Deep Incremental Scene Understanding. Federico Tombari & Christian Rupprecht Technical University of Munich, Germany
|
|
|
- John Bradley
- 6 years ago
- Views:
Transcription

1 Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany

 [Couprie14] SLAM from")
2 C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information" JMLR, 2014 S. Izadi et al., KinectFusion: Real-time 3D Reconstruction and Interaction Using a Moving Depth Camera, UIST 2011 Scene Understanding and SLAM Scene understanding with deep learning (typically frame-wise) [Couprie14] SLAM from RGB-D data allowing real-time scene reconstruction [Izadi11] Can we fuse the two, while still being real-time?

![Understanding on Dense SLAM [Li16] C. Li et al.](/docs-images/77/76111411/images/3-2.jpg ", Incremental scene understanding on dense SLAM, IROS 2016 R. Salas-Moreno et al.")
3 Beyond SLAM: fusing reconstruction with scene understanding Fusing multiple viewpoints over time improves semantic perception and object pose estimation SLAM++ [Salas-Moreno13] Incremental Scene Understanding on Dense SLAM [Li16] C. Li et al., Incremental scene understanding on dense SLAM, IROS 2016 R. Salas-Moreno et al., SLAM++: Simultaneous Localisation and Mapping at the Level of Objects, CVPR 2013
![Incremental 3D Segmentation Real-time segmentation of SLAM reconstruction [Tateno15], yielding constant complexity wrt.](/docs-images/77/76111411/images/4-1.jpg "the size of the reconstruction K. Tateno, F. Tombari, N.")
4 Incremental 3D Segmentation Real-time segmentation of SLAM reconstruction [Tateno15], yielding constant complexity wrt. the size of the reconstruction K. Tateno, F. Tombari, N. Navab, Real-Time and Scalable Incremental Segmentation on Dense SLAM, IROS 15

5 Real-time also on Google Tango..
6 What if a depth sensor is not available? Is semantic mapping/incremental scene understanding still possible from a single RGB camera?
![Monocular SLAM state of the art FEATURE-BASED DIRECT ORB-SLAM [Mur-Artal14] LSD-SLAM](/docs-images/77/76111411/images/7-1.jpg "[Engel14] Not dense on texture-less regions MAIN LIMITATIONS No pure rotational motions No")

7 Monocular SLAM state of the art FEATURE-BASED DIRECT ORB-SLAM [Mur-Artal14] LSD-SLAM [Engel14] Not dense on texture-less regions MAIN LIMITATIONS No pure rotational motions No absolute scale J. Engel et al., LSD-SLAM: Large-Scale Direct Monocular SLAM ECCV 2014 R. Mur-Artal et al., ORB-SLAM: A Versatile and Accurate Monocular SLAM System IEEE Trans. Robotics 2015
 Depth Prediction An alternative to monocular")
8 Depth prediction with CNNs Goal: Use a CNN to predict a dense depth map from a single RGB image RGB Image Depth Ground Truth (Kinect) Depth Prediction An alternative to monocular SLAM?
![FC ResNet with UpProjections [Laina16] CNN Architecture](/docs-images/77/76111411/images/9-1.jpg "ResNet-50 avg Memory FC limitations pool Restriction of")


9 FC ResNet with UpProjections [Laina16] CNN Architecture ResNet-50 avg Memory FC limitations pool Restriction of full connections: high dimensional outputs can produce billions of parameters Residual blocks I. Laina, C. Rupprecht, V. Belagiannis, F. Tombari, N. Navab: Deeper Depth Prediction using fully Convolutional Residual Networks, 3DV 2016



10 FC ResNet with UpProjections [Laina16] CNN Architecture avg FC pool difficult convergence blurry predictions need for bigger datasets vs ground truth prediction Residual blocks
![FC ResNet with UpProjections [Laina16] CNN Architecture](/docs-images/77/76111411/images/11-1.jpg "Residual blocks fully convolutional ResNet with progressive")
11 FC ResNet with UpProjections [Laina16] CNN Architecture Residual blocks fully convolutional ResNet with progressive up-sampling





12 FC ResNet with UpProjections [Laina16] CNN Architecture Residual blocks
13 FC ResNet with UpProjections [Laina16] CNN Architecture Residual blocks


14 FC ResNet with UpProjections [Laina16] CNN Architecture Residual blocks
 40-class (RGB + Depth Pred.")
15 Multi-task FC ResNet RGB Input Depth GT (Kinect) Depth Prediction 4-class Sem. Seg. 40-class (RGB-Only) 40-class (RGB + Depth Pred.)



16 Monocular SLAM and CNN depth prediction are complementary Monocular SLAM Accurate on depth borders but sparse CNN-SLAM [Tateno17] takes the best of both world by fusing monocular SLAM with depth prediction in real time CNN Depth Prediction Dense but imprecise along depth borders 1. can learn the absolute scale 2. dense maps 3. can deal with pure rotational motion K. Tateno, F. Tombari, I. Laina, N. Navab: CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction" CVPR, 2017
17 CNN-SLAM framework Every Key-frame Input RGB Image CNN Semantic Segmentation CNN Depth Prediction Key-frame Initialization Pose Graph Optimization Global Map and Semantic Label Fusion Camera Pose Estimation Frame-wise Depth Refinement Camera pose estimated via direct method at each new frame Set of key-frames, each associated to a depth map Each key-frame depth map D ki is Every input frame 1. initialized via Fully Convolutional ResNet [Laina16] 2. refined with depth values D t estimated via short-baseline stereo matching [Engel14], weighted by the associated uncertainty U ki, U t : D ki u = U t u D ki u + U ki u D t u U ki u + U t u


18 Key-frame depth refinement Key-frame depth refinement allows estimating fine structures on previously blurred surfaces Gradual fusion of CNN-predicted depth with monocular SLAM: elements near intensity gradients will be more and more refined by the frame-wise depth estimates elements within low-textured regions will gradually hold the predicted depth value from the CNN Refining depth in Key-frame RGB image in Key-frame RGB image in current frame

19 Qualitative results SLAM on pure rotational motion

20 Qualitative results Absolute scale estimation

21 First demonstration of fully monocular real-time semantic mapping


22 Many prediction tasks are ambiguous Many prediction tasks contain uncertainty. In some cases, uncertainty is inherent in the task itself [Rupprecht17]. What will the other driver do? What is the label for this image? C. Rupprecht, I. Laina, R. DiPietro, M. Baust, F. Tombari, N. Navab, G. D. Hager: Learning in an Uncertain World: Representing Ambiguity Through Multiple Hypotheses" arxiv: , 2017
23 Simple example: next frame prediction single prediction a square is bouncing around the frame it randomly switches color between black and white the CNN predicts the next frame in the sequence the mean of black and white is gray, which is also the background the frame is constant gray
24 Approximations with the mean p(x) x Learning the mean can lead to very unlikely solutions
25 Approximate with multiple hypotheses a simple meta-loss transforms any model into a multiple hypothesis predictor (MHP)
26 Simple example: next frame prediction prediction 1 prediction 2 now we transformed the same network into a multiple hypothesis model with two predictions it is able to separate black and white blocks for the future frame

