Information theory methods for feature selection
|
|
|
- Loren Gilbert
- 6 years ago
- Views:
Transcription

1 Information theory methods for feature selection Zuzana Reitermanová Department of Computer Science Faculty of Mathematics and Physics Charles University in Prague, Czech Republic Diplomový a doktorandský seminář I
2 Outline 1 Introduction Feature extraction 2 Basic approaches Filter methods Wrapper methods Embedded methods Ensemble learning NIPS 2003 Challenge results 3 Conclusion References
3 Introduction Feature extraction Introduction Feature extraction An integral part of the data mining process. Two steps Feature construction
4 Introduction Feature extraction Introduction Feature extraction An integral part of the data mining process. Two steps Feature construction Preprocessing techniques standardization, normalization, discretization,... Part of the model (ANN),... Extraction of local features, signal enhancement,... Space-embedding methods PCA, MDS (Multidimensional scaling),... Non-linear expansions...
5 Why to employ feature selection techniques?... to select relevant and informative features.... to select features that are useful to build a good predictor Moreover General data reduction decrease storage requirements and increase algorithm speed Feature set reduction save resources in the next round of data collection or during utilization Performance improvement increase predictive accuracy Better data understanding... Advantage Selected features retain the original meanings.
 but relatively few instances ( 1000) microarrays, transaction logs, Web")
6 Current challenges in Unlabeled data Knowledge-oriented sparse learning Detection of feature dependencies / interaction Data-sets with a huge number of features ( ) but relatively few instances ( 1000) microarrays, transaction logs, Web data,...
 but relatively few instances ( 1000) microarrays, transaction logs, Web data,... NIPS 2003 challenge:")
7 Current challenges in Unlabeled data Knowledge-oriented sparse learning Detection of feature dependencies / interaction Data-sets with a huge number of features ( ) but relatively few instances ( 1000) microarrays, transaction logs, Web data,... NIPS 2003 challenge:
8 Basic approaches Basic approaches to Filter models Select features without optimizing the performance of a predictor Feature ranking methods provide a complete order of features using a relevance index Wrapper models Use a predictor as a black box to score the feature subsets Embedded models is a part of the model training Hybrid approaches
9 Filter methods Filter methods Feature ranking methods Provide a complete order of features using a relevance index. Each feature is treated separately. Many many various relevance indices Correlation coefficients linear dependencies: Pearson: R(i) = cov(x i,y ) Estimate: R(i) =... var(xi )var(y ) k (xi k x i )(y k ȳ) k (xi k x i ) 2 k (y k ȳ) 2 Classical test statistics T-test, F-test, χ 2 -test,... Single variable predictors (for example decision trees) risk of overfitting Information theoretic ranking criteria non-linear dependencies...
10 Filter methods Relevance Measures Based on Information Theory Mutual information (Shannon) Entropy: H(X ) = x p(x)log 2p(x)dx Conditional entropy: H(Y X ) = x p(x)( y p(y x)log 2p(y x))dx Mutual information: MI (Y, X ) = H(Y ) H(Y X ) = x y p(x, y)log 2 p(x,y) p(x)p(y) dxdy Is MI for classification Bayes optimal? H(Y X ) 1 log 2 K e bayes (X ) 0.5 H(Y X ) Kullback-Leibler divergence: MI (X, Y ) D KL (p(x, y) p(y)p(x)), where D KL (p 1 p 2 ) = x p 1(x)log 2 p 1 (x) p 2 (x) dx
11 Filter methods Relevance Measures Based on Information Theory Mutual information MI (Y, X ) = H(Y ) H(Y X ) = x y p(x, y)log 2 p(x,y) p(x)p(y) dxdy Problem: p(x), p(y), p(x, y) are unknown and hard to estimate from the data Classification with nominal or discrete features The simplest case we can estimate the probabilities from the frequency counts This introduces a negative bias Harder estimate with larger numbers of classes and feature values
12 Filter methods Relevance Measures Based on Information Theory Mutual information MI (Y, X ) = H(Y ) H(Y X ) = x y p(x, y)log 2 p(x,y) p(x)p(y) dxdy Problem: p(x), p(y), p(x, y) are unknown and hard to estimate from the data Classification with nominal or discrete features MI corresponds to the Information Gain (IG) for Decision trees Many modifications of IG (avoiding bias towards the multivalued features) MI (Y,X ) H(X ), Information Gain Ratio IGR(Y, X ) = Gini-index, J-measure,... Relaxed entropy measures are more straightforward to estimate: Renyi Entropy H α (X ) = 1 1 α log 2( x p(x)α )dx Parzen window approach
13 Filter methods Relevance Measures Based on Information Theory Mutual information MI (Y, X ) = H(Y ) H(Y X ) = x y p(x, y)log 2 p(x,y) p(x)p(y) dxdy Problem: p(x), p(y), p(x, y) are unknown and hard to estimate from the data Regression with continous features The hardest case Possible solutions: Histogram-based discretization: MI is overestimated depending on the quantization level MI should be overestimated the same for all features Approximation of the densities (Parzen window,...) Normal distribution correlation coefficient Computational complexity...
14 Filter methods Filter methods Feature ranking methods Advantages Simple and cheap methods, good empirical results. Fast and effective even in the case when the number of samples is smaller than the number of features. Can be used as preprocessing for more sophisticated methods.
15 Filter methods Filter methods Feature ranking methods Limitations Which relevance index is the best? Select a redundand subset of features. A variable individually relevant may not be useful because of redundancies. A variable useless by itself can be useful together with others:
16 Filter methods Mutual information for multivariate feature selection How to exclude both irrelevant and redundant features? Greedy selection of variables may not work well when there are dependencies among relevant variables. multivariate filter MI (Y, {X 1,..., X n }) is hard to approximate and compute approximative MIFS algorithm and its variants: MIFS algorithm 1 X = argmax X A MI (X, Y ), F {X }, A A \ X 2 Repeat until F is desired: X = argmax X A [MI (X, Y ) β X F MI (X, X )], F F {X }, A A \ X
17 Filter methods Multivariate relevance criteria Relief algorithms Based on the k-nearest neighbor algorithm. Relevance of features in the context of oders. Example of the ranking index (for multi-classification): R(X ) = K i k=1 x i x Mk (i) i K k=1 x i x Hk (i), where x Mk (i), k = 1,.., K K closest examples of the same class (nearest misses) in the original feature space x Hk (i), k = 1,.., K K closest examples of a different class (nearest hits) Popular algorithm, low bias (NIPS 2003)
18 Wrapper methods Wrapper methods Multivariate feature selection Maximize the relevance of a subset of features X : R(Y, X ) Use a predictor to measure the relevance (i.e. accuracy). A validation set must be used to achieve a useful estimate K-fold cross-validation,... A useful accuracy estimate on a separate testing set Employ a search strategy Exhaustive search Sequential search (growing/prunning),... Stochastiic search (Simulated Annealing, GA,...) Limitations Slower than the filter methods Tendency to overfitting discrepancy between the evaluation score and the ultimate performance No valid good empirical results (NIPS 2003) High variance of the results
19 Embedded methods Embedded methods depends on the predictive model (SVM, ANN, DT,...) is a part of the model training Forward selection methods Backward elimination methods Nested methods Optimization of scaling factors over the compact interval [0, 1] n regularization techniques Advantages and limitations Slower than the filter methods Tendency to overfitting if not enough data is available Outperform filter methods if enough data is available High variance of the results
20 Ensemble learning Ensemble learning Help the model-based (wrapper and embedded) methods fast, greedy and unstable base learners (Decision trees, Neural networks,...) Robust variable selection Improve feature set stability. Improve stability generalization stability. Parallel ensembles Variance reduction Bagging Random forest,... Serial ensembles Reduction of both bias and variance Boosting Gradient tree boosting,...
21 Ensemble learning Random forests for variable selection Random forest (RF) Select a number n N, N is the number of variables. Each decision tree is trained on a bootstrap sample (about two-third of the training set). Each decision tree has maximal depth and it is not pruned. At each node, n variables are randomly chosen and the best split is considered on these variables. CART algorithm Grow trees until no more generalization improvement.
22 Ensemble learning Random forests for variable selection Variable importance measure for RF Compute an importance index for each variable and for each tree M(X i, T j ) = t T j I G (x i, t), I G (x i, t) is the decrease of impurity due to an actual (or potential) split on variable x i : I G (x i, t) = I (t) p L I (t L ) p r I (t R ), Impurity for regression: I (t) = 1 N(t) s t (y s ȳ) 2 Impurity for classification: I (t) = Gini(t) = y i y j p t t i p j Compute the average importance of each variable over all trees: M(x i ) = 1 NT N T j=1 M(x i, T j ) Optimal number of features is selected by trying cut-off points
23 Ensemble learning Random forests for variable selection Advantages Avoid over-fitting in the case when there are more features than examples. More stable results.
24 NIPS 2003 Challenge results NIPS 2003 Challenge results Top ranking challengers used a combination of filters and embedded methods. Very good results of methods using only filters, even simple correlation coefficients. Search strategies were generally unsophisticated. The winner was a combination of Bayesian neural networks and Dirichlet diffusion trees Ensemble methods (Random trees) were on the second and third position.
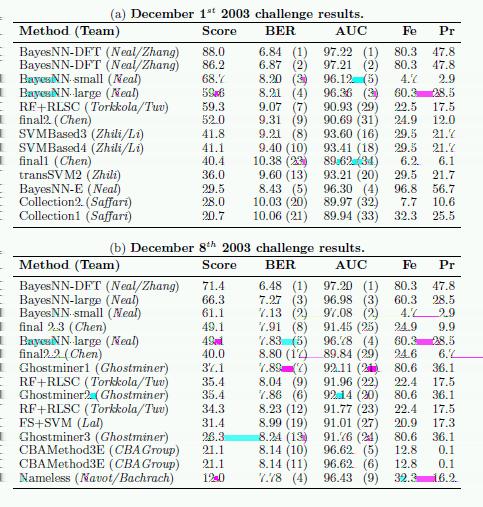
25 NIPS 2003 Challenge results NIPS 2003 Challenge results
26 NIPS 2003 Challenge results NIPS 2003 Challenge results Other (surprising) results Some of the top ranking challengers used almost all the probe features. Very good results for methods using only filters, even simple correlation coefficients. Non-linear classifiers outperformed the linear classifiers. They didn t overfit. The hyper-parameters are important. Several groups were using the same classifier (e.g. SVM) and reported significantly different results.
27 Conclusion Conclusion Many different approaches to feature selection Best results obtained by hybrid methods Advancing research Knowledge-based feature extraction Unsupervised feature extraction...
28 Conclusion References References Guyon, I. M., Gunn, S. R., Nikravesh, M. and Zadeh, L., eds., Feature Extraction, Foundations and Applications. Springer, Huan Liu, Hiroshi Motoda, Rudy Setiono, Zheng Zhao, Feature Selection: An Ever Evolving Frontier in Data Mining, in JMLR: Workshop and Conference Proceedings, volume 10, pages 4 13, 2010 Isabelle Guyon, André Elisseeff, An Introduction to Variable and Feature Selection, in JMLR: Workshop and Conference Proceedings, volume 3, pages , 2003 Journal of Machine Learning Research,
29 Conclusion References References R. Battiti, Using mutual information for selecting features in supervised neural net learning, in: Neural Networks, volume 5(4), pages , July Kari Torkkola, Feature extraction by non parametric mutual information maximization, in: The Journal of Machine Learning Research, volume 3, pages , Francois Fleuret, Fast Binary Feature Selection with Conditional Mutual Informationin, in: The Journal of Machine Learning Research, volume 4, pages , Kraskov, Alexander; Stögbauer, Harald; Grassberger, Peter, Estimating mutual information, Physical Review E, volume 69, Issue 6, 16 pages, 2004
Machine Learning Techniques for Data Mining
 Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Feature Selection. CE-725: Statistical Pattern Recognition Sharif University of Technology Spring Soleymani
 Feature Selection CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Dimensionality reduction Feature selection vs. feature extraction Filter univariate
Feature Selection CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Dimensionality reduction Feature selection vs. feature extraction Filter univariate
BENCHMARKING ATTRIBUTE SELECTION TECHNIQUES FOR MICROARRAY DATA
 BENCHMARKING ATTRIBUTE SELECTION TECHNIQUES FOR MICROARRAY DATA S. DeepaLakshmi 1 and T. Velmurugan 2 1 Bharathiar University, Coimbatore, India 2 Department of Computer Science, D. G. Vaishnav College,
BENCHMARKING ATTRIBUTE SELECTION TECHNIQUES FOR MICROARRAY DATA S. DeepaLakshmi 1 and T. Velmurugan 2 1 Bharathiar University, Coimbatore, India 2 Department of Computer Science, D. G. Vaishnav College,
Slides for Data Mining by I. H. Witten and E. Frank
 Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Contents. Preface to the Second Edition
 Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
MTTS1 Dimensionality Reduction and Visualization Spring 2014 Jaakko Peltonen
 MTTS1 Dimensionality Reduction and Visualization Spring 2014 Jaakko Peltonen Lecture 2: Feature selection Feature Selection feature selection (also called variable selection): choosing k < d important
MTTS1 Dimensionality Reduction and Visualization Spring 2014 Jaakko Peltonen Lecture 2: Feature selection Feature Selection feature selection (also called variable selection): choosing k < d important
Supervised Learning for Image Segmentation
 Supervised Learning for Image Segmentation Raphael Meier 06.10.2016 Raphael Meier MIA 2016 06.10.2016 1 / 52 References A. Ng, Machine Learning lecture, Stanford University. A. Criminisi, J. Shotton, E.
Supervised Learning for Image Segmentation Raphael Meier 06.10.2016 Raphael Meier MIA 2016 06.10.2016 1 / 52 References A. Ng, Machine Learning lecture, Stanford University. A. Criminisi, J. Shotton, E.
3 Feature Selection & Feature Extraction
 3 Feature Selection & Feature Extraction Overview: 3.1 Introduction 3.2 Feature Extraction 3.3 Feature Selection 3.3.1 Max-Dependency, Max-Relevance, Min-Redundancy 3.3.2 Relevance Filter 3.3.3 Redundancy
3 Feature Selection & Feature Extraction Overview: 3.1 Introduction 3.2 Feature Extraction 3.3 Feature Selection 3.3.1 Max-Dependency, Max-Relevance, Min-Redundancy 3.3.2 Relevance Filter 3.3.3 Redundancy
Forward Feature Selection Using Residual Mutual Information
 Forward Feature Selection Using Residual Mutual Information Erik Schaffernicht, Christoph Möller, Klaus Debes and Horst-Michael Gross Ilmenau University of Technology - Neuroinformatics and Cognitive Robotics
Forward Feature Selection Using Residual Mutual Information Erik Schaffernicht, Christoph Möller, Klaus Debes and Horst-Michael Gross Ilmenau University of Technology - Neuroinformatics and Cognitive Robotics
Variable Selection 6.783, Biomedical Decision Support
 6.783, Biomedical Decision Support (lrosasco@mit.edu) Department of Brain and Cognitive Science- MIT November 2, 2009 About this class Why selecting variables Approaches to variable selection Sparsity-based
6.783, Biomedical Decision Support (lrosasco@mit.edu) Department of Brain and Cognitive Science- MIT November 2, 2009 About this class Why selecting variables Approaches to variable selection Sparsity-based
Classification. Slide sources:
 Classification Slide sources: Gideon Dror, Academic College of TA Yaffo Nathan Ifill, Leicester MA4102 Data Mining and Neural Networks Andrew Moore, CMU : http://www.cs.cmu.edu/~awm/tutorials 1 Outline
Classification Slide sources: Gideon Dror, Academic College of TA Yaffo Nathan Ifill, Leicester MA4102 Data Mining and Neural Networks Andrew Moore, CMU : http://www.cs.cmu.edu/~awm/tutorials 1 Outline
Feature Selection. Department Biosysteme Karsten Borgwardt Data Mining Course Basel Fall Semester / 262
 Feature Selection Department Biosysteme Karsten Borgwardt Data Mining Course Basel Fall Semester 2016 239 / 262 What is Feature Selection? Department Biosysteme Karsten Borgwardt Data Mining Course Basel
Feature Selection Department Biosysteme Karsten Borgwardt Data Mining Course Basel Fall Semester 2016 239 / 262 What is Feature Selection? Department Biosysteme Karsten Borgwardt Data Mining Course Basel
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
Decision Tree CE-717 : Machine Learning Sharif University of Technology
 Decision Tree CE-717 : Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Some slides have been adapted from: Prof. Tom Mitchell Decision tree Approximating functions of usually discrete
Decision Tree CE-717 : Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Some slides have been adapted from: Prof. Tom Mitchell Decision tree Approximating functions of usually discrete
Random Forest A. Fornaser
 Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
8. Tree-based approaches
 Foundations of Machine Learning École Centrale Paris Fall 2015 8. Tree-based approaches Chloé-Agathe Azencott Centre for Computational Biology, Mines ParisTech chloe agathe.azencott@mines paristech.fr
Foundations of Machine Learning École Centrale Paris Fall 2015 8. Tree-based approaches Chloé-Agathe Azencott Centre for Computational Biology, Mines ParisTech chloe agathe.azencott@mines paristech.fr
7. Boosting and Bagging Bagging
 Group Prof. Daniel Cremers 7. Boosting and Bagging Bagging Bagging So far: Boosting as an ensemble learning method, i.e.: a combination of (weak) learners A different way to combine classifiers is known
Group Prof. Daniel Cremers 7. Boosting and Bagging Bagging Bagging So far: Boosting as an ensemble learning method, i.e.: a combination of (weak) learners A different way to combine classifiers is known
COMP61011 Foundations of Machine Learning. Feature Selection
 OMP61011 Foundations of Machine Learning Feature Selection Pattern Recognition: The Early Days Only 200 papers in the world! I wish! Pattern Recognition: The Early Days Using eight very simple measurements
OMP61011 Foundations of Machine Learning Feature Selection Pattern Recognition: The Early Days Only 200 papers in the world! I wish! Pattern Recognition: The Early Days Using eight very simple measurements
Preface to the Second Edition. Preface to the First Edition. 1 Introduction 1
 Preface to the Second Edition Preface to the First Edition vii xi 1 Introduction 1 2 Overview of Supervised Learning 9 2.1 Introduction... 9 2.2 Variable Types and Terminology... 9 2.3 Two Simple Approaches
Preface to the Second Edition Preface to the First Edition vii xi 1 Introduction 1 2 Overview of Supervised Learning 9 2.1 Introduction... 9 2.2 Variable Types and Terminology... 9 2.3 Two Simple Approaches
CS6375: Machine Learning Gautam Kunapuli. Mid-Term Review
 Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
SSV Criterion Based Discretization for Naive Bayes Classifiers
 SSV Criterion Based Discretization for Naive Bayes Classifiers Krzysztof Grąbczewski kgrabcze@phys.uni.torun.pl Department of Informatics, Nicolaus Copernicus University, ul. Grudziądzka 5, 87-100 Toruń,
SSV Criterion Based Discretization for Naive Bayes Classifiers Krzysztof Grąbczewski kgrabcze@phys.uni.torun.pl Department of Informatics, Nicolaus Copernicus University, ul. Grudziądzka 5, 87-100 Toruń,
Ensemble Learning. Another approach is to leverage the algorithms we have via ensemble methods
 Ensemble Learning Ensemble Learning So far we have seen learning algorithms that take a training set and output a classifier What if we want more accuracy than current algorithms afford? Develop new learning
Ensemble Learning Ensemble Learning So far we have seen learning algorithms that take a training set and output a classifier What if we want more accuracy than current algorithms afford? Develop new learning
Decision Trees Dr. G. Bharadwaja Kumar VIT Chennai
 Decision Trees Decision Tree Decision Trees (DTs) are a nonparametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target
Decision Trees Decision Tree Decision Trees (DTs) are a nonparametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target
We had several appearances of the curse of dimensionality:
 Short Recap We had several appearances of the curse of dimensionality: Concentration of distances => meaningless similarity/distance/neighborhood concept => instability of neighborhoods Growing hypothesis
Short Recap We had several appearances of the curse of dimensionality: Concentration of distances => meaningless similarity/distance/neighborhood concept => instability of neighborhoods Growing hypothesis
1) Give decision trees to represent the following Boolean functions:
 Give decision trees to represent the following Boolean functions:") 1) Give decision trees to represent the following Boolean functions: 1) A B 2) A [B C] 3) A XOR B 4) [A B] [C Dl Answer: 1) A B 2) A [B C] 1 3) A XOR B = (A B) ( A B) 4) [A B] [C D] 2 2) Consider the following
1) Give decision trees to represent the following Boolean functions: 1) A B 2) A [B C] 3) A XOR B 4) [A B] [C Dl Answer: 1) A B 2) A [B C] 1 3) A XOR B = (A B) ( A B) 4) [A B] [C D] 2 2) Consider the following
Regularization and model selection
 CS229 Lecture notes Andrew Ng Part VI Regularization and model selection Suppose we are trying select among several different models for a learning problem. For instance, we might be using a polynomial
CS229 Lecture notes Andrew Ng Part VI Regularization and model selection Suppose we are trying select among several different models for a learning problem. For instance, we might be using a polynomial
Big Data Methods. Chapter 5: Machine learning. Big Data Methods, Chapter 5, Slide 1
 Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
Data Mining Practical Machine Learning Tools and Techniques
 Engineering the input and output Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 7 of Data Mining by I. H. Witten and E. Frank Attribute selection z Scheme-independent, scheme-specific
Engineering the input and output Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 7 of Data Mining by I. H. Witten and E. Frank Attribute selection z Scheme-independent, scheme-specific
FEATURE SELECTION BASED ON INFORMATION THEORY, CONSISTENCY AND SEPARABILITY INDICES.
 FEATURE SELECTION BASED ON INFORMATION THEORY, CONSISTENCY AND SEPARABILITY INDICES. Włodzisław Duch 1, Krzysztof Grąbczewski 1, Tomasz Winiarski 1, Jacek Biesiada 2, Adam Kachel 2 1 Dept. of Informatics,
FEATURE SELECTION BASED ON INFORMATION THEORY, CONSISTENCY AND SEPARABILITY INDICES. Włodzisław Duch 1, Krzysztof Grąbczewski 1, Tomasz Winiarski 1, Jacek Biesiada 2, Adam Kachel 2 1 Dept. of Informatics,
Machine Learning. Supervised Learning. Manfred Huber
 Machine Learning Supervised Learning Manfred Huber 2015 1 Supervised Learning Supervised learning is learning where the training data contains the target output of the learning system. Training data D
Machine Learning Supervised Learning Manfred Huber 2015 1 Supervised Learning Supervised learning is learning where the training data contains the target output of the learning system. Training data D
An Empirical Comparison of Ensemble Methods Based on Classification Trees. Mounir Hamza and Denis Larocque. Department of Quantitative Methods
 An Empirical Comparison of Ensemble Methods Based on Classification Trees Mounir Hamza and Denis Larocque Department of Quantitative Methods HEC Montreal Canada Mounir Hamza and Denis Larocque 1 June 2005
An Empirical Comparison of Ensemble Methods Based on Classification Trees Mounir Hamza and Denis Larocque Department of Quantitative Methods HEC Montreal Canada Mounir Hamza and Denis Larocque 1 June 2005
CSC411 Fall 2014 Machine Learning & Data Mining. Ensemble Methods. Slides by Rich Zemel
 CSC411 Fall 2014 Machine Learning & Data Mining Ensemble Methods Slides by Rich Zemel Ensemble methods Typical application: classi.ication Ensemble of classi.iers is a set of classi.iers whose individual
CSC411 Fall 2014 Machine Learning & Data Mining Ensemble Methods Slides by Rich Zemel Ensemble methods Typical application: classi.ication Ensemble of classi.iers is a set of classi.iers whose individual
Filter methods for feature selection. A comparative study
 Filter methods for feature selection. A comparative study Noelia Sánchez-Maroño, Amparo Alonso-Betanzos, and María Tombilla-Sanromán University of A Coruña, Department of Computer Science, 15071 A Coruña,
Filter methods for feature selection. A comparative study Noelia Sánchez-Maroño, Amparo Alonso-Betanzos, and María Tombilla-Sanromán University of A Coruña, Department of Computer Science, 15071 A Coruña,
Information-Theoretic Feature Selection Algorithms for Text Classification
 Proceedings of International Joint Conference on Neural Networks, Montreal, Canada, July 31 - August 4, 5 Information-Theoretic Feature Selection Algorithms for Text Classification Jana Novovičová Institute
Proceedings of International Joint Conference on Neural Networks, Montreal, Canada, July 31 - August 4, 5 Information-Theoretic Feature Selection Algorithms for Text Classification Jana Novovičová Institute
Machine Learning. Chao Lan
 Machine Learning Chao Lan Machine Learning Prediction Models Regression Model - linear regression (least square, ridge regression, Lasso) Classification Model - naive Bayes, logistic regression, Gaussian
Machine Learning Chao Lan Machine Learning Prediction Models Regression Model - linear regression (least square, ridge regression, Lasso) Classification Model - naive Bayes, logistic regression, Gaussian
The exam is closed book, closed notes except your one-page (two-sided) cheat sheet.
 cheat sheet.") CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
Hybrid Correlation and Causal Feature Selection for Ensemble Classifiers
 Hybrid Correlation and Causal Feature Selection for Ensemble Classifiers Rakkrit Duangsoithong and Terry Windeatt Centre for Vision, Speech and Signal Processing University of Surrey Guildford, United
Hybrid Correlation and Causal Feature Selection for Ensemble Classifiers Rakkrit Duangsoithong and Terry Windeatt Centre for Vision, Speech and Signal Processing University of Surrey Guildford, United
Classification/Regression Trees and Random Forests
 Classification/Regression Trees and Random Forests Fabio G. Cozman - fgcozman@usp.br November 6, 2018 Classification tree Consider binary class variable Y and features X 1,..., X n. Decide Ŷ after a series
Classification/Regression Trees and Random Forests Fabio G. Cozman - fgcozman@usp.br November 6, 2018 Classification tree Consider binary class variable Y and features X 1,..., X n. Decide Ŷ after a series
What is machine learning?
 Machine learning, pattern recognition and statistical data modelling Lecture 12. The last lecture Coryn Bailer-Jones 1 What is machine learning? Data description and interpretation finding simpler relationship
Machine learning, pattern recognition and statistical data modelling Lecture 12. The last lecture Coryn Bailer-Jones 1 What is machine learning? Data description and interpretation finding simpler relationship
Supervised Learning Classification Algorithms Comparison
 Supervised Learning Classification Algorithms Comparison Aditya Singh Rathore B.Tech, J.K. Lakshmipat University -------------------------------------------------------------***---------------------------------------------------------
Supervised Learning Classification Algorithms Comparison Aditya Singh Rathore B.Tech, J.K. Lakshmipat University -------------------------------------------------------------***---------------------------------------------------------
An introduction to random forests
 An introduction to random forests Eric Debreuve / Team Morpheme Institutions: University Nice Sophia Antipolis / CNRS / Inria Labs: I3S / Inria CRI SA-M / ibv Outline Machine learning Decision tree Random
An introduction to random forests Eric Debreuve / Team Morpheme Institutions: University Nice Sophia Antipolis / CNRS / Inria Labs: I3S / Inria CRI SA-M / ibv Outline Machine learning Decision tree Random
Classification of Imbalanced Marketing Data with Balanced Random Sets
 JMLR: Workshop and Conference Proceedings 1: 1-8 KDD cup 2009 Classification of Imbalanced Marketing Data with Balanced Random Sets Vladimir Nikulin Department of Mathematics, University of Queensland,
JMLR: Workshop and Conference Proceedings 1: 1-8 KDD cup 2009 Classification of Imbalanced Marketing Data with Balanced Random Sets Vladimir Nikulin Department of Mathematics, University of Queensland,
COMP 465: Data Mining Classification Basics
 Supervised vs. Unsupervised Learning COMP 465: Data Mining Classification Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Supervised
Supervised vs. Unsupervised Learning COMP 465: Data Mining Classification Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Supervised
Topics In Feature Selection
 Topics In Feature Selection CSI 5388 Theme Presentation Joe Burpee 2005/2/16 Feature Selection (FS) aka Attribute Selection Witten and Frank book Section 7.1 Liu site http://athena.csee.umbc.edu/idm02/
Topics In Feature Selection CSI 5388 Theme Presentation Joe Burpee 2005/2/16 Feature Selection (FS) aka Attribute Selection Witten and Frank book Section 7.1 Liu site http://athena.csee.umbc.edu/idm02/
University of Florida CISE department Gator Engineering. Data Preprocessing. Dr. Sanjay Ranka
 Data Preprocessing Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville ranka@cise.ufl.edu Data Preprocessing What preprocessing step can or should
Data Preprocessing Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville ranka@cise.ufl.edu Data Preprocessing What preprocessing step can or should
Feature Selection for Supervised Classification: A Kolmogorov- Smirnov Class Correlation-Based Filter
 Feature Selection for Supervised Classification: A Kolmogorov- Smirnov Class Correlation-Based Filter Marcin Blachnik 1), Włodzisław Duch 2), Adam Kachel 1), Jacek Biesiada 1,3) 1) Silesian University
Feature Selection for Supervised Classification: A Kolmogorov- Smirnov Class Correlation-Based Filter Marcin Blachnik 1), Włodzisław Duch 2), Adam Kachel 1), Jacek Biesiada 1,3) 1) Silesian University
Comparison of different preprocessing techniques and feature selection algorithms in cancer datasets
 Comparison of different preprocessing techniques and feature selection algorithms in cancer datasets Konstantinos Sechidis School of Computer Science University of Manchester sechidik@cs.man.ac.uk Abstract
Comparison of different preprocessing techniques and feature selection algorithms in cancer datasets Konstantinos Sechidis School of Computer Science University of Manchester sechidik@cs.man.ac.uk Abstract
Using PageRank in Feature Selection
 Using PageRank in Feature Selection Dino Ienco, Rosa Meo, and Marco Botta Dipartimento di Informatica, Università di Torino, Italy {ienco,meo,botta}@di.unito.it Abstract. Feature selection is an important
Using PageRank in Feature Selection Dino Ienco, Rosa Meo, and Marco Botta Dipartimento di Informatica, Università di Torino, Italy {ienco,meo,botta}@di.unito.it Abstract. Feature selection is an important
Computer Vision Group Prof. Daniel Cremers. 8. Boosting and Bagging
 Prof. Daniel Cremers 8. Boosting and Bagging Repetition: Regression We start with a set of basis functions (x) =( 0 (x), 1(x),..., M 1(x)) x 2 í d The goal is to fit a model into the data y(x, w) =w T
Prof. Daniel Cremers 8. Boosting and Bagging Repetition: Regression We start with a set of basis functions (x) =( 0 (x), 1(x),..., M 1(x)) x 2 í d The goal is to fit a model into the data y(x, w) =w T
MIT Samberg Center Cambridge, MA, USA. May 30 th June 2 nd, by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA
 Exploratory Machine Learning studies for disruption prediction on DIII-D by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA Presented at the 2 nd IAEA Technical Meeting on
Exploratory Machine Learning studies for disruption prediction on DIII-D by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA Presented at the 2 nd IAEA Technical Meeting on
Naïve Bayes for text classification
 Road Map Basic concepts Decision tree induction Evaluation of classifiers Rule induction Classification using association rules Naïve Bayesian classification Naïve Bayes for text classification Support
Road Map Basic concepts Decision tree induction Evaluation of classifiers Rule induction Classification using association rules Naïve Bayesian classification Naïve Bayes for text classification Support
Data Preprocessing. Data Preprocessing
 Data Preprocessing Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville ranka@cise.ufl.edu Data Preprocessing What preprocessing step can or should
Data Preprocessing Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville ranka@cise.ufl.edu Data Preprocessing What preprocessing step can or should
Feature Selection in Knowledge Discovery
 Feature Selection in Knowledge Discovery Susana Vieira Technical University of Lisbon, Instituto Superior Técnico Department of Mechanical Engineering, Center of Intelligent Systems, IDMEC-LAETA Av. Rovisco
Feature Selection in Knowledge Discovery Susana Vieira Technical University of Lisbon, Instituto Superior Técnico Department of Mechanical Engineering, Center of Intelligent Systems, IDMEC-LAETA Av. Rovisco
CART. Classification and Regression Trees. Rebecka Jörnsten. Mathematical Sciences University of Gothenburg and Chalmers University of Technology
 CART Classification and Regression Trees Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology CART CART stands for Classification And Regression Trees.
CART Classification and Regression Trees Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology CART CART stands for Classification And Regression Trees.
Conditional Mutual Information Based Feature Selection for Classification Task
 Conditional Mutual Information Based Feature Selection for Classification Task Jana Novovičová 1,2, Petr Somol 1,2, Michal Haindl 1,2, and Pavel Pudil 2,1 1 Dept. of Pattern Recognition, Institute of Academy
Conditional Mutual Information Based Feature Selection for Classification Task Jana Novovičová 1,2, Petr Somol 1,2, Michal Haindl 1,2, and Pavel Pudil 2,1 1 Dept. of Pattern Recognition, Institute of Academy
Using Machine Learning to Optimize Storage Systems
 Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Features: representation, normalization, selection. Chapter e-9
 Features: representation, normalization, selection Chapter e-9 1 Features Distinguish between instances (e.g. an image that you need to classify), and the features you create for an instance. Features
Features: representation, normalization, selection Chapter e-9 1 Features Distinguish between instances (e.g. an image that you need to classify), and the features you create for an instance. Features
The digital copy of this thesis is protected by the Copyright Act 1994 (New Zealand).
.") http://waikato.researchgateway.ac.nz/ Research Commons at the University of Waikato Copyright Statement: The digital copy of this thesis is protected by the Copyright Act 1994 (New Zealand). The thesis
http://waikato.researchgateway.ac.nz/ Research Commons at the University of Waikato Copyright Statement: The digital copy of this thesis is protected by the Copyright Act 1994 (New Zealand). The thesis
Statistical Pattern Recognition
 Statistical Pattern Recognition Features and Feature Selection Hamid R. Rabiee Jafar Muhammadi Spring 2012 http://ce.sharif.edu/courses/90-91/2/ce725-1/ Agenda Features and Patterns The Curse of Size and
Statistical Pattern Recognition Features and Feature Selection Hamid R. Rabiee Jafar Muhammadi Spring 2012 http://ce.sharif.edu/courses/90-91/2/ce725-1/ Agenda Features and Patterns The Curse of Size and
Evaluation Measures. Sebastian Pölsterl. April 28, Computer Aided Medical Procedures Technische Universität München
 Evaluation Measures Sebastian Pölsterl Computer Aided Medical Procedures Technische Universität München April 28, 2015 Outline 1 Classification 1. Confusion Matrix 2. Receiver operating characteristics
Evaluation Measures Sebastian Pölsterl Computer Aided Medical Procedures Technische Universität München April 28, 2015 Outline 1 Classification 1. Confusion Matrix 2. Receiver operating characteristics
Using PageRank in Feature Selection
 Using PageRank in Feature Selection Dino Ienco, Rosa Meo, and Marco Botta Dipartimento di Informatica, Università di Torino, Italy fienco,meo,bottag@di.unito.it Abstract. Feature selection is an important
Using PageRank in Feature Selection Dino Ienco, Rosa Meo, and Marco Botta Dipartimento di Informatica, Università di Torino, Italy fienco,meo,bottag@di.unito.it Abstract. Feature selection is an important
Learning Bayesian Networks (part 2) Goals for the lecture
 Goals for the lecture") Learning ayesian Networks (part 2) Mark raven and avid Page omputer Sciences 0 Spring 20 www.biostat.wisc.edu/~craven/cs0/ Some of the slides in these lectures have been adapted/borrowed from materials
Learning ayesian Networks (part 2) Mark raven and avid Page omputer Sciences 0 Spring 20 www.biostat.wisc.edu/~craven/cs0/ Some of the slides in these lectures have been adapted/borrowed from materials
Building Classifiers using Bayesian Networks
 Building Classifiers using Bayesian Networks Nir Friedman and Moises Goldszmidt 1997 Presented by Brian Collins and Lukas Seitlinger Paper Summary The Naive Bayes classifier has reasonable performance
Building Classifiers using Bayesian Networks Nir Friedman and Moises Goldszmidt 1997 Presented by Brian Collins and Lukas Seitlinger Paper Summary The Naive Bayes classifier has reasonable performance
Predictive Analytics: Demystifying Current and Emerging Methodologies. Tom Kolde, FCAS, MAAA Linda Brobeck, FCAS, MAAA
 Predictive Analytics: Demystifying Current and Emerging Methodologies Tom Kolde, FCAS, MAAA Linda Brobeck, FCAS, MAAA May 18, 2017 About the Presenters Tom Kolde, FCAS, MAAA Consulting Actuary Chicago,
Predictive Analytics: Demystifying Current and Emerging Methodologies Tom Kolde, FCAS, MAAA Linda Brobeck, FCAS, MAAA May 18, 2017 About the Presenters Tom Kolde, FCAS, MAAA Consulting Actuary Chicago,
Cyber attack detection using decision tree approach
 Cyber attack detection using decision tree approach Amit Shinde Department of Industrial Engineering, Arizona State University,Tempe, AZ, USA {amit.shinde@asu.edu} In this information age, information
Cyber attack detection using decision tree approach Amit Shinde Department of Industrial Engineering, Arizona State University,Tempe, AZ, USA {amit.shinde@asu.edu} In this information age, information
SGN (4 cr) Chapter 10
 Chapter 10") SGN-41006 (4 cr) Chapter 10 Feature Selection and Extraction Jussi Tohka & Jari Niemi Department of Signal Processing Tampere University of Technology February 18, 2014 J. Tohka & J. Niemi (TUT-SGN) SGN-41006
SGN-41006 (4 cr) Chapter 10 Feature Selection and Extraction Jussi Tohka & Jari Niemi Department of Signal Processing Tampere University of Technology February 18, 2014 J. Tohka & J. Niemi (TUT-SGN) SGN-41006
Supervised vs unsupervised clustering
 Classification Supervised vs unsupervised clustering Cluster analysis: Classes are not known a- priori. Classification: Classes are defined a-priori Sometimes called supervised clustering Extract useful
Classification Supervised vs unsupervised clustering Cluster analysis: Classes are not known a- priori. Classification: Classes are defined a-priori Sometimes called supervised clustering Extract useful
Resampling methods for parameter-free and robust feature selection with mutual information
 Resampling methods for parameter-free and robust feature selection with mutual information D. François a, F. Rossi b, V. Wertz a and M. Verleysen c, a Université catholique de Louvain, Machine Learning
Resampling methods for parameter-free and robust feature selection with mutual information D. François a, F. Rossi b, V. Wertz a and M. Verleysen c, a Université catholique de Louvain, Machine Learning
Feature selection in environmental data mining combining Simulated Annealing and Extreme Learning Machine
 Feature selection in environmental data mining combining Simulated Annealing and Extreme Learning Machine Michael Leuenberger and Mikhail Kanevski University of Lausanne - Institute of Earth Surface Dynamics
Feature selection in environmental data mining combining Simulated Annealing and Extreme Learning Machine Michael Leuenberger and Mikhail Kanevski University of Lausanne - Institute of Earth Surface Dynamics
Pattern Recognition. Kjell Elenius. Speech, Music and Hearing KTH. March 29, 2007 Speech recognition
 Pattern Recognition Kjell Elenius Speech, Music and Hearing KTH March 29, 2007 Speech recognition 2007 1 Ch 4. Pattern Recognition 1(3) Bayes Decision Theory Minimum-Error-Rate Decision Rules Discriminant
Pattern Recognition Kjell Elenius Speech, Music and Hearing KTH March 29, 2007 Speech recognition 2007 1 Ch 4. Pattern Recognition 1(3) Bayes Decision Theory Minimum-Error-Rate Decision Rules Discriminant
Extra readings beyond the lecture slides are important:
 1 Notes To preview next lecture: Check the lecture notes, if slides are not available: http://web.cse.ohio-state.edu/~sun.397/courses/au2017/cse5243-new.html Check UIUC course on the same topic. All their
1 Notes To preview next lecture: Check the lecture notes, if slides are not available: http://web.cse.ohio-state.edu/~sun.397/courses/au2017/cse5243-new.html Check UIUC course on the same topic. All their
The exam is closed book, closed notes except your one-page (two-sided) cheat sheet.
 cheat sheet.") CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
Supervised Learning. Decision trees Artificial neural nets K-nearest neighbor Support vectors Linear regression Logistic regression...
 Supervised Learning Decision trees Artificial neural nets K-nearest neighbor Support vectors Linear regression Logistic regression... Supervised Learning y=f(x): true function (usually not known) D: training
Supervised Learning Decision trees Artificial neural nets K-nearest neighbor Support vectors Linear regression Logistic regression... Supervised Learning y=f(x): true function (usually not known) D: training
Predicting Rare Failure Events using Classification Trees on Large Scale Manufacturing Data with Complex Interactions
 2016 IEEE International Conference on Big Data (Big Data) Predicting Rare Failure Events using Classification Trees on Large Scale Manufacturing Data with Complex Interactions Jeff Hebert, Texas Instruments
2016 IEEE International Conference on Big Data (Big Data) Predicting Rare Failure Events using Classification Trees on Large Scale Manufacturing Data with Complex Interactions Jeff Hebert, Texas Instruments
AN HYBRID APPROACH TO FEATURE SELECTION FOR MIXED CATEGORICAL AND CONTINUOUS DATA
 AN HYBRID APPROACH TO FEATURE SELECTION FOR MIXED CATEGORICAL AND CONTINUOUS DATA Gauthier Doquire and Michel Verleysen ICTEAM Institute, Machine Learning Group, Université catholique de Louvain pl. du
AN HYBRID APPROACH TO FEATURE SELECTION FOR MIXED CATEGORICAL AND CONTINUOUS DATA Gauthier Doquire and Michel Verleysen ICTEAM Institute, Machine Learning Group, Université catholique de Louvain pl. du
International Journal of Scientific & Engineering Research, Volume 5, Issue 7, July ISSN
 International Journal of Scientific & Engineering Research, Volume 5, Issue 7, July-2014 445 Clusters using High Dimensional Data for Feature Subset Algorithm V. Abhilash M. Tech Student Department of
International Journal of Scientific & Engineering Research, Volume 5, Issue 7, July-2014 445 Clusters using High Dimensional Data for Feature Subset Algorithm V. Abhilash M. Tech Student Department of
Nearest neighbor classification DSE 220
 Nearest neighbor classification DSE 220 Decision Trees Target variable Label Dependent variable Output space Person ID Age Gender Income Balance Mortgag e payment 123213 32 F 25000 32000 Y 17824 49 M 12000-3000
Nearest neighbor classification DSE 220 Decision Trees Target variable Label Dependent variable Output space Person ID Age Gender Income Balance Mortgag e payment 123213 32 F 25000 32000 Y 17824 49 M 12000-3000
Overview. Non-Parametrics Models Definitions KNN. Ensemble Methods Definitions, Examples Random Forests. Clustering. k-means Clustering 2 / 8
 Tutorial 3 1 / 8 Overview Non-Parametrics Models Definitions KNN Ensemble Methods Definitions, Examples Random Forests Clustering Definitions, Examples k-means Clustering 2 / 8 Non-Parametrics Models Definitions
Tutorial 3 1 / 8 Overview Non-Parametrics Models Definitions KNN Ensemble Methods Definitions, Examples Random Forests Clustering Definitions, Examples k-means Clustering 2 / 8 Non-Parametrics Models Definitions
Medical Image Segmentation Based on Mutual Information Maximization
 Medical Image Segmentation Based on Mutual Information Maximization J.Rigau, M.Feixas, M.Sbert, A.Bardera, and I.Boada Institut d Informatica i Aplicacions, Universitat de Girona, Spain {jaume.rigau,miquel.feixas,mateu.sbert,anton.bardera,imma.boada}@udg.es
Medical Image Segmentation Based on Mutual Information Maximization J.Rigau, M.Feixas, M.Sbert, A.Bardera, and I.Boada Institut d Informatica i Aplicacions, Universitat de Girona, Spain {jaume.rigau,miquel.feixas,mateu.sbert,anton.bardera,imma.boada}@udg.es
Feature Selection with Decision Tree Criterion
 Feature Selection with Decision Tree Criterion Krzysztof Grąbczewski and Norbert Jankowski Department of Computer Methods Nicolaus Copernicus University Toruń, Poland kgrabcze,norbert@phys.uni.torun.pl
Feature Selection with Decision Tree Criterion Krzysztof Grąbczewski and Norbert Jankowski Department of Computer Methods Nicolaus Copernicus University Toruń, Poland kgrabcze,norbert@phys.uni.torun.pl
Lecture 7: Decision Trees
 Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
Three Embedded Methods
 Embedded Methods Review Wrappers Evaluation via a classifier, many search procedures possible. Slow. Often overfits. Filters Use statistics of the data. Fast but potentially naive. Embedded Methods A
Embedded Methods Review Wrappers Evaluation via a classifier, many search procedures possible. Slow. Often overfits. Filters Use statistics of the data. Fast but potentially naive. Embedded Methods A
International Journal of Scientific Research & Engineering Trends Volume 4, Issue 6, Nov-Dec-2018, ISSN (Online): X
: X") Analysis about Classification Techniques on Categorical Data in Data Mining Assistant Professor P. Meena Department of Computer Science Adhiyaman Arts and Science College for Women Uthangarai, Krishnagiri,
Analysis about Classification Techniques on Categorical Data in Data Mining Assistant Professor P. Meena Department of Computer Science Adhiyaman Arts and Science College for Women Uthangarai, Krishnagiri,
Feature-weighted k-nearest Neighbor Classifier
 Proceedings of the 27 IEEE Symposium on Foundations of Computational Intelligence (FOCI 27) Feature-weighted k-nearest Neighbor Classifier Diego P. Vivencio vivencio@comp.uf scar.br Estevam R. Hruschka
Proceedings of the 27 IEEE Symposium on Foundations of Computational Intelligence (FOCI 27) Feature-weighted k-nearest Neighbor Classifier Diego P. Vivencio vivencio@comp.uf scar.br Estevam R. Hruschka
Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.1-3
 Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.1-3 January 25, 2007 CSE-4412: Data Mining 1 Chapter 6 Classification and Prediction 1. What is classification? What is prediction?
Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.1-3 January 25, 2007 CSE-4412: Data Mining 1 Chapter 6 Classification and Prediction 1. What is classification? What is prediction?
Statistical Pattern Recognition
 Statistical Pattern Recognition Features and Feature Selection Hamid R. Rabiee Jafar Muhammadi Spring 2013 http://ce.sharif.edu/courses/91-92/2/ce725-1/ Agenda Features and Patterns The Curse of Size and
Statistical Pattern Recognition Features and Feature Selection Hamid R. Rabiee Jafar Muhammadi Spring 2013 http://ce.sharif.edu/courses/91-92/2/ce725-1/ Agenda Features and Patterns The Curse of Size and
ECG782: Multidimensional Digital Signal Processing
 ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
CSE4334/5334 DATA MINING
 CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018
![MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018](/thumbs/77/76295965.jpg "MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018") MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
INTRO TO RANDOM FOREST BY ANTHONY ANH QUOC DOAN
 INTRO TO RANDOM FOREST BY ANTHONY ANH QUOC DOAN MOTIVATION FOR RANDOM FOREST Random forest is a great statistical learning model. It works well with small to medium data. Unlike Neural Network which requires
INTRO TO RANDOM FOREST BY ANTHONY ANH QUOC DOAN MOTIVATION FOR RANDOM FOREST Random forest is a great statistical learning model. It works well with small to medium data. Unlike Neural Network which requires
Statistical Pattern Recognition
 Statistical Pattern Recognition Features and Feature Selection Hamid R. Rabiee Jafar Muhammadi Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Features and Patterns The Curse of Size and
Statistical Pattern Recognition Features and Feature Selection Hamid R. Rabiee Jafar Muhammadi Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Features and Patterns The Curse of Size and
Lars Schmidt-Thieme, Information Systems and Machine Learning Lab (ISMLL), University of Hildesheim, Germany
, University of Hildesheim, Germany") Syllabus Fri. 27.10. (1) 0. Introduction A. Supervised Learning: Linear Models & Fundamentals Fri. 3.11. (2) A.1 Linear Regression Fri. 10.11. (3) A.2 Linear Classification Fri. 17.11. (4) A.3 Regularization
Syllabus Fri. 27.10. (1) 0. Introduction A. Supervised Learning: Linear Models & Fundamentals Fri. 3.11. (2) A.1 Linear Regression Fri. 10.11. (3) A.2 Linear Classification Fri. 17.11. (4) A.3 Regularization
Probabilistic Approaches
 Probabilistic Approaches Chirayu Wongchokprasitti, PhD University of Pittsburgh Center for Causal Discovery Department of Biomedical Informatics chw20@pitt.edu http://www.pitt.edu/~chw20 Overview Independence
Probabilistic Approaches Chirayu Wongchokprasitti, PhD University of Pittsburgh Center for Causal Discovery Department of Biomedical Informatics chw20@pitt.edu http://www.pitt.edu/~chw20 Overview Independence
SOCIAL MEDIA MINING. Data Mining Essentials
 SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
Artificial Intelligence. Programming Styles
 Artificial Intelligence Intro to Machine Learning Programming Styles Standard CS: Explicitly program computer to do something Early AI: Derive a problem description (state) and use general algorithms to
Artificial Intelligence Intro to Machine Learning Programming Styles Standard CS: Explicitly program computer to do something Early AI: Derive a problem description (state) and use general algorithms to
Table Of Contents: xix Foreword to Second Edition
 Data Mining : Concepts and Techniques Table Of Contents: Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments xxxi About the Authors xxxv Chapter 1 Introduction 1 (38) 1.1 Why Data
Data Mining : Concepts and Techniques Table Of Contents: Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments xxxi About the Authors xxxv Chapter 1 Introduction 1 (38) 1.1 Why Data
10601 Machine Learning. Model and feature selection
 10601 Machine Learning Model and feature selection Model selection issues We have seen some of this before Selecting features (or basis functions) Logistic regression SVMs Selecting parameter value Prior
10601 Machine Learning Model and feature selection Model selection issues We have seen some of this before Selecting features (or basis functions) Logistic regression SVMs Selecting parameter value Prior
Lecture 27: Review. Reading: All chapters in ISLR. STATS 202: Data mining and analysis. December 6, 2017
 Lecture 27: Review Reading: All chapters in ISLR. STATS 202: Data mining and analysis December 6, 2017 1 / 16 Final exam: Announcements Tuesday, December 12, 8:30-11:30 am, in the following rooms: Last
Lecture 27: Review Reading: All chapters in ISLR. STATS 202: Data mining and analysis December 6, 2017 1 / 16 Final exam: Announcements Tuesday, December 12, 8:30-11:30 am, in the following rooms: Last
Data Mining & Feature Selection
 دااگشنه رتبيت م عل م Data Mining & Feature Selection M.M. Pedram pedram@tmu.ac.ir Faculty of Engineering, Tarbiat Moallem University The 11 th Iranian Confernce on Fuzzy systems, 5-7 July, 2011 Contents
دااگشنه رتبيت م عل م Data Mining & Feature Selection M.M. Pedram pedram@tmu.ac.ir Faculty of Engineering, Tarbiat Moallem University The 11 th Iranian Confernce on Fuzzy systems, 5-7 July, 2011 Contents
Machine Learning Lecture 3
 Machine Learning Lecture 3 Probability Density Estimation II 19.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Exam dates We re in the process
Machine Learning Lecture 3 Probability Density Estimation II 19.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Exam dates We re in the process