Exam Review Session. William Cohen
|
|
|
- Leslie Watson
- 6 years ago
- Views:
Transcription
1 Exam Review Session William Cohen 1
2 General hints in studying Understand what you ve done and why There will be questions that test your understanding of the techniques implemented why will/won t this shortcut work? what does the analysis say about the method? We re mostly about learning meets computation here there won t be many pure 601 questions 2
3 General hints in studying Techniques covered in class but not assignments: When/where/how to use them That usually includes understanding the analytic results presented in class Eg: is the lazy regularization update an approximation or not? when does it help? when does it not help? 3
4 General hints in studying What about assignments you haven t done? You should read through the assignments and be familiar with the algorithms being implemented There won t be questions about programming details that you could look up on line but you should know how architectures like Hadoop work (eg, when and where they communicate) you should be able to sketch out simple map- reduce algorithms No spark, but you should be able to read workqlow operators and discuss how they d be implemented how would you do a groupbykey in Hadoop? 4
5 General hints in studying There are not detailed questions on the guest speakers or the student projects (this year) If you use a previous year s exam as guidance the topics are a little different each year 5
6 General hints in exam taking You can bring in one 8 ½ by 11 sheet (front and back) Look over everything quickly and skip around probably nobody will know everything on the test If you re not sure what we ve got in mind: state your assumptions clearly in your answer. There s room for this even on true/false If you look at a question and don t know the answer: we probably haven t told you the answer but we ve told you enough to work it out imagine arguing for some answer and see if you like it 6
7 Outline major topics Hadoop stream- and- sort is how I ease you into that, not really a topic on its own Parallelizing learners (perceptron, LDA, ) Hash kernels and streaming SGD Distributed SGD for Matrix Factorization Randomized Algorithms Graph Algorithms: PR, PPR, SSL on graphs no assignment!= not on test Some of these are easier to ask questions about than others. 7
8 HADOOP 8

9 What data gets lost if the job tracker is rebooted? If I have a 1Tb Qile and shard it 1000 ways will it take longer than sharding it 10 ways? Where should a combiner run? 9

10 $ hadoop fs -ls rcv1/small/sharded! Found 10 items! -rw-r--r :28 /user/wcohen/rcv1/small/sharded/part-00000! -rw-r--r :28 /user/wcohen/rcv1/small/sharded/part-00001! -rw-r--r :28 /user/wcohen/rcv1/small/sharded/part-00002! -rw-r--r :28 /user/wcohen/rcv1/small/sharded/part-00003! -rw-r--r :28 /user/wcohen/rcv1/small/sharded/part-00004! -rw-r--r :28 /user/wcohen/rcv1/small/sharded/part-00005! -rw-r--r :28 /user/wcohen/rcv1/small/sharded/part-00006! -rw-r--r :28 /user/wcohen/rcv1/small/sharded/part-00007! -rw-r--r :28 /user/wcohen/rcv1/small/sharded/part-00008! -rw-r--r :28 /user/wcohen/rcv1/small/sharded/part-00009!! $ hadoop fs -tail rcv1/small/sharded/part-00005! weak as the arrival of arbitraged cargoes from the West has put the local market under pressure! M14,M143,MCAT The Brent crude market on the Singapore International!! Where is this data? How many disks is it on? If I set up a directory on /afs that looks the same will it work the same? what about a local disk? 10

11 11
12 12

13 13


14 Why do I see this same error over and over again? 14
15 PARALLEL LEARNERS 15

16 Parallelizing perceptrons take 2 w (previous) Instances/labels Split into example subsets Instances/labels 1 Instances/labels 2 Instances/labels 3 Compute local vk s w -1 w- 2 w-3 w Combine by some sort of weighted averaging 16

17 A theorem I probably won t ask about the proof, but I could definitely ask about the theorem. Corollary: if we weight the vectors uniformly, then the number of mistakes is still bounded. I.e., this is enough communication to guarantee convergence. 17



18 NAACL 2010 What does the word structured mean here? why is it important? would the results be better or worse with a regular perceptron? 18
19 STREAMING SGD 19

 to O(mVT) where n =")

20 Learning as optimization for regularized logistic regression Algorithm: what if you had a different update for the regularizer? Time goes from O(nT) to O(mVT) where n = number of non-zero entries, m = number of examples V = number of features T = number of passes over data 20
21 Formalization of the Hash Trick : First: Review of Kernels What is it? how does it work? what aspects of performance does it help? What did we say about it formally? 21
22 RANDOMIZED ALGORITHMS 22
23 Randomized Algorithms Hash kernels Countmin sketch Bloom Qilters LSH What are they, and what are they used for? When would you use which one? Why do they work - ie, what analytic results have we looked at? 23
24 Bloom filters - review An implementation Allocate M bits, bit[0],bit[1- M] Pick K hash functions hash(1,2),hash(2,s),. E.g: hash(i,s) = hash(s+ randomstring[i]) To add string s: For i=1 to k, set bit[hash(i,s)] = 1 To check contains(s): For i=1 to k, test bit[hash(i,s)] Return true if they re all set; otherwise, return false We ll discuss how to set M and K soon, but for now: Let M = 1.5*maxSize // less than two bits per item! Let K = 2*log(1/p) // about right with this M 24
25 Bloom filters An example application discarding rare features from a classiqier seldom hurts much, can speed up experiments Scan through data once and check each w: if bf1.contains(w): if bf2.contains(w): bf3.add(w) else bf2.add(w) else bf1.add(w) which needs more storage, bf1 or bf3? (same false positive rate) Now: bf2.contains(w) ó w appears >= 2x bf3.contains(w) ó w appears >= 3x Then train, ignoring words not in bf3 25
26 Bloom filters Here s two ideas for using Bloom Qilters for learning from sparse binary examples: compress every example with a BF either use each bit of the BF as a feature for a classiqier or: reconstruct the example at training time and train an ordinary classiqier pros and cons? 26
27 from: Minos Garofalakis CM Sketch Structure h 1 (s) +c <s, +c> +c +c d=log 1/δ h d (s) +c w = 2/ε n Each string is mapped to one bucket per row n Estimate A[j] by taking min k { CM[k,h k (j)] } n Errors are always over-estimates n Sizes: d=log 1/δ, w=2/ε è error is usually less than ε A 1 27
28 from: Minos Garofalakis CM Sketch Guarantees n [Cormode, Muthukrishnan 04] CM sketch guarantees approximation error on point queries less than ε A 1 in space O(1/ε log 1/δ) Probability of more error is less than 1-δ n This is sometimes enough: Estimating a multinomial: if A[s] = Pr(s ) then A 1 = 1 Multiclass classification: if A x [s] = Pr(x in class s) then A x 1 is probably small, since most x s will be in only a few classes 28



29 An Application of a Count-Min Sketch n Problem: find the semantic orientation of a work (positive or negative) using a large corpus. n Idea: positive words co-occur more frequently than expected near positive words; likewise for negative words so pick a few pos/neg seeds and compute x appears near y 29
30 LSH: key ideas n n Goal: map feature vector x to bit vector bx ensure that bx preserves similarity Basic idea: use random projections of x Repeat many times: n Pick a random hyperplane r by picking random weights for each feature (say from a Gaussian) n Compute the inner product of r with x n Record if x is close to r (r.x>=0) the next bit in bx n Theory says that if x and x have small cosine distance then bx and bx will have small Hamming distance 30
31 LSH applications Compact storage of data and we can still compute similarities LSH also gives very fast approximations: approx nearest neighbor method just look at other items with bx =bx also very fast nearest- neighbor methods for Hamming distance very fast clustering cluster = all things with same bx vector 31
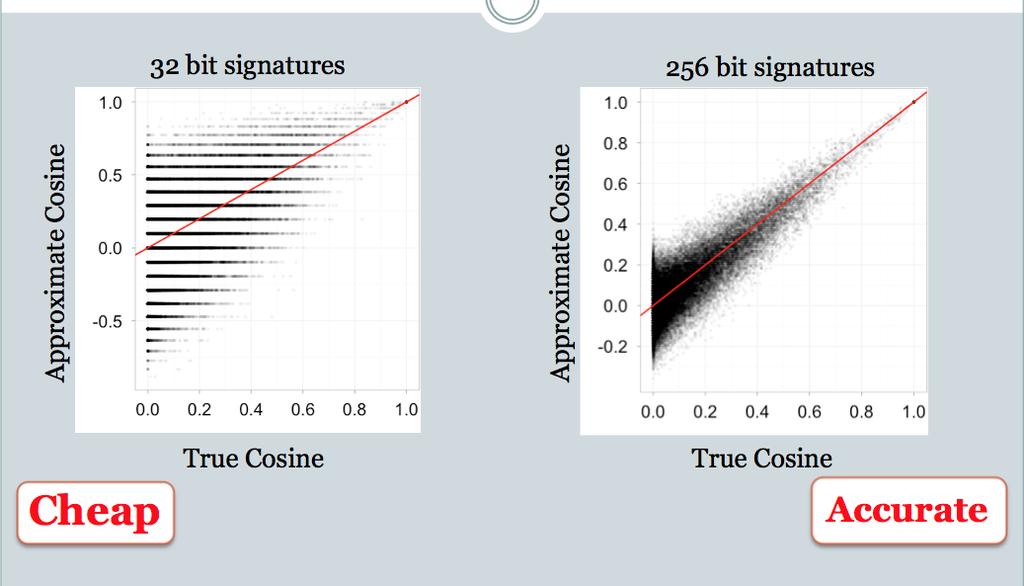
32 32
33 LSH What are some other ways of using LSH? What are some other ways of using CountMin sketchs? 33
34 GRAPH ALGORITHMS 34
35 Graph Algorithms The standard way of computing PageRank, iteratively, using the power method Properties of large data graphs The subsampling problem APR algorithm - how and why it works when we d use it what the analysis says SSL on graphs example algorithms, example use of CM Sketches 35
36 36

37 Degree distribution Plot cumulative degree X axis is degree Y axis is #nodes that have degree at least k Typically use a log- log scale Straight lines are a power law; normal curve dives to zero at some point Left: trust network in epinions web site from Richardson & Domingos 37
38 Homophily Another def n: excess edges between common neighbors of v CC( v) CC( V, = E) # trianglesconnected to v # pairs connected to v = 1 V v CC( v) CC' ( V, E) = #trianglesin graph #length 3 paths in graph 38
39 Approximate PageRank: Algorithm 39
40 Approximate PageRank: Key Idea By definition PageRank is fixed point of: Claim: Recursively compute PageRank of neighbors of s (=sw), then adjust Key idea in apr: do this recursive step repeatedly focus on nodes where finding PageRank from neighbors will be useful 40
41 Analysis linearity re-group & linearity pr(α, r - r(u)χ u ) +(1- α) pr(α, r(u)χ u W) = pr(α, r - r(u)χ u + (1- α) r(u)χ u W) 41
42 Q/A 42
Randomized Algorithms Wrap-Up. William Cohen
 Randomized Algorithms Wrap-Up William Cohen Announcements Quiz today! Projects there are no slots for 605 students free if you want to do a project send me a 1-2 page proposal with your cvs by Friday and
Randomized Algorithms Wrap-Up William Cohen Announcements Quiz today! Projects there are no slots for 605 students free if you want to do a project send me a 1-2 page proposal with your cvs by Friday and
Problem 1: Complexity of Update Rules for Logistic Regression
 Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox January 16 th, 2014 1
Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox January 16 th, 2014 1
ML from Large Datasets
 10-605 ML from Large Datasets 1 Announcements HW1b is going out today You should now be on autolab have a an account on stoat a locally-administered Hadoop cluster shortly receive a coupon for Amazon Web
10-605 ML from Large Datasets 1 Announcements HW1b is going out today You should now be on autolab have a an account on stoat a locally-administered Hadoop cluster shortly receive a coupon for Amazon Web
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu [Kumar et al. 99] 2/13/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu [Kumar et al. 99] 2/13/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu
Practice Questions for Midterm
 Practice Questions for Midterm - 10-605 Oct 14, 2015 (version 1) 10-605 Name: Fall 2015 Sample Questions Andrew ID: Time Limit: n/a Grade Table (for teacher use only) Question Points Score 1 6 2 6 3 15
Practice Questions for Midterm - 10-605 Oct 14, 2015 (version 1) 10-605 Name: Fall 2015 Sample Questions Andrew ID: Time Limit: n/a Grade Table (for teacher use only) Question Points Score 1 6 2 6 3 15
CS369G: Algorithmic Techniques for Big Data Spring
 CS369G: Algorithmic Techniques for Big Data Spring 2015-2016 Lecture 11: l 0 -Sampling and Introduction to Graph Streaming Prof. Moses Charikar Scribe: Austin Benson 1 Overview We present and analyze the
CS369G: Algorithmic Techniques for Big Data Spring 2015-2016 Lecture 11: l 0 -Sampling and Introduction to Graph Streaming Prof. Moses Charikar Scribe: Austin Benson 1 Overview We present and analyze the
INTRO TO SEMI-SUPERVISED LEARNING (SSL)
") SSL (on graphs) 1 INTRO TO SEMI-SUPERVISED LEARNING (SSL) Semi-supervised learning Given: A pool of labeled examples L A (usually larger) pool of unlabeled examples U Option 1 for using L and U : Ignore
SSL (on graphs) 1 INTRO TO SEMI-SUPERVISED LEARNING (SSL) Semi-supervised learning Given: A pool of labeled examples L A (usually larger) pool of unlabeled examples U Option 1 for using L and U : Ignore
Announcements: projects
 Announcements: projects 805 students: Project proposals are due Sun 10/1. If you d like to work with 605 students then indicate this on your proposal. 605 students: the week after 10/1 I will post the
Announcements: projects 805 students: Project proposals are due Sun 10/1. If you d like to work with 605 students then indicate this on your proposal. 605 students: the week after 10/1 I will post the
Nearest Neighbor with KD Trees
 Case Study 2: Document Retrieval Finding Similar Documents Using Nearest Neighbors Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Emily Fox January 22 nd, 2013 1 Nearest
Case Study 2: Document Retrieval Finding Similar Documents Using Nearest Neighbors Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Emily Fox January 22 nd, 2013 1 Nearest
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu /2/8 Jure Leskovec, Stanford CS246: Mining Massive Datasets 2 Task: Given a large number (N in the millions or
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu /2/8 Jure Leskovec, Stanford CS246: Mining Massive Datasets 2 Task: Given a large number (N in the millions or
Nearest Neighbor with KD Trees
 Case Study 2: Document Retrieval Finding Similar Documents Using Nearest Neighbors Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Emily Fox January 22 nd, 2013 1 Nearest
Case Study 2: Document Retrieval Finding Similar Documents Using Nearest Neighbors Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Emily Fox January 22 nd, 2013 1 Nearest
Finding Similar Sets. Applications Shingling Minhashing Locality-Sensitive Hashing
 Finding Similar Sets Applications Shingling Minhashing Locality-Sensitive Hashing Goals Many Web-mining problems can be expressed as finding similar sets:. Pages with similar words, e.g., for classification
Finding Similar Sets Applications Shingling Minhashing Locality-Sensitive Hashing Goals Many Web-mining problems can be expressed as finding similar sets:. Pages with similar words, e.g., for classification
Review: Memory, Disks, & Files. File Organizations and Indexing. Today: File Storage. Alternative File Organizations. Cost Model for Analysis
 File Organizations and Indexing Review: Memory, Disks, & Files Lecture 4 R&G Chapter 8 "If you don't find it in the index, look very carefully through the entire catalogue." -- Sears, Roebuck, and Co.,
File Organizations and Indexing Review: Memory, Disks, & Files Lecture 4 R&G Chapter 8 "If you don't find it in the index, look very carefully through the entire catalogue." -- Sears, Roebuck, and Co.,
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS46: Mining Massive Datasets Jure Leskovec, Stanford University http://cs46.stanford.edu /7/ Jure Leskovec, Stanford C46: Mining Massive Datasets Many real-world problems Web Search and Text Mining Billions
CS46: Mining Massive Datasets Jure Leskovec, Stanford University http://cs46.stanford.edu /7/ Jure Leskovec, Stanford C46: Mining Massive Datasets Many real-world problems Web Search and Text Mining Billions
Midterm Oct 18, Name: Fall 2016 Midterm Exam Andrew ID: Time Limit: 80 Minutes
 Midterm - 10-605 Oct 18, 2016 10-605 Name: Fall 2016 Midterm Exam Andrew ID: Time Limit: 80 Minutes Grade Table (for teacher use only) Question Points Score 1 10 2 4 3 10 4 12 5 12 6 8 7 8 8 8 9 6 10 12
Midterm - 10-605 Oct 18, 2016 10-605 Name: Fall 2016 Midterm Exam Andrew ID: Time Limit: 80 Minutes Grade Table (for teacher use only) Question Points Score 1 10 2 4 3 10 4 12 5 12 6 8 7 8 8 8 9 6 10 12
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Queries on streams
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Queries on streams
CSE547: Machine Learning for Big Data Spring Problem Set 1. Please read the homework submission policies.
 CSE547: Machine Learning for Big Data Spring 2019 Problem Set 1 Please read the homework submission policies. 1 Spark (25 pts) Write a Spark program that implements a simple People You Might Know social
CSE547: Machine Learning for Big Data Spring 2019 Problem Set 1 Please read the homework submission policies. 1 Spark (25 pts) Write a Spark program that implements a simple People You Might Know social
Instance-Based Learning: Nearest neighbor and kernel regression and classificiation
 Instance-Based Learning: Nearest neighbor and kernel regression and classificiation Emily Fox University of Washington February 3, 2017 Simplest approach: Nearest neighbor regression 1 Fit locally to each
Instance-Based Learning: Nearest neighbor and kernel regression and classificiation Emily Fox University of Washington February 3, 2017 Simplest approach: Nearest neighbor regression 1 Fit locally to each
Feature Extractors. CS 188: Artificial Intelligence Fall Some (Vague) Biology. The Binary Perceptron. Binary Decision Rule.
 Biology. The Binary Perceptron. Binary Decision Rule.") CS 188: Artificial Intelligence Fall 2008 Lecture 24: Perceptrons II 11/24/2008 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit
CS 188: Artificial Intelligence Fall 2008 Lecture 24: Perceptrons II 11/24/2008 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit
Mining Data Streams. Outline [Garofalakis, Gehrke & Rastogi 2002] Introduction. Summarization Methods. Clustering Data Streams
![Mining Data Streams. Outline [Garofalakis, Gehrke & Rastogi 2002] Introduction. Summarization Methods. Clustering Data Streams](/thumbs/85/93020188.jpg "Mining Data Streams. Outline [Garofalakis, Gehrke & Rastogi 2002] Introduction. Summarization Methods. Clustering Data Streams") Mining Data Streams Outline [Garofalakis, Gehrke & Rastogi 2002] Introduction Summarization Methods Clustering Data Streams Data Stream Classification Temporal Models CMPT 843, SFU, Martin Ester, 1-06
Mining Data Streams Outline [Garofalakis, Gehrke & Rastogi 2002] Introduction Summarization Methods Clustering Data Streams Data Stream Classification Temporal Models CMPT 843, SFU, Martin Ester, 1-06
CSE 5243 INTRO. TO DATA MINING
 CSE 53 INTRO. TO DATA MINING Locality Sensitive Hashing (LSH) Huan Sun, CSE@The Ohio State University Slides adapted from Prof. Jiawei Han @UIUC, Prof. Srinivasan Parthasarathy @OSU MMDS Secs. 3.-3.. Slides
CSE 53 INTRO. TO DATA MINING Locality Sensitive Hashing (LSH) Huan Sun, CSE@The Ohio State University Slides adapted from Prof. Jiawei Han @UIUC, Prof. Srinivasan Parthasarathy @OSU MMDS Secs. 3.-3.. Slides
Map-Reduce With Hadoop!
 Map-Reduce With Hadoop! Announcement 1/2! Assignments, in general:! Autolab is not secure and assignments aren t designed for adversarial interactions! Our policy: deliberately gaming an autograded assignment
Map-Reduce With Hadoop! Announcement 1/2! Assignments, in general:! Autolab is not secure and assignments aren t designed for adversarial interactions! Our policy: deliberately gaming an autograded assignment
Sublinear Time and Space Algorithms 2016B Lecture 7 Sublinear-Time Algorithms for Sparse Graphs
 Sublinear Time and Space Algorithms 2016B Lecture 7 Sublinear-Time Algorithms for Sparse Graphs Robert Krauthgamer 1 Approximating Average Degree in a Graph Input: A graph represented (say) as the adjacency
Sublinear Time and Space Algorithms 2016B Lecture 7 Sublinear-Time Algorithms for Sparse Graphs Robert Krauthgamer 1 Approximating Average Degree in a Graph Input: A graph represented (say) as the adjacency
Instance-Based Learning: Nearest neighbor and kernel regression and classificiation
 Instance-Based Learning: Nearest neighbor and kernel regression and classificiation Emily Fox University of Washington February 3, 2017 Simplest approach: Nearest neighbor regression 1 Fit locally to each
Instance-Based Learning: Nearest neighbor and kernel regression and classificiation Emily Fox University of Washington February 3, 2017 Simplest approach: Nearest neighbor regression 1 Fit locally to each
University of Washington Department of Computer Science and Engineering / Department of Statistics
 University of Washington Department of Computer Science and Engineering / Department of Statistics CSE 547 / Stat 548 Machine Learning (Statistics) for Big Data Homework 2 Spring 2015 Issued: Thursday,
University of Washington Department of Computer Science and Engineering / Department of Statistics CSE 547 / Stat 548 Machine Learning (Statistics) for Big Data Homework 2 Spring 2015 Issued: Thursday,
6 Randomized rounding of semidefinite programs
 6 Randomized rounding of semidefinite programs We now turn to a new tool which gives substantially improved performance guarantees for some problems We now show how nonlinear programming relaxations can
6 Randomized rounding of semidefinite programs We now turn to a new tool which gives substantially improved performance guarantees for some problems We now show how nonlinear programming relaxations can
Density estimation. In density estimation problems, we are given a random from an unknown density. Our objective is to estimate
 Density estimation In density estimation problems, we are given a random sample from an unknown density Our objective is to estimate? Applications Classification If we estimate the density for each class,
Density estimation In density estimation problems, we are given a random sample from an unknown density Our objective is to estimate? Applications Classification If we estimate the density for each class,
Snowball Sampling a Large Graph
 Snowball Sampling a Large Graph William Cohen Out March 20, 2013 Due Wed, April 3, 2013 via Blackboard 1 Background A snowball sample of a graph starts with some set of seed nodes of interest, and then
Snowball Sampling a Large Graph William Cohen Out March 20, 2013 Due Wed, April 3, 2013 via Blackboard 1 Background A snowball sample of a graph starts with some set of seed nodes of interest, and then
The exam is closed book, closed notes except your one-page (two-sided) cheat sheet.
 cheat sheet.") CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
Week - 04 Lecture - 01 Merge Sort. (Refer Slide Time: 00:02)
") Programming, Data Structures and Algorithms in Python Prof. Madhavan Mukund Department of Computer Science and Engineering Indian Institute of Technology, Madras Week - 04 Lecture - 01 Merge Sort (Refer
Programming, Data Structures and Algorithms in Python Prof. Madhavan Mukund Department of Computer Science and Engineering Indian Institute of Technology, Madras Week - 04 Lecture - 01 Merge Sort (Refer
Locality- Sensitive Hashing Random Projections for NN Search
 Case Study 2: Document Retrieval Locality- Sensitive Hashing Random Projections for NN Search Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 18, 2017 Sham Kakade
Case Study 2: Document Retrieval Locality- Sensitive Hashing Random Projections for NN Search Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 18, 2017 Sham Kakade
Coding for Random Projects
 Coding for Random Projects CS 584: Big Data Analytics Material adapted from Li s talk at ICML 2014 (http://techtalks.tv/talks/coding-for-random-projections/61085/) Random Projections for High-Dimensional
Coding for Random Projects CS 584: Big Data Analytics Material adapted from Li s talk at ICML 2014 (http://techtalks.tv/talks/coding-for-random-projections/61085/) Random Projections for High-Dimensional
Topic: Duplicate Detection and Similarity Computing
 Table of Content Topic: Duplicate Detection and Similarity Computing Motivation Shingling for duplicate comparison Minhashing LSH UCSB 290N, 2013 Tao Yang Some of slides are from text book [CMS] and Rajaraman/Ullman
Table of Content Topic: Duplicate Detection and Similarity Computing Motivation Shingling for duplicate comparison Minhashing LSH UCSB 290N, 2013 Tao Yang Some of slides are from text book [CMS] and Rajaraman/Ullman
Compact Data Representations and their Applications. Moses Charikar Princeton University
 Compact Data Representations and their Applications Moses Charikar Princeton University Lots and lots of data AT&T Information about who calls whom What information can be got from this data? Network router
Compact Data Representations and their Applications Moses Charikar Princeton University Lots and lots of data AT&T Information about who calls whom What information can be got from this data? Network router
COSC160: Detection and Classification. Jeremy Bolton, PhD Assistant Teaching Professor
 COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality
COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality
Near Neighbor Search in High Dimensional Data (1) Dr. Anwar Alhenshiri
 Dr. Anwar Alhenshiri") Near Neighbor Search in High Dimensional Data (1) Dr. Anwar Alhenshiri Scene Completion Problem The Bare Data Approach High Dimensional Data Many real-world problems Web Search and Text Mining Billions
Near Neighbor Search in High Dimensional Data (1) Dr. Anwar Alhenshiri Scene Completion Problem The Bare Data Approach High Dimensional Data Many real-world problems Web Search and Text Mining Billions
Treaps. 1 Binary Search Trees (BSTs) CSE341T/CSE549T 11/05/2014. Lecture 19
 CSE341T/CSE549T 11/05/2014. Lecture 19") CSE34T/CSE549T /05/04 Lecture 9 Treaps Binary Search Trees (BSTs) Search trees are tree-based data structures that can be used to store and search for items that satisfy a total order. There are many types
CSE34T/CSE549T /05/04 Lecture 9 Treaps Binary Search Trees (BSTs) Search trees are tree-based data structures that can be used to store and search for items that satisfy a total order. There are many types
CPSC 311: Analysis of Algorithms (Honors) Exam 1 October 11, 2002
 Exam 1 October 11, 2002") CPSC 311: Analysis of Algorithms (Honors) Exam 1 October 11, 2002 Name: Instructions: 1. This is a closed book exam. Do not use any notes or books, other than your 8.5-by-11 inch review sheet. Do not confer
CPSC 311: Analysis of Algorithms (Honors) Exam 1 October 11, 2002 Name: Instructions: 1. This is a closed book exam. Do not use any notes or books, other than your 8.5-by-11 inch review sheet. Do not confer
CS 6604: Data Mining Large Networks and Time-Series
 CS 6604: Data Mining Large Networks and Time-Series Soumya Vundekode Lecture #12: Centrality Metrics Prof. B Aditya Prakash Agenda Link Analysis and Web Search Searching the Web: The Problem of Ranking
CS 6604: Data Mining Large Networks and Time-Series Soumya Vundekode Lecture #12: Centrality Metrics Prof. B Aditya Prakash Agenda Link Analysis and Web Search Searching the Web: The Problem of Ranking
5 Learning hypothesis classes (16 points)
") 5 Learning hypothesis classes (16 points) Consider a classification problem with two real valued inputs. For each of the following algorithms, specify all of the separators below that it could have generated
5 Learning hypothesis classes (16 points) Consider a classification problem with two real valued inputs. For each of the following algorithms, specify all of the separators below that it could have generated
Introduction to Information Retrieval (Manning, Raghavan, Schutze)
") Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 3 Dictionaries and Tolerant retrieval Chapter 4 Index construction Chapter 5 Index compression Content Dictionary data structures
Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 3 Dictionaries and Tolerant retrieval Chapter 4 Index construction Chapter 5 Index compression Content Dictionary data structures
Research Students Lecture Series 2015
 Research Students Lecture Series 215 Analyse your big data with this one weird probabilistic approach! Or: applied probabilistic algorithms in 5 easy pieces Advait Sarkar advait.sarkar@cl.cam.ac.uk Research
Research Students Lecture Series 215 Analyse your big data with this one weird probabilistic approach! Or: applied probabilistic algorithms in 5 easy pieces Advait Sarkar advait.sarkar@cl.cam.ac.uk Research
MLlib and Distributing the " Singular Value Decomposition. Reza Zadeh
 MLlib and Distributing the " Singular Value Decomposition Reza Zadeh Outline Example Invocations Benefits of Iterations Singular Value Decomposition All-pairs Similarity Computation MLlib + {Streaming,
MLlib and Distributing the " Singular Value Decomposition Reza Zadeh Outline Example Invocations Benefits of Iterations Singular Value Decomposition All-pairs Similarity Computation MLlib + {Streaming,
Hashing with Graphs. Sanjiv Kumar (Google), and Shih Fu Chang (Columbia) June, 2011
, and Shih Fu Chang (Columbia) June, 2011") Hashing with Graphs Wei Liu (Columbia Columbia), Jun Wang (IBM IBM), Sanjiv Kumar (Google), and Shih Fu Chang (Columbia) June, 2011 Overview Graph Hashing Outline Anchor Graph Hashing Experiments Conclusions
Hashing with Graphs Wei Liu (Columbia Columbia), Jun Wang (IBM IBM), Sanjiv Kumar (Google), and Shih Fu Chang (Columbia) June, 2011 Overview Graph Hashing Outline Anchor Graph Hashing Experiments Conclusions
Practice EXAM: SPRING 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE
 Practice EXAM: SPRING 0 CS 6375 INSTRUCTOR: VIBHAV GOGATE The exam is closed book. You are allowed four pages of double sided cheat sheets. Answer the questions in the spaces provided on the question sheets.
Practice EXAM: SPRING 0 CS 6375 INSTRUCTOR: VIBHAV GOGATE The exam is closed book. You are allowed four pages of double sided cheat sheets. Answer the questions in the spaces provided on the question sheets.
CS 179 Lecture 16. Logistic Regression & Parallel SGD
 CS 179 Lecture 16 Logistic Regression & Parallel SGD 1 Outline logistic regression (stochastic) gradient descent parallelizing SGD for neural nets (with emphasis on Google s distributed neural net implementation)
CS 179 Lecture 16 Logistic Regression & Parallel SGD 1 Outline logistic regression (stochastic) gradient descent parallelizing SGD for neural nets (with emphasis on Google s distributed neural net implementation)
Lecture 5: Data Streaming Algorithms
 Great Ideas in Theoretical Computer Science Summer 2013 Lecture 5: Data Streaming Algorithms Lecturer: Kurt Mehlhorn & He Sun In the data stream scenario, the input arrive rapidly in an arbitrary order,
Great Ideas in Theoretical Computer Science Summer 2013 Lecture 5: Data Streaming Algorithms Lecturer: Kurt Mehlhorn & He Sun In the data stream scenario, the input arrive rapidly in an arbitrary order,
Data Structures and Algorithm Analysis (CSC317) Hash tables (part2)
 Hash tables (part2)") Data Structures and Algorithm Analysis (CSC317) Hash tables (part2) Hash table We have elements with key and satellite data Operations performed: Insert, Delete, Search/lookup We don t maintain order information
Data Structures and Algorithm Analysis (CSC317) Hash tables (part2) Hash table We have elements with key and satellite data Operations performed: Insert, Delete, Search/lookup We don t maintain order information
University of Washington Department of Computer Science and Engineering / Department of Statistics
 University of Washington Department of Computer Science and Engineering / Department of Statistics CSE 547 / Stat 548 Machine Learning (Statistics) for Big Data Homework 2 Winter 2014 Issued: Thursday,
University of Washington Department of Computer Science and Engineering / Department of Statistics CSE 547 / Stat 548 Machine Learning (Statistics) for Big Data Homework 2 Winter 2014 Issued: Thursday,
CSE 573: Artificial Intelligence Autumn 2010
 CSE 573: Artificial Intelligence Autumn 2010 Lecture 16: Machine Learning Topics 12/7/2010 Luke Zettlemoyer Most slides over the course adapted from Dan Klein. 1 Announcements Syllabus revised Machine
CSE 573: Artificial Intelligence Autumn 2010 Lecture 16: Machine Learning Topics 12/7/2010 Luke Zettlemoyer Most slides over the course adapted from Dan Klein. 1 Announcements Syllabus revised Machine
To earn the extra credit, one of the following has to hold true. Please circle and sign.
 CS 188 Spring 2011 Introduction to Artificial Intelligence Practice Final Exam To earn the extra credit, one of the following has to hold true. Please circle and sign. A I spent 3 or more hours on the
CS 188 Spring 2011 Introduction to Artificial Intelligence Practice Final Exam To earn the extra credit, one of the following has to hold true. Please circle and sign. A I spent 3 or more hours on the
Homework 3: Map-Reduce, Frequent Itemsets, LSH, Streams (due March 16 th, 9:30am in class hard-copy please)
") Virginia Tech. Computer Science CS 5614 (Big) Data Management Systems Spring 2017, Prakash Homework 3: Map-Reduce, Frequent Itemsets, LSH, Streams (due March 16 th, 9:30am in class hard-copy please) Reminders:
Virginia Tech. Computer Science CS 5614 (Big) Data Management Systems Spring 2017, Prakash Homework 3: Map-Reduce, Frequent Itemsets, LSH, Streams (due March 16 th, 9:30am in class hard-copy please) Reminders:
Algorithms for Nearest Neighbors
 Algorithms for Nearest Neighbors State-of-the-Art Yury Lifshits Steklov Institute of Mathematics at St.Petersburg Yandex Tech Seminar, April 2007 1 / 28 Outline 1 Problem Statement Applications Data Models
Algorithms for Nearest Neighbors State-of-the-Art Yury Lifshits Steklov Institute of Mathematics at St.Petersburg Yandex Tech Seminar, April 2007 1 / 28 Outline 1 Problem Statement Applications Data Models
Context. File Organizations and Indexing. Cost Model for Analysis. Alternative File Organizations. Some Assumptions in the Analysis.
 File Organizations and Indexing Context R&G Chapter 8 "If you don't find it in the index, look very carefully through the entire catalogue." -- Sears, Roebuck, and Co., Consumer's Guide, 1897 Query Optimization
File Organizations and Indexing Context R&G Chapter 8 "If you don't find it in the index, look very carefully through the entire catalogue." -- Sears, Roebuck, and Co., Consumer's Guide, 1897 Query Optimization
The exam is closed book, closed notes except your one-page cheat sheet.
 CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
Graphs (Part II) Shannon Quinn
 Shannon Quinn") Graphs (Part II) Shannon Quinn (with thanks to William Cohen and Aapo Kyrola of CMU, and J. Leskovec, A. Rajaraman, and J. Ullman of Stanford University) Parallel Graph Computation Distributed computation
Graphs (Part II) Shannon Quinn (with thanks to William Cohen and Aapo Kyrola of CMU, and J. Leskovec, A. Rajaraman, and J. Ullman of Stanford University) Parallel Graph Computation Distributed computation
CSE 546 Machine Learning, Autumn 2013 Homework 2
 CSE 546 Machine Learning, Autumn 2013 Homework 2 Due: Monday, October 28, beginning of class 1 Boosting [30 Points] We learned about boosting in lecture and the topic is covered in Murphy 16.4. On page
CSE 546 Machine Learning, Autumn 2013 Homework 2 Due: Monday, October 28, beginning of class 1 Boosting [30 Points] We learned about boosting in lecture and the topic is covered in Murphy 16.4. On page
Algorithms for Nearest Neighbors
 Algorithms for Nearest Neighbors Classic Ideas, New Ideas Yury Lifshits Steklov Institute of Mathematics at St.Petersburg http://logic.pdmi.ras.ru/~yura University of Toronto, July 2007 1 / 39 Outline
Algorithms for Nearest Neighbors Classic Ideas, New Ideas Yury Lifshits Steklov Institute of Mathematics at St.Petersburg http://logic.pdmi.ras.ru/~yura University of Toronto, July 2007 1 / 39 Outline
Density estimation. In density estimation problems, we are given a random from an unknown density. Our objective is to estimate
 Density estimation In density estimation problems, we are given a random sample from an unknown density Our objective is to estimate? Applications Classification If we estimate the density for each class,
Density estimation In density estimation problems, we are given a random sample from an unknown density Our objective is to estimate? Applications Classification If we estimate the density for each class,
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/24/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 High dim. data
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/24/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 High dim. data
Calculus II. Step 1 First, here is a quick sketch of the graph of the region we are interested in.
 Preface Here are the solutions to the practice problems for my Calculus II notes. Some solutions will have more or less detail than other solutions. As the difficulty level of the problems increases less
Preface Here are the solutions to the practice problems for my Calculus II notes. Some solutions will have more or less detail than other solutions. As the difficulty level of the problems increases less
Paul's Online Math Notes Calculus III (Notes) / Applications of Partial Derivatives / Lagrange Multipliers Problems][Assignment Problems]
![Paul's Online Math Notes Calculus III (Notes) / Applications of Partial Derivatives / Lagrange Multipliers Problems][Assignment Problems]](/thumbs/77/75726948.jpg "Paul's Online Math Notes Calculus III (Notes) / Applications of Partial Derivatives / Lagrange Multipliers Problems][Assignment Problems]") 1 of 9 25/04/2016 13:15 Paul's Online Math Notes Calculus III (Notes) / Applications of Partial Derivatives / Lagrange Multipliers Problems][Assignment Problems] [Notes] [Practice Calculus III - Notes
1 of 9 25/04/2016 13:15 Paul's Online Math Notes Calculus III (Notes) / Applications of Partial Derivatives / Lagrange Multipliers Problems][Assignment Problems] [Notes] [Practice Calculus III - Notes
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 22, 2016 Course Information Website: http://www.stat.ucdavis.edu/~chohsieh/teaching/ ECS289G_Fall2016/main.html My office: Mathematical Sciences
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 22, 2016 Course Information Website: http://www.stat.ucdavis.edu/~chohsieh/teaching/ ECS289G_Fall2016/main.html My office: Mathematical Sciences
/633 Introduction to Algorithms Lecturer: Michael Dinitz Topic: Sorting lower bound and Linear-time sorting Date: 9/19/17
 601.433/633 Introduction to Algorithms Lecturer: Michael Dinitz Topic: Sorting lower bound and Linear-time sorting Date: 9/19/17 5.1 Introduction You should all know a few ways of sorting in O(n log n)
601.433/633 Introduction to Algorithms Lecturer: Michael Dinitz Topic: Sorting lower bound and Linear-time sorting Date: 9/19/17 5.1 Introduction You should all know a few ways of sorting in O(n log n)
Logistic Regression: Probabilistic Interpretation
 Logistic Regression: Probabilistic Interpretation Approximate 0/1 Loss Logistic Regression Adaboost (z) SVM Solution: Approximate 0/1 loss with convex loss ( surrogate loss) 0-1 z = y w x SVM (hinge),
Logistic Regression: Probabilistic Interpretation Approximate 0/1 Loss Logistic Regression Adaboost (z) SVM Solution: Approximate 0/1 loss with convex loss ( surrogate loss) 0-1 z = y w x SVM (hinge),
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu HITS (Hypertext Induced Topic Selection) Is a measure of importance of pages or documents, similar to PageRank
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu HITS (Hypertext Induced Topic Selection) Is a measure of importance of pages or documents, similar to PageRank
10-701/15-781, Fall 2006, Final
 -7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
-7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
Perceptron Introduction to Machine Learning. Matt Gormley Lecture 5 Jan. 31, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Perceptron Matt Gormley Lecture 5 Jan. 31, 2018 1 Q&A Q: We pick the best hyperparameters
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Perceptron Matt Gormley Lecture 5 Jan. 31, 2018 1 Q&A Q: We pick the best hyperparameters
Summarizing and mining inverse distributions on data streams via dynamic inverse sampling
 Summarizing and mining inverse distributions on data streams via dynamic inverse sampling Presented by Graham Cormode cormode@bell-labs.com S. Muthukrishnan muthu@cs.rutgers.edu Irina Rozenbaum rozenbau@paul.rutgers.edu
Summarizing and mining inverse distributions on data streams via dynamic inverse sampling Presented by Graham Cormode cormode@bell-labs.com S. Muthukrishnan muthu@cs.rutgers.edu Irina Rozenbaum rozenbau@paul.rutgers.edu
Query Processing. Introduction to Databases CompSci 316 Fall 2017
 Query Processing Introduction to Databases CompSci 316 Fall 2017 2 Announcements (Tue., Nov. 14) Homework #3 sample solution posted in Sakai Homework #4 assigned today; due on 12/05 Project milestone #2
Query Processing Introduction to Databases CompSci 316 Fall 2017 2 Announcements (Tue., Nov. 14) Homework #3 sample solution posted in Sakai Homework #4 assigned today; due on 12/05 Project milestone #2
Conflict Graphs for Parallel Stochastic Gradient Descent
 Conflict Graphs for Parallel Stochastic Gradient Descent Darshan Thaker*, Guneet Singh Dhillon* Abstract We present various methods for inducing a conflict graph in order to effectively parallelize Pegasos.
Conflict Graphs for Parallel Stochastic Gradient Descent Darshan Thaker*, Guneet Singh Dhillon* Abstract We present various methods for inducing a conflict graph in order to effectively parallelize Pegasos.
One-Pass Streaming Algorithms
 One-Pass Streaming Algorithms Theory and Practice Complaints and Grievances about theory in practice Disclaimer Experiences with Gigascope. A practitioner s perspective. Will be using my own implementations,
One-Pass Streaming Algorithms Theory and Practice Complaints and Grievances about theory in practice Disclaimer Experiences with Gigascope. A practitioner s perspective. Will be using my own implementations,
Approximation Algorithms for Clustering Uncertain Data
 Approximation Algorithms for Clustering Uncertain Data Graham Cormode AT&T Labs - Research graham@research.att.com Andrew McGregor UCSD / MSR / UMass Amherst andrewm@ucsd.edu Introduction Many applications
Approximation Algorithms for Clustering Uncertain Data Graham Cormode AT&T Labs - Research graham@research.att.com Andrew McGregor UCSD / MSR / UMass Amherst andrewm@ucsd.edu Introduction Many applications
Data Streams. Everything Data CompSci 216 Spring 2018
 Data Streams Everything Data CompSci 216 Spring 2018 How much data is generated every 2 minute in the world? haps://fossbytes.com/how-much-data-is-generated-every-minute-in-the-world/ 3 Data stream A potentially
Data Streams Everything Data CompSci 216 Spring 2018 How much data is generated every 2 minute in the world? haps://fossbytes.com/how-much-data-is-generated-every-minute-in-the-world/ 3 Data stream A potentially
Scaling up: Naïve Bayes on Hadoop. What, How and Why?
 Scaling up: Naïve Bayes on Hadoop What, How and Why? Big ML c. 2001 (Banko & Brill, Scaling to Very Very Large, ACL 2001) Task: distinguish pairs of easily-confused words ( affect vs effect ) in context
Scaling up: Naïve Bayes on Hadoop What, How and Why? Big ML c. 2001 (Banko & Brill, Scaling to Very Very Large, ACL 2001) Task: distinguish pairs of easily-confused words ( affect vs effect ) in context
Predictive Indexing for Fast Search
 Predictive Indexing for Fast Search Sharad Goel, John Langford and Alex Strehl Yahoo! Research, New York Modern Massive Data Sets (MMDS) June 25, 2008 Goel, Langford & Strehl (Yahoo! Research) Predictive
Predictive Indexing for Fast Search Sharad Goel, John Langford and Alex Strehl Yahoo! Research, New York Modern Massive Data Sets (MMDS) June 25, 2008 Goel, Langford & Strehl (Yahoo! Research) Predictive
Linear methods for supervised learning
 Linear methods for supervised learning LDA Logistic regression Naïve Bayes PLA Maximum margin hyperplanes Soft-margin hyperplanes Least squares resgression Ridge regression Nonlinear feature maps Sometimes
Linear methods for supervised learning LDA Logistic regression Naïve Bayes PLA Maximum margin hyperplanes Soft-margin hyperplanes Least squares resgression Ridge regression Nonlinear feature maps Sometimes
CS224W: Analysis of Networks Jure Leskovec, Stanford University
 HW2 Q1.1 parts (b) and (c) cancelled. HW3 released. It is long. Start early. CS224W: Analysis of Networks Jure Leskovec, Stanford University http://cs224w.stanford.edu 10/26/17 Jure Leskovec, Stanford
HW2 Q1.1 parts (b) and (c) cancelled. HW3 released. It is long. Start early. CS224W: Analysis of Networks Jure Leskovec, Stanford University http://cs224w.stanford.edu 10/26/17 Jure Leskovec, Stanford
Bloom filters and their applications
 Bloom filters and their applications Fedor Nikitin June 11, 2006 1 Introduction The bloom filters, as a new approach to hashing, were firstly presented by Burton Bloom [Blo70]. He considered the task of
Bloom filters and their applications Fedor Nikitin June 11, 2006 1 Introduction The bloom filters, as a new approach to hashing, were firstly presented by Burton Bloom [Blo70]. He considered the task of
We have used both of the last two claims in previous algorithms and therefore their proof is omitted.
 Homework 3 Question 1 The algorithm will be based on the following logic: If an edge ( ) is deleted from the spanning tree, let and be the trees that were created, rooted at and respectively Adding any
Homework 3 Question 1 The algorithm will be based on the following logic: If an edge ( ) is deleted from the spanning tree, let and be the trees that were created, rooted at and respectively Adding any
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu SPAM FARMING 2/11/2013 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 2/11/2013 Jure Leskovec, Stanford
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu SPAM FARMING 2/11/2013 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 2/11/2013 Jure Leskovec, Stanford
Behavioral Data Mining. Lecture 18 Clustering
 Behavioral Data Mining Lecture 18 Clustering Outline Why? Cluster quality K-means Spectral clustering Generative Models Rationale Given a set {X i } for i = 1,,n, a clustering is a partition of the X i
Behavioral Data Mining Lecture 18 Clustering Outline Why? Cluster quality K-means Spectral clustering Generative Models Rationale Given a set {X i } for i = 1,,n, a clustering is a partition of the X i
CPSC 340: Machine Learning and Data Mining. Non-Parametric Models Fall 2016
 CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Admin Course add/drop deadline tomorrow. Assignment 1 is due Friday. Setup your CS undergrad account ASAP to use Handin: https://www.cs.ubc.ca/getacct
CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Admin Course add/drop deadline tomorrow. Assignment 1 is due Friday. Setup your CS undergrad account ASAP to use Handin: https://www.cs.ubc.ca/getacct
15-451/651: Design & Analysis of Algorithms October 11, 2018 Lecture #13: Linear Programming I last changed: October 9, 2018
 15-451/651: Design & Analysis of Algorithms October 11, 2018 Lecture #13: Linear Programming I last changed: October 9, 2018 In this lecture, we describe a very general problem called linear programming
15-451/651: Design & Analysis of Algorithms October 11, 2018 Lecture #13: Linear Programming I last changed: October 9, 2018 In this lecture, we describe a very general problem called linear programming
BigTable. CSE-291 (Cloud Computing) Fall 2016
 Fall 2016") BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
Equations of planes in
 Roberto s Notes on Linear Algebra Chapter 6: Lines, planes and other straight objects Section Equations of planes in What you need to know already: What vectors and vector operations are. What linear systems
Roberto s Notes on Linear Algebra Chapter 6: Lines, planes and other straight objects Section Equations of planes in What you need to know already: What vectors and vector operations are. What linear systems
Distributed Computing with Spark
 Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
Kernels and Clustering
 Kernels and Clustering Robert Platt Northeastern University All slides in this file are adapted from CS188 UC Berkeley Case-Based Learning Non-Separable Data Case-Based Reasoning Classification from similarity
Kernels and Clustering Robert Platt Northeastern University All slides in this file are adapted from CS188 UC Berkeley Case-Based Learning Non-Separable Data Case-Based Reasoning Classification from similarity
Kathleen Durant PhD Northeastern University CS Indexes
 Kathleen Durant PhD Northeastern University CS 3200 Indexes Outline for the day Index definition Types of indexes B+ trees ISAM Hash index Choosing indexed fields Indexes in InnoDB 2 Indexes A typical
Kathleen Durant PhD Northeastern University CS 3200 Indexes Outline for the day Index definition Types of indexes B+ trees ISAM Hash index Choosing indexed fields Indexes in InnoDB 2 Indexes A typical
Final Exam. Introduction to Artificial Intelligence. CS 188 Spring 2010 INSTRUCTIONS. You have 3 hours.
 CS 188 Spring 2010 Introduction to Artificial Intelligence Final Exam INSTRUCTIONS You have 3 hours. The exam is closed book, closed notes except a two-page crib sheet. Please use non-programmable calculators
CS 188 Spring 2010 Introduction to Artificial Intelligence Final Exam INSTRUCTIONS You have 3 hours. The exam is closed book, closed notes except a two-page crib sheet. Please use non-programmable calculators
Link Analysis in the Cloud
 Cloud Computing Link Analysis in the Cloud Dell Zhang Birkbeck, University of London 2017/18 Graph Problems & Representations What is a Graph? G = (V,E), where V represents the set of vertices (nodes)
Cloud Computing Link Analysis in the Cloud Dell Zhang Birkbeck, University of London 2017/18 Graph Problems & Representations What is a Graph? G = (V,E), where V represents the set of vertices (nodes)
Discrete Mathematics Course Review 3
 21-228 Discrete Mathematics Course Review 3 This document contains a list of the important definitions and theorems that have been covered thus far in the course. It is not a complete listing of what has
21-228 Discrete Mathematics Course Review 3 This document contains a list of the important definitions and theorems that have been covered thus far in the course. It is not a complete listing of what has
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
CS249: ADVANCED DATA MINING
 CS249: ADVANCED DATA MINING Classification Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu April 24, 2017 Homework 2 out Announcements Due May 3 rd (11:59pm) Course project proposal
CS249: ADVANCED DATA MINING Classification Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu April 24, 2017 Homework 2 out Announcements Due May 3 rd (11:59pm) Course project proposal
/633 Introduction to Algorithms Lecturer: Michael Dinitz Topic: Priority Queues / Heaps Date: 9/27/17
 01.433/33 Introduction to Algorithms Lecturer: Michael Dinitz Topic: Priority Queues / Heaps Date: 9/2/1.1 Introduction In this lecture we ll talk about a useful abstraction, priority queues, which are
01.433/33 Introduction to Algorithms Lecturer: Michael Dinitz Topic: Priority Queues / Heaps Date: 9/2/1.1 Introduction In this lecture we ll talk about a useful abstraction, priority queues, which are
Image Compression With Haar Discrete Wavelet Transform
 Image Compression With Haar Discrete Wavelet Transform Cory Cox ME 535: Computational Techniques in Mech. Eng. Figure 1 : An example of the 2D discrete wavelet transform that is used in JPEG2000. Source:
Image Compression With Haar Discrete Wavelet Transform Cory Cox ME 535: Computational Techniques in Mech. Eng. Figure 1 : An example of the 2D discrete wavelet transform that is used in JPEG2000. Source:
Lecture outline. Graph coloring Examples Applications Algorithms
 Lecture outline Graph coloring Examples Applications Algorithms Graph coloring Adjacent nodes must have different colors. How many colors do we need? Graph coloring Neighbors must have different colors
Lecture outline Graph coloring Examples Applications Algorithms Graph coloring Adjacent nodes must have different colors. How many colors do we need? Graph coloring Neighbors must have different colors
CS 4349 Lecture August 21st, 2017
 CS 4349 Lecture August 21st, 2017 Main topics for #lecture include #administrivia, #algorithms, #asymptotic_notation. Welcome and Administrivia Hi, I m Kyle! Welcome to CS 4349. This a class about algorithms.
CS 4349 Lecture August 21st, 2017 Main topics for #lecture include #administrivia, #algorithms, #asymptotic_notation. Welcome and Administrivia Hi, I m Kyle! Welcome to CS 4349. This a class about algorithms.
Chapter 1 - The Spark Machine Learning Library
 Chapter 1 - The Spark Machine Learning Library Objectives Key objectives of this chapter: The Spark Machine Learning Library (MLlib) MLlib dense and sparse vectors and matrices Types of distributed matrices
Chapter 1 - The Spark Machine Learning Library Objectives Key objectives of this chapter: The Spark Machine Learning Library (MLlib) MLlib dense and sparse vectors and matrices Types of distributed matrices
Combine the PA Algorithm with a Proximal Classifier
 Combine the Passive and Aggressive Algorithm with a Proximal Classifier Yuh-Jye Lee Joint work with Y.-C. Tseng Dept. of Computer Science & Information Engineering TaiwanTech. Dept. of Statistics@NCKU
Combine the Passive and Aggressive Algorithm with a Proximal Classifier Yuh-Jye Lee Joint work with Y.-C. Tseng Dept. of Computer Science & Information Engineering TaiwanTech. Dept. of Statistics@NCKU