Market basket analysis
|
|
|
- Kristin Caldwell
- 6 years ago
- Views:
Transcription
1 Market basket analysis Find joint values of the variables X = (X 1,..., X p ) that appear most frequently in the data base. It is most often applied to binary-valued data X j. In this context the observations are sales transactions, such as those occurring at the checkout counter of a store. The variables represent all of the items sold in the store. For observation i, each variable X j is assigned one of two values; { 1 If the jth item is purchased in ith transaction x ij = 0 Otherwise Those variables that frequently have joint values of one represent items that are frequently purchased together. This information can be quite useful for stocking shelves, cross-marketing in sales promotions, catalog design, and consumer segmentation based on buying patterns.
2 Market basket analysis Assume X 1,..., X p are all binary variables. Market basket analysis aims to find a subset of the integers K = {1,..., P} so that the following is large: ( ) P {X k = 1}. k K The set K is called an item set. The number of items in K is called its size. The above probability is called the Support or prevalence, T (K) of the item set K. It is estimated by ( ) ˆP {X k = 1} = 1 N x ik. N k K i=1 i K An observation i for which i K x ik = 1 is said to Contain the item set K. Given a lower bound t, the market basket analysis seeks all the item set K l with support in the data base greater than this lower bound t, i.e., {K l T (K l ) > t}.
3 The Apriori algorithm The solution to the market basket analysis can be obtained with feasible computation for very large data bases provided the threshold t is adjusted so that the solution consists of only a small fraction of all 2 p possible item sets. The Apriori algorithm (Agrawal et al., 1995) exploits several aspects of the curse of dimensionality to solve the problem with a small number of passes over the data. Specifically, for a given support threshold t: The cardinality {K T (K) > t} is relatively small. Any item set L consisting of a subset of the items in K must have support greater than or equal to that of K, i.e., if L K, then T (L) > T (K)
4 The Apriori algorithm The first pass over the data computes the support of all single-item sets. Those whose support is less than the threshold are discarded. The second pass computes the support of all item sets of size two that can be formed from pairs of the single items surviving the first pass. Each successive pass over the data considers only those item sets that can be formed by combining those that survived the previous pass with those retained from the first pass. Passes over the data continue until all candidate rules from the previous pass have support less than the specified threshold The Apriori algorithm requires only one pass over the data for each value of T (K), which is crucial since we assume the data cannot be fitted into a computer s main memory. If the data are sufficiently sparse (or if the threshold t is high enough), then the process will terminate in reasonable time even for huge data sets.
5 Association rule Each high support item set K returned by the Apriori algorithm is cast into a set of association rules. The items X k, k K, are partitioned into two disjoint subsets, A B = K, and written A => B. The first item subset A is called the antecedent and the second B the consequent. The support of the rule T (A => B) is the support of the item set they are derived. The confidence or predictability C(A => B) of the rule is its support divided by the support of the antecedent C(A => B) = T (A => B) T (A) which can be viewed as an estimate of P(B A)
6 The expected confidence is defined as the support of the consequent T (B), which is an estimate of the unconditional probability P(B). The lift of the rule is defined as the confidence divided by the expected confidence L(A => B) = C(A => B) T (B)
7 Association rule: example suppose the item set K = {butter, jelly, bread} and consider the rule {peanutbutter, jelly} => {bread}. A support value of 0.03 for this rule means that peanut butter, jelly, and bread appeared together in 3% of the market baskets. A confidence of 0.82 for this rule implies that when peanut butter and jelly were purchased, 82% of the time bread was also purchased. If bread appeared in 43% of all market baskets then the rule {peanutbutter, jelly} => {bread} would have a lift of 1.95.
8 Association rule Sometimes, the desired output of the entire analysis is a collection of association rules that satisfy the constraints T (A => B) > t and C(A => B) > c for some threshold t and c. For example, Display all transactions in which ice skates are the consequent that have confidence over 80% and support of more than 2%. Efficient algorithms based on the apriori algorithm have been developed. Association rules have become a popular tool for analyzing very large commercial data bases in settings where market basket is relevant. That is, when the data can be cast in the form of a multidimensional contingency table. The output is in the form of conjunctive rules that are easily understood and interpreted.
