FMM implementation on CPU and GPU. Nail A. Gumerov (Lecture for CMSC 828E)
|
|
|
- Jennifer Hopkins
- 6 years ago
- Views:
Transcription
1 FMM implementation on CPU and GPU Nail A. Gumerov (Lecture for CMSC 828E)
2 Outline Two parts of the FMM Data Structure Flow Chart of the Run Algorithm FMM Cost/Optimization on CPU Programming on GPU Fast Matrix-Vector Multiplication on GPU with On-Core Computable Kernel FMM Sparse Matrix-Vector Multiplication on GPU Change of the Cost/Optimization scheme on GPU compared to CPU Other steps Test Results Profile Accuracy Overall Performance
3 Publication The major part of this work has been published: N.A. Gumerov and R. Duraiswami Fast multipole methods on graphics processors. Journal of Computational Physics, 227, , 2008.
4 Two parts of the FMM Generate data structure (define the matrix); Perform Matrix-vector product (run); Two different types of problems: Static matrix (e.g. for iterative solution of large linear system): Data structure should be generated once, while run should be performed many times with different input vectors; Dynamic matrix (e.g. N-body problem) Data structure should be generated each time, when matrixvector multiplication is needed.
5 Data Structure We need O(NlogN) procedure to index all the boxes, find children/parent and neighbors; Implemented on CPU using bit-interleaving (Morton- Peano indexing in octree) and sorting; We generate lists of Children/Parent/Neighbors/E4- neighbors and store in global memory; Recently, graduate students Michael Lieberman and Adam O Donovan implemented basic data structures on GPU (prefix sort, etc.) and found of order 10 speedups compared to the CPU for large data sets. In the present lecture we will focus on the run algorithm, assuming that the necessary lists are generated and stored in the global memory.
6 Flow Chart of FMM Run Level l max Levels l max -1,, 2 Level 2 Levels 3,,l max 1. Get S-expansion coefficients (directly) 2. Get S-expansion coefficients from children (S S translation) 3. Get R-expansion coefficients from far neighbors (S R translation) 4. Get R-expansion coefficients from far neighbors (S R translation) Start End Level l max 7. Sum sources in close neighborhood (directly) Level l max 6. Evaluate R-expansions (directly) 5. Get R-expansion coefficients from parents (R R translation) Direct Sparse Matrix- Vector Multiplication Approximate Dense Matrix- Vector Multiplication
7 FMM Cost (Operations) Points are clustered with clustering parameter s, means not more that s points in the smallest octree box. Expansions have length p 2 (number of coefficients). There are O(N) points and O(N boxes )=O(N/s) in the octree. O(Np 2 ) O(N boxes p 3 ) O(p 3 ) O(N boxes p 3 ) Level l max 1. Get S-expansion coefficients (directly) Levels l max -1,, 2 2. Get S-expansion coefficients from children (S S translation) Level 2 3. Get R-expansion coefficients from far neighbors (S R translation) Levels 3,,l max 4. Get R-expansion coefficients from far neighbors (S R translation) Start End Level l max 7. Sum sources in close neighborhood (directly) Level l max 6. Evaluate R-expansions (directly) 5. Get R-expansion coefficients from parents (R R translation) O(Ns) O(Np 2 ) O(N boxes p 3 )
8 FMM Cost/Optimization Since p=o(1), we have (operations) TotalCost = AN+BN noxes +CNs =N(A+B/s+Cs) Total Cost Cs s opt =(B/C) 1/2 B/s s opt s
9 Challenges Complex FMM data structure; Problem is not native for SIMD semantics; non-uniformity of data causes problems with efficient work load (taking into account large number of threads); serial algorithms use recursive computations; existing libraries (CUBLAS) and middleware approach are not sufficient; high performing FMM functions should be redesigned and written in CU; Low fast (shared/constant) memory for efficient implementation of translation operators; Absence of good debugging tools for GPU.
10 FMM on GPU
11 Implementation Main algorithm is in Fortran 95 Data structures are computed on CPU Interface between Fortran and GPU is provided by our middleware (Flagon), which is a layer between Fortran and C++/CUDA High performance custom subroutines written using Cu

12 Availability Fortran-9X version is released for free public use. It is called FLAGON.
13 High performance direct summation on GPU (total) 1.E+04 1.E+03 Computations of potential y=ax 2 CPU: 2.67 GHz Intel Core 2 extreme QX 7400 (2GB RAM and one of four CPUs employed). 1.E+02 1.E+01 CPU, Direct y=bx 2 GPU: NVIDIA GeForce 8800 GTX (peak 330 GFLOPS). Time (s) 1.E+00 1.E-01 GPU, Direct Estimated achieved rate: 190 GFLOPS. 1.E-02 y=bx 2 +cx+d 1.E-03 1.E-04 b/a=600 3D Laplace 1.E+03 1.E+04 1.E+05 1.E+06 CPU direct: serial code; no use of partial caching; no loop unrolling; (simple execution of nested loop) Number of Sources
14 Algorithm (in words) 1. All source data, including coordinates and source intensities are stored in a single array in the global GPU memory (the size of the array is 4N for potential evaluation and 7N for potential/force evaluation). Two more large arrays reside in the global memory, one with the receiver coordinates (size 3M), and the other is allocated for the result of the matrix vector product (M for potential computations and 4M for potential and force computations). In case the sources and receivers are the same, as in particle dynamics computations, these can be reduced. 2. The routine is executed in CUDA on a one dimensional grid of one dimensional blocks of threads. By default each block contains 256 threads, which was determined via an empirical study of optimal thread-block size. This study also showed that for good performance the thread block grid should contain not less than 32 blocks for a 16 multiprocessor configuration. If the number of receivers is not a divisor of the block size, only the remaining number of threads is employed for computations of the last block. 3. Each thread in the block handles computation of one element of the output vector (or one receiver). For this purpose a register for potential calculation (and three registers for calculation of forces) are allocated and initialized to zero. The thread can take care of another receiver only after the entire block of threads is executed, threads are synchronized, and the shared memory can be overwritten. 4. Each thread reads the respective receiver coordinates directly from the global memory and puts them into the shared memory. 5. For a given block the source data are executed in a loop by batches of size B floats, where B depends on the type of the kernel (4 or 7 floats per source for monopole or monopole/dipole summations, respectively) and the size of the shared memory available. Currently we use 8 kb, or 2048 floats of the shared memory (so e.g. for monopole summation this determines B ј 512). If the number of sources is not a divisor of B the last batch takes care of the remaining number of sources. 6. All threads of the block are employed to read source data for the given batch from global memory and put them into the shared memory (consequent reading: one thread per one float, until the entire batch is loaded followed by thread synchronization). 7. Each thread computes the product of one matrix element (kernel) with the source intensity (or in the case of dipoles the dipole moment with the kernel) and sums it up with the content of the respective summation register. 8. After summation of contributions of all sources (all batches) each thread writes the sum from its register into the global memory.
15 Direct summation on GPU (final step in the FMM) Computations of potential, optimal settings for CPU 1.E+02 Sparse Matrix-Vector Product s max =60 y=bx CPU: 1.E+01 Time=CNs, s=8 -lmax N 1.E+00 CPU l max =5 y=cx GPU: Time (s) 1.E-01 1.E-02 1.E-03 2 y=ax GPU b/c=16 y=8 -lmax dx 2 +ex+8 lmax f Time=A 1 N+B 1 N/s+C 1 Ns read/write float computations 3D Laplace 1.E-04 1.E+02 1.E+03 1.E+04 1.E+05 1.E+06 1.E+07 Number of Sources access to box data These parameters depend on the hardware
16 Algorithm modification 1. Each block of threads executes computations for one receiver box (Blockper-box parallelization). 2. Each block of threads accesses the data structure. 3. Loop over all sources contributing to the result requires partially non-coalesced read of the source data (box by box).
17 Optimization Sparse M-V product Time Dense M-V product Time Time CPU: + = 0 s 0 s 0 s opt s Time Time Time GPU: + = 0 s1 0 0 s s s 1 s opt s
18 Direct summation on GPU (final step in the FMM) Compare GPU final summation complexity: and total FMM complexity: Cost =A 1 N+B 1 N/s+C 1 Ns. Cost = AN+BN/s+CNs. Optimal cluster size for direct summation step of the FMM s opt = (B 1 /C 1 ) 1/2, and this can be only increased for the full algorithm, since its complexity Cost =(A+A 1 )N+(B+B 1 )N/s+C 1 Ns, and s opt = ((B+B 1 )/C 1 ) 1/2.
19 Direct summation on GPU (final step in the FMM) Computations of potential, optimal settings for GPU 1.E+03 1.E+02 Sparse Matrix-Vector Product s max =320 y=bx 1.E+01 y=ax 2 CPU l max =4 y=cx Time (s) 1.E+00 1.E-01 1.E GPU b/c=300 1.E-03 y=8 -lmax dx 2 +ex+8 lmax f 3D Laplace 1.E-04 1.E+03 1.E+04 1.E+05 1.E+06 1.E+07 Number of Sources
20 Direct summation on GPU (final step in the FMM) Computations of potential, optimal settings for CPU and GPU N Serial CPU (s) GPU(s) Time Ratio E E E E E E E E E E E E E E E E E E-01 69
21 Important conclusion: Since the optimal max level of the octree when using GPU is lesser than that for the CPU, the importance of optimization of translation subroutines diminishes.
22 Other steps of the FMM on GPU Accelerations in range 5-60; Effective accelerations for N=1,048,576 (taking into account max level reduction):
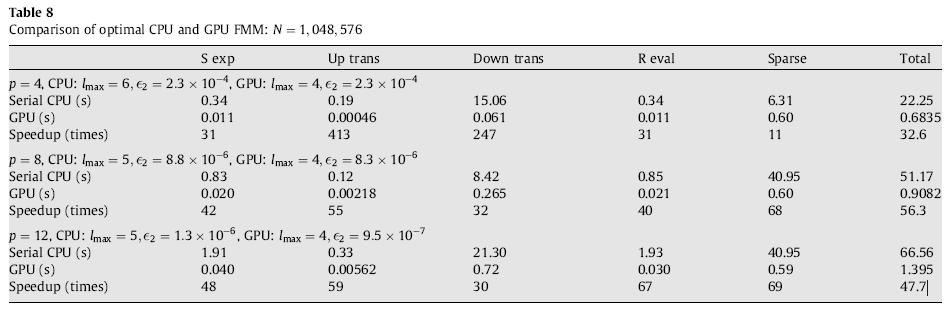
23 Profile
24 Accuracy Relative L 2 norm error measure: CPU single precision direct summation was taken as exact ; 100 sampling points were used.

25 What is more accurate for solution of large problems on GPU: direct summation or FMM? L2-relative error 1.E-02 1.E-03 1.E-04 1.E-05 1.E-06 1.E-07 1.E-08 1.E-09 Error in computations of potential FMM FMM FMM GPU CPU Direct p=8 p=4 1.E+02 1.E+03 1.E+04 1.E+05 1.E+06 1.E+07 Number of Sources p=12 Filled = GPU, Empty = CPU Error computed over a grid of 729 sampling points, relative to exact solution, which is direct summation with double precision. Possible reason why the GPU error in direct summation grows: systematic roundoff error in computation of function 1/sqrt(x). (still a question).
26 Performance N=1,048,576 (potential only) serial CPU GPU Ratio p= s s 33 p= s s 56 p= s s 48 N=1,048,576 (potential+forces (gradient)) serial CPU GPU Ratio p= s s 29 p= s s 72 p= s s 66
27 Performance p=4 p=8 p=12 1.E+02 3D Laplace y=ax 2 y=bx 2 y=cx 1.E+02 3D Laplace y=ax 2 y=bx 2 y=cx 1.E+02 3D Laplace y=ax 2 y=cx R u n T im e (s ) 1.E+01 1.E+00 1.E-01 CPU, Direct CPU, FMM GPU, Direct y=dx R u n T im e (s ) 1.E+01 1.E+00 1.E-01 CPU, Direct CPU, FMM GPU, Direct y=dx R u n T im e (s ) 1.E+01 1.E+00 1.E-01 CPU, Direct CPU, FMM y=bx 2 GPU, FMM y=dx 1.E-02 GPU, FMM 1.E-03 1.E+03 1.E+04 1.E+05 1.E+06 1.E+07 Number of Sources a/b = 600 c/d = 30 p=4, FMM error ~ E-02 GPU, FMM 1.E-03 1.E+03 1.E+04 1.E+05 1.E+06 1.E+07 Number of Sources a/b = 600 c/d = 50 p=8, FMM error ~ E-02 GPU, Direct 1.E-03 1.E+03 1.E+04 1.E+05 1.E+06 1.E+07 Number of Sources a/b = 600 c/d = 50 p=12, FMM error ~ 10-6
28 Performance FMM GPU Computations of the potential and forces: Peak performance of GPU for direct summation 290 Gigaflops, while for the FMM on GPU effective rates in range Teraflops are observed (following the citation below). dir CPU FMM M.S. Warren, J.K. Salmon, D.J. Becker, M.P. Goda, T. Sterling & G.S. Winckelmans. Pentium Pro inside: I. a treecode at 430 Gigaflops on ASCI Red, Bell price winning paper at SC 97, direct
CMSC 858M/AMSC 698R. Fast Multipole Methods. Nail A. Gumerov & Ramani Duraiswami. Lecture 20. Outline
 CMSC 858M/AMSC 698R Fast Multipole Methods Nail A. Gumerov & Ramani Duraiswami Lecture 20 Outline Two parts of the FMM Data Structures FMM Cost/Optimization on CPU Fine Grain Parallelization for Multicore
CMSC 858M/AMSC 698R Fast Multipole Methods Nail A. Gumerov & Ramani Duraiswami Lecture 20 Outline Two parts of the FMM Data Structures FMM Cost/Optimization on CPU Fine Grain Parallelization for Multicore
Terascale on the desktop: Fast Multipole Methods on Graphical Processors
 Terascale on the desktop: Fast Multipole Methods on Graphical Processors Nail A. Gumerov Fantalgo, LLC Institute for Advanced Computer Studies University of Maryland (joint work with Ramani Duraiswami)
Terascale on the desktop: Fast Multipole Methods on Graphical Processors Nail A. Gumerov Fantalgo, LLC Institute for Advanced Computer Studies University of Maryland (joint work with Ramani Duraiswami)
Fast Multipole and Related Algorithms
 Fast Multipole and Related Algorithms Ramani Duraiswami University of Maryland, College Park http://www.umiacs.umd.edu/~ramani Joint work with Nail A. Gumerov Efficiency by exploiting symmetry and A general
Fast Multipole and Related Algorithms Ramani Duraiswami University of Maryland, College Park http://www.umiacs.umd.edu/~ramani Joint work with Nail A. Gumerov Efficiency by exploiting symmetry and A general
Scientific Computing on Graphical Processors: FMM, Flagon, Signal Processing, Plasma and Astrophysics
 Scientific Computing on Graphical Processors: FMM, Flagon, Signal Processing, Plasma and Astrophysics Ramani Duraiswami Computer Science & UMIACS University of Maryland, College Park Joint work with Nail
Scientific Computing on Graphical Processors: FMM, Flagon, Signal Processing, Plasma and Astrophysics Ramani Duraiswami Computer Science & UMIACS University of Maryland, College Park Joint work with Nail
Efficient O(N log N) algorithms for scattered data interpolation
 algorithms for scattered data interpolation") Efficient O(N log N) algorithms for scattered data interpolation Nail Gumerov University of Maryland Institute for Advanced Computer Studies Joint work with Ramani Duraiswami February Fourier Talks 2007
Efficient O(N log N) algorithms for scattered data interpolation Nail Gumerov University of Maryland Institute for Advanced Computer Studies Joint work with Ramani Duraiswami February Fourier Talks 2007
FMM Data Structures. Content. Introduction Hierarchical Space Subdivision with 2 d -Trees Hierarchical Indexing System Parent & Children Finding
 FMM Data Structures Nail Gumerov & Ramani Duraiswami UMIACS [gumerov][ramani]@umiacs.umd.edu CSCAMM FAM4: 4/9/4 Duraiswami & Gumerov, -4 Content Introduction Hierarchical Space Subdivision with d -Trees
FMM Data Structures Nail Gumerov & Ramani Duraiswami UMIACS [gumerov][ramani]@umiacs.umd.edu CSCAMM FAM4: 4/9/4 Duraiswami & Gumerov, -4 Content Introduction Hierarchical Space Subdivision with d -Trees
Using GPUs to compute the multilevel summation of electrostatic forces
 Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Accelerating Octo-Tiger: Stellar Mergers on Intel Knights Landing with HPX
 Accelerating Octo-Tiger: Stellar Mergers on Intel Knights Landing with HPX David Pfander*, Gregor Daiß*, Dominic Marcello**, Hartmut Kaiser**, Dirk Pflüger* * University of Stuttgart ** Louisiana State
Accelerating Octo-Tiger: Stellar Mergers on Intel Knights Landing with HPX David Pfander*, Gregor Daiß*, Dominic Marcello**, Hartmut Kaiser**, Dirk Pflüger* * University of Stuttgart ** Louisiana State
FMM CMSC 878R/AMSC 698R. Lecture 13
 FMM CMSC 878R/AMSC 698R Lecture 13 Outline Results of the MLFMM tests Itemized Asymptotic Complexity of the MLFMM; Optimization of the Grouping (Clustering) Parameter; Regular mesh; Random distributions.
FMM CMSC 878R/AMSC 698R Lecture 13 Outline Results of the MLFMM tests Itemized Asymptotic Complexity of the MLFMM; Optimization of the Grouping (Clustering) Parameter; Regular mesh; Random distributions.
Center for Computational Science
 Center for Computational Science Toward GPU-accelerated meshfree fluids simulation using the fast multipole method Lorena A Barba Boston University Department of Mechanical Engineering with: Felipe Cruz,
Center for Computational Science Toward GPU-accelerated meshfree fluids simulation using the fast multipole method Lorena A Barba Boston University Department of Mechanical Engineering with: Felipe Cruz,
N-Body Simulation using CUDA. CSE 633 Fall 2010 Project by Suraj Alungal Balchand Advisor: Dr. Russ Miller State University of New York at Buffalo
 N-Body Simulation using CUDA CSE 633 Fall 2010 Project by Suraj Alungal Balchand Advisor: Dr. Russ Miller State University of New York at Buffalo Project plan Develop a program to simulate gravitational
N-Body Simulation using CUDA CSE 633 Fall 2010 Project by Suraj Alungal Balchand Advisor: Dr. Russ Miller State University of New York at Buffalo Project plan Develop a program to simulate gravitational
Scalable Fast Multipole Methods on Distributed Heterogeneous Architectures
 Scalable Fast Multipole Methods on Distributed Heterogeneous Architectures Qi Hu huqi@cs.umd.edu Nail A. Gumerov gumerov@umiacs.umd.edu Ramani Duraiswami ramani@umiacs.umd.edu Institute for Advanced Computer
Scalable Fast Multipole Methods on Distributed Heterogeneous Architectures Qi Hu huqi@cs.umd.edu Nail A. Gumerov gumerov@umiacs.umd.edu Ramani Duraiswami ramani@umiacs.umd.edu Institute for Advanced Computer
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Accelerating GPU computation through mixed-precision methods. Michael Clark Harvard-Smithsonian Center for Astrophysics Harvard University
 Accelerating GPU computation through mixed-precision methods Michael Clark Harvard-Smithsonian Center for Astrophysics Harvard University Outline Motivation Truncated Precision using CUDA Solving Linear
Accelerating GPU computation through mixed-precision methods Michael Clark Harvard-Smithsonian Center for Astrophysics Harvard University Outline Motivation Truncated Precision using CUDA Solving Linear
Administrative Issues. L11: Sparse Linear Algebra on GPUs. Triangular Solve (STRSM) A Few Details 2/25/11. Next assignment, triangular solve
 A Few Details 2/25/11. Next assignment, triangular solve") Administrative Issues L11: Sparse Linear Algebra on GPUs Next assignment, triangular solve Due 5PM, Tuesday, March 15 handin cs6963 lab 3 Project proposals Due 5PM, Wednesday, March 7 (hard
Administrative Issues L11: Sparse Linear Algebra on GPUs Next assignment, triangular solve Due 5PM, Tuesday, March 15 handin cs6963 lab 3 Project proposals Due 5PM, Wednesday, March 7 (hard
An Efficient CUDA Implementation of a Tree-Based N-Body Algorithm. Martin Burtscher Department of Computer Science Texas State University-San Marcos
 An Efficient CUDA Implementation of a Tree-Based N-Body Algorithm Martin Burtscher Department of Computer Science Texas State University-San Marcos Mapping Regular Code to GPUs Regular codes Operate on
An Efficient CUDA Implementation of a Tree-Based N-Body Algorithm Martin Burtscher Department of Computer Science Texas State University-San Marcos Mapping Regular Code to GPUs Regular codes Operate on
Iterative methods for use with the Fast Multipole Method
 Iterative methods for use with the Fast Multipole Method Ramani Duraiswami Perceptual Interfaces and Reality Lab. Computer Science & UMIACS University of Maryland, College Park, MD Joint work with Nail
Iterative methods for use with the Fast Multipole Method Ramani Duraiswami Perceptual Interfaces and Reality Lab. Computer Science & UMIACS University of Maryland, College Park, MD Joint work with Nail
Study and implementation of computational methods for Differential Equations in heterogeneous systems. Asimina Vouronikoy - Eleni Zisiou
 Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Data parallel algorithms, algorithmic building blocks, precision vs. accuracy
 Data parallel algorithms, algorithmic building blocks, precision vs. accuracy Robert Strzodka Architecture of Computing Systems GPGPU and CUDA Tutorials Dresden, Germany, February 25 2008 2 Overview Parallel
Data parallel algorithms, algorithmic building blocks, precision vs. accuracy Robert Strzodka Architecture of Computing Systems GPGPU and CUDA Tutorials Dresden, Germany, February 25 2008 2 Overview Parallel
GPU accelerated heterogeneous computing for Particle/FMM Approaches and for Acoustic Imaging
 GPU accelerated heterogeneous computing for Particle/FMM Approaches and for Acoustic Imaging Ramani Duraiswami University of Maryland, College Park http://www.umiacs.umd.edu/~ramani With Nail A. Gumerov,
GPU accelerated heterogeneous computing for Particle/FMM Approaches and for Acoustic Imaging Ramani Duraiswami University of Maryland, College Park http://www.umiacs.umd.edu/~ramani With Nail A. Gumerov,
Introduction to CUDA
 Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
A Cross-Input Adaptive Framework for GPU Program Optimizations
 A Cross-Input Adaptive Framework for GPU Program Optimizations Yixun Liu, Eddy Z. Zhang, Xipeng Shen Computer Science Department The College of William & Mary Outline GPU overview G-Adapt Framework Evaluation
A Cross-Input Adaptive Framework for GPU Program Optimizations Yixun Liu, Eddy Z. Zhang, Xipeng Shen Computer Science Department The College of William & Mary Outline GPU overview G-Adapt Framework Evaluation
Di Zhao Ohio State University MVAPICH User Group (MUG) Meeting, August , Columbus Ohio
 Meeting, August , Columbus Ohio") Di Zhao zhao.1029@osu.edu Ohio State University MVAPICH User Group (MUG) Meeting, August 26-27 2013, Columbus Ohio Nvidia Kepler K20X Intel Xeon Phi 7120 Launch Date November 2012 Q2 2013 Processor Per-processor
Di Zhao zhao.1029@osu.edu Ohio State University MVAPICH User Group (MUG) Meeting, August 26-27 2013, Columbus Ohio Nvidia Kepler K20X Intel Xeon Phi 7120 Launch Date November 2012 Q2 2013 Processor Per-processor
Device Memories and Matrix Multiplication
 Device Memories and Matrix Multiplication 1 Device Memories global, constant, and shared memories CUDA variable type qualifiers 2 Matrix Multiplication an application of tiling runningmatrixmul in the
Device Memories and Matrix Multiplication 1 Device Memories global, constant, and shared memories CUDA variable type qualifiers 2 Matrix Multiplication an application of tiling runningmatrixmul in the
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
SEASHORE / SARUMAN. Short Read Matching using GPU Programming. Tobias Jakobi
 SEASHORE SARUMAN Summary 1 / 24 SEASHORE / SARUMAN Short Read Matching using GPU Programming Tobias Jakobi Center for Biotechnology (CeBiTec) Bioinformatics Resource Facility (BRF) Bielefeld University
SEASHORE SARUMAN Summary 1 / 24 SEASHORE / SARUMAN Short Read Matching using GPU Programming Tobias Jakobi Center for Biotechnology (CeBiTec) Bioinformatics Resource Facility (BRF) Bielefeld University
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Advanced CUDA Optimization 1. Introduction
 Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
Porting the NAS-NPB Conjugate Gradient Benchmark to CUDA. NVIDIA Corporation
 Porting the NAS-NPB Conjugate Gradient Benchmark to CUDA NVIDIA Corporation Outline! Overview of CG benchmark! Overview of CUDA Libraries! CUSPARSE! CUBLAS! Porting Sequence! Algorithm Analysis! Data/Code
Porting the NAS-NPB Conjugate Gradient Benchmark to CUDA NVIDIA Corporation Outline! Overview of CG benchmark! Overview of CUDA Libraries! CUSPARSE! CUBLAS! Porting Sequence! Algorithm Analysis! Data/Code
Numerical Simulation on the GPU
 Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
The Fast Multipole Method on NVIDIA GPUs and Multicore Processors
 The Fast Multipole Method on NVIDIA GPUs and Multicore Processors Toru Takahashi, a Cris Cecka, b Eric Darve c a b c Department of Mechanical Science and Engineering, Nagoya University Institute for Applied
The Fast Multipole Method on NVIDIA GPUs and Multicore Processors Toru Takahashi, a Cris Cecka, b Eric Darve c a b c Department of Mechanical Science and Engineering, Nagoya University Institute for Applied
CS GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8. Markus Hadwiger, KAUST
 CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Optimization solutions for the segmented sum algorithmic function
 Optimization solutions for the segmented sum algorithmic function ALEXANDRU PÎRJAN Department of Informatics, Statistics and Mathematics Romanian-American University 1B, Expozitiei Blvd., district 1, code
Optimization solutions for the segmented sum algorithmic function ALEXANDRU PÎRJAN Department of Informatics, Statistics and Mathematics Romanian-American University 1B, Expozitiei Blvd., district 1, code
HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER PROF. BRYANT PROF. KAYVON 15618: PARALLEL COMPUTER ARCHITECTURE
 HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER AVISHA DHISLE PRERIT RODNEY ADHISLE PRODNEY 15618: PARALLEL COMPUTER ARCHITECTURE PROF. BRYANT PROF. KAYVON LET S
HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER AVISHA DHISLE PRERIT RODNEY ADHISLE PRODNEY 15618: PARALLEL COMPUTER ARCHITECTURE PROF. BRYANT PROF. KAYVON LET S
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
Accelerating Leukocyte Tracking Using CUDA: A Case Study in Leveraging Manycore Coprocessors
 Accelerating Leukocyte Tracking Using CUDA: A Case Study in Leveraging Manycore Coprocessors Michael Boyer, David Tarjan, Scott T. Acton, and Kevin Skadron University of Virginia IPDPS 2009 Outline Leukocyte
Accelerating Leukocyte Tracking Using CUDA: A Case Study in Leveraging Manycore Coprocessors Michael Boyer, David Tarjan, Scott T. Acton, and Kevin Skadron University of Virginia IPDPS 2009 Outline Leukocyte
Dense matching GPU implementation
 Dense matching GPU implementation Author: Hailong Fu. Supervisor: Prof. Dr.-Ing. Norbert Haala, Dipl. -Ing. Mathias Rothermel. Universität Stuttgart 1. Introduction Correspondence problem is an important
Dense matching GPU implementation Author: Hailong Fu. Supervisor: Prof. Dr.-Ing. Norbert Haala, Dipl. -Ing. Mathias Rothermel. Universität Stuttgart 1. Introduction Correspondence problem is an important
Lecture 5. Performance programming for stencil methods Vectorization Computing with GPUs
 Lecture 5 Performance programming for stencil methods Vectorization Computing with GPUs Announcements Forge accounts: set up ssh public key, tcsh Turnin was enabled for Programming Lab #1: due at 9pm today,
Lecture 5 Performance programming for stencil methods Vectorization Computing with GPUs Announcements Forge accounts: set up ssh public key, tcsh Turnin was enabled for Programming Lab #1: due at 9pm today,
FIELA: A Fast Image Encryption with Lorenz Attractor using Hybrid Computing
 FIELA: A Fast Image Encryption with Lorenz Attractor using Hybrid Computing P Kranthi Kumar, B V Nagendra Prasad, Gelli MBSS Kumar, V. Chandrasekaran, P.K.Baruah Sri Sathya Sai Institute of Higher Learning,
FIELA: A Fast Image Encryption with Lorenz Attractor using Hybrid Computing P Kranthi Kumar, B V Nagendra Prasad, Gelli MBSS Kumar, V. Chandrasekaran, P.K.Baruah Sri Sathya Sai Institute of Higher Learning,
A Kernel-independent Adaptive Fast Multipole Method
 A Kernel-independent Adaptive Fast Multipole Method Lexing Ying Caltech Joint work with George Biros and Denis Zorin Problem Statement Given G an elliptic PDE kernel, e.g. {x i } points in {φ i } charges
A Kernel-independent Adaptive Fast Multipole Method Lexing Ying Caltech Joint work with George Biros and Denis Zorin Problem Statement Given G an elliptic PDE kernel, e.g. {x i } points in {φ i } charges
CS560 Lecture Parallel Architecture 1
 Parallel Architecture Announcements The RamCT merge is done! Please repost introductions. Manaf s office hours HW0 is due tomorrow night, please try RamCT submission HW1 has been posted Today Isoefficiency
Parallel Architecture Announcements The RamCT merge is done! Please repost introductions. Manaf s office hours HW0 is due tomorrow night, please try RamCT submission HW1 has been posted Today Isoefficiency
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management
 X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
QR Decomposition on GPUs
 QR Decomposition QR Algorithms Block Householder QR Andrew Kerr* 1 Dan Campbell 1 Mark Richards 2 1 Georgia Tech Research Institute 2 School of Electrical and Computer Engineering Georgia Institute of
QR Decomposition QR Algorithms Block Householder QR Andrew Kerr* 1 Dan Campbell 1 Mark Richards 2 1 Georgia Tech Research Institute 2 School of Electrical and Computer Engineering Georgia Institute of
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Effect of memory latency
 CACHE AWARENESS Effect of memory latency Consider a processor operating at 1 GHz (1 ns clock) connected to a DRAM with a latency of 100 ns. Assume that the processor has two ALU units and it is capable
CACHE AWARENESS Effect of memory latency Consider a processor operating at 1 GHz (1 ns clock) connected to a DRAM with a latency of 100 ns. Assume that the processor has two ALU units and it is capable
Parallel FFT Program Optimizations on Heterogeneous Computers
 Parallel FFT Program Optimizations on Heterogeneous Computers Shuo Chen, Xiaoming Li Department of Electrical and Computer Engineering University of Delaware, Newark, DE 19716 Outline Part I: A Hybrid
Parallel FFT Program Optimizations on Heterogeneous Computers Shuo Chen, Xiaoming Li Department of Electrical and Computer Engineering University of Delaware, Newark, DE 19716 Outline Part I: A Hybrid
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
Lecture 1: Introduction and Computational Thinking
 PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
Introduction to Parallel Computing with CUDA. Oswald Haan
 Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Debunking the 100X GPU vs CPU Myth: An Evaluation of Throughput Computing on CPU and GPU
 Debunking the 100X GPU vs CPU Myth: An Evaluation of Throughput Computing on CPU and GPU The myth 10x-1000x speed up on GPU vs CPU Papers supporting the myth: Microsoft: N. K. Govindaraju, B. Lloyd, Y.
Debunking the 100X GPU vs CPU Myth: An Evaluation of Throughput Computing on CPU and GPU The myth 10x-1000x speed up on GPU vs CPU Papers supporting the myth: Microsoft: N. K. Govindaraju, B. Lloyd, Y.
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CUDA (Compute Unified Device Architecture)
") CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
Performance and accuracy of hardware-oriented. native-, solvers in FEM simulations
 Robert Strzodka, Stanford University Dominik Göddeke, Universität Dortmund Performance and accuracy of hardware-oriented native-, emulated- and mixed-precision solvers in FEM simulations Number of slices
Robert Strzodka, Stanford University Dominik Göddeke, Universität Dortmund Performance and accuracy of hardware-oriented native-, emulated- and mixed-precision solvers in FEM simulations Number of slices
Fast Multipole Method on the GPU
 Fast Multipole Method on the GPU with application to the Adaptive Vortex Method University of Bristol, Bristol, United Kingdom. 1 Introduction Particle methods Highly parallel Computational intensive Numerical
Fast Multipole Method on the GPU with application to the Adaptive Vortex Method University of Bristol, Bristol, United Kingdom. 1 Introduction Particle methods Highly parallel Computational intensive Numerical
DIFFERENTIAL. Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka
 USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
Applications of Berkeley s Dwarfs on Nvidia GPUs
 Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
Auto-Generation and Auto-Tuning of 3D Stencil Codes on GPU Clusters
 Auto-Generation and Auto-Tuning of 3D Stencil s on GPU Clusters Yongpeng Zhang, Frank Mueller North Carolina State University CGO 2012 Outline Motivation DSL front-end and Benchmarks Framework Experimental
Auto-Generation and Auto-Tuning of 3D Stencil s on GPU Clusters Yongpeng Zhang, Frank Mueller North Carolina State University CGO 2012 Outline Motivation DSL front-end and Benchmarks Framework Experimental
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Lecture 8: GPU Programming. CSE599G1: Spring 2017
 Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
On the limits of (and opportunities for?) GPU acceleration
 GPU acceleration") On the limits of (and opportunities for?) GPU acceleration Aparna Chandramowlishwaran, Jee Choi, Kenneth Czechowski, Murat (Efe) Guney, Logan Moon, Aashay Shringarpure, Richard (Rich) Vuduc HotPar 10,
On the limits of (and opportunities for?) GPU acceleration Aparna Chandramowlishwaran, Jee Choi, Kenneth Czechowski, Murat (Efe) Guney, Logan Moon, Aashay Shringarpure, Richard (Rich) Vuduc HotPar 10,
Large-scale Deep Unsupervised Learning using Graphics Processors
 Large-scale Deep Unsupervised Learning using Graphics Processors Rajat Raina Anand Madhavan Andrew Y. Ng Stanford University Learning from unlabeled data Classify vs. car motorcycle Input space Unlabeled
Large-scale Deep Unsupervised Learning using Graphics Processors Rajat Raina Anand Madhavan Andrew Y. Ng Stanford University Learning from unlabeled data Classify vs. car motorcycle Input space Unlabeled
GPU Performance Optimisation. Alan Gray EPCC The University of Edinburgh
 GPU Performance Optimisation EPCC The University of Edinburgh Hardware NVIDIA accelerated system: Memory Memory GPU vs CPU: Theoretical Peak capabilities NVIDIA Fermi AMD Magny-Cours (6172) Cores 448 (1.15GHz)
GPU Performance Optimisation EPCC The University of Edinburgh Hardware NVIDIA accelerated system: Memory Memory GPU vs CPU: Theoretical Peak capabilities NVIDIA Fermi AMD Magny-Cours (6172) Cores 448 (1.15GHz)
Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies
 Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies John C. Linford John Michalakes Manish Vachharajani Adrian Sandu IMAGe TOY 2009 Workshop 2 Virginia
Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies John C. Linford John Michalakes Manish Vachharajani Adrian Sandu IMAGe TOY 2009 Workshop 2 Virginia
Adaptive-Mesh-Refinement Hydrodynamic GPU Computation in Astrophysics
 Adaptive-Mesh-Refinement Hydrodynamic GPU Computation in Astrophysics H. Y. Schive ( 薛熙于 ) Graduate Institute of Physics, National Taiwan University Leung Center for Cosmology and Particle Astrophysics
Adaptive-Mesh-Refinement Hydrodynamic GPU Computation in Astrophysics H. Y. Schive ( 薛熙于 ) Graduate Institute of Physics, National Taiwan University Leung Center for Cosmology and Particle Astrophysics
POST-SIEVING ON GPUs
 POST-SIEVING ON GPUs Andrea Miele 1, Joppe W Bos 2, Thorsten Kleinjung 1, Arjen K Lenstra 1 1 LACAL, EPFL, Lausanne, Switzerland 2 NXP Semiconductors, Leuven, Belgium 1/18 NUMBER FIELD SIEVE (NFS) Asymptotically
POST-SIEVING ON GPUs Andrea Miele 1, Joppe W Bos 2, Thorsten Kleinjung 1, Arjen K Lenstra 1 1 LACAL, EPFL, Lausanne, Switzerland 2 NXP Semiconductors, Leuven, Belgium 1/18 NUMBER FIELD SIEVE (NFS) Asymptotically
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture
 An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
Optimizing Parallel Reduction in CUDA. Mark Harris NVIDIA Developer Technology
 Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
Graphics Processing Unit (GPU) Acceleration of Machine Vision Software for Space Flight Applications
 Acceleration of Machine Vision Software for Space Flight Applications") Graphics Processing Unit (GPU) Acceleration of Machine Vision Software for Space Flight Applications Workshop on Space Flight Software November 6, 2009 Brent Tweddle Massachusetts Institute of Technology
Graphics Processing Unit (GPU) Acceleration of Machine Vision Software for Space Flight Applications Workshop on Space Flight Software November 6, 2009 Brent Tweddle Massachusetts Institute of Technology
High Performance Computing and GPU Programming
 High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
University of Bielefeld
 Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
On Massively Parallel Algorithms to Track One Path of a Polynomial Homotopy
 On Massively Parallel Algorithms to Track One Path of a Polynomial Homotopy Jan Verschelde joint with Genady Yoffe and Xiangcheng Yu University of Illinois at Chicago Department of Mathematics, Statistics,
On Massively Parallel Algorithms to Track One Path of a Polynomial Homotopy Jan Verschelde joint with Genady Yoffe and Xiangcheng Yu University of Illinois at Chicago Department of Mathematics, Statistics,
Parallel Direct Simulation Monte Carlo Computation Using CUDA on GPUs
 Parallel Direct Simulation Monte Carlo Computation Using CUDA on GPUs C.-C. Su a, C.-W. Hsieh b, M. R. Smith b, M. C. Jermy c and J.-S. Wu a a Department of Mechanical Engineering, National Chiao Tung
Parallel Direct Simulation Monte Carlo Computation Using CUDA on GPUs C.-C. Su a, C.-W. Hsieh b, M. R. Smith b, M. C. Jermy c and J.-S. Wu a a Department of Mechanical Engineering, National Chiao Tung
Optimizing Parallel Reduction in CUDA. Mark Harris NVIDIA Developer Technology
 Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
Parallel Alternating Direction Implicit Solver for the Two-Dimensional Heat Diffusion Problem on Graphics Processing Units
 Parallel Alternating Direction Implicit Solver for the Two-Dimensional Heat Diffusion Problem on Graphics Processing Units Khor Shu Heng Engineering Science Programme National University of Singapore Abstract
Parallel Alternating Direction Implicit Solver for the Two-Dimensional Heat Diffusion Problem on Graphics Processing Units Khor Shu Heng Engineering Science Programme National University of Singapore Abstract
Chapter 04. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
Georgia Institute of Technology Center for Signal and Image Processing Steve Conover February 2009
 Georgia Institute of Technology Center for Signal and Image Processing Steve Conover February 2009 Introduction CUDA is a tool to turn your graphics card into a small computing cluster. It s not always
Georgia Institute of Technology Center for Signal and Image Processing Steve Conover February 2009 Introduction CUDA is a tool to turn your graphics card into a small computing cluster. It s not always
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture
 COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
Lecture 2: Memory Systems
 Lecture 2: Memory Systems Basic components Memory hierarchy Cache memory Virtual Memory Zebo Peng, IDA, LiTH Many Different Technologies Zebo Peng, IDA, LiTH 2 Internal and External Memories CPU Date transfer
Lecture 2: Memory Systems Basic components Memory hierarchy Cache memory Virtual Memory Zebo Peng, IDA, LiTH Many Different Technologies Zebo Peng, IDA, LiTH 2 Internal and External Memories CPU Date transfer
Complexity and Advanced Algorithms. Introduction to Parallel Algorithms
 Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
J. Blair Perot. Ali Khajeh-Saeed. Software Engineer CD-adapco. Mechanical Engineering UMASS, Amherst
 Ali Khajeh-Saeed Software Engineer CD-adapco J. Blair Perot Mechanical Engineering UMASS, Amherst Supercomputers Optimization Stream Benchmark Stag++ (3D Incompressible Flow Code) Matrix Multiply Function
Ali Khajeh-Saeed Software Engineer CD-adapco J. Blair Perot Mechanical Engineering UMASS, Amherst Supercomputers Optimization Stream Benchmark Stag++ (3D Incompressible Flow Code) Matrix Multiply Function
OpenCL Implementation Of A Heterogeneous Computing System For Real-time Rendering And Dynamic Updating Of Dense 3-d Volumetric Data
 OpenCL Implementation Of A Heterogeneous Computing System For Real-time Rendering And Dynamic Updating Of Dense 3-d Volumetric Data Andrew Miller Computer Vision Group Research Developer 3-D TERRAIN RECONSTRUCTION
OpenCL Implementation Of A Heterogeneous Computing System For Real-time Rendering And Dynamic Updating Of Dense 3-d Volumetric Data Andrew Miller Computer Vision Group Research Developer 3-D TERRAIN RECONSTRUCTION
ad-heap: an Efficient Heap Data Structure for Asymmetric Multicore Processors
 ad-heap: an Efficient Heap Data Structure for Asymmetric Multicore Processors Weifeng Liu and Brian Vinter Niels Bohr Institute University of Copenhagen Denmark {weifeng, vinter}@nbi.dk March 1, 2014 Weifeng
ad-heap: an Efficient Heap Data Structure for Asymmetric Multicore Processors Weifeng Liu and Brian Vinter Niels Bohr Institute University of Copenhagen Denmark {weifeng, vinter}@nbi.dk March 1, 2014 Weifeng
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes.
 HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
Programming in CUDA. Malik M Khan
 Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Solving Dense Linear Systems on Platforms with Multiple Hardware Accelerators
 Solving Dense Linear Systems on Platforms with Multiple Hardware Accelerators Francisco D. Igual Enrique S. Quintana-Ortí Gregorio Quintana-Ortí Universidad Jaime I de Castellón (Spain) Robert A. van de
Solving Dense Linear Systems on Platforms with Multiple Hardware Accelerators Francisco D. Igual Enrique S. Quintana-Ortí Gregorio Quintana-Ortí Universidad Jaime I de Castellón (Spain) Robert A. van de
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE)
") GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
Sparse Linear Algebra in CUDA
 Sparse Linear Algebra in CUDA HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 22 nd 2017 Table of Contents Homework - Worksheet 2
Sparse Linear Algebra in CUDA HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 22 nd 2017 Table of Contents Homework - Worksheet 2
Persistent RNNs. (stashing recurrent weights on-chip) Gregory Diamos. April 7, Baidu SVAIL
 Gregory Diamos. April 7, Baidu SVAIL") (stashing recurrent weights on-chip) Baidu SVAIL April 7, 2016 SVAIL Think hard AI. Goal Develop hard AI technologies that impact 100 million users. Deep Learning at SVAIL 100 GFLOP/s 1 laptop 6 TFLOP/s
(stashing recurrent weights on-chip) Baidu SVAIL April 7, 2016 SVAIL Think hard AI. Goal Develop hard AI technologies that impact 100 million users. Deep Learning at SVAIL 100 GFLOP/s 1 laptop 6 TFLOP/s
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs
 High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs Gordon Erlebacher Department of Scientific Computing Sept. 28, 2012 with Dimitri Komatitsch (Pau,France) David Michea
High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs Gordon Erlebacher Department of Scientific Computing Sept. 28, 2012 with Dimitri Komatitsch (Pau,France) David Michea