Measure of Distance. We wish to define the distance between two objects Distance metric between points:
|
|
|
- Rosalind Pope
- 6 years ago
- Views:
Transcription
1 Measure of Distance We wish to define the distance between two objects Distance metric between points: Euclidean distance (EUC) Manhattan distance (MAN) Pearson sample correlation (COR) Angle distance (EISEN considered by Eisen et al., 1998.) Spearman sample correlation (SPEAR) Kandall s τ sample correlation (TAU) Mahalanobis distance Distance metric between distributions: Kullback-Leibler information Hamming s mutual information
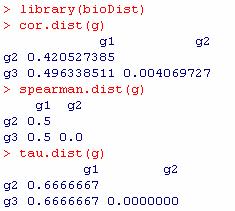
2 R: Distance Metric Between Points dist function in stat package: Euclidean Manhattan hopach package: disscosangle(x, na.rm = TRUE) ** biodist package: cor.dist spearman.dist tau.dist
 (1.51 3.70 2.07) (0.33 1.60)) ( 1.45 ( 1.51) 1.76 ( 1.93 0.29) (0.33 0.75)) ( 1.45 ( 0.04) 1.")
3 2.07) -1.60, 1.51, g 0.29) , 0.04, g 0.33) -1.45, (-1.76, g ( ( = = = Euclidean distance: 2.45 g g g2 g ) ( )) ( 1.60 ( 0.04) ( ) ( )) ( 1.45 ( 1.51) 1.76 ( ) ( )) ( 1.45 ( 0.04) 1.76 ( = + + = + + = + + g3 : vs g2 g3 : vs g1 g2 : vs g1
4 g g g = = = (-1.76, -1.45, 0.33) ( 0.04, , 0.29) ( 1.51, -1.60, 2.07) Manhattan distance: g1 g1 g2 vs vs vs g2 : (-0. 75) = g3 : (-1.60) = 5.16 g3 : (-1.60) = 4.10 g2 g3 g g2 4.10
, ( x y x y x y x y x where")
5 Cosine Correlation Distance Note: disscosangle(hopach) = = = = = n i i n i i i x y x d 1 2 1, 1 ), ( x y x y x y x y x where α
6 Correlation-based distance :
7 Measure of Distance We wish to define the distance between two objects Distance metric between points: Euclidean distance (EUC) Manhattan distance (MAN) Pearson sample correlation (COR) Angle distance (EISEN considered by Eisen et al., 1998.) Spearman sample correlation (SPEAR) Kandall s τ sample correlation (TAU) Mahalanobis distance Distance metric between distributions: Kullback-Leibler information Hamming s mutual information
8 Kullback-Leibler Information Kullback-Leibler information (KLI) considers if the shape of the distribution of features is similar between two genes. f 1 (x) f 2 (x)
9 Kullback-Leibler Information f1( x) KLI ( f1, f2) = log f f2( x) d KLD ( f1, f2) = [ KLI ( f1, f2) + 1 ( x) dx KLI ( f 2, f 1 )]/ 2 Note: 1. KLI (d KLD ) = 0 if f 1 (x) = f 2 (x). 2. KLI is not symmetric but d KLD is. 3. d KLD does not satisfy the triangle inequality 4. KLI or d KLD is not defined when f 1 (x) 0 but f 2 (x) = 0 for some x.
10 Mutual Information Mutual information(mi) attempts to measure the distance from independence. Note: f ( x, y) MI ( f = 1, f2) log f ( x, y) dydx x y f1( x) f2( y) 1. If x and y are independent then f(x,y) = f 1 (x)f 2 (y) so that MI = Does not satisfy the triangle inequality
11 Mutual Information (Joe, 1989) Transformation: δ * = [1 0 exp( 2MI)] δ * 1 1/ 2 δ* can be interpreted as a generalization of the correlation!
