Advances in Metaheuristics on GPU
|
|
|
- Rosaline Berry
- 6 years ago
- Views:
Transcription

1 Advances in Metaheuristics on GPU 1 Thé Van Luong, El-Ghazali Talbi and Nouredine Melab DOLPHIN Project Team May 2011
2 Interests in optimization methods 2 Exact Algorithms Heuristics Branch and X Dynamic programming CP Specific heuristics Metaheuristics Branch and bound Branch and cut Solution-based Population-based Local searches GRASP Evolutionary algorithms Ant colony
3 Parallel models for metaheuristics 3 f(s 1 ) f(s 2 ) M 5 M 1 M 2 Algorithmic-level parallel model M 3 Iteration-level parallel model f(s 3 ) f(s n ) M 4 Solution-level parallel model f 1 (s n ) f m (s n )
4 GPU Computing 4 Used in the past for graphics and video applications but now popular for many other applications such as scientific computing [Owens et al. 2008] In the metaheuristics field: Few existing works (Genetic algorithms [T-T. Wong 2006], Genetic programming [Harding et al. 2009], ), light tentative for the Tabu search algorithm [Zhu et al. 2009] Popularity due to the publication of the CUDA development toolkit allowing GPU programming in a C-like language [Garland et al. 2008]
5 Many-cores and a hierarchy of memories 5 Memory type Access latency Global Medium Big Size Registers Very fast Very small Block 0 Shared Memory GPU Block 1 Shared Memory Local Medium Medium Shared Fast Small Registers Registers Registers Registers Constant Fast (cached) Medium Texture Fast (cached) Medium Thread 0 Thread 1 Thread 0 Thread 1 - Highly parallel multithreaded many core - High memory bandwidth compared to CPU - Different levels of memory (different latencies) CPU Local Memory Global Memory Constant Memory Texture Memory Local Memory Local Memory Local Memory
6 Objective and challenging issues 6 Re-think the parallel models to take into account the characteristics of GPU Three major challenges Challenge 1: efficient CPU-GPU cooperation Work partitioning between CPU and GPU, data transfer optimization Challenge 2: efficient parallelism control Threads generation control (memory constraints) Efficient mapping between work units and threads Ids Challenge 3: efficient memory management Which data on which memory (latency and capacity constraints)?
7 Works completed 7 Iteration-level Algorithmic-level Local search algorithms Evolutionary algorithms Local search algorithms Evolutionary algorithms Re-design of parallel models on GPU which allows to produce a bunch of general methods: Hill climbing, tabu search, VNS, multi-start LS, GAs, EDAs, island model for GAs,
8 Works completed (2) 8 Application to 9 combinatorial problems and 10 continuous tests functions. Speed-ups from experiments provide promising results : Up to x50 for combinatorial problems Up to x2000 for continuous test functions 1 international journal. 9 international conference proceedings. 1 national conference proceeding. 2 conference abstracts. 7 workshops and talks. 1 research report. GTX 280 (2008 configuration)
9 Iteration-level parallel model 9 Generate a solution Current solution Full evaluation Select a neighbor of the solution Evaluation Yes Next neighbor? No No Replace the solution by the chosen neighbor STOP? Yes END Group of neighbors Need of massively parallel computing on very large neighborhoods
10 Parallelization scheme on GPU (1) 10 CPU Init solution Full evaluation m Neighborhood evaluation Replacement GPU copy solution Threads Block T0 T1 T2 Tm Evaluation function copy results Global Memory global solution, global fitnesses, data inputs no End? yes
11 Parallelization scheme on GPU (2) 11 Keypoints: Generation of the neighborhood on the GPU side to minimize the CPU GPU data transfer If possible, thread reduction for the best solution selection to minimize the GPU CPU data transfer Efficient parallelism control control: mapping neighboring onto threads ids, efficient kernel for fitness evaluation incremental evaluation Efficient memory management (e.g. use of texture memory or L2 cache for Fermi cards)
12 Cons: Data transfers at each iteration Definitely not better than an optimized problem-dependent implementation (data reorganization, alignment requirements, register pressure, ) Pros: Parallelization scheme on GPU (3) Common parallelization to many local search algorithms Application to many class of problems and local search algorithms Clear separation of concepts specific to the local search and specific to the parallelization -> framework GPU Computing for Parallel Local Search Metaheuristic Algorithms IEEE Transactions on Computers (under revision) 12
13 Outline 13 Application to Combinatorial Problems Application to Continuous Problems Thread Control Optimization Comparison with Other Parallel and Distributed Architectures Application to Other Algorithms Application to Multiobjective Optimization Problems Integration of GPU-based Concepts in the ParadisEO Platform
14 14 Application to Combinatorial Problems
15 Parameter settings 15 Hardware configurations Configuration 1: laptop (2006) Core 2 Duo 2 Ghz M GT 4 multiprocessors (32 cores) Configuration 2 : desktop-computer (2007) Core 2 Quad 2.4 Ghz GTX 16 multiprocessors (128 cores) Configuration 3 : workstation (2008) Intel Xeon 3 Ghz + GTX multiprocessors (240 cores) Tabu Search and parameters Neighborhood generation and evaluation on GPU iterations, 30 runs
/2 neighbors Delta evaluation: O(n) Permutation")
16 Quadratic Assignment Problem 16 Swap neighborhood: n*(n-1)/2 neighbors Delta evaluation: O(n) Permutation representation
 Binary")
17 Permuted Perceptron Problem (1) 17 1-Hamming distance neighborhood: n neighbors Delta evaluation: O(n) Binary encoding
/2")
18 Permuted Perceptron Problem (2) 18 2-Hamming distance neighborhood n*(n-1)/2 neighbors
*(n-2)/6")
19 Permuted Perceptron Problem (3) 19 3-Hamming distance neighborhood n*(n-1)*(n-2)/6 neighbors
20 Application to Continuous Problems 20
21 Continuous Neighborhood 21 X2 A candidate solution A neighbor Vector of real values Neighbors are taken by random selection of one point inside each crown [Siarry et al.] X1

22 Continuous Weierstrass Function (1) 22 Neighbor evaluation: O(n²) Vector of real values No data inputs Continuous neighborhood: neighbors

23 Continuous Weierstrass Function (2) 23 Dimension Problem: 2 Vary the neighborhood size
24 Thread Control Optimization 24
 Permutation")
25 Traveling Salesman Problem 25 Swap neighborhood: n*(n-1)/2 neighbors Delta evaluation: O(1) Permutation representation
26 Thread Control (1) 26 Neighborhood Solution Increase the threads granularity with associating each thread to MANY neighbors to avoid memory overflow (e.g. hardware register limitation)
27 Thread Control (2) 27 Iteration 1 Iteration 2 Iteration 3 Kernel call Kernel call Kernel call n threads 2n threads 4n threads Kernel execution Kernel execution Kernel execution 0.18s 0.12s 0.14s Iteration i Kernel call m threads Kernel execution 0.04s Iteration i+1 Kernel call 2m threads Kernel execution crash Dynamic heuristic for parameters auto-tuning To prevent the program from crashing To obtain extra performance
28 28 Heuristic performed on the first iterations Vary the total number of threads (*2) Vary the number of threads per block (+32) Time measurements of each configuration for a certain number of trials Return the best configuration for tuning the rest of the algorithm If an error is detected, restore the previous best configuration found
/2 neighbors Delta evaluation: O(1) Permutation")
29 Traveling Salesman Problem (2) 29 Thread control Swap neighborhood: n*(n-1)/2 neighbors Delta evaluation: O(1) Permutation representation
/2 neighbors Delta evaluation: O(n) Binary encoding Thread")
30 Permuted Perceptron Problem 30 2-Hamming distance neighborhood n*(n-1)/2 neighbors Delta evaluation: O(n) Binary encoding Thread control
31 Comparison with Other Parallel and Distributed Architectures 31
32 Parallel Implementations 32 Different parallel approaches and implementations have been proposed for local search algorithms on different architectures: Massively Parallel Processors [e.g. Chakrapani et al. 1993] Networks or Clusters of Workstations [e.g. T. Crainic et al. 1995] Shared Memory or SMP machines [e.g. T. James et al. 2009]. Large-scale computational grids [N. Melab et al. 2007]. Emergence of heterogeneous COWs and computational grids as standard platforms for high-performance computing.
