Methods for Intelligent Systems
|
|
|
- Erin Carson
- 6 years ago
- Views:
Transcription
1 Methods for Intelligent Systems Lecture Notes on Clustering (II) Davide Eynard Department of Electronics and Information Politecnico di Milano Davide Eynard - Lecture Notes on Clustering (II) p. 1/34 Course Schedule Date Topic 28/03/2006 Clustering Introduction & Algorithms (I) (K-Means, Hierarchical) 11/04/2006 Clustering Algorithms (II) (Fuzzy, SOM, Gaussians, PDDP) 16/05/2006 How many clusters? (Evaluations and tuning) 20/06/2006 Monography on Text Clustering (I) 21/06/2006 Monography on Text Clustering (II) (14.15 AM2) (+ exercises) Davide Eynard - Lecture Notes on Clustering (II) p. 2/34
2 Lecture outline PDDP Fuzzy C-Means Gaussian Mixtures Self-Organizing Maps Davide Eynard - Lecture Notes on Clustering (II) p. 3/34 PDDP PDDP stands for "Principal Direction Divisive Partitioning" Principal Direction, because the algorithm is based on the computation of the leading principal direction at each stage of the partitioning Partitioning, because we place all data into one cluster, so that at every stage clusters are disjoint and their union equals the entire set of documents Divisive, because it s a hierarchical divisive (vs. hierarchical agglomerative) clustering algorithm Davide Eynard - Lecture Notes on Clustering (II) p. 5/34
3 PDDP Algorithm Description Sample space of m samples in which each sample (document) is an n-vector containing a numerical value Each document is represented by a column vector of attribute values d = (d 1, d 2,..., d n ) T whose i-th entry, d i, is the relative frequency of the i-th word. Each document vector is normalized to have a euclidean length of 1: TF i d i = j (TF j) 2 where TF i is the number of occurrences of word i in the particular document d. Davide Eynard - Lecture Notes on Clustering (II) p. 6/34 PDDP Algorithm Description The entire set of documents is represented by an n m matrix M = (d 1,..., d m ) whose i-th column, d i, is the column vector representing the i-th document The algorithm proceeds by separating the entire set of documents into two partitions by using principal directions Each of the two partitions will be splitted into two subpartitions using the same process recursively The result is a hierarchical structure of partitions arranged into a binary tree What method is used to split a partition into two subpartitions? In what order are the partitions selected to be split? Davide Eynard - Lecture Notes on Clustering (II) p. 6/34
4 Splitting a partition The mean or centroid of the document set is w = d d m m = M e 1 m In the general case, the covariance matrix is C = (M we T ) (M we T ) T = A A T where e = (1,1,...,1) T is a vector of appropriate dimension. The eigenvectors corresponding to the k largest eigenvalues are called the principal components or principal directions. Davide Eynard - Lecture Notes on Clustering (II) p. 7/34 Splitting a partition A partition of p documents is represented by an n p matrix M p = (d 1,..., d p ) where each d i is an n-vector representing a document. The matrix M p is a submatrix of M consisting of some selection of p columns of M, not necessarily the first p in the set! The principal directions of the matrix M p are the eigenvectors of its sample covariance matrix C We re interested in temporarily projecting each document onto the single leading eigenvector u (the principal direction) Besides reducing the dimensionality, the transformation often has the effect of removing much noise present in the data Davide Eynard - Lecture Notes on Clustering (II) p. 7/34
5 Principal Component Analysis Davide Eynard - Lecture Notes on Clustering (II) p. 8/34 Principal Component Analysis Davide Eynard - Lecture Notes on Clustering (II) p. 8/34
6 Principal Component Analysis Davide Eynard - Lecture Notes on Clustering (II) p. 8/34 Splitting a partition The projection of the i-th document d i is given by the formula where σ is a positive constant. σv i = u T (d i w) All the documents are translated so that their mean is at the origin, then they re projected on the principal direction The values v 1,..., v k are used to determine the splitting (accordingly to their sign) We still have to decide at each stage which node should be split next: A "scatter" value is used to measure the distance between each document in the cluster and the overall mean of the cluster (a measure of its cohesiveness) Davide Eynard - Lecture Notes on Clustering (II) p. 9/34
7 The algorithm Start with n m matrix M of (scaled) document vectors, and a desired number of clusters c max. 1. Initialize Binary Tree with a single Root Node 2. For c = 2,3,..., c max do 3. Select node K with largest scat value 4. Create nodes L:=leftchild(K) and R:=rightchild(K) 5. Set indices(l):=indices of the non-positive entries in rightvec(k) 6. Set indices(r):=indices of the positive entries in rightvec(k) 7. Compute all the other fields for the nodes L,R 8. end. Result: A binary tree with c max leaf nodes forming a partitioning of the entire data set. Davide Eynard - Lecture Notes on Clustering (II) p. 10/34 Conclusions PDDP algorithm is effective at least as well as an agglomeration algorithm, but is much faster Its expected running time is linear in the number of documents, whereas unmodified agglomeration algorithms typically have O(m 2 ) running time Davide Eynard - Lecture Notes on Clustering (II) p. 11/34
8 Experimental results Davide Eynard - Lecture Notes on Clustering (II) p. 12/34 Experimental results Davide Eynard - Lecture Notes on Clustering (II) p. 12/34
9 Experimental results Davide Eynard - Lecture Notes on Clustering (II) p. 12/34 Fuzzy C-Means Fuzzy C-Means (FCM, developed by Dunn in 1973 and improved by Bezdek in 1981) is a method of clustering which allows one piece of data to belong to two or more clusters. frequently used in pattern recognition based on minimization of the following objective function: J m = N C u m ij x i c j 2,1 m < i=1 j=1 where: m is any real number greater than 1 (fuzzyness coefficient), u ij is the degree of membership of x i in the cluster j, x i is the i-th of d-dimensional measured data, c j is the d-dimension center of the cluster, is any norm expressing the similarity between measured data and the center. Davide Eynard - Lecture Notes on Clustering (II) p. 14/34
10 K-Means vs. FCM With K-Means, a datum either belongs to centroid A or to centroid B Davide Eynard - Lecture Notes on Clustering (II) p. 15/34 K-Means vs. FCM With FCM, the same datum does not belong exclusively to one cluster, but it may belong to several clusters with different values of the membership coefficient Davide Eynard - Lecture Notes on Clustering (II) p. 15/34
11 Data representation (KM)U N C = (FCM)U N C = Davide Eynard - Lecture Notes on Clustering (II) p. 16/34 FCM Algorithm The algorithm is composed of the following steps: 1. Initialize U = [u ij ] matrix, U (0) 2. At k-step: calculate the centers vectors C (k) = [c j ] with U (k) : c j = N i=1 um ij x i N i=1 um ij 3. Update U (k), U (k+1) : u j = 1 C k=1 ( xi c j x i c k ) 2 m 1 4. If U (k+1) U (k) < ε then STOP; otherwise return to step 2. Davide Eynard - Lecture Notes on Clustering (II) p. 17/34
 p.")
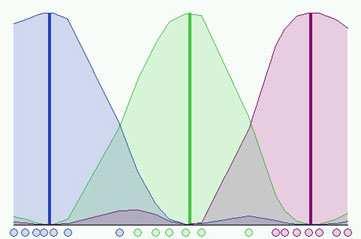
12 An Example Davide Eynard - Lecture Notes on Clustering (II) p. 18/34 An Example Davide Eynard - Lecture Notes on Clustering (II) p. 18/34
13 An Example Davide Eynard - Lecture Notes on Clustering (II) p. 18/34 Clustering as a Mixture of Gaussians Gaussians Mixture is a model-based clustering approach It uses a statistical model for clusters and attempts to optimize the fit between the data and the model. Each cluster can be mathematically represented by a parametric distribution, like a Gaussian (continuous) or a Poisson (discrete) The entire data set is modelled by a mixture of these distributions A mixture model with high likelihood tends to have the following traits: Component distributions have high "peaks" (data in one cluster are tight) The mixture model "covers" the data well (dominant patterns in data are captured by component distributions) Davide Eynard - Lecture Notes on Clustering (II) p. 21/34
14 Advantages of Model-Based Clustering well studied statistical inference techniques available flexibility in choosing the component distribution obtain a density estimation for each cluster a "soft" classification is available Davide Eynard - Lecture Notes on Clustering (II) p. 22/34 Mixture of Gaussians It is the most widely used model-based clustering method: we can actually consider clusters as Gaussian distributions centered on their barycentres (as we can see in the figure, where the grey circle represents the first variance of the distribution). Davide Eynard - Lecture Notes on Clustering (II) p. 23/34
15 How does it work? it chooses the component (the Gaussian) at random with probability P(ω i ) it samples a point N(µ i, σ 2 I) Let s suppose we have x 1, x 2,..., x n and P(ω 1 ),..., P(ω K ), σ We can obtain the likelihood of the sample: P(x ω i, µ 1, µ 2,..., µ K ) (probability that an observation from class ω i would have value x given class means µ 1,..., µ K ) What we really want is to maximize P(x µ 1, µ 2,..., µ K )... Can we do it? How? Davide Eynard - Lecture Notes on Clustering (II) p. 24/34 The Algorithm The algorithm is composed of the following steps: 1. Initialize parameters: 2. E-step: λ 0 = {µ (0) 1, µ(0) 2,..., µ(0) k, p(0) 1, p(0) 2,..., p(0) k } P(ω j x k, λ t ) = P(x k ω j, λ t )P(ω j λ t ) P(x k λ t ) = P(x k ω i, µ (t) i, σ 2 )p i (t) Pk P(x k ω j, µ (t) j, σ2 )p (t) j 3. M-step: µ (t+1) i = where R is the number of records p (t+1) i = P k P(ω i x k, λ t )x k P k P(ω i x k, λ t ) P k P(ω i x k, λ t ) R Davide Eynard - Lecture Notes on Clustering (II) p. 25/34


16 Self Organizing Features Maps Kohonen Self Organizing Features Maps (a.k.a. SOM) provide a way to represent multidimensional data in much lower dimensional spaces. They implement a data compression technique similar to vector quantization They store information in such a way that any topological relationships within the training set are maintained Example: Mapping of colors from their three dimensional components (i.e., red, green and blue) into two dimensions. Davide Eynard - Lecture Notes on Clustering (II) p. 28/34 Self Organizing Feature Maps: The Topology The network is a lattice of "nodes", each of which is fully connected to the input layer Each node has a specific topological position and contains a vector of weights of the same dimension as the input vectors There are no lateral connections between nodes within the lattice A SOM does not deed a target output to be specified; instead, where the node weights match the input vector, that area of the lattice is selectively optimized to more closely resemble the data vector Davide Eynard - Lecture Notes on Clustering (II) p. 29/34

17 Self Organizing Features Maps: The Algorithm Training occurs in several steps over many iterations: 1. Initialize each node s weights 2. Presented a random vector from the training set to the lattice 3. Examinate every node to calculate which one s weights are most like the input vector (the winning node is commonly known as the Best Matching Unit) 4. Calculate the radius of the neighborhood of the BMU (this is a value that starts large, typically set to the radius of the lattice, but diminishes each time-step), any nodes found within this radius are deemed to be inside the BMU s neighborhood 5. Each neighboring node s weights are adjusted to make them more like the input vector. The closer a node is to the BMU, the more its weights get altered 6. Repeat step 2 for N iterations Davide Eynard - Lecture Notes on Clustering (II) p. 30/34 Practical Learning of Self Organizing Features Maps There are few things that have to be specified in the previous algorithm: Choosing the weights initialization We select the Best Matching Unit according to its the weight distance from the input vector: x w i = q Pp k=1 (x[k] w i[k]) 2 Select the neighborhood according to some decreasing function h ij = e (i j)2 2σ 2 Define the updating rule 8 < w i (t + 1) = : w i + α(t)[x(t) w i (t)], w i, i N i (t) i / N i (t) Davide Eynard - Lecture Notes on Clustering (II) p. 31/34
18 Bibliography A Tutorial on Clustering Algorithms Online tutorial by M. Matteucci As usual, more info on del.icio.us Davide Eynard - Lecture Notes on Clustering (II) p. 33/34
Unsupervised Learning
 Networks for Pattern Recognition, 2014 Networks for Single Linkage K-Means Soft DBSCAN PCA Networks for Kohonen Maps Linear Vector Quantization Networks for Problems/Approaches in Machine Learning Supervised
Networks for Pattern Recognition, 2014 Networks for Single Linkage K-Means Soft DBSCAN PCA Networks for Kohonen Maps Linear Vector Quantization Networks for Problems/Approaches in Machine Learning Supervised
Clustering Lecture 5: Mixture Model
 Clustering Lecture 5: Mixture Model Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced topics
Clustering Lecture 5: Mixture Model Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced topics
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A
 MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
Cluster Analysis: Agglomerate Hierarchical Clustering
 Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
CS Introduction to Data Mining Instructor: Abdullah Mueen
 CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
Region-based Segmentation
 Region-based Segmentation Image Segmentation Group similar components (such as, pixels in an image, image frames in a video) to obtain a compact representation. Applications: Finding tumors, veins, etc.
Region-based Segmentation Image Segmentation Group similar components (such as, pixels in an image, image frames in a video) to obtain a compact representation. Applications: Finding tumors, veins, etc.
DATA MINING LECTURE 7. Hierarchical Clustering, DBSCAN The EM Algorithm
 DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
Cluster Analysis. Jia Li Department of Statistics Penn State University. Summer School in Statistics for Astronomers IV June 9-14, 2008
 Cluster Analysis Jia Li Department of Statistics Penn State University Summer School in Statistics for Astronomers IV June 9-1, 8 1 Clustering A basic tool in data mining/pattern recognition: Divide a
Cluster Analysis Jia Li Department of Statistics Penn State University Summer School in Statistics for Astronomers IV June 9-1, 8 1 Clustering A basic tool in data mining/pattern recognition: Divide a
Classification. Vladimir Curic. Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University
 Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Machine Learning. B. Unsupervised Learning B.1 Cluster Analysis. Lars Schmidt-Thieme
 Machine Learning B. Unsupervised Learning B.1 Cluster Analysis Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University of Hildesheim, Germany
Machine Learning B. Unsupervised Learning B.1 Cluster Analysis Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University of Hildesheim, Germany
Clustering Documents in Large Text Corpora
 Clustering Documents in Large Text Corpora Bin He Faculty of Computer Science Dalhousie University Halifax, Canada B3H 1W5 bhe@cs.dal.ca http://www.cs.dal.ca/ bhe Yongzheng Zhang Faculty of Computer Science
Clustering Documents in Large Text Corpora Bin He Faculty of Computer Science Dalhousie University Halifax, Canada B3H 1W5 bhe@cs.dal.ca http://www.cs.dal.ca/ bhe Yongzheng Zhang Faculty of Computer Science
Lecture 6: Unsupervised Machine Learning Dagmar Gromann International Center For Computational Logic
 SEMANTIC COMPUTING Lecture 6: Unsupervised Machine Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 23 November 2018 Overview Unsupervised Machine Learning overview Association
SEMANTIC COMPUTING Lecture 6: Unsupervised Machine Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 23 November 2018 Overview Unsupervised Machine Learning overview Association
CHAPTER 3 TUMOR DETECTION BASED ON NEURO-FUZZY TECHNIQUE
 32 CHAPTER 3 TUMOR DETECTION BASED ON NEURO-FUZZY TECHNIQUE 3.1 INTRODUCTION In this chapter we present the real time implementation of an artificial neural network based on fuzzy segmentation process
32 CHAPTER 3 TUMOR DETECTION BASED ON NEURO-FUZZY TECHNIQUE 3.1 INTRODUCTION In this chapter we present the real time implementation of an artificial neural network based on fuzzy segmentation process
Function approximation using RBF network. 10 basis functions and 25 data points.
 1 Function approximation using RBF network F (x j ) = m 1 w i ϕ( x j t i ) i=1 j = 1... N, m 1 = 10, N = 25 10 basis functions and 25 data points. Basis function centers are plotted with circles and data
1 Function approximation using RBF network F (x j ) = m 1 w i ϕ( x j t i ) i=1 j = 1... N, m 1 = 10, N = 25 10 basis functions and 25 data points. Basis function centers are plotted with circles and data
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Unsupervised Learning
 Unsupervised Learning Learning without Class Labels (or correct outputs) Density Estimation Learn P(X) given training data for X Clustering Partition data into clusters Dimensionality Reduction Discover
Unsupervised Learning Learning without Class Labels (or correct outputs) Density Estimation Learn P(X) given training data for X Clustering Partition data into clusters Dimensionality Reduction Discover
Figure (5) Kohonen Self-Organized Map
 Kohonen Self-Organized Map") 2- KOHONEN SELF-ORGANIZING MAPS (SOM) - The self-organizing neural networks assume a topological structure among the cluster units. - There are m cluster units, arranged in a one- or two-dimensional array;
2- KOHONEN SELF-ORGANIZING MAPS (SOM) - The self-organizing neural networks assume a topological structure among the cluster units. - There are m cluster units, arranged in a one- or two-dimensional array;
SGN (4 cr) Chapter 11
 Chapter 11") SGN-41006 (4 cr) Chapter 11 Clustering Jussi Tohka & Jari Niemi Department of Signal Processing Tampere University of Technology February 25, 2014 J. Tohka & J. Niemi (TUT-SGN) SGN-41006 (4 cr) Chapter
SGN-41006 (4 cr) Chapter 11 Clustering Jussi Tohka & Jari Niemi Department of Signal Processing Tampere University of Technology February 25, 2014 J. Tohka & J. Niemi (TUT-SGN) SGN-41006 (4 cr) Chapter
Behavioral Data Mining. Lecture 18 Clustering
 Behavioral Data Mining Lecture 18 Clustering Outline Why? Cluster quality K-means Spectral clustering Generative Models Rationale Given a set {X i } for i = 1,,n, a clustering is a partition of the X i
Behavioral Data Mining Lecture 18 Clustering Outline Why? Cluster quality K-means Spectral clustering Generative Models Rationale Given a set {X i } for i = 1,,n, a clustering is a partition of the X i
Classification. Vladimir Curic. Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University
 Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Clustering algorithms
 Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
Olmo S. Zavala Romero. Clustering Hierarchical Distance Group Dist. K-means. Center of Atmospheric Sciences, UNAM.
 Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
CLUSTER ANALYSIS. V. K. Bhatia I.A.S.R.I., Library Avenue, New Delhi
 CLUSTER ANALYSIS V. K. Bhatia I.A.S.R.I., Library Avenue, New Delhi-110 012 In multivariate situation, the primary interest of the experimenter is to examine and understand the relationship amongst the
CLUSTER ANALYSIS V. K. Bhatia I.A.S.R.I., Library Avenue, New Delhi-110 012 In multivariate situation, the primary interest of the experimenter is to examine and understand the relationship amongst the
CHAPTER 4 AN IMPROVED INITIALIZATION METHOD FOR FUZZY C-MEANS CLUSTERING USING DENSITY BASED APPROACH
 37 CHAPTER 4 AN IMPROVED INITIALIZATION METHOD FOR FUZZY C-MEANS CLUSTERING USING DENSITY BASED APPROACH 4.1 INTRODUCTION Genes can belong to any genetic network and are also coordinated by many regulatory
37 CHAPTER 4 AN IMPROVED INITIALIZATION METHOD FOR FUZZY C-MEANS CLUSTERING USING DENSITY BASED APPROACH 4.1 INTRODUCTION Genes can belong to any genetic network and are also coordinated by many regulatory
Clustering. CS294 Practical Machine Learning Junming Yin 10/09/06
 Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Seismic regionalization based on an artificial neural network
 Seismic regionalization based on an artificial neural network *Jaime García-Pérez 1) and René Riaño 2) 1), 2) Instituto de Ingeniería, UNAM, CU, Coyoacán, México D.F., 014510, Mexico 1) jgap@pumas.ii.unam.mx
Seismic regionalization based on an artificial neural network *Jaime García-Pérez 1) and René Riaño 2) 1), 2) Instituto de Ingeniería, UNAM, CU, Coyoacán, México D.F., 014510, Mexico 1) jgap@pumas.ii.unam.mx
Discriminate Analysis
 Discriminate Analysis Outline Introduction Linear Discriminant Analysis Examples 1 Introduction What is Discriminant Analysis? Statistical technique to classify objects into mutually exclusive and exhaustive
Discriminate Analysis Outline Introduction Linear Discriminant Analysis Examples 1 Introduction What is Discriminant Analysis? Statistical technique to classify objects into mutually exclusive and exhaustive
Data Mining and Data Warehousing Henryk Maciejewski Data Mining Clustering
 Data Mining and Data Warehousing Henryk Maciejewski Data Mining Clustering Clustering Algorithms Contents K-means Hierarchical algorithms Linkage functions Vector quantization SOM Clustering Formulation
Data Mining and Data Warehousing Henryk Maciejewski Data Mining Clustering Clustering Algorithms Contents K-means Hierarchical algorithms Linkage functions Vector quantization SOM Clustering Formulation
Statistics 202: Data Mining. c Jonathan Taylor. Week 8 Based in part on slides from textbook, slides of Susan Holmes. December 2, / 1
 Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
Objective of clustering
 Objective of clustering Discover structures and patterns in high-dimensional data. Group data with similar patterns together. This reduces the complexity and facilitates interpretation. Expression level
Objective of clustering Discover structures and patterns in high-dimensional data. Group data with similar patterns together. This reduces the complexity and facilitates interpretation. Expression level
Unsupervised: no target value to predict
 Clustering Unsupervised: no target value to predict Differences between models/algorithms: Exclusive vs. overlapping Deterministic vs. probabilistic Hierarchical vs. flat Incremental vs. batch learning
Clustering Unsupervised: no target value to predict Differences between models/algorithms: Exclusive vs. overlapping Deterministic vs. probabilistic Hierarchical vs. flat Incremental vs. batch learning
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering
 Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Clustering and Visualisation of Data
 Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Lecture 7: Segmentation. Thursday, Sept 20
 Lecture 7: Segmentation Thursday, Sept 20 Outline Why segmentation? Gestalt properties, fun illusions and/or revealing examples Clustering Hierarchical K-means Mean Shift Graph-theoretic Normalized cuts
Lecture 7: Segmentation Thursday, Sept 20 Outline Why segmentation? Gestalt properties, fun illusions and/or revealing examples Clustering Hierarchical K-means Mean Shift Graph-theoretic Normalized cuts
Community Detection. Community
 Community Detection Community In social sciences: Community is formed by individuals such that those within a group interact with each other more frequently than with those outside the group a.k.a. group,
Community Detection Community In social sciences: Community is formed by individuals such that those within a group interact with each other more frequently than with those outside the group a.k.a. group,
Exploratory Data Analysis using Self-Organizing Maps. Madhumanti Ray
 Exploratory Data Analysis using Self-Organizing Maps Madhumanti Ray Content Introduction Data Analysis methods Self-Organizing Maps Conclusion Visualization of high-dimensional data items Exploratory data
Exploratory Data Analysis using Self-Organizing Maps Madhumanti Ray Content Introduction Data Analysis methods Self-Organizing Maps Conclusion Visualization of high-dimensional data items Exploratory data
CS325 Artificial Intelligence Ch. 20 Unsupervised Machine Learning
 CS325 Artificial Intelligence Cengiz Spring 2013 Unsupervised Learning Missing teacher No labels, y Just input data, x What can you learn with it? Unsupervised Learning Missing teacher No labels, y Just
CS325 Artificial Intelligence Cengiz Spring 2013 Unsupervised Learning Missing teacher No labels, y Just input data, x What can you learn with it? Unsupervised Learning Missing teacher No labels, y Just
ECG782: Multidimensional Digital Signal Processing
 ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
EE 589 INTRODUCTION TO ARTIFICIAL NETWORK REPORT OF THE TERM PROJECT REAL TIME ODOR RECOGNATION SYSTEM FATMA ÖZYURT SANCAR
 EE 589 INTRODUCTION TO ARTIFICIAL NETWORK REPORT OF THE TERM PROJECT REAL TIME ODOR RECOGNATION SYSTEM FATMA ÖZYURT SANCAR 1.Introductıon. 2.Multi Layer Perception.. 3.Fuzzy C-Means Clustering.. 4.Real
EE 589 INTRODUCTION TO ARTIFICIAL NETWORK REPORT OF THE TERM PROJECT REAL TIME ODOR RECOGNATION SYSTEM FATMA ÖZYURT SANCAR 1.Introductıon. 2.Multi Layer Perception.. 3.Fuzzy C-Means Clustering.. 4.Real
Clustering: Classic Methods and Modern Views
 Clustering: Classic Methods and Modern Views Marina Meilă University of Washington mmp@stat.washington.edu June 22, 2015 Lorentz Center Workshop on Clusters, Games and Axioms Outline Paradigms for clustering
Clustering: Classic Methods and Modern Views Marina Meilă University of Washington mmp@stat.washington.edu June 22, 2015 Lorentz Center Workshop on Clusters, Games and Axioms Outline Paradigms for clustering
SYDE Winter 2011 Introduction to Pattern Recognition. Clustering
 SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
Machine Learning and Data Mining. Clustering (1): Basics. Kalev Kask
: Basics. Kalev Kask") Machine Learning and Data Mining Clustering (1): Basics Kalev Kask Unsupervised learning Supervised learning Predict target value ( y ) given features ( x ) Unsupervised learning Understand patterns of
Machine Learning and Data Mining Clustering (1): Basics Kalev Kask Unsupervised learning Supervised learning Predict target value ( y ) given features ( x ) Unsupervised learning Understand patterns of
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
4. Cluster Analysis. Francesc J. Ferri. Dept. d Informàtica. Universitat de València. Febrer F.J. Ferri (Univ. València) AIRF 2/ / 1
 AIRF 2/ / 1") Anàlisi d Imatges i Reconeixement de Formes Image Analysis and Pattern Recognition:. Cluster Analysis Francesc J. Ferri Dept. d Informàtica. Universitat de València Febrer 8 F.J. Ferri (Univ. València)
Anàlisi d Imatges i Reconeixement de Formes Image Analysis and Pattern Recognition:. Cluster Analysis Francesc J. Ferri Dept. d Informàtica. Universitat de València Febrer 8 F.J. Ferri (Univ. València)
Minoru SASAKI and Kenji KITA. Department of Information Science & Intelligent Systems. Faculty of Engineering, Tokushima University
 Information Retrieval System Using Concept Projection Based on PDDP algorithm Minoru SASAKI and Kenji KITA Department of Information Science & Intelligent Systems Faculty of Engineering, Tokushima University
Information Retrieval System Using Concept Projection Based on PDDP algorithm Minoru SASAKI and Kenji KITA Department of Information Science & Intelligent Systems Faculty of Engineering, Tokushima University
10-701/15-781, Fall 2006, Final
 -7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
-7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
Clustering K-means. Machine Learning CSEP546 Carlos Guestrin University of Washington February 18, Carlos Guestrin
 Clustering K-means Machine Learning CSEP546 Carlos Guestrin University of Washington February 18, 2014 Carlos Guestrin 2005-2014 1 Clustering images Set of Images [Goldberger et al.] Carlos Guestrin 2005-2014
Clustering K-means Machine Learning CSEP546 Carlos Guestrin University of Washington February 18, 2014 Carlos Guestrin 2005-2014 1 Clustering images Set of Images [Goldberger et al.] Carlos Guestrin 2005-2014
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Unsupervised learning Daniel Hennes 29.01.2018 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Supervised learning Regression (linear
Grundlagen der Künstlichen Intelligenz Unsupervised learning Daniel Hennes 29.01.2018 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Supervised learning Regression (linear
Mixture Models and the EM Algorithm
 Mixture Models and the EM Algorithm Padhraic Smyth, Department of Computer Science University of California, Irvine c 2017 1 Finite Mixture Models Say we have a data set D = {x 1,..., x N } where x i is
Mixture Models and the EM Algorithm Padhraic Smyth, Department of Computer Science University of California, Irvine c 2017 1 Finite Mixture Models Say we have a data set D = {x 1,..., x N } where x i is
A SURVEY ON CLUSTERING ALGORITHMS Ms. Kirti M. Patil 1 and Dr. Jagdish W. Bakal 2
 Ms. Kirti M. Patil 1 and Dr. Jagdish W. Bakal 2 1 P.G. Scholar, Department of Computer Engineering, ARMIET, Mumbai University, India 2 Principal of, S.S.J.C.O.E, Mumbai University, India ABSTRACT Now a
Ms. Kirti M. Patil 1 and Dr. Jagdish W. Bakal 2 1 P.G. Scholar, Department of Computer Engineering, ARMIET, Mumbai University, India 2 Principal of, S.S.J.C.O.E, Mumbai University, India ABSTRACT Now a
Cluster Analysis. Debashis Ghosh Department of Statistics Penn State University (based on slides from Jia Li, Dept. of Statistics)
") Cluster Analysis Debashis Ghosh Department of Statistics Penn State University (based on slides from Jia Li, Dept. of Statistics) Summer School in Statistics for Astronomers June 1-6, 9 Clustering: Intuition
Cluster Analysis Debashis Ghosh Department of Statistics Penn State University (based on slides from Jia Li, Dept. of Statistics) Summer School in Statistics for Astronomers June 1-6, 9 Clustering: Intuition
