Supervised vs unsupervised clustering
|
|
|
- Harold Gaines
- 6 years ago
- Views:
Transcription
1 Classification
2 Supervised vs unsupervised clustering Cluster analysis: Classes are not known a- priori. Classification: Classes are defined a-priori Sometimes called supervised clustering Extract useful features based on known class labels that separate classes in training set Assign new objects to classes based on rules developed on the training set
3 Different Classification methods Statistical methods: often aim to classify as well as to identify marker genes that characterize different classes Linear discriminant analysis Nearest neighbors Logistic regression Classification and regression tree Computer science methods: do not emphasize on parsimony or interpretation Bayesian network Neural network Support vector machine
4 General notation for classification X G x n
5 Toy example Space: 2 genes, finite range of expression measure.
6 Constructing and evaluating classifiers Training data: for constructing the classifiers Cross-validation: often cross-validation is used in training process -Leave one out: asymptotically equivalent to -Leave n ν out - (see Linear Model Selection by Cross-Validation, Shao J 1993 JASA for details) Test data: a separate set of data used to evaluate the performance
7
8
9
10
11 Bias-variance tradeoff High Bias Low Variance Low Bias High Variance test error error training error Low Model complexity High
12
13
14 Nearest-neighbors discriminant rule The training set has samples with known classes Define a distance measure Euclidean, 1-correlation, Mahalanobis For each sample in a test set, find k closest neighbors Predict the class by majority vote How to choose k: usually by cross-validation
15 Fisher s linear discriminant analysis
16 S pooled =[(N 1-1)S 1 +(N 2-1)S 2 ]/(N 1 +N 2-2) Discriminant rule: Assign x to Class 1 if otherwise to class 2. With microarray data, S is often singular, and generalized inverse of S, denoted by S - is often used
17
18 Fisher s linear discriminant analysis More general c>2 maximize between/within sum of squares
19 The problem is equivalent to Solution: find eigen values for Use the largest eigne vector v to form
20 Maximum likelihood discriminant rule ML discriminant rule Pr(x y=k) arg max k pr(x y=k) Recall Bayes rule: Sample ML discriminant rule Bayes rule
21 Maximum likelihood discriminant rule special cases Linear Discriminant analysis Diagonal quadratic discriminant analysis (DQDA): class densities have diagonal covariance matrices Diagonal linear discriminant analysis (DLDA):
22 Weighted gene voting scheme Variant of sample ML with same diagonal covariance For two-class case, classify a sample with gene expression profile x=(x 1,x 2,,x p ), vote from each gene j is weighted distance Classify to class 1 if i.e., In Golub et al (1999), is used instead of
23 Logistic discriminant function
24 Nearest centroid discriminant rule Variant of Bayes rule Ignoring covariance terms and assume same variance matrix for all k, If prior class probabilities are equal to 1/k, the rule assigns x to the class with the closest mean (centroid) Q: filter genes or not? How to filter genes?
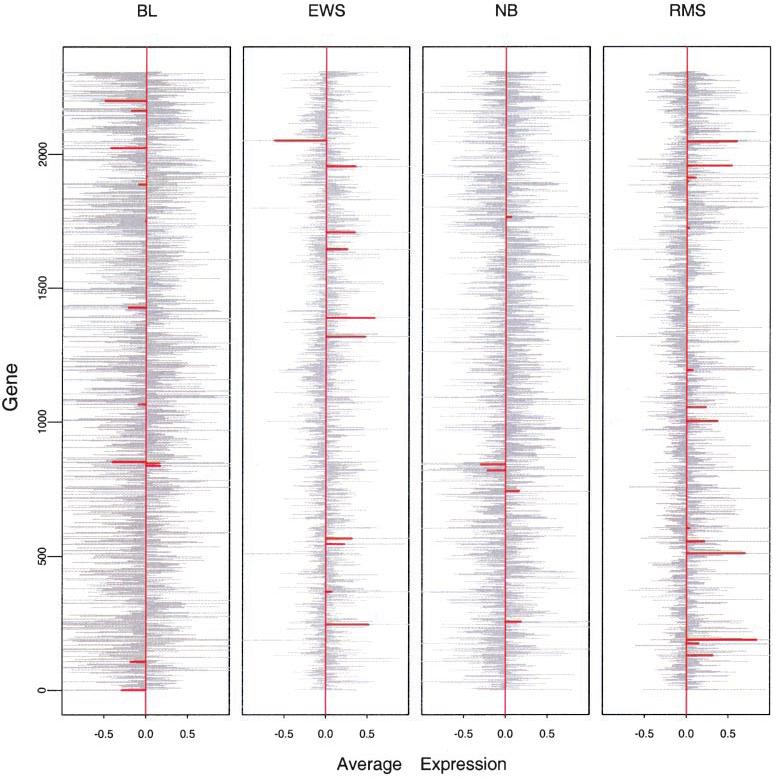
25 nearest shrunken centroid method Prediction Analysis for Microarrays (PAM) Centroid distance classification Regularize by shrinking the centroids gene i (1~G), sample j (1~n, in K classes): S i is pooled within-class standard deviation notice that is the standard error of d = ( x j x) /[ m j( s s0)] j +
26 Centroid: From overall center, each gene in each class centroid deviates from it Some genes are not associated with the classes Let s keep gene i if its statistic d is large enough (larger than Δ) i.e., d =d- Δ if d> Δ; d =d+ Δ if d<- Δ ; and 0 otherwise Soft thresholding
27 Soft thresholding/hard thresholding Both shrink the values within threshold to 0 Direct thresholding leaves other values intact Soft thresholding shrinks everything
28 Centroid: From overall center, each gene in each class centroid deviates from it Some genes are not associated with the classes Let s keep gene i if its statistic d is large enough (larger than Δ) i.e., d =d- Δ if d> Δ; d =d+ Δ if d<- Δ ; and 0 otherwise Shrunken Centroid: Shrunken to the global mean if difference is not significant Lastly: How to choose Δ

29
30
31 Discriminant rule and probability For one test sample
32
33
34
35 Split data using set of binary decisions Root node (with all data points) has certain impurity, splitting reduces impurity Highest on root, lowest (0) at leaf node Measure of impurities Entropy Gini index impurity Prune the tree to prevent over fit
36
37
38 A separating hyperplane in the feature space may correspond to a non-linear boundary in the input space. The figure shows the classification boundary (solid line) in a two-dimensional input space as well as the accompanying soft margins (dotted lines). Positive and negative examples fall on opposite sides of the decision boundary. The support vectors (circled) are the points lying closest to the decision boundary.
