Apprenticeship Learning for Reinforcement Learning. with application to RC helicopter flight Ritwik Anand, Nick Haliday, Audrey Huang
|
|
|
- Joshua Randall Adams
- 6 years ago
- Views:
Transcription
1 Apprenticeship Learning for Reinforcement Learning with application to RC helicopter flight Ritwik Anand, Nick Haliday, Audrey Huang
2 Table of Contents Introduction Theory Autonomous helicopter control problem Reinforcement Learning Apprenticeship Learning Learning dynamics [Abbeel, Ng 2005] Learning reward function [Abbeel, Ng 2004] Combining to get policy using control theory Putting into practice [Abbeel, Ng 2006] Conclusion


3 Autonomous Helicopter Flight Autonomous flight has important applications Wildland fire fighting Fixed-wing formation flight Helicopters have unique capabilities In-place hover Low-speed flight But it s a challenging control problem High-dimensional Asymmetric Noisy Nonlinear, non-minimum phase dynamics
4 It s a Reinforcement Learning (RL) Problem Learn an optimal decision policy by interacting with an environment and observing delayed or partial rewards. Learner (helicopter controller) performs actions (motion controls) Actions influence the state of the environment (helicopter) Position Orientation Velocity Angular velocity Environment returns reward How closely we are following desired trajectory

5 Markov Decision Process (MDP) Describes the reinforcement learning problem as a sextuple:
6 Objective: Find Optimal Policy A policy π maps states x S to actions u A Yields sum of rewards or value function We want to: Find optimal policy π* that maximizes value function:
7 MDP dynamics are unknown states (S) and actions (A) are physical properties of system, thus easily specified Time horizon (H) and initial state (I) and are given Assume for the moment that reward function (R) is known Dynamics (T) must be learned Discrete Continuous (linearly parameterized)

8 Discrete Dynamics Set of states S and actions A are finite Games such as Go and Atari Discrete transition probabilities P(x t+1 x t,u t )
9 Continuous Dynamics: Linearly Parameterized Set of states S and actions A are continuous Suited for autonomous helicopter control problem Linearly parameterized dynamics given by: x t+1 S is next state x t S is current state Φ is feature mapping of state space u t A is current action w t is process noise, I.I.D. multivariate Gaussian with known variance We need to estimate coefficient matrices A and B.
10 Learning dynamics: Exploration vs Exploitation Exploration Sufficiently visit all relevant parts of MDP Collect accurate transition probabilities Exploitation Given current MDP, maximize sum of rewards over time

11 Exploration Policies Are Impractical Example exploration policy - E 3 algorithm Strong bias for exploration policies Generate accurate MDP model Then uses exploitation policy to maximize reward Too aggressive for real system Computationally intractable Unsafe trajectories
12 Solution: Apprenticeship Learning??
13 Learns MDP dynamics from initial expert data.??
14 Apprenticeship Learning: MDP for Helicopters 1. Only system dynamics (T) are unknown. 2. But we do know system dynamics are linearly parameterized by:
15 Apprenticeship Learning: High-Level Algorithm INITIALIZE: 1. Expert demonstrates task. Record state-action trajectories. MAIN LOOP: 2. Use all state-action trajectories thus far to learn a dynamics model. Find a near-optimal policy using RL algorithm. 3. Test policy on real system. a. If as good as expert, RETURN policy. b. If not as good, add state-action trajectories to training set. GO to #2. Executes purely greedy, exploitative policies.
16 Algorithm: Details Given: α > 0, parameters N E and k 1, and expert policy π E. INITIALIZE: 1. Run N E trials under expert policy π E. 2. Record state-action trajectories (x curr, u curr, x next ). Add to training set. 3. Compute average sum of rewards over all N E trials, the utility U(π E ).
17 Algorithm: Details Given: α > 0, parameters N E and k 1, and expert policy π E. INITIALIZE: 1. Run N E trials under expert policy π E. 2. Record state-action trajectories (s curr, a curr, s next ). Add to training set. 3. Compute average sum of rewards over all N E trials, the utility U(π E ). MAIN LOOP: 1. Use regularized linear regression on all state-action trajectories thus far to estimate A and B. Call the new dynamics T (i). 2. From new dynamics T (i), use RL to derive optimal policy π (i). 3. Run k 1 trials under π (i) to get new trajectories and compute utility U(π (i) ). 4. If U(π (i) ) U(π E ) - α/2, return π (i) and exit. Otherwise, add new trajectories to training set and loop again.
18 Algorithm: Regularized Linear Regression Recall the linear dynamics predicts the next state using: Then the kth rows of A and B are estimated by:
19 Algorithm: Analysis optimal policy polynomial iterations polynomial expert trials polynomial policy trials The returned policy will be approximately optimal after a polynomial number of iterations and trials N E & k 1, with high probability.
20 High-Level Proof: Basis Lemmas: 1. Simulation Lemma: Accurate transition probabilities are sufficient for accurate policy evaluation. Facts: 1. After we have sufficient expert data, the estimated model is accurate for evaluating the utility of the expert s policy in every iteration. 2. Inaccurately modeled state-action pairs can only be visited a small number of times until all state-action pairs are accurately modeled.
21 High-Level Proof: Details 1. Consider policy π (i) in iteration i of the algorithm. π (i) is the optimal policy for the current training set/model.
22 High-Level Proof: Details 1. Consider policy π (i) in iteration i of the algorithm. We chose it because it s the optimal policy for the current training set/model. 2. π (i) utility is valued as lower than the π E s. Recall Termination Condition: If U(π (i) ) U(π E ) - α/2, return π (i) and exit. Otherwise, add new trajectories to training set and loop again.
23 High-Level Proof: Details 1. Consider policy π (i) in iteration i of the algorithm. We chose it because it s the optimal policy for the current training set/model. 2. π (i) utility is valued as lower than the π E s. Fact #1 says π E must be evaluated correctly. Recall Fact #1: After we have sufficient expert data, the estimated model is accurate for evaluating the utility of the expert s policy in every iteration.
24 High-Level Proof: Details 1. Consider policy π (i) in iteration i of the algorithm. We chose it because it s the optimal policy for the current training set/model. 2. π (i) utility is valued as lower than the π E s. Fact #1 says π E must be evaluated correctly. Then π (i) must be evaluated incorrectly.
25 High-Level Proof: Details 1. Consider policy π (i) in iteration i of the algorithm. We chose it because it s the optimal policy for the current training set/model. 2. π (i) utility is valued as lower than the π E s. Fact #1 says π E must be evaluated correctly. Then π (i) must be evaluated incorrectly. 3. From the Simulation Lemma, π (i) must be visiting inaccurately modeled state-action pairs. Recall Simulation Lemma: Accurate transition probabilities are sufficient for accurate policy evaluation. Contrapositive: Inaccurate policy evaluation means inaccurate transition probabilities.
26 High-Level Proof: Details 1. Consider policy π (i) in iteration i of the algorithm. We chose it because it s the optimal policy for the current training set/model. 2. π (i) utility is valued as lower than the π E s. Fact #1 says π E must be evaluated correctly. Then π (i) must be evaluated incorrectly. 3. From the Simulation Lemma, π (i) must be visiting inaccurately modeled stateaction pairs. 4. Fact #2 says we will only visit inaccurate pairs a small number of times until the dynamics are learned. Recall Fact #2: Inaccurately modeled state-action pairs can only be visited a small number of times until all state-action pairs are accurately modeled.
27 High-Level Proof: Details 1. Consider policy π (i) in iteration i of the algorithm. We chose it because it s the optimal policy for the current training set/model. 2. π (i) utility is valued as lower than the π E s. Fact #1 says π E must be evaluated correctly. Then π (i) must be evaluated incorrectly. 3. From the Simulation Lemma, π (i) must be visiting inaccurately modeled stateaction pairs. 4. Fact #2 says we will only visit inaccurate pairs a small number of times until the dynamics are learned. 5. The iterations are bounded.

28 Apprenticeship Learning: Review Applications: Find unknown dynamics for RL Exploration is risky Driving cars & aircraft Algorithm: Learns dynamics from expert demo Greedy, exploitation-only policy improvements Polynomial iterations
29 Now we have a dynamics model.
30 How can we learn a useful reward function?
31 Roadmap Will solve the problem of deriving a reward function from expert behavior Assume: expert maximizes some unknown reward function Assume: reward function is linear combination of known features Algorithm indirectly updates a reward function at each iteration
32 Variables Used MDP defined by tuple (S, A, T, γ, D, R) S: finite set of states of the system A: set of actions which cause a transition from a state to state with a given distribution of probabilities T: is the set of state transition probabilities, when taking a given action in a specific state γ: is the discount factor D: initial state distribution Φ: some vector of features which maps a state to [0, 1] k R: reward function linear w.r.t. Φ so R = w* Φ(s) with weights w* R k R is bounded by 1 w* 1 for the bound to hold
33 More Variables A policy π is a mapping from states to probability distributions over actions The expected value of a policy π is : Where the expectation is taken with respect to a initial start state s(0) drawn from distribution D and picking actions according to policy π
34 Feature Expectations For a policy π, define μ(π) to be the feature expectations: R is a linear combination of the known features Φ μ(π) completely determine the expected sum of discounted rewards for acting according to π
35 Initial Simplification We assume we are given an Markov Decision Process without the reward function, a feature mapping,,, We want to find a policy whose performance is close to that of the experts on the unknown reward function This is equivalent to finding s.t. :
36 Initial Simplification We use the fact that expectation is linear w.r.t. μ to get: Reduced the problem to finding μ(π ) close enough to μ(π E )
37 Inverse Reinforcement Algorithm Pick some arbitrary policy, compute and set i = 1 Compute Let be the value of w that attains the max If we terminate Using the RL algorithm, compute the optimal policy for the MDP using the Reward function Compute Set i = i+1 and loop back to step 2 Return the reward function Also generates a sequence of policies corresponding to maximizing the reward function at each iteration

38 Getting the Reward Function The maximization can be re-written as : Thus we can see that the algorithm is trying to find a reward function s.t. : Essentially a reward function on which the expert does better by a margin of t than any of the set of policies generated by the algorithm thus far
39 Assumptions of the Algorithm One key assumption we made was that the algorithm does eventually terminate. From Theorem 1 [Abbeel, Ng 2004] we have that the number of steps before the algorithm terminates with t (i) ϵ is upper bounded by We also assumed that the value μ E was known In practice must be estimated from monte-carlo samples. Theorem 2 [Abbeel, Ng 2004] states that Theorem 1 holds with probability 1-δ if we use m trajectories as samples. Where
40 So far...

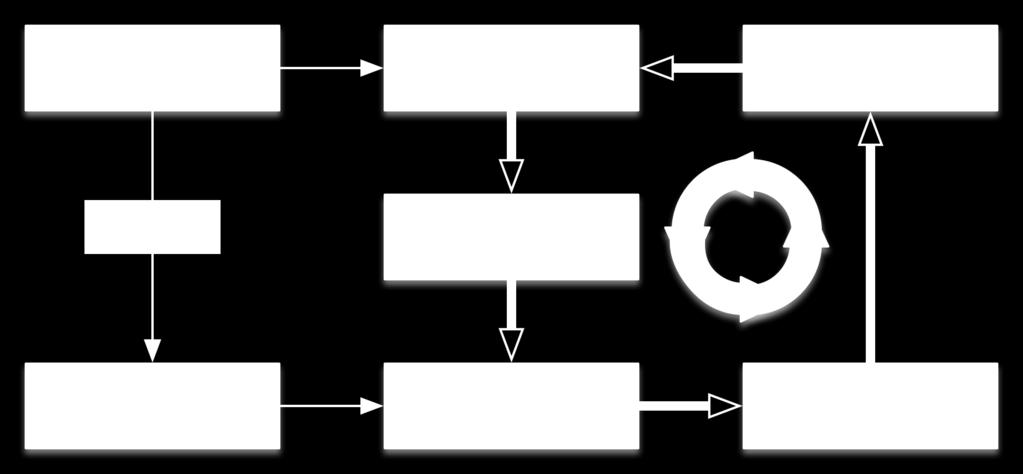
41 How do we get our policy?
42 How do we derive optimal actions to maximize reward?
.")
43 Control Theory Once we know the reward function, R, and the dynamics, f, we are left with a dynamic programming problem. Our reward function will be based on expert trajectory and two parameters (from inverse RL). Will build up solution from special case (LQR).
44 LQR: Linear dynamics with quadratic reward Suppose f is linear: And R is quadratic: Then...
. Assuming Q positive definite (PD), R positive semidefinite (PSD), P t+1 PD, B full rank, everything is well-defined.")
45 LQR: Linear dynamics with quadratic reward We can define the reward-to-go function, V t, and show via induction that it is quadratic and has simple to express policy (Riccati equation): Find by setting gradient to zero (valid by concavity). Assuming Q positive definite (PD), R positive semidefinite (PSD), P t+1 PD, B full rank, everything is well-defined. P t is PD by definition of V t (negative for all nonzero x).
46 Time-dependence Same idea with time dependent dynamics and rewards (will need the former). Just substitute time dependent parameters in place of A, B, Q, R in Riccati equation. Also fine if f t has zero-mean noise term (maximizing expectation so don t care).
47 What about non-linear dynamics? Our dynamics were only linear parameterized, not linear. Instead of optimizing over x t, u t, optimize over the error with respect to target trajectory: Errors will be small, so we can approximate the dynamics to first order Makes sense to design a reward function around deviation from the teacher s trajectory anyway.

48 Nonlinear optimization problem
49 Linearization

50 Linearized optimization problem
51 Iterative LQR Problem: We need the errors to be small. In practice this might not be true. So linear approximation will not match actual dynamics well. The solution: Linearize around current trajectory instead of target. Still penalize distance from target. Iteratively update toward target trajectory.

52 Iterative LQR
53 Results
54 Attempted four difficult maneuvers Flip Roll Tail-in funnel Nose-in funnel
55 Flip and Roll Flip: 360 rotation in place about lateral axis Initial cost matrices (Q, R) from algorithm oscillated Hand-tweaked matrices in simulator (following spirit but not letter of inverse RL algorithm). Eventually got a controller that could flip indefinitely. Penalty for changes in inputs over consecutive time steps was increased for final controller. Roll: 360 rotation in place about longitudinal axis Same Q, R as flips
56 Tail-in Funnel and Nose-in Funnel Tail-In Funnel: sideways medium-high speed circle, tail pointed towards center Repeatability (looping in place) is desired Autonomous funnels more accurate than human expert funnels. error over course of 12 autonomous funnels same as error over 2 human expert funnels Nose-In Funnel: sideways medium-high speed circle, nose pointed towards center Achieves same degree of increased accuracy as tail-in funnel

57 Video
58 Conclusion Can replace exploration with expert demonstrations and adjustments from repeated exploitation. Both reward and dynamics model can be learned from data. Inverse RL Good policy via iterative LQR Good theoretical guarantees (polynomial). Good performance in practice (with some hand-tweaking). More details at Simulator at com/site/rlcompetition2014/domains/helicopter.
59 References & Questions P. Abbeel, A. Coates, M. Quigley, A.Y. Ng, An Application of Reinforcement Learning to Aerobatic Helicopter Flight, NIPS P. Abbeel, A.Y. Ng, Apprenticeship Learning via Inverse Reinforcement Learning, ICML P. Abbeel, A.Y. Ng, Exploration and Apprenticeship Learning in Reinforcement Learning, ICML Later papers: A. Coates, P. Abbeel, A.Y. Ng, Learning for control from multiple demonstrations, ICML. (2008) doi: / P. Abbeel, A. Coates, A.Y. Ng, Autonomous Helicopter Aerobatics through Apprenticeship Learning, The International Journal of Robotics Research. 29 (2010) doi: /
Introduction to Reinforcement Learning. J. Zico Kolter Carnegie Mellon University
 Introduction to Reinforcement Learning J. Zico Kolter Carnegie Mellon University 1 Agent interaction with environment Agent State s Reward r Action a Environment 2 Of course, an oversimplification 3 Review:
Introduction to Reinforcement Learning J. Zico Kolter Carnegie Mellon University 1 Agent interaction with environment Agent State s Reward r Action a Environment 2 Of course, an oversimplification 3 Review:
Markov Decision Processes (MDPs) (cont.)
 (cont.)") Markov Decision Processes (MDPs) (cont.) Machine Learning 070/578 Carlos Guestrin Carnegie Mellon University November 29 th, 2007 Markov Decision Process (MDP) Representation State space: Joint state x
Markov Decision Processes (MDPs) (cont.) Machine Learning 070/578 Carlos Guestrin Carnegie Mellon University November 29 th, 2007 Markov Decision Process (MDP) Representation State space: Joint state x
Reinforcement Learning (INF11010) Lecture 6: Dynamic Programming for Reinforcement Learning (extended)
 Lecture 6: Dynamic Programming for Reinforcement Learning (extended)") Reinforcement Learning (INF11010) Lecture 6: Dynamic Programming for Reinforcement Learning (extended) Pavlos Andreadis, February 2 nd 2018 1 Markov Decision Processes A finite Markov Decision Process
Reinforcement Learning (INF11010) Lecture 6: Dynamic Programming for Reinforcement Learning (extended) Pavlos Andreadis, February 2 nd 2018 1 Markov Decision Processes A finite Markov Decision Process
ICRA 2012 Tutorial on Reinforcement Learning I. Introduction
 ICRA 2012 Tutorial on Reinforcement Learning I. Introduction Pieter Abbeel UC Berkeley Jan Peters TU Darmstadt Motivational Example: Helicopter Control Unstable Nonlinear Complicated dynamics Air flow
ICRA 2012 Tutorial on Reinforcement Learning I. Introduction Pieter Abbeel UC Berkeley Jan Peters TU Darmstadt Motivational Example: Helicopter Control Unstable Nonlinear Complicated dynamics Air flow
A Brief Introduction to Reinforcement Learning
 A Brief Introduction to Reinforcement Learning Minlie Huang ( ) Dept. of Computer Science, Tsinghua University aihuang@tsinghua.edu.cn 1 http://coai.cs.tsinghua.edu.cn/hml Reinforcement Learning Agent
A Brief Introduction to Reinforcement Learning Minlie Huang ( ) Dept. of Computer Science, Tsinghua University aihuang@tsinghua.edu.cn 1 http://coai.cs.tsinghua.edu.cn/hml Reinforcement Learning Agent
Slides credited from Dr. David Silver & Hung-Yi Lee
 Slides credited from Dr. David Silver & Hung-Yi Lee Review Reinforcement Learning 2 Reinforcement Learning RL is a general purpose framework for decision making RL is for an agent with the capacity to
Slides credited from Dr. David Silver & Hung-Yi Lee Review Reinforcement Learning 2 Reinforcement Learning RL is a general purpose framework for decision making RL is for an agent with the capacity to
15-780: MarkovDecisionProcesses
 15-780: MarkovDecisionProcesses J. Zico Kolter Feburary 29, 2016 1 Outline Introduction Formal definition Value iteration Policy iteration Linear programming for MDPs 2 1988 Judea Pearl publishes Probabilistic
15-780: MarkovDecisionProcesses J. Zico Kolter Feburary 29, 2016 1 Outline Introduction Formal definition Value iteration Policy iteration Linear programming for MDPs 2 1988 Judea Pearl publishes Probabilistic
10703 Deep Reinforcement Learning and Control
 10703 Deep Reinforcement Learning and Control Russ Salakhutdinov Machine Learning Department rsalakhu@cs.cmu.edu Policy Gradient I Used Materials Disclaimer: Much of the material and slides for this lecture
10703 Deep Reinforcement Learning and Control Russ Salakhutdinov Machine Learning Department rsalakhu@cs.cmu.edu Policy Gradient I Used Materials Disclaimer: Much of the material and slides for this lecture
When Network Embedding meets Reinforcement Learning?
 When Network Embedding meets Reinforcement Learning? ---Learning Combinatorial Optimization Problems over Graphs Changjun Fan 1 1. An Introduction to (Deep) Reinforcement Learning 2. How to combine NE
When Network Embedding meets Reinforcement Learning? ---Learning Combinatorial Optimization Problems over Graphs Changjun Fan 1 1. An Introduction to (Deep) Reinforcement Learning 2. How to combine NE
Markov Decision Processes. (Slides from Mausam)
") Markov Decision Processes (Slides from Mausam) Machine Learning Operations Research Graph Theory Control Theory Markov Decision Process Economics Robotics Artificial Intelligence Neuroscience /Psychology
Markov Decision Processes (Slides from Mausam) Machine Learning Operations Research Graph Theory Control Theory Markov Decision Process Economics Robotics Artificial Intelligence Neuroscience /Psychology
Reinforcement Learning: A brief introduction. Mihaela van der Schaar
 Reinforcement Learning: A brief introduction Mihaela van der Schaar Outline Optimal Decisions & Optimal Forecasts Markov Decision Processes (MDPs) States, actions, rewards and value functions Dynamic Programming
Reinforcement Learning: A brief introduction Mihaela van der Schaar Outline Optimal Decisions & Optimal Forecasts Markov Decision Processes (MDPs) States, actions, rewards and value functions Dynamic Programming
Applications of Reinforcement Learning. Ist künstliche Intelligenz gefährlich?
 Applications of Reinforcement Learning Ist künstliche Intelligenz gefährlich? Table of contents Playing Atari with Deep Reinforcement Learning Playing Super Mario World Stanford University Autonomous Helicopter
Applications of Reinforcement Learning Ist künstliche Intelligenz gefährlich? Table of contents Playing Atari with Deep Reinforcement Learning Playing Super Mario World Stanford University Autonomous Helicopter
Generalized Inverse Reinforcement Learning
 Generalized Inverse Reinforcement Learning James MacGlashan Cogitai, Inc. james@cogitai.com Michael L. Littman mlittman@cs.brown.edu Nakul Gopalan ngopalan@cs.brown.edu Amy Greenwald amy@cs.brown.edu Abstract
Generalized Inverse Reinforcement Learning James MacGlashan Cogitai, Inc. james@cogitai.com Michael L. Littman mlittman@cs.brown.edu Nakul Gopalan ngopalan@cs.brown.edu Amy Greenwald amy@cs.brown.edu Abstract
CS 687 Jana Kosecka. Reinforcement Learning Continuous State MDP s Value Function approximation
 CS 687 Jana Kosecka Reinforcement Learning Continuous State MDP s Value Function approximation Markov Decision Process - Review Formal definition 4-tuple (S, A, T, R) Set of states S - finite Set of actions
CS 687 Jana Kosecka Reinforcement Learning Continuous State MDP s Value Function approximation Markov Decision Process - Review Formal definition 4-tuple (S, A, T, R) Set of states S - finite Set of actions
Deep Reinforcement Learning
 Deep Reinforcement Learning 1 Outline 1. Overview of Reinforcement Learning 2. Policy Search 3. Policy Gradient and Gradient Estimators 4. Q-prop: Sample Efficient Policy Gradient and an Off-policy Critic
Deep Reinforcement Learning 1 Outline 1. Overview of Reinforcement Learning 2. Policy Search 3. Policy Gradient and Gradient Estimators 4. Q-prop: Sample Efficient Policy Gradient and an Off-policy Critic
Planning and Control: Markov Decision Processes
 CSE-571 AI-based Mobile Robotics Planning and Control: Markov Decision Processes Planning Static vs. Dynamic Predictable vs. Unpredictable Fully vs. Partially Observable Perfect vs. Noisy Environment What
CSE-571 AI-based Mobile Robotics Planning and Control: Markov Decision Processes Planning Static vs. Dynamic Predictable vs. Unpredictable Fully vs. Partially Observable Perfect vs. Noisy Environment What
10-701/15-781, Fall 2006, Final
 -7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
-7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
Using Inaccurate Models in Reinforcement Learning
 Pieter Abbeel Morgan Quigley Andrew Y. Ng Computer Science Department, Stanford University, Stanford, CA 94305, USA pabbeel@cs.stanford.edu mquigley@cs.stanford.edu ang@cs.stanford.edu Abstract In the
Pieter Abbeel Morgan Quigley Andrew Y. Ng Computer Science Department, Stanford University, Stanford, CA 94305, USA pabbeel@cs.stanford.edu mquigley@cs.stanford.edu ang@cs.stanford.edu Abstract In the
Reinforcement Learning in Discrete and Continuous Domains Applied to Ship Trajectory Generation
 POLISH MARITIME RESEARCH Special Issue S1 (74) 2012 Vol 19; pp. 31-36 10.2478/v10012-012-0020-8 Reinforcement Learning in Discrete and Continuous Domains Applied to Ship Trajectory Generation Andrzej Rak,
POLISH MARITIME RESEARCH Special Issue S1 (74) 2012 Vol 19; pp. 31-36 10.2478/v10012-012-0020-8 Reinforcement Learning in Discrete and Continuous Domains Applied to Ship Trajectory Generation Andrzej Rak,
Applying the Episodic Natural Actor-Critic Architecture to Motor Primitive Learning
 Applying the Episodic Natural Actor-Critic Architecture to Motor Primitive Learning Jan Peters 1, Stefan Schaal 1 University of Southern California, Los Angeles CA 90089, USA Abstract. In this paper, we
Applying the Episodic Natural Actor-Critic Architecture to Motor Primitive Learning Jan Peters 1, Stefan Schaal 1 University of Southern California, Los Angeles CA 90089, USA Abstract. In this paper, we
6 Randomized rounding of semidefinite programs
 6 Randomized rounding of semidefinite programs We now turn to a new tool which gives substantially improved performance guarantees for some problems We now show how nonlinear programming relaxations can
6 Randomized rounding of semidefinite programs We now turn to a new tool which gives substantially improved performance guarantees for some problems We now show how nonlinear programming relaxations can
Announcements. CS 188: Artificial Intelligence Spring Advanced Applications. Robot folds towels. Robotic Control Tasks
 CS 188: Artificial Intelligence Spring 2011 Advanced Applications: Robotics Announcements Practice Final Out (optional) Similar extra credit system as practice midterm Contest (optional): Tomorrow night
CS 188: Artificial Intelligence Spring 2011 Advanced Applications: Robotics Announcements Practice Final Out (optional) Similar extra credit system as practice midterm Contest (optional): Tomorrow night
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2011 Advanced Applications: Robotics Pieter Abbeel UC Berkeley A few slides from Sebastian Thrun, Dan Klein 1 Announcements Practice Final Out (optional) Similar
CS 188: Artificial Intelligence Spring 2011 Advanced Applications: Robotics Pieter Abbeel UC Berkeley A few slides from Sebastian Thrun, Dan Klein 1 Announcements Practice Final Out (optional) Similar
Data Analysis 3. Support Vector Machines. Jan Platoš October 30, 2017
 Data Analysis 3 Support Vector Machines Jan Platoš October 30, 2017 Department of Computer Science Faculty of Electrical Engineering and Computer Science VŠB - Technical University of Ostrava Table of
Data Analysis 3 Support Vector Machines Jan Platoš October 30, 2017 Department of Computer Science Faculty of Electrical Engineering and Computer Science VŠB - Technical University of Ostrava Table of
Learning to bounce a ball with a robotic arm
 Eric Wolter TU Darmstadt Thorsten Baark TU Darmstadt Abstract Bouncing a ball is a fun and challenging task for humans. It requires fine and complex motor controls and thus is an interesting problem for
Eric Wolter TU Darmstadt Thorsten Baark TU Darmstadt Abstract Bouncing a ball is a fun and challenging task for humans. It requires fine and complex motor controls and thus is an interesting problem for
Markov Decision Processes and Reinforcement Learning
 Lecture 14 and Marco Chiarandini Department of Mathematics & Computer Science University of Southern Denmark Slides by Stuart Russell and Peter Norvig Course Overview Introduction Artificial Intelligence
Lecture 14 and Marco Chiarandini Department of Mathematics & Computer Science University of Southern Denmark Slides by Stuart Russell and Peter Norvig Course Overview Introduction Artificial Intelligence
Robotic Search & Rescue via Online Multi-task Reinforcement Learning
 Lisa Lee Department of Mathematics, Princeton University, Princeton, NJ 08544, USA Advisor: Dr. Eric Eaton Mentors: Dr. Haitham Bou Ammar, Christopher Clingerman GRASP Laboratory, University of Pennsylvania,
Lisa Lee Department of Mathematics, Princeton University, Princeton, NJ 08544, USA Advisor: Dr. Eric Eaton Mentors: Dr. Haitham Bou Ammar, Christopher Clingerman GRASP Laboratory, University of Pennsylvania,
FMA901F: Machine Learning Lecture 3: Linear Models for Regression. Cristian Sminchisescu
 FMA901F: Machine Learning Lecture 3: Linear Models for Regression Cristian Sminchisescu Machine Learning: Frequentist vs. Bayesian In the frequentist setting, we seek a fixed parameter (vector), with value(s)
FMA901F: Machine Learning Lecture 3: Linear Models for Regression Cristian Sminchisescu Machine Learning: Frequentist vs. Bayesian In the frequentist setting, we seek a fixed parameter (vector), with value(s)
ADAPTIVE TILE CODING METHODS FOR THE GENERALIZATION OF VALUE FUNCTIONS IN THE RL STATE SPACE A THESIS SUBMITTED TO THE FACULTY OF THE GRADUATE SCHOOL
 ADAPTIVE TILE CODING METHODS FOR THE GENERALIZATION OF VALUE FUNCTIONS IN THE RL STATE SPACE A THESIS SUBMITTED TO THE FACULTY OF THE GRADUATE SCHOOL OF THE UNIVERSITY OF MINNESOTA BY BHARAT SIGINAM IN
ADAPTIVE TILE CODING METHODS FOR THE GENERALIZATION OF VALUE FUNCTIONS IN THE RL STATE SPACE A THESIS SUBMITTED TO THE FACULTY OF THE GRADUATE SCHOOL OF THE UNIVERSITY OF MINNESOTA BY BHARAT SIGINAM IN
Parameterized Maneuver Learning for Autonomous Helicopter Flight
 Parameterized Maneuver Learning for Autonomous Helicopter Flight Jie Tang, Arjun Singh, Nimbus Goehausen, and Pieter Abbeel Abstract Many robotic control tasks involve complex dynamics that are hard to
Parameterized Maneuver Learning for Autonomous Helicopter Flight Jie Tang, Arjun Singh, Nimbus Goehausen, and Pieter Abbeel Abstract Many robotic control tasks involve complex dynamics that are hard to
CSE 490R P3 - Model Learning and MPPI Due date: Sunday, Feb 28-11:59 PM
 CSE 490R P3 - Model Learning and MPPI Due date: Sunday, Feb 28-11:59 PM 1 Introduction In this homework, we revisit the concept of local control for robot navigation, as well as integrate our local controller
CSE 490R P3 - Model Learning and MPPI Due date: Sunday, Feb 28-11:59 PM 1 Introduction In this homework, we revisit the concept of local control for robot navigation, as well as integrate our local controller
The Current State of Autonomous Helicopter Flight
 The Current State of Autonomous Helicopter Flight Samuel Moczygemba December 16, 2009 Contents 1 Introduction 1 2 Applications 2 3 Tools 2 3.1 Reinforcement Learning.......................................
