arxiv: v1 [cs.cv] 8 Mar 2017 Abstract
|
|
|
- Brendan Bennett
- 6 years ago
- Views:
Transcription
1 Large Kernel Matters Improve Semantic Segmentation by Global Convolutional Network Chao Peng Xiangyu Zhang Gang Yu Guiming Luo Jian Sun School of Software, Tsinghua University, Megvii Inc. (Face++), {zhangxiangyu, yugang, arxiv: v1 [cs.cv] 8 Mar 2017 Abstract One of recent trends [30, 31, 14] in network architecture design is stacking small filters (e.g., 1x1 or 3x3) in the entire network because the stacked small filters is more efficient than a large kernel, given the same computational complexity. However, in the field of semantic segmentation, where we need to perform dense per-pixel prediction, we find that the large kernel (and effective receptive field) plays an important role when we have to perform the classification and localization tasks simultaneously. Following our design principle, we propose a Global Convolutional Network to address both the classification and localization issues for the semantic segmentation. We also suggest a residual-based boundary refinement to further refine the object boundaries. Our approach achieves state-of-art performance on two public benchmarks and significantly outperforms previous results, 82.2% (vs 80.2%) on PASCAL VOC 2012 dataset and 76.9% (vs 71.8%) on Cityscapes dataset. 1. Introduction Semantic segmentation can be considered as a per-pixel classification problem. There are two challenges in this task: 1) classification: an object associated to a specific semantic concept should be marked correctly; 2) localization: the classification label for a pixel must be aligned to the appropriate coordinates in output score map. A well-designed segmentation model should deal with the two issues simultaneously. However, these two tasks are naturally contradictory. For the classification task, the models are required to be invariant to various transformations like translation and rotation. But for the localization task, models should be transformation-sensitive, i.e., precisely locate every pixel for each semantic category. The conventional semantic segmentation algorithms mainly target for the localization issue, as shown in Figure 1 B. But this might decrease the Figure 1. A: Classification network; B: Conventional segmentation network, mainly designed for localization; C: Our Global Convolutional Network. classification performance. In this paper, we propose an improved net architecture, called Global Convolutional Network (GCN), to deal with the above two challenges simultaneously. We follow two design principles: 1) from the localization view, the model structure should be fully convolutional to retain the localization performance and no fully-connected or global pooling layers should be used as these layers will discard the localization information; 2) from the classification view, large kernel size should be adopted in the network architecture to enable densely connections between feature maps and per-pixel classifiers, which enhances the capability to handle different transformations. These two principles lead to our GCN, as in Figure 2 A. The FCN [25]-like structure is employed as our basic framework and our GCN is used to generate semantic score maps. To make global convolution practical, we adopt symmetric, separable large filters to reduce the model parameters and computation cost. To further improve the localization ability near the object boundaries, we introduce boundary refinement block to model the boundary alignment as a residual structure, shown in Figure 2 C. Unlike the CRF-like post-process [6], our boundary 1
2 refinement block is integrated into the network and trained end-to-end. Our contributions are summarized as follows: 1) we propose Global Convolutional Network for semantic segmentation which explicitly address the classification and localization problems simultaneously; 2) a Boundary Refinement block is introduced which can further improve the localization performance near the object boundaries; 3) we achieve state-of-art results on two standard benchmarks, with 82.2% on PASCAL VOC 2012 and 76.9% on the Cityscapes. 2. Related Work In this section we quickly review the literatures on semantic segmentation. One of the most popular CNN based work is the Fully Convolutional Network (FCN) [25]. By converting the fully-connected layers into convolutional layers and concatenating the intermediate score maps, FCN has outperformed a lot of traditional methods on semantic segmentation. Following the structure of FCN, there are several works trying to improve the semantic segmentation task based on the following three aspects. Context Embedding in semantic segmentation is a hot topic. Among the first, Zoom-out [26] proposes a handcrafted hierarchical context features, while ParseNet [23] adds a global pooling branch to extract context information. Further, Dilated-Net [36] appends several layers after the score map to embed the multi-scale context, and Deeplab- V2 [7] uses the Atrous Spatial Pyramid Pooling, which is a combination of convolutions, to embed the context directly from feature map. Resolution Enlarging is another research direction in semantic segmentation. Initially, FCN [25] proposes the deconvolution (i.e. inverse of convolution) operation to increase the resolution of small score map. Further, Deconv- Net [27] and SegNet [3] introduce the unpooling operation (i.e. inverse of pooling) and a glass-like network to learn the upsampling process. More recently, LRR [12] argues that upsampling a feature map is better than score map. Instead of learning the upsampling process, Deeplab [24] and Dilated-Net [36] propose a special dilated convolution to directly increase the spatial size of small feature maps, resulting in a larger score map. Boundary Alignment tries to refine the predictions near the object boundaries. Among the many methods, Conditional Random Field (CRF) is often employed here because of its good mathematical formation. Deeplab [6] directly employs densecrf [18], which is a CRF-variant built on fully-connected graph, as a post-processing method after CNN. Then CRFAsRNN [37] models the densecrf into a RNN-style operator and proposes an end-to-end pipeline, yet it involves too much CPU computation on Permutohedral Lattice [1]. DPN [24] makes a different approximation on densecrf and put the whole pipeline completely on GPU. Furthermore, Adelaide [21] deeply incorporates CRF and CNN where hand-crafted potentials is replaced by convolutions and nonlinearities. Besides, there are also some alternatives to CRF. [4] presents a similar model to CRF, called Bilateral Solver, yet achieves 10x speed and comparable performance. [16] introduces the bilateral filter to learn the specific pairwise potentials within CNN. In contrary to previous works, we argues that semantic segmentation is a classification task on large feature map and our Global Convolutional Network could simultaneously fulfill the demands of classification and localization. 3. Approach In this section, we first propose a novel Global Convolutional Network (GCN) to address the contradictory aspects classification and localization in semantic segmentation. Then using GCN we design a fully-convolutional framework for semantic segmentation task Global Convolutional Network The task of semantic segmentation, or pixel-wise classification, requires to output a score map assigning each pixel from the input image with semantic label. As mentioned in Introduction section, this task implies two challenges: classification and localization. However, we find that the requirements of classification and localization problems are naturally contradictory: (1) For classification task, models are required invariant to transformation on the inputs objects may be shifted, rotated or rescaled but the classification results are expected to be unchanged. (2) While for localization task, models should be transformation-sensitive because the localization results depend on the positions of inputs. In deep learning, the differences between classification and localization lead to different styles of models. For classification, most modern frameworks such as AlexNet [20], VGG Net [30], GoogleNet [31, 32] or ResNet [14] employ the Cone-shaped networks shown in Figure 1 A: features are extracted from a relatively small hidden layer, which is coarse on spatial dimensions, and classifiers are densely connected to entire feature map via fullyconnected layer [20, 30] or global pooling layer [31, 32, 14], which makes features robust to locally disturbances and allows classifiers to handle different types of input transformations. For localization, in contrast, we need relatively large feature maps to encode more spatial information. That is why most semantic segmentation frameworks, such as FCN [25, 29], DeepLab [6, 7], Deconv-Net [27], adopt Barrel-shaped networks shown in Figure 1 B. Techniques such as Deconvolution [25], Unpooling [27, 3] and Dilated- Convolution [6, 36] are used to generate high-resolution feature maps, then classifiers are connected locally to each

![We notice that current state-of-the-art semantic segmentation models [25, 6, 27] mainly follow the design principles for localization, however, which may be suboptimal for classification.](/docs-images/74/70449616/images/3-1.jpg "As classifiers are connected locally rather than globally to the feature map, it is difficult for classifiers to handle different variations of transformations on the input.")
 1 is large enough to hold the entire object.")
3 Figure 2. An overview of the whole pipeline in (A). The details of Global Convolutional Network (GCN) and Boundary Refinement (BR) block are illustrated in (B) and (C), respectively. spatial location on the feature map to generate pixel-wise semantic labels. We notice that current state-of-the-art semantic segmentation models [25, 6, 27] mainly follow the design principles for localization, however, which may be suboptimal for classification. As classifiers are connected locally rather than globally to the feature map, it is difficult for classifiers to handle different variations of transformations on the input. For example, consider the situations in Figure 3: a classifier is aligned to the center of an input object, so it is expected to give the semantic label for the object. At first, the valid receptive filed (VRF) 1 is large enough to hold the entire object. However, if the input object is resized to a large scale, then VRF can only cover a part of the object, which may be harmful for classification. It will be even worse if larger feature maps are used, because the gap between classification and localization becomes larger. Based on above observation, we try to design a new architecture to overcome the drawbacks. First from the localization view, the structure must be fully-convolutional without any fully-connected layer or global pooling layer that used by many classification networks, since the latter will 1 Feature maps from modern networks such as GoolgeNet or ResNet usually have very large receptive field because of the deep architecture. However, studies [38] show that network tends to gather information mainly from a much smaller region in the receptive field, which is called valid receptive field (VRF) in this paper. discard localization information. Second from the classification view, motivated by the densely-connected structure of classification models, the kernel size of the convolutional structure should be as large as possible. Specially, if the kernel size increases to the spatial size of feature map (named global convolution), the network will share the same benefit with pure classification models. Based on these two principles, we propose a novel Global Convolutional Network (GCN) in Figure 2 B. Instead of directly using larger kernel or global convolution, our GCN module employs a combination of 1 k + k 1 and k k convolutions, which enables densely connections within a large k k region in the feature map. Different from the separable kernels used by [32], we do not use any nonlinearity after convolution layers. Compared with the trivial k k convolution, our GCN structure involves only O( 2 k ) computation cost and number of parameters, which is more practical for large kernel sizes Overall Framework Our overall segmentation model are shown in Figure 2. We use pretrained ResNet [14] as the feature network and FCN4 [25, 35] as the segmentation framework. Multi-scale feature maps are extracted from different stages in the feature network. Global Convolutional Network structures are used to generate multi-scale semantic score maps for each
![Figure 3. Visualization of valid receptive field (VRF) introduced by [38]. Regions on images show the VRF for the score map located at the center of the bird.](/docs-images/74/70449616/images/4-0.jpg "For traditional segmentation model, even though the receptive field is as large as the input image, however, the VRF just covers the bird (A) and fails to hold the entire object if the input resized")

, where S is the coarse score map and R( ) is the residual branch.")
