layer design. Implementation details Our implementation is built upon the Caffe toolbox [16]. In all of the experiments, we use six visualization blocks (N v ) with two convolutional layers (N c ) and fully connected layers in each block (Figure 3). Details of the network structure are provided in Table 1. Normal vectors with negative z Normal vector with positive z and smaller depth Figure 5. An example with four vertexes projected to a same pixel. Two of them have negative values inz component of their normals (red arrows). Between the other two with positive values, the one with the smaller depth (closer to the image plane) is selected. Instead of using the sequentially pretrain strategy [42], we perform the joint end-to-end training from scratch. To better estimate the parameter update in each block and to increase the effectiveness when using visualization blocks, we set the weight of the loss function in the first visualization block to 1 and linearly increase the weights by one for each later block. This strategy helps the CNN to pay more attention to the landmark loss used in later blocks. Backpropagation of loss functions in the last blocks would have more impact in the first block, and the last block can adopt itself more quickly to the changes in the first block. In the training phase, we set the weight decay to 0.005, the momentum to0.99, the initial learning rate to1e 6. Besides, we decrease the learning rate to 5e 6 and 1e 7 after 20 and 29 epochs. In total, the training phase is continued for33 epochs for all experiments Quantitative Evaluations on AFLW and AFW The AFLW dataset [21] is very challenging with largepose face images (±90 yaw). We use the subset with3,901 training images and 1, 299 testing images released by [18]. All face images in this subset are labeled with34 landmarks and a bounding box. The AFW dataset [51] contains 205 images with 468 faces. Each image is labeled with at most 6 landmarks with visibility labels, as well as a bounding box. AFW is used only for testing in our experiments. The bounding boxes in both datasets are used as the initilization for our algorithm, as well as the baselines. We crop the region inside the bounding box and normalize it to Due to the memory constraint of GPUs, we have a pooling layer in the first visualization block after the first convolutional layer to decrease the size of feature maps to half. The input to the subsequent visualization blocks is Table 1. The number and size of convolutional filters in each visualization block. For all blocks, the two fully connected layers have the same length of800 and 236. # ,6 Conv. 12 (5 5) 20 (3 3) 28 (3 3) 36 (3 3) 40 (3 3) layers 16 (5 5) 24 (3 3) 32 (3 3) 40 (3 3) 40 (3 3)
6 Table 2. NME (%) of four methods on the AFLW dataset. Proposed method LPFA [18] PIFA RCPR Table 3. NME (%) of the proposed method at each visualization block on AFLW dataset. The initial NME is 25.8%. # NME of To augment the training data, we generate 20 different variations for each training image by adding noise to the location, width and height of the bounding boxes. For quantitative evaluations, we use two conventional metrics. The first one is Mean Average Pixel Error (MAPE) [44], which is the average of the pixel errors for the visible landmarks. The other one is Normalized Mean Error (NME), i.e., the average of the normalized estimation error of visible landmarks. The normalization factor is the square root of the face bounding box size [17], instead of the eye-to-eye distance in the frontal-view face alignment. We compare our method with several state-of-the-art LFPA approaches. On AFLW, we compare with LPFA [18], PIFA [17] and RCPR [5] with the NME metric. Table 2 shows that our proposed method achieves a higher accuracy than the alternatives. The heatmap-based method, named CALE [4], reported an NME of 2.96%, but suffers from several disadvantages as discussed in Section 2. To demonstrate the capabilities of each visualization block, the NME computed using the estimated P after each block is shown in Table 3. If a higher alignment speed is desirable, it is possible to skip the last two visualization blocks with a reasonable NME. On the AFW dataset, comparisons are conducted with LPFA [18], PIFA [17], CDM [44] and TSPM [51] with the MAPE metric. The results in Table 4 again show the superiority of the proposed method. Some examples of alignment results of the proposed method on AFLW and AFW datasets are shown in Figure 9. Three examples of visualization layer output at each visualization block are shown in Figure Evaluation on 300W dataset While our main goal is LPFA, we also evaluate on the most widely used near frontal 300W dataset [31]. 300W containes 3,148 training and 689 testing images, which are divided into common and challenging sets with 554 and 135 images, respectively. Table 5 shows the NME (normalized by the interocular distance) of the evaluated methods. The most relevant method is 3DDFA [50], which also estimates M and p. Our method outperforms it on both the common and challenging sets. Methods that do not employ shape constraints, e.g., via 3DMM, generally have higher freedom Table 4. MAPE of five methods on the AFW dataset. Proposed method LPFA [18] PIFA CDM TSPM Table 5. The NME of different methods on300w dataset. Method Common Challenging Full ESR [8] RCPR [5] SDM [41] LBF [29] CFSS [50] RCFA [37] RAR [40] DDFA [50] DDFA+SDM Proposed method and could achieve slightly better accuracy on frontal face cases. Nonetheless, they are typically less robust in more challenging cases. Another comparison is with MDM [34] via the failure rate using a threshold of The failure rates are 16.83% (ours) versus 6.80% (MDM) with 68 landmarks, and 8.99% (ours) versus 4.20% (MDM) with 51 landmarks Analysis of the Layer We perform four sets of experiments to study the properties of the visualization layer and network architectures. Influence of visualization layers To analyze the influence of the visualization layer in the testing phase, we add 5% noise to the fully connected layer of each visualization block, and compute the alignment error on the AFLW test set. The NMEs are [4.46,4.53,4.60,4.66,4.80, 5.16] when each block is modified seperately. This analysis shows that the visualized images have more influence on the later blocks, since imprecise of early blocks could be compensated by later blocks. In another experiment, we train the network without any visualization layer. The final NME on AFLW is7.18% which shows the importance of visualization layers in guiding the network training. Advantage of deeper features We train three CNN architectures shown in Figure 6 on AFLW. The inputs of the visualization block in the first architecture are the input images I, feature maps F and the visualization image V. The inputs of the second and the third architectures are {F, V} and {I, V}, respectively. The NME of each architecture is (a) (b) input image initial input image initial input image initial estimated estimated (c) Figure 6. Architectures of three CNNs with different inputs. estimated
 (F, V) (I, V) 4.45 4.48 5.06 shown in Table 6.")

7 average weight average weight average weight Table 6. The NME (%) of three architectures with different inputs (I: Input image, V:, F: Feature maps). Architecture a Architecture b Architecture c (I, F, V) (F, V) (I, V) shown in Table 6. While the first one performs the best, the substantial lower performance of the third one demonstrates the importance of deeper features learned across blocks. At the first convolutional layer of each visualization block, we compute the average of the filter weights, across both the kernel size and the number of maps. The averages for these three types of input features are shown in Figure 7. As observed, the weights decrease across blocks, leading to a more precise estimation of small-scale parameter updates. Considering the number of filters in Table 1, the total impact of feature maps are higher than the other two inputs in all blocks. This again shows the importance of deeper features in guiding the network to estimate. Furthermore, the average of the visualization filter is higher than that of the input image filter, demonstrating stronger influence of the proposed visualization during training. Advantage of using masks To show the advantage of using the mask in the visualization layer, we conduct an experiment with different masks. Specifically, we define another mask for comparison as shown in Figure 8. It has five positive areas, i.e., the eyes, nose tip and two lip corners. The values are normalized to zero-mean and unit standard deviation. Compared to the original mask in Fig. 4, this mask is more complicated and conveys more information about the informative facial areas to the network. Moreover, to show the necessity of using the mask, we also test using visualization layers without any mask. The NMEs of the trained networks with different masks are shown in Table 7. Comparison between the first and the third columns shows the benefit of using the mask, by differentiating the middle and contour areas of the face. By comparing the first and second columns, we can see that utilizing more complicated mask does not further improve the result, indicating the original mask provides sufficient information for its purpose. Different numbers of blocks and layers Given the total number of 12 convolutional layers in our network, we can partition them into visualization blocks of various sizes. To compare their performance, we train two additional CNNs. The first one consists of 4 visualization blocks, with 3 con Input image filters filters Feature maps filters Architecture a Architecture b Architecture c block number block number block number Figure 7. The average of filter weights for input image, visualization and feature maps in three architectures of Figure 6. The y-axis andx-axis show the average and the block index, respectively. Figure 8. Mask 2, a different designed mask with five positive areas on the eyes, top of the nose and sides of the lip. Table 7. NME (%) when different masks are used. Mask1 Mask2 No Mask Table 8. NME (%) when using different numbers of visualization blocks (N v) and convolutional layers (N c). N v = 6, N c = 2 N v = 4, N c = 3 N v = 3, N c = volutional layers in each. The other comes with3block and 4 convolutional layers per block. Hence, all three architectures have 12 convolutional layers in total. The NME of these architectures are shown in Table 8. Similar to [5], it shows that the number of regressors is important for face alignment and we can potentially achieve a higher accuracy by increasing the number of visualization blocks Time complexity Compared to the cascade of CNNs, one of the main advantages of end-to-end training a single CNN is the reduced training time. The proposed method needs 33 epochs which takes around 2.5 days. With the same training and testing data sets, [18] requires70 epochs for each CNN. With a total of six CNNs, it needs around 7 days. Similarly, the method in [50] needs around12 days to train three CNNs, each one with 20 epochs, despite using different training data. Compared to [18], our method reduces the training time by more than half. The testing speed of proposed method is 4.3 FPS on a Titan X GPU. It is much faster than the 0.6 FPS speed of [18] and is similar to the4fps speed of [40]. 5. Conclusions We propose a large-pose face alignment method with end-to-end training in a single CNN. The key is a differentiable visualization layer, which is integrated to the network and enables joint optimization by backpropagating the error from a later visualization blocks to early ones. It allows the visualization block to utilize the extracted features from previous blocks and extract deeper features, without extracting hand-crafted features. In addition, the proposed method converges faster during the training phase compared to the cascade of CNNs. Through extensive experiments, we demonstrate the superior results of the proposed method over the state-of-the-art approaches.















