Crime - Based Predictive Analysis and Warning System
|
|
|
- Corey Hutchinson
- 5 years ago
- Views:
Transcription
1 Crime - Based Predictive Analysis and Warning System Sahil Puri, Parul Verma
2 Outline Motivation Goal Dataset details Architecture Modelling and Approach Progress Future work
3 Motivation and Goal
4 Motivation Crime - based prediction analysis approaches have been proposed in many literatures but they mostly focus on policing and government services (e.g. PredPol). Lack of a smart warning system that alerts users about anticipated crime on their location. Utilize Geo-spatial Open Data available on the internet. Data on Chicago.gov.in Canada government made 2,00,000 datasets available.

5 Goal To design an architecture and implement a real time system that warns users about anticipated crime in their neighbourhood. Benefit of such system: Safety of citizens. Reduce the crime rate of the city. Deterrent for criminals. Can be used by authorities to track crime.
6 Dataset information
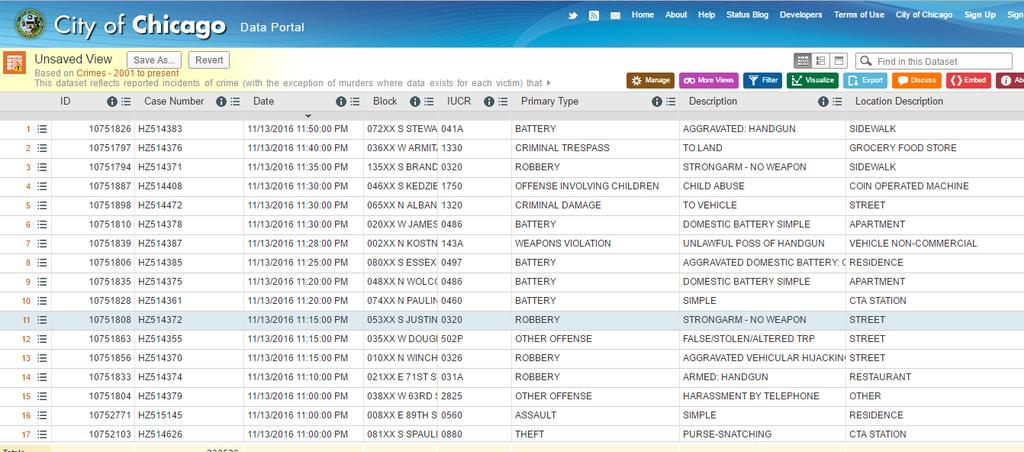
7 Dataset Details Crime data made available by Department of Police in Chicago. URL - Data provides details of: Crime Type Crime Description Date and Time of Crime Latitude and Longitude
8
9 Architecture

10 Architecture Modelling Preprocessing layer The amount of data is very large (nearly 200,000 rows). Convert it into a format consumable by next layer Clustering layer The approach in this process compares user location with crime point locations. How to reduce the computation time in big data? Data Mining Techniques comes to rescue Categorizer layer What features should contribute to anticipate the crime? User Interface
11 Preprocessing Data Unstructured data can converted into system consumable format. Removed noise data from raw data. Removed unnecessary columns not relevant to study (Ward Number, Case ID used by Police). Can also be used to join multiple datasets relevant to application and provide more insight. Canadian government has 2,00,000 open datasets available. Some contain crime information, some contain 911 calls information. These datasets can be aggregated and processed.
12 Clustering
13 Clustering The processed data is clustered using algorithms (discussed ahead) Clustering is performed on the basis of geospatial location to group the crime data into multiple clusters. A cluster is defined by its centroid. The centroid is defined on the basis of density distribution of the points contained inside a cluster.
14 Clustering Algorithms K-means Method of vector quantization popular for clustering analysis in data mining. Groups data of size 'n' into exactly 'k' points. Most suitable for signal processing. DBScan Groups the points based on the density i.e. which are closely packed Number of clusters are dynamic and not limited to a fixed number as in case of K-means. More suitable for geo-spatial points.
15 DBScan Algorithm Density Based Spatial Clustering of Application and Noise groups together the most closely related points based on three factors : Epsilon'. - Epsilon is the maximum distance between two points that belongs to same cluster. minnumpoints Minimum number of points that should be in a cluster. (0 in our case.) Noise Points that cannot be put into any cluster will be tagged as Noise. (Again, 0 In our case.). Steps in DBSCAN STEP 1 - For each point p in Dataset which is not visited, STEP 2 - Mark p as visited. STEP 3 - For each point q in dataset which is not visited, STEP 4 - Calculate distance =HaversteinDistance(p, q); STEP 5 -If distance < epsilon, put q in p s cluster. Mark q as visited. STEP 6 (MERGE) - For each point k in dataset which is not visited, repeat STEP 4 Cluster centroid : The point which represents the whole cluster. Calculated on the basis of density distribution of points in a cluster.
16 Deciding Epsilon? Deciding epsilon is tricky: Low epsilon => large no of clusters and less no of points per cluster. Large epsilon => small no of clusters and large no. Of points per cluster. Need to find optimum value to have evenly distributed clusters. Cluster Error Coefficient Deviation in number of points for a specific value of epsilon, i.e. degree of uneven distribution of points in clusters.
17 Limitations of DBSCAN Number of Entries Number Of Clusters Points in each cluster With epsilon value = 2, Data is not evenly distributed in clusters. There is not much improvement in number of point comparisons (97, 1) (406, 1, 1) (856, 3, 2, 1, 3, 1, 1, 1, 1, 1, 1) (4334, 11, 7, 1) (8348, 19, 13, 1) (34544, 29, 1)
18 DBSCAN_Extended It is a minimized version of DBScan which does not implement the MERGE process. Steps in DBSCAN_Extended STEP 1 - For each point p which is not visited STEP 2 - For each point q in dataset, STEP 3 - Calculate distance =HaversteinDistance(p, q); STEP 4 -If distance < epsilon, put q in p s cluster. Mark q as visited Because of removal of merge step, we should get more evenly distributed clusters. Also, we can have a point in multiple clusters. Cluster centroid : The point which represents the whole cluster. Calculated on the basis of density distribution of points in a cluster.
19 Deciding Epsilon for DBScan_Extended? Time required maximum for E = 1. Cluster error coefficient maximum for E = 5. For now, we use E = 2.
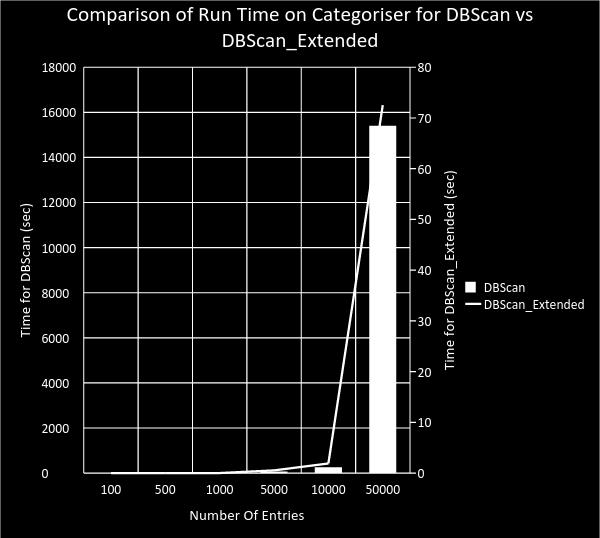
20 Comparison of DBScan vs DBScan_Extended Number of Entries DBScan Number Of Clusters Points in each cluster DBScan_Extended Number of Clusters Points in each cluster (97, 1) 44 (12, 10, 8, 4...) (406, 1, 1) 69 (47, 31, 24, 10 ) (856, 3, 2, 1, 3, 1, 1, 1, 1, 1, 1) (4334, 11, 7, 1) (8348, 19, 13, 1) 78 (35, 7, 24 ) 99 (371, 204, 47 ) 101 (789, 382, 158..) (34544, 29, 1) 109 (3903, )

21 Clustering Visualization The visualization contains the clusters formed using DBScan_Extended algorithm on 1000 points.
22 Categorization
23 Categorization Categorizer function will be given a crime point from the user cluster generated by DBScan_Extended and user location. It will generate a measure of how important each crime in the cluster is with respect to user s location. Input : Crime Point from a cluster User s location. Output : Ranked list of crimes with details.
24 Categorization Weightage Parameters Categorizer Function(pointLoc, userloc) Distance(pointLoc, usersloc) DateOldness(pointDate, userdate) timedifference(pointtime, usertime) Frequency(pointCrime, Cluster) Distance between the crime point and users location Number of days passed between crime and user s date. Time difference in crime point and user s time. Frequency of the crime in the cluster list.
25 Categorization Weightage Distribution The final weightage of a point with respect to user s location is calculated using the following formula : Weightage(Point, UserLocation) : W Distance = weightage to distance between the functions. W time = weightage to difference between the time in the points. W date = weightage to difference between the date of the points. Frequence of Crime = Number of instances of the crime in the cluster. Weight Point, UserLocation = 0.35 WDistance Wtime Wdate Frequence ofcrime. The crime points in the cluster can be ranked in the decreasing order of the weightage. The ranked crime list can be displayed to the user.



26 Comparison of DBScan vs DBScan_Extended for categorization

27 Categorization Visualization The visualization shows the anticipated crime at the location of the user. User can click on Next to see the crime rankings.
28 Schedule and Progress
29 Knowledge gathering and literature reading Categorisation design and prototype implementation App Creation, Project report. Completed Completed Completed In Progress TODO Clustering algorithms analysis Fine Tuning categoriser and research on more methods
30 Future Work and References
31 Future Work Need to fine tune the categorizer and improve its accuracy. A better UI interface like an Android / ios application for the project so that it can be used by general public. Research can be extended to predict crime based on user attributes: User location is continuously changing. Transportation mode of the user e.g driving a car or walking. A flexible system where users can also contribute and provide data. Research for other possible sources of data.
32 References Erica Kalotch (2002) "Clustering Algorithms for Spatial Databases: A Survey". Lawrence McClendon and Natarajan Meghanathan "Using Machine Learning Algorithms to analyze crime data". Jarrod S.Shingleton(2003) "Crime trend prediction using regression model for salinas"
33
34 Questions??
Crime Prediction and Analysis using Clustering Approaches and Regression Methods
 Crime Prediction and Analysis using Clustering Approaches and Regression Methods 1 Raghavendhar T.V, 2 Joslin Joshy, 3 Mahaalakshmi R, 4 Ashutosh Soni M 1 Department of CSE, SRM Institute of Science and
Crime Prediction and Analysis using Clustering Approaches and Regression Methods 1 Raghavendhar T.V, 2 Joslin Joshy, 3 Mahaalakshmi R, 4 Ashutosh Soni M 1 Department of CSE, SRM Institute of Science and
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
Streaming iphone sensor data to SAS Event Stream Processing
 SAS USER FORUM Streaming iphone sensor data to SAS Event Stream Processing Pasi Helenius Senior Advisor SAS Event Stream Processing 3 KEY CHARACTERISTICS Technology Process steams of data events, on the
SAS USER FORUM Streaming iphone sensor data to SAS Event Stream Processing Pasi Helenius Senior Advisor SAS Event Stream Processing 3 KEY CHARACTERISTICS Technology Process steams of data events, on the
Hot Tech Tips for using SPSS Statistics Part 1. Laura Watts Mitya Moitra Wednesday October 11 th 2017, 11AM
 Hot Tech Tips for using SPSS Statistics Part 1 Laura Watts Mitya Moitra Wednesday October 11 th 2017, 11AM Today s Tech Tips and Speakers Import / Export Automation Laura Watts Strategic Account Manager
Hot Tech Tips for using SPSS Statistics Part 1 Laura Watts Mitya Moitra Wednesday October 11 th 2017, 11AM Today s Tech Tips and Speakers Import / Export Automation Laura Watts Strategic Account Manager
Unsupervised Data Mining: Clustering. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Effect of Physical Constraints on Spatial Connectivity in Urban Areas
 Effect of Physical Constraints on Spatial Connectivity in Urban Areas Yoav Vered and Sagi Filin Department of Transportation and Geo-Information Technion Israel Institute of Technology Motivation Wide
Effect of Physical Constraints on Spatial Connectivity in Urban Areas Yoav Vered and Sagi Filin Department of Transportation and Geo-Information Technion Israel Institute of Technology Motivation Wide
Lecture 22 The Generalized Lasso
 Lecture 22 The Generalized Lasso 07 December 2015 Taylor B. Arnold Yale Statistics STAT 312/612 Class Notes Midterm II - Due today Problem Set 7 - Available now, please hand in by the 16th Motivation Today
Lecture 22 The Generalized Lasso 07 December 2015 Taylor B. Arnold Yale Statistics STAT 312/612 Class Notes Midterm II - Due today Problem Set 7 - Available now, please hand in by the 16th Motivation Today
EXTRACTION OF RELEVANT WEB PAGES USING DATA MINING
 Chapter 3 EXTRACTION OF RELEVANT WEB PAGES USING DATA MINING 3.1 INTRODUCTION Generally web pages are retrieved with the help of search engines which deploy crawlers for downloading purpose. Given a query,
Chapter 3 EXTRACTION OF RELEVANT WEB PAGES USING DATA MINING 3.1 INTRODUCTION Generally web pages are retrieved with the help of search engines which deploy crawlers for downloading purpose. Given a query,
CPSC 340: Machine Learning and Data Mining
 CPSC 340: Machine Learning and Data Mining Hierarchical Clustering and Outlier Detection Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart. Admin Assignment 2 is due
CPSC 340: Machine Learning and Data Mining Hierarchical Clustering and Outlier Detection Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart. Admin Assignment 2 is due
Summary of Last Chapter. Course Content. Chapter 3 Objectives. Chapter 3: Data Preprocessing. Dr. Osmar R. Zaïane. University of Alberta 4
 Principles of Knowledge Discovery in Data Fall 2004 Chapter 3: Data Preprocessing Dr. Osmar R. Zaïane University of Alberta Summary of Last Chapter What is a data warehouse and what is it for? What is
Principles of Knowledge Discovery in Data Fall 2004 Chapter 3: Data Preprocessing Dr. Osmar R. Zaïane University of Alberta Summary of Last Chapter What is a data warehouse and what is it for? What is
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Large-Scale Flight Phase identification from ADS-B Data Using Machine Learning Methods
 Large-Scale Flight Phase identification from ADS-B Data Using Methods Junzi Sun 06.2016 PhD student, ATM Control and Simulation, Aerospace Engineering Large-Scale Flight Phase identification from ADS-B
Large-Scale Flight Phase identification from ADS-B Data Using Methods Junzi Sun 06.2016 PhD student, ATM Control and Simulation, Aerospace Engineering Large-Scale Flight Phase identification from ADS-B
Chuck Cartledge, PhD. 23 September 2017
 Introduction Definitions Numerical data Hands-on Q&A Conclusion References Files Big Data: Data Analysis Boot Camp Agglomerative Clustering Chuck Cartledge, PhD 23 September 2017 1/30 Table of contents
Introduction Definitions Numerical data Hands-on Q&A Conclusion References Files Big Data: Data Analysis Boot Camp Agglomerative Clustering Chuck Cartledge, PhD 23 September 2017 1/30 Table of contents
COLLABORATIVE LOCATION AND ACTIVITY RECOMMENDATIONS WITH GPS HISTORY DATA
 COLLABORATIVE LOCATION AND ACTIVITY RECOMMENDATIONS WITH GPS HISTORY DATA Vincent W. Zheng, Yu Zheng, Xing Xie, Qiang Yang Hong Kong University of Science and Technology Microsoft Research Asia WWW 2010
COLLABORATIVE LOCATION AND ACTIVITY RECOMMENDATIONS WITH GPS HISTORY DATA Vincent W. Zheng, Yu Zheng, Xing Xie, Qiang Yang Hong Kong University of Science and Technology Microsoft Research Asia WWW 2010
Introduction to Trajectory Clustering. By YONGLI ZHANG
 Introduction to Trajectory Clustering By YONGLI ZHANG Outline 1. Problem Definition 2. Clustering Methods for Trajectory data 3. Model-based Trajectory Clustering 4. Applications 5. Conclusions 1 Problem
Introduction to Trajectory Clustering By YONGLI ZHANG Outline 1. Problem Definition 2. Clustering Methods for Trajectory data 3. Model-based Trajectory Clustering 4. Applications 5. Conclusions 1 Problem
Management Information Systems Review Questions. Chapter 6 Foundations of Business Intelligence: Databases and Information Management
 Management Information Systems Review Questions Chapter 6 Foundations of Business Intelligence: Databases and Information Management 1) The traditional file environment does not typically have a problem
Management Information Systems Review Questions Chapter 6 Foundations of Business Intelligence: Databases and Information Management 1) The traditional file environment does not typically have a problem
Geo-spatial technology enables & enhances the objectives of Safe City - Smart City
 Geo-spatial technology enables & enhances the objectives of Safe City - Smart City Presented By: Mr. Shishir Verma Vice President MapmyIndia (CE Info Systems Pvt. Ltd.) About Us Making Our World Better
Geo-spatial technology enables & enhances the objectives of Safe City - Smart City Presented By: Mr. Shishir Verma Vice President MapmyIndia (CE Info Systems Pvt. Ltd.) About Us Making Our World Better
Opportunities and challenges in personalization of online hotel search
 Opportunities and challenges in personalization of online hotel search David Zibriczky Data Science & Analytics Lead, User Profiling Introduction 2 Introduction About Mission: Helping the travelers to
Opportunities and challenges in personalization of online hotel search David Zibriczky Data Science & Analytics Lead, User Profiling Introduction 2 Introduction About Mission: Helping the travelers to
CPSC 340: Machine Learning and Data Mining. Hierarchical Clustering Fall 2017
 CPSC 340: Machine Learning and Data Mining Hierarchical Clustering Fall 2017 Assignment 1 is due Friday. Admin Follow the assignment guidelines naming convention (a1.zip/a1.pdf). Assignment 0 grades posted
CPSC 340: Machine Learning and Data Mining Hierarchical Clustering Fall 2017 Assignment 1 is due Friday. Admin Follow the assignment guidelines naming convention (a1.zip/a1.pdf). Assignment 0 grades posted
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Redistricting and Geographic Deployment at the Ottawa Police Service Esri Canada User Conference Ottawa October 12, 2017
 Redistricting and Geographic Deployment at the Ottawa Police Service Esri Canada User Conference Ottawa October 12, 2017 Introduction Alyson Yaraskovitch, B.A., M.A. Crime Intelligence Analyst Ottawa Police
Redistricting and Geographic Deployment at the Ottawa Police Service Esri Canada User Conference Ottawa October 12, 2017 Introduction Alyson Yaraskovitch, B.A., M.A. Crime Intelligence Analyst Ottawa Police
POLICE QUICK REPORTING SYSTEM (PQRS)
") POLICE QUICK REPORTING SYSTEM (PQRS) PROJECT REFERENCE NO. : 37S1140 COLLEGE : ADICHUNCHANAGIRI INSTITUTE OF TECHNOLOGY, CHIKAMAGALUR BRANCH : COMPUTER SCIENCE AND ENGINEERING GUIDES : DARSHAN L.M STUDENTS
POLICE QUICK REPORTING SYSTEM (PQRS) PROJECT REFERENCE NO. : 37S1140 COLLEGE : ADICHUNCHANAGIRI INSTITUTE OF TECHNOLOGY, CHIKAMAGALUR BRANCH : COMPUTER SCIENCE AND ENGINEERING GUIDES : DARSHAN L.M STUDENTS
ADCN: An Anisotropic Density-Based Clustering Algorithm for Discovering Spatial Point Patterns with Noise
 ADCN: An Anisotropic Density-Based Clustering Algorithm for Discovering Spatial Point Patterns with Noise Gengchen Mai 1, Krzysztof Janowicz 1, Yingjie Hu 2, Song Gao 1 1 STKO Lab, Department of Geography,
ADCN: An Anisotropic Density-Based Clustering Algorithm for Discovering Spatial Point Patterns with Noise Gengchen Mai 1, Krzysztof Janowicz 1, Yingjie Hu 2, Song Gao 1 1 STKO Lab, Department of Geography,
Data Collection, Preprocessing and Implementation
 Chapter 6 Data Collection, Preprocessing and Implementation 6.1 Introduction Data collection is the loosely controlled method of gathering the data. Such data are mostly out of range, impossible data combinations,
Chapter 6 Data Collection, Preprocessing and Implementation 6.1 Introduction Data collection is the loosely controlled method of gathering the data. Such data are mostly out of range, impossible data combinations,
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
CHAPTER-6 WEB USAGE MINING USING CLUSTERING
 CHAPTER-6 WEB USAGE MINING USING CLUSTERING 6.1 Related work in Clustering Technique 6.2 Quantifiable Analysis of Distance Measurement Techniques 6.3 Approaches to Formation of Clusters 6.4 Conclusion
CHAPTER-6 WEB USAGE MINING USING CLUSTERING 6.1 Related work in Clustering Technique 6.2 Quantifiable Analysis of Distance Measurement Techniques 6.3 Approaches to Formation of Clusters 6.4 Conclusion
CPSC 340: Machine Learning and Data Mining. Density-Based Clustering Fall 2017
 CPSC 340: Machine Learning and Data Mining Density-Based Clustering Fall 2017 Assignment 1 is due Friday. Admin Needs Julie 0.6 (you can use JuliaBox if you can t get Julia/PyPlot working). There was a
CPSC 340: Machine Learning and Data Mining Density-Based Clustering Fall 2017 Assignment 1 is due Friday. Admin Needs Julie 0.6 (you can use JuliaBox if you can t get Julia/PyPlot working). There was a
SOCIAL MEDIA MINING. Data Mining Essentials
 SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
CS Introduction to Data Mining Instructor: Abdullah Mueen
 CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
Preprocessing Short Lecture Notes cse352. Professor Anita Wasilewska
 Preprocessing Short Lecture Notes cse352 Professor Anita Wasilewska Data Preprocessing Why preprocess the data? Data cleaning Data integration and transformation Data reduction Discretization and concept
Preprocessing Short Lecture Notes cse352 Professor Anita Wasilewska Data Preprocessing Why preprocess the data? Data cleaning Data integration and transformation Data reduction Discretization and concept
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Understanding Clustering Supervising the unsupervised
 Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Self-Service Data Preparation for Qlik. Cookbook Series Self-Service Data Preparation for Qlik
 Self-Service Data Preparation for Qlik What is Data Preparation for Qlik? The key to deriving the full potential of solutions like QlikView and Qlik Sense lies in data preparation. Data Preparation is
Self-Service Data Preparation for Qlik What is Data Preparation for Qlik? The key to deriving the full potential of solutions like QlikView and Qlik Sense lies in data preparation. Data Preparation is
CS4445 Data Mining and Knowledge Discovery in Databases. A Term 2008 Exam 2 October 14, 2008
 CS4445 Data Mining and Knowledge Discovery in Databases. A Term 2008 Exam 2 October 14, 2008 Prof. Carolina Ruiz Department of Computer Science Worcester Polytechnic Institute NAME: Prof. Ruiz Problem
CS4445 Data Mining and Knowledge Discovery in Databases. A Term 2008 Exam 2 October 14, 2008 Prof. Carolina Ruiz Department of Computer Science Worcester Polytechnic Institute NAME: Prof. Ruiz Problem
Collaborative Filtering using Euclidean Distance in Recommendation Engine
 Indian Journal of Science and Technology, Vol 9(37), DOI: 10.17485/ijst/2016/v9i37/102074, October 2016 ISSN (Print) : 0974-6846 ISSN (Online) : 0974-5645 Collaborative Filtering using Euclidean Distance
Indian Journal of Science and Technology, Vol 9(37), DOI: 10.17485/ijst/2016/v9i37/102074, October 2016 ISSN (Print) : 0974-6846 ISSN (Online) : 0974-5645 Collaborative Filtering using Euclidean Distance
Parallel & Scalable Machine Learning Introduction to Machine Learning Algorithms
 Parallel & Scalable Machine Learning Introduction to Machine Learning Algorithms Dr. Ing. Morris Riedel Adjunct Associated Professor School of Engineering and Natural Sciences, University of Iceland Research
Parallel & Scalable Machine Learning Introduction to Machine Learning Algorithms Dr. Ing. Morris Riedel Adjunct Associated Professor School of Engineering and Natural Sciences, University of Iceland Research
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Big Data SONY Håkan Jonsson Vedran Sekara
 Big Data 2016 - SONY Håkan Jonsson Vedran Sekara Schedule 09:15-10:00 Cluster analysis, partition-based clustering 10.00 10.15 Break 10:15 12:00 Exercise 1: User segmentation based on app usage 12:00-13:15
Big Data 2016 - SONY Håkan Jonsson Vedran Sekara Schedule 09:15-10:00 Cluster analysis, partition-based clustering 10.00 10.15 Break 10:15 12:00 Exercise 1: User segmentation based on app usage 12:00-13:15
OSM-SVG Converting for Open Road Simulator
 OSM-SVG Converting for Open Road Simulator Rajashree S. Sokasane, Kyungbaek Kim Department of Electronics and Computer Engineering Chonnam National University Gwangju, Republic of Korea sokasaners@gmail.com,
OSM-SVG Converting for Open Road Simulator Rajashree S. Sokasane, Kyungbaek Kim Department of Electronics and Computer Engineering Chonnam National University Gwangju, Republic of Korea sokasaners@gmail.com,
Network Operations Intelligence. Evolving network operations by the power of intelligence
 Network Operations Intelligence Evolving network operations by the power of intelligence 1 Future of Network Operations 2 Evolution with Intelligence 3 KT s Experience 4 Considerations 01 Current: An Operations
Network Operations Intelligence Evolving network operations by the power of intelligence 1 Future of Network Operations 2 Evolution with Intelligence 3 KT s Experience 4 Considerations 01 Current: An Operations
A Study of the Correlation between the Spatial Attributes on Twitter
 A Study of the Correlation between the Spatial Attributes on Twitter Bumsuk Lee, Byung-Yeon Hwang Dept. of Computer Science and Engineering, The Catholic University of Korea 3 Jibong-ro, Wonmi-gu, Bucheon-si,
A Study of the Correlation between the Spatial Attributes on Twitter Bumsuk Lee, Byung-Yeon Hwang Dept. of Computer Science and Engineering, The Catholic University of Korea 3 Jibong-ro, Wonmi-gu, Bucheon-si,
Analysing crime data in Maps for Office and ArcGIS Online
 Analysing crime data in Maps for Office and ArcGIS Online For non-commercial use only by schools and universities Esri UK GIS for School Programme www.esriuk.com/schools Introduction ArcGIS Online is a
Analysing crime data in Maps for Office and ArcGIS Online For non-commercial use only by schools and universities Esri UK GIS for School Programme www.esriuk.com/schools Introduction ArcGIS Online is a
Kaggle See Click Fix Model Description
 Kaggle See Click Fix Model Description BY: Miroslaw Horbal & Bryan Gregory LOCATION: Waterloo, Ont, Canada & Dallas, TX CONTACT : miroslaw@gmail.com & bryan.gregory1@gmail.com CONTEST: See Click Predict
Kaggle See Click Fix Model Description BY: Miroslaw Horbal & Bryan Gregory LOCATION: Waterloo, Ont, Canada & Dallas, TX CONTACT : miroslaw@gmail.com & bryan.gregory1@gmail.com CONTEST: See Click Predict
An Overview of Smart Sustainable Cities and the Role of Information and Communication Technologies (ICTs)
") An Overview of Smart Sustainable Cities and the Role of Information and Communication Technologies (ICTs) Sekhar KONDEPUDI Ph.D. Vice Chair FG-SSC & Coordinator Working Group 1 ICT role and roadmap for
An Overview of Smart Sustainable Cities and the Role of Information and Communication Technologies (ICTs) Sekhar KONDEPUDI Ph.D. Vice Chair FG-SSC & Coordinator Working Group 1 ICT role and roadmap for
A Spectral-based Clustering Algorithm for Categorical Data Using Data Summaries (SCCADDS)
") A Spectral-based Clustering Algorithm for Categorical Data Using Data Summaries (SCCADDS) Eman Abdu eha90@aol.com Graduate Center The City University of New York Douglas Salane dsalane@jjay.cuny.edu Center
A Spectral-based Clustering Algorithm for Categorical Data Using Data Summaries (SCCADDS) Eman Abdu eha90@aol.com Graduate Center The City University of New York Douglas Salane dsalane@jjay.cuny.edu Center
Helping Administrators Prepare for Analytics 10
 Helping Administrators Prepare for Analytics 10 There are a few important configuration updates that Webtrends administrators can take in On Demand prior to the Analytics 10 release in order to prepare
Helping Administrators Prepare for Analytics 10 There are a few important configuration updates that Webtrends administrators can take in On Demand prior to the Analytics 10 release in order to prepare
A Planet of Smarter Cities: Security and critical infrastructures impact
 A Planet of Smarter Cities: Security and critical infrastructures impact Alberto Barrientos Director of Public Sector IBM Smarter Cities Alberto.barrientos@es.ibm.com Urban population growth expected to
A Planet of Smarter Cities: Security and critical infrastructures impact Alberto Barrientos Director of Public Sector IBM Smarter Cities Alberto.barrientos@es.ibm.com Urban population growth expected to
Data Mining and Data Warehousing Henryk Maciejewski Data Mining Clustering
 Data Mining and Data Warehousing Henryk Maciejewski Data Mining Clustering Clustering Algorithms Contents K-means Hierarchical algorithms Linkage functions Vector quantization SOM Clustering Formulation
Data Mining and Data Warehousing Henryk Maciejewski Data Mining Clustering Clustering Algorithms Contents K-means Hierarchical algorithms Linkage functions Vector quantization SOM Clustering Formulation
Learning Objectives for Data Concept and Visualization
 Learning Objectives for Data Concept and Visualization Assignment 1: Data Quality Concept and Impact of Data Quality Summarize concepts of data quality. Understand and describe the impact of data on actuarial
Learning Objectives for Data Concept and Visualization Assignment 1: Data Quality Concept and Impact of Data Quality Summarize concepts of data quality. Understand and describe the impact of data on actuarial
Clustering to Reduce Spatial Data Set Size
 Clustering to Reduce Spatial Data Set Size Geoff Boeing arxiv:1803.08101v1 [cs.lg] 21 Mar 2018 1 Introduction Department of City and Regional Planning University of California, Berkeley March 2018 Traditionally
Clustering to Reduce Spatial Data Set Size Geoff Boeing arxiv:1803.08101v1 [cs.lg] 21 Mar 2018 1 Introduction Department of City and Regional Planning University of California, Berkeley March 2018 Traditionally
LOG FILE ANALYSIS USING HADOOP AND ITS ECOSYSTEMS
 LOG FILE ANALYSIS USING HADOOP AND ITS ECOSYSTEMS Vandita Jain 1, Prof. Tripti Saxena 2, Dr. Vineet Richhariya 3 1 M.Tech(CSE)*,LNCT, Bhopal(M.P.)(India) 2 Prof. Dept. of CSE, LNCT, Bhopal(M.P.)(India)
LOG FILE ANALYSIS USING HADOOP AND ITS ECOSYSTEMS Vandita Jain 1, Prof. Tripti Saxena 2, Dr. Vineet Richhariya 3 1 M.Tech(CSE)*,LNCT, Bhopal(M.P.)(India) 2 Prof. Dept. of CSE, LNCT, Bhopal(M.P.)(India)
Mobility Data Management & Exploration
 Mobility Data Management & Exploration Ch. 07. Mobility Data Mining and Knowledge Discovery Nikos Pelekis & Yannis Theodoridis InfoLab University of Piraeus Greece infolab.cs.unipi.gr v.2014.05 Chapter
Mobility Data Management & Exploration Ch. 07. Mobility Data Mining and Knowledge Discovery Nikos Pelekis & Yannis Theodoridis InfoLab University of Piraeus Greece infolab.cs.unipi.gr v.2014.05 Chapter
Nowcasting. D B M G Data Base and Data Mining Group of Politecnico di Torino. Big Data: Hype or Hallelujah? Big data hype?
 Big data hype? Big Data: Hype or Hallelujah? Data Base and Data Mining Group of 2 Google Flu trends On the Internet February 2010 detected flu outbreak two weeks ahead of CDC data Nowcasting http://www.internetlivestats.com/
Big data hype? Big Data: Hype or Hallelujah? Data Base and Data Mining Group of 2 Google Flu trends On the Internet February 2010 detected flu outbreak two weeks ahead of CDC data Nowcasting http://www.internetlivestats.com/
2. (a) Briefly discuss the forms of Data preprocessing with neat diagram. (b) Explain about concept hierarchy generation for categorical data.
 Briefly discuss the forms of Data preprocessing with neat diagram. (b) Explain about concept hierarchy generation for categorical data.") Code No: M0502/R05 Set No. 1 1. (a) Explain data mining as a step in the process of knowledge discovery. (b) Differentiate operational database systems and data warehousing. [8+8] 2. (a) Briefly discuss
Code No: M0502/R05 Set No. 1 1. (a) Explain data mining as a step in the process of knowledge discovery. (b) Differentiate operational database systems and data warehousing. [8+8] 2. (a) Briefly discuss
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Applied Kernel Density Estimation: Dynamic Spatiotemporal Analysis of Density Maps on Crime Data
 Applied Kernel Density Estimation: Dynamic Spatiotemporal Analysis of Density Maps on Crime Data David G. Smalling Abstract The task of identifying meaningful patterns in spatiotemporal datasets lies at
Applied Kernel Density Estimation: Dynamic Spatiotemporal Analysis of Density Maps on Crime Data David G. Smalling Abstract The task of identifying meaningful patterns in spatiotemporal datasets lies at
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 3. Chapter 3: Data Preprocessing. Major Tasks in Data Preprocessing
 Chapter 3. Chapter 3: Data Preprocessing. Major Tasks in Data Preprocessing") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 3 1 Chapter 3: Data Preprocessing Data Preprocessing: An Overview Data Quality Major Tasks in Data Preprocessing Data Cleaning Data Integration Data
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 3 1 Chapter 3: Data Preprocessing Data Preprocessing: An Overview Data Quality Major Tasks in Data Preprocessing Data Cleaning Data Integration Data
Kapitel 4: Clustering
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
Based on Big Data: Hype or Hallelujah? by Elena Baralis
 Based on Big Data: Hype or Hallelujah? by Elena Baralis http://dbdmg.polito.it/wordpress/wp-content/uploads/2010/12/bigdata_2015_2x.pdf 1 3 February 2010 Google detected flu outbreak two weeks ahead of
Based on Big Data: Hype or Hallelujah? by Elena Baralis http://dbdmg.polito.it/wordpress/wp-content/uploads/2010/12/bigdata_2015_2x.pdf 1 3 February 2010 Google detected flu outbreak two weeks ahead of
Data Mining. Dr. Raed Ibraheem Hamed. University of Human Development, College of Science and Technology Department of Computer Science
 Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 201 Road map What is Cluster Analysis? Characteristics of Clustering
Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 201 Road map What is Cluster Analysis? Characteristics of Clustering
Esri and MarkLogic: Location Analytics, Multi-Model Data
 Esri and MarkLogic: Location Analytics, Multi-Model Data Ben Conklin, Industry Manager, Defense, Intel and National Security, Esri Anthony Roach, Product Manager, MarkLogic James Kerr, Technical Director,
Esri and MarkLogic: Location Analytics, Multi-Model Data Ben Conklin, Industry Manager, Defense, Intel and National Security, Esri Anthony Roach, Product Manager, MarkLogic James Kerr, Technical Director,
Text clustering based on a divide and merge strategy
 Available online at www.sciencedirect.com ScienceDirect Procedia Computer Science 55 (2015 ) 825 832 Information Technology and Quantitative Management (ITQM 2015) Text clustering based on a divide and
Available online at www.sciencedirect.com ScienceDirect Procedia Computer Science 55 (2015 ) 825 832 Information Technology and Quantitative Management (ITQM 2015) Text clustering based on a divide and
SMART POLICING FOR SMALL AGENCIES. Increase Community Safety with Intelligent Maps and Analytics
 SMART POLICING FOR SMALL AGENCIES Increase Community Safety with Intelligent Maps and Analytics Build a more efficient, productive agency using powerful map analytics. For more than 20 years, law enforcement
SMART POLICING FOR SMALL AGENCIES Increase Community Safety with Intelligent Maps and Analytics Build a more efficient, productive agency using powerful map analytics. For more than 20 years, law enforcement
Data Reduction and Partitioning in an Extreme Scale GPU-Based Clustering Algorithm
 Data Reduction and Partitioning in an Extreme Scale GPU-Based Clustering Algorithm Benjamin Welton and Barton Miller Paradyn Project University of Wisconsin - Madison DRBSD-2 Workshop November 17 th 2017
Data Reduction and Partitioning in an Extreme Scale GPU-Based Clustering Algorithm Benjamin Welton and Barton Miller Paradyn Project University of Wisconsin - Madison DRBSD-2 Workshop November 17 th 2017
Data Analytics at Logitech Snowflake + Tableau = #Winning
 Welcome # T C 1 8 Data Analytics at Logitech Snowflake + Tableau = #Winning Avinash Deshpande I am a futurist, scientist, engineer, designer, data evangelist at heart Find me at Avinash Deshpande Chief
Welcome # T C 1 8 Data Analytics at Logitech Snowflake + Tableau = #Winning Avinash Deshpande I am a futurist, scientist, engineer, designer, data evangelist at heart Find me at Avinash Deshpande Chief
By Mahesh R. Sanghavi Associate professor, SNJB s KBJ CoE, Chandwad
 By Mahesh R. Sanghavi Associate professor, SNJB s KBJ CoE, Chandwad Data Analytics life cycle Discovery Data preparation Preprocessing requirements data cleaning, data integration, data reduction, data
By Mahesh R. Sanghavi Associate professor, SNJB s KBJ CoE, Chandwad Data Analytics life cycle Discovery Data preparation Preprocessing requirements data cleaning, data integration, data reduction, data
White Paper: Next generation disaster data infrastructure CODATA LODGD Task Group 2017
 White Paper: Next generation disaster data infrastructure CODATA LODGD Task Group 2017 Call for Authors This call for authors seeks contributions from academics and scientists who are in the fields of
White Paper: Next generation disaster data infrastructure CODATA LODGD Task Group 2017 Call for Authors This call for authors seeks contributions from academics and scientists who are in the fields of
Data Mining: Models and Methods
 Data Mining: Models and Methods Author, Kirill Goltsman A White Paper July 2017 --------------------------------------------------- www.datascience.foundation Copyright 2016-2017 What is Data Mining? Data
Data Mining: Models and Methods Author, Kirill Goltsman A White Paper July 2017 --------------------------------------------------- www.datascience.foundation Copyright 2016-2017 What is Data Mining? Data
Visualizing Crime in San Francisco During the 2014 World Series
 Visualizing Crime in San Francisco During the 2014 World Series John Semerdjian and Bill Chambers Description The scope and focus of our project evolved over the course of its lifetime. Our goals were
Visualizing Crime in San Francisco During the 2014 World Series John Semerdjian and Bill Chambers Description The scope and focus of our project evolved over the course of its lifetime. Our goals were
Data Preprocessing. Why Data Preprocessing? MIT-652 Data Mining Applications. Chapter 3: Data Preprocessing. Multi-Dimensional Measure of Data Quality
 Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate data e.g., occupation = noisy: containing
Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate data e.g., occupation = noisy: containing
Data Preprocessing. Slides by: Shree Jaswal
 Data Preprocessing Slides by: Shree Jaswal Topics to be covered Why Preprocessing? Data Cleaning; Data Integration; Data Reduction: Attribute subset selection, Histograms, Clustering and Sampling; Data
Data Preprocessing Slides by: Shree Jaswal Topics to be covered Why Preprocessing? Data Cleaning; Data Integration; Data Reduction: Attribute subset selection, Histograms, Clustering and Sampling; Data
Overview. Introduction to Data Warehousing and Business Intelligence. BI Is Important. What is Business Intelligence (BI)?
?") Introduction to Data Warehousing and Business Intelligence Overview Why Business Intelligence? Data analysis problems Data Warehouse (DW) introduction A tour of the coming DW lectures DW Applications Loosely
Introduction to Data Warehousing and Business Intelligence Overview Why Business Intelligence? Data analysis problems Data Warehouse (DW) introduction A tour of the coming DW lectures DW Applications Loosely
PARALLEL AND DISTRIBUTED PLATFORM FOR PLUG-AND-PLAY AGENT-BASED SIMULATIONS. Wentong CAI
 PARALLEL AND DISTRIBUTED PLATFORM FOR PLUG-AND-PLAY AGENT-BASED SIMULATIONS Wentong CAI Parallel & Distributed Computing Centre School of Computer Engineering Nanyang Technological University Singapore
PARALLEL AND DISTRIBUTED PLATFORM FOR PLUG-AND-PLAY AGENT-BASED SIMULATIONS Wentong CAI Parallel & Distributed Computing Centre School of Computer Engineering Nanyang Technological University Singapore
SMARTATL. A Smart City Overview and Roadmap. Evanta CIO Executive Summit 1
 SMARTATL A Smart City Overview and Roadmap Evanta CIO Executive Summit 1 Southeast USA Overview Evanta CIO Executive Summit 2 Metro Atlanta Overview Evanta CIO Executive Summit 3 Permits, New Units under
SMARTATL A Smart City Overview and Roadmap Evanta CIO Executive Summit 1 Southeast USA Overview Evanta CIO Executive Summit 2 Metro Atlanta Overview Evanta CIO Executive Summit 3 Permits, New Units under
Chapter 4: Text Clustering
 4.1 Introduction to Text Clustering Clustering is an unsupervised method of grouping texts / documents in such a way that in spite of having little knowledge about the content of the documents, we can
4.1 Introduction to Text Clustering Clustering is an unsupervised method of grouping texts / documents in such a way that in spite of having little knowledge about the content of the documents, we can
Data Mining: STATISTICA
 Outline Data Mining: STATISTICA Prepare the data Classification and regression (C & R, ANN) Clustering Association rules Graphic user interface Prepare the Data Statistica can read from Excel,.txt and
Outline Data Mining: STATISTICA Prepare the data Classification and regression (C & R, ANN) Clustering Association rules Graphic user interface Prepare the Data Statistica can read from Excel,.txt and
Data Preprocessing. S1 Teknik Informatika Fakultas Teknologi Informasi Universitas Kristen Maranatha
 Data Preprocessing S1 Teknik Informatika Fakultas Teknologi Informasi Universitas Kristen Maranatha 1 Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking
Data Preprocessing S1 Teknik Informatika Fakultas Teknologi Informasi Universitas Kristen Maranatha 1 Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking
Event: PASS SQL Saturday - DC 2018 Presenter: Jon Tupitza, CTO Architect
 Event: PASS SQL Saturday - DC 2018 Presenter: Jon Tupitza, CTO Architect BEOP.CTO.TP4 Owner: OCTO Revision: 0001 Approved by: JAT Effective: 08/30/2018 Buchanan & Edwards Proprietary: Printed copies of
Event: PASS SQL Saturday - DC 2018 Presenter: Jon Tupitza, CTO Architect BEOP.CTO.TP4 Owner: OCTO Revision: 0001 Approved by: JAT Effective: 08/30/2018 Buchanan & Edwards Proprietary: Printed copies of
DIGIT.B4 Big Data PoC
 DIGIT.B4 Big Data PoC DIGIT 01 Social Media D02.01 PoC Requirements Table of contents 1 Introduction... 5 1.1 Context... 5 1.2 Objective... 5 2 Data SOURCES... 6 2.1 Data sources... 6 2.2 Data fields...
DIGIT.B4 Big Data PoC DIGIT 01 Social Media D02.01 PoC Requirements Table of contents 1 Introduction... 5 1.1 Context... 5 1.2 Objective... 5 2 Data SOURCES... 6 2.1 Data sources... 6 2.2 Data fields...
Enhancement in Next Web Page Recommendation with the help of Multi- Attribute Weight Prophecy
 2017 IJSRST Volume 3 Issue 1 Print ISSN: 2395-6011 Online ISSN: 2395-602X Themed Section: Science and Technology Enhancement in Next Web Page Recommendation with the help of Multi- Attribute Weight Prophecy
2017 IJSRST Volume 3 Issue 1 Print ISSN: 2395-6011 Online ISSN: 2395-602X Themed Section: Science and Technology Enhancement in Next Web Page Recommendation with the help of Multi- Attribute Weight Prophecy
HW4 VINH NGUYEN. Q1 (6 points). Chapter 8 Exercise 20
. Chapter 8 Exercise 20") HW4 VINH NGUYEN Q1 (6 points). Chapter 8 Exercise 20 a. For each figure, could you use single link to find the patterns represented by the nose, eyes and mouth? Explain? First, a single link is a MIN version
HW4 VINH NGUYEN Q1 (6 points). Chapter 8 Exercise 20 a. For each figure, could you use single link to find the patterns represented by the nose, eyes and mouth? Explain? First, a single link is a MIN version
CHAPTER 4 K-MEANS AND UCAM CLUSTERING ALGORITHM
 CHAPTER 4 K-MEANS AND UCAM CLUSTERING 4.1 Introduction ALGORITHM Clustering has been used in a number of applications such as engineering, biology, medicine and data mining. The most popular clustering
CHAPTER 4 K-MEANS AND UCAM CLUSTERING 4.1 Introduction ALGORITHM Clustering has been used in a number of applications such as engineering, biology, medicine and data mining. The most popular clustering
CHAPTER 4 AN IMPROVED INITIALIZATION METHOD FOR FUZZY C-MEANS CLUSTERING USING DENSITY BASED APPROACH
 37 CHAPTER 4 AN IMPROVED INITIALIZATION METHOD FOR FUZZY C-MEANS CLUSTERING USING DENSITY BASED APPROACH 4.1 INTRODUCTION Genes can belong to any genetic network and are also coordinated by many regulatory
37 CHAPTER 4 AN IMPROVED INITIALIZATION METHOD FOR FUZZY C-MEANS CLUSTERING USING DENSITY BASED APPROACH 4.1 INTRODUCTION Genes can belong to any genetic network and are also coordinated by many regulatory
International Journal of Data Mining & Knowledge Management Process (IJDKP) Vol.7, No.3, May Dr.Zakea Il-Agure and Mr.Hicham Noureddine Itani
 Vol.7, No.3, May Dr.Zakea Il-Agure and Mr.Hicham Noureddine Itani") LINK MINING PROCESS Dr.Zakea Il-Agure and Mr.Hicham Noureddine Itani Higher Colleges of Technology, United Arab Emirates ABSTRACT Many data mining and knowledge discovery methodologies and process models
LINK MINING PROCESS Dr.Zakea Il-Agure and Mr.Hicham Noureddine Itani Higher Colleges of Technology, United Arab Emirates ABSTRACT Many data mining and knowledge discovery methodologies and process models
Keywords Clustering, Goals of clustering, clustering techniques, clustering algorithms.
 Volume 3, Issue 5, May 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com A Survey of Clustering
Volume 3, Issue 5, May 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com A Survey of Clustering
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
3 Ways to Improve Your Regression
 3 Ways to Improve Your Regression Introduction This tutorial will take you through the steps demonstrated in the 3 Ways to Improve Your Regression webinar. First, you will be introduced to a dataset about
3 Ways to Improve Your Regression Introduction This tutorial will take you through the steps demonstrated in the 3 Ways to Improve Your Regression webinar. First, you will be introduced to a dataset about
A Novel Method for Activity Place Sensing Based on Behavior Pattern Mining Using Crowdsourcing Trajectory Data
 A Novel Method for Activity Place Sensing Based on Behavior Pattern Mining Using Crowdsourcing Trajectory Data Wei Yang 1, Tinghua Ai 1, Wei Lu 1, Tong Zhang 2 1 School of Resource and Environment Sciences,
A Novel Method for Activity Place Sensing Based on Behavior Pattern Mining Using Crowdsourcing Trajectory Data Wei Yang 1, Tinghua Ai 1, Wei Lu 1, Tong Zhang 2 1 School of Resource and Environment Sciences,
Discovering Playing Patterns: Time Series Clustering of Free-To-Play Game Data
 Discovering Playing Patterns: Time Series Clustering of Free-To-Play Game Data Alain Saas, Anna Guitart and África Periáñez (Silicon Studio) IEEE CIG 2016 Santorini 21 September, 2016 About us Who are
Discovering Playing Patterns: Time Series Clustering of Free-To-Play Game Data Alain Saas, Anna Guitart and África Periáñez (Silicon Studio) IEEE CIG 2016 Santorini 21 September, 2016 About us Who are
Data Preprocessing Yudho Giri Sucahyo y, Ph.D , CISA
 Obj ti Objectives Motivation: Why preprocess the Data? Data Preprocessing Techniques Data Cleaning Data Integration and Transformation Data Reduction Data Preprocessing Lecture 3/DMBI/IKI83403T/MTI/UI
Obj ti Objectives Motivation: Why preprocess the Data? Data Preprocessing Techniques Data Cleaning Data Integration and Transformation Data Reduction Data Preprocessing Lecture 3/DMBI/IKI83403T/MTI/UI
Nature Methods: doi: /nmeth Supplementary Figure 1
 Supplementary Figure 1 Performance analysis under four different clustering scenarios. Performance analysis under four different clustering scenarios. i) Standard Conditions, ii) a sparse data set with
Supplementary Figure 1 Performance analysis under four different clustering scenarios. Performance analysis under four different clustering scenarios. i) Standard Conditions, ii) a sparse data set with
Data Mining Cluster Analysis: Advanced Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining, 2 nd Edition
 Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Outline Prototype-based Fuzzy c-means
Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Outline Prototype-based Fuzzy c-means
Joe Hummel, PhD. Visiting Researcher: U. of California, Irvine Adjunct Professor: U. of Illinois, Chicago & Loyola U., Chicago
 Joe Hummel, PhD Visiting Researcher: U. of California, Irvine Adjunct Professor: U. of Illinois, Chicago & Loyola U., Chicago Materials: http://www.joehummel.net/downloads.html Email: joe@joehummel.net
Joe Hummel, PhD Visiting Researcher: U. of California, Irvine Adjunct Professor: U. of Illinois, Chicago & Loyola U., Chicago Materials: http://www.joehummel.net/downloads.html Email: joe@joehummel.net
An Improved Document Clustering Approach Using Weighted K-Means Algorithm
 An Improved Document Clustering Approach Using Weighted K-Means Algorithm 1 Megha Mandloi; 2 Abhay Kothari 1 Computer Science, AITR, Indore, M.P. Pin 453771, India 2 Computer Science, AITR, Indore, M.P.
An Improved Document Clustering Approach Using Weighted K-Means Algorithm 1 Megha Mandloi; 2 Abhay Kothari 1 Computer Science, AITR, Indore, M.P. Pin 453771, India 2 Computer Science, AITR, Indore, M.P.
Behavioral Data Mining. Lecture 9 Modeling People
 Behavioral Data Mining Lecture 9 Modeling People Outline Power Laws Big-5 Personality Factors Social Network Structure Power Laws Y-axis = frequency of word, X-axis = rank in decreasing order Power Laws
Behavioral Data Mining Lecture 9 Modeling People Outline Power Laws Big-5 Personality Factors Social Network Structure Power Laws Y-axis = frequency of word, X-axis = rank in decreasing order Power Laws
Contact: Ye Zhao, Professor Phone: Dept. of Computer Science, Kent State University, Ohio 44242
 Table of Contents I. Overview... 2 II. Trajectory Datasets and Data Types... 3 III. Data Loading and Processing Guide... 5 IV. Account and Web-based Data Access... 14 V. Visual Analytics Interface... 15
Table of Contents I. Overview... 2 II. Trajectory Datasets and Data Types... 3 III. Data Loading and Processing Guide... 5 IV. Account and Web-based Data Access... 14 V. Visual Analytics Interface... 15
Outlier Detection With SQL And R. Kevin Feasel, Engineering Manager, ChannelAdvisor Moderated By: Satya Jayanty
 Outlier Detection With SQL And R Kevin Feasel, Engineering Manager, ChannelAdvisor Moderated By: Satya Jayanty Technical Assistance If you require assistance during the session, type your inquiry into
Outlier Detection With SQL And R Kevin Feasel, Engineering Manager, ChannelAdvisor Moderated By: Satya Jayanty Technical Assistance If you require assistance during the session, type your inquiry into
Analysis and Extensions of Popular Clustering Algorithms
 Analysis and Extensions of Popular Clustering Algorithms Renáta Iváncsy, Attila Babos, Csaba Legány Department of Automation and Applied Informatics and HAS-BUTE Control Research Group Budapest University
Analysis and Extensions of Popular Clustering Algorithms Renáta Iváncsy, Attila Babos, Csaba Legány Department of Automation and Applied Informatics and HAS-BUTE Control Research Group Budapest University
Regression on SAT Scores of 374 High Schools and K-means on Clustering Schools
 Regression on SAT Scores of 374 High Schools and K-means on Clustering Schools Abstract In this project, we study 374 public high schools in New York City. The project seeks to use regression techniques
Regression on SAT Scores of 374 High Schools and K-means on Clustering Schools Abstract In this project, we study 374 public high schools in New York City. The project seeks to use regression techniques