FatMan vs. LittleBoy: Scaling up Linear Algebraic Operations in Scale-out Data Platforms
|
|
|
- Dominic Allen
- 6 years ago
- Views:
Transcription


 Sreenivas R.")
1 FatMan vs. LittleBoy: Scaling up Linear Algebraic Operations in Scale-out Data Platforms Luna Xu (Virginia Tech) Seung-Hwan Lim (ORNL) Ali R. Butt (Virginia Tech) Sreenivas R. Sukumar (ORNL) Ramakrishnan Kannan (ORNL) 5/5/2015


2 HPC is used to enable scientific discovery Scientific Simulation/Observation Data Analysis Scientific Discovery 2
 PMC. Web.")
3 Increasing role of data in HPC Source: Stephens, Zachary D. et al. Big Data: Astronomical or Genomical? PLoS Biology 13.7 (2015) PMC. Web. 3 Nov
4 Efficient big data processing à Faster HPC Scale of data to be analyzed is growing exponentially Observation: Data analysis in HPC is similar to data analysis in big data community Big data scale-out platforms can benefit data-based scientific discovery 4




5 Scale-out data processing is becoming popular 5


6 Problem: Unable to leverage accelerators GPU GPU GPU GPU GPU GPU GPU 6
7 Per node performance does not scale 7 Sources: Nvidia
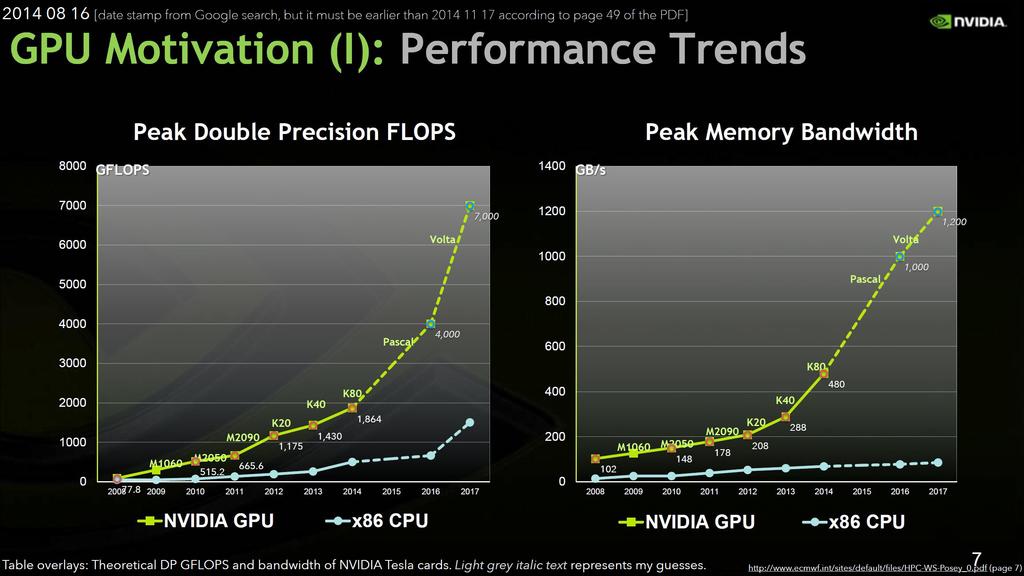
8 Per node performance does not scale 8 Sources: Nvidia

9 Our contribution: Scaling up linear algebra in scale-out data platforms Introduce the support for distributed dense matrix manipulations in Spark for scale-out matrix operations Adopt scale-up hardware acceleration for BLAS-3 operations of distributed matrices Design a flexible controller to decide when and whether to use hardware accelerators based on the density of matrices 9
10 Agenda Introduction Background Design Evaluation Conclusion 10
11 Distributed matrix support in Spark Input file Row Indexed Row Coordinate Block RDD 11 Sparse
12 Distributed matrix support in Spark Input file Row Indexed Row Coordinate Dependency between internal components in MLlib treats all matrices as sparse matrix regardless of density Block RDD 12 Sparse
13 Distributed matrix support in Spark Input file Row Indexed Row Coordinate X Block RDD Ad-hoc Scala Impl 13 Sparse
14 Distributed matrix support in Spark Input file Row Indexed Row Coordinate Ad-hoc implementation of sparse matrix multiplication prevents use of hardware acceleration X Block RDD Ad-hoc Scala Impl 14 Sparse

15 Agenda Introduction Background Design Evaluation Conclusion 15
16 Design considerations Enable user transparency Support scalable matrix multiplication Support dense and sparse matrices 16


17 System architecture matrix multiplication MLlib selector Spark cluster Scala Impl BLAS enabler JVM native netlib-java (JNI) Open BLAS NV BLAS worker CPU cublas xt GPU GPU GPU 17
18 Agenda Introduction Background Design Evaluation Conclusion 18
 Data analysis (all-pair")
19 Methodology Gramian matrix computation with GEMM XX T Machine learning (PCA, SVD) Data analysis (all-pair similarity) 19
20 Methodology Gramian matrix computation with GEMM XX T # of Rows (Cols) Density Raw size (GB) Machine learning (PCA, SVD) Data analysis (all-pair similarity)
21 Methodology System spec: System Rhea GPU node CPU Dual Intel Xeon E5 CPU cores 28 (56 HT) Memory 1TB GPU Dual NVIDIA K80 GPUcores 4992 x 2 GPU memory 24 x 2 GB CUDA 7.5 Spark configuration: Version: node cluster One executor per node (56 cores, 800GB) BLAS configuration OpenBLAS v (hand compile) NVBLAS v7.5 21
22 Overall performance: Dense OpenBLAS NVBLAS Speedup x x size baseline 22
23 Performance: Dense Time percentage (%) GC Shuffle Compute Others 85.2% size 23
24 Performance: Dense Time percentage (%) GC Shuffle Compute Others 92.9% 96.1% size 24
25 Overall performance: Sparse OpenBLAS NVBLAS % baseline Speedup size 25
26 Overall performance: Sparse OpenBLAS NVBLAS baseline Speedup size 36.7% 26
27 Performance: Sparse Time percentage (%) GC Shuffle Compute Others 22% 85.1% size 27
28 28 Conclusion We employ scale-up accelerations for linear algebraic operations in Spark Our approach decides whether to use hardware accelerations based on matrix density The system improves overall performance up to more than 2x compared to default Spark Contact: Luna Xu, DSSL:
Block Lanczos-Montgomery Method over Large Prime Fields with GPU Accelerated Dense Operations
 Block Lanczos-Montgomery Method over Large Prime Fields with GPU Accelerated Dense Operations D. Zheltkov, N. Zamarashkin INM RAS September 24, 2018 Scalability of Lanczos method Notations Matrix order
Block Lanczos-Montgomery Method over Large Prime Fields with GPU Accelerated Dense Operations D. Zheltkov, N. Zamarashkin INM RAS September 24, 2018 Scalability of Lanczos method Notations Matrix order
Accelerating Spark Workloads using GPUs
 Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Data Analytics and Machine Learning: From Node to Cluster
 Data Analytics and Machine Learning: From Node to Cluster Presented by Viswanath Puttagunta Ganesh Raju Understanding use cases to optimize on ARM Ecosystem Date BKK16-404B March 10th, 2016 Event Linaro
Data Analytics and Machine Learning: From Node to Cluster Presented by Viswanath Puttagunta Ganesh Raju Understanding use cases to optimize on ARM Ecosystem Date BKK16-404B March 10th, 2016 Event Linaro
A Workload-aware Resource Management and Scheduling System for Big Data Analysis
 A Workload-aware Resource Management and Scheduling System for Big Data Analysis Luna Xu Dissertation submitted to the Faculty of the Virginia Polytechnic Institute and State University in partial fulfillment
A Workload-aware Resource Management and Scheduling System for Big Data Analysis Luna Xu Dissertation submitted to the Faculty of the Virginia Polytechnic Institute and State University in partial fulfillment
GPU LIBRARY ADVISOR. DA _v8.0 September Application Note
 GPU LIBRARY ADVISOR DA-06762-001_v8.0 September 2016 Application Note TABLE OF CONTENTS Chapter 1. Overview... 1 Chapter 2. Usage... 2 DA-06762-001_v8.0 ii Chapter 1. OVERVIEW The NVIDIA is a cross-platform
GPU LIBRARY ADVISOR DA-06762-001_v8.0 September 2016 Application Note TABLE OF CONTENTS Chapter 1. Overview... 1 Chapter 2. Usage... 2 DA-06762-001_v8.0 ii Chapter 1. OVERVIEW The NVIDIA is a cross-platform
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE)
") GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
Matrix Computations and " Neural Networks in Spark
 Matrix Computations and " Neural Networks in Spark Reza Zadeh Paper: http://arxiv.org/abs/1509.02256 Joint work with many folks on paper. @Reza_Zadeh http://reza-zadeh.com Training Neural Networks Datasets
Matrix Computations and " Neural Networks in Spark Reza Zadeh Paper: http://arxiv.org/abs/1509.02256 Joint work with many folks on paper. @Reza_Zadeh http://reza-zadeh.com Training Neural Networks Datasets
Matrix Multiplications on Apache Spark through GPUs
 DEGREE PROJECT IN COMPUTER SCIENCE AND ENGINEERING, SECOND CYCLE, 30 CREDITS STOCKHOLM, SWEDEN 2017 Matrix Multiplications on Apache Spark through GPUs ARASH SAFARI KTH ROYAL INSTITUTE OF TECHNOLOGY SCHOOL
DEGREE PROJECT IN COMPUTER SCIENCE AND ENGINEERING, SECOND CYCLE, 30 CREDITS STOCKHOLM, SWEDEN 2017 Matrix Multiplications on Apache Spark through GPUs ARASH SAFARI KTH ROYAL INSTITUTE OF TECHNOLOGY SCHOOL
Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation
 Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation 1 Cheng-Han Du* I-Hsin Chung** Weichung Wang* * I n s t i t u t e o f A p p l i e d M
Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation 1 Cheng-Han Du* I-Hsin Chung** Weichung Wang* * I n s t i t u t e o f A p p l i e d M
A Cloud System for Machine Learning Exploiting a Parallel Array DBMS
 2017 28th International Workshop on Database and Expert Systems Applications A Cloud System for Machine Learning Exploiting a Parallel Array DBMS Yiqun Zhang, Carlos Ordonez, Lennart Johnsson Department
2017 28th International Workshop on Database and Expert Systems Applications A Cloud System for Machine Learning Exploiting a Parallel Array DBMS Yiqun Zhang, Carlos Ordonez, Lennart Johnsson Department
Modern GPUs (Graphics Processing Units)
") Modern GPUs (Graphics Processing Units) Powerful data parallel computation platform. High computation density, high memory bandwidth. Relatively low cost. NVIDIA GTX 580 512 cores 1.6 Tera FLOPs 1.5 GB
Modern GPUs (Graphics Processing Units) Powerful data parallel computation platform. High computation density, high memory bandwidth. Relatively low cost. NVIDIA GTX 580 512 cores 1.6 Tera FLOPs 1.5 GB
Scaled Machine Learning at Matroid
 Scaled Machine Learning at Matroid Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Machine Learning Pipeline Learning Algorithm Replicate model Data Trained Model Serve Model Repeat entire pipeline Scaling
Scaled Machine Learning at Matroid Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Machine Learning Pipeline Learning Algorithm Replicate model Data Trained Model Serve Model Repeat entire pipeline Scaling
Approaches to acceleration: GPUs vs Intel MIC. Fabio AFFINITO SCAI department
 Approaches to acceleration: GPUs vs Intel MIC Fabio AFFINITO SCAI department Single core Multi core Many core GPU Intel MIC 61 cores 512bit-SIMD units from http://www.karlrupp.net/ from http://www.karlrupp.net/
Approaches to acceleration: GPUs vs Intel MIC Fabio AFFINITO SCAI department Single core Multi core Many core GPU Intel MIC 61 cores 512bit-SIMD units from http://www.karlrupp.net/ from http://www.karlrupp.net/
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Workload Characterization and Optimization of TPC-H Queries on Apache Spark
 Workload Characterization and Optimization of TPC-H Queries on Apache Spark Tatsuhiro Chiba and Tamiya Onodera IBM Research - Tokyo April. 17-19, 216 IEEE ISPASS 216 @ Uppsala, Sweden Overview IBM Research
Workload Characterization and Optimization of TPC-H Queries on Apache Spark Tatsuhiro Chiba and Tamiya Onodera IBM Research - Tokyo April. 17-19, 216 IEEE ISPASS 216 @ Uppsala, Sweden Overview IBM Research
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016
 ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
System Design of Kepler Based HPC Solutions. Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering.
 System Design of Kepler Based HPC Solutions Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering. Introduction The System Level View K20 GPU is a powerful parallel processor! K20 has
System Design of Kepler Based HPC Solutions Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering. Introduction The System Level View K20 GPU is a powerful parallel processor! K20 has
Distributed Machine Learning" on Spark
 Distributed Machine Learning" on Spark Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Outline Data flow vs. traditional network programming Spark computing engine Optimization Example Matrix Computations
Distributed Machine Learning" on Spark Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Outline Data flow vs. traditional network programming Spark computing engine Optimization Example Matrix Computations
Scalable Machine Learning Computing a Data Summarization Matrix with a Parallel Array DBMS
 Noname manuscript No. (will be inserted by the editor) Scalable Machine Learning Computing a Data Summarization Matrix with a Parallel Array DBMS Carlos Ordonez Yiqun Zhang S. Lennart Johnsson the date
Noname manuscript No. (will be inserted by the editor) Scalable Machine Learning Computing a Data Summarization Matrix with a Parallel Array DBMS Carlos Ordonez Yiqun Zhang S. Lennart Johnsson the date
Portable, usable, and efficient sparse matrix vector multiplication
 Portable, usable, and efficient sparse matrix vector multiplication Albert-Jan Yzelman Parallel Computing and Big Data Huawei Technologies France 8th of July, 2016 Introduction Given a sparse m n matrix
Portable, usable, and efficient sparse matrix vector multiplication Albert-Jan Yzelman Parallel Computing and Big Data Huawei Technologies France 8th of July, 2016 Introduction Given a sparse m n matrix
MAGMA. Matrix Algebra on GPU and Multicore Architectures
 MAGMA Matrix Algebra on GPU and Multicore Architectures Innovative Computing Laboratory Electrical Engineering and Computer Science University of Tennessee Piotr Luszczek (presenter) web.eecs.utk.edu/~luszczek/conf/
MAGMA Matrix Algebra on GPU and Multicore Architectures Innovative Computing Laboratory Electrical Engineering and Computer Science University of Tennessee Piotr Luszczek (presenter) web.eecs.utk.edu/~luszczek/conf/
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures
 MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
A Heterogeneity-Aware Task Scheduler for Spark
 A Heterogeneity-Aware Task Scheduler for Spark Luna Xu, Ali R. Butt, Seung-Hwan Lim, Ramakrishnan Kannan Virginia Tech, Oak Ridge National Laboratory {xuluna, butta}@cs.vt.edu, {lims1, kannanr}@ornl.gov
A Heterogeneity-Aware Task Scheduler for Spark Luna Xu, Ali R. Butt, Seung-Hwan Lim, Ramakrishnan Kannan Virginia Tech, Oak Ridge National Laboratory {xuluna, butta}@cs.vt.edu, {lims1, kannanr}@ornl.gov
Deep Learning Frameworks with Spark and GPUs
 Deep Learning Frameworks with Spark and GPUs Abstract Spark is a powerful, scalable, real-time data analytics engine that is fast becoming the de facto hub for data science and big data. However, in parallel,
Deep Learning Frameworks with Spark and GPUs Abstract Spark is a powerful, scalable, real-time data analytics engine that is fast becoming the de facto hub for data science and big data. However, in parallel,
CafeGPI. Single-Sided Communication for Scalable Deep Learning
 CafeGPI Single-Sided Communication for Scalable Deep Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Deep Neural Networks
CafeGPI Single-Sided Communication for Scalable Deep Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Deep Neural Networks
TESLA V100 PERFORMANCE GUIDE. Life Sciences Applications
 TESLA V100 PERFORMANCE GUIDE Life Sciences Applications NOVEMBER 2017 TESLA V100 PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA V100 PERFORMANCE GUIDE Life Sciences Applications NOVEMBER 2017 TESLA V100 PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
Jose Aliaga (Universitat Jaume I, Castellon, Spain), Ruyman Reyes, Mehdi Goli (Codeplay Software) 2017 Codeplay Software Ltd.
, Ruyman Reyes, Mehdi Goli (Codeplay Software) 2017 Codeplay Software Ltd.") SYCL-BLAS: LeveragingSYCL-BLAS Expression Trees for Linear Algebra Jose Aliaga (Universitat Jaume I, Castellon, Spain), Ruyman Reyes, Mehdi Goli (Codeplay Software) 1 About me... Phd in Compilers and Parallel
SYCL-BLAS: LeveragingSYCL-BLAS Expression Trees for Linear Algebra Jose Aliaga (Universitat Jaume I, Castellon, Spain), Ruyman Reyes, Mehdi Goli (Codeplay Software) 1 About me... Phd in Compilers and Parallel
HPC with GPU and its applications from Inspur. Haibo Xie, Ph.D
 HPC with GPU and its applications from Inspur Haibo Xie, Ph.D xiehb@inspur.com 2 Agenda I. HPC with GPU II. YITIAN solution and application 3 New Moore s Law 4 HPC? HPC stands for High Heterogeneous Performance
HPC with GPU and its applications from Inspur Haibo Xie, Ph.D xiehb@inspur.com 2 Agenda I. HPC with GPU II. YITIAN solution and application 3 New Moore s Law 4 HPC? HPC stands for High Heterogeneous Performance
Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.
 Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.) Andreas Kurth 2017-12-05 1 In short: The situation Image credit:
Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.) Andreas Kurth 2017-12-05 1 In short: The situation Image credit:
AperTO - Archivio Istituzionale Open Access dell'università di Torino
 AperTO - Archivio Istituzionale Open Access dell'università di Torino An hybrid linear algebra framework for engineering This is the author's manuscript Original Citation: An hybrid linear algebra framework
AperTO - Archivio Istituzionale Open Access dell'università di Torino An hybrid linear algebra framework for engineering This is the author's manuscript Original Citation: An hybrid linear algebra framework
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster
 Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs
 An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
The Evolution of Big Data Platforms and Data Science
 IBM Analytics The Evolution of Big Data Platforms and Data Science ECC Conference 2016 Brandon MacKenzie June 13, 2016 2016 IBM Corporation Hello, I m Brandon MacKenzie. I work at IBM. Data Science - Offering
IBM Analytics The Evolution of Big Data Platforms and Data Science ECC Conference 2016 Brandon MacKenzie June 13, 2016 2016 IBM Corporation Hello, I m Brandon MacKenzie. I work at IBM. Data Science - Offering
HPC with Multicore and GPUs
 HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
NEW FEATURES IN CUDA 6 MAKE GPU ACCELERATION EASIER MARK HARRIS
 NEW FEATURES IN CUDA 6 MAKE GPU ACCELERATION EASIER MARK HARRIS 1 Unified Memory CUDA 6 2 3 XT and Drop-in Libraries GPUDirect RDMA in MPI 4 Developer Tools 1 Unified Memory CUDA 6 2 3 XT and Drop-in Libraries
NEW FEATURES IN CUDA 6 MAKE GPU ACCELERATION EASIER MARK HARRIS 1 Unified Memory CUDA 6 2 3 XT and Drop-in Libraries GPUDirect RDMA in MPI 4 Developer Tools 1 Unified Memory CUDA 6 2 3 XT and Drop-in Libraries
Quantum ESPRESSO on GPU accelerated systems
 Quantum ESPRESSO on GPU accelerated systems Massimiliano Fatica, Everett Phillips, Josh Romero - NVIDIA Filippo Spiga - University of Cambridge/ARM (UK) MaX International Conference, Trieste, Italy, January
Quantum ESPRESSO on GPU accelerated systems Massimiliano Fatica, Everett Phillips, Josh Romero - NVIDIA Filippo Spiga - University of Cambridge/ARM (UK) MaX International Conference, Trieste, Italy, January
Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid Architectures
 Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
CPU-GPU Heterogeneous Computing
 CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
RECENT TRENDS IN GPU ARCHITECTURES. Perspectives of GPU computing in Science, 26 th Sept 2016
 RECENT TRENDS IN GPU ARCHITECTURES Perspectives of GPU computing in Science, 26 th Sept 2016 NVIDIA THE AI COMPUTING COMPANY GPU Computing Computer Graphics Artificial Intelligence 2 NVIDIA POWERS WORLD
RECENT TRENDS IN GPU ARCHITECTURES Perspectives of GPU computing in Science, 26 th Sept 2016 NVIDIA THE AI COMPUTING COMPANY GPU Computing Computer Graphics Artificial Intelligence 2 NVIDIA POWERS WORLD
JÜLICH SUPERCOMPUTING CENTRE Site Introduction Michael Stephan Forschungszentrum Jülich
 JÜLICH SUPERCOMPUTING CENTRE Site Introduction 09.04.2018 Michael Stephan JSC @ Forschungszentrum Jülich FORSCHUNGSZENTRUM JÜLICH Research Centre Jülich One of the 15 Helmholtz Research Centers in Germany
JÜLICH SUPERCOMPUTING CENTRE Site Introduction 09.04.2018 Michael Stephan JSC @ Forschungszentrum Jülich FORSCHUNGSZENTRUM JÜLICH Research Centre Jülich One of the 15 Helmholtz Research Centers in Germany
A Multi-Tiered Optimization Framework for Heterogeneous Computing
 A Multi-Tiered Optimization Framework for Heterogeneous Computing IEEE HPEC 2014 Alan George Professor of ECE University of Florida Herman Lam Assoc. Professor of ECE University of Florida Andrew Milluzzi
A Multi-Tiered Optimization Framework for Heterogeneous Computing IEEE HPEC 2014 Alan George Professor of ECE University of Florida Herman Lam Assoc. Professor of ECE University of Florida Andrew Milluzzi
A GPU-based Approximate SVD Algorithm Blake Foster, Sridhar Mahadevan, Rui Wang
 A GPU-based Approximate SVD Algorithm Blake Foster, Sridhar Mahadevan, Rui Wang University of Massachusetts Amherst Introduction Singular Value Decomposition (SVD) A: m n matrix (m n) U, V: orthogonal
A GPU-based Approximate SVD Algorithm Blake Foster, Sridhar Mahadevan, Rui Wang University of Massachusetts Amherst Introduction Singular Value Decomposition (SVD) A: m n matrix (m n) U, V: orthogonal
Solving Dense Linear Systems on Graphics Processors
 Solving Dense Linear Systems on Graphics Processors Sergio Barrachina Maribel Castillo Francisco Igual Rafael Mayo Enrique S. Quintana-Ortí High Performance Computing & Architectures Group Universidad
Solving Dense Linear Systems on Graphics Processors Sergio Barrachina Maribel Castillo Francisco Igual Rafael Mayo Enrique S. Quintana-Ortí High Performance Computing & Architectures Group Universidad
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Linear Algebra libraries in Debian. DebConf 10 New York 05/08/2010 Sylvestre
 Linear Algebra libraries in Debian Who I am? Core developer of Scilab (daily job) Debian Developer Involved in Debian mainly in Science and Java aspects sylvestre.ledru@scilab.org / sylvestre@debian.org
Linear Algebra libraries in Debian Who I am? Core developer of Scilab (daily job) Debian Developer Involved in Debian mainly in Science and Java aspects sylvestre.ledru@scilab.org / sylvestre@debian.org
Study and implementation of computational methods for Differential Equations in heterogeneous systems. Asimina Vouronikoy - Eleni Zisiou
 Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
BigDataBench- S: An Open- source Scien6fic Big Data Benchmark Suite
 BigDataBench- S: An Open- source Scien6fic Big Data Benchmark Suite Xinhui Tian, Shaopeng Dai, Zhihui Du, Wanling Gao, Rui Ren, Yaodong Cheng, Zhifei Zhang, Zhen Jia, Peijian Wang and Jianfeng Zhan INSTITUTE
BigDataBench- S: An Open- source Scien6fic Big Data Benchmark Suite Xinhui Tian, Shaopeng Dai, Zhihui Du, Wanling Gao, Rui Ren, Yaodong Cheng, Zhifei Zhang, Zhen Jia, Peijian Wang and Jianfeng Zhan INSTITUTE
On the Comparative Performance of Parallel Algorithms on Small GPU/CUDA Clusters
 1 On the Comparative Performance of Parallel Algorithms on Small GPU/CUDA Clusters N. P. Karunadasa & D. N. Ranasinghe University of Colombo School of Computing, Sri Lanka nishantha@opensource.lk, dnr@ucsc.cmb.ac.lk
1 On the Comparative Performance of Parallel Algorithms on Small GPU/CUDA Clusters N. P. Karunadasa & D. N. Ranasinghe University of Colombo School of Computing, Sri Lanka nishantha@opensource.lk, dnr@ucsc.cmb.ac.lk
Parallel and Distributed Computing with MATLAB The MathWorks, Inc. 1
 Parallel and Distributed Computing with MATLAB 2018 The MathWorks, Inc. 1 Practical Application of Parallel Computing Why parallel computing? Need faster insight on more complex problems with larger datasets
Parallel and Distributed Computing with MATLAB 2018 The MathWorks, Inc. 1 Practical Application of Parallel Computing Why parallel computing? Need faster insight on more complex problems with larger datasets
HPC Enabling R&D at Philip Morris International
 HPC Enabling R&D at Philip Morris International Jim Geuther*, Filipe Bonjour, Bruce O Neel, Didier Bouttefeux, Sylvain Gubian, Stephane Cano, and Brian Suomela * Philip Morris International IT Service
HPC Enabling R&D at Philip Morris International Jim Geuther*, Filipe Bonjour, Bruce O Neel, Didier Bouttefeux, Sylvain Gubian, Stephane Cano, and Brian Suomela * Philip Morris International IT Service
Optimizing Data Locality for Iterative Matrix Solvers on CUDA
 Optimizing Data Locality for Iterative Matrix Solvers on CUDA Raymond Flagg, Jason Monk, Yifeng Zhu PhD., Bruce Segee PhD. Department of Electrical and Computer Engineering, University of Maine, Orono,
Optimizing Data Locality for Iterative Matrix Solvers on CUDA Raymond Flagg, Jason Monk, Yifeng Zhu PhD., Bruce Segee PhD. Department of Electrical and Computer Engineering, University of Maine, Orono,
Distributed Training of Deep Neural Networks: Theoretical and Practical Limits of Parallel Scalability
 Distributed Training of Deep Neural Networks: Theoretical and Practical Limits of Parallel Scalability Janis Keuper Itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern,
Distributed Training of Deep Neural Networks: Theoretical and Practical Limits of Parallel Scalability Janis Keuper Itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern,
NEW ADVANCES IN GPU LINEAR ALGEBRA
 GTC 2012: NEW ADVANCES IN GPU LINEAR ALGEBRA Kyle Spagnoli EM Photonics 5/16/2012 QUICK ABOUT US» HPC/GPU Consulting Firm» Specializations in:» Electromagnetics» Image Processing» Fluid Dynamics» Linear
GTC 2012: NEW ADVANCES IN GPU LINEAR ALGEBRA Kyle Spagnoli EM Photonics 5/16/2012 QUICK ABOUT US» HPC/GPU Consulting Firm» Specializations in:» Electromagnetics» Image Processing» Fluid Dynamics» Linear
Analysis of Performance Gap Between OpenACC and the Native Approach on P100 GPU and SW26010: A Case Study with GTC-P
 Analysis of Performance Gap Between OpenACC and the Native Approach on P100 GPU and SW26010: A Case Study with GTC-P Stephen Wang 1, James Lin 1, William Tang 2, Stephane Ethier 2, Bei Wang 2, Simon See
Analysis of Performance Gap Between OpenACC and the Native Approach on P100 GPU and SW26010: A Case Study with GTC-P Stephen Wang 1, James Lin 1, William Tang 2, Stephane Ethier 2, Bei Wang 2, Simon See
Accelerating Linpack Performance with Mixed Precision Algorithm on CPU+GPGPU Heterogeneous Cluster
 th IEEE International Conference on Computer and Information Technology (CIT ) Accelerating Linpack Performance with Mixed Precision Algorithm on CPU+GPGPU Heterogeneous Cluster WANG Lei ZHANG Yunquan
th IEEE International Conference on Computer and Information Technology (CIT ) Accelerating Linpack Performance with Mixed Precision Algorithm on CPU+GPGPU Heterogeneous Cluster WANG Lei ZHANG Yunquan
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Advanced CUDA Optimization 1. Introduction
 Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Parallel and Distributed Computing with MATLAB Gerardo Hernández Manager, Application Engineer
 Parallel and Distributed Computing with MATLAB Gerardo Hernández Manager, Application Engineer 2018 The MathWorks, Inc. 1 Practical Application of Parallel Computing Why parallel computing? Need faster
Parallel and Distributed Computing with MATLAB Gerardo Hernández Manager, Application Engineer 2018 The MathWorks, Inc. 1 Practical Application of Parallel Computing Why parallel computing? Need faster
Porting the NAS-NPB Conjugate Gradient Benchmark to CUDA. NVIDIA Corporation
 Porting the NAS-NPB Conjugate Gradient Benchmark to CUDA NVIDIA Corporation Outline! Overview of CG benchmark! Overview of CUDA Libraries! CUSPARSE! CUBLAS! Porting Sequence! Algorithm Analysis! Data/Code
Porting the NAS-NPB Conjugate Gradient Benchmark to CUDA NVIDIA Corporation Outline! Overview of CG benchmark! Overview of CUDA Libraries! CUSPARSE! CUBLAS! Porting Sequence! Algorithm Analysis! Data/Code
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING
 TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Table of Contents: The Accelerated Data Center Optimizing Data Center Productivity Same Throughput with Fewer Server Nodes
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Table of Contents: The Accelerated Data Center Optimizing Data Center Productivity Same Throughput with Fewer Server Nodes
GPU ACCELERATION OF CHOLMOD: BATCHING, HYBRID AND MULTI-GPU
 April 4-7, 2016 Silicon Valley GPU ACCELERATION OF CHOLMOD: BATCHING, HYBRID AND MULTI-GPU Steve Rennich, Darko Stosic, Tim Davis, April 6, 2016 OBJECTIVE Direct sparse methods are among the most widely
April 4-7, 2016 Silicon Valley GPU ACCELERATION OF CHOLMOD: BATCHING, HYBRID AND MULTI-GPU Steve Rennich, Darko Stosic, Tim Davis, April 6, 2016 OBJECTIVE Direct sparse methods are among the most widely
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design
 Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation
 ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
Stan Posey, CAE Industry Development NVIDIA, Santa Clara, CA, USA
 Stan Posey, CAE Industry Development NVIDIA, Santa Clara, CA, USA NVIDIA and HPC Evolution of GPUs Public, based in Santa Clara, CA ~$4B revenue ~5,500 employees Founded in 1999 with primary business in
Stan Posey, CAE Industry Development NVIDIA, Santa Clara, CA, USA NVIDIA and HPC Evolution of GPUs Public, based in Santa Clara, CA ~$4B revenue ~5,500 employees Founded in 1999 with primary business in
Parallel Methods for Convex Optimization. A. Devarakonda, J. Demmel, K. Fountoulakis, M. Mahoney
 Parallel Methods for Convex Optimization A. Devarakonda, J. Demmel, K. Fountoulakis, M. Mahoney Problems minimize g(x)+f(x; A, b) Sparse regression g(x) =kxk 1 f(x) =kax bk 2 2 mx Sparse SVM g(x) =kxk
Parallel Methods for Convex Optimization A. Devarakonda, J. Demmel, K. Fountoulakis, M. Mahoney Problems minimize g(x)+f(x; A, b) Sparse regression g(x) =kxk 1 f(x) =kax bk 2 2 mx Sparse SVM g(x) =kxk
Introduction to parallel Computing
 Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
NVBLAS LIBRARY. DU _v6.0 February User Guide
 NVBLAS LIBRARY DU-06702-001_v6.0 February 2014 User Guide DU-06702-001_v6.0 2 Chapter 1. INTRODUCTION The is a GPU-accelerated Libary that implements BLAS (Basic Linear Algebra Subprograms). It can accelerate
NVBLAS LIBRARY DU-06702-001_v6.0 February 2014 User Guide DU-06702-001_v6.0 2 Chapter 1. INTRODUCTION The is a GPU-accelerated Libary that implements BLAS (Basic Linear Algebra Subprograms). It can accelerate
A Hardware-Friendly Bilateral Solver for Real-Time Virtual-Reality Video
 A Hardware-Friendly Bilateral Solver for Real-Time Virtual-Reality Video Amrita Mazumdar Armin Alaghi Jonathan T. Barron David Gallup Luis Ceze Mark Oskin Steven M. Seitz University of Washington Google
A Hardware-Friendly Bilateral Solver for Real-Time Virtual-Reality Video Amrita Mazumdar Armin Alaghi Jonathan T. Barron David Gallup Luis Ceze Mark Oskin Steven M. Seitz University of Washington Google
Backtesting with Spark
 Backtesting with Spark Patrick Angeles, Cloudera Sandy Ryza, Cloudera Rick Carlin, Intel Sheetal Parade, Intel 1 Traditional Grid Shared storage Storage and compute scale independently Bottleneck on I/O
Backtesting with Spark Patrick Angeles, Cloudera Sandy Ryza, Cloudera Rick Carlin, Intel Sheetal Parade, Intel 1 Traditional Grid Shared storage Storage and compute scale independently Bottleneck on I/O
Carlos Reaño, Javier Prades and Federico Silla Technical University of Valencia (Spain)
") Carlos Reaño, Javier Prades and Federico Silla Technical University of Valencia (Spain) 4th IEEE International Workshop of High-Performance Interconnection Networks in the Exascale and Big-Data Era (HiPINEB
Carlos Reaño, Javier Prades and Federico Silla Technical University of Valencia (Spain) 4th IEEE International Workshop of High-Performance Interconnection Networks in the Exascale and Big-Data Era (HiPINEB
Applications of Berkeley s Dwarfs on Nvidia GPUs
 Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
Performance Analysis of BLAS Libraries in SuperLU_DIST for SuperLU_MCDT (Multi Core Distributed) Development
 Development") Available online at www.prace-ri.eu Partnership for Advanced Computing in Europe Performance Analysis of BLAS Libraries in SuperLU_DIST for SuperLU_MCDT (Multi Core Distributed) Development M. Serdar Celebi
Available online at www.prace-ri.eu Partnership for Advanced Computing in Europe Performance Analysis of BLAS Libraries in SuperLU_DIST for SuperLU_MCDT (Multi Core Distributed) Development M. Serdar Celebi
Distributed Computing with Spark
 Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
Optimizing and Accelerating Your MATLAB Code
 Optimizing and Accelerating Your MATLAB Code Sofia Mosesson Senior Application Engineer 2016 The MathWorks, Inc. 1 Agenda Optimizing for loops and using vector and matrix operations Indexing in different
Optimizing and Accelerating Your MATLAB Code Sofia Mosesson Senior Application Engineer 2016 The MathWorks, Inc. 1 Agenda Optimizing for loops and using vector and matrix operations Indexing in different
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
Harp-DAAL for High Performance Big Data Computing
 Harp-DAAL for High Performance Big Data Computing Large-scale data analytics is revolutionizing many business and scientific domains. Easy-touse scalable parallel techniques are necessary to process big
Harp-DAAL for High Performance Big Data Computing Large-scale data analytics is revolutionizing many business and scientific domains. Easy-touse scalable parallel techniques are necessary to process big
How to perform HPL on CPU&GPU clusters. Dr.sc. Draško Tomić
 How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
Scalable Machine Learning in R. with H2O
 Scalable Machine Learning in R with H2O Erin LeDell @ledell DSC July 2016 Introduction Statistician & Machine Learning Scientist at H2O.ai in Mountain View, California, USA Ph.D. in Biostatistics with
Scalable Machine Learning in R with H2O Erin LeDell @ledell DSC July 2016 Introduction Statistician & Machine Learning Scientist at H2O.ai in Mountain View, California, USA Ph.D. in Biostatistics with
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Kartik Lakhotia, Rajgopal Kannan, Viktor Prasanna USENIX ATC 18
 Accelerating PageRank using Partition-Centric Processing Kartik Lakhotia, Rajgopal Kannan, Viktor Prasanna USENIX ATC 18 Outline Introduction Partition-centric Processing Methodology Analytical Evaluation
Accelerating PageRank using Partition-Centric Processing Kartik Lakhotia, Rajgopal Kannan, Viktor Prasanna USENIX ATC 18 Outline Introduction Partition-centric Processing Methodology Analytical Evaluation
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay Mellanox Technologies
 Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay 1 Apache Spark - Intro Spark within the Big Data ecosystem Data Sources Data Acquisition / ETL Data Storage Data Analysis / ML Serving 3 Apache
Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay 1 Apache Spark - Intro Spark within the Big Data ecosystem Data Sources Data Acquisition / ETL Data Storage Data Analysis / ML Serving 3 Apache
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT
 TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G
 Joined Advanced Student School (JASS) 2009 March 29 - April 7, 2009 St. Petersburg, Russia G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G Dmitry Puzyrev St. Petersburg State University Faculty
Joined Advanced Student School (JASS) 2009 March 29 - April 7, 2009 St. Petersburg, Russia G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G Dmitry Puzyrev St. Petersburg State University Faculty
Evaluation and Exploration of Next Generation Systems for Applicability and Performance Volodymyr Kindratenko Guochun Shi
 Evaluation and Exploration of Next Generation Systems for Applicability and Performance Volodymyr Kindratenko Guochun Shi National Center for Supercomputing Applications University of Illinois at Urbana-Champaign
Evaluation and Exploration of Next Generation Systems for Applicability and Performance Volodymyr Kindratenko Guochun Shi National Center for Supercomputing Applications University of Illinois at Urbana-Champaign
Faster Code for Free: Linear Algebra Libraries. Advanced Research Compu;ng 22 Feb 2017
 Faster Code for Free: Linear Algebra Libraries Advanced Research Compu;ng 22 Feb 2017 Outline Introduc;on Implementa;ons Using them Use on ARC systems Hands on session Conclusions Introduc;on 3 BLAS Level
Faster Code for Free: Linear Algebra Libraries Advanced Research Compu;ng 22 Feb 2017 Outline Introduc;on Implementa;ons Using them Use on ARC systems Hands on session Conclusions Introduc;on 3 BLAS Level
GPU-PCC: A GPU Based Technique to Compute Pairwise Pearson s Correlation Coefficients for Big fmri Data
 Western Michigan University ScholarWorks at WMU Parallel Computing and Data Science Lab Technical Reports Computer Science 2017 GPU-PCC: A GPU Based Technique to Compute Pairwise Pearson s Correlation
Western Michigan University ScholarWorks at WMU Parallel Computing and Data Science Lab Technical Reports Computer Science 2017 GPU-PCC: A GPU Based Technique to Compute Pairwise Pearson s Correlation
The Future of High Performance Interconnects
 The Future of High Performance Interconnects Ashrut Ambastha HPC Advisory Council Perth, Australia :: August 2017 When Algorithms Go Rogue 2017 Mellanox Technologies 2 When Algorithms Go Rogue 2017 Mellanox
The Future of High Performance Interconnects Ashrut Ambastha HPC Advisory Council Perth, Australia :: August 2017 When Algorithms Go Rogue 2017 Mellanox Technologies 2 When Algorithms Go Rogue 2017 Mellanox
J. Blair Perot. Ali Khajeh-Saeed. Software Engineer CD-adapco. Mechanical Engineering UMASS, Amherst
 Ali Khajeh-Saeed Software Engineer CD-adapco J. Blair Perot Mechanical Engineering UMASS, Amherst Supercomputers Optimization Stream Benchmark Stag++ (3D Incompressible Flow Code) Matrix Multiply Function
Ali Khajeh-Saeed Software Engineer CD-adapco J. Blair Perot Mechanical Engineering UMASS, Amherst Supercomputers Optimization Stream Benchmark Stag++ (3D Incompressible Flow Code) Matrix Multiply Function
S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems
 S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems Khoa Huynh Senior Technical Staff Member (STSM), IBM Jonathan Samn Software Engineer, IBM Evolving from compute systems to
S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems Khoa Huynh Senior Technical Staff Member (STSM), IBM Jonathan Samn Software Engineer, IBM Evolving from compute systems to
A GPU Enhanced Linux Cluster for Accelerated FMS
 A GPU Enhanced Linux Cluster for Accelerated FMS Computational Sciences 21 June 07 Gene Wagenbreth genew@isi.edu (310)448-8213 Background Computational Sciences Division of ISI works with clusters, compilers
A GPU Enhanced Linux Cluster for Accelerated FMS Computational Sciences 21 June 07 Gene Wagenbreth genew@isi.edu (310)448-8213 Background Computational Sciences Division of ISI works with clusters, compilers
Using FPGAs as Microservices
 Using FPGAs as Microservices David Ojika, Ann Gordon-Ross, Herman Lam, Bhavesh Patel, Gaurav Kaul, Jayson Strayer (University of Florida, DELL EMC, Intel Corporation) The 9 th Workshop on Big Data Benchmarks,
Using FPGAs as Microservices David Ojika, Ann Gordon-Ross, Herman Lam, Bhavesh Patel, Gaurav Kaul, Jayson Strayer (University of Florida, DELL EMC, Intel Corporation) The 9 th Workshop on Big Data Benchmarks,
WHAT S NEW IN CUDA 8. Siddharth Sharma, Oct 2016
 WHAT S NEW IN CUDA 8 Siddharth Sharma, Oct 2016 WHAT S NEW IN CUDA 8 Why Should You Care >2X Run Computations Faster* Solve Larger Problems** Critical Path Analysis * HOOMD Blue v1.3.3 Lennard-Jones liquid
WHAT S NEW IN CUDA 8 Siddharth Sharma, Oct 2016 WHAT S NEW IN CUDA 8 Why Should You Care >2X Run Computations Faster* Solve Larger Problems** Critical Path Analysis * HOOMD Blue v1.3.3 Lennard-Jones liquid
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
Overcoming the Barriers of Graphs on GPUs: Delivering Graph Analy;cs 100X Faster and 40X Cheaper
 Overcoming the Barriers of Graphs on GPUs: Delivering Graph Analy;cs 100X Faster and 40X Cheaper November 18, 2015 Super Compu3ng 2015 The Amount of Graph Data is Exploding! Billion+ Edges! 2 Graph Applications
Overcoming the Barriers of Graphs on GPUs: Delivering Graph Analy;cs 100X Faster and 40X Cheaper November 18, 2015 Super Compu3ng 2015 The Amount of Graph Data is Exploding! Billion+ Edges! 2 Graph Applications
Accelerating GPU Kernels for Dense Linear Algebra
 Accelerating GPU Kernels for Dense Linear Algebra Rajib Nath, Stan Tomov, and Jack Dongarra Innovative Computing Lab University of Tennessee, Knoxville July 9, 21 xgemm performance of CUBLAS-2.3 on GTX28
Accelerating GPU Kernels for Dense Linear Algebra Rajib Nath, Stan Tomov, and Jack Dongarra Innovative Computing Lab University of Tennessee, Knoxville July 9, 21 xgemm performance of CUBLAS-2.3 on GTX28
Headline in Arial Bold 30pt. Visualisation using the Grid Jeff Adie Principal Systems Engineer, SAPK July 2008
 Headline in Arial Bold 30pt Visualisation using the Grid Jeff Adie Principal Systems Engineer, SAPK July 2008 Agenda Visualisation Today User Trends Technology Trends Grid Viz Nodes Software Ecosystem
Headline in Arial Bold 30pt Visualisation using the Grid Jeff Adie Principal Systems Engineer, SAPK July 2008 Agenda Visualisation Today User Trends Technology Trends Grid Viz Nodes Software Ecosystem