What is Cluster Analysis?
|
|
|
- Cuthbert Ferdinand Carpenter
- 6 years ago
- Views:
Transcription
1 Cluster Analysis
2 What is Cluster Analysis? Finding groups of objects (data points) such that the objects in a group will be similar (or related) to one another and different from (or unrelated to) the objects in other groups Intra-cluster distances are minimized Inter-cluster distances are maximized
3 Applications of Cluster Analysis 1. Clustering for Understanding Group related documents for browsing Group genes and proteins that have similar functionality Group stocks with similar price fluctuations Segment customers into a small number of groups for additional analysis and marketing activities Discovered Clusters Applied-Matl-DOWN,Bay-Network-Down,3-COM-DOWN, Cabletron-Sys-DOWN,CISCO-DOWN,HP-DOWN, DSC-Comm-DOWN,INTEL-DOWN,LSI-Logic-DOWN, Micron-Tech-DOWN,Texas-Inst-Down,Tellabs-Inc-Down, Natl-Semiconduct-DOWN,Oracl-DOWN,SGI-DOWN, Sun-DOWN Apple-Comp-DOWN,Autodesk-DOWN,DEC-DOWN, ADV-Micro-Device-DOWN,Andrew-Corp-DOWN, Computer-Assoc-DOWN,Circuit-City-DOWN, Compaq-DOWN, EMC-Corp-DOWN, Gen-Inst-DOWN, Motorola-DOWN,Microsoft-DOWN,Scientific-Atl-DOWN Fannie-Mae-DOWN,Fed-Home-Loan-DOWN, MBNA-Corp-DOWN,Morgan-Stanley-DOWN Baker-Hughes-UP,Dresser-Inds-UP,Halliburton-HLD-UP, Louisiana-Land-UP,Phillips-Petro-UP,Unocal-UP, 4 Schlumberger-UP Industry Group Technology1-DOWN Technology2-DOWN Financial-DOWN Oil-UP 2. Clustering for Summarization Reduce the size of large data sets Clustering precipitation in Australia
4 Similarity Similarity and Dissimilarity Numerical measure of how alike two data objects are. Higher when objects are more alike. Dissimilarity Numerical measure of how different are two data objects Lower when objects are more alike Proximity measures for objects with a number of attributes are defined by combining the proximities of individual attributes.
5 Similarity/Dissimilarity for Simple Attributes p and q are the attribute values for two data objects. Nominal E.g. province attribute of an address with values: {BC, AB, ON, QC, } Order not important. Dissimilarity d(p, q) = 0 if p = q d(p, q) = 1 if p q
6 Similarity/Dissimilarity for Simple Attributes p and q are the attribute values for two data objects. Ordinal E.g. quality attribute of a product with values: {poor, fair, OK, good, wonderful} Order is important, but exact difference between values is undefined or not important. Map the values of the attribute to successive integers {poor=0, fair=1, OK=2, good=3, wonderful=4} Dissimilarity d(p, q) = p q / (max_d min_d) e.g. d(wonderful, fair) = 4-1 / (4-0) =.75
7 Similarity/Dissimilarity for Simple Attributes p and q are the attribute values for two data objects. Continuous (or Interval) E.g. weight attribute of a product Dissimilarity d(p, q) = p q
8 Combining dissimilarities Sometimes attributes are of many different types, but an overall similarity/dissimilarity is needed. For each attribute (1 i m), compute a dissimilarity d i in the range [0,1]. Then, for two data points x and x : dissimilarity( x, x') m i = = 1 m d i
9 Euclidean Distance When all the attributes are continuous we can use the Euclidean Distance dist( x, x') = m i= 1 ( x i x' i 2 ) Where m is the number of dimensions (attributes) and x i and x i are, respectively, the i th attributes of data objects x and x. Standardization is necessary, if scales of attribute values differ E.g. weight, salary have different scales
10 Euclidean Distance p1 point x1 x2 p3 p4 p1 0 2 p2 2 0 p2 p p4 5 1 p1 p2 p3 p4 p p p p Distance Matrix
11 Minkowski Distance Minkowski Distance is a generalization of Euclidean Distance m dist( x, x') = r x i x' i i= 1 r Where r is a parameter, m is the number of dimensions (attributes) and x i and x i are, respectively, the ith attributes of data objects x and x. Examples r = 1 : City block (Manhattan, taxicab, L 1 norm) distance. r = 2 : Euclidean distance r. supremum (L max norm, L norm) distance. This is the maximum difference among all dimensions of the vectors.
12 Minkowski Distance point x1 x2 p1 0 2 p2 2 0 p3 3 1 p4 5 1 p1 p2 p3 p L1 p1 p2 p3 p4 p p p p L2 p1 p2 p3 p4 p p p p L p1 p2 p3 p4 p p p p Distance Matrix
13 Similarity Between Binary Vectors Common situation is that objects, x and x, have only binary attributes Compute similarities using the following quantities M 01 = the number of attributes where x was 0 and x was 1 M 10 = the number of attributes where x was 1 and x was 0 M 00 = the number of attributes where x was 0 and x was 0 M 11 = the number of attributes where x was 1 and x was 1 Simple Matching SMC = (M 11 + M 00 ) / (M 01 + M 10 + M 11 + M 00 ) = number of matches / number of attributes Jaccard Coefficients JC = (M 11 ) / (M 01 + M 10 + M 11 ) = number of M 11 matches / number of not-both-zero attributes
14 SMC versus Jaccard: Example x = x' = M 01 = 2 (the number of attributes where x was 0 and x was 1) M 10 = 1 (the number of attributes where x was 1 and x was 0) M 00 = 7 (the number of attributes where x was 0 and x was 0) M 11 = 0 (the number of attributes where x was 1 and x was 1) 11 SMC = (M 11 + M 00 )/(M 01 + M 10 + M 11 + M 00 ) = (0+7) / ( ) = 0.7 JC= (M 11 ) / (M 01 + M 10 + M 11 ) = 0 / ( ) = 0
15 Cosine Similarity If D 1 and D 2 are two document vectors, then cos(d 1, D 2 ) = (D 1 D 2 ) / D 1. D 2 where indicates vector dot product and D is the length of vector D. Example: D 1 D 2 =.4*0 +.33*0 + 0* *1 +.17*.33 =.0561 D 1 = sqrt( ) =.55 D 2 = sqrt( ) = 1.1 TID W1 W2 W3 W4 W5 D D D D D If the cosine similarity is 1, the angle between D 1 and D 2 is 0 o, and D 1 and D 2 are the same except for the magnitude. If the cosine similarity is 0, then the angle between D 1 and D 2 is 90 o, and they don t share any terms (words). cos( D 1, D 2 ) =.0561 / (.55 * 1.1) =.093
16 Types of Clusters: Well-Separated 1. Well-Separated Clusters: Any point in a cluster is closer (or more similar) to every other point in the cluster than to any point not in the cluster. 3 well-separated clusters
17 Types of Clusters: Center-Based 2. Center-based An object in a cluster is closer (more similar) to the center of the cluster, than to the center of any other cluster. The center of a cluster is often a centroid, the average of all the points in the cluster (for continuous attributes), or a medoid, the most representative point of a cluster (for discrete attributes ) 4 center-based clusters
18 Types of Clusters: Contiguity-Based 3. Contiguous Cluster (Nearest neighbor or Transitive) A point in a cluster is closer (or more similar) to one or more other points in the cluster than to any point not in the cluster. 8 contiguous clusters
19 Types of Clusters: Density-Based 4. Density-based A cluster is a dense region of points, which is separated, by lowdensity regions, from other regions of high density. Used when the clusters are irregular or intertwined, and when noise and outliers are present. 6 density-based clusters
20 K-means Clustering Algorithm: Each cluster is associated with a centroid (center point) Each point is assigned to the cluster with the closest centroid Centroids are recomputed Number of clusters, K, must be specified Basic algorithm is very simple
21 Example 3 Iteration y x
22 K-means Clustering Details Initial centroids may be chosen randomly. Clusters produced vary from one run to another. Rerun several times and pick the clustering with the smallest SSE (see next slide). The centroid is (typically) the mean of the points in the cluster. Closeness is measured by Euclidean distance, cosine similarity, etc. Most of the convergence happens in the first few iterations. Often the stopping condition is changed to Until relatively few points change clusters
23 Evaluating K-means Clusters Most common measure is Sum of Squared Error (SSE) For each data point, the error is the distance to the nearest centroid To get SSE, we square these errors and sum them up for K clusters. SSE K = = i= 1 x C i [ dist ( m, x )] i 2 x is a data point in cluster C i and m i is the representative point for cluster C i
24 Reducing SSE Obvious way to reduce the SSE is to find more clusters, i.e., to use a larger K. Try different K, looking at the change in the average distance to centroid, as K increases. Average falls rapidly until right K, then changes little. Average distance to centroid K
25 Limitations of K-means K-means has problems when clusters are of Differing sizes Differing densities Non-globular shapes
26 Limitations of K-means: Differing Sizes Original Points K-means (3 Clusters)
27 Limitations of K-means: Differing Density Original Points K-means (3 Clusters)
28 Limitations of K-means: Non-globular Shapes Original Points K-means (2 Clusters)
29 Overcoming K-means Limitations Original Points K-means Clusters One solution is to use many clusters, then - Find parts of clusters - Apply merge strategy (merge clusters that would cause the least increase in SSE)
30 Overcoming K-means Limitations Original Points K-means Clusters

31 Overcoming K-means Limitations Original Points K-means Clusters
32 Importance of Choosing Initial Centroids 8 Iteration y x Starting with two initial centroids in one cluster of each pair of clusters
33 Importance of Choosing Initial Centroids 8 Iteration 1 8 Iteration y 0 y x Iteration x Iteration y 0 y x Starting with two initial centroids in one cluster of each pair of clusters x
34 Importance of Choosing Initial Centroids 8 Iteration y x Starting with some pairs of clusters having three initial centroids, while other have only one.
35 Importance of Choosing Initial Centroids 8 Iteration 1 8 Iteration y 0 y Iteration x 3 Iteration x y 0 y x x Starting with some pairs of clusters having three initial centroids, while other have only one.
36 Problems with Selecting Initial Points Of course, the ideal would be to choose initial centroids, one from each true cluster. However, this is very difficult. If there are K real clusters then the chance of selecting one centroid from each cluster is small. Chance is relatively small when K is large If clusters are the same size, n, then For example, if K = 10, then probability = 10!/10 10 = Sometimes the initial centroids will readjust themselves in the right way, and sometimes they don t. Consider the previous example of five pairs of clusters
37 Solutions to Initial Centroids Problem Randomly selected initial centroids may be poor. 1. Perform multiple runs with different randomly chosen initial points, and select the set of clusters with minimum SSE. Might help, it depends on the type of data set or the number of clusters sought. 2. Use another variant of the algorithm Bisecting K-means Not as susceptible to initialization issues
38 Bisecting K-means Straightforward extension of the basic K-means algorithm. Simple idea: To obtain K clusters, split the set of points into two clusters, select one of these clusters to split, and so on, until K clusters have been produced. Algorithm Initialize the list of clusters to contain one cluster consisting of all points. repeat Choose and remove a cluster from the list of clusters. (biggest cluster or the cluster with the worst quality) //Perform several trial bisections of the chosen cluster. for i = 1 to number of trials do Bisect the selected cluster using basic K-means (i.e. 2-means). end for Select the two clusters from several bisections with the lowest total SSE. Add these two clusters to the list of clusters. until the list of clusters contains K clusters.
39 Bisecting K-means Example
40 Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits
41 Strengths of Hierarchical Clustering Do not have to assume any particular number of clusters cut the dendogram at the proper level to get the desired number of clusters. They may correspond to meaningful taxonomies Example in biological sciences e.g., animal kingdom, phylogeny reconstruction,
42 Hierarchical Clustering Algorithm Let each data point be a cluster Compute the proximity matrix Repeat Merge the two closest clusters Update the proximity matrix Until only a single cluster remains Key operation is the computation of the proximity of two clusters.
43 Starting Situation Start with clusters of individual points and a proximity matrix p1 p1 p2 p3 p4 p5... p2 p3 p4 p5... Proximity Matrix
44 Intermediate Situation After some merging steps, we have some clusters C1 C2 C3 C4 C5 C1 C3 C4 C1 C2 C3 C4 C5 Proximity Matrix C2 C5
45 Intermediate Situation We want to merge the two closest clusters (C2 and C5) and update the proximity matrix. C1 C2 C1 C2 C3 C4 C5 C3 C3 C1 C4 C4 C5 Proximity Matrix C2 C5
46 After Merging The question is How do we update the proximity matrix? C1 C2 U C5 C3 C4 C1? C3 C4 C2 U C5 C3 C4?????? C1 Proximity Matrix C2 U C5
47 How to Define Inter-Cluster Similarity p1 p2 p3 p4 p5... Distance? p1 p2 MIN (or Single Link) MAX (or Complete Link or Clique) Group Average p3 p4 p5... Proximity Matrix
48 How to Define Inter-Cluster Similarity p1 p2 p3 p4 p5... p1 p2 p3 p4 MIN MAX Group Average p5... Proximity Matrix
49 How to Define Inter-Cluster Similarity p1 p2 p3 p4 p5... p1 p2 p3 p4 MIN MAX Group Average p5... Proximity Matrix
50 How to Define Inter-Cluster Similarity p1 p2 p3 p4 p5... p1 p2 p3 p4 MIN MAX Group Average p5... Proximity Matrix
51 Cluster Similarity: MIN Similarity of two clusters is based on the two most similar (closest) points in the different clusters Determined by only one pair of points
52 Hierarchical Clustering: MIN Dendrogram Nested Clusters
53 Strength of MIN Original Points Two Clusters Can handle non-globular shapes
54 Limitations of MIN Original Points Four clusters Three clusters: Sensitive to noise and outliers The yellow points got wrongly merged with the red ones, as opposed to the green one.
55 Cluster Similarity: MAX Similarity of two clusters is based on the two least similar (most distant) points in the different clusters Determined by one pair of points in two clusters
56 Hierarchical Clustering: MAX Dendrogram Nested Clusters
57 Strengths of MAX Original Points Four clusters Three clusters: The yellow points get now merged with the green one. Less susceptible with respect to noise and outliers


58 Limitations of MAX Original Points Two Clusters Tends to break large clusters
59 Cluster Similarity: Group Average Proximity of two clusters C i, C j is the average of pairwise proximity between points in the two clusters. proximity ( C,C i j ) p C q C = i j proximity(p, q) C C i j C i is the size of cluster C i (the number of data points).
60 Hierarchical Clustering: Group Average Dendrogram 4 3 Nested Clusters
61 Hierarchical Clustering: Time and Space O(n 2 ) space since it uses the proximity matrix. n is the number of points. O(n 3 ) time in many cases There are n steps and at each step the size, n 2, proximity matrix must be updated and searched. Complexity can be reduced to O(n 2 log(n) ) time for some approaches.
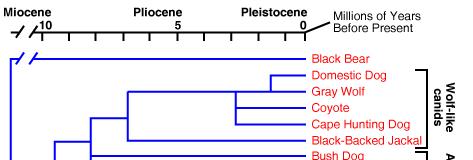
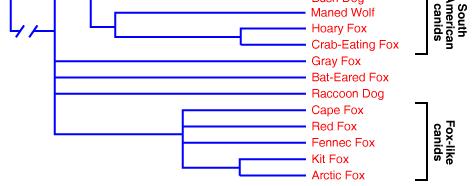
62 Hierarchical Clustering Example
63 Hierarchical Clustering Example From Indo-European languages tree by Levenshtein distance by M.Serva and F.Petroni
64 DBSCAN DBSCAN is a density-based clustering algorithm. Locates regions of high density that are separated from one another by regions of low density. Density = the number of points within a specified radius (Eps) A point is a core point if it has more than a specified number of points (MinPts) within Eps. These are points that are at the interior of a cluster. A border point has fewer than MinPts within Eps, but is in the neighborhood of a core point. A noise point is any point that is neither a core point nor a border point.
65 DBSCAN: Core, Border, and Noise Points
66 DBSCAN Algorithm First, specify the type of each point (core, border, noise) Eliminate noise points. Any two core points that are close enough --- within a distance Eps of one another --- are put in the same cluster. Likewise, any border point that is close enough to a core point is put in the same cluster as the core point. Ties may need to be resolved if a border point is close to core points from different clusters.

67 DBSCAN: Core, Border and Noise Points Original Points Point types: core, border and noise Eps = 10, MinPts = 4

68 When DBSCAN Works Well Original Points Clusters Resistant to Noise Can handle clusters of different shapes and sizes
69 When DBSCAN Does NOT Work Well Why DBSCAN doesn t work well here?
70 DBSCAN: Determining EPS and MinPts Look at the behavior of the distance from a point to its k-th nearest neighbor, called the k-dist. For points that belong to some cluster, the value of k-dist will be small [if k is not larger than the cluster size]. However, for points that are not in a cluster, such as noise points, the k-dist will be relatively large. So, if we compute the k-dist for all the data points for some k, sort them in increasing order, and then plot the sorted values, we expect to see a sharp change at the value of k-dist that corresponds to a suitable value of Eps. If we select this distance as the Eps parameter and take the value of k as the MinPts parameter, then points for which k-dist is less than Eps will be labeled as core points, while other points will be labeled as noise or border points.
71 DBSCAN: Determining EPS and MinPts Eps determined in this way depends on k, but does not change dramatically as k changes. If k is too small? Then even a small number of closely spaced points that are noise or outliers will be incorrectly labeled as clusters. If k is too large? then small clusters (of size less than k) are likely to be labeled as noise. Original DBSCAN used k = 4, which appears to be a reasonable value for most data sets.
Cluster Analysis: Basic Concepts and Algorithms
 Cluster Analysis: Basic Concepts and Algorithms Data Warehousing and Mining Lecture 10 by Hossen Asiful Mustafa What is Cluster Analysis? Finding groups of objects such that the objects in a group will
Cluster Analysis: Basic Concepts and Algorithms Data Warehousing and Mining Lecture 10 by Hossen Asiful Mustafa What is Cluster Analysis? Finding groups of objects such that the objects in a group will
Lecture Notes for Chapter 7. Introduction to Data Mining, 2 nd Edition. by Tan, Steinbach, Karpatne, Kumar
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, nd Edition by Tan, Steinbach, Karpatne, Kumar What is Cluster Analysis? Finding groups
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, nd Edition by Tan, Steinbach, Karpatne, Kumar What is Cluster Analysis? Finding groups
DATA MINING - 1DL105, 1Dl111. An introductory class in data mining
 1 DATA MINING - 1DL105, 1Dl111 Fall 007 An introductory class in data mining http://user.it.uu.se/~udbl/dm-ht007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
1 DATA MINING - 1DL105, 1Dl111 Fall 007 An introductory class in data mining http://user.it.uu.se/~udbl/dm-ht007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/4 What
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/4 What
Clustering Basic Concepts and Algorithms 1
 Clustering Basic Concepts and Algorithms 1 Jeff Howbert Introduction to Machine Learning Winter 014 1 Machine learning tasks Supervised Classification Regression Recommender systems Reinforcement learning
Clustering Basic Concepts and Algorithms 1 Jeff Howbert Introduction to Machine Learning Winter 014 1 Machine learning tasks Supervised Classification Regression Recommender systems Reinforcement learning
Clustering fundamentals
 Elena Baralis, Tania Cerquitelli Politecnico di Torino What is Cluster Analsis? Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from
Elena Baralis, Tania Cerquitelli Politecnico di Torino What is Cluster Analsis? Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from
Tan,Steinbach, Kumar Introduction to Data Mining 4/18/ Tan,Steinbach, Kumar Introduction to Data Mining 4/18/
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/004 What
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/004 What
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar (modified by Predrag Radivojac, 07) Old Faithful Geyser Data
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar (modified by Predrag Radivojac, 07) Old Faithful Geyser Data
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining /8/ What is Cluster
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining /8/ What is Cluster
Tan,Steinbach, Kumar Introduction to Data Mining 4/18/ Tan,Steinbach, Kumar Introduction to Data Mining 4/18/
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter Introduction to Data Mining b Tan, Steinbach, Kumar What is Cluster Analsis? Finding groups of objects such that the
Machine Learning 15/04/2015. Supervised learning vs. unsupervised learning. What is Cluster Analysis? Applications of Cluster Analysis
 // Supervised learning vs unsupervised learning Machine Learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These
// Supervised learning vs unsupervised learning Machine Learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These
Data Mining. Cluster Analysis: Basic Concepts and Algorithms
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Tan,Steinbach, Kumar Introduction to Data Mining /8/ What is Cluster Analsis? Finding groups of objects such that the objects in a group will
Data Mining Cluster Analsis: Basic Concepts and Algorithms Tan,Steinbach, Kumar Introduction to Data Mining /8/ What is Cluster Analsis? Finding groups of objects such that the objects in a group will
Cluster analysis. Agnieszka Nowak - Brzezinska
 Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
and Algorithms Dr. Hui Xiong Rutgers University Introduction to Data Mining 8/30/ Introduction to Data Mining 08/06/2006 1
 Cluster Analsis: Basic Concepts and Algorithms Dr. Hui Xiong Rutgers Universit Introduction to Data Mining 8//6 Introduction to Data Mining 8/6/6 What is Cluster Analsis? Finding groups of objects such
Cluster Analsis: Basic Concepts and Algorithms Dr. Hui Xiong Rutgers Universit Introduction to Data Mining 8//6 Introduction to Data Mining 8/6/6 What is Cluster Analsis? Finding groups of objects such
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 7. Introduction to Data Mining, 2 nd Edition
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, nd Edition b Tan, Steinbach, Karpatne, Kumar What is Cluster Analsis? Finding groups
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, nd Edition b Tan, Steinbach, Karpatne, Kumar What is Cluster Analsis? Finding groups
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
CSE 347/447: DATA MINING
 CSE 347/447: DATA MINING Lecture 6: Clustering II W. Teal Lehigh University CSE 347/447, Fall 2016 Hierarchical Clustering Definition Produces a set of nested clusters organized as a hierarchical tree
CSE 347/447: DATA MINING Lecture 6: Clustering II W. Teal Lehigh University CSE 347/447, Fall 2016 Hierarchical Clustering Definition Produces a set of nested clusters organized as a hierarchical tree
Data Mining: Clustering
 Data Mining: Clustering Knowledge Discovery in Databases Dino Pedreschi Pisa KDD Lab, ISTI-CNR & Univ. Pisa http://kdd.isti.cnr.it/ Master MAINS What is Cluster Analysis? Finding groups of objects such
Data Mining: Clustering Knowledge Discovery in Databases Dino Pedreschi Pisa KDD Lab, ISTI-CNR & Univ. Pisa http://kdd.isti.cnr.it/ Master MAINS What is Cluster Analysis? Finding groups of objects such
DATA MINING LECTURE 7. Hierarchical Clustering, DBSCAN The EM Algorithm
 DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
University of Florida CISE department Gator Engineering. Clustering Part 2
 Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
Hierarchical Clustering
 Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
CS7267 MACHINE LEARNING
 S7267 MAHINE LEARNING HIERARHIAL LUSTERING Ref: hengkai Li, Department of omputer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) Mingon Kang, Ph.D. omputer Science,
S7267 MAHINE LEARNING HIERARHIAL LUSTERING Ref: hengkai Li, Department of omputer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) Mingon Kang, Ph.D. omputer Science,
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Unsupervised Learning. Supervised learning vs. unsupervised learning. What is Cluster Analysis? Applications of Cluster Analysis
 7 Supervised learning vs unsupervised learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These patterns are then
7 Supervised learning vs unsupervised learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These patterns are then
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Introduction to Clustering
 Introduction to Clustering Ref: Chengkai Li, Department of Computer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) What is Cluster Analysis? Finding groups of
Introduction to Clustering Ref: Chengkai Li, Department of Computer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) What is Cluster Analysis? Finding groups of
Lecture Notes for Chapter 7. Introduction to Data Mining, 2 nd Edition. by Tan, Steinbach, Karpatne, Kumar
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Hierarchical Clustering Produces a set
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Hierarchical Clustering Produces a set
Hierarchical Clustering
 Hierarchical Clustering Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree-like diagram that records the sequences of merges
Hierarchical Clustering Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree-like diagram that records the sequences of merges
Data Mining Concepts & Techniques
 Data Mining Concepts & Techniques Lecture No 08 Cluster Analysis Naeem Ahmed Email: naeemmahoto@gmailcom Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro Outline
Data Mining Concepts & Techniques Lecture No 08 Cluster Analysis Naeem Ahmed Email: naeemmahoto@gmailcom Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro Outline
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/09/2018)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A
 MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Slides From Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Hierarchical clustering
 Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
Clustering Part 3. Hierarchical Clustering
 Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
Clustering Lecture 3: Hierarchical Methods
 Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Clustering Part 4 DBSCAN
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
5/15/16. Computational Methods for Data Analysis. Massimo Poesio UNSUPERVISED LEARNING. Clustering. Unsupervised learning introduction
 Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
University of Florida CISE department Gator Engineering. Clustering Part 4
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Knowledge Discovery in Databases
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture notes Knowledge Discovery in Databases Summer Semester 2012 Lecture 8: Clustering
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture notes Knowledge Discovery in Databases Summer Semester 2012 Lecture 8: Clustering
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest)
") Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Clustering Tips and Tricks in 45 minutes (maybe more :)
") Clustering Tips and Tricks in 45 minutes (maybe more :) Olfa Nasraoui, University of Louisville Tutorial for the Data Science for Social Good Fellowship 2015 cohort @DSSG2015@University of Chicago https://www.researchgate.net/profile/olfa_nasraoui
Clustering Tips and Tricks in 45 minutes (maybe more :) Olfa Nasraoui, University of Louisville Tutorial for the Data Science for Social Good Fellowship 2015 cohort @DSSG2015@University of Chicago https://www.researchgate.net/profile/olfa_nasraoui
Data Mining: Introduction. Lecture Notes for Chapter 1. Introduction to Data Mining
 Data Mining: Introduction Lecture Notes for Chapter 1 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Why Mine Data? Commercial Viewpoint
Data Mining: Introduction Lecture Notes for Chapter 1 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Why Mine Data? Commercial Viewpoint
Clustering Part 2. A Partitional Clustering
 Universit of Florida CISE department Gator Engineering Clustering Part Dr. Sanja Ranka Professor Computer and Information Science and Engineering Universit of Florida, Gainesville Universit of Florida
Universit of Florida CISE department Gator Engineering Clustering Part Dr. Sanja Ranka Professor Computer and Information Science and Engineering Universit of Florida, Gainesville Universit of Florida
Cluster Analysis: Basic Concepts and Algorithms
 7 Cluster Analysis: Basic Concepts and Algorithms Cluster analysis divides data into groups (clusters) that are meaningful, useful, or both. If meaningful groups are the goal, then the clusters should
7 Cluster Analysis: Basic Concepts and Algorithms Cluster analysis divides data into groups (clusters) that are meaningful, useful, or both. If meaningful groups are the goal, then the clusters should
Introduction to Data Mining. Komate AMPHAWAN
 Introduction to Data Mining Komate AMPHAWAN 1 Data mining(1970s) = Knowledge Discovery in (very large) Databases : KDD Automatically Find hidden patterns and hidden association from raw data by using computer(s).
Introduction to Data Mining Komate AMPHAWAN 1 Data mining(1970s) = Knowledge Discovery in (very large) Databases : KDD Automatically Find hidden patterns and hidden association from raw data by using computer(s).
DS504/CS586: Big Data Analytics Big Data Clustering II
 Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: AK 232 Fall 2016 More Discussions, Limitations v Center based clustering K-means BFR algorithm
Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: AK 232 Fall 2016 More Discussions, Limitations v Center based clustering K-means BFR algorithm
Statistics 202: Data Mining. c Jonathan Taylor. Clustering Based in part on slides from textbook, slides of Susan Holmes.
 Clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group will be similar (or
Clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group will be similar (or
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
University of Florida CISE department Gator Engineering. Clustering Part 5
 Clustering Part 5 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville SNN Approach to Clustering Ordinary distance measures have problems Euclidean
Clustering Part 5 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville SNN Approach to Clustering Ordinary distance measures have problems Euclidean
Statistics 202: Data Mining. c Jonathan Taylor. Week 8 Based in part on slides from textbook, slides of Susan Holmes. December 2, / 1
 Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
数据挖掘 Introduction to Data Mining
 数据挖掘 Introduction to Data Mining Philippe Fournier-Viger Full professor School of Natural Sciences and Humanities philfv8@yahoo.com Spring 2019 S8700113C 1 Introduction Last week: Association Analysis
数据挖掘 Introduction to Data Mining Philippe Fournier-Viger Full professor School of Natural Sciences and Humanities philfv8@yahoo.com Spring 2019 S8700113C 1 Introduction Last week: Association Analysis
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
DS504/CS586: Big Data Analytics Big Data Clustering II
 Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: KH 116 Fall 2017 Updates: v Progress Presentation: Week 15: 11/30 v Next Week Office hours
Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: KH 116 Fall 2017 Updates: v Progress Presentation: Week 15: 11/30 v Next Week Office hours
HW4 VINH NGUYEN. Q1 (6 points). Chapter 8 Exercise 20
. Chapter 8 Exercise 20") HW4 VINH NGUYEN Q1 (6 points). Chapter 8 Exercise 20 a. For each figure, could you use single link to find the patterns represented by the nose, eyes and mouth? Explain? First, a single link is a MIN version
HW4 VINH NGUYEN Q1 (6 points). Chapter 8 Exercise 20 a. For each figure, could you use single link to find the patterns represented by the nose, eyes and mouth? Explain? First, a single link is a MIN version
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
Data Mining: Data. What is Data? Lecture Notes for Chapter 2. Introduction to Data Mining. Properties of Attribute Values. Types of Attributes
 0 Data Mining: Data What is Data? Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar Collection of data objects and their attributes An attribute is a property or characteristic
0 Data Mining: Data What is Data? Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar Collection of data objects and their attributes An attribute is a property or characteristic
Data Mining: Data. Lecture Notes for Chapter 2. Introduction to Data Mining
 10 Data Mining: Data Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 What is Data? Collection of data objects
10 Data Mining: Data Lecture Notes for Chapter 2 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 What is Data? Collection of data objects
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/10/2017)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
Data Mining Algorithms
 for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
Part I. Hierarchical clustering. Hierarchical Clustering. Hierarchical clustering. Produces a set of nested clusters organized as a
 Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
DATA MINING LECTURE 1. Introduction
 DATA MINING LECTURE 1 Introduction What is data mining? After years of data mining there is still no unique answer to this question. A tentative definition: Data mining is the use of efficient techniques
DATA MINING LECTURE 1 Introduction What is data mining? After years of data mining there is still no unique answer to this question. A tentative definition: Data mining is the use of efficient techniques
Clustering Lecture 4: Density-based Methods
 Clustering Lecture 4: Density-based Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering Lecture 4: Density-based Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Data Mining. Clustering. Hamid Beigy. Sharif University of Technology. Fall 1394
 Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
Unsupervised Learning. Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi
 Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Forestry Applied Multivariate Statistics. Cluster Analysis
 1 Forestry 531 -- Applied Multivariate Statistics Cluster Analysis Purpose: To group similar entities together based on their attributes. Entities can be variables or observations. [illustration in Class]
1 Forestry 531 -- Applied Multivariate Statistics Cluster Analysis Purpose: To group similar entities together based on their attributes. Entities can be variables or observations. [illustration in Class]
Clustering in Data Mining
 Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
CS7267 MACHINE LEARNING NEAREST NEIGHBOR ALGORITHM. Mingon Kang, PhD Computer Science, Kennesaw State University
 CS7267 MACHINE LEARNING NEAREST NEIGHBOR ALGORITHM Mingon Kang, PhD Computer Science, Kennesaw State University KNN K-Nearest Neighbors (KNN) Simple, but very powerful classification algorithm Classifies
CS7267 MACHINE LEARNING NEAREST NEIGHBOR ALGORITHM Mingon Kang, PhD Computer Science, Kennesaw State University KNN K-Nearest Neighbors (KNN) Simple, but very powerful classification algorithm Classifies
Data Mining Cluster Analysis: Advanced Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining, 2 nd Edition
 Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Outline Prototype-based Fuzzy c-means
Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Outline Prototype-based Fuzzy c-means
Clustering. Informal goal. General types of clustering. Applications: Clustering in information search and analysis. Example applications in search
 Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Online Social Networks and Media. Community detection
 Online Social Networks and Media Community detection 1 Notes on Homework 1 1. You should write your own code for generating the graphs. You may use SNAP graph primitives (e.g., add node/edge) 2. For the
Online Social Networks and Media Community detection 1 Notes on Homework 1 1. You should write your own code for generating the graphs. You may use SNAP graph primitives (e.g., add node/edge) 2. For the
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Road map. Basic concepts
 Clustering Basic concepts Road map K-means algorithm Representation of clusters Hierarchical clustering Distance functions Data standardization Handling mixed attributes Which clustering algorithm to use?
Clustering Basic concepts Road map K-means algorithm Representation of clusters Hierarchical clustering Distance functions Data standardization Handling mixed attributes Which clustering algorithm to use?
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Proximity and Data Pre-processing
 Proximity and Data Pre-processing Slide 1/47 Proximity and Data Pre-processing Huiping Cao Proximity and Data Pre-processing Slide 2/47 Outline Types of data Data quality Measurement of proximity Data
Proximity and Data Pre-processing Slide 1/47 Proximity and Data Pre-processing Huiping Cao Proximity and Data Pre-processing Slide 2/47 Outline Types of data Data quality Measurement of proximity Data
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
CS 1675 Introduction to Machine Learning Lecture 18. Clustering. Clustering. Groups together similar instances in the data sample
 CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
Data Mining: Concepts and Techniques. Chapter March 8, 2007 Data Mining: Concepts and Techniques 1
 Data Mining: Concepts and Techniques Chapter 7.1-4 March 8, 2007 Data Mining: Concepts and Techniques 1 1. What is Cluster Analysis? 2. Types of Data in Cluster Analysis Chapter 7 Cluster Analysis 3. A
Data Mining: Concepts and Techniques Chapter 7.1-4 March 8, 2007 Data Mining: Concepts and Techniques 1 1. What is Cluster Analysis? 2. Types of Data in Cluster Analysis Chapter 7 Cluster Analysis 3. A
What to come. There will be a few more topics we will cover on supervised learning
 Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
Unsupervised Learning. Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team
 Unsupervised Learning Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team Table of Contents 1)Clustering: Introduction and Basic Concepts 2)An Overview of Popular Clustering Methods 3)Other Unsupervised
Unsupervised Learning Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team Table of Contents 1)Clustering: Introduction and Basic Concepts 2)An Overview of Popular Clustering Methods 3)Other Unsupervised
PAM algorithm. Types of Data in Cluster Analysis. A Categorization of Major Clustering Methods. Partitioning i Methods. Hierarchical Methods
 Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Clustering part II 1
 Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Hierarchical Clustering 4/5/17
 Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
CSE494 Information Retrieval Project C Report
 CSE494 Information Retrieval Project C Report By: Jianchun Fan Introduction In project C we implement several different clustering methods on the query results given by pagerank algorithms. The clustering
CSE494 Information Retrieval Project C Report By: Jianchun Fan Introduction In project C we implement several different clustering methods on the query results given by pagerank algorithms. The clustering
Unsupervised Data Mining: Clustering. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
9/17/2009. Wenyan Li (Emily Li) Sep. 15, Introduction to Clustering Analysis
 Sep. 15, Introduction to Clustering Analysis") Introduction ti to K-means Algorithm Wenan Li (Emil Li) Sep. 5, 9 Outline Introduction to Clustering Analsis K-means Algorithm Description Eample of K-means Algorithm Other Issues of K-means Algorithm
Introduction ti to K-means Algorithm Wenan Li (Emil Li) Sep. 5, 9 Outline Introduction to Clustering Analsis K-means Algorithm Description Eample of K-means Algorithm Other Issues of K-means Algorithm
Clustering. Lecture 6, 1/24/03 ECS289A
 Clustering Lecture 6, 1/24/03 What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
Clustering Lecture 6, 1/24/03 What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
Cluster Analysis. Angela Montanari and Laura Anderlucci
 Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a