33 COWs and grids 33 Machines on COWs and grids have been selected to have the same computational power than the previous GPU configurations. A Myri-10G gigabit ethernet connects the different machines of the COWs. For the grid, the high-performance computing Grid 5000 has been used involving respectively two, five and seven French sites.
34 Parallelization Scheme 34 Parallelization: the neighborhood is decomposed into different partitions of equal size which are distributed among the cores of the different machines. The parallelization is synchronous and one has to wait for the termination of the exploration of all partitions. An hybrid OpenMP/MPI version has been produced to take advantage of both multi-core and distributed environments.
/2 neighbors Delta evaluation: O(n) Binary")
35 Cluster of Worstations (1) 35 Permuted perceptron problem 2-Hamming distance neighborhood n*(n-1)/2 neighbors Delta evaluation: O(n) Binary encoding

36 Cluster of Worstations (2) 36 Analysis of the data transfers including synchronizations
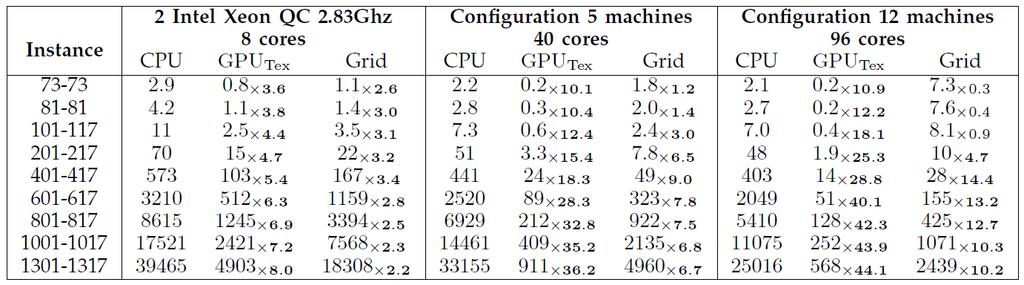
37 Computational Grid 37
38 Application to Other Algorithms 38
39 Iterated Local Search for the Q3AP 39 Instance Nug12 Nug13 Nug15 Nug18 Nug22 Best known value # solutions 49/50 37/50 50/50 31/50 50/50 CPU time 256 s 1879 s 1360 s s s GPUTex time 15 s 64 s 38 s 415 s 353 s Acceleration x 17.3 x 29.2 x 36.0 x 42.0 x 45.7 Iterative local search (100 iters) + tabu search (5000 iters) Competitive algorithm Configuration: GTX 280
40 Hybrid Genetic Algorithm for the QAP 40 Instance tai30a tai35a tai40a tai50a tai60a tai80a tai100a Best known value # solutions 27/30 23/30 18/30 10/30 6/30 4/30 2/30 CPU time 1h15min 2h24min 3h54min 10h2min 20h17min 66h 177h GPUTex time 8min50s 12min56s 18min16s 45min 1h30min 4h45min 12h6min Acceleration x 8.5 x 11.1 x 12.8 x 13.2 x 13.4 x 13.8 x individuals 10 generations Evolutionary algorithm + iterative local search (3 iters) + tabu search (10000 iters) Neighborhood based on a 3-exchange operator Competitive algorithm Configuration: GTX 280
41 Multiobjective Optimization Problems 41
42 Aggregated Tabu Search 42 Multiobjective Flowshop Scheduling 3 objectives (makespan, total tardiness and number of jobs delayed with regard to their due date) Taillard instances extended global iterations per algorithm and 30 runs Configuration: GTX 280 Instance CPU time 0.9s 1.9s 16s 32s 144s 271s 1190s 2221s GPUTex time 1.7s 4.3s 6s 7.8s 11.5s 21s 77s 139s Acceleration x 0.6 x 0.7 x 3.8 x 4.1 x 12.6 x 12.9 x 15.4 x 16.0
43 PLS-1 (dominating neighbors) 43 Pareto Multiobjective Local Search Only the dominating neighbors are added in the archive Archiving on CPU Instance CPU time 1.0s 1.9s 17s 33s 140s 275s 1172s 2196s GPUTex time 1.7s 3.0s 4.3s 7.8s 11.7s 21s 78s 140s Acceleration x 0.6 x 0.6 x 3.8 x 4.2 x 12.0 x 13.1 x 15.1 x 15.7 # nondominated solutions
44 PLS-1 (non-dominated neighbors) 44 Pareto Multiobjective Local Search Only the non-dominated neighbors are added in the archive Archiving on CPU Instance CPU time 1.2s 2.0s 21s 39s 253s 312s 1361s 2672s GPUTex time 1.8s 3.0s 8.2s 13.2s 49s 59s 218s 378s Acceleration x 0.7 x 0.7 x 2.5 x 3.0 x 5.1 x 5.3 x 6.4 x 7.1 # nondominated solutions
45 PLS-1 45 Analysis of the time spent for archiving
46 Integration of GPU-based Concepts in the ParadisEO Platform 46



47 ParadisEO-GPU Integration in ParadisEO 47 ParadisEO-PEO ParadisEO-MOEO ParadisEO-MO ParadisEO-EO One engineer position: Boufaras Karima (Feb 2010 Feb 2012)
48 Software <<actor>> User ParadisEO MO ParadisEO GPU Predefined neighbor and neighborhood Evaluation CUDA Specific data Hardware (1) (1) Allocate and copy of data (2) Parallel neighborhood evaluation (3) Copy of evaluation results <<host>> CPU (2) <<device>> GPU (3)
49 ParadisEO-MO Components defined by the user ParadisEO-MO-GPU Extra modifications provided by the user ParadisEO-MO-GPU Generic components provided and hidden to the user Solution representation Neighborhood Problem data inputs Solution evaluation Neighbor evaluation Keywords Explicit call to mapping function Keywords Explicit calls to allocation wrapper Keywords Explicit calls to allocation wrapper Linearizing multidimensional arrays Data transfers Mapping functions Memory allocation and deallocation Neighborhood results Parallel evaluation of the neighborhood Memory management

50 Results of the Platform (1) 50 Quadratic assignment problem Neighborhood based on a 2-exchange operator Configuration: GTX 280 Tabu search iterations
51 Results of the Platform (2) 51 Permuted perceptron problem (7 smallest instances) Neighborhood based on a Hamming distance of two Configuration: GTX 480 Tabu search iterations
52 Actual Features 52 First version will be released this month. Transparent use of GPU in local search algorithms. Flexibility and easiness of reuse at implementation. Support binary and permutation-based problems.
53 THANK YOU FOR YOUR ATTENTION 53
54 the_neighborhood: mogpuneighborhood the_eval: mogpueval GeForceGT: Device kernel: mogpukerneleval worker_eval: mogpuevalfunc set_mapping() send_mapping() neigh_eval() init_data() N threads launch_kernel() get_id() N threads get_data(id) worker_eval(id) N threads do_computation(id) N threads worker_result(id) N threads copy_results()
55 Mapping tables Indexed neighborhood Neighborhood size Mapping table Pre-defined neighborhoods for binary and permutation representations. k-exchanges and k-hamming distances neighborhoods.
Parallel Metaheuristics on GPU
 Ph.D. Defense - Thé Van LUONG December 1st 2011 Parallel Metaheuristics on GPU Advisors: Nouredine MELAB and El-Ghazali TALBI Outline 2 I. Scientific Context 1. Parallel Metaheuristics 2. GPU Computing
Ph.D. Defense - Thé Van LUONG December 1st 2011 Parallel Metaheuristics on GPU Advisors: Nouredine MELAB and El-Ghazali TALBI Outline 2 I. Scientific Context 1. Parallel Metaheuristics 2. GPU Computing
Towards ParadisEO-MO-GPU: a Framework for GPU-based Local Search Metaheuristics
 Towards ParadisEO-MO-GPU: a Framework for GPU-based Local Search Metaheuristics N. Melab, T-V. Luong, K. Boufaras and E-G. Talbi Dolphin Project INRIA Lille Nord Europe - LIFL/CNRS UMR 8022 - Université
Towards ParadisEO-MO-GPU: a Framework for GPU-based Local Search Metaheuristics N. Melab, T-V. Luong, K. Boufaras and E-G. Talbi Dolphin Project INRIA Lille Nord Europe - LIFL/CNRS UMR 8022 - Université
ParadisEO-MO-GPU: a Framework for Parallel GPU-based Local Search Metaheuristics
 ParadisEO-MO-GPU: a Framework for Parallel GPU-based Local Search Metaheuristics Nouredine Melab, Thé Van Luong, Karima Boufaras, El-Ghazali Talbi To cite this version: Nouredine Melab, Thé Van Luong,
ParadisEO-MO-GPU: a Framework for Parallel GPU-based Local Search Metaheuristics Nouredine Melab, Thé Van Luong, Karima Boufaras, El-Ghazali Talbi To cite this version: Nouredine Melab, Thé Van Luong,
GPU-based Multi-start Local Search Algorithms
 GPU-based Multi-start Local Search Algorithms Thé Van Luong, Nouredine Melab, El-Ghazali Talbi To cite this version: Thé Van Luong, Nouredine Melab, El-Ghazali Talbi. GPU-based Multi-start Local Search
GPU-based Multi-start Local Search Algorithms Thé Van Luong, Nouredine Melab, El-Ghazali Talbi To cite this version: Thé Van Luong, Nouredine Melab, El-Ghazali Talbi. GPU-based Multi-start Local Search
Accelerating local search algorithms for the travelling salesman problem through the effective use of GPU
 Available online at www.sciencedirect.com ScienceDirect Transportation Research Procedia 22 (2017) 409 418 www.elsevier.com/locate/procedia 19th EURO Working Group on Transportation Meeting, EWGT2016,
Available online at www.sciencedirect.com ScienceDirect Transportation Research Procedia 22 (2017) 409 418 www.elsevier.com/locate/procedia 19th EURO Working Group on Transportation Meeting, EWGT2016,
ACO and other (meta)heuristics for CO
heuristics for CO") ACO and other (meta)heuristics for CO 32 33 Outline Notes on combinatorial optimization and algorithmic complexity Construction and modification metaheuristics: two complementary ways of searching a solution
ACO and other (meta)heuristics for CO 32 33 Outline Notes on combinatorial optimization and algorithmic complexity Construction and modification metaheuristics: two complementary ways of searching a solution
pals: an Object Oriented Framework for Developing Parallel Cooperative Metaheuristics
 pals: an Object Oriented Framework for Developing Parallel Cooperative Metaheuristics Harold Castro, Andrés Bernal COMIT (COMunications and Information Technology) Systems and Computing Engineering Department
pals: an Object Oriented Framework for Developing Parallel Cooperative Metaheuristics Harold Castro, Andrés Bernal COMIT (COMunications and Information Technology) Systems and Computing Engineering Department
HEURISTICS optimization algorithms like 2-opt or 3-opt
 Parallel 2-Opt Local Search on GPU Wen-Bao Qiao, Jean-Charles Créput Abstract To accelerate the solution for large scale traveling salesman problems (TSP), a parallel 2-opt local search algorithm with
Parallel 2-Opt Local Search on GPU Wen-Bao Qiao, Jean-Charles Créput Abstract To accelerate the solution for large scale traveling salesman problems (TSP), a parallel 2-opt local search algorithm with
An Ant Approach to the Flow Shop Problem
 An Ant Approach to the Flow Shop Problem Thomas Stützle TU Darmstadt, Computer Science Department Alexanderstr. 10, 64283 Darmstadt Phone: +49-6151-166651, Fax +49-6151-165326 email: stuetzle@informatik.tu-darmstadt.de
An Ant Approach to the Flow Shop Problem Thomas Stützle TU Darmstadt, Computer Science Department Alexanderstr. 10, 64283 Darmstadt Phone: +49-6151-166651, Fax +49-6151-165326 email: stuetzle@informatik.tu-darmstadt.de
Optimization solutions for the segmented sum algorithmic function
 Optimization solutions for the segmented sum algorithmic function ALEXANDRU PÎRJAN Department of Informatics, Statistics and Mathematics Romanian-American University 1B, Expozitiei Blvd., district 1, code
Optimization solutions for the segmented sum algorithmic function ALEXANDRU PÎRJAN Department of Informatics, Statistics and Mathematics Romanian-American University 1B, Expozitiei Blvd., district 1, code
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
A Hybrid Genetic Algorithm for the Distributed Permutation Flowshop Scheduling Problem Yan Li 1, a*, Zhigang Chen 2, b
 International Conference on Information Technology and Management Innovation (ICITMI 2015) A Hybrid Genetic Algorithm for the Distributed Permutation Flowshop Scheduling Problem Yan Li 1, a*, Zhigang Chen
International Conference on Information Technology and Management Innovation (ICITMI 2015) A Hybrid Genetic Algorithm for the Distributed Permutation Flowshop Scheduling Problem Yan Li 1, a*, Zhigang Chen
Index. Encoding representation 330 Enterprise grid 39 Enterprise Grids 5
 Index Advanced Job Scheduler, Markov Availability Model, Resource Selection, Desktop Grid Computing, Stochastic scheduling 153 Agent 222, 224 226, 228, 233, 236 238 ApMon 223, 224, 239 Backlog 40, 45 Batch
Index Advanced Job Scheduler, Markov Availability Model, Resource Selection, Desktop Grid Computing, Stochastic scheduling 153 Agent 222, 224 226, 228, 233, 236 238 ApMon 223, 224, 239 Backlog 40, 45 Batch
Machine Learning for Software Engineering
