Perceptron: This is convolution!
|
|
|
- Alannah Barton
- 6 years ago
- Views:
Transcription

1

2

3

4

5 Perceptron: This is convolution!

6 v v v Shared weights v

7 Filter = local perceptron. Also called kernel.

8 By pooling responses at different locations, we gain robustness to the exact spatial location of image features.
9 AlexNet diagram (simplified) [Krizhevsky et al. 2012] Input size 227 x 227 x x3 Stride 2 3x3 Stride 2 Conv 1 11 x 11 x 3 Stride 4 96 filters Conv 2 5 x 5 x 96 Stride filters Conv 3 3 x 3 x 256 Stride filters Conv 4 3 x 3 x 192 Stride filters Conv 4 3 x 3 x 192 Stride filters

10
11 Training Neural Networks Learning the weight matrices W
12 Gradient descent f(x) x
13 General approach Pick random starting point. f(x) a 1 x
14 General approach Compute gradient at point (analytically or by finite differences) f(x) f(a 1 ) a 1 x
15 General approach Move along parameter space in direction of negative gradient f(x) a 2 = a 1 γ f a 1 γ = amount to move = learning rate a 1 a 2 x
16 General approach Move along parameter space in direction of negative gradient. f(x) a 3 = a 2 γ f a 2 γ = amount to move = learning rate a 1 a 2 a 3 x
17 General approach Stop when we don t move any more. f(x) a stop : a n 1 γ f a n 1 = 0 a 1 a 2 a 3 a stop x
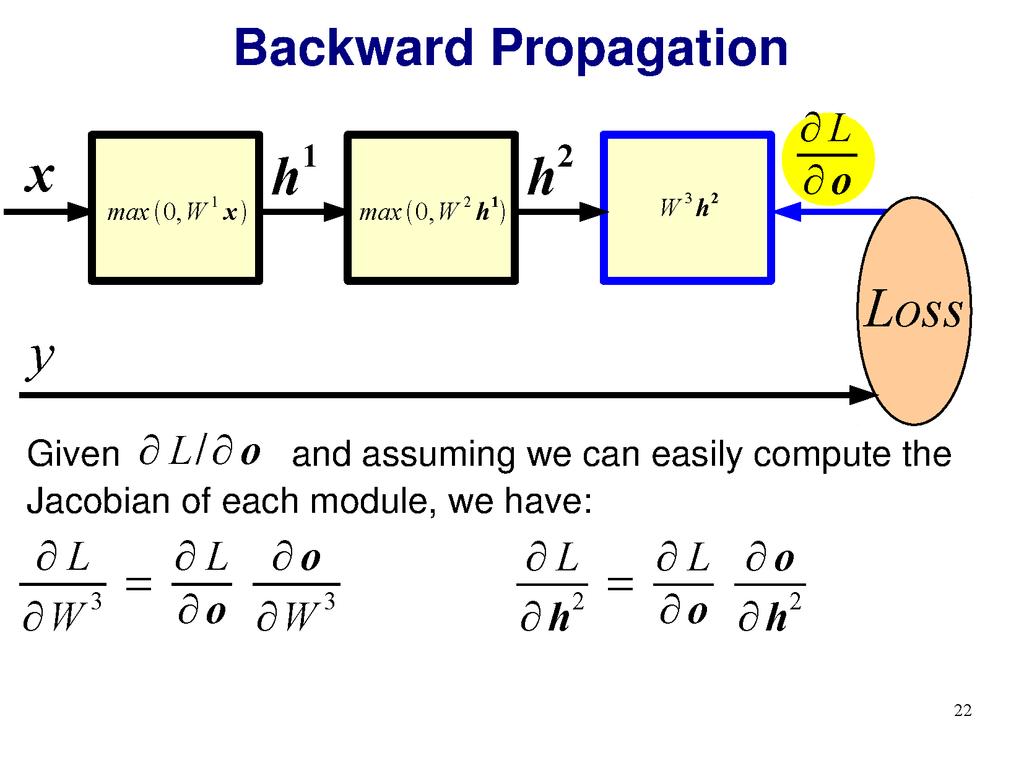
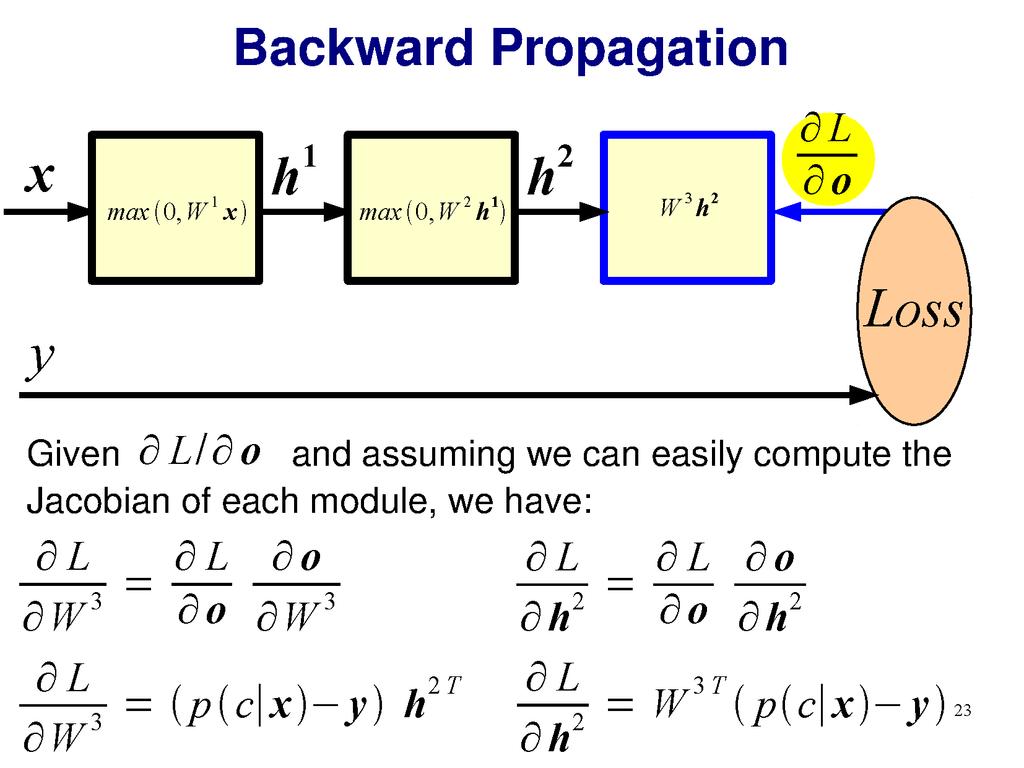
18 Gradient descent Optimizer for functions. Guaranteed to find optimum for convex functions. Non-convex = find local optimum. Most vision problems aren t convex. f(x) Works for multi-variate functions. Need to compute matrix of partial derivatives ( Jacobian ) x
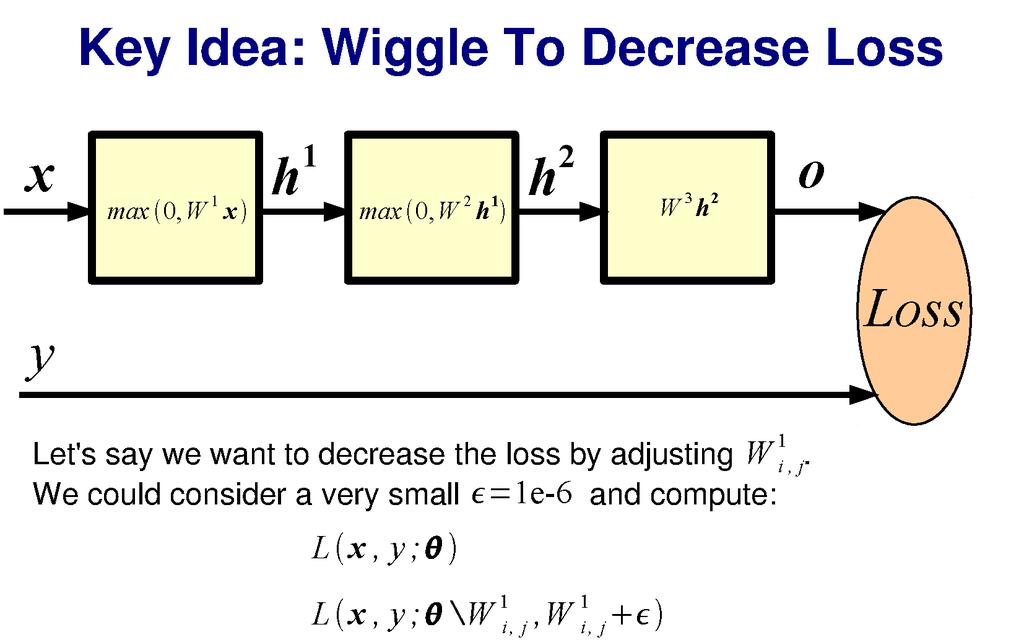
19 Train NN with Gradient Descent x i, y i = n training examples f x = feed forward neural network L(x, y; θ) = some loss function Loss function measures how good our network is at classifying the training examples wrt. the parameters of the model (the perceptron weights).
20 Train NN with Gradient Descent Loss function (Evaluate NN on training data) a 1 a 2 a 3 a stop Model parameters (perceptron weights)
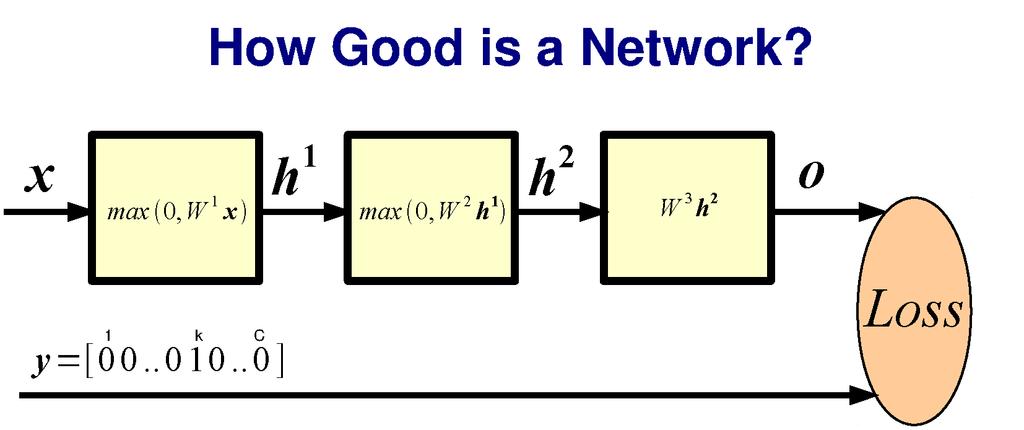
21 utput
22 What is an appropriate loss? Define some output threshold on detection Classification: compare training class to output class Zero-one loss L (per class) y = true label y = predicted label Is it good? Nope it s a step function. I need to compute the gradient of the loss. This loss is not differentiable, and flips easily.
23 Classification has binary outputs Special function on last layer - Softmax : "squashes" a C-dimensional vector O of arbitrary real values to a C-dimensional vector σ(o) of real values in the range (0, 1) that add up to 1. Turns the output into a probability distribution on classes.

24 Softmax utput Softmax
25 Cross-entropy loss function Negative log-likelihood L x, y; θ = j y j log p(c j x) Is it a good loss? Differentiable Cost decreases as probability increases L p(c j x)

26 utput Softmax
27
28
29

30
31
32
33
34
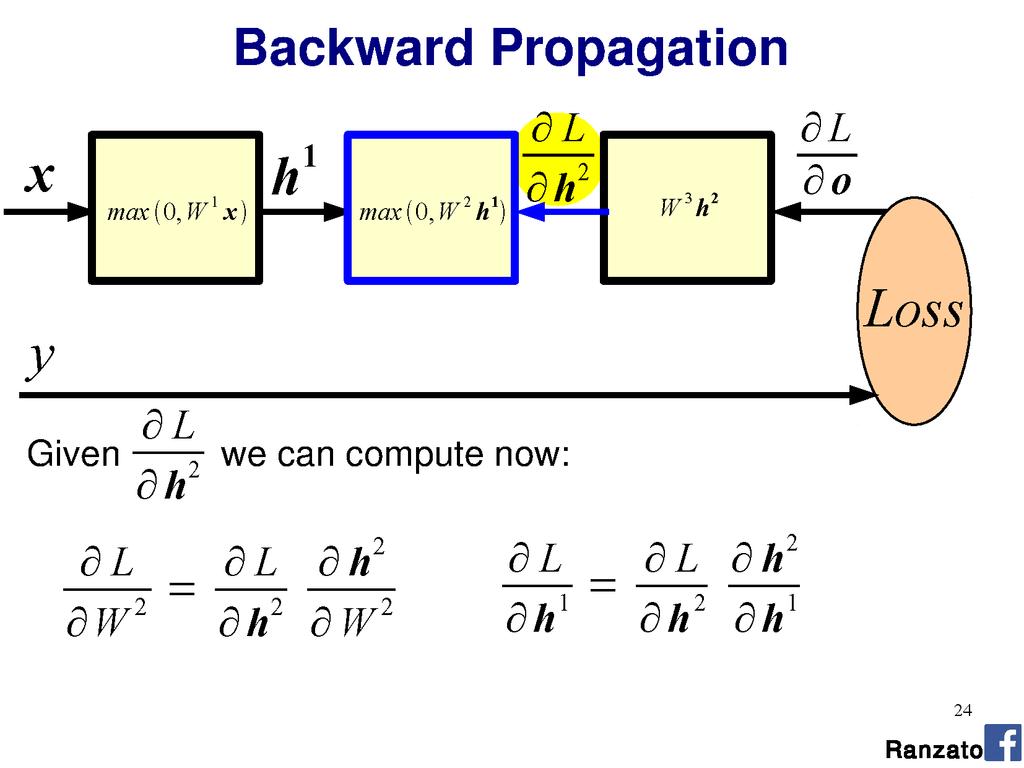
35
36

37
38 But the ReLU is not differentiable at 0! Right. Fudge! - 0 is the best place for this to occur, because we don t care about the result (it is no activation). - Dead perceptrons - ReLU has unbounded positive response: - Potential faster convergence / overstep
39
40 Optimization demo Thank you Matt Mazur
41
42 Stochastic Gradient Descent Dataset can be too large to strictly apply gradient descent. Instead, randomly sample a data point, perform gradient descent per point, and iterate. True gradient is approximated only Picking a subset of points: mini-batch Pick starting W and learning rate γ While not at minimum: Shuffle training set For each data point i=1 n (maybe as mini-batch) Gradient descent Epoch