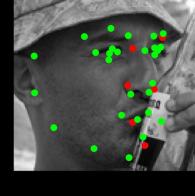

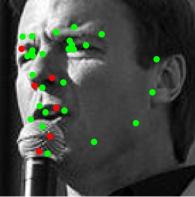




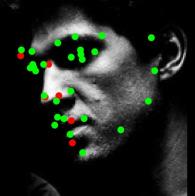

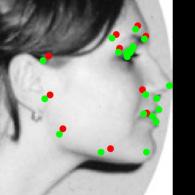


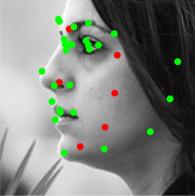




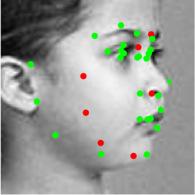



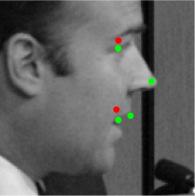
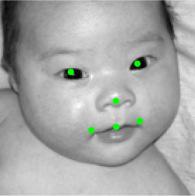
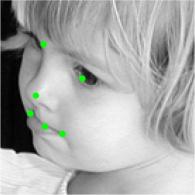









8 Figure 9. Results of alignment on AFLW and AFW datasets, green landmarks show the estimated locations of visible landmarks and red landmarks show estimated locations of invisible landmarks. First row: provided bounding box by AFLW with initial locations of landmarks, Second: estimated 3D dense shapes, Third: estimated landmarks, Fourth to sixth: estimated landmarks for AFLW, Seventh: estimated landmarks for AFW. initialization Figure 10. Three examples of outputs of visualization layer at each visualization block. The first row shows that the proposed method recovers the expression of the face gracefully, the third row shows the visualizations of a face with a more challenging pose.
9 References [1] V. Bettadapura. Face expression recognition and analysis: the state of the art. arxiv preprint arxiv: , [2] V. Blanz and T. Vetter. A morphable model for the synthesis of 3D faces. In ACM SIGGRAPH, pages , [3] V. Blanz and T. Vetter. Face recognition based on fitting a 3D morphable model. IEEE Trans. Pattern Anal. Mach. Intell., 25(9): , [4] A. Bulat and G. Tzimiropoulos. Convolutional aggregation of local evidence for large pose face alignment. In BMVC, , 6 [5] X. P. Burgos-Artizzu, P. Perona, and P. Dollár. Robust face landmark estimation under occlusion. In CVPR, pages , , 6, 7 [6] H. Caesar, J. Uijlings, and V. Ferrari. Region-based semantic segmentation with end-to-end training. In ECCV, pages , [7] C. Cao, Y. Weng, S. Zhou, Y. Tong, and K. Zhou. Facewarehouse: A 3D facial expression database for visual computing. IEEE Trans. Vis. Comput. Graphics, 20(3): , [8] X. Cao, Y. Wei, F. Wen, and J. Sun. Face alignment by explicit shape regression. Int. J. Comput. Vision, 107(2): , , 6 [9] T. F. Cootes, G. J. Edwards, C. J. Taylor, et al. Active appearance models. IEEE Trans. Pattern Anal. Mach. Intell., 23(6): , [10] D. Cristinacce and T. F. Cootes. Boosted regression active shape models. In BMVC, volume 1, page 7, [11] L. Gu and T. Kanade. 3D alignment of face in a single image. In CVPR, volume 1, pages , [12] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, [13] G.-S. Hsu, K.-H. Chang, and S.-C. Huang. Regressive tree structured model for facial landmark localization. In CVPR, pages , [14] M. Jaderberg, K. Simonyan, A. Zisserman, et al. Spatial transformer networks. In NIPS, pages , [15] L. A. Jeni, J. F. Cohn, and T. Kanade. Dense 3D face alignment from 2D videos in real-time. In FG, volume 1, pages 1 8, [16] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell. Caffe: Convolutional architecture for fast feature embedding. In ACM MM, pages , [17] A. Jourabloo and X. Liu. Pose-invariant 3D face alignment. In ICCV, pages , , 6 [18] A. Jourabloo and X. Liu. Large-pose face alignment via CNN-based dense 3D model fitting. In CVPR, , 2, 3, 5, 6, 7 [19] A. Jourabloo and X. Liu. Pose-invariant face alignment via CNN-based dense 3D model fitting. Int. J. Comput. Vision, pages 1 17, , 2 [20] I. Kemelmacher-Shlizerman and S. M. Seitz. Face reconstruction in the wild. In ICCV, pages , [21] M. Köstinger, P. Wohlhart, P. M. Roth, and H. Bischof. Annotated facial landmarks in the wild: A large-scale, realworld database for facial landmark localization. In ICCVW, pages , [22] Y. Li, B. Sun, T. Wu, Y. Wang, and W. Gao. Face detection with end-to-end integration of a convnet and a 3D model. In ECCV, [23] F. Liu, D. Zeng, Q. Zhao, and X. Liu. Joint face alignment and 3D face reconstruction. In ECCV, pages , , 2 [24] J. McDonagh and G. Tzimiropoulos. Joint face detection and alignment with a deformable hough transform model. In ECCV, pages , [25] H. Mohammadzade and D. Hatzinakos. Iterative closest normal point for 3D face recognition. IEEE Trans. Pattern Anal. Mach. Intell., 35(2): , , 4 [26] A. Newell, K. Yang, and J. Deng. Stacked hourglass networks for human pose estimation. In ECCV, pages , [27] P. Paysan, R. Knothe, B. Amberg, S. Romdhani, and T. Vetter. A 3D face model for pose and illumination invariant face recognition. In AVSS, pages , [28] X. Peng, R. S. Feris, X. Wang, and D. N. Metaxas. A recurrent encoder-decoder network for sequential face alignment. In ECCV, pages Springer, [29] S. Ren, X. Cao, Y. Wei, and J. Sun. Face alignment at 3000 fps via regressing local binary features. In CVPR, pages , [30] J. Roth, Y. Tong, and X. Liu. Adaptive 3D face reconstruction from unconstrained photo collections. In CVPR, , 4 [31] C. Sagonas, G. Tzimiropoulos, S. Zafeiriou, and M. Pantic. 300 faces in-the-wild challenge: The first facial landmark localization challenge. In ICCVW, pages , [32] J. M. Saragih, S. Lucey, and J. F. Cohn. Face alignment through subspace constrained mean-shifts. In ICCV, pages , [33] Y. Sun, X. Wang, and X. Tang. Deep convolutional network cascade for facial point detection. In CVPR, pages , , 2 [34] G. Trigeorgis, P. Snape, M. A. Nicolaou, E. Antonakos, and S. Zafeiriou. Mnemonic descent method: A recurrent process applied for end-to-end face alignment. In CVPR, , 2, 6 [35] S. Tulyakov and N. Sebe. Regressing a 3D face shape from a single image. In ICCV, pages , [36] A. Wagner, J. Wright, A. Ganesh, Z. Zhou, H. Mobahi, and Y. Ma. Toward a practical face recognition system: Robust alignment and illumination by sparse representation. IEEE Trans. Pattern Anal. Mach. Intell., 34(2): , [37] W. Wang, S. Tulyakov, and N. Sebe. Recurrent convolutional face alignment. In ACCV, , 6 [38] J. Wu, T. Xue, J. J. Lim, Y. Tian, J. B. Tenenbaum, A. Torralba, and W. T. Freeman. Single image 3D interpreter network. In ECCV, [39] Y. Wu and Q. Ji. Robust facial landmark detection under significant head poses and occlusion. In CVPR, pages ,