 Machine Learning for Software Engineering Introduction and Motivation Prof. Dr.-Ing. Norbert Siegmund Intelligent Software Systems 1 2 Organizational Stuff Lectures: Tuesday 11:00 12:30 in room SR015 Cover
Machine Learning for Software Engineering Introduction and Motivation Prof. Dr.-Ing. Norbert Siegmund Intelligent Software Systems 1 2 Organizational Stuff Lectures: Tuesday 11:00 12:30 in room SR015 Cover
ND-Tree: a Fast Online Algorithm for Updating the Pareto Archive
 ND-Tree: a Fast Online Algorithm for Updating the Pareto Archive i.e. return to Algorithms and Data structures Andrzej Jaszkiewicz, Thibaut Lust Multiobjective optimization " minimize" z1 f... " minimize"
ND-Tree: a Fast Online Algorithm for Updating the Pareto Archive i.e. return to Algorithms and Data structures Andrzej Jaszkiewicz, Thibaut Lust Multiobjective optimization " minimize" z1 f... " minimize"
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
GPU computing applied to linear and mixed-integer programming
 GPU computing applied to linear and mixed-integer programming CHAPTER 10 V. Boyer 1,D.ElBaz 2, M.A. Salazar-Aguilar 1 Graduate Program in Systems Engineering, Universidad Autónoma de Nuevo León, Mexico
GPU computing applied to linear and mixed-integer programming CHAPTER 10 V. Boyer 1,D.ElBaz 2, M.A. Salazar-Aguilar 1 Graduate Program in Systems Engineering, Universidad Autónoma de Nuevo León, Mexico
Using GPUs to compute the multilevel summation of electrostatic forces
 Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Outline of the talk. Local search meta-heuristics for combinatorial problems. Constraint Satisfaction Problems. The n-queens problem
 Università G. D Annunzio, maggio 00 Local search meta-heuristics for combinatorial problems Luca Di Gaspero Dipartimento di Ingegneria Elettrica, Gestionale e Meccanica Università degli Studi di Udine
Università G. D Annunzio, maggio 00 Local search meta-heuristics for combinatorial problems Luca Di Gaspero Dipartimento di Ingegneria Elettrica, Gestionale e Meccanica Università degli Studi di Udine
Parallel path-relinking method for the flow shop scheduling problem
 Parallel path-relinking method for the flow shop scheduling problem Wojciech Bożejko 1 and Mieczys law Wodecki 2 1 Wroc law University of Technology Institute of Computer Engineering, Control and Robotics
Parallel path-relinking method for the flow shop scheduling problem Wojciech Bożejko 1 and Mieczys law Wodecki 2 1 Wroc law University of Technology Institute of Computer Engineering, Control and Robotics
A Comparative Study for Efficient Synchronization of Parallel ACO on Multi-core Processors in Solving QAPs
 2 IEEE Symposium Series on Computational Intelligence A Comparative Study for Efficient Synchronization of Parallel ACO on Multi-core Processors in Solving Qs Shigeyoshi Tsutsui Management Information
2 IEEE Symposium Series on Computational Intelligence A Comparative Study for Efficient Synchronization of Parallel ACO on Multi-core Processors in Solving Qs Shigeyoshi Tsutsui Management Information
Parallel Computing in Combinatorial Optimization
 Parallel Computing in Combinatorial Optimization Bernard Gendron Université de Montréal gendron@iro.umontreal.ca Course Outline Objective: provide an overview of the current research on the design of parallel
Parallel Computing in Combinatorial Optimization Bernard Gendron Université de Montréal gendron@iro.umontreal.ca Course Outline Objective: provide an overview of the current research on the design of parallel
Dense matching GPU implementation
 Dense matching GPU implementation Author: Hailong Fu. Supervisor: Prof. Dr.-Ing. Norbert Haala, Dipl. -Ing. Mathias Rothermel. Universität Stuttgart 1. Introduction Correspondence problem is an important
Dense matching GPU implementation Author: Hailong Fu. Supervisor: Prof. Dr.-Ing. Norbert Haala, Dipl. -Ing. Mathias Rothermel. Universität Stuttgart 1. Introduction Correspondence problem is an important
GRASP. Greedy Randomized Adaptive. Search Procedure
 GRASP Greedy Randomized Adaptive Search Procedure Type of problems Combinatorial optimization problem: Finite ensemble E = {1,2,... n } Subset of feasible solutions F 2 Objective function f : 2 Minimisation
GRASP Greedy Randomized Adaptive Search Procedure Type of problems Combinatorial optimization problem: Finite ensemble E = {1,2,... n } Subset of feasible solutions F 2 Objective function f : 2 Minimisation
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
Fast BVH Construction on GPUs
 Fast BVH Construction on GPUs Published in EUROGRAGHICS, (2009) C. Lauterbach, M. Garland, S. Sengupta, D. Luebke, D. Manocha University of North Carolina at Chapel Hill NVIDIA University of California
Fast BVH Construction on GPUs Published in EUROGRAGHICS, (2009) C. Lauterbach, M. Garland, S. Sengupta, D. Luebke, D. Manocha University of North Carolina at Chapel Hill NVIDIA University of California
Metaheuristic Development Methodology. Fall 2009 Instructor: Dr. Masoud Yaghini
 Metaheuristic Development Methodology Fall 2009 Instructor: Dr. Masoud Yaghini Phases and Steps Phases and Steps Phase 1: Understanding Problem Step 1: State the Problem Step 2: Review of Existing Solution
Metaheuristic Development Methodology Fall 2009 Instructor: Dr. Masoud Yaghini Phases and Steps Phases and Steps Phase 1: Understanding Problem Step 1: State the Problem Step 2: Review of Existing Solution
ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS
 ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS Ferdinando Alessi Annalisa Massini Roberto Basili INGV Introduction The simulation of wave propagation
ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS Ferdinando Alessi Annalisa Massini Roberto Basili INGV Introduction The simulation of wave propagation
Parallelization Strategies for Local Search Algorithms on Graphics Processing Units
 Parallelization Strategies for Local Search Algorithms on Graphics Processing Units Audrey Delévacq, Pierre Delisle, and Michaël Krajecki CReSTIC, Université de Reims Champagne-Ardenne, Reims, France Abstract
Parallelization Strategies for Local Search Algorithms on Graphics Processing Units Audrey Delévacq, Pierre Delisle, and Michaël Krajecki CReSTIC, Université de Reims Champagne-Ardenne, Reims, France Abstract
Journal of Universal Computer Science, vol. 14, no. 14 (2008), submitted: 30/9/07, accepted: 30/4/08, appeared: 28/7/08 J.
, submitted: 30/9/07, accepted: 30/4/08, appeared: 28/7/08 J.") Journal of Universal Computer Science, vol. 14, no. 14 (2008), 2416-2427 submitted: 30/9/07, accepted: 30/4/08, appeared: 28/7/08 J.UCS Tabu Search on GPU Adam Janiak (Institute of Computer Engineering
Journal of Universal Computer Science, vol. 14, no. 14 (2008), 2416-2427 submitted: 30/9/07, accepted: 30/4/08, appeared: 28/7/08 J.UCS Tabu Search on GPU Adam Janiak (Institute of Computer Engineering
Escaping Local Optima: Genetic Algorithm
 Artificial Intelligence Escaping Local Optima: Genetic Algorithm Dae-Won Kim School of Computer Science & Engineering Chung-Ang University We re trying to escape local optima To achieve this, we have learned
Artificial Intelligence Escaping Local Optima: Genetic Algorithm Dae-Won Kim School of Computer Science & Engineering Chung-Ang University We re trying to escape local optima To achieve this, we have learned
GT HEURISTIC FOR SOLVING MULTI OBJECTIVE JOB SHOP SCHEDULING PROBLEMS
 GT HEURISTIC FOR SOLVING MULTI OBJECTIVE JOB SHOP SCHEDULING PROBLEMS M. Chandrasekaran 1, D. Lakshmipathy 1 and P. Sriramya 2 1 Department of Mechanical Engineering, Vels University, Chennai, India 2
GT HEURISTIC FOR SOLVING MULTI OBJECTIVE JOB SHOP SCHEDULING PROBLEMS M. Chandrasekaran 1, D. Lakshmipathy 1 and P. Sriramya 2 1 Department of Mechanical Engineering, Vels University, Chennai, India 2
A Particle Swarm Optimization Algorithm for Solving Flexible Job-Shop Scheduling Problem
 2011, TextRoad Publication ISSN 2090-4304 Journal of Basic and Applied Scientific Research www.textroad.com A Particle Swarm Optimization Algorithm for Solving Flexible Job-Shop Scheduling Problem Mohammad
2011, TextRoad Publication ISSN 2090-4304 Journal of Basic and Applied Scientific Research www.textroad.com A Particle Swarm Optimization Algorithm for Solving Flexible Job-Shop Scheduling Problem Mohammad
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
ACCELERATING THE ANT COLONY OPTIMIZATION
 ACCELERATING THE ANT COLONY OPTIMIZATION BY SMART ANTS, USING GENETIC OPERATOR Hassan Ismkhan Department of Computer Engineering, University of Bonab, Bonab, East Azerbaijan, Iran H.Ismkhan@bonabu.ac.ir
ACCELERATING THE ANT COLONY OPTIMIZATION BY SMART ANTS, USING GENETIC OPERATOR Hassan Ismkhan Department of Computer Engineering, University of Bonab, Bonab, East Azerbaijan, Iran H.Ismkhan@bonabu.ac.ir
Solving Traveling Salesman Problem on High Performance Computing using Message Passing Interface
 Solving Traveling Salesman Problem on High Performance Computing using Message Passing Interface IZZATDIN A. AZIZ, NAZLEENI HARON, MAZLINA MEHAT, LOW TAN JUNG, AISYAH NABILAH Computer and Information Sciences
Solving Traveling Salesman Problem on High Performance Computing using Message Passing Interface IZZATDIN A. AZIZ, NAZLEENI HARON, MAZLINA MEHAT, LOW TAN JUNG, AISYAH NABILAH Computer and Information Sciences
PMF: A Multicore-Enabled Framework for the Construction of Metaheuristics for Single and Multiobjective Optimization
 PMF: A Multicore-Enabled Framework for the Construction of Metaheuristics for Single and Multiobjective Optimization Deon Garrett 1 Department of Computer Science University of Memphis, Memphis, TN, USA
PMF: A Multicore-Enabled Framework for the Construction of Metaheuristics for Single and Multiobjective Optimization Deon Garrett 1 Department of Computer Science University of Memphis, Memphis, TN, USA
Variable Neighborhood Search for Solving the Balanced Location Problem
 TECHNISCHE UNIVERSITÄT WIEN Institut für Computergraphik und Algorithmen Variable Neighborhood Search for Solving the Balanced Location Problem Jozef Kratica, Markus Leitner, Ivana Ljubić Forschungsbericht
TECHNISCHE UNIVERSITÄT WIEN Institut für Computergraphik und Algorithmen Variable Neighborhood Search for Solving the Balanced Location Problem Jozef Kratica, Markus Leitner, Ivana Ljubić Forschungsbericht
Hybridization EVOLUTIONARY COMPUTING. Reasons for Hybridization - 1. Naming. Reasons for Hybridization - 3. Reasons for Hybridization - 2
 Hybridization EVOLUTIONARY COMPUTING Hybrid Evolutionary Algorithms hybridization of an EA with local search techniques (commonly called memetic algorithms) EA+LS=MA constructive heuristics exact methods
Hybridization EVOLUTIONARY COMPUTING Hybrid Evolutionary Algorithms hybridization of an EA with local search techniques (commonly called memetic algorithms) EA+LS=MA constructive heuristics exact methods
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Double-Precision Matrix Multiply on CUDA
 Double-Precision Matrix Multiply on CUDA Parallel Computation (CSE 60), Assignment Andrew Conegliano (A5055) Matthias Springer (A995007) GID G--665 February, 0 Assumptions All matrices are square matrices
Double-Precision Matrix Multiply on CUDA Parallel Computation (CSE 60), Assignment Andrew Conegliano (A5055) Matthias Springer (A995007) GID G--665 February, 0 Assumptions All matrices are square matrices
Performance potential for simulating spin models on GPU
 Performance potential for simulating spin models on GPU Martin Weigel Institut für Physik, Johannes-Gutenberg-Universität Mainz, Germany 11th International NTZ-Workshop on New Developments in Computational
Performance potential for simulating spin models on GPU Martin Weigel Institut für Physik, Johannes-Gutenberg-Universität Mainz, Germany 11th International NTZ-Workshop on New Developments in Computational
Flowshop Scheduling Problem Introduction
 Flowshop Scheduling Problem Introduction The challenge has as focus the PERMUTATION FLOWSHOP PROBLEM, in the MONO OBJECTIVE case, the objective function to be minimized being the overall completion time
Flowshop Scheduling Problem Introduction The challenge has as focus the PERMUTATION FLOWSHOP PROBLEM, in the MONO OBJECTIVE case, the objective function to be minimized being the overall completion time
A Parallel Simulated Annealing Algorithm for Weapon-Target Assignment Problem
 A Parallel Simulated Annealing Algorithm for Weapon-Target Assignment Problem Emrullah SONUC Department of Computer Engineering Karabuk University Karabuk, TURKEY Baha SEN Department of Computer Engineering
