Cluster Analysis. Ying Shen, SSE, Tongji University
|
|
|
- Jasper Watts
- 6 years ago
- Views:
Transcription
1 Cluster Analysis Ying Shen, SSE, Tongji University
2 Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group be similar to one another and They are different from the objects in the other groups.
3 Cluster analysis Cluster analysis is important in the following areas: Biology Information retrieval Medicine Business
4 Cluster analysis Cluster analysis provides an abstraction from individual data objects to the clusters in which those data objects reside. Some clustering techniques characterize each cluster in terms of a cluster prototype. The prototype is a data object that is representative of the other objects in the cluster.
5 Different types of clusterings We consider the following types of clusterings Partitional versus hierarchical Exclusive versus fuzzy Complete versus partial
6 Partitional versus hierarchical A partitional clustering is a division of the set of data objects into subsets (clusters). A hierarchical clustering is a set of nested clusters that are organized as a tree. Each node (cluster) in the tree (except for the leaf nodes) is the union of its children (sub-clusters). The root of the tree is the cluster containing all the objects. Often, but not always, the leaves of the tree are singleton clusters of individual data objects.
7 Partitional versus hierarchical The following figures form a hierarchical (nested) clustering with 1, 2, 4 and 6 clusters on each level. A hierarchical clustering can be viewed as a sequence of partitional clusterings. A partitional clustering can be obtained by taking any member of that sequence, i.e. by cutting the hierarchical tree at a certain level.
8 Partitional versus hierarchical
9 Exclusive versus fuzzy In an exclusive clustering, each object is assigned to a single cluster. However, there are many situations in which a point could reasonably be placed in more than one cluster.
10 Exclusive versus fuzzy In a fuzzy clustering, every object belongs to every cluster with a membership weight that is between 0 (absolutely does not belong) and 1 (absolutely belongs). This approach is useful for avoiding the arbitrariness of assigning an object to only one cluster when it is close to several. A fuzzy clustering can be converted to an exclusive clustering by assigning each object to the cluster in which its membership value is the highest.
11 Complete versus partial A complete clustering assigns every object to a cluster. A partial clustering does not assign every object to a cluster. The motivation of partial clustering is that some objects in a data set may not belong to well-defined groups. Instead, they may represent noise or outliers.
12 K-means K-means is a prototype-based clustering technique which creates a one-level partitioning of the data objects. Specifically, K-means defines a prototype in terms of the centroid of a group of points. K-means is typically applied to objects in a continuous n-dimensional space.
13 K-means The basic K-means algorithm is summarized below 1. Select K points as initial centroids 2. Repeat a. Form K clusters by assigning each point to its closest centroid. b. Recompute the centroid of each cluster. 3. Until centroids do not change.
14 K-means We first choose K initial centroids, where K is a userdefined parameter, namely, the number of clusters desired. Each point is then assigned to the closest centroid. Each collection of points assigned to a centroid is a cluster. The centroid of each cluster is then updated based on the points assigned to the cluster. We repeat the assignment and update steps until the centroids remain the same.
15 K-means These steps are illustrated in the following figures. Starting from three centroids, the final clusters are found in four assignment-update steps.
16 K-means
17 K-means Each sub-figure shows The centroids at the start of the iteration and The assignment of the points to those centroids. The centroids are indicated by the + symbol. All points belonging to the same cluster have the same marker shape.
18 K-means In the first step, points are assigned to the initial centroids, which are all in the largest group of points. After points are assigned to a centroid, the centroid is then updated. In the second step Points are assigned to the updated centroids and The centroids are updated again.
19 K-means We can observe that two of the centroids move to the two small groups of points at the bottom of the figures. When the K-means algorithm terminates, the centroids have identified the natural groupings of points.
20 Proximity measure To assign a point to the closest centroid, we need a proximity measure that quantifies the notion of closest. Euclidean (L 2 ) distance is often used for data point in Euclidean space.
21 Proximity measure The goal of the clustering is typically expressed by an objective function. Consider data whose proximity measure is Euclidean distance. For our objective function, which measures the quality of a clustering, we can use the sum of the squared error (SSE).
22 Proximity measure We calculate the Euclidean distance of each data point to its closest centroid. We then compute the total sum of the squared distances, which is also known as the sum of the squared error (SSE). A small value of SSE means that the prototypes (centroids) of this clustering are a better representation of the points in their cluster.
23 Proximity measure The SSE is defined as follows: In this equation x is a data object. C i is the i-th cluster. K SSS = d x, c i 2 i=1 x C i c i is the centroid of cluster C i. d is the Euclidean (L 2 ) distance between two objects in Euclidean space.
24 Proximity measure It can be shown that the mean of the data points in the cluster minimizes the SSE of the cluster. The centroid (mean) of the i-th cluster is defined as c i = 1 m i x x C i In this equation, m i is the number of objects in the i- th cluster
25 Proximity measure Steps 2a and 2b of the K-means algorithm attempt to minimize the SSE. Step 2a forms clusters by assigning points to their nearest centroid, which minimizes the SSE for the given set of centroids. Step 2b recomputes the centroids so as to further minimize the SSE.
26 Choosing initial centroids Choosing the proper initial centroids is the key step of the basic K-means procedure. A common approach is to choose the initial centroids randomly. Randomly selected initial centroids may be poor choices. This is illustrated in the following figures.
27 Choosing initial centroids
28 Choosing initial centroids One technique that is commonly used to address the problem of choosing initial centroids is to perform multiple runs. Each run uses a different set of randomly chosen initial centroids. We then choose the set of clusters with the minimum SSE.
29 Outliers When the Euclidean distance is used, outliers can influence the clusters that are found. When outliers are present, the resulting cluster centroids may not be as representative as they otherwise would be. The SSE will be higher as well. Because of this, it is often useful to discover outliers and eliminate them beforehand.
30 Outliers To identify the outliers, we can keep track of the contribution of each point to the SSE. We then eliminate those points with unusually high contributions to the SSE. We may also want to eliminate small clusters, since they frequently represent groups of outliers.
31 Post-processing Two post-processing strategies that decrease the SSE by increasing the number of clusters are Split a cluster The cluster with the largest SSE is usually chosen. Introduce a new cluster centroid Often the point that is farthest from its associated cluster center is chosen. We can determine this if we keep track of the contribution of each point to the SSE.
32 Post-processing Two post-processing strategies that decrease the number of clusters, while trying to minimize the increase in total SSE, are Disperse a cluster This is accomplished by removing the centroid that corresponds to the cluster. The points in that cluster are then re-assigned to other clusters. The cluster that is dispersed should be the one that increases the total SSE the least. Merge two clusters We can merge the two clusters that result in the smallest increase in total SSE.
33 Bisecting K-means Bisecting K-means algorithm is an extension of the basic K-means algorithm. The main steps of the algorithm are described as follows To obtain K clusters, split the set of all points into two clusters. Select one of these clusters to split. Continue the process until K clusters have been produced.
34 Bisecting K-means There are a number of different ways to choose which cluster to split. We can choose the largest cluster at each step. We can also choose the one with the largest SSE. We can also use a criterion based on both size and SSE. Different choices result in different clusters. We often refine the resulting clusters by using their centroids as the initial centroids for the basic K-means algorithm. The bisecting K-means algorithm is illustrated in the following figure.
35 Bisecting K-means
36 Limitations of K-means K-means and its variations have a number of limitations with respect to finding different types of clusters. In particular, K-means has difficulty detecting clusters with non-spherical shapes or widely different sizes or densities. This is because K-means is designed to look for globular clusters of similar sizes and densities, or clusters that are well separated. This is illustrated in the following examples.
37 Limitations of K-means In this example, K-means cannot find the three natural clusters because one of the clusters is much larger than the other two. As a result, the largest cluster is divided into subclusters. At the same time, one of the smaller clusters is combined with a portion of the largest cluster.
38 Limitations of K-means In this example, K-means fails to find the three natural clusters. This is because the two smaller clusters are much denser than the largest cluster.
39 Limitations of K-means In this example, K-means finds two clusters that mix portions of the two natural clusters. This is because the shape of the natural clusters is not globular.
40 Hierarchical clustering A hierarchical clustering is a set of nested clusters that are organized as a tree. There are two basic approaches for generating a hierarchical clustering Agglomerative Divisive
41 Hierarchical clustering In agglomerative hierarchical clustering, we start with the points as individual clusters. At each step, we merge the closest pair of clusters. This requires defining a notion of cluster proximity.
42 Hierarchical clustering In divisive hierarchical clustering, we start with one, all-inclusive cluster. At each step, we split a cluster. This process continues until only singleton clusters of individual points remain. In this case, we need to decide Which cluster to split at each step and How to do the splitting.
43 Hierarchical clustering A hierarchical clustering is often displayed graphically using a tree-like diagram called the dendrogram. The dendrogram displays both the cluster-subcluster relationships and the order in which the clusters are merged (agglomerative) or split (divisive). For sets of 2-D points, a hierarchical clustering can also be graphically represented using a nested cluster diagram.
44 Hierarchical clustering
45 Hierarchical clustering The basic agglomerative hierarchical clustering algorithm is summarized as follows Compute the proximity matrix. Repeat Merge the closest two clusters Update the proximity matrix to reflect the proximity between the new cluster and the original clusters. Until only one cluster remains
46 Hierarchical clustering Different definitions of cluster proximity leads to different versions of hierarchical clustering. These versions include Single link or MIN Complete link or MAX Group average Ward s method
47 Hierarchical clustering We consider the following set of data points. The Euclidean distance matrix for these data points is shown in the following slide.
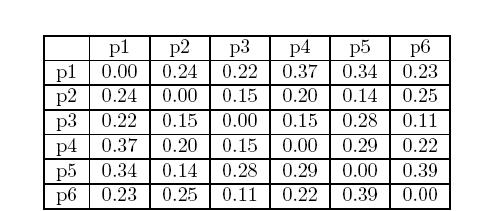
48 Hierarchical clustering
49 Single link We now consider the single link or MIN version of hierarchical clustering. In this case, the proximity of two clusters is defined as the minimum of the distance between any two points in the two different clusters. This technique is good at handling non-elliptical shapes. However, it is sensitive to noise and outliers.
50 Single link The following figure shows the result of applying single link technique to our example data. The left figure shows the nested clusters as a sequence of nested ellipses. The numbers associated with the ellipses indicate the order of the clustering. The right figure shows the same information in the form of a dendrogram. The height at which two clusters are merged in the dendrogram reflects the distance of the two clusters.
51 Single link
52 Single link For example, we see that the distance between points 3 and 6 is That is the height at which they are joined into one cluster in the dendrogram. As another example, the distance between clusters {3,6} and {2,5} is d 3,6, 2,5 = min (d 3,2, d 6,2, d 3,5, d 6,5 ) = min 0.15,0.25,0.28,0.39 = 0.15
53 Complete link We now consider the complete link or MAX version of hierarchical clustering. In this case, the proximity of two clusters is defined as the maximum of the distance between any two points in the two different clusters. Complete link is less susceptible to noise and outliers. However, it tends to produce clusters with globular shapes.
54 Complete link The following figure shows the results of applying the complete link approach to our sample data points. As with single link, points 3 and 6 are merged first. However, {3,6} is merged with {4}, instead of {2,5} or {1}.
55 Complete link
56 Complete link This can be explained by the following calculations d 3,6, 4 = max d 3,4, d 6,4 = max 0.15,0.22 = 0.22 d 3,6, 2,5 = max d 3,2, d 6,2, d 3,5, d 6,5 = max 0.15,0.25,0.28,0.39 = 0.39 d 3,6, 1 = max d 3,1, d 6,1 = max 0.22,0.23 = 0.23
57 Group average We now consider the group average version of hierarchical clustering. In this case, the proximity of two clusters is defined as the average pairwise proximity among all pairs of points in the different clusters. This is an intermediate approach between the single and complete link approaches.
58 Group average We consider two clusters C i and C j, which are of sizes m i and m j respectively. The distance between the two clusters can be expressed by the following equation d C i, C j = x C i,y C j d x, y m i m j
59 Group average The following figure shows the results of applying the group average to our sample data. The distance between some of the clusters are calculated as follows: d 3,6,4, 1 = = d 2,5, 1 = = d 3,6,4, 2,5 = =
60 Group average
61 Group average We observe that d({3,6,4},{2,5}) is smaller than d({3,6,4},{1}) and d({2,5},{1}). As a result, {3,6,4} and {2,5} are merged at the fourth stage.
62 Ward s method We now consider Ward s method for hierarchical clustering. In this case, the proximity between two clusters is defined as the increase in the sum of the squared error that results when they are merged. Thus, this method uses the same objective function as k-means clustering.
63 Ward s method The following figure shows the results of applying Ward s method to our sample data. The clustering that is produced is different from those produced by single link, complete link and group average.
64 Ward s method
65 Key issues Hierarchical clustering is effective when the underlying application requires the creation of a multi-level structure. However, they are expensive in terms of their computational and storage requirements. In addition, once a decision is made to merge two clusters, it cannot be undone at a later time.
Clustering Lecture 3: Hierarchical Methods
 Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering Part 3. Hierarchical Clustering
 Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
University of Florida CISE department Gator Engineering. Clustering Part 2
 Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Slides From Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Hierarchical Clustering
 Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Lecture Notes for Chapter 7. Introduction to Data Mining, 2 nd Edition. by Tan, Steinbach, Karpatne, Kumar
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Hierarchical Clustering Produces a set
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Hierarchical Clustering Produces a set
Hierarchical Clustering
 Hierarchical Clustering Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree-like diagram that records the sequences of merges
Hierarchical Clustering Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree-like diagram that records the sequences of merges
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Cluster Analysis: Basic Concepts and Algorithms
 7 Cluster Analysis: Basic Concepts and Algorithms Cluster analysis divides data into groups (clusters) that are meaningful, useful, or both. If meaningful groups are the goal, then the clusters should
7 Cluster Analysis: Basic Concepts and Algorithms Cluster analysis divides data into groups (clusters) that are meaningful, useful, or both. If meaningful groups are the goal, then the clusters should
Data Mining Concepts & Techniques
 Data Mining Concepts & Techniques Lecture No 08 Cluster Analysis Naeem Ahmed Email: naeemmahoto@gmailcom Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro Outline
Data Mining Concepts & Techniques Lecture No 08 Cluster Analysis Naeem Ahmed Email: naeemmahoto@gmailcom Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro Outline
Cluster analysis. Agnieszka Nowak - Brzezinska
 Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Hierarchical clustering
 Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
DATA MINING LECTURE 7. Hierarchical Clustering, DBSCAN The EM Algorithm
 DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
CSE 347/447: DATA MINING
 CSE 347/447: DATA MINING Lecture 6: Clustering II W. Teal Lehigh University CSE 347/447, Fall 2016 Hierarchical Clustering Definition Produces a set of nested clusters organized as a hierarchical tree
CSE 347/447: DATA MINING Lecture 6: Clustering II W. Teal Lehigh University CSE 347/447, Fall 2016 Hierarchical Clustering Definition Produces a set of nested clusters organized as a hierarchical tree
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CS7267 MACHINE LEARNING
 S7267 MAHINE LEARNING HIERARHIAL LUSTERING Ref: hengkai Li, Department of omputer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) Mingon Kang, Ph.D. omputer Science,
S7267 MAHINE LEARNING HIERARHIAL LUSTERING Ref: hengkai Li, Department of omputer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) Mingon Kang, Ph.D. omputer Science,
Lesson 3. Prof. Enza Messina
 Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A
 MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/09/2018)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
Unsupervised Learning. Supervised learning vs. unsupervised learning. What is Cluster Analysis? Applications of Cluster Analysis
 7 Supervised learning vs unsupervised learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These patterns are then
7 Supervised learning vs unsupervised learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These patterns are then
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
Olmo S. Zavala Romero. Clustering Hierarchical Distance Group Dist. K-means. Center of Atmospheric Sciences, UNAM.
 Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
DATA MINING - 1DL105, 1Dl111. An introductory class in data mining
 1 DATA MINING - 1DL105, 1Dl111 Fall 007 An introductory class in data mining http://user.it.uu.se/~udbl/dm-ht007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
1 DATA MINING - 1DL105, 1Dl111 Fall 007 An introductory class in data mining http://user.it.uu.se/~udbl/dm-ht007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
University of Florida CISE department Gator Engineering. Clustering Part 4
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
5/15/16. Computational Methods for Data Analysis. Massimo Poesio UNSUPERVISED LEARNING. Clustering. Unsupervised learning introduction
 Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Clustering Part 4 DBSCAN
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Unsupervised Learning. Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi
 Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/4 What
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/4 What
Clustering: Overview and K-means algorithm
 Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Clustering Part 2. A Partitional Clustering
 Universit of Florida CISE department Gator Engineering Clustering Part Dr. Sanja Ranka Professor Computer and Information Science and Engineering Universit of Florida, Gainesville Universit of Florida
Universit of Florida CISE department Gator Engineering Clustering Part Dr. Sanja Ranka Professor Computer and Information Science and Engineering Universit of Florida, Gainesville Universit of Florida
Knowledge Discovery in Databases
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture notes Knowledge Discovery in Databases Summer Semester 2012 Lecture 8: Clustering
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture notes Knowledge Discovery in Databases Summer Semester 2012 Lecture 8: Clustering
CS570: Introduction to Data Mining
 CS570: Introduction to Data Mining Scalable Clustering Methods: BIRCH and Others Reading: Chapter 10.3 Han, Chapter 9.5 Tan Cengiz Gunay, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei.
CS570: Introduction to Data Mining Scalable Clustering Methods: BIRCH and Others Reading: Chapter 10.3 Han, Chapter 9.5 Tan Cengiz Gunay, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei.
Hierarchy. No or very little supervision Some heuristic quality guidances on the quality of the hierarchy. Jian Pei: CMPT 459/741 Clustering (2) 1
 1") Hierarchy An arrangement or classification of things according to inclusiveness A natural way of abstraction, summarization, compression, and simplification for understanding Typical setting: organize
Hierarchy An arrangement or classification of things according to inclusiveness A natural way of abstraction, summarization, compression, and simplification for understanding Typical setting: organize
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering. Informal goal. General types of clustering. Applications: Clustering in information search and analysis. Example applications in search
 Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Clustering part II 1
 Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Cluster Analysis. Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX April 2008 April 2010
 Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Clustering Basic Concepts and Algorithms 1
 Clustering Basic Concepts and Algorithms 1 Jeff Howbert Introduction to Machine Learning Winter 014 1 Machine learning tasks Supervised Classification Regression Recommender systems Reinforcement learning
Clustering Basic Concepts and Algorithms 1 Jeff Howbert Introduction to Machine Learning Winter 014 1 Machine learning tasks Supervised Classification Regression Recommender systems Reinforcement learning
Lecture Notes for Chapter 7. Introduction to Data Mining, 2 nd Edition. by Tan, Steinbach, Karpatne, Kumar
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, nd Edition by Tan, Steinbach, Karpatne, Kumar What is Cluster Analysis? Finding groups
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, nd Edition by Tan, Steinbach, Karpatne, Kumar What is Cluster Analysis? Finding groups
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/004 What
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/004 What
9/17/2009. Wenyan Li (Emily Li) Sep. 15, Introduction to Clustering Analysis
 Sep. 15, Introduction to Clustering Analysis") Introduction ti to K-means Algorithm Wenan Li (Emil Li) Sep. 5, 9 Outline Introduction to Clustering Analsis K-means Algorithm Description Eample of K-means Algorithm Other Issues of K-means Algorithm
Introduction ti to K-means Algorithm Wenan Li (Emil Li) Sep. 5, 9 Outline Introduction to Clustering Analsis K-means Algorithm Description Eample of K-means Algorithm Other Issues of K-means Algorithm
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
Hard clustering. Each object is assigned to one and only one cluster. Hierarchical clustering is usually hard. Soft (fuzzy) clustering
 clustering") An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
Clustering: Overview and K-means algorithm
 Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Hierarchical clustering
 Aprendizagem Automática Hierarchical clustering Ludwig Krippahl Hierarchical clustering Summary Hierarchical Clustering Agglomerative Clustering Divisive Clustering Clustering Features 1 Aprendizagem Automática
Aprendizagem Automática Hierarchical clustering Ludwig Krippahl Hierarchical clustering Summary Hierarchical Clustering Agglomerative Clustering Divisive Clustering Clustering Features 1 Aprendizagem Automática
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest)
") Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Data Mining Cluster Analysis: Advanced Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining, 2 nd Edition
 Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Outline Prototype-based Fuzzy c-means
Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Outline Prototype-based Fuzzy c-means
Hierarchical Clustering Lecture 9
 Hierarchical Clustering Lecture 9 Marina Santini Acknowledgements Slides borrowed and adapted from: Data Mining by I. H. Witten, E. Frank and M. A. Hall 1 Lecture 9: Required Reading Witten et al. (2011:
Hierarchical Clustering Lecture 9 Marina Santini Acknowledgements Slides borrowed and adapted from: Data Mining by I. H. Witten, E. Frank and M. A. Hall 1 Lecture 9: Required Reading Witten et al. (2011:
Data Mining. Dr. Raed Ibraheem Hamed. University of Human Development, College of Science and Technology Department of Computer Science
 Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 06 07 Department of CS - DM - UHD Road map Cluster Analysis: Basic
Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 06 07 Department of CS - DM - UHD Road map Cluster Analysis: Basic
Cluster Analysis for Microarray Data
 Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
Part I. Hierarchical clustering. Hierarchical Clustering. Hierarchical clustering. Produces a set of nested clusters organized as a
 Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Road map. Basic concepts
 Clustering Basic concepts Road map K-means algorithm Representation of clusters Hierarchical clustering Distance functions Data standardization Handling mixed attributes Which clustering algorithm to use?
Clustering Basic concepts Road map K-means algorithm Representation of clusters Hierarchical clustering Distance functions Data standardization Handling mixed attributes Which clustering algorithm to use?
4. Ad-hoc I: Hierarchical clustering
 4. Ad-hoc I: Hierarchical clustering Hierarchical versus Flat Flat methods generate a single partition into k clusters. The number k of clusters has to be determined by the user ahead of time. Hierarchical
4. Ad-hoc I: Hierarchical clustering Hierarchical versus Flat Flat methods generate a single partition into k clusters. The number k of clusters has to be determined by the user ahead of time. Hierarchical
Cluster Analysis: Basic Concepts and Algorithms
 Cluster Analysis: Basic Concepts and Algorithms Data Warehousing and Mining Lecture 10 by Hossen Asiful Mustafa What is Cluster Analysis? Finding groups of objects such that the objects in a group will
Cluster Analysis: Basic Concepts and Algorithms Data Warehousing and Mining Lecture 10 by Hossen Asiful Mustafa What is Cluster Analysis? Finding groups of objects such that the objects in a group will
CS 1675 Introduction to Machine Learning Lecture 18. Clustering. Clustering. Groups together similar instances in the data sample
 CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
PAM algorithm. Types of Data in Cluster Analysis. A Categorization of Major Clustering Methods. Partitioning i Methods. Hierarchical Methods
 Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar (modified by Predrag Radivojac, 07) Old Faithful Geyser Data
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar (modified by Predrag Radivojac, 07) Old Faithful Geyser Data
Unsupervised Learning Hierarchical Methods
 Unsupervised Learning Hierarchical Methods Road Map. Basic Concepts 2. BIRCH 3. ROCK The Principle Group data objects into a tree of clusters Hierarchical methods can be Agglomerative: bottom-up approach
Unsupervised Learning Hierarchical Methods Road Map. Basic Concepts 2. BIRCH 3. ROCK The Principle Group data objects into a tree of clusters Hierarchical methods can be Agglomerative: bottom-up approach
Hierarchical Clustering 4/5/17
 Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Chapter VIII.3: Hierarchical Clustering
 Chapter VIII.3: Hierarchical Clustering 1. Basic idea 1.1. Dendrograms 1.2. Agglomerative and divisive 2. Cluster distances 2.1. Single link 2.2. Complete link 2.3. Group average and Mean distance 2.4.
Chapter VIII.3: Hierarchical Clustering 1. Basic idea 1.1. Dendrograms 1.2. Agglomerative and divisive 2. Cluster distances 2.1. Single link 2.2. Complete link 2.3. Group average and Mean distance 2.4.
数据挖掘 Introduction to Data Mining
 数据挖掘 Introduction to Data Mining Philippe Fournier-Viger Full professor School of Natural Sciences and Humanities philfv8@yahoo.com Spring 2019 S8700113C 1 Introduction Last week: Association Analysis
数据挖掘 Introduction to Data Mining Philippe Fournier-Viger Full professor School of Natural Sciences and Humanities philfv8@yahoo.com Spring 2019 S8700113C 1 Introduction Last week: Association Analysis
Applications. Foreground / background segmentation Finding skin-colored regions. Finding the moving objects. Intelligent scissors
 Segmentation I Goal Separate image into coherent regions Berkeley segmentation database: http://www.eecs.berkeley.edu/research/projects/cs/vision/grouping/segbench/ Slide by L. Lazebnik Applications Intelligent
Segmentation I Goal Separate image into coherent regions Berkeley segmentation database: http://www.eecs.berkeley.edu/research/projects/cs/vision/grouping/segbench/ Slide by L. Lazebnik Applications Intelligent
Cluster Analysis. Angela Montanari and Laura Anderlucci
 Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Online Social Networks and Media. Community detection
 Online Social Networks and Media Community detection 1 Notes on Homework 1 1. You should write your own code for generating the graphs. You may use SNAP graph primitives (e.g., add node/edge) 2. For the
Online Social Networks and Media Community detection 1 Notes on Homework 1 1. You should write your own code for generating the graphs. You may use SNAP graph primitives (e.g., add node/edge) 2. For the
HW4 VINH NGUYEN. Q1 (6 points). Chapter 8 Exercise 20
. Chapter 8 Exercise 20") HW4 VINH NGUYEN Q1 (6 points). Chapter 8 Exercise 20 a. For each figure, could you use single link to find the patterns represented by the nose, eyes and mouth? Explain? First, a single link is a MIN version
HW4 VINH NGUYEN Q1 (6 points). Chapter 8 Exercise 20 a. For each figure, could you use single link to find the patterns represented by the nose, eyes and mouth? Explain? First, a single link is a MIN version
CSE494 Information Retrieval Project C Report
 CSE494 Information Retrieval Project C Report By: Jianchun Fan Introduction In project C we implement several different clustering methods on the query results given by pagerank algorithms. The clustering
CSE494 Information Retrieval Project C Report By: Jianchun Fan Introduction In project C we implement several different clustering methods on the query results given by pagerank algorithms. The clustering
Clustering fundamentals
 Elena Baralis, Tania Cerquitelli Politecnico di Torino What is Cluster Analsis? Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from
Elena Baralis, Tania Cerquitelli Politecnico di Torino What is Cluster Analsis? Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from
Clustering in Data Mining
 Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering (COSC 416) Nazli Goharian. Document Clustering.
 Nazli Goharian. Document Clustering.") Clustering (COSC 416) Nazli Goharian nazli@cs.georgetown.edu 1 Document Clustering. Cluster Hypothesis : By clustering, documents relevant to the same topics tend to be grouped together. C. J. van Rijsbergen,
Clustering (COSC 416) Nazli Goharian nazli@cs.georgetown.edu 1 Document Clustering. Cluster Hypothesis : By clustering, documents relevant to the same topics tend to be grouped together. C. J. van Rijsbergen,
Clustering. Robert M. Haralick. Computer Science, Graduate Center City University of New York
 Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Multivariate Analysis
 Multivariate Analysis Cluster Analysis Prof. Dr. Anselmo E de Oliveira anselmo.quimica.ufg.br anselmo.disciplinas@gmail.com Unsupervised Learning Cluster Analysis Natural grouping Patterns in the data
Multivariate Analysis Cluster Analysis Prof. Dr. Anselmo E de Oliveira anselmo.quimica.ufg.br anselmo.disciplinas@gmail.com Unsupervised Learning Cluster Analysis Natural grouping Patterns in the data
CMPUT 391 Database Management Systems. Data Mining. Textbook: Chapter (without 17.10)
") CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
Clustering. CS294 Practical Machine Learning Junming Yin 10/09/06
 Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/10/2017)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
Clustering and Visualisation of Data
 Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Distances, Clustering! Rafael Irizarry!
 Distances, Clustering! Rafael Irizarry! Heatmaps! Distance! Clustering organizes things that are close into groups! What does it mean for two genes to be close?! What does it mean for two samples to
Distances, Clustering! Rafael Irizarry! Heatmaps! Distance! Clustering organizes things that are close into groups! What does it mean for two genes to be close?! What does it mean for two samples to
SYDE Winter 2011 Introduction to Pattern Recognition. Clustering
 SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
A Comparison of Document Clustering Techniques
 A Comparison of Document Clustering Techniques M. Steinbach, G. Karypis, V. Kumar Present by Leo Chen Feb-01 Leo Chen 1 Road Map Background & Motivation (2) Basic (6) Vector Space Model Cluster Quality
A Comparison of Document Clustering Techniques M. Steinbach, G. Karypis, V. Kumar Present by Leo Chen Feb-01 Leo Chen 1 Road Map Background & Motivation (2) Basic (6) Vector Space Model Cluster Quality
Cluster Analysis: Agglomerate Hierarchical Clustering
 Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Hierarchical Clustering
 What is clustering Partitioning of a data set into subsets. A cluster is a group of relatively homogeneous cases or observations Hierarchical Clustering Mikhail Dozmorov Fall 2016 2/61 What is clustering
What is clustering Partitioning of a data set into subsets. A cluster is a group of relatively homogeneous cases or observations Hierarchical Clustering Mikhail Dozmorov Fall 2016 2/61 What is clustering
Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
INF4820, Algorithms for AI and NLP: Hierarchical Clustering
 INF4820, Algorithms for AI and NLP: Hierarchical Clustering Erik Velldal University of Oslo Sept. 25, 2012 Agenda Topics we covered last week Evaluating classifiers Accuracy, precision, recall and F-score
INF4820, Algorithms for AI and NLP: Hierarchical Clustering Erik Velldal University of Oslo Sept. 25, 2012 Agenda Topics we covered last week Evaluating classifiers Accuracy, precision, recall and F-score
Tan,Steinbach, Kumar Introduction to Data Mining 4/18/ Tan,Steinbach, Kumar Introduction to Data Mining 4/18/
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
Cluster Analysis. Summer School on Geocomputation. 27 June July 2011 Vysoké Pole
 Cluster Analysis Summer School on Geocomputation 27 June 2011 2 July 2011 Vysoké Pole Lecture delivered by: doc. Mgr. Radoslav Harman, PhD. Faculty of Mathematics, Physics and Informatics Comenius University,
Cluster Analysis Summer School on Geocomputation 27 June 2011 2 July 2011 Vysoké Pole Lecture delivered by: doc. Mgr. Radoslav Harman, PhD. Faculty of Mathematics, Physics and Informatics Comenius University,
Clustering (COSC 488) Nazli Goharian. Document Clustering.
 Nazli Goharian. Document Clustering.") Clustering (COSC 488) Nazli Goharian nazli@ir.cs.georgetown.edu 1 Document Clustering. Cluster Hypothesis : By clustering, documents relevant to the same topics tend to be grouped together. C. J. van Rijsbergen,
Clustering (COSC 488) Nazli Goharian nazli@ir.cs.georgetown.edu 1 Document Clustering. Cluster Hypothesis : By clustering, documents relevant to the same topics tend to be grouped together. C. J. van Rijsbergen,
DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li
 Welcome to DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li Time: 6:00pm 8:50pm Thu Location: AK 232 Fall 2016 High Dimensional Data v Given a cloud of data points we want to understand
Welcome to DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li Time: 6:00pm 8:50pm Thu Location: AK 232 Fall 2016 High Dimensional Data v Given a cloud of data points we want to understand
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering
 Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Clustering algorithms
 Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised