Complexity and Advanced Algorithms. Introduction to Parallel Algorithms
|
|
|
- Prosper Ellis
- 6 years ago
- Views:
Transcription
1 Complexity and Advanced Algorithms Introduction to Parallel Algorithms
2 Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical motivations: Application requirements Architectural concerns. Why now? Soon may not be able to buy a good single core computer! Need to therefore study how to use parallel computers.
3 1. Application Requirements A computational fluid dynamics(cfd) calculation on an air plane wing 512 X 64 X 256 grid 5000 fl-pt operations per grid point 5000 steps 2.1x10 14 ft-ops. 3.5 minutes on a machine sustaining 1 trillion flops simulation of a full aircraft 3.5 x grid points total of 8.7 x ft-pt operations on the same machine requires more than 275,000 years to complete.
4 1. Application Requirements Digital movies and special effects fl-pt operations per frame and 50 frames per second 90-minute movie represents 2.7 x fl-pt operations. It would take 2,000 1-Gflops CPUs approximately 150 days to complete the computation.
5 1. Application Requirements Simulation of magnetic materials at the level of 2000-atom systems require 2.64 Tflops of computational power and 512 GB of storage. Full hard disk simulation 30 Tflops and 2 TB Current investigations limited about 1000 atoms 0.5 Tflops 250 GB Future investigations involving 10,000 atoms 100 Tflops 2.5TB Inventory planning, risk analysis, workforce scheduling and chip design.
6 2. Architectural Advances Moore's Law: The number of transistors that can be inexpensively placed on an integrated circuit is increasing exponentially, doubling approximately every two years. Present Difficulties Memory Wall Power Wall ILP Wall
7 The Brick Wall - 1 Memory Wall Memory latency up to 200 cycles per load/store. Floating point operations take no more than 4 cycles. Earlier, it was thought that multiply is slow but load and store is fast.
8 The Brick Wall - 2 Power Wall Enormous increase in power consumption. Power leakage. However, presently Power is expensive but transistors are free.
9 Basic Architecture Concepts t= Fetch Decode Execute Write Fetch Decode Execute Write Fetch Decode Execute Write Fetch Decode Execute Write Cache CPU Architecture 4 stages of instruction execution Too many cycles per instruction (CPI) To reduce the CPI, introduce pipelined execution Needs buffers to store results across stages. A cache to handle slow memory access times
10 Basic Architecture Concepts t= Fetch Decode Execute Write Fetch Decode Execute Write Fetch Decode Execute Write Cache CPU Architecture Fetch Decode Execute Write 4 stages of instruction execution Too many cycles per instruction (CPI) To reduce the CPI, introduce pipelined execution Needs buffers to store results across stages. A cache to handle slow memory access times Caches, out-of-order execution, branch prediction,...
11 The Brick Wall - 3 ILP Wall ILP via branch prediction, out-of-order and speculative execution Diminishing returns from instruction level parallelism.
12 Conventional Wisdom in Computer Architecture Power Wall + Memory Wall + ILP Wall = Brick Wall Old CW: Uniprocessor performance 2X / 1.5 yrs New CW: Uniprocessor performance only 2X / 5 yrs?
13 Multicores to the Rescue Predicted that 100+ core computers would be a reality soon. Increased number of cores without significant improvement in clock rates. Due to silicon technology improvements Big questions How to exploit these cores in parallel? What are the killer applications that can democratize these new models? Search, web,???
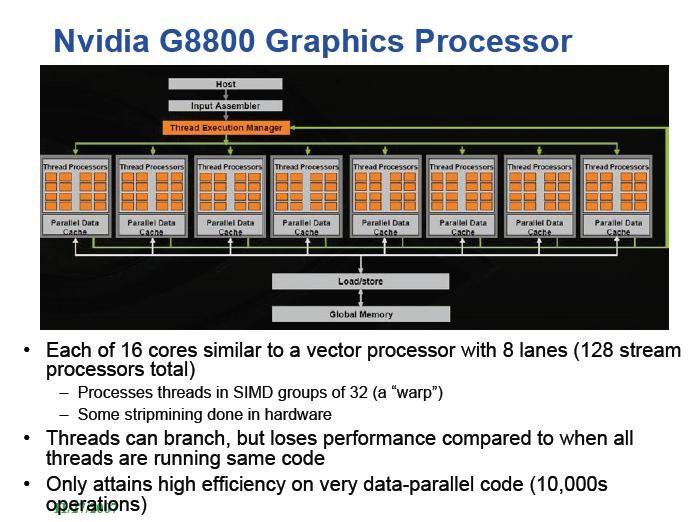
14 Multicore and Manycore Processors IBM Cell NVidia GeForce 8800 includes 128 scalar processors and Tesla Sun T1 and T2 Tilera Tile64 Picochip combines 430 simple RISC cores Cisco 188 TRIPS

15 Cell Broadband Engine Cell processing elements A standard PowerPC core 8 SIMD Cores (SPEs) Dual XDR memory controller and two I/O controllers Game controllers, HPC Power 100 W SPE local store of 256 KB
16
17 The NVidia Telsa The Tesla C870 GPU computing processor transforms a standard workstation into a personal supercomputer. With 128 streaming processor cores, the CUDA C-language development environment and developer tools, and a range of applications. Tesla C870 GPU specifications - One GPU (128 thread processors) gigaflops (peak) GB dedicated memory - Fits in one full-length, dual slot with one open PCI Express x16 slot Massively Multi-threaded Processor Architecture Solve compute problems at your workstation that previously required a large cluster 128 Floating Point Processor Cores Achieve up to 350 GFLOPS of performance (512 GFLOPS peak) with one C870 GPU Multi-GPU Computing Solve large-scale problems by dividing it across multiple GPUs Shared Data Memory Groups of processor cores can collaborate using shared data High Speed, PCI-Express Data Transfer Fast and high-bandwidth communication between CPU and GPU

18 The Nvidia Tesla

19 Some Performance Numbers






20 Some Performance Numbers The K Supercomputer Country: Japan Rated at 8 PFlops Tianhe 1 Supercomputer Country: China Rated at 2 PFlops The Jaguar Cray XT5 Country: USA Rated at 1.7 PFlops The Nebulae Country: China Rated at 1.27 PFlops Tsubame Supercomputer Country: Japan Rated at 1.19 PFlops The Eka Supercomputer Country: India Rated at 170 TFlops
21 The Academic Interest Algorithmics and compelxity How to design parallel algorithms? What are good theoretical models for parallel computing? How to analyze parallel algorithms? Can every sequential algorithm be parallelized? What are some complexity classes wrt parallel computing?
22 The Academic Interest Systems and Programming How to write parallel programs? What are some tools and environments. How to convert algorithms to efficient implementations. What are the differences to sequential programming? What are the performance measures? Can sequential programs be automatically converted to parallel programs?
23 The Academic Interest Architectures What are standard architectural designs? What new issues are raised due to multiple cores? Downstream concerns Does a programmer have to worry about this? How to support the systems software as architecture changes?
24 The Course Coverage Focus on algorithms and complexity Models for parallel algorithms Algorithm design methodologies with application Semi-numerical Lists Trees and graphs Some parallel programming practice Complexity, characterization, and connection to sequential complexity classes.
25 The PRAM Model P1 P2 P3 Pn Global Shared Memory An extension of the von Neumann model.
26 The PRAM Model A set of n identical processors A common access shared memory Synchronous time steps Access to the shared memory costs the same as a unit of computation. Different models to provide semantics for concurrent access to the shared memory EREW, CREW, CRCW(Common, Aribitrary, Priority,...)
27 The Semantics In all cases, it is the programmer to ensure that his program meets the required semantics. EREW : Exclusive Read, Exclusive Write No scope for memory contention. Usually the weakest model, and hence algorithm design is tough. CREW : Concurrent Read, Exclusive Write Allow processors to read simultaneously from the same memory location at the same instant. Can be made practically feasible with additional hardware
28 The Semantics CRCW : Concurrent Read, Concurrent Write Allow processors to read/write simultaneously from/to the same memory location at the same instant. Requires further specification of semantics for concurrent write. Popular variants include COMMON : Concurrent write is allowed so long as the all the values being attempted are equal. Example: Consider finding the Boolean OR of n bits. ARBITRARY : In case of a concurrent write, it is guaranteed that some processor succeeds and its write takes effect. PRIORITY : Assumes that processors have numbers that can be used to decide which write succeeds.
29 PRAM Model Advantages and Drawbacks Advantages A simple model for algorithm design Hides architectural details for the designer. A good starting point Disadvantages Ignores architectural features such as: memory bandwidth, communication cost and latency, scheduling,... Hardware may be difficult to realize
30 Example 1 Matrix Multiplication One of the fundamental parallel processing tasks. Applications to several important problems in linear algebra, signal processing and optimization. Several techniques that work in parallel also.
31 Example I Matrix Multiplication Recall that in C = A x B, C[i,j] = A[i,k].B[k,j]. Consider the following recursive approach: Works well in practice. A 00 A 01 X B 00 B 01 = C 00 C 01 A 10 A 11 B 10 B 11 C 10 C 11 C 00 = A 00. B 00 + A 01. B 10 C 01 = A 00. B 01 + A 01. B 11 C 10 = A 10. B 00 + A 11. B 10 C 11 = A 10. B 01 + A 11. B 11
32 Example I Matrix Multiplication Other approaches include Cannon's algorithm X = A B C Can overlap computation with communication. Works well when the number of processors is more.
33 Example 2 New Parallel Algorithm Listing 1: S(1) = A(1) for i = 2 to n do S(i) = S(i-1) o A(i) Prefix Computations: Given an array A of n elements and an associative operation o, compute A(1) o A(2) o... A(i) for each i. A very simple sequential algorithm exists for this problem.
34 Parallel Prefix Computation The sequential algorithm in Listing 1 is not efficient in parallel. Need a new algorithm approach. Balanced Binary Tree
35 Balanced Binary Tree An algorithm design approach for parallel algorithms Many problems can be solved with this design technique. Easily amenable to parallelization and analysis.
36 Balanced Binary Tree A complete binary tree with processors at each internal node. Input is at the leaf nodes Define operations to be executed at the internal nodes. Inputs for this operation at a node are the values at the children of this node. Computation as a tree traversal from leaf to root.
37 Balanced Binary Tree Prefix Sums a0 a1 a2 a3 a4 a5 a6 a7
38 Balanced Binary Tree Sum + a i a0 + a1 + a2 + a3 + + a4 + a5 + a6 + a7 a0 + a1 a2 + a3 a4 + a5 a6 + a a0 a1 a2 a3 a4 a5 a6 a7
39 Balanced Binary Tree Sum The above approach called as an ``upward traversal'' Data flow from the children to the root. Helpful in other situations also such as computing the max, expression evaluation. Analogously, can define a downward traversal Data flows from root to leaf Helps in settings such as element broadcast
40 Balanced Binary Tree Can use a combination of both upward and downward traversal. Prefix computation requires that. Illustration in the next slide.
41 Balanced Binary Tree Sum + a i a1 + a2 + a3 + a4 + + a5 + a6 + a7 + a8 a1 + a2 a3 + a4 a5 + a6 a7 + a a1 a2 a3 a4 a5 a6 a7 a8
42 Balanced Binary Tree Prefix Sum Upward traversal + a i a1 + a2 + a3 + a4 + + a5 + a6 + a7 + a8 a1 + a2 a3 + a4 a5 + a6 a7 + a a1 a2 a3 a4 a5 a6 a7 a8
43 Balanced Binary Tree Prefix Sum Downward traversal Even indices + a i + a1 + a2 + a3 + a4 + a5 + a6 + a7 + a8 a1 + a2 a3 + a4 a5 + a6 a7 + a8 a1 + a2 a1+a2+a i=16 a a i i 3 + a a1 a2 a3 a4 a5 a6 a7 a8 a1 a1+a2 a1+a2+a3+a4 i=16 a i a i
44 Balanced Binary Tree Prefix Sum Downward traversal Odd indices + a i + a1 + a2 + a3 + a4 + a5 + a6 + a7 + a a1 + a2 a3 + a4 a5 + a6 a7 + a8 a1 + a2 a1+a2+a i=16 a a i i 3 + a4 a1 a2 a3 a4 a5 a6 a7 a8 a1 (a1+a2) + a3 i=14 a i ) + a5 i=16 a i ) + a7
45 Balanced Binary Tree Prefix Sums Two traversals of a complete binary tree. The tree is only a visual aid. Map processors to locations in the tree Perform equivalent computations. Algorithm designed in the PRAM model. Works in logarithmic time, and optimal number of operations. //upward traversal 1. for i = 1 to n/2 do in parallel b i = a 2i-2 o a 2i 2. Recursively compute the prefix sums of B= (b 1, b 2,..., b n/2 ) and store them in C = (c 1, c 2,..., c n/2 ) //downward traversal 3. for i = 1 to n do in parallel i is even : s i = c i i= 1 : s 1 = c 1 i is odd : s i = c (i-1)/2 o a i
Complexity and Advanced Algorithms Monsoon Parallel Algorithms Lecture 2
 Complexity and Advanced Algorithms Monsoon 2011 Parallel Algorithms Lecture 2 Trivia ISRO has a new supercomputer rated at 220 Tflops Can be extended to Pflops. Consumes only 150 KW of power. LINPACK is
Complexity and Advanced Algorithms Monsoon 2011 Parallel Algorithms Lecture 2 Trivia ISRO has a new supercomputer rated at 220 Tflops Can be extended to Pflops. Consumes only 150 KW of power. LINPACK is
Introduction to Multicore architecture. Tao Zhang Oct. 21, 2010
 Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Why GPUs? Robert Strzodka (MPII), Dominik Göddeke G. TUDo), Dominik Behr (AMD)
, Dominik Göddeke G. TUDo), Dominik Behr (AMD)") Why GPUs? Robert Strzodka (MPII), Dominik Göddeke G (TUDo( TUDo), Dominik Behr (AMD) Conference on Parallel Processing and Applied Mathematics Wroclaw, Poland, September 13-16, 16, 2009 www.gpgpu.org/ppam2009
Why GPUs? Robert Strzodka (MPII), Dominik Göddeke G (TUDo( TUDo), Dominik Behr (AMD) Conference on Parallel Processing and Applied Mathematics Wroclaw, Poland, September 13-16, 16, 2009 www.gpgpu.org/ppam2009
Multicore Hardware and Parallelism
 Multicore Hardware and Parallelism Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3
Multicore Hardware and Parallelism Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3
6 February Parallel Computing: A View From Berkeley. E. M. Hielscher. Introduction. Applications and Dwarfs. Hardware. Programming Models
 Parallel 6 February 2008 Motivation All major processor manufacturers have switched to parallel architectures This switch driven by three Walls : the Power Wall, Memory Wall, and ILP Wall Power = Capacitance
Parallel 6 February 2008 Motivation All major processor manufacturers have switched to parallel architectures This switch driven by three Walls : the Power Wall, Memory Wall, and ILP Wall Power = Capacitance
Unit 9 : Fundamentals of Parallel Processing
 Unit 9 : Fundamentals of Parallel Processing Lesson 1 : Types of Parallel Processing 1.1. Learning Objectives On completion of this lesson you will be able to : classify different types of parallel processing
Unit 9 : Fundamentals of Parallel Processing Lesson 1 : Types of Parallel Processing 1.1. Learning Objectives On completion of this lesson you will be able to : classify different types of parallel processing
CS4230 Parallel Programming. Lecture 3: Introduction to Parallel Architectures 8/28/12. Homework 1: Parallel Programming Basics
 CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
BlueGene/L (No. 4 in the Latest Top500 List)
") BlueGene/L (No. 4 in the Latest Top500 List) first supercomputer in the Blue Gene project architecture. Individual PowerPC 440 processors at 700Mhz Two processors reside in a single chip. Two chips reside
BlueGene/L (No. 4 in the Latest Top500 List) first supercomputer in the Blue Gene project architecture. Individual PowerPC 440 processors at 700Mhz Two processors reside in a single chip. Two chips reside
Fundamentals of Computer Design
 Fundamentals of Computer Design Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
Fundamentals of Computer Design Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
GPU Programming. Lecture 1: Introduction. Miaoqing Huang University of Arkansas 1 / 27
 1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Memory Systems IRAM. Principle of IRAM
 Memory Systems 165 other devices of the module will be in the Standby state (which is the primary state of all RDRAM devices) or another state with low-power consumption. The RDRAM devices provide several
Memory Systems 165 other devices of the module will be in the Standby state (which is the primary state of all RDRAM devices) or another state with low-power consumption. The RDRAM devices provide several
Introduction to GPU computing
 Introduction to GPU computing Nagasaki Advanced Computing Center Nagasaki, Japan The GPU evolution The Graphic Processing Unit (GPU) is a processor that was specialized for processing graphics. The GPU
Introduction to GPU computing Nagasaki Advanced Computing Center Nagasaki, Japan The GPU evolution The Graphic Processing Unit (GPU) is a processor that was specialized for processing graphics. The GPU
What is Parallel Computing?
 What is Parallel Computing? Parallel Computing is several processing elements working simultaneously to solve a problem faster. 1/33 What is Parallel Computing? Parallel Computing is several processing
What is Parallel Computing? Parallel Computing is several processing elements working simultaneously to solve a problem faster. 1/33 What is Parallel Computing? Parallel Computing is several processing
represent parallel computers, so distributed systems such as Does not consider storage or I/O issues
 Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Fundamentals of Computers Design
 Computer Architecture J. Daniel Garcia Computer Architecture Group. Universidad Carlos III de Madrid Last update: September 8, 2014 Computer Architecture ARCOS Group. 1/45 Introduction 1 Introduction 2
Computer Architecture J. Daniel Garcia Computer Architecture Group. Universidad Carlos III de Madrid Last update: September 8, 2014 Computer Architecture ARCOS Group. 1/45 Introduction 1 Introduction 2
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS
 CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Lec 25: Parallel Processors. Announcements
 Lec 25: Parallel Processors Kavita Bala CS 340, Fall 2008 Computer Science Cornell University PA 3 out Hack n Seek Announcements The goal is to have fun with it Recitations today will talk about it Pizza
Lec 25: Parallel Processors Kavita Bala CS 340, Fall 2008 Computer Science Cornell University PA 3 out Hack n Seek Announcements The goal is to have fun with it Recitations today will talk about it Pizza
UC Berkeley CS61C : Machine Structures
 inst.eecs.berkeley.edu/~cs61c UC Berkeley CS61C : Machine Structures Lecture 39 Intra-machine Parallelism 2010-04-30!!!Head TA Scott Beamer!!!www.cs.berkeley.edu/~sbeamer Old-Fashioned Mud-Slinging with
inst.eecs.berkeley.edu/~cs61c UC Berkeley CS61C : Machine Structures Lecture 39 Intra-machine Parallelism 2010-04-30!!!Head TA Scott Beamer!!!www.cs.berkeley.edu/~sbeamer Old-Fashioned Mud-Slinging with
Top500 Supercomputer list
 Top500 Supercomputer list Tends to represent parallel computers, so distributed systems such as SETI@Home are neglected. Does not consider storage or I/O issues Both custom designed machines and commodity
Top500 Supercomputer list Tends to represent parallel computers, so distributed systems such as SETI@Home are neglected. Does not consider storage or I/O issues Both custom designed machines and commodity
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Parallelism in Hardware
 Parallelism in Hardware Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3 Moore s Law
Parallelism in Hardware Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3 Moore s Law
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
45-year CPU Evolution: 1 Law -2 Equations
 4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
GPU for HPC. October 2010
 GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
The Many-Core Revolution Understanding Change. Alejandro Cabrera January 29, 2009
 The Many-Core Revolution Understanding Change Alejandro Cabrera cpp.cabrera@gmail.com January 29, 2009 Disclaimer This presentation currently contains several claims requiring proper citations and a few
The Many-Core Revolution Understanding Change Alejandro Cabrera cpp.cabrera@gmail.com January 29, 2009 Disclaimer This presentation currently contains several claims requiring proper citations and a few
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
Spring 2011 Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim PowerPC-base Core @3.2GHz 1 VMX vector unit per core 512KB L2 cache 7 x SPE @3.2GHz 7 x 128b 128 SIMD GPRs 7 x 256KB SRAM for SPE 1 of 8 SPEs reserved for redundancy total
Spring 2011 Prof. Hyesoon Kim PowerPC-base Core @3.2GHz 1 VMX vector unit per core 512KB L2 cache 7 x SPE @3.2GHz 7 x 128b 128 SIMD GPRs 7 x 256KB SRAM for SPE 1 of 8 SPEs reserved for redundancy total
GPUs and GPGPUs. Greg Blanton John T. Lubia
 GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
CS 426 Parallel Computing. Parallel Computing Platforms
 CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
CS4961 Parallel Programming. Lecture 3: Introduction to Parallel Architectures 8/30/11. Administrative UPDATE. Mary Hall August 30, 2011
 CS4961 Parallel Programming Lecture 3: Introduction to Parallel Architectures Administrative UPDATE Nikhil office hours: - Monday, 2-3 PM, MEB 3115 Desk #12 - Lab hours on Tuesday afternoons during programming
CS4961 Parallel Programming Lecture 3: Introduction to Parallel Architectures Administrative UPDATE Nikhil office hours: - Monday, 2-3 PM, MEB 3115 Desk #12 - Lab hours on Tuesday afternoons during programming
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
COMP Parallel Computing. SMM (1) Memory Hierarchies and Shared Memory
 Memory Hierarchies and Shared Memory") COMP 633 - Parallel Computing Lecture 6 September 6, 2018 SMM (1) Memory Hierarchies and Shared Memory 1 Topics Memory systems organization caches and the memory hierarchy influence of the memory hierarchy
COMP 633 - Parallel Computing Lecture 6 September 6, 2018 SMM (1) Memory Hierarchies and Shared Memory 1 Topics Memory systems organization caches and the memory hierarchy influence of the memory hierarchy
CPU Pipelining Issues
 CPU Pipelining Issues What have you been beating your head against? This pipe stuff makes my head hurt! L17 Pipeline Issues & Memory 1 Pipelining Improve performance by increasing instruction throughput
CPU Pipelining Issues What have you been beating your head against? This pipe stuff makes my head hurt! L17 Pipeline Issues & Memory 1 Pipelining Improve performance by increasing instruction throughput
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
All About the Cell Processor
 All About the Cell H. Peter Hofstee, Ph. D. IBM Systems and Technology Group SCEI/Sony Toshiba IBM Design Center Austin, Texas Acknowledgements Cell is the result of a deep partnership between SCEI/Sony,
All About the Cell H. Peter Hofstee, Ph. D. IBM Systems and Technology Group SCEI/Sony Toshiba IBM Design Center Austin, Texas Acknowledgements Cell is the result of a deep partnership between SCEI/Sony,
Parallel Architecture. Hwansoo Han
 Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Parallel Programming
 Parallel Programming Introduction Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS15/16 Acknowledgements Prof. Felix Wolf, TU Darmstadt Prof. Matthias
Parallel Programming Introduction Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS15/16 Acknowledgements Prof. Felix Wolf, TU Darmstadt Prof. Matthias
B. Tech. Project Second Stage Report on
 B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
Fundamentals of. Parallel Computing. Sanjay Razdan. Alpha Science International Ltd. Oxford, U.K.
 Fundamentals of Parallel Computing Sanjay Razdan Alpha Science International Ltd. Oxford, U.K. CONTENTS Preface Acknowledgements vii ix 1. Introduction to Parallel Computing 1.1-1.37 1.1 Parallel Computing
Fundamentals of Parallel Computing Sanjay Razdan Alpha Science International Ltd. Oxford, U.K. CONTENTS Preface Acknowledgements vii ix 1. Introduction to Parallel Computing 1.1-1.37 1.1 Parallel Computing
Chapter 2 Parallel Computer Models & Classification Thoai Nam
 Chapter 2 Parallel Computer Models & Classification Thoai Nam Faculty of Computer Science and Engineering HCMC University of Technology Chapter 2: Parallel Computer Models & Classification Abstract Machine
Chapter 2 Parallel Computer Models & Classification Thoai Nam Faculty of Computer Science and Engineering HCMC University of Technology Chapter 2: Parallel Computer Models & Classification Abstract Machine
Marching Memory マーチングメモリ. UCAS-6 6 > Stanford > Imperial > Verify 中村維男 Based on Patent Application by Tadao Nakamura and Michael J.
 UCAS-6 6 > Stanford > Imperial > Verify 2011 Marching Memory マーチングメモリ Tadao Nakamura 中村維男 Based on Patent Application by Tadao Nakamura and Michael J. Flynn 1 Copyright 2010 Tadao Nakamura C-M-C Computer
UCAS-6 6 > Stanford > Imperial > Verify 2011 Marching Memory マーチングメモリ Tadao Nakamura 中村維男 Based on Patent Application by Tadao Nakamura and Michael J. Flynn 1 Copyright 2010 Tadao Nakamura C-M-C Computer
4.1 Introduction 4.3 Datapath 4.4 Control 4.5 Pipeline overview 4.6 Pipeline control * 4.7 Data hazard & forwarding * 4.
 Chapter 4: CPU 4.1 Introduction 4.3 Datapath 4.4 Control 4.5 Pipeline overview 4.6 Pipeline control * 4.7 Data hazard & forwarding * 4.8 Control hazard 4.14 Concluding Rem marks Hazards Situations that
Chapter 4: CPU 4.1 Introduction 4.3 Datapath 4.4 Control 4.5 Pipeline overview 4.6 Pipeline control * 4.7 Data hazard & forwarding * 4.8 Control hazard 4.14 Concluding Rem marks Hazards Situations that
Lecture 7: Parallel Processing
 Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Von Neumann architecture. The first computers used a single fixed program (like a numeric calculator).
.") Microprocessors Von Neumann architecture The first computers used a single fixed program (like a numeric calculator). To change the program, one has to re-wire, re-structure, or re-design the computer.
Microprocessors Von Neumann architecture The first computers used a single fixed program (like a numeric calculator). To change the program, one has to re-wire, re-structure, or re-design the computer.
Introduction to the MMAGIX Multithreading Supercomputer
 Introduction to the MMAGIX Multithreading Supercomputer A supercomputer is defined as a computer that can run at over a billion instructions per second (BIPS) sustained while executing over a billion floating
Introduction to the MMAGIX Multithreading Supercomputer A supercomputer is defined as a computer that can run at over a billion instructions per second (BIPS) sustained while executing over a billion floating
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
Introduction to CELL B.E. and GPU Programming. Agenda
 Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Overview. CS 472 Concurrent & Parallel Programming University of Evansville
 Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Parallel Computer Architecture - Basics -
 Parallel Computer Architecture - Basics - Christian Terboven 19.03.2012 / Aachen, Germany Stand: 15.03.2012 Version 2.3 Rechen- und Kommunikationszentrum (RZ) Agenda Processor
Parallel Computer Architecture - Basics - Christian Terboven 19.03.2012 / Aachen, Germany Stand: 15.03.2012 Version 2.3 Rechen- und Kommunikationszentrum (RZ) Agenda Processor
UC Berkeley CS61C : Machine Structures
 inst.eecs.berkeley.edu/~cs61c Review! UC Berkeley CS61C : Machine Structures Lecture 28 Intra-machine Parallelism Parallelism is necessary for performance! It looks like itʼs It is the future of computing!
inst.eecs.berkeley.edu/~cs61c Review! UC Berkeley CS61C : Machine Structures Lecture 28 Intra-machine Parallelism Parallelism is necessary for performance! It looks like itʼs It is the future of computing!
Parallelism. CS6787 Lecture 8 Fall 2017
 Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Multi-Processors and GPU
 Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
What does Heterogeneity bring?
 What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
Issues in Parallel Processing. Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University
 Issues in Parallel Processing Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Introduction Goal: connecting multiple computers to get higher performance
Issues in Parallel Processing Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Introduction Goal: connecting multiple computers to get higher performance
CUDA Accelerated Linpack on Clusters. E. Phillips, NVIDIA Corporation
 CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
The PRAM model. A. V. Gerbessiotis CIS 485/Spring 1999 Handout 2 Week 2
 The PRAM model A. V. Gerbessiotis CIS 485/Spring 1999 Handout 2 Week 2 Introduction The Parallel Random Access Machine (PRAM) is one of the simplest ways to model a parallel computer. A PRAM consists of
The PRAM model A. V. Gerbessiotis CIS 485/Spring 1999 Handout 2 Week 2 Introduction The Parallel Random Access Machine (PRAM) is one of the simplest ways to model a parallel computer. A PRAM consists of
Course II Parallel Computer Architecture. Week 2-3 by Dr. Putu Harry Gunawan
 Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
The Art of Parallel Processing
 The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
Architectures of Flynn s taxonomy -- A Comparison of Methods
 Architectures of Flynn s taxonomy -- A Comparison of Methods Neha K. Shinde Student, Department of Electronic Engineering, J D College of Engineering and Management, RTM Nagpur University, Maharashtra,
Architectures of Flynn s taxonomy -- A Comparison of Methods Neha K. Shinde Student, Department of Electronic Engineering, J D College of Engineering and Management, RTM Nagpur University, Maharashtra,
The Memory Hierarchy & Cache
 Removing The Ideal Memory Assumption: The Memory Hierarchy & Cache The impact of real memory on CPU Performance. Main memory basic properties: Memory Types: DRAM vs. SRAM The Motivation for The Memory
Removing The Ideal Memory Assumption: The Memory Hierarchy & Cache The impact of real memory on CPU Performance. Main memory basic properties: Memory Types: DRAM vs. SRAM The Motivation for The Memory
Computer Architecture
 Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
CUDA Memory Types All material not from online sources/textbook copyright Travis Desell, 2012
 CUDA Memory Types All material not from online sources/textbook copyright Travis Desell, 2012 Overview 1. Memory Access Efficiency 2. CUDA Memory Types 3. Reducing Global Memory Traffic 4. Example: Matrix-Matrix
CUDA Memory Types All material not from online sources/textbook copyright Travis Desell, 2012 Overview 1. Memory Access Efficiency 2. CUDA Memory Types 3. Reducing Global Memory Traffic 4. Example: Matrix-Matrix
Lecture 8: RISC & Parallel Computers. Parallel computers
 Lecture 8: RISC & Parallel Computers RISC vs CISC computers Parallel computers Final remarks Zebo Peng, IDA, LiTH 1 Introduction Reduced Instruction Set Computer (RISC) is an important innovation in computer
Lecture 8: RISC & Parallel Computers RISC vs CISC computers Parallel computers Final remarks Zebo Peng, IDA, LiTH 1 Introduction Reduced Instruction Set Computer (RISC) is an important innovation in computer
Chapter 2 Parallel Hardware
 Chapter 2 Parallel Hardware Part I. Preliminaries Chapter 1. What Is Parallel Computing? Chapter 2. Parallel Hardware Chapter 3. Parallel Software Chapter 4. Parallel Applications Chapter 5. Supercomputers
Chapter 2 Parallel Hardware Part I. Preliminaries Chapter 1. What Is Parallel Computing? Chapter 2. Parallel Hardware Chapter 3. Parallel Software Chapter 4. Parallel Applications Chapter 5. Supercomputers
Administration. Coursework. Prerequisites. CS 378: Programming for Performance. 4 or 5 programming projects
 CS 378: Programming for Performance Administration Instructors: Keshav Pingali (Professor, CS department & ICES) 4.126 ACES Email: pingali@cs.utexas.edu TA: Hao Wu (Grad student, CS department) Email:
CS 378: Programming for Performance Administration Instructors: Keshav Pingali (Professor, CS department & ICES) 4.126 ACES Email: pingali@cs.utexas.edu TA: Hao Wu (Grad student, CS department) Email:
Portland State University ECE 588/688. Cray-1 and Cray T3E
 Portland State University ECE 588/688 Cray-1 and Cray T3E Copyright by Alaa Alameldeen 2014 Cray-1 A successful Vector processor from the 1970s Vector instructions are examples of SIMD Contains vector
Portland State University ECE 588/688 Cray-1 and Cray T3E Copyright by Alaa Alameldeen 2014 Cray-1 A successful Vector processor from the 1970s Vector instructions are examples of SIMD Contains vector
Parallel Computer Architecture Concepts
 Outline Parallel Computer Architecture Concepts TDDD93 Lecture 1 Christoph Kessler PELAB / IDA Linköping university Sweden 2017 Lecture 1: Parallel Computer Architecture Concepts Parallel computer, multiprocessor,
Outline Parallel Computer Architecture Concepts TDDD93 Lecture 1 Christoph Kessler PELAB / IDA Linköping university Sweden 2017 Lecture 1: Parallel Computer Architecture Concepts Parallel computer, multiprocessor,
Fundamentals of Quantitative Design and Analysis
 Fundamentals of Quantitative Design and Analysis Dr. Jiang Li Adapted from the slides provided by the authors Computer Technology Performance improvements: Improvements in semiconductor technology Feature
Fundamentals of Quantitative Design and Analysis Dr. Jiang Li Adapted from the slides provided by the authors Computer Technology Performance improvements: Improvements in semiconductor technology Feature
Lecture 1: Introduction
 Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
Steve Scott, Tesla CTO SC 11 November 15, 2011
 Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 1. Copyright 2012, Elsevier Inc. All rights reserved. Computer Technology
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
CS5222 Advanced Computer Architecture. Lecture 1 Introduction
 CS5222 Advanced Computer Architecture Lecture 1 Introduction Overview Teaching Staff Introduction to Computer Architecture History Future / Trends Significance The course Content Workload Administrative
CS5222 Advanced Computer Architecture Lecture 1 Introduction Overview Teaching Staff Introduction to Computer Architecture History Future / Trends Significance The course Content Workload Administrative
Alternative GPU friendly assignment algorithms. Paul Richmond and Peter Heywood Department of Computer Science The University of Sheffield
 Alternative GPU friendly assignment algorithms Paul Richmond and Peter Heywood Department of Computer Science The University of Sheffield Graphics Processing Units (GPUs) Context: GPU Performance Accelerated
Alternative GPU friendly assignment algorithms Paul Richmond and Peter Heywood Department of Computer Science The University of Sheffield Graphics Processing Units (GPUs) Context: GPU Performance Accelerated
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes.
 HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Introduction to Microprocessor
 Introduction to Microprocessor Slide 1 Microprocessor A microprocessor is a multipurpose, programmable, clock-driven, register-based electronic device That reads binary instructions from a storage device
Introduction to Microprocessor Slide 1 Microprocessor A microprocessor is a multipurpose, programmable, clock-driven, register-based electronic device That reads binary instructions from a storage device
New Advances in Micro-Processors and computer architectures
 New Advances in Micro-Processors and computer architectures Prof. (Dr.) K.R. Chowdhary, Director SETG Email: kr.chowdhary@jietjodhpur.com Jodhpur Institute of Engineering and Technology, SETG August 27,
New Advances in Micro-Processors and computer architectures Prof. (Dr.) K.R. Chowdhary, Director SETG Email: kr.chowdhary@jietjodhpur.com Jodhpur Institute of Engineering and Technology, SETG August 27,
Double-Precision Matrix Multiply on CUDA
 Double-Precision Matrix Multiply on CUDA Parallel Computation (CSE 60), Assignment Andrew Conegliano (A5055) Matthias Springer (A995007) GID G--665 February, 0 Assumptions All matrices are square matrices
Double-Precision Matrix Multiply on CUDA Parallel Computation (CSE 60), Assignment Andrew Conegliano (A5055) Matthias Springer (A995007) GID G--665 February, 0 Assumptions All matrices are square matrices
Computer Organization and Design, 5th Edition: The Hardware/Software Interface
 Computer Organization and Design, 5th Edition: The Hardware/Software Interface 1 Computer Abstractions and Technology 1.1 Introduction 1.2 Eight Great Ideas in Computer Architecture 1.3 Below Your Program
Computer Organization and Design, 5th Edition: The Hardware/Software Interface 1 Computer Abstractions and Technology 1.1 Introduction 1.2 Eight Great Ideas in Computer Architecture 1.3 Below Your Program
Fra superdatamaskiner til grafikkprosessorer og
 Fra superdatamaskiner til grafikkprosessorer og Brødtekst maskinlæring Prof. Anne C. Elster IDI HPC/Lab Parallel Computing: Personal perspective 1980 s: Concurrent and Parallel Pascal 1986: Intel ipsc
Fra superdatamaskiner til grafikkprosessorer og Brødtekst maskinlæring Prof. Anne C. Elster IDI HPC/Lab Parallel Computing: Personal perspective 1980 s: Concurrent and Parallel Pascal 1986: Intel ipsc