Perceiving the 3D World from Images and Videos. Yu Xiang Postdoctoral Researcher University of Washington
|
|
|
- Loren Foster
- 5 years ago
- Views:
Transcription
1 Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1

2 2


3 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3


4 Understand the 3D World Navigation Manipulation Geometry Free space Surface Semantics Objects Affordances 4

5 Recognize Objects in 3D Semantics 3D Location 3D Orientation 5

6 Lula Robotics 6
7 6D Object Pose Estimation camera coordinate object coordinate 7

8 Related Work: Feature-based methods Texture-less objects Symmetry objects Occlusion Lowe, ICCV 99 Rothganger et al., IJCV 06 Savarese & Fei-Fei, ICCV 07 Collet et al., IJRR 11 8

9 Related Work: Template-based methods Texture-less objects Symmetry objects Occlusion Gu & Ren, ECCV 10 Hinterstoisser et al., ACCV 12 Xiang & Savarese, CVPR 12 Cao et al., ICRA 16 9


10 PoseCNN An input image Texture-less objects Symmetry objects Occlusion 6D poses Y. Xiang, T. Schmidt, V. Narayanan and D. Fox. PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes. In arxiv:

11 Decouple 3D Translation and 3D Rotation 3D Translation 2D center camera coordinate Distance object coordinate 3D Rotation 11

12 PoseCNN: Semantic Labeling Feature Extraction Embedding Classification #classes Labels Convolution + ReLU Max Pooling Deconvolution Addition 12
13 PoseCNN: Object Center Voting 13
14 PoseCNN: 3D Translation Estimation Feature Extraction Embedding Classification / Regression #classes Labels Center direction X #classes Center direction Y Center distance Convolution + ReLU Max Pooling Deconvolution Addition Hough Voting 14
15 PoseCNN: Center Estimation with RANSAC Center hypothesis 15
16 PoseCNN: 3D Rotation Regression Feature Extraction Embedding Classification / Regression #class Labels Convolution + ReLU Max Pooling Deconvolution Addition Hough Voting RoI Pooling Fully Connected #class Center direction X RoIs Center direction Y 512 Center distance For each RoI #class 6D Poses 16



17 The YCB-Video Dataset 21 YCB Objects 92 Videos, 133,827 frames17

 Average")

18 6D Pose Evaluation Metric Ground truth pose Average distance (non-symmetry) Average distance (symmetry) 3D model points Predicted pose 18
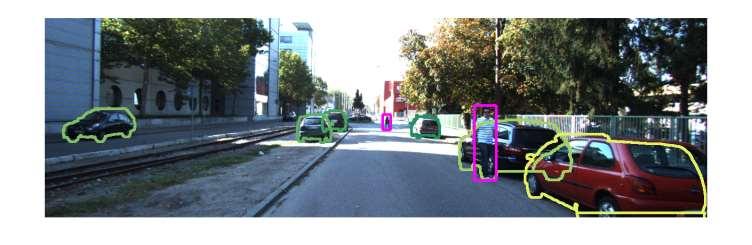
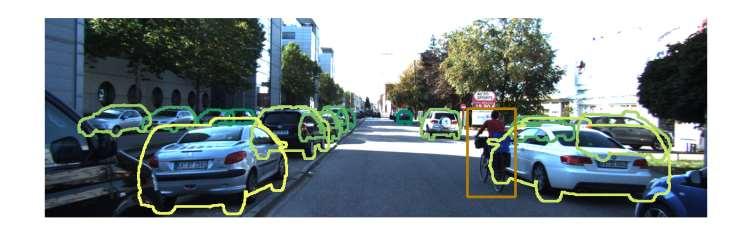
19 Results on the YCB-Video Dataset 19










20 Input Image Labeling Centers 6D Pose 20

21 Network Network + ICP Network + ICP + Multi-view 21
22 22
23 23

24 24

25 25 Y. Xiang, W. Choi, Y. Lin and S. Savarese. Subcategory-aware Convolutional Neural Networks for Object Proposals and Detection. In WACV, Y. Xiang, W. Choi, Y. Lin and S. Savarese. Data-Driven 3D Voxel Patterns for Object Category Recognition. In CVPR, 2015 (Oral).
.")
26 Online Multi-Object Tracking Y. Xiang, A. Alahi and S. Savarese. Learning to Track: Online Multi-Object Tracking by Decision Making. In ICCV, 2015 (Oral). Code available online 26

27 Semantic Mapping (Semantic SLAM) Geometry Semantics Camera poses 27

28 28



29 Semantic Mapping with Data Associated Recurrent Neural Networks (DA-RNNs) DA-RNN Code available online 29 Y. Xiang and D. Fox. DA-RNN: Semantic Mapping with Data Associated Recurrent Neural Networks. In RSS, 2017.

30 Related Work: 3D Scene Reconstruction KinectFusion Geometry Data Association Semantics Newcombe et al., ISMAR 11 Henry et al., IJRR 12, 3DV 13 Whelan et al., RSS Workshop 12, RSS 15 Keller et al., 3DV 13 30

31 Related Work: Semantic Labeling Geometry Data Association Semantics Long et al., CVPR 12 Zheng et al., ICCV 15 Chen et al., ICLR 15 Badrinarayanan et al., CVPR 15 31

32 Related Work: Semantic Mapping SemanticFusion Geometry Data Association Semantics Salas-Moreno et al., CVPR 13 McCormac et al., ICRA 17 Bowman et al. ICRA 17 32



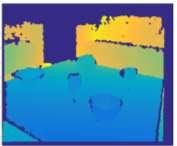




33 Our Contribution: DA-RNN Recurrent Neural Network RGB Images Data Association Semantic Labels Depth Images KinectFusion 3D Semantic Scene 33


34 Single Frame Labeling with FCNs Feature Extraction Embedding Classification Convolution + ReLU RGB Image Depth Image #classes Labels Max Pooling Concatenation Deconvolution Addition 34
![Results on RGB-D Scene Dataset [1] [1] K. Lai, L. Bo and D. Fox.](/docs-images/84/91199022/images/35-2.jpg "Unsupervised feature learning for 3D scene labeling.")
35 Results on RGB-D Scene Dataset [1] [1] K. Lai, L. Bo and D. Fox. Unsupervised feature learning for 3D scene labeling. In ICRA 14 35
36 Video Semantic Labeling with DA-RNNs RGB Image Time t Depth Image RGB Image Time t+1 Labels data association Labels Convolution + ReLU Max Pooling Concatenation Deconvolution Addition Recurrent Units Depth Image 36
37 Data Association from KinectFusion Depth is available Assumption: static scenes Iterative Closest Point (ICP) 37
38 Data Associated Recurrent Units (DA-RUs) Data Association Hidden state h t i DA-RU i h t+1 Classification Time t Time t+1 Recurrent layer Input i x t+1 Weighted Moving Averaging with learnable parameters 38
39 Results on RGB-D Scene Dataset [1] FCN DA-RNN [1] K. Lai, L. Bo and D. Fox. Unsupervised feature learning for 3D scene labeling. In ICRA
40 Experiments: Datasets RGB-D Scene Dataset [1] 14 RGB-D videos of indoor scenes 9 object classes ShapeNet Scene Dataset [2] 100 RGB-D videos of virtual table-top scenes 7 object classes [1] K. Lai, L. Bo and D. Fox. Unsupervised feature learning for 3D scene labeling. In ICRA 14. [2] Chang et al., ShapeNet: an information-rich 3D model repository. arxiv preprint arxiv: ,
41 Experiments: Comparison on Network Architectures RGB-D Scenes Methods FCN [1] Background 94.3 Bowl 78.6 Cap 61.2 Cereal Box 80.4 Coffee Mug 62.7 Coffee Table 93.6 Office Chair 67.3 Soda Can 73.5 Sofa 90.8 Table 84.2 MEAN 78.7 Metric: segmentation intersection over union (IoU) 41 [1] J. Long, E. Shelhamer and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR 15.
42 Experiments: Comparison on Network Architectures RGB-D Scenes Methods FCN [1] Our FCN Background Bowl Cap Cereal Box Coffee Mug Coffee Table Office Chair Soda Can Sofa Table MEAN Metric: segmentation intersection over union (IoU) 42 [1] J. Long, E. Shelhamer and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR 15.
43 Experiments: Comparison on Network Architectures RGB-D Scenes Methods FCN [1] Our FCN Our GRU-RNN Background Bowl Cap Cereal Box Coffee Mug Coffee Table Office Chair Soda Can Sofa Table MEAN Metric: segmentation intersection over union (IoU) 43 [1] J. Long, E. Shelhamer and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR 15.
44 Experiments: Comparison on Network Architectures RGB-D Scenes Methods FCN [1] Our FCN Our GRU-RNN Our DA-RNN Background Bowl Cap Cereal Box Coffee Mug Coffee Table Office Chair Soda Can Sofa Table MEAN Metric: segmentation intersection over union (IoU) 44 [1] J. Long, E. Shelhamer and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR 15.
45 Experiments: Comparison on Network Architectures RGB-D Scenes Methods FCN [1] Our FCN Our GRU-RNN Our DA-RNN No Data Association Background Bowl Cap Cereal Box Coffee Mug Coffee Table Office Chair Soda Can Sofa Table MEAN Metric: segmentation intersection over union (IoU) [1] J. Long, E. Shelhamer and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR


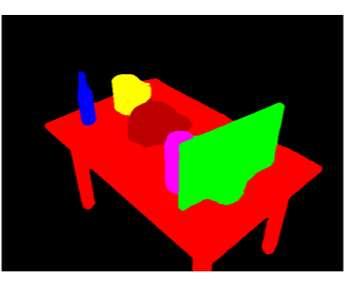

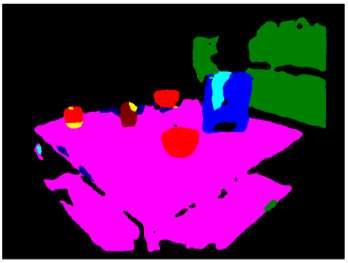
46 RGB Image Our FCN Our DA-RNN 46

47 Experiments: Analysis on Network Inputs 47





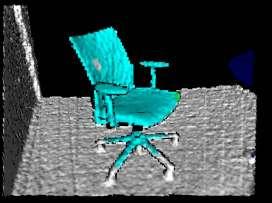


48 RGB Images Depth Images Semantic Mapping 48
49 Conclusion 6D Object Pose Estimation from images and videos Semantic Mapping from RGB-D videos Deep neural networks with geometric representations 49
50 Future Work: Perception for Robotics 3D object recognition for robot manipulation 3D scene understanding for robot navigation Perception Combing perception, planning and control Planning Control Learning Reinforcement learning with deep neural networks 50








51 Acknowledgements Thank you! 51
3D Object Recognition and Scene Understanding from RGB-D Videos. Yu Xiang Postdoctoral Researcher University of Washington
 3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
3D Object Recognition and Scene Understanding. Yu Xiang University of Washington
 3D Object Recognition and Scene Understanding Yu Xiang University of Washington 1 2 Image classification tagging/annotation Room Chair Fergus et al. CVPR 03 Fei-Fei et al. CVPRW 04 Chua et al. CIVR 09
3D Object Recognition and Scene Understanding Yu Xiang University of Washington 1 2 Image classification tagging/annotation Room Chair Fergus et al. CVPR 03 Fei-Fei et al. CVPRW 04 Chua et al. CIVR 09
Perceiving the 3D World from Images and Videos. Yu Xiang Postdoctoral Researcher University of Washington & NVIDIA Research
 Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington & NVIDIA Research 1 2 Acting in the 3D World Sensing Sound sensor Camera Depth sensor Touch sensor
Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington & NVIDIA Research 1 2 Acting in the 3D World Sensing Sound sensor Camera Depth sensor Touch sensor
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
(Deep) Learning for Robot Perception and Navigation. Wolfram Burgard
 Learning for Robot Perception and Navigation. Wolfram Burgard") (Deep) Learning for Robot Perception and Navigation Wolfram Burgard Deep Learning for Robot Perception (and Navigation) Lifeng Bo, Claas Bollen, Thomas Brox, Andreas Eitel, Dieter Fox, Gabriel L. Oliveira,
(Deep) Learning for Robot Perception and Navigation Wolfram Burgard Deep Learning for Robot Perception (and Navigation) Lifeng Bo, Claas Bollen, Thomas Brox, Andreas Eitel, Dieter Fox, Gabriel L. Oliveira,
Encoder-Decoder Networks for Semantic Segmentation. Sachin Mehta
 Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Learning from 3D Data
 Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Object Detection by 3D Aspectlets and Occlusion Reasoning
 Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan Silvio Savarese Stanford University In the 4th International IEEE Workshop on 3D Representation and Recognition
Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan Silvio Savarese Stanford University In the 4th International IEEE Workshop on 3D Representation and Recognition
RGB-D Multi-View Object Detection with Object Proposals and Shape Context
 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) Daejeon Convention Center October 9-14, 2016, Daejeon, Korea RGB-D Multi-View Object Detection with Object Proposals and
2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) Daejeon Convention Center October 9-14, 2016, Daejeon, Korea RGB-D Multi-View Object Detection with Object Proposals and
Deep Incremental Scene Understanding. Federico Tombari & Christian Rupprecht Technical University of Munich, Germany
 Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Car Bed Chair Sofa Table
 Supplementary Material for the Paper Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan yuxiang@umich.edu Silvio Savarese Stanford University ssilvio@stanford.edu
Supplementary Material for the Paper Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan yuxiang@umich.edu Silvio Savarese Stanford University ssilvio@stanford.edu
BOP: Benchmark for 6D Object Pose Estimation
 BOP: Benchmark for 6D Object Pose Estimation Hodan, Michel, Brachmann, Kehl, Buch, Kraft, Drost, Vidal, Ihrke, Zabulis, Sahin, Manhardt, Tombari, Kim, Matas, Rother 4th International Workshop on Recovering
BOP: Benchmark for 6D Object Pose Estimation Hodan, Michel, Brachmann, Kehl, Buch, Kraft, Drost, Vidal, Ihrke, Zabulis, Sahin, Manhardt, Tombari, Kim, Matas, Rother 4th International Workshop on Recovering
Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image. Supplementary Material
 Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image Supplementary Material Siyuan Huang 1,2, Siyuan Qi 1,2, Yixin Zhu 1,2, Yinxue Xiao 1, Yuanlu Xu 1,2, and Song-Chun Zhu 1,2 1 University
Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image Supplementary Material Siyuan Huang 1,2, Siyuan Qi 1,2, Yixin Zhu 1,2, Yinxue Xiao 1, Yuanlu Xu 1,2, and Song-Chun Zhu 1,2 1 University
Deep Models for 3D Reconstruction
 Deep Models for 3D Reconstruction Andreas Geiger Autonomous Vision Group, MPI for Intelligent Systems, Tübingen Computer Vision and Geometry Group, ETH Zürich October 12, 2017 Max Planck Institute for
Deep Models for 3D Reconstruction Andreas Geiger Autonomous Vision Group, MPI for Intelligent Systems, Tübingen Computer Vision and Geometry Group, ETH Zürich October 12, 2017 Max Planck Institute for