43 Stochastic Gradient Descent Loss will not always decrease (locally) as training data point is random. Still converges over time. Wikipedia
44 Gradient descent oscillations Wikipedia
45 Gradient descent oscillations Slow to converge to the (local) optimum Wikipedia
46 Momentum Adjust the gradient by a weighted sum of the previous amount plus the current amount. Without momentum: θ t+1 = θ t γ L θ With momentum (new α parameter): θ t+1 = θ t γ α L θ t 1 + L θ t
47 But James I thought we were going to treat machine learning like a black box? I like black boxes. Deep learning is: - a black box Training data Classifier

48 But James I thought we were going to treat machine learning like a black box? I like black boxes. Deep learning is: - a black box - also a black art.
49 But James I thought we were going to treat machine learning like a black box? I like black boxes. Many approaches and hyperparameters: Activation functions, learning rate, mini-batch size, momentum Often these need tweaking, and you need to know what they do to change them intelligently.
50 Nailing hyperparameters + trade-offs
51 Lowering the learning rate = smaller steps in SGD -Less ping pong -Takes longer to get to the optimum Wikipedia


52 Flat regions in energy landscape
53 Problem of fitting Too many parameters = overfitting Not enough parameters = underfitting More data = less chance to overfit How do we know what is required?
54 Regularization Attempt to guide solution to not overfit But still give freedom with many parameters
55 Data fitting problem [Nielson]
56 Which is better? Which is better a priori? 9 th order polynomial 1 st order polynomial [Nielson]
57 Regularization Attempt to guide solution to not overfit But still give freedom with many parameters Idea: Penalize the use of parameters to prefer small weights.
58 Regularization: Idea: add a cost to having high weights λ = regularization parameter λ [Nielson]
59 Both can describe the data but one is simpler. Occam s razor: Among competing hypotheses, the one with the fewest assumptions should be selected For us: Large weights cause large changes in behaviour in response to small changes in the input. Simpler models (or smaller changes) are more robust to noise.
60 Regularization Idea: add a cost to having high weights λ = regularization parameter λ λ Normal cross-entropy loss (binary classes) Regularization term [Nielson]

61 Regularization: Dropout Our networks typically start with random weights. Every time we train = slightly different outcome. Why random weights? If weights are all equal, response across filters will be equivalent. Network doesn t train. [Nielson]
62 Regularization Our networks typically start with random weights. Every time we train = slightly different outcome. Why not train 5 different networks with random starts and vote on their outcome? Works fine! Helps generalization because error is averaged.
63 Regularization: Dropout [Nielson]
64 Regularization: Dropout At each mini-batch: - Randomly select a subset of neurons. - Ignore them. On test: half weights outgoing to compensate for training on half neurons. Effect: - Neurons become less dependent on output of connected neurons. - Forces network to learn more robust features that are useful to more subsets of neurons. - Like averaging over many different trained networks with different random initializations. - Except cheaper to train. [Nielson]
65 Many forms of regularization Adding more data is a kind of regularization Pooling is a kind of regularization Data augmentation is a kind of regularization
Deep Learning with Tensorflow AlexNet
 Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Deep Learning for Computer Vision II
 IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
Improving the way neural networks learn Srikumar Ramalingam School of Computing University of Utah
 Improving the way neural networks learn Srikumar Ramalingam School of Computing University of Utah Reference Most of the slides are taken from the third chapter of the online book by Michael Nielson: neuralnetworksanddeeplearning.com
Improving the way neural networks learn Srikumar Ramalingam School of Computing University of Utah Reference Most of the slides are taken from the third chapter of the online book by Michael Nielson: neuralnetworksanddeeplearning.com
Deep Learning. Vladimir Golkov Technical University of Munich Computer Vision Group
 Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
Deep Neural Networks Optimization
 Deep Neural Networks Optimization Creative Commons (cc) by Akritasa http://arxiv.org/pdf/1406.2572.pdf Slides from Geoffrey Hinton CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy
Deep Neural Networks Optimization Creative Commons (cc) by Akritasa http://arxiv.org/pdf/1406.2572.pdf Slides from Geoffrey Hinton CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy
Lecture 37: ConvNets (Cont d) and Training
 and Training") Lecture 37: ConvNets (Cont d) and Training CS 4670/5670 Sean Bell [http://bbabenko.tumblr.com/post/83319141207/convolutional-learnings-things-i-learned-by] (Unrelated) Dog vs Food [Karen Zack, @teenybiscuit]
Lecture 37: ConvNets (Cont d) and Training CS 4670/5670 Sean Bell [http://bbabenko.tumblr.com/post/83319141207/convolutional-learnings-things-i-learned-by] (Unrelated) Dog vs Food [Karen Zack, @teenybiscuit]
COMP 551 Applied Machine Learning Lecture 16: Deep Learning
 COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
COMP9444 Neural Networks and Deep Learning 7. Image Processing. COMP9444 c Alan Blair, 2017
 COMP9444 Neural Networks and Deep Learning 7. Image Processing COMP9444 17s2 Image Processing 1 Outline Image Datasets and Tasks Convolution in Detail AlexNet Weight Initialization Batch Normalization
COMP9444 Neural Networks and Deep Learning 7. Image Processing COMP9444 17s2 Image Processing 1 Outline Image Datasets and Tasks Convolution in Detail AlexNet Weight Initialization Batch Normalization
Deep Learning Cook Book
 Deep Learning Cook Book Robert Haschke (CITEC) Overview Input Representation Output Layer + Cost Function Hidden Layer Units Initialization Regularization Input representation Choose an input representation
Deep Learning Cook Book Robert Haschke (CITEC) Overview Input Representation Output Layer + Cost Function Hidden Layer Units Initialization Regularization Input representation Choose an input representation
DECISION TREES & RANDOM FORESTS X CONVOLUTIONAL NEURAL NETWORKS
 DECISION TREES & RANDOM FORESTS X CONVOLUTIONAL NEURAL NETWORKS Deep Neural Decision Forests Microsoft Research Cambridge UK, ICCV 2015 Decision Forests, Convolutional Networks and the Models in-between
DECISION TREES & RANDOM FORESTS X CONVOLUTIONAL NEURAL NETWORKS Deep Neural Decision Forests Microsoft Research Cambridge UK, ICCV 2015 Decision Forests, Convolutional Networks and the Models in-between
Deep Learning and Its Applications
 Convolutional Neural Network and Its Application in Image Recognition Oct 28, 2016 Outline 1 A Motivating Example 2 The Convolutional Neural Network (CNN) Model 3 Training the CNN Model 4 Issues and Recent
Convolutional Neural Network and Its Application in Image Recognition Oct 28, 2016 Outline 1 A Motivating Example 2 The Convolutional Neural Network (CNN) Model 3 Training the CNN Model 4 Issues and Recent
CMU Lecture 18: Deep learning and Vision: Convolutional neural networks. Teacher: Gianni A. Di Caro
 CMU 15-781 Lecture 18: Deep learning and Vision: Convolutional neural networks Teacher: Gianni A. Di Caro DEEP, SHALLOW, CONNECTED, SPARSE? Fully connected multi-layer feed-forward perceptrons: More powerful
CMU 15-781 Lecture 18: Deep learning and Vision: Convolutional neural networks Teacher: Gianni A. Di Caro DEEP, SHALLOW, CONNECTED, SPARSE? Fully connected multi-layer feed-forward perceptrons: More powerful
Deep Learning. Visualizing and Understanding Convolutional Networks. Christopher Funk. Pennsylvania State University.
 Visualizing and Understanding Convolutional Networks Christopher Pennsylvania State University February 23, 2015 Some Slide Information taken from Pierre Sermanet (Google) presentation on and Computer
Visualizing and Understanding Convolutional Networks Christopher Pennsylvania State University February 23, 2015 Some Slide Information taken from Pierre Sermanet (Google) presentation on and Computer
Neural Network Optimization and Tuning / Spring 2018 / Recitation 3
 Neural Network Optimization and Tuning 11-785 / Spring 2018 / Recitation 3 1 Logistics You will work through a Jupyter notebook that contains sample and starter code with explanations and comments throughout.
Neural Network Optimization and Tuning 11-785 / Spring 2018 / Recitation 3 1 Logistics You will work through a Jupyter notebook that contains sample and starter code with explanations and comments throughout.
CS489/698: Intro to ML
 CS489/698: Intro to ML Lecture 14: Training of Deep NNs Instructor: Sun Sun 1 Outline Activation functions Regularization Gradient-based optimization 2 Examples of activation functions 3 5/28/18 Sun Sun
CS489/698: Intro to ML Lecture 14: Training of Deep NNs Instructor: Sun Sun 1 Outline Activation functions Regularization Gradient-based optimization 2 Examples of activation functions 3 5/28/18 Sun Sun
Machine Learning. MGS Lecture 3: Deep Learning
 Dr Michel F. Valstar http://cs.nott.ac.uk/~mfv/ Machine Learning MGS Lecture 3: Deep Learning Dr Michel F. Valstar http://cs.nott.ac.uk/~mfv/ WHAT IS DEEP LEARNING? Shallow network: Only one hidden layer
Dr Michel F. Valstar http://cs.nott.ac.uk/~mfv/ Machine Learning MGS Lecture 3: Deep Learning Dr Michel F. Valstar http://cs.nott.ac.uk/~mfv/ WHAT IS DEEP LEARNING? Shallow network: Only one hidden layer
All You Want To Know About CNNs. Yukun Zhu
 All You Want To Know About CNNs Yukun Zhu Deep Learning Deep Learning Image from http://imgur.com/ Deep Learning Image from http://imgur.com/ Deep Learning Image from http://imgur.com/ Deep Learning Image
All You Want To Know About CNNs Yukun Zhu Deep Learning Deep Learning Image from http://imgur.com/ Deep Learning Image from http://imgur.com/ Deep Learning Image from http://imgur.com/ Deep Learning Image
CSE 559A: Computer Vision
 CSE 559A: Computer Vision Fall 2018: T-R: 11:30-1pm @ Lopata 101 Instructor: Ayan Chakrabarti (ayan@wustl.edu). Course Staff: Zhihao Xia, Charlie Wu, Han Liu http://www.cse.wustl.edu/~ayan/courses/cse559a/
CSE 559A: Computer Vision Fall 2018: T-R: 11:30-1pm @ Lopata 101 Instructor: Ayan Chakrabarti (ayan@wustl.edu). Course Staff: Zhihao Xia, Charlie Wu, Han Liu http://www.cse.wustl.edu/~ayan/courses/cse559a/
Deep neural networks II
 Deep neural networks II May 31 st, 2018 Yong Jae Lee UC Davis Many slides from Rob Fergus, Svetlana Lazebnik, Jia-Bin Huang, Derek Hoiem, Adriana Kovashka, Why (convolutional) neural networks? State of
Deep neural networks II May 31 st, 2018 Yong Jae Lee UC Davis Many slides from Rob Fergus, Svetlana Lazebnik, Jia-Bin Huang, Derek Hoiem, Adriana Kovashka, Why (convolutional) neural networks? State of
Neural Networks. CE-725: Statistical Pattern Recognition Sharif University of Technology Spring Soleymani
 Neural Networks CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Biological and artificial neural networks Feed-forward neural networks Single layer
Neural Networks CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Biological and artificial neural networks Feed-forward neural networks Single layer
Lecture 20: Neural Networks for NLP. Zubin Pahuja
 Lecture 20: Neural Networks for NLP Zubin Pahuja zpahuja2@illinois.edu courses.engr.illinois.edu/cs447 CS447: Natural Language Processing 1 Today s Lecture Feed-forward neural networks as classifiers simple
Lecture 20: Neural Networks for NLP Zubin Pahuja zpahuja2@illinois.edu courses.engr.illinois.edu/cs447 CS447: Natural Language Processing 1 Today s Lecture Feed-forward neural networks as classifiers simple
The exam is closed book, closed notes except your one-page (two-sided) cheat sheet.
 cheat sheet.") CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
ImageNet Classification with Deep Convolutional Neural Networks
 ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky Ilya Sutskever Geoffrey Hinton University of Toronto Canada Paper with same name to appear in NIPS 2012 Main idea Architecture
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky Ilya Sutskever Geoffrey Hinton University of Toronto Canada Paper with same name to appear in NIPS 2012 Main idea Architecture
Deep Learning for Computer Vision
 Deep Learning for Computer Vision Lecture 7: Universal Approximation Theorem, More Hidden Units, Multi-Class Classifiers, Softmax, and Regularization Peter Belhumeur Computer Science Columbia University
Deep Learning for Computer Vision Lecture 7: Universal Approximation Theorem, More Hidden Units, Multi-Class Classifiers, Softmax, and Regularization Peter Belhumeur Computer Science Columbia University
A Brief Look at Optimization
 A Brief Look at Optimization CSC 412/2506 Tutorial David Madras January 18, 2018 Slides adapted from last year s version Overview Introduction Classes of optimization problems Linear programming Steepest
A Brief Look at Optimization CSC 412/2506 Tutorial David Madras January 18, 2018 Slides adapted from last year s version Overview Introduction Classes of optimization problems Linear programming Steepest
Global Optimality in Neural Network Training
 Global Optimality in Neural Network Training Benjamin D. Haeffele and René Vidal Johns Hopkins University, Center for Imaging Science. Baltimore, USA Questions in Deep Learning Architecture Design Optimization
Global Optimality in Neural Network Training Benjamin D. Haeffele and René Vidal Johns Hopkins University, Center for Imaging Science. Baltimore, USA Questions in Deep Learning Architecture Design Optimization
Intro to Deep Learning. Slides Credit: Andrej Karapathy, Derek Hoiem, Marc Aurelio, Yann LeCunn
 Intro to Deep Learning Slides Credit: Andrej Karapathy, Derek Hoiem, Marc Aurelio, Yann LeCunn Why this class? Deep Features Have been able to harness the big data in the most efficient and effective
Intro to Deep Learning Slides Credit: Andrej Karapathy, Derek Hoiem, Marc Aurelio, Yann LeCunn Why this class? Deep Features Have been able to harness the big data in the most efficient and effective
Research on Pruning Convolutional Neural Network, Autoencoder and Capsule Network
 Research on Pruning Convolutional Neural Network, Autoencoder and Capsule Network Tianyu Wang Australia National University, Colledge of Engineering and Computer Science u@anu.edu.au Abstract. Some tasks,
Research on Pruning Convolutional Neural Network, Autoencoder and Capsule Network Tianyu Wang Australia National University, Colledge of Engineering and Computer Science u@anu.edu.au Abstract. Some tasks,
CPSC 340: Machine Learning and Data Mining. More Linear Classifiers Fall 2017
 CPSC 340: Machine Learning and Data Mining More Linear Classifiers Fall 2017 Admin Assignment 3: Due Friday of next week. Midterm: Can view your exam during instructor office hours next week, or after
CPSC 340: Machine Learning and Data Mining More Linear Classifiers Fall 2017 Admin Assignment 3: Due Friday of next week. Midterm: Can view your exam during instructor office hours next week, or after
Knowledge Discovery and Data Mining. Neural Nets. A simple NN as a Mathematical Formula. Notes. Lecture 13 - Neural Nets. Tom Kelsey.
 Knowledge Discovery and Data Mining Lecture 13 - Neural Nets Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey ID5059-13-NN
Knowledge Discovery and Data Mining Lecture 13 - Neural Nets Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey ID5059-13-NN
CPSC 340: Machine Learning and Data Mining. Deep Learning Fall 2016
 CPSC 340: Machine Learning and Data Mining Deep Learning Fall 2016 Assignment 5: Due Friday. Assignment 6: Due next Friday. Final: Admin December 12 (8:30am HEBB 100) Covers Assignments 1-6. Final from
CPSC 340: Machine Learning and Data Mining Deep Learning Fall 2016 Assignment 5: Due Friday. Assignment 6: Due next Friday. Final: Admin December 12 (8:30am HEBB 100) Covers Assignments 1-6. Final from
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Lecture 13 - Neural Nets Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey ID5059-13-NN
Knowledge Discovery and Data Mining Lecture 13 - Neural Nets Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey ID5059-13-NN
Machine Learning. Topic 5: Linear Discriminants. Bryan Pardo, EECS 349 Machine Learning, 2013
 Machine Learning Topic 5: Linear Discriminants Bryan Pardo, EECS 349 Machine Learning, 2013 Thanks to Mark Cartwright for his extensive contributions to these slides Thanks to Alpaydin, Bishop, and Duda/Hart/Stork
Machine Learning Topic 5: Linear Discriminants Bryan Pardo, EECS 349 Machine Learning, 2013 Thanks to Mark Cartwright for his extensive contributions to these slides Thanks to Alpaydin, Bishop, and Duda/Hart/Stork
Fuzzy Set Theory in Computer Vision: Example 3, Part II
 Fuzzy Set Theory in Computer Vision: Example 3, Part II Derek T. Anderson and James M. Keller FUZZ-IEEE, July 2017 Overview Resource; CS231n: Convolutional Neural Networks for Visual Recognition https://github.com/tuanavu/stanford-
Fuzzy Set Theory in Computer Vision: Example 3, Part II Derek T. Anderson and James M. Keller FUZZ-IEEE, July 2017 Overview Resource; CS231n: Convolutional Neural Networks for Visual Recognition https://github.com/tuanavu/stanford-
Dynamic Routing Between Capsules
 Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
SEMANTIC COMPUTING. Lecture 8: Introduction to Deep Learning. TU Dresden, 7 December Dagmar Gromann International Center For Computational Logic
 SEMANTIC COMPUTING Lecture 8: Introduction to Deep Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 7 December 2018 Overview Introduction Deep Learning General Neural Networks
SEMANTIC COMPUTING Lecture 8: Introduction to Deep Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 7 December 2018 Overview Introduction Deep Learning General Neural Networks
Face Recognition A Deep Learning Approach
 Face Recognition A Deep Learning Approach Lihi Shiloh Tal Perl Deep Learning Seminar 2 Outline What about Cat recognition? Classical face recognition Modern face recognition DeepFace FaceNet Comparison
Face Recognition A Deep Learning Approach Lihi Shiloh Tal Perl Deep Learning Seminar 2 Outline What about Cat recognition? Classical face recognition Modern face recognition DeepFace FaceNet Comparison
Deep Learning. Practical introduction with Keras JORDI TORRES 27/05/2018. Chapter 3 JORDI TORRES
 Deep Learning Practical introduction with Keras Chapter 3 27/05/2018 Neuron A neural network is formed by neurons connected to each other; in turn, each connection of one neural network is associated
Deep Learning Practical introduction with Keras Chapter 3 27/05/2018 Neuron A neural network is formed by neurons connected to each other; in turn, each connection of one neural network is associated
SEMANTIC COMPUTING. Lecture 9: Deep Learning: Recurrent Neural Networks (RNNs) TU Dresden, 21 December 2018
 TU Dresden, 21 December 2018") SEMANTIC COMPUTING Lecture 9: Deep Learning: Recurrent Neural Networks (RNNs) Dagmar Gromann International Center For Computational Logic TU Dresden, 21 December 2018 Overview Handling Overfitting Recurrent
SEMANTIC COMPUTING Lecture 9: Deep Learning: Recurrent Neural Networks (RNNs) Dagmar Gromann International Center For Computational Logic TU Dresden, 21 December 2018 Overview Handling Overfitting Recurrent
Index. Umberto Michelucci 2018 U. Michelucci, Applied Deep Learning,
 A Acquisition function, 298, 301 Adam optimizer, 175 178 Anaconda navigator conda command, 3 Create button, 5 download and install, 1 installing packages, 8 Jupyter Notebook, 11 13 left navigation pane,
A Acquisition function, 298, 301 Adam optimizer, 175 178 Anaconda navigator conda command, 3 Create button, 5 download and install, 1 installing packages, 8 Jupyter Notebook, 11 13 left navigation pane,
Machine Learning 13. week
 Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Como funciona o Deep Learning
 Como funciona o Deep Learning Moacir Ponti (com ajuda de Gabriel Paranhos da Costa) ICMC, Universidade de São Paulo Contact: www.icmc.usp.br/~moacir moacir@icmc.usp.br Uberlandia-MG/Brazil October, 2017
Como funciona o Deep Learning Moacir Ponti (com ajuda de Gabriel Paranhos da Costa) ICMC, Universidade de São Paulo Contact: www.icmc.usp.br/~moacir moacir@icmc.usp.br Uberlandia-MG/Brazil October, 2017
Deep Learning for Embedded Security Evaluation
 Deep Learning for Embedded Security Evaluation Emmanuel Prouff 1 1 Laboratoire de Sécurité des Composants, ANSSI, France April 2018, CISCO April 2018, CISCO E. Prouff 1/22 Contents 1. Context and Motivation
Deep Learning for Embedded Security Evaluation Emmanuel Prouff 1 1 Laboratoire de Sécurité des Composants, ANSSI, France April 2018, CISCO April 2018, CISCO E. Prouff 1/22 Contents 1. Context and Motivation
Report: Privacy-Preserving Classification on Deep Neural Network
 Report: Privacy-Preserving Classification on Deep Neural Network Janno Veeorg Supervised by Helger Lipmaa and Raul Vicente Zafra May 25, 2017 1 Introduction In this report we consider following task: how
Report: Privacy-Preserving Classification on Deep Neural Network Janno Veeorg Supervised by Helger Lipmaa and Raul Vicente Zafra May 25, 2017 1 Introduction In this report we consider following task: how
Logistic Regression and Gradient Ascent
 Logistic Regression and Gradient Ascent CS 349-02 (Machine Learning) April 0, 207 The perceptron algorithm has a couple of issues: () the predictions have no probabilistic interpretation or confidence
Logistic Regression and Gradient Ascent CS 349-02 (Machine Learning) April 0, 207 The perceptron algorithm has a couple of issues: () the predictions have no probabilistic interpretation or confidence
How Learning Differs from Optimization. Sargur N. Srihari
 How Learning Differs from Optimization Sargur N. srihari@cedar.buffalo.edu 1 Topics in Optimization Optimization for Training Deep Models: Overview How learning differs from optimization Risk, empirical
How Learning Differs from Optimization Sargur N. srihari@cedar.buffalo.edu 1 Topics in Optimization Optimization for Training Deep Models: Overview How learning differs from optimization Risk, empirical
Ensemble methods in machine learning. Example. Neural networks. Neural networks
 Ensemble methods in machine learning Bootstrap aggregating (bagging) train an ensemble of models based on randomly resampled versions of the training set, then take a majority vote Example What if you
Ensemble methods in machine learning Bootstrap aggregating (bagging) train an ensemble of models based on randomly resampled versions of the training set, then take a majority vote Example What if you
CS 179 Lecture 16. Logistic Regression & Parallel SGD
 CS 179 Lecture 16 Logistic Regression & Parallel SGD 1 Outline logistic regression (stochastic) gradient descent parallelizing SGD for neural nets (with emphasis on Google s distributed neural net implementation)
CS 179 Lecture 16 Logistic Regression & Parallel SGD 1 Outline logistic regression (stochastic) gradient descent parallelizing SGD for neural nets (with emphasis on Google s distributed neural net implementation)
The exam is closed book, closed notes except your one-page cheat sheet.
 CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
CS 6501: Deep Learning for Computer Graphics. Training Neural Networks II. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Training Neural Networks II Connelly Barnes Overview Preprocessing Initialization Vanishing/exploding gradients problem Batch normalization Dropout Additional
CS 6501: Deep Learning for Computer Graphics Training Neural Networks II Connelly Barnes Overview Preprocessing Initialization Vanishing/exploding gradients problem Batch normalization Dropout Additional
Logistic Regression. Abstract
 Logistic Regression Tsung-Yi Lin, Chen-Yu Lee Department of Electrical and Computer Engineering University of California, San Diego {tsl008, chl60}@ucsd.edu January 4, 013 Abstract Logistic regression
Logistic Regression Tsung-Yi Lin, Chen-Yu Lee Department of Electrical and Computer Engineering University of California, San Diego {tsl008, chl60}@ucsd.edu January 4, 013 Abstract Logistic regression
Notes on Multilayer, Feedforward Neural Networks
 Notes on Multilayer, Feedforward Neural Networks CS425/528: Machine Learning Fall 2012 Prepared by: Lynne E. Parker [Material in these notes was gleaned from various sources, including E. Alpaydin s book
Notes on Multilayer, Feedforward Neural Networks CS425/528: Machine Learning Fall 2012 Prepared by: Lynne E. Parker [Material in these notes was gleaned from various sources, including E. Alpaydin s book
Hyperparameter optimization. CS6787 Lecture 6 Fall 2017
 Hyperparameter optimization CS6787 Lecture 6 Fall 2017 Review We ve covered many methods Stochastic gradient descent Step size/learning rate, how long to run Mini-batching Batch size Momentum Momentum
Hyperparameter optimization CS6787 Lecture 6 Fall 2017 Review We ve covered many methods Stochastic gradient descent Step size/learning rate, how long to run Mini-batching Batch size Momentum Momentum
A Deep Learning Approach to Vehicle Speed Estimation
 A Deep Learning Approach to Vehicle Speed Estimation Benjamin Penchas bpenchas@stanford.edu Tobin Bell tbell@stanford.edu Marco Monteiro marcorm@stanford.edu ABSTRACT Given car dashboard video footage,
A Deep Learning Approach to Vehicle Speed Estimation Benjamin Penchas bpenchas@stanford.edu Tobin Bell tbell@stanford.edu Marco Monteiro marcorm@stanford.edu ABSTRACT Given car dashboard video footage,
Lecture 2 Notes. Outline. Neural Networks. The Big Idea. Architecture. Instructors: Parth Shah, Riju Pahwa
 Instructors: Parth Shah, Riju Pahwa Lecture 2 Notes Outline 1. Neural Networks The Big Idea Architecture SGD and Backpropagation 2. Convolutional Neural Networks Intuition Architecture 3. Recurrent Neural
Instructors: Parth Shah, Riju Pahwa Lecture 2 Notes Outline 1. Neural Networks The Big Idea Architecture SGD and Backpropagation 2. Convolutional Neural Networks Intuition Architecture 3. Recurrent Neural
Neural Network Learning. Today s Lecture. Continuation of Neural Networks. Artificial Neural Networks. Lecture 24: Learning 3. Victor R.
 Lecture 24: Learning 3 Victor R. Lesser CMPSCI 683 Fall 2010 Today s Lecture Continuation of Neural Networks Artificial Neural Networks Compose of nodes/units connected by links Each link has a numeric
Lecture 24: Learning 3 Victor R. Lesser CMPSCI 683 Fall 2010 Today s Lecture Continuation of Neural Networks Artificial Neural Networks Compose of nodes/units connected by links Each link has a numeric
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
Keras: Handwritten Digit Recognition using MNIST Dataset
 Keras: Handwritten Digit Recognition using MNIST Dataset IIT PATNA January 31, 2018 1 / 30 OUTLINE 1 Keras: Introduction 2 Installing Keras 3 Keras: Building, Testing, Improving A Simple Network 2 / 30
Keras: Handwritten Digit Recognition using MNIST Dataset IIT PATNA January 31, 2018 1 / 30 OUTLINE 1 Keras: Introduction 2 Installing Keras 3 Keras: Building, Testing, Improving A Simple Network 2 / 30
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
CS 1674: Intro to Computer Vision. Neural Networks. Prof. Adriana Kovashka University of Pittsburgh November 16, 2016
 CS 1674: Intro to Computer Vision Neural Networks Prof. Adriana Kovashka University of Pittsburgh November 16, 2016 Announcements Please watch the videos I sent you, if you haven t yet (that s your reading)
CS 1674: Intro to Computer Vision Neural Networks Prof. Adriana Kovashka University of Pittsburgh November 16, 2016 Announcements Please watch the videos I sent you, if you haven t yet (that s your reading)
Mini-project 2 CMPSCI 689 Spring 2015 Due: Tuesday, April 07, in class
 Mini-project 2 CMPSCI 689 Spring 2015 Due: Tuesday, April 07, in class Guidelines Submission. Submit a hardcopy of the report containing all the figures and printouts of code in class. For readability
Mini-project 2 CMPSCI 689 Spring 2015 Due: Tuesday, April 07, in class Guidelines Submission. Submit a hardcopy of the report containing all the figures and printouts of code in class. For readability
Perceptron Introduction to Machine Learning. Matt Gormley Lecture 5 Jan. 31, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Perceptron Matt Gormley Lecture 5 Jan. 31, 2018 1 Q&A Q: We pick the best hyperparameters
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Perceptron Matt Gormley Lecture 5 Jan. 31, 2018 1 Q&A Q: We pick the best hyperparameters
6. Linear Discriminant Functions
 6. Linear Discriminant Functions Linear Discriminant Functions Assumption: we know the proper forms for the discriminant functions, and use the samples to estimate the values of parameters of the classifier
6. Linear Discriminant Functions Linear Discriminant Functions Assumption: we know the proper forms for the discriminant functions, and use the samples to estimate the values of parameters of the classifier
Alternatives to Direct Supervision
 CreativeAI: Deep Learning for Graphics Alternatives to Direct Supervision Niloy Mitra Iasonas Kokkinos Paul Guerrero Nils Thuerey Tobias Ritschel UCL UCL UCL TUM UCL Timetable Theory and Basics State of
CreativeAI: Deep Learning for Graphics Alternatives to Direct Supervision Niloy Mitra Iasonas Kokkinos Paul Guerrero Nils Thuerey Tobias Ritschel UCL UCL UCL TUM UCL Timetable Theory and Basics State of
Lecture #11: The Perceptron
 Lecture #11: The Perceptron Mat Kallada STAT2450 - Introduction to Data Mining Outline for Today Welcome back! Assignment 3 The Perceptron Learning Method Perceptron Learning Rule Assignment 3 Will be
Lecture #11: The Perceptron Mat Kallada STAT2450 - Introduction to Data Mining Outline for Today Welcome back! Assignment 3 The Perceptron Learning Method Perceptron Learning Rule Assignment 3 Will be
COMP 551 Applied Machine Learning Lecture 14: Neural Networks
 COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551 Unless otherwise noted, all material posted for this course
COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551 Unless otherwise noted, all material posted for this course
Machine Learning Basics: Stochastic Gradient Descent. Sargur N. Srihari
 Machine Learning Basics: Stochastic Gradient Descent Sargur N. srihari@cedar.buffalo.edu 1 Topics 1. Learning Algorithms 2. Capacity, Overfitting and Underfitting 3. Hyperparameters and Validation Sets
Machine Learning Basics: Stochastic Gradient Descent Sargur N. srihari@cedar.buffalo.edu 1 Topics 1. Learning Algorithms 2. Capacity, Overfitting and Underfitting 3. Hyperparameters and Validation Sets
Unsupervised Learning
 Deep Learning for Graphics Unsupervised Learning Niloy Mitra Iasonas Kokkinos Paul Guerrero Vladimir Kim Kostas Rematas Tobias Ritschel UCL UCL/Facebook UCL Adobe Research U Washington UCL Timetable Niloy
Deep Learning for Graphics Unsupervised Learning Niloy Mitra Iasonas Kokkinos Paul Guerrero Vladimir Kim Kostas Rematas Tobias Ritschel UCL UCL/Facebook UCL Adobe Research U Washington UCL Timetable Niloy
Practical Methodology. Lecture slides for Chapter 11 of Deep Learning Ian Goodfellow
 Practical Methodology Lecture slides for Chapter 11 of Deep Learning www.deeplearningbook.org Ian Goodfellow 2016-09-26 What drives success in ML? Arcane knowledge of dozens of obscure algorithms? Mountains
Practical Methodology Lecture slides for Chapter 11 of Deep Learning www.deeplearningbook.org Ian Goodfellow 2016-09-26 What drives success in ML? Arcane knowledge of dozens of obscure algorithms? Mountains
Efficient Deep Learning Optimization Methods
 11-785/ Spring 2019/ Recitation 3 Efficient Deep Learning Optimization Methods Josh Moavenzadeh, Kai Hu, and Cody Smith Outline 1 Review of optimization 2 Optimization practice 3 Training tips in PyTorch
11-785/ Spring 2019/ Recitation 3 Efficient Deep Learning Optimization Methods Josh Moavenzadeh, Kai Hu, and Cody Smith Outline 1 Review of optimization 2 Optimization practice 3 Training tips in PyTorch
Neural Network Neurons
 Neural Networks Neural Network Neurons 1 Receives n inputs (plus a bias term) Multiplies each input by its weight Applies activation function to the sum of results Outputs result Activation Functions Given
Neural Networks Neural Network Neurons 1 Receives n inputs (plus a bias term) Multiplies each input by its weight Applies activation function to the sum of results Outputs result Activation Functions Given
Deep Learning Workshop. Nov. 20, 2015 Andrew Fishberg, Rowan Zellers
 Deep Learning Workshop Nov. 20, 2015 Andrew Fishberg, Rowan Zellers Why deep learning? The ImageNet Challenge Goal: image classification with 1000 categories Top 5 error rate of 15%. Krizhevsky, Alex,
Deep Learning Workshop Nov. 20, 2015 Andrew Fishberg, Rowan Zellers Why deep learning? The ImageNet Challenge Goal: image classification with 1000 categories Top 5 error rate of 15%. Krizhevsky, Alex,
Study of Residual Networks for Image Recognition
 Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
Optimization. Industrial AI Lab.
 Optimization Industrial AI Lab. Optimization An important tool in 1) Engineering problem solving and 2) Decision science People optimize Nature optimizes 2 Optimization People optimize (source: http://nautil.us/blog/to-save-drowning-people-ask-yourself-what-would-light-do)
Optimization Industrial AI Lab. Optimization An important tool in 1) Engineering problem solving and 2) Decision science People optimize Nature optimizes 2 Optimization People optimize (source: http://nautil.us/blog/to-save-drowning-people-ask-yourself-what-would-light-do)
The exam is closed book, closed notes except your one-page (two-sided) cheat sheet.
 cheat sheet.") CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
CS 2750: Machine Learning. Neural Networks. Prof. Adriana Kovashka University of Pittsburgh April 13, 2016
 CS 2750: Machine Learning Neural Networks Prof. Adriana Kovashka University of Pittsburgh April 13, 2016 Plan for today Neural network definition and examples Training neural networks (backprop) Convolutional
CS 2750: Machine Learning Neural Networks Prof. Adriana Kovashka University of Pittsburgh April 13, 2016 Plan for today Neural network definition and examples Training neural networks (backprop) Convolutional
Neural Networks. Theory And Practice. Marco Del Vecchio 19/07/2017. Warwick Manufacturing Group University of Warwick
 Neural Networks Theory And Practice Marco Del Vecchio marco@delvecchiomarco.com Warwick Manufacturing Group University of Warwick 19/07/2017 Outline I 1 Introduction 2 Linear Regression Models 3 Linear
Neural Networks Theory And Practice Marco Del Vecchio marco@delvecchiomarco.com Warwick Manufacturing Group University of Warwick 19/07/2017 Outline I 1 Introduction 2 Linear Regression Models 3 Linear
INTRODUCTION TO DEEP LEARNING
 INTRODUCTION TO DEEP LEARNING CONTENTS Introduction to deep learning Contents 1. Examples 2. Machine learning 3. Neural networks 4. Deep learning 5. Convolutional neural networks 6. Conclusion 7. Additional
INTRODUCTION TO DEEP LEARNING CONTENTS Introduction to deep learning Contents 1. Examples 2. Machine learning 3. Neural networks 4. Deep learning 5. Convolutional neural networks 6. Conclusion 7. Additional
Gradient Descent. Wed Sept 20th, James McInenrey Adapted from slides by Francisco J. R. Ruiz
 Gradient Descent Wed Sept 20th, 2017 James McInenrey Adapted from slides by Francisco J. R. Ruiz Housekeeping A few clarifications of and adjustments to the course schedule: No more breaks at the midpoint
Gradient Descent Wed Sept 20th, 2017 James McInenrey Adapted from slides by Francisco J. R. Ruiz Housekeeping A few clarifications of and adjustments to the course schedule: No more breaks at the midpoint
CIS581: Computer Vision and Computational Photography Project 4, Part B: Convolutional Neural Networks (CNNs) Due: Dec.11, 2017 at 11:59 pm
 Due: Dec.11, 2017 at 11:59 pm") CIS581: Computer Vision and Computational Photography Project 4, Part B: Convolutional Neural Networks (CNNs) Due: Dec.11, 2017 at 11:59 pm Instructions CNNs is a team project. The maximum size of a team
CIS581: Computer Vision and Computational Photography Project 4, Part B: Convolutional Neural Networks (CNNs) Due: Dec.11, 2017 at 11:59 pm Instructions CNNs is a team project. The maximum size of a team
Lecture : Neural net: initialization, activations, normalizations and other practical details Anne Solberg March 10, 2017
 INF 5860 Machine learning for image classification Lecture : Neural net: initialization, activations, normalizations and other practical details Anne Solberg March 0, 207 Mandatory exercise Available tonight,
INF 5860 Machine learning for image classification Lecture : Neural net: initialization, activations, normalizations and other practical details Anne Solberg March 0, 207 Mandatory exercise Available tonight,
3D model classification using convolutional neural network
 3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
Akarsh Pokkunuru EECS Department Contractive Auto-Encoders: Explicit Invariance During Feature Extraction
 Akarsh Pokkunuru EECS Department 03-16-2017 Contractive Auto-Encoders: Explicit Invariance During Feature Extraction 1 AGENDA Introduction to Auto-encoders Types of Auto-encoders Analysis of different
Akarsh Pokkunuru EECS Department 03-16-2017 Contractive Auto-Encoders: Explicit Invariance During Feature Extraction 1 AGENDA Introduction to Auto-encoders Types of Auto-encoders Analysis of different
4.12 Generalization. In back-propagation learning, as many training examples as possible are typically used.
 1 4.12 Generalization In back-propagation learning, as many training examples as possible are typically used. It is hoped that the network so designed generalizes well. A network generalizes well when
1 4.12 Generalization In back-propagation learning, as many training examples as possible are typically used. It is hoped that the network so designed generalizes well. A network generalizes well when
Logical Rhythm - Class 3. August 27, 2018
 Logical Rhythm - Class 3 August 27, 2018 In this Class Neural Networks (Intro To Deep Learning) Decision Trees Ensemble Methods(Random Forest) Hyperparameter Optimisation and Bias Variance Tradeoff Biological
Logical Rhythm - Class 3 August 27, 2018 In this Class Neural Networks (Intro To Deep Learning) Decision Trees Ensemble Methods(Random Forest) Hyperparameter Optimisation and Bias Variance Tradeoff Biological
Machine Learning. Deep Learning. Eric Xing (and Pengtao Xie) , Fall Lecture 8, October 6, Eric CMU,
 , Fall Lecture 8, October 6, Eric CMU,") Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
COMPUTATIONAL INTELLIGENCE (INTRODUCTION TO MACHINE LEARNING) SS18. Lecture 2: Linear Regression Gradient Descent Non-linear basis functions
 SS18. Lecture 2: Linear Regression Gradient Descent Non-linear basis functions") COMPUTATIONAL INTELLIGENCE (INTRODUCTION TO MACHINE LEARNING) SS18 Lecture 2: Linear Regression Gradient Descent Non-linear basis functions LINEAR REGRESSION MOTIVATION Why Linear Regression? Simplest
COMPUTATIONAL INTELLIGENCE (INTRODUCTION TO MACHINE LEARNING) SS18 Lecture 2: Linear Regression Gradient Descent Non-linear basis functions LINEAR REGRESSION MOTIVATION Why Linear Regression? Simplest
11. Neural Network Regularization
 11. Neural Network Regularization CS 519 Deep Learning, Winter 2016 Fuxin Li With materials from Andrej Karpathy, Zsolt Kira Preventing overfitting Approach 1: Get more data! Always best if possible! If
11. Neural Network Regularization CS 519 Deep Learning, Winter 2016 Fuxin Li With materials from Andrej Karpathy, Zsolt Kira Preventing overfitting Approach 1: Get more data! Always best if possible! If
291 Programming Assignment #3
 000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
COMP9444 Neural Networks and Deep Learning 5. Geometry of Hidden Units
 COMP9 8s Geometry of Hidden Units COMP9 Neural Networks and Deep Learning 5. Geometry of Hidden Units Outline Geometry of Hidden Unit Activations Limitations of -layer networks Alternative transfer functions
COMP9 8s Geometry of Hidden Units COMP9 Neural Networks and Deep Learning 5. Geometry of Hidden Units Outline Geometry of Hidden Unit Activations Limitations of -layer networks Alternative transfer functions
Supervised Learning in Neural Networks (Part 2)
") Supervised Learning in Neural Networks (Part 2) Multilayer neural networks (back-propagation training algorithm) The input signals are propagated in a forward direction on a layer-bylayer basis. Learning
Supervised Learning in Neural Networks (Part 2) Multilayer neural networks (back-propagation training algorithm) The input signals are propagated in a forward direction on a layer-bylayer basis. Learning
Cost Functions in Machine Learning
 Cost Functions in Machine Learning Kevin Swingler Motivation Given some data that reflects measurements from the environment We want to build a model that reflects certain statistics about that data Something
Cost Functions in Machine Learning Kevin Swingler Motivation Given some data that reflects measurements from the environment We want to build a model that reflects certain statistics about that data Something
Neural Networks. Robot Image Credit: Viktoriya Sukhanova 123RF.com
 Neural Networks These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these slides
Neural Networks These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these slides
The Mathematics Behind Neural Networks
 The Mathematics Behind Neural Networks Pattern Recognition and Machine Learning by Christopher M. Bishop Student: Shivam Agrawal Mentor: Nathaniel Monson Courtesy of xkcd.com The Black Box Training the
The Mathematics Behind Neural Networks Pattern Recognition and Machine Learning by Christopher M. Bishop Student: Shivam Agrawal Mentor: Nathaniel Monson Courtesy of xkcd.com The Black Box Training the
Distributed Training of Deep Neural Networks: Theoretical and Practical Limits of Parallel Scalability
 Distributed Training of Deep Neural Networks: Theoretical and Practical Limits of Parallel Scalability Janis Keuper Itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern,
Distributed Training of Deep Neural Networks: Theoretical and Practical Limits of Parallel Scalability Janis Keuper Itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern,
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren Kaiming He Ross Girshick Jian Sun Present by: Yixin Yang Mingdong Wang 1 Object Detection 2 1 Applications Basic
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren Kaiming He Ross Girshick Jian Sun Present by: Yixin Yang Mingdong Wang 1 Object Detection 2 1 Applications Basic
FastText. Jon Koss, Abhishek Jindal
 FastText Jon Koss, Abhishek Jindal FastText FastText is on par with state-of-the-art deep learning classifiers in terms of accuracy But it is way faster: FastText can train on more than one billion words
FastText Jon Koss, Abhishek Jindal FastText FastText is on par with state-of-the-art deep learning classifiers in terms of accuracy But it is way faster: FastText can train on more than one billion words
Neural Nets & Deep Learning
 Neural Nets & Deep Learning The Inspiration Inputs Outputs Our brains are pretty amazing, what if we could do something similar with computers? Image Source: http://ib.bioninja.com.au/_media/neuron _med.jpeg
Neural Nets & Deep Learning The Inspiration Inputs Outputs Our brains are pretty amazing, what if we could do something similar with computers? Image Source: http://ib.bioninja.com.au/_media/neuron _med.jpeg
Machine Learning Classifiers and Boosting
 Machine Learning Classifiers and Boosting Reading Ch 18.6-18.12, 20.1-20.3.2 Outline Different types of learning problems Different types of learning algorithms Supervised learning Decision trees Naïve
Machine Learning Classifiers and Boosting Reading Ch 18.6-18.12, 20.1-20.3.2 Outline Different types of learning problems Different types of learning algorithms Supervised learning Decision trees Naïve
Classification: Linear Discriminant Functions
 Classification: Linear Discriminant Functions CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Discriminant functions Linear Discriminant functions
Classification: Linear Discriminant Functions CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Discriminant functions Linear Discriminant functions