Unsupervised Learning : Clustering
|
|
|
- Roger Lyons
- 6 years ago
- Views:
Transcription
1 Unsupervised Learning : Clustering
2 Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex multi-modal optimization problem.
3 3
4 4
5 What is Cluster Analysis? Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from (or unrelated to) the objects in other groups Intra-cluster distances are minimized Inter-cluster distances are maximized


6 However, Clustering Similarity is hard to define, and. We know it when we see it The real meaning of similarity is a philosophical question. We will take a more pragmatic approach. PC:
7 Notion of a Cluster can be Ambiguous How many clusters? Six Clusters Two Clusters Four Clusters
8 Types of Clustering A clustering is a set of clusters Important distinction between hierarchical and partitional sets of clusters Partitional Clustering A division data objects into non-overlapping subsets (clusters) such that each data object is in exactly one subset Hierarchical clustering A set of nested clusters organized as a hierarchical tree
9 Other Distinctions Between Sets of Clusters Exclusive versus non-exclusive In non-exclusive clustering, points may belong to multiple clusters. Can represent multiple classes or border points Fuzzy versus non-fuzzy In fuzzy clustering, a point belongs to every cluster with some weight (membership) between 0 and 1 Weights must sum to 1 Each cluster is a fuzzy set. Partial versus complete In some cases, we only want to cluster some of the data Heterogeneous versus homogeneous Cluster of widely different sizes, shapes, and densities
10 K-MEANS CLUSTERING The k-means algorithm is an algorithm to cluster n objects based on attributes into k partitions, where k < n. It is similar to the expectation-maximization algorithm for mixtures of Gaussians in that they both attempt to find the centers of natural clusters in the data. It assumes that the object attributes form a vector space.
11 An algorithm for partitioning (or clustering) N data points into k disjoint subsets S j containing data points so as to minimize the sum-of-squares criterion k 2 ( 1, 2,..., k ) ( i, j ) j= 1 Z C SSE ICS C C C d Z V = = Z i is a data point in cluster C j and V j is the representative point (most often the mean) for cluster C j. Given two clusters, we can choose the one with the smallest error One easy way to reduce SSE is to increase k, the number of clusters A good clustering with smaller k can have a higher SSE than a poor clustering with higher k i i
12 Simply speaking k-means clustering is an algorithm to classify or to group the objects based on attributes/features into K number of group. K is positive integer number. The grouping is done by minimizing the sum of squares of distances between data and the corresponding cluster centroid.
13 How the K-Mean Clustering algorithm works?
14 Step 1: Begin with a decision on the value of k = number of clusters. Step 2: Put any initial partition that classifies the data into k clusters. You may assign the training samples randomly,or systematically as the following: 1.Take the first k training sample as singleelement clusters 2. Assign each of the remaining (N-k) training sample to the cluster with the nearest centroid. After each assignment, recompute the centroid of the gaining cluster.
15 Step 3: Take each sample in sequence and compute its distance from the centroid of each of the clusters. If a sample is not currently in the cluster with the closest centroid, switch this sample to that cluster and update the centroid of the cluster gaining the new sample and the cluster losing the sample. Step 4. Repeat step 3 until convergence is achieved, that is until a pass through the training sample causes no new assignments.
16 A Simple example showing the implementation of k-means algorithm (using k=2)
17 Step 1: Initialization: Randomly we choose following two centroids (k=2) for two clusters. In this case the 2 centroid are: m1=(1.0,1.0) and m2=(5.0,7.0).
18 Step 2: Thus, we obtain two clusters containing: {1,2,3} and {4,5,6,7}. Their new centroids are:
19 Step 3: Now using these centroids we compute the Euclidean distance of each object, as shown in table. Therefore, the new clusters are: {1,2} and {3,4,5,6,7} Next centroids are: m1=(1.25,1.5) and m2 = (3.9,5.1)
20 Step 4 : The clusters obtained are: {1,2} and {3,4,5,6,7} Therefore, there is no change in the cluster. Thus, the algorithm comes Thus, the algorithm comes to a halt here and final result consist of 2 clusters {1,2} and {3,4,5,6,7}.
21 PLOT
22 (with K=3) Step 1 Step 2
23 PLOT
24 Real-Life Numerical Example of K-Means Clustering We have 4 medicines as our training data points object and each medicine has 2 attributes. Each attribute represents coordinate of the object. We have to determine which medicines belong to cluster 1 and which medicines belong to the other cluster. Object Medicine A Attribute1 (X): weight index Attribute 2 (Y): ph 1 1 Medicine B 2 1 Medicine C 4 3 Medicine D 5 4
25 Step 1: Initial value of centroids : Suppose we use medicine A and medicine B as the first centroids. Let and c 1 and c 2 denote the coordinate of the centroids, then c 1 =(1,1) and c 2 =(2,1)
26 Objects-Centroids distance : we calculate the distance between cluster centroid to each object. Let us use Euclidean distance, then we have distance matrix at iteration 0 is Each column in the distance matrix symbolizes the object. The first row of the distance matrix corresponds to the distance of each object to the first centroid and the second row is the distance of each object to the second centroid. For example, distance from medicine C = (4, 3) to the first centroid is, and its distance to the second centroid is, is etc.
27 Step 2: Objects clustering : We assign each object based on the minimum distance. Medicine A is assigned to group 1, medicine B to group 2, medicine C to group 2 and medicine D to group 2. The elements of Group matrix below is 1 if and only if the object is assigned to that group.
28 Iteration-1, Objects-Centroids distances : The next step is to compute the distance of all objects to the new centroids. Similar to step 2, we have distance matrix at iteration 1 is
29 Iteration-1, Objects clustering:based on the new distance matrix, we move the medicine B to Group 1 while all the other objects remain. The Group matrix is shown below Iteration 2, determine centroids: Now we repeat step 4 to calculate the new centroids coordinate based on the clustering of previous iteration. Group1 and group 2 both has two members, thus the new centroids are and
30 Iteration-2, Objects-Centroids distances : Repeat step 2 again, we have new distance matrix at iteration 2 as
31 Iteration-2, Objects clustering: Again, we assign each object based on the minimum distance. We obtain result that. Comparing the grouping of last iteration and this iteration reveals that the objects does not move group anymore. Thus, the computation of the k-mean clustering has reached its stability and no more iteration is needed..
32 Two different K-means Clustering Original Points 1.5 y x y y x Optimal Clustering x Sub-optimal Clustering
33 Importance of Choosing Initial Centroids 3 Iteration y x
34 Importance of Choosing Initial Centroids 3 Iteration 1 3 Iteration 2 3 Iteration y y y x x x 3 Iteration 4 3 Iteration 5 3 Iteration y y y x x x
35 Importance of Choosing Initial Centroids 3 Iteration y x
36 Types of Clusters Well-separated clusters Center-based clusters Contiguous clusters Density-based clusters Property or Conceptual Described by an Objective Function
37 Types of Clusters: Well-Separated Well-Separated Clusters: A cluster is a set of points such that any point in a cluster is closer (or more similar) to every other point in the cluster than to any point not in the cluster. 3 well-separated clusters
38 Types of Clusters: Center-Based Center-based A cluster is a set of objects such that an object in a cluster is closer (more similar) to the center of a cluster, than to the center of any other cluster The center of a cluster is often a centroid, the average of all the points in the cluster, or a medoid, the most representative point of a cluster 4 center-based clusters
39 Types of Clusters: Contiguity-Based Contiguous Cluster (Nearest neighbor or Transitive) A cluster is a set of points such that a point in a cluster is closer (or more similar) to one or more other points in the cluster than to any point not in the cluster. 8 contiguous clusters
40 Types of Clusters: Density-Based Density-based A cluster is a dense region of points, which is separated by low-density regions, from other regions of high density. Used when the clusters are irregular or intertwined, and when noise and outliers are present. 6 density-based clusters
41 Types of Clusters: Conceptual Clusters Shared Property or Conceptual Clusters Finds clusters that share some common property or represent a particular concept.. 2 Overlapping Circles
42 Types of Clusters: Objective Function Clusters Defined by an Objective Function Finds clusters that minimize or maximize an objective function. Enumerate all possible ways of dividing the points into clusters and evaluate the `goodness' of each potential set of clusters by using the given objective function. (No. of feasible partitions could be very large and the problem is NP Hard) Can have global or local objectives. Hierarchical clustering algorithms typically have local objectives Partitional algorithms typically have global objectives A variation of the global objective function approach is to fit the data to a parameterized model. Parameters for the model are determined from the data. Mixture models assume that the data is a mixture' of a number of statistical distributions.
43 Types of Clusters: Objective Function Map the clustering problem to a different domain and solve a related problem in that domain Proximity matrix defines a weighted graph, where the nodes are the points being clustered, and the weighted edges represent the proximities between points Clustering is equivalent to breaking the graph into connected components, one for each cluster. Want to minimize the edge weight between clusters and maximize the edge weight within clusters
44 Evaluating K-means Clusters Most common measure is Sum of Squared Error (SSE) or summed Intra Cluster Spread (ICS) For each point, the error is the distance to the nearest cluster center To get SSE, we square these errors and sum them. SSE = ICS( C ( Z, m k 2 1, C2,..., Ck ) = d i j j = 1 Z C Z i is a data point in cluster C i and m i is the representative point for cluster C i can show that m i corresponds to the center (mean) of the cluster Given two clusters, we can choose the one with the smallest error One easy way to reduce SSE is to increase k, the number of clusters A good clustering with smaller k can have a lower SSE than a poor clustering with higher k i i )
45 Problems with Selecting Initial Points skip If there are K real clusters then the chance of selecting one centroid from each cluster is small. Chance is relatively small when K is large If clusters are the same size, n, then For example, if K = 10, then probability = 10!/10 10 = Sometimes the initial centroids will readjust themselves in right way, and sometimes they don t
46 Solutions to Initial Centroids Problem Multiple runs Helps, but probability is not on your side Sample and use hierarchical clustering to determine initial centroids Select more than k initial centroids and then select among these initial centroids Select most widely separated Postprocessing Bisecting K-means Not as susceptible to initialization issues
47 Handling Empty Clusters Basic K-means algorithm can yield empty clusters Several strategies Choose the point that contributes most to SSE Choose a point from the cluster with the highest SSE If there are several empty clusters, the above can be repeated several times.
48 Limitations of K-means K-means has problems when clusters are of differing Sizes Densities Non-globular shapes K-means has problems when the data contains outliers.
49 Limitations of K-means: Differing Sizes Original Points K-means (3 Clusters)
50 Limitations of K-means: Differing Density Original Points K-means (3 Clusters)

51 Limitations of K-means: Non-globular and linearly non-separable Shapes Original Points K-means (2 Clusters)
52 Overcoming K-means Limitations Original Points K-means Clusters One solution is to use many clusters. Find parts of clusters, but need to put together.
53 Cluster Validity For supervised classification we have a variety of measures to evaluate how good our model is Accuracy, precision, recall For cluster analysis, the analogous question is how to evaluate the goodness of the resulting clusters? But clusters are in the eye of the beholder! Then why do we want to evaluate them? To avoid finding patterns in noise To compare clustering algorithms To compare two sets of clusters To compare two clusters
54 Clusters found in Random Data Random Points y y DBSCAN x x K-means Complete Link y 0.5 y x x
55 Different Aspects of Cluster Validation 1. Determining the clustering tendency of a set of data, i.e., distinguishing whether non-random structure actually exists in the data. 2. Comparing the results of a cluster analysis to externally known results, e.g., to externally given class labels. 3. Evaluating how well the results of a cluster analysis fit the data without reference to external information. - Use only the data 4. Comparing the results of two different sets of cluster analyses to determine which is better. 5. Determining the correct number of clusters. For 2, 3, and 4, we can further distinguish whether we want to evaluate the entire clustering or just individual clusters.
 = d i, m j j= 1 Z C i i ) Example of an extremely simple one-dimensional dataset Fitness function (Reciprocal of ICS) plot")
56 Landscape for Clustering Problem The k-means objective function ICS( C ( Z k 2 1, C2,..., Ck ) = d i, m j j= 1 Z C i i ) Example of an extremely simple one-dimensional dataset Fitness function (Reciprocal of ICS) plot of the hard c-means algorithm for above dataset
 The previous data but now With some noise points Fitness function (Reciprocal of ICS) plot of the hard c-means algorithm for above dataset In addition to two global minima, we have local minima at:")
57 Landscape for Clustering Problem (Contd.) The previous data but now With some noise points Fitness function (Reciprocal of ICS) plot of the hard c-means algorithm for above dataset In addition to two global minima, we have local minima at: approximately (0, 10), (5, 10), (10, 0), (10, 5). For these local minima one prototype covers one of the data clusters, while the other prototype is mislead to the noise cluster.
58 K Nearest Neighbor Classifiers


59
60
61
62

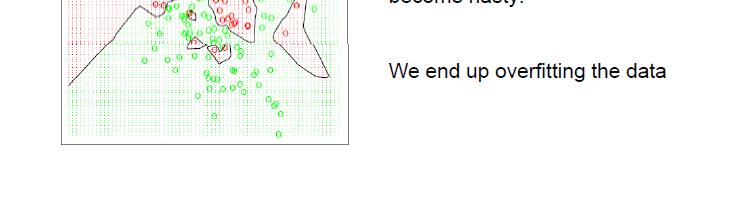
63
64

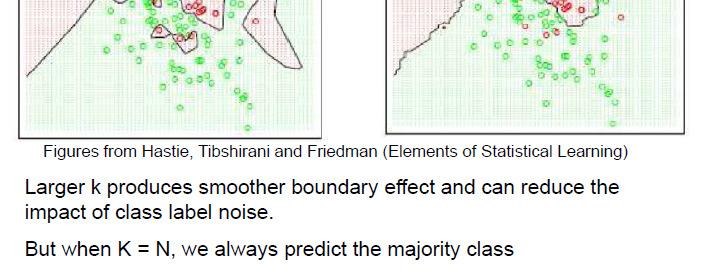
65
66


67

68


69
University of Florida CISE department Gator Engineering. Clustering Part 2
 Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
Clustering Basic Concepts and Algorithms 1
 Clustering Basic Concepts and Algorithms 1 Jeff Howbert Introduction to Machine Learning Winter 014 1 Machine learning tasks Supervised Classification Regression Recommender systems Reinforcement learning
Clustering Basic Concepts and Algorithms 1 Jeff Howbert Introduction to Machine Learning Winter 014 1 Machine learning tasks Supervised Classification Regression Recommender systems Reinforcement learning
Lecture Notes for Chapter 7. Introduction to Data Mining, 2 nd Edition. by Tan, Steinbach, Karpatne, Kumar
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, nd Edition by Tan, Steinbach, Karpatne, Kumar What is Cluster Analysis? Finding groups
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, nd Edition by Tan, Steinbach, Karpatne, Kumar What is Cluster Analysis? Finding groups
Cluster Analysis: Basic Concepts and Algorithms
 Cluster Analysis: Basic Concepts and Algorithms Data Warehousing and Mining Lecture 10 by Hossen Asiful Mustafa What is Cluster Analysis? Finding groups of objects such that the objects in a group will
Cluster Analysis: Basic Concepts and Algorithms Data Warehousing and Mining Lecture 10 by Hossen Asiful Mustafa What is Cluster Analysis? Finding groups of objects such that the objects in a group will
Tan,Steinbach, Kumar Introduction to Data Mining 4/18/ Tan,Steinbach, Kumar Introduction to Data Mining 4/18/
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
DATA MINING - 1DL105, 1Dl111. An introductory class in data mining
 1 DATA MINING - 1DL105, 1Dl111 Fall 007 An introductory class in data mining http://user.it.uu.se/~udbl/dm-ht007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
1 DATA MINING - 1DL105, 1Dl111 Fall 007 An introductory class in data mining http://user.it.uu.se/~udbl/dm-ht007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/004 What
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/004 What
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/4 What
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/4 What
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar (modified by Predrag Radivojac, 07) Old Faithful Geyser Data
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar (modified by Predrag Radivojac, 07) Old Faithful Geyser Data
Introduction to Clustering
 Introduction to Clustering Ref: Chengkai Li, Department of Computer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) What is Cluster Analysis? Finding groups of
Introduction to Clustering Ref: Chengkai Li, Department of Computer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) What is Cluster Analysis? Finding groups of
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Slides From Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Unsupervised Learning. Supervised learning vs. unsupervised learning. What is Cluster Analysis? Applications of Cluster Analysis
 7 Supervised learning vs unsupervised learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These patterns are then
7 Supervised learning vs unsupervised learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These patterns are then
Statistics 202: Data Mining. c Jonathan Taylor. Clustering Based in part on slides from textbook, slides of Susan Holmes.
 Clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group will be similar (or
Clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group will be similar (or
Clustering Part 2. A Partitional Clustering
 Universit of Florida CISE department Gator Engineering Clustering Part Dr. Sanja Ranka Professor Computer and Information Science and Engineering Universit of Florida, Gainesville Universit of Florida
Universit of Florida CISE department Gator Engineering Clustering Part Dr. Sanja Ranka Professor Computer and Information Science and Engineering Universit of Florida, Gainesville Universit of Florida
Cluster Analysis: Basic Concepts and Algorithms
 7 Cluster Analysis: Basic Concepts and Algorithms Cluster analysis divides data into groups (clusters) that are meaningful, useful, or both. If meaningful groups are the goal, then the clusters should
7 Cluster Analysis: Basic Concepts and Algorithms Cluster analysis divides data into groups (clusters) that are meaningful, useful, or both. If meaningful groups are the goal, then the clusters should
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest)
") Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Statistics 202: Data Mining. c Jonathan Taylor. Week 8 Based in part on slides from textbook, slides of Susan Holmes. December 2, / 1
 Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
University of Florida CISE department Gator Engineering. Clustering Part 5
 Clustering Part 5 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville SNN Approach to Clustering Ordinary distance measures have problems Euclidean
Clustering Part 5 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville SNN Approach to Clustering Ordinary distance measures have problems Euclidean
DATA MINING LECTURE 7. Hierarchical Clustering, DBSCAN The EM Algorithm
 DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
数据挖掘 Introduction to Data Mining
 数据挖掘 Introduction to Data Mining Philippe Fournier-Viger Full professor School of Natural Sciences and Humanities philfv8@yahoo.com Spring 2019 S8700113C 1 Introduction Last week: Association Analysis
数据挖掘 Introduction to Data Mining Philippe Fournier-Viger Full professor School of Natural Sciences and Humanities philfv8@yahoo.com Spring 2019 S8700113C 1 Introduction Last week: Association Analysis
Cluster analysis. Agnieszka Nowak - Brzezinska
 Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Clustering. Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
CS7267 MACHINE LEARNING
 S7267 MAHINE LEARNING HIERARHIAL LUSTERING Ref: hengkai Li, Department of omputer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) Mingon Kang, Ph.D. omputer Science,
S7267 MAHINE LEARNING HIERARHIAL LUSTERING Ref: hengkai Li, Department of omputer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) Mingon Kang, Ph.D. omputer Science,
What is Cluster Analysis?
 Cluster Analysis What is Cluster Analysis? Finding groups of objects (data points) such that the objects in a group will be similar (or related) to one another and different from (or unrelated to) the
Cluster Analysis What is Cluster Analysis? Finding groups of objects (data points) such that the objects in a group will be similar (or related) to one another and different from (or unrelated to) the
Clustering and Visualisation of Data
 Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/09/2018)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering
 INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
9/17/2009. Wenyan Li (Emily Li) Sep. 15, Introduction to Clustering Analysis
 Sep. 15, Introduction to Clustering Analysis") Introduction ti to K-means Algorithm Wenan Li (Emil Li) Sep. 5, 9 Outline Introduction to Clustering Analsis K-means Algorithm Description Eample of K-means Algorithm Other Issues of K-means Algorithm
Introduction ti to K-means Algorithm Wenan Li (Emil Li) Sep. 5, 9 Outline Introduction to Clustering Analsis K-means Algorithm Description Eample of K-means Algorithm Other Issues of K-means Algorithm
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
CSE 494/598 Lecture-11: Clustering & Classification
 CSE 494/598 Lecture-11: Clustering & Classification LYDIA MANIKONDA HT TP://WWW.PUBLIC.ASU.EDU/~LMANIKON / **With permission, content adapted from last year s slides and from Intro to DM dmbook@cs.umn.edu
CSE 494/598 Lecture-11: Clustering & Classification LYDIA MANIKONDA HT TP://WWW.PUBLIC.ASU.EDU/~LMANIKON / **With permission, content adapted from last year s slides and from Intro to DM dmbook@cs.umn.edu
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Clustering Lecture 3: Hierarchical Methods
 Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Understanding Clustering Supervising the unsupervised
 Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CS Introduction to Data Mining Instructor: Abdullah Mueen
 CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 Clustering and EM Barnabás Póczos & Aarti Singh Contents Clustering K-means Mixture of Gaussians Expectation Maximization Variational Methods 2 Clustering 3 K-
Introduction to Machine Learning CMU-10701 Clustering and EM Barnabás Póczos & Aarti Singh Contents Clustering K-means Mixture of Gaussians Expectation Maximization Variational Methods 2 Clustering 3 K-
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Introduction to Mobile Robotics
 Introduction to Mobile Robotics Clustering Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann Clustering (1) Common technique for statistical data analysis (machine learning,
Introduction to Mobile Robotics Clustering Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann Clustering (1) Common technique for statistical data analysis (machine learning,
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining /8/ What is Cluster
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining /8/ What is Cluster
Data Mining. Dr. Raed Ibraheem Hamed. University of Human Development, College of Science and Technology Department of Computer Science
 Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 201 Road map What is Cluster Analysis? Characteristics of Clustering
Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 201 Road map What is Cluster Analysis? Characteristics of Clustering
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
University of Florida CISE department Gator Engineering. Clustering Part 4
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
INF4820 Algorithms for AI and NLP. Evaluating Classifiers Clustering
 INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Murhaf Fares & Stephan Oepen Language Technology Group (LTG) September 27, 2017 Today 2 Recap Evaluation of classifiers Unsupervised
INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Murhaf Fares & Stephan Oepen Language Technology Group (LTG) September 27, 2017 Today 2 Recap Evaluation of classifiers Unsupervised
Unsupervised Data Mining: Clustering. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Learning
 Unsupervised Learning Unsupervised learning Until now, we have assumed our training samples are labeled by their category membership. Methods that use labeled samples are said to be supervised. However,
Unsupervised Learning Unsupervised learning Until now, we have assumed our training samples are labeled by their category membership. Methods that use labeled samples are said to be supervised. However,
Clustering Part 4 DBSCAN
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Note Set 4: Finite Mixture Models and the EM Algorithm
 Note Set 4: Finite Mixture Models and the EM Algorithm Padhraic Smyth, Department of Computer Science University of California, Irvine Finite Mixture Models A finite mixture model with K components, for
Note Set 4: Finite Mixture Models and the EM Algorithm Padhraic Smyth, Department of Computer Science University of California, Irvine Finite Mixture Models A finite mixture model with K components, for
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
Tan,Steinbach, Kumar Introduction to Data Mining 4/18/ Tan,Steinbach, Kumar Introduction to Data Mining 4/18/
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
Unsupervised Learning. Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi
 Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Hard clustering. Each object is assigned to one and only one cluster. Hierarchical clustering is usually hard. Soft (fuzzy) clustering
 clustering") An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
Clustering: Overview and K-means algorithm
 Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
DS504/CS586: Big Data Analytics Big Data Clustering II
 Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: AK 232 Fall 2016 More Discussions, Limitations v Center based clustering K-means BFR algorithm
Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: AK 232 Fall 2016 More Discussions, Limitations v Center based clustering K-means BFR algorithm
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Data Mining. Clustering. Hamid Beigy. Sharif University of Technology. Fall 1394
 Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
HW4 VINH NGUYEN. Q1 (6 points). Chapter 8 Exercise 20
. Chapter 8 Exercise 20") HW4 VINH NGUYEN Q1 (6 points). Chapter 8 Exercise 20 a. For each figure, could you use single link to find the patterns represented by the nose, eyes and mouth? Explain? First, a single link is a MIN version
HW4 VINH NGUYEN Q1 (6 points). Chapter 8 Exercise 20 a. For each figure, could you use single link to find the patterns represented by the nose, eyes and mouth? Explain? First, a single link is a MIN version
Data Informatics. Seon Ho Kim, Ph.D.
 Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu Clustering Overview Supervised vs. Unsupervised Learning Supervised learning (classification) Supervision: The training data (observations, measurements,
Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu Clustering Overview Supervised vs. Unsupervised Learning Supervised learning (classification) Supervision: The training data (observations, measurements,
Chapter DM:II. II. Cluster Analysis
 Chapter DM:II II. Cluster Analysis Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained Cluster Analysis DM:II-1
Chapter DM:II II. Cluster Analysis Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained Cluster Analysis DM:II-1
INF4820 Algorithms for AI and NLP. Evaluating Classifiers Clustering
 INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
Classification. Vladimir Curic. Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University
 Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Clustering: Overview and K-means algorithm
 Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
What to come. There will be a few more topics we will cover on supervised learning
 Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A
 MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
Data Mining Cluster Analysis: Advanced Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining, 2 nd Edition
 Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Outline Prototype-based Fuzzy c-means
Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Outline Prototype-based Fuzzy c-means
DS504/CS586: Big Data Analytics Big Data Clustering II
 Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: KH 116 Fall 2017 Updates: v Progress Presentation: Week 15: 11/30 v Next Week Office hours
Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: KH 116 Fall 2017 Updates: v Progress Presentation: Week 15: 11/30 v Next Week Office hours
CSE 347/447: DATA MINING
 CSE 347/447: DATA MINING Lecture 6: Clustering II W. Teal Lehigh University CSE 347/447, Fall 2016 Hierarchical Clustering Definition Produces a set of nested clusters organized as a hierarchical tree
CSE 347/447: DATA MINING Lecture 6: Clustering II W. Teal Lehigh University CSE 347/447, Fall 2016 Hierarchical Clustering Definition Produces a set of nested clusters organized as a hierarchical tree
9.1. K-means Clustering
 424 9. MIXTURE MODELS AND EM Section 9.2 Section 9.3 Section 9.4 view of mixture distributions in which the discrete latent variables can be interpreted as defining assignments of data points to specific
424 9. MIXTURE MODELS AND EM Section 9.2 Section 9.3 Section 9.4 view of mixture distributions in which the discrete latent variables can be interpreted as defining assignments of data points to specific
SYDE Winter 2011 Introduction to Pattern Recognition. Clustering
 SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
CLUSTERING. CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16
 CLUSTERING CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16 1. K-medoids: REFERENCES https://www.coursera.org/learn/cluster-analysis/lecture/nj0sb/3-4-the-k-medoids-clustering-method https://anuradhasrinivas.files.wordpress.com/2013/04/lesson8-clustering.pdf
CLUSTERING CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16 1. K-medoids: REFERENCES https://www.coursera.org/learn/cluster-analysis/lecture/nj0sb/3-4-the-k-medoids-clustering-method https://anuradhasrinivas.files.wordpress.com/2013/04/lesson8-clustering.pdf
 http://www.xkcd.com/233/ Text Clustering David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Administrative 2 nd status reports Paper review
http://www.xkcd.com/233/ Text Clustering David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Administrative 2 nd status reports Paper review
Clustering Part 3. Hierarchical Clustering
 Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/10/2017)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
Machine Learning. B. Unsupervised Learning B.1 Cluster Analysis. Lars Schmidt-Thieme, Nicolas Schilling
 Machine Learning B. Unsupervised Learning B.1 Cluster Analysis Lars Schmidt-Thieme, Nicolas Schilling Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University of Hildesheim,
Machine Learning B. Unsupervised Learning B.1 Cluster Analysis Lars Schmidt-Thieme, Nicolas Schilling Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University of Hildesheim,
Cluster Analysis: Agglomerate Hierarchical Clustering
 Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Clustering: K-means and Kernel K-means
 Clustering: K-means and Kernel K-means Piyush Rai Machine Learning (CS771A) Aug 31, 2016 Machine Learning (CS771A) Clustering: K-means and Kernel K-means 1 Clustering Usually an unsupervised learning problem
Clustering: K-means and Kernel K-means Piyush Rai Machine Learning (CS771A) Aug 31, 2016 Machine Learning (CS771A) Clustering: K-means and Kernel K-means 1 Clustering Usually an unsupervised learning problem
Olmo S. Zavala Romero. Clustering Hierarchical Distance Group Dist. K-means. Center of Atmospheric Sciences, UNAM.
 Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Clustering in Data Mining
 Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Online Social Networks and Media. Community detection
 Online Social Networks and Media Community detection 1 Notes on Homework 1 1. You should write your own code for generating the graphs. You may use SNAP graph primitives (e.g., add node/edge) 2. For the
Online Social Networks and Media Community detection 1 Notes on Homework 1 1. You should write your own code for generating the graphs. You may use SNAP graph primitives (e.g., add node/edge) 2. For the
Part I. Hierarchical clustering. Hierarchical Clustering. Hierarchical clustering. Produces a set of nested clusters organized as a
 Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
INF 4300 Classification III Anne Solberg The agenda today:
 INF 4300 Classification III Anne Solberg 28.10.15 The agenda today: More on estimating classifier accuracy Curse of dimensionality and simple feature selection knn-classification K-means clustering 28.10.15
INF 4300 Classification III Anne Solberg 28.10.15 The agenda today: More on estimating classifier accuracy Curse of dimensionality and simple feature selection knn-classification K-means clustering 28.10.15
COSC 6397 Big Data Analytics. Fuzzy Clustering. Some slides based on a lecture by Prof. Shishir Shah. Edgar Gabriel Spring 2015.
 COSC 6397 Big Data Analytics Fuzzy Clustering Some slides based on a lecture by Prof. Shishir Shah Edgar Gabriel Spring 215 Clustering Clustering is a technique for finding similarity groups in data, called
COSC 6397 Big Data Analytics Fuzzy Clustering Some slides based on a lecture by Prof. Shishir Shah Edgar Gabriel Spring 215 Clustering Clustering is a technique for finding similarity groups in data, called
Clustering fundamentals
 Elena Baralis, Tania Cerquitelli Politecnico di Torino What is Cluster Analsis? Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from
Elena Baralis, Tania Cerquitelli Politecnico di Torino What is Cluster Analsis? Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from
Based on Raymond J. Mooney s slides
 Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Fuzzy Segmentation. Chapter Introduction. 4.2 Unsupervised Clustering.
 Chapter 4 Fuzzy Segmentation 4. Introduction. The segmentation of objects whose color-composition is not common represents a difficult task, due to the illumination and the appropriate threshold selection
Chapter 4 Fuzzy Segmentation 4. Introduction. The segmentation of objects whose color-composition is not common represents a difficult task, due to the illumination and the appropriate threshold selection
COSC 6339 Big Data Analytics. Fuzzy Clustering. Some slides based on a lecture by Prof. Shishir Shah. Edgar Gabriel Spring 2017.
 COSC 6339 Big Data Analytics Fuzzy Clustering Some slides based on a lecture by Prof. Shishir Shah Edgar Gabriel Spring 217 Clustering Clustering is a technique for finding similarity groups in data, called
COSC 6339 Big Data Analytics Fuzzy Clustering Some slides based on a lecture by Prof. Shishir Shah Edgar Gabriel Spring 217 Clustering Clustering is a technique for finding similarity groups in data, called
A Comparative study of Clustering Algorithms using MapReduce in Hadoop
 A Comparative study of Clustering Algorithms using MapReduce in Hadoop Dweepna Garg 1, Khushboo Trivedi 2, B.B.Panchal 3 1 Department of Computer Science and Engineering, Parul Institute of Engineering
A Comparative study of Clustering Algorithms using MapReduce in Hadoop Dweepna Garg 1, Khushboo Trivedi 2, B.B.Panchal 3 1 Department of Computer Science and Engineering, Parul Institute of Engineering