Lecture Topic Projects
 Lecture Topic Projects 1 Intro, schedule, and logistics 2 Applications of visual analytics, basic tasks, data types 3 Introduction to D3, basic vis techniques for non-spatial data Project #1 out 4 Data
Lecture Topic Projects 1 Intro, schedule, and logistics 2 Applications of visual analytics, basic tasks, data types 3 Introduction to D3, basic vis techniques for non-spatial data Project #1 out 4 Data
Machine Learning. B. Unsupervised Learning B.1 Cluster Analysis. Lars Schmidt-Thieme, Nicolas Schilling
 Machine Learning B. Unsupervised Learning B.1 Cluster Analysis Lars Schmidt-Thieme, Nicolas Schilling Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University of Hildesheim,
Machine Learning B. Unsupervised Learning B.1 Cluster Analysis Lars Schmidt-Thieme, Nicolas Schilling Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University of Hildesheim,
Approaches to Clustering
 Clustering A basic tool in data mining/pattern recognition: Divide a set of data into groups. Samples in one cluster are close and clusters are far apart. 6 5 4 3 1 1 3 1 1 3 4 5 6 Motivations: Discover
Clustering A basic tool in data mining/pattern recognition: Divide a set of data into groups. Samples in one cluster are close and clusters are far apart. 6 5 4 3 1 1 3 1 1 3 4 5 6 Motivations: Discover
Content-based image and video analysis. Machine learning
 Content-based image and video analysis Machine learning for multimedia retrieval 04.05.2009 What is machine learning? Some problems are very hard to solve by writing a computer program by hand Almost all
Content-based image and video analysis Machine learning for multimedia retrieval 04.05.2009 What is machine learning? Some problems are very hard to solve by writing a computer program by hand Almost all
Fuzzy Segmentation. Chapter Introduction. 4.2 Unsupervised Clustering.
 Chapter 4 Fuzzy Segmentation 4. Introduction. The segmentation of objects whose color-composition is not common represents a difficult task, due to the illumination and the appropriate threshold selection
Chapter 4 Fuzzy Segmentation 4. Introduction. The segmentation of objects whose color-composition is not common represents a difficult task, due to the illumination and the appropriate threshold selection
Introduction to Pattern Recognition Part II. Selim Aksoy Bilkent University Department of Computer Engineering
 Introduction to Pattern Recognition Part II Selim Aksoy Bilkent University Department of Computer Engineering saksoy@cs.bilkent.edu.tr RETINA Pattern Recognition Tutorial, Summer 2005 Overview Statistical
Introduction to Pattern Recognition Part II Selim Aksoy Bilkent University Department of Computer Engineering saksoy@cs.bilkent.edu.tr RETINA Pattern Recognition Tutorial, Summer 2005 Overview Statistical
10/14/2017. Dejan Sarka. Anomaly Detection. Sponsors
 Dejan Sarka Anomaly Detection Sponsors About me SQL Server MVP (17 years) and MCT (20 years) 25 years working with SQL Server Authoring 16 th book Authoring many courses, articles Agenda Introduction Simple
Dejan Sarka Anomaly Detection Sponsors About me SQL Server MVP (17 years) and MCT (20 years) 25 years working with SQL Server Authoring 16 th book Authoring many courses, articles Agenda Introduction Simple
k-means demo Administrative Machine learning: Unsupervised learning" Assignment 5 out
 Machine learning: Unsupervised learning" David Kauchak cs Spring 0 adapted from: http://www.stanford.edu/class/cs76/handouts/lecture7-clustering.ppt http://www.youtube.com/watch?v=or_-y-eilqo Administrative
Machine learning: Unsupervised learning" David Kauchak cs Spring 0 adapted from: http://www.stanford.edu/class/cs76/handouts/lecture7-clustering.ppt http://www.youtube.com/watch?v=or_-y-eilqo Administrative
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CIE L*a*b* color model
 CIE L*a*b* color model To further strengthen the correlation between the color model and human perception, we apply the following non-linear transformation: with where (X n,y n,z n ) are the tristimulus
CIE L*a*b* color model To further strengthen the correlation between the color model and human perception, we apply the following non-linear transformation: with where (X n,y n,z n ) are the tristimulus
Cluster Analysis for Microarray Data
 Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
SD 372 Pattern Recognition
 SD 372 Pattern Recognition Lab 2: Model Estimation and Discriminant Functions 1 Purpose This lab examines the areas of statistical model estimation and classifier aggregation. Model estimation will be
SD 372 Pattern Recognition Lab 2: Model Estimation and Discriminant Functions 1 Purpose This lab examines the areas of statistical model estimation and classifier aggregation. Model estimation will be
CIS 520, Machine Learning, Fall 2015: Assignment 7 Due: Mon, Nov 16, :59pm, PDF to Canvas [100 points]
![CIS 520, Machine Learning, Fall 2015: Assignment 7 Due: Mon, Nov 16, :59pm, PDF to Canvas [100 points]](/thumbs/89/100746783.jpg "CIS 520, Machine Learning, Fall 2015: Assignment 7 Due: Mon, Nov 16, :59pm, PDF to Canvas [100 points]") CIS 520, Machine Learning, Fall 2015: Assignment 7 Due: Mon, Nov 16, 2015. 11:59pm, PDF to Canvas [100 points] Instructions. Please write up your responses to the following problems clearly and concisely.
CIS 520, Machine Learning, Fall 2015: Assignment 7 Due: Mon, Nov 16, 2015. 11:59pm, PDF to Canvas [100 points] Instructions. Please write up your responses to the following problems clearly and concisely.
Part I. Hierarchical clustering. Hierarchical Clustering. Hierarchical clustering. Produces a set of nested clusters organized as a
 Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Chapter 7: Competitive learning, clustering, and self-organizing maps
 Chapter 7: Competitive learning, clustering, and self-organizing maps António R. C. Paiva EEL 6814 Spring 2008 Outline Competitive learning Clustering Self-Organizing Maps What is competition in neural
Chapter 7: Competitive learning, clustering, and self-organizing maps António R. C. Paiva EEL 6814 Spring 2008 Outline Competitive learning Clustering Self-Organizing Maps What is competition in neural
An Introduction to PDF Estimation and Clustering
 Sigmedia, Electronic Engineering Dept., Trinity College, Dublin. 1 An Introduction to PDF Estimation and Clustering David Corrigan corrigad@tcd.ie Electrical and Electronic Engineering Dept., University
Sigmedia, Electronic Engineering Dept., Trinity College, Dublin. 1 An Introduction to PDF Estimation and Clustering David Corrigan corrigad@tcd.ie Electrical and Electronic Engineering Dept., University
Dimension reduction : PCA and Clustering
 Dimension reduction : PCA and Clustering By Hanne Jarmer Slides by Christopher Workman Center for Biological Sequence Analysis DTU The DNA Array Analysis Pipeline Array design Probe design Question Experimental
Dimension reduction : PCA and Clustering By Hanne Jarmer Slides by Christopher Workman Center for Biological Sequence Analysis DTU The DNA Array Analysis Pipeline Array design Probe design Question Experimental
COMS 4771 Clustering. Nakul Verma
 COMS 4771 Clustering Nakul Verma Supervised Learning Data: Supervised learning Assumption: there is a (relatively simple) function such that for most i Learning task: given n examples from the data, find
COMS 4771 Clustering Nakul Verma Supervised Learning Data: Supervised learning Assumption: there is a (relatively simple) function such that for most i Learning task: given n examples from the data, find
Artificial Neural Networks Unsupervised learning: SOM
 Artificial Neural Networks Unsupervised learning: SOM 01001110 01100101 01110101 01110010 01101111 01101110 01101111 01110110 01100001 00100000 01110011 01101011 01110101 01110000 01101001 01101110 01100001
Artificial Neural Networks Unsupervised learning: SOM 01001110 01100101 01110101 01110010 01101111 01101110 01101111 01110110 01100001 00100000 01110011 01101011 01110101 01110000 01101001 01101110 01100001
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Fuzzy C-MeansC. By Balaji K Juby N Zacharias
 Fuzzy C-MeansC By Balaji K Juby N Zacharias What is Clustering? Clustering of data is a method by which large sets of data is grouped into clusters of smaller sets of similar data. Example: The balls of
Fuzzy C-MeansC By Balaji K Juby N Zacharias What is Clustering? Clustering of data is a method by which large sets of data is grouped into clusters of smaller sets of similar data. Example: The balls of
( ) =cov X Y = W PRINCIPAL COMPONENT ANALYSIS. Eigenvectors of the covariance matrix are the principal components
 =cov X Y = W PRINCIPAL COMPONENT ANALYSIS. Eigenvectors of the covariance matrix are the principal components") Review Lecture 14 ! PRINCIPAL COMPONENT ANALYSIS Eigenvectors of the covariance matrix are the principal components 1. =cov X Top K principal components are the eigenvectors with K largest eigenvalues
Review Lecture 14 ! PRINCIPAL COMPONENT ANALYSIS Eigenvectors of the covariance matrix are the principal components 1. =cov X Top K principal components are the eigenvectors with K largest eigenvalues
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
22 October, 2012 MVA ENS Cachan. Lecture 5: Introduction to generative models Iasonas Kokkinos
 Machine Learning for Computer Vision 1 22 October, 2012 MVA ENS Cachan Lecture 5: Introduction to generative models Iasonas Kokkinos Iasonas.kokkinos@ecp.fr Center for Visual Computing Ecole Centrale Paris
Machine Learning for Computer Vision 1 22 October, 2012 MVA ENS Cachan Lecture 5: Introduction to generative models Iasonas Kokkinos Iasonas.kokkinos@ecp.fr Center for Visual Computing Ecole Centrale Paris
6.801/866. Segmentation and Line Fitting. T. Darrell
 6.801/866 Segmentation and Line Fitting T. Darrell Segmentation and Line Fitting Gestalt grouping Background subtraction K-Means Graph cuts Hough transform Iterative fitting (Next time: Probabilistic segmentation)
6.801/866 Segmentation and Line Fitting T. Darrell Segmentation and Line Fitting Gestalt grouping Background subtraction K-Means Graph cuts Hough transform Iterative fitting (Next time: Probabilistic segmentation)
IBL and clustering. Relationship of IBL with CBR
 IBL and clustering Distance based methods IBL and knn Clustering Distance based and hierarchical Probability-based Expectation Maximization (EM) Relationship of IBL with CBR + uses previously processed
IBL and clustering Distance based methods IBL and knn Clustering Distance based and hierarchical Probability-based Expectation Maximization (EM) Relationship of IBL with CBR + uses previously processed
Unsupervised Learning
 Unsupervised Learning Unsupervised learning Until now, we have assumed our training samples are labeled by their category membership. Methods that use labeled samples are said to be supervised. However,
Unsupervised Learning Unsupervised learning Until now, we have assumed our training samples are labeled by their category membership. Methods that use labeled samples are said to be supervised. However,
Robust Kernel Methods in Clustering and Dimensionality Reduction Problems
 Robust Kernel Methods in Clustering and Dimensionality Reduction Problems Jian Guo, Debadyuti Roy, Jing Wang University of Michigan, Department of Statistics Introduction In this report we propose robust
Robust Kernel Methods in Clustering and Dimensionality Reduction Problems Jian Guo, Debadyuti Roy, Jing Wang University of Michigan, Department of Statistics Introduction In this report we propose robust
Pattern Recognition. Kjell Elenius. Speech, Music and Hearing KTH. March 29, 2007 Speech recognition
 Pattern Recognition Kjell Elenius Speech, Music and Hearing KTH March 29, 2007 Speech recognition 2007 1 Ch 4. Pattern Recognition 1(3) Bayes Decision Theory Minimum-Error-Rate Decision Rules Discriminant
Pattern Recognition Kjell Elenius Speech, Music and Hearing KTH March 29, 2007 Speech recognition 2007 1 Ch 4. Pattern Recognition 1(3) Bayes Decision Theory Minimum-Error-Rate Decision Rules Discriminant
Clustering Lecture 3: Hierarchical Methods
 Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering & Classification (chapter 15)
") Clustering & Classification (chapter 5) Kai Goebel Bill Cheetham RPI/GE Global Research goebel@cs.rpi.edu cheetham@cs.rpi.edu Outline k-means Fuzzy c-means Mountain Clustering knn Fuzzy knn Hierarchical
Clustering & Classification (chapter 5) Kai Goebel Bill Cheetham RPI/GE Global Research goebel@cs.rpi.edu cheetham@cs.rpi.edu Outline k-means Fuzzy c-means Mountain Clustering knn Fuzzy knn Hierarchical
Solution Sketches Midterm Exam COSC 6342 Machine Learning March 20, 2013
 Your Name: Your student id: Solution Sketches Midterm Exam COSC 6342 Machine Learning March 20, 2013 Problem 1 [5+?]: Hypothesis Classes Problem 2 [8]: Losses and Risks Problem 3 [11]: Model Generation
Your Name: Your student id: Solution Sketches Midterm Exam COSC 6342 Machine Learning March 20, 2013 Problem 1 [5+?]: Hypothesis Classes Problem 2 [8]: Losses and Risks Problem 3 [11]: Model Generation
Lecture 11: E-M and MeanShift. CAP 5415 Fall 2007
 Lecture 11: E-M and MeanShift CAP 5415 Fall 2007 Review on Segmentation by Clustering Each Pixel Data Vector Example (From Comanciu and Meer) Review of k-means Let's find three clusters in this data These
Lecture 11: E-M and MeanShift CAP 5415 Fall 2007 Review on Segmentation by Clustering Each Pixel Data Vector Example (From Comanciu and Meer) Review of k-means Let's find three clusters in this data These
Data Mining Cluster Analysis: Advanced Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining, 2 nd Edition
 Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Outline Prototype-based Fuzzy c-means
Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Outline Prototype-based Fuzzy c-means
Inference and Representation
 Inference and Representation Rachel Hodos New York University Lecture 5, October 6, 2015 Rachel Hodos Lecture 5: Inference and Representation Today: Learning with hidden variables Outline: Unsupervised
Inference and Representation Rachel Hodos New York University Lecture 5, October 6, 2015 Rachel Hodos Lecture 5: Inference and Representation Today: Learning with hidden variables Outline: Unsupervised
Overview. Efficient Simplification of Point-sampled Surfaces. Introduction. Introduction. Neighborhood. Local Surface Analysis
 Overview Efficient Simplification of Pointsampled Surfaces Introduction Local surface analysis Simplification methods Error measurement Comparison PointBased Computer Graphics Mark Pauly PointBased Computer
Overview Efficient Simplification of Pointsampled Surfaces Introduction Local surface analysis Simplification methods Error measurement Comparison PointBased Computer Graphics Mark Pauly PointBased Computer
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning
 COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
INF4820, Algorithms for AI and NLP: Hierarchical Clustering
 INF4820, Algorithms for AI and NLP: Hierarchical Clustering Erik Velldal University of Oslo Sept. 25, 2012 Agenda Topics we covered last week Evaluating classifiers Accuracy, precision, recall and F-score
INF4820, Algorithms for AI and NLP: Hierarchical Clustering Erik Velldal University of Oslo Sept. 25, 2012 Agenda Topics we covered last week Evaluating classifiers Accuracy, precision, recall and F-score
Image Analysis, Classification and Change Detection in Remote Sensing
 Image Analysis, Classification and Change Detection in Remote Sensing WITH ALGORITHMS FOR ENVI/IDL Morton J. Canty Taylor &. Francis Taylor & Francis Group Boca Raton London New York CRC is an imprint
Image Analysis, Classification and Change Detection in Remote Sensing WITH ALGORITHMS FOR ENVI/IDL Morton J. Canty Taylor &. Francis Taylor & Francis Group Boca Raton London New York CRC is an imprint
Nonlinear dimensionality reduction of large datasets for data exploration
 Data Mining VII: Data, Text and Web Mining and their Business Applications 3 Nonlinear dimensionality reduction of large datasets for data exploration V. Tomenko & V. Popov Wessex Institute of Technology,
Data Mining VII: Data, Text and Web Mining and their Business Applications 3 Nonlinear dimensionality reduction of large datasets for data exploration V. Tomenko & V. Popov Wessex Institute of Technology,
The K-modes and Laplacian K-modes algorithms for clustering
 The K-modes and Laplacian K-modes algorithms for clustering Miguel Á. Carreira-Perpiñán Electrical Engineering and Computer Science University of California, Merced http://faculty.ucmerced.edu/mcarreira-perpinan
The K-modes and Laplacian K-modes algorithms for clustering Miguel Á. Carreira-Perpiñán Electrical Engineering and Computer Science University of California, Merced http://faculty.ucmerced.edu/mcarreira-perpinan
Pattern Recognition ( , RIT) Exercise 1 Solution
 Exercise 1 Solution") Pattern Recognition (4005-759, 20092 RIT) Exercise 1 Solution Instructor: Prof. Richard Zanibbi The following exercises are to help you review for the upcoming midterm examination on Thursday of Week 5
Pattern Recognition (4005-759, 20092 RIT) Exercise 1 Solution Instructor: Prof. Richard Zanibbi The following exercises are to help you review for the upcoming midterm examination on Thursday of Week 5
Spectral Methods for Network Community Detection and Graph Partitioning
 Spectral Methods for Network Community Detection and Graph Partitioning M. E. J. Newman Department of Physics, University of Michigan Presenters: Yunqi Guo Xueyin Yu Yuanqi Li 1 Outline: Community Detection
Spectral Methods for Network Community Detection and Graph Partitioning M. E. J. Newman Department of Physics, University of Michigan Presenters: Yunqi Guo Xueyin Yu Yuanqi Li 1 Outline: Community Detection