Three-Dimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients
 ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
arxiv: v2 [cs.cv] 28 Sep 2016
![arxiv: v2 [cs.cv] 28 Sep 2016](/thumbs/72/67749716.jpg "arxiv: v2 [cs.cv] 28 Sep 2016") SemanticFusion: Dense 3D Semantic Mapping with Convolutional Neural Networks John McCormac, Ankur Handa, Andrew Davison, and Stefan Leutenegger Dyson Robotics Lab, Imperial College London arxiv:1609.05130v2
SemanticFusion: Dense 3D Semantic Mapping with Convolutional Neural Networks John McCormac, Ankur Handa, Andrew Davison, and Stefan Leutenegger Dyson Robotics Lab, Imperial College London arxiv:1609.05130v2
3D Attention-Driven Depth Acquisition for Object Identification
 3D Attention-Driven Depth Acquisition for Object Identification Kai Xu, Yifei Shi, Lintao Zheng, Junyu Zhang, Min Liu, Hui Huang, Hao Su, Daniel Cohen-Or and Baoquan Chen National University of Defense
3D Attention-Driven Depth Acquisition for Object Identification Kai Xu, Yifei Shi, Lintao Zheng, Junyu Zhang, Min Liu, Hui Huang, Hao Su, Daniel Cohen-Or and Baoquan Chen National University of Defense
From 3D descriptors to monocular 6D pose: what have we learned?
 ECCV Workshop on Recovering 6D Object Pose From 3D descriptors to monocular 6D pose: what have we learned? Federico Tombari CAMP - TUM Dynamic occlusion Low latency High accuracy, low jitter No expensive
ECCV Workshop on Recovering 6D Object Pose From 3D descriptors to monocular 6D pose: what have we learned? Federico Tombari CAMP - TUM Dynamic occlusion Low latency High accuracy, low jitter No expensive
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Learning to generate 3D shapes
 Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
ECCV Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016
 ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
Surface Oriented Traverse for Robust Instance Detection in RGB-D
 Surface Oriented Traverse for Robust Instance Detection in RGB-D Ruizhe Wang Gérard G. Medioni Wenyi Zhao Abstract We address the problem of robust instance detection in RGB-D image in the presence of
Surface Oriented Traverse for Robust Instance Detection in RGB-D Ruizhe Wang Gérard G. Medioni Wenyi Zhao Abstract We address the problem of robust instance detection in RGB-D image in the presence of
3D Deep Learning on Geometric Forms. Hao Su
 3D Deep Learning on Geometric Forms Hao Su Many 3D representations are available Candidates: multi-view images depth map volumetric polygonal mesh point cloud primitive-based CAD models 3D representation
3D Deep Learning on Geometric Forms Hao Su Many 3D representations are available Candidates: multi-view images depth map volumetric polygonal mesh point cloud primitive-based CAD models 3D representation
Learning Semantic Environment Perception for Cognitive Robots
 Learning Semantic Environment Perception for Cognitive Robots Sven Behnke University of Bonn, Germany Computer Science Institute VI Autonomous Intelligent Systems Some of Our Cognitive Robots Equipped
Learning Semantic Environment Perception for Cognitive Robots Sven Behnke University of Bonn, Germany Computer Science Institute VI Autonomous Intelligent Systems Some of Our Cognitive Robots Equipped
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
LSTM and its variants for visual recognition. Xiaodan Liang Sun Yat-sen University
 LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
Detection and Fine 3D Pose Estimation of Texture-less Objects in RGB-D Images
 Detection and Pose Estimation of Texture-less Objects in RGB-D Images Tomáš Hodaň1, Xenophon Zabulis2, Manolis Lourakis2, Šťěpán Obdržálek1, Jiří Matas1 1 Center for Machine Perception, CTU in Prague,
Detection and Pose Estimation of Texture-less Objects in RGB-D Images Tomáš Hodaň1, Xenophon Zabulis2, Manolis Lourakis2, Šťěpán Obdržálek1, Jiří Matas1 1 Center for Machine Perception, CTU in Prague,
Efficient Segmentation-Aided Text Detection For Intelligent Robots
 Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning
 Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Real-Time Vision-Based State Estimation and (Dense) Mapping
 Mapping") Real-Time Vision-Based State Estimation and (Dense) Mapping Stefan Leutenegger IROS 2016 Workshop on State Estimation and Terrain Perception for All Terrain Mobile Robots The Perception-Action Cycle in
Real-Time Vision-Based State Estimation and (Dense) Mapping Stefan Leutenegger IROS 2016 Workshop on State Estimation and Terrain Perception for All Terrain Mobile Robots The Perception-Action Cycle in
What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today?
