Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University
|
|
|
- Debra York
- 6 years ago
- Views:
Transcription


1 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit your own needs. If you make use of a significant portion of these slides in your own lecture, please include this message, or a link to our web site: Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University






2 High dim. data Graph data Infinite data Machine learning Apps Locality sensi-ve hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detec-on Web adver-sing Decision Trees Associa-on Rules Dimensional ity reduc-on Spam Detec-on Queries on streams Perceptron, knn Duplicate document detec-on


3 Customer X Buys Metallica CD Buys Megadeth CD Customer Y Does search on Metallica Recommender system suggests Megadeth from data collected about customer X







4 Examples: Search Recommendations Items Products, web sites, blogs, news items,
5 Shelf space is a scarce commodity for tradi6onal retailers Also: TV networks, movie theaters, Web enables near- zero- cost dissemina6on of informa6on about products From scarcity to abundance More choice necessitates be=er filters Recommenda-on engines How Into Thin Air made Touching the Void a bestseller: hlp://

 6")
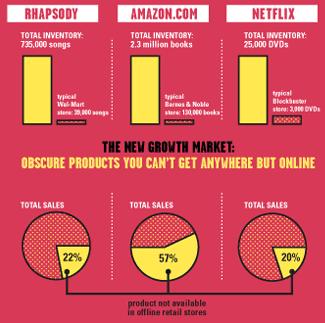
6 Source: Chris Anderson (00) 6


7 Read to learn more! 7
8 Editorial and hand curated List of favorites Lists of essen-al items Simple aggregates Top 0, Most Popular, Recent Uploads Tailored to individual users Amazon, Ne]lix, 8
9 X = set of Customers S = set of Items U6lity func6on u: X S à R R = set of ra-ngs R is a totally ordered set e.g., 0- stars, real number in [0,] 9




10 Avatar LOTR Matrix Pirates Alice 0. Bob Carol 0. David 0. 0


11 () Gathering known ra6ngs for matrix How to collect the data in the u-lity matrix () Extrapolate unknown ra6ngs from the known ones Mainly interested in high unknown ra-ngs We are not interested in knowing what you don t like but what you like () Evalua6ng extrapola6on methods How to measure success/performance of recommenda-on methods
12 Explicit Ask people to rate items Doesn t work well in prac-ce people can t be bothered Implicit Learn ra-ngs from user ac-ons E.g., purchase implies high ra-ng What about low ra-ngs?
13 Key problem: U-lity matrix U is sparse Most people have not rated most items Cold start: New items have no ra-ngs New users have no history Three approaches to recommender systems: ) Content- based ) Collabora-ve ) Latent factor based Today!

14
15 Main idea: Recommend items to customer x similar to previous items rated highly by x Example: Movie recommenda6ons Recommend movies with same actor(s), director, genre, Websites, blogs, news Recommend other sites with similar content
16 Item profiles likes recommend build match Red Circles Triangles User profile 6
17 For each item, create an item profile Profile is a set (vector) of features Movies: author, -tle, actor, director, Text: Set of important words in document How to pick important features? Usual heuris-c from text mining is TF- IDF (Term frequency * Inverse Doc Frequency) Term Feature Document Item 7
18 f ij = frequency of term (feature) i in doc (item) j n i = number of docs that men-on term i N = total number of docs Note: we normalize TF to discount for longer documents TF- IDF score: w ij = TF ij IDF i Doc profile = set of words with highest TF- IDF scores, together with their scores 8
19 User profile possibili6es: Weighted average of rated item profiles Varia6on: weight by difference from average ra-ng for item Predic6on heuris6c: Given user profile x and item profile i, es-mate u(x,i) = cos (x,i) = x i/ x i 9
20 +: No need for data on other users No cold- start or sparsity problems +: Able to recommend to users with unique tastes +: Able to recommend new & unpopular items No first- rater problem +: Able to provide explana6ons Can provide explana-ons of recommended items by lis-ng content- features that caused an item to be recommended 0
21 : Finding the appropriate features is hard E.g., images, movies, music : Recommenda6ons for new users How to build a user profile? : Overspecializa6on Never recommends items outside user s content profile People might have mul-ple interests Unable to exploit quality judgments of other users
22 Harnessing quality judgments of other users


23 Consider user x Find set N of other users whose ra-ngs are similar to x s ra-ngs Es-mate x s ra-ngs based on ra-ngs of users in N x N
24 Let r x be the vector of user x s ra-ngs Jaccard similarity measure Problem: Ignores the value of the ra-ng Cosine similarity measure r x = [*, _, _, *, ***] r y = [*, _, **, **, _] sim(x, y) = cos(r x, r y ) = r x r y / r x r y Problem: Treats missing ra-ngs as nega-ve Pearson correla6on coefficient S xy = items rated by both users x and y r x, r y as sets: r x = {,, } r y = {,, } r x, r y as points: r x = {, 0, 0,, } r y = {, 0,,, 0} sim(x,y)= s S xy ( r xs r x )( r ys r y ) / s S xy ( r xs r x ) r x, r y avg. rating of x, y
25 Cosine sim(x, sim: y) = i r xi r yi Intui6vely we want: sim(a, B) > sim(a, C) Jaccard similarity: / < / Cosine similarity: 0.86 > 0. Considers missing ra-ngs as nega-ve Solu6on: subtract the (row) mean sim A,B vs. A,C: 0.09 > -0.9 Notice cosine sim. is correlation when data is centered at 0
26 From similarity metric to recommenda6ons: Let r x be the vector of user x s ra-ngs Let N be the set of k users most similar to x who have rated item i Predic6on for item s of user x: r xi = /k y N r yi Shorthand: s xy =sim(x,y) r xi = y N s xy r yi / y N s xy Other op-ons? Many other tricks possible 6
27 So far: User- user collabora6ve filtering Another view: Item- item For item i, find other similar items Es-mate ra-ng for item i based on ra-ngs for similar items Can use same similarity metrics and predic-on func-ons as in user- user model r xi = j N ( i; x) s ij j N ( i; x) s r ij xj s ij similarity of items i and j r xj rating of user u on item j N(i;x) set items rated by x similar to i 7
28 users movies - unknown rating - rating between to 8
29 ? 6 users - estimate rating of movie by user 9 movies
30 users? sim(,m) movies Neighbor selection: Identify movies similar to movie, rated by user Here we use Pearson correlation as similarity: ) Subtract mean rating m i from each movie i m = (++++)/ =.6 row : [-.6, 0, -0.6, 0, 0,., 0, 0,., 0, 0., 0] ) Compute cosine similarities between rows 0
31 users? sim(,m) movies Compute similarity weights: s, =0., s,6 =0.9
32 users Predict by taking weighted average: r. = (0.* + 0.9*) / (0.+0.9) =.6 movies r ix = j N(i;x) s ij r
33 Define similarity s ij of items i and j Select k nearest neighbors N(i; x) Before: Items most similar to i, that were rated by x Es-mate ra-ng r xi as the weighted average: r xi = j N ( i; x) s j N ( i; x) ij s r ij xj r xi = b xi + j N ( i; x) s ij ( r j N ( i; x) xj s ij b xj ) baseline estimate for r xi μ = overall mean movie ra-ng b xi =μ+ b x + b i b x = ra-ng devia-on of user x = (avg. ra'ng of user x) μ b i = ra-ng devia-on of movie i



34 Avatar LOTR Matrix Pirates Alice 0.8 Bob Carol David 0. In prac6ce, it has been observed that item- item olen works be=er than user- user Why? Items are simpler, users have mul-ple tastes
35 + Works for any kind of item No feature selec-on needed - Cold Start: Need enough users in the system to find a match - Sparsity: The user/ra-ngs matrix is sparse Hard to find users that have rated the same items - First rater: Cannot recommend an item that has not been previously rated New items, Esoteric items - Popularity bias: Cannot recommend items to someone with unique taste Tends to recommend popular items
36 Implement two or more different recommenders and combine predic6ons Perhaps using a linear model Add content- based methods to collabora6ve filtering Item profiles for new item problem Demographics to deal with new user problem 6
37 - Evalua6on - Error metrics - Complexity / Speed 7
38 movies users 8
39 users movies????? Test Data Set 9
40 Compare predic6ons with known ra6ngs Root- mean- square error (RMSE) xi ( r xi r xi ) where rxi is predicted, r xi is the true ra-ng of x on i Precision at top 0: % of those in top 0 Rank Correla6on: Spearman s correla'on between system s and user s complete rankings Another approach: 0/ model Coverage: Number of items/users for which system can make predic-ons Precision: Accuracy of predic-ons Receiver opera6ng characteris6c (ROC) Tradeoff curve between false posi-ves and false nega-ves 0
41 Narrow focus on accuracy some6mes misses the point Predic-on Diversity Predic-on Context Order of predic-ons In prac6ce, we care only to predict high ra6ngs: RMSE might penalize a method that does well for high ra-ngs and badly for others
42 Expensive step is finding k most similar customers: O( X ) Too expensive to do at run6me Could pre- compute Naïve pre- computa-on takes -me O(k X ) X set of customers We already know how to do this! Near- neighbor search in high dimensions (LSH) Clustering Dimensionality reduc-on

43 Leverage all the data Don t try to reduce data size in an effort to make fancy algorithms work Simple methods on large data do best Add more data e.g., add IMDB data on genres More data beats be=er algorithms
Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University Infinite data. Filtering data streams
 /9/7 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them
/9/7 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them
Thanks to Jure Leskovec, Anand Rajaraman, Jeff Ullman
 Thanks to Jure Leskovec, Anand Rajaraman, Jeff Ullman http://www.mmds.org Overview of Recommender Systems Content-based Systems Collaborative Filtering J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive
Thanks to Jure Leskovec, Anand Rajaraman, Jeff Ullman http://www.mmds.org Overview of Recommender Systems Content-based Systems Collaborative Filtering J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu //8 Jure Leskovec, Stanford CS6: Mining Massive Datasets High dim. data Graph data Infinite data Machine learning
CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu //8 Jure Leskovec, Stanford CS6: Mining Massive Datasets High dim. data Graph data Infinite data Machine learning
Introduction to Data Mining
 Introduction to Data Mining Lecture #7: Recommendation Content based & Collaborative Filtering Seoul National University In This Lecture Understand the motivation and the problem of recommendation Compare
Introduction to Data Mining Lecture #7: Recommendation Content based & Collaborative Filtering Seoul National University In This Lecture Understand the motivation and the problem of recommendation Compare
BBS654 Data Mining. Pinar Duygulu
 BBS6 Data Mining Pinar Duygulu Slides are adapted from J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org Mustafa Ozdal Example: Recommender Systems Customer X Buys Metallica
BBS6 Data Mining Pinar Duygulu Slides are adapted from J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org Mustafa Ozdal Example: Recommender Systems Customer X Buys Metallica
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu Customer X Buys Metalica CD Buys Megadeth CD Customer Y Does search on Metalica Recommender system suggests Megadeth
CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu Customer X Buys Metalica CD Buys Megadeth CD Customer Y Does search on Metalica Recommender system suggests Megadeth
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu /7/0 Jure Leskovec, Stanford CS6: Mining Massive Datasets, http://cs6.stanford.edu High dim. data Graph data Infinite
CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu /7/0 Jure Leskovec, Stanford CS6: Mining Massive Datasets, http://cs6.stanford.edu High dim. data Graph data Infinite
CS 124/LINGUIST 180 From Languages to Information
 CS /LINGUIST 80 From Languages to Information Dan Jurafsky Stanford University Recommender Systems & Collaborative Filtering Slides adapted from Jure Leskovec Recommender Systems Customer X Buys Metallica
CS /LINGUIST 80 From Languages to Information Dan Jurafsky Stanford University Recommender Systems & Collaborative Filtering Slides adapted from Jure Leskovec Recommender Systems Customer X Buys Metallica
CS 5614: (Big) Data Management Systems. B. Aditya Prakash Lecture #16: Recommenda2on Systems
 Data Management Systems. B. Aditya Prakash Lecture #16: Recommenda2on Systems") CS 6: (Big) Data Management Systems B. Aditya Prakash Lecture #6: Recommendaon Systems Example: Recommender Systems Customer X Buys Metallica CD Buys Megadeth CD Customer Y Does search on Metallica Recommender
CS 6: (Big) Data Management Systems B. Aditya Prakash Lecture #6: Recommendaon Systems Example: Recommender Systems Customer X Buys Metallica CD Buys Megadeth CD Customer Y Does search on Metallica Recommender
CS 124/LINGUIST 180 From Languages to Information
 CS /LINGUIST 80 From Languages to Information Dan Jurafsky Stanford University Recommender Systems & Collaborative Filtering Slides adapted from Jure Leskovec Recommender Systems Customer X Buys CD of
CS /LINGUIST 80 From Languages to Information Dan Jurafsky Stanford University Recommender Systems & Collaborative Filtering Slides adapted from Jure Leskovec Recommender Systems Customer X Buys CD of
CS 124/LINGUIST 180 From Languages to Information
 CS /LINGUIST 80 From Languages to Information Dan Jurafsky Stanford University Recommender Systems & Collaborative Filtering Slides adapted from Jure Leskovec Recommender Systems Customer X Buys CD of
CS /LINGUIST 80 From Languages to Information Dan Jurafsky Stanford University Recommender Systems & Collaborative Filtering Slides adapted from Jure Leskovec Recommender Systems Customer X Buys CD of
Recommendation and Advertising. Shannon Quinn (with thanks to J. Leskovec, A. Rajaraman, and J. Ullman of Stanford University)
") Recommendation and Advertising Shannon Quinn (with thanks to J. Leskovec, A. Rajaraman, and J. Ullman of Stanford University) Lecture breakdown Part : Advertising Bipartite Matching AdWords Part : Recommendation
Recommendation and Advertising Shannon Quinn (with thanks to J. Leskovec, A. Rajaraman, and J. Ullman of Stanford University) Lecture breakdown Part : Advertising Bipartite Matching AdWords Part : Recommendation
Instructor: Dr. Mehmet Aktaş. Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University
 Instructor: Dr. Mehmet Aktaş Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
Instructor: Dr. Mehmet Aktaş Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
Recommender Systems Collabora2ve Filtering and Matrix Factoriza2on
 Recommender Systems Collaborave Filtering and Matrix Factorizaon Narges Razavian Thanks to lecture slides from Alex Smola@CMU Yahuda Koren@Yahoo labs and Bing Liu@UIC We Know What You Ought To Be Watching
Recommender Systems Collaborave Filtering and Matrix Factorizaon Narges Razavian Thanks to lecture slides from Alex Smola@CMU Yahuda Koren@Yahoo labs and Bing Liu@UIC We Know What You Ought To Be Watching
Recommender Systems - Content, Collaborative, Hybrid
 BOBBY B. LYLE SCHOOL OF ENGINEERING Department of Engineering Management, Information and Systems EMIS 8331 Advanced Data Mining Recommender Systems - Content, Collaborative, Hybrid Scott F Eisenhart 1
BOBBY B. LYLE SCHOOL OF ENGINEERING Department of Engineering Management, Information and Systems EMIS 8331 Advanced Data Mining Recommender Systems - Content, Collaborative, Hybrid Scott F Eisenhart 1
Recommender Systems 6CCS3WSN-7CCSMWAL
 Recommender Systems 6CCS3WSN-7CCSMWAL http://insidebigdata.com/wp-content/uploads/2014/06/humorrecommender.jpg Some basic methods of recommendation Recommend popular items Collaborative Filtering Item-to-Item:
Recommender Systems 6CCS3WSN-7CCSMWAL http://insidebigdata.com/wp-content/uploads/2014/06/humorrecommender.jpg Some basic methods of recommendation Recommend popular items Collaborative Filtering Item-to-Item:
Recommender Systems. Collaborative Filtering & Content-Based Recommending
 Recommender Systems Collaborative Filtering & Content-Based Recommending 1 Recommender Systems Systems for recommending items (e.g. books, movies, CD s, web pages, newsgroup messages) to users based on
Recommender Systems Collaborative Filtering & Content-Based Recommending 1 Recommender Systems Systems for recommending items (e.g. books, movies, CD s, web pages, newsgroup messages) to users based on
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/24/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 High dim. data
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/24/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 High dim. data
CS 345A Data Mining Lecture 1. Introduction to Web Mining
 CS 345A Data Mining Lecture 1 Introduction to Web Mining What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns Web Mining v. Data Mining Structure (or lack of
CS 345A Data Mining Lecture 1 Introduction to Web Mining What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns Web Mining v. Data Mining Structure (or lack of
Real-time Recommendations on Spark. Jan Neumann, Sridhar Alla (Comcast Labs) DC Spark Interactive Meetup East May
 DC Spark Interactive Meetup East May") Real-time Recommendations on Spark Jan Neumann, Sridhar Alla (Comcast Labs) DC Spark Interactive Meetup East May 19 2015 Who am I? Jan Neumann, Lead of Big Data and Content Analysis Research Teams This
Real-time Recommendations on Spark Jan Neumann, Sridhar Alla (Comcast Labs) DC Spark Interactive Meetup East May 19 2015 Who am I? Jan Neumann, Lead of Big Data and Content Analysis Research Teams This
COMP 465: Data Mining Recommender Systems
 //0 movies COMP 6: Data Mining Recommender Systems Slides Adapted From: www.mmds.org (Mining Massive Datasets) movies Compare predictions with known ratings (test set T)????? Test Data Set Root-mean-square
//0 movies COMP 6: Data Mining Recommender Systems Slides Adapted From: www.mmds.org (Mining Massive Datasets) movies Compare predictions with known ratings (test set T)????? Test Data Set Root-mean-square
Recommendation Systems
 Recommendation Systems CS 534: Machine Learning Slides adapted from Alex Smola, Jure Leskovec, Anand Rajaraman, Jeff Ullman, Lester Mackey, Dietmar Jannach, and Gerhard Friedrich Recommender Systems (RecSys)
Recommendation Systems CS 534: Machine Learning Slides adapted from Alex Smola, Jure Leskovec, Anand Rajaraman, Jeff Ullman, Lester Mackey, Dietmar Jannach, and Gerhard Friedrich Recommender Systems (RecSys)
Data Mining Lecture 2: Recommender Systems
 Data Mining Lecture 2: Recommender Systems Jo Houghton ECS Southampton February 19, 2019 1 / 32 Recommender Systems - Introduction Making recommendations: Big Money 35% of Amazons income from recommendations
Data Mining Lecture 2: Recommender Systems Jo Houghton ECS Southampton February 19, 2019 1 / 32 Recommender Systems - Introduction Making recommendations: Big Money 35% of Amazons income from recommendations
Recommender Systems - Introduction. Data Mining Lecture 2: Recommender Systems
 Recommender Systems - Introduction Making recommendations: Big Money 35% of amazons income from recommendations Netflix recommendation engine worth $ Billion per year And yet, Amazon seems to be able to
Recommender Systems - Introduction Making recommendations: Big Money 35% of amazons income from recommendations Netflix recommendation engine worth $ Billion per year And yet, Amazon seems to be able to
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 3/12/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 3/12/2014 Jure
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 3/12/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 3/12/2014 Jure
Introduction to Data Mining
 Introduction to Data Mining Lecture #1: Course Introduction U Kang Seoul National University U Kang 1 In This Lecture Motivation to study data mining Administrative information for this course U Kang 2
Introduction to Data Mining Lecture #1: Course Introduction U Kang Seoul National University U Kang 1 In This Lecture Motivation to study data mining Administrative information for this course U Kang 2
Knowledge Discovery and Data Mining 1 (VO) ( )
 ( )") Knowledge Discovery and Data Mining 1 (VO) (707.003) Data Matrices and Vector Space Model Denis Helic KTI, TU Graz Nov 6, 2014 Denis Helic (KTI, TU Graz) KDDM1 Nov 6, 2014 1 / 55 Big picture: KDDM Probability
Knowledge Discovery and Data Mining 1 (VO) (707.003) Data Matrices and Vector Space Model Denis Helic KTI, TU Graz Nov 6, 2014 Denis Helic (KTI, TU Graz) KDDM1 Nov 6, 2014 1 / 55 Big picture: KDDM Probability
COMP6237 Data Mining Making Recommendations. Jonathon Hare
 COMP6237 Data Mining Making Recommendations Jonathon Hare jsh2@ecs.soton.ac.uk Introduction Recommender systems 101 Taxonomy of recommender systems Collaborative Filtering Collecting user preferences as
COMP6237 Data Mining Making Recommendations Jonathon Hare jsh2@ecs.soton.ac.uk Introduction Recommender systems 101 Taxonomy of recommender systems Collaborative Filtering Collecting user preferences as
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu /2/8 Jure Leskovec, Stanford CS246: Mining Massive Datasets 2 Task: Given a large number (N in the millions or
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu /2/8 Jure Leskovec, Stanford CS246: Mining Massive Datasets 2 Task: Given a large number (N in the millions or
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu Training data 00 million ratings, 80,000 users, 7,770 movies 6 years of data: 000 00 Test data Last few ratings of
CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu Training data 00 million ratings, 80,000 users, 7,770 movies 6 years of data: 000 00 Test data Last few ratings of
Agenda. Collabora-ve Filtering (CF)
") - 1 - Agenda Collabora-ve Filtering (CF) Pure CF approaches User-based nearest-neighbor The Pearson Correla9on similarity measure Memory-based and model-based approaches Item-based nearest-neighbor The
- 1 - Agenda Collabora-ve Filtering (CF) Pure CF approaches User-based nearest-neighbor The Pearson Correla9on similarity measure Memory-based and model-based approaches Item-based nearest-neighbor The
Part 12: Advanced Topics in Collaborative Filtering. Francesco Ricci
 Part 12: Advanced Topics in Collaborative Filtering Francesco Ricci Content Generating recommendations in CF using frequency of ratings Role of neighborhood size Comparison of CF with association rules
Part 12: Advanced Topics in Collaborative Filtering Francesco Ricci Content Generating recommendations in CF using frequency of ratings Role of neighborhood size Comparison of CF with association rules
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS46: Mining Massive Datasets Jure Leskovec, Stanford University http://cs46.stanford.edu /7/ Jure Leskovec, Stanford C46: Mining Massive Datasets Many real-world problems Web Search and Text Mining Billions
CS46: Mining Massive Datasets Jure Leskovec, Stanford University http://cs46.stanford.edu /7/ Jure Leskovec, Stanford C46: Mining Massive Datasets Many real-world problems Web Search and Text Mining Billions
3 announcements: Thanks for filling out the HW1 poll HW2 is due today 5pm (scans must be readable) HW3 will be posted today
 HW3 will be posted today") 3 announcements: Thanks for filling out the HW1 poll HW2 is due today 5pm (scans must be readable) HW3 will be posted today CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu
3 announcements: Thanks for filling out the HW1 poll HW2 is due today 5pm (scans must be readable) HW3 will be posted today CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu
High dim. data. Graph data. Infinite data. Machine learning. Apps. Locality sensitive hashing. Filtering data streams.
 http://www.mmds.org High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Network Analysis
http://www.mmds.org High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Network Analysis
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
Recommender System. What is it? How to build it? Challenges. R package: recommenderlab
 Recommender System What is it? How to build it? Challenges R package: recommenderlab 1 What is a recommender system Wiki definition: A recommender system or a recommendation system (sometimes replacing
Recommender System What is it? How to build it? Challenges R package: recommenderlab 1 What is a recommender system Wiki definition: A recommender system or a recommendation system (sometimes replacing
Using Social Networks to Improve Movie Rating Predictions
 Introduction Using Social Networks to Improve Movie Rating Predictions Suhaas Prasad Recommender systems based on collaborative filtering techniques have become a large area of interest ever since the
Introduction Using Social Networks to Improve Movie Rating Predictions Suhaas Prasad Recommender systems based on collaborative filtering techniques have become a large area of interest ever since the
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Queries on streams
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Queries on streams
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Text classification II CE-324: Modern Information Retrieval Sharif University of Technology
 Text classification II CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2015 Some slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Text classification II CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2015 Some slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Towards a hybrid approach to Netflix Challenge
 Towards a hybrid approach to Netflix Challenge Abhishek Gupta, Abhijeet Mohapatra, Tejaswi Tenneti March 12, 2009 1 Introduction Today Recommendation systems [3] have become indispensible because of the
Towards a hybrid approach to Netflix Challenge Abhishek Gupta, Abhijeet Mohapatra, Tejaswi Tenneti March 12, 2009 1 Introduction Today Recommendation systems [3] have become indispensible because of the
Recommender Systems. Techniques of AI
 Recommender Systems Techniques of AI Recommender Systems User ratings Collect user preferences (scores, likes, purchases, views...) Find similarities between items and/or users Predict user scores for
Recommender Systems Techniques of AI Recommender Systems User ratings Collect user preferences (scores, likes, purchases, views...) Find similarities between items and/or users Predict user scores for
Use of KNN for the Netflix Prize Ted Hong, Dimitris Tsamis Stanford University
 Use of KNN for the Netflix Prize Ted Hong, Dimitris Tsamis Stanford University {tedhong, dtsamis}@stanford.edu Abstract This paper analyzes the performance of various KNNs techniques as applied to the
Use of KNN for the Netflix Prize Ted Hong, Dimitris Tsamis Stanford University {tedhong, dtsamis}@stanford.edu Abstract This paper analyzes the performance of various KNNs techniques as applied to the
Part 11: Collaborative Filtering. Francesco Ricci
 Part : Collaborative Filtering Francesco Ricci Content An example of a Collaborative Filtering system: MovieLens The collaborative filtering method n Similarity of users n Methods for building the rating
Part : Collaborative Filtering Francesco Ricci Content An example of a Collaborative Filtering system: MovieLens The collaborative filtering method n Similarity of users n Methods for building the rating
Mining Social Network Graphs
 Mining Social Network Graphs Analysis of Large Graphs: Community Detection Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com Note to other teachers and users of these slides: We would be
Mining Social Network Graphs Analysis of Large Graphs: Community Detection Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com Note to other teachers and users of these slides: We would be
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu //8 Jure Leskovec, Stanford CS6: Mining Massive Datasets Training data 00 million ratings, 80,000 users, 7,770 movies
CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu //8 Jure Leskovec, Stanford CS6: Mining Massive Datasets Training data 00 million ratings, 80,000 users, 7,770 movies
CS 229 Final Project - Using machine learning to enhance a collaborative filtering recommendation system for Yelp
 CS 229 Final Project - Using machine learning to enhance a collaborative filtering recommendation system for Yelp Chris Guthrie Abstract In this paper I present my investigation of machine learning as
CS 229 Final Project - Using machine learning to enhance a collaborative filtering recommendation system for Yelp Chris Guthrie Abstract In this paper I present my investigation of machine learning as
CS249: ADVANCED DATA MINING
 CS249: ADVANCED DATA MINING Recommender Systems II Instructor: Yizhou Sun yzsun@cs.ucla.edu May 31, 2017 Recommender Systems Recommendation via Information Network Analysis Hybrid Collaborative Filtering
CS249: ADVANCED DATA MINING Recommender Systems II Instructor: Yizhou Sun yzsun@cs.ucla.edu May 31, 2017 Recommender Systems Recommendation via Information Network Analysis Hybrid Collaborative Filtering
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
CSE 5243 INTRO. TO DATA MINING
 CSE 53 INTRO. TO DATA MINING Locality Sensitive Hashing (LSH) Huan Sun, CSE@The Ohio State University Slides adapted from Prof. Jiawei Han @UIUC, Prof. Srinivasan Parthasarathy @OSU MMDS Secs. 3.-3.. Slides
CSE 53 INTRO. TO DATA MINING Locality Sensitive Hashing (LSH) Huan Sun, CSE@The Ohio State University Slides adapted from Prof. Jiawei Han @UIUC, Prof. Srinivasan Parthasarathy @OSU MMDS Secs. 3.-3.. Slides
Data Mining Techniques
 Data Mining Techniques CS 6 - Section - Spring 7 Lecture Jan-Willem van de Meent (credit: Andrew Ng, Alex Smola, Yehuda Koren, Stanford CS6) Project Project Deadlines Feb: Form teams of - people 7 Feb:
Data Mining Techniques CS 6 - Section - Spring 7 Lecture Jan-Willem van de Meent (credit: Andrew Ng, Alex Smola, Yehuda Koren, Stanford CS6) Project Project Deadlines Feb: Form teams of - people 7 Feb:
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu /6/01 Jure Leskovec, Stanford C6: Mining Massive Datasets Training data 100 million ratings, 80,000 users, 17,770
CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu /6/01 Jure Leskovec, Stanford C6: Mining Massive Datasets Training data 100 million ratings, 80,000 users, 17,770
CS246: Mining Massive Datasets Jure Leskovec, Stanford University.
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 3/9/20 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 Overlaps with machine learning, statistics, artificial
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 3/9/20 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 Overlaps with machine learning, statistics, artificial
Machine Learning using MapReduce
 Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Data Mining Techniques
 Data Mining Techniques CS 60 - Section - Fall 06 Lecture Jan-Willem van de Meent (credit: Andrew Ng, Alex Smola, Yehuda Koren, Stanford CS6) Recommender Systems The Long Tail (from: https://www.wired.com/00/0/tail/)
Data Mining Techniques CS 60 - Section - Fall 06 Lecture Jan-Willem van de Meent (credit: Andrew Ng, Alex Smola, Yehuda Koren, Stanford CS6) Recommender Systems The Long Tail (from: https://www.wired.com/00/0/tail/)
CS224W Project: Recommendation System Models in Product Rating Predictions
 CS224W Project: Recommendation System Models in Product Rating Predictions Xiaoye Liu xiaoye@stanford.edu Abstract A product recommender system based on product-review information and metadata history
CS224W Project: Recommendation System Models in Product Rating Predictions Xiaoye Liu xiaoye@stanford.edu Abstract A product recommender system based on product-review information and metadata history
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/6/2013 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 High dim. data Graph data Infinite data Machine
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/6/2013 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 High dim. data Graph data Infinite data Machine
Jeff Howbert Introduction to Machine Learning Winter
 Collaborative Filtering Nearest es Neighbor Approach Jeff Howbert Introduction to Machine Learning Winter 2012 1 Bad news Netflix Prize data no longer available to public. Just after contest t ended d
Collaborative Filtering Nearest es Neighbor Approach Jeff Howbert Introduction to Machine Learning Winter 2012 1 Bad news Netflix Prize data no longer available to public. Just after contest t ended d
DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li
 Welcome to DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li Time: 6:00pm 8:50pm Thu Location: AK 232 Fall 2016 High Dimensional Data v Given a cloud of data points we want to understand
Welcome to DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li Time: 6:00pm 8:50pm Thu Location: AK 232 Fall 2016 High Dimensional Data v Given a cloud of data points we want to understand
Predicting User Ratings Using Status Models on Amazon.com
 Predicting User Ratings Using Status Models on Amazon.com Borui Wang Stanford University borui@stanford.edu Guan (Bell) Wang Stanford University guanw@stanford.edu Group 19 Zhemin Li Stanford University
Predicting User Ratings Using Status Models on Amazon.com Borui Wang Stanford University borui@stanford.edu Guan (Bell) Wang Stanford University guanw@stanford.edu Group 19 Zhemin Li Stanford University
CSE 258 Lecture 8. Web Mining and Recommender Systems. Extensions of latent-factor models, (and more on the Netflix prize)
") CSE 258 Lecture 8 Web Mining and Recommender Systems Extensions of latent-factor models, (and more on the Netflix prize) Summary so far Recap 1. Measuring similarity between users/items for binary prediction
CSE 258 Lecture 8 Web Mining and Recommender Systems Extensions of latent-factor models, (and more on the Netflix prize) Summary so far Recap 1. Measuring similarity between users/items for binary prediction
Feature Extractors. CS 188: Artificial Intelligence Fall Some (Vague) Biology. The Binary Perceptron. Binary Decision Rule.
 Biology. The Binary Perceptron. Binary Decision Rule.") CS 188: Artificial Intelligence Fall 2008 Lecture 24: Perceptrons II 11/24/2008 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit
CS 188: Artificial Intelligence Fall 2008 Lecture 24: Perceptrons II 11/24/2008 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit
Near Neighbor Search in High Dimensional Data (1) Dr. Anwar Alhenshiri
 Dr. Anwar Alhenshiri") Near Neighbor Search in High Dimensional Data (1) Dr. Anwar Alhenshiri Scene Completion Problem The Bare Data Approach High Dimensional Data Many real-world problems Web Search and Text Mining Billions
Near Neighbor Search in High Dimensional Data (1) Dr. Anwar Alhenshiri Scene Completion Problem The Bare Data Approach High Dimensional Data Many real-world problems Web Search and Text Mining Billions
Recommendation Algorithms: Collaborative Filtering. CSE 6111 Presentation Advanced Algorithms Fall Presented by: Farzana Yasmeen
 Recommendation Algorithms: Collaborative Filtering CSE 6111 Presentation Advanced Algorithms Fall. 2013 Presented by: Farzana Yasmeen 2013.11.29 Contents What are recommendation algorithms? Recommendations
Recommendation Algorithms: Collaborative Filtering CSE 6111 Presentation Advanced Algorithms Fall. 2013 Presented by: Farzana Yasmeen 2013.11.29 Contents What are recommendation algorithms? Recommendations
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu [Kumar et al. 99] 2/13/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu [Kumar et al. 99] 2/13/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu
Performance Comparison of Algorithms for Movie Rating Estimation
 Performance Comparison of Algorithms for Movie Rating Estimation Alper Köse, Can Kanbak, Noyan Evirgen Research Laboratory of Electronics, Massachusetts Institute of Technology Department of Electrical
Performance Comparison of Algorithms for Movie Rating Estimation Alper Köse, Can Kanbak, Noyan Evirgen Research Laboratory of Electronics, Massachusetts Institute of Technology Department of Electrical
Web Personalization & Recommender Systems
 Web Personalization & Recommender Systems COSC 488 Slides are based on: - Bamshad Mobasher, Depaul University - Recent publications: see the last page (Reference section) Web Personalization & Recommender
Web Personalization & Recommender Systems COSC 488 Slides are based on: - Bamshad Mobasher, Depaul University - Recent publications: see the last page (Reference section) Web Personalization & Recommender
arxiv: v4 [cs.ir] 28 Jul 2016
![arxiv: v4 [cs.ir] 28 Jul 2016](/thumbs/77/76321758.jpg "arxiv: v4 [cs.ir] 28 Jul 2016") Review-Based Rating Prediction arxiv:1607.00024v4 [cs.ir] 28 Jul 2016 Tal Hadad Dept. of Information Systems Engineering, Ben-Gurion University E-mail: tah@post.bgu.ac.il Abstract Recommendation systems
Review-Based Rating Prediction arxiv:1607.00024v4 [cs.ir] 28 Jul 2016 Tal Hadad Dept. of Information Systems Engineering, Ben-Gurion University E-mail: tah@post.bgu.ac.il Abstract Recommendation systems
Web Personalization & Recommender Systems
 Web Personalization & Recommender Systems COSC 488 Slides are based on: - Bamshad Mobasher, Depaul University - Recent publications: see the last page (Reference section) Web Personalization & Recommender
Web Personalization & Recommender Systems COSC 488 Slides are based on: - Bamshad Mobasher, Depaul University - Recent publications: see the last page (Reference section) Web Personalization & Recommender
Collaborative Filtering using Weighted BiPartite Graph Projection A Recommendation System for Yelp
 Collaborative Filtering using Weighted BiPartite Graph Projection A Recommendation System for Yelp Sumedh Sawant sumedh@stanford.edu Team 38 December 10, 2013 Abstract We implement a personal recommendation
Collaborative Filtering using Weighted BiPartite Graph Projection A Recommendation System for Yelp Sumedh Sawant sumedh@stanford.edu Team 38 December 10, 2013 Abstract We implement a personal recommendation
CSE 158 Lecture 8. Web Mining and Recommender Systems. Extensions of latent-factor models, (and more on the Netflix prize)
") CSE 158 Lecture 8 Web Mining and Recommender Systems Extensions of latent-factor models, (and more on the Netflix prize) Summary so far Recap 1. Measuring similarity between users/items for binary prediction
CSE 158 Lecture 8 Web Mining and Recommender Systems Extensions of latent-factor models, (and more on the Netflix prize) Summary so far Recap 1. Measuring similarity between users/items for binary prediction
Part 11: Collaborative Filtering. Francesco Ricci
 Part : Collaborative Filtering Francesco Ricci Content An example of a Collaborative Filtering system: MovieLens The collaborative filtering method n Similarity of users n Methods for building the rating
Part : Collaborative Filtering Francesco Ricci Content An example of a Collaborative Filtering system: MovieLens The collaborative filtering method n Similarity of users n Methods for building the rating
Distributed Itembased Collaborative Filtering with Apache Mahout. Sebastian Schelter twitter.com/sscdotopen. 7.
 Distributed Itembased Collaborative Filtering with Apache Mahout Sebastian Schelter ssc@apache.org twitter.com/sscdotopen 7. October 2010 Overview 1. What is Apache Mahout? 2. Introduction to Collaborative
Distributed Itembased Collaborative Filtering with Apache Mahout Sebastian Schelter ssc@apache.org twitter.com/sscdotopen 7. October 2010 Overview 1. What is Apache Mahout? 2. Introduction to Collaborative
Problem 1: Complexity of Update Rules for Logistic Regression
 Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox January 16 th, 2014 1
Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox January 16 th, 2014 1
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/25/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 3 In many data mining
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/25/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 3 In many data mining
Matrix-Vector Multiplication by MapReduce. From Rajaraman / Ullman- Ch.2 Part 1
 Matrix-Vector Multiplication by MapReduce From Rajaraman / Ullman- Ch.2 Part 1 Google implementation of MapReduce created to execute very large matrix-vector multiplications When ranking of Web pages that
Matrix-Vector Multiplication by MapReduce From Rajaraman / Ullman- Ch.2 Part 1 Google implementation of MapReduce created to execute very large matrix-vector multiplications When ranking of Web pages that
CSE 158. Web Mining and Recommender Systems. Midterm recap
 CSE 158 Web Mining and Recommender Systems Midterm recap Midterm on Wednesday! 5:10 pm 6:10 pm Closed book but I ll provide a similar level of basic info as in the last page of previous midterms CSE 158
CSE 158 Web Mining and Recommender Systems Midterm recap Midterm on Wednesday! 5:10 pm 6:10 pm Closed book but I ll provide a similar level of basic info as in the last page of previous midterms CSE 158
The influence of social filtering in recommender systems
 The influence of social filtering in recommender systems 1 Introduction Nick Dekkers 3693406 Recommender systems have become more and more intertwined in our everyday usage of the web. Think about the
The influence of social filtering in recommender systems 1 Introduction Nick Dekkers 3693406 Recommender systems have become more and more intertwined in our everyday usage of the web. Think about the
General Instructions. Questions
 CS246: Mining Massive Data Sets Winter 2018 Problem Set 2 Due 11:59pm February 8, 2018 Only one late period is allowed for this homework (11:59pm 2/13). General Instructions Submission instructions: These
CS246: Mining Massive Data Sets Winter 2018 Problem Set 2 Due 11:59pm February 8, 2018 Only one late period is allowed for this homework (11:59pm 2/13). General Instructions Submission instructions: These
COSC160: Detection and Classification. Jeremy Bolton, PhD Assistant Teaching Professor
 COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality
COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 We need your help with our research on human interpretable machine learning. Please complete a survey at http://stanford.io/1wpokco. It should be fun and take about 1min to complete. Thanks a lot for your
We need your help with our research on human interpretable machine learning. Please complete a survey at http://stanford.io/1wpokco. It should be fun and take about 1min to complete. Thanks a lot for your
International Journal of Advance Engineering and Research Development. A Facebook Profile Based TV Shows and Movies Recommendation System
 Scientific Journal of Impact Factor (SJIF): 4.72 International Journal of Advance Engineering and Research Development Volume 4, Issue 3, March -2017 A Facebook Profile Based TV Shows and Movies Recommendation
Scientific Journal of Impact Factor (SJIF): 4.72 International Journal of Advance Engineering and Research Development Volume 4, Issue 3, March -2017 A Facebook Profile Based TV Shows and Movies Recommendation
CS 5614: (Big) Data Management Systems. B. Aditya Prakash Lecture #19: Machine Learning 1
 Data Management Systems. B. Aditya Prakash Lecture #19: Machine Learning 1") CS 5614: (Big) Data Management Systems B. Aditya Prakash Lecture #19: Machine Learning 1 Supervised Learning Would like to do predicbon: esbmate a func3on f(x) so that y = f(x) Where y can be: Real number:
CS 5614: (Big) Data Management Systems B. Aditya Prakash Lecture #19: Machine Learning 1 Supervised Learning Would like to do predicbon: esbmate a func3on f(x) so that y = f(x) Where y can be: Real number:
Feature Extractors. CS 188: Artificial Intelligence Fall Nearest-Neighbor Classification. The Perceptron Update Rule.
 CS 188: Artificial Intelligence Fall 2007 Lecture 26: Kernels 11/29/2007 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit your
CS 188: Artificial Intelligence Fall 2007 Lecture 26: Kernels 11/29/2007 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit your
Machine Learning and Data Mining. Collaborative Filtering & Recommender Systems. Kalev Kask
 Machine Learning and Data Mining Collaborative Filtering & Recommender Systems Kalev Kask Recommender systems Automated recommendations Inputs User information Situation context, demographics, preferences,
Machine Learning and Data Mining Collaborative Filtering & Recommender Systems Kalev Kask Recommender systems Automated recommendations Inputs User information Situation context, demographics, preferences,
Announcements. CS 188: Artificial Intelligence Spring Classification: Feature Vectors. Classification: Weights. Learning: Binary Perceptron
 CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/20/2010 Announcements W7 due Thursday [that s your last written for the semester!] Project 5 out Thursday Contest running
CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/20/2010 Announcements W7 due Thursday [that s your last written for the semester!] Project 5 out Thursday Contest running
A probabilistic model to resolve diversity-accuracy challenge of recommendation systems
 A probabilistic model to resolve diversity-accuracy challenge of recommendation systems AMIN JAVARI MAHDI JALILI 1 Received: 17 Mar 2013 / Revised: 19 May 2014 / Accepted: 30 Jun 2014 Recommendation systems
A probabilistic model to resolve diversity-accuracy challenge of recommendation systems AMIN JAVARI MAHDI JALILI 1 Received: 17 Mar 2013 / Revised: 19 May 2014 / Accepted: 30 Jun 2014 Recommendation systems
CS425: Algorithms for Web Scale Data
 CS425: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS425. The original slides can be accessed at: www.mmds.org J.
CS425: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS425. The original slides can be accessed at: www.mmds.org J.
Text Analytics (Text Mining)
") CSE 6242 / CX 4242 Apr 1, 2014 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer,
CSE 6242 / CX 4242 Apr 1, 2014 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer,
CPSC 340: Machine Learning and Data Mining. Recommender Systems Fall 2017
 CPSC 340: Machine Learning and Data Mining Recommender Systems Fall 2017 Assignment 4: Admin Due tonight, 1 late day for Monday, 2 late days for Wednesday. Assignment 5: Posted, due Monday of last week
CPSC 340: Machine Learning and Data Mining Recommender Systems Fall 2017 Assignment 4: Admin Due tonight, 1 late day for Monday, 2 late days for Wednesday. Assignment 5: Posted, due Monday of last week
Classification: Feature Vectors
 Classification: Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free YOUR_NAME MISSPELLED FROM_FRIEND... : : : : 2 0 2 0 PIXEL 7,12
Classification: Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free YOUR_NAME MISSPELLED FROM_FRIEND... : : : : 2 0 2 0 PIXEL 7,12
Text Analytics (Text Mining)
") CSE 6242 / CX 4242 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko,
CSE 6242 / CX 4242 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko,
Collaborative Filtering using Euclidean Distance in Recommendation Engine
 Indian Journal of Science and Technology, Vol 9(37), DOI: 10.17485/ijst/2016/v9i37/102074, October 2016 ISSN (Print) : 0974-6846 ISSN (Online) : 0974-5645 Collaborative Filtering using Euclidean Distance
Indian Journal of Science and Technology, Vol 9(37), DOI: 10.17485/ijst/2016/v9i37/102074, October 2016 ISSN (Print) : 0974-6846 ISSN (Online) : 0974-5645 Collaborative Filtering using Euclidean Distance
CPSC 340: Machine Learning and Data Mining. Non-Parametric Models Fall 2016
 CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Assignment 0: Admin 1 late day to hand it in tonight, 2 late days for Wednesday. Assignment 1 is out: Due Friday of next week.
CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Assignment 0: Admin 1 late day to hand it in tonight, 2 late days for Wednesday. Assignment 1 is out: Due Friday of next week.
Analysis of Large Graphs: TrustRank and WebSpam
 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Slides based on those in:
 Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org A 3.3 B 38.4 C 34.3 D 3.9 E 8.1 F 3.9 1.6 1.6 1.6 1.6 1.6 2 y 0.8 ½+0.2 ⅓ M 1/2 1/2 0 0.8 1/2 0 0 + 0.2 0 1/2 1 [1/N]
Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org A 3.3 B 38.4 C 34.3 D 3.9 E 8.1 F 3.9 1.6 1.6 1.6 1.6 1.6 2 y 0.8 ½+0.2 ⅓ M 1/2 1/2 0 0.8 1/2 0 0 + 0.2 0 1/2 1 [1/N]
SOCIAL MEDIA MINING. Data Mining Essentials
 SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
Nearest Neighbor with KD Trees
 Case Study 2: Document Retrieval Finding Similar Documents Using Nearest Neighbors Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Emily Fox January 22 nd, 2013 1 Nearest
Case Study 2: Document Retrieval Finding Similar Documents Using Nearest Neighbors Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Emily Fox January 22 nd, 2013 1 Nearest