DATA MINING LECTURE 7. Hierarchical Clustering, DBSCAN The EM Algorithm
|
|
|
- Preston Holland
- 6 years ago
- Views:
Transcription
1 DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm
2 CLUSTERING
3 What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related) to one another and different from (or unrelated to) the objects in other groups Intra-cluster distances are minimized Inter-cluster distances are maximized
4 Clustering Algorithms K-means and its variants Hierarchical clustering DBSCAN
5 HIERARCHICAL CLUSTERING
6 Hierarchical Clustering Two main types of hierarchical clustering Agglomerative: Start with the points as individual clusters At each step, merge the closest pair of clusters until only one cluster (or k clusters) left Divisive: Start with one, all-inclusive cluster At each step, split a cluster until each cluster contains a point (or there are k clusters) Traditional hierarchical algorithms use a similarity or distance matrix Merge or split one cluster at a time
7 Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits
8 Strengths of Hierarchical Clustering Do not have to assume any particular number of clusters Any desired number of clusters can be obtained by cutting the dendogram at the proper level They may correspond to meaningful taxonomies Example in biological sciences (e.g., animal kingdom, phylogeny reconstruction, )
9 Agglomerative Clustering Algorithm More popular hierarchical clustering technique Basic algorithm is straightforward 1. Compute the proximity matrix 2. Let each data point be a cluster 3. Repeat 4. Merge the two closest clusters 5. Update the proximity matrix 6. Until only a single cluster remains Key operation is the computation of the proximity of two clusters Different approaches to defining the distance between clusters distinguish the different algorithms
10 Starting Situation Start with clusters of individual points and a proximity matrix p1 p2 p3 p4 p5.. p1 p2 p3 p4 p5.... Proximity Matrix... p1 p2 p3 p4 p9 p10 p11 p12
11 Intermediate Situation After some merging steps, we have some clusters C1 C2 C3 C4 C5 C1 C3 C4 C2 C3 C4 C1 C5 Proximity Matrix C2 C5... p1 p2 p3 p4 p9 p10 p11 p12
12 Intermediate Situation We want to merge the two closest clusters (C2 and C5) and update the proximity matrix. C3 C4 C1 C1 C2 C3 C4 C5 C1 C2 C3 C4 C5 Proximity Matrix C2 C5... p1 p2 p3 p4 p9 p10 p11 p12
13 After Merging The question is How do we update the proximity matrix? C1 C3 C4 C1 C2 U C5 C3 C4 C1 C2 U C5??????? C3 Proximity Matrix C4 C2 U C5... p1 p2 p3 p4 p9 p10 p11 p12
14 How to Define Inter-Cluster Similarity Similarity? p1 p2 p3 p1 p2 p3 p4 p5... MIN MAX Group Average Distance Between Centroids Other methods driven by an objective function Ward s Method uses squared error p4 p5... Proximity Matrix
15 How to Define Inter-Cluster Similarity p1 p1 p2 p3 p4 p5... p2 p3 MIN MAX Group Average Distance Between Centroids Other methods driven by an objective function Ward s Method uses squared error p4 p5... Proximity Matrix
16 How to Define Inter-Cluster Similarity p1 p1 p2 p3 p4 p5... p2 p3 MIN MAX Group Average Distance Between Centroids Other methods driven by an objective function Ward s Method uses squared error p4 p5... Proximity Matrix
17 How to Define Inter-Cluster Similarity p1 p1 p2 p3 p4 p5... p2 p3 MIN MAX Group Average Distance Between Centroids Other methods driven by an objective function Ward s Method uses squared error p4 p5... Proximity Matrix
18 How to Define Inter-Cluster Similarity p1 p2 p3 p1 p2 p3 p4 p5... MIN MAX Group Average Distance Between Centroids Other methods driven by an objective function Ward s Method uses squared error p4 p5... Proximity Matrix
19 Single Link Complete Link Another way to view the processing of the hierarchical algorithm is that we create links between their elements in order of increasing distance The MIN Single Link, will merge two clusters when a single pair of elements is linked The MAX Complete Linkage will merge two clusters when all pairs of elements have been linked.
20 Hierarchical Clustering: MIN Nested Clusters Dendrogram
21 Strength of MIN Original Points Two Clusters Can handle non-elliptical shapes
22 Limitations of MIN Original Points Two Clusters Sensitive to noise and outliers
23 Hierarchical Clustering: MAX Nested Clusters Dendrogram
24 Strength of MAX Original Points Two Clusters Less susceptible to noise and outliers
25 Limitations of MAX Original Points Two Clusters Tends to break large clusters Biased towards globular clusters
26 Cluster Similarity: Group Average Proximity of two clusters is the average of pairwise proximity between points in the two clusters. pi Cluster i p Cluster proximity(p,p j j proximity(cluster i, Cluster j) Cluster Cluster Need to use average connectivity for scalability since total proximity favors large clusters i i j j )
27 Hierarchical Clustering: Group Average Nested Clusters Dendrogram
28 Hierarchical Clustering: Group Average Compromise between Single and Complete Link Strengths Less susceptible to noise and outliers Limitations Biased towards globular clusters
29 Cluster Similarity: Ward s Method Similarity of two clusters is based on the increase in squared error (SSE) when two clusters are merged Similar to group average if distance between points is distance squared Less susceptible to noise and outliers Biased towards globular clusters Hierarchical analogue of K-means Can be used to initialize K-means
30 Hierarchical Clustering: Comparison Group Average Ward s Method MIN MAX
31 Hierarchical Clustering: Time and Space requirements O(N 2 ) space since it uses the proximity matrix. N is the number of points. O(N 3 ) time in many cases There are N steps and at each step the size, N 2, proximity matrix must be updated and searched Complexity can be reduced to O(N 2 log(n) ) time for some approaches
32 Hierarchical Clustering: Problems and Limitations Computational complexity in time and space Once a decision is made to combine two clusters, it cannot be undone No objective function is directly minimized Different schemes have problems with one or more of the following: Sensitivity to noise and outliers Difficulty handling different sized clusters and convex shapes Breaking large clusters
33 DBSCAN
34 DBSCAN: Density-Based Clustering DBSCAN is a Density-Based Clustering algorithm Reminder: In density based clustering we partition points into dense regions separated by not-so-dense regions. Important Questions: How do we measure density? What is a dense region? DBSCAN: Density at point p: number of points within a circle of radius Eps Dense Region: A circle of radius Eps that contains at least MinPts points
35 DBSCAN Characterization of points A point is a core point if it has more than a specified number of points (MinPts) within Eps These points belong in a dense region and are at the interior of a cluster A border point has fewer than MinPts within Eps, but is in the neighborhood of a core point. A noise point is any point that is not a core point or a border point.
36 DBSCAN: Core, Border, and Noise Points

37 DBSCAN: Core, Border and Noise Points Original Points Point types: core, border and noise Eps = 10, MinPts = 4
38 Density-Connected points Density edge We place an edge between two core points q and p if they are within distance Eps. q p 1 p Density-connected A point p is density-connected to a point q if there is a path of edges from p to q p q o
39 DBSCAN Algorithm Label points as core, border and noise Eliminate noise points For every core point p that has not been assigned to a cluster Create a new cluster with the point p and all the points that are density-connected to p. Assign border points to the cluster of the closest core point.
40 DBSCAN: Determining Eps and MinPts Idea is that for points in a cluster, their k th nearest neighbors are at roughly the same distance Noise points have the k th nearest neighbor at farther distance So, plot sorted distance of every point to its k th nearest neighbor Find the distance d where there is a knee in the curve Eps = d, MinPts = k Eps ~ 7-10 MinPts = 4
41 When DBSCAN Works Well Original Points Clusters Resistant to Noise Can handle clusters of different shapes and sizes
. Varying densities High-dimensional data (MinPts=4, Eps=9.")
42 When DBSCAN Does NOT Work Well Original Points (MinPts=4, Eps=9.75). Varying densities High-dimensional data (MinPts=4, Eps=9.92)


43 DBSCAN: Sensitive to Parameters
44 Other algorithms PAM, CLARANS: Solutions for the k-medoids problem BIRCH: Constructs a hierarchical tree that acts a summary of the data, and then clusters the leaves. MST: Clustering using the Minimum Spanning Tree. ROCK: clustering categorical data by neighbor and link analysis LIMBO, COOLCAT: Clustering categorical data using information theoretic tools. CURE: Hierarchical algorithm uses different representation of the cluster CHAMELEON: Hierarchical algorithm uses closeness and interconnectivity for merging
45 MIXTURE MODELS AND THE EM ALGORITHM
46 Model-based clustering In order to understand our data, we will assume that there is a generative process (a model) that creates/describes the data, and we will try to find the model that best fits the data. Models of different complexity can be defined, but we will assume that our model is a distribution from which data points are sampled Example: the data is the height of all people in Greece In most cases, a single distribution is not good enough to describe all data points: different parts of the data follow a different distribution Example: the data is the height of all people in Greece and China We need a mixture model Different distributions correspond to different clusters in the data.
47 Gaussian Distribution Example: the data is the height of all people in Greece Experience has shown that this data follows a Gaussian (Normal) distribution Reminder: Normal distribution: P x = 1 2πσ e μ = mean, σ = standard deviation x μ 2 2σ 2
48 Gaussian Model What is a model? A Gaussian distribution is fully defined by the mean μ and the standard deviation σ We define our model as the pair of parameters θ = (μ, σ) This is a general principle: a model is defined as a vector of parameters θ
49 Fitting the model We want to find the normal distribution that best fits our data Find the best values for μ and σ But what does best fit mean?
50 Maximum Likelihood Estimation (MLE) Suppose that we have a vector X = (x 1,, x n ) of values And we want to fit a Gaussian N(μ, σ) model to the data Probability of observing point x i : P x i = 1 2πσ e Probability of observing all points (assume independence) n P X = P x i i=1 = x i μ 2 2σ 2 1 2πσ e x i μ 2 2σ 2 We want to find the parameters θ = (μ, σ) that maximize the probability P(X θ) n i=1
51 Maximum Likelihood Estimation (MLE) The probability P(X θ) as a function of θ is called the Likelihood function L(θ) = 1 2πσ e It is usually easier to work with the Log-Likelihood function Maximum Likelihood Estimation x i μ 2 2σ 2 Find parameters μ, σ that maximize LL(θ) μ = 1 n n i=1 x i = μ X LL θ = n i=1 n i=1 Sample Mean x i μ 2 2σ 2 σ 2 = 1 n 1 n log 2π n log σ 2 n i=1 (x i μ) 2 = σ X 2 Sample Variance
52 MLE Note: these are also the most likely parameters given the data P θ X = P X θ P(θ) P(X) If we have no prior information about θ, or X, then maximizing P X θ is the same as maximizing P θ X
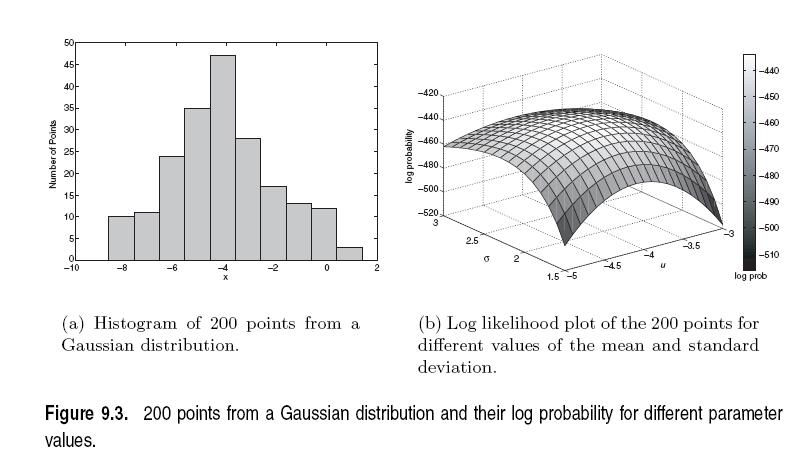
53
54 Mixture of Gaussians Suppose that you have the heights of people from Greece and China and the distribution looks like the figure below (dramatization)
55 Mixture of Gaussians In this case the data is the result of the mixture of two Gaussians One for Greek people, and one for Chinese people Identifying for each value which Gaussian is most likely to have generated it will give us a clustering.
56 Mixture model A value x i is generated according to the following process: First select the nationality With probability π G select Greek, with probability π C select China (π G + π C = 1) Given the nationality, generate the point from the corresponding Gaussian P x i θ G ~ N μ G, σ G if Greece P x i θ G ~ N μ G, σ G if China We can also thing of this as a Hidden Variable Z
57 Mixture Model Our model has the following parameters Θ = (π G, π C, μ G, μ C, σ G, σ C ) Mixture probabilities Distribution Parameters For value x i, we have: P x i Θ = π G P x i θ G + π C P(x i θ C ) For all values X = x 1,, x n P X Θ = P(x i Θ) i=1 We want to estimate the parameters that maximize the Likelihood of the data n
58 Mixture Models Once we have the parameters Θ = (π G, π C, μ G, μ C, σ G, σ C ) we can estimate the membership probabilities P G x i and P C x i for each point x i : This is the probability that point x i belongs to the Greek or the Chinese population (cluster) P G x i = = P x i G P(G) P x i G P G + P x i C P(C) P x i G π G P x i G π G + P x i C π C
59 EM (Expectation Maximization) Algorithm Initialize the values of the parameters in Θ to some random values Repeat until convergence E-Step: Given the parameters Θ estimate the membership probabilities P G x i and P C x i M-Step: Compute the parameter values that (in expectation) maximize the data likelihood π G = 1 n μ C = σ C 2 = n i=1 n i=1 n i=1 P(G x i ) P C x i n π C x i P C x i n π C x i μ C 2 π C = 1 n μ G = σ G 2 = n i=1 n i=1 n i=1 P(C x i ) P G x i n π G x i P G x i n π G x i μ G 2 Fraction of population in G,C MLE Estimates if π s were fixed
60 Relationship to K-means E-Step: Assignment of points to clusters K-means: hard assignment, EM: soft assignment M-Step: Computation of centroids K-means assumes common fixed variance (spherical clusters) EM: can change the variance for different clusters or different dimensions (elipsoid clusters) If the variance is fixed then both minimize the same error function
61
62
63
CSE 347/447: DATA MINING
 CSE 347/447: DATA MINING Lecture 6: Clustering II W. Teal Lehigh University CSE 347/447, Fall 2016 Hierarchical Clustering Definition Produces a set of nested clusters organized as a hierarchical tree
CSE 347/447: DATA MINING Lecture 6: Clustering II W. Teal Lehigh University CSE 347/447, Fall 2016 Hierarchical Clustering Definition Produces a set of nested clusters organized as a hierarchical tree
Hierarchical Clustering
 Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Lecture Notes for Chapter 7. Introduction to Data Mining, 2 nd Edition. by Tan, Steinbach, Karpatne, Kumar
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Hierarchical Clustering Produces a set
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Hierarchical Clustering Produces a set
Data Mining Concepts & Techniques
 Data Mining Concepts & Techniques Lecture No 08 Cluster Analysis Naeem Ahmed Email: naeemmahoto@gmailcom Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro Outline
Data Mining Concepts & Techniques Lecture No 08 Cluster Analysis Naeem Ahmed Email: naeemmahoto@gmailcom Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro Outline
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
Clustering Part 3. Hierarchical Clustering
 Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A
 MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CS7267 MACHINE LEARNING
 S7267 MAHINE LEARNING HIERARHIAL LUSTERING Ref: hengkai Li, Department of omputer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) Mingon Kang, Ph.D. omputer Science,
S7267 MAHINE LEARNING HIERARHIAL LUSTERING Ref: hengkai Li, Department of omputer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) Mingon Kang, Ph.D. omputer Science,
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Slides From Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Hierarchical Clustering
 Hierarchical Clustering Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree-like diagram that records the sequences of merges
Hierarchical Clustering Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree-like diagram that records the sequences of merges
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
DATA MINING - 1DL105, 1Dl111. An introductory class in data mining
 1 DATA MINING - 1DL105, 1Dl111 Fall 007 An introductory class in data mining http://user.it.uu.se/~udbl/dm-ht007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
1 DATA MINING - 1DL105, 1Dl111 Fall 007 An introductory class in data mining http://user.it.uu.se/~udbl/dm-ht007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
Clustering Lecture 3: Hierarchical Methods
 Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/09/2018)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/4 What
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/4 What
Hierarchical clustering
 Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
Knowledge Discovery in Databases
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture notes Knowledge Discovery in Databases Summer Semester 2012 Lecture 8: Clustering
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture notes Knowledge Discovery in Databases Summer Semester 2012 Lecture 8: Clustering
Cluster analysis. Agnieszka Nowak - Brzezinska
 Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Part I. Hierarchical clustering. Hierarchical Clustering. Hierarchical clustering. Produces a set of nested clusters organized as a
 Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/004 What
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/004 What
5/15/16. Computational Methods for Data Analysis. Massimo Poesio UNSUPERVISED LEARNING. Clustering. Unsupervised learning introduction
 Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar (modified by Predrag Radivojac, 07) Old Faithful Geyser Data
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar (modified by Predrag Radivojac, 07) Old Faithful Geyser Data
Clustering Part 4 DBSCAN
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
University of Florida CISE department Gator Engineering. Clustering Part 4
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Unsupervised Learning. Supervised learning vs. unsupervised learning. What is Cluster Analysis? Applications of Cluster Analysis
 7 Supervised learning vs unsupervised learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These patterns are then
7 Supervised learning vs unsupervised learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These patterns are then
ALTERNATIVE METHODS FOR CLUSTERING
 ALTERNATIVE METHODS FOR CLUSTERING K-Means Algorithm Termination conditions Several possibilities, e.g., A fixed number of iterations Objects partition unchanged Centroid positions don t change Convergence
ALTERNATIVE METHODS FOR CLUSTERING K-Means Algorithm Termination conditions Several possibilities, e.g., A fixed number of iterations Objects partition unchanged Centroid positions don t change Convergence
What is Cluster Analysis?
 Cluster Analysis What is Cluster Analysis? Finding groups of objects (data points) such that the objects in a group will be similar (or related) to one another and different from (or unrelated to) the
Cluster Analysis What is Cluster Analysis? Finding groups of objects (data points) such that the objects in a group will be similar (or related) to one another and different from (or unrelated to) the
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Clustering fundamentals
 Elena Baralis, Tania Cerquitelli Politecnico di Torino What is Cluster Analsis? Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from
Elena Baralis, Tania Cerquitelli Politecnico di Torino What is Cluster Analsis? Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/10/2017)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
University of Florida CISE department Gator Engineering. Clustering Part 2
 Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Cluster Analysis: Basic Concepts and Algorithms
 Cluster Analysis: Basic Concepts and Algorithms Data Warehousing and Mining Lecture 10 by Hossen Asiful Mustafa What is Cluster Analysis? Finding groups of objects such that the objects in a group will
Cluster Analysis: Basic Concepts and Algorithms Data Warehousing and Mining Lecture 10 by Hossen Asiful Mustafa What is Cluster Analysis? Finding groups of objects such that the objects in a group will
Clustering Lecture 4: Density-based Methods
 Clustering Lecture 4: Density-based Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering Lecture 4: Density-based Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Data Mining Cluster Analysis: Advanced Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining, 2 nd Edition
 Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Outline Prototype-based Fuzzy c-means
Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Outline Prototype-based Fuzzy c-means
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University
 Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining /8/ What is Cluster
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining /8/ What is Cluster
COMP20008 Elements of Data Processing. Outlier Detection and Clustering
 COMP20008 Elements of Data Processing Outlier Detection and Clustering Today Outlier detection for high dimensional data (part I) A digression clustering algorithms K-means Hierarchical clustering Outlier
COMP20008 Elements of Data Processing Outlier Detection and Clustering Today Outlier detection for high dimensional data (part I) A digression clustering algorithms K-means Hierarchical clustering Outlier
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
DS504/CS586: Big Data Analytics Big Data Clustering II
 Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: AK 232 Fall 2016 More Discussions, Limitations v Center based clustering K-means BFR algorithm
Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: AK 232 Fall 2016 More Discussions, Limitations v Center based clustering K-means BFR algorithm
Tan,Steinbach, Kumar Introduction to Data Mining 4/18/ Tan,Steinbach, Kumar Introduction to Data Mining 4/18/
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
DS504/CS586: Big Data Analytics Big Data Clustering II
 Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: KH 116 Fall 2017 Updates: v Progress Presentation: Week 15: 11/30 v Next Week Office hours
Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: KH 116 Fall 2017 Updates: v Progress Presentation: Week 15: 11/30 v Next Week Office hours
CS570: Introduction to Data Mining
 CS570: Introduction to Data Mining Scalable Clustering Methods: BIRCH and Others Reading: Chapter 10.3 Han, Chapter 9.5 Tan Cengiz Gunay, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei.
CS570: Introduction to Data Mining Scalable Clustering Methods: BIRCH and Others Reading: Chapter 10.3 Han, Chapter 9.5 Tan Cengiz Gunay, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei.
Clustering in R d. Clustering. Widely-used clustering methods. The k-means optimization problem CSE 250B
 Clustering in R d Clustering CSE 250B Two common uses of clustering: Vector quantization Find a finite set of representatives that provides good coverage of a complex, possibly infinite, high-dimensional
Clustering in R d Clustering CSE 250B Two common uses of clustering: Vector quantization Find a finite set of representatives that provides good coverage of a complex, possibly infinite, high-dimensional
Statistics 202: Data Mining. c Jonathan Taylor. Week 8 Based in part on slides from textbook, slides of Susan Holmes. December 2, / 1
 Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
CS Introduction to Data Mining Instructor: Abdullah Mueen
 CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
Data Mining. Clustering. Hamid Beigy. Sharif University of Technology. Fall 1394
 Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
Clustering part II 1
 Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Clustering Tips and Tricks in 45 minutes (maybe more :)
") Clustering Tips and Tricks in 45 minutes (maybe more :) Olfa Nasraoui, University of Louisville Tutorial for the Data Science for Social Good Fellowship 2015 cohort @DSSG2015@University of Chicago https://www.researchgate.net/profile/olfa_nasraoui
Clustering Tips and Tricks in 45 minutes (maybe more :) Olfa Nasraoui, University of Louisville Tutorial for the Data Science for Social Good Fellowship 2015 cohort @DSSG2015@University of Chicago https://www.researchgate.net/profile/olfa_nasraoui
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Introduction to Mobile Robotics
 Introduction to Mobile Robotics Clustering Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann Clustering (1) Common technique for statistical data analysis (machine learning,
Introduction to Mobile Robotics Clustering Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann Clustering (1) Common technique for statistical data analysis (machine learning,
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Chapter VIII.3: Hierarchical Clustering
 Chapter VIII.3: Hierarchical Clustering 1. Basic idea 1.1. Dendrograms 1.2. Agglomerative and divisive 2. Cluster distances 2.1. Single link 2.2. Complete link 2.3. Group average and Mean distance 2.4.
Chapter VIII.3: Hierarchical Clustering 1. Basic idea 1.1. Dendrograms 1.2. Agglomerative and divisive 2. Cluster distances 2.1. Single link 2.2. Complete link 2.3. Group average and Mean distance 2.4.
PAM algorithm. Types of Data in Cluster Analysis. A Categorization of Major Clustering Methods. Partitioning i Methods. Hierarchical Methods
 Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
HW4 VINH NGUYEN. Q1 (6 points). Chapter 8 Exercise 20
. Chapter 8 Exercise 20") HW4 VINH NGUYEN Q1 (6 points). Chapter 8 Exercise 20 a. For each figure, could you use single link to find the patterns represented by the nose, eyes and mouth? Explain? First, a single link is a MIN version
HW4 VINH NGUYEN Q1 (6 points). Chapter 8 Exercise 20 a. For each figure, could you use single link to find the patterns represented by the nose, eyes and mouth? Explain? First, a single link is a MIN version
Hard clustering. Each object is assigned to one and only one cluster. Hierarchical clustering is usually hard. Soft (fuzzy) clustering
 clustering") An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
Clustering in Data Mining
 Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Lesson 3. Prof. Enza Messina
 Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
SYDE Winter 2011 Introduction to Pattern Recognition. Clustering
 SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest)
") Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
数据挖掘 Introduction to Data Mining
 数据挖掘 Introduction to Data Mining Philippe Fournier-Viger Full professor School of Natural Sciences and Humanities philfv8@yahoo.com Spring 2019 S8700113C 1 Introduction Last week: Association Analysis
数据挖掘 Introduction to Data Mining Philippe Fournier-Viger Full professor School of Natural Sciences and Humanities philfv8@yahoo.com Spring 2019 S8700113C 1 Introduction Last week: Association Analysis
Clustering in Ratemaking: Applications in Territories Clustering
 Clustering in Ratemaking: Applications in Territories Clustering Ji Yao, PhD FIA ASTIN 13th-16th July 2008 INTRODUCTION Structure of talk Quickly introduce clustering and its application in insurance ratemaking
Clustering in Ratemaking: Applications in Territories Clustering Ji Yao, PhD FIA ASTIN 13th-16th July 2008 INTRODUCTION Structure of talk Quickly introduce clustering and its application in insurance ratemaking
University of Florida CISE department Gator Engineering. Clustering Part 5
 Clustering Part 5 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville SNN Approach to Clustering Ordinary distance measures have problems Euclidean
Clustering Part 5 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville SNN Approach to Clustering Ordinary distance measures have problems Euclidean
CHAMELEON: A Hierarchical Clustering Algorithm Using Dynamic Modeling
 To Appear in the IEEE Computer CHAMELEON: A Hierarchical Clustering Algorithm Using Dynamic Modeling George Karypis Eui-Hong (Sam) Han Vipin Kumar Department of Computer Science and Engineering University
To Appear in the IEEE Computer CHAMELEON: A Hierarchical Clustering Algorithm Using Dynamic Modeling George Karypis Eui-Hong (Sam) Han Vipin Kumar Department of Computer Science and Engineering University
Clustering Lecture 5: Mixture Model
 Clustering Lecture 5: Mixture Model Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced topics
Clustering Lecture 5: Mixture Model Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced topics
10701 Machine Learning. Clustering
 171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Online Social Networks and Media. Community detection
 Online Social Networks and Media Community detection 1 Notes on Homework 1 1. You should write your own code for generating the graphs. You may use SNAP graph primitives (e.g., add node/edge) 2. For the
Online Social Networks and Media Community detection 1 Notes on Homework 1 1. You should write your own code for generating the graphs. You may use SNAP graph primitives (e.g., add node/edge) 2. For the
Data Mining. Cluster Analysis: Basic Concepts and Algorithms
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Tan,Steinbach, Kumar Introduction to Data Mining /8/ What is Cluster Analsis? Finding groups of objects such that the objects in a group will
Data Mining Cluster Analsis: Basic Concepts and Algorithms Tan,Steinbach, Kumar Introduction to Data Mining /8/ What is Cluster Analsis? Finding groups of objects such that the objects in a group will
Cluster Analysis. Summer School on Geocomputation. 27 June July 2011 Vysoké Pole
 Cluster Analysis Summer School on Geocomputation 27 June 2011 2 July 2011 Vysoké Pole Lecture delivered by: doc. Mgr. Radoslav Harman, PhD. Faculty of Mathematics, Physics and Informatics Comenius University,
Cluster Analysis Summer School on Geocomputation 27 June 2011 2 July 2011 Vysoké Pole Lecture delivered by: doc. Mgr. Radoslav Harman, PhD. Faculty of Mathematics, Physics and Informatics Comenius University,
Understanding Clustering Supervising the unsupervised
 Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Data Mining Algorithms
 for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
STATS306B STATS306B. Clustering. Jonathan Taylor Department of Statistics Stanford University. June 3, 2010
 STATS306B Jonathan Taylor Department of Statistics Stanford University June 3, 2010 Spring 2010 Outline K-means, K-medoids, EM algorithm choosing number of clusters: Gap test hierarchical clustering spectral
STATS306B Jonathan Taylor Department of Statistics Stanford University June 3, 2010 Spring 2010 Outline K-means, K-medoids, EM algorithm choosing number of clusters: Gap test hierarchical clustering spectral
SGN (4 cr) Chapter 11
 Chapter 11") SGN-41006 (4 cr) Chapter 11 Clustering Jussi Tohka & Jari Niemi Department of Signal Processing Tampere University of Technology February 25, 2014 J. Tohka & J. Niemi (TUT-SGN) SGN-41006 (4 cr) Chapter
SGN-41006 (4 cr) Chapter 11 Clustering Jussi Tohka & Jari Niemi Department of Signal Processing Tampere University of Technology February 25, 2014 J. Tohka & J. Niemi (TUT-SGN) SGN-41006 (4 cr) Chapter
DBSCAN. Presented by: Garrett Poppe
 DBSCAN Presented by: Garrett Poppe A density-based algorithm for discovering clusters in large spatial databases with noise by Martin Ester, Hans-peter Kriegel, Jörg S, Xiaowei Xu Slides adapted from resources
DBSCAN Presented by: Garrett Poppe A density-based algorithm for discovering clusters in large spatial databases with noise by Martin Ester, Hans-peter Kriegel, Jörg S, Xiaowei Xu Slides adapted from resources
d(2,1) d(3,1 ) d (3,2) 0 ( n, ) ( n ,2)......
 d(3,1 ) d (3,2) 0 ( n, ) ( n ,2)......") Data Mining i Topic: Clustering CSEE Department, e t, UMBC Some of the slides used in this presentation are prepared by Jiawei Han and Micheline Kamber Cluster Analysis What is Cluster Analysis? Types
Data Mining i Topic: Clustering CSEE Department, e t, UMBC Some of the slides used in this presentation are prepared by Jiawei Han and Micheline Kamber Cluster Analysis What is Cluster Analysis? Types
Machine Learning. Unsupervised Learning. Manfred Huber
 Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering
 Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Statistics 202: Data Mining. c Jonathan Taylor. Clustering Based in part on slides from textbook, slides of Susan Holmes.
 Clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group will be similar (or
Clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group will be similar (or
Today. Lecture 4: Last time. The EM algorithm. We examine clustering in a little more detail; we went over it a somewhat quickly last time
 Today Lecture 4: We examine clustering in a little more detail; we went over it a somewhat quickly last time The CAD data will return and give us an opportunity to work with curves (!) We then examine
Today Lecture 4: We examine clustering in a little more detail; we went over it a somewhat quickly last time The CAD data will return and give us an opportunity to work with curves (!) We then examine
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Unsupervised Learning. Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team
 Unsupervised Learning Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team Table of Contents 1)Clustering: Introduction and Basic Concepts 2)An Overview of Popular Clustering Methods 3)Other Unsupervised
Unsupervised Learning Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team Table of Contents 1)Clustering: Introduction and Basic Concepts 2)An Overview of Popular Clustering Methods 3)Other Unsupervised
What is Cluster Analysis? COMP 465: Data Mining Clustering Basics. Applications of Cluster Analysis. Clustering: Application Examples 3/17/2015
 // What is Cluster Analysis? COMP : Data Mining Clustering Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, rd ed. Cluster: A collection of data
// What is Cluster Analysis? COMP : Data Mining Clustering Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, rd ed. Cluster: A collection of data
Olmo S. Zavala Romero. Clustering Hierarchical Distance Group Dist. K-means. Center of Atmospheric Sciences, UNAM.
 Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Machine Learning and Data Mining. Clustering (1): Basics. Kalev Kask
: Basics. Kalev Kask") Machine Learning and Data Mining Clustering (1): Basics Kalev Kask Unsupervised learning Supervised learning Predict target value ( y ) given features ( x ) Unsupervised learning Understand patterns of
Machine Learning and Data Mining Clustering (1): Basics Kalev Kask Unsupervised learning Supervised learning Predict target value ( y ) given features ( x ) Unsupervised learning Understand patterns of
Machine Learning 15/04/2015. Supervised learning vs. unsupervised learning. What is Cluster Analysis? Applications of Cluster Analysis
 // Supervised learning vs unsupervised learning Machine Learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These
// Supervised learning vs unsupervised learning Machine Learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These
Unsupervised Learning. Clustering and the EM Algorithm. Unsupervised Learning is Model Learning
 Unsupervised Learning Clustering and the EM Algorithm Susanna Ricco Supervised Learning Given data in the form < x, y >, y is the target to learn. Good news: Easy to tell if our algorithm is giving the
Unsupervised Learning Clustering and the EM Algorithm Susanna Ricco Supervised Learning Given data in the form < x, y >, y is the target to learn. Good news: Easy to tell if our algorithm is giving the
Clustering algorithms
 Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
K-means and Hierarchical Clustering
 K-means and Hierarchical Clustering Xiaohui Xie University of California, Irvine K-means and Hierarchical Clustering p.1/18 Clustering Given n data points X = {x 1, x 2,, x n }. Clustering is the partitioning
K-means and Hierarchical Clustering Xiaohui Xie University of California, Irvine K-means and Hierarchical Clustering p.1/18 Clustering Given n data points X = {x 1, x 2,, x n }. Clustering is the partitioning
Based on Raymond J. Mooney s slides
 Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
k-means demo Administrative Machine learning: Unsupervised learning" Assignment 5 out
 Machine learning: Unsupervised learning" David Kauchak cs Spring 0 adapted from: http://www.stanford.edu/class/cs76/handouts/lecture7-clustering.ppt http://www.youtube.com/watch?v=or_-y-eilqo Administrative
Machine learning: Unsupervised learning" David Kauchak cs Spring 0 adapted from: http://www.stanford.edu/class/cs76/handouts/lecture7-clustering.ppt http://www.youtube.com/watch?v=or_-y-eilqo Administrative