12 R: Distance Between Distributions biodist package: KLD.matrix (kernel density) KLdist.matrix (binning) mutualinfo
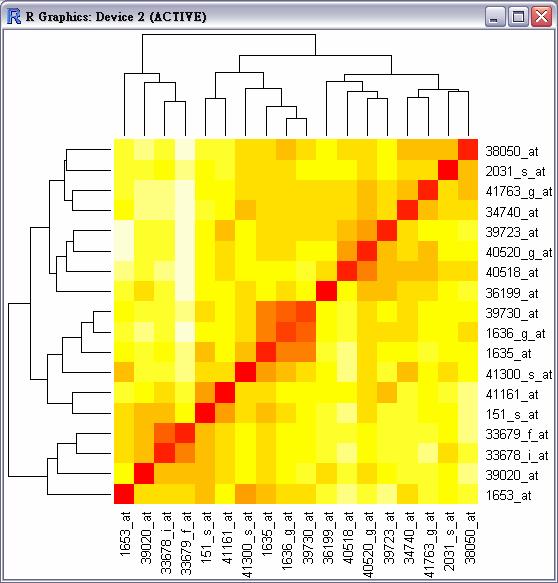
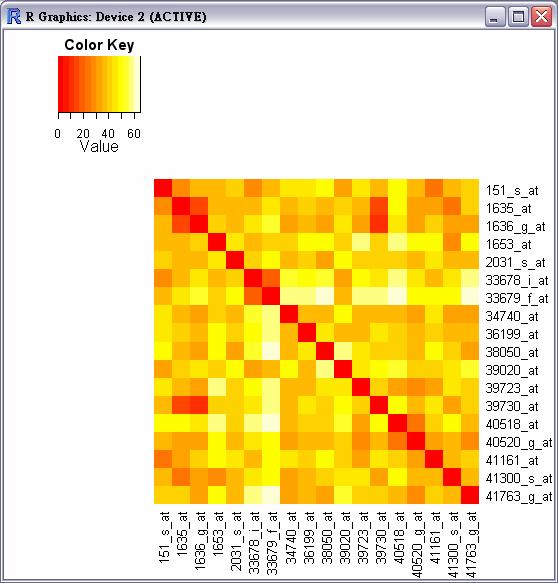
13 Exercise: Apop.xls Try to compute the distances between the rows (genes).
14 Distance: Visualization man = dist(apop,"manhattan") heatmap(as.matrix(man)) heatmap(as.matrix(man),rowv=na,colv=na) heatmap(as.matrix(man),rowv=na,colv=na,symm=t) library(gplots) heatmap.2(as.matrix(man),dendrogram="none",keysize=1.5, Rowv=F,Colv=F, trace="none",density.info="none") 4
15 1 2
16 2 3
17 4
18 pairs(cbind(man,mi,klsmooth,klbin))
19 Cluster Analysis Clustering is the process of grouping together similar entities. It is appropriate when there is no prior knowledge about the data. In a machine learning framework, it is known as unsupervised learning since there is no known desired answer for any particular gene or experiment.
20 Cluster Analysis The entities that are similar to each other are grouping together and form a cluster. Step 1:Defining the similarity between entities distance metric Step 2:Forming clusters clustering algorithms
21 Measure of Distance Distance metric between points: Euclidean distance (EUC) Manhattan distance (MAN) Pearson sample correlation (COR) Angle distance (EISEN considered by Eisen et al., 1998.) Spearman sample correlation (SPEAR) Kandall s τ sample correlation (TAU) Mahalanobis distance Distance metric between distributions: Kullback-Leibler information Hamming s mutual information
22 Cluster Analysis The entities that are similar to each other are grouping together and form a cluster. Step 1: Defining the similarity between entities distance metric Step 2:Forming clusters clustering algorithms
23 Clustering According to distance between two objects, the entities that are closer to each other are grouping together and form a cluster. clustering algorithms Note: Anything can be clustered. The clustering results may not be related to any biological meanings between the members of a given cluster.

24 Clustering Usually the results of clustering is shown in a clustering tree, or a dendrogram.
25 Clustering Algorithm Partitioning: k-means, PAM Hierarchical clustering Model based: SOM
26 Partitioning Algorithms Partitioning method: Construct a partition of n objects into a set of k clusters k = 3
27 Partitioning Algorithms Given a k, find a partition of k clusters that optimizes the chosen partitioning criterion k-means: Each cluster is represented by the center of the cluster k-medoids or PAM (Partition around medoids): Each cluster is represented by one of the objects in the cluster
28 K-means Clustering Step 1: Determine the number of clusters, k. Step 2: Randomly choose k point as the centers of clusters. Step 3: Calculate the distance from each pattern to k centers and associate every object with the closest cluster center. Step 4: Calculate a new center for the updated clusters. Step 5: Repeat steps 3 and 4 until no objects are relocated.
29 K-means Clustering Example: k = 2 Step 3 Step 4
30 K-means Clustering Example: k = 2 Repeat Step 3 Repeat Step 4

31 Example of K-means Clustering Result Average distance to the center of clusters
32 k-mean Clustering: Properties 1. It is possible to produce empty clusters. To avoid such situation, one can: (i) let the starting cluster centers be in the general area populated by the given data. (ii) randomly choose k points as initial centers.
33 k-mean Clustering: Properties 2. The results of the algorithm can change between successive runs of the algorithm.
34 PAM PAM (Partitioning Around Medoids): starts from an initial set of medoids (objects) iteratively replaces one of the medoids by one of the nonmedoids if it improves the total distance of the resulting clustering provides a novel graphical display, the silhouette plot, which allows the user to select the optimal number of clusters. works effectively for small data sets, but does not scale well for large data sets
35 PAM Step 1: Select k representative objects arbitrarily. Step 2: For each pair of non-selected object h and selected object i, calculate the total swapping cost TC ih If TC ih < 0, i is replaced by h Then assign each non-selected object to the most similar representative object Step 3: Repeat Step 2 until there is no change.
36 PAM Total Cost = Arbitrary choose k object as initial medoids Assign each remaining object to nearest medoids K=2 Total Cost = 26 Randomly select a nonmedoid object,o ramdom Do loop Until no change Swapping O and O ramdom If quality is improved Compute total cost of swapping
37 PAM the next plot is called a silhouette plot each observation is represented by a horizontal bar the groups are slightly separated the length of a bar is a measure of how close the observation is to its assigned group (versus the others)
38 Silhouette plot of pam(x = as.dist(d), k = 3, diss = TRUE) ALL B ALL ALL B ALL ALL B ALL B ALL ALL B ALL B ALL ALL B ALL ALL B ALL ALL B ALL B ALL ALL B ALL T ALL ALL T ALL T ALL ALL T ALL T ALL AML AML AML AML AML AML AML AML AML AML AML ALL B n = 38 3 clusters C j j : n j ave i Cj s i 1 : : : Average silhouette width : 0.53 Silhouette width s i
39 Partitioning Methods: Comment Number of clusters, k: If there are features that clearly distinguish between the classes (e.g. cancer and healthy), the algorithm might use them to construct meaningful clusters. If the analysis has an exploratory character, one could repeat the clustering for several values of k.
40 Clustering Algorithm Partitioning: k-means, PAM Hierarchical clustering Model based: SOM
41 Hierarchical Clustering k-means clustering returns a set of k clusters. Hierarchical clustering returns a complete tree with individual patterns as leaves and the convergence points of all branches as the root. root complete tree Distance leaf
42 Hierarchical Clustering Step 1: Choose one distance measurement Step 2: Construct the hierarchical tree: Bottom-up (agglomerative) method: n 1; starting from the individual patterns and putting smaller clusters together to form bigger clusters. Top-down (divisive) method: 1 n; starting at the root and splitting clusters into smaller ones by nonhierarchical algorithms (e.g., k-means with k = 2).
43 Hierarchical Clustering: Example Example: Consider 5 experiments (A, B, C, D, E) with the following distance metric: Bottom-up (agglomerative) method: putting similar clusters together to form bigger clusters. A B C D E A B C D 200 E
44 Hierarchical Clustering: Example {A,B} C D E {A,B}??? C D 200 E Need to define inter-cluster distances
45 Inter-Cluster Distances Single Linkage Complete Linkage Centroid Linkage Average Linkage
46 Hierarchical Clustering: Example If we use average linkage: d {A,B},C = (d A,C +d B,C ) / 2, etc. {A,B} C D E {A,B} C D 200 E d {A,B},C = (d A,C +d B,C ) / 2 = ( )/2
47 Hierarchical Clustering: Example * use average linkage {A,B} C {D,E} {A,B} C 500 {D,E}
48 Cutting Tree Diagrams A hierarchical clustering diagram can be used to divide the data into a pre-determined number of clusters by cutting the tree at a certain depth. 2 groups 4 groups
49 Properties of Hierarchical Clustering Different tree-constructing methods: The same data and the same process obtain the same results by running the same bottom-up method. The same data and the same process obtain two different results by running the same top-down method. Different linkage type produce different results.
50 Hierarchical Clustering: Comments Objective of the research: To obtain a clustering that reflects the structure of the data. The dendrogram itself is almost never the answer to the research question. Various implementations of hierarchical clustering should not be judged simply by their speed; slower algorithms may be trying to do a better job pf extracting the data features. The order of the objects and clusters in the dendrogram may be misleading.
51 Orders in Dendrogram
52 Clustering Algorithm Partitioning: k-means, PAM Hierarchical clustering Model based: SOM
53 SOM: Motivation Misleading dendrograms: K-means Hierarchical The SOM clustering is designed to create a plot in which similar patterns are plotted next to each other.

54 Self-Organizing Feature Maps (SOM) SOM: A map consists of many simple elements (nodes or neurons); it is constructed by training. SOMs are believed to resemble processing that can occur in the brain Useful for visualizing high-dimensional data in 2- or 3- D space
55 Self-Organizing Feature Maps (SOM) Clustering is performed by having several units competing for the current object The unit whose weight vector is closest to the current object wins The winner and its neighbors learn by having their weights adjusted

56 Self-Organizing Feature Maps (SOM) This process can be visualized by imagining all SOM units being connected to each other by rubber bands. A 2D SOFM trained on 3-dimensional data.
57 paper: Eisen 1998 Algorithmic Approaches to Clustering Gene Expression Data Tibshirani, Hastie, Narasimhan and Chu (2002) Rousseeuw, P.J. (1987) Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math., 20, 53 65
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
Clustering. Lecture 6, 1/24/03 ECS289A
 Clustering Lecture 6, 1/24/03 What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
Clustering Lecture 6, 1/24/03 What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Cluster Analysis for Microarray Data
 Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
biodist July 15, 2010 Continuous version of Kullback-Leibler Distance (KLD) KLD.matrix Description
 KLD.matrix Description") biodist July 15, 2010 KLD.matri Continuous version of Kullback-Leibler Distance (KLD) Calculate KLD by estimating by smoothing log(f()/g()) f() and then integrating. KLD.matri(,...) n by p matri or list
biodist July 15, 2010 KLD.matri Continuous version of Kullback-Leibler Distance (KLD) Calculate KLD by estimating by smoothing log(f()/g()) f() and then integrating. KLD.matri(,...) n by p matri or list
Package biodist. R topics documented: April 9, Title Different distance measures Version Author B. Ding, R. Gentleman and Vincent Carey
 Title Different distance measures Version 1.38.0 Author B. Ding, R. Gentleman and Vincent Carey Package biodist April 9, 2015 A collection of software tools for calculating distance measures. Maintainer
Title Different distance measures Version 1.38.0 Author B. Ding, R. Gentleman and Vincent Carey Package biodist April 9, 2015 A collection of software tools for calculating distance measures. Maintainer
ECS 234: Data Analysis: Clustering ECS 234
 : Data Analysis: Clustering What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
: Data Analysis: Clustering What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
Exploratory data analysis for microarrays
 Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Distance Measures for Gene Expression (and other high-dimensional) Data
 Data") Distance Measures for Gene Expression (and other high-dimensional) Data Utah State University Spring 04 STAT 5570: Statistical Bioinformatics Notes. References Chapter of Bioconductor Monograph (course
Distance Measures for Gene Expression (and other high-dimensional) Data Utah State University Spring 04 STAT 5570: Statistical Bioinformatics Notes. References Chapter of Bioconductor Monograph (course
Hard clustering. Each object is assigned to one and only one cluster. Hierarchical clustering is usually hard. Soft (fuzzy) clustering
 clustering") An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
Hierarchical Clustering
 What is clustering Partitioning of a data set into subsets. A cluster is a group of relatively homogeneous cases or observations Hierarchical Clustering Mikhail Dozmorov Fall 2016 2/61 What is clustering
What is clustering Partitioning of a data set into subsets. A cluster is a group of relatively homogeneous cases or observations Hierarchical Clustering Mikhail Dozmorov Fall 2016 2/61 What is clustering
Multivariate analyses in ecology. Cluster (part 2) Ordination (part 1 & 2)
 Ordination (part 1 & 2)") Multivariate analyses in ecology Cluster (part 2) Ordination (part 1 & 2) 1 Exercise 9B - solut 2 Exercise 9B - solut 3 Exercise 9B - solut 4 Exercise 9B - solut 5 Multivariate analyses in ecology Cluster
Multivariate analyses in ecology Cluster (part 2) Ordination (part 1 & 2) 1 Exercise 9B - solut 2 Exercise 9B - solut 3 Exercise 9B - solut 4 Exercise 9B - solut 5 Multivariate analyses in ecology Cluster
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Cluster Analysis: Agglomerate Hierarchical Clustering
 Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
Data Mining Algorithms
 for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
Data Mining: Concepts and Techniques. Chapter March 8, 2007 Data Mining: Concepts and Techniques 1
 Data Mining: Concepts and Techniques Chapter 7.1-4 March 8, 2007 Data Mining: Concepts and Techniques 1 1. What is Cluster Analysis? 2. Types of Data in Cluster Analysis Chapter 7 Cluster Analysis 3. A
Data Mining: Concepts and Techniques Chapter 7.1-4 March 8, 2007 Data Mining: Concepts and Techniques 1 1. What is Cluster Analysis? 2. Types of Data in Cluster Analysis Chapter 7 Cluster Analysis 3. A
Unsupervised Learning
 Unsupervised Learning A review of clustering and other exploratory data analysis methods HST.951J: Medical Decision Support Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision
Unsupervised Learning A review of clustering and other exploratory data analysis methods HST.951J: Medical Decision Support Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision
CS 1675 Introduction to Machine Learning Lecture 18. Clustering. Clustering. Groups together similar instances in the data sample
 CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Cluster Analysis. Angela Montanari and Laura Anderlucci
 Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Distances, Clustering! Rafael Irizarry!
 Distances, Clustering! Rafael Irizarry! Heatmaps! Distance! Clustering organizes things that are close into groups! What does it mean for two genes to be close?! What does it mean for two samples to
Distances, Clustering! Rafael Irizarry! Heatmaps! Distance! Clustering organizes things that are close into groups! What does it mean for two genes to be close?! What does it mean for two samples to
High throughput Data Analysis 2. Cluster Analysis
 High throughput Data Analysis 2 Cluster Analysis Overview Why clustering? Hierarchical clustering K means clustering Issues with above two Other methods Quality of clustering results Introduction WHY DO
High throughput Data Analysis 2 Cluster Analysis Overview Why clustering? Hierarchical clustering K means clustering Issues with above two Other methods Quality of clustering results Introduction WHY DO
Data Mining. Dr. Raed Ibraheem Hamed. University of Human Development, College of Science and Technology Department of Computer Science
 Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 201 Road map What is Cluster Analysis? Characteristics of Clustering
Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 201 Road map What is Cluster Analysis? Characteristics of Clustering
Clustering. Chapter 10 in Introduction to statistical learning
 Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
What is Unsupervised Learning?
 Clustering What is Unsupervised Learning? Unlike in supervised learning, in unsupervised learning, there are no labels We simply a search for patterns in the data Examples Clustering Density Estimation
Clustering What is Unsupervised Learning? Unlike in supervised learning, in unsupervised learning, there are no labels We simply a search for patterns in the data Examples Clustering Density Estimation
Olmo S. Zavala Romero. Clustering Hierarchical Distance Group Dist. K-means. Center of Atmospheric Sciences, UNAM.
 Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Unsupervised Learning. Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team
 Unsupervised Learning Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team Table of Contents 1)Clustering: Introduction and Basic Concepts 2)An Overview of Popular Clustering Methods 3)Other Unsupervised
Unsupervised Learning Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team Table of Contents 1)Clustering: Introduction and Basic Concepts 2)An Overview of Popular Clustering Methods 3)Other Unsupervised
Foundations of Machine Learning CentraleSupélec Fall Clustering Chloé-Agathe Azencot
 Foundations of Machine Learning CentraleSupélec Fall 2017 12. Clustering Chloé-Agathe Azencot Centre for Computational Biology, Mines ParisTech chloe-agathe.azencott@mines-paristech.fr Learning objectives
Foundations of Machine Learning CentraleSupélec Fall 2017 12. Clustering Chloé-Agathe Azencot Centre for Computational Biology, Mines ParisTech chloe-agathe.azencott@mines-paristech.fr Learning objectives
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Chapter 6: Cluster Analysis
 Chapter 6: Cluster Analysis The major goal of cluster analysis is to separate individual observations, or items, into groups, or clusters, on the basis of the values for the q variables measured on each
Chapter 6: Cluster Analysis The major goal of cluster analysis is to separate individual observations, or items, into groups, or clusters, on the basis of the values for the q variables measured on each
Cluster Analysis. Summer School on Geocomputation. 27 June July 2011 Vysoké Pole
 Cluster Analysis Summer School on Geocomputation 27 June 2011 2 July 2011 Vysoké Pole Lecture delivered by: doc. Mgr. Radoslav Harman, PhD. Faculty of Mathematics, Physics and Informatics Comenius University,
Cluster Analysis Summer School on Geocomputation 27 June 2011 2 July 2011 Vysoké Pole Lecture delivered by: doc. Mgr. Radoslav Harman, PhD. Faculty of Mathematics, Physics and Informatics Comenius University,
Statistics 202: Data Mining. c Jonathan Taylor. Week 8 Based in part on slides from textbook, slides of Susan Holmes. December 2, / 1
 Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Clustering Gene Expression Data: Acknowledgement: Elizabeth Garrett-Mayer; Shirley Liu; Robert Tibshirani; Guenther Walther; Trevor Hastie
 Clustering Gene Expression Data: Acknowledgement: Elizabeth Garrett-Mayer; Shirley Liu; Robert Tibshirani; Guenther Walther; Trevor Hastie Data from Garber et al. PNAS (98), 2001. Clustering Clustering
Clustering Gene Expression Data: Acknowledgement: Elizabeth Garrett-Mayer; Shirley Liu; Robert Tibshirani; Guenther Walther; Trevor Hastie Data from Garber et al. PNAS (98), 2001. Clustering Clustering
Stat 321: Transposable Data Clustering
 Stat 321: Transposable Data Clustering Art B. Owen Stanford Statistics Art B. Owen (Stanford Statistics) Clustering 1 / 27 Clustering Given n objects with d attributes, place them (the objects) into groups.
Stat 321: Transposable Data Clustering Art B. Owen Stanford Statistics Art B. Owen (Stanford Statistics) Clustering 1 / 27 Clustering Given n objects with d attributes, place them (the objects) into groups.
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
University of Florida CISE department Gator Engineering. Clustering Part 2
 Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering, cont. Genome 373 Genomic Informatics Elhanan Borenstein. Some slides adapted from Jacques van Helden
 Clustering, cont Genome 373 Genomic Informatics Elhanan Borenstein Some slides adapted from Jacques van Helden Improving the search heuristic: Multiple starting points Simulated annealing Genetic algorithms
Clustering, cont Genome 373 Genomic Informatics Elhanan Borenstein Some slides adapted from Jacques van Helden Improving the search heuristic: Multiple starting points Simulated annealing Genetic algorithms
Cluster analysis. Agnieszka Nowak - Brzezinska
 Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
3. Cluster analysis Overview
 Université Laval Analyse multivariable - mars-avril 2008 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
Université Laval Analyse multivariable - mars-avril 2008 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
Understanding Clustering Supervising the unsupervised
 Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Finding Clusters 1 / 60
 Finding Clusters Types of Clustering Approaches: Linkage Based, e.g. Hierarchical Clustering Clustering by Partitioning, e.g. k-means Density Based Clustering, e.g. DBScan Grid Based Clustering 1 / 60
Finding Clusters Types of Clustering Approaches: Linkage Based, e.g. Hierarchical Clustering Clustering by Partitioning, e.g. k-means Density Based Clustering, e.g. DBScan Grid Based Clustering 1 / 60
University of California, Berkeley
 University of California, Berkeley U.C. Berkeley Division of Biostatistics Working Paper Series Year 2002 Paper 105 A New Partitioning Around Medoids Algorithm Mark J. van der Laan Katherine S. Pollard
University of California, Berkeley U.C. Berkeley Division of Biostatistics Working Paper Series Year 2002 Paper 105 A New Partitioning Around Medoids Algorithm Mark J. van der Laan Katherine S. Pollard
Chapter 6 Continued: Partitioning Methods
 Chapter 6 Continued: Partitioning Methods Partitioning methods fix the number of clusters k and seek the best possible partition for that k. The goal is to choose the partition which gives the optimal
Chapter 6 Continued: Partitioning Methods Partitioning methods fix the number of clusters k and seek the best possible partition for that k. The goal is to choose the partition which gives the optimal
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Chapter DM:II. II. Cluster Analysis
 Chapter DM:II II. Cluster Analysis Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained Cluster Analysis DM:II-1
Chapter DM:II II. Cluster Analysis Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained Cluster Analysis DM:II-1
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Unsupervised Learning. Supervised learning vs. unsupervised learning. What is Cluster Analysis? Applications of Cluster Analysis
 7 Supervised learning vs unsupervised learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These patterns are then
7 Supervised learning vs unsupervised learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These patterns are then
Clustering part II 1
 Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
3. Cluster analysis Overview
 Université Laval Multivariate analysis - February 2006 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
Université Laval Multivariate analysis - February 2006 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
Statistics 202: Data Mining. c Jonathan Taylor. Clustering Based in part on slides from textbook, slides of Susan Holmes.
 Clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group will be similar (or
Clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group will be similar (or
Hierarchical Clustering 4/5/17
 Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Unsupervised Learning
 Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support, Fall 2005 Instructors: Professor Lucila Ohno-Machado and Professor Staal Vinterbo 6.873/HST.951 Medical Decision
Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support, Fall 2005 Instructors: Professor Lucila Ohno-Machado and Professor Staal Vinterbo 6.873/HST.951 Medical Decision
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Multivariate Analysis
 Multivariate Analysis Cluster Analysis Prof. Dr. Anselmo E de Oliveira anselmo.quimica.ufg.br anselmo.disciplinas@gmail.com Unsupervised Learning Cluster Analysis Natural grouping Patterns in the data
Multivariate Analysis Cluster Analysis Prof. Dr. Anselmo E de Oliveira anselmo.quimica.ufg.br anselmo.disciplinas@gmail.com Unsupervised Learning Cluster Analysis Natural grouping Patterns in the data
Community Detection. Jian Pei: CMPT 741/459 Clustering (1) 2
 2") Clustering Community Detection http://image.slidesharecdn.com/communitydetectionitilecturejune0-0609559-phpapp0/95/community-detection-in-social-media--78.jpg?cb=3087368 Jian Pei: CMPT 74/459 Clustering
Clustering Community Detection http://image.slidesharecdn.com/communitydetectionitilecturejune0-0609559-phpapp0/95/community-detection-in-social-media--78.jpg?cb=3087368 Jian Pei: CMPT 74/459 Clustering
PAM algorithm. Types of Data in Cluster Analysis. A Categorization of Major Clustering Methods. Partitioning i Methods. Hierarchical Methods
 Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Based on Raymond J. Mooney s slides
 Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Lesson 3. Prof. Enza Messina
 Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Multivariate Methods