10 [40] S. Xiao, J. Feng, J. Xing, H. Lai, S. Yan, and A. Kassim. Robust facial landmark detection via recurrent attentiverefinement networks. In ECCV, pages 57 72, , 6, 7 [41] X. Xiong and F. De la Torre. Supervised descent method and its applications to face alignment. In CVPR, pages , , 6 [42] Z. Yan, H. Zhang, R. Piramuthu, V. Jagadeesh, D. DeCoste, W. Di, and Y. Yu. HD-CNN: hierarchical deep convolutional neural networks for large scale visual recognition. In ICCV, pages , [43] J. Yang, S. E. Reed, M.-H. Yang, and H. Lee. Weaklysupervised disentangling with recurrent transformations for 3D view synthesis. In NIPS, pages , [44] X. Yu, J. Huang, S. Zhang, W. Yan, and D. N. Metaxas. Posefree facial landmark fitting via optimized part mixtures and cascaded deformable shape model. In ICCV, pages , , 6 [45] J. Zhang, S. Shan, M. Kan, and X. Chen. Coarse-to-Fine Auto-encoder Networks (cfan) for real-time face alignment. In ECCV, pages 1 16, , 2 [46] Z. Zhang, P. Luo, C. C. Loy, and X. Tang. Facial landmark detection by deep multi-task learning. In ECCV, pages , [47] R. Zhao, Y. Wang, C. F. Benitez-Quiroz, Y. Liu, and A. M. Martinez. Fast and precise face alignment and 3D shape reconstruction from a single 2D image. In ECCV, pages , [48] E. Zhou, H. Fan, Z. Cao, Y. Jiang, and Q. Yin. Extensive facial landmark localization with coarse-to-fine convolutional network cascade. In ICCVW, pages , [49] S. Zhu, C. Li, C. C. Loy, and X. Tang. Unconstrained face alignment via cascaded compositional learning. In CVPR, , 2 [50] X. Zhu, Z. Lei, X. Liu, H. Shi, and S. Z. Li. Face alignment across large poses: A 3D solution. In CVPR, , 2, 3, 6, 7 [51] X. Zhu and D. Ramanan. Face detection, pose estimation, and landmark localization in the wild. In CVPR, pages , , 5, 6
arxiv: v1 [cs.cv] 16 Nov 2015
![arxiv: v1 [cs.cv] 16 Nov 2015](/thumbs/85/92600288.jpg "arxiv: v1 [cs.cv] 16 Nov 2015") Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
arxiv: v1 [cs.cv] 29 Sep 2016
![arxiv: v1 [cs.cv] 29 Sep 2016](/thumbs/76/73787064.jpg "arxiv: v1 [cs.cv] 29 Sep 2016") arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
arxiv: v1 [cs.cv] 11 Jun 2015
![arxiv: v1 [cs.cv] 11 Jun 2015](/thumbs/92/109137547.jpg "arxiv: v1 [cs.cv] 11 Jun 2015") Pose-Invariant 3D Face Alignment Amin Jourabloo, Xiaoming Liu Department of Computer Science and Engineering Michigan State University, East Lansing MI 48824 {jourablo, liuxm}@msu.edu arxiv:506.03799v
Pose-Invariant 3D Face Alignment Amin Jourabloo, Xiaoming Liu Department of Computer Science and Engineering Michigan State University, East Lansing MI 48824 {jourablo, liuxm}@msu.edu arxiv:506.03799v
Supplemental Material for Face Alignment Across Large Poses: A 3D Solution
 Supplemental Material for Face Alignment Across Large Poses: A 3D Solution Xiangyu Zhu 1 Zhen Lei 1 Xiaoming Liu 2 Hailin Shi 1 Stan Z. Li 1 1 Institute of Automation, Chinese Academy of Sciences 2 Department
Supplemental Material for Face Alignment Across Large Poses: A 3D Solution Xiangyu Zhu 1 Zhen Lei 1 Xiaoming Liu 2 Hailin Shi 1 Stan Z. Li 1 1 Institute of Automation, Chinese Academy of Sciences 2 Department
Robust FEC-CNN: A High Accuracy Facial Landmark Detection System
 Robust FEC-CNN: A High Accuracy Facial Landmark Detection System Zhenliang He 1,2 Jie Zhang 1,2 Meina Kan 1,3 Shiguang Shan 1,3 Xilin Chen 1 1 Key Lab of Intelligent Information Processing of Chinese Academy
Robust FEC-CNN: A High Accuracy Facial Landmark Detection System Zhenliang He 1,2 Jie Zhang 1,2 Meina Kan 1,3 Shiguang Shan 1,3 Xilin Chen 1 1 Key Lab of Intelligent Information Processing of Chinese Academy
A Fully End-to-End Cascaded CNN for Facial Landmark Detection
 2017 IEEE 12th International Conference on Automatic Face & Gesture Recognition A Fully End-to-End Cascaded CNN for Facial Landmark Detection Zhenliang He 1,2 Meina Kan 1,3 Jie Zhang 1,2 Xilin Chen 1 Shiguang
2017 IEEE 12th International Conference on Automatic Face & Gesture Recognition A Fully End-to-End Cascaded CNN for Facial Landmark Detection Zhenliang He 1,2 Meina Kan 1,3 Jie Zhang 1,2 Xilin Chen 1 Shiguang
MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction
 MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction Ayush Tewari Michael Zollhofer Hyeongwoo Kim Pablo Garrido Florian Bernard Patrick Perez Christian Theobalt
MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction Ayush Tewari Michael Zollhofer Hyeongwoo Kim Pablo Garrido Florian Bernard Patrick Perez Christian Theobalt
Deep Face Feature for Face Alignment and Reconstruction
 1 Deep Face Feature for Face Alignment and Reconstruction Boyi Jiang, Juyong Zhang, Bailin Deng, Yudong Guo and Ligang Liu arxiv:1708.02721v1 [cs.cv] 9 Aug 2017 Abstract In this paper, we propose a novel
1 Deep Face Feature for Face Alignment and Reconstruction Boyi Jiang, Juyong Zhang, Bailin Deng, Yudong Guo and Ligang Liu arxiv:1708.02721v1 [cs.cv] 9 Aug 2017 Abstract In this paper, we propose a novel
Pose-Invariant Face Alignment via CNN-Based Dense 3D Model Fitting
 DOI 10.1007/s11263-017-1012-z Pose-Invariant Face Alignment via CNN-Based Dense 3D Model Fitting Amin Jourabloo 1 Xiaoming Liu 1 Received: 12 June 2016 / Accepted: 6 April 2017 Springer Science+Business
DOI 10.1007/s11263-017-1012-z Pose-Invariant Face Alignment via CNN-Based Dense 3D Model Fitting Amin Jourabloo 1 Xiaoming Liu 1 Received: 12 June 2016 / Accepted: 6 April 2017 Springer Science+Business
FACIAL POINT DETECTION BASED ON A CONVOLUTIONAL NEURAL NETWORK WITH OPTIMAL MINI-BATCH PROCEDURE. Chubu University 1200, Matsumoto-cho, Kasugai, AICHI
 FACIAL POINT DETECTION BASED ON A CONVOLUTIONAL NEURAL NETWORK WITH OPTIMAL MINI-BATCH PROCEDURE Masatoshi Kimura Takayoshi Yamashita Yu Yamauchi Hironobu Fuyoshi* Chubu University 1200, Matsumoto-cho,
FACIAL POINT DETECTION BASED ON A CONVOLUTIONAL NEURAL NETWORK WITH OPTIMAL MINI-BATCH PROCEDURE Masatoshi Kimura Takayoshi Yamashita Yu Yamauchi Hironobu Fuyoshi* Chubu University 1200, Matsumoto-cho,
Face Alignment across Large Pose via MT-CNN based 3D Shape Reconstruction
 Face Alignment across Large Pose via MT-CNN based 3D Shape Reconstruction Gang Zhang 1,2, Hu Han 1, Shiguang Shan 1,2,3, Xingguang Song 4, Xilin Chen 1,2 1 Key Laboratory of Intelligent Information Processing
Face Alignment across Large Pose via MT-CNN based 3D Shape Reconstruction Gang Zhang 1,2, Hu Han 1, Shiguang Shan 1,2,3, Xingguang Song 4, Xilin Chen 1,2 1 Key Laboratory of Intelligent Information Processing
Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material
 Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material Ayush Tewari 1,2 Michael Zollhöfer 1,2,3 Pablo Garrido 1,2 Florian Bernard 1,2 Hyeongwoo
Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material Ayush Tewari 1,2 Michael Zollhöfer 1,2,3 Pablo Garrido 1,2 Florian Bernard 1,2 Hyeongwoo
Unconstrained Face Alignment without Face Detection
 Unconstrained Face Alignment without Face Detection Xiaohu Shao 1,2, Junliang Xing 3, Jiangjing Lv 1,2, Chunlin Xiao 4, Pengcheng Liu 1, Youji Feng 1, Cheng Cheng 1 1 Chongqing Institute of Green and Intelligent
Unconstrained Face Alignment without Face Detection Xiaohu Shao 1,2, Junliang Xing 3, Jiangjing Lv 1,2, Chunlin Xiao 4, Pengcheng Liu 1, Youji Feng 1, Cheng Cheng 1 1 Chongqing Institute of Green and Intelligent
Intensity-Depth Face Alignment Using Cascade Shape Regression
 Intensity-Depth Face Alignment Using Cascade Shape Regression Yang Cao 1 and Bao-Liang Lu 1,2 1 Center for Brain-like Computing and Machine Intelligence Department of Computer Science and Engineering Shanghai
Intensity-Depth Face Alignment Using Cascade Shape Regression Yang Cao 1 and Bao-Liang Lu 1,2 1 Center for Brain-like Computing and Machine Intelligence Department of Computer Science and Engineering Shanghai
OVer the last few years, cascaded-regression (CR) based
 based") 1 Random Cascaded-Regression Copse for Robust Facial Landmark Detection Zhen-Hua Feng 1,2, Student Member, IEEE, Patrik Huber 2, Josef Kittler 2, Life Member, IEEE, William Christmas 2, and Xiao-Jun Wu
1 Random Cascaded-Regression Copse for Robust Facial Landmark Detection Zhen-Hua Feng 1,2, Student Member, IEEE, Patrik Huber 2, Josef Kittler 2, Life Member, IEEE, William Christmas 2, and Xiao-Jun Wu
Tweaked residual convolutional network for face alignment
 Journal of Physics: Conference Series PAPER OPEN ACCESS Tweaked residual convolutional network for face alignment To cite this article: Wenchao Du et al 2017 J. Phys.: Conf. Ser. 887 012077 Related content
Journal of Physics: Conference Series PAPER OPEN ACCESS Tweaked residual convolutional network for face alignment To cite this article: Wenchao Du et al 2017 J. Phys.: Conf. Ser. 887 012077 Related content
Locating Facial Landmarks Using Probabilistic Random Forest
 2324 IEEE SIGNAL PROCESSING LETTERS, VOL. 22, NO. 12, DECEMBER 2015 Locating Facial Landmarks Using Probabilistic Random Forest Changwei Luo, Zengfu Wang, Shaobiao Wang, Juyong Zhang, and Jun Yu Abstract
2324 IEEE SIGNAL PROCESSING LETTERS, VOL. 22, NO. 12, DECEMBER 2015 Locating Facial Landmarks Using Probabilistic Random Forest Changwei Luo, Zengfu Wang, Shaobiao Wang, Juyong Zhang, and Jun Yu Abstract
How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks)
") How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks) Adrian Bulat and Georgios Tzimiropoulos Computer Vision Laboratory, The University of Nottingham
How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks) Adrian Bulat and Georgios Tzimiropoulos Computer Vision Laboratory, The University of Nottingham
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
arxiv:submit/ [cs.cv] 7 Sep 2017
![arxiv:submit/ [cs.cv] 7 Sep 2017](/thumbs/82/85530844.jpg "arxiv:submit/ [cs.cv] 7 Sep 2017") How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks) arxiv:submit/2000193 [cs.cv] 7 Sep 2017 Adrian Bulat and Georgios Tzimiropoulos Computer Vision
How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks) arxiv:submit/2000193 [cs.cv] 7 Sep 2017 Adrian Bulat and Georgios Tzimiropoulos Computer Vision
Combining Local and Global Features for 3D Face Tracking
 Combining Local and Global Features for 3D Face Tracking Pengfei Xiong, Guoqing Li, Yuhang Sun Megvii (face++) Research {xiongpengfei, liguoqing, sunyuhang}@megvii.com Abstract In this paper, we propose
Combining Local and Global Features for 3D Face Tracking Pengfei Xiong, Guoqing Li, Yuhang Sun Megvii (face++) Research {xiongpengfei, liguoqing, sunyuhang}@megvii.com Abstract In this paper, we propose
FACIAL POINT DETECTION USING CONVOLUTIONAL NEURAL NETWORK TRANSFERRED FROM A HETEROGENEOUS TASK
 FACIAL POINT DETECTION USING CONVOLUTIONAL NEURAL NETWORK TRANSFERRED FROM A HETEROGENEOUS TASK Takayoshi Yamashita* Taro Watasue** Yuji Yamauchi* Hironobu Fujiyoshi* *Chubu University, **Tome R&D 1200,
FACIAL POINT DETECTION USING CONVOLUTIONAL NEURAL NETWORK TRANSFERRED FROM A HETEROGENEOUS TASK Takayoshi Yamashita* Taro Watasue** Yuji Yamauchi* Hironobu Fujiyoshi* *Chubu University, **Tome R&D 1200,
Face Alignment Across Large Poses: A 3D Solution
 Face Alignment Across Large Poses: A 3D Solution Outline Face Alignment Related Works 3D Morphable Model Projected Normalized Coordinate Code Network Structure 3D Image Rotation Performance on Datasets
Face Alignment Across Large Poses: A 3D Solution Outline Face Alignment Related Works 3D Morphable Model Projected Normalized Coordinate Code Network Structure 3D Image Rotation Performance on Datasets
Deep Multi-Center Learning for Face Alignment
 1 Deep Multi-Center Learning for Face Alignment Zhiwen Shao 1, Hengliang Zhu 1, Xin Tan 1, Yangyang Hao 1, and Lizhuang Ma 2,1 1 Department of Computer Science and Engineering, Shanghai Jiao Tong University,
1 Deep Multi-Center Learning for Face Alignment Zhiwen Shao 1, Hengliang Zhu 1, Xin Tan 1, Yangyang Hao 1, and Lizhuang Ma 2,1 1 Department of Computer Science and Engineering, Shanghai Jiao Tong University,
Shape Augmented Regression for 3D Face Alignment
 Shape Augmented Regression for 3D Face Alignment Chao Gou 1,3(B),YueWu 2, Fei-Yue Wang 1,3, and Qiang Ji 2 1 Institute of Automation, Chinese Academy of Sciences, Beijing, China {gouchao2012,feiyue.wang}@ia.ac.cn
Shape Augmented Regression for 3D Face Alignment Chao Gou 1,3(B),YueWu 2, Fei-Yue Wang 1,3, and Qiang Ji 2 1 Institute of Automation, Chinese Academy of Sciences, Beijing, China {gouchao2012,feiyue.wang}@ia.ac.cn
arxiv: v2 [cs.cv] 8 Sep 2017
![arxiv: v2 [cs.cv] 8 Sep 2017](/thumbs/73/69323728.jpg "arxiv: v2 [cs.cv] 8 Sep 2017") Large Pose 3D Face Reconstruction from a Single Image via Direct Volumetric CNN Regression Aaron S. Jackson 1 Adrian Bulat 1 Vasileios Argyriou 2 Georgios Tzimiropoulos 1 1 The University of Nottingham,
Large Pose 3D Face Reconstruction from a Single Image via Direct Volumetric CNN Regression Aaron S. Jackson 1 Adrian Bulat 1 Vasileios Argyriou 2 Georgios Tzimiropoulos 1 1 The University of Nottingham,
Facial Landmark Detection via Progressive Initialization
 Facial Landmark Detection via Progressive Initialization Shengtao Xiao Shuicheng Yan Ashraf A. Kassim Department of Electrical and Computer Engineering, National University of Singapore Singapore 117576
Facial Landmark Detection via Progressive Initialization Shengtao Xiao Shuicheng Yan Ashraf A. Kassim Department of Electrical and Computer Engineering, National University of Singapore Singapore 117576
Deep Alignment Network: A convolutional neural network for robust face alignment
 Deep Alignment Network: A convolutional neural network for robust face alignment Marek Kowalski, Jacek Naruniec, and Tomasz Trzcinski Warsaw University of Technology m.kowalski@ire.pw.edu.pl, j.naruniec@ire.pw.edu.pl,
Deep Alignment Network: A convolutional neural network for robust face alignment Marek Kowalski, Jacek Naruniec, and Tomasz Trzcinski Warsaw University of Technology m.kowalski@ire.pw.edu.pl, j.naruniec@ire.pw.edu.pl,
Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling
 [DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
[DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
Improved Face Detection and Alignment using Cascade Deep Convolutional Network
 Improved Face Detection and Alignment using Cascade Deep Convolutional Network Weilin Cong, Sanyuan Zhao, Hui Tian, and Jianbing Shen Beijing Key Laboratory of Intelligent Information Technology, School
Improved Face Detection and Alignment using Cascade Deep Convolutional Network Weilin Cong, Sanyuan Zhao, Hui Tian, and Jianbing Shen Beijing Key Laboratory of Intelligent Information Technology, School
arxiv: v1 [cs.cv] 13 Jul 2015
![arxiv: v1 [cs.cv] 13 Jul 2015](/thumbs/92/110223043.jpg "arxiv: v1 [cs.cv] 13 Jul 2015") Unconstrained Facial Landmark Localization with Backbone-Branches Fully-Convolutional Networks arxiv:7.349v [cs.cv] 3 Jul 2 Zhujin Liang, Shengyong Ding, Liang Lin Sun Yat-Sen University Guangzhou Higher
Unconstrained Facial Landmark Localization with Backbone-Branches Fully-Convolutional Networks arxiv:7.349v [cs.cv] 3 Jul 2 Zhujin Liang, Shengyong Ding, Liang Lin Sun Yat-Sen University Guangzhou Higher
Finding Tiny Faces Supplementary Materials
 Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks
 Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks Zhen-Hua Feng 1 Josef Kittler 1 Muhammad Awais 1 Patrik Huber 1 Xiao-Jun Wu 2 1 Centre for Vision, Speech and Signal
Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks Zhen-Hua Feng 1 Josef Kittler 1 Muhammad Awais 1 Patrik Huber 1 Xiao-Jun Wu 2 1 Centre for Vision, Speech and Signal
One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models
 One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models [Supplemental Materials] 1. Network Architecture b ref b ref +1 We now describe the architecture of the networks
One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models [Supplemental Materials] 1. Network Architecture b ref b ref +1 We now describe the architecture of the networks
Joint Head Pose Estimation and Face Alignment Framework Using Global and Local CNN Features
 2017 IEEE 12th International Conference on Automatic Face & Gesture Recognition Joint Head Pose Estimation and Face Alignment Framework Using Global and Local CNN Features Xiang Xu and Ioannis A. Kakadiaris
2017 IEEE 12th International Conference on Automatic Face & Gesture Recognition Joint Head Pose Estimation and Face Alignment Framework Using Global and Local CNN Features Xiang Xu and Ioannis A. Kakadiaris
arxiv: v1 [cs.cv] 16 Feb 2017
![arxiv: v1 [cs.cv] 16 Feb 2017](/thumbs/88/114857056.jpg "arxiv: v1 [cs.cv] 16 Feb 2017") KEPLER: Keypoint and Pose Estimation of Unconstrained Faces by Learning Efficient H-CNN Regressors Amit Kumar, Azadeh Alavi and Rama Chellappa Department of Electrical and Computer Engineering, CFAR and
KEPLER: Keypoint and Pose Estimation of Unconstrained Faces by Learning Efficient H-CNN Regressors Amit Kumar, Azadeh Alavi and Rama Chellappa Department of Electrical and Computer Engineering, CFAR and
Simultaneous Facial Landmark Detection, Pose and Deformation Estimation under Facial Occlusion
 Simultaneous Facial Landmark Detection, Pose and Deformation Estimation under Facial Occlusion Yue Wu Chao Gou Qiang Ji ECSE Department Institute of Automation ECSE Department Rensselaer Polytechnic Institute
Simultaneous Facial Landmark Detection, Pose and Deformation Estimation under Facial Occlusion Yue Wu Chao Gou Qiang Ji ECSE Department Institute of Automation ECSE Department Rensselaer Polytechnic Institute
A Deep Regression Architecture with Two-Stage Re-initialization for High Performance Facial Landmark Detection
 A Deep Regression Architecture with Two-Stage Re-initialization for High Performance Facial Landmark Detection Jiangjing Lv 1,2, Xiaohu Shao 1,2, Junliang Xing 3, Cheng Cheng 1, Xi Zhou 1 1 Chongqing Institute
A Deep Regression Architecture with Two-Stage Re-initialization for High Performance Facial Landmark Detection Jiangjing Lv 1,2, Xiaohu Shao 1,2, Junliang Xing 3, Cheng Cheng 1, Xi Zhou 1 1 Chongqing Institute
LEARNING A MULTI-CENTER CONVOLUTIONAL NETWORK FOR UNCONSTRAINED FACE ALIGNMENT. Zhiwen Shao, Hengliang Zhu, Yangyang Hao, Min Wang, and Lizhuang Ma
 LEARNING A MULTI-CENTER CONVOLUTIONAL NETWORK FOR UNCONSTRAINED FACE ALIGNMENT Zhiwen Shao, Hengliang Zhu, Yangyang Hao, Min Wang, and Lizhuang Ma Department of Computer Science and Engineering, Shanghai
LEARNING A MULTI-CENTER CONVOLUTIONAL NETWORK FOR UNCONSTRAINED FACE ALIGNMENT Zhiwen Shao, Hengliang Zhu, Yangyang Hao, Min Wang, and Lizhuang Ma Department of Computer Science and Engineering, Shanghai
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
arxiv: v2 [cs.cv] 10 Aug 2017
![arxiv: v2 [cs.cv] 10 Aug 2017](/thumbs/74/69722894.jpg "arxiv: v2 [cs.cv] 10 Aug 2017") Deep Alignment Network: A convolutional neural network for robust face alignment Marek Kowalski, Jacek Naruniec, and Tomasz Trzcinski arxiv:1706.01789v2 [cs.cv] 10 Aug 2017 Warsaw University of Technology
Deep Alignment Network: A convolutional neural network for robust face alignment Marek Kowalski, Jacek Naruniec, and Tomasz Trzcinski arxiv:1706.01789v2 [cs.cv] 10 Aug 2017 Warsaw University of Technology
Detecting facial landmarks in the video based on a hybrid framework
 Detecting facial landmarks in the video based on a hybrid framework Nian Cai 1, *, Zhineng Lin 1, Fu Zhang 1, Guandong Cen 1, Han Wang 2 1 School of Information Engineering, Guangdong University of Technology,
Detecting facial landmarks in the video based on a hybrid framework Nian Cai 1, *, Zhineng Lin 1, Fu Zhang 1, Guandong Cen 1, Han Wang 2 1 School of Information Engineering, Guangdong University of Technology,
Facial shape tracking via spatio-temporal cascade shape regression
 Facial shape tracking via spatio-temporal cascade shape regression Jing Yang nuist yj@126.com Jiankang Deng jiankangdeng@gmail.com Qingshan Liu Kaihua Zhang zhkhua@gmail.com qsliu@nuist.edu.cn Nanjing
Facial shape tracking via spatio-temporal cascade shape regression Jing Yang nuist yj@126.com Jiankang Deng jiankangdeng@gmail.com Qingshan Liu Kaihua Zhang zhkhua@gmail.com qsliu@nuist.edu.cn Nanjing
Landmark Weighting for 3DMM Shape Fitting
 Landmark Weighting for 3DMM Shape Fitting Yu Yang a, Xiao-Jun Wu a, and Josef Kittler b a School of Internet of Things Engineering, Jiangnan University, Wuxi 214122, China b CVSSP, University of Surrey,
Landmark Weighting for 3DMM Shape Fitting Yu Yang a, Xiao-Jun Wu a, and Josef Kittler b a School of Internet of Things Engineering, Jiangnan University, Wuxi 214122, China b CVSSP, University of Surrey,
Disentangling 3D Pose in A Dendritic CNN for Unconstrained 2D Face Alignment
 Disentangling 3D Pose in A Dendritic CNN for Unconstrained 2D Face Alignment Amit Kumar Rama Chellappa Department of Electrical and Computer Engineering, CFAR and UMIACS University of Maryland-College
Disentangling 3D Pose in A Dendritic CNN for Unconstrained 2D Face Alignment Amit Kumar Rama Chellappa Department of Electrical and Computer Engineering, CFAR and UMIACS University of Maryland-College
Nonrigid Surface Modelling. and Fast Recovery. Department of Computer Science and Engineering. Committee: Prof. Leo J. Jia and Prof. K. H.
 Nonrigid Surface Modelling and Fast Recovery Zhu Jianke Supervisor: Prof. Michael R. Lyu Committee: Prof. Leo J. Jia and Prof. K. H. Wong Department of Computer Science and Engineering May 11, 2007 1 2
Nonrigid Surface Modelling and Fast Recovery Zhu Jianke Supervisor: Prof. Michael R. Lyu Committee: Prof. Leo J. Jia and Prof. K. H. Wong Department of Computer Science and Engineering May 11, 2007 1 2
Real-time Object Detection CS 229 Course Project
 Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Robust Facial Landmark Detection under Significant Head Poses and Occlusion
 Robust Facial Landmark Detection under Significant Head Poses and Occlusion Yue Wu Qiang Ji ECSE Department, Rensselaer Polytechnic Institute 110 8th street, Troy, NY, USA {wuy9,jiq}@rpi.edu Abstract There
Robust Facial Landmark Detection under Significant Head Poses and Occlusion Yue Wu Qiang Ji ECSE Department, Rensselaer Polytechnic Institute 110 8th street, Troy, NY, USA {wuy9,jiq}@rpi.edu Abstract There
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep learning for dense per-pixel prediction. Chunhua Shen The University of Adelaide, Australia
 Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Convolutional Experts Constrained Local Model for 3D Facial Landmark Detection
 Correction Network FC200 FC200 Final Prediction Convolutional Experts Constrained Local Model for 3D Facial Landmark Detection Amir Zadeh, Yao Chong Lim, Tadas Baltrušaitis, Louis-Philippe Morency Carnegie
Correction Network FC200 FC200 Final Prediction Convolutional Experts Constrained Local Model for 3D Facial Landmark Detection Amir Zadeh, Yao Chong Lim, Tadas Baltrušaitis, Louis-Philippe Morency Carnegie
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Multi-Glance Attention Models For Image Classification
 Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
MULTI-POSE FACE HALLUCINATION VIA NEIGHBOR EMBEDDING FOR FACIAL COMPONENTS. Yanghao Li, Jiaying Liu, Wenhan Yang, Zongming Guo
 MULTI-POSE FACE HALLUCINATION VIA NEIGHBOR EMBEDDING FOR FACIAL COMPONENTS Yanghao Li, Jiaying Liu, Wenhan Yang, Zongg Guo Institute of Computer Science and Technology, Peking University, Beijing, P.R.China,
MULTI-POSE FACE HALLUCINATION VIA NEIGHBOR EMBEDDING FOR FACIAL COMPONENTS Yanghao Li, Jiaying Liu, Wenhan Yang, Zongg Guo Institute of Computer Science and Technology, Peking University, Beijing, P.R.China,
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
Facial Landmark Point Localization using Coarse-to-Fine Deep Recurrent Neural Network
 MAHPOD et al.: CCNN 1 Facial Landmark Point Localization using Coarse-to-Fine Deep Recurrent Neural Network arxiv:1805.01760v2 [cs.cv] 17 Jan 2019 Shahar Mahpod, Rig Das, Emanuele Maiorana, Yosi Keller,
MAHPOD et al.: CCNN 1 Facial Landmark Point Localization using Coarse-to-Fine Deep Recurrent Neural Network arxiv:1805.01760v2 [cs.cv] 17 Jan 2019 Shahar Mahpod, Rig Das, Emanuele Maiorana, Yosi Keller,
Extended Supervised Descent Method for Robust Face Alignment
 Extended Supervised Descent Method for Robust Face Alignment Liu Liu, Jiani Hu, Shuo Zhang, Weihong Deng Beijing University of Posts and Telecommunications, Beijing, China Abstract. Supervised Descent
Extended Supervised Descent Method for Robust Face Alignment Liu Liu, Jiani Hu, Shuo Zhang, Weihong Deng Beijing University of Posts and Telecommunications, Beijing, China Abstract. Supervised Descent
De-mark GAN: Removing Dense Watermark With Generative Adversarial Network
 De-mark GAN: Removing Dense Watermark With Generative Adversarial Network Jinlin Wu, Hailin Shi, Shu Zhang, Zhen Lei, Yang Yang, Stan Z. Li Center for Biometrics and Security Research & National Laboratory
De-mark GAN: Removing Dense Watermark With Generative Adversarial Network Jinlin Wu, Hailin Shi, Shu Zhang, Zhen Lei, Yang Yang, Stan Z. Li Center for Biometrics and Security Research & National Laboratory
Feature-Fused SSD: Fast Detection for Small Objects
 Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
RSRN: Rich Side-output Residual Network for Medial Axis Detection
 RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
Learning to Estimate 3D Human Pose and Shape from a Single Color Image Supplementary material
 Learning to Estimate 3D Human Pose and Shape from a Single Color Image Supplementary material Georgios Pavlakos 1, Luyang Zhu 2, Xiaowei Zhou 3, Kostas Daniilidis 1 1 University of Pennsylvania 2 Peking
Learning to Estimate 3D Human Pose and Shape from a Single Color Image Supplementary material Georgios Pavlakos 1, Luyang Zhu 2, Xiaowei Zhou 3, Kostas Daniilidis 1 1 University of Pennsylvania 2 Peking
On 3D face reconstruction via cascaded regression in shape space
 1978 Liu et al. / Front Inform Technol Electron Eng 2017 18(12):1978-1990 Frontiers of Information Technology & Electronic Engineering www.jzus.zju.edu.cn; engineering.cae.cn; www.springerlink.com ISSN
1978 Liu et al. / Front Inform Technol Electron Eng 2017 18(12):1978-1990 Frontiers of Information Technology & Electronic Engineering www.jzus.zju.edu.cn; engineering.cae.cn; www.springerlink.com ISSN
Disentangling Features in 3D Face Shapes for Joint Face Reconstruction and Recognition
 Disentangling Features in 3D Face Shapes for Joint Face Reconstruction and Recognition Feng Liu 1, Ronghang Zhu 1,DanZeng 1, Qijun Zhao 1,, and Xiaoming Liu 2 1 College of Computer Science, Sichuan University
Disentangling Features in 3D Face Shapes for Joint Face Reconstruction and Recognition Feng Liu 1, Ronghang Zhu 1,DanZeng 1, Qijun Zhao 1,, and Xiaoming Liu 2 1 College of Computer Science, Sichuan University
arxiv: v1 [cs.cv] 6 Jul 2016
![arxiv: v1 [cs.cv] 6 Jul 2016](/thumbs/80/81416563.jpg "arxiv: v1 [cs.cv] 6 Jul 2016") arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
Machine Learning. Deep Learning. Eric Xing (and Pengtao Xie) , Fall Lecture 8, October 6, Eric CMU,
 , Fall Lecture 8, October 6, Eric CMU,") Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Real-Time Rotation-Invariant Face Detection with Progressive Calibration Networks
 Real-Time Rotation-Invariant Face Detection with Progressive Calibration Networks Xuepeng Shi 1,2 Shiguang Shan 1,3 Meina Kan 1,3 Shuzhe Wu 1,2 Xilin Chen 1 1 Key Lab of Intelligent Information Processing
Real-Time Rotation-Invariant Face Detection with Progressive Calibration Networks Xuepeng Shi 1,2 Shiguang Shan 1,3 Meina Kan 1,3 Shuzhe Wu 1,2 Xilin Chen 1 1 Key Lab of Intelligent Information Processing
Faster Than Real-time Facial Alignment: A 3D Spatial Transformer Network Approach in Unconstrained Poses
 Faster Than Real-time Facial Alignment: A 3D Spatial Transformer Network Approach in Unconstrained Poses Chandrasekhar Bhagavatula, Chenchen Zhu, Khoa Luu, and Marios Savvides Carnegie Mellon University
Faster Than Real-time Facial Alignment: A 3D Spatial Transformer Network Approach in Unconstrained Poses Chandrasekhar Bhagavatula, Chenchen Zhu, Khoa Luu, and Marios Savvides Carnegie Mellon University
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network. Nathan Sun CIS601
 with Facial KeyPoints using Spatial Fusion Convolutional Network. Nathan Sun CIS601") Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601 Introduction Face ID is complicated by alterations to an individual s appearance Beard,
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601 Introduction Face ID is complicated by alterations to an individual s appearance Beard,
arxiv: v1 [cs.cv] 21 Mar 2018
![arxiv: v1 [cs.cv] 21 Mar 2018](/thumbs/84/89303890.jpg "arxiv: v1 [cs.cv] 21 Mar 2018") arxiv:1803.07835v1 [cs.cv] 21 Mar 2018 Joint 3D Face Reconstruction and Dense Alignment with Position Map Regression Network Yao Feng, Fan Wu, Xiaohu Shao, Yanfeng Wang, Xi Zhou Shanghai Jiao Tong University,
arxiv:1803.07835v1 [cs.cv] 21 Mar 2018 Joint 3D Face Reconstruction and Dense Alignment with Position Map Regression Network Yao Feng, Fan Wu, Xiaohu Shao, Yanfeng Wang, Xi Zhou Shanghai Jiao Tong University,
Face Alignment Under Various Poses and Expressions
 Face Alignment Under Various Poses and Expressions Shengjun Xin and Haizhou Ai Computer Science and Technology Department, Tsinghua University, Beijing 100084, China ahz@mail.tsinghua.edu.cn Abstract.
Face Alignment Under Various Poses and Expressions Shengjun Xin and Haizhou Ai Computer Science and Technology Department, Tsinghua University, Beijing 100084, China ahz@mail.tsinghua.edu.cn Abstract.
Facial Expression Analysis
 Facial Expression Analysis Jeff Cohn Fernando De la Torre Human Sensing Laboratory Tutorial Looking @ People June 2012 Facial Expression Analysis F. De la Torre/J. Cohn Looking @ People (CVPR-12) 1 Outline
Facial Expression Analysis Jeff Cohn Fernando De la Torre Human Sensing Laboratory Tutorial Looking @ People June 2012 Facial Expression Analysis F. De la Torre/J. Cohn Looking @ People (CVPR-12) 1 Outline
Look at Boundary: A Boundary-Aware Face Alignment Algorithm
 Look at Boundary: A Boundary-Aware Face Alignment Algorithm Wayne Wu 1,2, Chen Qian2, Shuo Yang3, Quan Wang2, Yici Cai1, Qiang Zhou1 1 Tsinghua National Laboratory for Information Science and Technology
Look at Boundary: A Boundary-Aware Face Alignment Algorithm Wayne Wu 1,2, Chen Qian2, Shuo Yang3, Quan Wang2, Yici Cai1, Qiang Zhou1 1 Tsinghua National Laboratory for Information Science and Technology
GoDP: Globally Optimized Dual Pathway deep network architecture for facial landmark localization in-the-wild
 GoDP: Globally Optimized Dual Pathway deep network architecture for facial landmark localization in-the-wild Yuhang Wu, Shishir K. Shah, Ioannis A. Kakadiaris 1 {ywu35,sshah,ikakadia}@central.uh.edu Computational
GoDP: Globally Optimized Dual Pathway deep network architecture for facial landmark localization in-the-wild Yuhang Wu, Shishir K. Shah, Ioannis A. Kakadiaris 1 {ywu35,sshah,ikakadia}@central.uh.edu Computational
One Millisecond Face Alignment with an Ensemble of Regression Trees
 One Millisecond Face Alignment with an Ensemble of Regression Trees Vahid Kazemi and Josephine Sullivan KTH, Royal Institute of Technology Computer Vision and Active Perception Lab Teknikringen 14, Stockholm,
One Millisecond Face Alignment with an Ensemble of Regression Trees Vahid Kazemi and Josephine Sullivan KTH, Royal Institute of Technology Computer Vision and Active Perception Lab Teknikringen 14, Stockholm,
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Estimating Human Pose in Images. Navraj Singh December 11, 2009
 Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Pix2Face: Direct 3D Face Model Estimation
 Pix2Face: Direct 3D Face Model Estimation Daniel Crispell Maxim Bazik Vision Systems, Inc Providence, RI USA danielcrispell, maximbazik@visionsystemsinccom Abstract An efficient, fully automatic method
Pix2Face: Direct 3D Face Model Estimation Daniel Crispell Maxim Bazik Vision Systems, Inc Providence, RI USA danielcrispell, maximbazik@visionsystemsinccom Abstract An efficient, fully automatic method
Evaluation of Dense 3D Reconstruction from 2D Face Images in the Wild
 Evaluation of Dense 3D Reconstruction from 2D Face Images in the Wild Zhen-Hua Feng 1 Patrik Huber 1 Josef Kittler 1 Peter Hancock 2 Xiao-Jun Wu 3 Qijun Zhao 4 Paul Koppen 1 Matthias Rätsch 5 1 Centre
Evaluation of Dense 3D Reconstruction from 2D Face Images in the Wild Zhen-Hua Feng 1 Patrik Huber 1 Josef Kittler 1 Peter Hancock 2 Xiao-Jun Wu 3 Qijun Zhao 4 Paul Koppen 1 Matthias Rätsch 5 1 Centre
Constrained Joint Cascade Regression Framework for Simultaneous Facial Action Unit Recognition and Facial Landmark Detection
 Constrained Joint Cascade Regression Framework for Simultaneous Facial Action Unit Recognition and Facial Landmark Detection Yue Wu Qiang Ji ECSE Department, Rensselaer Polytechnic Institute 110 8th street,
Constrained Joint Cascade Regression Framework for Simultaneous Facial Action Unit Recognition and Facial Landmark Detection Yue Wu Qiang Ji ECSE Department, Rensselaer Polytechnic Institute 110 8th street,
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
Real-time Hand Tracking under Occlusion from an Egocentric RGB-D Sensor Supplemental Document
 Real-time Hand Tracking under Occlusion from an Egocentric RGB-D Sensor Supplemental Document Franziska Mueller 1,2 Dushyant Mehta 1,2 Oleksandr Sotnychenko 1 Srinath Sridhar 1 Dan Casas 3 Christian Theobalt
Real-time Hand Tracking under Occlusion from an Egocentric RGB-D Sensor Supplemental Document Franziska Mueller 1,2 Dushyant Mehta 1,2 Oleksandr Sotnychenko 1 Srinath Sridhar 1 Dan Casas 3 Christian Theobalt
Face Tracking. Synonyms. Definition. Main Body Text. Amit K. Roy-Chowdhury and Yilei Xu. Facial Motion Estimation
 Face Tracking Amit K. Roy-Chowdhury and Yilei Xu Department of Electrical Engineering, University of California, Riverside, CA 92521, USA {amitrc,yxu}@ee.ucr.edu Synonyms Facial Motion Estimation Definition
Face Tracking Amit K. Roy-Chowdhury and Yilei Xu Department of Electrical Engineering, University of California, Riverside, CA 92521, USA {amitrc,yxu}@ee.ucr.edu Synonyms Facial Motion Estimation Definition
Joint 3D Face Reconstruction and Dense Alignment with Position Map Regression Network
 Joint 3D Face Reconstruction and Dense Alignment with Position Map Regression Network Yao Feng 1[0000 0002 9481 9783], Fan Wu 2[0000 0003 1970 3470], Xiaohu Shao 3,4[0000 0003 1141 6020], Yanfeng Wang
Joint 3D Face Reconstruction and Dense Alignment with Position Map Regression Network Yao Feng 1[0000 0002 9481 9783], Fan Wu 2[0000 0003 1970 3470], Xiaohu Shao 3,4[0000 0003 1141 6020], Yanfeng Wang
arxiv: v1 [cs.cv] 31 Mar 2017
![arxiv: v1 [cs.cv] 31 Mar 2017](/thumbs/80/81467687.jpg "arxiv: v1 [cs.cv] 31 Mar 2017") End-to-End Spatial Transform Face Detection and Recognition Liying Chi Zhejiang University charrin0531@gmail.com Hongxin Zhang Zhejiang University zhx@cad.zju.edu.cn Mingxiu Chen Rokid.inc cmxnono@rokid.com
End-to-End Spatial Transform Face Detection and Recognition Liying Chi Zhejiang University charrin0531@gmail.com Hongxin Zhang Zhejiang University zhx@cad.zju.edu.cn Mingxiu Chen Rokid.inc cmxnono@rokid.com
Deep Learning in Visual Recognition. Thanks Da Zhang for the slides
 Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Nonlinear Hierarchical Part-Based Regression for Unconstrained Face Alignment
 Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Nonlinear Hierarchical Part-Based Regression for Unconstrained Face Alignment Xiang Yu, Zhe Lin, Shaoting
Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Nonlinear Hierarchical Part-Based Regression for Unconstrained Face Alignment Xiang Yu, Zhe Lin, Shaoting
Geometry-aware Traffic Flow Analysis by Detection and Tracking
 Geometry-aware Traffic Flow Analysis by Detection and Tracking 1,2 Honghui Shi, 1 Zhonghao Wang, 1,2 Yang Zhang, 1,3 Xinchao Wang, 1 Thomas Huang 1 IFP Group, Beckman Institute at UIUC, 2 IBM Research,
Geometry-aware Traffic Flow Analysis by Detection and Tracking 1,2 Honghui Shi, 1 Zhonghao Wang, 1,2 Yang Zhang, 1,3 Xinchao Wang, 1 Thomas Huang 1 IFP Group, Beckman Institute at UIUC, 2 IBM Research,
Image Resizing Based on Gradient Vector Flow Analysis
 Image Resizing Based on Gradient Vector Flow Analysis Sebastiano Battiato battiato@dmi.unict.it Giovanni Puglisi puglisi@dmi.unict.it Giovanni Maria Farinella gfarinellao@dmi.unict.it Daniele Ravì rav@dmi.unict.it
Image Resizing Based on Gradient Vector Flow Analysis Sebastiano Battiato battiato@dmi.unict.it Giovanni Puglisi puglisi@dmi.unict.it Giovanni Maria Farinella gfarinellao@dmi.unict.it Daniele Ravì rav@dmi.unict.it
Face Detection, Bounding Box Aggregation and Pose Estimation for Robust Facial Landmark Localisation in the Wild
 Face Detection, Bounding Box Aggregation and Pose Estimation for Robust Facial Landmark Localisation in the Wild Zhen-Hua Feng 1,2 Josef Kittler 1 Muhammad Awais 1 Patrik Huber 1 Xiao-Jun Wu 2 1 Centre
Face Detection, Bounding Box Aggregation and Pose Estimation for Robust Facial Landmark Localisation in the Wild Zhen-Hua Feng 1,2 Josef Kittler 1 Muhammad Awais 1 Patrik Huber 1 Xiao-Jun Wu 2 1 Centre
Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network
 Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network Anurag Arnab and Philip H.S. Torr University of Oxford {anurag.arnab, philip.torr}@eng.ox.ac.uk 1. Introduction
Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network Anurag Arnab and Philip H.S. Torr University of Oxford {anurag.arnab, philip.torr}@eng.ox.ac.uk 1. Introduction
Deep Evolutionary 3D Diffusion Heat Maps for Large-pose Face Alignment
 SUN, SHAO, XIA, FU: DEEP EVOLUTIONARY 3D DHM FOR FACE ALIGNMENT 1 Deep Evolutionary 3D Diffusion Heat Maps for Large-pose Face Alignment Bin Sun 1 sun.bi@husky.neu.edu Ming Shao 2 mshao@umassd.edu Siyu
SUN, SHAO, XIA, FU: DEEP EVOLUTIONARY 3D DHM FOR FACE ALIGNMENT 1 Deep Evolutionary 3D Diffusion Heat Maps for Large-pose Face Alignment Bin Sun 1 sun.bi@husky.neu.edu Ming Shao 2 mshao@umassd.edu Siyu
CNN for Low Level Image Processing. Huanjing Yue
 CNN for Low Level Image Processing Huanjing Yue 2017.11 1 Deep Learning for Image Restoration General formulation: min Θ L( x, x) s. t. x = F(y; Θ) Loss function Parameters to be learned Key issues The
CNN for Low Level Image Processing Huanjing Yue 2017.11 1 Deep Learning for Image Restoration General formulation: min Θ L( x, x) s. t. x = F(y; Θ) Loss function Parameters to be learned Key issues The
Sparse Shape Registration for Occluded Facial Feature Localization
 Shape Registration for Occluded Facial Feature Localization Fei Yang, Junzhou Huang and Dimitris Metaxas Abstract This paper proposes a sparsity driven shape registration method for occluded facial feature
Shape Registration for Occluded Facial Feature Localization Fei Yang, Junzhou Huang and Dimitris Metaxas Abstract This paper proposes a sparsity driven shape registration method for occluded facial feature
A Deeply-initialized Coarse-to-fine Ensemble of Regression Trees for Face Alignment
 A Deeply-initialized Coarse-to-fine Ensemble of Regression Trees for Face Alignment Roberto Valle 1[0000 0003 1423 1478], José M. Buenaposada 2[0000 0002 4308 9653], Antonio Valdés 3, and Luis Baumela
A Deeply-initialized Coarse-to-fine Ensemble of Regression Trees for Face Alignment Roberto Valle 1[0000 0003 1423 1478], José M. Buenaposada 2[0000 0002 4308 9653], Antonio Valdés 3, and Luis Baumela