Unsupervised Learning. Pantelis P. Analytis. Introduction. Finding structure in graphs. Clustering analysis. Dimensionality reduction.
|
|
|
- Rodger Bishop
- 5 years ago
- Views:
Transcription
1 March 19, / 40
2 / 40
3 What s unsupervised learning? Most of the data available on the internet do not have labels. How can we make sense of it? 3 / 40
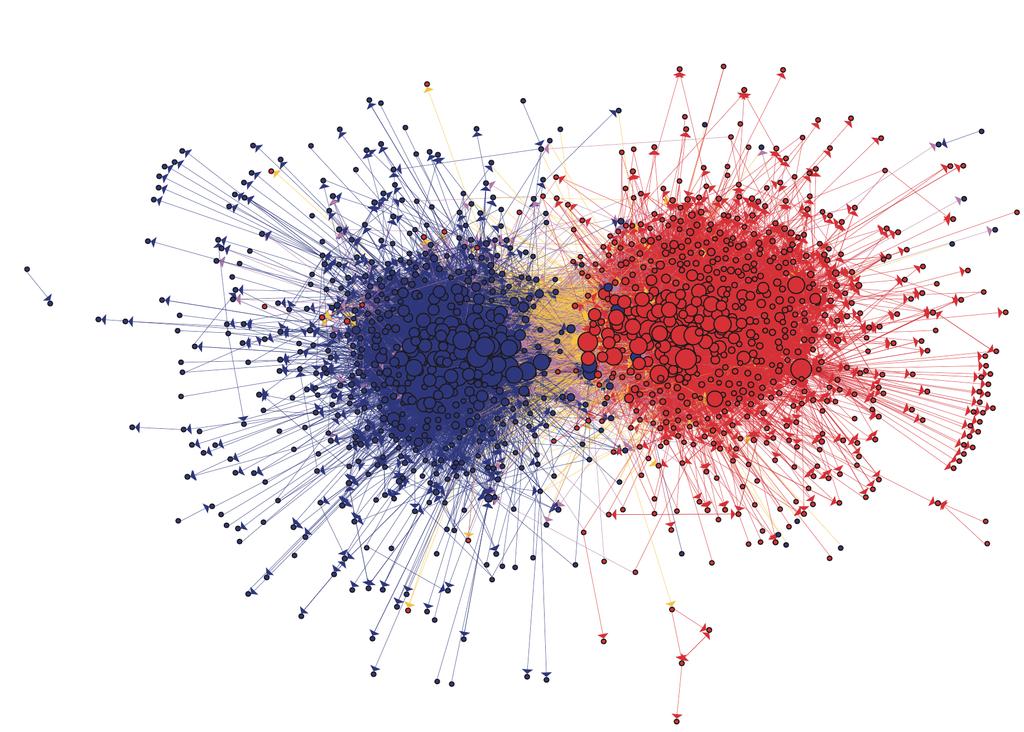
4 4 / 40
5 5 / 40

6 Organizing the web First attempts to organize the web were based on human curated directories (Yahoo, looksmart). People also used methods from information retrieval to uncover relevant documents. Yet he web has a deluge of untrusted documents, spam, random webpages, advertisements etc. 6 / 40
7 Elements of the PageRank algorithm Solution: Use social feedback to rank the quality of documents. You can see links as vote. A page is more important when it has more incoming links. For instance has numerous incoming notes, as opposed to Links from important questions count more Recursiveness. 7 / 40
8 The iterative PageRank algorithm At t = 0, assume an initial probability distribution: PR(p i ; 0) = 1 N. At each time step, the computation yields: PR(p i ; t + 1) = 1 d N + d p j M(p i ) PR(p j ;t) L(p j ) 8 / 40
9 At t = 0, assume an initial probability distribution: PR(p i ; 0) = 1 N. At each time step, the computation yields: PR(p i ; t + 1) = 1 d N + d PR(p j ;t) p j M(p i ) L(p j ) 9 / 40
10 10 / 40
11 Page Rank Equilibrium 11 / 40
12 PageRank: The spider trap 12 / 40
13 PageRank: The spider trap 13 / 40
14 The Scaled PageRank algorithm Scaled PageRank Update Rule Apply basic PR rule. Scale all values down by factor s. Divide the 1-s leftover units of PR evenly over nodes. 14 / 40
15 What s unsupervised learning? Most of the data available on the internet do not have labels. How can we make sense of it? 15 / 40
16 : the k-means algorithm Input: K, set of points x 1,..., x n Place centroids c 1,..., c k randomly Then repeat until convergence: For each point x i find the nearest centroid c j and assign that point to that cluster In math notation: argmin j D(x i, c j ) For each cluster j = 1,..., K find the new centroid of all points x i assigned to cluster j in previous step. In math notation: c j (a) = 1/n j x i (a) for a = 1,..., d x i c j Stop when the algorithm has converged i.e. none of the items changes cluster. 16 / 40
17 Converging to clusters 17 / 40
18 How do we select k? There are diminishing returns in the size of different clusters. An intuitive approach suggests picking the after which the distance flattens out. 18 / 40
19 Hierarchical 19 / 40
20 Agglomerative vs. divisive Agglomerative clustering starts from the bottom and moves to larger clusters. Divisive clustering starts with one cluster which is gradually disintegrated into smaller ones. 20 / 40
21 Agglomerative vs. divisive How do we determine the nearness of clusters? Complete linkage: D(X, Y ) = max x X,y Y d(x, y) Single linkage: D(X, Y ) = min x X,y Y d(x, y) Average linkage: 1 X Y x X y Y d(x, y). 21 / 40
22 Agglomerative Pick k upfront, stop when we have k clusters. Stop when a cluster with low cohesion is created (diameter, radius or density-based approaches). 22 / 40
23 Kohonen s self-organizing maps Step 0: Randomly position the grid s neurons in the data space. 23 / 40
24 Kohonen s self-organizing maps Step 1: Select one data point, either randomly or systematically cycling through the dataset in order 24 / 40
25 Kohonen s self-organizing maps Step 2: Find the neuron that is closest to the chosen data point. This neuron is called the Best Matching Unit (BMU). 25 / 40
26 Kohonen s self-organizing maps Step 3: Move the BMU closer to that data point. The distance moved by the BMU is determined by a learning rate, which decreases after each iteration. 26 / 40
27 Kohonen s self-organizing maps Step 4: Move the BMU s neighbors closer to that data point as well, with farther away neighbors moving less. Neighbors are identified using a radius around the BMU, and the value for this radius decreases after each iteration. 27 / 40
28 Kohonen s self-organizing maps 28 / 40
29 Kohonen s self-organizing maps 29 / 40
30 Kohonen s self-organizing maps 30 / 40
31 Kohonen s self-organizing maps 31 / 40
32 Kohonen s self-organizing maps Update the learning rate and BMU radius, before repeating Steps 1 to 4. Iterate these steps until positions of neurons have been stabilized. 32 / 40

33 Kohonen s self-organizing maps 33 / 40
34 Principal component 34 / 40
35 Principal component 35 / 40
36 Principal component 36 / 40
37 Principal component Often used to accelerate supervised learning. Visualization 37 / 40
38 Principal component 38 / 40
39 Principal component 39 / 40
40 in recommender systems 40 / 40
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Data Mining and Data Warehousing Henryk Maciejewski Data Mining Clustering
 Data Mining and Data Warehousing Henryk Maciejewski Data Mining Clustering Clustering Algorithms Contents K-means Hierarchical algorithms Linkage functions Vector quantization SOM Clustering Formulation
Data Mining and Data Warehousing Henryk Maciejewski Data Mining Clustering Clustering Algorithms Contents K-means Hierarchical algorithms Linkage functions Vector quantization SOM Clustering Formulation
Clustering Results. Result List Example. Clustering Results. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Presenting Results Clustering Clustering Results! Result lists often contain documents related to different aspects of the query topic! Clustering is used to
Information Retrieval INFO 4300 / CS 4300! Presenting Results Clustering Clustering Results! Result lists often contain documents related to different aspects of the query topic! Clustering is used to
Cluster Analysis: Agglomerate Hierarchical Clustering
 Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Introduction to Data Mining
 Introduction to Data Mining Lecture #14: Clustering Seoul National University 1 In This Lecture Learn the motivation, applications, and goal of clustering Understand the basic methods of clustering (bottom-up
Introduction to Data Mining Lecture #14: Clustering Seoul National University 1 In This Lecture Learn the motivation, applications, and goal of clustering Understand the basic methods of clustering (bottom-up
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Part 1: Link Analysis & Page Rank
 Chapter 8: Graph Data Part 1: Link Analysis & Page Rank Based on Leskovec, Rajaraman, Ullman 214: Mining of Massive Datasets 1 Graph Data: Social Networks [Source: 4-degrees of separation, Backstrom-Boldi-Rosa-Ugander-Vigna,
Chapter 8: Graph Data Part 1: Link Analysis & Page Rank Based on Leskovec, Rajaraman, Ullman 214: Mining of Massive Datasets 1 Graph Data: Social Networks [Source: 4-degrees of separation, Backstrom-Boldi-Rosa-Ugander-Vigna,
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
Machine Learning and Data Mining. Clustering. (adapted from) Prof. Alexander Ihler
 Prof. Alexander Ihler") Machine Learning and Data Mining Clustering (adapted from) Prof. Alexander Ihler Overview What is clustering and its applications? Distance between two clusters. Hierarchical Agglomerative clustering.
Machine Learning and Data Mining Clustering (adapted from) Prof. Alexander Ihler Overview What is clustering and its applications? Distance between two clusters. Hierarchical Agglomerative clustering.
Unsupervised Learning and Data Mining
 Unsupervised Learning and Data Mining Unsupervised Learning and Data Mining Clustering Supervised Learning ó Decision trees ó Artificial neural nets ó K-nearest neighbor ó Support vectors ó Linear regression
Unsupervised Learning and Data Mining Unsupervised Learning and Data Mining Clustering Supervised Learning ó Decision trees ó Artificial neural nets ó K-nearest neighbor ó Support vectors ó Linear regression
How to organize the Web?
 How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second try: Web Search Information Retrieval attempts to find relevant docs in a small and trusted set Newspaper
How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second try: Web Search Information Retrieval attempts to find relevant docs in a small and trusted set Newspaper
Administrative. Machine learning code. Supervised learning (e.g. classification) Machine learning: Unsupervised learning" BANANAS APPLES
 Machine learning: Unsupervised learning BANANAS APPLES") Administrative Machine learning: Unsupervised learning" Assignment 5 out soon David Kauchak cs311 Spring 2013 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Machine
Administrative Machine learning: Unsupervised learning" Assignment 5 out soon David Kauchak cs311 Spring 2013 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Machine
Clustering and Dimensionality Reduction. Stony Brook University CSE545, Fall 2017
 Clustering and Dimensionality Reduction Stony Brook University CSE545, Fall 2017 Goal: Generalize to new data Model New Data? Original Data Does the model accurately reflect new data? Supervised vs. Unsupervised
Clustering and Dimensionality Reduction Stony Brook University CSE545, Fall 2017 Goal: Generalize to new data Model New Data? Original Data Does the model accurately reflect new data? Supervised vs. Unsupervised
4. Cluster Analysis. Francesc J. Ferri. Dept. d Informàtica. Universitat de València. Febrer F.J. Ferri (Univ. València) AIRF 2/ / 1
 AIRF 2/ / 1") Anàlisi d Imatges i Reconeixement de Formes Image Analysis and Pattern Recognition:. Cluster Analysis Francesc J. Ferri Dept. d Informàtica. Universitat de València Febrer 8 F.J. Ferri (Univ. València)
Anàlisi d Imatges i Reconeixement de Formes Image Analysis and Pattern Recognition:. Cluster Analysis Francesc J. Ferri Dept. d Informàtica. Universitat de València Febrer 8 F.J. Ferri (Univ. València)
4. Ad-hoc I: Hierarchical clustering
 4. Ad-hoc I: Hierarchical clustering Hierarchical versus Flat Flat methods generate a single partition into k clusters. The number k of clusters has to be determined by the user ahead of time. Hierarchical
4. Ad-hoc I: Hierarchical clustering Hierarchical versus Flat Flat methods generate a single partition into k clusters. The number k of clusters has to be determined by the user ahead of time. Hierarchical
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University
 Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
K-Means Clustering 3/3/17
 K-Means Clustering 3/3/17 Unsupervised Learning We have a collection of unlabeled data points. We want to find underlying structure in the data. Examples: Identify groups of similar data points. Clustering
K-Means Clustering 3/3/17 Unsupervised Learning We have a collection of unlabeled data points. We want to find underlying structure in the data. Examples: Identify groups of similar data points. Clustering
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Hierarchical Clustering 4/5/17
 Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Unsupervised Learning Hierarchical Methods
 Unsupervised Learning Hierarchical Methods Road Map. Basic Concepts 2. BIRCH 3. ROCK The Principle Group data objects into a tree of clusters Hierarchical methods can be Agglomerative: bottom-up approach
Unsupervised Learning Hierarchical Methods Road Map. Basic Concepts 2. BIRCH 3. ROCK The Principle Group data objects into a tree of clusters Hierarchical methods can be Agglomerative: bottom-up approach
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Node Importance and Neighborhoods
 Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Node Importance and Neighborhoods Matthias Schubert, Matthias Renz, Felix Borutta, Evgeniy Faerman, Christian Frey, Klaus Arthur
Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Node Importance and Neighborhoods Matthias Schubert, Matthias Renz, Felix Borutta, Evgeniy Faerman, Christian Frey, Klaus Arthur
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest)
") Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Clustering algorithms
 Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
CSE494 Information Retrieval Project C Report
 CSE494 Information Retrieval Project C Report By: Jianchun Fan Introduction In project C we implement several different clustering methods on the query results given by pagerank algorithms. The clustering
CSE494 Information Retrieval Project C Report By: Jianchun Fan Introduction In project C we implement several different clustering methods on the query results given by pagerank algorithms. The clustering
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Introduction to Artificial Intelligence
 Introduction to Artificial Intelligence COMP307 Machine Learning 2: 3-K Techniques Yi Mei yi.mei@ecs.vuw.ac.nz 1 Outline K-Nearest Neighbour method Classification (Supervised learning) Basic NN (1-NN)
Introduction to Artificial Intelligence COMP307 Machine Learning 2: 3-K Techniques Yi Mei yi.mei@ecs.vuw.ac.nz 1 Outline K-Nearest Neighbour method Classification (Supervised learning) Basic NN (1-NN)
Cluster Analysis for Microarray Data
 Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
Unsupervised Learning
 Networks for Pattern Recognition, 2014 Networks for Single Linkage K-Means Soft DBSCAN PCA Networks for Kohonen Maps Linear Vector Quantization Networks for Problems/Approaches in Machine Learning Supervised
Networks for Pattern Recognition, 2014 Networks for Single Linkage K-Means Soft DBSCAN PCA Networks for Kohonen Maps Linear Vector Quantization Networks for Problems/Approaches in Machine Learning Supervised
Supervised vs.unsupervised Learning
 Supervised vs.unsupervised Learning In supervised learning we train algorithms with predefined concepts and functions based on labeled data D = { ( x, y ) x X, y {yes,no}. In unsupervised learning we are
Supervised vs.unsupervised Learning In supervised learning we train algorithms with predefined concepts and functions based on labeled data D = { ( x, y ) x X, y {yes,no}. In unsupervised learning we are
Lesson 3. Prof. Enza Messina
 Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
ECG782: Multidimensional Digital Signal Processing
 ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
Methods for Intelligent Systems
 Methods for Intelligent Systems Lecture Notes on Clustering (II) Davide Eynard eynard@elet.polimi.it Department of Electronics and Information Politecnico di Milano Davide Eynard - Lecture Notes on Clustering
Methods for Intelligent Systems Lecture Notes on Clustering (II) Davide Eynard eynard@elet.polimi.it Department of Electronics and Information Politecnico di Milano Davide Eynard - Lecture Notes on Clustering
Clustering Color/Intensity. Group together pixels of similar color/intensity.
 Clustering Color/Intensity Group together pixels of similar color/intensity. Agglomerative Clustering Cluster = connected pixels with similar color. Optimal decomposition may be hard. For example, find
Clustering Color/Intensity Group together pixels of similar color/intensity. Agglomerative Clustering Cluster = connected pixels with similar color. Optimal decomposition may be hard. For example, find
Figure (5) Kohonen Self-Organized Map
 Kohonen Self-Organized Map") 2- KOHONEN SELF-ORGANIZING MAPS (SOM) - The self-organizing neural networks assume a topological structure among the cluster units. - There are m cluster units, arranged in a one- or two-dimensional array;
2- KOHONEN SELF-ORGANIZING MAPS (SOM) - The self-organizing neural networks assume a topological structure among the cluster units. - There are m cluster units, arranged in a one- or two-dimensional array;
DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li
 Welcome to DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li Time: 6:00pm 8:50pm Thu Location: AK 232 Fall 2016 High Dimensional Data v Given a cloud of data points we want to understand
Welcome to DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li Time: 6:00pm 8:50pm Thu Location: AK 232 Fall 2016 High Dimensional Data v Given a cloud of data points we want to understand
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Data Informatics. Seon Ho Kim, Ph.D.
 Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu Clustering Overview Supervised vs. Unsupervised Learning Supervised learning (classification) Supervision: The training data (observations, measurements,
Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu Clustering Overview Supervised vs. Unsupervised Learning Supervised learning (classification) Supervision: The training data (observations, measurements,
Unsupervised Data Mining: Clustering. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Statistics 202: Data Mining. c Jonathan Taylor. Clustering Based in part on slides from textbook, slides of Susan Holmes.
 Clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group will be similar (or
Clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group will be similar (or
Measure of Distance. We wish to define the distance between two objects Distance metric between points:
 Measure of Distance We wish to define the distance between two objects Distance metric between points: Euclidean distance (EUC) Manhattan distance (MAN) Pearson sample correlation (COR) Angle distance
Measure of Distance We wish to define the distance between two objects Distance metric between points: Euclidean distance (EUC) Manhattan distance (MAN) Pearson sample correlation (COR) Angle distance
Data Warehousing and Machine Learning
 Data Warehousing and Machine Learning Preprocessing Thomas D. Nielsen Aalborg University Department of Computer Science Spring 2008 DWML Spring 2008 1 / 35 Preprocessing Before you can start on the actual
Data Warehousing and Machine Learning Preprocessing Thomas D. Nielsen Aalborg University Department of Computer Science Spring 2008 DWML Spring 2008 1 / 35 Preprocessing Before you can start on the actual
5/15/16. Computational Methods for Data Analysis. Massimo Poesio UNSUPERVISED LEARNING. Clustering. Unsupervised learning introduction
 Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Uninformed Search Methods. Informed Search Methods. Midterm Exam 3/13/18. Thursday, March 15, 7:30 9:30 p.m. room 125 Ag Hall
 Midterm Exam Thursday, March 15, 7:30 9:30 p.m. room 125 Ag Hall Covers topics through Decision Trees and Random Forests (does not include constraint satisfaction) Closed book 8.5 x 11 sheet with notes
Midterm Exam Thursday, March 15, 7:30 9:30 p.m. room 125 Ag Hall Covers topics through Decision Trees and Random Forests (does not include constraint satisfaction) Closed book 8.5 x 11 sheet with notes
Clustering Algorithm (DBSCAN) VISHAL BHARTI Computer Science Dept. GC, CUNY
 VISHAL BHARTI Computer Science Dept. GC, CUNY") Clustering Algorithm (DBSCAN) VISHAL BHARTI Computer Science Dept. GC, CUNY Clustering Algorithm Clustering is an unsupervised machine learning algorithm that divides a data into meaningful sub-groups,
Clustering Algorithm (DBSCAN) VISHAL BHARTI Computer Science Dept. GC, CUNY Clustering Algorithm Clustering is an unsupervised machine learning algorithm that divides a data into meaningful sub-groups,
Clustering. Unsupervised Learning
 Clustering. Unsupervised Learning Maria-Florina Balcan 03/02/2016 Clustering, Informal Goals Goal: Automatically partition unlabeled data into groups of similar datapoints. Question: When and why would
Clustering. Unsupervised Learning Maria-Florina Balcan 03/02/2016 Clustering, Informal Goals Goal: Automatically partition unlabeled data into groups of similar datapoints. Question: When and why would
Clustering. Robert M. Haralick. Computer Science, Graduate Center City University of New York
 Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu HITS (Hypertext Induced Topic Selection) Is a measure of importance of pages or documents, similar to PageRank
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu HITS (Hypertext Induced Topic Selection) Is a measure of importance of pages or documents, similar to PageRank
Today s lecture. Clustering and unsupervised learning. Hierarchical clustering. K-means, K-medoids, VQ
 Clustering CS498 Today s lecture Clustering and unsupervised learning Hierarchical clustering K-means, K-medoids, VQ Unsupervised learning Supervised learning Use labeled data to do something smart What
Clustering CS498 Today s lecture Clustering and unsupervised learning Hierarchical clustering K-means, K-medoids, VQ Unsupervised learning Supervised learning Use labeled data to do something smart What
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
Preprocessing DWML, /33
 Preprocessing DWML, 2007 1/33 Preprocessing Before you can start on the actual data mining, the data may require some preprocessing: Attributes may be redundant. Values may be missing. The data contains
Preprocessing DWML, 2007 1/33 Preprocessing Before you can start on the actual data mining, the data may require some preprocessing: Attributes may be redundant. Values may be missing. The data contains
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu SPAM FARMING 2/11/2013 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 2/11/2013 Jure Leskovec, Stanford
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu SPAM FARMING 2/11/2013 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 2/11/2013 Jure Leskovec, Stanford
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning
 COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
Olmo S. Zavala Romero. Clustering Hierarchical Distance Group Dist. K-means. Center of Atmospheric Sciences, UNAM.
 Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Clustering analysis of gene expression data
 Clustering analysis of gene expression data Chapter 11 in Jonathan Pevsner, Bioinformatics and Functional Genomics, 3 rd edition (Chapter 9 in 2 nd edition) Human T cell expression data The matrix contains
Clustering analysis of gene expression data Chapter 11 in Jonathan Pevsner, Bioinformatics and Functional Genomics, 3 rd edition (Chapter 9 in 2 nd edition) Human T cell expression data The matrix contains
Hard clustering. Each object is assigned to one and only one cluster. Hierarchical clustering is usually hard. Soft (fuzzy) clustering
 clustering") An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
Introduction to Machine Learning. Xiaojin Zhu
 Introduction to Machine Learning Xiaojin Zhu jerryzhu@cs.wisc.edu Read Chapter 1 of this book: Xiaojin Zhu and Andrew B. Goldberg. Introduction to Semi- Supervised Learning. http://www.morganclaypool.com/doi/abs/10.2200/s00196ed1v01y200906aim006
Introduction to Machine Learning Xiaojin Zhu jerryzhu@cs.wisc.edu Read Chapter 1 of this book: Xiaojin Zhu and Andrew B. Goldberg. Introduction to Semi- Supervised Learning. http://www.morganclaypool.com/doi/abs/10.2200/s00196ed1v01y200906aim006
Machine Learning. Unsupervised Learning. Manfred Huber
 Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Clustering: K-means and Kernel K-means
 Clustering: K-means and Kernel K-means Piyush Rai Machine Learning (CS771A) Aug 31, 2016 Machine Learning (CS771A) Clustering: K-means and Kernel K-means 1 Clustering Usually an unsupervised learning problem
Clustering: K-means and Kernel K-means Piyush Rai Machine Learning (CS771A) Aug 31, 2016 Machine Learning (CS771A) Clustering: K-means and Kernel K-means 1 Clustering Usually an unsupervised learning problem
Clustering. Partition unlabeled examples into disjoint subsets of clusters, such that:
 Text Clustering 1 Clustering Partition unlabeled examples into disjoint subsets of clusters, such that: Examples within a cluster are very similar Examples in different clusters are very different Discover
Text Clustering 1 Clustering Partition unlabeled examples into disjoint subsets of clusters, such that: Examples within a cluster are very similar Examples in different clusters are very different Discover
Clustering k-mean clustering
 Clustering k-mean clustering Genome 373 Genomic Informatics Elhanan Borenstein The clustering problem: partition genes into distinct sets with high homogeneity and high separation Clustering (unsupervised)
Clustering k-mean clustering Genome 373 Genomic Informatics Elhanan Borenstein The clustering problem: partition genes into distinct sets with high homogeneity and high separation Clustering (unsupervised)
Cluster Analysis. Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX April 2008 April 2010
 Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
Clustering. RNA-seq: What is it good for? Finding Similarly Expressed Genes. Data... And Lots of It!
 RNA-seq: What is it good for? Clustering High-throughput RNA sequencing experiments (RNA-seq) offer the ability to measure simultaneously the expression level of thousands of genes in a single experiment!
RNA-seq: What is it good for? Clustering High-throughput RNA sequencing experiments (RNA-seq) offer the ability to measure simultaneously the expression level of thousands of genes in a single experiment!
A Tutorial on the Probabilistic Framework for Centrality Analysis, Community Detection and Clustering
 A Tutorial on the Probabilistic Framework for Centrality Analysis, Community Detection and Clustering 1 Cheng-Shang Chang All rights reserved Abstract Analysis of networked data has received a lot of attention
A Tutorial on the Probabilistic Framework for Centrality Analysis, Community Detection and Clustering 1 Cheng-Shang Chang All rights reserved Abstract Analysis of networked data has received a lot of attention
CS325 Artificial Intelligence Ch. 20 Unsupervised Machine Learning
 CS325 Artificial Intelligence Cengiz Spring 2013 Unsupervised Learning Missing teacher No labels, y Just input data, x What can you learn with it? Unsupervised Learning Missing teacher No labels, y Just
CS325 Artificial Intelligence Cengiz Spring 2013 Unsupervised Learning Missing teacher No labels, y Just input data, x What can you learn with it? Unsupervised Learning Missing teacher No labels, y Just
Clustering. Unsupervised Learning
 Clustering. Unsupervised Learning Maria-Florina Balcan 11/05/2018 Clustering, Informal Goals Goal: Automatically partition unlabeled data into groups of similar datapoints. Question: When and why would
Clustering. Unsupervised Learning Maria-Florina Balcan 11/05/2018 Clustering, Informal Goals Goal: Automatically partition unlabeled data into groups of similar datapoints. Question: When and why would
Unsupervised Learning
 Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support, Fall 2005 Instructors: Professor Lucila Ohno-Machado and Professor Staal Vinterbo 6.873/HST.951 Medical Decision
Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support, Fall 2005 Instructors: Professor Lucila Ohno-Machado and Professor Staal Vinterbo 6.873/HST.951 Medical Decision
STATS306B STATS306B. Clustering. Jonathan Taylor Department of Statistics Stanford University. June 3, 2010
 STATS306B Jonathan Taylor Department of Statistics Stanford University June 3, 2010 Spring 2010 Outline K-means, K-medoids, EM algorithm choosing number of clusters: Gap test hierarchical clustering spectral
STATS306B Jonathan Taylor Department of Statistics Stanford University June 3, 2010 Spring 2010 Outline K-means, K-medoids, EM algorithm choosing number of clusters: Gap test hierarchical clustering spectral
Unsupervised learning on Color Images
 Unsupervised learning on Color Images Sindhuja Vakkalagadda 1, Prasanthi Dhavala 2 1 Computer Science and Systems Engineering, Andhra University, AP, India 2 Computer Science and Systems Engineering, Andhra
Unsupervised learning on Color Images Sindhuja Vakkalagadda 1, Prasanthi Dhavala 2 1 Computer Science and Systems Engineering, Andhra University, AP, India 2 Computer Science and Systems Engineering, Andhra
Based on Raymond J. Mooney s slides
 Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
An Unsupervised Approach for Combining Scores of Outlier Detection Techniques, Based on Similarity Measures
 An Unsupervised Approach for Combining Scores of Outlier Detection Techniques, Based on Similarity Measures José Ramón Pasillas-Díaz, Sylvie Ratté Presenter: Christoforos Leventis 1 Basic concepts Outlier
An Unsupervised Approach for Combining Scores of Outlier Detection Techniques, Based on Similarity Measures José Ramón Pasillas-Díaz, Sylvie Ratté Presenter: Christoforos Leventis 1 Basic concepts Outlier
Chapter 9. Classification and Clustering
 Chapter 9 Classification and Clustering Classification and Clustering Classification and clustering are classical pattern recognition and machine learning problems Classification, also referred to as categorization
Chapter 9 Classification and Clustering Classification and Clustering Classification and clustering are classical pattern recognition and machine learning problems Classification, also referred to as categorization
CSE 40171: Artificial Intelligence. Learning from Data: Unsupervised Learning
 CSE 40171: Artificial Intelligence Learning from Data: Unsupervised Learning 32 Homework #6 has been released. It is due at 11:59PM on 11/7. 33 CSE Seminar: 11/1 Amy Reibman Purdue University 3:30pm DBART
CSE 40171: Artificial Intelligence Learning from Data: Unsupervised Learning 32 Homework #6 has been released. It is due at 11:59PM on 11/7. 33 CSE Seminar: 11/1 Amy Reibman Purdue University 3:30pm DBART
Information Networks: PageRank
 Information Networks: PageRank Web Science (VU) (706.716) Elisabeth Lex ISDS, TU Graz June 18, 2018 Elisabeth Lex (ISDS, TU Graz) Links June 18, 2018 1 / 38 Repetition Information Networks Shape of the
Information Networks: PageRank Web Science (VU) (706.716) Elisabeth Lex ISDS, TU Graz June 18, 2018 Elisabeth Lex (ISDS, TU Graz) Links June 18, 2018 1 / 38 Repetition Information Networks Shape of the
Unsupervised: no target value to predict
 Clustering Unsupervised: no target value to predict Differences between models/algorithms: Exclusive vs. overlapping Deterministic vs. probabilistic Hierarchical vs. flat Incremental vs. batch learning
Clustering Unsupervised: no target value to predict Differences between models/algorithms: Exclusive vs. overlapping Deterministic vs. probabilistic Hierarchical vs. flat Incremental vs. batch learning
Exploratory Data Analysis using Self-Organizing Maps. Madhumanti Ray
 Exploratory Data Analysis using Self-Organizing Maps Madhumanti Ray Content Introduction Data Analysis methods Self-Organizing Maps Conclusion Visualization of high-dimensional data items Exploratory data
Exploratory Data Analysis using Self-Organizing Maps Madhumanti Ray Content Introduction Data Analysis methods Self-Organizing Maps Conclusion Visualization of high-dimensional data items Exploratory data
Computational Statistics The basics of maximum likelihood estimation, Bayesian estimation, object recognitions
 Computational Statistics The basics of maximum likelihood estimation, Bayesian estimation, object recognitions Thomas Giraud Simon Chabot October 12, 2013 Contents 1 Discriminant analysis 3 1.1 Main idea................................
Computational Statistics The basics of maximum likelihood estimation, Bayesian estimation, object recognitions Thomas Giraud Simon Chabot October 12, 2013 Contents 1 Discriminant analysis 3 1.1 Main idea................................
Midterm Examination CS540-2: Introduction to Artificial Intelligence
 Midterm Examination CS540-2: Introduction to Artificial Intelligence March 15, 2018 LAST NAME: FIRST NAME: Problem Score Max Score 1 12 2 13 3 9 4 11 5 8 6 13 7 9 8 16 9 9 Total 100 Question 1. [12] Search
Midterm Examination CS540-2: Introduction to Artificial Intelligence March 15, 2018 LAST NAME: FIRST NAME: Problem Score Max Score 1 12 2 13 3 9 4 11 5 8 6 13 7 9 8 16 9 9 Total 100 Question 1. [12] Search
CS249: SPECIAL TOPICS MINING INFORMATION/SOCIAL NETWORKS
 CS249: SPECIAL TOPICS MINING INFORMATION/SOCIAL NETWORKS Overview of Networks Instructor: Yizhou Sun yzsun@cs.ucla.edu January 10, 2017 Overview of Information Network Analysis Network Representation Network
CS249: SPECIAL TOPICS MINING INFORMATION/SOCIAL NETWORKS Overview of Networks Instructor: Yizhou Sun yzsun@cs.ucla.edu January 10, 2017 Overview of Information Network Analysis Network Representation Network
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
Hierarchical clustering
 Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
K Nearest Neighbor Wrap Up K- Means Clustering. Slides adapted from Prof. Carpuat
 K Nearest Neighbor Wrap Up K- Means Clustering Slides adapted from Prof. Carpuat K Nearest Neighbor classification Classification is based on Test instance with Training Data K: number of neighbors that
K Nearest Neighbor Wrap Up K- Means Clustering Slides adapted from Prof. Carpuat K Nearest Neighbor classification Classification is based on Test instance with Training Data K: number of neighbors that
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering
 INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
Applications. Foreground / background segmentation Finding skin-colored regions. Finding the moving objects. Intelligent scissors
 Segmentation I Goal Separate image into coherent regions Berkeley segmentation database: http://www.eecs.berkeley.edu/research/projects/cs/vision/grouping/segbench/ Slide by L. Lazebnik Applications Intelligent
Segmentation I Goal Separate image into coherent regions Berkeley segmentation database: http://www.eecs.berkeley.edu/research/projects/cs/vision/grouping/segbench/ Slide by L. Lazebnik Applications Intelligent
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Flat Clustering. Slides are mostly from Hinrich Schütze. March 27, 2017
 Flat Clustering Slides are mostly from Hinrich Schütze March 7, 07 / 79 Overview Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? / 79 Outline Recap Clustering:
Flat Clustering Slides are mostly from Hinrich Schütze March 7, 07 / 79 Overview Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? / 79 Outline Recap Clustering:
Clustering in Data Mining
 Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Finding Clusters 1 / 60
 Finding Clusters Types of Clustering Approaches: Linkage Based, e.g. Hierarchical Clustering Clustering by Partitioning, e.g. k-means Density Based Clustering, e.g. DBScan Grid Based Clustering 1 / 60
Finding Clusters Types of Clustering Approaches: Linkage Based, e.g. Hierarchical Clustering Clustering by Partitioning, e.g. k-means Density Based Clustering, e.g. DBScan Grid Based Clustering 1 / 60
MIDTERM EXAMINATION Networked Life (NETS 112) November 21, 2013 Prof. Michael Kearns
 November 21, 2013 Prof. Michael Kearns") MIDTERM EXAMINATION Networked Life (NETS 112) November 21, 2013 Prof. Michael Kearns This is a closed-book exam. You should have no material on your desk other than the exam itself and a pencil or pen.
MIDTERM EXAMINATION Networked Life (NETS 112) November 21, 2013 Prof. Michael Kearns This is a closed-book exam. You should have no material on your desk other than the exam itself and a pencil or pen.