39
40 Resources for learning SVM and application in microarrays SVM classification and validation of cancer tissue samples using microarray expression data (T S Furey et al, 2000 Bioinformatics) Support Vector Machine Classification of Microarray Gene Expression Data x.html CLASSIFYING MICROARRAY DATA USING SUPPORT VECTOR MACHINES
Classification with PAM and Random Forest
 5/7/2007 Classification with PAM and Random Forest Markus Ruschhaupt Practical Microarray Analysis 2007 - Regensburg Two roads to classification Given: patient profiles already diagnosed by an expert.
5/7/2007 Classification with PAM and Random Forest Markus Ruschhaupt Practical Microarray Analysis 2007 - Regensburg Two roads to classification Given: patient profiles already diagnosed by an expert.
CS6375: Machine Learning Gautam Kunapuli. Mid-Term Review
 Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Classification by Nearest Shrunken Centroids and Support Vector Machines
 Classification by Nearest Shrunken Centroids and Support Vector Machines Florian Markowetz florian.markowetz@molgen.mpg.de Max Planck Institute for Molecular Genetics, Computational Diagnostics Group,
Classification by Nearest Shrunken Centroids and Support Vector Machines Florian Markowetz florian.markowetz@molgen.mpg.de Max Planck Institute for Molecular Genetics, Computational Diagnostics Group,
Topics in Machine Learning
 Topics in Machine Learning Gilad Lerman School of Mathematics University of Minnesota Text/slides stolen from G. James, D. Witten, T. Hastie, R. Tibshirani and A. Ng Machine Learning - Motivation Arthur
Topics in Machine Learning Gilad Lerman School of Mathematics University of Minnesota Text/slides stolen from G. James, D. Witten, T. Hastie, R. Tibshirani and A. Ng Machine Learning - Motivation Arthur
Supervised Learning Classification Algorithms Comparison
 Supervised Learning Classification Algorithms Comparison Aditya Singh Rathore B.Tech, J.K. Lakshmipat University -------------------------------------------------------------***---------------------------------------------------------
Supervised Learning Classification Algorithms Comparison Aditya Singh Rathore B.Tech, J.K. Lakshmipat University -------------------------------------------------------------***---------------------------------------------------------
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
The Curse of Dimensionality
 The Curse of Dimensionality ACAS 2002 p1/66 Curse of Dimensionality The basic idea of the curse of dimensionality is that high dimensional data is difficult to work with for several reasons: Adding more
The Curse of Dimensionality ACAS 2002 p1/66 Curse of Dimensionality The basic idea of the curse of dimensionality is that high dimensional data is difficult to work with for several reasons: Adding more
Classification. Vladimir Curic. Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University
 Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
CS 229 Midterm Review
 CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
Preface to the Second Edition. Preface to the First Edition. 1 Introduction 1
 Preface to the Second Edition Preface to the First Edition vii xi 1 Introduction 1 2 Overview of Supervised Learning 9 2.1 Introduction... 9 2.2 Variable Types and Terminology... 9 2.3 Two Simple Approaches
Preface to the Second Edition Preface to the First Edition vii xi 1 Introduction 1 2 Overview of Supervised Learning 9 2.1 Introduction... 9 2.2 Variable Types and Terminology... 9 2.3 Two Simple Approaches
Machine Learning in Biology
 Università degli studi di Padova Machine Learning in Biology Luca Silvestrin (Dottorando, XXIII ciclo) Supervised learning Contents Class-conditional probability density Linear and quadratic discriminant
Università degli studi di Padova Machine Learning in Biology Luca Silvestrin (Dottorando, XXIII ciclo) Supervised learning Contents Class-conditional probability density Linear and quadratic discriminant
10/14/2017. Dejan Sarka. Anomaly Detection. Sponsors
 Dejan Sarka Anomaly Detection Sponsors About me SQL Server MVP (17 years) and MCT (20 years) 25 years working with SQL Server Authoring 16 th book Authoring many courses, articles Agenda Introduction Simple
Dejan Sarka Anomaly Detection Sponsors About me SQL Server MVP (17 years) and MCT (20 years) 25 years working with SQL Server Authoring 16 th book Authoring many courses, articles Agenda Introduction Simple
Data Mining and Analytics
 Data Mining and Analytics Aik Choon Tan, Ph.D. Associate Professor of Bioinformatics Division of Medical Oncology Department of Medicine aikchoon.tan@ucdenver.edu 9/22/2017 http://tanlab.ucdenver.edu/labhomepage/teaching/bsbt6111/
Data Mining and Analytics Aik Choon Tan, Ph.D. Associate Professor of Bioinformatics Division of Medical Oncology Department of Medicine aikchoon.tan@ucdenver.edu 9/22/2017 http://tanlab.ucdenver.edu/labhomepage/teaching/bsbt6111/
Applying Supervised Learning
 Applying Supervised Learning When to Consider Supervised Learning A supervised learning algorithm takes a known set of input data (the training set) and known responses to the data (output), and trains
Applying Supervised Learning When to Consider Supervised Learning A supervised learning algorithm takes a known set of input data (the training set) and known responses to the data (output), and trains
ADVANCED CLASSIFICATION TECHNIQUES
 Admin ML lab next Monday Project proposals: Sunday at 11:59pm ADVANCED CLASSIFICATION TECHNIQUES David Kauchak CS 159 Fall 2014 Project proposal presentations Machine Learning: A Geometric View 1 Apples
Admin ML lab next Monday Project proposals: Sunday at 11:59pm ADVANCED CLASSIFICATION TECHNIQUES David Kauchak CS 159 Fall 2014 Project proposal presentations Machine Learning: A Geometric View 1 Apples
CANCER PREDICTION USING PATTERN CLASSIFICATION OF MICROARRAY DATA. By: Sudhir Madhav Rao &Vinod Jayakumar Instructor: Dr.
 CANCER PREDICTION USING PATTERN CLASSIFICATION OF MICROARRAY DATA By: Sudhir Madhav Rao &Vinod Jayakumar Instructor: Dr. Michael Nechyba 1. Abstract The objective of this project is to apply well known
CANCER PREDICTION USING PATTERN CLASSIFICATION OF MICROARRAY DATA By: Sudhir Madhav Rao &Vinod Jayakumar Instructor: Dr. Michael Nechyba 1. Abstract The objective of this project is to apply well known
Performance Evaluation of Various Classification Algorithms
 Performance Evaluation of Various Classification Algorithms Shafali Deora Amritsar College of Engineering & Technology, Punjab Technical University -----------------------------------------------------------***----------------------------------------------------------
Performance Evaluation of Various Classification Algorithms Shafali Deora Amritsar College of Engineering & Technology, Punjab Technical University -----------------------------------------------------------***----------------------------------------------------------
Lecture 11: Classification
 Lecture 11: Classification 1 2009-04-28 Patrik Malm Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University 2 Reading instructions Chapters for this lecture 12.1 12.2 in
Lecture 11: Classification 1 2009-04-28 Patrik Malm Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University 2 Reading instructions Chapters for this lecture 12.1 12.2 in
Machine Learning. Chao Lan
 Machine Learning Chao Lan Machine Learning Prediction Models Regression Model - linear regression (least square, ridge regression, Lasso) Classification Model - naive Bayes, logistic regression, Gaussian
Machine Learning Chao Lan Machine Learning Prediction Models Regression Model - linear regression (least square, ridge regression, Lasso) Classification Model - naive Bayes, logistic regression, Gaussian
Artificial Intelligence. Programming Styles
 Artificial Intelligence Intro to Machine Learning Programming Styles Standard CS: Explicitly program computer to do something Early AI: Derive a problem description (state) and use general algorithms to
Artificial Intelligence Intro to Machine Learning Programming Styles Standard CS: Explicitly program computer to do something Early AI: Derive a problem description (state) and use general algorithms to
The supclust Package
 The supclust Package May 18, 2005 Title Supervised Clustering of Genes Version 1.0-5 Date 2005-05-18 Methodology for Supervised Grouping of Predictor Variables Author Marcel Dettling and Martin Maechler
The supclust Package May 18, 2005 Title Supervised Clustering of Genes Version 1.0-5 Date 2005-05-18 Methodology for Supervised Grouping of Predictor Variables Author Marcel Dettling and Martin Maechler
Bioinformatics - Lecture 07
 Bioinformatics - Lecture 07 Bioinformatics Clusters and networks Martin Saturka http://www.bioplexity.org/lectures/ EBI version 0.4 Creative Commons Attribution-Share Alike 2.5 License Learning on profiles
Bioinformatics - Lecture 07 Bioinformatics Clusters and networks Martin Saturka http://www.bioplexity.org/lectures/ EBI version 0.4 Creative Commons Attribution-Share Alike 2.5 License Learning on profiles
Clustering and Classification. Basic principles of clustering. Clustering. Classification
 Classification Clustering and Classification Task: assign objects to classes (groups) on the basis of measurements made on the objects Jean Yee Hwa Yang University of California, San Francisco http://www.biostat.ucsf.edu/jean/
Classification Clustering and Classification Task: assign objects to classes (groups) on the basis of measurements made on the objects Jean Yee Hwa Yang University of California, San Francisco http://www.biostat.ucsf.edu/jean/
Computational Statistics The basics of maximum likelihood estimation, Bayesian estimation, object recognitions
 Computational Statistics The basics of maximum likelihood estimation, Bayesian estimation, object recognitions Thomas Giraud Simon Chabot October 12, 2013 Contents 1 Discriminant analysis 3 1.1 Main idea................................
Computational Statistics The basics of maximum likelihood estimation, Bayesian estimation, object recognitions Thomas Giraud Simon Chabot October 12, 2013 Contents 1 Discriminant analysis 3 1.1 Main idea................................
Exploratory data analysis for microarrays
 Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
MTTS1 Dimensionality Reduction and Visualization Spring 2014 Jaakko Peltonen
 MTTS1 Dimensionality Reduction and Visualization Spring 2014 Jaakko Peltonen Lecture 2: Feature selection Feature Selection feature selection (also called variable selection): choosing k < d important
MTTS1 Dimensionality Reduction and Visualization Spring 2014 Jaakko Peltonen Lecture 2: Feature selection Feature Selection feature selection (also called variable selection): choosing k < d important
Problems 1 and 5 were graded by Amin Sorkhei, Problems 2 and 3 by Johannes Verwijnen and Problem 4 by Jyrki Kivinen. Entropy(D) = Gini(D) = 1
 = Gini(D) = 1") Problems and were graded by Amin Sorkhei, Problems and 3 by Johannes Verwijnen and Problem by Jyrki Kivinen.. [ points] (a) Gini index and Entropy are impurity measures which can be used in order to measure
Problems and were graded by Amin Sorkhei, Problems and 3 by Johannes Verwijnen and Problem by Jyrki Kivinen.. [ points] (a) Gini index and Entropy are impurity measures which can be used in order to measure
INF 4300 Classification III Anne Solberg The agenda today:
 INF 4300 Classification III Anne Solberg 28.10.15 The agenda today: More on estimating classifier accuracy Curse of dimensionality and simple feature selection knn-classification K-means clustering 28.10.15
INF 4300 Classification III Anne Solberg 28.10.15 The agenda today: More on estimating classifier accuracy Curse of dimensionality and simple feature selection knn-classification K-means clustering 28.10.15
Generative and discriminative classification techniques
 Generative and discriminative classification techniques Machine Learning and Category Representation 013-014 Jakob Verbeek, December 13+0, 013 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.13.14
Generative and discriminative classification techniques Machine Learning and Category Representation 013-014 Jakob Verbeek, December 13+0, 013 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.13.14
Machine Learning. Topic 5: Linear Discriminants. Bryan Pardo, EECS 349 Machine Learning, 2013
 Machine Learning Topic 5: Linear Discriminants Bryan Pardo, EECS 349 Machine Learning, 2013 Thanks to Mark Cartwright for his extensive contributions to these slides Thanks to Alpaydin, Bishop, and Duda/Hart/Stork
Machine Learning Topic 5: Linear Discriminants Bryan Pardo, EECS 349 Machine Learning, 2013 Thanks to Mark Cartwright for his extensive contributions to these slides Thanks to Alpaydin, Bishop, and Duda/Hart/Stork
Pattern Recognition. Kjell Elenius. Speech, Music and Hearing KTH. March 29, 2007 Speech recognition
 Pattern Recognition Kjell Elenius Speech, Music and Hearing KTH March 29, 2007 Speech recognition 2007 1 Ch 4. Pattern Recognition 1(3) Bayes Decision Theory Minimum-Error-Rate Decision Rules Discriminant
Pattern Recognition Kjell Elenius Speech, Music and Hearing KTH March 29, 2007 Speech recognition 2007 1 Ch 4. Pattern Recognition 1(3) Bayes Decision Theory Minimum-Error-Rate Decision Rules Discriminant
Supervised Learning (contd) Linear Separation. Mausam (based on slides by UW-AI faculty)
 Linear Separation. Mausam (based on slides by UW-AI faculty)") Supervised Learning (contd) Linear Separation Mausam (based on slides by UW-AI faculty) Images as Vectors Binary handwritten characters Treat an image as a highdimensional vector (e.g., by reading pixel
Supervised Learning (contd) Linear Separation Mausam (based on slides by UW-AI faculty) Images as Vectors Binary handwritten characters Treat an image as a highdimensional vector (e.g., by reading pixel
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Naïve Bayes for text classification
 Road Map Basic concepts Decision tree induction Evaluation of classifiers Rule induction Classification using association rules Naïve Bayesian classification Naïve Bayes for text classification Support
Road Map Basic concepts Decision tree induction Evaluation of classifiers Rule induction Classification using association rules Naïve Bayesian classification Naïve Bayes for text classification Support
Support Vector Machines: Brief Overview" November 2011 CPSC 352
 Support Vector Machines: Brief Overview" Outline Microarray Example Support Vector Machines (SVMs) Software: libsvm A Baseball Example with libsvm Classifying Cancer Tissue: The ALL/AML Dataset Golub et
Support Vector Machines: Brief Overview" Outline Microarray Example Support Vector Machines (SVMs) Software: libsvm A Baseball Example with libsvm Classifying Cancer Tissue: The ALL/AML Dataset Golub et
Data Mining: Concepts and Techniques. Chapter 9 Classification: Support Vector Machines. Support Vector Machines (SVMs)
") Data Mining: Concepts and Techniques Chapter 9 Classification: Support Vector Machines 1 Support Vector Machines (SVMs) SVMs are a set of related supervised learning methods used for classification Based
Data Mining: Concepts and Techniques Chapter 9 Classification: Support Vector Machines 1 Support Vector Machines (SVMs) SVMs are a set of related supervised learning methods used for classification Based
Using Machine Learning to Optimize Storage Systems
 Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Classification. Vladimir Curic. Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University
 Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Introduction to Pattern Recognition Part II. Selim Aksoy Bilkent University Department of Computer Engineering
 Introduction to Pattern Recognition Part II Selim Aksoy Bilkent University Department of Computer Engineering saksoy@cs.bilkent.edu.tr RETINA Pattern Recognition Tutorial, Summer 2005 Overview Statistical
Introduction to Pattern Recognition Part II Selim Aksoy Bilkent University Department of Computer Engineering saksoy@cs.bilkent.edu.tr RETINA Pattern Recognition Tutorial, Summer 2005 Overview Statistical
Clustering. Mihaela van der Schaar. January 27, Department of Engineering Science University of Oxford
 Department of Engineering Science University of Oxford January 27, 2017 Many datasets consist of multiple heterogeneous subsets. Cluster analysis: Given an unlabelled data, want algorithms that automatically
Department of Engineering Science University of Oxford January 27, 2017 Many datasets consist of multiple heterogeneous subsets. Cluster analysis: Given an unlabelled data, want algorithms that automatically
Content-based image and video analysis. Machine learning
 Content-based image and video analysis Machine learning for multimedia retrieval 04.05.2009 What is machine learning? Some problems are very hard to solve by writing a computer program by hand Almost all
Content-based image and video analysis Machine learning for multimedia retrieval 04.05.2009 What is machine learning? Some problems are very hard to solve by writing a computer program by hand Almost all
CSE 158. Web Mining and Recommender Systems. Midterm recap
 CSE 158 Web Mining and Recommender Systems Midterm recap Midterm on Wednesday! 5:10 pm 6:10 pm Closed book but I ll provide a similar level of basic info as in the last page of previous midterms CSE 158
CSE 158 Web Mining and Recommender Systems Midterm recap Midterm on Wednesday! 5:10 pm 6:10 pm Closed book but I ll provide a similar level of basic info as in the last page of previous midterms CSE 158
Statistical Analysis of Metabolomics Data. Xiuxia Du Department of Bioinformatics & Genomics University of North Carolina at Charlotte
 Statistical Analysis of Metabolomics Data Xiuxia Du Department of Bioinformatics & Genomics University of North Carolina at Charlotte Outline Introduction Data pre-treatment 1. Normalization 2. Centering,
Statistical Analysis of Metabolomics Data Xiuxia Du Department of Bioinformatics & Genomics University of North Carolina at Charlotte Outline Introduction Data pre-treatment 1. Normalization 2. Centering,
Clustering. CS294 Practical Machine Learning Junming Yin 10/09/06
 Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Problem 1: Complexity of Update Rules for Logistic Regression
 Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox January 16 th, 2014 1
Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox January 16 th, 2014 1
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
Evaluation of different biological data and computational classification methods for use in protein interaction prediction.
 Evaluation of different biological data and computational classification methods for use in protein interaction prediction. Yanjun Qi, Ziv Bar-Joseph, Judith Klein-Seetharaman Protein 2006 Motivation Correctly
Evaluation of different biological data and computational classification methods for use in protein interaction prediction. Yanjun Qi, Ziv Bar-Joseph, Judith Klein-Seetharaman Protein 2006 Motivation Correctly
Support Vector Machines
 Support Vector Machines Chapter 9 Chapter 9 1 / 50 1 91 Maximal margin classifier 2 92 Support vector classifiers 3 93 Support vector machines 4 94 SVMs with more than two classes 5 95 Relationshiop to
Support Vector Machines Chapter 9 Chapter 9 1 / 50 1 91 Maximal margin classifier 2 92 Support vector classifiers 3 93 Support vector machines 4 94 SVMs with more than two classes 5 95 Relationshiop to
Stat 602X Exam 2 Spring 2011
 Stat 60X Exam Spring 0 I have neither given nor received unauthorized assistance on this exam. Name Signed Date Name Printed . Below is a small p classification training set (for classes) displayed in
Stat 60X Exam Spring 0 I have neither given nor received unauthorized assistance on this exam. Name Signed Date Name Printed . Below is a small p classification training set (for classes) displayed in
Based on Raymond J. Mooney s slides
 Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Decision Trees Dr. G. Bharadwaja Kumar VIT Chennai
 Decision Trees Decision Tree Decision Trees (DTs) are a nonparametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target
Decision Trees Decision Tree Decision Trees (DTs) are a nonparametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target
DATA MINING LECTURE 10B. Classification k-nearest neighbor classifier Naïve Bayes Logistic Regression Support Vector Machines
 DATA MINING LECTURE 10B Classification k-nearest neighbor classifier Naïve Bayes Logistic Regression Support Vector Machines NEAREST NEIGHBOR CLASSIFICATION 10 10 Illustrating Classification Task Tid Attrib1
DATA MINING LECTURE 10B Classification k-nearest neighbor classifier Naïve Bayes Logistic Regression Support Vector Machines NEAREST NEIGHBOR CLASSIFICATION 10 10 Illustrating Classification Task Tid Attrib1
Machine Learning: Think Big and Parallel
 Day 1 Inderjit S. Dhillon Dept of Computer Science UT Austin CS395T: Topics in Multicore Programming Oct 1, 2013 Outline Scikit-learn: Machine Learning in Python Supervised Learning day1 Regression: Least
Day 1 Inderjit S. Dhillon Dept of Computer Science UT Austin CS395T: Topics in Multicore Programming Oct 1, 2013 Outline Scikit-learn: Machine Learning in Python Supervised Learning day1 Regression: Least
Contents. Preface to the Second Edition
 Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
Overview Citation. ML Introduction. Overview Schedule. ML Intro Dataset. Introduction to Semi-Supervised Learning Review 10/4/2010
 INFORMATICS SEMINAR SEPT. 27 & OCT. 4, 2010 Introduction to Semi-Supervised Learning Review 2 Overview Citation X. Zhu and A.B. Goldberg, Introduction to Semi- Supervised Learning, Morgan & Claypool Publishers,
INFORMATICS SEMINAR SEPT. 27 & OCT. 4, 2010 Introduction to Semi-Supervised Learning Review 2 Overview Citation X. Zhu and A.B. Goldberg, Introduction to Semi- Supervised Learning, Morgan & Claypool Publishers,
9/29/13. Outline Data mining tasks. Clustering algorithms. Applications of clustering in biology
 9/9/ I9 Introduction to Bioinformatics, Clustering algorithms Yuzhen Ye (yye@indiana.edu) School of Informatics & Computing, IUB Outline Data mining tasks Predictive tasks vs descriptive tasks Example
9/9/ I9 Introduction to Bioinformatics, Clustering algorithms Yuzhen Ye (yye@indiana.edu) School of Informatics & Computing, IUB Outline Data mining tasks Predictive tasks vs descriptive tasks Example
Model Assessment and Selection. Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer
 Model Assessment and Selection Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer 1 Model Training data Testing data Model Testing error rate Training error
Model Assessment and Selection Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer 1 Model Training data Testing data Model Testing error rate Training error
Classification Algorithms in Data Mining
 August 9th, 2016 Suhas Mallesh Yash Thakkar Ashok Choudhary CIS660 Data Mining and Big Data Processing -Dr. Sunnie S. Chung Classification Algorithms in Data Mining Deciding on the classification algorithms
August 9th, 2016 Suhas Mallesh Yash Thakkar Ashok Choudhary CIS660 Data Mining and Big Data Processing -Dr. Sunnie S. Chung Classification Algorithms in Data Mining Deciding on the classification algorithms
Data Analysis 3. Support Vector Machines. Jan Platoš October 30, 2017
 Data Analysis 3 Support Vector Machines Jan Platoš October 30, 2017 Department of Computer Science Faculty of Electrical Engineering and Computer Science VŠB - Technical University of Ostrava Table of
Data Analysis 3 Support Vector Machines Jan Platoš October 30, 2017 Department of Computer Science Faculty of Electrical Engineering and Computer Science VŠB - Technical University of Ostrava Table of
Classification: Linear Discriminant Functions
 Classification: Linear Discriminant Functions CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Discriminant functions Linear Discriminant functions
Classification: Linear Discriminant Functions CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Discriminant functions Linear Discriminant functions
Support Vector Machines + Classification for IR
 Support Vector Machines + Classification for IR Pierre Lison University of Oslo, Dep. of Informatics INF3800: Søketeknologi April 30, 2014 Outline of the lecture Recap of last week Support Vector Machines
Support Vector Machines + Classification for IR Pierre Lison University of Oslo, Dep. of Informatics INF3800: Søketeknologi April 30, 2014 Outline of the lecture Recap of last week Support Vector Machines
Clustering and Visualisation of Data
 Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Classification by Support Vector Machines
 Classification by Support Vector Machines Florian Markowetz Max-Planck-Institute for Molecular Genetics Computational Molecular Biology Berlin Practical DNA Microarray Analysis 2003 1 Overview I II III
Classification by Support Vector Machines Florian Markowetz Max-Planck-Institute for Molecular Genetics Computational Molecular Biology Berlin Practical DNA Microarray Analysis 2003 1 Overview I II III
6.034 Quiz 2, Spring 2005
 6.034 Quiz 2, Spring 2005 Open Book, Open Notes Name: Problem 1 (13 pts) 2 (8 pts) 3 (7 pts) 4 (9 pts) 5 (8 pts) 6 (16 pts) 7 (15 pts) 8 (12 pts) 9 (12 pts) Total (100 pts) Score 1 1 Decision Trees (13
6.034 Quiz 2, Spring 2005 Open Book, Open Notes Name: Problem 1 (13 pts) 2 (8 pts) 3 (7 pts) 4 (9 pts) 5 (8 pts) 6 (16 pts) 7 (15 pts) 8 (12 pts) 9 (12 pts) Total (100 pts) Score 1 1 Decision Trees (13
Machine Learning. Nonparametric methods for Classification. Eric Xing , Fall Lecture 2, September 12, 2016
 Machine Learning 10-701, Fall 2016 Nonparametric methods for Classification Eric Xing Lecture 2, September 12, 2016 Reading: 1 Classification Representing data: Hypothesis (classifier) 2 Clustering 3 Supervised
Machine Learning 10-701, Fall 2016 Nonparametric methods for Classification Eric Xing Lecture 2, September 12, 2016 Reading: 1 Classification Representing data: Hypothesis (classifier) 2 Clustering 3 Supervised
Support Vector Machines.
 Support Vector Machines srihari@buffalo.edu SVM Discussion Overview 1. Overview of SVMs 2. Margin Geometry 3. SVM Optimization 4. Overlapping Distributions 5. Relationship to Logistic Regression 6. Dealing
Support Vector Machines srihari@buffalo.edu SVM Discussion Overview 1. Overview of SVMs 2. Margin Geometry 3. SVM Optimization 4. Overlapping Distributions 5. Relationship to Logistic Regression 6. Dealing
MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018
![MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018](/thumbs/77/76295965.jpg "MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018") MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
10-701/15-781, Fall 2006, Final
 -7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
-7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
The exam is closed book, closed notes except your one-page (two-sided) cheat sheet.
 cheat sheet.") CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
Machine Learning / Jan 27, 2010
 Revisiting Logistic Regression & Naïve Bayes Aarti Singh Machine Learning 10-701/15-781 Jan 27, 2010 Generative and Discriminative Classifiers Training classifiers involves learning a mapping f: X -> Y,
Revisiting Logistic Regression & Naïve Bayes Aarti Singh Machine Learning 10-701/15-781 Jan 27, 2010 Generative and Discriminative Classifiers Training classifiers involves learning a mapping f: X -> Y,
Function Algorithms: Linear Regression, Logistic Regression
 CS 4510/9010: Applied Machine Learning 1 Function Algorithms: Linear Regression, Logistic Regression Paula Matuszek Fall, 2016 Some of these slides originated from Andrew Moore Tutorials, at http://www.cs.cmu.edu/~awm/tutorials.html
CS 4510/9010: Applied Machine Learning 1 Function Algorithms: Linear Regression, Logistic Regression Paula Matuszek Fall, 2016 Some of these slides originated from Andrew Moore Tutorials, at http://www.cs.cmu.edu/~awm/tutorials.html
Classifiers and Detection. D.A. Forsyth
 Classifiers and Detection D.A. Forsyth Classifiers Take a measurement x, predict a bit (yes/no; 1/-1; 1/0; etc) Detection with a classifier Search all windows at relevant scales Prepare features Classify
Classifiers and Detection D.A. Forsyth Classifiers Take a measurement x, predict a bit (yes/no; 1/-1; 1/0; etc) Detection with a classifier Search all windows at relevant scales Prepare features Classify
Support Vector Machines
 Support Vector Machines RBF-networks Support Vector Machines Good Decision Boundary Optimization Problem Soft margin Hyperplane Non-linear Decision Boundary Kernel-Trick Approximation Accurancy Overtraining
Support Vector Machines RBF-networks Support Vector Machines Good Decision Boundary Optimization Problem Soft margin Hyperplane Non-linear Decision Boundary Kernel-Trick Approximation Accurancy Overtraining
Lecture on Modeling Tools for Clustering & Regression
 Lecture on Modeling Tools for Clustering & Regression CS 590.21 Analysis and Modeling of Brain Networks Department of Computer Science University of Crete Data Clustering Overview Organizing data into
Lecture on Modeling Tools for Clustering & Regression CS 590.21 Analysis and Modeling of Brain Networks Department of Computer Science University of Crete Data Clustering Overview Organizing data into
Multi-label Classification. Jingzhou Liu Dec
 Multi-label Classification Jingzhou Liu Dec. 6 2016 Introduction Multi-class problem, Training data (x $, y $ ) ( ), x $ X R., y $ Y = 1,2,, L Learn a mapping f: X Y Each instance x $ is associated with
Multi-label Classification Jingzhou Liu Dec. 6 2016 Introduction Multi-class problem, Training data (x $, y $ ) ( ), x $ X R., y $ Y = 1,2,, L Learn a mapping f: X Y Each instance x $ is associated with
The exam is closed book, closed notes except your one-page cheat sheet.
 CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
Supervised Learning for Image Segmentation
 Supervised Learning for Image Segmentation Raphael Meier 06.10.2016 Raphael Meier MIA 2016 06.10.2016 1 / 52 References A. Ng, Machine Learning lecture, Stanford University. A. Criminisi, J. Shotton, E.
Supervised Learning for Image Segmentation Raphael Meier 06.10.2016 Raphael Meier MIA 2016 06.10.2016 1 / 52 References A. Ng, Machine Learning lecture, Stanford University. A. Criminisi, J. Shotton, E.
Introduction to Machine Learning CANB 7640
 Introduction to Machine Learning CANB 7640 Aik Choon Tan, Ph.D. Associate Professor of Bioinformatics Division of Medical Oncology Department of Medicine aikchoon.tan@ucdenver.edu 9/5/2017 http://tanlab.ucdenver.edu/labhomepage/teaching/canb7640/
Introduction to Machine Learning CANB 7640 Aik Choon Tan, Ph.D. Associate Professor of Bioinformatics Division of Medical Oncology Department of Medicine aikchoon.tan@ucdenver.edu 9/5/2017 http://tanlab.ucdenver.edu/labhomepage/teaching/canb7640/
5 Learning hypothesis classes (16 points)
") 5 Learning hypothesis classes (16 points) Consider a classification problem with two real valued inputs. For each of the following algorithms, specify all of the separators below that it could have generated
5 Learning hypothesis classes (16 points) Consider a classification problem with two real valued inputs. For each of the following algorithms, specify all of the separators below that it could have generated
CIS 520, Machine Learning, Fall 2015: Assignment 7 Due: Mon, Nov 16, :59pm, PDF to Canvas [100 points]
![CIS 520, Machine Learning, Fall 2015: Assignment 7 Due: Mon, Nov 16, :59pm, PDF to Canvas [100 points]](/thumbs/89/100746783.jpg "CIS 520, Machine Learning, Fall 2015: Assignment 7 Due: Mon, Nov 16, :59pm, PDF to Canvas [100 points]") CIS 520, Machine Learning, Fall 2015: Assignment 7 Due: Mon, Nov 16, 2015. 11:59pm, PDF to Canvas [100 points] Instructions. Please write up your responses to the following problems clearly and concisely.
CIS 520, Machine Learning, Fall 2015: Assignment 7 Due: Mon, Nov 16, 2015. 11:59pm, PDF to Canvas [100 points] Instructions. Please write up your responses to the following problems clearly and concisely.
Large-Scale Lasso and Elastic-Net Regularized Generalized Linear Models
 Large-Scale Lasso and Elastic-Net Regularized Generalized Linear Models DB Tsai Steven Hillion Outline Introduction Linear / Nonlinear Classification Feature Engineering - Polynomial Expansion Big-data
Large-Scale Lasso and Elastic-Net Regularized Generalized Linear Models DB Tsai Steven Hillion Outline Introduction Linear / Nonlinear Classification Feature Engineering - Polynomial Expansion Big-data
Support Vector Machines
 Support Vector Machines RBF-networks Support Vector Machines Good Decision Boundary Optimization Problem Soft margin Hyperplane Non-linear Decision Boundary Kernel-Trick Approximation Accurancy Overtraining
Support Vector Machines RBF-networks Support Vector Machines Good Decision Boundary Optimization Problem Soft margin Hyperplane Non-linear Decision Boundary Kernel-Trick Approximation Accurancy Overtraining
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning
 COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
CSE4334/5334 DATA MINING
 CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
Lecture 7: Decision Trees
 Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
Practice EXAM: SPRING 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE
 Practice EXAM: SPRING 0 CS 6375 INSTRUCTOR: VIBHAV GOGATE The exam is closed book. You are allowed four pages of double sided cheat sheets. Answer the questions in the spaces provided on the question sheets.
Practice EXAM: SPRING 0 CS 6375 INSTRUCTOR: VIBHAV GOGATE The exam is closed book. You are allowed four pages of double sided cheat sheets. Answer the questions in the spaces provided on the question sheets.
Machine Learning Classifiers and Boosting
 Machine Learning Classifiers and Boosting Reading Ch 18.6-18.12, 20.1-20.3.2 Outline Different types of learning problems Different types of learning algorithms Supervised learning Decision trees Naïve
Machine Learning Classifiers and Boosting Reading Ch 18.6-18.12, 20.1-20.3.2 Outline Different types of learning problems Different types of learning algorithms Supervised learning Decision trees Naïve
What is machine learning?
 Machine learning, pattern recognition and statistical data modelling Lecture 12. The last lecture Coryn Bailer-Jones 1 What is machine learning? Data description and interpretation finding simpler relationship
Machine learning, pattern recognition and statistical data modelling Lecture 12. The last lecture Coryn Bailer-Jones 1 What is machine learning? Data description and interpretation finding simpler relationship
INF4820, Algorithms for AI and NLP: Hierarchical Clustering
 INF4820, Algorithms for AI and NLP: Hierarchical Clustering Erik Velldal University of Oslo Sept. 25, 2012 Agenda Topics we covered last week Evaluating classifiers Accuracy, precision, recall and F-score
INF4820, Algorithms for AI and NLP: Hierarchical Clustering Erik Velldal University of Oslo Sept. 25, 2012 Agenda Topics we covered last week Evaluating classifiers Accuracy, precision, recall and F-score
SVM Classification in -Arrays
 SVM Classification in -Arrays SVM classification and validation of cancer tissue samples using microarray expression data Furey et al, 2000 Special Topics in Bioinformatics, SS10 A. Regl, 7055213 What
SVM Classification in -Arrays SVM classification and validation of cancer tissue samples using microarray expression data Furey et al, 2000 Special Topics in Bioinformatics, SS10 A. Regl, 7055213 What
Unsupervised Learning
 Unsupervised Learning Learning without Class Labels (or correct outputs) Density Estimation Learn P(X) given training data for X Clustering Partition data into clusters Dimensionality Reduction Discover
Unsupervised Learning Learning without Class Labels (or correct outputs) Density Estimation Learn P(X) given training data for X Clustering Partition data into clusters Dimensionality Reduction Discover
Data Mining Practical Machine Learning Tools and Techniques. Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank
 Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank Implementation: Real machine learning schemes Decision trees Classification
Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank Implementation: Real machine learning schemes Decision trees Classification
Expectation Maximization (EM) and Gaussian Mixture Models
 and Gaussian Mixture Models") Expectation Maximization (EM) and Gaussian Mixture Models Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer 1 2 3 4 5 6 7 8 Unsupervised Learning Motivation
Expectation Maximization (EM) and Gaussian Mixture Models Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer 1 2 3 4 5 6 7 8 Unsupervised Learning Motivation
CPSC 340: Machine Learning and Data Mining. Kernel Trick Fall 2017
 CPSC 340: Machine Learning and Data Mining Kernel Trick Fall 2017 Admin Assignment 3: Due Friday. Midterm: Can view your exam during instructor office hours or after class this week. Digression: the other
CPSC 340: Machine Learning and Data Mining Kernel Trick Fall 2017 Admin Assignment 3: Due Friday. Midterm: Can view your exam during instructor office hours or after class this week. Digression: the other
Lecture 9: Support Vector Machines
 Lecture 9: Support Vector Machines William Webber (william@williamwebber.com) COMP90042, 2014, Semester 1, Lecture 8 What we ll learn in this lecture Support Vector Machines (SVMs) a highly robust and
Lecture 9: Support Vector Machines William Webber (william@williamwebber.com) COMP90042, 2014, Semester 1, Lecture 8 What we ll learn in this lecture Support Vector Machines (SVMs) a highly robust and
Evaluation Metrics. (Classifiers) CS229 Section Anand Avati
 CS229 Section Anand Avati") Evaluation Metrics (Classifiers) CS Section Anand Avati Topics Why? Binary classifiers Metrics Rank view Thresholding Confusion Matrix Point metrics: Accuracy, Precision, Recall / Sensitivity, Specificity,
Evaluation Metrics (Classifiers) CS Section Anand Avati Topics Why? Binary classifiers Metrics Rank view Thresholding Confusion Matrix Point metrics: Accuracy, Precision, Recall / Sensitivity, Specificity,
CPSC 340: Machine Learning and Data Mining. Principal Component Analysis Fall 2016
 CPSC 340: Machine Learning and Data Mining Principal Component Analysis Fall 2016 A2/Midterm: Admin Grades/solutions will be posted after class. Assignment 4: Posted, due November 14. Extra office hours:
CPSC 340: Machine Learning and Data Mining Principal Component Analysis Fall 2016 A2/Midterm: Admin Grades/solutions will be posted after class. Assignment 4: Posted, due November 14. Extra office hours:
MIT Samberg Center Cambridge, MA, USA. May 30 th June 2 nd, by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA
 Exploratory Machine Learning studies for disruption prediction on DIII-D by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA Presented at the 2 nd IAEA Technical Meeting on
Exploratory Machine Learning studies for disruption prediction on DIII-D by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA Presented at the 2 nd IAEA Technical Meeting on
Machine Learning Techniques for Data Mining
 Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Support Vector Machines
 Support Vector Machines About the Name... A Support Vector A training sample used to define classification boundaries in SVMs located near class boundaries Support Vector Machines Binary classifiers whose
Support Vector Machines About the Name... A Support Vector A training sample used to define classification boundaries in SVMs located near class boundaries Support Vector Machines Binary classifiers whose