Classification Key Concepts
|
|
|
- Theodore Elliott
- 6 years ago
- Views:
Transcription
 Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Parishit Ram GT")
1 CSE6242 / CX4242: Data & Visual Analytics Classification Key Concepts Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Parishit Ram GT PhD alum; SkyTree Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Parishit Ram (GT PhD alum; SkyTree), Alex Gray 1

2 How will I rate "Chopin's 5th Symphony"? Songs Like? Some nights Skyfall Comfortably numb We are young Chopin's 5th??? 2
3 Classification What tools do you need for classification? 1. Data S = {(x i, y i )} i = 1,...,n o o x i : data example with d attributes y i : label of example (what you care about) 2. Classification model f (a,b,c,...) with some parameters a, b, c, Loss function L(y, f(x)) o how to penalize mistakes 3
4 Terminology Explanation Data S = {(x i, y i )} i = 1,...,n o o x i : data example with d attributes y i : label of example data example = data instance attribute = feature = dimension label = target attribute Song name Artist Length... Like? Some nights Fun 4:23... Skyfall Adele 4:00... Comf. numb Pink Fl. 6:13... We are young Fun 3: Chopin's 5th Chopin 5:32...?? 4
5 What is a model? a simplified representation of reality created to serve a purpose Data Science for Business Example: maps are abstract models of the physical world There can be many models!! (Everyone sees the world differently, so each of us has a different model.) In data science, a model is formula to estimate what you care about. The formula may be mathematical, a set of rules, a combination, etc. 5
6 Training a classifier = building the model How do you learn appropriate values for parameters a, b, c,...? Analogy: how do you know your map is a good map of the physical world? 6
7 Classification loss function Most common loss: 0-1 loss function More general loss functions are defined by a m x m cost matrix C such that where y = a and f(x) = b T0 (true class 0), T1 (true class 1) P0 (predicted class 0), P1 (predicted class 1) Class T0 T1 P0 0 C 10 P1 C
8 An ideal model should correctly estimate: o o known or seen data examples labels unknown or unseen data examples labels Song name Artist Length... Like? Some nights Fun 4:23... Skyfall Adele 4:00... Comf. numb Pink Fl. 6:13... We are young Fun 3: Chopin's 5th Chopin 5:32...?? 8
9 Training a classifier = building the model Q: How do you learn appropriate values for parameters a, b, c,...? (Analogy: how do you know your map is a good map?) y i = f (a,b,c,...) (x i ), i = 1,..., n o Low/no error on training data ( seen or known ) y = f (a,b,c,...)(x), for any new x o Low/no error on test data ( unseen or unknown ) It is very easy to achieve perfect classification Possible A: on training/seen/known Minimize data. Why? with respect to a, b, c,... 9
10 If your model works really well for training data, but poorly for test data, your model is overfitting. How to avoid overfitting? 10
 Image credit: http://stats.stackexchange.")
11 Example: one run of 5-fold cross validation You should do a few runs and compute the average (e.g., error rates if that s your evaluation metrics) Image credit: 11
12 Cross validation 1.Divide your data into n parts 2.Hold 1 part as test set or hold out set 3.Train classifier on remaining n-1 parts training set 4.Compute test error on test set 5.Repeat above steps n times, once for each n-th part 6.Compute the average test error over all n folds (i.e., cross-validation test error) 12
13 Cross-validation variations Leave-one-out cross-validation (LOO-CV) test sets of size 1 K-fold cross-validation Test sets of size (n / K) K = 10 is most common (i.e., 10-fold CV) 13
14 Example: k-nearest-neighbor classifier Like Whiskey Don t like whiskey Image credit: Data Science for Business 14
15 k-nearest-neighbor Classifier The classifier: f(x) = majority label of the k nearest neighbors (NN) of x Model parameters: Number of neighbors k Distance/similarity function d(.,.) 15
 Image credit: https://www.fool.")
16 But k-nn is so simple! It can work really well! Pandora uses it or has used it: (from the book Data Mining for Business Intelligence ) Image credit: 16

")


")
17 What are good models? Simple (few parameters) Effective Complex (more parameters) Complex (many parameters) Effective (if significantly more so than simple methods) Not-so-effective 17
18 k-nearest-neighbor Classifier If k and d(.,.) are fixed Things to learn:? How to learn them:? If d(.,.) is fixed, but you can change k Things to learn:? How to learn them:? 18
19 k-nearest-neighbor Classifier If k and d(.,.) are fixed Things to learn: Nothing How to learn them: N/A If d(.,.) is fixed, but you can change k Selecting k: How? 19
20 How to find best k in k-nn? Use cross validation (CV). 20
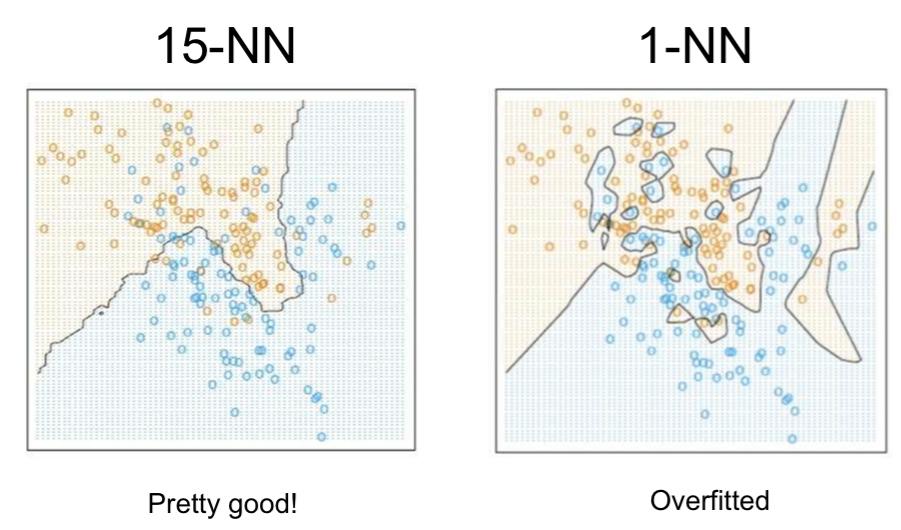
21 21
22 k-nearest-neighbor Classifier If k is fixed, but you can change d(.,.) Possible distance functions: Euclidean distance: Manhattan distance: 22
23 Summary on k-nn classifier Advantages o Little learning (unless you are learning the o distance functions) quite powerful in practice (and has theoretical guarantees as well) Caveats o Computationally expensive at test time Reading material: ESL book, Chapter 13.3http://www-stat.stanford.edu/ ~tibs/elemstatlearn/printings/eslii_print10.pdf Le Song's slides on knn classifierhttp:// 23