A Parallel Simulated Annealing Algorithm for Weapon-Target Assignment Problem Emrullah SONUC Department of Computer Engineering Karabuk University Karabuk, TURKEY Baha SEN Department of Computer Engineering
Using Genetic Algorithms to solve the Minimum Labeling Spanning Tree Problem
 Using to solve the Minimum Labeling Spanning Tree Problem Final Presentation, oliverr@umd.edu Advisor: Dr Bruce L. Golden, bgolden@rhsmith.umd.edu R. H. Smith School of Business (UMD) May 3, 2012 1 / 42
Using to solve the Minimum Labeling Spanning Tree Problem Final Presentation, oliverr@umd.edu Advisor: Dr Bruce L. Golden, bgolden@rhsmith.umd.edu R. H. Smith School of Business (UMD) May 3, 2012 1 / 42
Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies
 Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies John C. Linford John Michalakes Manish Vachharajani Adrian Sandu IMAGe TOY 2009 Workshop 2 Virginia
Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies John C. Linford John Michalakes Manish Vachharajani Adrian Sandu IMAGe TOY 2009 Workshop 2 Virginia
Parallel Path-Relinking Method for the Flow Shop Scheduling Problem
 Parallel Path-Relinking Method for the Flow Shop Scheduling Problem Wojciech Bożejko 1 and Mieczys law Wodecki 2 1 Wroc law University of Technology Institute of Computer Engineering, Control and Robotics
Parallel Path-Relinking Method for the Flow Shop Scheduling Problem Wojciech Bożejko 1 and Mieczys law Wodecki 2 1 Wroc law University of Technology Institute of Computer Engineering, Control and Robotics
GPU-based Island Model for Evolutionary Algorithms
 GPU-based Island Model for Evolutionary Algorithms Thé Van Luong, Nouredine Melab, El-Ghazali Talbi To cite this version: Thé Van Luong, Nouredine Melab, El-Ghazali Talbi. GPU-based Island Model for Evolutionary
GPU-based Island Model for Evolutionary Algorithms Thé Van Luong, Nouredine Melab, El-Ghazali Talbi To cite this version: Thé Van Luong, Nouredine Melab, El-Ghazali Talbi. GPU-based Island Model for Evolutionary
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
ARTIFICIAL INTELLIGENCE (CSCU9YE ) LECTURE 5: EVOLUTIONARY ALGORITHMS
 LECTURE 5: EVOLUTIONARY ALGORITHMS") ARTIFICIAL INTELLIGENCE (CSCU9YE ) LECTURE 5: EVOLUTIONARY ALGORITHMS Gabriela Ochoa http://www.cs.stir.ac.uk/~goc/ OUTLINE Optimisation problems Optimisation & search Two Examples The knapsack problem
ARTIFICIAL INTELLIGENCE (CSCU9YE ) LECTURE 5: EVOLUTIONARY ALGORITHMS Gabriela Ochoa http://www.cs.stir.ac.uk/~goc/ OUTLINE Optimisation problems Optimisation & search Two Examples The knapsack problem
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Tabu search and genetic algorithms: a comparative study between pure and hybrid agents in an A-teams approach
 Tabu search and genetic algorithms: a comparative study between pure and hybrid agents in an A-teams approach Carlos A. S. Passos (CenPRA) carlos.passos@cenpra.gov.br Daniel M. Aquino (UNICAMP, PIBIC/CNPq)
Tabu search and genetic algorithms: a comparative study between pure and hybrid agents in an A-teams approach Carlos A. S. Passos (CenPRA) carlos.passos@cenpra.gov.br Daniel M. Aquino (UNICAMP, PIBIC/CNPq)
A Cross-Input Adaptive Framework for GPU Program Optimizations
 A Cross-Input Adaptive Framework for GPU Program Optimizations Yixun Liu, Eddy Z. Zhang, Xipeng Shen Computer Science Department The College of William & Mary Outline GPU overview G-Adapt Framework Evaluation
A Cross-Input Adaptive Framework for GPU Program Optimizations Yixun Liu, Eddy Z. Zhang, Xipeng Shen Computer Science Department The College of William & Mary Outline GPU overview G-Adapt Framework Evaluation
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation
 Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation Nikolai Sakharnykh - NVIDIA San Jose Convention Center, San Jose, CA September 21, 2010 Introduction Tridiagonal solvers very popular
Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation Nikolai Sakharnykh - NVIDIA San Jose Convention Center, San Jose, CA September 21, 2010 Introduction Tridiagonal solvers very popular
Outline of the module
 Evolutionary and Heuristic Optimisation (ITNPD8) Lecture 2: Heuristics and Metaheuristics Gabriela Ochoa http://www.cs.stir.ac.uk/~goc/ Computing Science and Mathematics, School of Natural Sciences University
Evolutionary and Heuristic Optimisation (ITNPD8) Lecture 2: Heuristics and Metaheuristics Gabriela Ochoa http://www.cs.stir.ac.uk/~goc/ Computing Science and Mathematics, School of Natural Sciences University
High Performance GPU Accelerated Local Optimization in TSP
 2013 IEEE 27th International Symposium on Parallel & Distributed Processing Workshops and PhD Forum High Performance GPU Accelerated Local Optimization in TSP Kamil Rocki, Reiji Suda The University of
2013 IEEE 27th International Symposium on Parallel & Distributed Processing Workshops and PhD Forum High Performance GPU Accelerated Local Optimization in TSP Kamil Rocki, Reiji Suda The University of
GPU. Ben de Waal Summer 2008
 GPU Ben de Waal Summer 2008 Agenda Quick Roadmap A few observations And a few positions 2 GPUs are Great at Graphics Crysis 2006 Crytek / Electronic Arts Hellgate: London 2005-2006 Flagship 3 Studios,
GPU Ben de Waal Summer 2008 Agenda Quick Roadmap A few observations And a few positions 2 GPUs are Great at Graphics Crysis 2006 Crytek / Electronic Arts Hellgate: London 2005-2006 Flagship 3 Studios,
A TALENTED CPU-TO-GPU MEMORY MAPPING TECHNIQUE
 A TALENTED CPU-TO-GPU MEMORY MAPPING TECHNIQUE Abu Asaduzzaman, Deepthi Gummadi, and Chok M. Yip Department of Electrical Engineering and Computer Science Wichita State University Wichita, Kansas, USA
A TALENTED CPU-TO-GPU MEMORY MAPPING TECHNIQUE Abu Asaduzzaman, Deepthi Gummadi, and Chok M. Yip Department of Electrical Engineering and Computer Science Wichita State University Wichita, Kansas, USA
Shadowfax: Scaling in Heterogeneous Cluster Systems via GPGPU Assemblies
 Shadowfax: Scaling in Heterogeneous Cluster Systems via GPGPU Assemblies Alexander Merritt, Vishakha Gupta, Abhishek Verma, Ada Gavrilovska, Karsten Schwan {merritt.alex,abhishek.verma}@gatech.edu {vishakha,ada,schwan}@cc.gtaech.edu
Shadowfax: Scaling in Heterogeneous Cluster Systems via GPGPU Assemblies Alexander Merritt, Vishakha Gupta, Abhishek Verma, Ada Gavrilovska, Karsten Schwan {merritt.alex,abhishek.verma}@gatech.edu {vishakha,ada,schwan}@cc.gtaech.edu
Computing on GPUs. Prof. Dr. Uli Göhner. DYNAmore GmbH. Stuttgart, Germany
 Computing on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Summary: The increasing power of GPUs has led to the intent to transfer computing load from CPUs to GPUs. A first example has been
Computing on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Summary: The increasing power of GPUs has led to the intent to transfer computing load from CPUs to GPUs. A first example has been
RESEARCH ARTICLE. Accelerating Ant Colony Optimization for the Traveling Salesman Problem on the GPU
 The International Journal of Parallel, Emergent and Distributed Systems Vol. 00, No. 00, Month 2011, 1 21 RESEARCH ARTICLE Accelerating Ant Colony Optimization for the Traveling Salesman Problem on the
The International Journal of Parallel, Emergent and Distributed Systems Vol. 00, No. 00, Month 2011, 1 21 RESEARCH ARTICLE Accelerating Ant Colony Optimization for the Traveling Salesman Problem on the
LOW AND HIGH LEVEL HYBRIDIZATION OF ANT COLONY SYSTEM AND GENETIC ALGORITHM FOR JOB SCHEDULING IN GRID COMPUTING
 LOW AND HIGH LEVEL HYBRIDIZATION OF ANT COLONY SYSTEM AND GENETIC ALGORITHM FOR JOB SCHEDULING IN GRID COMPUTING Mustafa Muwafak Alobaedy 1, and Ku Ruhana Ku-Mahamud 2 2 Universiti Utara Malaysia), Malaysia,
LOW AND HIGH LEVEL HYBRIDIZATION OF ANT COLONY SYSTEM AND GENETIC ALGORITHM FOR JOB SCHEDULING IN GRID COMPUTING Mustafa Muwafak Alobaedy 1, and Ku Ruhana Ku-Mahamud 2 2 Universiti Utara Malaysia), Malaysia,
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Duksu Kim. Professional Experience Senior researcher, KISTI High performance visualization
 Duksu Kim Assistant professor, KORATEHC Education Ph.D. Computer Science, KAIST Parallel Proximity Computation on Heterogeneous Computing Systems for Graphics Applications Professional Experience Senior
Duksu Kim Assistant professor, KORATEHC Education Ph.D. Computer Science, KAIST Parallel Proximity Computation on Heterogeneous Computing Systems for Graphics Applications Professional Experience Senior
GPU-accelerated Verification of the Collatz Conjecture
 GPU-accelerated Verification of the Collatz Conjecture Takumi Honda, Yasuaki Ito, and Koji Nakano Department of Information Engineering, Hiroshima University, Kagamiyama 1-4-1, Higashi Hiroshima 739-8527,
GPU-accelerated Verification of the Collatz Conjecture Takumi Honda, Yasuaki Ito, and Koji Nakano Department of Information Engineering, Hiroshima University, Kagamiyama 1-4-1, Higashi Hiroshima 739-8527,
Stream Processing with CUDA TM A Case Study Using Gamebryo's Floodgate Technology
 Stream Processing with CUDA TM A Case Study Using Gamebryo's Floodgate Technology Dan Amerson, Technical Director, Emergent Game Technologies Purpose Why am I giving this talk? To answer this question:
Stream Processing with CUDA TM A Case Study Using Gamebryo's Floodgate Technology Dan Amerson, Technical Director, Emergent Game Technologies Purpose Why am I giving this talk? To answer this question:
OpenMP Optimization and its Translation to OpenGL
 OpenMP Optimization and its Translation to OpenGL Santosh Kumar SITRC-Nashik, India Dr. V.M.Wadhai MAE-Pune, India Prasad S.Halgaonkar MITCOE-Pune, India Kiran P.Gaikwad GHRIEC-Pune, India ABSTRACT For
OpenMP Optimization and its Translation to OpenGL Santosh Kumar SITRC-Nashik, India Dr. V.M.Wadhai MAE-Pune, India Prasad S.Halgaonkar MITCOE-Pune, India Kiran P.Gaikwad GHRIEC-Pune, India ABSTRACT For
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
GPU Cluster Computing. Advanced Computing Center for Research and Education
 GPU Cluster Computing Advanced Computing Center for Research and Education 1 What is GPU Computing? Gaming industry and high- defini3on graphics drove the development of fast graphics processing Use of
GPU Cluster Computing Advanced Computing Center for Research and Education 1 What is GPU Computing? Gaming industry and high- defini3on graphics drove the development of fast graphics processing Use of
Parallel local search on GPU and CPU with OpenCL Language
 Parallel local search on GPU and CPU with OpenCL Language Omar ABDELKAFI, Khalil CHEBIL, Mahdi KHEMAKHEM LOGIQ, UNIVERSITY OF SFAX SFAX-TUNISIA omarabd.recherche@gmail.com, chebilkhalil@gmail.com, mahdi.khemakhem@isecs.rnu.tn
Parallel local search on GPU and CPU with OpenCL Language Omar ABDELKAFI, Khalil CHEBIL, Mahdi KHEMAKHEM LOGIQ, UNIVERSITY OF SFAX SFAX-TUNISIA omarabd.recherche@gmail.com, chebilkhalil@gmail.com, mahdi.khemakhem@isecs.rnu.tn
A GPU Implementation of Tiled Belief Propagation on Markov Random Fields. Hassan Eslami Theodoros Kasampalis Maria Kotsifakou
 A GPU Implementation of Tiled Belief Propagation on Markov Random Fields Hassan Eslami Theodoros Kasampalis Maria Kotsifakou BP-M AND TILED-BP 2 BP-M 3 Tiled BP T 0 T 1 T 2 T 3 T 4 T 5 T 6 T 7 T 8 4 Tiled
A GPU Implementation of Tiled Belief Propagation on Markov Random Fields Hassan Eslami Theodoros Kasampalis Maria Kotsifakou BP-M AND TILED-BP 2 BP-M 3 Tiled BP T 0 T 1 T 2 T 3 T 4 T 5 T 6 T 7 T 8 4 Tiled
GRID SCHEDULING USING ENHANCED PSO ALGORITHM
 GRID SCHEDULING USING ENHANCED PSO ALGORITHM Mr. P.Mathiyalagan 1 U.R.Dhepthie 2 Dr. S.N.Sivanandam 3 1 Lecturer 2 Post Graduate Student 3 Professor and Head Department of Computer Science and Engineering
GRID SCHEDULING USING ENHANCED PSO ALGORITHM Mr. P.Mathiyalagan 1 U.R.Dhepthie 2 Dr. S.N.Sivanandam 3 1 Lecturer 2 Post Graduate Student 3 Professor and Head Department of Computer Science and Engineering
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture
 COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer
 CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer Outline We ll be focussing on optimizing global memory throughput on Fermi-class GPUs
CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer Outline We ll be focussing on optimizing global memory throughput on Fermi-class GPUs
GPU Implementation of the Branch and Bound method for knapsack problems
 2012 IEEE 201226th IEEE International 26th International Parallel Parallel and Distributed and Distributed Processing Processing Symposium Symposium Workshops Workshops & PhD Forum GPU Implementation of
2012 IEEE 201226th IEEE International 26th International Parallel Parallel and Distributed and Distributed Processing Processing Symposium Symposium Workshops Workshops & PhD Forum GPU Implementation of
A Parallel Architecture for the Generalized Traveling Salesman Problem
 A Parallel Architecture for the Generalized Traveling Salesman Problem Max Scharrenbroich AMSC 663 Project Proposal Advisor: Dr. Bruce L. Golden R. H. Smith School of Business 1 Background and Introduction
A Parallel Architecture for the Generalized Traveling Salesman Problem Max Scharrenbroich AMSC 663 Project Proposal Advisor: Dr. Bruce L. Golden R. H. Smith School of Business 1 Background and Introduction
Computational Complexity CSC Professor: Tom Altman. Capacitated Problem
 Computational Complexity CSC 5802 Professor: Tom Altman Capacitated Problem Agenda: Definition Example Solution Techniques Implementation Capacitated VRP (CPRV) CVRP is a Vehicle Routing Problem (VRP)
Computational Complexity CSC 5802 Professor: Tom Altman Capacitated Problem Agenda: Definition Example Solution Techniques Implementation Capacitated VRP (CPRV) CVRP is a Vehicle Routing Problem (VRP)
Parallel Systems I The GPU architecture. Jan Lemeire
 Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
Parallel Ant Colonies for Combinatorial. Abstract. Ant Colonies (AC) optimization take inspiration from the behavior
 optimization take inspiration from the behavior") Parallel Ant Colonies for Combinatorial Optimization Problems El-ghazali Talbi?, Olivier Roux, Cyril Fonlupt, Denis Robillard?? Abstract. Ant Colonies (AC) optimization take inspiration from the behavior
Parallel Ant Colonies for Combinatorial Optimization Problems El-ghazali Talbi?, Olivier Roux, Cyril Fonlupt, Denis Robillard?? Abstract. Ant Colonies (AC) optimization take inspiration from the behavior
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management
 X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
CUDA OPTIMIZATIONS ISC 2011 Tutorial
 CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Advanced CUDA Optimization 1. Introduction
 Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
Accelerating image registration on GPUs
 Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
A heuristic approach to find the global optimum of function
 Journal of Computational and Applied Mathematics 209 (2007) 160 166 www.elsevier.com/locate/cam A heuristic approach to find the global optimum of function M. Duran Toksarı Engineering Faculty, Industrial
Journal of Computational and Applied Mathematics 209 (2007) 160 166 www.elsevier.com/locate/cam A heuristic approach to find the global optimum of function M. Duran Toksarı Engineering Faculty, Industrial
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
The Use of Cloud Computing Resources in an HPC Environment
 The Use of Cloud Computing Resources in an HPC Environment Bill, Labate, UCLA Office of Information Technology Prakashan Korambath, UCLA Institute for Digital Research & Education Cloud computing becomes
The Use of Cloud Computing Resources in an HPC Environment Bill, Labate, UCLA Office of Information Technology Prakashan Korambath, UCLA Institute for Digital Research & Education Cloud computing becomes
Adaptive-Mesh-Refinement Hydrodynamic GPU Computation in Astrophysics
 Adaptive-Mesh-Refinement Hydrodynamic GPU Computation in Astrophysics H. Y. Schive ( 薛熙于 ) Graduate Institute of Physics, National Taiwan University Leung Center for Cosmology and Particle Astrophysics
Adaptive-Mesh-Refinement Hydrodynamic GPU Computation in Astrophysics H. Y. Schive ( 薛熙于 ) Graduate Institute of Physics, National Taiwan University Leung Center for Cosmology and Particle Astrophysics
GPU Computing in Discrete Optimization
 Noname manuscript No. (will be inserted by the editor) GPU Computing in Discrete Optimization Part II: Survey Focused on Routing Problems Christian Schulz Geir Hasle André R. Brodtkorb Trond R. Hagen Received:
Noname manuscript No. (will be inserted by the editor) GPU Computing in Discrete Optimization Part II: Survey Focused on Routing Problems Christian Schulz Geir Hasle André R. Brodtkorb Trond R. Hagen Received:
Improved Event Generation at NLO and NNLO. or Extending MCFM to include NNLO processes
 Improved Event Generation at NLO and NNLO or Extending MCFM to include NNLO processes W. Giele, RadCor 2015 NNLO in MCFM: Jettiness approach: Using already well tested NLO MCFM as the double real and virtual-real
Improved Event Generation at NLO and NNLO or Extending MCFM to include NNLO processes W. Giele, RadCor 2015 NNLO in MCFM: Jettiness approach: Using already well tested NLO MCFM as the double real and virtual-real
Optimization Principles and Application Performance Evaluation of a Multithreaded GPU Using CUDA
 Optimization Principles and Application Performance Evaluation of a Multithreaded GPU Using CUDA Shane Ryoo, Christopher I. Rodrigues, Sara S. Baghsorkhi, Sam S. Stone, David B. Kirk, and Wen-mei H. Hwu
Optimization Principles and Application Performance Evaluation of a Multithreaded GPU Using CUDA Shane Ryoo, Christopher I. Rodrigues, Sara S. Baghsorkhi, Sam S. Stone, David B. Kirk, and Wen-mei H. Hwu
Fast Tridiagonal Solvers on GPU
 Fast Tridiagonal Solvers on GPU Yao Zhang John Owens UC Davis Jonathan Cohen NVIDIA GPU Technology Conference 2009 Outline Introduction Algorithms Design algorithms for GPU architecture Performance Bottleneck-based
Fast Tridiagonal Solvers on GPU Yao Zhang John Owens UC Davis Jonathan Cohen NVIDIA GPU Technology Conference 2009 Outline Introduction Algorithms Design algorithms for GPU architecture Performance Bottleneck-based
Chapter 16 Heuristic Search
 Chapter 16 Heuristic Search Part I. Preliminaries Part II. Tightly Coupled Multicore Chapter 6. Parallel Loops Chapter 7. Parallel Loop Schedules Chapter 8. Parallel Reduction Chapter 9. Reduction Variables
Chapter 16 Heuristic Search Part I. Preliminaries Part II. Tightly Coupled Multicore Chapter 6. Parallel Loops Chapter 7. Parallel Loop Schedules Chapter 8. Parallel Reduction Chapter 9. Reduction Variables
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware