ECS 289H: Visual Recognition Fall Yong Jae Lee Department of Computer Science
|
|
|
- Sharon Jackson
- 6 years ago
- Views:
Transcription

1 ECS 289H: Visual Recognition Fall 2014 Yong Jae Lee Department of Computer Science
2 Plan for today Questions? Research overview



3 Standard supervised visual learning building Category models Annotators tree Novel images Number of training images required can be costly Assumes closed-world setting where all categories are known 4
4 Unsupervised visual discovery Discovered categories Visual world 5





5 Unsupervised visual discovery Visual world Object segmentations in images and video 6

6 Unsupervised visual discovery 1:00 pm 2:00 pm 3:00 pm 4:00 pm Storyboard visual summary Visual world No human to explicitly guide visual recognition process 7



7 Why visual discovery? Exploring new environments 8





8 Summarization Why visual discovery? MSR Sensecam 9






9 Why visual discovery? 6 billion images 70 billion images 1 billion images served daily 10 billion images 100 hours uploaded per minute From : Almost 90% of web traffic is visual! Most of it is unlabeled!! 10





















10 Inputs today Understand and organize and Personal photo albums Movies, news, sports index all this data!! Surveillance and security Svetlana Lazebnik Medical and scientific images
11 Let s first explore what we can do with big data!
12 Everyday use of big data: Predictive text 13
13 Predictive drawing? 14
14 video ShadowDraw
15 Research goal: Visual discovery Discovered categories Visual world 16
16 Key challenges Simultaneously estimate segmentation and groups Unknown variability in appearance What is the proper distance metric? 17
17 How similar are two pictures? CLIME - CRIME = hamming distance of 1 letter y y x - x = Euclidian distance of 5 units - = Grayvalue distance of 50 values - =? Alyosha Efros 18


18 How similar are two pictures?? = 19
19 Problem Clusters formed from full image matches



20 Mutual Relationship between Foreground Features and Clusters If we have only foreground features, we can form good clusters Clusters formed from full image matches Clusters formed from foreground matches





21 Mutual Relationship between Foreground Features and Clusters If we have good clusters, we can detect the foreground

22 Our Approach Feature weights Feature index Update cluster based on weighted feature matches Refine feature weights given current clusters Unsupervised task that iteratively seeks the mutual support between discovered objects and their defining features [Lee & Grauman, Foreground Focus, IJCV 2009]

23 Cluster and Feature Weight Refinement: Iteration 1 Normalized Images Initial Pair-wise as Set Local Cuts of Feature Clustering Matching Clusters Sets Feature weights Feature index

24 Cluster and Feature Weight Refinement: Iteration 1 Feature weights Feature index New Compute Feature Feature Weights Weights

25 Cluster and Feature Weight Refinement: Iteration 2 New Set of Clusters Feature weights Feature index New Compute Feature Feature Weights Weights


26 Cluster and Feature Weight Refinement: Iteration 3 Pair-wise Final Set of Matching + Clusters Normalized Cuts Feature weights Feature index New Feature Weights
27 Quality of Clusters Formed Black dotted lines indicate the best possible quality that could be obtained if the ground truth segmentation were known


28 Quality of Foreground Detection 10-classes subset - highly weighted features


 variations Can we")

29 Shape Invariant to lighting conditions Relatively stable compared to intra-category appearance (texture, color) variations Can we discover common object shapes within unlabeled multicategory collections of images?
30 Anchoring Edge Fragments to Local Patches Even with accurate patch matches, there s a limit to how much shape information can be captured. By anchoring edge fragments to patch features, we can produce more reliable matches and describe the object s shape.

31 Foreground Shape Discovery: Prototypical Shape Examples of discovered object contours Our shapes [Lee & Grauman, Shape Discovery, CVPR 2009]


32 Works well for object-centric images Complex images with multiple objects remains challenging
33 Existing approaches Previous work treats unsupervised visual discovery as an appearance-grouping problem
34 Our idea How can seeing previously learned objects in novel images help to discover new categories?
35 Our idea Our idea: Discover visual categories within unlabeled images by modeling interactions between the unfamiliar regions and familiar objects [Lee & Grauman, Object-graphs, CVPR 2010] 52




36 Context-aware visual discovery??? sky sky sky driveway house? grass grass house truck fence grass house?? driveway driveway [Lee & Grauman, Object-graphs, CVPR 2010] 53






















37 Learn Models Detect Unknowns Object-level Context Discovery Learn known categories tree building sky road Offline: Train region-based classifiers for N known categories using labeled training data. 54
38 Learn Models Detect Unknowns Object-level Context Discovery Identifying unknown regions Input: unlabeled pool of novel images Compute multiple segmentations for each unlabeled image 55
 Learn Models Detect Unknowns")


39 P(class region) P(class region) P(class region) P(class region) Learn Models Detect Unknowns Object-level Context Discovery Identifying unknown regions Prediction: known High entropy Prediction: unknown Prediction: known Prediction: known Deem each segment as known or unknown based on resulting entropy: 56
40 Learn Models Detect Unknowns Object-level Context Discovery Object-graphs An unknown region within an image Model the topology of category predictions relative to the unknown (unfamiliar) region. 57


![0 self b t s r 1a above b t s r 1b below g(s) = [,,, ] b t s r H 0 (s) 0](/docs-images/78/77070009/images/41-3.jpg "self b t s r Ra above b t s r Rb below b t s r H 1 (s) H R (s) 1 st")
41 Learn Models Detect Unknowns Object-level Context Discovery An unknown region within an image Object-graphs Closest nodes in its object-graph 3a 1a 2a S 0 3b 2b 1b Consider spatially near regions above and below, record distributions for each known class. 0 self b t s r 1a above b t s r 1b below g(s) = [,,, ] b t s r H 0 (s) 0 self b t s r Ra above b t s r Rb below b t s r H 1 (s) H R (s) 1 st nearest region out to R th nearest 58



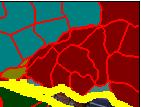
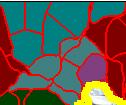
42 Example object-graphs unknown building sky road Colors indicate the predicted known category (max posterior) 59
43 Learn Models Detect Unknowns Object-level Context Discovery Clusters from region-region affinities Unknown Regions Object-level context provides more robust affinities 60








































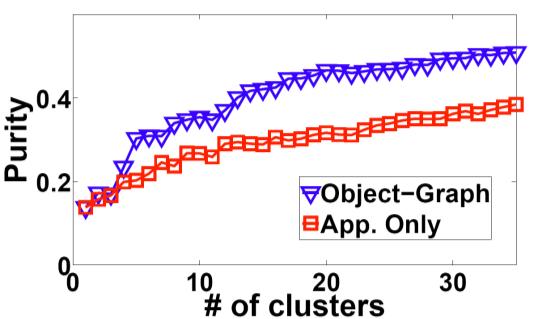
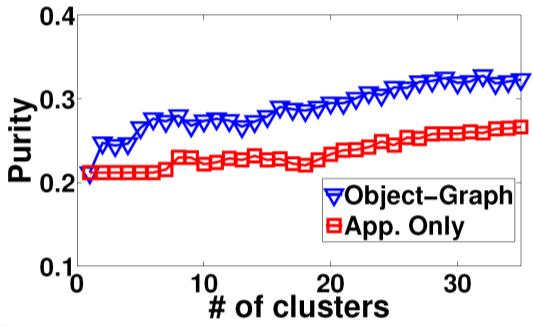
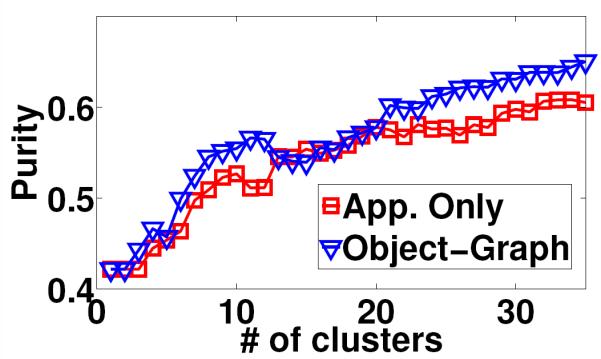
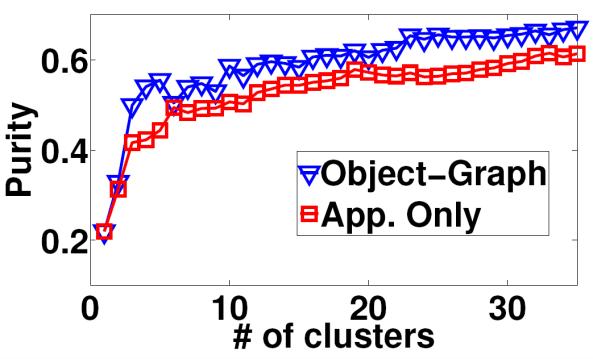
44 Results: object discovery accuracy MSRC-v2 PASCAL 2008 MSRC-v0 Corel 61







45 Example discoveries 62







46 Context-aware face discovery Kate David Kate David Kate Kate Kate name? David System can suggest novel people to name based on their appearance and co-occurrence with familiar people. [Lee & Grauman, Face discovery, BMVC 2011] 63



47 Results: Context-aware face discovery Dataset: Gallagher, Friends, Buffy 12,542 images, 8,452 faces and 23 unique people Two splits: 8 unknowns, and 15 unknowns Discovered Face Co-occurring faces [Lee & Grauman, Face discovery, BMVC 2011] 64




48 Self-paced discovery Previous work treats unsupervised visual discovery as a one-pass batch procedure. Traditional Batch k-way 66




 [Lee &")
49 Self-paced discovery Focus on the easier instances first, and gradually discover new models of increasing complexity. Single Easiest (Ours) [Lee & Grauman, Self-paced discovery, CVPR 2011] 67
 Context-Awareness (CA)")

50 Initialize Stuff Detect Easy Instances Discover New Category Expand Knowledge Identify Easy Objects + Objectness (Obj) Context-Awareness (CA) Easiness (ES) Familiarity Map (F) Obj: how well a window contains any generic object. CA: how well surrounding regions resemble familiar categories. 68

51 Initialize Stuff Detect Easy Instances Discover New Category Expand Knowledge Identify Easy Objects 69
52 Object Discovery Accuracy
53 Unsupervised visual discovery Visual world Object segmentations in images and video 71




 Best")
")

54 Collect-Cut Unsupervised Segmentation Examples Discovered Ensemble from Unlabeled Multi-Object Images Unlabeled Images Collect-Cut (ours) Best Bottom-up (with multi-segs) [Lee & Grauman, Collect-Cut, CVPR 2010] 72

55 Problem: Video object segmentation How to segment the foreground objects in video when background is moving and changing categories of foreground objects are unknown in advance Input: Unannotated video Desired output: Segmentation of high-ranking foreground object Existing methods group pixels using low-level features, which can result in an over-segmentation. [Brendel & Todorovic 2009, Vazquez-Reina et al. 2010, Grundmann et al. 2010, Brox & Malik 2010] 73
56 Key-segment discovery Discover a set of object-like key-segments for category independent video object segmentation Resist over-segmentation by detecting regions with object-like appearance and motion [Lee, Kim, Grauman, Key-segments, ICCV 2011] 74





57 Key-segment discovery 1) Find object-like regions using appearance and motion cues 2) Group regions across video to discover key-segment hypotheses 3) Rank hypotheses and build segmentation models for each hypothesis 4) For a given hypothesis, segment the corresponding foreground object using the models Color model Output segmentation Shape model [Lee, Kim, Grauman, Key-segments, ICCV 2011] 75
58 Results: Key-segment video segmentation Detect and segment people and discovered important objects without category-specific models Success in spite of moving camera, bg changes, low resolution 76















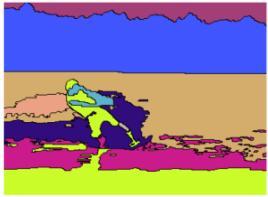


59 Results: Key-segment video segmentation Grundmann et al Ours Grundmann et al Ours Resists over-segmentation by detecting regions with objectlike appearance and motion 77

60 Results: Key-segment video segmentation Segmentation error rate Background subtraction falls apart Ours produces state-of-the-art results even when compared to supervised methods [29]: Tsai et al. BMVC 2010, [7]: Chockalingam et al. ICCV
61 Unsupervised visual discovery 1:00 pm 2:00 pm 3:00 pm 4:00 pm Storyboard visual summary Visual world 79







62 Mining first-person camera data GoPro Google Glass Looxcie Tobii SMI Pivothead 80




63 Mining first-person camera data 90 s Steve Mann life logger 81






64 Problem: Summarizing egocentric videos Wearable camera Input: Egocentric video of the camera wearer s day 9:00 am 10:00 am 11:00 am 12:00 pm 1:00 pm 2:00 pm Output: Storyboard summary of discovered important people and objects [Lee, Ghosh, Grauman, Egocentric video summarization, CVPR 2012] 82
65 Important person/object discovery Discover important people and objects for egocentric video summarization Important: things with which the camera wearer has significant interaction [Lee, Ghosh, Grauman, Egocentric video summarization, CVPR 2012] 83


66 Collect training data Learn Importance Segment video into events Discover important regions Storyboard summary Data collection 15 fps, 320 x 480 resolution 10 videos, 3-5 hrs in length; total of 37 hrs Four subjects: one undergraduate, two grad students, and one office worker 84
67 Collect training data Learn Importance Segment video into events Discover important regions Storyboard summary Egocentric features: Learning region importance distance to hand distance to frame center frequency 85


![frequency Object features: [ ] candidate region s](/docs-images/78/77070009/images/68-2.jpg "appearance, motion [ ] surrounding area s")

68 Collect training data Learn Importance Segment video into events Discover important regions Storyboard summary Egocentric features: Learning region importance distance to hand distance to frame center frequency Object features: [ ] candidate region s appearance, motion [ ] surrounding area s appearance, motion Object-like appearance, motion Region features: size, width, height, centroid overlap w/ face detection 86
69 Collect training data Learn Importance Segment video into events Discover important regions Storyboard summary Learning region importance importance learned parameters i th feature value Regressor to learn and predict a region s degree of importance Expect significant interactions between the features; e.g., a region near the hand is important only if it is object-like in appearance For training: For testing: predict I(r) given x i (r) s 87


![[Carreira, 2010]](/docs-images/78/77070009/images/70-2.jpg "[Endres, 2010]")

70 Results: Important region prediction Ours Object-like [Carreira, 2010] Object-like [Endres, 2010] Saliency [Walther, 2006] Good predictions 88


![[Carreira, 2010]](/docs-images/78/77070009/images/71-2.jpg "[Endres, 2010]")

71 Results: Important region prediction Ours Object-like [Carreira, 2010] Object-like [Endres, 2010] Saliency [Walther, 2006] Failure cases 89








72 Collect training data Learn Importance Segment video into events Discover important regions Storyboard summary Generating a storyboard summary Event 1 Event 2 Event 3 Event 3 Event 4 Display event boundaries and frames of the selected important people and objects 90

 Our summary (12")
73 Results: Egocentric video summarization Original video (3 hours) Our summary (12 frames) 91

74 Results: Egocentric video summarization 92

75 Fine-grained recognition 94
76 video AverageExplorer
77
78 Sign-up for papers Coming up Next class Object Recognition from Local Scale-Invariant Features. D. Lowe. ICCV Video Google: A Text Retrieval Approach to Object Matching in Videos. J. Sivic and A. Zisserman. ICCV Read both papers Write a review for one of them
Self-Supervised Learning & Visual Discovery
 CS 2770: Computer Vision Self-Supervised Learning & Visual Discovery Prof. Adriana Kovashka University of Pittsburgh April 10, 2017 Motivation So far we ve assumed access to plentiful labeled data How
CS 2770: Computer Vision Self-Supervised Learning & Visual Discovery Prof. Adriana Kovashka University of Pittsburgh April 10, 2017 Motivation So far we ve assumed access to plentiful labeled data How
Unsupervised discovery of category and object models. The task
 Unsupervised discovery of category and object models Martial Hebert The task 1 Common ingredients 1. Generate candidate segments 2. Estimate similarity between candidate segments 3. Prune resulting (implicit)
Unsupervised discovery of category and object models Martial Hebert The task 1 Common ingredients 1. Generate candidate segments 2. Estimate similarity between candidate segments 3. Prune resulting (implicit)
CAP 6412 Advanced Computer Vision
 CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
CS 2750: Machine Learning. Clustering. Prof. Adriana Kovashka University of Pittsburgh January 17, 2017
 CS 2750: Machine Learning Clustering Prof. Adriana Kovashka University of Pittsburgh January 17, 2017 What is clustering? Grouping items that belong together (i.e. have similar features) Unsupervised:
CS 2750: Machine Learning Clustering Prof. Adriana Kovashka University of Pittsburgh January 17, 2017 What is clustering? Grouping items that belong together (i.e. have similar features) Unsupervised:
Copyright by Yong Jae Lee 2012
 Copyright by Yong Jae Lee 2012 The Dissertation Committee for Yong Jae Lee certifies that this is the approved version of the following dissertation: Visual Object Category Discovery in Images and Videos
Copyright by Yong Jae Lee 2012 The Dissertation Committee for Yong Jae Lee certifies that this is the approved version of the following dissertation: Visual Object Category Discovery in Images and Videos
Collect-Cut: Segmentation with Top-Down Cues Discovered in Multi-Object Images
 Collect-Cut: Segmentation with Top-Down Cues Discovered in Multi-Object Images Yong Jae Lee and Kristen Grauman University of Texas at Austin yjlee0222@mail.utexas.edu, grauman@cs.utexas.edu Abstract We
Collect-Cut: Segmentation with Top-Down Cues Discovered in Multi-Object Images Yong Jae Lee and Kristen Grauman University of Texas at Austin yjlee0222@mail.utexas.edu, grauman@cs.utexas.edu Abstract We
Instances on a Budget
 Retrieving Similar or Informative Instances on a Budget Kristen Grauman Dept. of Computer Science University of Texas at Austin Work with Sudheendra Vijayanarasimham Work with Sudheendra Vijayanarasimham,
Retrieving Similar or Informative Instances on a Budget Kristen Grauman Dept. of Computer Science University of Texas at Austin Work with Sudheendra Vijayanarasimham Work with Sudheendra Vijayanarasimham,
Joint Inference in Image Databases via Dense Correspondence. Michael Rubinstein MIT CSAIL (while interning at Microsoft Research)
") Joint Inference in Image Databases via Dense Correspondence Michael Rubinstein MIT CSAIL (while interning at Microsoft Research) My work Throughout the year (and my PhD thesis): Temporal Video Analysis
Joint Inference in Image Databases via Dense Correspondence Michael Rubinstein MIT CSAIL (while interning at Microsoft Research) My work Throughout the year (and my PhD thesis): Temporal Video Analysis
Beyond bags of features: Adding spatial information. Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba
 Beyond bags of features: Adding spatial information Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba Adding spatial information Forming vocabularies from pairs of nearby features doublets
Beyond bags of features: Adding spatial information Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba Adding spatial information Forming vocabularies from pairs of nearby features doublets
Indexing local features and instance recognition May 16 th, 2017
 Indexing local features and instance recognition May 16 th, 2017 Yong Jae Lee UC Davis Announcements PS2 due next Monday 11:59 am 2 Recap: Features and filters Transforming and describing images; textures,
Indexing local features and instance recognition May 16 th, 2017 Yong Jae Lee UC Davis Announcements PS2 due next Monday 11:59 am 2 Recap: Features and filters Transforming and describing images; textures,
Segmentation and Grouping April 19 th, 2018
 Segmentation and Grouping April 19 th, 2018 Yong Jae Lee UC Davis Features and filters Transforming and describing images; textures, edges 2 Grouping and fitting [fig from Shi et al] Clustering, segmentation,
Segmentation and Grouping April 19 th, 2018 Yong Jae Lee UC Davis Features and filters Transforming and describing images; textures, edges 2 Grouping and fitting [fig from Shi et al] Clustering, segmentation,
Segmentation by Clustering. Segmentation by Clustering Reading: Chapter 14 (skip 14.5) General ideas
 General ideas") Reading: Chapter 14 (skip 14.5) Data reduction - obtain a compact representation for interesting image data in terms of a set of components Find components that belong together (form clusters) Frame differencing
Reading: Chapter 14 (skip 14.5) Data reduction - obtain a compact representation for interesting image data in terms of a set of components Find components that belong together (form clusters) Frame differencing
Texture April 17 th, 2018
 Texture April 17 th, 2018 Yong Jae Lee UC Davis Announcements PS1 out today Due 5/2 nd, 11:59 pm start early! 2 Review: last time Edge detection: Filter for gradient Threshold gradient magnitude, thin
Texture April 17 th, 2018 Yong Jae Lee UC Davis Announcements PS1 out today Due 5/2 nd, 11:59 pm start early! 2 Review: last time Edge detection: Filter for gradient Threshold gradient magnitude, thin
Segmentation by Clustering Reading: Chapter 14 (skip 14.5)
") Segmentation by Clustering Reading: Chapter 14 (skip 14.5) Data reduction - obtain a compact representation for interesting image data in terms of a set of components Find components that belong together
Segmentation by Clustering Reading: Chapter 14 (skip 14.5) Data reduction - obtain a compact representation for interesting image data in terms of a set of components Find components that belong together
Video Object Proposals
 Video Object Proposals Gilad Sharir Tinne Tuytelaars KU Leuven ESAT/PSI - IBBT Abstract In this paper, we extend a recently proposed method for generic object detection in images, category-independent
Video Object Proposals Gilad Sharir Tinne Tuytelaars KU Leuven ESAT/PSI - IBBT Abstract In this paper, we extend a recently proposed method for generic object detection in images, category-independent
Indexing local features and instance recognition May 14 th, 2015
 Indexing local features and instance recognition May 14 th, 2015 Yong Jae Lee UC Davis Announcements PS2 due Saturday 11:59 am 2 We can approximate the Laplacian with a difference of Gaussians; more efficient
Indexing local features and instance recognition May 14 th, 2015 Yong Jae Lee UC Davis Announcements PS2 due Saturday 11:59 am 2 We can approximate the Laplacian with a difference of Gaussians; more efficient
Analysis: TextonBoost and Semantic Texton Forests. Daniel Munoz Februrary 9, 2009
 Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Image warping and stitching
 Image warping and stitching May 4 th, 2017 Yong Jae Lee UC Davis Last time Interactive segmentation Feature-based alignment 2D transformations Affine fit RANSAC 2 Alignment problem In alignment, we will
Image warping and stitching May 4 th, 2017 Yong Jae Lee UC Davis Last time Interactive segmentation Feature-based alignment 2D transformations Affine fit RANSAC 2 Alignment problem In alignment, we will
ACM MM Dong Liu, Shuicheng Yan, Yong Rui and Hong-Jiang Zhang
 ACM MM 2010 Dong Liu, Shuicheng Yan, Yong Rui and Hong-Jiang Zhang Harbin Institute of Technology National University of Singapore Microsoft Corporation Proliferation of images and videos on the Internet
ACM MM 2010 Dong Liu, Shuicheng Yan, Yong Rui and Hong-Jiang Zhang Harbin Institute of Technology National University of Singapore Microsoft Corporation Proliferation of images and videos on the Internet
Using the Kolmogorov-Smirnov Test for Image Segmentation
 Using the Kolmogorov-Smirnov Test for Image Segmentation Yong Jae Lee CS395T Computational Statistics Final Project Report May 6th, 2009 I. INTRODUCTION Image segmentation is a fundamental task in computer
Using the Kolmogorov-Smirnov Test for Image Segmentation Yong Jae Lee CS395T Computational Statistics Final Project Report May 6th, 2009 I. INTRODUCTION Image segmentation is a fundamental task in computer
Image warping and stitching
 Image warping and stitching May 5 th, 2015 Yong Jae Lee UC Davis PS2 due next Friday Announcements 2 Last time Interactive segmentation Feature-based alignment 2D transformations Affine fit RANSAC 3 Alignment
Image warping and stitching May 5 th, 2015 Yong Jae Lee UC Davis PS2 due next Friday Announcements 2 Last time Interactive segmentation Feature-based alignment 2D transformations Affine fit RANSAC 3 Alignment
Outline. Segmentation & Grouping. Examples of grouping in vision. Grouping in vision. Grouping in vision 2/9/2011. CS 376 Lecture 7 Segmentation 1
 Outline What are grouping problems in vision? Segmentation & Grouping Wed, Feb 9 Prof. UT-Austin Inspiration from human perception Gestalt properties Bottom-up segmentation via clustering Algorithms: Mode
Outline What are grouping problems in vision? Segmentation & Grouping Wed, Feb 9 Prof. UT-Austin Inspiration from human perception Gestalt properties Bottom-up segmentation via clustering Algorithms: Mode
Texture April 14 th, 2015
 Texture April 14 th, 2015 Yong Jae Lee UC Davis Announcements PS1 out today due 4/29 th, 11:59 pm start early! 2 Review: last time Edge detection: Filter for gradient Threshold gradient magnitude, thin
Texture April 14 th, 2015 Yong Jae Lee UC Davis Announcements PS1 out today due 4/29 th, 11:59 pm start early! 2 Review: last time Edge detection: Filter for gradient Threshold gradient magnitude, thin
Applications. Foreground / background segmentation Finding skin-colored regions. Finding the moving objects. Intelligent scissors
 Segmentation I Goal Separate image into coherent regions Berkeley segmentation database: http://www.eecs.berkeley.edu/research/projects/cs/vision/grouping/segbench/ Slide by L. Lazebnik Applications Intelligent
Segmentation I Goal Separate image into coherent regions Berkeley segmentation database: http://www.eecs.berkeley.edu/research/projects/cs/vision/grouping/segbench/ Slide by L. Lazebnik Applications Intelligent
The Kinect Sensor. Luís Carriço FCUL 2014/15
 Advanced Interaction Techniques The Kinect Sensor Luís Carriço FCUL 2014/15 Sources: MS Kinect for Xbox 360 John C. Tang. Using Kinect to explore NUI, Ms Research, From Stanford CS247 Shotton et al. Real-Time
Advanced Interaction Techniques The Kinect Sensor Luís Carriço FCUL 2014/15 Sources: MS Kinect for Xbox 360 John C. Tang. Using Kinect to explore NUI, Ms Research, From Stanford CS247 Shotton et al. Real-Time
Learning Spatial Context: Using Stuff to Find Things
 Learning Spatial Context: Using Stuff to Find Things Wei-Cheng Su Motivation 2 Leverage contextual information to enhance detection Some context objects are non-rigid and are more naturally classified
Learning Spatial Context: Using Stuff to Find Things Wei-Cheng Su Motivation 2 Leverage contextual information to enhance detection Some context objects are non-rigid and are more naturally classified
Unsupervised Learning
 Unsupervised Learning Unsupervised learning Until now, we have assumed our training samples are labeled by their category membership. Methods that use labeled samples are said to be supervised. However,
Unsupervised Learning Unsupervised learning Until now, we have assumed our training samples are labeled by their category membership. Methods that use labeled samples are said to be supervised. However,
Discovering Important People and Objects for Egocentric Video Summarization
 To appear, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2012. Discovering Important People and Objects for Egocentric Video Summarization Yong Jae Lee, Joydeep
To appear, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2012. Discovering Important People and Objects for Egocentric Video Summarization Yong Jae Lee, Joydeep
Segmentation. Bottom up Segmentation Semantic Segmentation
 Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
End-to-End Localization and Ranking for Relative Attributes
 End-to-End Localization and Ranking for Relative Attributes Krishna Kumar Singh and Yong Jae Lee Presented by Minhao Cheng [Farhadi et al. 2009, Kumar et al. 2009, Lampert et al. 2009, [Slide: Xiao and
End-to-End Localization and Ranking for Relative Attributes Krishna Kumar Singh and Yong Jae Lee Presented by Minhao Cheng [Farhadi et al. 2009, Kumar et al. 2009, Lampert et al. 2009, [Slide: Xiao and
Discriminative classifiers for image recognition
 Discriminative classifiers for image recognition May 26 th, 2015 Yong Jae Lee UC Davis Outline Last time: window-based generic object detection basic pipeline face detection with boosting as case study
Discriminative classifiers for image recognition May 26 th, 2015 Yong Jae Lee UC Davis Outline Last time: window-based generic object detection basic pipeline face detection with boosting as case study
Video Google faces. Josef Sivic, Mark Everingham, Andrew Zisserman. Visual Geometry Group University of Oxford
 Video Google faces Josef Sivic, Mark Everingham, Andrew Zisserman Visual Geometry Group University of Oxford The objective Retrieve all shots in a video, e.g. a feature length film, containing a particular
Video Google faces Josef Sivic, Mark Everingham, Andrew Zisserman Visual Geometry Group University of Oxford The objective Retrieve all shots in a video, e.g. a feature length film, containing a particular
Segmentation and Grouping April 21 st, 2015
 Segmentation and Grouping April 21 st, 2015 Yong Jae Lee UC Davis Announcements PS0 grades are up on SmartSite Please put name on answer sheet 2 Features and filters Transforming and describing images;
Segmentation and Grouping April 21 st, 2015 Yong Jae Lee UC Davis Announcements PS0 grades are up on SmartSite Please put name on answer sheet 2 Features and filters Transforming and describing images;
Segmentation and Tracking of Partial Planar Templates
 Segmentation and Tracking of Partial Planar Templates Abdelsalam Masoud William Hoff Colorado School of Mines Colorado School of Mines Golden, CO 800 Golden, CO 800 amasoud@mines.edu whoff@mines.edu Abstract
Segmentation and Tracking of Partial Planar Templates Abdelsalam Masoud William Hoff Colorado School of Mines Colorado School of Mines Golden, CO 800 Golden, CO 800 amasoud@mines.edu whoff@mines.edu Abstract
Image Segmentation. Srikumar Ramalingam School of Computing University of Utah. Slides borrowed from Ross Whitaker
 Image Segmentation Srikumar Ramalingam School of Computing University of Utah Slides borrowed from Ross Whitaker Segmentation Semantic Segmentation Indoor layout estimation What is Segmentation? Partitioning
Image Segmentation Srikumar Ramalingam School of Computing University of Utah Slides borrowed from Ross Whitaker Segmentation Semantic Segmentation Indoor layout estimation What is Segmentation? Partitioning
CS 4495 Computer Vision. Segmentation. Aaron Bobick (slides by Tucker Hermans) School of Interactive Computing. Segmentation
 School of Interactive Computing. Segmentation") CS 4495 Computer Vision Aaron Bobick (slides by Tucker Hermans) School of Interactive Computing Administrivia PS 4: Out but I was a bit late so due date pushed back to Oct 29. OpenCV now has real SIFT
CS 4495 Computer Vision Aaron Bobick (slides by Tucker Hermans) School of Interactive Computing Administrivia PS 4: Out but I was a bit late so due date pushed back to Oct 29. OpenCV now has real SIFT
Window based detectors
 Window based detectors CS 554 Computer Vision Pinar Duygulu Bilkent University (Source: James Hays, Brown) Today Window-based generic object detection basic pipeline boosting classifiers face detection
Window based detectors CS 554 Computer Vision Pinar Duygulu Bilkent University (Source: James Hays, Brown) Today Window-based generic object detection basic pipeline boosting classifiers face detection
human vision: grouping k-means clustering graph-theoretic clustering Hough transform line fitting RANSAC
 COS 429: COMPUTER VISON Segmentation human vision: grouping k-means clustering graph-theoretic clustering Hough transform line fitting RANSAC Reading: Chapters 14, 15 Some of the slides are credited to:
COS 429: COMPUTER VISON Segmentation human vision: grouping k-means clustering graph-theoretic clustering Hough transform line fitting RANSAC Reading: Chapters 14, 15 Some of the slides are credited to:
Previously. Part-based and local feature models for generic object recognition. Bag-of-words model 4/20/2011
 Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Boundaries and Sketches
 Boundaries and Sketches Szeliski 4.2 Computer Vision James Hays Many slides from Michael Maire, Jitendra Malek Today s lecture Segmentation vs Boundary Detection Why boundaries / Grouping? Recap: Canny
Boundaries and Sketches Szeliski 4.2 Computer Vision James Hays Many slides from Michael Maire, Jitendra Malek Today s lecture Segmentation vs Boundary Detection Why boundaries / Grouping? Recap: Canny
on learned visual embedding patrick pérez Allegro Workshop Inria Rhônes-Alpes 22 July 2015
 on learned visual embedding patrick pérez Allegro Workshop Inria Rhônes-Alpes 22 July 2015 Vector visual representation Fixed-size image representation High-dim (100 100,000) Generic, unsupervised: BoW,
on learned visual embedding patrick pérez Allegro Workshop Inria Rhônes-Alpes 22 July 2015 Vector visual representation Fixed-size image representation High-dim (100 100,000) Generic, unsupervised: BoW,
Shape Discovery from Unlabeled Image Collections
 Shape Discovery from Unlabeled Image Collections Yong Jae Lee and Kristen Grauman University of Texas at Austin yjlee222@mail.utexas.edu, grauman@cs.utexas.edu Abstract Can we discover common object shapes
Shape Discovery from Unlabeled Image Collections Yong Jae Lee and Kristen Grauman University of Texas at Austin yjlee222@mail.utexas.edu, grauman@cs.utexas.edu Abstract Can we discover common object shapes
Segmenting Objects in Weakly Labeled Videos
 Segmenting Objects in Weakly Labeled Videos Mrigank Rochan, Shafin Rahman, Neil D.B. Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, Canada {mrochan, shafin12, bruce, ywang}@cs.umanitoba.ca
Segmenting Objects in Weakly Labeled Videos Mrigank Rochan, Shafin Rahman, Neil D.B. Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, Canada {mrochan, shafin12, bruce, ywang}@cs.umanitoba.ca
Object Recognition. Computer Vision. Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce
 Object Recognition Computer Vision Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce How many visual object categories are there? Biederman 1987 ANIMALS PLANTS OBJECTS
Object Recognition Computer Vision Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce How many visual object categories are there? Biederman 1987 ANIMALS PLANTS OBJECTS
Ping Tan. Simon Fraser University
 Ping Tan Simon Fraser University Photos vs. Videos (live photos) A good photo tells a story Stories are better told in videos Videos in the Mobile Era (mobile & share) More videos are captured by mobile
Ping Tan Simon Fraser University Photos vs. Videos (live photos) A good photo tells a story Stories are better told in videos Videos in the Mobile Era (mobile & share) More videos are captured by mobile
Flow-free Video Object Segmentation
 1 Flow-free Video Object Segmentation Aditya Vora and Shanmuganathan Raman Electrical Engineering, Indian Institute of Technology Gandhinagar, Gujarat, India, 382355 Email: aditya.vora@iitgn.ac.in, shanmuga@iitgn.ac.in
1 Flow-free Video Object Segmentation Aditya Vora and Shanmuganathan Raman Electrical Engineering, Indian Institute of Technology Gandhinagar, Gujarat, India, 382355 Email: aditya.vora@iitgn.ac.in, shanmuga@iitgn.ac.in
CS4495/6495 Introduction to Computer Vision. 8C-L1 Classification: Discriminative models
 CS4495/6495 Introduction to Computer Vision 8C-L1 Classification: Discriminative models Remember: Supervised classification Given a collection of labeled examples, come up with a function that will predict
CS4495/6495 Introduction to Computer Vision 8C-L1 Classification: Discriminative models Remember: Supervised classification Given a collection of labeled examples, come up with a function that will predict
Supervised learning. y = f(x) function
 function") Supervised learning y = f(x) output prediction function Image feature Training: given a training set of labeled examples {(x 1,y 1 ),, (x N,y N )}, estimate the prediction function f by minimizing the
Supervised learning y = f(x) output prediction function Image feature Training: given a training set of labeled examples {(x 1,y 1 ),, (x N,y N )}, estimate the prediction function f by minimizing the
Colorado School of Mines. Computer Vision. Professor William Hoff Dept of Electrical Engineering &Computer Science.
 Professor William Hoff Dept of Electrical Engineering &Computer Science http://inside.mines.edu/~whoff/ 1 Object Recognition in Large Databases Some material for these slides comes from www.cs.utexas.edu/~grauman/courses/spring2011/slides/lecture18_index.pptx
Professor William Hoff Dept of Electrical Engineering &Computer Science http://inside.mines.edu/~whoff/ 1 Object Recognition in Large Databases Some material for these slides comes from www.cs.utexas.edu/~grauman/courses/spring2011/slides/lecture18_index.pptx
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deformable Part Models
 CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
Data-driven Depth Inference from a Single Still Image
 Data-driven Depth Inference from a Single Still Image Kyunghee Kim Computer Science Department Stanford University kyunghee.kim@stanford.edu Abstract Given an indoor image, how to recover its depth information
Data-driven Depth Inference from a Single Still Image Kyunghee Kim Computer Science Department Stanford University kyunghee.kim@stanford.edu Abstract Given an indoor image, how to recover its depth information
Patch-Based Image Classification Using Image Epitomes
 Patch-Based Image Classification Using Image Epitomes David Andrzejewski CS 766 - Final Project December 19, 2005 Abstract Automatic image classification has many practical applications, including photo
Patch-Based Image Classification Using Image Epitomes David Andrzejewski CS 766 - Final Project December 19, 2005 Abstract Automatic image classification has many practical applications, including photo
K-Nearest Neighbors. Jia-Bin Huang. Virginia Tech Spring 2019 ECE-5424G / CS-5824
 K-Nearest Neighbors Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative Check out review materials Probability Linear algebra Python and NumPy Start your HW 0 On your Local machine:
K-Nearest Neighbors Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative Check out review materials Probability Linear algebra Python and NumPy Start your HW 0 On your Local machine:
Human Upper Body Pose Estimation in Static Images
 1. Research Team Human Upper Body Pose Estimation in Static Images Project Leader: Graduate Students: Prof. Isaac Cohen, Computer Science Mun Wai Lee 2. Statement of Project Goals This goal of this project
1. Research Team Human Upper Body Pose Estimation in Static Images Project Leader: Graduate Students: Prof. Isaac Cohen, Computer Science Mun Wai Lee 2. Statement of Project Goals This goal of this project
Unsupervised Learning Partitioning Methods
 Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
Patch Descriptors. EE/CSE 576 Linda Shapiro
 Patch Descriptors EE/CSE 576 Linda Shapiro 1 How can we find corresponding points? How can we find correspondences? How do we describe an image patch? How do we describe an image patch? Patches with similar
Patch Descriptors EE/CSE 576 Linda Shapiro 1 How can we find corresponding points? How can we find correspondences? How do we describe an image patch? How do we describe an image patch? Patches with similar
Object recognition (part 2)
") Object recognition (part 2) CSE P 576 Larry Zitnick (larryz@microsoft.com) 1 2 3 Support Vector Machines Modified from the slides by Dr. Andrew W. Moore http://www.cs.cmu.edu/~awm/tutorials Linear Classifiers
Object recognition (part 2) CSE P 576 Larry Zitnick (larryz@microsoft.com) 1 2 3 Support Vector Machines Modified from the slides by Dr. Andrew W. Moore http://www.cs.cmu.edu/~awm/tutorials Linear Classifiers
Segmentation and Grouping
 CS 1699: Intro to Computer Vision Segmentation and Grouping Prof. Adriana Kovashka University of Pittsburgh September 24, 2015 Goals: Grouping in vision Gather features that belong together Obtain an intermediate
CS 1699: Intro to Computer Vision Segmentation and Grouping Prof. Adriana Kovashka University of Pittsburgh September 24, 2015 Goals: Grouping in vision Gather features that belong together Obtain an intermediate
Grouping and Segmentation
 Grouping and Segmentation CS 554 Computer Vision Pinar Duygulu Bilkent University (Source:Kristen Grauman ) Goals: Grouping in vision Gather features that belong together Obtain an intermediate representation
Grouping and Segmentation CS 554 Computer Vision Pinar Duygulu Bilkent University (Source:Kristen Grauman ) Goals: Grouping in vision Gather features that belong together Obtain an intermediate representation
Grouping and Segmentation
 03/17/15 Grouping and Segmentation Computer Vision CS 543 / ECE 549 University of Illinois Derek Hoiem Today s class Segmentation and grouping Gestalt cues By clustering (mean-shift) By boundaries (watershed)
03/17/15 Grouping and Segmentation Computer Vision CS 543 / ECE 549 University of Illinois Derek Hoiem Today s class Segmentation and grouping Gestalt cues By clustering (mean-shift) By boundaries (watershed)
Learning Realistic Human Actions from Movies
 Learning Realistic Human Actions from Movies Ivan Laptev*, Marcin Marszałek**, Cordelia Schmid**, Benjamin Rozenfeld*** INRIA Rennes, France ** INRIA Grenoble, France *** Bar-Ilan University, Israel Presented
Learning Realistic Human Actions from Movies Ivan Laptev*, Marcin Marszałek**, Cordelia Schmid**, Benjamin Rozenfeld*** INRIA Rennes, France ** INRIA Grenoble, France *** Bar-Ilan University, Israel Presented
Region-based Segmentation and Object Detection
 Region-based Segmentation and Object Detection Stephen Gould Tianshi Gao Daphne Koller Presented at NIPS 2009 Discussion and Slides by Eric Wang April 23, 2010 Outline Introduction Model Overview Model
Region-based Segmentation and Object Detection Stephen Gould Tianshi Gao Daphne Koller Presented at NIPS 2009 Discussion and Slides by Eric Wang April 23, 2010 Outline Introduction Model Overview Model
CS 4495 Computer Vision Classification 3: Bag of Words. Aaron Bobick School of Interactive Computing
 CS 4495 Computer Vision Classification 3: Bag of Words Aaron Bobick School of Interactive Computing Administrivia PS 6 is out. Due Tues Nov 25th, 11:55pm. One more assignment after that Mea culpa This
CS 4495 Computer Vision Classification 3: Bag of Words Aaron Bobick School of Interactive Computing Administrivia PS 6 is out. Due Tues Nov 25th, 11:55pm. One more assignment after that Mea culpa This
Spatial Latent Dirichlet Allocation
 Spatial Latent Dirichlet Allocation Xiaogang Wang and Eric Grimson Computer Science and Computer Science and Artificial Intelligence Lab Massachusetts Tnstitute of Technology, Cambridge, MA, 02139, USA
Spatial Latent Dirichlet Allocation Xiaogang Wang and Eric Grimson Computer Science and Computer Science and Artificial Intelligence Lab Massachusetts Tnstitute of Technology, Cambridge, MA, 02139, USA
By Suren Manvelyan,
 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan,
By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan,
Beyond Bags of features Spatial information & Shape models
 Beyond Bags of features Spatial information & Shape models Jana Kosecka Many slides adapted from S. Lazebnik, FeiFei Li, Rob Fergus, and Antonio Torralba Detection, recognition (so far )! Bags of features
Beyond Bags of features Spatial information & Shape models Jana Kosecka Many slides adapted from S. Lazebnik, FeiFei Li, Rob Fergus, and Antonio Torralba Detection, recognition (so far )! Bags of features
Image Segmentation. Ross Whitaker SCI Institute, School of Computing University of Utah
 Image Segmentation Ross Whitaker SCI Institute, School of Computing University of Utah What is Segmentation? Partitioning images/volumes into meaningful pieces Partitioning problem Labels Isolating a specific
Image Segmentation Ross Whitaker SCI Institute, School of Computing University of Utah What is Segmentation? Partitioning images/volumes into meaningful pieces Partitioning problem Labels Isolating a specific
Image Segmentation continued Graph Based Methods. Some slides: courtesy of O. Capms, Penn State, J.Ponce and D. Fortsyth, Computer Vision Book
 Image Segmentation continued Graph Based Methods Some slides: courtesy of O. Capms, Penn State, J.Ponce and D. Fortsyth, Computer Vision Book Previously Binary segmentation Segmentation by thresholding
Image Segmentation continued Graph Based Methods Some slides: courtesy of O. Capms, Penn State, J.Ponce and D. Fortsyth, Computer Vision Book Previously Binary segmentation Segmentation by thresholding
Object Recognition. Lecture 11, April 21 st, Lexing Xie. EE4830 Digital Image Processing
 Object Recognition Lecture 11, April 21 st, 2008 Lexing Xie EE4830 Digital Image Processing http://www.ee.columbia.edu/~xlx/ee4830/ 1 Announcements 2 HW#5 due today HW#6 last HW of the semester Due May
Object Recognition Lecture 11, April 21 st, 2008 Lexing Xie EE4830 Digital Image Processing http://www.ee.columbia.edu/~xlx/ee4830/ 1 Announcements 2 HW#5 due today HW#6 last HW of the semester Due May
Announcements. Recognition. Recognition. Recognition. Recognition. Homework 3 is due May 18, 11:59 PM Reading: Computer Vision I CSE 152 Lecture 14
 Announcements Computer Vision I CSE 152 Lecture 14 Homework 3 is due May 18, 11:59 PM Reading: Chapter 15: Learning to Classify Chapter 16: Classifying Images Chapter 17: Detecting Objects in Images Given
Announcements Computer Vision I CSE 152 Lecture 14 Homework 3 is due May 18, 11:59 PM Reading: Chapter 15: Learning to Classify Chapter 16: Classifying Images Chapter 17: Detecting Objects in Images Given
Summarization of Egocentric Moving Videos for Generating Walking Route Guidance
 Summarization of Egocentric Moving Videos for Generating Walking Route Guidance Masaya Okamoto and Keiji Yanai Department of Informatics, The University of Electro-Communications 1-5-1 Chofugaoka, Chofu-shi,
Summarization of Egocentric Moving Videos for Generating Walking Route Guidance Masaya Okamoto and Keiji Yanai Department of Informatics, The University of Electro-Communications 1-5-1 Chofugaoka, Chofu-shi,
3D Spatial Layout Propagation in a Video Sequence
 3D Spatial Layout Propagation in a Video Sequence Alejandro Rituerto 1, Roberto Manduchi 2, Ana C. Murillo 1 and J. J. Guerrero 1 arituerto@unizar.es, manduchi@soe.ucsc.edu, acm@unizar.es, and josechu.guerrero@unizar.es
3D Spatial Layout Propagation in a Video Sequence Alejandro Rituerto 1, Roberto Manduchi 2, Ana C. Murillo 1 and J. J. Guerrero 1 arituerto@unizar.es, manduchi@soe.ucsc.edu, acm@unizar.es, and josechu.guerrero@unizar.es
Part based models for recognition. Kristen Grauman
 Part based models for recognition Kristen Grauman UT Austin Limitations of window-based models Not all objects are box-shaped Assuming specific 2d view of object Local components themselves do not necessarily
Part based models for recognition Kristen Grauman UT Austin Limitations of window-based models Not all objects are box-shaped Assuming specific 2d view of object Local components themselves do not necessarily
CSE 473/573 Computer Vision and Image Processing (CVIP) Ifeoma Nwogu. Lectures 21 & 22 Segmentation and clustering
 Ifeoma Nwogu. Lectures 21 & 22 Segmentation and clustering") CSE 473/573 Computer Vision and Image Processing (CVIP) Ifeoma Nwogu Lectures 21 & 22 Segmentation and clustering 1 Schedule Last class We started on segmentation Today Segmentation continued Readings
CSE 473/573 Computer Vision and Image Processing (CVIP) Ifeoma Nwogu Lectures 21 & 22 Segmentation and clustering 1 Schedule Last class We started on segmentation Today Segmentation continued Readings
Image Analysis Lecture Segmentation. Idar Dyrdal
 Image Analysis Lecture 9.1 - Segmentation Idar Dyrdal Segmentation Image segmentation is the process of partitioning a digital image into multiple parts The goal is to divide the image into meaningful
Image Analysis Lecture 9.1 - Segmentation Idar Dyrdal Segmentation Image segmentation is the process of partitioning a digital image into multiple parts The goal is to divide the image into meaningful
K Nearest Neighbor Wrap Up K- Means Clustering. Slides adapted from Prof. Carpuat
 K Nearest Neighbor Wrap Up K- Means Clustering Slides adapted from Prof. Carpuat K Nearest Neighbor classification Classification is based on Test instance with Training Data K: number of neighbors that
K Nearest Neighbor Wrap Up K- Means Clustering Slides adapted from Prof. Carpuat K Nearest Neighbor classification Classification is based on Test instance with Training Data K: number of neighbors that
AN ENHANCED ATTRIBUTE RERANKING DESIGN FOR WEB IMAGE SEARCH
 AN ENHANCED ATTRIBUTE RERANKING DESIGN FOR WEB IMAGE SEARCH Sai Tejaswi Dasari #1 and G K Kishore Babu *2 # Student,Cse, CIET, Lam,Guntur, India * Assistant Professort,Cse, CIET, Lam,Guntur, India Abstract-
AN ENHANCED ATTRIBUTE RERANKING DESIGN FOR WEB IMAGE SEARCH Sai Tejaswi Dasari #1 and G K Kishore Babu *2 # Student,Cse, CIET, Lam,Guntur, India * Assistant Professort,Cse, CIET, Lam,Guntur, India Abstract-
Fitting a transformation: Feature-based alignment April 30 th, Yong Jae Lee UC Davis
 Fitting a transformation: Feature-based alignment April 3 th, 25 Yong Jae Lee UC Davis Announcements PS2 out toda; due 5/5 Frida at :59 pm Color quantization with k-means Circle detection with the Hough
Fitting a transformation: Feature-based alignment April 3 th, 25 Yong Jae Lee UC Davis Announcements PS2 out toda; due 5/5 Frida at :59 pm Color quantization with k-means Circle detection with the Hough
Articulated Pose Estimation with Flexible Mixtures-of-Parts
 Articulated Pose Estimation with Flexible Mixtures-of-Parts PRESENTATION: JESSE DAVIS CS 3710 VISUAL RECOGNITION Outline Modeling Special Cases Inferences Learning Experiments Problem and Relevance Problem:
Articulated Pose Estimation with Flexible Mixtures-of-Parts PRESENTATION: JESSE DAVIS CS 3710 VISUAL RECOGNITION Outline Modeling Special Cases Inferences Learning Experiments Problem and Relevance Problem:
SSD: Single Shot MultiBox Detector. Author: Wei Liu et al. Presenter: Siyu Jiang
 SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
Video Object Segmentation by Salient Segment Chain Composition
 2013 IEEE International Conference on Computer Vision Workshops Video Object Segmentation by Salient Segment Chain Composition Dan Banica 1, Alexandru Agape 1, Adrian Ion 2, Cristian Sminchisescu 3,1 1
2013 IEEE International Conference on Computer Vision Workshops Video Object Segmentation by Salient Segment Chain Composition Dan Banica 1, Alexandru Agape 1, Adrian Ion 2, Cristian Sminchisescu 3,1 1
A Statistical Approach to Culture Colors Distribution in Video Sensors Angela D Angelo, Jean-Luc Dugelay
 A Statistical Approach to Culture Colors Distribution in Video Sensors Angela D Angelo, Jean-Luc Dugelay VPQM 2010, Scottsdale, Arizona, U.S.A, January 13-15 Outline Introduction Proposed approach Colors
A Statistical Approach to Culture Colors Distribution in Video Sensors Angela D Angelo, Jean-Luc Dugelay VPQM 2010, Scottsdale, Arizona, U.S.A, January 13-15 Outline Introduction Proposed approach Colors
Copyright by Yong Jae Lee 2008
 Copyright by Yong Jae Lee 2008 Foreground Focus: Finding Meaningful Features in Unlabeled Images by Yong Jae Lee, B.S. THESIS Presented to the Faculty of the Graduate School of The University of Texas
Copyright by Yong Jae Lee 2008 Foreground Focus: Finding Meaningful Features in Unlabeled Images by Yong Jae Lee, B.S. THESIS Presented to the Faculty of the Graduate School of The University of Texas
Learning the Ecological Statistics of Perceptual Organization
 Learning the Ecological Statistics of Perceptual Organization Charless Fowlkes work with David Martin, Xiaofeng Ren and Jitendra Malik at University of California at Berkeley 1 How do ideas from perceptual
Learning the Ecological Statistics of Perceptual Organization Charless Fowlkes work with David Martin, Xiaofeng Ren and Jitendra Malik at University of California at Berkeley 1 How do ideas from perceptual
Unsupervised Patch-based Context from Millions of Images
 Carnegie Mellon University Research Showcase @ CMU Robotics Institute School of Computer Science 12-2011 Unsupervised Patch-based Context from Millions of Images Santosh K. Divvala Carnegie Mellon University
Carnegie Mellon University Research Showcase @ CMU Robotics Institute School of Computer Science 12-2011 Unsupervised Patch-based Context from Millions of Images Santosh K. Divvala Carnegie Mellon University
Spatio-temporal Feature Classifier
 Spatio-temporal Feature Classifier Send Orders for Reprints to reprints@benthamscience.ae The Open Automation and Control Systems Journal, 2015, 7, 1-7 1 Open Access Yun Wang 1,* and Suxing Liu 2 1 School
Spatio-temporal Feature Classifier Send Orders for Reprints to reprints@benthamscience.ae The Open Automation and Control Systems Journal, 2015, 7, 1-7 1 Open Access Yun Wang 1,* and Suxing Liu 2 1 School
CS 231A Computer Vision (Winter 2014) Problem Set 3
 Problem Set 3") CS 231A Computer Vision (Winter 2014) Problem Set 3 Due: Feb. 18 th, 2015 (11:59pm) 1 Single Object Recognition Via SIFT (45 points) In his 2004 SIFT paper, David Lowe demonstrates impressive object recognition
CS 231A Computer Vision (Winter 2014) Problem Set 3 Due: Feb. 18 th, 2015 (11:59pm) 1 Single Object Recognition Via SIFT (45 points) In his 2004 SIFT paper, David Lowe demonstrates impressive object recognition
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network. Nathan Sun CIS601
 with Facial KeyPoints using Spatial Fusion Convolutional Network. Nathan Sun CIS601") Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601 Introduction Face ID is complicated by alterations to an individual s appearance Beard,
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601 Introduction Face ID is complicated by alterations to an individual s appearance Beard,
Mining Discriminative Adjectives and Prepositions for Natural Scene Recognition
 Mining Discriminative Adjectives and Prepositions for Natural Scene Recognition Bangpeng Yao 1, Juan Carlos Niebles 2,3, Li Fei-Fei 1 1 Department of Computer Science, Princeton University, NJ 08540, USA
Mining Discriminative Adjectives and Prepositions for Natural Scene Recognition Bangpeng Yao 1, Juan Carlos Niebles 2,3, Li Fei-Fei 1 1 Department of Computer Science, Princeton University, NJ 08540, USA
Segmentation by Weighted Aggregation for Video. CVPR 2014 Tutorial Slides! Jason Corso!
 Segmentation by Weighted Aggregation for Video CVPR 2014 Tutorial Slides! Jason Corso! Segmentation by Weighted Aggregation Set-Up Define the problem on a graph:! Edges are sparse, to neighbors.! Each
Segmentation by Weighted Aggregation for Video CVPR 2014 Tutorial Slides! Jason Corso! Segmentation by Weighted Aggregation Set-Up Define the problem on a graph:! Edges are sparse, to neighbors.! Each
EECS 442 Computer Vision fall 2011
 EECS 442 Computer Vision fall 2011 Instructor Silvio Savarese silvio@eecs.umich.edu Office: ECE Building, room: 4435 Office hour: Tues 4:30-5:30pm or under appoint. (after conversation hour) GSIs: Mohit
EECS 442 Computer Vision fall 2011 Instructor Silvio Savarese silvio@eecs.umich.edu Office: ECE Building, room: 4435 Office hour: Tues 4:30-5:30pm or under appoint. (after conversation hour) GSIs: Mohit
Scale and Rotation Invariant Approach to Tracking Human Body Part Regions in Videos
 Scale and Rotation Invariant Approach to Tracking Human Body Part Regions in Videos Yihang Bo Institute of Automation, CAS & Boston College yihang.bo@gmail.com Hao Jiang Computer Science Department, Boston
Scale and Rotation Invariant Approach to Tracking Human Body Part Regions in Videos Yihang Bo Institute of Automation, CAS & Boston College yihang.bo@gmail.com Hao Jiang Computer Science Department, Boston
Medical images, segmentation and analysis
 Medical images, segmentation and analysis ImageLab group http://imagelab.ing.unimo.it Università degli Studi di Modena e Reggio Emilia Medical Images Macroscopic Dermoscopic ELM enhance the features of
Medical images, segmentation and analysis ImageLab group http://imagelab.ing.unimo.it Università degli Studi di Modena e Reggio Emilia Medical Images Macroscopic Dermoscopic ELM enhance the features of
Part-based and local feature models for generic object recognition
 Part-based and local feature models for generic object recognition May 28 th, 2015 Yong Jae Lee UC Davis Announcements PS2 grades up on SmartSite PS2 stats: Mean: 80.15 Standard Dev: 22.77 Vote on piazza
Part-based and local feature models for generic object recognition May 28 th, 2015 Yong Jae Lee UC Davis Announcements PS2 grades up on SmartSite PS2 stats: Mean: 80.15 Standard Dev: 22.77 Vote on piazza
Contexts and 3D Scenes
 Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Nov 30 th 3:30 PM 4:45 PM Grading Three senior graders (30%)
Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Nov 30 th 3:30 PM 4:45 PM Grading Three senior graders (30%)
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Discovering Visual Hierarchy through Unsupervised Learning Haider Razvi
 Discovering Visual Hierarchy through Unsupervised Learning Haider Razvi hrazvi@stanford.edu 1 Introduction: We present a method for discovering visual hierarchy in a set of images. Automatically grouping
Discovering Visual Hierarchy through Unsupervised Learning Haider Razvi hrazvi@stanford.edu 1 Introduction: We present a method for discovering visual hierarchy in a set of images. Automatically grouping
Local features and image matching. Prof. Xin Yang HUST
 Local features and image matching Prof. Xin Yang HUST Last time RANSAC for robust geometric transformation estimation Translation, Affine, Homography Image warping Given a 2D transformation T and a source
Local features and image matching Prof. Xin Yang HUST Last time RANSAC for robust geometric transformation estimation Translation, Affine, Homography Image warping Given a 2D transformation T and a source
Why study Computer Vision?
 Computer Vision Why study Computer Vision? Images and movies are everywhere Fast-growing collection of useful applications building representations of the 3D world from pictures automated surveillance
Computer Vision Why study Computer Vision? Images and movies are everywhere Fast-growing collection of useful applications building representations of the 3D world from pictures automated surveillance