24 Decision trees (DT) Visual introduction to decision tree Weather? The classifier: f T (x): majority class in the leaf in the tree T containing x Model parameters: The tree structure and size 24
25 Decision trees Things to learn:? How to learn them:? Cross-validation:? Weather? 25
26 Learning the Tree Structure Things to learn: the tree structure How to learn them: (greedily) minimize the overall classification loss Cross-validation: finding the best sized tree with K-fold cross-validation 26
27 Decision trees Pieces: 1. Find the best split on the chosen attribute 2. Find the best attribute to split on 3. Decide on when to stop splitting 4. Cross-validation Highly recommended lecture slides from CMU 27
28 Choosing the split point Split types for a selected attribute j: 1. Categorical attribute (e.g. genre ) x 1j = Rock, x 2j = Classical, x 3j = Pop 2. Ordinal attribute (e.g., achievement ) x 1j =Platinum, x 2j =Gold, x 3j =Silver 3. Continuous attribute (e.g., song duration) x 1j = 235, x 2j = 543, x 3j = 378 x 1,x 2,x 3 x 1,x 2,x 3 x 1,x 2,x 3 Rock Classical Pop Plat. Gold Silver x 1 x 2 x 3 x 1 x 2 x 3 x 1,x 3 x 2 Split on genre Split on achievement Split on duration 28
29 Choosing the split point At a node T for a given attribute d, select a split s as following: min s loss(t L ) + loss(t R ) where loss(t) is the loss at node T Common node loss functions: Misclassification rate Expected loss Normalized negative log-likelihood (= cross-entropy) More details on loss functions, see Chapter 3.3: 29
30 Choosing the attribute Choice of attribute: 1. Attribute providing the maximum improvement in training loss 2. Attribute with highest information gain (mutual information) Intuition: an attribute with highest information gain helps most rapidly describe an instance (i.e., most rapidly reduces uncertainty ) 30
31 Let s look at an excellent example using information gain to pick splitting attribute and split point (for that attribute) Slide 7 onwards 31

32 When to stop splitting? Common strategies: 1. Pure and impure leave nodes All points belong to the same class; OR All points from one class completely overlap with points from another class (i.e., same attributes) Output majority class as this leaf s label 2. Node contains points fewer than some threshold 3. Node purity is higher than some threshold 4. Further splits provide no improvement in training loss (loss(t) <= loss(t L ) + loss(t R )) Graphics from: 32
33 Parameters vs Hyper-parameters Example hyper-parameters (need to experiment ) k-nn: k, similarity function Decision tree: #node, Can be determined using CV and grid search ( Example parameters (can be learned / estimated / computed directly from data) Decision tree (entropy-based): which attribute to split split point for an attribute 33
34 Summary on decision trees Advantages Easy to implement Interpretable Very fast test time Can work seamlessly with mixed attributes Works quite well in practice Caveats too basic but OK if it works! Training can be very expensive Cross-validation is hard (node-level CV) 34
Classification Key Concepts
 http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Classification Key Concepts Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech 1 How will
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Classification Key Concepts Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech 1 How will
Introduction to Machine Learning. Duen Horng (Polo) Chau Associate Director, MS Analytics Associate Professor, CSE, College of Computing Georgia Tech
 Chau Associate Director, MS Analytics Associate Professor, CSE, College of Computing Georgia Tech") Introduction to Machine Learning Duen Horng (Polo) Chau Associate Director, MS Analytics Associate Professor, CSE, College of Computing Georgia Tech 1 Google Polo Chau if interested in my professional
Introduction to Machine Learning Duen Horng (Polo) Chau Associate Director, MS Analytics Associate Professor, CSE, College of Computing Georgia Tech 1 Google Polo Chau if interested in my professional
How to predict a discrete variable?
 CSE 6242 / CX 4242 Classificatin Hw t predict a discrete variable? Based n Parishit Ram s slides. Pari nw at SkyTree. Graduated frm PhD frm GT. Als based n Alex Gray s slides. Hw will I rate "Chpin's 5th
CSE 6242 / CX 4242 Classificatin Hw t predict a discrete variable? Based n Parishit Ram s slides. Pari nw at SkyTree. Graduated frm PhD frm GT. Als based n Alex Gray s slides. Hw will I rate "Chpin's 5th
How to predict a discrete variable?
 CSE 6242 / CX 4242 Classificatin Hw t predict a discrete variable? Based n Parishit Ram s slides. Pari nw at SkyTree. Graduated frm PhD frm GT. Als based n Alex Gray s slides. Hw will I rate "Chpin's 5th
CSE 6242 / CX 4242 Classificatin Hw t predict a discrete variable? Based n Parishit Ram s slides. Pari nw at SkyTree. Graduated frm PhD frm GT. Als based n Alex Gray s slides. Hw will I rate "Chpin's 5th
Feb 27, 2014 CSE 6242 / CX Classification. How to predict a discrete variable? Based on Parishit Ram s slides
 Feb 27, 2014 CSE 6242 / CX 4242 Classificatin Hw t predict a discrete variable? Based n Parishit Ram s slides Hw will I rate "Chpin's 5th Symphny"? Sngs Label Sme nights Skyfall Cmfrtably numb We are yung............
Feb 27, 2014 CSE 6242 / CX 4242 Classificatin Hw t predict a discrete variable? Based n Parishit Ram s slides Hw will I rate "Chpin's 5th Symphny"? Sngs Label Sme nights Skyfall Cmfrtably numb We are yung............
Scaling Up HBase. Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics
 Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up HBase Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up HBase Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
Scaling Up Pig. Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics
 Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up Pig Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up Pig Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
Scaling Up Pig. Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics
 Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up Pig Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up Pig Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
Text Analytics (Text Mining)
") CSE 6242 / CX 4242 Apr 1, 2014 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer,
CSE 6242 / CX 4242 Apr 1, 2014 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer,
Data Mining Concepts & Tasks
 Data Mining Concepts & Tasks Duen Horng (Polo) Chau Georgia Tech CSE6242 / CX4242 Sept 9, 2014 Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos Last Time
Data Mining Concepts & Tasks Duen Horng (Polo) Chau Georgia Tech CSE6242 / CX4242 Sept 9, 2014 Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos Last Time
Text Analytics (Text Mining)
") CSE 6242 / CX 4242 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko,
CSE 6242 / CX 4242 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko,
Data Mining Concepts & Tasks
 Data Mining Concepts & Tasks Duen Horng (Polo) Chau Georgia Tech CSE6242 / CX4242 Jan 16, 2014 Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos Last Time
Data Mining Concepts & Tasks Duen Horng (Polo) Chau Georgia Tech CSE6242 / CX4242 Jan 16, 2014 Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos Last Time
Data Mining Concepts. Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech
 Chau Assistant Professor Associate Director, MS Analytics Georgia Tech") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Data Mining Concepts Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Data Mining Concepts Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on
Data Integration. Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics
 Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Data Integration Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Data Integration Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
Analytics Building Blocks
 http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Analytics Building Blocks Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Analytics Building Blocks Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based
Graphs / Networks. CSE 6242/ CX 4242 Feb 18, Centrality measures, algorithms, interactive applications. Duen Horng (Polo) Chau Georgia Tech
 Chau Georgia Tech") CSE 6242/ CX 4242 Feb 18, 2014 Graphs / Networks Centrality measures, algorithms, interactive applications Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors Guy Lebanon, Jeffrey
CSE 6242/ CX 4242 Feb 18, 2014 Graphs / Networks Centrality measures, algorithms, interactive applications Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors Guy Lebanon, Jeffrey
Data Collection, Simple Storage (SQLite) & Cleaning
 & Cleaning") Data Collection, Simple Storage (SQLite) & Cleaning Duen Horng (Polo) Chau Georgia Tech CSE 6242 A / CS 4803 DVA Jan 15, 2013 Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko,
Data Collection, Simple Storage (SQLite) & Cleaning Duen Horng (Polo) Chau Georgia Tech CSE 6242 A / CS 4803 DVA Jan 15, 2013 Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko,
Lecture 7: Decision Trees
 Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
Extra readings beyond the lecture slides are important:
 1 Notes To preview next lecture: Check the lecture notes, if slides are not available: http://web.cse.ohio-state.edu/~sun.397/courses/au2017/cse5243-new.html Check UIUC course on the same topic. All their
1 Notes To preview next lecture: Check the lecture notes, if slides are not available: http://web.cse.ohio-state.edu/~sun.397/courses/au2017/cse5243-new.html Check UIUC course on the same topic. All their
MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018
![MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018](/thumbs/77/76295965.jpg "MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018") MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
CSE4334/5334 DATA MINING
 CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
Nearest Neighbor Classification
 Nearest Neighbor Classification Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms January 11, 2017 1 / 48 Outline 1 Administration 2 First learning algorithm: Nearest
Nearest Neighbor Classification Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms January 11, 2017 1 / 48 Outline 1 Administration 2 First learning algorithm: Nearest
Classification and Regression
 Classification and Regression Announcements Study guide for exam is on the LMS Sample exam will be posted by Monday Reminder that phase 3 oral presentations are being held next week during workshops Plan
Classification and Regression Announcements Study guide for exam is on the LMS Sample exam will be posted by Monday Reminder that phase 3 oral presentations are being held next week during workshops Plan
Graphs / Networks CSE 6242/ CX Interactive applications. Duen Horng (Polo) Chau Georgia Tech
 Chau Georgia Tech") CSE 6242/ CX 4242 Graphs / Networks Interactive applications Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le Song
CSE 6242/ CX 4242 Graphs / Networks Interactive applications Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le Song
Graphs III. CSE 6242 A / CS 4803 DVA Feb 26, Duen Horng (Polo) Chau Georgia Tech. (Interactive) Applications
 Chau Georgia Tech. (Interactive) Applications") CSE 6242 A / CS 4803 DVA Feb 26, 2013 Graphs III (Interactive) Applications Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos
CSE 6242 A / CS 4803 DVA Feb 26, 2013 Graphs III (Interactive) Applications Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos
Scaling Up 1 CSE 6242 / CX Duen Horng (Polo) Chau Georgia Tech. Hadoop, Pig
 Chau Georgia Tech. Hadoop, Pig") CSE 6242 / CX 4242 Scaling Up 1 Hadoop, Pig Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le
CSE 6242 / CX 4242 Scaling Up 1 Hadoop, Pig Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le
Using Machine Learning to Optimize Storage Systems
 Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
CISC 4631 Data Mining
 CISC 4631 Data Mining Lecture 03: Nearest Neighbor Learning Theses slides are based on the slides by Tan, Steinbach and Kumar (textbook authors) Prof. R. Mooney (UT Austin) Prof E. Keogh (UCR), Prof. F.
CISC 4631 Data Mining Lecture 03: Nearest Neighbor Learning Theses slides are based on the slides by Tan, Steinbach and Kumar (textbook authors) Prof. R. Mooney (UT Austin) Prof E. Keogh (UCR), Prof. F.
Basics, how to build & store graphs, laws, etc. Centrality, and algorithms you should know
 http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Graphs / Networks Basics, how to build & store graphs, laws, etc. Centrality, and algorithms you should know Duen Horng (Polo)
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Graphs / Networks Basics, how to build & store graphs, laws, etc. Centrality, and algorithms you should know Duen Horng (Polo)
Basics, how to build & store graphs, laws, etc. Centrality, and algorithms you should know
 http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Graphs / Networks Basics, how to build & store graphs, laws, etc. Centrality, and algorithms you should know Duen Horng (Polo)
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Graphs / Networks Basics, how to build & store graphs, laws, etc. Centrality, and algorithms you should know Duen Horng (Polo)
Lazy Decision Trees Ronny Kohavi
 Lazy Decision Trees Ronny Kohavi Data Mining and Visualization Group Silicon Graphics, Inc. Joint work with Jerry Friedman and Yeogirl Yun Stanford University Motivation: Average Impurity = / interesting
Lazy Decision Trees Ronny Kohavi Data Mining and Visualization Group Silicon Graphics, Inc. Joint work with Jerry Friedman and Yeogirl Yun Stanford University Motivation: Average Impurity = / interesting
CSCI567 Machine Learning (Fall 2014)
") CSCI567 Machine Learning (Fall 2014) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu September 9, 2014 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 2014) September 9, 2014 1 / 47
CSCI567 Machine Learning (Fall 2014) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu September 9, 2014 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 2014) September 9, 2014 1 / 47
Data Mining Lecture 8: Decision Trees
 Data Mining Lecture 8: Decision Trees Jo Houghton ECS Southampton March 8, 2019 1 / 30 Decision Trees - Introduction A decision tree is like a flow chart. E. g. I need to buy a new car Can I afford it?
Data Mining Lecture 8: Decision Trees Jo Houghton ECS Southampton March 8, 2019 1 / 30 Decision Trees - Introduction A decision tree is like a flow chart. E. g. I need to buy a new car Can I afford it?
CS178: Machine Learning and Data Mining. Complexity & Nearest Neighbor Methods
 + CS78: Machine Learning and Data Mining Complexity & Nearest Neighbor Methods Prof. Erik Sudderth Some materials courtesy Alex Ihler & Sameer Singh Machine Learning Complexity and Overfitting Nearest
+ CS78: Machine Learning and Data Mining Complexity & Nearest Neighbor Methods Prof. Erik Sudderth Some materials courtesy Alex Ihler & Sameer Singh Machine Learning Complexity and Overfitting Nearest
Text Analytics (Text Mining)
") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Text Analytics (Text Mining) Concepts, Algorithms, LSI/SVD Duen Horng (Polo) Chau Assistant Professor Associate Director, MS
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Text Analytics (Text Mining) Concepts, Algorithms, LSI/SVD Duen Horng (Polo) Chau Assistant Professor Associate Director, MS
Lecture outline. Decision-tree classification
 Lecture outline Decision-tree classification Decision Trees Decision tree A flow-chart-like tree structure Internal node denotes a test on an attribute Branch represents an outcome of the test Leaf nodes
Lecture outline Decision-tree classification Decision Trees Decision tree A flow-chart-like tree structure Internal node denotes a test on an attribute Branch represents an outcome of the test Leaf nodes
Data Mining Concepts & Techniques
 Data Mining Concepts & Techniques Lecture No. 03 Data Processing, Data Mining Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
Data Mining Concepts & Techniques Lecture No. 03 Data Processing, Data Mining Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
Data mining. Classification k-nn Classifier. Piotr Paszek. (Piotr Paszek) Data mining k-nn 1 / 20
 Data mining k-nn 1 / 20") Data mining Piotr Paszek Classification k-nn Classifier (Piotr Paszek) Data mining k-nn 1 / 20 Plan of the lecture 1 Lazy Learner 2 k-nearest Neighbor Classifier 1 Distance (metric) 2 How to Determine
Data mining Piotr Paszek Classification k-nn Classifier (Piotr Paszek) Data mining k-nn 1 / 20 Plan of the lecture 1 Lazy Learner 2 k-nearest Neighbor Classifier 1 Distance (metric) 2 How to Determine
CSE 6242/CX Ensemble Methods. Or, Model Combination. Based on lecture by Parikshit Ram
 CSE 6242/CX 4242 Ensemble Methods Or, Model Combination Based on lecture by Parikshit Ram Numerous Possible Classifiers! Classifier Training time Cross validation Testing time Accuracy knn classifier None
CSE 6242/CX 4242 Ensemble Methods Or, Model Combination Based on lecture by Parikshit Ram Numerous Possible Classifiers! Classifier Training time Cross validation Testing time Accuracy knn classifier None
Classification: Basic Concepts, Decision Trees, and Model Evaluation
 Classification: Basic Concepts, Decision Trees, and Model Evaluation Data Warehousing and Mining Lecture 4 by Hossen Asiful Mustafa Classification: Definition Given a collection of records (training set
Classification: Basic Concepts, Decision Trees, and Model Evaluation Data Warehousing and Mining Lecture 4 by Hossen Asiful Mustafa Classification: Definition Given a collection of records (training set
Supervised Learning: K-Nearest Neighbors and Decision Trees
 Supervised Learning: K-Nearest Neighbors and Decision Trees Piyush Rai CS5350/6350: Machine Learning August 25, 2011 (CS5350/6350) K-NN and DT August 25, 2011 1 / 20 Supervised Learning Given training
Supervised Learning: K-Nearest Neighbors and Decision Trees Piyush Rai CS5350/6350: Machine Learning August 25, 2011 (CS5350/6350) K-NN and DT August 25, 2011 1 / 20 Supervised Learning Given training
Text Categorization. Foundations of Statistic Natural Language Processing The MIT Press1999
 Text Categorization Foundations of Statistic Natural Language Processing The MIT Press1999 Outline Introduction Decision Trees Maximum Entropy Modeling (optional) Perceptrons K Nearest Neighbor Classification
Text Categorization Foundations of Statistic Natural Language Processing The MIT Press1999 Outline Introduction Decision Trees Maximum Entropy Modeling (optional) Perceptrons K Nearest Neighbor Classification
Nonparametric Methods Recap
 Nonparametric Methods Recap Aarti Singh Machine Learning 10-701/15-781 Oct 4, 2010 Nonparametric Methods Kernel Density estimate (also Histogram) Weighted frequency Classification - K-NN Classifier Majority
Nonparametric Methods Recap Aarti Singh Machine Learning 10-701/15-781 Oct 4, 2010 Nonparametric Methods Kernel Density estimate (also Histogram) Weighted frequency Classification - K-NN Classifier Majority
10/5/2017 MIST.6060 Business Intelligence and Data Mining 1. Nearest Neighbors. In a p-dimensional space, the Euclidean distance between two records,
 10/5/2017 MIST.6060 Business Intelligence and Data Mining 1 Distance Measures Nearest Neighbors In a p-dimensional space, the Euclidean distance between two records, a = a, a,..., a ) and b = b, b,...,
10/5/2017 MIST.6060 Business Intelligence and Data Mining 1 Distance Measures Nearest Neighbors In a p-dimensional space, the Euclidean distance between two records, a = a, a,..., a ) and b = b, b,...,
Data Mining. Lecture 03: Nearest Neighbor Learning
 Data Mining Lecture 03: Nearest Neighbor Learning Theses slides are based on the slides by Tan, Steinbach and Kumar (textbook authors) Prof. R. Mooney (UT Austin) Prof E. Keogh (UCR), Prof. F. Provost
Data Mining Lecture 03: Nearest Neighbor Learning Theses slides are based on the slides by Tan, Steinbach and Kumar (textbook authors) Prof. R. Mooney (UT Austin) Prof E. Keogh (UCR), Prof. F. Provost
Example of DT Apply Model Example Learn Model Hunt s Alg. Measures of Node Impurity DT Examples and Characteristics. Classification.
 lassification-decision Trees, Slide 1/56 Classification Decision Trees Huiping Cao lassification-decision Trees, Slide 2/56 Examples of a Decision Tree Tid Refund Marital Status Taxable Income Cheat 1
lassification-decision Trees, Slide 1/56 Classification Decision Trees Huiping Cao lassification-decision Trees, Slide 2/56 Examples of a Decision Tree Tid Refund Marital Status Taxable Income Cheat 1
Data Mining Classification - Part 1 -
 Data Mining Classification - Part 1 - Universität Mannheim Bizer: Data Mining I FSS2019 (Version: 20.2.2018) Slide 1 Outline 1. What is Classification? 2. K-Nearest-Neighbors 3. Decision Trees 4. Model
Data Mining Classification - Part 1 - Universität Mannheim Bizer: Data Mining I FSS2019 (Version: 20.2.2018) Slide 1 Outline 1. What is Classification? 2. K-Nearest-Neighbors 3. Decision Trees 4. Model
Machine Learning. Decision Trees. Le Song /15-781, Spring Lecture 6, September 6, 2012 Based on slides from Eric Xing, CMU
 Machine Learning 10-701/15-781, Spring 2008 Decision Trees Le Song Lecture 6, September 6, 2012 Based on slides from Eric Xing, CMU Reading: Chap. 1.6, CB & Chap 3, TM Learning non-linear functions f:
Machine Learning 10-701/15-781, Spring 2008 Decision Trees Le Song Lecture 6, September 6, 2012 Based on slides from Eric Xing, CMU Reading: Chap. 1.6, CB & Chap 3, TM Learning non-linear functions f:
Data Preprocessing. Supervised Learning
 Supervised Learning Regression Given the value of an input X, the output Y belongs to the set of real values R. The goal is to predict output accurately for a new input. The predictions or outputs y are
Supervised Learning Regression Given the value of an input X, the output Y belongs to the set of real values R. The goal is to predict output accurately for a new input. The predictions or outputs y are
CS Machine Learning
 CS 60050 Machine Learning Decision Tree Classifier Slides taken from course materials of Tan, Steinbach, Kumar 10 10 Illustrating Classification Task Tid Attrib1 Attrib2 Attrib3 Class 1 Yes Large 125K
CS 60050 Machine Learning Decision Tree Classifier Slides taken from course materials of Tan, Steinbach, Kumar 10 10 Illustrating Classification Task Tid Attrib1 Attrib2 Attrib3 Class 1 Yes Large 125K
Introduction to Artificial Intelligence
 Introduction to Artificial Intelligence COMP307 Machine Learning 2: 3-K Techniques Yi Mei yi.mei@ecs.vuw.ac.nz 1 Outline K-Nearest Neighbour method Classification (Supervised learning) Basic NN (1-NN)
Introduction to Artificial Intelligence COMP307 Machine Learning 2: 3-K Techniques Yi Mei yi.mei@ecs.vuw.ac.nz 1 Outline K-Nearest Neighbour method Classification (Supervised learning) Basic NN (1-NN)
K-Nearest Neighbour Classifier. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 K-Nearest Neighbour Classifier Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Reminder Supervised data mining Classification Decision Trees Izabela
K-Nearest Neighbour Classifier Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Reminder Supervised data mining Classification Decision Trees Izabela
Graphs / Networks CSE 6242/ CX Centrality measures, algorithms, interactive applications. Duen Horng (Polo) Chau Georgia Tech
 Chau Georgia Tech") CSE 6242/ CX 4242 Graphs / Networks Centrality measures, algorithms, interactive applications Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John
CSE 6242/ CX 4242 Graphs / Networks Centrality measures, algorithms, interactive applications Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John
COMP 465: Data Mining Classification Basics
 Supervised vs. Unsupervised Learning COMP 465: Data Mining Classification Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Supervised
Supervised vs. Unsupervised Learning COMP 465: Data Mining Classification Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Supervised
Data Mining and Knowledge Discovery Practice notes: Numeric Prediction, Association Rules
 Keywords Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si Data Attribute, example, attribute-value data, target variable, class, discretization Algorithms
Keywords Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si Data Attribute, example, attribute-value data, target variable, class, discretization Algorithms
CPSC 340: Machine Learning and Data Mining
 CPSC 340: Machine Learning and Data Mining Fundamentals of learning (continued) and the k-nearest neighbours classifier Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart.
CPSC 340: Machine Learning and Data Mining Fundamentals of learning (continued) and the k-nearest neighbours classifier Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart.
Distribution-free Predictive Approaches
 Distribution-free Predictive Approaches The methods discussed in the previous sections are essentially model-based. Model-free approaches such as tree-based classification also exist and are popular for
Distribution-free Predictive Approaches The methods discussed in the previous sections are essentially model-based. Model-free approaches such as tree-based classification also exist and are popular for
Nominal Data. May not have a numerical representation Distance measures might not make sense. PR and ANN
 NonMetric Data Nominal Data So far we consider patterns to be represented by feature vectors of real or integer values Easy to come up with a distance (similarity) measure by using a variety of mathematical
NonMetric Data Nominal Data So far we consider patterns to be represented by feature vectors of real or integer values Easy to come up with a distance (similarity) measure by using a variety of mathematical
CS 584 Data Mining. Classification 1
 CS 584 Data Mining Classification 1 Classification: Definition Given a collection of records (training set ) Each record contains a set of attributes, one of the attributes is the class. Find a model for
CS 584 Data Mining Classification 1 Classification: Definition Given a collection of records (training set ) Each record contains a set of attributes, one of the attributes is the class. Find a model for
Tree-based methods for classification and regression
 Tree-based methods for classification and regression Ryan Tibshirani Data Mining: 36-462/36-662 April 11 2013 Optional reading: ISL 8.1, ESL 9.2 1 Tree-based methods Tree-based based methods for predicting
Tree-based methods for classification and regression Ryan Tibshirani Data Mining: 36-462/36-662 April 11 2013 Optional reading: ISL 8.1, ESL 9.2 1 Tree-based methods Tree-based based methods for predicting
Data Mining and Knowledge Discovery: Practice Notes
 Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2013/12/09 1 Practice plan 2013/11/11: Predictive data mining 1 Decision trees Evaluating classifiers 1: separate
Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2013/12/09 1 Practice plan 2013/11/11: Predictive data mining 1 Decision trees Evaluating classifiers 1: separate
Nearest neighbor classification DSE 220
 Nearest neighbor classification DSE 220 Decision Trees Target variable Label Dependent variable Output space Person ID Age Gender Income Balance Mortgag e payment 123213 32 F 25000 32000 Y 17824 49 M 12000-3000
Nearest neighbor classification DSE 220 Decision Trees Target variable Label Dependent variable Output space Person ID Age Gender Income Balance Mortgag e payment 123213 32 F 25000 32000 Y 17824 49 M 12000-3000
Mathematics of Data. INFO-4604, Applied Machine Learning University of Colorado Boulder. September 5, 2017 Prof. Michael Paul
 Mathematics of Data INFO-4604, Applied Machine Learning University of Colorado Boulder September 5, 2017 Prof. Michael Paul Goals In the intro lecture, every visualization was in 2D What happens when we
Mathematics of Data INFO-4604, Applied Machine Learning University of Colorado Boulder September 5, 2017 Prof. Michael Paul Goals In the intro lecture, every visualization was in 2D What happens when we
Evaluation. Evaluate what? For really large amounts of data... A: Use a validation set.
 Evaluate what? Evaluation Charles Sutton Data Mining and Exploration Spring 2012 Do you want to evaluate a classifier or a learning algorithm? Do you want to predict accuracy or predict which one is better?
Evaluate what? Evaluation Charles Sutton Data Mining and Exploration Spring 2012 Do you want to evaluate a classifier or a learning algorithm? Do you want to predict accuracy or predict which one is better?
Clustering & Classification (chapter 15)
") Clustering & Classification (chapter 5) Kai Goebel Bill Cheetham RPI/GE Global Research goebel@cs.rpi.edu cheetham@cs.rpi.edu Outline k-means Fuzzy c-means Mountain Clustering knn Fuzzy knn Hierarchical
Clustering & Classification (chapter 5) Kai Goebel Bill Cheetham RPI/GE Global Research goebel@cs.rpi.edu cheetham@cs.rpi.edu Outline k-means Fuzzy c-means Mountain Clustering knn Fuzzy knn Hierarchical
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
Nonparametric Classification Methods
 Nonparametric Classification Methods We now examine some modern, computationally intensive methods for regression and classification. Recall that the LDA approach constructs a line (or plane or hyperplane)
Nonparametric Classification Methods We now examine some modern, computationally intensive methods for regression and classification. Recall that the LDA approach constructs a line (or plane or hyperplane)
CS5670: Computer Vision
 CS5670: Computer Vision Noah Snavely Lecture 33: Recognition Basics Slides from Andrej Karpathy and Fei-Fei Li http://vision.stanford.edu/teaching/cs231n/ Announcements Quiz moved to Tuesday Project 4
CS5670: Computer Vision Noah Snavely Lecture 33: Recognition Basics Slides from Andrej Karpathy and Fei-Fei Li http://vision.stanford.edu/teaching/cs231n/ Announcements Quiz moved to Tuesday Project 4
Decision Tree CE-717 : Machine Learning Sharif University of Technology
 Decision Tree CE-717 : Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Some slides have been adapted from: Prof. Tom Mitchell Decision tree Approximating functions of usually discrete
Decision Tree CE-717 : Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Some slides have been adapted from: Prof. Tom Mitchell Decision tree Approximating functions of usually discrete
Data Mining and Knowledge Discovery: Practice Notes
 Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2016/01/12 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2016/01/12 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
Part I. Instructor: Wei Ding
 Classification Part I Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Classification: Definition Given a collection of records (training set ) Each record contains a set
Classification Part I Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Classification: Definition Given a collection of records (training set ) Each record contains a set
PROBLEM 4
 PROBLEM 2 PROBLEM 4 PROBLEM 5 PROBLEM 6 PROBLEM 7 PROBLEM 8 PROBLEM 9 PROBLEM 10 PROBLEM 11 PROBLEM 12 PROBLEM 13 PROBLEM 14 PROBLEM 16 PROBLEM 17 PROBLEM 22 PROBLEM 23 PROBLEM 24 PROBLEM 25
PROBLEM 2 PROBLEM 4 PROBLEM 5 PROBLEM 6 PROBLEM 7 PROBLEM 8 PROBLEM 9 PROBLEM 10 PROBLEM 11 PROBLEM 12 PROBLEM 13 PROBLEM 14 PROBLEM 16 PROBLEM 17 PROBLEM 22 PROBLEM 23 PROBLEM 24 PROBLEM 25
Machine Learning (CSE 446): Concepts & the i.i.d. Supervised Learning Paradigm
: Concepts & the i.i.d. Supervised Learning Paradigm") Machine Learning (CSE 446): Concepts & the i.i.d. Supervised Learning Paradigm Sham M Kakade c 2018 University of Washington cse446-staff@cs.washington.edu 1 / 17 Review 1 / 17 Decision Tree: Making a
Machine Learning (CSE 446): Concepts & the i.i.d. Supervised Learning Paradigm Sham M Kakade c 2018 University of Washington cse446-staff@cs.washington.edu 1 / 17 Review 1 / 17 Decision Tree: Making a
7. Decision or classification trees
 7. Decision or classification trees Next we are going to consider a rather different approach from those presented so far to machine learning that use one of the most common and important data structure,
7. Decision or classification trees Next we are going to consider a rather different approach from those presented so far to machine learning that use one of the most common and important data structure,
Data Mining and Knowledge Discovery Practice notes: Numeric Prediction, Association Rules
 Keywords Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 06/0/ Data Attribute, example, attribute-value data, target variable, class, discretization Algorithms
Keywords Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 06/0/ Data Attribute, example, attribute-value data, target variable, class, discretization Algorithms
Data Mining and Knowledge Discovery: Practice Notes
 Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2016/01/12 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2016/01/12 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
CPSC 340: Machine Learning and Data Mining. Non-Parametric Models Fall 2016
 CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Assignment 0: Admin 1 late day to hand it in tonight, 2 late days for Wednesday. Assignment 1 is out: Due Friday of next week.
CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Assignment 0: Admin 1 late day to hand it in tonight, 2 late days for Wednesday. Assignment 1 is out: Due Friday of next week.
Classification. Instructor: Wei Ding
 Classification Decision Tree Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Preliminaries Each data record is characterized by a tuple (x, y), where x is the attribute
Classification Decision Tree Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Preliminaries Each data record is characterized by a tuple (x, y), where x is the attribute
9/6/14. Our first learning algorithm. Comp 135 Introduction to Machine Learning and Data Mining. knn Algorithm. knn Algorithm (simple form)
") Comp 135 Introduction to Machine Learning and Data Mining Our first learning algorithm How would you classify the next example? Fall 2014 Professor: Roni Khardon Computer Science Tufts University o o o
Comp 135 Introduction to Machine Learning and Data Mining Our first learning algorithm How would you classify the next example? Fall 2014 Professor: Roni Khardon Computer Science Tufts University o o o
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu [Kumar et al. 99] 2/13/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu [Kumar et al. 99] 2/13/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu
Intro to Artificial Intelligence
 Intro to Artificial Intelligence Ahmed Sallam { Lecture 5: Machine Learning ://. } ://.. 2 Review Probabilistic inference Enumeration Approximate inference 3 Today What is machine learning? Supervised
Intro to Artificial Intelligence Ahmed Sallam { Lecture 5: Machine Learning ://. } ://.. 2 Review Probabilistic inference Enumeration Approximate inference 3 Today What is machine learning? Supervised
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
CPSC 340: Machine Learning and Data Mining. Probabilistic Classification Fall 2017
 CPSC 340: Machine Learning and Data Mining Probabilistic Classification Fall 2017 Admin Assignment 0 is due tonight: you should be almost done. 1 late day to hand it in Monday, 2 late days for Wednesday.
CPSC 340: Machine Learning and Data Mining Probabilistic Classification Fall 2017 Admin Assignment 0 is due tonight: you should be almost done. 1 late day to hand it in Monday, 2 late days for Wednesday.
Lecture 3. Oct
 Lecture 3 Oct 3 2008 Review of last lecture A supervised learning example spam filter, and the design choices one need to make for this problem use bag-of-words to represent emails linear functions as
Lecture 3 Oct 3 2008 Review of last lecture A supervised learning example spam filter, and the design choices one need to make for this problem use bag-of-words to represent emails linear functions as
Lecture 6 K- Nearest Neighbors(KNN) And Predictive Accuracy
 And Predictive Accuracy") Lecture 6 K- Nearest Neighbors(KNN) And Predictive Accuracy Machine Learning Dr.Ammar Mohammed Nearest Neighbors Set of Stored Cases Atr1... AtrN Class A Store the training samples Use training samples
Lecture 6 K- Nearest Neighbors(KNN) And Predictive Accuracy Machine Learning Dr.Ammar Mohammed Nearest Neighbors Set of Stored Cases Atr1... AtrN Class A Store the training samples Use training samples
K- Nearest Neighbors(KNN) And Predictive Accuracy
 And Predictive Accuracy") Contact: mailto: Ammar@cu.edu.eg Drammarcu@gmail.com K- Nearest Neighbors(KNN) And Predictive Accuracy Dr. Ammar Mohammed Associate Professor of Computer Science ISSR, Cairo University PhD of CS ( Uni.
Contact: mailto: Ammar@cu.edu.eg Drammarcu@gmail.com K- Nearest Neighbors(KNN) And Predictive Accuracy Dr. Ammar Mohammed Associate Professor of Computer Science ISSR, Cairo University PhD of CS ( Uni.
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.4. Spring 2010 Instructor: Dr. Masoud Yaghini Outline Using IF-THEN Rules for Classification Rule Extraction from a Decision Tree 1R Algorithm Sequential Covering Algorithms
Data Mining Part 5. Prediction 5.4. Spring 2010 Instructor: Dr. Masoud Yaghini Outline Using IF-THEN Rules for Classification Rule Extraction from a Decision Tree 1R Algorithm Sequential Covering Algorithms
Nominal Data. May not have a numerical representation Distance measures might not make sense PR, ANN, & ML
 Decision Trees Nominal Data So far we consider patterns to be represented by feature vectors of real or integer values Easy to come up with a distance (similarity) measure by using a variety of mathematical
Decision Trees Nominal Data So far we consider patterns to be represented by feature vectors of real or integer values Easy to come up with a distance (similarity) measure by using a variety of mathematical
UVA CS 6316/4501 Fall 2016 Machine Learning. Lecture 15: K-nearest-neighbor Classifier / Bias-Variance Tradeoff. Dr. Yanjun Qi. University of Virginia
 UVA CS 6316/4501 Fall 2016 Machine Learning Lecture 15: K-nearest-neighbor Classifier / Bias-Variance Tradeoff Dr. Yanjun Qi University of Virginia Department of Computer Science 11/9/16 1 Rough Plan HW5
UVA CS 6316/4501 Fall 2016 Machine Learning Lecture 15: K-nearest-neighbor Classifier / Bias-Variance Tradeoff Dr. Yanjun Qi University of Virginia Department of Computer Science 11/9/16 1 Rough Plan HW5
1) Give decision trees to represent the following Boolean functions:
 Give decision trees to represent the following Boolean functions:") 1) Give decision trees to represent the following Boolean functions: 1) A B 2) A [B C] 3) A XOR B 4) [A B] [C Dl Answer: 1) A B 2) A [B C] 1 3) A XOR B = (A B) ( A B) 4) [A B] [C D] 2 2) Consider the following
1) Give decision trees to represent the following Boolean functions: 1) A B 2) A [B C] 3) A XOR B 4) [A B] [C Dl Answer: 1) A B 2) A [B C] 1 3) A XOR B = (A B) ( A B) 4) [A B] [C D] 2 2) Consider the following
PARALLEL CLASSIFICATION ALGORITHMS
 PARALLEL CLASSIFICATION ALGORITHMS By: Faiz Quraishi Riti Sharma 9 th May, 2013 OVERVIEW Introduction Types of Classification Linear Classification Support Vector Machines Parallel SVM Approach Decision
PARALLEL CLASSIFICATION ALGORITHMS By: Faiz Quraishi Riti Sharma 9 th May, 2013 OVERVIEW Introduction Types of Classification Linear Classification Support Vector Machines Parallel SVM Approach Decision
Chapter 2: Classification & Prediction
 Chapter 2: Classification & Prediction 2.1 Basic Concepts of Classification and Prediction 2.2 Decision Tree Induction 2.3 Bayes Classification Methods 2.4 Rule Based Classification 2.4.1 The principle
Chapter 2: Classification & Prediction 2.1 Basic Concepts of Classification and Prediction 2.2 Decision Tree Induction 2.3 Bayes Classification Methods 2.4 Rule Based Classification 2.4.1 The principle
MLCC 2018 Local Methods and Bias Variance Trade-Off. Lorenzo Rosasco UNIGE-MIT-IIT
 MLCC 2018 Local Methods and Bias Variance Trade-Off Lorenzo Rosasco UNIGE-MIT-IIT About this class 1. Introduce a basic class of learning methods, namely local methods. 2. Discuss the fundamental concept
MLCC 2018 Local Methods and Bias Variance Trade-Off Lorenzo Rosasco UNIGE-MIT-IIT About this class 1. Introduce a basic class of learning methods, namely local methods. 2. Discuss the fundamental concept
Lecture 19: Decision trees
 Lecture 19: Decision trees Reading: Section 8.1 STATS 202: Data mining and analysis November 10, 2017 1 / 17 Decision trees, 10,000 foot view R2 R5 t4 1. Find a partition of the space of predictors. X2
Lecture 19: Decision trees Reading: Section 8.1 STATS 202: Data mining and analysis November 10, 2017 1 / 17 Decision trees, 10,000 foot view R2 R5 t4 1. Find a partition of the space of predictors. X2
Text classification II CE-324: Modern Information Retrieval Sharif University of Technology
 Text classification II CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2015 Some slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Text classification II CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2015 Some slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Lecture 10 - Classification trees Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey
Knowledge Discovery and Data Mining Lecture 10 - Classification trees Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey
COMPUTATIONAL INTELLIGENCE SEW (INTRODUCTION TO MACHINE LEARNING) SS18. Lecture 6: k-nn Cross-validation Regularization
 SS18. Lecture 6: k-nn Cross-validation Regularization") COMPUTATIONAL INTELLIGENCE SEW (INTRODUCTION TO MACHINE LEARNING) SS18 Lecture 6: k-nn Cross-validation Regularization LEARNING METHODS Lazy vs eager learning Eager learning generalizes training data before
COMPUTATIONAL INTELLIGENCE SEW (INTRODUCTION TO MACHINE LEARNING) SS18 Lecture 6: k-nn Cross-validation Regularization LEARNING METHODS Lazy vs eager learning Eager learning generalizes training data before
Decision Trees Dr. G. Bharadwaja Kumar VIT Chennai
 Decision Trees Decision Tree Decision Trees (DTs) are a nonparametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target
Decision Trees Decision Tree Decision Trees (DTs) are a nonparametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target
Case-Based Reasoning. CS 188: Artificial Intelligence Fall Nearest-Neighbor Classification. Parametric / Non-parametric.
 CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008
 CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley 1 1 Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley 1 1 Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance