Contexts and 3D Scenes
|
|
|
- Tracy Bradley
- 6 years ago
- Views:
Transcription

1 Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem
2 Administrative stuffs Final project presentation Nov 30 th 3:30 PM 4:45 PM Grading Three senior graders (30%) Peer reviews (70%) Presentation 2.5 mins per group

3 Context in Recognition Objects usually are surrounded by a scene that can provide context in the form of nearby objects, surfaces, scene category, geometry, etc.
4 Context provides clues for function What is this? These examples from Antonio Torralba


5 Context provides clues for function What is this? Now can you tell?
6 Sometimes context is the major component of recognition What is this?


7 Sometimes context is the major component of recognition What is this? Now can you tell?
8 More Low-Res What are these blobs?

9 More Low-Res The same pixels! (a car)
10 There are many types of context Local pixels window, surround, image neighborhood, object boundary/shape, global image statistics 2D Scene Gist global image statistics 3D Geometric 3D scene layout, support surface, surface orientations, occlusions, contact points, etc. Semantic event/activity depicted, scene category, objects present in the scene and their spatial extents, keywords Photogrammetric camera height orientation, focal length, lens distorition, radiometric, response function Illumination sun direction, sky color, cloud cover, shadow contrast, etc. Geographic GPS location, terrain type, land use category, elevation, population density, etc. Temporal nearby frames of video, photos taken at similar times, videos of similar scenes, time of capture Cultural photographer bias, dataset selection bias, visual cliches, etc. from Divvala et al. CVPR 2009

11 Cultural context Jason Salavon:

12 Cultural context Mildred and Lisa : Who is Mildred? Who is Lisa? Andrew Gallagher:
13 Cultural context Age given Appearance Age given Name Andrew Gallagher:




14 Spatial layout is especially important 1. Context for recognition

15 Spatial layout is especially important 1. Context for recognition

16 Spatial layout is especially important 1. Context for recognition 2. Scene understanding

 2D to 3D conversion for 3D TV")
17 Spatial layout is especially important 1. Context for recognition 2. Scene understanding 3. Many direct applications a) Assisted driving b) Robot navigation/interaction c) 2D to 3D conversion for 3D TV d) Object insertion
18 Spatial Layout: 2D vs. 3D?


![Freeman 2004]](/docs-images/79/79508147/images/19-3.jpg "[Kumar Hebert")
![2005] [He](/docs-images/79/79508147/images/19-4.jpg "Zemel")
19 Context in Image Space [Torralba Murphy Freeman 2004] [Kumar Hebert 2005] [He Zemel Cerreira-Perpiñán 2004]

20 But object relations are in 3D Close Not Close
21 How to represent scene space?

22 Wide variety of possible representations Figs from Hoiem - Savarese 2011 book

23 Figs from Hoiem - Savarese 2011 book

24 Figs from Hoiem - Savarese 2011 book
25 Key Trade-offs Level of detail: rough gist, or detailed point cloud? Precision vs. accuracy Difficulty of inference Abstraction: depth at each pixel, or ground planes and walls? What is it for: e.g., metric reconstruction vs. navigation


26 Low detail, Low/Med abstraction Holistic Scene Space: Gist Torralba & Oliva 2002 Oliva & Torralba 2001


27 High detail, Low abstraction Depth Map Saxena, Chung & Ng 2005, 2007

28 Medium detail, High abstraction Room as a Box Hedau Hoiem Forsyth 2009


29 Med-High detail, High abstraction Complete 3D Layout Guo Zou Hoiem 2015
30 Examples of spatial layout estimation Surface layout Application to 3D reconstruction The room as a box Application to object recognition






31 Surface Layout: describe 3D surfaces with geometric classes Sky Non-Planar Porous Vertical Non-Planar Solid Support Planar (Left/Center/Right)


32 The challenge???


33 Our World is Structured Abstract World Our World Image Credit (left): F. Cunin and M.J. Sailor, UCSD
34 Learn the Structure of the World Training Images

35 Infer the most likely interpretation Unlikely Likely

36 Geometry estimation as recognition Region Features Color Texture Perspective Position Surface Geometry Classifier Vertical, Planar Training Data



37 Use a variety of image cues Color, texture, image location Vanishing points, lines Texture gradient

38 Surface Layout Algorithm Input Image Segmentation Features Perspective Color Texture Position Surface Labels Trained Region Classifier Training Data Hoiem Efros Hebert (2007)
39 Surface Layout Algorithm Input Image Multiple Segmentations Features Perspective Color Texture Position Confidence-Weighted Predictions Final Surface Labels Trained Region Classifier Training Data Hoiem Efros Hebert (2007)

40 Surface Description Result





41 Results Input Image Ground Truth Our Result





42 Results Input Image Ground Truth Our Result






43 Results Input Image Ground Truth Our Result





44 Failures: Reflections, Rare Viewpoint Input Image Ground Truth Our Result
45 Average Accuracy Main Class: 88% Subclasses: 61%


46 Automatic Photo Popup Labeled Image Fit Ground-Vertical Boundary with Line Segments Form Segments into Polylines Cut and Fold Final Pop-up Model [Hoiem Efros Hebert 2005]

47 Automatic Photo Popup

48
49 Mini-conclusions Can learn to predict surface geometry from a single image

50 Tour into picture Adobe Affer Effect
51 Interpretation of indoor scenes
52 Vision = assigning labels to pixels? Lamp Wall Sofa Table Floor Floor

53 Vision = interpreting within physical space Wall Sofa Table Floor
54 Physical space needed for affordance Is this a good place to sit? Could I stand over here? Can I put my cup here? Walkable path


55 Physical space needed for recognition Apparent shape depends strongly on viewpoint

56 Physical space needed for recognition


57 Physical space needed to predict appearance
58 Physical space needed to predict appearance
59 Key challenges How to represent the physical space? Requires seeing beyond the visible How to estimate the physical space? Requires simplified models Requires learning from examples
60 Our Box Layout Hedau Hoiem Forsyth, ICCV 2009 Room is an oriented 3D box Three vanishing points specify orientation Two pairs of sampled rays specify position/size

61 Our Box Layout Room is an oriented 3D box Three vanishing points (VPs) specify orientation Two pairs of sampled rays specify position/size Another box consistent with the same vanishing points

62 Image Cues for Box Layout Straight edges Edges on floor/wall surfaces are usually oriented towards VPs Edges on objects might mislead Appearance of visible surfaces Floor, wall, ceiling, object labels should be consistent with box floor left wall right wall objects


63 Box Layout Algorithm 1. Detect edges 2. Estimate 3 orthogonal vanishing points + 3. Apply region classifier to label pixels with visible surfaces Boosted decision trees on region based on color, texture, edges, position 4. Generate box candidates by sampling pairs of rays from VPs 5. Score each box based on edges and pixel labels Learn score via structured learning 6. Jointly refine box layout and pixel labels to get final estimate






64 Evaluation Dataset: 308 indoor images Train with 204 images, test with 104 images





65 Experimental results Detected Edges Surface Labels Box Layout Detected Edges Surface Labels Box Layout



66 Experimental results Detected Edges Surface Labels Box Layout Detected Edges Surface Labels Box Layout
67 Experimental results Joint reasoning of surface label / box layout helps Pixel error: 26.5% 21.2% Corner error: 7.4% 6.3% Similar performance for cluttered and uncluttered rooms
68 Mini-Conclusions Can fit a 3D box to the rooms boundaries from one image Robust to occluding objects Decent accuracy, but still much room for improvement

69 Using room layout to improve object detection Box layout helps 1. Predict the appearance of objects, because they are often aligned with the room 2. Predict the position and size of objects, due to physical constraints and size consistency 2D Bed Detection 3D Bed Detection with Scene Geometry Hedau, Hoiem, Forsyth, ECCV 2010, CVPR 2012






70 Search for objects in room coordinates Recover Room Coordinates Rectify Features to Room Coordinates Rectified Sliding Windows Hedau Forsyth Hoiem (2010)


71 Reason about 3D room and bed space Joint Inference with Priors Beds close to walls Beds within room Consistent bed/wall size Two objects cannot occupy the same space Hedau Forsyth Hoiem (2010)

72 3D Bed Detection from an Image
73 Generic boxy object detection Hedau et al. 2012

74 Generic boxy object detection

75 Generic boxy object detection

76 SUN RGB-D SUN RGB-D: A RGB-D Scene Understanding Benchmark Suite, CVPR 2015

77 ObjectNet3D ObjectNet3D: A Large Scale Database for 3D Object Recognition, ECCV 2016
78 Mini-Conclusions Simple room box layout helps detect objects by predicting appearance and constraining position We can search for objects in 3D space and directly evaluate on 3D localization


79 Predicting complete models from RGBD Key idea: create complete 3D scene hypothesis that is consistent with observed depth and appearance Guo Hoiem Zou 2015











80 Overview of approach RGB-D Input Layout Proposals Composing Object Proposals Exemplar Region Retrieval 3D Model Fitting Annotated Scene... Retrieved Region Source 3D Model Transferred Model Retrieved Region Source 3D Model Transferred Model


81 Example result (fully automatic)



82 Original Image Manual Segmentation Composition with Manual Segmentation Ground Truth Annotation Auto Proposal Composition with Auto Proposal



83 Original Image Manual Segmentation Composition w. Manual Segmentation Ground Truth Annotation Auto Proposal Composition w. Auto Proposal

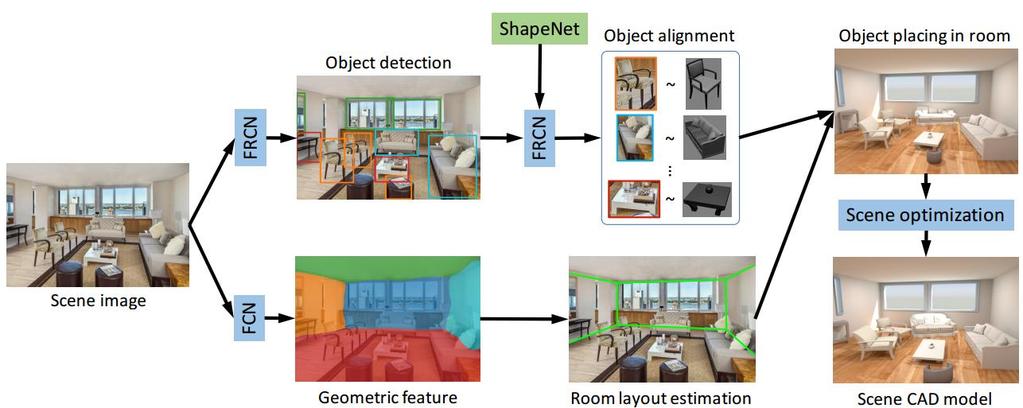
84 Im2CAD Im2CAD
85 Things to remember Objects should be interpreted in the context of the surrounding scene Many types of context to consider Spatial layout is an important part of scene interpretation, but many open problems How to represent space? How to learn and infer spatial models? Important to see beyond the visible Consider trade-off of abstraction vs. precision
Contexts and 3D Scenes
 Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Dec 1 st 3:30 PM 4:45 PM Goodwin Hall Atrium Grading Three
Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Dec 1 st 3:30 PM 4:45 PM Goodwin Hall Atrium Grading Three
CS 558: Computer Vision 13 th Set of Notes
 CS 558: Computer Vision 13 th Set of Notes Instructor: Philippos Mordohai Webpage: www.cs.stevens.edu/~mordohai E-mail: Philippos.Mordohai@stevens.edu Office: Lieb 215 Overview Context and Spatial Layout
CS 558: Computer Vision 13 th Set of Notes Instructor: Philippos Mordohai Webpage: www.cs.stevens.edu/~mordohai E-mail: Philippos.Mordohai@stevens.edu Office: Lieb 215 Overview Context and Spatial Layout
Context. CS 554 Computer Vision Pinar Duygulu Bilkent University. (Source:Antonio Torralba, James Hays)
") Context CS 554 Computer Vision Pinar Duygulu Bilkent University (Source:Antonio Torralba, James Hays) A computer vision goal Recognize many different objects under many viewing conditions in unconstrained
Context CS 554 Computer Vision Pinar Duygulu Bilkent University (Source:Antonio Torralba, James Hays) A computer vision goal Recognize many different objects under many viewing conditions in unconstrained
Single-view 3D Reconstruction
 Single-view 3D Reconstruction 10/12/17 Computational Photography Derek Hoiem, University of Illinois Some slides from Alyosha Efros, Steve Seitz Notes about Project 4 (Image-based Lighting) You can work
Single-view 3D Reconstruction 10/12/17 Computational Photography Derek Hoiem, University of Illinois Some slides from Alyosha Efros, Steve Seitz Notes about Project 4 (Image-based Lighting) You can work
Three-Dimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients
 ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
Automatic Photo Popup
 Automatic Photo Popup Derek Hoiem Alexei A. Efros Martial Hebert Carnegie Mellon University What Is Automatic Photo Popup Introduction Creating 3D models from images is a complex process Time-consuming
Automatic Photo Popup Derek Hoiem Alexei A. Efros Martial Hebert Carnegie Mellon University What Is Automatic Photo Popup Introduction Creating 3D models from images is a complex process Time-consuming
Support surfaces prediction for indoor scene understanding
 2013 IEEE International Conference on Computer Vision Support surfaces prediction for indoor scene understanding Anonymous ICCV submission Paper ID 1506 Abstract In this paper, we present an approach to
2013 IEEE International Conference on Computer Vision Support surfaces prediction for indoor scene understanding Anonymous ICCV submission Paper ID 1506 Abstract In this paper, we present an approach to
3D Spatial Layout Propagation in a Video Sequence
 3D Spatial Layout Propagation in a Video Sequence Alejandro Rituerto 1, Roberto Manduchi 2, Ana C. Murillo 1 and J. J. Guerrero 1 arituerto@unizar.es, manduchi@soe.ucsc.edu, acm@unizar.es, and josechu.guerrero@unizar.es
3D Spatial Layout Propagation in a Video Sequence Alejandro Rituerto 1, Roberto Manduchi 2, Ana C. Murillo 1 and J. J. Guerrero 1 arituerto@unizar.es, manduchi@soe.ucsc.edu, acm@unizar.es, and josechu.guerrero@unizar.es
Can Similar Scenes help Surface Layout Estimation?
 Can Similar Scenes help Surface Layout Estimation? Santosh K. Divvala, Alexei A. Efros, Martial Hebert Robotics Institute, Carnegie Mellon University. {santosh,efros,hebert}@cs.cmu.edu Abstract We describe
Can Similar Scenes help Surface Layout Estimation? Santosh K. Divvala, Alexei A. Efros, Martial Hebert Robotics Institute, Carnegie Mellon University. {santosh,efros,hebert}@cs.cmu.edu Abstract We describe
CS395T paper review. Indoor Segmentation and Support Inference from RGBD Images. Chao Jia Sep
 CS395T paper review Indoor Segmentation and Support Inference from RGBD Images Chao Jia Sep 28 2012 Introduction What do we want -- Indoor scene parsing Segmentation and labeling Support relationships
CS395T paper review Indoor Segmentation and Support Inference from RGBD Images Chao Jia Sep 28 2012 Introduction What do we want -- Indoor scene parsing Segmentation and labeling Support relationships
Recovering the Spatial Layout of Cluttered Rooms
 Recovering the Spatial Layout of Cluttered Rooms Varsha Hedau Electical and Computer Engg. Department University of Illinois at Urbana Champaign vhedau2@uiuc.edu Derek Hoiem, David Forsyth Computer Science
Recovering the Spatial Layout of Cluttered Rooms Varsha Hedau Electical and Computer Engg. Department University of Illinois at Urbana Champaign vhedau2@uiuc.edu Derek Hoiem, David Forsyth Computer Science
Correcting User Guided Image Segmentation
 Correcting User Guided Image Segmentation Garrett Bernstein (gsb29) Karen Ho (ksh33) Advanced Machine Learning: CS 6780 Abstract We tackle the problem of segmenting an image into planes given user input.
Correcting User Guided Image Segmentation Garrett Bernstein (gsb29) Karen Ho (ksh33) Advanced Machine Learning: CS 6780 Abstract We tackle the problem of segmenting an image into planes given user input.
Object Detection by 3D Aspectlets and Occlusion Reasoning
 Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan Silvio Savarese Stanford University In the 4th International IEEE Workshop on 3D Representation and Recognition
Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan Silvio Savarese Stanford University In the 4th International IEEE Workshop on 3D Representation and Recognition
Visual localization using global visual features and vanishing points
 Visual localization using global visual features and vanishing points Olivier Saurer, Friedrich Fraundorfer, and Marc Pollefeys Computer Vision and Geometry Group, ETH Zürich, Switzerland {saurero,fraundorfer,marc.pollefeys}@inf.ethz.ch
Visual localization using global visual features and vanishing points Olivier Saurer, Friedrich Fraundorfer, and Marc Pollefeys Computer Vision and Geometry Group, ETH Zürich, Switzerland {saurero,fraundorfer,marc.pollefeys}@inf.ethz.ch
Closing the Loop in Scene Interpretation
 Closing the Loop in Scene Interpretation Derek Hoiem Beckman Institute University of Illinois dhoiem@uiuc.edu Alexei A. Efros Robotics Institute Carnegie Mellon University efros@cs.cmu.edu Martial Hebert
Closing the Loop in Scene Interpretation Derek Hoiem Beckman Institute University of Illinois dhoiem@uiuc.edu Alexei A. Efros Robotics Institute Carnegie Mellon University efros@cs.cmu.edu Martial Hebert
IDE-3D: Predicting Indoor Depth Utilizing Geometric and Monocular Cues
 2016 International Conference on Computational Science and Computational Intelligence IDE-3D: Predicting Indoor Depth Utilizing Geometric and Monocular Cues Taylor Ripke Department of Computer Science
2016 International Conference on Computational Science and Computational Intelligence IDE-3D: Predicting Indoor Depth Utilizing Geometric and Monocular Cues Taylor Ripke Department of Computer Science
Learning and Inferring Depth from Monocular Images. Jiyan Pan April 1, 2009
 Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Data-driven Depth Inference from a Single Still Image
 Data-driven Depth Inference from a Single Still Image Kyunghee Kim Computer Science Department Stanford University kyunghee.kim@stanford.edu Abstract Given an indoor image, how to recover its depth information
Data-driven Depth Inference from a Single Still Image Kyunghee Kim Computer Science Department Stanford University kyunghee.kim@stanford.edu Abstract Given an indoor image, how to recover its depth information
CEng Computational Vision
 CEng 583 - Computational Vision 2011-2012 Spring Week 4 18 th of March, 2011 Today 3D Vision Binocular (Multi-view) cues: Stereopsis Motion Monocular cues Shading Texture Familiar size etc. "God must
CEng 583 - Computational Vision 2011-2012 Spring Week 4 18 th of March, 2011 Today 3D Vision Binocular (Multi-view) cues: Stereopsis Motion Monocular cues Shading Texture Familiar size etc. "God must
arxiv: v1 [cs.cv] 3 Jul 2016
![arxiv: v1 [cs.cv] 3 Jul 2016](/thumbs/95/123101257.jpg "arxiv: v1 [cs.cv] 3 Jul 2016") A Coarse-to-Fine Indoor Layout Estimation (CFILE) Method Yuzhuo Ren, Chen Chen, Shangwen Li, and C.-C. Jay Kuo arxiv:1607.00598v1 [cs.cv] 3 Jul 2016 Abstract. The task of estimating the spatial layout
A Coarse-to-Fine Indoor Layout Estimation (CFILE) Method Yuzhuo Ren, Chen Chen, Shangwen Li, and C.-C. Jay Kuo arxiv:1607.00598v1 [cs.cv] 3 Jul 2016 Abstract. The task of estimating the spatial layout
Shadows in the graphics pipeline
 Shadows in the graphics pipeline Steve Marschner Cornell University CS 569 Spring 2008, 19 February There are a number of visual cues that help let the viewer know about the 3D relationships between objects
Shadows in the graphics pipeline Steve Marschner Cornell University CS 569 Spring 2008, 19 February There are a number of visual cues that help let the viewer know about the 3D relationships between objects
Local cues and global constraints in image understanding
 Local cues and global constraints in image understanding Olga Barinova Lomonosov Moscow State University *Many slides adopted from the courses of Anton Konushin Image understanding «To see means to know
Local cues and global constraints in image understanding Olga Barinova Lomonosov Moscow State University *Many slides adopted from the courses of Anton Konushin Image understanding «To see means to know
What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today?
 Introduction What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today? What are we trying to achieve? Example from Scott Satkin 3D interpretation
Introduction What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today? What are we trying to achieve? Example from Scott Satkin 3D interpretation
c 2011 Varsha Chandrashekhar Hedau
 c 2011 Varsha Chandrashekhar Hedau 3D SPATIAL LAYOUT AND GEOMETRIC CONSTRAINTS FOR SCENE UNDERSTANDING BY VARSHA CHANDRASHEKHAR HEDAU DISSERTATION Submitted in partial fulfillment of the requirements for
c 2011 Varsha Chandrashekhar Hedau 3D SPATIAL LAYOUT AND GEOMETRIC CONSTRAINTS FOR SCENE UNDERSTANDING BY VARSHA CHANDRASHEKHAR HEDAU DISSERTATION Submitted in partial fulfillment of the requirements for
Viewpoint Invariant Features from Single Images Using 3D Geometry
 Viewpoint Invariant Features from Single Images Using 3D Geometry Yanpeng Cao and John McDonald Department of Computer Science National University of Ireland, Maynooth, Ireland {y.cao,johnmcd}@cs.nuim.ie
Viewpoint Invariant Features from Single Images Using 3D Geometry Yanpeng Cao and John McDonald Department of Computer Science National University of Ireland, Maynooth, Ireland {y.cao,johnmcd}@cs.nuim.ie
Segmentation. Bottom up Segmentation Semantic Segmentation
 Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
Single-view 3D reasoning
 Single-view 3D reasoning Lecturer: Bryan Russell UW CSE 576, May 2013 Slides borrowed from Antonio Torralba, Alyosha Efros, Antonio Criminisi, Derek Hoiem, Steve Seitz, Stephen Palmer, Abhinav Gupta, James
Single-view 3D reasoning Lecturer: Bryan Russell UW CSE 576, May 2013 Slides borrowed from Antonio Torralba, Alyosha Efros, Antonio Criminisi, Derek Hoiem, Steve Seitz, Stephen Palmer, Abhinav Gupta, James
Detection III: Analyzing and Debugging Detection Methods
 CS 1699: Intro to Computer Vision Detection III: Analyzing and Debugging Detection Methods Prof. Adriana Kovashka University of Pittsburgh November 17, 2015 Today Review: Deformable part models How can
CS 1699: Intro to Computer Vision Detection III: Analyzing and Debugging Detection Methods Prof. Adriana Kovashka University of Pittsburgh November 17, 2015 Today Review: Deformable part models How can
Simple 3D Reconstruction of Single Indoor Image with Perspe
 Simple 3D Reconstruction of Single Indoor Image with Perspective Cues Jingyuan Huang Bill Cowan University of Waterloo May 26, 2009 1 Introduction 2 Our Method 3 Results and Conclusions Problem Statement
Simple 3D Reconstruction of Single Indoor Image with Perspective Cues Jingyuan Huang Bill Cowan University of Waterloo May 26, 2009 1 Introduction 2 Our Method 3 Results and Conclusions Problem Statement
Separating Objects and Clutter in Indoor Scenes
 Separating Objects and Clutter in Indoor Scenes Salman H. Khan School of Computer Science & Software Engineering, The University of Western Australia Co-authors: Xuming He, Mohammed Bennamoun, Ferdous
Separating Objects and Clutter in Indoor Scenes Salman H. Khan School of Computer Science & Software Engineering, The University of Western Australia Co-authors: Xuming He, Mohammed Bennamoun, Ferdous
Supplementary Material: Piecewise Planar and Compact Floorplan Reconstruction from Images
 Supplementary Material: Piecewise Planar and Compact Floorplan Reconstruction from Images Ricardo Cabral Carnegie Mellon University rscabral@cmu.edu Yasutaka Furukawa Washington University in St. Louis
Supplementary Material: Piecewise Planar and Compact Floorplan Reconstruction from Images Ricardo Cabral Carnegie Mellon University rscabral@cmu.edu Yasutaka Furukawa Washington University in St. Louis
3D layout propagation to improve object recognition in egocentric videos
 3D layout propagation to improve object recognition in egocentric videos Alejandro Rituerto, Ana C. Murillo and José J. Guerrero {arituerto,acm,josechu.guerrero}@unizar.es Instituto de Investigación en
3D layout propagation to improve object recognition in egocentric videos Alejandro Rituerto, Ana C. Murillo and José J. Guerrero {arituerto,acm,josechu.guerrero}@unizar.es Instituto de Investigación en
Texton Clustering for Local Classification using Scene-Context Scale
 Texton Clustering for Local Classification using Scene-Context Scale Yousun Kang Tokyo Polytechnic University Atsugi, Kanakawa, Japan 243-0297 Email: yskang@cs.t-kougei.ac.jp Sugimoto Akihiro National
Texton Clustering for Local Classification using Scene-Context Scale Yousun Kang Tokyo Polytechnic University Atsugi, Kanakawa, Japan 243-0297 Email: yskang@cs.t-kougei.ac.jp Sugimoto Akihiro National
Combining Semantic Scene Priors and Haze Removal for Single Image Depth Estimation
 Combining Semantic Scene Priors and Haze Removal for Single Image Depth Estimation Ke Wang Enrique Dunn Joseph Tighe Jan-Michael Frahm University of North Carolina at Chapel Hill Chapel Hill, NC, USA {kewang,dunn,jtighe,jmf}@cs.unc.edu
Combining Semantic Scene Priors and Haze Removal for Single Image Depth Estimation Ke Wang Enrique Dunn Joseph Tighe Jan-Michael Frahm University of North Carolina at Chapel Hill Chapel Hill, NC, USA {kewang,dunn,jtighe,jmf}@cs.unc.edu
CS381V Experiment Presentation. Chun-Chen Kuo
 CS381V Experiment Presentation Chun-Chen Kuo The Paper Indoor Segmentation and Support Inference from RGBD Images. N. Silberman, D. Hoiem, P. Kohli, and R. Fergus. ECCV 2012. 50 100 150 200 250 300 350
CS381V Experiment Presentation Chun-Chen Kuo The Paper Indoor Segmentation and Support Inference from RGBD Images. N. Silberman, D. Hoiem, P. Kohli, and R. Fergus. ECCV 2012. 50 100 150 200 250 300 350
Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image. Supplementary Material
 Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image Supplementary Material Siyuan Huang 1,2, Siyuan Qi 1,2, Yixin Zhu 1,2, Yinxue Xiao 1, Yuanlu Xu 1,2, and Song-Chun Zhu 1,2 1 University
Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image Supplementary Material Siyuan Huang 1,2, Siyuan Qi 1,2, Yixin Zhu 1,2, Yinxue Xiao 1, Yuanlu Xu 1,2, and Song-Chun Zhu 1,2 1 University
3DNN: Viewpoint Invariant 3D Geometry Matching for Scene Understanding
 3DNN: Viewpoint Invariant 3D Geometry Matching for Scene Understanding Scott Satkin Google Inc satkin@googlecom Martial Hebert Carnegie Mellon University hebert@ricmuedu Abstract We present a new algorithm
3DNN: Viewpoint Invariant 3D Geometry Matching for Scene Understanding Scott Satkin Google Inc satkin@googlecom Martial Hebert Carnegie Mellon University hebert@ricmuedu Abstract We present a new algorithm
Room Reconstruction from a Single Spherical Image by Higher-order Energy Minimization
 Room Reconstruction from a Single Spherical Image by Higher-order Energy Minimization Kosuke Fukano, Yoshihiko Mochizuki, Satoshi Iizuka, Edgar Simo-Serra, Akihiro Sugimoto, and Hiroshi Ishikawa Waseda
Room Reconstruction from a Single Spherical Image by Higher-order Energy Minimization Kosuke Fukano, Yoshihiko Mochizuki, Satoshi Iizuka, Edgar Simo-Serra, Akihiro Sugimoto, and Hiroshi Ishikawa Waseda
SUN RGB-D: A RGB-D Scene Understanding Benchmark Suite Supplimentary Material
 SUN RGB-D: A RGB-D Scene Understanding Benchmark Suite Supplimentary Material Shuran Song Samuel P. Lichtenberg Jianxiong Xiao Princeton University http://rgbd.cs.princeton.edu. Segmetation Result wall
SUN RGB-D: A RGB-D Scene Understanding Benchmark Suite Supplimentary Material Shuran Song Samuel P. Lichtenberg Jianxiong Xiao Princeton University http://rgbd.cs.princeton.edu. Segmetation Result wall
DEPT: Depth Estimation by Parameter Transfer for Single Still Images
 DEPT: Depth Estimation by Parameter Transfer for Single Still Images Xiu Li 1, 2, Hongwei Qin 1,2, Yangang Wang 3, Yongbing Zhang 1,2, and Qionghai Dai 1 1. Dept. of Automation, Tsinghua University 2.
DEPT: Depth Estimation by Parameter Transfer for Single Still Images Xiu Li 1, 2, Hongwei Qin 1,2, Yangang Wang 3, Yongbing Zhang 1,2, and Qionghai Dai 1 1. Dept. of Automation, Tsinghua University 2.
Decomposing a Scene into Geometric and Semantically Consistent Regions
 Decomposing a Scene into Geometric and Semantically Consistent Regions Stephen Gould sgould@stanford.edu Richard Fulton rafulton@cs.stanford.edu Daphne Koller koller@cs.stanford.edu IEEE International
Decomposing a Scene into Geometric and Semantically Consistent Regions Stephen Gould sgould@stanford.edu Richard Fulton rafulton@cs.stanford.edu Daphne Koller koller@cs.stanford.edu IEEE International
LEARNING BOUNDARIES WITH COLOR AND DEPTH. Zhaoyin Jia, Andrew Gallagher, Tsuhan Chen
 LEARNING BOUNDARIES WITH COLOR AND DEPTH Zhaoyin Jia, Andrew Gallagher, Tsuhan Chen School of Electrical and Computer Engineering, Cornell University ABSTRACT To enable high-level understanding of a scene,
LEARNING BOUNDARIES WITH COLOR AND DEPTH Zhaoyin Jia, Andrew Gallagher, Tsuhan Chen School of Electrical and Computer Engineering, Cornell University ABSTRACT To enable high-level understanding of a scene,
Interpreting 3D Scenes Using Object-level Constraints
 Interpreting 3D Scenes Using Object-level Constraints Rehan Hameed Stanford University 353 Serra Mall, Stanford CA rhameed@stanford.edu Abstract As humans we are able to understand the structure of a scene
Interpreting 3D Scenes Using Object-level Constraints Rehan Hameed Stanford University 353 Serra Mall, Stanford CA rhameed@stanford.edu Abstract As humans we are able to understand the structure of a scene
Object Recognition. Computer Vision. Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce
 Object Recognition Computer Vision Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce How many visual object categories are there? Biederman 1987 ANIMALS PLANTS OBJECTS
Object Recognition Computer Vision Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce How many visual object categories are there? Biederman 1987 ANIMALS PLANTS OBJECTS
Opportunities of Scale
 Opportunities of Scale 11/07/17 Computational Photography Derek Hoiem, University of Illinois Most slides from Alyosha Efros Graphic from Antonio Torralba Today s class Opportunities of Scale: Data-driven
Opportunities of Scale 11/07/17 Computational Photography Derek Hoiem, University of Illinois Most slides from Alyosha Efros Graphic from Antonio Torralba Today s class Opportunities of Scale: Data-driven
Multi-view Stereo. Ivo Boyadzhiev CS7670: September 13, 2011
 Multi-view Stereo Ivo Boyadzhiev CS7670: September 13, 2011 What is stereo vision? Generic problem formulation: given several images of the same object or scene, compute a representation of its 3D shape
Multi-view Stereo Ivo Boyadzhiev CS7670: September 13, 2011 What is stereo vision? Generic problem formulation: given several images of the same object or scene, compute a representation of its 3D shape
Imagining the Unseen: Stability-based Cuboid Arrangements for Scene Understanding
 : Stability-based Cuboid Arrangements for Scene Understanding Tianjia Shao* Aron Monszpart Youyi Zheng Bongjin Koo Weiwei Xu Kun Zhou * Niloy J. Mitra * Background A fundamental problem for single view
: Stability-based Cuboid Arrangements for Scene Understanding Tianjia Shao* Aron Monszpart Youyi Zheng Bongjin Koo Weiwei Xu Kun Zhou * Niloy J. Mitra * Background A fundamental problem for single view
Object Detection by 3D Aspectlets and Occlusion Reasoning
 Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan yuxiang@umich.edu Silvio Savarese Stanford University ssilvio@stanford.edu Abstract We propose a novel framework
Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan yuxiang@umich.edu Silvio Savarese Stanford University ssilvio@stanford.edu Abstract We propose a novel framework
Learning from 3D Data
 Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Scene Modeling for a Single View
 Scene Modeling for a Single View René MAGRITTE Portrait d'edward James with a lot of slides stolen from Steve Seitz and David Brogan, Breaking out of 2D now we are ready to break out of 2D And enter the
Scene Modeling for a Single View René MAGRITTE Portrait d'edward James with a lot of slides stolen from Steve Seitz and David Brogan, Breaking out of 2D now we are ready to break out of 2D And enter the
Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction
 Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction Marc Pollefeys Joined work with Nikolay Savinov, Christian Haene, Lubor Ladicky 2 Comparison to Volumetric Fusion Higher-order ray
Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction Marc Pollefeys Joined work with Nikolay Savinov, Christian Haene, Lubor Ladicky 2 Comparison to Volumetric Fusion Higher-order ray
Single-view metrology
 Single-view metrology Magritte, Personal Values, 952 Many slides from S. Seitz, D. Hoiem Camera calibration revisited What if world coordinates of reference 3D points are not known? We can use scene features
Single-view metrology Magritte, Personal Values, 952 Many slides from S. Seitz, D. Hoiem Camera calibration revisited What if world coordinates of reference 3D points are not known? We can use scene features
3D Scene Understanding by Voxel-CRF
 3D Scene Understanding by Voxel-CRF Byung-soo Kim University of Michigan bsookim@umich.edu Pushmeet Kohli Microsoft Research Cambridge pkohli@microsoft.com Silvio Savarese Stanford University ssilvio@stanford.edu
3D Scene Understanding by Voxel-CRF Byung-soo Kim University of Michigan bsookim@umich.edu Pushmeet Kohli Microsoft Research Cambridge pkohli@microsoft.com Silvio Savarese Stanford University ssilvio@stanford.edu
Attributes and More Crowdsourcing
 Attributes and More Crowdsourcing Computer Vision CS 143, Brown James Hays Many slides from Derek Hoiem Recap: Human Computation Active Learning: Let the classifier tell you where more annotation is needed.
Attributes and More Crowdsourcing Computer Vision CS 143, Brown James Hays Many slides from Derek Hoiem Recap: Human Computation Active Learning: Let the classifier tell you where more annotation is needed.
Attributes. Computer Vision. James Hays. Many slides from Derek Hoiem
 Many slides from Derek Hoiem Attributes Computer Vision James Hays Recap: Human Computation Active Learning: Let the classifier tell you where more annotation is needed. Human-in-the-loop recognition:
Many slides from Derek Hoiem Attributes Computer Vision James Hays Recap: Human Computation Active Learning: Let the classifier tell you where more annotation is needed. Human-in-the-loop recognition:
Revisiting 3D Geometric Models for Accurate Object Shape and Pose
 Revisiting 3D Geometric Models for Accurate Object Shape and Pose M. 1 Michael Stark 2,3 Bernt Schiele 3 Konrad Schindler 1 1 Photogrammetry and Remote Sensing Laboratory Swiss Federal Institute of Technology
Revisiting 3D Geometric Models for Accurate Object Shape and Pose M. 1 Michael Stark 2,3 Bernt Schiele 3 Konrad Schindler 1 1 Photogrammetry and Remote Sensing Laboratory Swiss Federal Institute of Technology
Indoor Object Recognition of 3D Kinect Dataset with RNNs
 Indoor Object Recognition of 3D Kinect Dataset with RNNs Thiraphat Charoensripongsa, Yue Chen, Brian Cheng 1. Introduction Recent work at Stanford in the area of scene understanding has involved using
Indoor Object Recognition of 3D Kinect Dataset with RNNs Thiraphat Charoensripongsa, Yue Chen, Brian Cheng 1. Introduction Recent work at Stanford in the area of scene understanding has involved using
Local features: detection and description. Local invariant features
 Local features: detection and description Local invariant features Detection of interest points Harris corner detection Scale invariant blob detection: LoG Description of local patches SIFT : Histograms
Local features: detection and description Local invariant features Detection of interest points Harris corner detection Scale invariant blob detection: LoG Description of local patches SIFT : Histograms
Discriminative classifiers for image recognition
 Discriminative classifiers for image recognition May 26 th, 2015 Yong Jae Lee UC Davis Outline Last time: window-based generic object detection basic pipeline face detection with boosting as case study
Discriminative classifiers for image recognition May 26 th, 2015 Yong Jae Lee UC Davis Outline Last time: window-based generic object detection basic pipeline face detection with boosting as case study
Scene Modeling for a Single View
 on to 3D Scene Modeling for a Single View We want real 3D scene walk-throughs: rotation translation Can we do it from a single photograph? Reading: A. Criminisi, I. Reid and A. Zisserman, Single View Metrology
on to 3D Scene Modeling for a Single View We want real 3D scene walk-throughs: rotation translation Can we do it from a single photograph? Reading: A. Criminisi, I. Reid and A. Zisserman, Single View Metrology
SIMPLE ROOM SHAPE MODELING WITH SPARSE 3D POINT INFORMATION USING PHOTOGRAMMETRY AND APPLICATION SOFTWARE
 SIMPLE ROOM SHAPE MODELING WITH SPARSE 3D POINT INFORMATION USING PHOTOGRAMMETRY AND APPLICATION SOFTWARE S. Hirose R&D Center, TOPCON CORPORATION, 75-1, Hasunuma-cho, Itabashi-ku, Tokyo, Japan Commission
SIMPLE ROOM SHAPE MODELING WITH SPARSE 3D POINT INFORMATION USING PHOTOGRAMMETRY AND APPLICATION SOFTWARE S. Hirose R&D Center, TOPCON CORPORATION, 75-1, Hasunuma-cho, Itabashi-ku, Tokyo, Japan Commission
Projective Geometry and Camera Models
 /2/ Projective Geometry and Camera Models Computer Vision CS 543 / ECE 549 University of Illinois Derek Hoiem Note about HW Out before next Tues Prob: covered today, Tues Prob2: covered next Thurs Prob3:
/2/ Projective Geometry and Camera Models Computer Vision CS 543 / ECE 549 University of Illinois Derek Hoiem Note about HW Out before next Tues Prob: covered today, Tues Prob2: covered next Thurs Prob3:
ELL 788 Computational Perception & Cognition July November 2015
 ELL 788 Computational Perception & Cognition July November 2015 Module 6 Role of context in object detection Objects and cognition Ambiguous objects Unfavorable viewing condition Context helps in object
ELL 788 Computational Perception & Cognition July November 2015 Module 6 Role of context in object detection Objects and cognition Ambiguous objects Unfavorable viewing condition Context helps in object
Optimizing Monocular Cues for Depth Estimation from Indoor Images
 Optimizing Monocular Cues for Depth Estimation from Indoor Images Aditya Venkatraman 1, Sheetal Mahadik 2 1, 2 Department of Electronics and Telecommunication, ST Francis Institute of Technology, Mumbai,
Optimizing Monocular Cues for Depth Estimation from Indoor Images Aditya Venkatraman 1, Sheetal Mahadik 2 1, 2 Department of Electronics and Telecommunication, ST Francis Institute of Technology, Mumbai,
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Line Image Signature for Scene Understanding with a Wearable Vision System
 Line Image Signature for Scene Understanding with a Wearable Vision System Alejandro Rituerto DIIS - I3A, University of Zaragoza, Spain arituerto@unizar.es Ana C. Murillo DIIS - I3A, University of Zaragoza,
Line Image Signature for Scene Understanding with a Wearable Vision System Alejandro Rituerto DIIS - I3A, University of Zaragoza, Spain arituerto@unizar.es Ana C. Murillo DIIS - I3A, University of Zaragoza,
Photo Tourism: Exploring Photo Collections in 3D