The Current State of Autonomous Helicopter Flight Samuel Moczygemba December 16, 2009 Contents 1 Introduction 1 2 Applications 2 3 Tools 2 3.1 Reinforcement Learning.......................................
Announcements. CS 188: Artificial Intelligence Spring Classification: Feature Vectors. Classification: Weights. Learning: Binary Perceptron
 CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/20/2010 Announcements W7 due Thursday [that s your last written for the semester!] Project 5 out Thursday Contest running
CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/20/2010 Announcements W7 due Thursday [that s your last written for the semester!] Project 5 out Thursday Contest running
Lecture 13: Learning from Demonstration
 CS 294-5 Algorithmic Human-Robot Interaction Fall 206 Lecture 3: Learning from Demonstration Scribes: Samee Ibraheem and Malayandi Palaniappan - Adapted from Notes by Avi Singh and Sammy Staszak 3. Introduction
CS 294-5 Algorithmic Human-Robot Interaction Fall 206 Lecture 3: Learning from Demonstration Scribes: Samee Ibraheem and Malayandi Palaniappan - Adapted from Notes by Avi Singh and Sammy Staszak 3. Introduction
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound. Lecture 12: Deep Reinforcement Learning
: Multimodal Learning with Vision, Language and Sound. Lecture 12: Deep Reinforcement Learning") Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 12: Deep Reinforcement Learning Types of Learning Supervised training Learning from the teacher Training data includes
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 12: Deep Reinforcement Learning Types of Learning Supervised training Learning from the teacher Training data includes
arxiv: v2 [cs.ai] 21 Sep 2017
![arxiv: v2 [cs.ai] 21 Sep 2017](/thumbs/82/86250689.jpg "arxiv: v2 [cs.ai] 21 Sep 2017") Learning to Drive using Inverse Reinforcement Learning and Deep Q-Networks arxiv:161203653v2 [csai] 21 Sep 2017 Sahand Sharifzadeh 1 Ioannis Chiotellis 1 Rudolph Triebel 1,2 Daniel Cremers 1 1 Department
Learning to Drive using Inverse Reinforcement Learning and Deep Q-Networks arxiv:161203653v2 [csai] 21 Sep 2017 Sahand Sharifzadeh 1 Ioannis Chiotellis 1 Rudolph Triebel 1,2 Daniel Cremers 1 1 Department
Kernel Methods & Support Vector Machines
 & Support Vector Machines & Support Vector Machines Arvind Visvanathan CSCE 970 Pattern Recognition 1 & Support Vector Machines Question? Draw a single line to separate two classes? 2 & Support Vector
& Support Vector Machines & Support Vector Machines Arvind Visvanathan CSCE 970 Pattern Recognition 1 & Support Vector Machines Question? Draw a single line to separate two classes? 2 & Support Vector
Adversarial Policy Switching with Application to RTS Games
 Adversarial Policy Switching with Application to RTS Games Brian King 1 and Alan Fern 2 and Jesse Hostetler 2 Department of Electrical Engineering and Computer Science Oregon State University 1 kingbria@lifetime.oregonstate.edu
Adversarial Policy Switching with Application to RTS Games Brian King 1 and Alan Fern 2 and Jesse Hostetler 2 Department of Electrical Engineering and Computer Science Oregon State University 1 kingbria@lifetime.oregonstate.edu
Machine Learning / Jan 27, 2010
 Revisiting Logistic Regression & Naïve Bayes Aarti Singh Machine Learning 10-701/15-781 Jan 27, 2010 Generative and Discriminative Classifiers Training classifiers involves learning a mapping f: X -> Y,
Revisiting Logistic Regression & Naïve Bayes Aarti Singh Machine Learning 10-701/15-781 Jan 27, 2010 Generative and Discriminative Classifiers Training classifiers involves learning a mapping f: X -> Y,
10703 Deep Reinforcement Learning and Control
 10703 Deep Reinforcement Learning and Control Russ Salakhutdinov Machine Learning Department rsalakhu@cs.cmu.edu Policy Gradient II Used Materials Disclaimer: Much of the material and slides for this lecture
10703 Deep Reinforcement Learning and Control Russ Salakhutdinov Machine Learning Department rsalakhu@cs.cmu.edu Policy Gradient II Used Materials Disclaimer: Much of the material and slides for this lecture
CSEP 573: Artificial Intelligence
 CSEP 573: Artificial Intelligence Machine Learning: Perceptron Ali Farhadi Many slides over the course adapted from Luke Zettlemoyer and Dan Klein. 1 Generative vs. Discriminative Generative classifiers:
CSEP 573: Artificial Intelligence Machine Learning: Perceptron Ali Farhadi Many slides over the course adapted from Luke Zettlemoyer and Dan Klein. 1 Generative vs. Discriminative Generative classifiers:
Probabilistic Graphical Models
 School of Computer Science Probabilistic Graphical Models Theory of Variational Inference: Inner and Outer Approximation Eric Xing Lecture 14, February 29, 2016 Reading: W & J Book Chapters Eric Xing @
School of Computer Science Probabilistic Graphical Models Theory of Variational Inference: Inner and Outer Approximation Eric Xing Lecture 14, February 29, 2016 Reading: W & J Book Chapters Eric Xing @
Apprenticeship Learning for Helicopter Control By Adam Coates, Pieter Abbeel, and Andrew Y. Ng
 Apprenticeship Learning for Helicopter Control By Adam Coates, Pieter Abbeel, and Andrew Y. Ng doi:1.1145/1538788.1538812 Abstract Autonomous helicopter flight is widely regarded to be a highly challenging
Apprenticeship Learning for Helicopter Control By Adam Coates, Pieter Abbeel, and Andrew Y. Ng doi:1.1145/1538788.1538812 Abstract Autonomous helicopter flight is widely regarded to be a highly challenging
Problem characteristics. Dynamic Optimization. Examples. Policies vs. Trajectories. Planning using dynamic optimization. Dynamic Optimization Issues
 Problem characteristics Planning using dynamic optimization Chris Atkeson 2004 Want optimal plan, not just feasible plan We will minimize a cost function C(execution). Some examples: C() = c T (x T ) +
Problem characteristics Planning using dynamic optimization Chris Atkeson 2004 Want optimal plan, not just feasible plan We will minimize a cost function C(execution). Some examples: C() = c T (x T ) +
Monte Carlo Tree Search PAH 2015
 Monte Carlo Tree Search PAH 2015 MCTS animation and RAVE slides by Michèle Sebag and Romaric Gaudel Markov Decision Processes (MDPs) main formal model Π = S, A, D, T, R states finite set of states of the
Monte Carlo Tree Search PAH 2015 MCTS animation and RAVE slides by Michèle Sebag and Romaric Gaudel Markov Decision Processes (MDPs) main formal model Π = S, A, D, T, R states finite set of states of the
This chapter explains two techniques which are frequently used throughout
 Chapter 2 Basic Techniques This chapter explains two techniques which are frequently used throughout this thesis. First, we will introduce the concept of particle filters. A particle filter is a recursive
Chapter 2 Basic Techniques This chapter explains two techniques which are frequently used throughout this thesis. First, we will introduce the concept of particle filters. A particle filter is a recursive
Algorithms for Solving RL: Temporal Difference Learning (TD) Reinforcement Learning Lecture 10
 Reinforcement Learning Lecture 10") Algorithms for Solving RL: Temporal Difference Learning (TD) 1 Reinforcement Learning Lecture 10 Gillian Hayes 8th February 2007 Incremental Monte Carlo Algorithm TD Prediction TD vs MC vs DP TD for control:
Algorithms for Solving RL: Temporal Difference Learning (TD) 1 Reinforcement Learning Lecture 10 Gillian Hayes 8th February 2007 Incremental Monte Carlo Algorithm TD Prediction TD vs MC vs DP TD for control:
The exam is closed book, closed calculator, and closed notes except your one-page crib sheet.
 CS Summer Introduction to Artificial Intelligence Midterm You have approximately minutes. The exam is closed book, closed calculator, and closed notes except your one-page crib sheet. Mark your answers
CS Summer Introduction to Artificial Intelligence Midterm You have approximately minutes. The exam is closed book, closed calculator, and closed notes except your one-page crib sheet. Mark your answers
Support vector machines
 Support vector machines When the data is linearly separable, which of the many possible solutions should we prefer? SVM criterion: maximize the margin, or distance between the hyperplane and the closest
Support vector machines When the data is linearly separable, which of the many possible solutions should we prefer? SVM criterion: maximize the margin, or distance between the hyperplane and the closest
Partially Observable Markov Decision Processes. Mausam (slides by Dieter Fox)
") Partially Observable Markov Decision Processes Mausam (slides by Dieter Fox) Stochastic Planning: MDPs Static Environment Fully Observable Perfect What action next? Stochastic Instantaneous Percepts Actions
Partially Observable Markov Decision Processes Mausam (slides by Dieter Fox) Stochastic Planning: MDPs Static Environment Fully Observable Perfect What action next? Stochastic Instantaneous Percepts Actions
In Homework 1, you determined the inverse dynamics model of the spinbot robot to be
 Robot Learning Winter Semester 22/3, Homework 2 Prof. Dr. J. Peters, M.Eng. O. Kroemer, M. Sc. H. van Hoof Due date: Wed 6 Jan. 23 Note: Please fill in the solution on this sheet but add sheets for the
Robot Learning Winter Semester 22/3, Homework 2 Prof. Dr. J. Peters, M.Eng. O. Kroemer, M. Sc. H. van Hoof Due date: Wed 6 Jan. 23 Note: Please fill in the solution on this sheet but add sheets for the
Classification: Feature Vectors
 Classification: Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free YOUR_NAME MISSPELLED FROM_FRIEND... : : : : 2 0 2 0 PIXEL 7,12
Classification: Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free YOUR_NAME MISSPELLED FROM_FRIEND... : : : : 2 0 2 0 PIXEL 7,12
An introduction to multi-armed bandits
 An introduction to multi-armed bandits Henry WJ Reeve (Manchester) (henry.reeve@manchester.ac.uk) A joint work with Joe Mellor (Edinburgh) & Professor Gavin Brown (Manchester) Plan 1. An introduction to
An introduction to multi-armed bandits Henry WJ Reeve (Manchester) (henry.reeve@manchester.ac.uk) A joint work with Joe Mellor (Edinburgh) & Professor Gavin Brown (Manchester) Plan 1. An introduction to
Note Set 4: Finite Mixture Models and the EM Algorithm
 Note Set 4: Finite Mixture Models and the EM Algorithm Padhraic Smyth, Department of Computer Science University of California, Irvine Finite Mixture Models A finite mixture model with K components, for
Note Set 4: Finite Mixture Models and the EM Algorithm Padhraic Smyth, Department of Computer Science University of California, Irvine Finite Mixture Models A finite mixture model with K components, for
CSE151 Assignment 2 Markov Decision Processes in the Grid World
 CSE5 Assignment Markov Decision Processes in the Grid World Grace Lin A484 gclin@ucsd.edu Tom Maddock A55645 tmaddock@ucsd.edu Abstract Markov decision processes exemplify sequential problems, which are
CSE5 Assignment Markov Decision Processes in the Grid World Grace Lin A484 gclin@ucsd.edu Tom Maddock A55645 tmaddock@ucsd.edu Abstract Markov decision processes exemplify sequential problems, which are
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 8: GRAPHICAL MODELS
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 8: GRAPHICAL MODELS Bayesian Networks Directed Acyclic Graph (DAG) Bayesian Networks General Factorization Bayesian Curve Fitting (1) Polynomial Bayesian
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 8: GRAPHICAL MODELS Bayesian Networks Directed Acyclic Graph (DAG) Bayesian Networks General Factorization Bayesian Curve Fitting (1) Polynomial Bayesian
Learning Swing-free Trajectories for UAVs with a Suspended Load in Obstacle-free Environments
 Learning Swing-free Trajectories for UAVs with a Suspended Load in Obstacle-free Environments Aleksandra Faust, Ivana Palunko 2, Patricio Cruz 3, Rafael Fierro 3, and Lydia Tapia Abstract Attaining autonomous
Learning Swing-free Trajectories for UAVs with a Suspended Load in Obstacle-free Environments Aleksandra Faust, Ivana Palunko 2, Patricio Cruz 3, Rafael Fierro 3, and Lydia Tapia Abstract Attaining autonomous
ˆ The exam is closed book, closed calculator, and closed notes except your one-page crib sheet.
 CS Summer Introduction to Artificial Intelligence Midterm ˆ You have approximately minutes. ˆ The exam is closed book, closed calculator, and closed notes except your one-page crib sheet. ˆ Mark your answers
CS Summer Introduction to Artificial Intelligence Midterm ˆ You have approximately minutes. ˆ The exam is closed book, closed calculator, and closed notes except your one-page crib sheet. ˆ Mark your answers
Value Iteration. Reinforcement Learning: Introduction to Machine Learning. Matt Gormley Lecture 23 Apr. 10, 2019
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Reinforcement Learning: Value Iteration Matt Gormley Lecture 23 Apr. 10, 2019 1
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Reinforcement Learning: Value Iteration Matt Gormley Lecture 23 Apr. 10, 2019 1
What is Learning? CS 343: Artificial Intelligence Machine Learning. Raymond J. Mooney. Problem Solving / Planning / Control.
 What is Learning? CS 343: Artificial Intelligence Machine Learning Herbert Simon: Learning is any process by which a system improves performance from experience. What is the task? Classification Problem
What is Learning? CS 343: Artificial Intelligence Machine Learning Herbert Simon: Learning is any process by which a system improves performance from experience. What is the task? Classification Problem
Learning Motor Behaviors: Past & Present Work
 Stefan Schaal Computer Science & Neuroscience University of Southern California, Los Angeles & ATR Computational Neuroscience Laboratory Kyoto, Japan sschaal@usc.edu http://www-clmc.usc.edu Learning Motor
Stefan Schaal Computer Science & Neuroscience University of Southern California, Los Angeles & ATR Computational Neuroscience Laboratory Kyoto, Japan sschaal@usc.edu http://www-clmc.usc.edu Learning Motor
Gradient Reinforcement Learning of POMDP Policy Graphs
 1 Gradient Reinforcement Learning of POMDP Policy Graphs Douglas Aberdeen Research School of Information Science and Engineering Australian National University Jonathan Baxter WhizBang! Labs July 23, 2001
1 Gradient Reinforcement Learning of POMDP Policy Graphs Douglas Aberdeen Research School of Information Science and Engineering Australian National University Jonathan Baxter WhizBang! Labs July 23, 2001
Lecture Notes on Congestion Games
 Lecture Notes on Department of Computer Science RWTH Aachen SS 2005 Definition and Classification Description of n agents share a set of resources E strategy space of player i is S i 2 E latency for resource
Lecture Notes on Department of Computer Science RWTH Aachen SS 2005 Definition and Classification Description of n agents share a set of resources E strategy space of player i is S i 2 E latency for resource
Apprenticeship Learning via Inverse Reinforcement Learning
 Apprenticeship Learning via Inverse Reinforcement Learning Pieter Abbeel Andrew Y. Ng Computer Science Department, Stanford University, Stanford, CA 94305, USA pabbeel@cs.stanford.edu ang@cs.stanford.edu
Apprenticeship Learning via Inverse Reinforcement Learning Pieter Abbeel Andrew Y. Ng Computer Science Department, Stanford University, Stanford, CA 94305, USA pabbeel@cs.stanford.edu ang@cs.stanford.edu
MOBILE sensor networks can be deployed to efficiently
 32 IEEE TRANSACTIONS ON AUTOMATIC CONTROL, VOL. 55, NO. 1, JANUARY 2010 Mobile Sensor Network Control Using Mutual Information Methods and Particle Filters Gabriel M. Hoffmann, Member, IEEE, and Claire
32 IEEE TRANSACTIONS ON AUTOMATIC CONTROL, VOL. 55, NO. 1, JANUARY 2010 Mobile Sensor Network Control Using Mutual Information Methods and Particle Filters Gabriel M. Hoffmann, Member, IEEE, and Claire
Robotics. Lecture 5: Monte Carlo Localisation. See course website for up to date information.
 Robotics Lecture 5: Monte Carlo Localisation See course website http://www.doc.ic.ac.uk/~ajd/robotics/ for up to date information. Andrew Davison Department of Computing Imperial College London Review:
Robotics Lecture 5: Monte Carlo Localisation See course website http://www.doc.ic.ac.uk/~ajd/robotics/ for up to date information. Andrew Davison Department of Computing Imperial College London Review:
Support Vector Machines
 Support Vector Machines SVM Discussion Overview. Importance of SVMs. Overview of Mathematical Techniques Employed 3. Margin Geometry 4. SVM Training Methodology 5. Overlapping Distributions 6. Dealing
Support Vector Machines SVM Discussion Overview. Importance of SVMs. Overview of Mathematical Techniques Employed 3. Margin Geometry 4. SVM Training Methodology 5. Overlapping Distributions 6. Dealing
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
Function Approximation. Pieter Abbeel UC Berkeley EECS
 Function Approximation Pieter Abbeel UC Berkeley EECS Outline Value iteration with function approximation Linear programming with function approximation Value Iteration Algorithm: Start with for all s.
Function Approximation Pieter Abbeel UC Berkeley EECS Outline Value iteration with function approximation Linear programming with function approximation Value Iteration Algorithm: Start with for all s.
REINFORCEMENT LEARNING: MDP APPLIED TO AUTONOMOUS NAVIGATION
 REINFORCEMENT LEARNING: MDP APPLIED TO AUTONOMOUS NAVIGATION ABSTRACT Mark A. Mueller Georgia Institute of Technology, Computer Science, Atlanta, GA USA The problem of autonomous vehicle navigation between
REINFORCEMENT LEARNING: MDP APPLIED TO AUTONOMOUS NAVIGATION ABSTRACT Mark A. Mueller Georgia Institute of Technology, Computer Science, Atlanta, GA USA The problem of autonomous vehicle navigation between
Optimal Crane Scheduling
 Optimal Crane Scheduling IonuŃ Aron Iiro Harjunkoski John Hooker Latife Genç Kaya March 2007 1 Problem Schedule 2 cranes to transfer material between locations in a manufacturing plant. For example, copper
Optimal Crane Scheduling IonuŃ Aron Iiro Harjunkoski John Hooker Latife Genç Kaya March 2007 1 Problem Schedule 2 cranes to transfer material between locations in a manufacturing plant. For example, copper
Targeting Specific Distributions of Trajectories in MDPs
 Targeting Specific Distributions of Trajectories in MDPs David L. Roberts 1, Mark J. Nelson 1, Charles L. Isbell, Jr. 1, Michael Mateas 1, Michael L. Littman 2 1 College of Computing, Georgia Institute
Targeting Specific Distributions of Trajectories in MDPs David L. Roberts 1, Mark J. Nelson 1, Charles L. Isbell, Jr. 1, Michael Mateas 1, Michael L. Littman 2 1 College of Computing, Georgia Institute
Theoretical Concepts of Machine Learning
 Theoretical Concepts of Machine Learning Part 2 Institute of Bioinformatics Johannes Kepler University, Linz, Austria Outline 1 Introduction 2 Generalization Error 3 Maximum Likelihood 4 Noise Models 5
Theoretical Concepts of Machine Learning Part 2 Institute of Bioinformatics Johannes Kepler University, Linz, Austria Outline 1 Introduction 2 Generalization Error 3 Maximum Likelihood 4 Noise Models 5
Using Markov decision processes to optimise a non-linear functional of the final distribution, with manufacturing applications.
 Using Markov decision processes to optimise a non-linear functional of the final distribution, with manufacturing applications. E.J. Collins 1 1 Department of Mathematics, University of Bristol, University
Using Markov decision processes to optimise a non-linear functional of the final distribution, with manufacturing applications. E.J. Collins 1 1 Department of Mathematics, University of Bristol, University
CS6375: Machine Learning Gautam Kunapuli. Mid-Term Review
 Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Introduction to Mobile Robotics
 Introduction to Mobile Robotics Gaussian Processes Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann SS08, University of Freiburg, Department for Computer Science Announcement
Introduction to Mobile Robotics Gaussian Processes Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann SS08, University of Freiburg, Department for Computer Science Announcement
Support Vector Machines
 Support Vector Machines . Importance of SVM SVM is a discriminative method that brings together:. computational learning theory. previously known methods in linear discriminant functions 3. optimization
Support Vector Machines . Importance of SVM SVM is a discriminative method that brings together:. computational learning theory. previously known methods in linear discriminant functions 3. optimization
CSE 573: Artificial Intelligence Autumn 2010
 CSE 573: Artificial Intelligence Autumn 2010 Lecture 16: Machine Learning Topics 12/7/2010 Luke Zettlemoyer Most slides over the course adapted from Dan Klein. 1 Announcements Syllabus revised Machine
CSE 573: Artificial Intelligence Autumn 2010 Lecture 16: Machine Learning Topics 12/7/2010 Luke Zettlemoyer Most slides over the course adapted from Dan Klein. 1 Announcements Syllabus revised Machine
Combining Deep Reinforcement Learning and Safety Based Control for Autonomous Driving
 Combining Deep Reinforcement Learning and Safety Based Control for Autonomous Driving Xi Xiong Jianqiang Wang Fang Zhang Keqiang Li State Key Laboratory of Automotive Safety and Energy, Tsinghua University
Combining Deep Reinforcement Learning and Safety Based Control for Autonomous Driving Xi Xiong Jianqiang Wang Fang Zhang Keqiang Li State Key Laboratory of Automotive Safety and Energy, Tsinghua University
CS 234 Winter 2018: Assignment #2
 Due date: 2/10 (Sat) 11:00 PM (23:00) PST These questions require thought, but do not require long answers. Please be as concise as possible. We encourage students to discuss in groups for assignments.
Due date: 2/10 (Sat) 11:00 PM (23:00) PST These questions require thought, but do not require long answers. Please be as concise as possible. We encourage students to discuss in groups for assignments.
Inverse Reinforcement Learning in Partially Observable Environments
 Journal of Machine Learning Research 12 (2011) 691-730 Submitted 2/10; Revised 11/10; Published 3/11 Inverse Reinforcement Learning in Partially Observable Environments Jaedeug Choi Kee-Eung Kim Department
Journal of Machine Learning Research 12 (2011) 691-730 Submitted 2/10; Revised 11/10; Published 3/11 Inverse Reinforcement Learning in Partially Observable Environments Jaedeug Choi Kee-Eung Kim Department
Convexization in Markov Chain Monte Carlo
 in Markov Chain Monte Carlo 1 IBM T. J. Watson Yorktown Heights, NY 2 Department of Aerospace Engineering Technion, Israel August 23, 2011 Problem Statement MCMC processes in general are governed by non
in Markov Chain Monte Carlo 1 IBM T. J. Watson Yorktown Heights, NY 2 Department of Aerospace Engineering Technion, Israel August 23, 2011 Problem Statement MCMC processes in general are governed by non
Learning Swing-free Trajectories for UAVs with a Suspended Load
 Learning Swing-free Trajectories for UAVs with a Suspended Load Aleksandra Faust, Ivana Palunko, Patricio Cruz, Rafael Fierro, and Lydia Tapia Abstract Attaining autonomous flight is an important task
Learning Swing-free Trajectories for UAVs with a Suspended Load Aleksandra Faust, Ivana Palunko, Patricio Cruz, Rafael Fierro, and Lydia Tapia Abstract Attaining autonomous flight is an important task
Linear Methods for Regression and Shrinkage Methods
 Linear Methods for Regression and Shrinkage Methods Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer 1 Linear Regression Models Least Squares Input vectors
Linear Methods for Regression and Shrinkage Methods Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer 1 Linear Regression Models Least Squares Input vectors
CS 188: Artificial Intelligence Spring Recap Search I
 CS 188: Artificial Intelligence Spring 2011 Midterm Review 3/14/2011 Pieter Abbeel UC Berkeley Recap Search I Agents that plan ahead à formalization: Search Search problem: States (configurations of the
CS 188: Artificial Intelligence Spring 2011 Midterm Review 3/14/2011 Pieter Abbeel UC Berkeley Recap Search I Agents that plan ahead à formalization: Search Search problem: States (configurations of the
Knowledge Transfer for Deep Reinforcement Learning with Hierarchical Experience Replay
 Knowledge Transfer for Deep Reinforcement Learning with Hierarchical Experience Replay Haiyan (Helena) Yin, Sinno Jialin Pan School of Computer Science and Engineering Nanyang Technological University
Knowledge Transfer for Deep Reinforcement Learning with Hierarchical Experience Replay Haiyan (Helena) Yin, Sinno Jialin Pan School of Computer Science and Engineering Nanyang Technological University
All lecture slides will be available at CSC2515_Winter15.html
 CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 9: Support Vector Machines All lecture slides will be available at http://www.cs.toronto.edu/~urtasun/courses/csc2515/ CSC2515_Winter15.html Many
CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 9: Support Vector Machines All lecture slides will be available at http://www.cs.toronto.edu/~urtasun/courses/csc2515/ CSC2515_Winter15.html Many
Beikrit Samia Falaschini Clara Abdolhosseini Mahyar Capotescu Florin. Qball Quadrotor Helicopter
 Beikrit Samia Falaschini Clara Abdolhosseini Mahyar Capotescu Florin Qball Quadrotor Helicopter Flight Control Systems Project : Objectives for the Qball quadrotor helicopter 1) Develop non linear and
Beikrit Samia Falaschini Clara Abdolhosseini Mahyar Capotescu Florin Qball Quadrotor Helicopter Flight Control Systems Project : Objectives for the Qball quadrotor helicopter 1) Develop non linear and
Policy Search via the Signed Derivative
 Robotics: Science and Systems 29 Seattle, WA, USA, June 28 - July, 29 Policy Search via the Signed Derivative J. Zico Kolter and Andrew Y. Ng Computer Science Department, Stanford University {kolter,ang}@cs.stanford.edu
Robotics: Science and Systems 29 Seattle, WA, USA, June 28 - July, 29 Policy Search via the Signed Derivative J. Zico Kolter and Andrew Y. Ng Computer Science Department, Stanford University {kolter,ang}@cs.stanford.edu
Residual Advantage Learning Applied to a Differential Game
 Presented at the International Conference on Neural Networks (ICNN 96), Washington DC, 2-6 June 1996. Residual Advantage Learning Applied to a Differential Game Mance E. Harmon Wright Laboratory WL/AAAT
Presented at the International Conference on Neural Networks (ICNN 96), Washington DC, 2-6 June 1996. Residual Advantage Learning Applied to a Differential Game Mance E. Harmon Wright Laboratory WL/AAAT
The transition: Each student passes half his store of candies to the right. students with an odd number of candies eat one.
 Kate s problem: The students are distributed around a circular table The teacher distributes candies to all the students, so that each student has an even number of candies The transition: Each student
Kate s problem: The students are distributed around a circular table The teacher distributes candies to all the students, so that each student has an even number of candies The transition: Each student
Announcements. CS 188: Artificial Intelligence Spring Generative vs. Discriminative. Classification: Feature Vectors. Project 4: due Friday.
 CS 188: Artificial Intelligence Spring 2011 Lecture 21: Perceptrons 4/13/2010 Announcements Project 4: due Friday. Final Contest: up and running! Project 5 out! Pieter Abbeel UC Berkeley Many slides adapted
CS 188: Artificial Intelligence Spring 2011 Lecture 21: Perceptrons 4/13/2010 Announcements Project 4: due Friday. Final Contest: up and running! Project 5 out! Pieter Abbeel UC Berkeley Many slides adapted
Introduction to Deep Q-network
 Introduction to Deep Q-network Presenter: Yunshu Du CptS 580 Deep Learning 10/10/2016 Deep Q-network (DQN) Deep Q-network (DQN) An artificial agent for general Atari game playing Learn to master 49 different
Introduction to Deep Q-network Presenter: Yunshu Du CptS 580 Deep Learning 10/10/2016 Deep Q-network (DQN) Deep Q-network (DQN) An artificial agent for general Atari game playing Learn to master 49 different
Lecture 7: Support Vector Machine
 Lecture 7: Support Vector Machine Hien Van Nguyen University of Houston 9/28/2017 Separating hyperplane Red and green dots can be separated by a separating hyperplane Two classes are separable, i.e., each
Lecture 7: Support Vector Machine Hien Van Nguyen University of Houston 9/28/2017 Separating hyperplane Red and green dots can be separated by a separating hyperplane Two classes are separable, i.e., each
Linear Regression & Gradient Descent
 Linear Regression & Gradient Descent These slides were assembled by Byron Boots, with grateful acknowledgement to Eric Eaton and the many others who made their course materials freely available online.
Linear Regression & Gradient Descent These slides were assembled by Byron Boots, with grateful acknowledgement to Eric Eaton and the many others who made their course materials freely available online.
Unit 2: Locomotion Kinematics of Wheeled Robots: Part 3
 Unit 2: Locomotion Kinematics of Wheeled Robots: Part 3 Computer Science 4766/6778 Department of Computer Science Memorial University of Newfoundland January 28, 2014 COMP 4766/6778 (MUN) Kinematics of
Unit 2: Locomotion Kinematics of Wheeled Robots: Part 3 Computer Science 4766/6778 Department of Computer Science Memorial University of Newfoundland January 28, 2014 COMP 4766/6778 (MUN) Kinematics of
Feature Extractors. CS 188: Artificial Intelligence Fall Some (Vague) Biology. The Binary Perceptron. Binary Decision Rule.
 Biology. The Binary Perceptron. Binary Decision Rule.") CS 188: Artificial Intelligence Fall 2008 Lecture 24: Perceptrons II 11/24/2008 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit
CS 188: Artificial Intelligence Fall 2008 Lecture 24: Perceptrons II 11/24/2008 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit
GAMES Webinar: Rendering Tutorial 2. Monte Carlo Methods. Shuang Zhao
 GAMES Webinar: Rendering Tutorial 2 Monte Carlo Methods Shuang Zhao Assistant Professor Computer Science Department University of California, Irvine GAMES Webinar Shuang Zhao 1 Outline 1. Monte Carlo integration
GAMES Webinar: Rendering Tutorial 2 Monte Carlo Methods Shuang Zhao Assistant Professor Computer Science Department University of California, Irvine GAMES Webinar Shuang Zhao 1 Outline 1. Monte Carlo integration
Instance-based Learning
 Instance-based Learning Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 19 th, 2007 2005-2007 Carlos Guestrin 1 Why not just use Linear Regression? 2005-2007 Carlos Guestrin
Instance-based Learning Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 19 th, 2007 2005-2007 Carlos Guestrin 1 Why not just use Linear Regression? 2005-2007 Carlos Guestrin
Perceptron: This is convolution!
 Perceptron: This is convolution! v v v Shared weights v Filter = local perceptron. Also called kernel. By pooling responses at different locations, we gain robustness to the exact spatial location of image
Perceptron: This is convolution! v v v Shared weights v Filter = local perceptron. Also called kernel. By pooling responses at different locations, we gain robustness to the exact spatial location of image