4 Figure 3. Visualization of valid receptive field (VRF) introduced by [38]. Regions on images show the VRF for the score map located at the center of the bird. For traditional segmentation model, even though the receptive field is as large as the input image, however, the VRF just covers the bird (A) and fails to hold the entire object if the input resized to a larger scale (B). As a comparison, our Global Convolution Network significantly enlarges the VRF (C). class. Similar to [25, 35], score maps of lower resolution will be upsampled with a deconvolution layer, then added up with higher ones to generate new score maps. The final semantic score map will be generated after the last upsampling, which is used to output the prediction results. In addition, we propose a Boundary Refinement (BR) block shown in Figure 2 C. Here, we models the boundary alignment as a residual structure. More specifically, we define S as the refined score map: S = S + R(S), where S is the coarse score map and R( ) is the residual branch. The details can be referred to Figure 2. mentioned above, we use PASCAL VOC 2012 validation set for the evaluation. For all succeeding experiments, we pad each input image into so that the top-most feature map is Experiment We evaluate our approach on the standard benchmark PASCAL VOC 2012 [11, 10] and Cityscapes [8]. PAS- CAL VOC 2012 has 1464 images for training, 1449 images for validation and 1456 images for testing, which belongs to 20 object classes along with one background class. We also use the Semantic Boundaries Dataset [13] as auxiliary dataset, resulting in 10,582 images for training. We choose the state-of-the-art network ResNet 152 [14] (pretrained on ImageNet [28]) as our base model for fine tuning. During the training time, we use standard SGD [20] with batch size 1, momentum 0.99 and weight decay Data augmentations like mean subtraction and horizontal flip are also applied in training. The performance is measured by standard mean intersection-over-union (IoU). All the experiments are running with Caffe [17] tool. In the next subsections, first we will perform a series of ablation experiments to evaluate the effectiveness of our approach. Then we will report the full results on PASCAL VOC 2012 and Cityscapes Ablation Experiments In this subsection, we will make apple-to-apple comparisons to evaluate our approaches proposed in Section 3. As Figure 4. (A) Global Convolutional Network. (B) 1 1 convolution baseline. (C) k k convolution. (D) stack of 3 3 convolutions Global Convolutional Network Large Kernel Matters In Section 3.1 we propose Global Convolutional Network (GCN) to enable densely connections between classifiers and features. The key idea of GCN is to use large kernels, whose size is controlled by the parameter k (see Figure 2 B). To verify this intuition, we enumerate different k and test the performance respectively. The overall network architecture is shown as in Figure 2 A except that Boundary Refinement block is not applied. For better comparison, a naive baseline is added just to replace GCN with a simple 1 1 convolution (shown in Figure 4 B). The results are presented in Table 1. We try different kernel sizes ranging from 3 to 15. Note that only odd size are used just to avoid alignment error. In the case k = 15, which roughly equals to the feature map size (16 16), the structure becomes really global convolu-
5 k base Score Table 1. Experimental results on different k settings of Global Convolutional Network. The score is evaluated by standard mean IoU(%) on PASCAL VOC 2012 validation set. tional. From the results, we can find that the performance consistently increases with the kernel size k. Especially, the global convolutional version (k = 15) surpasses the smallest one by a significant margin 5.5%. Results show that large kernel brings great benefit in our GCN structure, which is consistent with our analysis in Section 3.1. Further Discussion: In the experiments in Table 1, since there are other differences between baseline and different versions of GCN, it seems not so confirmed to attribute the improvements to large kernels or GCN. For example, one may argue that the extra parameters brought by larger k lead to the performance gain. Or someone may think to use another simple structure instead of GCN to achieve large equivalent kernel size. So we will give more evidences for better understanding. (1) Are more parameters helpful? In GCN, the number of parameters increases linearity with kernel size k, so one natural hypothesis is that the improvements in Table 1 are mainly brought by the increased number of parameters. To address this, we compare our GCN with the trivial large kernel design with a trivial k k convolution shown in Figure 4 C. Results are shown in Table 2. From the results we can see that for any given kernel size, the trivial convolution design contains more parameters than GCN. However, the latter is consistently better than the former in performance respectively. It is also clear that for trivial convolution version, k Score (GCN) Score (Conv) # of Params (GCN) 260K 434K 608K 782K # of Params (Conv) 387K 1075K 2107K 3484K Table 2. Comparison experiments between Global Convolutional Network and the trivial implementation. The score is measured under standard mean IoU(%), and the 3rd and 4th rows show number of parameters of GCN and trivial Convolution after res-5. larger kernel will result in better performance if k 5, yet for k 7 the performance drops. One hypothesis is that too many parameters make the training suffer from overfit, which weakens the benefits from larger kernels. However, in training we find trivial large kernels in fact make the network difficult to converge, while our GCN structure will not suffer from this drawback. Thus the actual reason still needs further study. (2) GCN vs. Stack of small convolutions. Instead of GCN, another trivial approach to form a large kernel is to use stack of small kernel convolutions(for example, stack of 3 3 kernels in Figure 4 D),, which is very common in modern CNN architectures such as VGG-net [30]. For example, we can use two 3 3 convolutions to approximate a 5 5 kernel. In Table 3, we compare GCN with convolutional stacks under different equivalent kernel sizes. Different from [30], we do not apply nonlinearity within convolutional stacks so as to keep consistent with GCN structure. Results shows that GCN still outperforms trivial convolution stacks for any large kernel sizes. k Score (GCN) Score (Stack) Table 3. Comparison Experiments between Global Convolutional Network and the equivalent stack of small kernel convolutions. The score is measured under standard mean IoU(%). GCN is still better with large kernels (k > 7). For large kernel size (e.g. k = 7) 3 3 convolutional stack will bring much more parameters than GCN, which may have side effects on the results. So we try to reduce the number of intermediate feature maps for convolutional stack and make further comparison. Results are listed in Table 4. It is clear that its performance suffers from degradation with fewer parameters. In conclusion, GCN is a better structure compared with trivial convolutional stacks. m (Stack) (GCN) Score # of Params 75885K 28505K 4307K 608K Table 4. Experimental results on the channels of stacking of small kernel convolutions. The score is measured under standard mean IoU. GCN outperforms the convolutional stack design with less parameters. (3) How GCN contributes to the segmentation results? In Section 3.1, we claim that GCN improves the classification capability of segmentation model by introducing densely connections to the feature map, which is helpful to handle large variations of transformations. Based on this, we can infer that pixels lying in the center of large objects may benefit more from GCN because it is very close to pure classification problem. As for the boundary pixels of objects, however, the performance is mainly affected by the localization ability. To verify our inference, we divide the segmentation score map into two parts: a) boundary region, whose pixels locate close to objects boundary (distance 7), and b) internal region as other pixels. We evaluate our segmentation model (GCN with k = 15) in both regions. Results are shown in Table 5. We find that our GCN model mainly
6 improves the accuracy in internal region while the effect in boundary region is minor, which strongly supports our argument. Furthermore, in Table 5 we also evaluate the boundary refinement (BF) block referred in Section 3.2. In contrary to GCN structure, BF mainly improves the accuracy in boundary region, which also confirms its effectiveness. Model Boundary (acc.) Internal (acc. ) Overall (IoU) Baseline GCN GCN + BR Table 5. Experimental results on Residual Boundary Alignment. The Boundary and Internal columns are measured by the per-pixel accuracy while the 3rd column is measured by standard mean IoU Global Convolutional Network for Pretrained Model In the above subsection our segmentation models are finetuned from ResNet-152 network. Since large kernel plays a critical role in segmentation tasks, it is nature to apply the idea of GCN also on the pretrained model. Thus we propose a new ResNet-GCN structure, as shown in Figure 5. We remove the first two layers in the original bottleneck structure used by ResNet, and replace them with a GCN module. In order to keep consistent with the original, we also apply Batch Normalization [15] and ReLU after each of the convolution layers. Figure 5. A: the bottleneck module in original ResNet. B: our Global Convolutional Network in ResNet-GCN. We compare our ResNet-GCN structure with the original ResNet model. For fair comparison, sizes for ResNet-GCN are carefully selected so that both network have similar computation cost and number of parameters. More details are provided in the appendix. We first pretrain ResNet-GCN on ImageNet 2015 [28] and fine tune on PASCAL VOC 2012 segmentation dataset. Results are shown in Table 6. Note that we take ResNet50 model (with or without GCN) for comparison because the training of large ResNet152 is very costly. From the results we can see that our GCNbased ResNet is slightly poorer than original ResNet as an ImageNet classification model. However, after finetuning on segmentation dataset ResNet-GCN model outperforms original ResNet significantly by 5.5%. With the application of GCN and boundary refinement, the gain of GCNbased pretrained model becomes minor but still prevails. We can safely conclude that GCN mainly helps to improve segmentation performance, no matter in pretrained model or segmentation-specific structures. Pretrained Model ResNet50 ResNet50-GCN ImageNet cls err (%) Seg. Score (Baseline) Seg. Score (GCN + BR) Table 6. Experimental results on ResNet50 and ResNet50-GCN. Top-5 error of center-crop on image is used in ImageNet classification error. The segmentation score is measured under standard mean IoU PASCAL VOC 2012 In this section we discuss our practice on PASCAL VOC 2012 dataset. Following [6, 37, 24, 7], we employ the Microsoft COCO dataset [22] to pre-train our model. COCO has 80 classes and here we only retain the images including the same 20 classes in PASCAL VOC The training phase is split into three stages: (1) In Stage-1, we mix up all the images from COCO, SBD and standard PASCAL VOC 2012, resulting in 109,892 images for training. (2) During the Stage-2, we use the SBD and standard PASCAL VOC 2012 images, the same as Section 4.1. (3) For Stage-3, we only use the standard PASCAL VOC 2012 dataset. The input image is padded to in Stage-1 and for Stage-2 and Stage-3. The evaluation on validation set is shown in Table 7. Phase Baseline GCN GCN + BR Stage-1(%) Stage-2(%) Stage-3(%) Stage-3-MS(%) 80.4 Stage-3-MS-CRF(%) 81.0 Table 7. Experimental results on PASCAL VOC 2012 validation set. The results are evaluated by standard mean IoU. Our GCN + BR model clearly prevails, meanwhile the post-processing multi-scale and densecrf [18] also bring benefits. Some visual comparisons are given in Figure 6. We also submit our best model to the on-line evaluation server, obtaining 82.2% on PASCAL VOC 2012 test set,

, Global Convolutional Network (GCN) (C), Global")
. as shown in Table 8.")
 FCN-8s-heavy [29] 67.")
![2 TTI zoomout v2 [26] 69.6 MSRA BoxSup [9] 71.](/docs-images/74/70449616/images/7-4.jpg "0 DeepLab-MSc-CRF-LargeFOV [6] 71.")
![6 Oxford TVG CRF RNN COCO [37] 74.7 CUHK DPN COCO [24] 77.](/docs-images/74/70449616/images/7-5.jpg "5 Oxford TVG HO CRF [2] 77.9 CASIA IVA OASeg [33] 78.")
![3 Adelaide VeryDeep FCN VOC [34] 79.](/docs-images/74/70449616/images/7-6.jpg "1 LRR 4x ResNet COCO [12] 79.3 Deeplabv2-CRF [7] 79.")
![7 CentraleSupelec Deep G-CRF[5] 80.2 Our approach 82.2 Table 8.](/docs-images/74/70449616/images/7-7.jpg "Experimental results on PASCAL VOC 2012 test set. 4.3.")
![Cityscapes Cityscapes [8] is a dataset collected for semantic](/docs-images/74/70449616/images/7-8.jpg "segmentation on urban street scenes.")





7 Figure 6. Examples of semantic segmentation results on PASCAL VOC For every row we list input image (A), 1 1 convolution baseline (B), Global Convolutional Network (GCN) (C), Global Convolutional Network plus Boundary Refinement (GCN + BR) (D), and Ground truth (E). as shown in Table 8. Our work has outperformed all the previous state-of-the-arts. Method mean-iou(%) FCN-8s-heavy [29] 67.2 TTI zoomout v2 [26] 69.6 MSRA BoxSup [9] 71.0 DeepLab-MSc-CRF-LargeFOV [6] 71.6 Oxford TVG CRF RNN COCO [37] 74.7 CUHK DPN COCO [24] 77.5 Oxford TVG HO CRF [2] 77.9 CASIA IVA OASeg [33] 78.3 Adelaide VeryDeep FCN VOC [34] 79.1 LRR 4x ResNet COCO [12] 79.3 Deeplabv2-CRF [7] 79.7 CentraleSupelec Deep G-CRF[5] 80.2 Our approach 82.2 Table 8. Experimental results on PASCAL VOC 2012 test set Cityscapes Cityscapes [8] is a dataset collected for semantic segmentation on urban street scenes. It contains images from 50 cities with different conditions, which belongs to 30 classes without background class. For some reasons, only 19 out of 30 classes are evaluated on leaderboard. The images are split into two set according to their labeling quality. 5,000 of them are fine annotated while the other 19,998 are coarse annotated. The 5,000 fine annotated images are further grouped into 2975 training images, 500 validation images and 1525 testing images. The images in Cityscapes have a fixed size of , which is too large to our network architecture. Therefore we randomly crop the images into during training phase. We also increase k of GCN from 15 to 25 as the final feature map is The training phase is split into two stages: (1) In Stage-1, we mix up the coarse annotated images and the training set, resulting in 22,973
8 images. (2) For Stage-2, we only finetune the network on training set. During the evaluation phase, we split the images into four crops and fuse their score maps. The results are given in Table 9. Phase GCN + BR Stage-1(%) 73.0 Stage-2(%) 76.9 Stage-2-MS(%) 77.2 Stage-2-MS-CRF(%) 77.4 Table 9. Experimental results on Cityscapes validation set. The standard mean IoU is used here. We submit our best model to the on-line evaluation server, obtaining 76.9% on Cityscapes test set as shown in Table 10. Once again, we outperforms all the previous publications and reaches the new state-of-art. 5. Conclusion According to our analysis on classification and segmentation, we find that large kernels is crucial to relieve the contradiction between classification and localization. Following the principle of large-size kernels, we propose the Global Convolutional Network. The ablation experiments show that our proposed structures meet a good trade-off between valid receptive field and the number of parameters, while achieves good performance. To further refine the object boundaries, we present a novel Boundary Refinement block. Qualitatively, our Global Convolutional Network mainly improve the internal regions while Boundary Refinement increase performance near boundaries. Our best model achieves state-of-the-art on two public benchmarks: PASCAL VOC 2012 (82.2%) and Cityscapes (76.9%). References [1] A. Adams, J. Baek, and M. A. Davis. Fast high-dimensional filtering using the permutohedral lattice. In Computer Graphics Forum, volume 29, pages Wiley Online Library, [2] A. Arnab, S. Jayasumana, S. Zheng, and P. H. Torr. Higher order conditional random fields in deep neural networks. In European Conference on Computer Vision, pages Springer, [3] V. Badrinarayanan, A. Handa, and R. Cipolla. Segnet: A deep convolutional encoder-decoder architecture for robust semantic pixel-wise labelling. arxiv preprint arxiv: , [4] J. T. Barron and B. Poole. The fast bilateral solver. ECCV, [5] S. Chandra and I. Kokkinos. Fast, exact and multi-scale inference for semantic image segmentation with deep gaussian crfs. arxiv preprint arxiv: , Method mean-iou(%) FCN 8s [29] 65.3 DPN [24] 59.1 CRFasRNN [37] 62.5 Scale invariant CNN + CRF [19] 66.3 Dilation10 [36] 67.1 DeepLabv2-CRF [7] 70.4 Adelaide context [21] 71.6 LRR-4x [12] 71.8 Our approach 76.9 Table 10. Experimental results on Cityscapes test set. [6] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Semantic image segmentation with deep convolutional nets and fully connected crfs. In ICLR, , 2, 3, 6, 7 [7] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. arxiv preprint arxiv: , , 6, 7, 8 [8] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. arxiv preprint arxiv: , , 7 [9] J. Dai, K. He, and J. Sun. Boxsup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, pages , [10] M. Everingham, S. A. Eslami, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman. The pascal visual object classes challenge: A retrospective. International Journal of Computer Vision, 111(1):98 136, [11] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman. The pascal visual object classes (voc) challenge. International journal of computer vision, 88(2): , [12] G. Ghiasi and C. C. Fowlkes. Laplacian pyramid reconstruction and refinement for semantic segmentation. In European Conference on Computer Vision, pages Springer, , 7, 8 [13] B. Hariharan, P. Arbeláez, L. Bourdev, S. Maji, and J. Malik. Semantic contours from inverse detectors. In 2011 International Conference on Computer Vision, pages IEEE, [14] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June , 2, 3, 4 [15] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of The 32nd International Conference on Machine Learning, pages , [16] V. Jampani, M. Kiefel, and P. V. Gehler. Learning sparse high dimensional filters: Image filtering, dense crfs and bilateral
9 neural networks. In IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), June [17] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell. Caffe: Convolutional architecture for fast feature embedding. arxiv preprint arxiv: , [18] V. Koltun. Efficient inference in fully connected crfs with gaussian edge potentials. Adv. Neural Inf. Process. Syst, , 6 [19] I. Krešo, D. Čaušević, J. Krapac, and S. Šegvić. Convolutional scale invariance for semantic segmentation. In German Conference on Pattern Recognition, pages Springer, [20] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages , , 4 [21] G. Lin, C. Shen, A. van den Hengel, and I. Reid. Efficient piecewise training of deep structured models for semantic segmentation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June , 8 [22] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick. Microsoft coco: Common objects in context. In European Conference on Computer Vision, pages Springer, [23] W. Liu, A. Rabinovich, and A. C. Berg. Parsenet: Looking wider to see better. arxiv preprint arxiv: , [24] Z. Liu, X. Li, P. Luo, C.-C. Loy, and X. Tang. Semantic image segmentation via deep parsing network. In Proceedings of the IEEE International Conference on Computer Vision, pages , , 6, 7, 8 [25] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages , , 2, 3, 4 [26] M. Mostajabi, P. Yadollahpour, and G. Shakhnarovich. Feedforward semantic segmentation with zoom-out features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages , , 7 [27] H. Noh, S. Hong, and B. Han. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, pages , , 3 [28] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision (IJCV), 115(3): , , 6 [29] E. Shelhamer, J. Long, and T. Darrell. Fully convolutional networks for semantic segmentation , 7, 8 [30] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arxiv preprint arxiv: , , 2, 5 [31] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1 9, , 2 [32] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. arxiv preprint arxiv: , , 3 [33] Y. Wang, J. Liu, Y. Li, J. Yan, and H. Lu. Objectness-aware semantic segmentation. In Proceedings of the 2016 ACM on Multimedia Conference, pages ACM, [34] Z. Wu, C. Shen, and A. v. d. Hengel. High-performance semantic segmentation using very deep fully convolutional networks. arxiv preprint arxiv: , [35] S. Xie and Z. Tu. Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision, pages , , 4 [36] F. Yu and V. Koltun. Multi-scale context aggregation by dilated convolutions. arxiv preprint arxiv: , , 8 [37] S. Zheng, S. Jayasumana, B. Romera-Paredes, V. Vineet, Z. Su, D. Du, C. Huang, and P. H. Torr. Conditional random fields as recurrent neural networks. In Proceedings of the IEEE International Conference on Computer Vision, pages , , 6, 7, 8 [38] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba. Object detectors emerge in deep scene cnns. arxiv preprint arxiv: , , 4
10 Appendix.A ResNet50 and ResNet50-GCN Component Output Size ResNet50 ResNet50-GCN conv , 64, stride max pool, stride 2 1 1, , 64 res , , , , 256 res res res , , , , , , , , , , , , 512 (1 5, 85) (5 1, 85) (5 1, 85) (1 5, 85) 6 1 1, 1024 (1 7, 128) (7 1, 128) (7 1, 128) (1 7, 128) 3 1 1, 2048 ImageNet Classifier 1 1 global average pool, 1000-d fc, softmax MFlops (Conv) Table 11. Architectures for ResNet50 and ResNet50-GCN, discussed in Section The bottleneck and GCN blocks are shown in brackets (referred to Figure 5). Downsampling is performed between every components with stride 2 convolution. Output Size (2nd column) is measured with standard ImangeNet images. The computational complexity of convolutions is shown in last row.








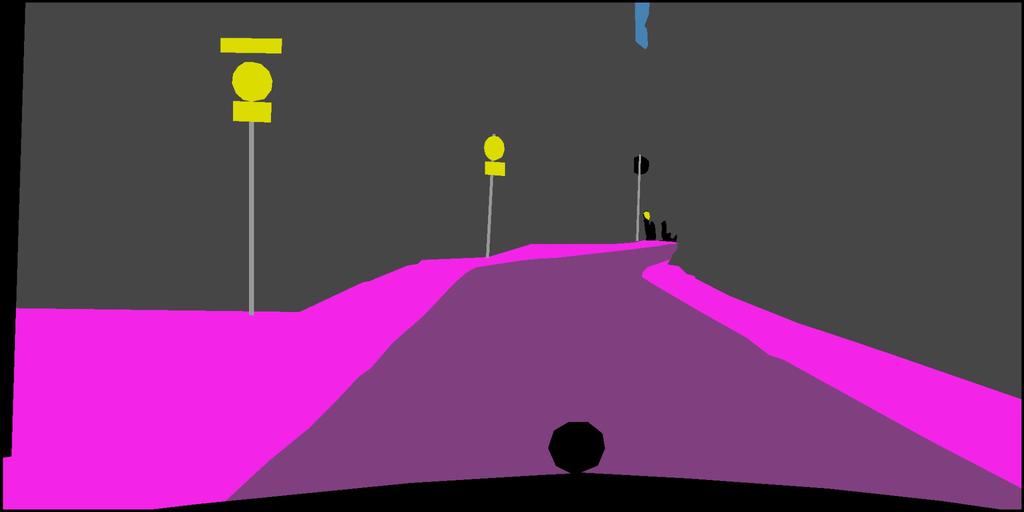





11 Appendix.B Examples of semantic segmentation results on Cityscapes. Figure 7. Examples of semantic segmentation results on Cityscapes. For every row we list input Image (A), Global Convolutional Network plus Boundary Refinement (GCN + BR) (B) and Ground Truth (C).
R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection
 The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection Zeming Li, 1 Yilun Chen, 2 Gang Yu, 2 Yangdong
The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection Zeming Li, 1 Yilun Chen, 2 Gang Yu, 2 Yangdong
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
arxiv: v1 [cs.cv] 11 Apr 2018
![arxiv: v1 [cs.cv] 11 Apr 2018](/thumbs/89/99253021.jpg "arxiv: v1 [cs.cv] 11 Apr 2018") arxiv:1804.03821v1 [cs.cv] 11 Apr 2018 ExFuse: Enhancing Feature Fusion for Semantic Segmentation Zhenli Zhang 1, Xiangyu Zhang 2, Chao Peng 2, Dazhi Cheng 3, Jian Sun 2 1 Fudan University, 2 Megvii Inc.
arxiv:1804.03821v1 [cs.cv] 11 Apr 2018 ExFuse: Enhancing Feature Fusion for Semantic Segmentation Zhenli Zhang 1, Xiangyu Zhang 2, Chao Peng 2, Dazhi Cheng 3, Jian Sun 2 1 Fudan University, 2 Megvii Inc.
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs
 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION
 HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION Chien-Yao Wang, Jyun-Hong Li, Seksan Mathulaprangsan, Chin-Chin Chiang, and Jia-Ching Wang Department of Computer Science and Information
HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION Chien-Yao Wang, Jyun-Hong Li, Seksan Mathulaprangsan, Chin-Chin Chiang, and Jia-Ching Wang Department of Computer Science and Information
Deconvolutions in Convolutional Neural Networks
 Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
arxiv: v1 [cs.cv] 24 May 2016
![arxiv: v1 [cs.cv] 24 May 2016](/thumbs/80/80473828.jpg "arxiv: v1 [cs.cv] 24 May 2016") Dense CNN Learning with Equivalent Mappings arxiv:1605.07251v1 [cs.cv] 24 May 2016 Jianxin Wu Chen-Wei Xie Jian-Hao Luo National Key Laboratory for Novel Software Technology, Nanjing University 163 Xianlin
Dense CNN Learning with Equivalent Mappings arxiv:1605.07251v1 [cs.cv] 24 May 2016 Jianxin Wu Chen-Wei Xie Jian-Hao Luo National Key Laboratory for Novel Software Technology, Nanjing University 163 Xianlin
Encoder-Decoder Networks for Semantic Segmentation. Sachin Mehta
 Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
arxiv: v4 [cs.cv] 6 Jul 2016
![arxiv: v4 [cs.cv] 6 Jul 2016](/thumbs/93/112985717.jpg "arxiv: v4 [cs.cv] 6 Jul 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu, C.-C. Jay Kuo (qinhuang@usc.edu) arxiv:1603.09742v4 [cs.cv] 6 Jul 2016 Abstract. Semantic segmentation
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu, C.-C. Jay Kuo (qinhuang@usc.edu) arxiv:1603.09742v4 [cs.cv] 6 Jul 2016 Abstract. Semantic segmentation
RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
 : Multi-Path Refinement Networks for High-Resolution Semantic Segmentation Guosheng Lin 1,2, Anton Milan 1, Chunhua Shen 1,2, Ian Reid 1,2 1 The University of Adelaide, 2 Australian Centre for Robotic
: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation Guosheng Lin 1,2, Anton Milan 1, Chunhua Shen 1,2, Ian Reid 1,2 1 The University of Adelaide, 2 Australian Centre for Robotic
RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
 : Multi-Path Refinement Networks for High-Resolution Semantic Segmentation Guosheng Lin 1 Anton Milan 2 Chunhua Shen 2,3 Ian Reid 2,3 1 Nanyang Technological University 2 University of Adelaide 3 Australian
: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation Guosheng Lin 1 Anton Milan 2 Chunhua Shen 2,3 Ian Reid 2,3 1 Nanyang Technological University 2 University of Adelaide 3 Australian
Learning Fully Dense Neural Networks for Image Semantic Segmentation
 Learning Fully Dense Neural Networks for Image Semantic Segmentation Mingmin Zhen 1, Jinglu Wang 2, Lei Zhou 1, Tian Fang 3, Long Quan 1 1 Hong Kong University of Science and Technology, 2 Microsoft Research
Learning Fully Dense Neural Networks for Image Semantic Segmentation Mingmin Zhen 1, Jinglu Wang 2, Lei Zhou 1, Tian Fang 3, Long Quan 1 1 Hong Kong University of Science and Technology, 2 Microsoft Research
arxiv: v2 [cs.cv] 18 Jul 2017
![arxiv: v2 [cs.cv] 18 Jul 2017](/thumbs/72/67294650.jpg "arxiv: v2 [cs.cv] 18 Jul 2017") PHAM, ITO, KOZAKAYA: BISEG 1 arxiv:1706.02135v2 [cs.cv] 18 Jul 2017 BiSeg: Simultaneous Instance Segmentation and Semantic Segmentation with Fully Convolutional Networks Viet-Quoc Pham quocviet.pham@toshiba.co.jp
PHAM, ITO, KOZAKAYA: BISEG 1 arxiv:1706.02135v2 [cs.cv] 18 Jul 2017 BiSeg: Simultaneous Instance Segmentation and Semantic Segmentation with Fully Convolutional Networks Viet-Quoc Pham quocviet.pham@toshiba.co.jp
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
arxiv: v1 [cs.cv] 2 Aug 2018
![arxiv: v1 [cs.cv] 2 Aug 2018](/thumbs/93/114042775.jpg "arxiv: v1 [cs.cv] 2 Aug 2018") arxiv:1808.00897v1 [cs.cv] 2 Aug 2018 BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation Changqian Yu 1[0000 0002 4488 4157], Jingbo Wang 2[0000 0001 9700 6262], Chao Peng 3[0000
arxiv:1808.00897v1 [cs.cv] 2 Aug 2018 BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation Changqian Yu 1[0000 0002 4488 4157], Jingbo Wang 2[0000 0001 9700 6262], Chao Peng 3[0000
arxiv: v1 [cs.cv] 4 Dec 2016
![arxiv: v1 [cs.cv] 4 Dec 2016](/thumbs/89/97692264.jpg "arxiv: v1 [cs.cv] 4 Dec 2016") Pyramid Scene Parsing Network Hengshuang Zhao 1 Jianping Shi 2 Xiaojuan Qi 1 Xiaogang Wang 1 Jiaya Jia 1 1 The Chinese University of Hong Kong 2 SenseTime Group Limited {hszhao, xjqi, leojia}@cse.cuhk.edu.hk,
Pyramid Scene Parsing Network Hengshuang Zhao 1 Jianping Shi 2 Xiaojuan Qi 1 Xiaogang Wang 1 Jiaya Jia 1 1 The Chinese University of Hong Kong 2 SenseTime Group Limited {hszhao, xjqi, leojia}@cse.cuhk.edu.hk,
In Defense of Fully Connected Layers in Visual Representation Transfer
 In Defense of Fully Connected Layers in Visual Representation Transfer Chen-Lin Zhang, Jian-Hao Luo, Xiu-Shen Wei, Jianxin Wu National Key Laboratory for Novel Software Technology, Nanjing University,
In Defense of Fully Connected Layers in Visual Representation Transfer Chen-Lin Zhang, Jian-Hao Luo, Xiu-Shen Wei, Jianxin Wu National Key Laboratory for Novel Software Technology, Nanjing University,
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
SEMANTIC SEGMENTATION AVIRAM BAR HAIM & IRIS TAL
 SEMANTIC SEGMENTATION AVIRAM BAR HAIM & IRIS TAL IMAGE DESCRIPTIONS IN THE WILD (IDW-CNN) LARGE KERNEL MATTERS (GCN) DEEP LEARNING SEMINAR, TAU NOVEMBER 2017 TOPICS IDW-CNN: Improving Semantic Segmentation
SEMANTIC SEGMENTATION AVIRAM BAR HAIM & IRIS TAL IMAGE DESCRIPTIONS IN THE WILD (IDW-CNN) LARGE KERNEL MATTERS (GCN) DEEP LEARNING SEMINAR, TAU NOVEMBER 2017 TOPICS IDW-CNN: Improving Semantic Segmentation
LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation
 LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation Abhishek Chaurasia School of Electrical and Computer Engineering Purdue University West Lafayette, USA Email: aabhish@purdue.edu
LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation Abhishek Chaurasia School of Electrical and Computer Engineering Purdue University West Lafayette, USA Email: aabhish@purdue.edu
Feature-Fused SSD: Fast Detection for Small Objects
 Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
arxiv: v1 [cs.cv] 5 Oct 2015
![arxiv: v1 [cs.cv] 5 Oct 2015](/thumbs/71/66021937.jpg "arxiv: v1 [cs.cv] 5 Oct 2015") Efficient Object Detection for High Resolution Images Yongxi Lu 1 and Tara Javidi 1 arxiv:1510.01257v1 [cs.cv] 5 Oct 2015 Abstract Efficient generation of high-quality object proposals is an essential
Efficient Object Detection for High Resolution Images Yongxi Lu 1 and Tara Javidi 1 arxiv:1510.01257v1 [cs.cv] 5 Oct 2015 Abstract Efficient generation of high-quality object proposals is an essential
Supplementary material for Analyzing Filters Toward Efficient ConvNet
 Supplementary material for Analyzing Filters Toward Efficient Net Takumi Kobayashi National Institute of Advanced Industrial Science and Technology, Japan takumi.kobayashi@aist.go.jp A. Orthonormal Steerable
Supplementary material for Analyzing Filters Toward Efficient Net Takumi Kobayashi National Institute of Advanced Industrial Science and Technology, Japan takumi.kobayashi@aist.go.jp A. Orthonormal Steerable
Elastic Neural Networks for Classification
 Elastic Neural Networks for Classification Yi Zhou 1, Yue Bai 1, Shuvra S. Bhattacharyya 1, 2 and Heikki Huttunen 1 1 Tampere University of Technology, Finland, 2 University of Maryland, USA arxiv:1810.00589v3
Elastic Neural Networks for Classification Yi Zhou 1, Yue Bai 1, Shuvra S. Bhattacharyya 1, 2 and Heikki Huttunen 1 1 Tampere University of Technology, Finland, 2 University of Maryland, USA arxiv:1810.00589v3
Dense Image Labeling Using Deep Convolutional Neural Networks
 Dense Image Labeling Using Deep Convolutional Neural Networks Md Amirul Islam, Neil Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, MB {amirul, bruce, ywang}@cs.umanitoba.ca
Dense Image Labeling Using Deep Convolutional Neural Networks Md Amirul Islam, Neil Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, MB {amirul, bruce, ywang}@cs.umanitoba.ca
arxiv: v2 [cs.cv] 10 Apr 2017
![arxiv: v2 [cs.cv] 10 Apr 2017](/thumbs/80/82485703.jpg "arxiv: v2 [cs.cv] 10 Apr 2017") Fully Convolutional Instance-aware Semantic Segmentation Yi Li 1,2 Haozhi Qi 2 Jifeng Dai 2 Xiangyang Ji 1 Yichen Wei 2 1 Tsinghua University 2 Microsoft Research Asia {liyi14,xyji}@tsinghua.edu.cn, {v-haoq,jifdai,yichenw}@microsoft.com
Fully Convolutional Instance-aware Semantic Segmentation Yi Li 1,2 Haozhi Qi 2 Jifeng Dai 2 Xiangyang Ji 1 Yichen Wei 2 1 Tsinghua University 2 Microsoft Research Asia {liyi14,xyji}@tsinghua.edu.cn, {v-haoq,jifdai,yichenw}@microsoft.com
arxiv: v1 [cs.cv] 15 Oct 2018
![arxiv: v1 [cs.cv] 15 Oct 2018](/thumbs/89/99052786.jpg "arxiv: v1 [cs.cv] 15 Oct 2018") Instance Segmentation and Object Detection with Bounding Shape Masks Ha Young Kim 1,2,*, Ba Rom Kang 2 1 Department of Financial Engineering, Ajou University Worldcupro 206, Yeongtong-gu, Suwon, 16499,
Instance Segmentation and Object Detection with Bounding Shape Masks Ha Young Kim 1,2,*, Ba Rom Kang 2 1 Department of Financial Engineering, Ajou University Worldcupro 206, Yeongtong-gu, Suwon, 16499,
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation
 BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation Jifeng Dai Kaiming He Jian Sun Microsoft Research {jifdai,kahe,jiansun}@microsoft.com Abstract Recent leading
BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation Jifeng Dai Kaiming He Jian Sun Microsoft Research {jifdai,kahe,jiansun}@microsoft.com Abstract Recent leading
Object detection with CNNs
 Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
arxiv: v1 [cs.cv] 20 Dec 2016
![arxiv: v1 [cs.cv] 20 Dec 2016](/thumbs/73/68905842.jpg "arxiv: v1 [cs.cv] 20 Dec 2016") End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
Laplacian Pyramid Reconstruction and Refinement for Semantic Segmentation
 Laplacian Pyramid Reconstruction and Refinement for Semantic Segmentation Golnaz Ghiasi (B) and Charless C. Fowlkes Department of Computer Science, University of California, Irvine, USA {gghiasi,fowlkes}@ics.uci.edu
Laplacian Pyramid Reconstruction and Refinement for Semantic Segmentation Golnaz Ghiasi (B) and Charless C. Fowlkes Department of Computer Science, University of California, Irvine, USA {gghiasi,fowlkes}@ics.uci.edu
[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors
![[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors](/thumbs/89/97941029.jpg "[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors") [Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors Junhyug Noh Soochan Lee Beomsu Kim Gunhee Kim Department of Computer Science and Engineering
[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors Junhyug Noh Soochan Lee Beomsu Kim Gunhee Kim Department of Computer Science and Engineering
HENet: A Highly Efficient Convolutional Neural. Networks Optimized for Accuracy, Speed and Storage
 HENet: A Highly Efficient Convolutional Neural Networks Optimized for Accuracy, Speed and Storage Qiuyu Zhu Shanghai University zhuqiuyu@staff.shu.edu.cn Ruixin Zhang Shanghai University chriszhang96@shu.edu.cn
HENet: A Highly Efficient Convolutional Neural Networks Optimized for Accuracy, Speed and Storage Qiuyu Zhu Shanghai University zhuqiuyu@staff.shu.edu.cn Ruixin Zhang Shanghai University chriszhang96@shu.edu.cn
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
RSRN: Rich Side-output Residual Network for Medial Axis Detection
 RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
SGN: Sequential Grouping Networks for Instance Segmentation
 SGN: Sequential Grouping Networks for Instance Segmentation Shu Liu Jiaya Jia,[ Sanja Fidler Raquel Urtasun, The Chinese University of Hong Kong [ Youtu Lab, Tencent Uber Advanced Technologies Group University
SGN: Sequential Grouping Networks for Instance Segmentation Shu Liu Jiaya Jia,[ Sanja Fidler Raquel Urtasun, The Chinese University of Hong Kong [ Youtu Lab, Tencent Uber Advanced Technologies Group University
Pixel Offset Regression (POR) for Single-shot Instance Segmentation
 for Single-shot Instance Segmentation") Pixel Offset Regression (POR) for Single-shot Instance Segmentation Yuezun Li 1, Xiao Bian 2, Ming-ching Chang 1, Longyin Wen 2 and Siwei Lyu 1 1 University at Albany, State University of New York, NY,
Pixel Offset Regression (POR) for Single-shot Instance Segmentation Yuezun Li 1, Xiao Bian 2, Ming-ching Chang 1, Longyin Wen 2 and Siwei Lyu 1 1 University at Albany, State University of New York, NY,
arxiv: v2 [cs.cv] 19 Apr 2018
![arxiv: v2 [cs.cv] 19 Apr 2018](/thumbs/83/87325597.jpg "arxiv: v2 [cs.cv] 19 Apr 2018") arxiv:1804.06215v2 [cs.cv] 19 Apr 2018 DetNet: A Backbone network for Object Detection Zeming Li 1, Chao Peng 2, Gang Yu 2, Xiangyu Zhang 2, Yangdong Deng 1, Jian Sun 2 1 School of Software, Tsinghua University,
arxiv:1804.06215v2 [cs.cv] 19 Apr 2018 DetNet: A Backbone network for Object Detection Zeming Li 1, Chao Peng 2, Gang Yu 2, Xiangyu Zhang 2, Yangdong Deng 1, Jian Sun 2 1 School of Software, Tsinghua University,
arxiv: v2 [cs.cv] 28 May 2017
![arxiv: v2 [cs.cv] 28 May 2017](/thumbs/76/73843498.jpg "arxiv: v2 [cs.cv] 28 May 2017") Fused DNN: A deep neural network fusion approach to fast and robust pedestrian detection Xianzhi Du 1, Mostafa El-Khamy 2, Jungwon Lee 2, Larry S. Davis 1 arxiv:1610.03466v2 [cs.cv] 28 May 2017 1 Computer
Fused DNN: A deep neural network fusion approach to fast and robust pedestrian detection Xianzhi Du 1, Mostafa El-Khamy 2, Jungwon Lee 2, Larry S. Davis 1 arxiv:1610.03466v2 [cs.cv] 28 May 2017 1 Computer
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK. Wenjie Guan, YueXian Zou*, Xiaoqun Zhou
 MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
Dataset Augmentation with Synthetic Images Improves Semantic Segmentation
 Dataset Augmentation with Synthetic Images Improves Semantic Segmentation P. S. Rajpura IIT Gandhinagar param.rajpura@iitgn.ac.in M. Goyal IIT Varanasi manik.goyal.cse15@iitbhu.ac.in H. Bojinov Innit Inc.
Dataset Augmentation with Synthetic Images Improves Semantic Segmentation P. S. Rajpura IIT Gandhinagar param.rajpura@iitgn.ac.in M. Goyal IIT Varanasi manik.goyal.cse15@iitbhu.ac.in H. Bojinov Innit Inc.
PSANet: Point-wise Spatial Attention Network for Scene Parsing
 PSANet: Point-wise Spatial Attention Network for Scene Parsing engshuang Zhao 1, Yi Zhang 2, Shu Liu 1, Jianping Shi 3, Chen Change Loy 4, Dahua Lin 2, and Jiaya Jia 1,5 1 The Chinese University of ong
PSANet: Point-wise Spatial Attention Network for Scene Parsing engshuang Zhao 1, Yi Zhang 2, Shu Liu 1, Jianping Shi 3, Chen Change Loy 4, Dahua Lin 2, and Jiaya Jia 1,5 1 The Chinese University of ong
Efficient Segmentation-Aided Text Detection For Intelligent Robots
 Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network
 Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network Anurag Arnab and Philip H.S. Torr University of Oxford {anurag.arnab, philip.torr}@eng.ox.ac.uk 1. Introduction
Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network Anurag Arnab and Philip H.S. Torr University of Oxford {anurag.arnab, philip.torr}@eng.ox.ac.uk 1. Introduction
arxiv: v1 [cs.cv] 7 Jun 2016
![arxiv: v1 [cs.cv] 7 Jun 2016](/thumbs/86/93207990.jpg "arxiv: v1 [cs.cv] 7 Jun 2016") ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation arxiv:1606.02147v1 [cs.cv] 7 Jun 2016 Adam Paszke Faculty of Mathematics, Informatics and Mechanics University of Warsaw, Poland
ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation arxiv:1606.02147v1 [cs.cv] 7 Jun 2016 Adam Paszke Faculty of Mathematics, Informatics and Mechanics University of Warsaw, Poland
arxiv: v2 [cs.cv] 19 Nov 2018
![arxiv: v2 [cs.cv] 19 Nov 2018](/thumbs/90/103457332.jpg "arxiv: v2 [cs.cv] 19 Nov 2018") OCNet: Object Context Network for Scene Parsing Yuhui Yuan Jingdong Wang Microsoft Research {yuyua,jingdw}@microsoft.com arxiv:1809.00916v2 [cs.cv] 19 Nov 2018 Abstract In this paper, we address the problem
OCNet: Object Context Network for Scene Parsing Yuhui Yuan Jingdong Wang Microsoft Research {yuyua,jingdw}@microsoft.com arxiv:1809.00916v2 [cs.cv] 19 Nov 2018 Abstract In this paper, we address the problem
arxiv: v1 [cs.cv] 26 Jun 2017
![arxiv: v1 [cs.cv] 26 Jun 2017](/thumbs/80/82184026.jpg "arxiv: v1 [cs.cv] 26 Jun 2017") Detecting Small Signs from Large Images arxiv:1706.08574v1 [cs.cv] 26 Jun 2017 Zibo Meng, Xiaochuan Fan, Xin Chen, Min Chen and Yan Tong Computer Science and Engineering University of South Carolina, Columbia,
Detecting Small Signs from Large Images arxiv:1706.08574v1 [cs.cv] 26 Jun 2017 Zibo Meng, Xiaochuan Fan, Xin Chen, Min Chen and Yan Tong Computer Science and Engineering University of South Carolina, Columbia,
Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab.
 [ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
[ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
Deep Dual Learning for Semantic Image Segmentation
 Deep Dual Learning for Semantic Image Segmentation Ping Luo 2 Guangrun Wang 1,2 Liang Lin 1,3 Xiaogang Wang 2 1 Sun Yat-Sen University 2 The Chinese University of Hong Kong 3 SenseTime Group (Limited)
Deep Dual Learning for Semantic Image Segmentation Ping Luo 2 Guangrun Wang 1,2 Liang Lin 1,3 Xiaogang Wang 2 1 Sun Yat-Sen University 2 The Chinese University of Hong Kong 3 SenseTime Group (Limited)
Scene Parsing with Global Context Embedding
 Scene Parsing with Global Context Embedding Wei-Chih Hung 1, Yi-Hsuan Tsai 1,2, Xiaohui Shen 3, Zhe Lin 3, Kalyan Sunkavalli 3, Xin Lu 3, Ming-Hsuan Yang 1 1 University of California, Merced 2 NEC Laboratories
Scene Parsing with Global Context Embedding Wei-Chih Hung 1, Yi-Hsuan Tsai 1,2, Xiaohui Shen 3, Zhe Lin 3, Kalyan Sunkavalli 3, Xin Lu 3, Ming-Hsuan Yang 1 1 University of California, Merced 2 NEC Laboratories
FCHD: A fast and accurate head detector
 JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1 FCHD: A fast and accurate head detector Aditya Vora, Johnson Controls Inc. arxiv:1809.08766v2 [cs.cv] 26 Sep 2018 Abstract In this paper, we
JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1 FCHD: A fast and accurate head detector Aditya Vora, Johnson Controls Inc. arxiv:1809.08766v2 [cs.cv] 26 Sep 2018 Abstract In this paper, we
Mimicking Very Efficient Network for Object Detection
 Mimicking Very Efficient Network for Object Detection Quanquan Li 1, Shengying Jin 2, Junjie Yan 1 1 SenseTime 2 Beihang University liquanquan@sensetime.com, jsychffy@gmail.com, yanjunjie@outlook.com Abstract
Mimicking Very Efficient Network for Object Detection Quanquan Li 1, Shengying Jin 2, Junjie Yan 1 1 SenseTime 2 Beihang University liquanquan@sensetime.com, jsychffy@gmail.com, yanjunjie@outlook.com Abstract
DFT-based Transformation Invariant Pooling Layer for Visual Classification
 DFT-based Transformation Invariant Pooling Layer for Visual Classification Jongbin Ryu 1, Ming-Hsuan Yang 2, and Jongwoo Lim 1 1 Hanyang University 2 University of California, Merced Abstract. We propose
DFT-based Transformation Invariant Pooling Layer for Visual Classification Jongbin Ryu 1, Ming-Hsuan Yang 2, and Jongwoo Lim 1 1 Hanyang University 2 University of California, Merced Abstract. We propose
FishNet: A Versatile Backbone for Image, Region, and Pixel Level Prediction
 FishNet: A Versatile Backbone for Image, Region, and Pixel Level Prediction Shuyang Sun 1, Jiangmiao Pang 3, Jianping Shi 2, Shuai Yi 2, Wanli Ouyang 1 1 The University of Sydney 2 SenseTime Research 3
FishNet: A Versatile Backbone for Image, Region, and Pixel Level Prediction Shuyang Sun 1, Jiangmiao Pang 3, Jianping Shi 2, Shuai Yi 2, Wanli Ouyang 1 1 The University of Sydney 2 SenseTime Research 3
Inception and Residual Networks. Hantao Zhang. Deep Learning with Python.
 Inception and Residual Networks Hantao Zhang Deep Learning with Python https://en.wikipedia.org/wiki/residual_neural_network Deep Neural Network Progress from Large Scale Visual Recognition Challenge (ILSVRC)
Inception and Residual Networks Hantao Zhang Deep Learning with Python https://en.wikipedia.org/wiki/residual_neural_network Deep Neural Network Progress from Large Scale Visual Recognition Challenge (ILSVRC)
Conditional Random Fields as Recurrent Neural Networks
 BIL722 - Deep Learning for Computer Vision Conditional Random Fields as Recurrent Neural Networks S. Zheng, S. Jayasumana, B. Romera-Paredes V. Vineet, Z. Su, D. Du, C. Huang, P.H.S. Torr Introduction
BIL722 - Deep Learning for Computer Vision Conditional Random Fields as Recurrent Neural Networks S. Zheng, S. Jayasumana, B. Romera-Paredes V. Vineet, Z. Su, D. Du, C. Huang, P.H.S. Torr Introduction
Study of Residual Networks for Image Recognition
 Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Thinking Outside the Box: Spatial Anticipation of Semantic Categories
 GARBADE, GALL: SPATIAL ANTICIPATION OF SEMANTIC CATEGORIES 1 Thinking Outside the Box: Spatial Anticipation of Semantic Categories Martin Garbade garbade@iai.uni-bonn.de Juergen Gall gall@iai.uni-bonn.de
GARBADE, GALL: SPATIAL ANTICIPATION OF SEMANTIC CATEGORIES 1 Thinking Outside the Box: Spatial Anticipation of Semantic Categories Martin Garbade garbade@iai.uni-bonn.de Juergen Gall gall@iai.uni-bonn.de
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network
 Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
Deep learning for dense per-pixel prediction. Chunhua Shen The University of Adelaide, Australia
 Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Fused DNN: A deep neural network fusion approach to fast and robust pedestrian detection
 2017 IEEE Winter Conference on Applications of Computer Vision Fused DNN: A deep neural network fusion approach to fast and robust pedestrian detection Xianzhi Du 1, Mostafa El-Khamy 2, Jungwon Lee 3,
2017 IEEE Winter Conference on Applications of Computer Vision Fused DNN: A deep neural network fusion approach to fast and robust pedestrian detection Xianzhi Du 1, Mostafa El-Khamy 2, Jungwon Lee 3,
Illuminating Pedestrians via Simultaneous Detection & Segmentation
 Illuminating Pedestrians via Simultaneous Detection & Segmentation Garrick Brazil, Xi Yin, Xiaoming Liu Michigan State University, East Lansing, MI 48824 {brazilga, yinxi1, liuxm}@msu.edu Abstract Pedestrian
Illuminating Pedestrians via Simultaneous Detection & Segmentation Garrick Brazil, Xi Yin, Xiaoming Liu Michigan State University, East Lansing, MI 48824 {brazilga, yinxi1, liuxm}@msu.edu Abstract Pedestrian
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Supplementary Material: Unconstrained Salient Object Detection via Proposal Subset Optimization
 Supplementary Material: Unconstrained Salient Object via Proposal Subset Optimization 1. Proof of the Submodularity According to Eqns. 10-12 in our paper, the objective function of the proposed optimization
Supplementary Material: Unconstrained Salient Object via Proposal Subset Optimization 1. Proof of the Submodularity According to Eqns. 10-12 in our paper, the objective function of the proposed optimization
arxiv: v1 [cs.cv] 1 Feb 2018
![arxiv: v1 [cs.cv] 1 Feb 2018](/thumbs/89/100586364.jpg "arxiv: v1 [cs.cv] 1 Feb 2018") Learning Semantic Segmentation with Diverse Supervision Linwei Ye University of Manitoba yel3@cs.umanitoba.ca Zhi Liu Shanghai University liuzhi@staff.shu.edu.cn Yang Wang University of Manitoba ywang@cs.umanitoba.ca
Learning Semantic Segmentation with Diverse Supervision Linwei Ye University of Manitoba yel3@cs.umanitoba.ca Zhi Liu Shanghai University liuzhi@staff.shu.edu.cn Yang Wang University of Manitoba ywang@cs.umanitoba.ca
Object Detection Based on Deep Learning
 Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Ladder-style DenseNets for Semantic Segmentation of Large Natural Images
 Ladder-style DenseNets for Semantic Segmentation of Large Natural Images Ivan Krešo Siniša Šegvić Faculty of Electrical Engineering and Computing University of Zagreb, Croatia name.surname@fer.hr Josip
Ladder-style DenseNets for Semantic Segmentation of Large Natural Images Ivan Krešo Siniša Šegvić Faculty of Electrical Engineering and Computing University of Zagreb, Croatia name.surname@fer.hr Josip
arxiv: v1 [cs.cv] 4 Dec 2014
![arxiv: v1 [cs.cv] 4 Dec 2014](/thumbs/83/87999872.jpg "arxiv: v1 [cs.cv] 4 Dec 2014") Convolutional Neural Networks at Constrained Time Cost Kaiming He Jian Sun Microsoft Research {kahe,jiansun}@microsoft.com arxiv:1412.1710v1 [cs.cv] 4 Dec 2014 Abstract Though recent advanced convolutional
Convolutional Neural Networks at Constrained Time Cost Kaiming He Jian Sun Microsoft Research {kahe,jiansun}@microsoft.com arxiv:1412.1710v1 [cs.cv] 4 Dec 2014 Abstract Though recent advanced convolutional
Person Part Segmentation based on Weak Supervision
 JIANG, CHI: PERSON PART SEGMENTATION BASED ON WEAK SUPERVISION 1 Person Part Segmentation based on Weak Supervision Yalong Jiang 1 yalong.jiang@connect.polyu.hk Zheru Chi 1 chi.zheru@polyu.edu.hk 1 Department
JIANG, CHI: PERSON PART SEGMENTATION BASED ON WEAK SUPERVISION 1 Person Part Segmentation based on Weak Supervision Yalong Jiang 1 yalong.jiang@connect.polyu.hk Zheru Chi 1 chi.zheru@polyu.edu.hk 1 Department
Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform Supplementary Material
 Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform Supplementary Material Xintao Wang 1 Ke Yu 1 Chao Dong 2 Chen Change Loy 1 1 CUHK - SenseTime Joint Lab, The Chinese
Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform Supplementary Material Xintao Wang 1 Ke Yu 1 Chao Dong 2 Chen Change Loy 1 1 CUHK - SenseTime Joint Lab, The Chinese
Unified, real-time object detection
 Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
Gated Bi-directional CNN for Object Detection
 Gated Bi-directional CNN for Object Detection Xingyu Zeng,, Wanli Ouyang, Bin Yang, Junjie Yan, Xiaogang Wang The Chinese University of Hong Kong, Sensetime Group Limited {xyzeng,wlouyang}@ee.cuhk.edu.hk,
Gated Bi-directional CNN for Object Detection Xingyu Zeng,, Wanli Ouyang, Bin Yang, Junjie Yan, Xiaogang Wang The Chinese University of Hong Kong, Sensetime Group Limited {xyzeng,wlouyang}@ee.cuhk.edu.hk,
Advanced Video Analysis & Imaging
 Advanced Video Analysis & Imaging (5LSH0), Module 09B Machine Learning with Convolutional Neural Networks (CNNs) - Workout Farhad G. Zanjani, Clint Sebastian, Egor Bondarev, Peter H.N. de With ( p.h.n.de.with@tue.nl
Advanced Video Analysis & Imaging (5LSH0), Module 09B Machine Learning with Convolutional Neural Networks (CNNs) - Workout Farhad G. Zanjani, Clint Sebastian, Egor Bondarev, Peter H.N. de With ( p.h.n.de.with@tue.nl
Foreground Segmentation for Anomaly Detection in Surveillance Videos Using Deep Residual Networks
 Foreground Segmentation for Anomaly Detection in Surveillance Videos Using Deep Residual Networks Lucas P. Cinelli, Lucas A. Thomaz, Allan F. da Silva, Eduardo A. B. da Silva and Sergio L. Netto Abstract
Foreground Segmentation for Anomaly Detection in Surveillance Videos Using Deep Residual Networks Lucas P. Cinelli, Lucas A. Thomaz, Allan F. da Silva, Eduardo A. B. da Silva and Sergio L. Netto Abstract
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
3D Densely Convolutional Networks for Volumetric Segmentation. Toan Duc Bui, Jitae Shin, and Taesup Moon
 3D Densely Convolutional Networks for Volumetric Segmentation Toan Duc Bui, Jitae Shin, and Taesup Moon School of Electronic and Electrical Engineering, Sungkyunkwan University, Republic of Korea arxiv:1709.03199v2
3D Densely Convolutional Networks for Volumetric Segmentation Toan Duc Bui, Jitae Shin, and Taesup Moon School of Electronic and Electrical Engineering, Sungkyunkwan University, Republic of Korea arxiv:1709.03199v2
Presentation Outline. Semantic Segmentation. Overview. Presentation Outline CNN. Learning Deconvolution Network for Semantic Segmentation 6/6/16
 6/6/16 Learning Deconvolution Network for Semantic Segmentation Hyeonwoo Noh, Seunghoon Hong,Bohyung Han Department of Computer Science and Engineering, POSTECH, Korea Shai Rozenberg 6/6/2016 1 2 Semantic
6/6/16 Learning Deconvolution Network for Semantic Segmentation Hyeonwoo Noh, Seunghoon Hong,Bohyung Han Department of Computer Science and Engineering, POSTECH, Korea Shai Rozenberg 6/6/2016 1 2 Semantic
Pixel-Level Encoding and Depth Layering for Instance-Level Semantic Labeling
 Pixel-Level Encoding and Depth Layering for Instance-Level Semantic Labeling Jonas Uhrig 1,2(B), Marius Cordts 1,3,UweFranke 1, and Thomas Brox 2 1 Daimler AG R&D, Stuttgart, Germany jonas.uhrig@daimler.com
Pixel-Level Encoding and Depth Layering for Instance-Level Semantic Labeling Jonas Uhrig 1,2(B), Marius Cordts 1,3,UweFranke 1, and Thomas Brox 2 1 Daimler AG R&D, Stuttgart, Germany jonas.uhrig@daimler.com
arxiv: v3 [cs.cv] 18 Oct 2017
![arxiv: v3 [cs.cv] 18 Oct 2017](/thumbs/75/72627087.jpg "arxiv: v3 [cs.cv] 18 Oct 2017") SSH: Single Stage Headless Face Detector Mahyar Najibi* Pouya Samangouei* Rama Chellappa University of Maryland arxiv:78.3979v3 [cs.cv] 8 Oct 27 najibi@cs.umd.edu Larry S. Davis {pouya,rama,lsd}@umiacs.umd.edu
SSH: Single Stage Headless Face Detector Mahyar Najibi* Pouya Samangouei* Rama Chellappa University of Maryland arxiv:78.3979v3 [cs.cv] 8 Oct 27 najibi@cs.umd.edu Larry S. Davis {pouya,rama,lsd}@umiacs.umd.edu
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
arxiv: v2 [cs.cv] 23 Nov 2017
![arxiv: v2 [cs.cv] 23 Nov 2017](/thumbs/75/71682984.jpg "arxiv: v2 [cs.cv] 23 Nov 2017") Light-Head R-CNN: In Defense of Two-Stage Object Detector Zeming Li 1, Chao Peng 2, Gang Yu 2, Xiangyu Zhang 2, Yangdong Deng 1, Jian Sun 2 1 School of Software, Tsinghua University, {lizm15@mails.tsinghua.edu.cn,
Light-Head R-CNN: In Defense of Two-Stage Object Detector Zeming Li 1, Chao Peng 2, Gang Yu 2, Xiangyu Zhang 2, Yangdong Deng 1, Jian Sun 2 1 School of Software, Tsinghua University, {lizm15@mails.tsinghua.edu.cn,
Team G-RMI: Google Research & Machine Intelligence
 Team G-RMI: Google Research & Machine Intelligence Alireza Fathi (alirezafathi@google.com) Nori Kanazawa, Kai Yang, George Papandreou, Tyler Zhu, Jonathan Huang, Vivek Rathod, Chen Sun, Kevin Murphy, et
Team G-RMI: Google Research & Machine Intelligence Alireza Fathi (alirezafathi@google.com) Nori Kanazawa, Kai Yang, George Papandreou, Tyler Zhu, Jonathan Huang, Vivek Rathod, Chen Sun, Kevin Murphy, et
Semantic Segmentation via Structured Patch Prediction, Context CRF and Guidance CRF
 Semantic Segmentation via Structured Patch Prediction, Context CRF and Guidance CRF Falong Shen 1 Rui Gan 1 Shuicheng Yan 2,3 Gang Zeng 1 1 Peking University 2 360 AI Institute 3 National University of
Semantic Segmentation via Structured Patch Prediction, Context CRF and Guidance CRF Falong Shen 1 Rui Gan 1 Shuicheng Yan 2,3 Gang Zeng 1 1 Peking University 2 360 AI Institute 3 National University of
In-Place Activated BatchNorm for Memory- Optimized Training of DNNs
 In-Place Activated BatchNorm for Memory- Optimized Training of DNNs Samuel Rota Bulò, Lorenzo Porzi, Peter Kontschieder Mapillary Research Paper: https://arxiv.org/abs/1712.02616 Code: https://github.com/mapillary/inplace_abn
In-Place Activated BatchNorm for Memory- Optimized Training of DNNs Samuel Rota Bulò, Lorenzo Porzi, Peter Kontschieder Mapillary Research Paper: https://arxiv.org/abs/1712.02616 Code: https://github.com/mapillary/inplace_abn
arxiv: v2 [cs.cv] 8 Apr 2018
![arxiv: v2 [cs.cv] 8 Apr 2018](/thumbs/86/94330536.jpg "arxiv: v2 [cs.cv] 8 Apr 2018") Single-Shot Object Detection with Enriched Semantics Zhishuai Zhang 1 Siyuan Qiao 1 Cihang Xie 1 Wei Shen 1,2 Bo Wang 3 Alan L. Yuille 1 Johns Hopkins University 1 Shanghai University 2 Hikvision Research
Single-Shot Object Detection with Enriched Semantics Zhishuai Zhang 1 Siyuan Qiao 1 Cihang Xie 1 Wei Shen 1,2 Bo Wang 3 Alan L. Yuille 1 Johns Hopkins University 1 Shanghai University 2 Hikvision Research
A MultiPath Network for Object Detection
 ZAGORUYKO et al.: A MULTIPATH NETWORK FOR OBJECT DETECTION 1 A MultiPath Network for Object Detection Sergey Zagoruyko, Adam Lerer, Tsung-Yi Lin, Pedro O. Pinheiro, Sam Gross, Soumith Chintala, Piotr Dollár
ZAGORUYKO et al.: A MULTIPATH NETWORK FOR OBJECT DETECTION 1 A MultiPath Network for Object Detection Sergey Zagoruyko, Adam Lerer, Tsung-Yi Lin, Pedro O. Pinheiro, Sam Gross, Soumith Chintala, Piotr Dollár
arxiv: v1 [cs.cv] 5 Apr 2017
![arxiv: v1 [cs.cv] 5 Apr 2017](/thumbs/81/82990255.jpg "arxiv: v1 [cs.cv] 5 Apr 2017") Not All Pixels Are Equal: Difficulty-Aware Semantic Segmentation via Deep Layer Cascade Xiaoxiao Li 1 Ziwei Liu 1 Ping Luo 2,1 Chen Change Loy 1,2 Xiaoou Tang 1,2 1 Department of Information Engineering,
Not All Pixels Are Equal: Difficulty-Aware Semantic Segmentation via Deep Layer Cascade Xiaoxiao Li 1 Ziwei Liu 1 Ping Luo 2,1 Chen Change Loy 1,2 Xiaoou Tang 1,2 1 Department of Information Engineering,
arxiv: v1 [cs.cv] 26 Jul 2018
![arxiv: v1 [cs.cv] 26 Jul 2018](/thumbs/88/117269915.jpg "arxiv: v1 [cs.cv] 26 Jul 2018") A Better Baseline for AVA Rohit Girdhar João Carreira Carl Doersch Andrew Zisserman DeepMind Carnegie Mellon University University of Oxford arxiv:1807.10066v1 [cs.cv] 26 Jul 2018 Abstract We introduce
A Better Baseline for AVA Rohit Girdhar João Carreira Carl Doersch Andrew Zisserman DeepMind Carnegie Mellon University University of Oxford arxiv:1807.10066v1 [cs.cv] 26 Jul 2018 Abstract We introduce
Semantic Segmentation
 Semantic Segmentation UCLA:https://goo.gl/images/I0VTi2 OUTLINE Semantic Segmentation Why? Paper to talk about: Fully Convolutional Networks for Semantic Segmentation. J. Long, E. Shelhamer, and T. Darrell,
Semantic Segmentation UCLA:https://goo.gl/images/I0VTi2 OUTLINE Semantic Segmentation Why? Paper to talk about: Fully Convolutional Networks for Semantic Segmentation. J. Long, E. Shelhamer, and T. Darrell,
Neural Networks with Input Specified Thresholds
 Neural Networks with Input Specified Thresholds Fei Liu Stanford University liufei@stanford.edu Junyang Qian Stanford University junyangq@stanford.edu Abstract In this project report, we propose a method
Neural Networks with Input Specified Thresholds Fei Liu Stanford University liufei@stanford.edu Junyang Qian Stanford University junyangq@stanford.edu Abstract In this project report, we propose a method
An Analysis of Scale Invariance in Object Detection SNIP
 An Analysis of Scale Invariance in Object Detection SNIP Bharat Singh Larry S. Davis University of Maryland, College Park {bharat,lsd}@cs.umd.edu Abstract An analysis of different techniques for recognizing
An Analysis of Scale Invariance in Object Detection SNIP Bharat Singh Larry S. Davis University of Maryland, College Park {bharat,lsd}@cs.umd.edu Abstract An analysis of different techniques for recognizing
arxiv: v1 [cs.cv] 14 Dec 2015
![arxiv: v1 [cs.cv] 14 Dec 2015](/thumbs/72/67245194.jpg "arxiv: v1 [cs.cv] 14 Dec 2015") Instance-aware Semantic Segmentation via Multi-task Network Cascades Jifeng Dai Kaiming He Jian Sun Microsoft Research {jifdai,kahe,jiansun}@microsoft.com arxiv:1512.04412v1 [cs.cv] 14 Dec 2015 Abstract
Instance-aware Semantic Segmentation via Multi-task Network Cascades Jifeng Dai Kaiming He Jian Sun Microsoft Research {jifdai,kahe,jiansun}@microsoft.com arxiv:1512.04412v1 [cs.cv] 14 Dec 2015 Abstract