 Photo Tourism: Exploring Photo Collections in 3D SIGGRAPH 2006 Noah Snavely Steven M. Seitz University of Washington Richard Szeliski Microsoft Research 2006 2006 Noah Snavely Noah Snavely Reproduced with
Photo Tourism: Exploring Photo Collections in 3D SIGGRAPH 2006 Noah Snavely Steven M. Seitz University of Washington Richard Szeliski Microsoft Research 2006 2006 Noah Snavely Noah Snavely Reproduced with
Object Detection Using Cascaded Classification Models
 Object Detection Using Cascaded Classification Models Chau Nguyen December 17, 2010 Abstract Building a robust object detector for robots is alway essential for many robot operations. The traditional problem
Object Detection Using Cascaded Classification Models Chau Nguyen December 17, 2010 Abstract Building a robust object detector for robots is alway essential for many robot operations. The traditional problem
arxiv: v1 [cs.cv] 23 Mar 2018
![arxiv: v1 [cs.cv] 23 Mar 2018](/thumbs/80/81847201.jpg "arxiv: v1 [cs.cv] 23 Mar 2018") LayoutNet: Reconstructing the 3D Room Layout from a Single RGB Image Chuhang Zou Alex Colburn Qi Shan Derek Hoiem University of Illinois at Urbana-Champaign Zillow Group {czou4, dhoiem}@illinois.edu {alexco,
LayoutNet: Reconstructing the 3D Room Layout from a Single RGB Image Chuhang Zou Alex Colburn Qi Shan Derek Hoiem University of Illinois at Urbana-Champaign Zillow Group {czou4, dhoiem}@illinois.edu {alexco,
24 hours of Photo Sharing. installation by Erik Kessels
 24 hours of Photo Sharing installation by Erik Kessels And sometimes Internet photos have useful labels Im2gps. Hays and Efros. CVPR 2008 But what if we want more? Image Categorization Training Images
24 hours of Photo Sharing installation by Erik Kessels And sometimes Internet photos have useful labels Im2gps. Hays and Efros. CVPR 2008 But what if we want more? Image Categorization Training Images
Fundamentals of Stereo Vision Michael Bleyer LVA Stereo Vision
 Fundamentals of Stereo Vision Michael Bleyer LVA Stereo Vision What Happened Last Time? Human 3D perception (3D cinema) Computational stereo Intuitive explanation of what is meant by disparity Stereo matching
Fundamentals of Stereo Vision Michael Bleyer LVA Stereo Vision What Happened Last Time? Human 3D perception (3D cinema) Computational stereo Intuitive explanation of what is meant by disparity Stereo matching
From 3D Scene Geometry to Human Workspace
 From 3D Scene Geometry to Human Workspace Abhinav Gupta, Scott Satkin, Alexei A. Efros and Martial Hebert The Robotics Institute, Carnegie Mellon University {abhinavg,ssatkin,efros,hebert}@ri.cmu.edu Abstract
From 3D Scene Geometry to Human Workspace Abhinav Gupta, Scott Satkin, Alexei A. Efros and Martial Hebert The Robotics Institute, Carnegie Mellon University {abhinavg,ssatkin,efros,hebert}@ri.cmu.edu Abstract
Focusing Attention on Visual Features that Matter
 TSAI, KUIPERS: FOCUSING ATTENTION ON VISUAL FEATURES THAT MATTER 1 Focusing Attention on Visual Features that Matter Grace Tsai gstsai@umich.edu Benjamin Kuipers kuipers@umich.edu Electrical Engineering
TSAI, KUIPERS: FOCUSING ATTENTION ON VISUAL FEATURES THAT MATTER 1 Focusing Attention on Visual Features that Matter Grace Tsai gstsai@umich.edu Benjamin Kuipers kuipers@umich.edu Electrical Engineering
STRUCTURAL EDGE LEARNING FOR 3-D RECONSTRUCTION FROM A SINGLE STILL IMAGE. Nan Hu. Stanford University Electrical Engineering
 STRUCTURAL EDGE LEARNING FOR 3-D RECONSTRUCTION FROM A SINGLE STILL IMAGE Nan Hu Stanford University Electrical Engineering nanhu@stanford.edu ABSTRACT Learning 3-D scene structure from a single still
STRUCTURAL EDGE LEARNING FOR 3-D RECONSTRUCTION FROM A SINGLE STILL IMAGE Nan Hu Stanford University Electrical Engineering nanhu@stanford.edu ABSTRACT Learning 3-D scene structure from a single still
Object Category Detection. Slides mostly from Derek Hoiem
 Object Category Detection Slides mostly from Derek Hoiem Today s class: Object Category Detection Overview of object category detection Statistical template matching with sliding window Part-based Models
Object Category Detection Slides mostly from Derek Hoiem Today s class: Object Category Detection Overview of object category detection Statistical template matching with sliding window Part-based Models
CS 4495 Computer Vision A. Bobick. Motion and Optic Flow. Stereo Matching
 Stereo Matching Fundamental matrix Let p be a point in left image, p in right image l l Epipolar relation p maps to epipolar line l p maps to epipolar line l p p Epipolar mapping described by a 3x3 matrix
Stereo Matching Fundamental matrix Let p be a point in left image, p in right image l l Epipolar relation p maps to epipolar line l p maps to epipolar line l p p Epipolar mapping described by a 3x3 matrix
12/3/2009. What is Computer Vision? Applications. Application: Assisted driving Pedestrian and car detection. Application: Improving online search
 Introduction to Artificial Intelligence V22.0472-001 Fall 2009 Lecture 26: Computer Vision Rob Fergus Dept of Computer Science, Courant Institute, NYU Slides from Andrew Zisserman What is Computer Vision?
Introduction to Artificial Intelligence V22.0472-001 Fall 2009 Lecture 26: Computer Vision Rob Fergus Dept of Computer Science, Courant Institute, NYU Slides from Andrew Zisserman What is Computer Vision?
arxiv: v3 [cs.cv] 18 Aug 2017
![arxiv: v3 [cs.cv] 18 Aug 2017](/thumbs/73/69392953.jpg "arxiv: v3 [cs.cv] 18 Aug 2017") Predicting Complete 3D Models of Indoor Scenes Ruiqi Guo UIUC, Google Chuhang Zou UIUC Derek Hoiem UIUC arxiv:1504.02437v3 [cs.cv] 18 Aug 2017 Abstract One major goal of vision is to infer physical models
Predicting Complete 3D Models of Indoor Scenes Ruiqi Guo UIUC, Google Chuhang Zou UIUC Derek Hoiem UIUC arxiv:1504.02437v3 [cs.cv] 18 Aug 2017 Abstract One major goal of vision is to infer physical models
Beyond bags of features: Adding spatial information. Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba
 Beyond bags of features: Adding spatial information Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba Adding spatial information Forming vocabularies from pairs of nearby features doublets
Beyond bags of features: Adding spatial information Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba Adding spatial information Forming vocabularies from pairs of nearby features doublets
Learning Spatial Context: Using Stuff to Find Things
 Learning Spatial Context: Using Stuff to Find Things Wei-Cheng Su Motivation 2 Leverage contextual information to enhance detection Some context objects are non-rigid and are more naturally classified
Learning Spatial Context: Using Stuff to Find Things Wei-Cheng Su Motivation 2 Leverage contextual information to enhance detection Some context objects are non-rigid and are more naturally classified
Scene Modeling for a Single View
 Scene Modeling for a Single View René MAGRITTE Portrait d'edward James CS194: Image Manipulation & Computational Photography with a lot of slides stolen from Alexei Efros, UC Berkeley, Fall 2014 Steve
Scene Modeling for a Single View René MAGRITTE Portrait d'edward James CS194: Image Manipulation & Computational Photography with a lot of slides stolen from Alexei Efros, UC Berkeley, Fall 2014 Steve
3D-Based Reasoning with Blocks, Support, and Stability
 3D-Based Reasoning with Blocks, Support, and Stability Zhaoyin Jia, Andrew Gallagher, Ashutosh Saxena, Tsuhan Chen School of Electrical and Computer Engineering, Cornell University. Department of Computer
3D-Based Reasoning with Blocks, Support, and Stability Zhaoyin Jia, Andrew Gallagher, Ashutosh Saxena, Tsuhan Chen School of Electrical and Computer Engineering, Cornell University. Department of Computer
Understanding Bayesian rooms using composite 3D object models
 2013 IEEE Conference on Computer Vision and Pattern Recognition Understanding Bayesian rooms using composite 3D object models Luca Del Pero Joshua Bowdish Bonnie Kermgard Emily Hartley Kobus Barnard University
2013 IEEE Conference on Computer Vision and Pattern Recognition Understanding Bayesian rooms using composite 3D object models Luca Del Pero Joshua Bowdish Bonnie Kermgard Emily Hartley Kobus Barnard University
Local features: detection and description May 12 th, 2015
 Local features: detection and description May 12 th, 2015 Yong Jae Lee UC Davis Announcements PS1 grades up on SmartSite PS1 stats: Mean: 83.26 Standard Dev: 28.51 PS2 deadline extended to Saturday, 11:59
Local features: detection and description May 12 th, 2015 Yong Jae Lee UC Davis Announcements PS1 grades up on SmartSite PS1 stats: Mean: 83.26 Standard Dev: 28.51 PS2 deadline extended to Saturday, 11:59
Multi-view stereo. Many slides adapted from S. Seitz
 Multi-view stereo Many slides adapted from S. Seitz Beyond two-view stereo The third eye can be used for verification Multiple-baseline stereo Pick a reference image, and slide the corresponding window
Multi-view stereo Many slides adapted from S. Seitz Beyond two-view stereo The third eye can be used for verification Multiple-baseline stereo Pick a reference image, and slide the corresponding window
DEPT: Depth Estimation by Parameter Transfer for Single Still Images
 DEPT: Depth Estimation by Parameter Transfer for Single Still Images Xiu Li 1,2, Hongwei Qin 1,2(B), Yangang Wang 3, Yongbing Zhang 1,2, and Qionghai Dai 1 1 Department of Automation, Tsinghua University,
DEPT: Depth Estimation by Parameter Transfer for Single Still Images Xiu Li 1,2, Hongwei Qin 1,2(B), Yangang Wang 3, Yongbing Zhang 1,2, and Qionghai Dai 1 1 Department of Automation, Tsinghua University,
Previously. Part-based and local feature models for generic object recognition. Bag-of-words model 4/20/2011
 Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Blocks World Revisited: Image Understanding Using Qualitative Geometry and Mechanics
 Carnegie Mellon University Research Showcase @ CMU Robotics Institute School of Computer Science 9-2010 Blocks World Revisited: Image Understanding Using Qualitative Geometry and Mechanics Abhinav Gupta
Carnegie Mellon University Research Showcase @ CMU Robotics Institute School of Computer Science 9-2010 Blocks World Revisited: Image Understanding Using Qualitative Geometry and Mechanics Abhinav Gupta
Local Features and Bag of Words Models
 10/14/11 Local Features and Bag of Words Models Computer Vision CS 143, Brown James Hays Slides from Svetlana Lazebnik, Derek Hoiem, Antonio Torralba, David Lowe, Fei Fei Li and others Computer Engineering
10/14/11 Local Features and Bag of Words Models Computer Vision CS 143, Brown James Hays Slides from Svetlana Lazebnik, Derek Hoiem, Antonio Torralba, David Lowe, Fei Fei Li and others Computer Engineering
CHAPTER 3. Single-view Geometry. 1. Consequences of Projection
 CHAPTER 3 Single-view Geometry When we open an eye or take a photograph, we see only a flattened, two-dimensional projection of the physical underlying scene. The consequences are numerous and startling.
CHAPTER 3 Single-view Geometry When we open an eye or take a photograph, we see only a flattened, two-dimensional projection of the physical underlying scene. The consequences are numerous and startling.
Introduction to 3D Concepts
 PART I Introduction to 3D Concepts Chapter 1 Scene... 3 Chapter 2 Rendering: OpenGL (OGL) and Adobe Ray Tracer (ART)...19 1 CHAPTER 1 Scene s0010 1.1. The 3D Scene p0010 A typical 3D scene has several
PART I Introduction to 3D Concepts Chapter 1 Scene... 3 Chapter 2 Rendering: OpenGL (OGL) and Adobe Ray Tracer (ART)...19 1 CHAPTER 1 Scene s0010 1.1. The 3D Scene p0010 A typical 3D scene has several
Pinhole Camera Model 10/05/17. Computational Photography Derek Hoiem, University of Illinois
 Pinhole Camera Model /5/7 Computational Photography Derek Hoiem, University of Illinois Next classes: Single-view Geometry How tall is this woman? How high is the camera? What is the camera rotation? What
Pinhole Camera Model /5/7 Computational Photography Derek Hoiem, University of Illinois Next classes: Single-view Geometry How tall is this woman? How high is the camera? What is the camera rotation? What
Course Administration
 Course Administration Project 2 results are online Project 3 is out today The first quiz is a week from today (don t panic!) Covers all material up to the quiz Emphasizes lecture material NOT project topics
Course Administration Project 2 results are online Project 3 is out today The first quiz is a week from today (don t panic!) Covers all material up to the quiz Emphasizes lecture material NOT project topics
More Single View Geometry
 More Single View Geometry with a lot of slides stolen from Steve Seitz Cyclops Odilon Redon 1904 15-463: Computational Photography Alexei Efros, CMU, Fall 2007 Final Projects Are coming up fast! Undergrads
More Single View Geometry with a lot of slides stolen from Steve Seitz Cyclops Odilon Redon 1904 15-463: Computational Photography Alexei Efros, CMU, Fall 2007 Final Projects Are coming up fast! Undergrads
Deformable Part Models
 CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
OCCLUSION BOUNDARIES ESTIMATION FROM A HIGH-RESOLUTION SAR IMAGE
 OCCLUSION BOUNDARIES ESTIMATION FROM A HIGH-RESOLUTION SAR IMAGE Wenju He, Marc Jäger, and Olaf Hellwich Berlin University of Technology FR3-1, Franklinstr. 28, 10587 Berlin, Germany {wenjuhe, jaeger,
OCCLUSION BOUNDARIES ESTIMATION FROM A HIGH-RESOLUTION SAR IMAGE Wenju He, Marc Jäger, and Olaf Hellwich Berlin University of Technology FR3-1, Franklinstr. 28, 10587 Berlin, Germany {wenjuhe, jaeger,
ECE 6554:Advanced Computer Vision Pose Estimation
 ECE 6554:Advanced Computer Vision Pose Estimation Sujay Yadawadkar, Virginia Tech, Agenda: Pose Estimation: Part Based Models for Pose Estimation Pose Estimation with Convolutional Neural Networks (Deep
ECE 6554:Advanced Computer Vision Pose Estimation Sujay Yadawadkar, Virginia Tech, Agenda: Pose Estimation: Part Based Models for Pose Estimation Pose Estimation with Convolutional Neural Networks (Deep
International Journal of Advance Engineering and Research Development
 Scientific Journal of Impact Factor (SJIF): 4.14 International Journal of Advance Engineering and Research Development Volume 3, Issue 3, March -2016 e-issn (O): 2348-4470 p-issn (P): 2348-6406 Research
Scientific Journal of Impact Factor (SJIF): 4.14 International Journal of Advance Engineering and Research Development Volume 3, Issue 3, March -2016 e-issn (O): 2348-4470 p-issn (P): 2348-6406 Research
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus
 Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate