(Deep) Learning for Robot Perception and Navigation. Wolfram Burgard
|
|
|
- Amberlynn King
- 6 years ago
- Views:
Transcription


1 (Deep) Learning for Robot Perception and Navigation Wolfram Burgard
2 Deep Learning for Robot Perception (and Navigation) Lifeng Bo, Claas Bollen, Thomas Brox, Andreas Eitel, Dieter Fox, Gabriel L. Oliveira, Luciano Spinello, Jost Tobias Springenberg, Martin Riedmiller, Michael Ruhnke, Abhinav Valada
3 Perception in Robotics Robot perception is a challenging problem and involves many different aspects such as Scene understanding Object detection Detection of humans Goal: improve perception in robotics scenarios using state-of-the-art deep learning methods
4 Why Deep Learning? Multiple layers of abstraction provide an advantage for solving complex pattern recognition problems Successful in computer vision for detection, recognition, and segmentation problems One set of techniques can serve different fields and be applied to solve a wide range of problems


5 What Our Robots Should Do RGB-D object recognition Images human part segmentation Sound terrain classification Asphalt Mowed Grass Grass
6 Multimodal Deep Learning for Robust RGB-D Object Recognition Andreas Eitel, Jost Tobias Springenberg, Martin Riedmiller, Wolfram Burgard [IROS 2015]




7 RGB-D Object Recognition
8 RGB-Depth Object Recognition Learned features + classifier Learned features Learning algorithm Sparse coding networks [Bo et. al 2012] Deep CNN features [Schwarz et. al 2015] End-to-end learning / Deep learning RGB-D CNN Learning algorithm Convolutional recurrent neural networks [Socher et. al 2012]
9 Often too little Data for Deep Learning Solutions Deep networks are hard to train and require large amounts of data Lack of large amount of labeled training data for RGB-D domain How to deal with limited sizes of available datasets?
10 Data often too Clean for Deep Learning Solutions Large portion of RGB-D data is recorded under controlled settings How to improve recognition in realworld scenes when the training data is clean? How to deal with sensor noise from RGB-D sensors?
11 Solution: Transfer Deep RGB Features to Depth Domain Both domains share similar features such as edges, corners, curves,


12 Solution: Transfer Deep RGB Features to Depth Domain Depth domain Pre-trained RGB CNN RGB domain Transfer* Depth encoding Fine-tune Re-train network features for depth * Similar to [Schwarz et. al 2015, Gupta et. al 2014]
13 Solution: Transfer Deep RGB Features to Depth Domain Depth domain Pre-trained RGB CNN RGB domain Transfer* Depth encoding Fine-tune Re-train network features for depth * Similar to [Schwarz et. al 2015, Gupta et. al 2014]

14 Multimodal Deep Convolutional Neural Network Two input modalities Late fusion network 10 convolutional layers Max pooling layers 4 fully connected layers Softmax classifier 2xAlexNet + fusion net



15 How to Encode Depth Images? Distribute depth over color channels Compute min and max value of depth map Shift depth map to min/max range Normalize depth values to lie between 0 and 255 Colorize image using jet colormap (red = near, blue = far) Depth encoding improves recognition accuracy by 1.8 percentage points RGB Raw depth Colorized depth

16 Solution: Noise-aware Depth Feature Learning Clean training data Noise samples Noise adaptation Classify


17 Training with Noise Samples Noise samples: 50,000 Randomly sample noise for each training batch Shuffle noise samples Training batch Input image

18 RGB Network Training Maximum likelihood learning Fine-tune from pre-trained AlexNet weights

19 Depth Network Training Maximum likelihood learning Fine-tune from pre-trained AlexNet weights




20 Fusion Network Training Fusion layers automatically learn to combine feature responses of the two network streams During training, weights in first layers stay fixed
21 UW RGB-D Object Dataset [Lai et. al, 2011] Category-Level Recognition [%] (51 categories) Method RGB Depth RGB-D CNN-RNN HMP CaRFs N/A N/A 88.1 CNN Features 83.1 N/A 89.4
 Method RGB Depth RGB-D CNN-RNN 80.8 78.9 86.8 HMP 82.4 81.")
22 UW RGB-D Object Dataset [Lai et. al, 2011] Category-Level Recognition [%] (51 categories) Method RGB Depth RGB-D CNN-RNN HMP CaRFs N/A N/A 88.1 CNN Features 83.1 N/A 89.4 This work, Fus-CNN




23 Confusion Matrix Label Prediction mushroom garlic pitcher coffee mug peach garlic
 cereal box coffee mug class avg. - 97.5 68.5 66.5 66.6 96.2 79.1 79.1 96.")
24 Recognition in Noisy RGB-D Scenes bowl cap soda can coffee mug Recognition using Noise adapt. flashlight annotated bounding boxes cap bowl soda can Noise adapt. = correct prediction No adapt. = false prediction Category-Level Recognition [%] depth modality (6 categories) cereal box coffee mug class avg
25 Deep Learning for RGB-D Object Recognition Novel RGB-D object recognition for robotics Two-stream CNN with late fusion architecture Depth image transfer and noise augmentation training strategy State of the art on UW RGB-D Object dataset for category recognition: 91.3% Recognition accuracy of 82.1% on the RGB-D Scenes dataset
26 Deep Learning for Human Part Discovery in Images Gabriel L. Oliveira, Abhinav Valada, Claas Bollen, Wolfram Burgard, Thomas Brox [submitted to ICRA 2016]




27 Deep Learning for Human Part Discovery in Images Human-robot interaction Robot rescue





28 Deep Learning for Human Part Discovery in Images Dense prediction can provide pixel classification of the image Human part segmentation is naturally challenging due to Non-rigid aspect of body Occlusions PASCAL Parts MS COCO Freiburg Sitting

29 Network Architecture Fully convolutional network Contraction and expansion of network input Up-convolution operation for expansion Pixel input, pixel output
30 Experiments Evaluation of approach on Publicly available computer vision datasets Real-world datasets with ground and aerial robots Comparison against state-of-the-art semantic segmentation approach: FCN proposed by Long et al. [1] [1] John Long, Evan Shelhamer, Trevor Darrell, CVPR 2015


 Color")
31 Data Augmentation Due to the low number of images in the available datasets, augmentation is crucial Spatial augmentation (rotation + scaling) Color augmentation
32 PASCAL Parts Dataset PASCAL Parts, 4 classes, IOU PASCAL Parts, 14 classes, IOU


33 Freiburg Sitting People Part Segmentation Dataset We present a novel dataset for human part segmentation in wheelchairs Input Image Ground Truth Segmentation mask


34 Robot Experiments Range experiments with ground robot Aerial platform for disaster scenario Segmentation under severe body occlusions


 1.")
 3.")
 5.")
35 Range Experiments Recorded using Bumblebee camera Robust to radial distortion Robust to scale (a) 1.0 meter (b) 2.0 meters (c) 3.0 meters (d) 4.0 meters (e) 5.0 meters (f) 6.0 meters

36 Freiburg People in Disaster Dataset designed to test severe occlusions Input Image Ground Truth Segmentation mask
37 Future Work Investigate the potential for human keypoint annotation Real-time part segmentation for small hardware Human part segmentation in videos
38 Deep Feature Learning for Acoustics-based Terrain Classification Abhinav Valada, Luciano Spinello, Wolfram Bugard [ISRR 2015]





39 Motivation Robots are increasingly being used in unstructured real-world environments



40 Motivation Lighting Variations Shadows Dirt on Lens Optical sensors are highly sensitive to visual changes

41 Motivation Use sound from vehicle-terrain interactions to classify terrain


42 Network Architecture Novel architecture designed for unstructured sound data Global pooling gathers statistics of learned features across time







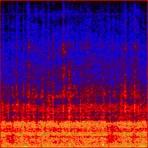
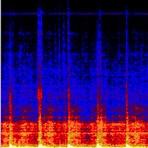
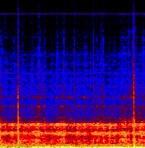

43 Data Collection Wood Linoleum Carpet P3-DX Asphalt Mowed Grass Grass Paving Cobble Stone Offroad
44 Results - Baseline Comparison (300ms window) [1] [2] [5] [6] [3] [4] 16.9% 99.41% improvement using a 500ms over window the previous state of the art [1] T. Giannakopoulos, K. Dimitrios, A. Andreas, and T. Sergios, SETN 2006 [2] M. C. Wellman, N. Srour, and D. B. Hillis, SPIE [3] J. Libby and A. Stentz, ICRA 2012 [4] D. Ellis, ISMIR 2007 [5] G. Tzanetakis and P. Cook, IEEE TASLP 2002 [6] V. Brijesh, and M. Blumenstein, Pattern Recognition Technologies and Applications 2008

45 Robustness to Noise Per-class Precision
46 Noise Adaptive Fine-Tuning Avg. accuracy of 99.57% on the base model


47 Real-World Stress Testing - True Positives - False Positives Avg. accuracy of 98.54%
48 Can you guess the terrain? Social Experiment Avg. human performance = 24.66% Avg. network performance = 99.5% Go to deepterrain.cs.unifreiburg.de Listen to five sound clips of a robot traversing on different terrains Guess what terrain they are
49 Conclusions Classifies terrain using only sound State-of-the art performance in proprioceptive terrain classification New DCNN architecture outperforms traditional approaches Noise adaptation boosts performance Experiments with a low-quality microphone demonstrates robustness
50 Overall Conclusions Deep networks are a promising approach to solve complex perception problems in robotics The key challenges are finding the proper architecture using proper data augmentation strategies
3D Object Recognition and Scene Understanding from RGB-D Videos. Yu Xiang Postdoctoral Researcher University of Washington
 3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
arxiv: v2 [cs.cv] 18 Aug 2015
![arxiv: v2 [cs.cv] 18 Aug 2015](/thumbs/91/105403407.jpg "arxiv: v2 [cs.cv] 18 Aug 2015") Multimodal Deep Learning for Robust RGB-D Object Recognition Andreas Eitel Jost Tobias Springenberg Luciano Spinello Martin Riedmiller Wolfram Burgard arxiv:57.682v2 [cs.cv] 8 Aug 25 Abstract Robust object
Multimodal Deep Learning for Robust RGB-D Object Recognition Andreas Eitel Jost Tobias Springenberg Luciano Spinello Martin Riedmiller Wolfram Burgard arxiv:57.682v2 [cs.cv] 8 Aug 25 Abstract Robust object
Perceiving the 3D World from Images and Videos. Yu Xiang Postdoctoral Researcher University of Washington
 Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
Convolutional-Recursive Deep Learning for 3D Object Classification
 Convolutional-Recursive Deep Learning for 3D Object Classification Richard Socher, Brody Huval, Bharath Bhat, Christopher D. Manning, Andrew Y. Ng NIPS 2012 Iro Armeni, Manik Dhar Motivation Hand-designed
Convolutional-Recursive Deep Learning for 3D Object Classification Richard Socher, Brody Huval, Bharath Bhat, Christopher D. Manning, Andrew Y. Ng NIPS 2012 Iro Armeni, Manik Dhar Motivation Hand-designed
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Efficient Segmentation-Aided Text Detection For Intelligent Robots
 Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs
 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
Encoder-Decoder Networks for Semantic Segmentation. Sachin Mehta
 Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Large-scale Video Classification with Convolutional Neural Networks
 Large-scale Video Classification with Convolutional Neural Networks Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, Li Fei-Fei Note: Slide content mostly from : Bay Area
Large-scale Video Classification with Convolutional Neural Networks Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, Li Fei-Fei Note: Slide content mostly from : Bay Area
arxiv: v1 [cs.ro] 18 Jul 2017
![arxiv: v1 [cs.ro] 18 Jul 2017](/thumbs/84/89731203.jpg "arxiv: v1 [cs.ro] 18 Jul 2017") Choosing Smartly: Adaptive Multimodal Fusion for Object Detection in Changing Environments Oier Mees Andreas Eitel Wolfram Burgard arxiv:1707.05733v1 [cs.ro] 18 Jul 2017 Abstract Object detection is an
Choosing Smartly: Adaptive Multimodal Fusion for Object Detection in Changing Environments Oier Mees Andreas Eitel Wolfram Burgard arxiv:1707.05733v1 [cs.ro] 18 Jul 2017 Abstract Object detection is an
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS. Zhao Chen Machine Learning Intern, NVIDIA
 JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
Object Detection on Self-Driving Cars in China. Lingyun Li
 Object Detection on Self-Driving Cars in China Lingyun Li Introduction Motivation: Perception is the key of self-driving cars Data set: 10000 images with annotation 2000 images without annotation (not
Object Detection on Self-Driving Cars in China Lingyun Li Introduction Motivation: Perception is the key of self-driving cars Data set: 10000 images with annotation 2000 images without annotation (not
Semantic Segmentation
 Semantic Segmentation UCLA:https://goo.gl/images/I0VTi2 OUTLINE Semantic Segmentation Why? Paper to talk about: Fully Convolutional Networks for Semantic Segmentation. J. Long, E. Shelhamer, and T. Darrell,
Semantic Segmentation UCLA:https://goo.gl/images/I0VTi2 OUTLINE Semantic Segmentation Why? Paper to talk about: Fully Convolutional Networks for Semantic Segmentation. J. Long, E. Shelhamer, and T. Darrell,
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
CS231N Section. Video Understanding 6/1/2018
 CS231N Section Video Understanding 6/1/2018 Outline Background / Motivation / History Video Datasets Models Pre-deep learning CNN + RNN 3D convolution Two-stream What we ve seen in class so far... Image
CS231N Section Video Understanding 6/1/2018 Outline Background / Motivation / History Video Datasets Models Pre-deep learning CNN + RNN 3D convolution Two-stream What we ve seen in class so far... Image
Learning Semantic Environment Perception for Cognitive Robots
 Learning Semantic Environment Perception for Cognitive Robots Sven Behnke University of Bonn, Germany Computer Science Institute VI Autonomous Intelligent Systems Some of Our Cognitive Robots Equipped
Learning Semantic Environment Perception for Cognitive Robots Sven Behnke University of Bonn, Germany Computer Science Institute VI Autonomous Intelligent Systems Some of Our Cognitive Robots Equipped
Presentation Outline. Semantic Segmentation. Overview. Presentation Outline CNN. Learning Deconvolution Network for Semantic Segmentation 6/6/16
 6/6/16 Learning Deconvolution Network for Semantic Segmentation Hyeonwoo Noh, Seunghoon Hong,Bohyung Han Department of Computer Science and Engineering, POSTECH, Korea Shai Rozenberg 6/6/2016 1 2 Semantic
6/6/16 Learning Deconvolution Network for Semantic Segmentation Hyeonwoo Noh, Seunghoon Hong,Bohyung Han Department of Computer Science and Engineering, POSTECH, Korea Shai Rozenberg 6/6/2016 1 2 Semantic
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Object Detection. CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR
 Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
SSD: Single Shot MultiBox Detector. Author: Wei Liu et al. Presenter: Siyu Jiang
 SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
Multi-view 3D Models from Single Images with a Convolutional Network
 Multi-view 3D Models from Single Images with a Convolutional Network Maxim Tatarchenko University of Freiburg Skoltech - 2nd Christmas Colloquium on Computer Vision Humans have prior knowledge about 3D
Multi-view 3D Models from Single Images with a Convolutional Network Maxim Tatarchenko University of Freiburg Skoltech - 2nd Christmas Colloquium on Computer Vision Humans have prior knowledge about 3D
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Dynamic Routing Between Capsules
 Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS
 LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS Alexey Dosovitskiy, Jost Tobias Springenberg and Thomas Brox University of Freiburg Presented by: Shreyansh Daftry Visual Learning and Recognition
LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS Alexey Dosovitskiy, Jost Tobias Springenberg and Thomas Brox University of Freiburg Presented by: Shreyansh Daftry Visual Learning and Recognition
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network. Nathan Sun CIS601
 with Facial KeyPoints using Spatial Fusion Convolutional Network. Nathan Sun CIS601") Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601 Introduction Face ID is complicated by alterations to an individual s appearance Beard,
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601 Introduction Face ID is complicated by alterations to an individual s appearance Beard,
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018
 Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018 Outline: Introduction Action classification architectures
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018 Outline: Introduction Action classification architectures
Classification of objects from Video Data (Group 30)
") Classification of objects from Video Data (Group 30) Sheallika Singh 12665 Vibhuti Mahajan 12792 Aahitagni Mukherjee 12001 M Arvind 12385 1 Motivation Video surveillance has been employed for a long time
Classification of objects from Video Data (Group 30) Sheallika Singh 12665 Vibhuti Mahajan 12792 Aahitagni Mukherjee 12001 M Arvind 12385 1 Motivation Video surveillance has been employed for a long time
Aalborg Universitet. Published in: International Joint Conference on Computational Intelligence
 Aalborg Universitet Depth Value Pre-Processing for Accurate Transfer Learning Based RGB-D Object Recognition Aakerberg, Andreas; Nasrollahi, Kamal; Rasmussen, Christoffer Bøgelund; Moeslund, Thomas B.
Aalborg Universitet Depth Value Pre-Processing for Accurate Transfer Learning Based RGB-D Object Recognition Aakerberg, Andreas; Nasrollahi, Kamal; Rasmussen, Christoffer Bøgelund; Moeslund, Thomas B.
S7348: Deep Learning in Ford's Autonomous Vehicles. Bryan Goodman Argo AI 9 May 2017
 S7348: Deep Learning in Ford's Autonomous Vehicles Bryan Goodman Argo AI 9 May 2017 1 Ford s 12 Year History in Autonomous Driving Today: examples from Stereo image processing Object detection Using RNN
S7348: Deep Learning in Ford's Autonomous Vehicles Bryan Goodman Argo AI 9 May 2017 1 Ford s 12 Year History in Autonomous Driving Today: examples from Stereo image processing Object detection Using RNN
Deep Learning. Visualizing and Understanding Convolutional Networks. Christopher Funk. Pennsylvania State University.
 Visualizing and Understanding Convolutional Networks Christopher Pennsylvania State University February 23, 2015 Some Slide Information taken from Pierre Sermanet (Google) presentation on and Computer
Visualizing and Understanding Convolutional Networks Christopher Pennsylvania State University February 23, 2015 Some Slide Information taken from Pierre Sermanet (Google) presentation on and Computer
Deep Incremental Scene Understanding. Federico Tombari & Christian Rupprecht Technical University of Munich, Germany
 Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
RGBD Occlusion Detection via Deep Convolutional Neural Networks
 1 RGBD Occlusion Detection via Deep Convolutional Neural Networks Soumik Sarkar 1,2, Vivek Venugopalan 1, Kishore Reddy 1, Michael Giering 1, Julian Ryde 3, Navdeep Jaitly 4,5 1 United Technologies Research
1 RGBD Occlusion Detection via Deep Convolutional Neural Networks Soumik Sarkar 1,2, Vivek Venugopalan 1, Kishore Reddy 1, Michael Giering 1, Julian Ryde 3, Navdeep Jaitly 4,5 1 United Technologies Research
CEA LIST s participation to the Scalable Concept Image Annotation task of ImageCLEF 2015
 CEA LIST s participation to the Scalable Concept Image Annotation task of ImageCLEF 2015 Etienne Gadeski, Hervé Le Borgne, and Adrian Popescu CEA, LIST, Laboratory of Vision and Content Engineering, France
CEA LIST s participation to the Scalable Concept Image Annotation task of ImageCLEF 2015 Etienne Gadeski, Hervé Le Borgne, and Adrian Popescu CEA, LIST, Laboratory of Vision and Content Engineering, France
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Multimodal Gesture Recognition using Multi-stream Recurrent Neural Network
 Multimodal Gesture Recognition using Multi-stream Recurrent Neural Network Noriki Nishida and Hideki Nakayama Machine Perception Group Graduate School of Information Science and Technology The University
Multimodal Gesture Recognition using Multi-stream Recurrent Neural Network Noriki Nishida and Hideki Nakayama Machine Perception Group Graduate School of Information Science and Technology The University
Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet.
 Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet 7D Labs VINNOVA https://7dlabs.com Photo-realistic image synthesis
Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet 7D Labs VINNOVA https://7dlabs.com Photo-realistic image synthesis
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK
 TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
Deep Learning For Video Classification. Presented by Natalie Carlebach & Gil Sharon
 Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
Mapping with Dynamic-Object Probabilities Calculated from Single 3D Range Scans
 Mapping with Dynamic-Object Probabilities Calculated from Single 3D Range Scans Philipp Ruchti Wolfram Burgard Abstract Various autonomous robotic systems require maps for robust and safe navigation. Particularly
Mapping with Dynamic-Object Probabilities Calculated from Single 3D Range Scans Philipp Ruchti Wolfram Burgard Abstract Various autonomous robotic systems require maps for robust and safe navigation. Particularly
P-CNN: Pose-based CNN Features for Action Recognition. Iman Rezazadeh
 P-CNN: Pose-based CNN Features for Action Recognition Iman Rezazadeh Introduction automatic understanding of dynamic scenes strong variations of people and scenes in motion and appearance Fine-grained
P-CNN: Pose-based CNN Features for Action Recognition Iman Rezazadeh Introduction automatic understanding of dynamic scenes strong variations of people and scenes in motion and appearance Fine-grained
COMP 551 Applied Machine Learning Lecture 16: Deep Learning
 COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
arxiv: v1 [cs.cv] 20 Dec 2016
![arxiv: v1 [cs.cv] 20 Dec 2016](/thumbs/73/68905842.jpg "arxiv: v1 [cs.cv] 20 Dec 2016") End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
Martian lava field, NASA, Wikipedia
 Martian lava field, NASA, Wikipedia Old Man of the Mountain, Franconia, New Hampshire Pareidolia http://smrt.ccel.ca/203/2/6/pareidolia/ Reddit for more : ) https://www.reddit.com/r/pareidolia/top/ Pareidolia
Martian lava field, NASA, Wikipedia Old Man of the Mountain, Franconia, New Hampshire Pareidolia http://smrt.ccel.ca/203/2/6/pareidolia/ Reddit for more : ) https://www.reddit.com/r/pareidolia/top/ Pareidolia
Deep learning for dense per-pixel prediction. Chunhua Shen The University of Adelaide, Australia
 Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
Two-Stream Convolutional Networks for Action Recognition in Videos
 Two-Stream Convolutional Networks for Action Recognition in Videos Karen Simonyan Andrew Zisserman Cemil Zalluhoğlu Introduction Aim Extend deep Convolution Networks to action recognition in video. Motivation
Two-Stream Convolutional Networks for Action Recognition in Videos Karen Simonyan Andrew Zisserman Cemil Zalluhoğlu Introduction Aim Extend deep Convolution Networks to action recognition in video. Motivation
Recurrent Convolutional Neural Networks for Scene Labeling
 Recurrent Convolutional Neural Networks for Scene Labeling Pedro O. Pinheiro, Ronan Collobert Reviewed by Yizhe Zhang August 14, 2015 Scene labeling task Scene labeling: assign a class label to each pixel
Recurrent Convolutional Neural Networks for Scene Labeling Pedro O. Pinheiro, Ronan Collobert Reviewed by Yizhe Zhang August 14, 2015 Scene labeling task Scene labeling: assign a class label to each pixel
TorontoCity: Seeing the World with a Million Eyes
 TorontoCity: Seeing the World with a Million Eyes Authors Shenlong Wang, Min Bai, Gellert Mattyus, Hang Chu, Wenjie Luo, Bin Yang Justin Liang, Joel Cheverie, Sanja Fidler, Raquel Urtasun * Project Completed
TorontoCity: Seeing the World with a Million Eyes Authors Shenlong Wang, Min Bai, Gellert Mattyus, Hang Chu, Wenjie Luo, Bin Yang Justin Liang, Joel Cheverie, Sanja Fidler, Raquel Urtasun * Project Completed
Ryerson University CP8208. Soft Computing and Machine Intelligence. Naive Road-Detection using CNNS. Authors: Sarah Asiri - Domenic Curro
 Ryerson University CP8208 Soft Computing and Machine Intelligence Naive Road-Detection using CNNS Authors: Sarah Asiri - Domenic Curro April 24 2016 Contents 1 Abstract 2 2 Introduction 2 3 Motivation
Ryerson University CP8208 Soft Computing and Machine Intelligence Naive Road-Detection using CNNS Authors: Sarah Asiri - Domenic Curro April 24 2016 Contents 1 Abstract 2 2 Introduction 2 3 Motivation
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas
 PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas Big Data + Deep Representation Learning Robot Perception Augmented Reality
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas Big Data + Deep Representation Learning Robot Perception Augmented Reality
Tri-modal Human Body Segmentation
 Tri-modal Human Body Segmentation Master of Science Thesis Cristina Palmero Cantariño Advisor: Sergio Escalera Guerrero February 6, 2014 Outline 1 Introduction 2 Tri-modal dataset 3 Proposed baseline 4
Tri-modal Human Body Segmentation Master of Science Thesis Cristina Palmero Cantariño Advisor: Sergio Escalera Guerrero February 6, 2014 Outline 1 Introduction 2 Tri-modal dataset 3 Proposed baseline 4
Supplementary: Cross-modal Deep Variational Hand Pose Estimation
 Supplementary: Cross-modal Deep Variational Hand Pose Estimation Adrian Spurr, Jie Song, Seonwook Park, Otmar Hilliges ETH Zurich {spurra,jsong,spark,otmarh}@inf.ethz.ch Encoder/Decoder Linear(512) Table
Supplementary: Cross-modal Deep Variational Hand Pose Estimation Adrian Spurr, Jie Song, Seonwook Park, Otmar Hilliges ETH Zurich {spurra,jsong,spark,otmarh}@inf.ethz.ch Encoder/Decoder Linear(512) Table
Multi-View 3D Object Detection Network for Autonomous Driving
 Multi-View 3D Object Detection Network for Autonomous Driving Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, Tian Xia CVPR 2017 (Spotlight) Presented By: Jason Ku Overview Motivation Dataset Network Architecture
Multi-View 3D Object Detection Network for Autonomous Driving Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, Tian Xia CVPR 2017 (Spotlight) Presented By: Jason Ku Overview Motivation Dataset Network Architecture
Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization
 Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization Krishna Kumar Singh and Yong Jae Lee University of California, Davis ---- Paper Presentation Yixian
Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization Krishna Kumar Singh and Yong Jae Lee University of California, Davis ---- Paper Presentation Yixian
Visual Material Traits Recognizing Per-Pixel Material Context
 Visual Material Traits Recognizing Per-Pixel Material Context Gabriel Schwartz gbs25@drexel.edu Ko Nishino kon@drexel.edu 1 / 22 2 / 22 Materials as Visual Context What tells us this road is unsafe? 3
Visual Material Traits Recognizing Per-Pixel Material Context Gabriel Schwartz gbs25@drexel.edu Ko Nishino kon@drexel.edu 1 / 22 2 / 22 Materials as Visual Context What tells us this road is unsafe? 3
CAP 6412 Advanced Computer Vision
 CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
Mask R-CNN. By Kaiming He, Georgia Gkioxari, Piotr Dollar and Ross Girshick Presented By Aditya Sanghi
 Mask R-CNN By Kaiming He, Georgia Gkioxari, Piotr Dollar and Ross Girshick Presented By Aditya Sanghi Types of Computer Vision Tasks http://cs231n.stanford.edu/ Semantic vs Instance Segmentation Image
Mask R-CNN By Kaiming He, Georgia Gkioxari, Piotr Dollar and Ross Girshick Presented By Aditya Sanghi Types of Computer Vision Tasks http://cs231n.stanford.edu/ Semantic vs Instance Segmentation Image
Training models for road scene understanding with automated ground truth Dan Levi
 Training models for road scene understanding with automated ground truth Dan Levi With: Noa Garnett, Ethan Fetaya, Shai Silberstein, Rafi Cohen, Shaul Oron, Uri Verner, Ariel Ayash, Kobi Horn, Vlad Golder,
Training models for road scene understanding with automated ground truth Dan Levi With: Noa Garnett, Ethan Fetaya, Shai Silberstein, Rafi Cohen, Shaul Oron, Uri Verner, Ariel Ayash, Kobi Horn, Vlad Golder,
Conditional Random Fields as Recurrent Neural Networks
 BIL722 - Deep Learning for Computer Vision Conditional Random Fields as Recurrent Neural Networks S. Zheng, S. Jayasumana, B. Romera-Paredes V. Vineet, Z. Su, D. Du, C. Huang, P.H.S. Torr Introduction
BIL722 - Deep Learning for Computer Vision Conditional Random Fields as Recurrent Neural Networks S. Zheng, S. Jayasumana, B. Romera-Paredes V. Vineet, Z. Su, D. Du, C. Huang, P.H.S. Torr Introduction
Action recognition in robot-assisted minimally invasive surgery
 Action recognition in robot-assisted minimally invasive surgery Candidate: Laura Erica Pescatori Co-Tutor: Hirenkumar Chandrakant Nakawala Tutor: Elena De Momi 1 Project Objective da Vinci Robot: Console
Action recognition in robot-assisted minimally invasive surgery Candidate: Laura Erica Pescatori Co-Tutor: Hirenkumar Chandrakant Nakawala Tutor: Elena De Momi 1 Project Objective da Vinci Robot: Console
Supplemental Material for Can Visual Recognition Benefit from Auxiliary Information in Training?
 Supplemental Material for Can Visual Recognition Benefit from Auxiliary Information in Training? Qilin Zhang, Gang Hua, Wei Liu 2, Zicheng Liu 3, Zhengyou Zhang 3 Stevens Institute of Technolog, Hoboken,
Supplemental Material for Can Visual Recognition Benefit from Auxiliary Information in Training? Qilin Zhang, Gang Hua, Wei Liu 2, Zicheng Liu 3, Zhengyou Zhang 3 Stevens Institute of Technolog, Hoboken,
Rich feature hierarchies for accurate object detection and semantic segmentation
 Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik Presented by Pandian Raju and Jialin Wu Last class SGD for Document
Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik Presented by Pandian Raju and Jialin Wu Last class SGD for Document
A Deep Learning Approach to Vehicle Speed Estimation
 A Deep Learning Approach to Vehicle Speed Estimation Benjamin Penchas bpenchas@stanford.edu Tobin Bell tbell@stanford.edu Marco Monteiro marcorm@stanford.edu ABSTRACT Given car dashboard video footage,
A Deep Learning Approach to Vehicle Speed Estimation Benjamin Penchas bpenchas@stanford.edu Tobin Bell tbell@stanford.edu Marco Monteiro marcorm@stanford.edu ABSTRACT Given car dashboard video footage,
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Regionlet Object Detector with Hand-crafted and CNN Feature
 Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK. Wenjie Guan, YueXian Zou*, Xiaoqun Zhou
 MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
Internet of things that video
 Video recognition from a sentence Cees Snoek Intelligent Sensory Information Systems Lab University of Amsterdam The Netherlands Internet of things that video 45 billion cameras by 2022 [LDV Capital] 2
Video recognition from a sentence Cees Snoek Intelligent Sensory Information Systems Lab University of Amsterdam The Netherlands Internet of things that video 45 billion cameras by 2022 [LDV Capital] 2
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
AUTOMATIC 3D HUMAN ACTION RECOGNITION Ajmal Mian Associate Professor Computer Science & Software Engineering
 AUTOMATIC 3D HUMAN ACTION RECOGNITION Ajmal Mian Associate Professor Computer Science & Software Engineering www.csse.uwa.edu.au/~ajmal/ Overview Aim of automatic human action recognition Applications
AUTOMATIC 3D HUMAN ACTION RECOGNITION Ajmal Mian Associate Professor Computer Science & Software Engineering www.csse.uwa.edu.au/~ajmal/ Overview Aim of automatic human action recognition Applications
Presented at the FIG Congress 2018, May 6-11, 2018 in Istanbul, Turkey
 Presented at the FIG Congress 2018, May 6-11, 2018 in Istanbul, Turkey Evangelos MALTEZOS, Charalabos IOANNIDIS, Anastasios DOULAMIS and Nikolaos DOULAMIS Laboratory of Photogrammetry, School of Rural
Presented at the FIG Congress 2018, May 6-11, 2018 in Istanbul, Turkey Evangelos MALTEZOS, Charalabos IOANNIDIS, Anastasios DOULAMIS and Nikolaos DOULAMIS Laboratory of Photogrammetry, School of Rural
LEARNING TO INFER GRAPHICS PROGRAMS FROM HAND DRAWN IMAGES
 LEARNING TO INFER GRAPHICS PROGRAMS FROM HAND DRAWN IMAGES Kevin Ellis - MIT, Daniel Ritchie - Brown University, Armando Solar-Lezama - MIT, Joshua b. Tenenbaum - MIT Presented by : Maliha Arif Advanced
LEARNING TO INFER GRAPHICS PROGRAMS FROM HAND DRAWN IMAGES Kevin Ellis - MIT, Daniel Ritchie - Brown University, Armando Solar-Lezama - MIT, Joshua b. Tenenbaum - MIT Presented by : Maliha Arif Advanced
An Exploration of Computer Vision Techniques for Bird Species Classification
 An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab.
 [ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
[ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
Semantic RGB-D Perception for Cognitive Robots
 Semantic RGB-D Perception for Cognitive Robots Sven Behnke Computer Science Institute VI Autonomous Intelligent Systems Our Domestic Service Robots Dynamaid Cosero Size: 100-180 cm, weight: 30-35 kg 36
Semantic RGB-D Perception for Cognitive Robots Sven Behnke Computer Science Institute VI Autonomous Intelligent Systems Our Domestic Service Robots Dynamaid Cosero Size: 100-180 cm, weight: 30-35 kg 36
Visual features detection based on deep neural network in autonomous driving tasks
 430 Fomin I., Gromoshinskii D., Stepanov D. Visual features detection based on deep neural network in autonomous driving tasks Ivan Fomin, Dmitrii Gromoshinskii, Dmitry Stepanov Computer vision lab Russian
430 Fomin I., Gromoshinskii D., Stepanov D. Visual features detection based on deep neural network in autonomous driving tasks Ivan Fomin, Dmitrii Gromoshinskii, Dmitry Stepanov Computer vision lab Russian
Camera-based Vehicle Velocity Estimation using Spatiotemporal Depth and Motion Features
 Camera-based Vehicle Velocity Estimation using Spatiotemporal Depth and Motion Features Moritz Kampelmuehler* kampelmuehler@student.tugraz.at Michael Mueller* michael.g.mueller@student.tugraz.at Christoph
Camera-based Vehicle Velocity Estimation using Spatiotemporal Depth and Motion Features Moritz Kampelmuehler* kampelmuehler@student.tugraz.at Michael Mueller* michael.g.mueller@student.tugraz.at Christoph
THe goal of scene recognition is to predict scene labels. Learning Effective RGB-D Representations for Scene Recognition
 IEEE TRANSACTIONS ON IMAGE PROCESSING 1 Learning Effective RGB-D Representations for Scene Recognition Xinhang Song, Shuqiang Jiang* IEEE Senior Member, Luis Herranz, Chengpeng Chen Abstract Deep convolutional
IEEE TRANSACTIONS ON IMAGE PROCESSING 1 Learning Effective RGB-D Representations for Scene Recognition Xinhang Song, Shuqiang Jiang* IEEE Senior Member, Luis Herranz, Chengpeng Chen Abstract Deep convolutional
Finding Tiny Faces Supplementary Materials
 Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Photo OCR ( )
") Photo OCR (2017-2018) Xiang Bai Huazhong University of Science and Technology Outline VALSE2018, DaLian Xiang Bai 2 Deep Direct Regression for Multi-Oriented Scene Text Detection [He et al., ICCV, 2017.]
Photo OCR (2017-2018) Xiang Bai Huazhong University of Science and Technology Outline VALSE2018, DaLian Xiang Bai 2 Deep Direct Regression for Multi-Oriented Scene Text Detection [He et al., ICCV, 2017.]
VISION & LANGUAGE From Captions to Visual Concepts and Back
 VISION & LANGUAGE From Captions to Visual Concepts and Back Brady Fowler & Kerry Jones Tuesday, February 28th 2017 CS 6501-004 VICENTE Agenda Problem Domain Object Detection Language Generation Sentence
VISION & LANGUAGE From Captions to Visual Concepts and Back Brady Fowler & Kerry Jones Tuesday, February 28th 2017 CS 6501-004 VICENTE Agenda Problem Domain Object Detection Language Generation Sentence
Hand-Object Interaction Detection with Fully Convolutional Networks
 Hand-Object Interaction Detection with Fully Convolutional Networks Matthias Schröder Helge Ritter Neuroinformatics Group, Bielefeld University {maschroe,helge}@techfak.uni-bielefeld.de Abstract Detecting
Hand-Object Interaction Detection with Fully Convolutional Networks Matthias Schröder Helge Ritter Neuroinformatics Group, Bielefeld University {maschroe,helge}@techfak.uni-bielefeld.de Abstract Detecting
MASTER THESIS. A Local - Global Approach to Semantic Segmentation in Aerial Images
 University Politehnica of Bucharest Automatic Control and Computers Faculty, Computer Science and Engineering Department arxiv:1607.05620v1 [cs.cv] 19 Jul 2016 MASTER THESIS A Local - Global Approach to
University Politehnica of Bucharest Automatic Control and Computers Faculty, Computer Science and Engineering Department arxiv:1607.05620v1 [cs.cv] 19 Jul 2016 MASTER THESIS A Local - Global Approach to
Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning
 Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
Learning to Segment Object Candidates
 Learning to Segment Object Candidates Pedro Pinheiro, Ronan Collobert and Piotr Dollar Presented by - Sivaraman, Kalpathy Sitaraman, M.S. in Computer Science, University of Virginia Facebook Artificial
Learning to Segment Object Candidates Pedro Pinheiro, Ronan Collobert and Piotr Dollar Presented by - Sivaraman, Kalpathy Sitaraman, M.S. in Computer Science, University of Virginia Facebook Artificial
Amodal and Panoptic Segmentation. Stephanie Liu, Andrew Zhou
 Amodal and Panoptic Segmentation Stephanie Liu, Andrew Zhou This lecture: 1. 2. 3. 4. Semantic Amodal Segmentation Cityscapes Dataset ADE20K Dataset Panoptic Segmentation Semantic Amodal Segmentation Yan
Amodal and Panoptic Segmentation Stephanie Liu, Andrew Zhou This lecture: 1. 2. 3. 4. Semantic Amodal Segmentation Cityscapes Dataset ADE20K Dataset Panoptic Segmentation Semantic Amodal Segmentation Yan
EE-559 Deep learning Networks for semantic segmentation
 EE-559 Deep learning 7.4. Networks for semantic segmentation François Fleuret https://fleuret.org/ee559/ Mon Feb 8 3:35:5 UTC 209 ÉCOLE POLYTECHNIQUE FÉDÉRALE DE LAUSANNE The historical approach to image
EE-559 Deep learning 7.4. Networks for semantic segmentation François Fleuret https://fleuret.org/ee559/ Mon Feb 8 3:35:5 UTC 209 ÉCOLE POLYTECHNIQUE FÉDÉRALE DE LAUSANNE The historical approach to image
Learning-based Localization
 Learning-based Localization Eric Brachmann ECCV 2018 Tutorial on Visual Localization - Feature-based vs. Learned Approaches Torsten Sattler, Eric Brachmann Roadmap Machine Learning Basics [10min] Convolutional
Learning-based Localization Eric Brachmann ECCV 2018 Tutorial on Visual Localization - Feature-based vs. Learned Approaches Torsten Sattler, Eric Brachmann Roadmap Machine Learning Basics [10min] Convolutional
Classifying Depositional Environments in Satellite Images
 Classifying Depositional Environments in Satellite Images Alex Miltenberger and Rayan Kanfar Department of Geophysics School of Earth, Energy, and Environmental Sciences Stanford University 1 Introduction
Classifying Depositional Environments in Satellite Images Alex Miltenberger and Rayan Kanfar Department of Geophysics School of Earth, Energy, and Environmental Sciences Stanford University 1 Introduction
A Deep Learning Framework for Authorship Classification of Paintings
 A Deep Learning Framework for Authorship Classification of Paintings Kai-Lung Hua ( 花凱龍 ) Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology Taipei,
A Deep Learning Framework for Authorship Classification of Paintings Kai-Lung Hua ( 花凱龍 ) Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology Taipei,
YOLO9000: Better, Faster, Stronger
 YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
ECE 5470 Classification, Machine Learning, and Neural Network Review
 ECE 5470 Classification, Machine Learning, and Neural Network Review Due December 1. Solution set Instructions: These questions are to be answered on this document which should be submitted to blackboard
ECE 5470 Classification, Machine Learning, and Neural Network Review Due December 1. Solution set Instructions: These questions are to be answered on this document which should be submitted to blackboard
Rich feature hierarchies for accurate object detection and semant
 Rich feature hierarchies for accurate object detection and semantic segmentation Speaker: Yucong Shen 4/5/2018 Develop of Object Detection 1 DPM (Deformable parts models) 2 R-CNN 3 Fast R-CNN 4 Faster
Rich feature hierarchies for accurate object detection and semantic segmentation Speaker: Yucong Shen 4/5/2018 Develop of Object Detection 1 DPM (Deformable parts models) 2 R-CNN 3 Fast R-CNN 4 Faster
ABC-CNN: Attention Based CNN for Visual Question Answering
 ABC-CNN: Attention Based CNN for Visual Question Answering CIS 601 PRESENTED BY: MAYUR RUMALWALA GUIDED BY: DR. SUNNIE CHUNG AGENDA Ø Introduction Ø Understanding CNN Ø Framework of ABC-CNN Ø Datasets
ABC-CNN: Attention Based CNN for Visual Question Answering CIS 601 PRESENTED BY: MAYUR RUMALWALA GUIDED BY: DR. SUNNIE CHUNG AGENDA Ø Introduction Ø Understanding CNN Ø Framework of ABC-CNN Ø Datasets
Generative Adversarial Text to Image Synthesis
 Generative Adversarial Text to Image Synthesis Scott Reed, Zeynep Akata, Xinchen Yan, Lajanugen Logeswaran, Bernt Schiele, Honglak Lee Presented by: Jingyao Zhan Contents Introduction Related Work Method
Generative Adversarial Text to Image Synthesis Scott Reed, Zeynep Akata, Xinchen Yan, Lajanugen Logeswaran, Bernt Schiele, Honglak Lee Presented by: Jingyao Zhan Contents Introduction Related Work Method
Real-Time Grasp Detection Using Convolutional Neural Networks
 Real-Time Grasp Detection Using Convolutional Neural Networks Joseph Redmon 1, Anelia Angelova 2 Abstract We present an accurate, real-time approach to robotic grasp detection based on convolutional neural
Real-Time Grasp Detection Using Convolutional Neural Networks Joseph Redmon 1, Anelia Angelova 2 Abstract We present an accurate, real-time approach to robotic grasp detection based on convolutional neural
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
COSC160: Detection and Classification. Jeremy Bolton, PhD Assistant Teaching Professor
 COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality
COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality