NONPARAMETRIC REGRESSION TECHNIQUES
|
|
|
- Joseph Fowler
- 6 years ago
- Views:
Transcription
1 NONPARAMETRIC REGRESSION TECHNIQUES C&PE 940, 28 November 2005 Geoff Bohling Assistant Scientist Kansas Geological Survey Overheads and other resources available at: 1
2 Modeling Continuous Variables: Regression In regression-style applications we are trying to develop a model for predicting a continuous-valued (numerical) response variable, Y, from one or more predictor variables, X, that is Y = f ( X ) In more classical statistical terminology, the X variables would be referred to as independent variables, and Y as the dependent variable. In the language of the machine learning community, the X s might be referred to as inputs and the Y as an output. We will limit our discussion to: Supervised learning: In which the response function, f, is learned based on a set of training data with known X & Y values. Deterministic X: That is, the noise or measurement error is considered to be strictly in the Y values, so that regression (in the general sense) of Y on X is the appropriate approach, rather than an approach aiming to minimize error in both directions (e.g., RMA regression). In other words, we are looking at the case where each observed response, y i, is given by y = f i x i ( ) + εi where x i is the corresponding vector of observed predictors and i ε is the noise or measurement error in the i th observation of y. 2
3 f is not known exactly and we instead substitute some convenient approximating function, f ˆ( X ;θ ), with a set of parameters, θ, that we can adjust to produce a reasonable match between the observed and predicted y values in our training data set. In typical statistical modeling, the form of ( X ) What constitutes a reasonable match is measured by an objective function, some measure of the discrepancy between y i and f ˆ( x i ;θ ) averaged over the training dataset. Ideally, the form of the objective function would be chosen to correspond to the statistical distribution of the error values, ε i, but usually this distribution is also unknown and the form of the objective function is chosen more as a matter of convenience. By far the most commonly used form is the sum of squared deviations between observed and predicted responses, or residual sum of squares: N ( i x i ) ( ) = y fˆ ( ; θ ) R θ. i= 1 If the errors are independent and distributed according to a common normal distribution, N ( 0,σ ), then the residual sum of squares (RSS) is in fact the correct form for the objective function, in the sense that minimizing the RSS with respect to θ yields the maximum likelihood estimates for the parameters. Because of its computational convenience, least squares minimization is used in many settings regardless of the actual form of the error distribution. 2 3
4 A fairly common variant is weighted least squares minimization, with the objective function R (?) = N i= 1 y fˆ σ i x i ( ; θ ) i 2 which would be appropriate if each error value was distributed according to ε i ~ N ( 0, σ i ). However, we rarely have external information from which to evaluate the varying standard deviations, σ i. One approach to this problem is to use iteratively reweighted least squares (IRLS), where the σ i values for each successive fit are approximated from the computed residuals for the previous fit. IRLS is more robust to the influence of outliers than standard least squares minimization because observations with large residuals (far from the fitted surface) will be assigned large σ i values and thus downweighted with respect to other observations. Probably the only other form of objective function (for regressionstyle applications) that sees much use is the sum of absolute (rather than squared) deviations: R N (?) = y fˆ ( ; θ ) i= 1 i x i which is appropriate when the errors follow an exponential distribution, rather than a normal distribution. Minimizing the absolute residuals (the L 1 norm) is also more robust to outliers than minimizing the squared residuals (the L 2 norm), since squaring enhances the influence of the larger residuals. However, L 1 minimization is difficult, due to discontinuities in the derivatives of the objective function with respect to the parameters. 4
5 So, the basic ingredients for supervised learning are: A training dataset: Paired values of y i and x i for a set of N observations. An approximating function: We must assume some form for the approximating function, f ˆ( X ;θ ), preferably one that is flexible enough to mimic a variety of true functions and with reasonably simple dependence on the adjustable parameters, θ. An objective function: We must also assume a form for the objective function which we will attempt to minimize with respect to? to obtain the parameter estimates. The form of the objective function implies a distributional form for the errors, although we may often ignore this implication. Even if we focus solely on the least squares objective function, as we will here, the variety of possible choices for f ˆ( X ;θ ) leads to a bewildering array of modeling techniques. However, all of these techniques share some common properties, elaborated below. Another important ingredient for developing a reliable model is a test dataset independent from the training dataset but with known y i values on which we can test our model s predictions. Without evaluating the performance on a test dataset, we will almost certainly be drawn into overfitting the training data, meaning we will develop a model that reproduces the training data well but performs poorly on other datasets. In the absence of a truly independent test dataset, people often resort to crossvalidation, withholding certain subsets from the training data and then predicting on the withheld data. 5
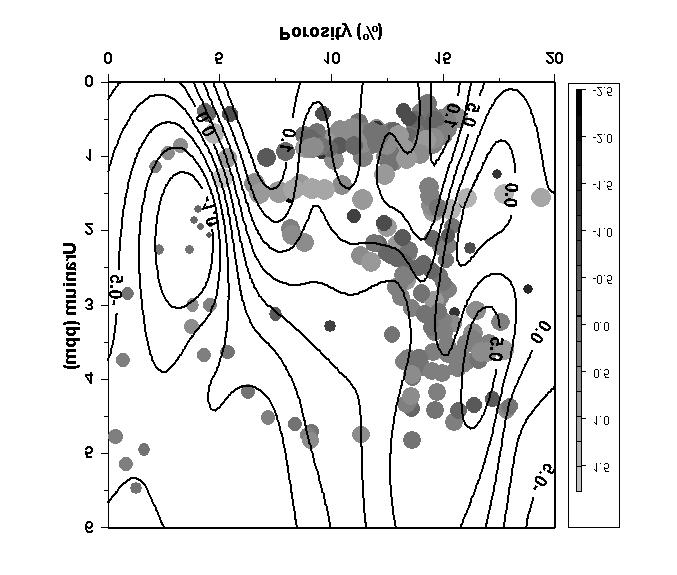
6 We will return to the Chase Group permeability example presented earlier by Dr. Doveton, except with a somewhat expanded (and messier) set of data. Here are the permeability data plotted versus porosity and uranium concentration. The circle sizes are proportional to the base 10 logarithm of permeability in millidarcies, with the permeability values ranging from md (LogPerm = -1.85) to 32.7 md (LogPerm = 1.52). The contours represent LogPerm predicted from a linear regression on porosity and uranium. The residuals from the fit, represented by the gray scale, range from to 1.27 with a standard deviation of For this dataset, the linear regression explains only 28% of the variation in LogPerm. 6

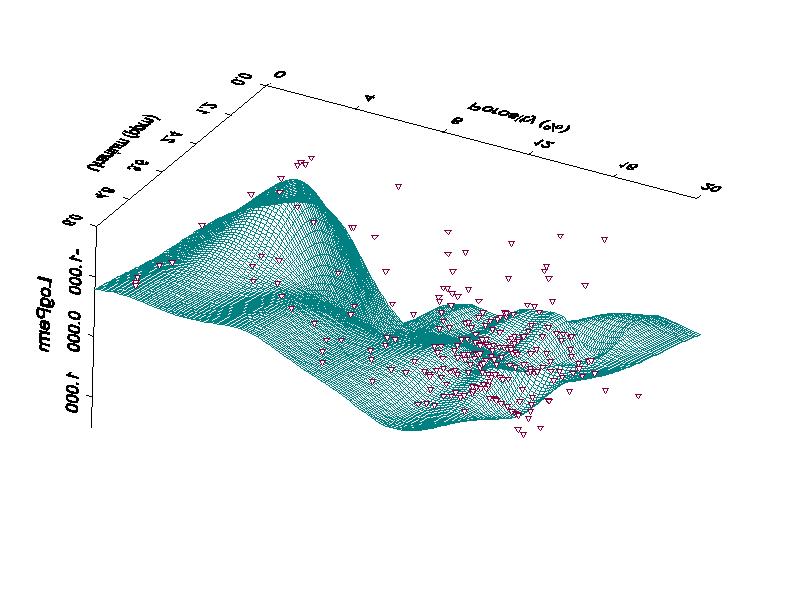
7 Here is a perspective view of the fitted surface followed by the prediction results versus depth: 7
8 To start thinking about different approaches for estimating Y = f ( X ), imagine sitting at some point, x, in the predictor space, looking at the surrounding training data points, and trying to figure out something reasonable to do with the y i values at those points to estimate y at x. Nearest-neighbor averaging: For each estimation point, x, select k nearest neighbors in training dataset and average their responses: Yˆ ( x) = 1 k Nk y ( x ) i ( x) N k means the neighborhood surrounding x containing k training data points. This approach is extremely simple. It is also very flexible in the sense that we can match any training dataset perfectly by choosing k = 1 (assuming there are no duplicate x i values with different y i values). Using one nearest neighbor amounts to assigning the constant value, y i, to the region of space that is closer to x i than to any other training data point the Thiessen polygon of x i. Why do we not just always use nearest-neighbor averaging? Because it does not generalize well, particularly in higher dimensions (larger numbers of predictor variables). It is very strongly affected by the curse of dimensionality... 8
9 The Curse of Dimensionality We are trying to map out a surface in the space of predictor variables, which has a dimension d equal to the number of predictor variables. Imagine that all the variables have been standardized to a common scale and that we are considering a hypercube with a side length of c in that common scale. The volume of this hypercube is given by d V = c So, the volume of the hypercube increases as a power of the dimension. This means that it becomes harder and harder for the training data to fill the volume as the dimensionality increases, and that the probability that an estimation point will fall in empty space far from any training data point increases as a power of the number of predictor variables. So, even a seemingly huge training dataset could be inadequate for modeling in high dimensions. Another way of looking at the curse of dimensionality is that if n training data points seem adequate for developing a onedimensional model (with a single predictor variable), then n d data points are required to get a comparable training data density for a d-dimensional problem. So, if 100 training data points were adequate for a 1-dimensional estimation problem, then = data points would be required to give a comparable density for a 10-dimensional problem. For any realistic training dataset, almost all of the predictor variable space would be far from the nearest data point and nearest-neighbor averaging would give questionable results. 9
10 A number of methods can be used to bridge the gap between a rigid global linear model and an overly flexible nearest-neighbor regression. Most of these methods use a set of basis or kernel functions to interpolate between training data points in a controlled fashion. These methods usually involve a large number of fitting parameters, but they are referred to as nonparametric because the resulting models are not restricted to simple parametric forms. The primary danger of nonparametric techniques is their ability to overfit the training data, at the expense of their ability to generalize to other data sets. All these techniques offer some means of controlling the trade-off between localization (representation of detail in the training data) and generalization (smoothing) by selection of one or more tuning parameters. The specification of the tuning parameters is usually external to the actual fitting process, but optimal tuning parameter values are often estimated via crossvalidation. Global regression with higher-order basis functions: The approximating function is represented as a linear expansion in a set h m x : of global basis or transformation functions, ( ) fˆ θ M ( x) = θ h ( x) m= 1 The basis functions could represent polynomial terms, logarithmic transformations, trigonometric functions, etc. As long as the basis functions do not have any fitting parameters buried in them in a nonlinear fashion, this is still linear regression that is, the dependence on the parameters is linear and we can solve for them in a single step using the standard approach for multivariate linear regression. The tuning here is in the selection of basis functions. For example, we could fit the training data arbitrarily well by selecting a large enough set of polynomial terms, but the resulting surface would flap about wildly away from data points. m m 10
11 Kernel Methods and Locally Weighted Regression: This involves weighting each neighboring data point according to a kernel function giving a decreasing weight with distance and then computing a weighted local mean or linear or polynomial regression model. So, this is basically the same as (smoothing) interpolation in geographic space, but now in the space of the predictor variables. The primary tuning parameter is the bandwidth of the kernel function, which is generally specified in a relative fashion so that the same value can be applied along all predictor axes. Larger bandwidths result in smoother functions. The form of the kernel function is of secondary importance. Smoothing Splines: This involves fitting a sequence of local polynomial basis functions to minimize an objective function involving both model fit and model curvature, as measured by the second derivative, expressed in one dimension as: RSS N 2 ( f, λ ) = { y f ( x )} + { f ( t) } i i λ i= i The smoothing parameter, λ, controls the trade-off between data fit and smoothness, with larger values leading to smoother functions but larger residuals (on the training data, anyway). The smoothing parameter can be selected through automated crossvalidation, choosing a value that minimizes the average error on the withheld data. The approach can be generalized to higher dimensions. The natural form of the smoothing spline in two dimensions is referred to as a thin-plate spline. The figures below show the optimal thin-plate spline fit for the Chase LogPerm data. The residuals from the fit range from to 1.42 with a standard deviation of 0.48 (compared to to 1.27 with a standard deviation of 0.61 for the linear regression fit). The spline fit accounts for 56% of the total variation about the mean, compared to 28% for the least-squares fit. 2 dt 11
12 12
13 Here are the measured and thin-plate spline predicted LogPerms versus depth: 13
14 Neural Networks: There is a variety of neural network types, but the most commonly applied form builds up the fitted surface as a summation of sigmoid (S-shaped) basis functions, each oriented along a different direction in variable space. A direction in variable space corresponds to a particular linear combination of the predictor variables. That is, for a set of coefficients, α, j = 1, K d, where j indexes the set of variables, plus an j, intercept coefficient, α 0, the linear combination α d 0 + α j = 1 represents a combined variable that increases in a particular direction in predictor space essentially a rotated axis in that space. For notational simplicity, we often add a column of 1 s to the set of predictor variables, that is, X 0 = 1 for every data point, so that the linear combination can be represented more compactly as d j = 0 jx j α = α X j X j The second expression shows the summation as the inner product of the coefficient vector and the variable vector. A typical neural network will develop some number, M, linear combinations like the one above meaning M different coefficient vectors, α m and pass each one through a sigmoid transfer function to form a new variable (basis function), Zm ( α X) = 1 ( 1+ ( α X) ) = σ exp m m 14
15 For continuous-variable prediction, the predicted output is then typically just a linear combination of the Z values: fˆ M = 0 m m ( X ) β + β Z = β Z = β Z m= 1 M m= 0 where again we have collapsed the intercept term into the coefficient vector by introducing Z 0 = 1. The complete expression for the approximating function is then fˆ M ( X ) = β mσ d m= 0 j = 0 α m m, j m X j 15
16 If we chose to use M = 4 sigmoid basis functions for the Chase example, the network could be represented schematically as: The input layer contains three nodes representing the bias term X 0 = 1 and the two input variables, porosity and uranium. The hidden layer in the middle contains the four nodes that compute the sigmoid transfer functions, Z m, plus the bias term Z 0 = 1. The lines connecting the input- and hidden-layer nodes represent the coefficients or weights α. The input to each hidden-layer m, j node (excluding the hidden-layer bias node) is one of the linear combinations of input variables and the output is one of the Z m values. The lines connecting the hidden layer node to the output 16
17 node represent the coefficients or weights β m, so the output node computes the linear combination β mz m, our estimate for LogPerm. M m = 0 Training the network means adjusting the network weights to minimize the objective function measuring the mismatch between predicted and observed response variables in a training data set. For continuous-variable prediction, this is usually the least-squares objective function introduced above. Adjusting the weights is an iterative optimization process involving the following steps: 0. Scale the input variables (e.g., to zero mean and unit standard deviation) so that they have roughly equal influence 1. Guess an initial set of weights, usually a set of random numbers 2. Compute predicted response values for the training dataset using current weights 3. Compute residuals or errors between observed & predicted responses 4. Backpropagate errors through network, adjusting weights to reduce errors on next go-round 5. Return to step 2 and repeat until weights stop changing significantly or objective function is sufficiently small Any of a number of algorithms suitable for large-scale optimization can be used -- meaning suitable for problems with a large number of unknown parameters, which are the network weights in this case. Given d input variables and M hidden-layer nodes (actually M+1 including the bias node) the total number of weights to estimate is N w = ( d + 1) M + ( M + 1) -- α s plus β s -- which can get to be quite a few parameters fairly easily. 17
 starting from a different set of initial weights.")
18 Because we are trying to minimize the objective function in an N w - dimensional space, it is very easy for the optimization process to get stuck in a local minimum, rather than finding the global minimum, and typically you will get different results (find a different local minimum) starting from a different set of initial weights. Thus the neural network has a stochastic aspect to it and each set of estimated weights should be considered one possible realization of the network, rather than the correct answer. The most fundamental control on the complexity of the estimated function fˆ ( X ) is the choice of the number of hidden-layer nodes, M. (Usually the bias node is left out of the count of hidden-layer nodes.) We will refer to M as the size of the network. A larger network allows a richer, more detailed representation of the training data, with a smaller network yielding a more generalized representation. Here is the result of using a network with a single hidden-layer node just one sigmoid basis function for the Chase permeability example: 18

19 Here the network finds a rotated axis in Phi-U space oriented in the direction of the most obvious LogPerm trend, from lower values in the northwest to higher values in the southeast, and fits a very sharp sigmoid function practically a step function in this direction. If we use three basis functions, we might get a representation like the following: This looks like our first basis function plus one oriented roughly along the uranium axis, centered at about U = 1.2, and one oriented along an axis running from lower left to upper right, helping to separate out the low values in the southwest corner. 19
 + λ( α ) i x i +, β i= 1 Minimizing this augmented function forces the network weights to be smaller than they would be in the absence of the second term, increasingly so as the damping or")
20 Quite often a term involving the magnitudes of the network weights is added to the objective function, so that the weights are now adjusted to minimize R ( α β ) + λj( α, β ) = y fˆ ( ; α, β ) N ( ) + λ( α ) i x i +, β i= 1 Minimizing this augmented function forces the network weights to be smaller than they would be in the absence of the second term, increasingly so as the damping or decay parameter, λ, increases. Forcing the weights to be smaller generally forces the sigmoid functions to be spread more broadly, leading to smoother representations overall. Here is the fit for a network with three hidden-layer nodes using a decay parameter of λ = 0. 01: You can see that the basis functions developed here are much less step-like than those developed before with no decay ( λ = 0). 20
21 Thus, the primary tuning parameters for this kind of neural network a single hidden-layer neural network with sigmoid basis functions are the size of network, M, and the decay parameter, λ. One strategy for choosing these might be to use a fairly large number of hidden-layer nodes, allowing the network to compute a large number of directions in predictor-variable space along which the response might show significant variation, and a large decay parameter, λ, forcing the resulting basis functions to be fairly smooth and also tending to reduce weights associated with directions of less significant variation. I have used crossvalidation to attempt to estimate the optimal values for M and λ for the Chase example, using an R-language script to run over a range of values of both parameters, M and λ and, for each parameter combination... Split the data at random into a training set (2/3 of the data) consisting of two-thirds of the data and a test set (remaining 1/3) Train a network on the training set Predict on the prediction set Compute the root-mean-squared residual on the prediction set. To account for the random variations due to the selection of training and testing data and due to the stochastic nature of the neural network, I have run the splitting-training-testing cycle 100 times over (different splits and different initial weights each time) for each parameter combination to yield... 21
 occurs for a network size of 3 and a decay of 1 (Log10(decay) of 0), but the results for M = 10 and λ = 0.01 are slightly better in that the median rmsr is almost the same (0.")
22 The lines follow the median and upper and lower quartiles of the rms residual values for each parameter combination. The lowest median rmsr (0.341) occurs for a network size of 3 and a decay of 1 (Log10(decay) of 0), but the results for M = 10 and λ = 0.01 are slightly better in that the median rmsr is almost the same (0.342) and the upper and lower quartiles are a little lower. Using these values for M and λ and training on the whole dataset four different times leads to the following four realizations of the fitted surface: 22

23 The R 2 values (percent variation explained) for the above fits are 63% (upper left), 58% (upper right), 63% (lower left), and 62% (lower right). As with geostatistical stochastic simulation, the range of variation in results for different realizations of the network could be taken as a measure of the uncertainty in your knowledge of the true surface, f ( X ), leading to an ensemble of prediction results, rather than a single prediction for each value of X. You could of course average the predictions from a number of different network realizations. 23
24 Despite the varied appearance of the fitted surfaces vs. Phi-U, the results do not vary greatly at the data points and look much the same plotted versus depth: We would expect more variation at points in Phi-U space at some distance from the nearest training data point. However, in this case, predictions versus depth at a nearby prediction well also look quite similar for the four different networks. Reference T. Hastie, R. Tibshirani, and J. Friedman, The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2001, Springer. 24
LOESS curve fitted to a population sampled from a sine wave with uniform noise added. The LOESS curve approximates the original sine wave.
 LOESS curve fitted to a population sampled from a sine wave with uniform noise added. The LOESS curve approximates the original sine wave. http://en.wikipedia.org/wiki/local_regression Local regression
LOESS curve fitted to a population sampled from a sine wave with uniform noise added. The LOESS curve approximates the original sine wave. http://en.wikipedia.org/wiki/local_regression Local regression
3 Nonlinear Regression
 3 Linear models are often insufficient to capture the real-world phenomena. That is, the relation between the inputs and the outputs we want to be able to predict are not linear. As a consequence, nonlinear
3 Linear models are often insufficient to capture the real-world phenomena. That is, the relation between the inputs and the outputs we want to be able to predict are not linear. As a consequence, nonlinear
3 Nonlinear Regression
 CSC 4 / CSC D / CSC C 3 Sometimes linear models are not sufficient to capture the real-world phenomena, and thus nonlinear models are necessary. In regression, all such models will have the same basic
CSC 4 / CSC D / CSC C 3 Sometimes linear models are not sufficient to capture the real-world phenomena, and thus nonlinear models are necessary. In regression, all such models will have the same basic
Model Assessment and Selection. Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer
 Model Assessment and Selection Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer 1 Model Training data Testing data Model Testing error rate Training error
Model Assessment and Selection Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer 1 Model Training data Testing data Model Testing error rate Training error
Homework. Gaussian, Bishop 2.3 Non-parametric, Bishop 2.5 Linear regression Pod-cast lecture on-line. Next lectures:
 Homework Gaussian, Bishop 2.3 Non-parametric, Bishop 2.5 Linear regression 3.0-3.2 Pod-cast lecture on-line Next lectures: I posted a rough plan. It is flexible though so please come with suggestions Bayes
Homework Gaussian, Bishop 2.3 Non-parametric, Bishop 2.5 Linear regression 3.0-3.2 Pod-cast lecture on-line Next lectures: I posted a rough plan. It is flexible though so please come with suggestions Bayes
FMA901F: Machine Learning Lecture 3: Linear Models for Regression. Cristian Sminchisescu
 FMA901F: Machine Learning Lecture 3: Linear Models for Regression Cristian Sminchisescu Machine Learning: Frequentist vs. Bayesian In the frequentist setting, we seek a fixed parameter (vector), with value(s)
FMA901F: Machine Learning Lecture 3: Linear Models for Regression Cristian Sminchisescu Machine Learning: Frequentist vs. Bayesian In the frequentist setting, we seek a fixed parameter (vector), with value(s)
Spatial Analysis and Modeling (GIST 4302/5302) Guofeng Cao Department of Geosciences Texas Tech University
 Guofeng Cao Department of Geosciences Texas Tech University") Spatial Analysis and Modeling (GIST 4302/5302) Guofeng Cao Department of Geosciences Texas Tech University 1 Outline of This Week Last topic, we learned: Spatial autocorrelation of areal data Spatial regression
Spatial Analysis and Modeling (GIST 4302/5302) Guofeng Cao Department of Geosciences Texas Tech University 1 Outline of This Week Last topic, we learned: Spatial autocorrelation of areal data Spatial regression
( ) = Y ˆ. Calibration Definition A model is calibrated if its predictions are right on average: ave(response Predicted value) = Predicted value.
 = Y ˆ. Calibration Definition A model is calibrated if its predictions are right on average: ave(response Predicted value) = Predicted value.") Calibration OVERVIEW... 2 INTRODUCTION... 2 CALIBRATION... 3 ANOTHER REASON FOR CALIBRATION... 4 CHECKING THE CALIBRATION OF A REGRESSION... 5 CALIBRATION IN SIMPLE REGRESSION (DISPLAY.JMP)... 5 TESTING
Calibration OVERVIEW... 2 INTRODUCTION... 2 CALIBRATION... 3 ANOTHER REASON FOR CALIBRATION... 4 CHECKING THE CALIBRATION OF A REGRESSION... 5 CALIBRATION IN SIMPLE REGRESSION (DISPLAY.JMP)... 5 TESTING
Random Forest A. Fornaser
 Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Machine Learning: An Applied Econometric Approach Online Appendix
 Machine Learning: An Applied Econometric Approach Online Appendix Sendhil Mullainathan mullain@fas.harvard.edu Jann Spiess jspiess@fas.harvard.edu April 2017 A How We Predict In this section, we detail
Machine Learning: An Applied Econometric Approach Online Appendix Sendhil Mullainathan mullain@fas.harvard.edu Jann Spiess jspiess@fas.harvard.edu April 2017 A How We Predict In this section, we detail
CPSC 340: Machine Learning and Data Mining. More Regularization Fall 2017
 CPSC 340: Machine Learning and Data Mining More Regularization Fall 2017 Assignment 3: Admin Out soon, due Friday of next week. Midterm: You can view your exam during instructor office hours or after class
CPSC 340: Machine Learning and Data Mining More Regularization Fall 2017 Assignment 3: Admin Out soon, due Friday of next week. Midterm: You can view your exam during instructor office hours or after class
What is machine learning?
 Machine learning, pattern recognition and statistical data modelling Lecture 12. The last lecture Coryn Bailer-Jones 1 What is machine learning? Data description and interpretation finding simpler relationship
Machine learning, pattern recognition and statistical data modelling Lecture 12. The last lecture Coryn Bailer-Jones 1 What is machine learning? Data description and interpretation finding simpler relationship
CPSC 340: Machine Learning and Data Mining. Principal Component Analysis Fall 2016
 CPSC 340: Machine Learning and Data Mining Principal Component Analysis Fall 2016 A2/Midterm: Admin Grades/solutions will be posted after class. Assignment 4: Posted, due November 14. Extra office hours:
CPSC 340: Machine Learning and Data Mining Principal Component Analysis Fall 2016 A2/Midterm: Admin Grades/solutions will be posted after class. Assignment 4: Posted, due November 14. Extra office hours:
Supplementary Figure 1. Decoding results broken down for different ROIs
 Supplementary Figure 1 Decoding results broken down for different ROIs Decoding results for areas V1, V2, V3, and V1 V3 combined. (a) Decoded and presented orientations are strongly correlated in areas
Supplementary Figure 1 Decoding results broken down for different ROIs Decoding results for areas V1, V2, V3, and V1 V3 combined. (a) Decoded and presented orientations are strongly correlated in areas
Perceptron as a graph
 Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 10 th, 2007 2005-2007 Carlos Guestrin 1 Perceptron as a graph 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0-6 -4-2
Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 10 th, 2007 2005-2007 Carlos Guestrin 1 Perceptron as a graph 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0-6 -4-2
Chapter 7: Dual Modeling in the Presence of Constant Variance
 Chapter 7: Dual Modeling in the Presence of Constant Variance 7.A Introduction An underlying premise of regression analysis is that a given response variable changes systematically and smoothly due to
Chapter 7: Dual Modeling in the Presence of Constant Variance 7.A Introduction An underlying premise of regression analysis is that a given response variable changes systematically and smoothly due to
Module 4. Non-linear machine learning econometrics: Support Vector Machine
 Module 4. Non-linear machine learning econometrics: Support Vector Machine THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Introduction When the assumption of linearity
Module 4. Non-linear machine learning econometrics: Support Vector Machine THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Introduction When the assumption of linearity
Bootstrapping Method for 14 June 2016 R. Russell Rhinehart. Bootstrapping
 Bootstrapping Method for www.r3eda.com 14 June 2016 R. Russell Rhinehart Bootstrapping This is extracted from the book, Nonlinear Regression Modeling for Engineering Applications: Modeling, Model Validation,
Bootstrapping Method for www.r3eda.com 14 June 2016 R. Russell Rhinehart Bootstrapping This is extracted from the book, Nonlinear Regression Modeling for Engineering Applications: Modeling, Model Validation,
CPSC 340: Machine Learning and Data Mining. Regularization Fall 2016
 CPSC 340: Machine Learning and Data Mining Regularization Fall 2016 Assignment 2: Admin 2 late days to hand it in Friday, 3 for Monday. Assignment 3 is out. Due next Wednesday (so we can release solutions
CPSC 340: Machine Learning and Data Mining Regularization Fall 2016 Assignment 2: Admin 2 late days to hand it in Friday, 3 for Monday. Assignment 3 is out. Due next Wednesday (so we can release solutions
Machine Learning / Jan 27, 2010
 Revisiting Logistic Regression & Naïve Bayes Aarti Singh Machine Learning 10-701/15-781 Jan 27, 2010 Generative and Discriminative Classifiers Training classifiers involves learning a mapping f: X -> Y,
Revisiting Logistic Regression & Naïve Bayes Aarti Singh Machine Learning 10-701/15-781 Jan 27, 2010 Generative and Discriminative Classifiers Training classifiers involves learning a mapping f: X -> Y,
The exam is closed book, closed notes except your one-page cheat sheet.
 CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
Machine Learning Lecture 3
 Machine Learning Lecture 3 Probability Density Estimation II 19.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Exam dates We re in the process
Machine Learning Lecture 3 Probability Density Estimation II 19.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Exam dates We re in the process
Recent advances in Metamodel of Optimal Prognosis. Lectures. Thomas Most & Johannes Will
 Lectures Recent advances in Metamodel of Optimal Prognosis Thomas Most & Johannes Will presented at the Weimar Optimization and Stochastic Days 2010 Source: www.dynardo.de/en/library Recent advances in
Lectures Recent advances in Metamodel of Optimal Prognosis Thomas Most & Johannes Will presented at the Weimar Optimization and Stochastic Days 2010 Source: www.dynardo.de/en/library Recent advances in
Machine Learning and Pervasive Computing
 Stephan Sigg Georg-August-University Goettingen, Computer Networks 17.12.2014 Overview and Structure 22.10.2014 Organisation 22.10.3014 Introduction (Def.: Machine learning, Supervised/Unsupervised, Examples)
Stephan Sigg Georg-August-University Goettingen, Computer Networks 17.12.2014 Overview and Structure 22.10.2014 Organisation 22.10.3014 Introduction (Def.: Machine learning, Supervised/Unsupervised, Examples)
The K-modes and Laplacian K-modes algorithms for clustering
 The K-modes and Laplacian K-modes algorithms for clustering Miguel Á. Carreira-Perpiñán Electrical Engineering and Computer Science University of California, Merced http://faculty.ucmerced.edu/mcarreira-perpinan
The K-modes and Laplacian K-modes algorithms for clustering Miguel Á. Carreira-Perpiñán Electrical Engineering and Computer Science University of California, Merced http://faculty.ucmerced.edu/mcarreira-perpinan
Regression III: Advanced Methods
 Lecture 3: Distributions Regression III: Advanced Methods William G. Jacoby Michigan State University Goals of the lecture Examine data in graphical form Graphs for looking at univariate distributions
Lecture 3: Distributions Regression III: Advanced Methods William G. Jacoby Michigan State University Goals of the lecture Examine data in graphical form Graphs for looking at univariate distributions
Nonparametric Regression
 Nonparametric Regression John Fox Department of Sociology McMaster University 1280 Main Street West Hamilton, Ontario Canada L8S 4M4 jfox@mcmaster.ca February 2004 Abstract Nonparametric regression analysis
Nonparametric Regression John Fox Department of Sociology McMaster University 1280 Main Street West Hamilton, Ontario Canada L8S 4M4 jfox@mcmaster.ca February 2004 Abstract Nonparametric regression analysis
Spatial Interpolation & Geostatistics
 (Z i Z j ) 2 / 2 Spatial Interpolation & Geostatistics Lag Lag Mean Distance between pairs of points 1 Tobler s Law All places are related, but nearby places are related more than distant places Corollary:
(Z i Z j ) 2 / 2 Spatial Interpolation & Geostatistics Lag Lag Mean Distance between pairs of points 1 Tobler s Law All places are related, but nearby places are related more than distant places Corollary:
Box-Cox Transformation for Simple Linear Regression
 Chapter 192 Box-Cox Transformation for Simple Linear Regression Introduction This procedure finds the appropriate Box-Cox power transformation (1964) for a dataset containing a pair of variables that are
Chapter 192 Box-Cox Transformation for Simple Linear Regression Introduction This procedure finds the appropriate Box-Cox power transformation (1964) for a dataset containing a pair of variables that are
Introduction to ANSYS DesignXplorer
 Lecture 4 14. 5 Release Introduction to ANSYS DesignXplorer 1 2013 ANSYS, Inc. September 27, 2013 s are functions of different nature where the output parameters are described in terms of the input parameters
Lecture 4 14. 5 Release Introduction to ANSYS DesignXplorer 1 2013 ANSYS, Inc. September 27, 2013 s are functions of different nature where the output parameters are described in terms of the input parameters
The Curse of Dimensionality
 The Curse of Dimensionality ACAS 2002 p1/66 Curse of Dimensionality The basic idea of the curse of dimensionality is that high dimensional data is difficult to work with for several reasons: Adding more
The Curse of Dimensionality ACAS 2002 p1/66 Curse of Dimensionality The basic idea of the curse of dimensionality is that high dimensional data is difficult to work with for several reasons: Adding more
Chapter 18. Geometric Operations
 Chapter 18 Geometric Operations To this point, the image processing operations have computed the gray value (digital count) of the output image pixel based on the gray values of one or more input pixels;
Chapter 18 Geometric Operations To this point, the image processing operations have computed the gray value (digital count) of the output image pixel based on the gray values of one or more input pixels;
Adaptive Metric Nearest Neighbor Classification
 Adaptive Metric Nearest Neighbor Classification Carlotta Domeniconi Jing Peng Dimitrios Gunopulos Computer Science Department Computer Science Department Computer Science Department University of California
Adaptive Metric Nearest Neighbor Classification Carlotta Domeniconi Jing Peng Dimitrios Gunopulos Computer Science Department Computer Science Department Computer Science Department University of California
Model Generalization and the Bias-Variance Trade-Off
 Charu C. Aggarwal IBM T J Watson Research Center Yorktown Heights, NY Model Generalization and the Bias-Variance Trade-Off Neural Networks and Deep Learning, Springer, 2018 Chapter 4, Section 4.1-4.2 What
Charu C. Aggarwal IBM T J Watson Research Center Yorktown Heights, NY Model Generalization and the Bias-Variance Trade-Off Neural Networks and Deep Learning, Springer, 2018 Chapter 4, Section 4.1-4.2 What
Density estimation. In density estimation problems, we are given a random from an unknown density. Our objective is to estimate
 Density estimation In density estimation problems, we are given a random sample from an unknown density Our objective is to estimate? Applications Classification If we estimate the density for each class,
Density estimation In density estimation problems, we are given a random sample from an unknown density Our objective is to estimate? Applications Classification If we estimate the density for each class,
Elemental Set Methods. David Banks Duke University
 Elemental Set Methods David Banks Duke University 1 1. Introduction Data mining deals with complex, high-dimensional data. This means that datasets often combine different kinds of structure. For example:
Elemental Set Methods David Banks Duke University 1 1. Introduction Data mining deals with complex, high-dimensional data. This means that datasets often combine different kinds of structure. For example:
Evaluation Measures. Sebastian Pölsterl. April 28, Computer Aided Medical Procedures Technische Universität München
 Evaluation Measures Sebastian Pölsterl Computer Aided Medical Procedures Technische Universität München April 28, 2015 Outline 1 Classification 1. Confusion Matrix 2. Receiver operating characteristics
Evaluation Measures Sebastian Pölsterl Computer Aided Medical Procedures Technische Universität München April 28, 2015 Outline 1 Classification 1. Confusion Matrix 2. Receiver operating characteristics
Lecture 7: Linear Regression (continued)
") Lecture 7: Linear Regression (continued) Reading: Chapter 3 STATS 2: Data mining and analysis Jonathan Taylor, 10/8 Slide credits: Sergio Bacallado 1 / 14 Potential issues in linear regression 1. Interactions
Lecture 7: Linear Regression (continued) Reading: Chapter 3 STATS 2: Data mining and analysis Jonathan Taylor, 10/8 Slide credits: Sergio Bacallado 1 / 14 Potential issues in linear regression 1. Interactions
Adaptive Robotics - Final Report Extending Q-Learning to Infinite Spaces
 Adaptive Robotics - Final Report Extending Q-Learning to Infinite Spaces Eric Christiansen Michael Gorbach May 13, 2008 Abstract One of the drawbacks of standard reinforcement learning techniques is that
Adaptive Robotics - Final Report Extending Q-Learning to Infinite Spaces Eric Christiansen Michael Gorbach May 13, 2008 Abstract One of the drawbacks of standard reinforcement learning techniques is that
Performance Estimation and Regularization. Kasthuri Kannan, PhD. Machine Learning, Spring 2018
 Performance Estimation and Regularization Kasthuri Kannan, PhD. Machine Learning, Spring 2018 Bias- Variance Tradeoff Fundamental to machine learning approaches Bias- Variance Tradeoff Error due to Bias:
Performance Estimation and Regularization Kasthuri Kannan, PhD. Machine Learning, Spring 2018 Bias- Variance Tradeoff Fundamental to machine learning approaches Bias- Variance Tradeoff Error due to Bias:
Lecture 24: Generalized Additive Models Stat 704: Data Analysis I, Fall 2010
 Lecture 24: Generalized Additive Models Stat 704: Data Analysis I, Fall 2010 Tim Hanson, Ph.D. University of South Carolina T. Hanson (USC) Stat 704: Data Analysis I, Fall 2010 1 / 26 Additive predictors
Lecture 24: Generalized Additive Models Stat 704: Data Analysis I, Fall 2010 Tim Hanson, Ph.D. University of South Carolina T. Hanson (USC) Stat 704: Data Analysis I, Fall 2010 1 / 26 Additive predictors
Chap.12 Kernel methods [Book, Chap.7]
![Chap.12 Kernel methods [Book, Chap.7]](/thumbs/83/87786394.jpg "Chap.12 Kernel methods [Book, Chap.7]") Chap.12 Kernel methods [Book, Chap.7] Neural network methods became popular in the mid to late 1980s, but by the mid to late 1990s, kernel methods have also become popular in machine learning. The first
Chap.12 Kernel methods [Book, Chap.7] Neural network methods became popular in the mid to late 1980s, but by the mid to late 1990s, kernel methods have also become popular in machine learning. The first
UVA CS 6316/4501 Fall 2016 Machine Learning. Lecture 15: K-nearest-neighbor Classifier / Bias-Variance Tradeoff. Dr. Yanjun Qi. University of Virginia
 UVA CS 6316/4501 Fall 2016 Machine Learning Lecture 15: K-nearest-neighbor Classifier / Bias-Variance Tradeoff Dr. Yanjun Qi University of Virginia Department of Computer Science 11/9/16 1 Rough Plan HW5
UVA CS 6316/4501 Fall 2016 Machine Learning Lecture 15: K-nearest-neighbor Classifier / Bias-Variance Tradeoff Dr. Yanjun Qi University of Virginia Department of Computer Science 11/9/16 1 Rough Plan HW5
Applying Supervised Learning
 Applying Supervised Learning When to Consider Supervised Learning A supervised learning algorithm takes a known set of input data (the training set) and known responses to the data (output), and trains
Applying Supervised Learning When to Consider Supervised Learning A supervised learning algorithm takes a known set of input data (the training set) and known responses to the data (output), and trains
Spatial Interpolation - Geostatistics 4/3/2018
 Spatial Interpolation - Geostatistics 4/3/201 (Z i Z j ) 2 / 2 Spatial Interpolation & Geostatistics Lag Distance between pairs of points Lag Mean Tobler s Law All places are related, but nearby places
Spatial Interpolation - Geostatistics 4/3/201 (Z i Z j ) 2 / 2 Spatial Interpolation & Geostatistics Lag Distance between pairs of points Lag Mean Tobler s Law All places are related, but nearby places
Chapter 2 Basic Structure of High-Dimensional Spaces
 Chapter 2 Basic Structure of High-Dimensional Spaces Data is naturally represented geometrically by associating each record with a point in the space spanned by the attributes. This idea, although simple,
Chapter 2 Basic Structure of High-Dimensional Spaces Data is naturally represented geometrically by associating each record with a point in the space spanned by the attributes. This idea, although simple,
4.12 Generalization. In back-propagation learning, as many training examples as possible are typically used.
 1 4.12 Generalization In back-propagation learning, as many training examples as possible are typically used. It is hoped that the network so designed generalizes well. A network generalizes well when
1 4.12 Generalization In back-propagation learning, as many training examples as possible are typically used. It is hoped that the network so designed generalizes well. A network generalizes well when
Knowledge Discovery and Data Mining. Neural Nets. A simple NN as a Mathematical Formula. Notes. Lecture 13 - Neural Nets. Tom Kelsey.
 Knowledge Discovery and Data Mining Lecture 13 - Neural Nets Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey ID5059-13-NN
Knowledge Discovery and Data Mining Lecture 13 - Neural Nets Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey ID5059-13-NN
GAMs semi-parametric GLMs. Simon Wood Mathematical Sciences, University of Bath, U.K.
 GAMs semi-parametric GLMs Simon Wood Mathematical Sciences, University of Bath, U.K. Generalized linear models, GLM 1. A GLM models a univariate response, y i as g{e(y i )} = X i β where y i Exponential
GAMs semi-parametric GLMs Simon Wood Mathematical Sciences, University of Bath, U.K. Generalized linear models, GLM 1. A GLM models a univariate response, y i as g{e(y i )} = X i β where y i Exponential
Instance-based Learning
 Instance-based Learning Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 19 th, 2007 2005-2007 Carlos Guestrin 1 Why not just use Linear Regression? 2005-2007 Carlos Guestrin
Instance-based Learning Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 19 th, 2007 2005-2007 Carlos Guestrin 1 Why not just use Linear Regression? 2005-2007 Carlos Guestrin
Edge and local feature detection - 2. Importance of edge detection in computer vision
 Edge and local feature detection Gradient based edge detection Edge detection by function fitting Second derivative edge detectors Edge linking and the construction of the chain graph Edge and local feature
Edge and local feature detection Gradient based edge detection Edge detection by function fitting Second derivative edge detectors Edge linking and the construction of the chain graph Edge and local feature
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Lecture 13 - Neural Nets Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey ID5059-13-NN
Knowledge Discovery and Data Mining Lecture 13 - Neural Nets Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey ID5059-13-NN
Lecture 26: Missing data
 Lecture 26: Missing data Reading: ESL 9.6 STATS 202: Data mining and analysis December 1, 2017 1 / 10 Missing data is everywhere Survey data: nonresponse. 2 / 10 Missing data is everywhere Survey data:
Lecture 26: Missing data Reading: ESL 9.6 STATS 202: Data mining and analysis December 1, 2017 1 / 10 Missing data is everywhere Survey data: nonresponse. 2 / 10 Missing data is everywhere Survey data:
Non-Linear Regression. Business Analytics Practice Winter Term 2015/16 Stefan Feuerriegel
 Non-Linear Regression Business Analytics Practice Winter Term 2015/16 Stefan Feuerriegel Today s Lecture Objectives 1 Understanding the need for non-parametric regressions 2 Familiarizing with two common
Non-Linear Regression Business Analytics Practice Winter Term 2015/16 Stefan Feuerriegel Today s Lecture Objectives 1 Understanding the need for non-parametric regressions 2 Familiarizing with two common
Lesson 5 overview. Concepts. Interpolators. Assessing accuracy Exercise 5
 Interpolation Tools Lesson 5 overview Concepts Sampling methods Creating continuous surfaces Interpolation Density surfaces in GIS Interpolators IDW, Spline,Trend, Kriging,Natural neighbors TopoToRaster
Interpolation Tools Lesson 5 overview Concepts Sampling methods Creating continuous surfaces Interpolation Density surfaces in GIS Interpolators IDW, Spline,Trend, Kriging,Natural neighbors TopoToRaster
Splines. Patrick Breheny. November 20. Introduction Regression splines (parametric) Smoothing splines (nonparametric)
 Smoothing splines (nonparametric)") Splines Patrick Breheny November 20 Patrick Breheny STA 621: Nonparametric Statistics 1/46 Introduction Introduction Problems with polynomial bases We are discussing ways to estimate the regression function
Splines Patrick Breheny November 20 Patrick Breheny STA 621: Nonparametric Statistics 1/46 Introduction Introduction Problems with polynomial bases We are discussing ways to estimate the regression function
Using Excel for Graphical Analysis of Data
 Using Excel for Graphical Analysis of Data Introduction In several upcoming labs, a primary goal will be to determine the mathematical relationship between two variable physical parameters. Graphs are
Using Excel for Graphical Analysis of Data Introduction In several upcoming labs, a primary goal will be to determine the mathematical relationship between two variable physical parameters. Graphs are
Topics in Machine Learning
 Topics in Machine Learning Gilad Lerman School of Mathematics University of Minnesota Text/slides stolen from G. James, D. Witten, T. Hastie, R. Tibshirani and A. Ng Machine Learning - Motivation Arthur
Topics in Machine Learning Gilad Lerman School of Mathematics University of Minnesota Text/slides stolen from G. James, D. Witten, T. Hastie, R. Tibshirani and A. Ng Machine Learning - Motivation Arthur
Data can be in the form of numbers, words, measurements, observations or even just descriptions of things.
 + What is Data? Data is a collection of facts. Data can be in the form of numbers, words, measurements, observations or even just descriptions of things. In most cases, data needs to be interpreted and
+ What is Data? Data is a collection of facts. Data can be in the form of numbers, words, measurements, observations or even just descriptions of things. In most cases, data needs to be interpreted and
Robust Regression. Robust Data Mining Techniques By Boonyakorn Jantaranuson
 Robust Regression Robust Data Mining Techniques By Boonyakorn Jantaranuson Outline Introduction OLS and important terminology Least Median of Squares (LMedS) M-estimator Penalized least squares What is
Robust Regression Robust Data Mining Techniques By Boonyakorn Jantaranuson Outline Introduction OLS and important terminology Least Median of Squares (LMedS) M-estimator Penalized least squares What is
Nonparametric Approaches to Regression
 Nonparametric Approaches to Regression In traditional nonparametric regression, we assume very little about the functional form of the mean response function. In particular, we assume the model where m(xi)
Nonparametric Approaches to Regression In traditional nonparametric regression, we assume very little about the functional form of the mean response function. In particular, we assume the model where m(xi)
CPSC 340: Machine Learning and Data Mining. Robust Regression Fall 2015
 CPSC 340: Machine Learning and Data Mining Robust Regression Fall 2015 Admin Can you see Assignment 1 grades on UBC connect? Auditors, don t worry about it. You should already be working on Assignment
CPSC 340: Machine Learning and Data Mining Robust Regression Fall 2015 Admin Can you see Assignment 1 grades on UBC connect? Auditors, don t worry about it. You should already be working on Assignment
Lecture on Modeling Tools for Clustering & Regression
 Lecture on Modeling Tools for Clustering & Regression CS 590.21 Analysis and Modeling of Brain Networks Department of Computer Science University of Crete Data Clustering Overview Organizing data into
Lecture on Modeling Tools for Clustering & Regression CS 590.21 Analysis and Modeling of Brain Networks Department of Computer Science University of Crete Data Clustering Overview Organizing data into
Nearest Neighbor Predictors
 Nearest Neighbor Predictors September 2, 2018 Perhaps the simplest machine learning prediction method, from a conceptual point of view, and perhaps also the most unusual, is the nearest-neighbor method,
Nearest Neighbor Predictors September 2, 2018 Perhaps the simplest machine learning prediction method, from a conceptual point of view, and perhaps also the most unusual, is the nearest-neighbor method,
Graphical Analysis of Data using Microsoft Excel [2016 Version]
![Graphical Analysis of Data using Microsoft Excel [2016 Version]](/thumbs/72/67574169.jpg "Graphical Analysis of Data using Microsoft Excel [2016 Version]") Graphical Analysis of Data using Microsoft Excel [2016 Version] Introduction In several upcoming labs, a primary goal will be to determine the mathematical relationship between two variable physical parameters.
Graphical Analysis of Data using Microsoft Excel [2016 Version] Introduction In several upcoming labs, a primary goal will be to determine the mathematical relationship between two variable physical parameters.
CS489/698: Intro to ML
 CS489/698: Intro to ML Lecture 14: Training of Deep NNs Instructor: Sun Sun 1 Outline Activation functions Regularization Gradient-based optimization 2 Examples of activation functions 3 5/28/18 Sun Sun
CS489/698: Intro to ML Lecture 14: Training of Deep NNs Instructor: Sun Sun 1 Outline Activation functions Regularization Gradient-based optimization 2 Examples of activation functions 3 5/28/18 Sun Sun
Locally Weighted Least Squares Regression for Image Denoising, Reconstruction and Up-sampling
 Locally Weighted Least Squares Regression for Image Denoising, Reconstruction and Up-sampling Moritz Baecher May 15, 29 1 Introduction Edge-preserving smoothing and super-resolution are classic and important
Locally Weighted Least Squares Regression for Image Denoising, Reconstruction and Up-sampling Moritz Baecher May 15, 29 1 Introduction Edge-preserving smoothing and super-resolution are classic and important
Model selection and validation 1: Cross-validation
 Model selection and validation 1: Cross-validation Ryan Tibshirani Data Mining: 36-462/36-662 March 26 2013 Optional reading: ISL 2.2, 5.1, ESL 7.4, 7.10 1 Reminder: modern regression techniques Over the
Model selection and validation 1: Cross-validation Ryan Tibshirani Data Mining: 36-462/36-662 March 26 2013 Optional reading: ISL 2.2, 5.1, ESL 7.4, 7.10 1 Reminder: modern regression techniques Over the
Four equations are necessary to evaluate these coefficients. Eqn
 1.2 Splines 11 A spline function is a piecewise defined function with certain smoothness conditions [Cheney]. A wide variety of functions is potentially possible; polynomial functions are almost exclusively
1.2 Splines 11 A spline function is a piecewise defined function with certain smoothness conditions [Cheney]. A wide variety of functions is potentially possible; polynomial functions are almost exclusively
Recap: Gaussian (or Normal) Distribution. Recap: Minimizing the Expected Loss. Topics of This Lecture. Recap: Maximum Likelihood Approach
 Distribution. Recap: Minimizing the Expected Loss. Topics of This Lecture. Recap: Maximum Likelihood Approach") Truth Course Outline Machine Learning Lecture 3 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Probability Density Estimation II 2.04.205 Discriminative Approaches (5 weeks)
Truth Course Outline Machine Learning Lecture 3 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Probability Density Estimation II 2.04.205 Discriminative Approaches (5 weeks)
Mapping of Hierarchical Activation in the Visual Cortex Suman Chakravartula, Denise Jones, Guillaume Leseur CS229 Final Project Report. Autumn 2008.
 Mapping of Hierarchical Activation in the Visual Cortex Suman Chakravartula, Denise Jones, Guillaume Leseur CS229 Final Project Report. Autumn 2008. Introduction There is much that is unknown regarding
Mapping of Hierarchical Activation in the Visual Cortex Suman Chakravartula, Denise Jones, Guillaume Leseur CS229 Final Project Report. Autumn 2008. Introduction There is much that is unknown regarding
Generalized Additive Model
 Generalized Additive Model by Huimin Liu Department of Mathematics and Statistics University of Minnesota Duluth, Duluth, MN 55812 December 2008 Table of Contents Abstract... 2 Chapter 1 Introduction 1.1
Generalized Additive Model by Huimin Liu Department of Mathematics and Statistics University of Minnesota Duluth, Duluth, MN 55812 December 2008 Table of Contents Abstract... 2 Chapter 1 Introduction 1.1
Section 4 Matching Estimator
 Section 4 Matching Estimator Matching Estimators Key Idea: The matching method compares the outcomes of program participants with those of matched nonparticipants, where matches are chosen on the basis
Section 4 Matching Estimator Matching Estimators Key Idea: The matching method compares the outcomes of program participants with those of matched nonparticipants, where matches are chosen on the basis
Lecture 13: Model selection and regularization
 Lecture 13: Model selection and regularization Reading: Sections 6.1-6.2.1 STATS 202: Data mining and analysis October 23, 2017 1 / 17 What do we know so far In linear regression, adding predictors always
Lecture 13: Model selection and regularization Reading: Sections 6.1-6.2.1 STATS 202: Data mining and analysis October 23, 2017 1 / 17 What do we know so far In linear regression, adding predictors always
Machine Learning Lecture 3
 Many slides adapted from B. Schiele Machine Learning Lecture 3 Probability Density Estimation II 26.04.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course
Many slides adapted from B. Schiele Machine Learning Lecture 3 Probability Density Estimation II 26.04.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course
Machine Learning Lecture 3
 Course Outline Machine Learning Lecture 3 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Probability Density Estimation II 26.04.206 Discriminative Approaches (5 weeks) Linear
Course Outline Machine Learning Lecture 3 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Probability Density Estimation II 26.04.206 Discriminative Approaches (5 weeks) Linear
5 Learning hypothesis classes (16 points)
") 5 Learning hypothesis classes (16 points) Consider a classification problem with two real valued inputs. For each of the following algorithms, specify all of the separators below that it could have generated
5 Learning hypothesis classes (16 points) Consider a classification problem with two real valued inputs. For each of the following algorithms, specify all of the separators below that it could have generated
Partitioning Data. IRDS: Evaluation, Debugging, and Diagnostics. Cross-Validation. Cross-Validation for parameter tuning
 Partitioning Data IRDS: Evaluation, Debugging, and Diagnostics Charles Sutton University of Edinburgh Training Validation Test Training : Running learning algorithms Validation : Tuning parameters of learning
Partitioning Data IRDS: Evaluation, Debugging, and Diagnostics Charles Sutton University of Edinburgh Training Validation Test Training : Running learning algorithms Validation : Tuning parameters of learning
A popular method for moving beyond linearity. 2. Basis expansion and regularization 1. Examples of transformations. Piecewise-polynomials and splines
 A popular method for moving beyond linearity 2. Basis expansion and regularization 1 Idea: Augment the vector inputs x with additional variables which are transformation of x use linear models in this
A popular method for moving beyond linearity 2. Basis expansion and regularization 1 Idea: Augment the vector inputs x with additional variables which are transformation of x use linear models in this
SUPERVISED LEARNING METHODS. Stanley Liang, PhD Candidate, Lassonde School of Engineering, York University Helix Science Engagement Programs 2018
 SUPERVISED LEARNING METHODS Stanley Liang, PhD Candidate, Lassonde School of Engineering, York University Helix Science Engagement Programs 2018 2 CHOICE OF ML You cannot know which algorithm will work
SUPERVISED LEARNING METHODS Stanley Liang, PhD Candidate, Lassonde School of Engineering, York University Helix Science Engagement Programs 2018 2 CHOICE OF ML You cannot know which algorithm will work
Multimedia Computing: Algorithms, Systems, and Applications: Edge Detection
 Multimedia Computing: Algorithms, Systems, and Applications: Edge Detection By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854, USA Part of the slides
Multimedia Computing: Algorithms, Systems, and Applications: Edge Detection By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854, USA Part of the slides
Using Excel for Graphical Analysis of Data
 EXERCISE Using Excel for Graphical Analysis of Data Introduction In several upcoming experiments, a primary goal will be to determine the mathematical relationship between two variable physical parameters.
EXERCISE Using Excel for Graphical Analysis of Data Introduction In several upcoming experiments, a primary goal will be to determine the mathematical relationship between two variable physical parameters.
Geology Geomath Estimating the coefficients of various Mathematical relationships in Geology
 Geology 351 - Geomath Estimating the coefficients of various Mathematical relationships in Geology Throughout the semester you ve encountered a variety of mathematical relationships between various geologic
Geology 351 - Geomath Estimating the coefficients of various Mathematical relationships in Geology Throughout the semester you ve encountered a variety of mathematical relationships between various geologic
Economics Nonparametric Econometrics
 Economics 217 - Nonparametric Econometrics Topics covered in this lecture Introduction to the nonparametric model The role of bandwidth Choice of smoothing function R commands for nonparametric models
Economics 217 - Nonparametric Econometrics Topics covered in this lecture Introduction to the nonparametric model The role of bandwidth Choice of smoothing function R commands for nonparametric models
Comparing different interpolation methods on two-dimensional test functions
 Comparing different interpolation methods on two-dimensional test functions Thomas Mühlenstädt, Sonja Kuhnt May 28, 2009 Keywords: Interpolation, computer experiment, Kriging, Kernel interpolation, Thin
Comparing different interpolation methods on two-dimensional test functions Thomas Mühlenstädt, Sonja Kuhnt May 28, 2009 Keywords: Interpolation, computer experiment, Kriging, Kernel interpolation, Thin
Digital Image Processing. Prof. P. K. Biswas. Department of Electronic & Electrical Communication Engineering
 Digital Image Processing Prof. P. K. Biswas Department of Electronic & Electrical Communication Engineering Indian Institute of Technology, Kharagpur Lecture - 21 Image Enhancement Frequency Domain Processing
Digital Image Processing Prof. P. K. Biswas Department of Electronic & Electrical Communication Engineering Indian Institute of Technology, Kharagpur Lecture - 21 Image Enhancement Frequency Domain Processing
Spatial Interpolation & Geostatistics
 (Z i Z j ) 2 / 2 Spatial Interpolation & Geostatistics Lag Lag Mean Distance between pairs of points 11/3/2016 GEO327G/386G, UT Austin 1 Tobler s Law All places are related, but nearby places are related
(Z i Z j ) 2 / 2 Spatial Interpolation & Geostatistics Lag Lag Mean Distance between pairs of points 11/3/2016 GEO327G/386G, UT Austin 1 Tobler s Law All places are related, but nearby places are related
Lecture 27, April 24, Reading: See class website. Nonparametric regression and kernel smoothing. Structured sparse additive models (GroupSpAM)
") School of Computer Science Probabilistic Graphical Models Structured Sparse Additive Models Junming Yin and Eric Xing Lecture 7, April 4, 013 Reading: See class website 1 Outline Nonparametric regression
School of Computer Science Probabilistic Graphical Models Structured Sparse Additive Models Junming Yin and Eric Xing Lecture 7, April 4, 013 Reading: See class website 1 Outline Nonparametric regression
Points Lines Connected points X-Y Scatter. X-Y Matrix Star Plot Histogram Box Plot. Bar Group Bar Stacked H-Bar Grouped H-Bar Stacked
 Plotting Menu: QCExpert Plotting Module graphs offers various tools for visualization of uni- and multivariate data. Settings and options in different types of graphs allow for modifications and customizations
Plotting Menu: QCExpert Plotting Module graphs offers various tools for visualization of uni- and multivariate data. Settings and options in different types of graphs allow for modifications and customizations
Sandeep Kharidhi and WenSui Liu ChoicePoint Precision Marketing
 Generalized Additive Model and Applications in Direct Marketing Sandeep Kharidhi and WenSui Liu ChoicePoint Precision Marketing Abstract Logistic regression 1 has been widely used in direct marketing applications
Generalized Additive Model and Applications in Direct Marketing Sandeep Kharidhi and WenSui Liu ChoicePoint Precision Marketing Abstract Logistic regression 1 has been widely used in direct marketing applications
Neural Networks. CE-725: Statistical Pattern Recognition Sharif University of Technology Spring Soleymani
 Neural Networks CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Biological and artificial neural networks Feed-forward neural networks Single layer
Neural Networks CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Biological and artificial neural networks Feed-forward neural networks Single layer
Applied Statistics : Practical 9
 Applied Statistics : Practical 9 This practical explores nonparametric regression and shows how to fit a simple additive model. The first item introduces the necessary R commands for nonparametric regression
Applied Statistics : Practical 9 This practical explores nonparametric regression and shows how to fit a simple additive model. The first item introduces the necessary R commands for nonparametric regression
Splines and penalized regression
 Splines and penalized regression November 23 Introduction We are discussing ways to estimate the regression function f, where E(y x) = f(x) One approach is of course to assume that f has a certain shape,
Splines and penalized regression November 23 Introduction We are discussing ways to estimate the regression function f, where E(y x) = f(x) One approach is of course to assume that f has a certain shape,
Feature Detectors and Descriptors: Corners, Lines, etc.
 Feature Detectors and Descriptors: Corners, Lines, etc. Edges vs. Corners Edges = maxima in intensity gradient Edges vs. Corners Corners = lots of variation in direction of gradient in a small neighborhood
Feature Detectors and Descriptors: Corners, Lines, etc. Edges vs. Corners Edges = maxima in intensity gradient Edges vs. Corners Corners = lots of variation in direction of gradient in a small neighborhood
Watershed Sciences 4930 & 6920 GEOGRAPHIC INFORMATION SYSTEMS
 HOUSEKEEPING Watershed Sciences 4930 & 6920 GEOGRAPHIC INFORMATION SYSTEMS Quizzes Lab 8? WEEK EIGHT Lecture INTERPOLATION & SPATIAL ESTIMATION Joe Wheaton READING FOR TODAY WHAT CAN WE COLLECT AT POINTS?
HOUSEKEEPING Watershed Sciences 4930 & 6920 GEOGRAPHIC INFORMATION SYSTEMS Quizzes Lab 8? WEEK EIGHT Lecture INTERPOLATION & SPATIAL ESTIMATION Joe Wheaton READING FOR TODAY WHAT CAN WE COLLECT AT POINTS?
Density estimation. In density estimation problems, we are given a random from an unknown density. Our objective is to estimate
 Density estimation In density estimation problems, we are given a random sample from an unknown density Our objective is to estimate? Applications Classification If we estimate the density for each class,
Density estimation In density estimation problems, we are given a random sample from an unknown density Our objective is to estimate? Applications Classification If we estimate the density for each class,
COMPUTATIONAL INTELLIGENCE SEW (INTRODUCTION TO MACHINE LEARNING) SS18. Lecture 6: k-nn Cross-validation Regularization
 SS18. Lecture 6: k-nn Cross-validation Regularization") COMPUTATIONAL INTELLIGENCE SEW (INTRODUCTION TO MACHINE LEARNING) SS18 Lecture 6: k-nn Cross-validation Regularization LEARNING METHODS Lazy vs eager learning Eager learning generalizes training data before
COMPUTATIONAL INTELLIGENCE SEW (INTRODUCTION TO MACHINE LEARNING) SS18 Lecture 6: k-nn Cross-validation Regularization LEARNING METHODS Lazy vs eager learning Eager learning generalizes training data before
Index. Umberto Michelucci 2018 U. Michelucci, Applied Deep Learning,
 A Acquisition function, 298, 301 Adam optimizer, 175 178 Anaconda navigator conda command, 3 Create button, 5 download and install, 1 installing packages, 8 Jupyter Notebook, 11 13 left navigation pane,
A Acquisition function, 298, 301 Adam optimizer, 175 178 Anaconda navigator conda command, 3 Create button, 5 download and install, 1 installing packages, 8 Jupyter Notebook, 11 13 left navigation pane,
Improving the way neural networks learn Srikumar Ramalingam School of Computing University of Utah
 Improving the way neural networks learn Srikumar Ramalingam School of Computing University of Utah Reference Most of the slides are taken from the third chapter of the online book by Michael Nielson: neuralnetworksanddeeplearning.com
Improving the way neural networks learn Srikumar Ramalingam School of Computing University of Utah Reference Most of the slides are taken from the third chapter of the online book by Michael Nielson: neuralnetworksanddeeplearning.com
DS Machine Learning and Data Mining I. Alina Oprea Associate Professor, CCIS Northeastern University
 DS 4400 Machine Learning and Data Mining I Alina Oprea Associate Professor, CCIS Northeastern University September 20 2018 Review Solution for multiple linear regression can be computed in closed form
DS 4400 Machine Learning and Data Mining I Alina Oprea Associate Professor, CCIS Northeastern University September 20 2018 Review Solution for multiple linear regression can be computed in closed form