 Multivariate Methods Cluster Analysis http://www.isrec.isb-sib.ch/~darlene/embnet/ Classification Historically, objects are classified into groups periodic table of the elements (chemistry) taxonomy (zoology,
Multivariate Methods Cluster Analysis http://www.isrec.isb-sib.ch/~darlene/embnet/ Classification Historically, objects are classified into groups periodic table of the elements (chemistry) taxonomy (zoology,
Cluster Analysis. CSE634 Data Mining
 Cluster Analysis CSE634 Data Mining Agenda Introduction Clustering Requirements Data Representation Partitioning Methods K-Means Clustering K-Medoids Clustering Constrained K-Means clustering Introduction
Cluster Analysis CSE634 Data Mining Agenda Introduction Clustering Requirements Data Representation Partitioning Methods K-Means Clustering K-Medoids Clustering Constrained K-Means clustering Introduction
Unsupervised learning: Clustering & Dimensionality reduction. Theo Knijnenburg Jorma de Ronde
 Unsupervised learning: Clustering & Dimensionality reduction Theo Knijnenburg Jorma de Ronde Source of slides Marcel Reinders TU Delft Lodewyk Wessels NKI Bioalgorithms.info Jeffrey D. Ullman Stanford
Unsupervised learning: Clustering & Dimensionality reduction Theo Knijnenburg Jorma de Ronde Source of slides Marcel Reinders TU Delft Lodewyk Wessels NKI Bioalgorithms.info Jeffrey D. Ullman Stanford
11/2/2017 MIST.6060 Business Intelligence and Data Mining 1. Clustering. Two widely used distance metrics to measure the distance between two records
 11/2/2017 MIST.6060 Business Intelligence and Data Mining 1 An Example Clustering X 2 X 1 Objective of Clustering The objective of clustering is to group the data into clusters such that the records within
11/2/2017 MIST.6060 Business Intelligence and Data Mining 1 An Example Clustering X 2 X 1 Objective of Clustering The objective of clustering is to group the data into clusters such that the records within
Clustering. CS294 Practical Machine Learning Junming Yin 10/09/06
 Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
9/17/2009. Wenyan Li (Emily Li) Sep. 15, Introduction to Clustering Analysis
 Sep. 15, Introduction to Clustering Analysis") Introduction ti to K-means Algorithm Wenan Li (Emil Li) Sep. 5, 9 Outline Introduction to Clustering Analsis K-means Algorithm Description Eample of K-means Algorithm Other Issues of K-means Algorithm
Introduction ti to K-means Algorithm Wenan Li (Emil Li) Sep. 5, 9 Outline Introduction to Clustering Analsis K-means Algorithm Description Eample of K-means Algorithm Other Issues of K-means Algorithm
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University
 Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Kapitel 4: Clustering
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
9/29/13. Outline Data mining tasks. Clustering algorithms. Applications of clustering in biology
 9/9/ I9 Introduction to Bioinformatics, Clustering algorithms Yuzhen Ye (yye@indiana.edu) School of Informatics & Computing, IUB Outline Data mining tasks Predictive tasks vs descriptive tasks Example
9/9/ I9 Introduction to Bioinformatics, Clustering algorithms Yuzhen Ye (yye@indiana.edu) School of Informatics & Computing, IUB Outline Data mining tasks Predictive tasks vs descriptive tasks Example
MSA220 - Statistical Learning for Big Data
 MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
Data Exploration with PCA and Unsupervised Learning with Clustering Paul Rodriguez, PhD PACE SDSC
 Data Exploration with PCA and Unsupervised Learning with Clustering Paul Rodriguez, PhD PACE SDSC Clustering Idea Given a set of data can we find a natural grouping? Essential R commands: D =rnorm(12,0,1)
Data Exploration with PCA and Unsupervised Learning with Clustering Paul Rodriguez, PhD PACE SDSC Clustering Idea Given a set of data can we find a natural grouping? Essential R commands: D =rnorm(12,0,1)
5/15/16. Computational Methods for Data Analysis. Massimo Poesio UNSUPERVISED LEARNING. Clustering. Unsupervised learning introduction
 Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Clustering Lecture 3: Hierarchical Methods
 Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering. Cluster Analysis of Microarray Data. Microarray Data for Clustering. Data for Clustering
 Clustering Cluster Analysis of Microarray Data 4/3/009 Copyright 009 Dan Nettleton Group obects that are siilar to one another together in a cluster. Separate obects that are dissiilar fro each other into
Clustering Cluster Analysis of Microarray Data 4/3/009 Copyright 009 Dan Nettleton Group obects that are siilar to one another together in a cluster. Separate obects that are dissiilar fro each other into
Administrative. Machine learning code. Supervised learning (e.g. classification) Machine learning: Unsupervised learning" BANANAS APPLES
 Machine learning: Unsupervised learning BANANAS APPLES") Administrative Machine learning: Unsupervised learning" Assignment 5 out soon David Kauchak cs311 Spring 2013 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Machine
Administrative Machine learning: Unsupervised learning" Assignment 5 out soon David Kauchak cs311 Spring 2013 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Machine
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Hierarchical clustering
 Aprendizagem Automática Hierarchical clustering Ludwig Krippahl Hierarchical clustering Summary Hierarchical Clustering Agglomerative Clustering Divisive Clustering Clustering Features 1 Aprendizagem Automática
Aprendizagem Automática Hierarchical clustering Ludwig Krippahl Hierarchical clustering Summary Hierarchical Clustering Agglomerative Clustering Divisive Clustering Clustering Features 1 Aprendizagem Automática
DATA MINING LECTURE 7. Hierarchical Clustering, DBSCAN The EM Algorithm
 DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
10601 Machine Learning. Hierarchical clustering. Reading: Bishop: 9-9.2
 161 Machine Learning Hierarchical clustering Reading: Bishop: 9-9.2 Second half: Overview Clustering - Hierarchical, semi-supervised learning Graphical models - Bayesian networks, HMMs, Reasoning under
161 Machine Learning Hierarchical clustering Reading: Bishop: 9-9.2 Second half: Overview Clustering - Hierarchical, semi-supervised learning Graphical models - Bayesian networks, HMMs, Reasoning under
What is Cluster Analysis? COMP 465: Data Mining Clustering Basics. Applications of Cluster Analysis. Clustering: Application Examples 3/17/2015
 // What is Cluster Analysis? COMP : Data Mining Clustering Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, rd ed. Cluster: A collection of data
// What is Cluster Analysis? COMP : Data Mining Clustering Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, rd ed. Cluster: A collection of data
Stats 170A: Project in Data Science Exploratory Data Analysis: Clustering Algorithms
 Stats 170A: Project in Data Science Exploratory Data Analysis: Clustering Algorithms Padhraic Smyth Department of Computer Science Bren School of Information and Computer Sciences University of California,
Stats 170A: Project in Data Science Exploratory Data Analysis: Clustering Algorithms Padhraic Smyth Department of Computer Science Bren School of Information and Computer Sciences University of California,
CS7267 MACHINE LEARNING
 S7267 MAHINE LEARNING HIERARHIAL LUSTERING Ref: hengkai Li, Department of omputer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) Mingon Kang, Ph.D. omputer Science,
S7267 MAHINE LEARNING HIERARHIAL LUSTERING Ref: hengkai Li, Department of omputer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) Mingon Kang, Ph.D. omputer Science,
4. Cluster Analysis. Francesc J. Ferri. Dept. d Informàtica. Universitat de València. Febrer F.J. Ferri (Univ. València) AIRF 2/ / 1
 AIRF 2/ / 1") Anàlisi d Imatges i Reconeixement de Formes Image Analysis and Pattern Recognition:. Cluster Analysis Francesc J. Ferri Dept. d Informàtica. Universitat de València Febrer 8 F.J. Ferri (Univ. València)
Anàlisi d Imatges i Reconeixement de Formes Image Analysis and Pattern Recognition:. Cluster Analysis Francesc J. Ferri Dept. d Informàtica. Universitat de València Febrer 8 F.J. Ferri (Univ. València)
10701 Machine Learning. Clustering
 171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
How do microarrays work
 Lecture 3 (continued) Alvis Brazma European Bioinformatics Institute How do microarrays work condition mrna cdna hybridise to microarray condition Sample RNA extract labelled acid acid acid nucleic acid
Lecture 3 (continued) Alvis Brazma European Bioinformatics Institute How do microarrays work condition mrna cdna hybridise to microarray condition Sample RNA extract labelled acid acid acid nucleic acid
Clustering. Robert M. Haralick. Computer Science, Graduate Center City University of New York
 Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Unsupervised Learning. Pantelis P. Analytis. Introduction. Finding structure in graphs. Clustering analysis. Dimensionality reduction.
 March 19, 2018 1 / 40 1 2 3 4 2 / 40 What s unsupervised learning? Most of the data available on the internet do not have labels. How can we make sense of it? 3 / 40 4 / 40 5 / 40 Organizing the web First
March 19, 2018 1 / 40 1 2 3 4 2 / 40 What s unsupervised learning? Most of the data available on the internet do not have labels. How can we make sense of it? 3 / 40 4 / 40 5 / 40 Organizing the web First
A new algorithm for hybrid hierarchical clustering with visualization and the bootstrap
 A new algorithm for hybrid hierarchical clustering with visualization and the bootstrap Mark J. van der Laan and Katherine S. Pollard Abstract We propose a hybrid clustering method, Hierarchical Ordered
A new algorithm for hybrid hierarchical clustering with visualization and the bootstrap Mark J. van der Laan and Katherine S. Pollard Abstract We propose a hybrid clustering method, Hierarchical Ordered
Introduction to Clustering
 Introduction to Clustering Ref: Chengkai Li, Department of Computer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) What is Cluster Analysis? Finding groups of
Introduction to Clustering Ref: Chengkai Li, Department of Computer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) What is Cluster Analysis? Finding groups of
Hierarchical Clustering
 Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Cluster Analysis chapter 7. cse634 Data Mining. Professor Anita Wasilewska Compute Science Department Stony Brook University NY
 Cluster Analysis chapter 7 cse634 Data Mining Professor Anita Wasilewska Compute Science Department Stony Brook University NY Sources Cited [1] Driver, H. E. and A. L. Kroeber (1932) Quantitative expression
Cluster Analysis chapter 7 cse634 Data Mining Professor Anita Wasilewska Compute Science Department Stony Brook University NY Sources Cited [1] Driver, H. E. and A. L. Kroeber (1932) Quantitative expression
Lecture Notes for Chapter 7. Introduction to Data Mining, 2 nd Edition. by Tan, Steinbach, Karpatne, Kumar
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, nd Edition by Tan, Steinbach, Karpatne, Kumar What is Cluster Analysis? Finding groups
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, nd Edition by Tan, Steinbach, Karpatne, Kumar What is Cluster Analysis? Finding groups