27 Image Classification

28 Human Pose Estimation the variance of prediction can help detecting ambiguities the predictions for the location of the hands varies much more than for the shoulders

29 Future Frame Prediction with more predictions future frames become sharper the model does not need to blend together all possible outcomes

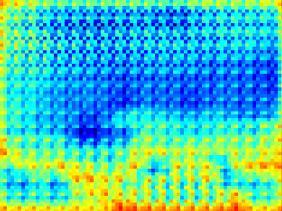
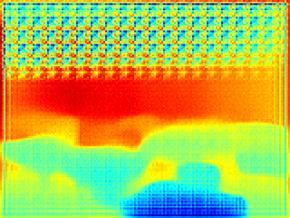
30 hypotheses Multiple Hypothesis for Depth Prediction input ground truth hypotheses mean variance


31 Multiple Hypothesis Prediction for CNN-SLAM the variance can be used to estimate confidences confidences will be used as initialization for the refinement of the keyframe with MHP depth prediction the overall accuracy increases original CNN-SLAM CNN-SLAM with MHP correct pixels: 10.6% correct pixels: 36.0%
32 Conclusion We presented a framework for real-time scene understanding fusing semantic segmentation and SLAM reconstruction Depth prediction complements monocular SLAM in low texture regions and global scale Multiple hypotheses allow for improved 3D reconstruction Combine deep learning with 3D computer vision to leverage the best of both worlds Slide 32
33 Credits (alphabetical) Dr. Max Baust Dr. Vasilis Belagiannis Robert DiPietro Prof. Greg Hager Iro Laina Prof. Nassir Navab Keisuke Tateno We gratefully acknowledge the donation from Nvidia of two GPUs that helped the development of the presented research activities.
34 References [Couprie14] C. Couprie, C. Farabet, L. Najman, Y. LeCun: "Toward Real-time Indoor Semantic Segmentation Using Depth Information" JMLR, 2014 [Engel14] J. Engel et al., LSD-SLAM: Large-Scale Direct Monocular SLAM ECCV 2014 [Izadi11] S. Izadi et al., KinectFusion: Real-time 3D Reconstruction and Interaction Using a Moving Depth Camera, UIST 2011 [Laina16] I. Laina, C. Rupprecht, V. Belagiannis, F. Tombari, N. Navab: Deeper Depth Prediction using fully Convolutional Residual Networks, 3DV 2016 [Li16] C. Li et al., Incremental scene understanding on dense SLAM, IROS 2016 [Mur-Artal15] R. Mur-Artal et al., ORB-SLAM: A Versatile and Accurate Monocular SLAM System IEEE Trans. Robotics 2015 [Rupprecht17] C. Rupprecht, I. Laina, R. DiPietro, M. Baust, F. Tombari, N. Navab, G. D. Hager: Learning in an Uncertain World: Representing Ambiguity Through Multiple Hypotheses" arxiv: , 2017 [Salas-Moreno13] R. Salas-Moreno et al., SLAM++: Simultaneous Localisation and Mapping at the Level of Objects, CVPR 2013 [Tateno15] K. Tateno, F. Tombari, N. Navab, Real-Time and Scalable Incremental Segmentation on Dense SLAM, IROS 15 [Tateno17] K. Tateno, F. Tombari, I. Laina, N. Navab: CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction" CVPR, 2017
CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction
 CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction Keisuke Tateno 1,2, Federico Tombari 1, Iro Laina 1, Nassir Navab 1,3 {tateno, tombari, laina, navab}@in.tum.de 1 CAMP - TU Munich
CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction Keisuke Tateno 1,2, Federico Tombari 1, Iro Laina 1, Nassir Navab 1,3 {tateno, tombari, laina, navab}@in.tum.de 1 CAMP - TU Munich
From 3D descriptors to monocular 6D pose: what have we learned?
 ECCV Workshop on Recovering 6D Object Pose From 3D descriptors to monocular 6D pose: what have we learned? Federico Tombari CAMP - TUM Dynamic occlusion Low latency High accuracy, low jitter No expensive
ECCV Workshop on Recovering 6D Object Pose From 3D descriptors to monocular 6D pose: what have we learned? Federico Tombari CAMP - TUM Dynamic occlusion Low latency High accuracy, low jitter No expensive
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation
 AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth
Fully Convolutional Network for Depth Estimation and Semantic Segmentation
 Fully Convolutional Network for Depth Estimation and Semantic Segmentation Yokila Arora ICME Stanford University yarora@stanford.edu Ishan Patil Department of Electrical Engineering Stanford University
Fully Convolutional Network for Depth Estimation and Semantic Segmentation Yokila Arora ICME Stanford University yarora@stanford.edu Ishan Patil Department of Electrical Engineering Stanford University
Deep learning for dense per-pixel prediction. Chunhua Shen The University of Adelaide, Australia
 Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Direct Methods in Visual Odometry
 Direct Methods in Visual Odometry July 24, 2017 Direct Methods in Visual Odometry July 24, 2017 1 / 47 Motivation for using Visual Odometry Wheel odometry is affected by wheel slip More accurate compared
Direct Methods in Visual Odometry July 24, 2017 Direct Methods in Visual Odometry July 24, 2017 1 / 47 Motivation for using Visual Odometry Wheel odometry is affected by wheel slip More accurate compared
3D Object Recognition and Scene Understanding from RGB-D Videos. Yu Xiang Postdoctoral Researcher University of Washington
 3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
Real-Time Vision-Based State Estimation and (Dense) Mapping
 Mapping") Real-Time Vision-Based State Estimation and (Dense) Mapping Stefan Leutenegger IROS 2016 Workshop on State Estimation and Terrain Perception for All Terrain Mobile Robots The Perception-Action Cycle in
Real-Time Vision-Based State Estimation and (Dense) Mapping Stefan Leutenegger IROS 2016 Workshop on State Estimation and Terrain Perception for All Terrain Mobile Robots The Perception-Action Cycle in
Dense Tracking and Mapping for Autonomous Quadrocopters. Jürgen Sturm
 Computer Vision Group Prof. Daniel Cremers Dense Tracking and Mapping for Autonomous Quadrocopters Jürgen Sturm Joint work with Frank Steinbrücker, Jakob Engel, Christian Kerl, Erik Bylow, and Daniel Cremers
Computer Vision Group Prof. Daniel Cremers Dense Tracking and Mapping for Autonomous Quadrocopters Jürgen Sturm Joint work with Frank Steinbrücker, Jakob Engel, Christian Kerl, Erik Bylow, and Daniel Cremers
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting
 Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting R. Maier 1,2, K. Kim 1, D. Cremers 2, J. Kautz 1, M. Nießner 2,3 Fusion Ours 1
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting R. Maier 1,2, K. Kim 1, D. Cremers 2, J. Kautz 1, M. Nießner 2,3 Fusion Ours 1
arxiv: v4 [cs.cv] 26 Jul 2018
![arxiv: v4 [cs.cv] 26 Jul 2018](/thumbs/94/119445605.jpg "arxiv: v4 [cs.cv] 26 Jul 2018") Scene Coordinate and Correspondence Learning for Image-Based Localization Mai Bui 1, Shadi Albarqouni 1, Slobodan Ilic 1,2 and Nassir Navab 1,3 arxiv:1805.08443v4 [cs.cv] 26 Jul 2018 Abstract Scene coordinate
Scene Coordinate and Correspondence Learning for Image-Based Localization Mai Bui 1, Shadi Albarqouni 1, Slobodan Ilic 1,2 and Nassir Navab 1,3 arxiv:1805.08443v4 [cs.cv] 26 Jul 2018 Abstract Scene coordinate
Perceiving the 3D World from Images and Videos. Yu Xiang Postdoctoral Researcher University of Washington
 Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
EasyChair Preprint. Visual Odometry Based on Convolutional Neural Networks for Large-Scale Scenes
 EasyChair Preprint 413 Visual Odometry Based on Convolutional Neural Networks for Large-Scale Scenes Xuyang Meng, Chunxiao Fan and Yue Ming EasyChair preprints are intended for rapid dissemination of research
EasyChair Preprint 413 Visual Odometry Based on Convolutional Neural Networks for Large-Scale Scenes Xuyang Meng, Chunxiao Fan and Yue Ming EasyChair preprints are intended for rapid dissemination of research
Reconstruction, Motion Estimation and SLAM from Events
 Reconstruction, Motion Estimation and SLAM from Events Andrew Davison Robot Vision Group and Dyson Robotics Laboratory Department of Computing Imperial College London www.google.com/+andrewdavison June
Reconstruction, Motion Estimation and SLAM from Events Andrew Davison Robot Vision Group and Dyson Robotics Laboratory Department of Computing Imperial College London www.google.com/+andrewdavison June
ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems (Supplementary Materials)
") ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems (Supplementary Materials) Yinda Zhang 1,2, Sameh Khamis 1, Christoph Rhemann 1, Julien Valentin 1, Adarsh Kowdle 1, Vladimir
ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems (Supplementary Materials) Yinda Zhang 1,2, Sameh Khamis 1, Christoph Rhemann 1, Julien Valentin 1, Adarsh Kowdle 1, Vladimir
Segmentation and Tracking of Partial Planar Templates
 Segmentation and Tracking of Partial Planar Templates Abdelsalam Masoud William Hoff Colorado School of Mines Colorado School of Mines Golden, CO 800 Golden, CO 800 amasoud@mines.edu whoff@mines.edu Abstract
Segmentation and Tracking of Partial Planar Templates Abdelsalam Masoud William Hoff Colorado School of Mines Colorado School of Mines Golden, CO 800 Golden, CO 800 amasoud@mines.edu whoff@mines.edu Abstract
Semi-Dense Direct SLAM
 Computer Vision Group Technical University of Munich Jakob Engel Jakob Engel, Daniel Cremers David Caruso, Thomas Schöps, Lukas von Stumberg, Vladyslav Usenko, Jörg Stückler, Jürgen Sturm Technical University
Computer Vision Group Technical University of Munich Jakob Engel Jakob Engel, Daniel Cremers David Caruso, Thomas Schöps, Lukas von Stumberg, Vladyslav Usenko, Jörg Stückler, Jürgen Sturm Technical University
Depth Estimation from Single Image Using CNN-Residual Network
 Depth Estimation from Single Image Using CNN-Residual Network Xiaobai Ma maxiaoba@stanford.edu Zhenglin Geng zhenglin@stanford.edu Zhi Bie zhib@stanford.edu Abstract In this project, we tackle the problem
Depth Estimation from Single Image Using CNN-Residual Network Xiaobai Ma maxiaoba@stanford.edu Zhenglin Geng zhenglin@stanford.edu Zhi Bie zhib@stanford.edu Abstract In this project, we tackle the problem
Lecture 19: Depth Cameras. Visual Computing Systems CMU , Fall 2013
 Lecture 19: Depth Cameras Visual Computing Systems Continuing theme: computational photography Cameras capture light, then extensive processing produces the desired image Today: - Capturing scene depth
Lecture 19: Depth Cameras Visual Computing Systems Continuing theme: computational photography Cameras capture light, then extensive processing produces the desired image Today: - Capturing scene depth
arxiv: v1 [cs.cv] 13 Nov 2016 Abstract
![arxiv: v1 [cs.cv] 13 Nov 2016 Abstract](/thumbs/76/74154168.jpg "arxiv: v1 [cs.cv] 13 Nov 2016 Abstract") Semi-Dense 3D Semantic Mapping from Monocular SLAM Xuanpeng LI Southeast University 2 Si Pai Lou, Nanjing, China li xuanpeng@seu.edu.cn Rachid Belaroussi IFSTTAR, COSYS/LIVIC 25 allée des Marronniers,
Semi-Dense 3D Semantic Mapping from Monocular SLAM Xuanpeng LI Southeast University 2 Si Pai Lou, Nanjing, China li xuanpeng@seu.edu.cn Rachid Belaroussi IFSTTAR, COSYS/LIVIC 25 allée des Marronniers,
Single Image Depth Estimation via Deep Learning
 Single Image Depth Estimation via Deep Learning Wei Song Stanford University Stanford, CA Abstract The goal of the project is to apply direct supervised deep learning to the problem of monocular depth
Single Image Depth Estimation via Deep Learning Wei Song Stanford University Stanford, CA Abstract The goal of the project is to apply direct supervised deep learning to the problem of monocular depth
FLaME: Fast Lightweight Mesh Estimation using Variational Smoothing on Delaunay Graphs
 FLaME: Fast Lightweight Mesh Estimation using Variational Smoothing on Delaunay Graphs W. Nicholas Greene Robust Robotics Group, MIT CSAIL LPM Workshop IROS 2017 September 28, 2017 with Nicholas Roy 1
FLaME: Fast Lightweight Mesh Estimation using Variational Smoothing on Delaunay Graphs W. Nicholas Greene Robust Robotics Group, MIT CSAIL LPM Workshop IROS 2017 September 28, 2017 with Nicholas Roy 1
Monocular Tracking and Reconstruction in Non-Rigid Environments
 Monocular Tracking and Reconstruction in Non-Rigid Environments Kick-Off Presentation, M.Sc. Thesis Supervisors: Federico Tombari, Ph.D; Benjamin Busam, M.Sc. Patrick Ruhkamp 13.01.2017 Introduction Motivation:
Monocular Tracking and Reconstruction in Non-Rigid Environments Kick-Off Presentation, M.Sc. Thesis Supervisors: Federico Tombari, Ph.D; Benjamin Busam, M.Sc. Patrick Ruhkamp 13.01.2017 Introduction Motivation:
Geometric Reconstruction Dense reconstruction of scene geometry
 Lecture 5. Dense Reconstruction and Tracking with Real-Time Applications Part 2: Geometric Reconstruction Dr Richard Newcombe and Dr Steven Lovegrove Slide content developed from: [Newcombe, Dense Visual
Lecture 5. Dense Reconstruction and Tracking with Real-Time Applications Part 2: Geometric Reconstruction Dr Richard Newcombe and Dr Steven Lovegrove Slide content developed from: [Newcombe, Dense Visual
Fast Semantic Segmentation of RGB-D Scenes with GPU-Accelerated Deep Neural Networks
 Fast Semantic Segmentation of RGB-D Scenes with GPU-Accelerated Deep Neural Networks Nico Höft, Hannes Schulz, and Sven Behnke Rheinische Friedrich-Wilhelms-Universität Bonn Institut für Informatik VI,
Fast Semantic Segmentation of RGB-D Scenes with GPU-Accelerated Deep Neural Networks Nico Höft, Hannes Schulz, and Sven Behnke Rheinische Friedrich-Wilhelms-Universität Bonn Institut für Informatik VI,
3D Computer Vision. Depth Cameras. Prof. Didier Stricker. Oliver Wasenmüller
 3D Computer Vision Depth Cameras Prof. Didier Stricker Oliver Wasenmüller Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de
3D Computer Vision Depth Cameras Prof. Didier Stricker Oliver Wasenmüller Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de
arxiv: v2 [cs.ro] 26 Feb 2018
![arxiv: v2 [cs.ro] 26 Feb 2018](/thumbs/81/83191831.jpg "arxiv: v2 [cs.ro] 26 Feb 2018") Sparse-to-Dense: Depth Prediction from Sparse Depth Samples and a Single Image Fangchang Ma 1 and Sertac Karaman 1 arxiv:179.7492v2 [cs.ro] 26 Feb 218 Abstract We consider the problem of dense depth prediction
Sparse-to-Dense: Depth Prediction from Sparse Depth Samples and a Single Image Fangchang Ma 1 and Sertac Karaman 1 arxiv:179.7492v2 [cs.ro] 26 Feb 218 Abstract We consider the problem of dense depth prediction
Super-Resolution Keyframe Fusion for 3D Modeling with High-Quality Textures
 Super-Resolution Keyframe Fusion for 3D Modeling with High-Quality Textures Robert Maier, Jörg Stückler, Daniel Cremers International Conference on 3D Vision (3DV) October 2015, Lyon, France Motivation
Super-Resolution Keyframe Fusion for 3D Modeling with High-Quality Textures Robert Maier, Jörg Stückler, Daniel Cremers International Conference on 3D Vision (3DV) October 2015, Lyon, France Motivation
Stereo and Epipolar geometry
 Previously Image Primitives (feature points, lines, contours) Today: Stereo and Epipolar geometry How to match primitives between two (multiple) views) Goals: 3D reconstruction, recognition Jana Kosecka
Previously Image Primitives (feature points, lines, contours) Today: Stereo and Epipolar geometry How to match primitives between two (multiple) views) Goals: 3D reconstruction, recognition Jana Kosecka
Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image. Supplementary Material
 Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image Supplementary Material Siyuan Huang 1,2, Siyuan Qi 1,2, Yixin Zhu 1,2, Yinxue Xiao 1, Yuanlu Xu 1,2, and Song-Chun Zhu 1,2 1 University
Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image Supplementary Material Siyuan Huang 1,2, Siyuan Qi 1,2, Yixin Zhu 1,2, Yinxue Xiao 1, Yuanlu Xu 1,2, and Song-Chun Zhu 1,2 1 University
Jakob Engel, Thomas Schöps, Daniel Cremers Technical University Munich. LSD-SLAM: Large-Scale Direct Monocular SLAM
 Computer Vision Group Technical University of Munich Jakob Engel LSD-SLAM: Large-Scale Direct Monocular SLAM Jakob Engel, Thomas Schöps, Daniel Cremers Technical University Munich Monocular Video Engel,
Computer Vision Group Technical University of Munich Jakob Engel LSD-SLAM: Large-Scale Direct Monocular SLAM Jakob Engel, Thomas Schöps, Daniel Cremers Technical University Munich Monocular Video Engel,
arxiv: v2 [cs.cv] 21 Feb 2018
![arxiv: v2 [cs.cv] 21 Feb 2018](/thumbs/80/82171285.jpg "arxiv: v2 [cs.cv] 21 Feb 2018") UnDeepVO: Monocular Visual Odometry through Unsupervised Deep Learning Ruihao Li 1, Sen Wang 2, Zhiqiang Long 3 and Dongbing Gu 1 arxiv:1709.06841v2 [cs.cv] 21 Feb 2018 Abstract We propose a novel monocular
UnDeepVO: Monocular Visual Odometry through Unsupervised Deep Learning Ruihao Li 1, Sen Wang 2, Zhiqiang Long 3 and Dongbing Gu 1 arxiv:1709.06841v2 [cs.cv] 21 Feb 2018 Abstract We propose a novel monocular
Deep Models for 3D Reconstruction
 Deep Models for 3D Reconstruction Andreas Geiger Autonomous Vision Group, MPI for Intelligent Systems, Tübingen Computer Vision and Geometry Group, ETH Zürich October 12, 2017 Max Planck Institute for
Deep Models for 3D Reconstruction Andreas Geiger Autonomous Vision Group, MPI for Intelligent Systems, Tübingen Computer Vision and Geometry Group, ETH Zürich October 12, 2017 Max Planck Institute for
Lecture 10 Dense 3D Reconstruction
 Institute of Informatics Institute of Neuroinformatics Lecture 10 Dense 3D Reconstruction Davide Scaramuzza 1 REMODE: Probabilistic, Monocular Dense Reconstruction in Real Time M. Pizzoli, C. Forster,
Institute of Informatics Institute of Neuroinformatics Lecture 10 Dense 3D Reconstruction Davide Scaramuzza 1 REMODE: Probabilistic, Monocular Dense Reconstruction in Real Time M. Pizzoli, C. Forster,
arxiv: v1 [cs.cv] 17 Oct 2016
![arxiv: v1 [cs.cv] 17 Oct 2016](/thumbs/83/87289105.jpg "arxiv: v1 [cs.cv] 17 Oct 2016") Parse Geometry from a Line: Monocular Depth Estimation with Partial Laser Observation Yiyi Liao 1, Lichao Huang 2, Yue Wang 1, Sarath Kodagoda 3, Yinan Yu 2, Yong Liu 1 arxiv:1611.02174v1 [cs.cv] 17 Oct
Parse Geometry from a Line: Monocular Depth Estimation with Partial Laser Observation Yiyi Liao 1, Lichao Huang 2, Yue Wang 1, Sarath Kodagoda 3, Yinan Yu 2, Yong Liu 1 arxiv:1611.02174v1 [cs.cv] 17 Oct
Semantic Segmentation
 Semantic Segmentation UCLA:https://goo.gl/images/I0VTi2 OUTLINE Semantic Segmentation Why? Paper to talk about: Fully Convolutional Networks for Semantic Segmentation. J. Long, E. Shelhamer, and T. Darrell,
Semantic Segmentation UCLA:https://goo.gl/images/I0VTi2 OUTLINE Semantic Segmentation Why? Paper to talk about: Fully Convolutional Networks for Semantic Segmentation. J. Long, E. Shelhamer, and T. Darrell,
Towards a visual perception system for LNG pipe inspection
 Towards a visual perception system for LNG pipe inspection LPV Project Team: Brett Browning (PI), Peter Rander (co PI), Peter Hansen Hatem Alismail, Mohamed Mustafa, Joey Gannon Qri8 Lab A Brief Overview
Towards a visual perception system for LNG pipe inspection LPV Project Team: Brett Browning (PI), Peter Rander (co PI), Peter Hansen Hatem Alismail, Mohamed Mustafa, Joey Gannon Qri8 Lab A Brief Overview
視覚情報処理論. (Visual Information Processing ) 開講所属 : 学際情報学府水 (Wed)5 [16:50-18:35]
![視覚情報処理論. (Visual Information Processing ) 開講所属 : 学際情報学府水 (Wed)5 [16:50-18:35]](/thumbs/95/123948781.jpg "視覚情報処理論. (Visual Information Processing ) 開講所属 : 学際情報学府水 (Wed)5 [16:50-18:35]") 視覚情報処理論 (Visual Information Processing ) 開講所属 : 学際情報学府水 (Wed)5 [16:50-18:35] Computer Vision Design algorithms to implement the function of human vision 3D reconstruction from 2D image (retinal image)
視覚情報処理論 (Visual Information Processing ) 開講所属 : 学際情報学府水 (Wed)5 [16:50-18:35] Computer Vision Design algorithms to implement the function of human vision 3D reconstruction from 2D image (retinal image)
arxiv: v2 [cs.cv] 14 May 2018
![arxiv: v2 [cs.cv] 14 May 2018](/thumbs/79/79495201.jpg "arxiv: v2 [cs.cv] 14 May 2018") ContextVP: Fully Context-Aware Video Prediction Wonmin Byeon 1234, Qin Wang 1, Rupesh Kumar Srivastava 3, and Petros Koumoutsakos 1 arxiv:1710.08518v2 [cs.cv] 14 May 2018 Abstract Video prediction models
ContextVP: Fully Context-Aware Video Prediction Wonmin Byeon 1234, Qin Wang 1, Rupesh Kumar Srivastava 3, and Petros Koumoutsakos 1 arxiv:1710.08518v2 [cs.cv] 14 May 2018 Abstract Video prediction models
Lecture 10 Multi-view Stereo (3D Dense Reconstruction) Davide Scaramuzza
 Davide Scaramuzza") Lecture 10 Multi-view Stereo (3D Dense Reconstruction) Davide Scaramuzza REMODE: Probabilistic, Monocular Dense Reconstruction in Real Time, ICRA 14, by Pizzoli, Forster, Scaramuzza [M. Pizzoli, C. Forster,
Lecture 10 Multi-view Stereo (3D Dense Reconstruction) Davide Scaramuzza REMODE: Probabilistic, Monocular Dense Reconstruction in Real Time, ICRA 14, by Pizzoli, Forster, Scaramuzza [M. Pizzoli, C. Forster,
Learning 6D Object Pose Estimation and Tracking
 Learning 6D Object Pose Estimation and Tracking Carsten Rother presented by: Alexander Krull 21/12/2015 6D Pose Estimation Input: RGBD-image Known 3D model Output: 6D rigid body transform of object 21/12/2015
Learning 6D Object Pose Estimation and Tracking Carsten Rother presented by: Alexander Krull 21/12/2015 6D Pose Estimation Input: RGBD-image Known 3D model Output: 6D rigid body transform of object 21/12/2015
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
Multi-View 3D Object Detection Network for Autonomous Driving
 Multi-View 3D Object Detection Network for Autonomous Driving Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, Tian Xia CVPR 2017 (Spotlight) Presented By: Jason Ku Overview Motivation Dataset Network Architecture
Multi-View 3D Object Detection Network for Autonomous Driving Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, Tian Xia CVPR 2017 (Spotlight) Presented By: Jason Ku Overview Motivation Dataset Network Architecture
RGBD Occlusion Detection via Deep Convolutional Neural Networks
 1 RGBD Occlusion Detection via Deep Convolutional Neural Networks Soumik Sarkar 1,2, Vivek Venugopalan 1, Kishore Reddy 1, Michael Giering 1, Julian Ryde 3, Navdeep Jaitly 4,5 1 United Technologies Research
1 RGBD Occlusion Detection via Deep Convolutional Neural Networks Soumik Sarkar 1,2, Vivek Venugopalan 1, Kishore Reddy 1, Michael Giering 1, Julian Ryde 3, Navdeep Jaitly 4,5 1 United Technologies Research
15 Years of Visual SLAM
 15 Years of Visual SLAM Andrew Davison Robot Vision Group and Dyson Robotics Laboratory Department of Computing Imperial College London www.google.com/+andrewdavison December 18, 2015 What Has Defined
15 Years of Visual SLAM Andrew Davison Robot Vision Group and Dyson Robotics Laboratory Department of Computing Imperial College London www.google.com/+andrewdavison December 18, 2015 What Has Defined
Deeper Depth Prediction with Fully Convolutional Residual Networks
 Deeper Depth Prediction with Fully Convolutional Residual Networks Iro Laina 1 iro.laina@tum.de Christian Rupprecht 1,2 Vasileios Belagiannis 3 christian.rupprecht@in.tum.de vb@robots.ox.ac.uk Federico
Deeper Depth Prediction with Fully Convolutional Residual Networks Iro Laina 1 iro.laina@tum.de Christian Rupprecht 1,2 Vasileios Belagiannis 3 christian.rupprecht@in.tum.de vb@robots.ox.ac.uk Federico
DeMoN: Depth and Motion Network for Learning Monocular Stereo Supplementary Material
 Learning rate : Depth and Motion Network for Learning Monocular Stereo Supplementary Material A. Network Architecture Details Our network is a chain of encoder-decoder networks. Figures 15 and 16 explain
Learning rate : Depth and Motion Network for Learning Monocular Stereo Supplementary Material A. Network Architecture Details Our network is a chain of encoder-decoder networks. Figures 15 and 16 explain
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network. Nathan Sun CIS601
 with Facial KeyPoints using Spatial Fusion Convolutional Network. Nathan Sun CIS601") Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601 Introduction Face ID is complicated by alterations to an individual s appearance Beard,
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601 Introduction Face ID is complicated by alterations to an individual s appearance Beard,
Mask-SLAM: Robust feature-based monocular SLAM by masking using semantic segmentation
 Mask-SLAM: Robust feature-based monocular SLAM by masking using semantic segmentation Masaya Kaneko Kazuya Iwami Toru Ogawa Toshihiko Yamasaki Kiyoharu Aizawa The University of Tokyo {kaneko, iwami, t
Mask-SLAM: Robust feature-based monocular SLAM by masking using semantic segmentation Masaya Kaneko Kazuya Iwami Toru Ogawa Toshihiko Yamasaki Kiyoharu Aizawa The University of Tokyo {kaneko, iwami, t
Efficient Online Surface Correction for Real-time Large-Scale 3D Reconstruction
 MAIER ET AL.: EFFICIENT LARGE-SCALE ONLINE SURFACE CORRECTION 1 Efficient Online Surface Correction for Real-time Large-Scale 3D Reconstruction Robert Maier maierr@in.tum.de Raphael Schaller schaller@in.tum.de
MAIER ET AL.: EFFICIENT LARGE-SCALE ONLINE SURFACE CORRECTION 1 Efficient Online Surface Correction for Real-time Large-Scale 3D Reconstruction Robert Maier maierr@in.tum.de Raphael Schaller schaller@in.tum.de
Recovering 6D Object Pose and Predicting Next-Best-View in the Crowd Supplementary Material
 Recovering 6D Object Pose and Predicting Next-Best-View in the Crowd Supplementary Material Andreas Doumanoglou 1,2, Rigas Kouskouridas 1, Sotiris Malassiotis 2, Tae-Kyun Kim 1 1 Imperial College London
Recovering 6D Object Pose and Predicting Next-Best-View in the Crowd Supplementary Material Andreas Doumanoglou 1,2, Rigas Kouskouridas 1, Sotiris Malassiotis 2, Tae-Kyun Kim 1 1 Imperial College London
Learning Semantic Environment Perception for Cognitive Robots
 Learning Semantic Environment Perception for Cognitive Robots Sven Behnke University of Bonn, Germany Computer Science Institute VI Autonomous Intelligent Systems Some of Our Cognitive Robots Equipped
Learning Semantic Environment Perception for Cognitive Robots Sven Behnke University of Bonn, Germany Computer Science Institute VI Autonomous Intelligent Systems Some of Our Cognitive Robots Equipped
Deep Learning for Virtual Shopping. Dr. Jürgen Sturm Group Leader RGB-D
 Deep Learning for Virtual Shopping Dr. Jürgen Sturm Group Leader RGB-D metaio GmbH Augmented Reality with the Metaio SDK: IKEA Catalogue App Metaio: Augmented Reality Metaio SDK for ios, Android and Windows
Deep Learning for Virtual Shopping Dr. Jürgen Sturm Group Leader RGB-D metaio GmbH Augmented Reality with the Metaio SDK: IKEA Catalogue App Metaio: Augmented Reality Metaio SDK for ios, Android and Windows
Multi-Output Learning for Camera Relocalization
 Multi-Output Learning for Camera Relocalization Abner Guzman-Rivera Pushmeet Kohli Ben Glocker Jamie Shotton Toby Sharp Andrew Fitzgibbon Shahram Izadi Microsoft Research University of Illinois Imperial
Multi-Output Learning for Camera Relocalization Abner Guzman-Rivera Pushmeet Kohli Ben Glocker Jamie Shotton Toby Sharp Andrew Fitzgibbon Shahram Izadi Microsoft Research University of Illinois Imperial
3D Fusion of Infrared Images with Dense RGB Reconstruction from Multiple Views - with Application to Fire-fighting Robots
 3D Fusion of Infrared Images with Dense RGB Reconstruction from Multiple Views - with Application to Fire-fighting Robots Yuncong Chen 1 and Will Warren 2 1 Department of Computer Science and Engineering,
3D Fusion of Infrared Images with Dense RGB Reconstruction from Multiple Views - with Application to Fire-fighting Robots Yuncong Chen 1 and Will Warren 2 1 Department of Computer Science and Engineering,
Training models for road scene understanding with automated ground truth Dan Levi
 Training models for road scene understanding with automated ground truth Dan Levi With: Noa Garnett, Ethan Fetaya, Shai Silberstein, Rafi Cohen, Shaul Oron, Uri Verner, Ariel Ayash, Kobi Horn, Vlad Golder,
Training models for road scene understanding with automated ground truth Dan Levi With: Noa Garnett, Ethan Fetaya, Shai Silberstein, Rafi Cohen, Shaul Oron, Uri Verner, Ariel Ayash, Kobi Horn, Vlad Golder,
Depth from Stereo. Dominic Cheng February 7, 2018
 Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Multi-scale Voxel Hashing and Efficient 3D Representation for Mobile Augmented Reality
 Multi-scale Voxel Hashing and Efficient 3D Representation for Mobile Augmented Reality Yi Xu Yuzhang Wu Hui Zhou JD.COM Silicon Valley Research Center, JD.COM American Technologies Corporation Mountain
Multi-scale Voxel Hashing and Efficient 3D Representation for Mobile Augmented Reality Yi Xu Yuzhang Wu Hui Zhou JD.COM Silicon Valley Research Center, JD.COM American Technologies Corporation Mountain
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Visual SLAM. An Overview. L. Freda. ALCOR Lab DIAG University of Rome La Sapienza. May 3, 2016
 An Overview L. Freda ALCOR Lab DIAG University of Rome La Sapienza May 3, 2016 L. Freda (University of Rome La Sapienza ) Visual SLAM May 3, 2016 1 / 39 Outline 1 Introduction What is SLAM Motivations
An Overview L. Freda ALCOR Lab DIAG University of Rome La Sapienza May 3, 2016 L. Freda (University of Rome La Sapienza ) Visual SLAM May 3, 2016 1 / 39 Outline 1 Introduction What is SLAM Motivations
Omnidirectional DSO: Direct Sparse Odometry with Fisheye Cameras
 Omnidirectional DSO: Direct Sparse Odometry with Fisheye Cameras Hidenobu Matsuki 1,2, Lukas von Stumberg 2,3, Vladyslav Usenko 2, Jörg Stückler 2 and Daniel Cremers 2 Abstract We propose a novel real-time
Omnidirectional DSO: Direct Sparse Odometry with Fisheye Cameras Hidenobu Matsuki 1,2, Lukas von Stumberg 2,3, Vladyslav Usenko 2, Jörg Stückler 2 and Daniel Cremers 2 Abstract We propose a novel real-time
3D Line Segments Extraction from Semi-dense SLAM
 3D Line Segments Extraction from Semi-dense SLAM Shida He Xuebin Qin Zichen Zhang Martin Jagersand University of Alberta Abstract Despite the development of Simultaneous Localization and Mapping (SLAM),
3D Line Segments Extraction from Semi-dense SLAM Shida He Xuebin Qin Zichen Zhang Martin Jagersand University of Alberta Abstract Despite the development of Simultaneous Localization and Mapping (SLAM),
Detection and Fine 3D Pose Estimation of Texture-less Objects in RGB-D Images
 Detection and Pose Estimation of Texture-less Objects in RGB-D Images Tomáš Hodaň1, Xenophon Zabulis2, Manolis Lourakis2, Šťěpán Obdržálek1, Jiří Matas1 1 Center for Machine Perception, CTU in Prague,
Detection and Pose Estimation of Texture-less Objects in RGB-D Images Tomáš Hodaň1, Xenophon Zabulis2, Manolis Lourakis2, Šťěpán Obdržálek1, Jiří Matas1 1 Center for Machine Perception, CTU in Prague,
LSTM and its variants for visual recognition. Xiaodan Liang Sun Yat-sen University
 LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
Incremental 3D Line Segment Extraction from Semi-dense SLAM
 Incremental 3D Line Segment Extraction from Semi-dense SLAM Shida He Xuebin Qin Zichen Zhang Martin Jagersand University of Alberta arxiv:1708.03275v3 [cs.cv] 26 Apr 2018 Abstract Although semi-dense Simultaneous
Incremental 3D Line Segment Extraction from Semi-dense SLAM Shida He Xuebin Qin Zichen Zhang Martin Jagersand University of Alberta arxiv:1708.03275v3 [cs.cv] 26 Apr 2018 Abstract Although semi-dense Simultaneous
Computer Vision Lecture 16
 Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Uncertainty-Driven 6D Pose Estimation of Objects and Scenes from a Single RGB Image - Supplementary Material -
 Uncertainty-Driven 6D Pose Estimation of s and Scenes from a Single RGB Image - Supplementary Material - Eric Brachmann*, Frank Michel, Alexander Krull, Michael Ying Yang, Stefan Gumhold, Carsten Rother
Uncertainty-Driven 6D Pose Estimation of s and Scenes from a Single RGB Image - Supplementary Material - Eric Brachmann*, Frank Michel, Alexander Krull, Michael Ying Yang, Stefan Gumhold, Carsten Rother
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
CS231N Section. Video Understanding 6/1/2018
 CS231N Section Video Understanding 6/1/2018 Outline Background / Motivation / History Video Datasets Models Pre-deep learning CNN + RNN 3D convolution Two-stream What we ve seen in class so far... Image
CS231N Section Video Understanding 6/1/2018 Outline Background / Motivation / History Video Datasets Models Pre-deep learning CNN + RNN 3D convolution Two-stream What we ve seen in class so far... Image
Depth Estimation from a Single Image Using a Deep Neural Network Milestone Report
 Figure 1: The architecture of the convolutional network. Input: a single view image; Output: a depth map. 3 Related Work In [4] they used depth maps of indoor scenes produced by a Microsoft Kinect to successfully
Figure 1: The architecture of the convolutional network. Input: a single view image; Output: a depth map. 3 Related Work In [4] they used depth maps of indoor scenes produced by a Microsoft Kinect to successfully
ECE 6554:Advanced Computer Vision Pose Estimation
 ECE 6554:Advanced Computer Vision Pose Estimation Sujay Yadawadkar, Virginia Tech, Agenda: Pose Estimation: Part Based Models for Pose Estimation Pose Estimation with Convolutional Neural Networks (Deep
ECE 6554:Advanced Computer Vision Pose Estimation Sujay Yadawadkar, Virginia Tech, Agenda: Pose Estimation: Part Based Models for Pose Estimation Pose Estimation with Convolutional Neural Networks (Deep
Learning-based Localization
 Learning-based Localization Eric Brachmann ECCV 2018 Tutorial on Visual Localization - Feature-based vs. Learned Approaches Torsten Sattler, Eric Brachmann Roadmap Machine Learning Basics [10min] Convolutional
Learning-based Localization Eric Brachmann ECCV 2018 Tutorial on Visual Localization - Feature-based vs. Learned Approaches Torsten Sattler, Eric Brachmann Roadmap Machine Learning Basics [10min] Convolutional
arxiv: v1 [cs.cv] 3 Apr 2018
![arxiv: v1 [cs.cv] 3 Apr 2018](/thumbs/84/89084601.jpg "arxiv: v1 [cs.cv] 3 Apr 2018") CodeSLAM Learning a Compact, Optimisable Representation for Dense Visual SLAM Michael Bloesch, Jan Czarnowski, Ronald Clark, Stefan Leutenegger, Andrew J. Davison Dyson Robotics Laboratory at Imperial
CodeSLAM Learning a Compact, Optimisable Representation for Dense Visual SLAM Michael Bloesch, Jan Czarnowski, Ronald Clark, Stefan Leutenegger, Andrew J. Davison Dyson Robotics Laboratory at Imperial
Live Metric 3D Reconstruction on Mobile Phones ICCV 2013
 Live Metric 3D Reconstruction on Mobile Phones ICCV 2013 Main Contents 1. Target & Related Work 2. Main Features of This System 3. System Overview & Workflow 4. Detail of This System 5. Experiments 6.
Live Metric 3D Reconstruction on Mobile Phones ICCV 2013 Main Contents 1. Target & Related Work 2. Main Features of This System 3. System Overview & Workflow 4. Detail of This System 5. Experiments 6.
Computer Vision 2 Lecture 1
 Computer Vision 2 Lecture 1 Introduction (14.04.2016) leibe@vision.rwth-aachen.de, stueckler@vision.rwth-aachen.de RWTH Aachen University, Computer Vision Group http://www.vision.rwth-aachen.de Organization
Computer Vision 2 Lecture 1 Introduction (14.04.2016) leibe@vision.rwth-aachen.de, stueckler@vision.rwth-aachen.de RWTH Aachen University, Computer Vision Group http://www.vision.rwth-aachen.de Organization
The Kinect Sensor. Luís Carriço FCUL 2014/15
 Advanced Interaction Techniques The Kinect Sensor Luís Carriço FCUL 2014/15 Sources: MS Kinect for Xbox 360 John C. Tang. Using Kinect to explore NUI, Ms Research, From Stanford CS247 Shotton et al. Real-Time
Advanced Interaction Techniques The Kinect Sensor Luís Carriço FCUL 2014/15 Sources: MS Kinect for Xbox 360 John C. Tang. Using Kinect to explore NUI, Ms Research, From Stanford CS247 Shotton et al. Real-Time
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS. Zhao Chen Machine Learning Intern, NVIDIA
 JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
Colored Point Cloud Registration Revisited Supplementary Material
 Colored Point Cloud Registration Revisited Supplementary Material Jaesik Park Qian-Yi Zhou Vladlen Koltun Intel Labs A. RGB-D Image Alignment Section introduced a joint photometric and geometric objective
Colored Point Cloud Registration Revisited Supplementary Material Jaesik Park Qian-Yi Zhou Vladlen Koltun Intel Labs A. RGB-D Image Alignment Section introduced a joint photometric and geometric objective
Encoder-Decoder Networks for Semantic Segmentation. Sachin Mehta
 Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Human Pose Estimation with Deep Learning. Wei Yang
 Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
Real-Time Depth Estimation from 2D Images
 Real-Time Depth Estimation from 2D Images Jack Zhu Ralph Ma jackzhu@stanford.edu ralphma@stanford.edu. Abstract ages. We explore the differences in training on an untrained network, and on a network pre-trained
Real-Time Depth Estimation from 2D Images Jack Zhu Ralph Ma jackzhu@stanford.edu ralphma@stanford.edu. Abstract ages. We explore the differences in training on an untrained network, and on a network pre-trained
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Deep Learning for Computer Vision II
 IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
arxiv: v2 [cs.cv] 28 Sep 2016
![arxiv: v2 [cs.cv] 28 Sep 2016](/thumbs/72/67749716.jpg "arxiv: v2 [cs.cv] 28 Sep 2016") SemanticFusion: Dense 3D Semantic Mapping with Convolutional Neural Networks John McCormac, Ankur Handa, Andrew Davison, and Stefan Leutenegger Dyson Robotics Lab, Imperial College London arxiv:1609.05130v2
SemanticFusion: Dense 3D Semantic Mapping with Convolutional Neural Networks John McCormac, Ankur Handa, Andrew Davison, and Stefan Leutenegger Dyson Robotics Lab, Imperial College London arxiv:1609.05130v2
arxiv: v1 [cs.cv] 22 Jan 2019
![arxiv: v1 [cs.cv] 22 Jan 2019](/thumbs/88/116253383.jpg "arxiv: v1 [cs.cv] 22 Jan 2019") Unsupervised Learning-based Depth Estimation aided Visual SLAM Approach Mingyang Geng 1, Suning Shang 1, Bo Ding 1, Huaimin Wang 1, Pengfei Zhang 1, and Lei Zhang 2 National Key Laboratory of Parallel
Unsupervised Learning-based Depth Estimation aided Visual SLAM Approach Mingyang Geng 1, Suning Shang 1, Bo Ding 1, Huaimin Wang 1, Pengfei Zhang 1, and Lei Zhang 2 National Key Laboratory of Parallel
Computer Vision: Making machines see
 Computer Vision: Making machines see Roberto Cipolla Department of Engineering http://www.eng.cam.ac.uk/~cipolla/people.html http://www.toshiba.eu/eu/cambridge-research- Laboratory/ Vision: what is where
Computer Vision: Making machines see Roberto Cipolla Department of Engineering http://www.eng.cam.ac.uk/~cipolla/people.html http://www.toshiba.eu/eu/cambridge-research- Laboratory/ Vision: what is where
COMP 551 Applied Machine Learning Lecture 16: Deep Learning
 COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
Learning to generate 3D shapes
 Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
Fitting (LMedS, RANSAC)
") Fitting (LMedS, RANSAC) Thursday, 23/03/2017 Antonis Argyros e-mail: argyros@csd.uoc.gr LMedS and RANSAC What if we have very many outliers? 2 1 Least Median of Squares ri : Residuals Least Squares n 2
Fitting (LMedS, RANSAC) Thursday, 23/03/2017 Antonis Argyros e-mail: argyros@csd.uoc.gr LMedS and RANSAC What if we have very many outliers? 2 1 Least Median of Squares ri : Residuals Least Squares n 2
CS 4495 Computer Vision A. Bobick. Motion and Optic Flow. Stereo Matching
 Stereo Matching Fundamental matrix Let p be a point in left image, p in right image l l Epipolar relation p maps to epipolar line l p maps to epipolar line l p p Epipolar mapping described by a 3x3 matrix
Stereo Matching Fundamental matrix Let p be a point in left image, p in right image l l Epipolar relation p maps to epipolar line l p maps to epipolar line l p p Epipolar mapping described by a 3x3 matrix
3D Computer Vision. Structured Light II. Prof. Didier Stricker. Kaiserlautern University.
 3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
(Deep) Learning for Robot Perception and Navigation. Wolfram Burgard
 Learning for Robot Perception and Navigation. Wolfram Burgard") (Deep) Learning for Robot Perception and Navigation Wolfram Burgard Deep Learning for Robot Perception (and Navigation) Lifeng Bo, Claas Bollen, Thomas Brox, Andreas Eitel, Dieter Fox, Gabriel L. Oliveira,
(Deep) Learning for Robot Perception and Navigation Wolfram Burgard Deep Learning for Robot Perception (and Navigation) Lifeng Bo, Claas Bollen, Thomas Brox, Andreas Eitel, Dieter Fox, Gabriel L. Oliveira,
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
DepthNet: A Recurrent Neural Network Architecture for Monocular Depth Prediction
 DepthNet: A Recurrent Neural Network Architecture for Monocular Depth Prediction Arun CS Kumar Suchendra M. Bhandarkar The University of Georgia aruncs@uga.edu suchi@cs.uga.edu Mukta Prasad Trinity College
DepthNet: A Recurrent Neural Network Architecture for Monocular Depth Prediction Arun CS Kumar Suchendra M. Bhandarkar The University of Georgia aruncs@uga.edu suchi@cs.uga.edu Mukta Prasad Trinity College
Scanning and Printing Objects in 3D Jürgen Sturm
 Scanning and Printing Objects in 3D Jürgen Sturm Metaio (formerly Technical University of Munich) My Research Areas Visual navigation for mobile robots RoboCup Kinematic Learning Articulated Objects Quadrocopters
Scanning and Printing Objects in 3D Jürgen Sturm Metaio (formerly Technical University of Munich) My Research Areas Visual navigation for mobile robots RoboCup Kinematic Learning Articulated Objects Quadrocopters
Simultaneous Localization and Mapping (SLAM)
") Simultaneous Localization and Mapping (SLAM) RSS Lecture 16 April 8, 2013 Prof. Teller Text: Siegwart and Nourbakhsh S. 5.8 SLAM Problem Statement Inputs: No external coordinate reference Time series of
Simultaneous Localization and Mapping (SLAM) RSS Lecture 16 April 8, 2013 Prof. Teller Text: Siegwart and Nourbakhsh S. 5.8 SLAM Problem Statement Inputs: No external coordinate reference Time series of
arxiv: v1 [cs.cv] 23 Apr 2017
![arxiv: v1 [cs.cv] 23 Apr 2017](/thumbs/75/72430434.jpg "arxiv: v1 [cs.cv] 23 Apr 2017") Proxy Templates for Inverse Compositional Photometric Bundle Adjustment Christopher Ham, Simon Lucey 2, and Surya Singh Robotics Design Lab 2 Robotics Institute The University of Queensland, Australia
Proxy Templates for Inverse Compositional Photometric Bundle Adjustment Christopher Ham, Simon Lucey 2, and Surya Singh Robotics Design Lab 2 Robotics Institute The University of Queensland, Australia
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs
 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
Structured Light II. Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov
 Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter