Speedup Altair RADIOSS Solvers Using NVIDIA GPU
|
|
|
- Emil Fox
- 6 years ago
- Views:
Transcription
1 Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012
2 Innovation Intelligence ALTAIR OVERVIEW
3 Altair s Vision Simulation, predictive analytics and optimization leveraging high performance computing for engineering and business decision making 3

4 Altair Engineering Years of Innovation Offices in 16 Countries Employees Worldwide 4
5 Altair s Brands and Companies Engineering Simulation Platform On-demand Cloud Computing Technology Product Innovation Consulting Industrial Design Technology Business Intelligence & Data Analytics Solutions Solid State Lighting Products 5
6 HyperWorks for Analysis and Optimization Pre-Post Statics NVH Non-Linear (Implicit) Non-Linear (Explicit) Thermal and CFD Multi-Body Dynamics 1-D Systems, Fatigue, Ergonomics, Industrial Design, Injection Molding, Noise and Vibration (NVH), Composite Materials, Electromagnetics RADIOSS AcuSolve MotionSolve Partner Alliance Solutions Optimization OptiStruct and HyperStudy Data and Process Management 6









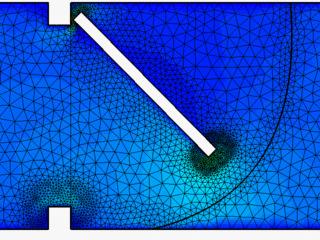
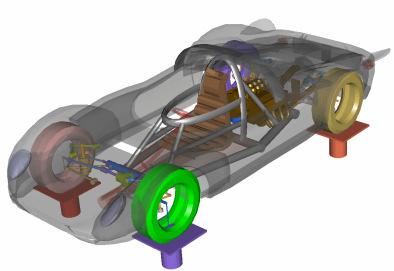
7 Simulate Real-life Models with HyperWorks Solvers 7

8 AcuSolve Already Benefits from GPU Accelerator High performance computational fluid dynamics software (CFD) The leading finite element based CFD technology High accuracy and scalability on massively parallel architectures S-duct 80K Degrees of Freedom Hybrid MPI/OpenMP for Multi-GPU test Xeon Nehalem CPU Nehalem CPU + Tesla GPU core CPU core + 1 GPU 4 core CPU 165 2X* 3.3X* 2 core + 2 GPU Lower is better *Performance gain versus 4 core CPU
9 Innovation Intelligence RADIOSS PORTING ON GPU
10 Motivations to use GPU Cost effective solution Power efficient solution How much of the peak can we get? Which part of the code is best suited? Which coding effort is required? What is the speedup for my application? Gflops ,74 0,74 1 Node Intel X Nodes Intel X , Node+1 Nvidia M ,5 2,1 1 Node+2 Nvidia M2090 Gflop Peak (DP) Gflop cost in $ Gflops per Watt 60 $
11 RADIOSS Porting on Nvidia GPU Assess the potential of GPU for RADIOSS Focus on Implicit Direct Solver Highly optimized compute intensive solver Limited scalability on multicores and cluster Iterative Solver Ability to solve huge problems with low memory requirement Efficient parallelization High cost on CPU due to large number of iterations for convergence Double precision required Integrate GPU parallelization into our Hybrid parallelization technology 11
12 Innovation Intelligence RADIOSS DIRECT SOLVER PORTING
13 Multifrontal Sparse Direct Solver do j = 1, N assemble(a(j)) factor(j) update(j) end Non-pivoting: Cholesky Pivoting: LDLT 13
14 Concerns with GPU Acceleration CUBLAS (DGEMM) perfect candidate to speed up update module Frontal matrix could be too huge to fit in GPU memory Frontal matrix could be too small and thus inefficient w/ GPU Data transfer is not trivial Only the lower triangular matrix is interesting Pivoting is required in real applications Pivot searching is a sequential operation Factor module has limited parallel potential It could be as expensive as update module in extreme case 14
15 CUBLAS speedup Update module Improve profile of Update module Base BCSLIB4.3 Asynchronous computing S1 S2 S3 Overlap the computation Overlap the communication T U = LDL 15
 improved elapsed (s) 1200 1000 800 600 400 200 0 Lower is better 3.9X 4 CPU 4 CPU + 1GPU 2.")
16 Numerical Test : Non-Pivoting Case Linear static - Non-pivoting case Benchmark 2,8 Millions of Degrees of Freedom Platform Intel Xeon X5550, 4 Core, 48GB RAM Nvidia C2070, CUDA 4.0 MKL 10.3, RHEL 5.1 GPU speedup - non-pivoting case solver elapsed 1,2 1 base(bcslib-ext) improved elapsed (s) Lower is better 3.9X 4 CPU 4 CPU + 1GPU 2.9X profile(%) 0,8 0,6 0,4 0,2 0 update total 16
17 Numerical Test: Pivoting Case Nonlinear static - Pivoting case Customer model Engine Block Benchmark Platform 2,5 Millions of Degrees of Freedom Intel Xeon X5550, 4 Core, 48GB RAM Nvidia C2070, CUDA 4.0 MKL 10.3, RHEL 5.1 GPU speedup - pivoting case elapsed (s) solver Lower is better elapsed profile(%) 1,2 1 0,8 0,6 0,4 base(bcslib-ext) improved ,2 2.8X 2.5X CPU 4 CPU + 1GPU update total 17
18 Challenging Work 1,2 On models update is not that 1 base(bcslib-ext) improved dominated E.g. engine block with 1 st order element profile(%) 0,8 0,6 0,4 0,2 In-core / Quasi in-core is preferred A memory threshold to get reasonable good speedup will be provided to the user Make sure the essential computation is in core Elapsed (s) update solver total 1.5 Millions of DOFs with Pivoting Lower is better elapsed 2.1X 1.8X 0 4 CPU 4 CPU + 1GPU 18
19 Summary & Perspectives GPU and CUDA enhance the performance of direct solver significantly CUBLAS on Fermi card is so fast! Asynchronous computing is the key component Improving the profile is a necessary procedure Amdahl's law Application Area Nonlinear analysis robust and accurate solution Optimization matrix factorization reused in sensitivity analysis Future works Other dynamic solvers Block Lanczos Eigen value solver Altair AMSES (automated multilevel-substructure Eigen value solver) 19
20 Innovation Intelligence RADIOSS ITERATIVE SOLVER PORTING
21 Preconditioned Conjugate Gradient Method Problem Solve linear equation Ax b = 0 with A symmetric positive-definite Solution Preconditioned Conjugate Gradient (PCG) solves iteratively: M -1. (Ax b) = 0 Method quickly converges Efficiency depends on M Other advantages Low memory consumption Efficient parallelization: SMP, MPI 21
22 PCG Porting on GPU using Cuda Pretty simple original Fortran code Few kernels to write in Cuda Sparse Matrix Vector Focus optimization effort on this kernel Use of CUBLAS DAXPY DDOT r 0 = b Ax 0 z 0 = M -1 r 0 p 0 = z 0 k = 0 DO WHILE NOT DONE alpha k = r kt. z k / p kt. A. p k x k+1 = x k + alpha k p k r k+1 = r k alpha k A. p k IF(r k+1 < precision) THEN END IF DONE = TRUE z k+1 = M -1. r k+1 beta k = z k+1t. r k+1 / z k t. r k p k+1 = z k+1 + beta k p k k = k+1 END DO result = x k+1 22
23 Hybrid MPP Computing with CUDA and MPI Hybrid MPP version of RADIOSS 2 parallelization levels MPI parallelization based on domain decomposition Multi-threaded MPI processes under OpenMP Enhanced performance Higher scalability Better efficiency RADIOSS 11 Hybrid MPP Speedup Extend Hybrid to multi GPUs programming Integrate GPU parallelization into our hybrid programming model MPI to manage communication between GPUs Portions of code not GPU enable benefit from OpenMP parallelization Programming model expendable to multi nodes with multi GPUs 23

24 PCG Multi GPUs Parallelization Domain decomposition to split original problem Optimal load balancing MPI Communications between domains Controlled by the CPU One GPU associated to one MPI OpenMP Multithreading Speedup calculations not performed under GPU Leverage the available CPU cores 24
25 Benchmark #1 400 Linear Problem #1 Hood of a car with pressure loads SMP 6-core Hybrid 2 MPI x 6 SMP SMP GPU Compute displacements and stresses Benchmark 0,9 Millions of Degrees of Freedom Elapsed(s) Hybrid 2 MPI x 6 SMP + 2 GPUs Platform 24 Millions of non zero Shells Solids RBE iterations Nvidia PSG Cluster 2 nodes with: X* 1 node - 2 Nividia M X* Lower is better Dual Nvidia M2090 GPUs Cuda v3.2 Intel Westmere 2x6 X5670@2,93Ghz Linux RHEL 5.4 with Intel MPI 4.0 Elapsed(s) Hybrid 4 MPI x 6 SMP Hybrid 4 MPI x 6 SMP + 4 GPUs 38 Performance Elapsed time decreased by up to 9X X* 0 2 nodes - 4 Nvidia M2090 *Performance gain versus SMP 6-core 25
26 Benchmark #2 Linear Problem #2 Hood of a car with pressure loads Refined model Compute displacements and stresses Benchmark 2,2 Millions of Degrees of Freedom 62 Millions of non zero Shells Solids RBE iterations Platform Nvidia PSG Cluster 2 nodes with: Dual Nvidia M2090 GPUs Cuda v3.2 Intel Westmere 2x6 X5670@2,93Ghz Elapsed(s) Elapsed(s) SMP 6-core Hybrid 2 MPI x 6 SMP SMP GPU Hybrid 2 MPI x 6 SMP + 2 GPUs X* 7.5X* 1 node - 2 Nividia M Hybrid 4 MPI x 6 SMP Hybrid 4 MPI x 6 SMP + 4 GPUs Lower is better Performance Linux RHEL 5.4 with Intel MPI 4.0 Elapsed time decreased by up to 13X X* 2 nodes - 4 Nvidia M2090 *Performance gain versus SMP 6-core 26
27 Benchmark #3 Gravity Problem with contacts Full car model Compute displacements and stresses Benchmark 0,85 Millions of Degrees of Freedom 21 Millions of non zero Shells Solids D elements Rigid bodies + 6 Rigid walls 1 Gravity load and 22 Contact interfaces ~ 9000 iterations Elapsed(s) SMP 6-core 1223 Hybrid 2 MPI x 6 SMP SMP GPU Hybrid 2 MPI x 6 SMP + 2 GPUs node - 2 Nividia M X* 6.4X* Lower is better Platform Nvidia PSG Cluster 2 nodes with: Dual Nvidia M2090 GPUs Cuda v3.2 Elapsed(s) Hybrid 4 MPI x 6 SMP Hybrid 4 MPI x 6 SMP + 4 GPUs Intel Westmere 2x6 X5670@2,93Ghz Performance Linux RHEL 5.4 with Intel MPI 4.0 Elapsed time decreased by up to 9X X* 2 nodes - 4 Nvidia M2090 *Performance gain versus SMP 6-core 27
28 Innovation Intelligence CONCLUSION
29 Conclusion RADIOSS implicit direct & iterative solvers have been successfully ported on Nvidia GPU using Cuda Adding GPU improves significantly the performance of these solvers For iterative solver, Hybrid MPP allows to run on multi GPU card workstation and GPU cluster with good scalability and enhanced performance GPU support for implicit solvers is planed for HyperWorks 12 A big thanks to the Nvidia team for their great support: Stan Posey, Steven Rennich, Thomas Reed, Peng Wang! 29
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Intel Xeon Processor E7 v2 Family-Based Platforms
 Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
GPU COMPUTING WITH MSC NASTRAN 2013
 SESSION TITLE WILL BE COMPLETED BY MSC SOFTWARE GPU COMPUTING WITH MSC NASTRAN 2013 Srinivas Kodiyalam, NVIDIA, Santa Clara, USA THEME Accelerated computing with GPUs SUMMARY Current trends in HPC (High
SESSION TITLE WILL BE COMPLETED BY MSC SOFTWARE GPU COMPUTING WITH MSC NASTRAN 2013 Srinivas Kodiyalam, NVIDIA, Santa Clara, USA THEME Accelerated computing with GPUs SUMMARY Current trends in HPC (High
HPC and IT Issues Session Agenda. Deployment of Simulation (Trends and Issues Impacting IT) Mapping HPC to Performance (Scaling, Technology Advances)
 Mapping HPC to Performance (Scaling, Technology Advances)") HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
ANSYS HPC. Technology Leadership. Barbara Hutchings ANSYS, Inc. September 20, 2011
 ANSYS HPC Technology Leadership Barbara Hutchings barbara.hutchings@ansys.com 1 ANSYS, Inc. September 20, Why ANSYS Users Need HPC Insight you can t get any other way HPC enables high-fidelity Include
ANSYS HPC Technology Leadership Barbara Hutchings barbara.hutchings@ansys.com 1 ANSYS, Inc. September 20, Why ANSYS Users Need HPC Insight you can t get any other way HPC enables high-fidelity Include
ANSYS HPC Technology Leadership
 ANSYS HPC Technology Leadership 1 ANSYS, Inc. November 14, Why ANSYS Users Need HPC Insight you can t get any other way It s all about getting better insight into product behavior quicker! HPC enables
ANSYS HPC Technology Leadership 1 ANSYS, Inc. November 14, Why ANSYS Users Need HPC Insight you can t get any other way It s all about getting better insight into product behavior quicker! HPC enables
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation
 ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE)
") GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
Solving Large Complex Problems. Efficient and Smart Solutions for Large Models
 Solving Large Complex Problems Efficient and Smart Solutions for Large Models 1 ANSYS Structural Mechanics Solutions offers several techniques 2 Current trends in simulation show an increased need for
Solving Large Complex Problems Efficient and Smart Solutions for Large Models 1 ANSYS Structural Mechanics Solutions offers several techniques 2 Current trends in simulation show an increased need for
Stan Posey, CAE Industry Development NVIDIA, Santa Clara, CA, USA
 Stan Posey, CAE Industry Development NVIDIA, Santa Clara, CA, USA NVIDIA and HPC Evolution of GPUs Public, based in Santa Clara, CA ~$4B revenue ~5,500 employees Founded in 1999 with primary business in
Stan Posey, CAE Industry Development NVIDIA, Santa Clara, CA, USA NVIDIA and HPC Evolution of GPUs Public, based in Santa Clara, CA ~$4B revenue ~5,500 employees Founded in 1999 with primary business in
Faster Innovation - Accelerating SIMULIA Abaqus Simulations with NVIDIA GPUs. Baskar Rajagopalan Accelerated Computing, NVIDIA
 Faster Innovation - Accelerating SIMULIA Abaqus Simulations with NVIDIA GPUs Baskar Rajagopalan Accelerated Computing, NVIDIA 1 Engineering & IT Challenges/Trends NVIDIA GPU Solutions AGENDA Abaqus GPU
Faster Innovation - Accelerating SIMULIA Abaqus Simulations with NVIDIA GPUs Baskar Rajagopalan Accelerated Computing, NVIDIA 1 Engineering & IT Challenges/Trends NVIDIA GPU Solutions AGENDA Abaqus GPU
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures
 MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
Two-Phase flows on massively parallel multi-gpu clusters
 Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
Performance Benefits of NVIDIA GPUs for LS-DYNA
 Performance Benefits of NVIDIA GPUs for LS-DYNA Mr. Stan Posey and Dr. Srinivas Kodiyalam NVIDIA Corporation, Santa Clara, CA, USA Summary: This work examines the performance characteristics of LS-DYNA
Performance Benefits of NVIDIA GPUs for LS-DYNA Mr. Stan Posey and Dr. Srinivas Kodiyalam NVIDIA Corporation, Santa Clara, CA, USA Summary: This work examines the performance characteristics of LS-DYNA
Performance of Implicit Solver Strategies on GPUs
 9. LS-DYNA Forum, Bamberg 2010 IT / Performance Performance of Implicit Solver Strategies on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Abstract: The increasing power of GPUs can be used
9. LS-DYNA Forum, Bamberg 2010 IT / Performance Performance of Implicit Solver Strategies on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Abstract: The increasing power of GPUs can be used
Enhancing Analysis-Based Design with Quad-Core Intel Xeon Processor-Based Workstations
 Performance Brief Quad-Core Workstation Enhancing Analysis-Based Design with Quad-Core Intel Xeon Processor-Based Workstations With eight cores and up to 80 GFLOPS of peak performance at your fingertips,
Performance Brief Quad-Core Workstation Enhancing Analysis-Based Design with Quad-Core Intel Xeon Processor-Based Workstations With eight cores and up to 80 GFLOPS of peak performance at your fingertips,
A Comprehensive Study on the Performance of Implicit LS-DYNA
 12 th International LS-DYNA Users Conference Computing Technologies(4) A Comprehensive Study on the Performance of Implicit LS-DYNA Yih-Yih Lin Hewlett-Packard Company Abstract This work addresses four
12 th International LS-DYNA Users Conference Computing Technologies(4) A Comprehensive Study on the Performance of Implicit LS-DYNA Yih-Yih Lin Hewlett-Packard Company Abstract This work addresses four
HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER PROF. BRYANT PROF. KAYVON 15618: PARALLEL COMPUTER ARCHITECTURE
 HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER AVISHA DHISLE PRERIT RODNEY ADHISLE PRODNEY 15618: PARALLEL COMPUTER ARCHITECTURE PROF. BRYANT PROF. KAYVON LET S
HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER AVISHA DHISLE PRERIT RODNEY ADHISLE PRODNEY 15618: PARALLEL COMPUTER ARCHITECTURE PROF. BRYANT PROF. KAYVON LET S
Accelerating Implicit LS-DYNA with GPU
 Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
How to perform HPL on CPU&GPU clusters. Dr.sc. Draško Tomić
 How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid Architectures
 Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
The Fermi GPU and HPC Application Breakthroughs
 The Fermi GPU and HPC Application Breakthroughs Peng Wang, PhD HPC Developer Technology Group Stan Posey HPC Industry Development NVIDIA, Santa Clara, CA, USA NVIDIA Corporation 2009 Overview GPU Computing:
The Fermi GPU and HPC Application Breakthroughs Peng Wang, PhD HPC Developer Technology Group Stan Posey HPC Industry Development NVIDIA, Santa Clara, CA, USA NVIDIA Corporation 2009 Overview GPU Computing:
MAGMA. Matrix Algebra on GPU and Multicore Architectures
 MAGMA Matrix Algebra on GPU and Multicore Architectures Innovative Computing Laboratory Electrical Engineering and Computer Science University of Tennessee Piotr Luszczek (presenter) web.eecs.utk.edu/~luszczek/conf/
MAGMA Matrix Algebra on GPU and Multicore Architectures Innovative Computing Laboratory Electrical Engineering and Computer Science University of Tennessee Piotr Luszczek (presenter) web.eecs.utk.edu/~luszczek/conf/
HPC with Multicore and GPUs
 HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS. Kyle Spagnoli. Research EM Photonics 3/20/2013
 GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS Kyle Spagnoli Research Engineer @ EM Photonics 3/20/2013 INTRODUCTION» Sparse systems» Iterative solvers» High level benchmarks»
GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS Kyle Spagnoli Research Engineer @ EM Photonics 3/20/2013 INTRODUCTION» Sparse systems» Iterative solvers» High level benchmarks»
TFLOP Performance for ANSYS Mechanical
 TFLOP Performance for ANSYS Mechanical Dr. Herbert Güttler Engineering GmbH Holunderweg 8 89182 Bernstadt www.microconsult-engineering.de Engineering H. Güttler 19.06.2013 Seite 1 May 2009, Ansys12, 512
TFLOP Performance for ANSYS Mechanical Dr. Herbert Güttler Engineering GmbH Holunderweg 8 89182 Bernstadt www.microconsult-engineering.de Engineering H. Güttler 19.06.2013 Seite 1 May 2009, Ansys12, 512
CUDA Accelerated Linpack on Clusters. E. Phillips, NVIDIA Corporation
 CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016
 ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
Intel Performance Libraries
 Intel Performance Libraries Powerful Mathematical Library Intel Math Kernel Library (Intel MKL) Energy Science & Research Engineering Design Financial Analytics Signal Processing Digital Content Creation
Intel Performance Libraries Powerful Mathematical Library Intel Math Kernel Library (Intel MKL) Energy Science & Research Engineering Design Financial Analytics Signal Processing Digital Content Creation
High performance Computing and O&G Challenges
 High performance Computing and O&G Challenges 2 Seismic exploration challenges High Performance Computing and O&G challenges Worldwide Context Seismic,sub-surface imaging Computing Power needs Accelerating
High performance Computing and O&G Challenges 2 Seismic exploration challenges High Performance Computing and O&G challenges Worldwide Context Seismic,sub-surface imaging Computing Power needs Accelerating
Industrial finite element analysis: Evolution and current challenges. Keynote presentation at NAFEMS World Congress Crete, Greece June 16-19, 2009
 Industrial finite element analysis: Evolution and current challenges Keynote presentation at NAFEMS World Congress Crete, Greece June 16-19, 2009 Dr. Chief Numerical Analyst Office of Architecture and
Industrial finite element analysis: Evolution and current challenges Keynote presentation at NAFEMS World Congress Crete, Greece June 16-19, 2009 Dr. Chief Numerical Analyst Office of Architecture and
ANSYS High. Computing. User Group CAE Associates
 ANSYS High Performance Computing User Group 010 010 CAE Associates Parallel Processing in ANSYS ANSYS offers two parallel processing methods: Shared-memory ANSYS: Shared-memory ANSYS uses the sharedmemory
ANSYS High Performance Computing User Group 010 010 CAE Associates Parallel Processing in ANSYS ANSYS offers two parallel processing methods: Shared-memory ANSYS: Shared-memory ANSYS uses the sharedmemory
Engineers can be significantly more productive when ANSYS Mechanical runs on CPUs with a high core count. Executive Summary
 white paper Computer-Aided Engineering ANSYS Mechanical on Intel Xeon Processors Engineer Productivity Boosted by Higher-Core CPUs Engineers can be significantly more productive when ANSYS Mechanical runs
white paper Computer-Aided Engineering ANSYS Mechanical on Intel Xeon Processors Engineer Productivity Boosted by Higher-Core CPUs Engineers can be significantly more productive when ANSYS Mechanical runs
Simulation-Driven Design Has Never Been Easier
 solution brief Simulation-Driven Design Has Never Been Easier Access a complete HPC design environment in minutes for faster, smarter innovation. Simpler and more powerful tools for simulation-based design
solution brief Simulation-Driven Design Has Never Been Easier Access a complete HPC design environment in minutes for faster, smarter innovation. Simpler and more powerful tools for simulation-based design
MAGMA: a New Generation
 1.3 MAGMA: a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Jack Dongarra T. Dong, M. Gates, A. Haidar, S. Tomov, and I. Yamazaki University of Tennessee, Knoxville Release
1.3 MAGMA: a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Jack Dongarra T. Dong, M. Gates, A. Haidar, S. Tomov, and I. Yamazaki University of Tennessee, Knoxville Release
Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs
 Presented at the 2014 ANSYS Regional Conference- Detroit, June 5, 2014 Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs Bhushan Desam, Ph.D. NVIDIA Corporation 1 NVIDIA Enterprise
Presented at the 2014 ANSYS Regional Conference- Detroit, June 5, 2014 Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs Bhushan Desam, Ph.D. NVIDIA Corporation 1 NVIDIA Enterprise
Accelerating MCAE with GPUs
 Accelerating MCAE with GPUs Information Sciences Institute 15 Sept 2010 15 Sept 2010 Bob Lucas, Gene Wagenbreth, Dan Davis, Roger Grimes {rflucas,genew,ddavis}@isi.edu and grimes@lstc.com Report Documentation
Accelerating MCAE with GPUs Information Sciences Institute 15 Sept 2010 15 Sept 2010 Bob Lucas, Gene Wagenbreth, Dan Davis, Roger Grimes {rflucas,genew,ddavis}@isi.edu and grimes@lstc.com Report Documentation
S0432 NEW IDEAS FOR MASSIVELY PARALLEL PRECONDITIONERS
 S0432 NEW IDEAS FOR MASSIVELY PARALLEL PRECONDITIONERS John R Appleyard Jeremy D Appleyard Polyhedron Software with acknowledgements to Mark A Wakefield Garf Bowen Schlumberger Outline of Talk Reservoir
S0432 NEW IDEAS FOR MASSIVELY PARALLEL PRECONDITIONERS John R Appleyard Jeremy D Appleyard Polyhedron Software with acknowledgements to Mark A Wakefield Garf Bowen Schlumberger Outline of Talk Reservoir
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster
 Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation
 Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation 1 Cheng-Han Du* I-Hsin Chung** Weichung Wang* * I n s t i t u t e o f A p p l i e d M
Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation 1 Cheng-Han Du* I-Hsin Chung** Weichung Wang* * I n s t i t u t e o f A p p l i e d M
Multi-GPU simulations in OpenFOAM with SpeedIT technology.
 Multi-GPU simulations in OpenFOAM with SpeedIT technology. Attempt I: SpeedIT GPU-based library of iterative solvers for Sparse Linear Algebra and CFD. Current version: 2.2. Version 1.0 in 2008. CMRS format
Multi-GPU simulations in OpenFOAM with SpeedIT technology. Attempt I: SpeedIT GPU-based library of iterative solvers for Sparse Linear Algebra and CFD. Current version: 2.2. Version 1.0 in 2008. CMRS format
A GPU Sparse Direct Solver for AX=B
 1 / 25 A GPU Sparse Direct Solver for AX=B Jonathan Hogg, Evgueni Ovtchinnikov, Jennifer Scott* STFC Rutherford Appleton Laboratory 26 March 2014 GPU Technology Conference San Jose, California * Thanks
1 / 25 A GPU Sparse Direct Solver for AX=B Jonathan Hogg, Evgueni Ovtchinnikov, Jennifer Scott* STFC Rutherford Appleton Laboratory 26 March 2014 GPU Technology Conference San Jose, California * Thanks
MAGMA. LAPACK for GPUs. Stan Tomov Research Director Innovative Computing Laboratory Department of Computer Science University of Tennessee, Knoxville
 MAGMA LAPACK for GPUs Stan Tomov Research Director Innovative Computing Laboratory Department of Computer Science University of Tennessee, Knoxville Keeneland GPU Tutorial 2011, Atlanta, GA April 14-15,
MAGMA LAPACK for GPUs Stan Tomov Research Director Innovative Computing Laboratory Department of Computer Science University of Tennessee, Knoxville Keeneland GPU Tutorial 2011, Atlanta, GA April 14-15,
Sparse Multifrontal Performance Gains via NVIDIA GPU January 16, 2009
 Sparse Multifrontal Performance Gains via NVIDIA GPU January 16, 2009 Dan l Pierce, PhD, MBA, CEO & President AAI Joint with: Yukai Hung, Chia-Chi Liu, Yao-Hung Tsai, Weichung Wang, and David Yu Access
Sparse Multifrontal Performance Gains via NVIDIA GPU January 16, 2009 Dan l Pierce, PhD, MBA, CEO & President AAI Joint with: Yukai Hung, Chia-Chi Liu, Yao-Hung Tsai, Weichung Wang, and David Yu Access
Fast and reliable linear system solutions on new parallel architectures
 Fast and reliable linear system solutions on new parallel architectures Marc Baboulin Université Paris-Sud Chaire Inria Saclay Île-de-France Séminaire Aristote - Ecole Polytechnique 15 mai 2013 Marc Baboulin
Fast and reliable linear system solutions on new parallel architectures Marc Baboulin Université Paris-Sud Chaire Inria Saclay Île-de-France Séminaire Aristote - Ecole Polytechnique 15 mai 2013 Marc Baboulin
Accelerated ANSYS Fluent: Algebraic Multigrid on a GPU. Robert Strzodka NVAMG Project Lead
 Accelerated ANSYS Fluent: Algebraic Multigrid on a GPU Robert Strzodka NVAMG Project Lead A Parallel Success Story in Five Steps 2 Step 1: Understand Application ANSYS Fluent Computational Fluid Dynamics
Accelerated ANSYS Fluent: Algebraic Multigrid on a GPU Robert Strzodka NVAMG Project Lead A Parallel Success Story in Five Steps 2 Step 1: Understand Application ANSYS Fluent Computational Fluid Dynamics
Recent Developments in LS-DYNA II
 9. LS-DYNA Forum, Bamberg 2010 Keynote-Vorträge II Recent Developments in LS-DYNA II J. Hallquist Livermore Software Technology Corporation A - II - 7 Keynote-Vorträge II 9. LS-DYNA Forum, Bamberg 2010
9. LS-DYNA Forum, Bamberg 2010 Keynote-Vorträge II Recent Developments in LS-DYNA II J. Hallquist Livermore Software Technology Corporation A - II - 7 Keynote-Vorträge II 9. LS-DYNA Forum, Bamberg 2010
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
Large scale Imaging on Current Many- Core Platforms
 Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
NEW ADVANCES IN GPU LINEAR ALGEBRA
 GTC 2012: NEW ADVANCES IN GPU LINEAR ALGEBRA Kyle Spagnoli EM Photonics 5/16/2012 QUICK ABOUT US» HPC/GPU Consulting Firm» Specializations in:» Electromagnetics» Image Processing» Fluid Dynamics» Linear
GTC 2012: NEW ADVANCES IN GPU LINEAR ALGEBRA Kyle Spagnoli EM Photonics 5/16/2012 QUICK ABOUT US» HPC/GPU Consulting Firm» Specializations in:» Electromagnetics» Image Processing» Fluid Dynamics» Linear
The Cray CX1 puts massive power and flexibility right where you need it in your workgroup
 The Cray CX1 puts massive power and flexibility right where you need it in your workgroup Up to 96 cores of Intel 5600 compute power 3D visualization Up to 32TB of storage GPU acceleration Small footprint
The Cray CX1 puts massive power and flexibility right where you need it in your workgroup Up to 96 cores of Intel 5600 compute power 3D visualization Up to 32TB of storage GPU acceleration Small footprint
Porting the NAS-NPB Conjugate Gradient Benchmark to CUDA. NVIDIA Corporation
 Porting the NAS-NPB Conjugate Gradient Benchmark to CUDA NVIDIA Corporation Outline! Overview of CG benchmark! Overview of CUDA Libraries! CUSPARSE! CUBLAS! Porting Sequence! Algorithm Analysis! Data/Code
Porting the NAS-NPB Conjugate Gradient Benchmark to CUDA NVIDIA Corporation Outline! Overview of CG benchmark! Overview of CUDA Libraries! CUSPARSE! CUBLAS! Porting Sequence! Algorithm Analysis! Data/Code
Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters
 Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
High performance 2D Discrete Fourier Transform on Heterogeneous Platforms. Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli
 High performance 2D Discrete Fourier Transform on Heterogeneous Platforms Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli Motivation Fourier Transform widely used in Physics, Astronomy, Engineering
High performance 2D Discrete Fourier Transform on Heterogeneous Platforms Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli Motivation Fourier Transform widely used in Physics, Astronomy, Engineering
Study and implementation of computational methods for Differential Equations in heterogeneous systems. Asimina Vouronikoy - Eleni Zisiou
 Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Evaluation of sparse LU factorization and triangular solution on multicore architectures. X. Sherry Li
 Evaluation of sparse LU factorization and triangular solution on multicore architectures X. Sherry Li Lawrence Berkeley National Laboratory ParLab, April 29, 28 Acknowledgement: John Shalf, LBNL Rich Vuduc,
Evaluation of sparse LU factorization and triangular solution on multicore architectures X. Sherry Li Lawrence Berkeley National Laboratory ParLab, April 29, 28 Acknowledgement: John Shalf, LBNL Rich Vuduc,
GPU-Acceleration of CAE Simulations. Bhushan Desam NVIDIA Corporation
 GPU-Acceleration of CAE Simulations Bhushan Desam NVIDIA Corporation bdesam@nvidia.com 1 AGENDA GPUs in Enterprise Computing Business Challenges in Product Development NVIDIA GPUs for CAE Applications
GPU-Acceleration of CAE Simulations Bhushan Desam NVIDIA Corporation bdesam@nvidia.com 1 AGENDA GPUs in Enterprise Computing Business Challenges in Product Development NVIDIA GPUs for CAE Applications
Advances of parallel computing. Kirill Bogachev May 2016
 Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Matrix-free IPM with GPU acceleration
 Matrix-free IPM with GPU acceleration Julian Hall, Edmund Smith and Jacek Gondzio School of Mathematics University of Edinburgh jajhall@ed.ac.uk 29th June 2011 Linear programming theory Primal-dual pair
Matrix-free IPM with GPU acceleration Julian Hall, Edmund Smith and Jacek Gondzio School of Mathematics University of Edinburgh jajhall@ed.ac.uk 29th June 2011 Linear programming theory Primal-dual pair
GPU Implementation of Elliptic Solvers in NWP. Numerical Weather- and Climate- Prediction
 1/8 GPU Implementation of Elliptic Solvers in Numerical Weather- and Climate- Prediction Eike Hermann Müller, Robert Scheichl Department of Mathematical Sciences EHM, Xu Guo, Sinan Shi and RS: http://arxiv.org/abs/1302.7193
1/8 GPU Implementation of Elliptic Solvers in Numerical Weather- and Climate- Prediction Eike Hermann Müller, Robert Scheichl Department of Mathematical Sciences EHM, Xu Guo, Sinan Shi and RS: http://arxiv.org/abs/1302.7193
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC. Guest Lecturer: Sukhyun Song (original slides by Alan Sussman)
") CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
AcuSolve Performance Benchmark and Profiling. October 2011
 AcuSolve Performance Benchmark and Profiling October 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, Altair Compute
AcuSolve Performance Benchmark and Profiling October 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, Altair Compute
New Features in LS-DYNA HYBRID Version
 11 th International LS-DYNA Users Conference Computing Technology New Features in LS-DYNA HYBRID Version Nick Meng 1, Jason Wang 2, Satish Pathy 2 1 Intel Corporation, Software and Services Group 2 Livermore
11 th International LS-DYNA Users Conference Computing Technology New Features in LS-DYNA HYBRID Version Nick Meng 1, Jason Wang 2, Satish Pathy 2 1 Intel Corporation, Software and Services Group 2 Livermore
High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs
 High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs Gordon Erlebacher Department of Scientific Computing Sept. 28, 2012 with Dimitri Komatitsch (Pau,France) David Michea
High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs Gordon Erlebacher Department of Scientific Computing Sept. 28, 2012 with Dimitri Komatitsch (Pau,France) David Michea
ME964 High Performance Computing for Engineering Applications
 ME964 High Performance Computing for Engineering Applications Outlining Midterm Projects Topic 3: GPU-based FEA Topic 4: GPU Direct Solver for Sparse Linear Algebra March 01, 2011 Dan Negrut, 2011 ME964
ME964 High Performance Computing for Engineering Applications Outlining Midterm Projects Topic 3: GPU-based FEA Topic 4: GPU Direct Solver for Sparse Linear Algebra March 01, 2011 Dan Negrut, 2011 ME964
Code modernization of Polyhedron benchmark suite
 Code modernization of Polyhedron benchmark suite Manel Fernández Intel HPC Software Workshop Series 2016 HPC Code Modernization for Intel Xeon and Xeon Phi February 18 th 2016, Barcelona Approaches for
Code modernization of Polyhedron benchmark suite Manel Fernández Intel HPC Software Workshop Series 2016 HPC Code Modernization for Intel Xeon and Xeon Phi February 18 th 2016, Barcelona Approaches for
Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM
 Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM Alexander Monakov, amonakov@ispras.ru Institute for System Programming of Russian Academy of Sciences March 20, 2013 1 / 17 Problem Statement In OpenFOAM,
Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM Alexander Monakov, amonakov@ispras.ru Institute for System Programming of Russian Academy of Sciences March 20, 2013 1 / 17 Problem Statement In OpenFOAM,
GPU PROGRESS AND DIRECTIONS IN APPLIED CFD
 Eleventh International Conference on CFD in the Minerals and Process Industries CSIRO, Melbourne, Australia 7-9 December 2015 GPU PROGRESS AND DIRECTIONS IN APPLIED CFD Stan POSEY 1*, Simon SEE 2, and
Eleventh International Conference on CFD in the Minerals and Process Industries CSIRO, Melbourne, Australia 7-9 December 2015 GPU PROGRESS AND DIRECTIONS IN APPLIED CFD Stan POSEY 1*, Simon SEE 2, and
MUMPS. The MUMPS library. Abdou Guermouche and MUMPS team, June 22-24, Univ. Bordeaux 1 and INRIA
 The MUMPS library Abdou Guermouche and MUMPS team, Univ. Bordeaux 1 and INRIA June 22-24, 2010 MUMPS Outline MUMPS status Recently added features MUMPS and multicores? Memory issues GPU computing Future
The MUMPS library Abdou Guermouche and MUMPS team, Univ. Bordeaux 1 and INRIA June 22-24, 2010 MUMPS Outline MUMPS status Recently added features MUMPS and multicores? Memory issues GPU computing Future
3D ADI Method for Fluid Simulation on Multiple GPUs. Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA
 3D ADI Method for Fluid Simulation on Multiple GPUs Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA Introduction Fluid simulation using direct numerical methods Gives the most accurate result Requires
3D ADI Method for Fluid Simulation on Multiple GPUs Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA Introduction Fluid simulation using direct numerical methods Gives the most accurate result Requires
A Study of High Performance Computing and the Cray SV1 Supercomputer. Michael Sullivan TJHSST Class of 2004
 A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
Algorithms, System and Data Centre Optimisation for Energy Efficient HPC
 2015-09-14 Algorithms, System and Data Centre Optimisation for Energy Efficient HPC Vincent Heuveline URZ Computing Centre of Heidelberg University EMCL Engineering Mathematics and Computing Lab 1 Energy
2015-09-14 Algorithms, System and Data Centre Optimisation for Energy Efficient HPC Vincent Heuveline URZ Computing Centre of Heidelberg University EMCL Engineering Mathematics and Computing Lab 1 Energy
ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS
 ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS Ferdinando Alessi Annalisa Massini Roberto Basili INGV Introduction The simulation of wave propagation
ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS Ferdinando Alessi Annalisa Massini Roberto Basili INGV Introduction The simulation of wave propagation
On the Parallel Solution of Sparse Triangular Linear Systems. M. Naumov* San Jose, CA May 16, 2012 *NVIDIA
 On the Parallel Solution of Sparse Triangular Linear Systems M. Naumov* San Jose, CA May 16, 2012 *NVIDIA Why Is This Interesting? There exist different classes of parallel problems Embarrassingly parallel
On the Parallel Solution of Sparse Triangular Linear Systems M. Naumov* San Jose, CA May 16, 2012 *NVIDIA Why Is This Interesting? There exist different classes of parallel problems Embarrassingly parallel
PhD Student. Associate Professor, Co-Director, Center for Computational Earth and Environmental Science. Abdulrahman Manea.
 Abdulrahman Manea PhD Student Hamdi Tchelepi Associate Professor, Co-Director, Center for Computational Earth and Environmental Science Energy Resources Engineering Department School of Earth Sciences
Abdulrahman Manea PhD Student Hamdi Tchelepi Associate Professor, Co-Director, Center for Computational Earth and Environmental Science Energy Resources Engineering Department School of Earth Sciences
Premiers retours d expérience sur l utilisation de GPU pour des applications de mécanique des structures
 Premiers retours d expérience sur l utilisation de GPU pour des applications de mécanique des structures Antoine Petitet et Stefanos Vlachoutsis Juin 2011 Copyright ESI Group, 2009. 2010. All rights reserved.
Premiers retours d expérience sur l utilisation de GPU pour des applications de mécanique des structures Antoine Petitet et Stefanos Vlachoutsis Juin 2011 Copyright ESI Group, 2009. 2010. All rights reserved.
RADIOSS Benchmark Underscores Solver s Scalability, Quality and Robustness
 RADIOSS Benchmark Underscores Solver s Scalability, Quality and Robustness HPC Advisory Council studies performance evaluation, scalability analysis and optimization tuning of RADIOSS 12.0 on a modern
RADIOSS Benchmark Underscores Solver s Scalability, Quality and Robustness HPC Advisory Council studies performance evaluation, scalability analysis and optimization tuning of RADIOSS 12.0 on a modern
CODE Product Solutions
 CODE Product Solutions Simulation Innovations Glass Fiber Reinforced Structural Components for a Group 1 Child Harold van Aken About Code Product Solutions Engineering service provider Specialised in Multiphysics
CODE Product Solutions Simulation Innovations Glass Fiber Reinforced Structural Components for a Group 1 Child Harold van Aken About Code Product Solutions Engineering service provider Specialised in Multiphysics
PARDISO - PARallel DIrect SOlver to solve SLAE on shared memory architectures
 PARDISO - PARallel DIrect SOlver to solve SLAE on shared memory architectures Solovev S. A, Pudov S.G sergey.a.solovev@intel.com, sergey.g.pudov@intel.com Intel Xeon, Intel Core 2 Duo are trademarks of
PARDISO - PARallel DIrect SOlver to solve SLAE on shared memory architectures Solovev S. A, Pudov S.G sergey.a.solovev@intel.com, sergey.g.pudov@intel.com Intel Xeon, Intel Core 2 Duo are trademarks of
Optimizing Data Locality for Iterative Matrix Solvers on CUDA
 Optimizing Data Locality for Iterative Matrix Solvers on CUDA Raymond Flagg, Jason Monk, Yifeng Zhu PhD., Bruce Segee PhD. Department of Electrical and Computer Engineering, University of Maine, Orono,
Optimizing Data Locality for Iterative Matrix Solvers on CUDA Raymond Flagg, Jason Monk, Yifeng Zhu PhD., Bruce Segee PhD. Department of Electrical and Computer Engineering, University of Maine, Orono,
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
International Conference on Computational Science (ICCS 2017)
") International Conference on Computational Science (ICCS 2017) Exploiting Hybrid Parallelism in the Kinematic Analysis of Multibody Systems Based on Group Equations G. Bernabé, J. C. Cano, J. Cuenca, A.
International Conference on Computational Science (ICCS 2017) Exploiting Hybrid Parallelism in the Kinematic Analysis of Multibody Systems Based on Group Equations G. Bernabé, J. C. Cano, J. Cuenca, A.
ESPRESO ExaScale PaRallel FETI Solver. Hybrid FETI Solver Report
 ESPRESO ExaScale PaRallel FETI Solver Hybrid FETI Solver Report Lubomir Riha, Tomas Brzobohaty IT4Innovations Outline HFETI theory from FETI to HFETI communication hiding and avoiding techniques our new
ESPRESO ExaScale PaRallel FETI Solver Hybrid FETI Solver Report Lubomir Riha, Tomas Brzobohaty IT4Innovations Outline HFETI theory from FETI to HFETI communication hiding and avoiding techniques our new
Introduction to parallel Computing
 Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
J. Blair Perot. Ali Khajeh-Saeed. Software Engineer CD-adapco. Mechanical Engineering UMASS, Amherst
 Ali Khajeh-Saeed Software Engineer CD-adapco J. Blair Perot Mechanical Engineering UMASS, Amherst Supercomputers Optimization Stream Benchmark Stag++ (3D Incompressible Flow Code) Matrix Multiply Function
Ali Khajeh-Saeed Software Engineer CD-adapco J. Blair Perot Mechanical Engineering UMASS, Amherst Supercomputers Optimization Stream Benchmark Stag++ (3D Incompressible Flow Code) Matrix Multiply Function
Second Conference on Parallel, Distributed, Grid and Cloud Computing for Engineering
 State of the art distributed parallel computational techniques in industrial finite element analysis Second Conference on Parallel, Distributed, Grid and Cloud Computing for Engineering Ajaccio, France
State of the art distributed parallel computational techniques in industrial finite element analysis Second Conference on Parallel, Distributed, Grid and Cloud Computing for Engineering Ajaccio, France
Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies
 Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies John C. Linford John Michalakes Manish Vachharajani Adrian Sandu IMAGe TOY 2009 Workshop 2 Virginia
Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies John C. Linford John Michalakes Manish Vachharajani Adrian Sandu IMAGe TOY 2009 Workshop 2 Virginia
Altair RADIOSS Performance Benchmark and Profiling. May 2013
 Altair RADIOSS Performance Benchmark and Profiling May 2013 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Altair, AMD, Dell, Mellanox Compute
Altair RADIOSS Performance Benchmark and Profiling May 2013 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Altair, AMD, Dell, Mellanox Compute
Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers
 Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation
 Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation Nikolai Sakharnykh - NVIDIA San Jose Convention Center, San Jose, CA September 21, 2010 Introduction Tridiagonal solvers very popular
Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation Nikolai Sakharnykh - NVIDIA San Jose Convention Center, San Jose, CA September 21, 2010 Introduction Tridiagonal solvers very popular
Particleworks: Particle-based CAE Software fully ported to GPU
 Particleworks: Particle-based CAE Software fully ported to GPU Introduction PrometechVideo_v3.2.3.wmv 3.5 min. Particleworks Why the particle method? Existing methods FEM, FVM, FLIP, Fluid calculation
Particleworks: Particle-based CAE Software fully ported to GPU Introduction PrometechVideo_v3.2.3.wmv 3.5 min. Particleworks Why the particle method? Existing methods FEM, FVM, FLIP, Fluid calculation
Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
 Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 What is Cray Libsci_acc? Provide basic scientific
Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 What is Cray Libsci_acc? Provide basic scientific
Intel MKL Sparse Solvers. Software Solutions Group - Developer Products Division
 Intel MKL Sparse Solvers - Agenda Overview Direct Solvers Introduction PARDISO: main features PARDISO: advanced functionality DSS Performance data Iterative Solvers Performance Data Reference Copyright
Intel MKL Sparse Solvers - Agenda Overview Direct Solvers Introduction PARDISO: main features PARDISO: advanced functionality DSS Performance data Iterative Solvers Performance Data Reference Copyright
Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs
 Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Report of Linear Solver Implementation on GPU
 Report of Linear Solver Implementation on GPU XIANG LI Abstract As the development of technology and the linear equation solver is used in many aspects such as smart grid, aviation and chemical engineering,
Report of Linear Solver Implementation on GPU XIANG LI Abstract As the development of technology and the linear equation solver is used in many aspects such as smart grid, aviation and chemical engineering,
14MMFD-34 Parallel Efficiency and Algorithmic Optimality in Reservoir Simulation on GPUs
 14MMFD-34 Parallel Efficiency and Algorithmic Optimality in Reservoir Simulation on GPUs K. Esler, D. Dembeck, K. Mukundakrishnan, V. Natoli, J. Shumway and Y. Zhang Stone Ridge Technology, Bel Air, MD
14MMFD-34 Parallel Efficiency and Algorithmic Optimality in Reservoir Simulation on GPUs K. Esler, D. Dembeck, K. Mukundakrishnan, V. Natoli, J. Shumway and Y. Zhang Stone Ridge Technology, Bel Air, MD
Intel Math Kernel Library (Intel MKL) BLAS. Victor Kostin Intel MKL Dense Solvers team manager
 BLAS. Victor Kostin Intel MKL Dense Solvers team manager") Intel Math Kernel Library (Intel MKL) BLAS Victor Kostin Intel MKL Dense Solvers team manager Intel MKL BLAS/Sparse BLAS Original ( dense ) BLAS available from www.netlib.org Additionally Intel MKL provides
Intel Math Kernel Library (Intel MKL) BLAS Victor Kostin Intel MKL Dense Solvers team manager Intel MKL BLAS/Sparse BLAS Original ( dense ) BLAS available from www.netlib.org Additionally Intel MKL provides
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU