Visualizing and Understanding Deep Texture Representations
|
|
|
- Hilda Curtis
- 5 years ago
- Views:
Transcription


![Recently, several attempts have been made in order to understand CNNs by visualizing the layers of a trained model [40], studying the invariances by inverting the model [8, 28, 35], and evaluating](/docs-images/82/87030271/images/1-3.jpg "the performance of CNNs for various recognition tasks. In this work we attempt to provide a similar understanding for CNN-based teture representations.")
![Our starting point is the bilinear CNN model of our previous work [25].](/docs-images/82/87030271/images/1-4.jpg "The technique builds an orderless image representation by taking the location-wise outer product of image features etracted from CNNs and aggregating them by averaging.")

1 Visualizing and Understanding Deep Teture Representations Tsung-Yu Lin University of Massachusetts, Amherst Subhransu Maji University of Massachusetts, Amherst lead to better accuracy and improved domain adaptation not only for teture recognition, but also for scene categorization, object classification, and fine-grained recognition. Despite their success little is known how these models represent invariances at the image and category level. Recently, several attempts have been made in order to understand CNNs by visualizing the layers of a trained model [40], studying the invariances by inverting the model [8, 28, 35], and evaluating the performance of CNNs for various recognition tasks. In this work we attempt to provide a similar understanding for CNN-based teture representations. Our starting point is the bilinear CNN model of our previous work [25]. The technique builds an orderless image representation by taking the location-wise outer product of image features etracted from CNNs and aggregating them by averaging. The model is closely related to Fisher vectors but has the advantage that gradients of the model can be easily computed allowing fine-tuning and inversion. Moreover, when the two CNNs are identical the biarxiv: v2 [cs.cv] 12 Apr 2016 Abstract A number of recent approaches have used deep convolutional neural networks CNNs to build teture representations. Nevertheless, it is still unclear how these models represent teture and invariances to categorical variations. This work conducts a systematic evaluation of recent CNN-based teture descriptors for recognition and attempts to understand the nature of invariances captured by these representations. First we show that the recently proposed bilinear CNN model [25] is an ecellent generalpurpose teture descriptor and compares favorably to other CNN-based descriptors on various teture and scene recognition benchmarks. The model is translationally invariant and obtains better accuracy on the ImageNet dataset without requiring spatial jittering of data compared to corresponding models trained with spatial jittering. Based on recent work [13, 28] we propose a technique to visualize pre-images, providing a means for understanding categorical properties that are captured by these representations. Finally, we show preliminary results on how a unified parametric model of teture analysis and synthesis can be used for attribute-based image manipulation, e.g. to make an image more swirly, honeycombed, or knitted. The source code and additional visualizations are available at 1. Introduction The study of teture has inspired many of the early representations of images. The idea of representing teture using the statistics of image patches have led to the development of tetons [21, 24], the popular bag-of-words models [6] and their variants such as the Fisher vector [30] and VLAD [19]. These fell out of favor when the latest generation of deep Convolutional Neural Networks CNNs showed significant improvements in recognition performance over a wide range of visual tasks [2, 14, 20, 33]. Recently however, the interest in teture descriptors have been revived by architectures that combine aspects of teture representations with CNNs. For instance, Cimpoi et al. [4] showed that Fisher vectors built on top of CNN activations dotted water landromat honeycombed wood bookstore Figure 1. How is teture represented in deep models? Visualizing various categories by inverting the bilinear CNN model [25] trained on DTD [3], FMD [34], and MIT Indoor dataset [32] each column from left to right. These images were obtained by starting from a random image and adjusting it though gradient descent to obtain high log-likelihood for the given category label using a multi-layer bilinear CNN model See Sect. 2 for details. Best viewed in color and with zoom.
2 linear features capture correlations between filter channels, similar to the early work in parametric teture representation of Portilla and Simoncelli [31]. Our first contribution is a systematic study of bilinear CNN features for teture recognition. Using the Flickr Material Dataset FMD [34], Describable Teture Dataset DTD [3] and KTH-T2b [1] we show that it performs favorably to Fisher vector CNN model [4], which is the current state of the art. Similar results are also reported for scene classification on the MIT indoor scene dataset [32]. We also evaluate the role of different layers, effect of scale, and fine-tuning for teture recognition. Our eperiments reveal that multi-scale information helps, but also that features from different layers are complementary and can be combined to improve performance in agreement with recent work [16, 26, 29]. Our second contribution is to investigate the role of translational invariance of these models due to the orderless pooling of local descriptors. Recently, we showed [25] that bilinear CNNs initialized by pre-training a standard CNN e.g., VGG-M [2] on ImageNet, truncating the network at a lower convolutional layer e.g., conv5, adding bilinear pooling modules, followed by domain-specific fine-tuning leads to significant improvements in accuracy for a number of fine-grained recognition tasks. These models capture localized feature interactions in a translationally invariant manner which is useful for making fine-grained distinctions between species of birds or models of cars. However, it remains unclear what the tradeoffs are between eplicit translational invariance in these models versus implicit invariance obtained by spatial jittering of data during training. To this end we conduct eperiments on the ImageNet LSVRC 2012 dataset [7] by training several models using different amounts of data augmentation. Our eperiments reveal that bilinear CNN models can be trained from scratch, resulting in better accuracy without requiring spatial jittering of data than the corresponding CNN architectures that consist of standard fully-connected layers trained with jittering. Our third contribution is a technique to invert these models to construct invariant s and visualize preimages for categories. Fig. 1 shows the inverse images for various categories materials such as wood and water, describable attributes such as honeycombed and dotted, and scene categories such as laundromat and bookstore. These images reveal what categorical properties are learned by these teture models. Recently, Gatys et al. [13] showed that bilinear features they call it the Gram matri representation etracted from various layers of the verydeep VGG network [36] can be inverted for teture synthesis. The synthesized results are visually appealing, demonstrating that the convolutional layers of a CNN capture tetural properties significantly better than the first and second order statistics of wavelet coefficients of Portilla and Simoncelli. However, the approach remains impractical since it requires hundreds of CNN evaluations and is orders of magnitude slower than non-parametric patch-based methods such as image ing [9]. We show that the two approaches are complementary and one can significantly speed up the convergence of gradient-based inversion by initializing the inverse image using image ing. The global adjustment of the image through gradient descent also removes many artifacts that ing introduces. Finally, we show a novel application of our approach for image manipulation with teture attributes. A unified parametric model of teture representation and recognition allows us to adjust an image with high-level attributes to make an image more swirly or honeycombed, or generate hybrid images that are a combination of multiple teture attributes, e.g., chequered and interlaced Related work Teture recognition is a widely studied area. Current state-of-the-art results on teture and material recognition are obtained by hybrid approaches that build orderless representations on top of CNN activations. Cimpoi et al. [4] use Fisher vector pooling for material and scene recognition, Gong et al. [15] use VLAD pooling for scene recognition, etc. Our previous work [25] proposed a general orderless pooling architecture called the bilinear CNN that outperforms Fisher vector on many fine-grained datasets. These descriptors are inspired by early work on teture representations [6, 24, 30, 19] that were built on top of wavelet coefficients, linear filter bank responses, or SIFT features [27]. Teture synthesis has received attention from both the vision and graphics communities due to its numerous applications. Heeger and Bergen [17] synthesized teture images by histogram matching. Portilla and Simoncelli were one of the early proponents of parametric approaches. The idea is to represent teture as the first and second order statistics of various filter bank responses e.g., wavelets, steerable pyramids, etc.. However, these approaches were outperformed by simpler non-parametric approaches. For instance, Efros and Lueng [10] proposed a piel-by-piel synthesis approach based on sampling similar patches the method was simple and effective for a wide range of tetures. Later, Efros and Freeman proposed a ing-based approach that was significantly faster [9]. A number of other non-parametric approaches have been proposed for this problem [23, 39]. Recently, Gatys et al. showed that replacing the linear filterbanks by CNN filterbanks results in better reconstructions. Notably, the Gram matri representation used in their approach is identical to the bilinear CNN features of Lin et al., suggesting that these features might be good for teture recognition as well. However for synthesis, the parametric approaches remain impractical as they are orders of magnitude slower than non-parametric approaches.
3 Understanding CNNs through visualizations has also been widely studied given their remarkable performance. Zieler and Fergus [40] visualize CNNs using the top activations of filters and show per-piel heatmaps by tracking the position of the highest responses. Simonyan and Zisserman [35] visualize parts of the image that cause the highest change in class labels computed by back-propagation. Mahendran and Vedaldi [28] etend this approach by introducing natural image priors which result in inverse images that have fewer artifacts. Dosovitskiy and Bro [8] propose a deconvolutional network to invert a CNN in a feed-forward manner. However, the approach tends to produce blurry images since the inverse is not uniquely defined. Our approach is also related to prior work on editing images based on eample images. Ideas from patch-based teture synthesis have been etended in a number of ways to modify the style of the image based on an eample [18], adjusting teture synthesis based on the content of another image [5, 9], etc. Recently, in a separate work, Gatys et al. [12] proposed a neural style approach that combines ideas from inverting CNNs with their work on teture synthesis. They generate images that match the style and content of two different images producing compelling results. Although the approach is not practical compared to eisting patch-based methods for editing styles, it provides a basis for a rich parametric model of teture. We describe an novel approach to manipulate images with high-level attributes and show several eamples of editing images with teture attributes. There is relatively little prior work on manipulating the content of an image using semantic attributes. 2. Methodology and overview We describe our framework for parametric teture recognition, synthesis, inversion, and attribute-based manipulation using CNNs. For an image I one can compute the activations of the CNN at a given layer r i to obtain a set of features F ri = {f j } indeed by their location j. The bilinear feature B ri I of F ri is obtained by computing the outer product of each feature f j with itself and aggregating them across locations by averaging, i.e., B ri I = 1 N N f j fj T. 1 j=1 The bilinear feature or the Gram matri representation is an orderless representation of the image and hence is suitable for modeling teture. Let r i, i = 1,..., n, be the inde of the i th layer with the bilinear feature representation B ri. Gatys et al. [13] propose a method for teture synthesis from an image I by obtaining an image R H W C that matches the bilinear features at various layers by solving the following optimization: min n α i L 1 B ri, ˆB ri + γγ. 2 Here, ˆBri = B ri I, α i is the weight of the i th layer, Γ is a natural image prior such as the total variation norm TV norm, and γ is the weight on the prior. Note that we have dropped the implicit dependence of B ri on for brevity. Using the squared loss-function L 1, y = i y i 2 and starting from a random image where each piel initialized with a i.i.d zero mean Gaussian, a local optimum is reached through gradient descent. The authors employ L-BFGS, but any other optimization method can be used e.g., Mahendran and Vedaldi [28] use stochastic gradient descent with momentum. Prior work on minimizing the reconstruction error with respect to the un-pooled features F ri has shown that the content of the image in terms of the color and spatial structure is well-preserved even in the higher convolutional layers. Recently, Gatys et al. in a separate work [12] synthesize images that match the style and content of two different images I and I respectively by minimizing a weighted sum of the teture and content reconstruction errors: min λl 1 F s, ˆF s + n α i L 1 B ri, ˆB ri + γγ. 3 Here ˆF s = F s I are features from a layer s from which the target content features are computed for an image I. The bilinear features can also be used for predicting attributes by first normalizing the features signed square-root and l 2 and training a linear classifier in a supervised manner [25]. Let l i : i = 1,..., m be the inde of the i th layer from which we obtain attribute prediction probabilities C li. The prediction layers may be different from those used for teture synthesis. Given a target attribute Ĉ we can obtain an image that matches the target label and is similar to the teture of a given image I by solving the following optimization: min n α i L 1 B ri, ˆB ri + β m L 2 C li, Ĉ + γγ. 4 Here, L 2 is a loss function such as the negative loglikelihood of the label Ĉ and β is a tradeoff parameter. If multiple targets Ĉj are available then the losses can be blended with weights β j resulting in the following optimization: min n α i L 1 B ri, ˆB ri +β j m,j L 2 C li, Ĉj +γγ. 5
4 Implementation details. We use the 16-layer VGG network [36] trained on ImageNet for all our eperiments. For the image prior Γ we use the TV β norm with β = 2: Γ = i,j i,j+1 i,j 2 + i+1,j i,j 2 β 2. 6 The eponent β = 2 was empirically found to lead to better reconstructions in [28] as it leads to fewer spike artifacts than β = 1. In all our eperiments, given an image we resize it to piels before computing the target bilinear features and solve for R This is primarily for speed since the size of the bilinear features are independent of the size of the image. Hence, an output of any size can be obtained by minimizing Eqn. 5. We use L-BFGS for optimization and compute the gradients of the objective with respect to using back-propagation. One detail we found to be critical for good reconstructions is that we l 1 normalize the gradients with respect to each of the L 1 loss terms to balance the losses during optimization. Mahendran and Vedaldi [28] suggest normalizing each L 1 loss term by the l 2 norm of the target feature ˆB ri. Without some from of normalization the losses from different layers are of vastly different scales leading to numerical stability issues during optimization. Using this framework we: i study the effectiveness of bilinear features B ri etracted from various layers of a network for teture and scene recognition Sect. 3, ii investigate the nature of invariances of these features by evaluating the effect of training with different amounts of data augmentation Sect. 4, iii provide insights into the learned models by inverting them Sect. 5, and iv show results for modifying the content of an image with teture attributes Sect. 6. We conclude in Sect Teture recognition In this section we evaluate the bilinear CNN B-CNN representation for teture recognition and scene recognition. Datasets and evaluation. We eperiment on three teture datasets the Describable Teture Dataset DTD [3], Flickr Material Dataset FMD [34], and KTH-TISP2-b KTH-T2b [1]. DTD consists of 5640 images labeled with 47 describable teture attributes. FMD consists of 10 material categories, each of which contains 100 images. Unlike DTD and FMD where images are collected from the Internet, KTH-T2b contains 4752 images of 11 materials captured under controlled scale, pose, and illumination. The KTH-T2b dataset splits the images into four samples for each category. We follow the standard protocol by training on one sample and test on the remaining three. On DTD and FMD, we randomly divide the dataset into 10 splits and report the mean accuracy across splits. Besides these, we also evaluate our models on MIT indoor scene dataset [32]. Indoor scenes are weakly structured and orderless teture representations have been shown to be effective here. The dataset consists of 67 indoor categories and a defined training and test split. Descriptor details and training protocol. Our features are based on the verydeep VGG network [36] consisting of 16 convolutional layers pre-trained on the ImageNet dataset. The FV-CNN builds a Fisher Vector representation by etracting CNN filterbank responses from a particular layer of the CNN using 64 Gaussian miture components, identical to setup of Cimpoi et al. [4]. The B-CNN features are similarly built by taking the location-wise outer product of the filterbank responses and average pooling across all locations identical to B-CNN [D,D] in Lin et al. [25]. Both these features are passed through signed square-root and l 2 normalization which has been shown to improve performance. During training we learn one-vs-all SVMs trained with SVM hyperparameter C = 1 and weights scaled such that the median positive and negative class scores in the training data is +1 and 1 respectively. At test time we assign the class with the highest score. Our code in implemented using MatConvNet [38] and VLFEAT [37] libraries Eperiments The following are the main conclusions of the eperiments: 1. B-CNN compares favorably to FV-CNN. Tab. 1 shows results using the B-CNN and FV-CNN on various datasets. Across all scales of the image the performance using B-CNN and FV-CNN is virtually identical. The FV-CNN multi-scale results reported here are comparable ±1% to the results reported in Cimpoi et al. [4] for all datasets ecept KTH-T2b 4%. These differences in results are likely due to the choice of the CNN 1 and the range of scales. These results show that the bilinear pooling is as good as the Fisher vector pooling for teture recognition. One drawback is that the FV-CNN features with 64 GMM components has half as many dimensions as the bilinear features However, it is known that these features are highly redundant and their dimensionality can be reduced by an order of magnitude without loss in performance [11, 25]. 2. Multi-scale analysis improves performance. Tab. 1 shows the results by combining features from multiple scales 2 s, s {1.5:-0.5:-3} relative to the image. We discard scales for which the image is smaller than the size of the receptive fields of the filters, or larger than piels for efficiency. Multiple scales consistently lead to an improvement in accuracy. 1 they use the conv5 4 layer of the 19-layer VGG network.
5 FV-CNN B-CNN Dataset s = 1 s = 2 ms s = 1 s = 2 ms DTD ±0.9 ±0.9 ±1.0 ±0.7 ±0.8 ±0.8 FMD ±2.3 ±1.4 ±1.7 ±1.9 ±1.5 ±1.7 KTH-T2b ±2.6 ±2.4 ±2.0 ±2.8 ±3.5 ±3.1 MIT indoor Table 1. Comparison of B-CNN and FV-CNN. We report mean per-class accuracy on DTD, FMD, KTH-T2b and MIT indoor datasets using FV-CNN and B-CNN representations constructed on top of relu5 3 layer outputs of the 16-layer VGG network [36]. Results are reported using images at different scales: s = 1, s = 2 and ms are with images resized to , and pooled across multiple scales respectively. Dataset relu2 2 relu3 3 relu4 3 relu5 3 DTD FMD KTH-T2b MIT indoor Table 2. Layer by layer performance. The classification accuracy using B-CNN features based on the outputs of different layers on several datasets using at s = 1, i.e piels. The numbers are reported on the first split of all datasets. 3. Higher layers perform better. Tab. 2 shows the performance using various layers of the CNN. The accuracy improves using the higher layers in agreement with [4]. 4. Multi-layer features improve performance. By combining features from all the layers we observe a small but significant improvement in accuracy on DTD 69.9% 70.7% and on MIT indoor from 72.8% 74.9%. This suggests that the features from multiple layers capture complementary information and can be combined to improve performance. This is in agreement with the hypercolumn approach of Hariharan et al. [16]. 5. Fine-tuning leads to a small improvement. On the MIT indoor dataset fine-tuning the network using the B- CNN architecture leads to a small improvement 72.8% 73.8% using relu5 3 and s = 1. Fine-tuning on teture datasets led to insignificant improvements which might be attributed to their small size. On larger and specialized datasets, such as fine-grained recognition, the effect of finetuning can be significant [25]. 4. The role of translational invariance Earlier eperiments on B-CNN and FV-CNN were reported using pre-trained networks. Here we eperiment with training a B-CNN model from scratch on the ImageNet LSRVC 2012 dataset. We eperimenting with the effect of spatial jittering of training data on the classification performance. For these eperiments we use the VGG-M [2] architecture which performs better than AleNet [22] with a moderate decrease in classification speed. For the B-CNN model we replace the last two fully-connected layers with a linear classifier and softma layer on the outputs of the square-root and l 2 normalized bilinear features of the relu5 layer outputs. The evaluation speed for B-CNN is 80% of that of the standard CNN, hence the overall training times for both architectures are comparable. We train various models with different amounts of spatial jittering f1 for flip, f5 for flip + 5 translations and f25 for flip + 25 translations. In each case the training is done using stochastic sampling where one of the jittered copies is randomly selected for each eample. The network parameters are randomly initialized and trained using stochastic gradient descent with momentum for a number of epochs. We start with a high learning rate and reduce it by a factor of 10 when the validation error stops decreasing. We stop training when the validation error stops decreasing. Fig. 2 shows the top1 validation errors and compares the B-CNN network to the standard VGG-M model. The validation error is reported on a single center cropped image. Note that we train all networks with neither PCA color jittering nor batch normalization and our baseline results are within 2% of the top1 errors reported in [2]. The VGG- M model achieves 46.4% top1 error with flip augmentation during training. The performance improves significantly to 39.6% with f25 augmentation. As fully connected layers in a standard CNN network encode spatial information, the model loses performance without spatial jittering. For B- CNN network, the model achieves 38.7% top1 error with f1 augmentation, outperforming VGG-M with f25 augmentation. With more augmentations, B-CNN model improves top1 error by 1.6% 38.7% 37.1%. Going from f5 to f25, B-CNN model improves marginally by < 1%. The results show that B-CNN feature is discriminative and robust to translation. With a small amount of data jittering, B-CNN network achieves fairly good performance, suggesting that eplicit translation invariance might be preferable to the implicit invariance obtained by data jittering. 5. Understanding teture representations In this section we aim to understand B-CNN teture representation by synthesizing invariant images, i.e. images that are nearly identical to a given image according to the bilinear features, and inverse images for a given category. Visualizing invariant images for objects. We use relu1 1, relu2 1, relu3 1, relu4 1, relu5 1 layers for teture representation. Fig. 3 shows several invariant images to the image on the top left, i.e. these images are virtually identical as far as the bilinear features for these layers are con-




![relu4 1, relu5 1 of the VGG network [36]. cerned.](/docs-images/82/87030271/images/6-4.jpg "Translational invariance manifests as shuffling of patches but important local structure is preserved within the images.")










6 relu2 2 top1 error B-CNN f1 B-CNN f5 B-CNN f25 CNN f1 CNN f25 + relu3 3 + relu4 3 + relu5 3 water error foliage epoch Figure 2. Effect of spatial jittering on ImageNet LRVC 2012 classification. The top1 validation error on a single center crop on ImageNet dataset using the VGG-M network and the corresponding B-CNN model. The networks are trained with different levels of data jittering: f1, f5, and f25 indicating flip, flip + 5 translations, and flip + 25 translations respectively. Figure 3. Invariant s. These si images are virtually identical when compared using the bilinear features of layers relu1 1, relu2 1, relu3 1, relu4 1, relu5 1 of the VGG network [36]. cerned. Translational invariance manifests as shuffling of patches but important local structure is preserved within the images. These images were obtained using γ = 1e 6 and αi = 1 i in Eqn. 5. We found that as long as some higher and lower layers are used together the synthesized tetures look reasonable, similar to the observations of Gatys et al. Role of initialization on teture synthesis. Although the same approach can be used for teture synthesis, it is not practical since it requires several hundreds of CNN evaluations, which takes several minutes on a high-end GPU. In comparison, non-parametric patch-based approaches such as image ing [9] are orders of magnitude faster. Quilting introduces artifacts when adjacent patches do not align with each other. The original paper proposed an approach bowling Figure 4. Effect of layers on inversion. Pre-images obtained by inverting class labels using different layers. The leftmost column shows inverses using predictions of relu2 2 only. In the following columns we add layers relu3 3, relu4 3, and relu5 3 one by one. where a one-dimensional cut is found that minimizes artifacts. However, this can fail since local adjustments cannot remove large structural errors in the synthesis. We instead investigate the use of ing to initialize the gradient-based synthesis approach. Fig. 5 shows the objective through iterations of L-BFGS starting from a random and ingbased initialization. Quilting starts at a lower objective and reaches the final objective of the random initialization significantly faster. Moreover, the global adjustments of the image through gradient descent remove many artifacts that ing introduces digitally zoom in to the onion image to see this. Fig. 6 show the results using image ing as initialization for style transfer [12]. Here two images are given as, one for content measured as the conv4 2 layer output, and one for style measured as the bilinear features. Similar to teture synthesis, the ing-based initialization starts from lower objective value and the optimization converges faster. These eperiments suggest that patch-based and parametric approaches for teture synthesis are complementary and can be combined effectively. Visualizing teture categories. We learn linear classifiers to predict categories using bilinear features from relu2 2, relu3 3, relu4 3, relu5 3 layers of the CNN on various datasets and visualize images that produce high prediction scores for each class. Fig. 1 shows some eample inverse images for various categories for the DTD, FMD and MIT indoor datasets. These images were obtained by setting β = 100, γ = 1e 6, and C to various class labels in Eqn. 5. These images reveal how the model represents teture and scene categories. For instance, the dotted category of DTD contains images of various colors and dot sizes and the inverse image is composed of multi-scale multi-colored dots. The inverse images of water and wood from FMD are


![image ing: syn. The results using image ing [9] are shown as.](/docs-images/82/87030271/images/7-2.jpg "On the right is the objective function for the optimization for 5 random initializations.")








![from a random image: tranfrand, and image ing: tranf. The results using image ing [9] are shown as.](/docs-images/82/87030271/images/7-11.jpg "On the bottom right is the objective function for the optimization for 5 random initializations.")




7 compare init rand objective iter init compare rand objective synrand syn iter Objective vs. iterations an image, syn Figure 5. Effect of initialization onsynrand teture synthesis. Given the solution reached by the L-BFGS after 250 iterations starting from a random image: synrand, and image ing: syn. The results using image ing [9] are shown as. On the right is the objective function for the optimization for 5 random initializations. Quilting-based initialization starts at a lower objective value and matches the final objective of the random initialization in far fewer iterations. Moreover, many artifacts of ing are removed in the final solution e.g., the top row. Best viewed with digital zoom. Images are obtained from content style tranf tranfrand the MIT indoor dataset reveal key properties that the model learns a bookstore is visualized as racks of books while a laundromat has laundry machines at various scales and locations. In Fig. 4 we visualize reconstructions by incrementally adding layers in the teture representation. Lower layers preserve color and small-scale structure and combining all the layers leads to better reconstructions. Even though the relu5 3 layer provides the best recognition accuracy, simply using that layer did not produce good inverse images not shown. Notably, color information is discarded in the upper layers. Fig. 7 shows visualizations of some other categories across datasets. 6. Manipulating images with teture attributes content style tranf tranfrand Figure 6. Effect of initialization on style transfer. Given a content and a style image the style transfer reached using L-BFGS after 100 iterations starting from a random image: tranfrand, and image ing: tranf. The results using image ing [9] are shown as. On the bottom right is the objective function for the optimization for 5 random initializations. highly representative of these categories. Note that these images cannot be obtained by simply averaging instances within a category which is likely to produce a blurry image. The orderless nature of the teture descriptor is essential to produce such sharp images. The inverse scene images from Our framework can be used to edit images with teture attributes. For instance, we can make a teture or the content of an image more honeycombed or swirly. Fig. 8 shows some eamples where we have modified images with various attributes. The top two rows of images were obtained by setting αi = 1 i, β = 1000 and γ = 1e 6 and varying C to represent the target class. The bottom row is obtained by setting αi = 0 i, and using the relu4 2 layer for content reconstruction with weight λ = 5e 8. The difference between the two is that in the content reconstruction the overall structure of the image is preserved. The approach is similar to the neural style approach [12], but instead of providing a style image we adjust the image with attributes. This leads to interesting results. For instance, when the face image is adjusted with the interlaced attribute Fig. 8 bottom row the result matches the scale and orientation of the underlying image. No single image in the DTD dataset has all these variations but the categorical representation does. The approach can be used to modify an image with other high-level attributes such as artistic styles by learning style classifiers.




![model [25] trained on DTD [3],](/docs-images/82/87030271/images/8-6.jpg "FMD [34], and MIT Indoor dataset")
![[32] two columns each from left](/docs-images/82/87030271/images/8-7.jpg "to right.")

















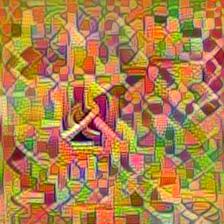







8 braided bubbly foliage leather bakery bowling cobwebbed scaly metal stone classroom closet Figure 7. Eamples of teture inverses Fig. 1 cont. Visualizing various categories by inverting the bilinear CNN model [25] trained on DTD [3], FMD [34], and MIT Indoor dataset [32] two columns each from left to right. Best viewed in color and with zoom. fibrous paisley chequered β1 /β2 = 2.11 interlaced honeycombed swirly grid β1 /β2 = 1.19 knitted veined bumpy swirly β1 /β2 = 0.75 paisley Figure 9. Hybrid tetures obtained by blending the teture on the left and right according to weights β1 and β2. freckled interlaced marbled Figure 8. Manipulating images with attributes. Given an image we synthesize a new image that matches its teture top two rows or its content bottom two rows according to a given attribute shown in the image. We can also blend teture categories using weights βj of the targets C j. Fig. 9 shows some eamples. On the left is the first category, on the right is the second category, and in the middle is where a transition occurs selected manually. 7. Conclusion We present a systematic study of recent CNN-based teture representations by investigating their effectiveness on recognition tasks and studying their invariances by inverting them. The main conclusion is that translational invariance is a useful property not only for teture and scene recognition, but also for general object classification on the ImageNet dataset. The resulting models provide a rich parametric approach for teture synthesis and manipulation of content of images using teture attributes. The key challenge is that the approach is computationally epensive, and we present an initialization scheme based on image ing that significantly speeds up the convergence and also removes many structural artifacts that ing introduces. The complementary qualities of patch-based and gradient-based methods may be useful for other applications. Acknowledgement The GPUs used in this research were generously donated by NVIDIA.
9 References [1] B. Caputo, E. Hayman, and P. Mallikarjuna. Class-specific material categorisation. In ICCV, , 4 [2] K. Chatfield, K. Simonyan, A. Vedaldi, and A. Zisserman. Return of the devil in the details: Delving deep into convolutional nets. In BMVC, , 2, 5 [3] M. Cimpoi, S. Maji, I. Kokkinos, S. Mohamed,, and A. Vedaldi. Describing tetures in the wild. In CVPR, , 2, 4, 8 [4] M. Cimpoi, S. Maji, I. Kokkinos, and A. Vedaldi. Deep filter banks for teture recognition, description, and segmentation. IJCV, pages 1 30, , 2, 4, 5 [5] A. Criminisi, P. Pérez, and K. Toyama. Region filling and object removal by eemplar-based image inpainting. Image Processing, IEEE Transactions on, 139, [6] G. Csurka, C. R. Dance, L. Dan, J. Willamowski, and C. Bray. Visual categorization with bags of keypoints. In ECCV Workshop on Stat. Learn. in Comp. Vision, , 2 [7] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. ImageNet: A Large-Scale Hierarchical Image Database. In CVPR, [8] A. Dosovitskiy and T.Bro. Inverting visual representations with convolutional networks. In CVPR, , 3 [9] A. Efros and W. T. Freeman. Image ing for teture synthesis and transfer. In SIGGRAPH, , 3, 6, 7 [10] A. Efros and T. Leung. Teture synthesis by non-parametric sampling. In CVPR, [11] Y. Gao, O. Beijbom, N. Zhang, and T. Darrell. Compact bilinear pooling. arxiv preprint arxiv: , [12] L. A. Gatys, A. S. Ecker, and M. Bethge. A neural algorithm of artistic style. arxiv preprint arxiv: , , 6, 7 [13] L. A. Gatys, A. S. Ecker, and M. Bethge. Teture synthesis and the controlled generation of natural stimuli using convolutional neural networks. In NIPS, , 2, 3 [14] R. B. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, [15] Y. Gong, L. Wang, R. Guo, and S. Lazebnik. Multi-scale orderless pooling of deep convolutional activation features. In ECCV, [16] B. Hariharan, P. Arbeláez, R. Girshick, and J. Malik. Hypercolumns for object segmentation and fine-grained localization. In CVPR, , 5 [17] D. J. Heeger and J. R. Bergen. Pyramid-based teture analysis/synthesis. In SIGGRAPH, [18] A. Hertzmann, C. E. Jacobs, N. Oliver, B. Curless, and D. H. Salesin. Image analogies. In SIGGRAPH, [19] H. Jégou, M. Douze, C. Schmid, and P. Pérez. Aggregating local descriptors into a compact image representation. In CVPR, , 2 [20] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell. Caffe: Convolutional architecture for fast feature embedding. In ACM Multimedia ACM MM, [21] B. Julesz and J. R. Bergen. Tetons, the fundamental elements in preattentive vision and perception of tetures. Bell System Technical Journal, 626, Pt 3: , Jul-Aug [22] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, [23] V. Kwatra, A. Schödl, I. Essa, G. Turk, and A. Bobick. Graphcut tetures: image and video synthesis using graph cuts. In ACM Transactions on Graphics ToG, [24] T. Leung and J. Malik. Representing and recognizing the visual appearance of materials using three-dimensional tetons. IJCV, 431:29 44, , 2 [25] T.-Y. Lin, A. RoyChowdhury, and S. Maji. Bilinear CNN Models for Fine-grained Visual Recognition. In ICCV, , 2, 3, 4, 5, 8 [26] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, [27] D. G. Lowe. Object recognition from local scale-invariant features. In ICCV, [28] A. Mahendran and A. Vedaldi. Understanding deep image representations by inverting them. In CVPR, , 3, 4 [29] M. Mostajabi, P. Yadollahpour, and G. Shakhnarovich. Feedforward semantic segmentation with zoom-out features. In CVPR, [30] F. Perronnin and C. R. Dance. Fisher kernels on visual vocabularies for image categorization. In CVPR, , 2 [31] J. Portilla and E. Simoncelli. A parametric teture model based on joint statistics of comple wavelet coefficients. IJCV, 401:49 70, [32] A. Quattoni and A. Torralba. Recognizing indoor scenes. In CVPR, , 2, 4, 8 [33] A. S. Razavin, H. Azizpour, J. Sullivan, and S. Carlsson. Cnn features off-the-shelf: An astounding baseline for recognition. In DeepVision workshop, [34] L. Sharan, R. Rosenholtz, and E. H. Adelson. Material perceprion: What can you see in a brief glance? Journal of Vision, 9:7848, , 2, 4, 8 [35] K. Simonyan, A. Vedaldi, and A. Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps. In ICLR workshop, , 3 [36] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, , 3, 4, 5, 6 [37] A. Vedaldi and B. Fulkerson. VLFeat: an open and portable library of computer vision algorithms. In ACM Multimedia ACM MM, [38] A. Vedaldi and K. Lenc. MatConvNet: convolutional neural networks for matlab. In ACM Multimedia ACM MM, [39] L. Wei and M. Levoy. Fast teture synthesis using treestructured vector quantization. In SIGGRAPH, [40] M. D. Zeiler and R. Fergus. Visualizing and understanding convolutional networks. In ECCV, , 3
Bilinear Models for Fine-Grained Visual Recognition
 Bilinear Models for Fine-Grained Visual Recognition Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst Fine-grained visual recognition Example: distinguish
Bilinear Models for Fine-Grained Visual Recognition Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst Fine-grained visual recognition Example: distinguish
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
Aggregating Descriptors with Local Gaussian Metrics
 Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
Texture attribute synthesis and transfer using feed-forward CNNs
 Texture attribute synthesis and transfer using feed-forward CNNs Thomas Irmer Ruhr University Bochum thomas.irmer@rub.de Tobias Glasmachers Ruhr University Bochum tobias.glasmachers@ini.rub.de Subhransu
Texture attribute synthesis and transfer using feed-forward CNNs Thomas Irmer Ruhr University Bochum thomas.irmer@rub.de Tobias Glasmachers Ruhr University Bochum tobias.glasmachers@ini.rub.de Subhransu
Robust Scene Classification with Cross-level LLC Coding on CNN Features
 Robust Scene Classification with Cross-level LLC Coding on CNN Features Zequn Jie 1, Shuicheng Yan 2 1 Keio-NUS CUTE Center, National University of Singapore, Singapore 2 Department of Electrical and Computer
Robust Scene Classification with Cross-level LLC Coding on CNN Features Zequn Jie 1, Shuicheng Yan 2 1 Keio-NUS CUTE Center, National University of Singapore, Singapore 2 Department of Electrical and Computer
DFT-based Transformation Invariant Pooling Layer for Visual Classification
 DFT-based Transformation Invariant Pooling Layer for Visual Classification Jongbin Ryu 1, Ming-Hsuan Yang 2, and Jongwoo Lim 1 1 Hanyang University 2 University of California, Merced Abstract. We propose
DFT-based Transformation Invariant Pooling Layer for Visual Classification Jongbin Ryu 1, Ming-Hsuan Yang 2, and Jongwoo Lim 1 1 Hanyang University 2 University of California, Merced Abstract. We propose
Part Localization by Exploiting Deep Convolutional Networks
 Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
arxiv: v1 [cs.cv] 6 Jul 2016
![arxiv: v1 [cs.cv] 6 Jul 2016](/thumbs/80/81416563.jpg "arxiv: v1 [cs.cv] 6 Jul 2016") arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
A Neural Algorithm of Artistic Style. Leon A. Gatys, Alexander S. Ecker, Mattthias Bethge Presented by Weidi Xie (1st Oct 2015 )
") A Neural Algorithm of Artistic Style Leon A. Gatys, Alexander S. Ecker, Mattthias Bethge Presented by Weidi Xie (1st Oct 2015 ) What does the paper do? 2 Create artistic images of high perceptual quality.
A Neural Algorithm of Artistic Style Leon A. Gatys, Alexander S. Ecker, Mattthias Bethge Presented by Weidi Xie (1st Oct 2015 ) What does the paper do? 2 Create artistic images of high perceptual quality.
Deep Neural Networks:
 Deep Neural Networks: Part II Convolutional Neural Network (CNN) Yuan-Kai Wang, 2016 Web site of this course: http://pattern-recognition.weebly.com source: CNN for ImageClassification, by S. Lazebnik,
Deep Neural Networks: Part II Convolutional Neural Network (CNN) Yuan-Kai Wang, 2016 Web site of this course: http://pattern-recognition.weebly.com source: CNN for ImageClassification, by S. Lazebnik,
Locally-Transferred Fisher Vectors for Texture Classification
 Locally-Transferred Fisher Vectors for Texture Classification Yang Song 1, Fan Zhang 2, Qing Li 1, Heng Huang 3, Lauren J. O Donnell 2, Weidong Cai 1 1 School of Information Technologies, University of
Locally-Transferred Fisher Vectors for Texture Classification Yang Song 1, Fan Zhang 2, Qing Li 1, Heng Huang 3, Lauren J. O Donnell 2, Weidong Cai 1 1 School of Information Technologies, University of
Convolutional Neural Networks + Neural Style Transfer. Justin Johnson 2/1/2017
 Convolutional Neural Networks + Neural Style Transfer Justin Johnson 2/1/2017 Outline Convolutional Neural Networks Convolution Pooling Feature Visualization Neural Style Transfer Feature Inversion Texture
Convolutional Neural Networks + Neural Style Transfer Justin Johnson 2/1/2017 Outline Convolutional Neural Networks Convolution Pooling Feature Visualization Neural Style Transfer Feature Inversion Texture
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
PARTIAL STYLE TRANSFER USING WEAKLY SUPERVISED SEMANTIC SEGMENTATION. Shin Matsuo Wataru Shimoda Keiji Yanai
 PARTIAL STYLE TRANSFER USING WEAKLY SUPERVISED SEMANTIC SEGMENTATION Shin Matsuo Wataru Shimoda Keiji Yanai Department of Informatics, The University of Electro-Communications, Tokyo 1-5-1 Chofugaoka,
PARTIAL STYLE TRANSFER USING WEAKLY SUPERVISED SEMANTIC SEGMENTATION Shin Matsuo Wataru Shimoda Keiji Yanai Department of Informatics, The University of Electro-Communications, Tokyo 1-5-1 Chofugaoka,
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Supplementary material for Analyzing Filters Toward Efficient ConvNet
 Supplementary material for Analyzing Filters Toward Efficient Net Takumi Kobayashi National Institute of Advanced Industrial Science and Technology, Japan takumi.kobayashi@aist.go.jp A. Orthonormal Steerable
Supplementary material for Analyzing Filters Toward Efficient Net Takumi Kobayashi National Institute of Advanced Industrial Science and Technology, Japan takumi.kobayashi@aist.go.jp A. Orthonormal Steerable
In Defense of Fully Connected Layers in Visual Representation Transfer
 In Defense of Fully Connected Layers in Visual Representation Transfer Chen-Lin Zhang, Jian-Hao Luo, Xiu-Shen Wei, Jianxin Wu National Key Laboratory for Novel Software Technology, Nanjing University,
In Defense of Fully Connected Layers in Visual Representation Transfer Chen-Lin Zhang, Jian-Hao Luo, Xiu-Shen Wei, Jianxin Wu National Key Laboratory for Novel Software Technology, Nanjing University,
Texture Synthesis and Manipulation Project Proposal. Douglas Lanman EN 256: Computer Vision 19 October 2006
 Texture Synthesis and Manipulation Project Proposal Douglas Lanman EN 256: Computer Vision 19 October 2006 1 Outline Introduction to Texture Synthesis Previous Work Project Goals and Timeline Douglas Lanman
Texture Synthesis and Manipulation Project Proposal Douglas Lanman EN 256: Computer Vision 19 October 2006 1 Outline Introduction to Texture Synthesis Previous Work Project Goals and Timeline Douglas Lanman
Real-time Object Detection CS 229 Course Project
 Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Mixtures of Gaussians and Advanced Feature Encoding
 Mixtures of Gaussians and Advanced Feature Encoding Computer Vision Ali Borji UWM Many slides from James Hayes, Derek Hoiem, Florent Perronnin, and Hervé Why do good recognition systems go bad? E.g. Why
Mixtures of Gaussians and Advanced Feature Encoding Computer Vision Ali Borji UWM Many slides from James Hayes, Derek Hoiem, Florent Perronnin, and Hervé Why do good recognition systems go bad? E.g. Why
FINE-GRAINED recognition involves classification of instances
 1 Bilinear CNNs for Fine-grained Visual Recognition Tsung-Yu Lin Aruni RoyChowdhury Subhransu Maji arxiv:1504.07889v6 [cs.cv] 1 Jun 2017 Abstract We present a simple and effective architecture for fine-grained
1 Bilinear CNNs for Fine-grained Visual Recognition Tsung-Yu Lin Aruni RoyChowdhury Subhransu Maji arxiv:1504.07889v6 [cs.cv] 1 Jun 2017 Abstract We present a simple and effective architecture for fine-grained
arxiv: v2 [cs.cv] 30 Jul 2016
![arxiv: v2 [cs.cv] 30 Jul 2016](/thumbs/74/71012099.jpg "arxiv: v2 [cs.cv] 30 Jul 2016") arxiv:1512.04065v2 [cs.cv] 30 Jul 2016 Cross-dimensional Weighting for Aggregated Deep Convolutional Features Yannis Kalantidis, Clayton Mellina and Simon Osindero Computer Vision and Machine Learning
arxiv:1512.04065v2 [cs.cv] 30 Jul 2016 Cross-dimensional Weighting for Aggregated Deep Convolutional Features Yannis Kalantidis, Clayton Mellina and Simon Osindero Computer Vision and Machine Learning
Deep Spatial Pyramid Ensemble for Cultural Event Recognition
 215 IEEE International Conference on Computer Vision Workshops Deep Spatial Pyramid Ensemble for Cultural Event Recognition Xiu-Shen Wei Bin-Bin Gao Jianxin Wu National Key Laboratory for Novel Software
215 IEEE International Conference on Computer Vision Workshops Deep Spatial Pyramid Ensemble for Cultural Event Recognition Xiu-Shen Wei Bin-Bin Gao Jianxin Wu National Key Laboratory for Novel Software
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
Diversified Texture Synthesis with Feed-forward Networks
 Diversified Texture Synthesis with Feed-forward Networks Yijun Li 1, Chen Fang 2, Jimei Yang 2, Zhaowen Wang 2, Xin Lu 2, and Ming-Hsuan Yang 1 1 University of California, Merced 2 Adobe Research {yli62,mhyang}@ucmerced.edu
Diversified Texture Synthesis with Feed-forward Networks Yijun Li 1, Chen Fang 2, Jimei Yang 2, Zhaowen Wang 2, Xin Lu 2, and Ming-Hsuan Yang 1 1 University of California, Merced 2 Adobe Research {yli62,mhyang}@ucmerced.edu
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Recognize Complex Events from Static Images by Fusing Deep Channels Supplementary Materials
 Recognize Complex Events from Static Images by Fusing Deep Channels Supplementary Materials Yuanjun Xiong 1 Kai Zhu 1 Dahua Lin 1 Xiaoou Tang 1,2 1 Department of Information Engineering, The Chinese University
Recognize Complex Events from Static Images by Fusing Deep Channels Supplementary Materials Yuanjun Xiong 1 Kai Zhu 1 Dahua Lin 1 Xiaoou Tang 1,2 1 Department of Information Engineering, The Chinese University
Return of the Devil in the Details: Delving Deep into Convolutional Nets
 Return of the Devil in the Details: Delving Deep into Convolutional Nets Ken Chatfield - Karen Simonyan - Andrea Vedaldi - Andrew Zisserman University of Oxford The Devil is still in the Details 2011 2014
Return of the Devil in the Details: Delving Deep into Convolutional Nets Ken Chatfield - Karen Simonyan - Andrea Vedaldi - Andrew Zisserman University of Oxford The Devil is still in the Details 2011 2014
Efficient Convolutional Network Learning using Parametric Log based Dual-Tree Wavelet ScatterNet
 Efficient Convolutional Network Learning using Parametric Log based Dual-Tree Wavelet ScatterNet Amarjot Singh, Nick Kingsbury Signal Processing Group, Department of Engineering, University of Cambridge,
Efficient Convolutional Network Learning using Parametric Log based Dual-Tree Wavelet ScatterNet Amarjot Singh, Nick Kingsbury Signal Processing Group, Department of Engineering, University of Cambridge,
arxiv: v1 [cs.cv] 22 Feb 2017
![arxiv: v1 [cs.cv] 22 Feb 2017](/thumbs/75/72094284.jpg "arxiv: v1 [cs.cv] 22 Feb 2017") Synthesising Dynamic Textures using Convolutional Neural Networks arxiv:1702.07006v1 [cs.cv] 22 Feb 2017 Christina M. Funke, 1, 2, 3, Leon A. Gatys, 1, 2, 4, Alexander S. Ecker 1, 2, 5 1, 2, 3, 6 and Matthias
Synthesising Dynamic Textures using Convolutional Neural Networks arxiv:1702.07006v1 [cs.cv] 22 Feb 2017 Christina M. Funke, 1, 2, 3, Leon A. Gatys, 1, 2, 4, Alexander S. Ecker 1, 2, 5 1, 2, 3, 6 and Matthias
CEA LIST s participation to the Scalable Concept Image Annotation task of ImageCLEF 2015
 CEA LIST s participation to the Scalable Concept Image Annotation task of ImageCLEF 2015 Etienne Gadeski, Hervé Le Borgne, and Adrian Popescu CEA, LIST, Laboratory of Vision and Content Engineering, France
CEA LIST s participation to the Scalable Concept Image Annotation task of ImageCLEF 2015 Etienne Gadeski, Hervé Le Borgne, and Adrian Popescu CEA, LIST, Laboratory of Vision and Content Engineering, France
Bilinear CNN Models for Fine-grained Visual Recognition
 Bilinear CNN Models for Fine-grained Visual Recognition Tsung-Yu Lin Aruni RoyChowdhury Subhransu Maji University of Massachusetts, Amherst {tsungyulin,arunirc,smaji}@cs.umass.edu Abstract We propose bilinear
Bilinear CNN Models for Fine-grained Visual Recognition Tsung-Yu Lin Aruni RoyChowdhury Subhransu Maji University of Massachusetts, Amherst {tsungyulin,arunirc,smaji}@cs.umass.edu Abstract We propose bilinear
DeepIndex for Accurate and Efficient Image Retrieval
 DeepIndex for Accurate and Efficient Image Retrieval Yu Liu, Yanming Guo, Song Wu, Michael S. Lew Media Lab, Leiden Institute of Advance Computer Science Outline Motivation Proposed Approach Results Conclusions
DeepIndex for Accurate and Efficient Image Retrieval Yu Liu, Yanming Guo, Song Wu, Michael S. Lew Media Lab, Leiden Institute of Advance Computer Science Outline Motivation Proposed Approach Results Conclusions
arxiv: v2 [cs.cv] 21 Jul 2015
![arxiv: v2 [cs.cv] 21 Jul 2015](/thumbs/82/86953432.jpg "arxiv: v2 [cs.cv] 21 Jul 2015") Understanding Intra-Class Knowledge Inside CNN Donglai Wei Bolei Zhou Antonio Torrabla William Freeman {donglai, bzhou, torrabla, billf} @csail.mit.edu Abstract uncutcut balltable arxiv:1507.02379v2 [cs.cv]
Understanding Intra-Class Knowledge Inside CNN Donglai Wei Bolei Zhou Antonio Torrabla William Freeman {donglai, bzhou, torrabla, billf} @csail.mit.edu Abstract uncutcut balltable arxiv:1507.02379v2 [cs.cv]
Texture Synthesis Through Convolutional Neural Networks and Spectrum Constraints
 Texture Synthesis Through Convolutional Neural Networks and Spectrum Constraints Gang Liu, Yann Gousseau Telecom-ParisTech, LTCI CNRS 46 Rue Barrault, 75013 Paris, France. {gang.liu, gousseau}@telecom-paristech.fr
Texture Synthesis Through Convolutional Neural Networks and Spectrum Constraints Gang Liu, Yann Gousseau Telecom-ParisTech, LTCI CNRS 46 Rue Barrault, 75013 Paris, France. {gang.liu, gousseau}@telecom-paristech.fr
Spatial Control in Neural Style Transfer
 Spatial Control in Neural Style Transfer Tom Henighan Stanford Physics henighan@stanford.edu Abstract Recent studies have shown that convolutional neural networks (convnets) can be used to transfer style
Spatial Control in Neural Style Transfer Tom Henighan Stanford Physics henighan@stanford.edu Abstract Recent studies have shown that convolutional neural networks (convnets) can be used to transfer style
Visual Material Traits Recognizing Per-Pixel Material Context
 Visual Material Traits Recognizing Per-Pixel Material Context Gabriel Schwartz gbs25@drexel.edu Ko Nishino kon@drexel.edu 1 / 22 2 / 22 Materials as Visual Context What tells us this road is unsafe? 3
Visual Material Traits Recognizing Per-Pixel Material Context Gabriel Schwartz gbs25@drexel.edu Ko Nishino kon@drexel.edu 1 / 22 2 / 22 Materials as Visual Context What tells us this road is unsafe? 3
Multi-Glance Attention Models For Image Classification
 Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
arxiv: v1 [cs.cv] 26 Oct 2015
![arxiv: v1 [cs.cv] 26 Oct 2015](/thumbs/88/115359803.jpg "arxiv: v1 [cs.cv] 26 Oct 2015") Aggregating Deep Convolutional Features for Image Retrieval Artem Babenko Yandex Moscow Institute of Physics and Technology artem.babenko@phystech.edu Victor Lempitsky Skolkovo Institute of Science and
Aggregating Deep Convolutional Features for Image Retrieval Artem Babenko Yandex Moscow Institute of Physics and Technology artem.babenko@phystech.edu Victor Lempitsky Skolkovo Institute of Science and
Artistic ideation based on computer vision methods
 Journal of Theoretical and Applied Computer Science Vol. 6, No. 2, 2012, pp. 72 78 ISSN 2299-2634 http://www.jtacs.org Artistic ideation based on computer vision methods Ferran Reverter, Pilar Rosado,
Journal of Theoretical and Applied Computer Science Vol. 6, No. 2, 2012, pp. 72 78 ISSN 2299-2634 http://www.jtacs.org Artistic ideation based on computer vision methods Ferran Reverter, Pilar Rosado,
Multiple VLAD encoding of CNNs for image classification
 Multiple VLAD encoding of CNNs for image classification Qing Li, Qiang Peng, Chuan Yan 1 arxiv:1707.00058v1 [cs.cv] 30 Jun 2017 Abstract Despite the effectiveness of convolutional neural networks (CNNs)
Multiple VLAD encoding of CNNs for image classification Qing Li, Qiang Peng, Chuan Yan 1 arxiv:1707.00058v1 [cs.cv] 30 Jun 2017 Abstract Despite the effectiveness of convolutional neural networks (CNNs)
Transfer Learning. Style Transfer in Deep Learning
 Transfer Learning & Style Transfer in Deep Learning 4-DEC-2016 Gal Barzilai, Ram Machlev Deep Learning Seminar School of Electrical Engineering Tel Aviv University Part 1: Transfer Learning in Deep Learning
Transfer Learning & Style Transfer in Deep Learning 4-DEC-2016 Gal Barzilai, Ram Machlev Deep Learning Seminar School of Electrical Engineering Tel Aviv University Part 1: Transfer Learning in Deep Learning
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK
 TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
Improved Bilinear Pooling with CNNs
 LIN AND MAJI: IMPROVED BILINEAR POOLING WITH CNNS 1 Improved Bilinear Pooling with CNNs Tsung-Yu Lin tsyungyulin@cs.umass.edu Subhransu Maji smaji@cs.umass.edu University of Massachusetts, Amherst Amherst,
LIN AND MAJI: IMPROVED BILINEAR POOLING WITH CNNS 1 Improved Bilinear Pooling with CNNs Tsung-Yu Lin tsyungyulin@cs.umass.edu Subhransu Maji smaji@cs.umass.edu University of Massachusetts, Amherst Amherst,
An Exploration of Computer Vision Techniques for Bird Species Classification
 An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
Deep filter banks for texture recognition and segmentation
 Deep filter banks for texture recognition and segmentation Mircea Cimpoi University of Oxford Subhransu Maji University of Massachusetts, Amherst Andrea Vedaldi University of Oxford mircea@robots.ox.ac.uk
Deep filter banks for texture recognition and segmentation Mircea Cimpoi University of Oxford Subhransu Maji University of Massachusetts, Amherst Andrea Vedaldi University of Oxford mircea@robots.ox.ac.uk
arxiv: v1 [cs.cv] 4 Dec 2014
![arxiv: v1 [cs.cv] 4 Dec 2014](/thumbs/83/87999872.jpg "arxiv: v1 [cs.cv] 4 Dec 2014") Convolutional Neural Networks at Constrained Time Cost Kaiming He Jian Sun Microsoft Research {kahe,jiansun}@microsoft.com arxiv:1412.1710v1 [cs.cv] 4 Dec 2014 Abstract Though recent advanced convolutional
Convolutional Neural Networks at Constrained Time Cost Kaiming He Jian Sun Microsoft Research {kahe,jiansun}@microsoft.com arxiv:1412.1710v1 [cs.cv] 4 Dec 2014 Abstract Though recent advanced convolutional
arxiv: v1 [cs.cv] 18 Apr 2016
![arxiv: v1 [cs.cv] 18 Apr 2016](/thumbs/72/67458129.jpg "arxiv: v1 [cs.cv] 18 Apr 2016") arxiv:1604.04994v1 [cs.cv] 18 Apr 2016 Selective Convolutional Descriptor Aggregation for Fine-Grained Image Retrieval Xiu-Shen Wei, Jian-Hao Luo, and Jianxin Wu National Key Laboratory for Novel Software
arxiv:1604.04994v1 [cs.cv] 18 Apr 2016 Selective Convolutional Descriptor Aggregation for Fine-Grained Image Retrieval Xiu-Shen Wei, Jian-Hao Luo, and Jianxin Wu National Key Laboratory for Novel Software
Encoder-Decoder Networks for Semantic Segmentation. Sachin Mehta
 Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Texture Synthesis Using Convolutional Neural Networks
 Texture Synthesis Using Convolutional Neural Networks Leon A. Gatys Centre for Integrative Neuroscience, University of Tübingen, Germany Bernstein Center for Computational Neuroscience, Tübingen, Germany
Texture Synthesis Using Convolutional Neural Networks Leon A. Gatys Centre for Integrative Neuroscience, University of Tübingen, Germany Bernstein Center for Computational Neuroscience, Tübingen, Germany
An Improved Texture Synthesis Algorithm Using Morphological Processing with Image Analogy
 An Improved Texture Synthesis Algorithm Using Morphological Processing with Image Analogy Jiang Ni Henry Schneiderman CMU-RI-TR-04-52 October 2004 Robotics Institute Carnegie Mellon University Pittsburgh,
An Improved Texture Synthesis Algorithm Using Morphological Processing with Image Analogy Jiang Ni Henry Schneiderman CMU-RI-TR-04-52 October 2004 Robotics Institute Carnegie Mellon University Pittsburgh,
Convolutional Networks in Scene Labelling
 Convolutional Networks in Scene Labelling Ashwin Paranjape Stanford ashwinpp@stanford.edu Ayesha Mudassir Stanford aysh@stanford.edu Abstract This project tries to address a well known problem of multi-class
Convolutional Networks in Scene Labelling Ashwin Paranjape Stanford ashwinpp@stanford.edu Ayesha Mudassir Stanford aysh@stanford.edu Abstract This project tries to address a well known problem of multi-class
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
arxiv: v1 [cs.cv] 8 Dec 2016
![arxiv: v1 [cs.cv] 8 Dec 2016](/thumbs/94/118262259.jpg "arxiv: v1 [cs.cv] 8 Dec 2016") Deep TEN: Texture Encoding Network Hang Zhang Jia Xue Kristin Dana Department of Electrical and Computer Engineering, Rutgers University, Piscataway, NJ 08854 {zhang.hang,jia.xue}@rutgers.edu, kdana@ece.rutgers.edu
Deep TEN: Texture Encoding Network Hang Zhang Jia Xue Kristin Dana Department of Electrical and Computer Engineering, Rutgers University, Piscataway, NJ 08854 {zhang.hang,jia.xue}@rutgers.edu, kdana@ece.rutgers.edu
Compact Bilinear Pooling
 Compact Bilinear Pooling Yang Gao 1, Oscar Beijbom 1, Ning Zhang 2, Trevor Darrell 1 1 EECS, UC Berkeley 2 Snapchat Inc. {yg, obeijbom, trevor}@eecs.berkeley.edu {ning.zhang}@snapchat.com Abstract Bilinear
Compact Bilinear Pooling Yang Gao 1, Oscar Beijbom 1, Ning Zhang 2, Trevor Darrell 1 1 EECS, UC Berkeley 2 Snapchat Inc. {yg, obeijbom, trevor}@eecs.berkeley.edu {ning.zhang}@snapchat.com Abstract Bilinear
Beyond bags of features: Adding spatial information. Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba
 Beyond bags of features: Adding spatial information Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba Adding spatial information Forming vocabularies from pairs of nearby features doublets
Beyond bags of features: Adding spatial information Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba Adding spatial information Forming vocabularies from pairs of nearby features doublets
Deep Learning in Visual Recognition. Thanks Da Zhang for the slides
 Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Ryerson University CP8208. Soft Computing and Machine Intelligence. Naive Road-Detection using CNNS. Authors: Sarah Asiri - Domenic Curro
 Ryerson University CP8208 Soft Computing and Machine Intelligence Naive Road-Detection using CNNS Authors: Sarah Asiri - Domenic Curro April 24 2016 Contents 1 Abstract 2 2 Introduction 2 3 Motivation
Ryerson University CP8208 Soft Computing and Machine Intelligence Naive Road-Detection using CNNS Authors: Sarah Asiri - Domenic Curro April 24 2016 Contents 1 Abstract 2 2 Introduction 2 3 Motivation
arxiv: v2 [cs.cv] 23 May 2016
![arxiv: v2 [cs.cv] 23 May 2016](/thumbs/88/115196824.jpg "arxiv: v2 [cs.cv] 23 May 2016") Localizing by Describing: Attribute-Guided Attention Localization for Fine-Grained Recognition arxiv:1605.06217v2 [cs.cv] 23 May 2016 Xiao Liu Jiang Wang Shilei Wen Errui Ding Yuanqing Lin Baidu Research
Localizing by Describing: Attribute-Guided Attention Localization for Fine-Grained Recognition arxiv:1605.06217v2 [cs.cv] 23 May 2016 Xiao Liu Jiang Wang Shilei Wen Errui Ding Yuanqing Lin Baidu Research
Computer Vision Lecture 16
 Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Deep Learning for Computer Vision II
 IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
Deep Learning with Tensorflow AlexNet
 Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Object Detection Based on Deep Learning
 Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Deconvolutions in Convolutional Neural Networks
 Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
arxiv: v2 [cs.cv] 19 Dec 2014
![arxiv: v2 [cs.cv] 19 Dec 2014](/thumbs/93/112260289.jpg "arxiv: v2 [cs.cv] 19 Dec 2014") Fisher Kernel for Deep Neural Activations Donggeun Yoo, Sunggyun Park, Joon-Young Lee, and In So Kweon arxiv:42.628v2 [cs.cv] 9 Dec 204 KAIST Daejeon, 305-70, Korea. dgyoo@rcv.kaist.ac.kr, sunggyun@kaist.ac.kr,
Fisher Kernel for Deep Neural Activations Donggeun Yoo, Sunggyun Park, Joon-Young Lee, and In So Kweon arxiv:42.628v2 [cs.cv] 9 Dec 204 KAIST Daejeon, 305-70, Korea. dgyoo@rcv.kaist.ac.kr, sunggyun@kaist.ac.kr,
The Treasure beneath Convolutional Layers: Cross-convolutional-layer Pooling for Image Classification
 The Treasure beneath Convolutional Layers: Cross-convolutional-layer Pooling for Image Classification Lingqiao Liu 1, Chunhua Shen 1,2, Anton van den Hengel 1,2 The University of Adelaide, Australia 1
The Treasure beneath Convolutional Layers: Cross-convolutional-layer Pooling for Image Classification Lingqiao Liu 1, Chunhua Shen 1,2, Anton van den Hengel 1,2 The University of Adelaide, Australia 1
Learning a Representative and Discriminative Part Model with Deep Convolutional Features for Scene Recognition
 Learning a Representative and Discriminative Part Model with Deep Convolutional Features for Scene Recognition Bingyuan Liu, Jing Liu, Jingqiao Wang, Hanqing Lu Institute of Automation, Chinese Academy
Learning a Representative and Discriminative Part Model with Deep Convolutional Features for Scene Recognition Bingyuan Liu, Jing Liu, Jingqiao Wang, Hanqing Lu Institute of Automation, Chinese Academy
Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab.
 [ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
[ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task
 Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task Kyunghee Kim Stanford University 353 Serra Mall Stanford, CA 94305 kyunghee.kim@stanford.edu Abstract We use a
Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task Kyunghee Kim Stanford University 353 Serra Mall Stanford, CA 94305 kyunghee.kim@stanford.edu Abstract We use a
Bag-of-features. Cordelia Schmid
 Bag-of-features for category classification Cordelia Schmid Visual search Particular objects and scenes, large databases Category recognition Image classification: assigning a class label to the image
Bag-of-features for category classification Cordelia Schmid Visual search Particular objects and scenes, large databases Category recognition Image classification: assigning a class label to the image
arxiv: v1 [cs.cv] 24 Apr 2015
![arxiv: v1 [cs.cv] 24 Apr 2015](/thumbs/90/103057793.jpg "arxiv: v1 [cs.cv] 24 Apr 2015") Object Level Deep Feature Pooling for Compact Image Representation arxiv:1504.06591v1 [cs.cv] 24 Apr 2015 Konda Reddy Mopuri and R. Venkatesh Babu Video Analytics Lab, SERC, Indian Institute of Science,
Object Level Deep Feature Pooling for Compact Image Representation arxiv:1504.06591v1 [cs.cv] 24 Apr 2015 Konda Reddy Mopuri and R. Venkatesh Babu Video Analytics Lab, SERC, Indian Institute of Science,
Image Analogies for Visual Domain Adaptation
 Image Analogies for Visual Domain Adaptation Jeff Donahue UC Berkeley EECS jdonahue@eecs.berkeley.edu Abstract In usual approaches to visual domain adaptation, algorithms are used to infer a common domain
Image Analogies for Visual Domain Adaptation Jeff Donahue UC Berkeley EECS jdonahue@eecs.berkeley.edu Abstract In usual approaches to visual domain adaptation, algorithms are used to infer a common domain
arxiv: v1 [cs.cv] 29 Sep 2016
![arxiv: v1 [cs.cv] 29 Sep 2016](/thumbs/76/73787064.jpg "arxiv: v1 [cs.cv] 29 Sep 2016") arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
Fast CNN-Based Object Tracking Using Localization Layers and Deep Features Interpolation
 Fast CNN-Based Object Tracking Using Localization Layers and Deep Features Interpolation Al-Hussein A. El-Shafie Faculty of Engineering Cairo University Giza, Egypt elshafie_a@yahoo.com Mohamed Zaki Faculty
Fast CNN-Based Object Tracking Using Localization Layers and Deep Features Interpolation Al-Hussein A. El-Shafie Faculty of Engineering Cairo University Giza, Egypt elshafie_a@yahoo.com Mohamed Zaki Faculty
Study of Residual Networks for Image Recognition
 Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
HENet: A Highly Efficient Convolutional Neural. Networks Optimized for Accuracy, Speed and Storage
 HENet: A Highly Efficient Convolutional Neural Networks Optimized for Accuracy, Speed and Storage Qiuyu Zhu Shanghai University zhuqiuyu@staff.shu.edu.cn Ruixin Zhang Shanghai University chriszhang96@shu.edu.cn
HENet: A Highly Efficient Convolutional Neural Networks Optimized for Accuracy, Speed and Storage Qiuyu Zhu Shanghai University zhuqiuyu@staff.shu.edu.cn Ruixin Zhang Shanghai University chriszhang96@shu.edu.cn
Deep Learning. Visualizing and Understanding Convolutional Networks. Christopher Funk. Pennsylvania State University.
 Visualizing and Understanding Convolutional Networks Christopher Pennsylvania State University February 23, 2015 Some Slide Information taken from Pierre Sermanet (Google) presentation on and Computer
Visualizing and Understanding Convolutional Networks Christopher Pennsylvania State University February 23, 2015 Some Slide Information taken from Pierre Sermanet (Google) presentation on and Computer
A model for full local image interpretation
 A model for full local image interpretation Guy Ben-Yosef 1 (guy.ben-yosef@weizmann.ac.il)) Liav Assif 1 (liav.assif@weizmann.ac.il) Daniel Harari 1,2 (hararid@mit.edu) Shimon Ullman 1,2 (shimon.ullman@weizmann.ac.il)
A model for full local image interpretation Guy Ben-Yosef 1 (guy.ben-yosef@weizmann.ac.il)) Liav Assif 1 (liav.assif@weizmann.ac.il) Daniel Harari 1,2 (hararid@mit.edu) Shimon Ullman 1,2 (shimon.ullman@weizmann.ac.il)
Supervised learning. y = f(x) function
 function") Supervised learning y = f(x) output prediction function Image feature Training: given a training set of labeled examples {(x 1,y 1 ),, (x N,y N )}, estimate the prediction function f by minimizing the
Supervised learning y = f(x) output prediction function Image feature Training: given a training set of labeled examples {(x 1,y 1 ),, (x N,y N )}, estimate the prediction function f by minimizing the
Using Machine Learning for Classification of Cancer Cells
 Using Machine Learning for Classification of Cancer Cells Camille Biscarrat University of California, Berkeley I Introduction Cell screening is a commonly used technique in the development of new drugs.
Using Machine Learning for Classification of Cancer Cells Camille Biscarrat University of California, Berkeley I Introduction Cell screening is a commonly used technique in the development of new drugs.
Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization. Presented by: Karen Lucknavalai and Alexandr Kuznetsov
 Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization Presented by: Karen Lucknavalai and Alexandr Kuznetsov Example Style Content Result Motivation Transforming content of an image
Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization Presented by: Karen Lucknavalai and Alexandr Kuznetsov Example Style Content Result Motivation Transforming content of an image
Multi-Scale Orderless Pooling of Deep Convolutional Activation Features
 Multi-Scale Orderless Pooling of Deep Convolutional Activation Features Yunchao Gong, Liwei Wang 2, Ruiqi Guo 2, and Svetlana Lazebnik 2 University of North Carolina at Chapel Hill yunchao@cs.unc.edu 2
Multi-Scale Orderless Pooling of Deep Convolutional Activation Features Yunchao Gong, Liwei Wang 2, Ruiqi Guo 2, and Svetlana Lazebnik 2 University of North Carolina at Chapel Hill yunchao@cs.unc.edu 2
Object detection with CNNs
 Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Action recognition in videos
 Action recognition in videos Cordelia Schmid INRIA Grenoble Joint work with V. Ferrari, A. Gaidon, Z. Harchaoui, A. Klaeser, A. Prest, H. Wang Action recognition - goal Short actions, i.e. drinking, sit
Action recognition in videos Cordelia Schmid INRIA Grenoble Joint work with V. Ferrari, A. Gaidon, Z. Harchaoui, A. Klaeser, A. Prest, H. Wang Action recognition - goal Short actions, i.e. drinking, sit
Object Recognition. Computer Vision. Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce
 Object Recognition Computer Vision Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce How many visual object categories are there? Biederman 1987 ANIMALS PLANTS OBJECTS
Object Recognition Computer Vision Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce How many visual object categories are there? Biederman 1987 ANIMALS PLANTS OBJECTS
Cultural Event Recognition by Subregion Classification with Convolutional Neural Network
 Cultural Event Recognition by Subregion Classification with Convolutional Neural Network Sungheon Park and Nojun Kwak Graduate School of CST, Seoul National University Seoul, Korea {sungheonpark,nojunk}@snu.ac.kr
Cultural Event Recognition by Subregion Classification with Convolutional Neural Network Sungheon Park and Nojun Kwak Graduate School of CST, Seoul National University Seoul, Korea {sungheonpark,nojunk}@snu.ac.kr
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Object detection using Region Proposals (RCNN) Ernest Cheung COMP Presentation
 Ernest Cheung COMP Presentation") Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS. Zhao Chen Machine Learning Intern, NVIDIA
 JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
IMAGE CLASSIFICATION WITH MAX-SIFT DESCRIPTORS
 IMAGE CLASSIFICATION WITH MAX-SIFT DESCRIPTORS Lingxi Xie 1, Qi Tian 2, Jingdong Wang 3, and Bo Zhang 4 1,4 LITS, TNLIST, Dept. of Computer Sci&Tech, Tsinghua University, Beijing 100084, China 2 Department
IMAGE CLASSIFICATION WITH MAX-SIFT DESCRIPTORS Lingxi Xie 1, Qi Tian 2, Jingdong Wang 3, and Bo Zhang 4 1,4 LITS, TNLIST, Dept. of Computer Sci&Tech, Tsinghua University, Beijing 100084, China 2 Department
CS 2750: Machine Learning. Neural Networks. Prof. Adriana Kovashka University of Pittsburgh April 13, 2016
 CS 2750: Machine Learning Neural Networks Prof. Adriana Kovashka University of Pittsburgh April 13, 2016 Plan for today Neural network definition and examples Training neural networks (backprop) Convolutional
CS 2750: Machine Learning Neural Networks Prof. Adriana Kovashka University of Pittsburgh April 13, 2016 Plan for today Neural network definition and examples Training neural networks (backprop) Convolutional
Image Transformation via Neural Network Inversion
 Image Transformation via Neural Network Inversion Asha Anoosheh Rishi Kapadia Jared Rulison Abstract While prior experiments have shown it is possible to approximately reconstruct inputs to a neural net
Image Transformation via Neural Network Inversion Asha Anoosheh Rishi Kapadia Jared Rulison Abstract While prior experiments have shown it is possible to approximately reconstruct inputs to a neural net
String distance for automatic image classification
 String distance for automatic image classification Nguyen Hong Thinh*, Le Vu Ha*, Barat Cecile** and Ducottet Christophe** *University of Engineering and Technology, Vietnam National University of HaNoi,
String distance for automatic image classification Nguyen Hong Thinh*, Le Vu Ha*, Barat Cecile** and Ducottet Christophe** *University of Engineering and Technology, Vietnam National University of HaNoi,
One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models
 One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models [Supplemental Materials] 1. Network Architecture b ref b ref +1 We now describe the architecture of the networks
One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models [Supplemental Materials] 1. Network Architecture b ref b ref +1 We now describe the architecture of the networks
Deep Convolutional Neural Networks for Efficient Pose Estimation in Gesture Videos
 Deep Convolutional Neural Networks for Efficient Pose Estimation in Gesture Videos Tomas Pfister 1, Karen Simonyan 1, James Charles 2 and Andrew Zisserman 1 1 Visual Geometry Group, Department of Engineering
Deep Convolutional Neural Networks for Efficient Pose Estimation in Gesture Videos Tomas Pfister 1, Karen Simonyan 1, James Charles 2 and Andrew Zisserman 1 1 Visual Geometry Group, Department of Engineering