9 The Apriori algorithm allows this analysis to be applied to huge data bases, much larger that are amenable to other types of analyses. Association rules are among data mining s biggest successes. The number of solution item sets, their size, and the number of passes required over the data can grow exponentially with decreasing size of this lower bound. Thus, rules with high confidence or lift, but low support, will not be discovered. For example, a high confi- dence rule such as vodka => caviar will not be uncovered owing to the low sales volume of the consequent caviar.
10 We illustrate the use of Apriori on a moderately sized demographics data base. This data set consists of N = 9409 questionnaires filled out by shopping mall customers in the San Francisco Bay Area (Impact Resources, Inc., Columbus OH, 1987). Here we use answers to the first 14 questions, relating to demographics, for illustration.
11 A freeware implementation of the Apriori algorithm due to Christian Borgelt is used. After removing observations with missing values, each ordinal predictor was cut at its median and coded by two dummy variables; each categorical predictor with k categories was coded by k dummy variables. This resulted in a 6876 Π50 matrix of 6876 observations on 50 dummy variables. The algorithm found a total of 6288 association rules, involving??? 5 predictors, with support of at least 10%. Understanding this large set of rules is itself a challenging data analysis task.
12 Here are three examples of association rules found by the Apriori algorithm: Association rule 1: Support 25%, confidence 99.7% and lift 1.03.
13 Association rule 2: Support 13.4%, confidence 80.8%, and lift 2.13.
14 Association rule 3: Support 26.5%, confidence 82.8% and lift 2.15.
15 Cluster anlaysis Group or segment a collection of objects into subsets or clusters, such that those within each cluster are more closely related to one another than objects assigned to different clusters. Central to all of the goals of cluster analysis is the notion of the degree of similarity (or dissimilarity) between the individual objects being clustered. A clustering method attempts to group the objects based on the definition of similarity supplied to it. Definition of similarity can only come from subject matter considerations. The situation is somewhat similar to the specification of a loss or cost function in prediction problems (supervised learning). There the cost associated with an inaccurate prediction depends on considerations outside the data.
16 Proximity matrices Most algorithms presume a matrix of dissimilarities with nonnegative entries and zero diagonal elements: d ii = 0, i = 1, 2,..., N. If the original data were collected as similarities, a suitable monotone-decreasing function can be used to convert them to dissimilarities. most algorithms assume symmetric dissimilarity matrices, so if the original matrix D is not symmetric it must be replaced by (D + D T )/2
17 Attribute dissimilarity For the jth attribute of objects x ij and x i j, let d j (x ij, x i j) be the dissimilarity between them on the jth attribute. Quantitative variables: d j (x ij, x i j) = (x ij x i j) 2 Ordinal variables: Error measures for ordinal variables are generally defined by replacing their M original values with i 1/2, i = 1,..., M M in the prescribed order of their original values. They are then treated as quantitative variables on this scale. Nominal variables: d j (x ij, x ij ) = { 1 if xij = x i j 0 otherwise
18 Object Dissimilarity Combining the p-individual attribute dissimilarities d j (x ij, x i j), j = 1,..., p into a single overall measure of dissimilarity D(x i, x i ) between two objects or observations, is usually done through convex combination: D(x i, x i ) = p w j d j (x ij, x i j), j=1 p w j = 1. j=1 It is important to realize that setting the weight w j to the same value for each variable does not necessarily give all attributes equal influence. When the squared error distance is used, the relative importance of each variable is proportional to its variance over the data. With the squared error distance, setting the weight to be the inverse of the vairance leads to equal influence of all attributes in the overall dissimilarity between objects.
19 Standardization in clustering? If the goal is to discover natural groupings in the data, some attributes may exhibit more of a grouping tendency than others. Variables that are more relevant in separating the groups should be assigned a higher influence in defining object dissimilarity. Giving all attributes equal influence in this case will tend to obscure the groups to the point where a clustering algorithm cannot uncover them. Although simple generic prescriptions for choosing the individual attribute dissimilarities d j (x ij, x i j) and their weights w j can be comforting, there is no substitute for careful thought in the context of each individual problem. Specifying an appropriate dissimilarity measure is far more important in obtaining success with clustering than choice of clustering algorithm. This aspect of the problem is emphasized less in the clustering literature than the algorithms themselves, since it depends on domain knowledge specifics and is less amenable to general research.
20 Standardization in clustering? Figure: Simulated data: on the left, K-means clustering (with K = 2) has been applied to the raw data. The two colors indicate the cluster memberships. On the right, the features were first standardized before clustering. This is equivalent to using feature weights 1/[2var(X j )]. The standardization has obscured the two well-separated groups. Note that each plot uses the same units in the horizontal and vertical axes.
21 K-means clustering The K-means algorithm is one of the most popular iterative descent clustering methods. It is intended for situations in which all variables are of the quantitative type, and squared Euclidean distance is chosen as the dissimilarity measure. The within-cluster point scatter is W (C) = 1 2 K k=1 C(i)=k C(i )=k x i x i 2 = K k=1 N k C(i)=k x i x k 2 where x k is the mean vector associated with the kth cluster under the clustering rule C(i), and N k is the number of observations belonging to cluster k.
22 The K-means clustering algorithm aims find a clustering rule C such that K K C = min N k x i x k 2. C Notice that k=1 k=1 C(i)=k x S = argmin m x i m 2 Hence we can obtain C by solving the enlarged optimization problem K x i m k 2 min C,m 1,m 2,...,m K k=1 N k i S C(i)=k This can be minimized by an alternatiing optimization procedure given in the next algorithm.
23
24 The K-means is guaranteed to converge. However, the result may represent a suboptimal local minimum. one should start the algorithm with many different random choices for the starting means, and choose the solution having smallest value of the objective function. K-means clustering has shortcomings. For one, it does not give a linear ordering of objects within a cluster: we have simply listed them in alphabetic order above. Secondly, as the number of clusters K is changed, the cluster memberships can change in arbitrary ways. That is, with say four clusters, the clusters need not be nested within the three clusters above. For these reasons, hierarchical clustering, is probably preferable for this application.
25 Figure: Successive iterations of the K-means clustering algorithm for a simulated data.
26 K =medoids clustering
27 K medoids clustering Medoids clustering does not require all variables to be of the quantitative type. squared Euclidean distance can be replaced with distances robust to outliers. Finding the center of each cluster with Medoids clustering costs O(N 2 k ) flops, while with K-means, it costs O(N k). Thus, K-medoids is far more computationally intensive than K-means.
28 Initialization of K centers Choose one center uniformly at random from among the data points. For each data point x, compute D(x), the distance between x and the nearest center that has already been chosen. Choose one new data point at random as a new center, using a weighted probability distribution where a point x is chosen with probability proportional to D(x) 2. Repeat Steps 2 and 3 until k centers have been chosen. Now that the initial centers have been chosen, proceed using standard K-means clustering. This seeding method yields considerable improvement in the final error of K-means. Although the initial selection in the algorithm takes extra time, the K-means part itself converges very quickly after this seeding and thus the algorithm actually lowers the computation time.
29 Choice of K Cross-validation chooses large K, because the within cluster dissimilarity W K decreases as K increases, even for test data! An estimate K for the optimal K can be obtained by identifying a kink in the plot of W k as a function of K, that is, a sharp decrease of W k followed by a slight decrease. Uses the Gap statistic - it chooses the K where the data look most clustered when compared to uniformly-distributed data. For each K, compute the within cluster dissimilarity W K and its standard deviation s K, for m sets of ranomly generated uniformly-distributed data. Choose K such that G(K) G(K + 1) sk 1 + 1/m with G(K) = log W k log W K.
30 Gap statistic
31 Hierarchical clustering (Agglomerative) Produce hierarchical representations in which the clusters at each level of the hierarchy are created by merging clusters at the next lower level. Do not require initial configuration assignment and initial choice of the number of clusters Do require the user to specify a measure of dissimilarity between (disjoint) groups of observations, based on the pairwise dissimilarities among the observations in the two groups.
32 Agglomerative clustering Begin with every observation representing a singleton cluster. At each of the N 1 steps the closest two (least dissimilar) clusters are merged into a single cluster, producing one less cluster at the next higher level, according to a measure of dissimilarity between two clusters. Let G and H represent two groups. Single linkage(sl) clustering: d SL (G, H) = min i G,i H d ii
33 Complete linkage (CL) clustering: d CL (G, H) = Group average clustering: max i G,i H d ii d GA (G, H) = 1 N G N H i G i H where N G and N H are the respective number of observations in each group. d ii
34
35 Comparison of different cluster dissimilarity measures If the data exhibit a strong clustering tendency, with each of the clusters being compact and well separated from others, then all three methods produce similar results. Clusters are compact if all of the observations within them are relatively close together (small dissimilarities) as compared with observations in different clusters. Single linkage has a tendency to combine, at relatively low thresholds, observations linked by a series of close intermediate observations. This phenomenon, referred to as chaining, is often considered a defect of the method. The clusters produced by single linkage can violate the compactness property Complete linkage will tend to produce compact clusters. However, it can produce clusters that violate the closeness property. That is, observations assigned to a cluster can be much closer to members of other clusters than they are to some members of their own cluster. Group average represents a compromise between the two.
36 Comparison of different cluster dissimilarity measures Single linkage and complete linkage clustering are invariant to monotone transformation of the distance function, but the group average clustering is not. The group average dissimilarity is an estimate of d(x, x )p G (x)p H (x )dxdx which is a kind of distance between the two densities p G for group G and p H for group H. On the other hand, single linkage dissimilarity approaches zero and complete linkage dissimilarity approaches infinity as N. Thus, it is not clear what aspects of the population distribution are being estimated by the two group dissimilarities.
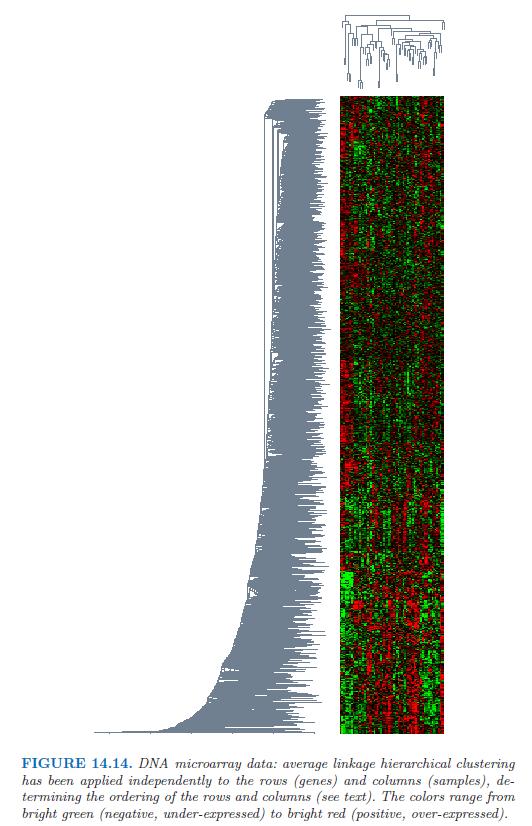
37
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Unsupervised Learning
 Unsupervised Learning Chapter 14: The Elements of Statistical Learning Presented for 540 by Len Tanaka Objectives Introduction Techniques: Association Rules Cluster Analysis Self-Organizing Maps Projective
Unsupervised Learning Chapter 14: The Elements of Statistical Learning Presented for 540 by Len Tanaka Objectives Introduction Techniques: Association Rules Cluster Analysis Self-Organizing Maps Projective
Machine Learning for OR & FE
 Machine Learning for OR & FE Unsupervised Learning: Clustering Martin Haugh Department of Industrial Engineering and Operations Research Columbia University Email: martin.b.haugh@gmail.com (Some material
Machine Learning for OR & FE Unsupervised Learning: Clustering Martin Haugh Department of Industrial Engineering and Operations Research Columbia University Email: martin.b.haugh@gmail.com (Some material
Clustering. Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Hierarchical clustering
 Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
STATS306B STATS306B. Clustering. Jonathan Taylor Department of Statistics Stanford University. June 3, 2010
 STATS306B Jonathan Taylor Department of Statistics Stanford University June 3, 2010 Spring 2010 Outline K-means, K-medoids, EM algorithm choosing number of clusters: Gap test hierarchical clustering spectral
STATS306B Jonathan Taylor Department of Statistics Stanford University June 3, 2010 Spring 2010 Outline K-means, K-medoids, EM algorithm choosing number of clusters: Gap test hierarchical clustering spectral
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
Lesson 3. Prof. Enza Messina
 Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
COMS 4721: Machine Learning for Data Science Lecture 23, 4/20/2017
 COMS 4721: Machine Learning for Data Science Lecture 23, 4/20/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University ASSOCIATION ANALYSIS SETUP Many businesses
COMS 4721: Machine Learning for Data Science Lecture 23, 4/20/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University ASSOCIATION ANALYSIS SETUP Many businesses
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
Clustering in Data Mining
 Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Clustering. Chapter 10 in Introduction to statistical learning
 Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Clustering part II 1
 Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Hierarchical clustering
 Hierarchical clustering Rebecca C. Steorts, Duke University STA 325, Chapter 10 ISL 1 / 63 Agenda K-means versus Hierarchical clustering Agglomerative vs divisive clustering Dendogram (tree) Hierarchical
Hierarchical clustering Rebecca C. Steorts, Duke University STA 325, Chapter 10 ISL 1 / 63 Agenda K-means versus Hierarchical clustering Agglomerative vs divisive clustering Dendogram (tree) Hierarchical
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Part I. Hierarchical clustering. Hierarchical Clustering. Hierarchical clustering. Produces a set of nested clusters organized as a
 Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Lecture 12: Unsupervised learning
 1 / 40 Lecture 12: Unsupervised learning Clustering, Association Rule Learning Prof Alexandra Chouldechova 95-791: Data Mining April 20, 2016 2 / 40 Agenda What is Unsupervised learning? K-means clustering
1 / 40 Lecture 12: Unsupervised learning Clustering, Association Rule Learning Prof Alexandra Chouldechova 95-791: Data Mining April 20, 2016 2 / 40 Agenda What is Unsupervised learning? K-means clustering
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Clustering Part 3. Hierarchical Clustering
 Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
Clustering. CS294 Practical Machine Learning Junming Yin 10/09/06
 Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Multivariate Analysis
 Multivariate Analysis Cluster Analysis Prof. Dr. Anselmo E de Oliveira anselmo.quimica.ufg.br anselmo.disciplinas@gmail.com Unsupervised Learning Cluster Analysis Natural grouping Patterns in the data
Multivariate Analysis Cluster Analysis Prof. Dr. Anselmo E de Oliveira anselmo.quimica.ufg.br anselmo.disciplinas@gmail.com Unsupervised Learning Cluster Analysis Natural grouping Patterns in the data
Clustering Part 4 DBSCAN
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
PAM algorithm. Types of Data in Cluster Analysis. A Categorization of Major Clustering Methods. Partitioning i Methods. Hierarchical Methods
 Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Lecture 6: Unsupervised Machine Learning Dagmar Gromann International Center For Computational Logic
 SEMANTIC COMPUTING Lecture 6: Unsupervised Machine Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 23 November 2018 Overview Unsupervised Machine Learning overview Association
SEMANTIC COMPUTING Lecture 6: Unsupervised Machine Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 23 November 2018 Overview Unsupervised Machine Learning overview Association
INF4820 Algorithms for AI and NLP. Evaluating Classifiers Clustering
 INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
Hierarchical Clustering
 Hierarchical Clustering Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree-like diagram that records the sequences of merges
Hierarchical Clustering Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree-like diagram that records the sequences of merges
DATA MINING LECTURE 7. Hierarchical Clustering, DBSCAN The EM Algorithm
 DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
University of Florida CISE department Gator Engineering. Clustering Part 4
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Cluster Analysis. Angela Montanari and Laura Anderlucci
 Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Road map. Basic concepts
 Clustering Basic concepts Road map K-means algorithm Representation of clusters Hierarchical clustering Distance functions Data standardization Handling mixed attributes Which clustering algorithm to use?
Clustering Basic concepts Road map K-means algorithm Representation of clusters Hierarchical clustering Distance functions Data standardization Handling mixed attributes Which clustering algorithm to use?
Machine learning - HT Clustering
 Machine learning - HT 2016 10. Clustering Varun Kanade University of Oxford March 4, 2016 Announcements Practical Next Week - No submission Final Exam: Pick up on Monday Material covered next week is not
Machine learning - HT 2016 10. Clustering Varun Kanade University of Oxford March 4, 2016 Announcements Practical Next Week - No submission Final Exam: Pick up on Monday Material covered next week is not
3. Cluster analysis Overview
 Université Laval Analyse multivariable - mars-avril 2008 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
Université Laval Analyse multivariable - mars-avril 2008 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
Cluster Analysis. Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX April 2008 April 2010
 Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Cluster analysis. Agnieszka Nowak - Brzezinska
 Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Statistics 202: Data Mining. c Jonathan Taylor. Week 8 Based in part on slides from textbook, slides of Susan Holmes. December 2, / 1
 Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
INF4820, Algorithms for AI and NLP: Hierarchical Clustering
 INF4820, Algorithms for AI and NLP: Hierarchical Clustering Erik Velldal University of Oslo Sept. 25, 2012 Agenda Topics we covered last week Evaluating classifiers Accuracy, precision, recall and F-score
INF4820, Algorithms for AI and NLP: Hierarchical Clustering Erik Velldal University of Oslo Sept. 25, 2012 Agenda Topics we covered last week Evaluating classifiers Accuracy, precision, recall and F-score
Association Pattern Mining. Lijun Zhang
 Association Pattern Mining Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction The Frequent Pattern Mining Model Association Rule Generation Framework Frequent Itemset Mining Algorithms
Association Pattern Mining Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction The Frequent Pattern Mining Model Association Rule Generation Framework Frequent Itemset Mining Algorithms
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A
 MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering
 Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Cluster Analysis for Microarray Data
 Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering
 INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Clustering Lecture 3: Hierarchical Methods
 Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Cluster Analysis: Agglomerate Hierarchical Clustering
 Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Machine Learning: Symbolische Ansätze
 Machine Learning: Symbolische Ansätze Unsupervised Learning Clustering Association Rules V2.0 WS 10/11 J. Fürnkranz Different Learning Scenarios Supervised Learning A teacher provides the value for the
Machine Learning: Symbolische Ansätze Unsupervised Learning Clustering Association Rules V2.0 WS 10/11 J. Fürnkranz Different Learning Scenarios Supervised Learning A teacher provides the value for the
Lecture 4 Hierarchical clustering
 CSE : Unsupervised learning Spring 00 Lecture Hierarchical clustering. Multiple levels of granularity So far we ve talked about the k-center, k-means, and k-medoid problems, all of which involve pre-specifying
CSE : Unsupervised learning Spring 00 Lecture Hierarchical clustering. Multiple levels of granularity So far we ve talked about the k-center, k-means, and k-medoid problems, all of which involve pre-specifying
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
3. Cluster analysis Overview
 Université Laval Multivariate analysis - February 2006 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
Université Laval Multivariate analysis - February 2006 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
MSA220 - Statistical Learning for Big Data
 MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/10/2017)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
SYDE Winter 2011 Introduction to Pattern Recognition. Clustering
 SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
Market Basket Analysis: an Introduction. José Miguel Hernández Lobato Computational and Biological Learning Laboratory Cambridge University
 Market Basket Analysis: an Introduction José Miguel Hernández Lobato Computational and Biological Learning Laboratory Cambridge University 20/09/2011 1 Market Basket Analysis Allows us to identify patterns
Market Basket Analysis: an Introduction José Miguel Hernández Lobato Computational and Biological Learning Laboratory Cambridge University 20/09/2011 1 Market Basket Analysis Allows us to identify patterns
CS 1675 Introduction to Machine Learning Lecture 18. Clustering. Clustering. Groups together similar instances in the data sample
 CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
Value Added Association Rules
 Value Added Association Rules T.Y. Lin San Jose State University drlin@sjsu.edu Glossary Association Rule Mining A Association Rule Mining is an exploratory learning task to discover some hidden, dependency
Value Added Association Rules T.Y. Lin San Jose State University drlin@sjsu.edu Glossary Association Rule Mining A Association Rule Mining is an exploratory learning task to discover some hidden, dependency
Clustering. SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic
 Clustering SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic Clustering is one of the fundamental and ubiquitous tasks in exploratory data analysis a first intuition about the
Clustering SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic Clustering is one of the fundamental and ubiquitous tasks in exploratory data analysis a first intuition about the
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/09/2018)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
Data Mining Clustering
 Data Mining Clustering Jingpeng Li 1 of 34 Supervised Learning F(x): true function (usually not known) D: training sample (x, F(x)) 57,M,195,0,125,95,39,25,0,1,0,0,0,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,0,0 0
Data Mining Clustering Jingpeng Li 1 of 34 Supervised Learning F(x): true function (usually not known) D: training sample (x, F(x)) 57,M,195,0,125,95,39,25,0,1,0,0,0,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,0,0 0
Workload Characterization Techniques
 Workload Characterization Techniques Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 Jain@cse.wustl.edu These slides are available on-line at: http://www.cse.wustl.edu/~jain/cse567-08/
Workload Characterization Techniques Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 Jain@cse.wustl.edu These slides are available on-line at: http://www.cse.wustl.edu/~jain/cse567-08/
Hierarchical Clustering Lecture 9
 Hierarchical Clustering Lecture 9 Marina Santini Acknowledgements Slides borrowed and adapted from: Data Mining by I. H. Witten, E. Frank and M. A. Hall 1 Lecture 9: Required Reading Witten et al. (2011:
Hierarchical Clustering Lecture 9 Marina Santini Acknowledgements Slides borrowed and adapted from: Data Mining by I. H. Witten, E. Frank and M. A. Hall 1 Lecture 9: Required Reading Witten et al. (2011:
Today s lecture. Clustering and unsupervised learning. Hierarchical clustering. K-means, K-medoids, VQ
 Clustering CS498 Today s lecture Clustering and unsupervised learning Hierarchical clustering K-means, K-medoids, VQ Unsupervised learning Supervised learning Use labeled data to do something smart What
Clustering CS498 Today s lecture Clustering and unsupervised learning Hierarchical clustering K-means, K-medoids, VQ Unsupervised learning Supervised learning Use labeled data to do something smart What
Unsupervised Data Mining: Clustering. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Forestry Applied Multivariate Statistics. Cluster Analysis
 1 Forestry 531 -- Applied Multivariate Statistics Cluster Analysis Purpose: To group similar entities together based on their attributes. Entities can be variables or observations. [illustration in Class]
1 Forestry 531 -- Applied Multivariate Statistics Cluster Analysis Purpose: To group similar entities together based on their attributes. Entities can be variables or observations. [illustration in Class]
Finding Clusters 1 / 60
 Finding Clusters Types of Clustering Approaches: Linkage Based, e.g. Hierarchical Clustering Clustering by Partitioning, e.g. k-means Density Based Clustering, e.g. DBScan Grid Based Clustering 1 / 60
Finding Clusters Types of Clustering Approaches: Linkage Based, e.g. Hierarchical Clustering Clustering by Partitioning, e.g. k-means Density Based Clustering, e.g. DBScan Grid Based Clustering 1 / 60
Hard clustering. Each object is assigned to one and only one cluster. Hierarchical clustering is usually hard. Soft (fuzzy) clustering
 clustering") An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
CS7267 MACHINE LEARNING
 S7267 MAHINE LEARNING HIERARHIAL LUSTERING Ref: hengkai Li, Department of omputer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) Mingon Kang, Ph.D. omputer Science,
S7267 MAHINE LEARNING HIERARHIAL LUSTERING Ref: hengkai Li, Department of omputer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) Mingon Kang, Ph.D. omputer Science,
A Review on Cluster Based Approach in Data Mining
 A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
Clustering and Visualisation of Data
 Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Unsupervised Learning. Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi
 Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Association Rule Mining and Clustering
 Association Rule Mining and Clustering Lecture Outline: Classification vs. Association Rule Mining vs. Clustering Association Rule Mining Clustering Types of Clusters Clustering Algorithms Hierarchical:
Association Rule Mining and Clustering Lecture Outline: Classification vs. Association Rule Mining vs. Clustering Association Rule Mining Clustering Types of Clusters Clustering Algorithms Hierarchical:
Clustering algorithms and introduction to persistent homology
 Foundations of Geometric Methods in Data Analysis 2017-18 Clustering algorithms and introduction to persistent homology Frédéric Chazal INRIA Saclay - Ile-de-France frederic.chazal@inria.fr Introduction
Foundations of Geometric Methods in Data Analysis 2017-18 Clustering algorithms and introduction to persistent homology Frédéric Chazal INRIA Saclay - Ile-de-France frederic.chazal@inria.fr Introduction
Unsupervised Learning. Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team
 Unsupervised Learning Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team Table of Contents 1)Clustering: Introduction and Basic Concepts 2)An Overview of Popular Clustering Methods 3)Other Unsupervised
Unsupervised Learning Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team Table of Contents 1)Clustering: Introduction and Basic Concepts 2)An Overview of Popular Clustering Methods 3)Other Unsupervised
INF4820 Algorithms for AI and NLP. Evaluating Classifiers Clustering
 INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Murhaf Fares & Stephan Oepen Language Technology Group (LTG) September 27, 2017 Today 2 Recap Evaluation of classifiers Unsupervised
INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Murhaf Fares & Stephan Oepen Language Technology Group (LTG) September 27, 2017 Today 2 Recap Evaluation of classifiers Unsupervised
Data Mining. Clustering. Hamid Beigy. Sharif University of Technology. Fall 1394
 Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Applications. Foreground / background segmentation Finding skin-colored regions. Finding the moving objects. Intelligent scissors
 Segmentation I Goal Separate image into coherent regions Berkeley segmentation database: http://www.eecs.berkeley.edu/research/projects/cs/vision/grouping/segbench/ Slide by L. Lazebnik Applications Intelligent
Segmentation I Goal Separate image into coherent regions Berkeley segmentation database: http://www.eecs.berkeley.edu/research/projects/cs/vision/grouping/segbench/ Slide by L. Lazebnik Applications Intelligent
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Administration. Final Exam: Next Tuesday, 12/6 12:30, in class. HW 7: Due on Thursday 12/1. Final Projects:
 Administration Final Exam: Next Tuesday, 12/6 12:30, in class. Material: Everything covered from the beginning of the semester Format: Similar to mid-term; closed books Review session on Thursday HW 7:
Administration Final Exam: Next Tuesday, 12/6 12:30, in class. Material: Everything covered from the beginning of the semester Format: Similar to mid-term; closed books Review session on Thursday HW 7:
Hierarchical Clustering
 Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Unsupervised learning in Vision
 Chapter 7 Unsupervised learning in Vision The fields of Computer Vision and Machine Learning complement each other in a very natural way: the aim of the former is to extract useful information from visual
Chapter 7 Unsupervised learning in Vision The fields of Computer Vision and Machine Learning complement each other in a very natural way: the aim of the former is to extract useful information from visual
Data mining techniques for actuaries: an overview
 Data mining techniques for actuaries: an overview Emiliano A. Valdez joint work with Banghee So and Guojun Gan University of Connecticut Advances in Predictive Analytics (APA) Conference University of
Data mining techniques for actuaries: an overview Emiliano A. Valdez joint work with Banghee So and Guojun Gan University of Connecticut Advances in Predictive Analytics (APA) Conference University of
Segmentation Computer Vision Spring 2018, Lecture 27
 Segmentation http://www.cs.cmu.edu/~16385/ 16-385 Computer Vision Spring 218, Lecture 27 Course announcements Homework 7 is due on Sunday 6 th. - Any questions about homework 7? - How many of you have
Segmentation http://www.cs.cmu.edu/~16385/ 16-385 Computer Vision Spring 218, Lecture 27 Course announcements Homework 7 is due on Sunday 6 th. - Any questions about homework 7? - How many of you have
Classification. Vladimir Curic. Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University
 Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Statistical Methods for Data Mining
 Statistical Methods for Data Mining Kuangnan Fang Xiamen University Email: xmufkn@xmu.edu.cn Unsupervised Learning Unsupervised vs Supervised Learning: Most of this course focuses on supervised learning
Statistical Methods for Data Mining Kuangnan Fang Xiamen University Email: xmufkn@xmu.edu.cn Unsupervised Learning Unsupervised vs Supervised Learning: Most of this course focuses on supervised learning
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Slides From Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Data Informatics. Seon Ho Kim, Ph.D.
 Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu Clustering Overview Supervised vs. Unsupervised Learning Supervised learning (classification) Supervision: The training data (observations, measurements,
Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu Clustering Overview Supervised vs. Unsupervised Learning Supervised learning (classification) Supervision: The training data (observations, measurements,
Chapter 2 Basic Structure of High-Dimensional Spaces
 Chapter 2 Basic Structure of High-Dimensional Spaces Data is naturally represented geometrically by associating each record with a point in the space spanned by the attributes. This idea, although simple,
Chapter 2 Basic Structure of High-Dimensional Spaces Data is naturally represented geometrically by associating each record with a point in the space spanned by the attributes. This idea, although simple,
Clustering. So far in the course. Clustering. Clustering. Subhransu Maji. CMPSCI 689: Machine Learning. dist(x, y) = x y 2 2
 = x y 2 2") So far in the course Clustering Subhransu Maji : Machine Learning 2 April 2015 7 April 2015 Supervised learning: learning with a teacher You had training data which was (feature, label) pairs and the goal
So far in the course Clustering Subhransu Maji : Machine Learning 2 April 2015 7 April 2015 Supervised learning: learning with a teacher You had training data which was (feature, label) pairs and the goal