An introduction to multi-armed bandits
|
|
|
- Marjory Preston
- 6 years ago
- Views:
Transcription
1 An introduction to multi-armed bandits Henry WJ Reeve (Manchester) A joint work with Joe Mellor (Edinburgh) & Professor Gavin Brown (Manchester)
2 Plan 1. An introduction to multi-armed bandits 2. The multi-armed bandit with covariates and the k-nearest neighbour UCB algorithm.
3 Plan: Intro to multi-armed bandits 1. The concept of reinforcement learning 2. Multi-armed bandits 3. The exploration vs. exploitation trade-off 4. The upper confidence bound algorithm (UCB) 5. The concentration of measure phenomenon 6. A regret bound for the UCB algorithm
4 Supervised learning and reinforcement learning
5 Supervised learning
6 Supervised learning
7 Supervised learning

8 Learning with animals
9 Learning with animals




10 Learning with animals
11 Reinforcement learning Environment Agent
12 Reinforcement learning Environment Action Agent
13 Reinforcement learning Environment Reward Action Agent
14 Reinforcement learning Environment Reward Action Agent Learning
15 Reinforcement learning No supervision - the only feedback given is the reward An agent s action affects the information it receives A sequential learning problem
16 The multi-armed bandit problem
17 The multi-armed bandit problem Bandit 1 Random reward Bandit 2
18 Multi-armed bandit formalism For Choose an arm to pull based on the reward history Receive a reward


19 Multi-armed bandit formalism For Choose an arm to pull based on the reward history Receive a reward Rewards i.i.d with
20 Applications Sequential clinical trials


21 Applications Sequential clinical trials Online advertisement optimisation
22 Notation Expected reward for each arm Arm pulled at time t Number of times each arm has been pulled at time t Empirical average of rewards for each arm at time t
23 The exploration vs. exploitation trade-off
24 Exploration vs. exploitation Exploration: Obtain more accurate estimates Choose i so that is small.,


25 Exploration vs. exploitation Exploration: Obtain more accurate estimates Choose i so that, is small. Exploitation: Achieve a high reward Choose i so that is large.
26 The upper confidence bound (UCB) algorithm: Optimism in the face of uncertainty
27 The UCB algorithm
28 The UCB algorithm
29 The UCB algorithm

30 Regret Compare oracle policy with the
31 UCB Regret Bound The gap Auer et al. (2002): The UCB policy achieves a logarithmic regret bound
32 Big O notation




33 Big O notation
34 UCB Regret Bound The gap Auer et al. (2002): The UCB policy achieves a logarithmic regret bound
35 Concentration of measure



36 Concentration of measure I flip a coin times. I get heads times and tails times. If I flip the same coin again, what s the probability I get a head?
37 Hoeffding s Inequality (1963) Independent random variables with for
38 Hoeffding s Inequality (1963) Independent random variables with for Define the empirical average



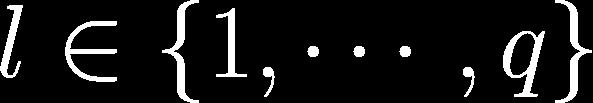
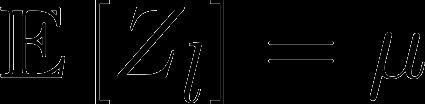

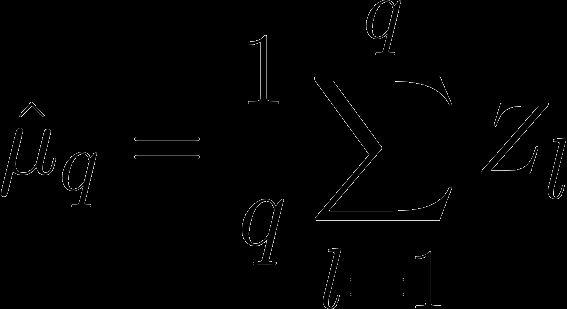
39 Hoeffding s Inequality (1963) Independent random variables with for Define the empirical average
40 Proof of the UCB regret bound
41 UCB Regret Bound The gap Auer et al. (2002): The UCB policy achieves a logarithmic regret bound
42 Notation Expected reward for each arm Arm pulled at time t Number of times each arm has been pulled at time t Empirical average of rewards for each arm at time t
43 Bad events Let s define bad events Lemma 1 for by
44 Proof of Lemma 1
45 Proof of Lemma 1


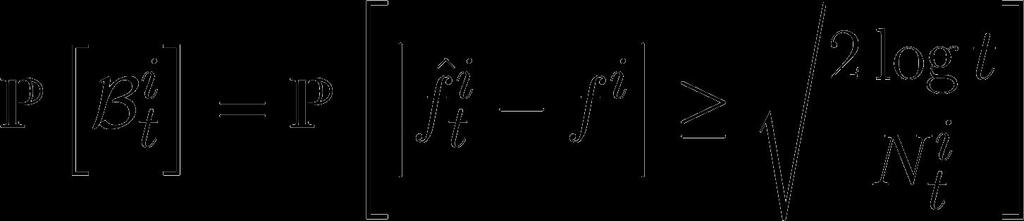
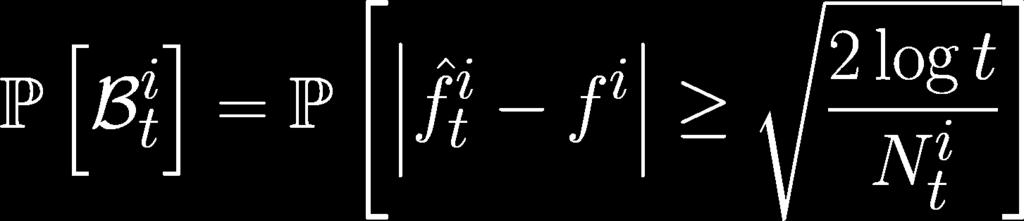
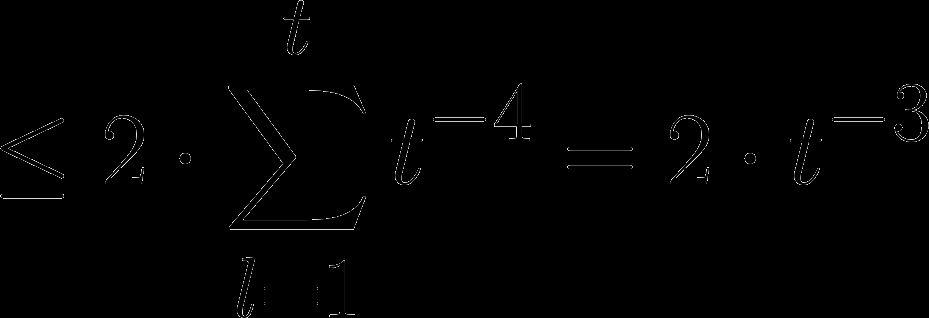
46 Proof of Lemma 1 Hoeffding s Inequality




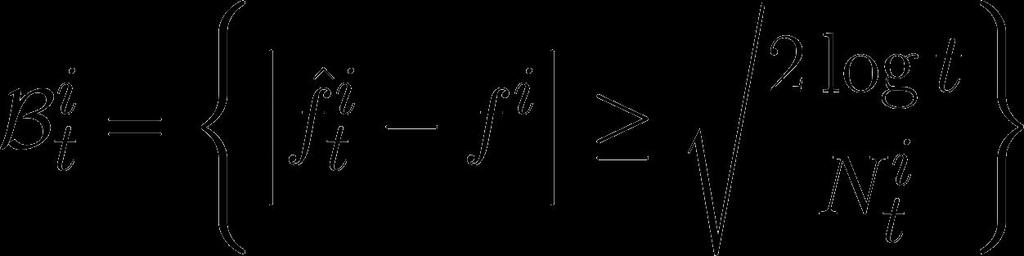
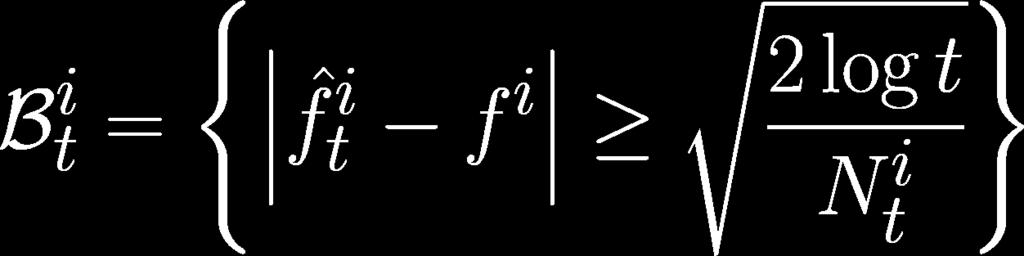
47 Lemma 1 We defined bad events Lemma 1 for by
48 Lemma 2 Suppose, & Then At least one of or hold.
49 Proof of Lemma 2 Suppose neither one of or Then & From hold.
50 Proof of Lemma
51 Proof of Lemma & 2.

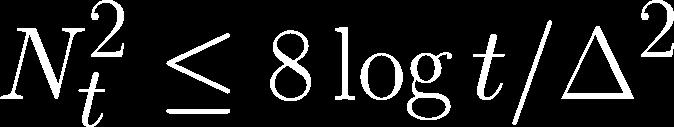
52 Proof of Lemma & 2.

53 Lemma 2 Suppose, & Then At least one of or hold.
54 Lemma 3 Lemma 1 + Lemma 3 Suppose. Then Lemma 2


55 Lemma 4 Lemma 3 Suppose. Then Lemma 4 Suppose. Then
56 Proof of Lemma 4
57 Proof of Lemma 4
58 Proof of Lemma 4

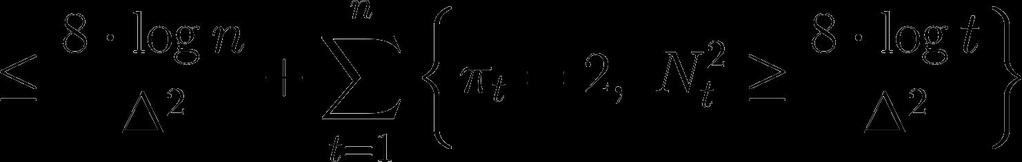
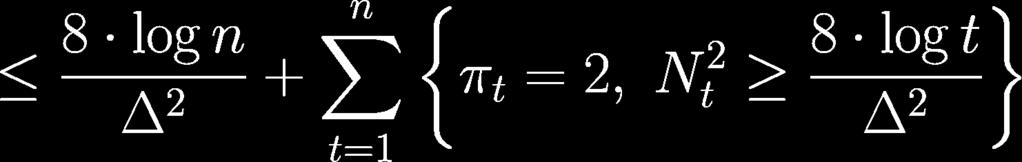
59 Proof of Lemma 4
60 Proof of UCB Regret bound Suppose. Then
61 Proof of UCB Regret bound Suppose. Then
62 Proof of UCB Regret bound Suppose. Then

63 Proof of UCB Regret bound Suppose. Then
64 The multi-armed bandit problem with covariates and the k-nearest neighbour UCB algorithm Henry WJ Reeve (Manchester) A joint work with Joe Mellor (Edinburgh) & Professor Gavin Brown (Manchester)
65 Plan 1. Multi-armed bandits with covariates 2. Non-parametric assumptions 3. Partition based policies and the UCBogram 4. Manifolds 5. The k-nearest neighbour UCB algorithm
66 The multi-armed bandit with covariates
67 Bandits with side-information Multi-armed bandits with additional side-information Example 1: Personalised sequential clinical trials - access to a patient's genome sequence. Example 2: Personalised online advertisement placement - access to a customer s interests, browsing and purchasing history.
68 Multi-armed bandit with covariates For Observe a covariate Choose an arm to pull based on & the reward history Receive a reward


69 Multi-armed bandit with covariates Covariates drawn from For each is drawn i.i.d from Expected reward, on.
70 Bandits with covariates
71 Bandits with covariates
72 Regret for bandits with covariates Compare Regret: with the oracle policy
73 Non-parametric assumptions
74 The Lipschitz assumption For define by Lipschitz assumption:, b,.
75 The Lipschitz assumption

76 The Lipschitz assumption
77 The Margin assumption Define the margin function by Margin assumption:,,.
78 The margin assumption
79 The margin assumption
80 Histogram based policies
 consider UCBogram 1.")

81 The UCBogram Rigollet and Zeevi (COLT, 2010) consider UCBogram 1. Partition cubes, into 2. Apply UCB locally on each of the separate cubes.
82 The UCBogram
83 The UCBogram UCB c UCB c UCB c UCB c UCB c UCB c UCB c UCB c UCB c
84 The UCBogram Rigollet and Zeevi (2010): Suppose & is is absolutely continuous, with a well-behaved density. Suppose that the bandit satisfies the Lipchitz condition & the margin condition with Then the UCBogram satisfies:
85 Adaptively Binned Successive Elimination Perchet & Rigollet (2011): ABSE: 1. Refine the partition whenever 2. Run a standard bandit algorithm locally until the subsequent refinement
86 Adaptively Binned Successive Elimination SE SE SE SE
87 Adaptively Binned Successive Elimination SE SE SE SE SE SE SE
88 Adaptively Binned Successive Elimination SE SE SE SE SE SE SE SE SE SE SE SE SE
89 Adaptively Binned Successive Elimination Perchet & Rigollet (2011): Suppose & is is absolutely continuous, with a well-behaved density. Suppose that the bandit satisfies the Lipchitz condition & the margin condition with any Then the ABSE satisfies:
90 Bandits on manifolds

91 Manifolds A - dimensional manifold Looks locally like - dimensional Euclidean space
92 Manifolds In many applications d is large, but the data close to a -dimensional smooth manifold with. Eg. statistical regularities in the space of MRI scans/ genome sequences We should be able to exploit this property - but the manifold is not known in advance!
93 The k-nearest neighbour method in supervised learning
94 The k-nearest neighbour method The k-nearest neighbour method is simple & intuitive Effectively manages the bias-variance trade-off in supervised learning.
95 The k-nearest neighbour method Kpotufe (2012): k-nearest neighbours achieves minimax optimal rates in supervised regression (adapts to intrinsic dimension) Chaudhuri & Dasgupta (2014): k-nearest neighbours achieves minimax optimal rates in supervised classification with the margin condition Reeve & Brown (2017): k-nearest neighbours achieves minimax optimal rates for cost-sensitive learning on manifolds.
96 k-nearest Neighbours UCB
97 K-Nearest Neighbours UCB Given and we define The number of times, amongst the k-nearest neighbours of x, that arm i was pulled The cumulative reward over all the times that arm i was pulled and was amongst the k-nearest neighbours of x The k-nearest neighbour reward estimate


98 Defining uncertainty The distance to the k-th nearest neighbour Uncertainty Standard deviation Bias
99 K-nearest neighbour UCB
100 K-nearest neighbour UCB

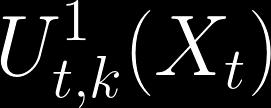
101 K-nearest neighbour UCB
102 Choosing k? Cross-validation is not a good option in the online setting In the supervised regression setting Kpotufe (2012) Choose k by minimising an upper bound on the squared error Choose k to minimise uncertainty:
103 The K-NN UCB algorithm For Observe a covariate For Receive a reward
104 The Lipschitz assumption For define by Lipschitz assumption:, b,.
105 The margin assumption Define the margin function by Margin assumption:,,.
106 The dimension assumption Holds whenever the covariates are chosen from a well-behaved measure on a compact Riemannian manifold of dimension
107 The Regret Bound Reeve, Mellor & Brown (2017): Suppose that: 1) The Lipschitz assumption holds, 2) The margin assumption holds, 3) The dimension assumption holds, Then we have the following regret bound:
108 Empirical validation Cumulative regret A two-dimensional manifold in a fifteen-dimensional feature space Time
109 Discussion Doesn t require prior knowledge of: The time horizon The dimension of the manifold Achieves the minimax optimal rate, up to a logarithmic factor The regret bound extends to any finite number of arms & reward distributions with sub-gaussian noise
110 Thank you for listening!
Homework. Gaussian, Bishop 2.3 Non-parametric, Bishop 2.5 Linear regression Pod-cast lecture on-line. Next lectures:
 Homework Gaussian, Bishop 2.3 Non-parametric, Bishop 2.5 Linear regression 3.0-3.2 Pod-cast lecture on-line Next lectures: I posted a rough plan. It is flexible though so please come with suggestions Bayes
Homework Gaussian, Bishop 2.3 Non-parametric, Bishop 2.5 Linear regression 3.0-3.2 Pod-cast lecture on-line Next lectures: I posted a rough plan. It is flexible though so please come with suggestions Bayes
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu Web advertising We discussed how to match advertisers to queries in real-time But we did not discuss how to estimate
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu Web advertising We discussed how to match advertisers to queries in real-time But we did not discuss how to estimate
Monte Carlo Tree Search PAH 2015
 Monte Carlo Tree Search PAH 2015 MCTS animation and RAVE slides by Michèle Sebag and Romaric Gaudel Markov Decision Processes (MDPs) main formal model Π = S, A, D, T, R states finite set of states of the
Monte Carlo Tree Search PAH 2015 MCTS animation and RAVE slides by Michèle Sebag and Romaric Gaudel Markov Decision Processes (MDPs) main formal model Π = S, A, D, T, R states finite set of states of the
Where we are. Exploratory Graph Analysis (40 min) Focused Graph Mining (40 min) Refinement of Query Results (40 min)
 Focused Graph Mining (40 min) Refinement of Query Results (40 min)") Where we are Background (15 min) Graph models, subgraph isomorphism, subgraph mining, graph clustering Eploratory Graph Analysis (40 min) Focused Graph Mining (40 min) Refinement of Query Results (40 min)
Where we are Background (15 min) Graph models, subgraph isomorphism, subgraph mining, graph clustering Eploratory Graph Analysis (40 min) Focused Graph Mining (40 min) Refinement of Query Results (40 min)
CSE 417T: Introduction to Machine Learning. Lecture 6: Bias-Variance Trade-off. Henry Chai 09/13/18
 CSE 417T: Introduction to Machine Learning Lecture 6: Bias-Variance Trade-off Henry Chai 09/13/18 Let! ", $ = the maximum number of dichotomies on " points s.t. no subset of $ points is shattered Recall
CSE 417T: Introduction to Machine Learning Lecture 6: Bias-Variance Trade-off Henry Chai 09/13/18 Let! ", $ = the maximum number of dichotomies on " points s.t. no subset of $ points is shattered Recall
Overview of various smoothers
 Chapter 2 Overview of various smoothers A scatter plot smoother is a tool for finding structure in a scatter plot: Figure 2.1: CD4 cell count since seroconversion for HIV infected men. CD4 counts vs Time
Chapter 2 Overview of various smoothers A scatter plot smoother is a tool for finding structure in a scatter plot: Figure 2.1: CD4 cell count since seroconversion for HIV infected men. CD4 counts vs Time
Empirical risk minimization (ERM) A first model of learning. The excess risk. Getting a uniform guarantee
 A first model of learning. The excess risk. Getting a uniform guarantee") A first model of learning Let s restrict our attention to binary classification our labels belong to (or ) Empirical risk minimization (ERM) Recall the definitions of risk/empirical risk We observe the
A first model of learning Let s restrict our attention to binary classification our labels belong to (or ) Empirical risk minimization (ERM) Recall the definitions of risk/empirical risk We observe the
Apprenticeship Learning for Reinforcement Learning. with application to RC helicopter flight Ritwik Anand, Nick Haliday, Audrey Huang
 Apprenticeship Learning for Reinforcement Learning with application to RC helicopter flight Ritwik Anand, Nick Haliday, Audrey Huang Table of Contents Introduction Theory Autonomous helicopter control
Apprenticeship Learning for Reinforcement Learning with application to RC helicopter flight Ritwik Anand, Nick Haliday, Audrey Huang Table of Contents Introduction Theory Autonomous helicopter control
Non-Parametric Modeling
 Non-Parametric Modeling CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Non-Parametric Density Estimation Parzen Windows Kn-Nearest Neighbor
Non-Parametric Modeling CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Non-Parametric Density Estimation Parzen Windows Kn-Nearest Neighbor
CME323 Report: Distributed Multi-Armed Bandits
 CME323 Report: Distributed Multi-Armed Bandits Milind Rao milind@stanford.edu 1 Introduction Consider the multi-armed bandit (MAB) problem. In this sequential optimization problem, a player gets to pull
CME323 Report: Distributed Multi-Armed Bandits Milind Rao milind@stanford.edu 1 Introduction Consider the multi-armed bandit (MAB) problem. In this sequential optimization problem, a player gets to pull
Last time... Coryn Bailer-Jones. check and if appropriate remove outliers, errors etc. linear regression
 Machine learning, pattern recognition and statistical data modelling Lecture 3. Linear Methods (part 1) Coryn Bailer-Jones Last time... curse of dimensionality local methods quickly become nonlocal as
Machine learning, pattern recognition and statistical data modelling Lecture 3. Linear Methods (part 1) Coryn Bailer-Jones Last time... curse of dimensionality local methods quickly become nonlocal as
CS6375: Machine Learning Gautam Kunapuli. Mid-Term Review
 Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Edges and Triangles. Po-Shen Loh. Carnegie Mellon University. Joint work with Jacob Fox
 Edges and Triangles Po-Shen Loh Carnegie Mellon University Joint work with Jacob Fox Edges in triangles Observation There are graphs with the property that every edge is contained in a triangle, but no
Edges and Triangles Po-Shen Loh Carnegie Mellon University Joint work with Jacob Fox Edges in triangles Observation There are graphs with the property that every edge is contained in a triangle, but no
Nonparametric Methods Recap
 Nonparametric Methods Recap Aarti Singh Machine Learning 10-701/15-781 Oct 4, 2010 Nonparametric Methods Kernel Density estimate (also Histogram) Weighted frequency Classification - K-NN Classifier Majority
Nonparametric Methods Recap Aarti Singh Machine Learning 10-701/15-781 Oct 4, 2010 Nonparametric Methods Kernel Density estimate (also Histogram) Weighted frequency Classification - K-NN Classifier Majority
Optimization Methods for Machine Learning (OMML)
") Optimization Methods for Machine Learning (OMML) 2nd lecture Prof. L. Palagi References: 1. Bishop Pattern Recognition and Machine Learning, Springer, 2006 (Chap 1) 2. V. Cherlassky, F. Mulier - Learning
Optimization Methods for Machine Learning (OMML) 2nd lecture Prof. L. Palagi References: 1. Bishop Pattern Recognition and Machine Learning, Springer, 2006 (Chap 1) 2. V. Cherlassky, F. Mulier - Learning
Pruning Nearest Neighbor Cluster Trees
 Pruning Nearest Neighbor Cluster Trees Samory Kpotufe Max Planck Institute for Intelligent Systems Tuebingen, Germany Joint work with Ulrike von Luxburg We ll discuss: An interesting notion of clusters
Pruning Nearest Neighbor Cluster Trees Samory Kpotufe Max Planck Institute for Intelligent Systems Tuebingen, Germany Joint work with Ulrike von Luxburg We ll discuss: An interesting notion of clusters
Parametrizing the easiness of machine learning problems. Sanjoy Dasgupta, UC San Diego
 Parametrizing the easiness of machine learning problems Sanjoy Dasgupta, UC San Diego Outline Linear separators Mixture models Nonparametric clustering Nonparametric classification and regression Nearest
Parametrizing the easiness of machine learning problems Sanjoy Dasgupta, UC San Diego Outline Linear separators Mixture models Nonparametric clustering Nonparametric classification and regression Nearest
Real-world bandit applications: Bridging the gap between theory and practice
 Real-world bandit applications: Bridging the gap between theory and practice Audrey Durand EWRL 2018 The bandit setting (Thompson, 1933; Robbins, 1952; Lai and Robbins, 1985) Action Agent Context Environment
Real-world bandit applications: Bridging the gap between theory and practice Audrey Durand EWRL 2018 The bandit setting (Thompson, 1933; Robbins, 1952; Lai and Robbins, 1985) Action Agent Context Environment
Unsupervised Learning: Clustering
 Unsupervised Learning: Clustering Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein & Luke Zettlemoyer Machine Learning Supervised Learning Unsupervised Learning
Unsupervised Learning: Clustering Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein & Luke Zettlemoyer Machine Learning Supervised Learning Unsupervised Learning
COMPUTATIONAL STATISTICS UNSUPERVISED LEARNING
 COMPUTATIONAL STATISTICS UNSUPERVISED LEARNING Luca Bortolussi Department of Mathematics and Geosciences University of Trieste Office 238, third floor, H2bis luca@dmi.units.it Trieste, Winter Semester
COMPUTATIONAL STATISTICS UNSUPERVISED LEARNING Luca Bortolussi Department of Mathematics and Geosciences University of Trieste Office 238, third floor, H2bis luca@dmi.units.it Trieste, Winter Semester
Section 4 Matching Estimator
 Section 4 Matching Estimator Matching Estimators Key Idea: The matching method compares the outcomes of program participants with those of matched nonparticipants, where matches are chosen on the basis
Section 4 Matching Estimator Matching Estimators Key Idea: The matching method compares the outcomes of program participants with those of matched nonparticipants, where matches are chosen on the basis
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 12 Combining
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 12 Combining
Instance-based Learning CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2015
 Instance-based Learning CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2015 Outline Non-parametric approach Unsupervised: Non-parametric density estimation Parzen Windows K-Nearest
Instance-based Learning CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2015 Outline Non-parametric approach Unsupervised: Non-parametric density estimation Parzen Windows K-Nearest
Recap: Gaussian (or Normal) Distribution. Recap: Minimizing the Expected Loss. Topics of This Lecture. Recap: Maximum Likelihood Approach
 Distribution. Recap: Minimizing the Expected Loss. Topics of This Lecture. Recap: Maximum Likelihood Approach") Truth Course Outline Machine Learning Lecture 3 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Probability Density Estimation II 2.04.205 Discriminative Approaches (5 weeks)
Truth Course Outline Machine Learning Lecture 3 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Probability Density Estimation II 2.04.205 Discriminative Approaches (5 weeks)
MODEL SELECTION AND REGULARIZATION PARAMETER CHOICE
 MODEL SELECTION AND REGULARIZATION PARAMETER CHOICE REGULARIZATION METHODS FOR HIGH DIMENSIONAL LEARNING Francesca Odone and Lorenzo Rosasco odone@disi.unige.it - lrosasco@mit.edu June 3, 2013 ABOUT THIS
MODEL SELECTION AND REGULARIZATION PARAMETER CHOICE REGULARIZATION METHODS FOR HIGH DIMENSIONAL LEARNING Francesca Odone and Lorenzo Rosasco odone@disi.unige.it - lrosasco@mit.edu June 3, 2013 ABOUT THIS
Feature Selection for Image Retrieval and Object Recognition
 Feature Selection for Image Retrieval and Object Recognition Nuno Vasconcelos et al. Statistical Visual Computing Lab ECE, UCSD Presented by Dashan Gao Scalable Discriminant Feature Selection for Image
Feature Selection for Image Retrieval and Object Recognition Nuno Vasconcelos et al. Statistical Visual Computing Lab ECE, UCSD Presented by Dashan Gao Scalable Discriminant Feature Selection for Image
0x1A Great Papers in Computer Security
 CS 380S 0x1A Great Papers in Computer Security Vitaly Shmatikov http://www.cs.utexas.edu/~shmat/courses/cs380s/ C. Dwork Differential Privacy (ICALP 2006 and many other papers) Basic Setting DB= x 1 x
CS 380S 0x1A Great Papers in Computer Security Vitaly Shmatikov http://www.cs.utexas.edu/~shmat/courses/cs380s/ C. Dwork Differential Privacy (ICALP 2006 and many other papers) Basic Setting DB= x 1 x
Semi-supervised Learning
 Semi-supervised Learning Piyush Rai CS5350/6350: Machine Learning November 8, 2011 Semi-supervised Learning Supervised Learning models require labeled data Learning a reliable model usually requires plenty
Semi-supervised Learning Piyush Rai CS5350/6350: Machine Learning November 8, 2011 Semi-supervised Learning Supervised Learning models require labeled data Learning a reliable model usually requires plenty
Generative and discriminative classification techniques
 Generative and discriminative classification techniques Machine Learning and Category Representation 2014-2015 Jakob Verbeek, November 28, 2014 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.14.15
Generative and discriminative classification techniques Machine Learning and Category Representation 2014-2015 Jakob Verbeek, November 28, 2014 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.14.15
CSC 411: Lecture 05: Nearest Neighbors
 CSC 411: Lecture 05: Nearest Neighbors Raquel Urtasun & Rich Zemel University of Toronto Sep 28, 2015 Urtasun & Zemel (UofT) CSC 411: 05-Nearest Neighbors Sep 28, 2015 1 / 13 Today Non-parametric models
CSC 411: Lecture 05: Nearest Neighbors Raquel Urtasun & Rich Zemel University of Toronto Sep 28, 2015 Urtasun & Zemel (UofT) CSC 411: 05-Nearest Neighbors Sep 28, 2015 1 / 13 Today Non-parametric models
What is machine learning?
 Machine learning, pattern recognition and statistical data modelling Lecture 12. The last lecture Coryn Bailer-Jones 1 What is machine learning? Data description and interpretation finding simpler relationship
Machine learning, pattern recognition and statistical data modelling Lecture 12. The last lecture Coryn Bailer-Jones 1 What is machine learning? Data description and interpretation finding simpler relationship
Conditional Volatility Estimation by. Conditional Quantile Autoregression
 International Journal of Mathematical Analysis Vol. 8, 2014, no. 41, 2033-2046 HIKARI Ltd, www.m-hikari.com http://dx.doi.org/10.12988/ijma.2014.47210 Conditional Volatility Estimation by Conditional Quantile
International Journal of Mathematical Analysis Vol. 8, 2014, no. 41, 2033-2046 HIKARI Ltd, www.m-hikari.com http://dx.doi.org/10.12988/ijma.2014.47210 Conditional Volatility Estimation by Conditional Quantile
MODEL SELECTION AND REGULARIZATION PARAMETER CHOICE
 MODEL SELECTION AND REGULARIZATION PARAMETER CHOICE REGULARIZATION METHODS FOR HIGH DIMENSIONAL LEARNING Francesca Odone and Lorenzo Rosasco odone@disi.unige.it - lrosasco@mit.edu June 6, 2011 ABOUT THIS
MODEL SELECTION AND REGULARIZATION PARAMETER CHOICE REGULARIZATION METHODS FOR HIGH DIMENSIONAL LEARNING Francesca Odone and Lorenzo Rosasco odone@disi.unige.it - lrosasco@mit.edu June 6, 2011 ABOUT THIS
PSU Student Research Symposium 2017 Bayesian Optimization for Refining Object Proposals, with an Application to Pedestrian Detection Anthony D.
 PSU Student Research Symposium 2017 Bayesian Optimization for Refining Object Proposals, with an Application to Pedestrian Detection Anthony D. Rhodes 5/10/17 What is Machine Learning? Machine learning
PSU Student Research Symposium 2017 Bayesian Optimization for Refining Object Proposals, with an Application to Pedestrian Detection Anthony D. Rhodes 5/10/17 What is Machine Learning? Machine learning
Going nonparametric: Nearest neighbor methods for regression and classification
 Going nonparametric: Nearest neighbor methods for regression and classification STAT/CSE 46: Machine Learning Emily Fox University of Washington May 3, 208 Locality sensitive hashing for approximate NN
Going nonparametric: Nearest neighbor methods for regression and classification STAT/CSE 46: Machine Learning Emily Fox University of Washington May 3, 208 Locality sensitive hashing for approximate NN
CS 229 Midterm Review
 CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
Notes and Announcements
 Notes and Announcements Midterm exam: Oct 20, Wednesday, In Class Late Homeworks Turn in hardcopies to Michelle. DO NOT ask Michelle for extensions. Note down the date and time of submission. If submitting
Notes and Announcements Midterm exam: Oct 20, Wednesday, In Class Late Homeworks Turn in hardcopies to Michelle. DO NOT ask Michelle for extensions. Note down the date and time of submission. If submitting
Machine Learning. Topic 5: Linear Discriminants. Bryan Pardo, EECS 349 Machine Learning, 2013
 Machine Learning Topic 5: Linear Discriminants Bryan Pardo, EECS 349 Machine Learning, 2013 Thanks to Mark Cartwright for his extensive contributions to these slides Thanks to Alpaydin, Bishop, and Duda/Hart/Stork
Machine Learning Topic 5: Linear Discriminants Bryan Pardo, EECS 349 Machine Learning, 2013 Thanks to Mark Cartwright for his extensive contributions to these slides Thanks to Alpaydin, Bishop, and Duda/Hart/Stork
Chapter 4: Non-Parametric Techniques
 Chapter 4: Non-Parametric Techniques Introduction Density Estimation Parzen Windows Kn-Nearest Neighbor Density Estimation K-Nearest Neighbor (KNN) Decision Rule Supervised Learning How to fit a density
Chapter 4: Non-Parametric Techniques Introduction Density Estimation Parzen Windows Kn-Nearest Neighbor Density Estimation K-Nearest Neighbor (KNN) Decision Rule Supervised Learning How to fit a density
Clustering. Mihaela van der Schaar. January 27, Department of Engineering Science University of Oxford
 Department of Engineering Science University of Oxford January 27, 2017 Many datasets consist of multiple heterogeneous subsets. Cluster analysis: Given an unlabelled data, want algorithms that automatically
Department of Engineering Science University of Oxford January 27, 2017 Many datasets consist of multiple heterogeneous subsets. Cluster analysis: Given an unlabelled data, want algorithms that automatically
Homework 4: Clustering, Recommenders, Dim. Reduction, ML and Graph Mining (due November 19 th, 2014, 2:30pm, in class hard-copy please)
") Virginia Tech. Computer Science CS 5614 (Big) Data Management Systems Fall 2014, Prakash Homework 4: Clustering, Recommenders, Dim. Reduction, ML and Graph Mining (due November 19 th, 2014, 2:30pm, in
Virginia Tech. Computer Science CS 5614 (Big) Data Management Systems Fall 2014, Prakash Homework 4: Clustering, Recommenders, Dim. Reduction, ML and Graph Mining (due November 19 th, 2014, 2:30pm, in
Nonparametric Risk Attribution for Factor Models of Portfolios. October 3, 2017 Kellie Ottoboni
 Nonparametric Risk Attribution for Factor Models of Portfolios October 3, 2017 Kellie Ottoboni Outline The problem Page 3 Additive model of returns Page 7 Euler s formula for risk decomposition Page 11
Nonparametric Risk Attribution for Factor Models of Portfolios October 3, 2017 Kellie Ottoboni Outline The problem Page 3 Additive model of returns Page 7 Euler s formula for risk decomposition Page 11
Machine Learning and Pervasive Computing
 Stephan Sigg Georg-August-University Goettingen, Computer Networks 17.12.2014 Overview and Structure 22.10.2014 Organisation 22.10.3014 Introduction (Def.: Machine learning, Supervised/Unsupervised, Examples)
Stephan Sigg Georg-August-University Goettingen, Computer Networks 17.12.2014 Overview and Structure 22.10.2014 Organisation 22.10.3014 Introduction (Def.: Machine learning, Supervised/Unsupervised, Examples)
Nearest Neighbor Classification
 Nearest Neighbor Classification Charles Elkan elkan@cs.ucsd.edu October 9, 2007 The nearest-neighbor method is perhaps the simplest of all algorithms for predicting the class of a test example. The training
Nearest Neighbor Classification Charles Elkan elkan@cs.ucsd.edu October 9, 2007 The nearest-neighbor method is perhaps the simplest of all algorithms for predicting the class of a test example. The training
CPSC 340: Machine Learning and Data Mining. Non-Parametric Models Fall 2016
 CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Admin Course add/drop deadline tomorrow. Assignment 1 is due Friday. Setup your CS undergrad account ASAP to use Handin: https://www.cs.ubc.ca/getacct
CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Admin Course add/drop deadline tomorrow. Assignment 1 is due Friday. Setup your CS undergrad account ASAP to use Handin: https://www.cs.ubc.ca/getacct
The Boundary Graph Supervised Learning Algorithm for Regression and Classification
 The Boundary Graph Supervised Learning Algorithm for Regression and Classification! Jonathan Yedidia! Disney Research!! Outline Motivation Illustration using a toy classification problem Some simple refinements
The Boundary Graph Supervised Learning Algorithm for Regression and Classification! Jonathan Yedidia! Disney Research!! Outline Motivation Illustration using a toy classification problem Some simple refinements
Overfitting. Machine Learning CSE546 Carlos Guestrin University of Washington. October 2, Bias-Variance Tradeoff
 Overfitting Machine Learning CSE546 Carlos Guestrin University of Washington October 2, 2013 1 Bias-Variance Tradeoff Choice of hypothesis class introduces learning bias More complex class less bias More
Overfitting Machine Learning CSE546 Carlos Guestrin University of Washington October 2, 2013 1 Bias-Variance Tradeoff Choice of hypothesis class introduces learning bias More complex class less bias More
CPSC 340: Machine Learning and Data Mining. Non-Parametric Models Fall 2016
 CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Assignment 0: Admin 1 late day to hand it in tonight, 2 late days for Wednesday. Assignment 1 is out: Due Friday of next week.
CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Assignment 0: Admin 1 late day to hand it in tonight, 2 late days for Wednesday. Assignment 1 is out: Due Friday of next week.
Model Assessment and Selection. Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer
 Model Assessment and Selection Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer 1 Model Training data Testing data Model Testing error rate Training error
Model Assessment and Selection Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer 1 Model Training data Testing data Model Testing error rate Training error
Learning from High Dimensional fmri Data using Random Projections
 Learning from High Dimensional fmri Data using Random Projections Author: Madhu Advani December 16, 011 Introduction The term the Curse of Dimensionality refers to the difficulty of organizing and applying
Learning from High Dimensional fmri Data using Random Projections Author: Madhu Advani December 16, 011 Introduction The term the Curse of Dimensionality refers to the difficulty of organizing and applying
Planning and Control: Markov Decision Processes
 CSE-571 AI-based Mobile Robotics Planning and Control: Markov Decision Processes Planning Static vs. Dynamic Predictable vs. Unpredictable Fully vs. Partially Observable Perfect vs. Noisy Environment What
CSE-571 AI-based Mobile Robotics Planning and Control: Markov Decision Processes Planning Static vs. Dynamic Predictable vs. Unpredictable Fully vs. Partially Observable Perfect vs. Noisy Environment What
5 Learning hypothesis classes (16 points)
") 5 Learning hypothesis classes (16 points) Consider a classification problem with two real valued inputs. For each of the following algorithms, specify all of the separators below that it could have generated
5 Learning hypothesis classes (16 points) Consider a classification problem with two real valued inputs. For each of the following algorithms, specify all of the separators below that it could have generated
Introduction to machine learning, pattern recognition and statistical data modelling Coryn Bailer-Jones
 Introduction to machine learning, pattern recognition and statistical data modelling Coryn Bailer-Jones What is machine learning? Data interpretation describing relationship between predictors and responses
Introduction to machine learning, pattern recognition and statistical data modelling Coryn Bailer-Jones What is machine learning? Data interpretation describing relationship between predictors and responses
Supervised vs unsupervised clustering
 Classification Supervised vs unsupervised clustering Cluster analysis: Classes are not known a- priori. Classification: Classes are defined a-priori Sometimes called supervised clustering Extract useful
Classification Supervised vs unsupervised clustering Cluster analysis: Classes are not known a- priori. Classification: Classes are defined a-priori Sometimes called supervised clustering Extract useful
Machine Learning Techniques for Data Mining
 Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
3D Point Cloud Processing
 3D Point Cloud Processing The image depicts how our robot Irma3D sees itself in a mirror. The laser looking into itself creates distortions as well as changes in intensity that give the robot a single
3D Point Cloud Processing The image depicts how our robot Irma3D sees itself in a mirror. The laser looking into itself creates distortions as well as changes in intensity that give the robot a single
Nearest Neighbor Classification
 Nearest Neighbor Classification Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms January 11, 2017 1 / 48 Outline 1 Administration 2 First learning algorithm: Nearest
Nearest Neighbor Classification Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms January 11, 2017 1 / 48 Outline 1 Administration 2 First learning algorithm: Nearest
Announcements. CS 188: Artificial Intelligence Spring Classification: Feature Vectors. Classification: Weights. Learning: Binary Perceptron
 CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/20/2010 Announcements W7 due Thursday [that s your last written for the semester!] Project 5 out Thursday Contest running
CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/20/2010 Announcements W7 due Thursday [that s your last written for the semester!] Project 5 out Thursday Contest running
Risk bounds for some classification and regression models that interpolate
 Risk bounds for some classification and regression models that interpolate Daniel Hsu Columbia University Joint work with: Misha Belkin (The Ohio State University) Partha Mitra (Cold Spring Harbor Laboratory)
Risk bounds for some classification and regression models that interpolate Daniel Hsu Columbia University Joint work with: Misha Belkin (The Ohio State University) Partha Mitra (Cold Spring Harbor Laboratory)
We use non-bold capital letters for all random variables in these notes, whether they are scalar-, vector-, matrix-, or whatever-valued.
 The Bayes Classifier We have been starting to look at the supervised classification problem: we are given data (x i, y i ) for i = 1,..., n, where x i R d, and y i {1,..., K}. In this section, we suppose
The Bayes Classifier We have been starting to look at the supervised classification problem: we are given data (x i, y i ) for i = 1,..., n, where x i R d, and y i {1,..., K}. In this section, we suppose
Slides for Data Mining by I. H. Witten and E. Frank
 Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Chapter 3: Supervised Learning
 Chapter 3: Supervised Learning Road Map Basic concepts Evaluation of classifiers Classification using association rules Naïve Bayesian classification Naïve Bayes for text classification Summary 2 An example
Chapter 3: Supervised Learning Road Map Basic concepts Evaluation of classifiers Classification using association rules Naïve Bayesian classification Naïve Bayes for text classification Summary 2 An example
Using the Kolmogorov-Smirnov Test for Image Segmentation
 Using the Kolmogorov-Smirnov Test for Image Segmentation Yong Jae Lee CS395T Computational Statistics Final Project Report May 6th, 2009 I. INTRODUCTION Image segmentation is a fundamental task in computer
Using the Kolmogorov-Smirnov Test for Image Segmentation Yong Jae Lee CS395T Computational Statistics Final Project Report May 6th, 2009 I. INTRODUCTION Image segmentation is a fundamental task in computer
Coding for Random Projects
 Coding for Random Projects CS 584: Big Data Analytics Material adapted from Li s talk at ICML 2014 (http://techtalks.tv/talks/coding-for-random-projections/61085/) Random Projections for High-Dimensional
Coding for Random Projects CS 584: Big Data Analytics Material adapted from Li s talk at ICML 2014 (http://techtalks.tv/talks/coding-for-random-projections/61085/) Random Projections for High-Dimensional
Bumptrees for Efficient Function, Constraint, and Classification Learning
 umptrees for Efficient Function, Constraint, and Classification Learning Stephen M. Omohundro International Computer Science Institute 1947 Center Street, Suite 600 erkeley, California 94704 Abstract A
umptrees for Efficient Function, Constraint, and Classification Learning Stephen M. Omohundro International Computer Science Institute 1947 Center Street, Suite 600 erkeley, California 94704 Abstract A
Supervised Learning: K-Nearest Neighbors and Decision Trees
 Supervised Learning: K-Nearest Neighbors and Decision Trees Piyush Rai CS5350/6350: Machine Learning August 25, 2011 (CS5350/6350) K-NN and DT August 25, 2011 1 / 20 Supervised Learning Given training
Supervised Learning: K-Nearest Neighbors and Decision Trees Piyush Rai CS5350/6350: Machine Learning August 25, 2011 (CS5350/6350) K-NN and DT August 25, 2011 1 / 20 Supervised Learning Given training
Applied Statistics for Neuroscientists Part IIa: Machine Learning
 Applied Statistics for Neuroscientists Part IIa: Machine Learning Dr. Seyed-Ahmad Ahmadi 04.04.2017 16.11.2017 Outline Machine Learning Difference between statistics and machine learning Modeling the problem
Applied Statistics for Neuroscientists Part IIa: Machine Learning Dr. Seyed-Ahmad Ahmadi 04.04.2017 16.11.2017 Outline Machine Learning Difference between statistics and machine learning Modeling the problem
CS178: Machine Learning and Data Mining. Complexity & Nearest Neighbor Methods
 + CS78: Machine Learning and Data Mining Complexity & Nearest Neighbor Methods Prof. Erik Sudderth Some materials courtesy Alex Ihler & Sameer Singh Machine Learning Complexity and Overfitting Nearest
+ CS78: Machine Learning and Data Mining Complexity & Nearest Neighbor Methods Prof. Erik Sudderth Some materials courtesy Alex Ihler & Sameer Singh Machine Learning Complexity and Overfitting Nearest
Feature Extractors. CS 188: Artificial Intelligence Fall Some (Vague) Biology. The Binary Perceptron. Binary Decision Rule.
 Biology. The Binary Perceptron. Binary Decision Rule.") CS 188: Artificial Intelligence Fall 2008 Lecture 24: Perceptrons II 11/24/2008 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit
CS 188: Artificial Intelligence Fall 2008 Lecture 24: Perceptrons II 11/24/2008 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit
Combinatorial Methods in Density Estimation
 Luc Devroye Gabor Lugosi Combinatorial Methods in Density Estimation Springer Contents Preface vii 1. Introduction 1 a 1.1. References 3 2. Concentration Inequalities 4 2.1. Hoeffding's Inequality 4 2.2.
Luc Devroye Gabor Lugosi Combinatorial Methods in Density Estimation Springer Contents Preface vii 1. Introduction 1 a 1.1. References 3 2. Concentration Inequalities 4 2.1. Hoeffding's Inequality 4 2.2.
MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018
![MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018](/thumbs/77/76295965.jpg "MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018") MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
These slides follow closely the (English) course textbook Pattern Recognition and Machine Learning by Christopher Bishop
 course textbook Pattern Recognition and Machine Learning by Christopher Bishop") Machine Learning Algorithms (IFT6266 A7) Prof. Douglas Eck, Université de Montréal These slides follow closely the (English) course textbook Pattern Recognition and Machine Learning by Christopher Bishop
Machine Learning Algorithms (IFT6266 A7) Prof. Douglas Eck, Université de Montréal These slides follow closely the (English) course textbook Pattern Recognition and Machine Learning by Christopher Bishop
FMA901F: Machine Learning Lecture 3: Linear Models for Regression. Cristian Sminchisescu
 FMA901F: Machine Learning Lecture 3: Linear Models for Regression Cristian Sminchisescu Machine Learning: Frequentist vs. Bayesian In the frequentist setting, we seek a fixed parameter (vector), with value(s)
FMA901F: Machine Learning Lecture 3: Linear Models for Regression Cristian Sminchisescu Machine Learning: Frequentist vs. Bayesian In the frequentist setting, we seek a fixed parameter (vector), with value(s)
CPSC 340: Machine Learning and Data Mining. More Regularization Fall 2017
 CPSC 340: Machine Learning and Data Mining More Regularization Fall 2017 Assignment 3: Admin Out soon, due Friday of next week. Midterm: You can view your exam during instructor office hours or after class
CPSC 340: Machine Learning and Data Mining More Regularization Fall 2017 Assignment 3: Admin Out soon, due Friday of next week. Midterm: You can view your exam during instructor office hours or after class
Classification: Feature Vectors
 Classification: Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free YOUR_NAME MISSPELLED FROM_FRIEND... : : : : 2 0 2 0 PIXEL 7,12
Classification: Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free YOUR_NAME MISSPELLED FROM_FRIEND... : : : : 2 0 2 0 PIXEL 7,12
Topics in Machine Learning
 Topics in Machine Learning Gilad Lerman School of Mathematics University of Minnesota Text/slides stolen from G. James, D. Witten, T. Hastie, R. Tibshirani and A. Ng Machine Learning - Motivation Arthur
Topics in Machine Learning Gilad Lerman School of Mathematics University of Minnesota Text/slides stolen from G. James, D. Witten, T. Hastie, R. Tibshirani and A. Ng Machine Learning - Motivation Arthur
Machine Learning Lecture 3
 Machine Learning Lecture 3 Probability Density Estimation II 19.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Exam dates We re in the process
Machine Learning Lecture 3 Probability Density Estimation II 19.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Exam dates We re in the process
Bayesian Optimization Nando de Freitas
 Bayesian Optimization Nando de Freitas Eric Brochu, Ruben Martinez-Cantin, Matt Hoffman, Ziyu Wang, More resources This talk follows the presentation in the following review paper available fro Oxford
Bayesian Optimization Nando de Freitas Eric Brochu, Ruben Martinez-Cantin, Matt Hoffman, Ziyu Wang, More resources This talk follows the presentation in the following review paper available fro Oxford
Machine Learning in Biology
 Università degli studi di Padova Machine Learning in Biology Luca Silvestrin (Dottorando, XXIII ciclo) Supervised learning Contents Class-conditional probability density Linear and quadratic discriminant
Università degli studi di Padova Machine Learning in Biology Luca Silvestrin (Dottorando, XXIII ciclo) Supervised learning Contents Class-conditional probability density Linear and quadratic discriminant
A popular method for moving beyond linearity. 2. Basis expansion and regularization 1. Examples of transformations. Piecewise-polynomials and splines
 A popular method for moving beyond linearity 2. Basis expansion and regularization 1 Idea: Augment the vector inputs x with additional variables which are transformation of x use linear models in this
A popular method for moving beyond linearity 2. Basis expansion and regularization 1 Idea: Augment the vector inputs x with additional variables which are transformation of x use linear models in this
Distribution-free Predictive Approaches
 Distribution-free Predictive Approaches The methods discussed in the previous sections are essentially model-based. Model-free approaches such as tree-based classification also exist and are popular for
Distribution-free Predictive Approaches The methods discussed in the previous sections are essentially model-based. Model-free approaches such as tree-based classification also exist and are popular for
w KLUWER ACADEMIC PUBLISHERS Global Optimization with Non-Convex Constraints Sequential and Parallel Algorithms Roman G. Strongin Yaroslav D.
 Global Optimization with Non-Convex Constraints Sequential and Parallel Algorithms by Roman G. Strongin Nizhni Novgorod State University, Nizhni Novgorod, Russia and Yaroslav D. Sergeyev Institute of Systems
Global Optimization with Non-Convex Constraints Sequential and Parallel Algorithms by Roman G. Strongin Nizhni Novgorod State University, Nizhni Novgorod, Russia and Yaroslav D. Sergeyev Institute of Systems
Classification. Vladimir Curic. Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University
 Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
DATA MINING LECTURE 10B. Classification k-nearest neighbor classifier Naïve Bayes Logistic Regression Support Vector Machines
 DATA MINING LECTURE 10B Classification k-nearest neighbor classifier Naïve Bayes Logistic Regression Support Vector Machines NEAREST NEIGHBOR CLASSIFICATION 10 10 Illustrating Classification Task Tid Attrib1
DATA MINING LECTURE 10B Classification k-nearest neighbor classifier Naïve Bayes Logistic Regression Support Vector Machines NEAREST NEIGHBOR CLASSIFICATION 10 10 Illustrating Classification Task Tid Attrib1
Introduction to Mobile Robotics
 Introduction to Mobile Robotics Gaussian Processes Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann SS08, University of Freiburg, Department for Computer Science Announcement
Introduction to Mobile Robotics Gaussian Processes Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann SS08, University of Freiburg, Department for Computer Science Announcement
CSE 573: Artificial Intelligence Autumn 2010
 CSE 573: Artificial Intelligence Autumn 2010 Lecture 16: Machine Learning Topics 12/7/2010 Luke Zettlemoyer Most slides over the course adapted from Dan Klein. 1 Announcements Syllabus revised Machine
CSE 573: Artificial Intelligence Autumn 2010 Lecture 16: Machine Learning Topics 12/7/2010 Luke Zettlemoyer Most slides over the course adapted from Dan Klein. 1 Announcements Syllabus revised Machine
TECHNICAL REPORT NO Random Forests and Adaptive Nearest Neighbors 1
 DEPARTMENT OF STATISTICS University of Wisconsin 1210 West Dayton St. Madison, WI 53706 TECHNICAL REPORT NO. 1055 May 29, 2002 Random Forests and Adaptive Nearest Neighbors 1 by Yi Lin and Yongho Jeon
DEPARTMENT OF STATISTICS University of Wisconsin 1210 West Dayton St. Madison, WI 53706 TECHNICAL REPORT NO. 1055 May 29, 2002 Random Forests and Adaptive Nearest Neighbors 1 by Yi Lin and Yongho Jeon
An Empirical Study of Hoeffding Racing for Model Selection in k-nearest Neighbor Classification
 An Empirical Study of Hoeffding Racing for Model Selection in k-nearest Neighbor Classification Flora Yu-Hui Yeh and Marcus Gallagher School of Information Technology and Electrical Engineering University
An Empirical Study of Hoeffding Racing for Model Selection in k-nearest Neighbor Classification Flora Yu-Hui Yeh and Marcus Gallagher School of Information Technology and Electrical Engineering University
Data Knowledge and Optimization. Patrick De Causmaecker CODeS-imec Department of Computer Science KU Leuven/ KULAK
 Data Knowledge and Optimization Patrick De Causmaecker CODeS-imec Department of Computer Science KU Leuven/ KULAK Whishes from West-Flanders, Belgium 10 rules for success in supply chain mngmnt & logistics
Data Knowledge and Optimization Patrick De Causmaecker CODeS-imec Department of Computer Science KU Leuven/ KULAK Whishes from West-Flanders, Belgium 10 rules for success in supply chain mngmnt & logistics
Last time... Bias-Variance decomposition. This week
 Machine learning, pattern recognition and statistical data modelling Lecture 4. Going nonlinear: basis expansions and splines Last time... Coryn Bailer-Jones linear regression methods for high dimensional
Machine learning, pattern recognition and statistical data modelling Lecture 4. Going nonlinear: basis expansions and splines Last time... Coryn Bailer-Jones linear regression methods for high dimensional
Machine Learning and Data Mining. Clustering (1): Basics. Kalev Kask
: Basics. Kalev Kask") Machine Learning and Data Mining Clustering (1): Basics Kalev Kask Unsupervised learning Supervised learning Predict target value ( y ) given features ( x ) Unsupervised learning Understand patterns of
Machine Learning and Data Mining Clustering (1): Basics Kalev Kask Unsupervised learning Supervised learning Predict target value ( y ) given features ( x ) Unsupervised learning Understand patterns of
Stanford University CS359G: Graph Partitioning and Expanders Handout 18 Luca Trevisan March 3, 2011
 Stanford University CS359G: Graph Partitioning and Expanders Handout 8 Luca Trevisan March 3, 20 Lecture 8 In which we prove properties of expander graphs. Quasirandomness of Expander Graphs Recall that
Stanford University CS359G: Graph Partitioning and Expanders Handout 8 Luca Trevisan March 3, 20 Lecture 8 In which we prove properties of expander graphs. Quasirandomness of Expander Graphs Recall that
Thorsten Joachims Then: Universität Dortmund, Germany Now: Cornell University, USA
 Retrospective ICML99 Transductive Inference for Text Classification using Support Vector Machines Thorsten Joachims Then: Universität Dortmund, Germany Now: Cornell University, USA Outline The paper in
Retrospective ICML99 Transductive Inference for Text Classification using Support Vector Machines Thorsten Joachims Then: Universität Dortmund, Germany Now: Cornell University, USA Outline The paper in
Information Driven Healthcare:
 Information Driven Healthcare: Machine Learning course Lecture: Feature selection I --- Concepts Centre for Doctoral Training in Healthcare Innovation Dr. Athanasios Tsanas ( Thanasis ), Wellcome Trust
Information Driven Healthcare: Machine Learning course Lecture: Feature selection I --- Concepts Centre for Doctoral Training in Healthcare Innovation Dr. Athanasios Tsanas ( Thanasis ), Wellcome Trust
Chapter 3. Bootstrap. 3.1 Introduction. 3.2 The general idea
 Chapter 3 Bootstrap 3.1 Introduction The estimation of parameters in probability distributions is a basic problem in statistics that one tends to encounter already during the very first course on the subject.
Chapter 3 Bootstrap 3.1 Introduction The estimation of parameters in probability distributions is a basic problem in statistics that one tends to encounter already during the very first course on the subject.
Supplementary Figure 1. Decoding results broken down for different ROIs
 Supplementary Figure 1 Decoding results broken down for different ROIs Decoding results for areas V1, V2, V3, and V1 V3 combined. (a) Decoded and presented orientations are strongly correlated in areas
Supplementary Figure 1 Decoding results broken down for different ROIs Decoding results for areas V1, V2, V3, and V1 V3 combined. (a) Decoded and presented orientations are strongly correlated in areas
Estimating survival from Gray s flexible model. Outline. I. Introduction. I. Introduction. I. Introduction
 Estimating survival from s flexible model Zdenek Valenta Department of Medical Informatics Institute of Computer Science Academy of Sciences of the Czech Republic I. Introduction Outline II. Semi parametric
Estimating survival from s flexible model Zdenek Valenta Department of Medical Informatics Institute of Computer Science Academy of Sciences of the Czech Republic I. Introduction Outline II. Semi parametric
Bioinformatics - Lecture 07
 Bioinformatics - Lecture 07 Bioinformatics Clusters and networks Martin Saturka http://www.bioplexity.org/lectures/ EBI version 0.4 Creative Commons Attribution-Share Alike 2.5 License Learning on profiles
Bioinformatics - Lecture 07 Bioinformatics Clusters and networks Martin Saturka http://www.bioplexity.org/lectures/ EBI version 0.4 Creative Commons Attribution-Share Alike 2.5 License Learning on profiles
Part I. Hierarchical clustering. Hierarchical Clustering. Hierarchical clustering. Produces a set of nested clusters organized as a
 Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Learning with minimal supervision
 Learning with minimal supervision Sanjoy Dasgupta University of California, San Diego Learning with minimal supervision There are many sources of almost unlimited unlabeled data: Images from the web Speech
Learning with minimal supervision Sanjoy Dasgupta University of California, San Diego Learning with minimal supervision There are many sources of almost unlimited unlabeled data: Images from the web Speech