Recurrent Neural Networks. Nand Kishore, Audrey Huang, Rohan Batra
|
|
|
- Evangeline Parsons
- 5 years ago
- Views:
Transcription
1 Recurrent Neural Networks Nand Kishore, Audrey Huang, Rohan Batra
2 Roadmap Issues Motivation 1 Application 1: Sequence Level Training 2 Basic Structure 3 4 Variations 5 Application 3: Image Classification 6 7 Application 2: Tree Structure Prediction 2
3 Motivation Sequential data is found everywhere Sentence is sequence of words Video is sequence of images Time-series data is sequence across time Given a sequence (x1, x2,...xi) The xi s are not i.i.d! Might be strongly correlated Can we take advantage of sequential structure?
4 Machine Learning Tasks Sequence Prediction Predict next element in sequence: (x1, x2,,xi) -> xi+1 Sequence Labelling/Seq-to-Seq Assign label to each element in sequence: (x1, x2,,xi) -> (y1, y2,...yi) Sequence Classification Classify entire sequence (x1, x2,, xi) -> y

5 Machine Learning Tasks
6 Hidden Markov Model (HMM) Generative Model Markov Assumption on Hidden States
7 Hidden Markov Model (HMM) Weaknesses N states can only encode log(n) bits of information In practice, generative models tend to be more computationally intensive/less accurate

8 Feedforward Neural Networks
9 Weaknesses of Feedforward Networks Fixed # outputs and inputs Inputs are independent
10 Recurrent Neural Networks Overcome These Problems Fixed # outputs and inputs Inputs are independent Variable # outputs and inputs Inputs can be correlated
11 Roadmap 1 Application 1: Sequence Level Training Issues Motivation 2 Basic Structure 3 4 Variations 5 Application 3: Image Classification 6 7 Application 2: Tree Structure Prediction 11
12 Recurrent Neural Network - Structure RNNs are neural networks with loops Previous hidden states or predictions used as inputs
13 Recurrent Neural Network - Structure How you loop the nodes depends on the problem
14 Recurrent Neural Networks - Training Unroll the network through time Becomes a feedforward network Train using gradient descent backpropagation through time (BPTT)
15 Recurrent Neural Network - Equations Updating Hidden States st at time t st function of previous hidden state st-1 and current input xt encodes prior information ( memory )
16 Recurrent Neural Network - Equations Making Sequential Predictions ot at time t ot is function of current hidden state st
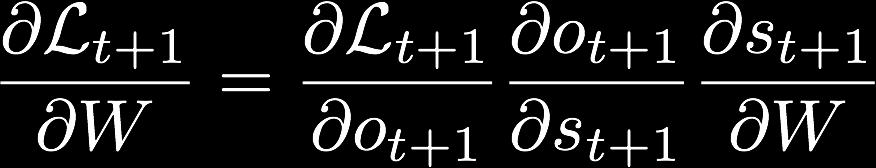
17 Backpropagation - Chain Rule
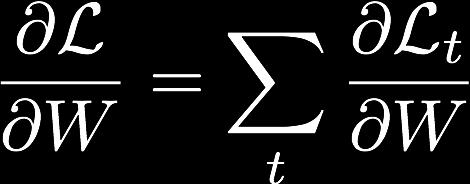
18 Backpropagation - Chain Rule
19 Example 1 - Learning A Language Model Predicted distribution over letters Hidden states One-hot encoding of letters
20 Example 1 - Learning A Language Model E H
21 Example 1 - Learning A Language Model E H E
22 Example 1 - Learning A Language Model E H L L O E L L
23 Example 2 - Machine Translation I like socks J aime les chaussettes

24 Example 3 - Sentiment Analysis POSITIVE CS159 is lit!1!!!!!
25 Roadmap 1 Application 1: Sequence Level Training Issues Motivation 2 Basic Structure 3 4 Variations 5 Application 3: Image Classification 6 7 Application 2: Tree Structure Prediction 25
26 Vanishing and Exploding Gradient Composition of many nonlinear functions can lead to problems When we backpropagate, gradient increases exponentially with W Behavior depends on eigenvalues of W If eigenvalues > 1, Wn may cause gradient to explodes If eigenvalues < 1, Wn may cause gradient to vanish


27 Short-term Memory In practice, simple RNN s tend to only retain information from few time-steps in the past RNN s are good at remembering recent information RNN s have a harder time remembering relevant information from farther back
28 Roadmap 1 Application 1: Sequence Level Training Issues Motivation 2 Basic Structure 3 4 Variations 5 Application 3: Image Classification 6 7 Application 2: Tree Structure Prediction 28


29 Long short-term memory (LSTM) Adds a memory cell with input, forget, and output gates Can help learn long-term dependencies Helps solve exploding/vanishing gradient problem

30 Forget gate layer
31 Input gate layer
32 Update cell state
33 Generate filtered output
34 But wait... there s more A number of challenging problems remain in sequence learning Let s take a look at how the papers address these issues
35 Roadmap 1 Application 1: Sequence Level Training Issues Motivation 2 Basic Structure 3 4 Variations 5 Application 3: Image Classification 6 7 Application 2: Tree Structure Prediction 35
36 SEQUENCE LEVEL TRAINING WITH RECURRENT NEURAL NETWORKS By: Marc Aurelio Ranzato, Sumit Chopra, Michael Auli, Wojciech Zaremba
37 Text Generation Consider the problem of text generation Machine Translation Summarization Question Answering
38 Text Generation We want to predict a sequence of words [w1, w2,, wt] (that makes sense) At each time step, may take as input some context ct
39 RNN Let s use an RNN
40 Text Generation Simple Elman RNN:
41 Training Optimize cross-entropy loss at each time-step Given a target sequence [w1, w2,, wt]
42 Why is this a problem? Notice that the RNN is trained to maximize pθ(w wt,ht+1), where wt is the ground truth Loss function causes model to be good at predicting the next word given previous ground-truth word
43 Why is this a problem? But we don t have the ground truth at test time!!! Remember that we re trying to generate sequences At test time, the model needs to use it s own predictions to generate the next words
44 Why is this a problem? This can lead to predicting sub-optimal sequences The most likely sequence might actually contain a sub-optimal word at some time-step
45 Techniques Beam Search At each point instead of just taking highest scoring word, look at k next word candidates Significantly slows down word generation process Data as Demonstrator During training, with certain probability take either model prediction or ground truth Alignment issues I took a long walk vs. I took a walk End to End Backprop Instead of ground-truth, propagate top-k words at previous time-step Weigh each word by its score and re-normalize
46 Reinforcement Learning Suppose our RNN is an agent Parameters define a policy Picks an action After taking an action, updates internal states At the end of sequence, observes a reward Can use any reward function, authors use BLUE and ROUGE-2
47 REINFORCE We want to find parameters that maximize expected reward Loss is negative expected reward In practice, we actually approximate the expected reward with a single sample...
48 REINFORCE For estimating the gradients, If is a baseline estimator that can reduce variance Authors use linear regression with the hidden states of RNN as input to estimate this Unclear what is best technique to select this encourages word choice, or else discourages word choice
49 MIXED INCREMENTAL CROSS-ENTROPY REINFORCE Instead of starting from poor random policy, start from RNN trained using ground truth with cross-entropy Start using REINFORCE according to an annealing schedule

50 Results ROUGE-2 score for summarization BLEU-4 score for translation and image captioning
51 Results Algorithms + k Beam Search
52 Roadmap 1 Application 1: Sequence Level Training Issues Motivation 2 Basic Structure 3 4 Variations 5 Application 3: Image Classification 6 7 Application 2: Tree Structure Prediction 52
53 Tree-Structured Decoding with Doubly-Recurrent Neural Networks By: David Alvarez-Melis, Tommi S. Jaakkola
54 Motivation Given an encoding as input, generate a tree structure RNN s best suited for sequential data Trees and graphs do not naturally conform to linear ordering Various types of sequential data can be represented in trees Parse trees for sentences Abstract syntax trees for computer programs Problem: generate full tree structure with node-labels using encoder-decoder framework
55 Encoder-Decoder Framework Given ground-truth tree and string representation of tree Use RNN to encode vector representation from string Use RNN to decode tree from vector representation
56 Example ROOT B W F J V Preorder Traversal String Representation Input Tree X Encoder Vector Representation Decoder Output
57 Challenges with decoding Must generate tree top-down Don t know node labels beforehand Generating child node vs sibling node How to pass information? Label of siblings not independent A verb in a parse tree reduces chance of sibling nodes of being verb
58 Doubly Recurrent Neural Networks (DRNN) Ancestral and sibling flows of information Two input states: Receive from parent node, update, send to descendent Receive from previous sibling, update, send to next sibling Unrolled DRNN Nodes labeled in order generated Solid lines are ancestral, dotted lines are fraternal connections
59 Inside a node Update node s hidden ancestral and fraternal states Combine to obtain predictive hidden state
60 Producing an output Get probability of stopping ancestral or fraternal branch Combine to get output, binary variables corresponding to ground truth (training) or, (testing) Assign node label
61 Experiment: Synthetic Tree Recovery Generate dataset of labeled trees Vocabulary is 26 letters Condition label of each node on ancestors and siblings Probabilities of children or next-siblings dependent only on label and depth Generate string representations with pre-order traversal RNN encoder String to vector DRNN with LSTM module decoder Vector to tree

62 Results Node retrieval: 75% Edge retrieval: 71%
63 Results
64 Results
65 Experiment: Computer program generation Mapping sentences to functional programs Given sentence description of computer program, generate abstract syntax tree DRNN performed better than all other baselines
66 Summary DRNN s are an extension of sequential recurrent architectures to tree structures Information flow Parent to offspring Sibling to sibling Performed better than baselines on tasks involving tree generation
67 Roadmap 1 Application 1: Sequence Level Training Issues Motivation 2 Basic Structure 3 4 Variations 5 Application 3: Image Classification 6 7 Application 2: Tree Structure Prediction 67
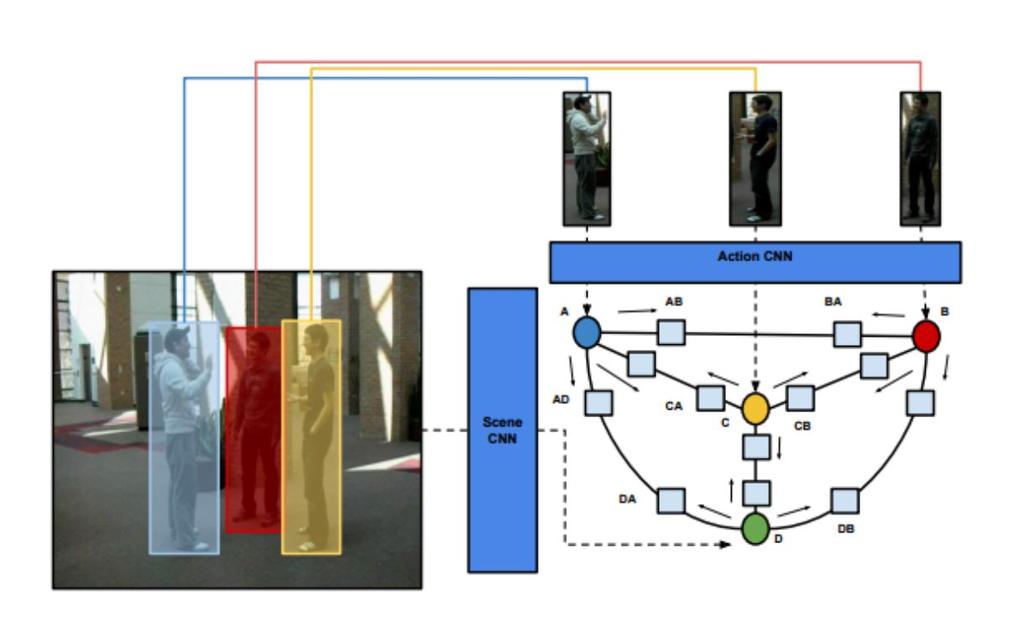
68 Structure Inference Machines: Recurrent Neural Networks for Analyzing Relations in Group Activity Recognition By: Zhiwei Deng, Arash Vahdat, Hexiang Hu, Greg Mori
69 Group Activity Recognition Classification Problem: What is each person doing? What is the scene as a whole doing?
70 Group Activity Recognition CNN action? CNN action? Classification Problem: What is each person doing? What is the scene as a whole doing?
71 Group Activity Recognition Classification Problem: What is each person doing? What is the scene as a whole doing? CNN action?
72 Group Activity Recognition waiting biking walking waiting Classification Problem: What is each person doing? waiting walking biking What is the scene as a whole doing? waiting
73 Improving Group Activity Recognition - Model Relationships waiting? walking? Individual actions inform other individual actions & the scene action relationships
74 Improving Group Activity Recognition - Model Relationships waiting together Individual actions inform other individual actions & the scene action relationships

75 Group Activity Recognition waiting waiting Relationships depend on Spatial distance Relative motions Concurrent actions Number of people
76 Model Relationships Using RNNs RNN structure reflects learning problem Fully connected Each edge represents a relationship Model learns how important each relationship is Train edge weights

77 Train Using Iterative Message Passing/Gradient Descent
78 Why do we need multiple iterations of message passing? Graphs are cyclic so exact inference isn t possible
79
80 Graph Model A B C S
81 Training the Model For each iteration t For each edge (i, j) Update messages mi -> j(t) and mj -> i(t) Update gates gi -> j(t) and gj -> i(t) Impose gates on messages For each node i Calculate prediction ci(t) Output: Final predictions at time T, ci(t)
82 General Message-Passing Update Equations At time t, message m(t) is a function f of weighted sum with Input features x Last message m(t-1) Last prediction c(t-1) At time t, prediction c(t) is a function f of weighted sum with Input features x Current message m(t)
83 RNN Model A B C S
84 RNN Model - Get Feature Inputs A B Individual Features CNN C CNN CNN S Scene Features CNN

85 RNN Model - Initialize Messages at Time t=0 A B C S
86 Training the Model For each iteration t For each edge (i, j) Update messages mi -> j(t) and mj -> i(t) Update gates gi -> j(t) and gj -> i(t) Impose gates on messages For each node i Calculate prediction ci(t) Output: Final predictions at time T, ci(t)
87 Training the Model - Updating Messages at Time t A B C S
88 Training the Model - Updating Messages at Time t A B C S Activation function on weighted sum of Input features to messaging node Prev. prediction by messaging node Prev. messages to messaging node
89 Training the Model - Updating Messages at Time t A B C S
90 Training the Model For each iteration t For each edge (i, j) Update messages mi -> j(t) and mj -> i(t) Update gates gi -> j(t) and gj -> i(t) Impose gates on messages For each node i Calculate prediction ci(t) Output: Final predictions at time T, ci(t)
91 Training the Model - Updating Gates at Time t A B C S
92 Training the Model - Updating Gates at Time t A B C S Activation function on weighted sum of Input features to target node Prev. prediction by target node Current messages to target node
93 Training the Model - Updating Gates at Time t A B C S

94 Training the Model - Imposing Gates at Time t A B C Just multiply message vectors by gate scalars S
95 Training the Model - Updating Gates at Time t A B C S Gate Intuition: Determines whether edge is useful Modulates importance of edge
96 Training the Model - Imposing Gates A B C S Over Several Iterations Learns to ignore some dges And focus more on others
97 Training the Model For each iteration t For each edge (i, j) Update messages mi -> j(t) and mj -> i(t) Update gates gi -> j(t) and gj -> i(t) Impose gates on messages For each node i Calculate prediction ci(t) Output: Final predictions at time T, ci(t)
98 Training the Model - Getting Predictions ci(t) at Time t A B C S
99 Training the Model - Getting Predictions ci(t) at Time t A B C S Activation function on weighted sum of Input features to node Current messages to node
100 Training the Model - Getting Predictions ci(t) at Time t A B C S
101 Training the Model For each iteration t For each edge (i, j) Update messages mi -> j(t) and mj -> i(t) Update gates gi -> j(t) and gj -> i(t) Impose gates on messages For each node i Calculate prediction ci(t) Output: Final predictions at time T, ci(t)
102 Output - Getting Final Predictions ci(t) at Time T A B C S

103 Applied to Collective Activity Dataset 44 videos 7 actions Crossing Waiting Queueing Talking Jogging Dancing N/A

104 Visualization of Results on Collective Activity Dataset

105 Results on Collective Activity Dataset
106 Key Takeaways Previous outputs and hidden states can be looped back in as inputs Model problems where inputs are highly correlated
107 thanks
Machine Learning 13. week
 Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Recurrent Neural Network (RNN) Industrial AI Lab.
 Industrial AI Lab.") Recurrent Neural Network (RNN) Industrial AI Lab. For example (Deterministic) Time Series Data Closed- form Linear difference equation (LDE) and initial condition High order LDEs 2 (Stochastic) Time Series
Recurrent Neural Network (RNN) Industrial AI Lab. For example (Deterministic) Time Series Data Closed- form Linear difference equation (LDE) and initial condition High order LDEs 2 (Stochastic) Time Series
CSC 578 Neural Networks and Deep Learning
 CSC 578 Neural Networks and Deep Learning Fall 2018/19 7. Recurrent Neural Networks (Some figures adapted from NNDL book) 1 Recurrent Neural Networks 1. Recurrent Neural Networks (RNNs) 2. RNN Training
CSC 578 Neural Networks and Deep Learning Fall 2018/19 7. Recurrent Neural Networks (Some figures adapted from NNDL book) 1 Recurrent Neural Networks 1. Recurrent Neural Networks (RNNs) 2. RNN Training
Sequence Modeling: Recurrent and Recursive Nets. By Pyry Takala 14 Oct 2015
 Sequence Modeling: Recurrent and Recursive Nets By Pyry Takala 14 Oct 2015 Agenda Why Recurrent neural networks? Anatomy and basic training of an RNN (10.2, 10.2.1) Properties of RNNs (10.2.2, 8.2.6) Using
Sequence Modeling: Recurrent and Recursive Nets By Pyry Takala 14 Oct 2015 Agenda Why Recurrent neural networks? Anatomy and basic training of an RNN (10.2, 10.2.1) Properties of RNNs (10.2.2, 8.2.6) Using
27: Hybrid Graphical Models and Neural Networks
 10-708: Probabilistic Graphical Models 10-708 Spring 2016 27: Hybrid Graphical Models and Neural Networks Lecturer: Matt Gormley Scribes: Jakob Bauer Otilia Stretcu Rohan Varma 1 Motivation We first look
10-708: Probabilistic Graphical Models 10-708 Spring 2016 27: Hybrid Graphical Models and Neural Networks Lecturer: Matt Gormley Scribes: Jakob Bauer Otilia Stretcu Rohan Varma 1 Motivation We first look
LSTM for Language Translation and Image Captioning. Tel Aviv University Deep Learning Seminar Oran Gafni & Noa Yedidia
 1 LSTM for Language Translation and Image Captioning Tel Aviv University Deep Learning Seminar Oran Gafni & Noa Yedidia 2 Part I LSTM for Language Translation Motivation Background (RNNs, LSTMs) Model
1 LSTM for Language Translation and Image Captioning Tel Aviv University Deep Learning Seminar Oran Gafni & Noa Yedidia 2 Part I LSTM for Language Translation Motivation Background (RNNs, LSTMs) Model
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
 Show, Attend and Tell: Neural Image Caption Generation with Visual Attention Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhutdinov, Richard Zemel, Yoshua Bengio Presented
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhutdinov, Richard Zemel, Yoshua Bengio Presented
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
 Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling Authors: Junyoung Chung, Caglar Gulcehre, KyungHyun Cho and Yoshua Bengio Presenter: Yu-Wei Lin Background: Recurrent Neural
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling Authors: Junyoung Chung, Caglar Gulcehre, KyungHyun Cho and Yoshua Bengio Presenter: Yu-Wei Lin Background: Recurrent Neural
DEEP LEARNING REVIEW. Yann LeCun, Yoshua Bengio & Geoffrey Hinton Nature Presented by Divya Chitimalla
 DEEP LEARNING REVIEW Yann LeCun, Yoshua Bengio & Geoffrey Hinton Nature 2015 -Presented by Divya Chitimalla What is deep learning Deep learning allows computational models that are composed of multiple
DEEP LEARNING REVIEW Yann LeCun, Yoshua Bengio & Geoffrey Hinton Nature 2015 -Presented by Divya Chitimalla What is deep learning Deep learning allows computational models that are composed of multiple
LSTM and its variants for visual recognition. Xiaodan Liang Sun Yat-sen University
 LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
Deep Learning. Deep Learning. Practical Application Automatically Adding Sounds To Silent Movies
 http://blog.csdn.net/zouxy09/article/details/8775360 Automatic Colorization of Black and White Images Automatically Adding Sounds To Silent Movies Traditionally this was done by hand with human effort
http://blog.csdn.net/zouxy09/article/details/8775360 Automatic Colorization of Black and White Images Automatically Adding Sounds To Silent Movies Traditionally this was done by hand with human effort
Gated Recurrent Models. Stephan Gouws & Richard Klein
 Gated Recurrent Models Stephan Gouws & Richard Klein Outline Part 1: Intuition, Inference and Training Building intuitions: From Feedforward to Recurrent Models Inference in RNNs: Fprop Training in RNNs:
Gated Recurrent Models Stephan Gouws & Richard Klein Outline Part 1: Intuition, Inference and Training Building intuitions: From Feedforward to Recurrent Models Inference in RNNs: Fprop Training in RNNs:
SEMANTIC COMPUTING. Lecture 8: Introduction to Deep Learning. TU Dresden, 7 December Dagmar Gromann International Center For Computational Logic
 SEMANTIC COMPUTING Lecture 8: Introduction to Deep Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 7 December 2018 Overview Introduction Deep Learning General Neural Networks
SEMANTIC COMPUTING Lecture 8: Introduction to Deep Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 7 December 2018 Overview Introduction Deep Learning General Neural Networks
Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks
 Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks Zelun Luo Department of Computer Science Stanford University zelunluo@stanford.edu Te-Lin Wu Department of
Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks Zelun Luo Department of Computer Science Stanford University zelunluo@stanford.edu Te-Lin Wu Department of
Natural Language Processing with Deep Learning CS224N/Ling284
 Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 8: Recurrent Neural Networks Christopher Manning and Richard Socher Organization Extra project office hour today after lecture Overview
Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 8: Recurrent Neural Networks Christopher Manning and Richard Socher Organization Extra project office hour today after lecture Overview
Convolutional Sequence to Sequence Learning. Denis Yarats with Jonas Gehring, Michael Auli, David Grangier, Yann Dauphin Facebook AI Research
 Convolutional Sequence to Sequence Learning Denis Yarats with Jonas Gehring, Michael Auli, David Grangier, Yann Dauphin Facebook AI Research Sequence generation Need to model a conditional distribution
Convolutional Sequence to Sequence Learning Denis Yarats with Jonas Gehring, Michael Auli, David Grangier, Yann Dauphin Facebook AI Research Sequence generation Need to model a conditional distribution
Lecture 20: Neural Networks for NLP. Zubin Pahuja
 Lecture 20: Neural Networks for NLP Zubin Pahuja zpahuja2@illinois.edu courses.engr.illinois.edu/cs447 CS447: Natural Language Processing 1 Today s Lecture Feed-forward neural networks as classifiers simple
Lecture 20: Neural Networks for NLP Zubin Pahuja zpahuja2@illinois.edu courses.engr.illinois.edu/cs447 CS447: Natural Language Processing 1 Today s Lecture Feed-forward neural networks as classifiers simple
Asynchronous Parallel Learning for Neural Networks and Structured Models with Dense Features
 Asynchronous Parallel Learning for Neural Networks and Structured Models with Dense Features Xu SUN ( 孙栩 ) Peking University xusun@pku.edu.cn Motivation Neural networks -> Good Performance CNN, RNN, LSTM
Asynchronous Parallel Learning for Neural Networks and Structured Models with Dense Features Xu SUN ( 孙栩 ) Peking University xusun@pku.edu.cn Motivation Neural networks -> Good Performance CNN, RNN, LSTM
CS839: Probabilistic Graphical Models. Lecture 22: The Attention Mechanism. Theo Rekatsinas
 CS839: Probabilistic Graphical Models Lecture 22: The Attention Mechanism Theo Rekatsinas 1 Why Attention? Consider machine translation: We need to pay attention to the word we are currently translating.
CS839: Probabilistic Graphical Models Lecture 22: The Attention Mechanism Theo Rekatsinas 1 Why Attention? Consider machine translation: We need to pay attention to the word we are currently translating.
Lecture 2 Notes. Outline. Neural Networks. The Big Idea. Architecture. Instructors: Parth Shah, Riju Pahwa
 Instructors: Parth Shah, Riju Pahwa Lecture 2 Notes Outline 1. Neural Networks The Big Idea Architecture SGD and Backpropagation 2. Convolutional Neural Networks Intuition Architecture 3. Recurrent Neural
Instructors: Parth Shah, Riju Pahwa Lecture 2 Notes Outline 1. Neural Networks The Big Idea Architecture SGD and Backpropagation 2. Convolutional Neural Networks Intuition Architecture 3. Recurrent Neural
Gate-Variants of Gated Recurrent Unit (GRU) Neural Networks
 Neural Networks") Gate-Variants of Gated Recurrent Unit (GRU) Neural Networks Rahul Dey and Fathi M. Salem Circuits, Systems, and Neural Networks (CSANN) LAB Department of Electrical and Computer Engineering Michigan State
Gate-Variants of Gated Recurrent Unit (GRU) Neural Networks Rahul Dey and Fathi M. Salem Circuits, Systems, and Neural Networks (CSANN) LAB Department of Electrical and Computer Engineering Michigan State
10-701/15-781, Fall 2006, Final
 -7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
-7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
Natural Language Processing CS 6320 Lecture 6 Neural Language Models. Instructor: Sanda Harabagiu
 Natural Language Processing CS 6320 Lecture 6 Neural Language Models Instructor: Sanda Harabagiu In this lecture We shall cover: Deep Neural Models for Natural Language Processing Introduce Feed Forward
Natural Language Processing CS 6320 Lecture 6 Neural Language Models Instructor: Sanda Harabagiu In this lecture We shall cover: Deep Neural Models for Natural Language Processing Introduce Feed Forward
House Price Prediction Using LSTM
 House Price Prediction Using LSTM Xiaochen Chen Lai Wei The Hong Kong University of Science and Technology Jiaxin Xu ABSTRACT In this paper, we use the house price data ranging from January 2004 to October
House Price Prediction Using LSTM Xiaochen Chen Lai Wei The Hong Kong University of Science and Technology Jiaxin Xu ABSTRACT In this paper, we use the house price data ranging from January 2004 to October
RNNs as Directed Graphical Models
 RNNs as Directed Graphical Models Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 10. Topics in Sequence Modeling Overview
RNNs as Directed Graphical Models Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 10. Topics in Sequence Modeling Overview
Encoding RNNs, 48 End of sentence (EOS) token, 207 Exploding gradient, 131 Exponential function, 42 Exponential Linear Unit (ELU), 44
 token, 207 Exploding gradient, 131 Exponential function, 42 Exponential Linear Unit (ELU), 44") A Activation potential, 40 Annotated corpus add padding, 162 check versions, 158 create checkpoints, 164, 166 create input, 160 create train and validation datasets, 163 dropout, 163 DRUG-AE.rel file,
A Activation potential, 40 Annotated corpus add padding, 162 check versions, 158 create checkpoints, 164, 166 create input, 160 create train and validation datasets, 163 dropout, 163 DRUG-AE.rel file,
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound. Lecture 12: Deep Reinforcement Learning
: Multimodal Learning with Vision, Language and Sound. Lecture 12: Deep Reinforcement Learning") Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 12: Deep Reinforcement Learning Types of Learning Supervised training Learning from the teacher Training data includes
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 12: Deep Reinforcement Learning Types of Learning Supervised training Learning from the teacher Training data includes
Residual Networks And Attention Models. cs273b Recitation 11/11/2016. Anna Shcherbina
 Residual Networks And Attention Models cs273b Recitation 11/11/2016 Anna Shcherbina Introduction to ResNets Introduced in 2015 by Microsoft Research Deep Residual Learning for Image Recognition (He, Zhang,
Residual Networks And Attention Models cs273b Recitation 11/11/2016 Anna Shcherbina Introduction to ResNets Introduced in 2015 by Microsoft Research Deep Residual Learning for Image Recognition (He, Zhang,
Alternatives to Direct Supervision
 CreativeAI: Deep Learning for Graphics Alternatives to Direct Supervision Niloy Mitra Iasonas Kokkinos Paul Guerrero Nils Thuerey Tobias Ritschel UCL UCL UCL TUM UCL Timetable Theory and Basics State of
CreativeAI: Deep Learning for Graphics Alternatives to Direct Supervision Niloy Mitra Iasonas Kokkinos Paul Guerrero Nils Thuerey Tobias Ritschel UCL UCL UCL TUM UCL Timetable Theory and Basics State of
Code Mania Artificial Intelligence: a. Module - 1: Introduction to Artificial intelligence and Python:
 Code Mania 2019 Artificial Intelligence: a. Module - 1: Introduction to Artificial intelligence and Python: 1. Introduction to Artificial Intelligence 2. Introduction to python programming and Environment
Code Mania 2019 Artificial Intelligence: a. Module - 1: Introduction to Artificial intelligence and Python: 1. Introduction to Artificial Intelligence 2. Introduction to python programming and Environment
Recurrent Neural Networks
 Recurrent Neural Networks Javier Béjar Deep Learning 2018/2019 Fall Master in Artificial Intelligence (FIB-UPC) Introduction Sequential data Many problems are described by sequences Time series Video/audio
Recurrent Neural Networks Javier Béjar Deep Learning 2018/2019 Fall Master in Artificial Intelligence (FIB-UPC) Introduction Sequential data Many problems are described by sequences Time series Video/audio
Midterm Examination CS540-2: Introduction to Artificial Intelligence
 Midterm Examination CS540-2: Introduction to Artificial Intelligence March 15, 2018 LAST NAME: FIRST NAME: Problem Score Max Score 1 12 2 13 3 9 4 11 5 8 6 13 7 9 8 16 9 9 Total 100 Question 1. [12] Search
Midterm Examination CS540-2: Introduction to Artificial Intelligence March 15, 2018 LAST NAME: FIRST NAME: Problem Score Max Score 1 12 2 13 3 9 4 11 5 8 6 13 7 9 8 16 9 9 Total 100 Question 1. [12] Search
Motivation: Shortcomings of Hidden Markov Model. Ko, Youngjoong. Solution: Maximum Entropy Markov Model (MEMM)
") Motivation: Shortcomings of Hidden Markov Model Maximum Entropy Markov Models and Conditional Random Fields Ko, Youngjoong Dept. of Computer Engineering, Dong-A University Intelligent System Laboratory,
Motivation: Shortcomings of Hidden Markov Model Maximum Entropy Markov Models and Conditional Random Fields Ko, Youngjoong Dept. of Computer Engineering, Dong-A University Intelligent System Laboratory,
Conditional Random Fields. Mike Brodie CS 778
 Conditional Random Fields Mike Brodie CS 778 Motivation Part-Of-Speech Tagger 2 Motivation object 3 Motivation I object! 4 Motivation object Do you see that object? 5 Motivation Part-Of-Speech Tagger -
Conditional Random Fields Mike Brodie CS 778 Motivation Part-Of-Speech Tagger 2 Motivation object 3 Motivation I object! 4 Motivation object Do you see that object? 5 Motivation Part-Of-Speech Tagger -
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Image Data: Classification via Neural Networks Instructor: Yizhou Sun yzsun@ccs.neu.edu November 19, 2015 Methods to Learn Classification Clustering Frequent Pattern Mining
CS6220: DATA MINING TECHNIQUES Image Data: Classification via Neural Networks Instructor: Yizhou Sun yzsun@ccs.neu.edu November 19, 2015 Methods to Learn Classification Clustering Frequent Pattern Mining
A new approach for supervised power disaggregation by using a deep recurrent LSTM network
 A new approach for supervised power disaggregation by using a deep recurrent LSTM network GlobalSIP 2015, 14th Dec. Lukas Mauch and Bin Yang Institute of Signal Processing and System Theory University
A new approach for supervised power disaggregation by using a deep recurrent LSTM network GlobalSIP 2015, 14th Dec. Lukas Mauch and Bin Yang Institute of Signal Processing and System Theory University
Image Captioning with Object Detection and Localization
 Image Captioning with Object Detection and Localization Zhongliang Yang, Yu-Jin Zhang, Sadaqat ur Rehman, Yongfeng Huang, Department of Electronic Engineering, Tsinghua University, Beijing 100084, China
Image Captioning with Object Detection and Localization Zhongliang Yang, Yu-Jin Zhang, Sadaqat ur Rehman, Yongfeng Huang, Department of Electronic Engineering, Tsinghua University, Beijing 100084, China
A Hidden Markov Model for Alphabet Soup Word Recognition
 A Hidden Markov Model for Alphabet Soup Word Recognition Shaolei Feng 1 Nicholas R. Howe 2 R. Manmatha 1 1 University of Massachusetts, Amherst 2 Smith College Motivation: Inaccessible Treasures Historical
A Hidden Markov Model for Alphabet Soup Word Recognition Shaolei Feng 1 Nicholas R. Howe 2 R. Manmatha 1 1 University of Massachusetts, Amherst 2 Smith College Motivation: Inaccessible Treasures Historical
Deep Learning Applications
 October 20, 2017 Overview Supervised Learning Feedforward neural network Convolution neural network Recurrent neural network Recursive neural network (Recursive neural tensor network) Unsupervised Learning
October 20, 2017 Overview Supervised Learning Feedforward neural network Convolution neural network Recurrent neural network Recursive neural network (Recursive neural tensor network) Unsupervised Learning
Artificial Neural Networks. Introduction to Computational Neuroscience Ardi Tampuu
 Artificial Neural Networks Introduction to Computational Neuroscience Ardi Tampuu 7.0.206 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Artificial Neural Networks Introduction to Computational Neuroscience Ardi Tampuu 7.0.206 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Unsupervised Learning
 Deep Learning for Graphics Unsupervised Learning Niloy Mitra Iasonas Kokkinos Paul Guerrero Vladimir Kim Kostas Rematas Tobias Ritschel UCL UCL/Facebook UCL Adobe Research U Washington UCL Timetable Niloy
Deep Learning for Graphics Unsupervised Learning Niloy Mitra Iasonas Kokkinos Paul Guerrero Vladimir Kim Kostas Rematas Tobias Ritschel UCL UCL/Facebook UCL Adobe Research U Washington UCL Timetable Niloy
Grounded Compositional Semantics for Finding and Describing Images with Sentences
 Grounded Compositional Semantics for Finding and Describing Images with Sentences R. Socher, A. Karpathy, V. Le,D. Manning, A Y. Ng - 2013 Ali Gharaee 1 Alireza Keshavarzi 2 1 Department of Computational
Grounded Compositional Semantics for Finding and Describing Images with Sentences R. Socher, A. Karpathy, V. Le,D. Manning, A Y. Ng - 2013 Ali Gharaee 1 Alireza Keshavarzi 2 1 Department of Computational
Speech and Language Processing. Daniel Jurafsky & James H. Martin. Copyright c All rights reserved. Draft of September 23, 2018.
 Speech and Language Processing. Daniel Jurafsky & James H. Martin. Copyright c 2018. All rights reserved. Draft of September 23, 2018. CHAPTER 9 Sequence Processing with Recurrent Networks Time will explain.
Speech and Language Processing. Daniel Jurafsky & James H. Martin. Copyright c 2018. All rights reserved. Draft of September 23, 2018. CHAPTER 9 Sequence Processing with Recurrent Networks Time will explain.
Lecture 7: Neural network acoustic models in speech recognition
 CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 7: Neural network acoustic models in speech recognition Outline Hybrid acoustic modeling overview Basic
CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 7: Neural network acoustic models in speech recognition Outline Hybrid acoustic modeling overview Basic
Structured Perceptron. Ye Qiu, Xinghui Lu, Yue Lu, Ruofei Shen
 Structured Perceptron Ye Qiu, Xinghui Lu, Yue Lu, Ruofei Shen 1 Outline 1. 2. 3. 4. Brief review of perceptron Structured Perceptron Discriminative Training Methods for Hidden Markov Models: Theory and
Structured Perceptron Ye Qiu, Xinghui Lu, Yue Lu, Ruofei Shen 1 Outline 1. 2. 3. 4. Brief review of perceptron Structured Perceptron Discriminative Training Methods for Hidden Markov Models: Theory and
Recurrent Convolutional Neural Networks for Scene Labeling
 Recurrent Convolutional Neural Networks for Scene Labeling Pedro O. Pinheiro, Ronan Collobert Reviewed by Yizhe Zhang August 14, 2015 Scene labeling task Scene labeling: assign a class label to each pixel
Recurrent Convolutional Neural Networks for Scene Labeling Pedro O. Pinheiro, Ronan Collobert Reviewed by Yizhe Zhang August 14, 2015 Scene labeling task Scene labeling: assign a class label to each pixel
The exam is closed book, closed notes except your one-page (two-sided) cheat sheet.
 cheat sheet.") CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
Multi-Glance Attention Models For Image Classification
 Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
An undirected graph is a tree if and only of there is a unique simple path between any 2 of its vertices.
 Trees Trees form the most widely used subclasses of graphs. In CS, we make extensive use of trees. Trees are useful in organizing and relating data in databases, file systems and other applications. Formal
Trees Trees form the most widely used subclasses of graphs. In CS, we make extensive use of trees. Trees are useful in organizing and relating data in databases, file systems and other applications. Formal
Slides credited from Dr. David Silver & Hung-Yi Lee
 Slides credited from Dr. David Silver & Hung-Yi Lee Review Reinforcement Learning 2 Reinforcement Learning RL is a general purpose framework for decision making RL is for an agent with the capacity to
Slides credited from Dr. David Silver & Hung-Yi Lee Review Reinforcement Learning 2 Reinforcement Learning RL is a general purpose framework for decision making RL is for an agent with the capacity to
CS489/698: Intro to ML
 CS489/698: Intro to ML Lecture 14: Training of Deep NNs Instructor: Sun Sun 1 Outline Activation functions Regularization Gradient-based optimization 2 Examples of activation functions 3 5/28/18 Sun Sun
CS489/698: Intro to ML Lecture 14: Training of Deep NNs Instructor: Sun Sun 1 Outline Activation functions Regularization Gradient-based optimization 2 Examples of activation functions 3 5/28/18 Sun Sun
CS5670: Computer Vision
 CS5670: Computer Vision Noah Snavely Lecture 33: Recognition Basics Slides from Andrej Karpathy and Fei-Fei Li http://vision.stanford.edu/teaching/cs231n/ Announcements Quiz moved to Tuesday Project 4
CS5670: Computer Vision Noah Snavely Lecture 33: Recognition Basics Slides from Andrej Karpathy and Fei-Fei Li http://vision.stanford.edu/teaching/cs231n/ Announcements Quiz moved to Tuesday Project 4
Deep Learning in Visual Recognition. Thanks Da Zhang for the slides
 Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Semantic image search using queries
 Semantic image search using queries Shabaz Basheer Patel, Anand Sampat Department of Electrical Engineering Stanford University CA 94305 shabaz@stanford.edu,asampat@stanford.edu Abstract Previous work,
Semantic image search using queries Shabaz Basheer Patel, Anand Sampat Department of Electrical Engineering Stanford University CA 94305 shabaz@stanford.edu,asampat@stanford.edu Abstract Previous work,
Deep Learning for Computer Vision
 Deep Learning for Computer Vision Lecture 7: Universal Approximation Theorem, More Hidden Units, Multi-Class Classifiers, Softmax, and Regularization Peter Belhumeur Computer Science Columbia University
Deep Learning for Computer Vision Lecture 7: Universal Approximation Theorem, More Hidden Units, Multi-Class Classifiers, Softmax, and Regularization Peter Belhumeur Computer Science Columbia University
CAP 6412 Advanced Computer Vision
 CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 5th, 2016 Today Administrivia LSTM Attribute in computer vision, by Abdullah and Samer Project II posted, due
CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 5th, 2016 Today Administrivia LSTM Attribute in computer vision, by Abdullah and Samer Project II posted, due
CS 224n: Assignment #3
 CS 224n: Assignment #3 Due date: 2/27 11:59 PM PST (You are allowed to use 3 late days maximum for this assignment) These questions require thought, but do not require long answers. Please be as concise
CS 224n: Assignment #3 Due date: 2/27 11:59 PM PST (You are allowed to use 3 late days maximum for this assignment) These questions require thought, but do not require long answers. Please be as concise
Empirical Evaluation of RNN Architectures on Sentence Classification Task
 Empirical Evaluation of RNN Architectures on Sentence Classification Task Lei Shen, Junlin Zhang Chanjet Information Technology lorashen@126.com, zhangjlh@chanjet.com Abstract. Recurrent Neural Networks
Empirical Evaluation of RNN Architectures on Sentence Classification Task Lei Shen, Junlin Zhang Chanjet Information Technology lorashen@126.com, zhangjlh@chanjet.com Abstract. Recurrent Neural Networks
Neural Network Weight Selection Using Genetic Algorithms
 Neural Network Weight Selection Using Genetic Algorithms David Montana presented by: Carl Fink, Hongyi Chen, Jack Cheng, Xinglong Li, Bruce Lin, Chongjie Zhang April 12, 2005 1 Neural Networks Neural networks
Neural Network Weight Selection Using Genetic Algorithms David Montana presented by: Carl Fink, Hongyi Chen, Jack Cheng, Xinglong Li, Bruce Lin, Chongjie Zhang April 12, 2005 1 Neural Networks Neural networks
CMU Lecture 18: Deep learning and Vision: Convolutional neural networks. Teacher: Gianni A. Di Caro
 CMU 15-781 Lecture 18: Deep learning and Vision: Convolutional neural networks Teacher: Gianni A. Di Caro DEEP, SHALLOW, CONNECTED, SPARSE? Fully connected multi-layer feed-forward perceptrons: More powerful
CMU 15-781 Lecture 18: Deep learning and Vision: Convolutional neural networks Teacher: Gianni A. Di Caro DEEP, SHALLOW, CONNECTED, SPARSE? Fully connected multi-layer feed-forward perceptrons: More powerful
Natural Language Processing
 Natural Language Processing Classification III Dan Klein UC Berkeley 1 Classification 2 Linear Models: Perceptron The perceptron algorithm Iteratively processes the training set, reacting to training errors
Natural Language Processing Classification III Dan Klein UC Berkeley 1 Classification 2 Linear Models: Perceptron The perceptron algorithm Iteratively processes the training set, reacting to training errors
Logical Rhythm - Class 3. August 27, 2018
 Logical Rhythm - Class 3 August 27, 2018 In this Class Neural Networks (Intro To Deep Learning) Decision Trees Ensemble Methods(Random Forest) Hyperparameter Optimisation and Bias Variance Tradeoff Biological
Logical Rhythm - Class 3 August 27, 2018 In this Class Neural Networks (Intro To Deep Learning) Decision Trees Ensemble Methods(Random Forest) Hyperparameter Optimisation and Bias Variance Tradeoff Biological
7. Boosting and Bagging Bagging
 Group Prof. Daniel Cremers 7. Boosting and Bagging Bagging Bagging So far: Boosting as an ensemble learning method, i.e.: a combination of (weak) learners A different way to combine classifiers is known
Group Prof. Daniel Cremers 7. Boosting and Bagging Bagging Bagging So far: Boosting as an ensemble learning method, i.e.: a combination of (weak) learners A different way to combine classifiers is known
D-Separation. b) the arrows meet head-to-head at the node, and neither the node, nor any of its descendants, are in the set C.
 the arrows meet head-to-head at the node, and neither the node, nor any of its descendants, are in the set C.") D-Separation Say: A, B, and C are non-intersecting subsets of nodes in a directed graph. A path from A to B is blocked by C if it contains a node such that either a) the arrows on the path meet either
D-Separation Say: A, B, and C are non-intersecting subsets of nodes in a directed graph. A path from A to B is blocked by C if it contains a node such that either a) the arrows on the path meet either
Sentiment Classification of Food Reviews
 Sentiment Classification of Food Reviews Hua Feng Department of Electrical Engineering Stanford University Stanford, CA 94305 fengh15@stanford.edu Ruixi Lin Department of Electrical Engineering Stanford
Sentiment Classification of Food Reviews Hua Feng Department of Electrical Engineering Stanford University Stanford, CA 94305 fengh15@stanford.edu Ruixi Lin Department of Electrical Engineering Stanford
Hidden Units. Sargur N. Srihari
 Hidden Units Sargur N. srihari@cedar.buffalo.edu 1 Topics in Deep Feedforward Networks Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation
Hidden Units Sargur N. srihari@cedar.buffalo.edu 1 Topics in Deep Feedforward Networks Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation
1 Overview Definitions (read this section carefully) 2
 2") MLPerf User Guide Version 0.5 May 2nd, 2018 1 Overview 2 1.1 Definitions (read this section carefully) 2 2 General rules 3 2.1 Strive to be fair 3 2.2 System and framework must be consistent 4 2.3 System
MLPerf User Guide Version 0.5 May 2nd, 2018 1 Overview 2 1.1 Definitions (read this section carefully) 2 2 General rules 3 2.1 Strive to be fair 3 2.2 System and framework must be consistent 4 2.3 System
Binary Trees
 Binary Trees 4-7-2005 Opening Discussion What did we talk about last class? Do you have any code to show? Do you have any questions about the assignment? What is a Tree? You are all familiar with what
Binary Trees 4-7-2005 Opening Discussion What did we talk about last class? Do you have any code to show? Do you have any questions about the assignment? What is a Tree? You are all familiar with what
Ensemble Methods, Decision Trees
 CS 1675: Intro to Machine Learning Ensemble Methods, Decision Trees Prof. Adriana Kovashka University of Pittsburgh November 13, 2018 Plan for This Lecture Ensemble methods: introduction Boosting Algorithm
CS 1675: Intro to Machine Learning Ensemble Methods, Decision Trees Prof. Adriana Kovashka University of Pittsburgh November 13, 2018 Plan for This Lecture Ensemble methods: introduction Boosting Algorithm
Building Classifiers using Bayesian Networks
 Building Classifiers using Bayesian Networks Nir Friedman and Moises Goldszmidt 1997 Presented by Brian Collins and Lukas Seitlinger Paper Summary The Naive Bayes classifier has reasonable performance
Building Classifiers using Bayesian Networks Nir Friedman and Moises Goldszmidt 1997 Presented by Brian Collins and Lukas Seitlinger Paper Summary The Naive Bayes classifier has reasonable performance
Statistical Machine Translation Part IV Log-Linear Models
 Statistical Machine Translation art IV Log-Linear Models Alexander Fraser Institute for Natural Language rocessing University of Stuttgart 2011.11.25 Seminar: Statistical MT Where we have been We have
Statistical Machine Translation art IV Log-Linear Models Alexander Fraser Institute for Natural Language rocessing University of Stuttgart 2011.11.25 Seminar: Statistical MT Where we have been We have
Evolutionary Algorithms. CS Evolutionary Algorithms 1
 Evolutionary Algorithms CS 478 - Evolutionary Algorithms 1 Evolutionary Computation/Algorithms Genetic Algorithms l Simulate natural evolution of structures via selection and reproduction, based on performance
Evolutionary Algorithms CS 478 - Evolutionary Algorithms 1 Evolutionary Computation/Algorithms Genetic Algorithms l Simulate natural evolution of structures via selection and reproduction, based on performance
CSE 250B Project Assignment 4
 CSE 250B Project Assignment 4 Hani Altwary haltwa@cs.ucsd.edu Kuen-Han Lin kul016@ucsd.edu Toshiro Yamada toyamada@ucsd.edu Abstract The goal of this project is to implement the Semi-Supervised Recursive
CSE 250B Project Assignment 4 Hani Altwary haltwa@cs.ucsd.edu Kuen-Han Lin kul016@ucsd.edu Toshiro Yamada toyamada@ucsd.edu Abstract The goal of this project is to implement the Semi-Supervised Recursive
COMP9444 Neural Networks and Deep Learning 5. Geometry of Hidden Units
 COMP9 8s Geometry of Hidden Units COMP9 Neural Networks and Deep Learning 5. Geometry of Hidden Units Outline Geometry of Hidden Unit Activations Limitations of -layer networks Alternative transfer functions
COMP9 8s Geometry of Hidden Units COMP9 Neural Networks and Deep Learning 5. Geometry of Hidden Units Outline Geometry of Hidden Unit Activations Limitations of -layer networks Alternative transfer functions
Module 1 Lecture Notes 2. Optimization Problem and Model Formulation
 Optimization Methods: Introduction and Basic concepts 1 Module 1 Lecture Notes 2 Optimization Problem and Model Formulation Introduction In the previous lecture we studied the evolution of optimization
Optimization Methods: Introduction and Basic concepts 1 Module 1 Lecture Notes 2 Optimization Problem and Model Formulation Introduction In the previous lecture we studied the evolution of optimization
CS231N Section. Video Understanding 6/1/2018
 CS231N Section Video Understanding 6/1/2018 Outline Background / Motivation / History Video Datasets Models Pre-deep learning CNN + RNN 3D convolution Two-stream What we ve seen in class so far... Image
CS231N Section Video Understanding 6/1/2018 Outline Background / Motivation / History Video Datasets Models Pre-deep learning CNN + RNN 3D convolution Two-stream What we ve seen in class so far... Image
FastText. Jon Koss, Abhishek Jindal
 FastText Jon Koss, Abhishek Jindal FastText FastText is on par with state-of-the-art deep learning classifiers in terms of accuracy But it is way faster: FastText can train on more than one billion words
FastText Jon Koss, Abhishek Jindal FastText FastText is on par with state-of-the-art deep learning classifiers in terms of accuracy But it is way faster: FastText can train on more than one billion words
COMP 551 Applied Machine Learning Lecture 16: Deep Learning
 COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
Deep Learning. Vladimir Golkov Technical University of Munich Computer Vision Group
 Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
COMP9444 Neural Networks and Deep Learning 7. Image Processing. COMP9444 c Alan Blair, 2017
 COMP9444 Neural Networks and Deep Learning 7. Image Processing COMP9444 17s2 Image Processing 1 Outline Image Datasets and Tasks Convolution in Detail AlexNet Weight Initialization Batch Normalization
COMP9444 Neural Networks and Deep Learning 7. Image Processing COMP9444 17s2 Image Processing 1 Outline Image Datasets and Tasks Convolution in Detail AlexNet Weight Initialization Batch Normalization
Image Question Answering using Convolutional Neural Network with Dynamic Parameter Prediction
 Image Question Answering using Convolutional Neural Network with Dynamic Parameter Prediction by Noh, Hyeonwoo, Paul Hongsuck Seo, and Bohyung Han.[1] Presented : Badri Patro 1 1 Computer Vision Reading
Image Question Answering using Convolutional Neural Network with Dynamic Parameter Prediction by Noh, Hyeonwoo, Paul Hongsuck Seo, and Bohyung Han.[1] Presented : Badri Patro 1 1 Computer Vision Reading
Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting
 Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting Yaguang Li Joint work with Rose Yu, Cyrus Shahabi, Yan Liu Page 1 Introduction Traffic congesting is wasteful of time,
Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting Yaguang Li Joint work with Rose Yu, Cyrus Shahabi, Yan Liu Page 1 Introduction Traffic congesting is wasteful of time,
Structured Attention Networks
 Structured Attention Networks Yoon Kim Carl Denton Luong Hoang Alexander M. Rush HarvardNLP ICLR, 2017 Presenter: Chao Jiang ICLR, 2017 Presenter: Chao Jiang 1 / Outline 1 Deep Neutral Networks for Text
Structured Attention Networks Yoon Kim Carl Denton Luong Hoang Alexander M. Rush HarvardNLP ICLR, 2017 Presenter: Chao Jiang ICLR, 2017 Presenter: Chao Jiang 1 / Outline 1 Deep Neutral Networks for Text
Deep Generative Models Variational Autoencoders
 Deep Generative Models Variational Autoencoders Sudeshna Sarkar 5 April 2017 Generative Nets Generative models that represent probability distributions over multiple variables in some way. Directed Generative
Deep Generative Models Variational Autoencoders Sudeshna Sarkar 5 April 2017 Generative Nets Generative models that represent probability distributions over multiple variables in some way. Directed Generative
16-785: Integrated Intelligence in Robotics: Vision, Language, and Planning. Spring 2018 Lecture 14. Image to Text
 16-785: Integrated Intelligence in Robotics: Vision, Language, and Planning Spring 2018 Lecture 14. Image to Text Input Output Classification tasks 4/1/18 CMU 16-785: Integrated Intelligence in Robotics
16-785: Integrated Intelligence in Robotics: Vision, Language, and Planning Spring 2018 Lecture 14. Image to Text Input Output Classification tasks 4/1/18 CMU 16-785: Integrated Intelligence in Robotics
CAP 6412 Advanced Computer Vision
 CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong Feb 04, 2016 Today Administrivia Attention Modeling in Image Captioning, by Karan Neural networks & Backpropagation
CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong Feb 04, 2016 Today Administrivia Attention Modeling in Image Captioning, by Karan Neural networks & Backpropagation
Crowd Scene Understanding with Coherent Recurrent Neural Networks
 Crowd Scene Understanding with Coherent Recurrent Neural Networks Hang Su, Yinpeng Dong, Jun Zhu May 22, 2016 Hang Su, Yinpeng Dong, Jun Zhu IJCAI 2016 May 22, 2016 1 / 26 Outline 1 Introduction 2 LSTM
Crowd Scene Understanding with Coherent Recurrent Neural Networks Hang Su, Yinpeng Dong, Jun Zhu May 22, 2016 Hang Su, Yinpeng Dong, Jun Zhu IJCAI 2016 May 22, 2016 1 / 26 Outline 1 Introduction 2 LSTM
Deep Learning. Practical introduction with Keras JORDI TORRES 27/05/2018. Chapter 3 JORDI TORRES
 Deep Learning Practical introduction with Keras Chapter 3 27/05/2018 Neuron A neural network is formed by neurons connected to each other; in turn, each connection of one neural network is associated
Deep Learning Practical introduction with Keras Chapter 3 27/05/2018 Neuron A neural network is formed by neurons connected to each other; in turn, each connection of one neural network is associated
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 12 Combining
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 12 Combining
The Mathematics Behind Neural Networks
 The Mathematics Behind Neural Networks Pattern Recognition and Machine Learning by Christopher M. Bishop Student: Shivam Agrawal Mentor: Nathaniel Monson Courtesy of xkcd.com The Black Box Training the
The Mathematics Behind Neural Networks Pattern Recognition and Machine Learning by Christopher M. Bishop Student: Shivam Agrawal Mentor: Nathaniel Monson Courtesy of xkcd.com The Black Box Training the
Transition-based Parsing with Neural Nets
 CS11-747 Neural Networks for NLP Transition-based Parsing with Neural Nets Graham Neubig Site https://phontron.com/class/nn4nlp2017/ Two Types of Linguistic Structure Dependency: focus on relations between
CS11-747 Neural Networks for NLP Transition-based Parsing with Neural Nets Graham Neubig Site https://phontron.com/class/nn4nlp2017/ Two Types of Linguistic Structure Dependency: focus on relations between
Computer Vision Group Prof. Daniel Cremers. 4. Probabilistic Graphical Models Directed Models
 Prof. Daniel Cremers 4. Probabilistic Graphical Models Directed Models The Bayes Filter (Rep.) (Bayes) (Markov) (Tot. prob.) (Markov) (Markov) 2 Graphical Representation (Rep.) We can describe the overall
Prof. Daniel Cremers 4. Probabilistic Graphical Models Directed Models The Bayes Filter (Rep.) (Bayes) (Markov) (Tot. prob.) (Markov) (Markov) 2 Graphical Representation (Rep.) We can describe the overall
Trees. CSE 373 Data Structures
 Trees CSE 373 Data Structures Readings Reading Chapter 7 Trees 2 Why Do We Need Trees? Lists, Stacks, and Queues are linear relationships Information often contains hierarchical relationships File directories
Trees CSE 373 Data Structures Readings Reading Chapter 7 Trees 2 Why Do We Need Trees? Lists, Stacks, and Queues are linear relationships Information often contains hierarchical relationships File directories
7.1 Introduction. A (free) tree T is A simple graph such that for every pair of vertices v and w there is a unique path from v to w
 tree T is A simple graph such that for every pair of vertices v and w there is a unique path from v to w") Chapter 7 Trees 7.1 Introduction A (free) tree T is A simple graph such that for every pair of vertices v and w there is a unique path from v to w Tree Terminology Parent Ancestor Child Descendant Siblings
Chapter 7 Trees 7.1 Introduction A (free) tree T is A simple graph such that for every pair of vertices v and w there is a unique path from v to w Tree Terminology Parent Ancestor Child Descendant Siblings
Recurrent Neural Nets II
 Recurrent Neural Nets II Steven Spielberg Pon Kumar, Tingke (Kevin) Shen Machine Learning Reading Group, Fall 2016 9 November, 2016 Outline 1 Introduction 2 Problem Formulations with RNNs 3 LSTM for Optimization
Recurrent Neural Nets II Steven Spielberg Pon Kumar, Tingke (Kevin) Shen Machine Learning Reading Group, Fall 2016 9 November, 2016 Outline 1 Introduction 2 Problem Formulations with RNNs 3 LSTM for Optimization
TREES Lecture 10 CS2110 Spring2014
 TREES Lecture 10 CS2110 Spring2014 Readings and Homework 2 Textbook, Chapter 23, 24 Homework: A thought problem (draw pictures!) Suppose you use trees to represent student schedules. For each student there
TREES Lecture 10 CS2110 Spring2014 Readings and Homework 2 Textbook, Chapter 23, 24 Homework: A thought problem (draw pictures!) Suppose you use trees to represent student schedules. For each student there
12/5/17. trees. CS 220: Discrete Structures and their Applications. Trees Chapter 11 in zybooks. rooted trees. rooted trees
 trees CS 220: Discrete Structures and their Applications A tree is an undirected graph that is connected and has no cycles. Trees Chapter 11 in zybooks rooted trees Rooted trees. Given a tree T, choose
trees CS 220: Discrete Structures and their Applications A tree is an undirected graph that is connected and has no cycles. Trees Chapter 11 in zybooks rooted trees Rooted trees. Given a tree T, choose
Transition-Based Dependency Parsing with Stack Long Short-Term Memory
 Transition-Based Dependency Parsing with Stack Long Short-Term Memory Chris Dyer, Miguel Ballesteros, Wang Ling, Austin Matthews, Noah A. Smith Association for Computational Linguistics (ACL), 2015 Presented
Transition-Based Dependency Parsing with Stack Long Short-Term Memory Chris Dyer, Miguel Ballesteros, Wang Ling, Austin Matthews, Noah A. Smith Association for Computational Linguistics (ACL), 2015 Presented
LSTM: An Image Classification Model Based on Fashion-MNIST Dataset
 LSTM: An Image Classification Model Based on Fashion-MNIST Dataset Kexin Zhang, Research School of Computer Science, Australian National University Kexin Zhang, U6342657@anu.edu.au Abstract. The application
LSTM: An Image Classification Model Based on Fashion-MNIST Dataset Kexin Zhang, Research School of Computer Science, Australian National University Kexin Zhang, U6342657@anu.edu.au Abstract. The application
CS381V Experiment Presentation. Chun-Chen Kuo
 CS381V Experiment Presentation Chun-Chen Kuo The Paper Indoor Segmentation and Support Inference from RGBD Images. N. Silberman, D. Hoiem, P. Kohli, and R. Fergus. ECCV 2012. 50 100 150 200 250 300 350
CS381V Experiment Presentation Chun-Chen Kuo The Paper Indoor Segmentation and Support Inference from RGBD Images. N. Silberman, D. Hoiem, P. Kohli, and R. Fergus. ECCV 2012. 50 100 150 200 250 300 350