 Introduction What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today? What are we trying to achieve? Example from Scott Satkin 3D interpretation
Introduction What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today? What are we trying to achieve? Example from Scott Satkin 3D interpretation
3D Scene Understanding from RGB-D Images. Thomas Funkhouser
 3D Scene Understanding from RGB-D Images Thomas Funkhouser Recent Ph.D. Student Current Postdocs Current Ph.D. Students Disclaimer: I am talking about the work of these people Shuran Song Yinda Zhang Andy
3D Scene Understanding from RGB-D Images Thomas Funkhouser Recent Ph.D. Student Current Postdocs Current Ph.D. Students Disclaimer: I am talking about the work of these people Shuran Song Yinda Zhang Andy
PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes
 PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes Yu Xiang 1,2, Tanner Schmidt 2, Venkatraman Narayanan 3 and Dieter Fox 1,2 1 NVIDIA Research, 2 University of Washington,
PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes Yu Xiang 1,2, Tanner Schmidt 2, Venkatraman Narayanan 3 and Dieter Fox 1,2 1 NVIDIA Research, 2 University of Washington,
Object Detection. CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR
 Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
Human Pose Estimation with Deep Learning. Wei Yang
 Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
CVPR 2014 Visual SLAM Tutorial Kintinuous
 CVPR 2014 Visual SLAM Tutorial Kintinuous kaess@cmu.edu The Robotics Institute Carnegie Mellon University Recap: KinectFusion [Newcombe et al., ISMAR 2011] RGB-D camera GPU 3D/color model RGB TSDF (volumetric
CVPR 2014 Visual SLAM Tutorial Kintinuous kaess@cmu.edu The Robotics Institute Carnegie Mellon University Recap: KinectFusion [Newcombe et al., ISMAR 2011] RGB-D camera GPU 3D/color model RGB TSDF (volumetric
Deconvolutions in Convolutional Neural Networks
 Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
Learning-based Localization
 Learning-based Localization Eric Brachmann ECCV 2018 Tutorial on Visual Localization - Feature-based vs. Learned Approaches Torsten Sattler, Eric Brachmann Roadmap Machine Learning Basics [10min] Convolutional
Learning-based Localization Eric Brachmann ECCV 2018 Tutorial on Visual Localization - Feature-based vs. Learned Approaches Torsten Sattler, Eric Brachmann Roadmap Machine Learning Basics [10min] Convolutional
Photo OCR ( )
") Photo OCR (2017-2018) Xiang Bai Huazhong University of Science and Technology Outline VALSE2018, DaLian Xiang Bai 2 Deep Direct Regression for Multi-Oriented Scene Text Detection [He et al., ICCV, 2017.]
Photo OCR (2017-2018) Xiang Bai Huazhong University of Science and Technology Outline VALSE2018, DaLian Xiang Bai 2 Deep Direct Regression for Multi-Oriented Scene Text Detection [He et al., ICCV, 2017.]
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material
 Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Colored Point Cloud Registration Revisited Supplementary Material
 Colored Point Cloud Registration Revisited Supplementary Material Jaesik Park Qian-Yi Zhou Vladlen Koltun Intel Labs A. RGB-D Image Alignment Section introduced a joint photometric and geometric objective
Colored Point Cloud Registration Revisited Supplementary Material Jaesik Park Qian-Yi Zhou Vladlen Koltun Intel Labs A. RGB-D Image Alignment Section introduced a joint photometric and geometric objective
DeepContext: Context-Encoding Neural Pathways for 3D Holistic Scene Understanding
 DeepContext: Context-Encoding Neural Pathways for 3D Holistic Scene Understanding Yinda Zhang Mingru Bai Pushmeet Kohli 2,5 Shahram Izadi 3,5 Jianxiong Xiao,4 Princeton University 2 DeepMind 3 PerceptiveIO
DeepContext: Context-Encoding Neural Pathways for 3D Holistic Scene Understanding Yinda Zhang Mingru Bai Pushmeet Kohli 2,5 Shahram Izadi 3,5 Jianxiong Xiao,4 Princeton University 2 DeepMind 3 PerceptiveIO
Semantic RGB-D Perception for Cognitive Robots
 Semantic RGB-D Perception for Cognitive Robots Sven Behnke Computer Science Institute VI Autonomous Intelligent Systems Our Domestic Service Robots Dynamaid Cosero Size: 100-180 cm, weight: 30-35 kg 36
Semantic RGB-D Perception for Cognitive Robots Sven Behnke Computer Science Institute VI Autonomous Intelligent Systems Our Domestic Service Robots Dynamaid Cosero Size: 100-180 cm, weight: 30-35 kg 36
DeepContext: Context-Encoding Neural Pathways for 3D Holistic Scene Understanding
 DeepContext: Context-Encoding Neural Pathways for 3D Holistic Scene Understanding Yinda Zhang Mingru Bai Pushmeet Kohli 2,5 Shahram Izadi 3,5 Jianxiong Xiao,4 Princeton University 2 DeepMind 3 PerceptiveIO
DeepContext: Context-Encoding Neural Pathways for 3D Holistic Scene Understanding Yinda Zhang Mingru Bai Pushmeet Kohli 2,5 Shahram Izadi 3,5 Jianxiong Xiao,4 Princeton University 2 DeepMind 3 PerceptiveIO
Label Propagation in RGB-D Video
 Label Propagation in RGB-D Video Md. Alimoor Reza, Hui Zheng, Georgios Georgakis, Jana Košecká Abstract We propose a new method for the propagation of semantic labels in RGB-D video of indoor scenes given
Label Propagation in RGB-D Video Md. Alimoor Reza, Hui Zheng, Georgios Georgakis, Jana Košecká Abstract We propose a new method for the propagation of semantic labels in RGB-D video of indoor scenes given
3D model classification using convolutional neural network
 3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
Object Detection Based on Deep Learning
 Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Depth from Stereo. Dominic Cheng February 7, 2018
 Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Planning, Execution and Learning Application: Examples of Planning in Perception
 15-887 Planning, Execution and Learning Application: Examples of Planning in Perception Maxim Likhachev Robotics Institute Carnegie Mellon University Two Examples Graph search for perception Planning for
15-887 Planning, Execution and Learning Application: Examples of Planning in Perception Maxim Likhachev Robotics Institute Carnegie Mellon University Two Examples Graph search for perception Planning for
Reconstruction, Motion Estimation and SLAM from Events
 Reconstruction, Motion Estimation and SLAM from Events Andrew Davison Robot Vision Group and Dyson Robotics Laboratory Department of Computing Imperial College London www.google.com/+andrewdavison June
Reconstruction, Motion Estimation and SLAM from Events Andrew Davison Robot Vision Group and Dyson Robotics Laboratory Department of Computing Imperial College London www.google.com/+andrewdavison June
Presentation Outline. Semantic Segmentation. Overview. Presentation Outline CNN. Learning Deconvolution Network for Semantic Segmentation 6/6/16
 6/6/16 Learning Deconvolution Network for Semantic Segmentation Hyeonwoo Noh, Seunghoon Hong,Bohyung Han Department of Computer Science and Engineering, POSTECH, Korea Shai Rozenberg 6/6/2016 1 2 Semantic
6/6/16 Learning Deconvolution Network for Semantic Segmentation Hyeonwoo Noh, Seunghoon Hong,Bohyung Han Department of Computer Science and Engineering, POSTECH, Korea Shai Rozenberg 6/6/2016 1 2 Semantic
LEARNING BOUNDARIES WITH COLOR AND DEPTH. Zhaoyin Jia, Andrew Gallagher, Tsuhan Chen
 LEARNING BOUNDARIES WITH COLOR AND DEPTH Zhaoyin Jia, Andrew Gallagher, Tsuhan Chen School of Electrical and Computer Engineering, Cornell University ABSTRACT To enable high-level understanding of a scene,
LEARNING BOUNDARIES WITH COLOR AND DEPTH Zhaoyin Jia, Andrew Gallagher, Tsuhan Chen School of Electrical and Computer Engineering, Cornell University ABSTRACT To enable high-level understanding of a scene,
SemanticFusion: Dense 3D Semantic Mapping with Convolutional Neural Networks
 SemanticFusion: Dense 3D Semantic Mapping with Convolutional Neural Networks John McCormac, Ankur Handa, Andrew Davison, and Stefan Leutenegger Dyson Robotics Lab, Imperial College London Abstract Ever
SemanticFusion: Dense 3D Semantic Mapping with Convolutional Neural Networks John McCormac, Ankur Handa, Andrew Davison, and Stefan Leutenegger Dyson Robotics Lab, Imperial College London Abstract Ever
Learning 6D Object Pose Estimation and Tracking
 Learning 6D Object Pose Estimation and Tracking Carsten Rother presented by: Alexander Krull 21/12/2015 6D Pose Estimation Input: RGBD-image Known 3D model Output: 6D rigid body transform of object 21/12/2015
Learning 6D Object Pose Estimation and Tracking Carsten Rother presented by: Alexander Krull 21/12/2015 6D Pose Estimation Input: RGBD-image Known 3D model Output: 6D rigid body transform of object 21/12/2015
arxiv: v1 [cs.cv] 28 Mar 2018
![arxiv: v1 [cs.cv] 28 Mar 2018](/thumbs/86/94008018.jpg "arxiv: v1 [cs.cv] 28 Mar 2018") arxiv:1803.10409v1 [cs.cv] 28 Mar 2018 3DMV: Joint 3D-Multi-View Prediction for 3D Semantic Scene Segmentation Angela Dai 1 Matthias Nießner 2 1 Stanford University 2 Technical University of Munich Fig.
arxiv:1803.10409v1 [cs.cv] 28 Mar 2018 3DMV: Joint 3D-Multi-View Prediction for 3D Semantic Scene Segmentation Angela Dai 1 Matthias Nießner 2 1 Stanford University 2 Technical University of Munich Fig.
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus
 Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
arxiv: v2 [cs.cv] 18 Aug 2015
![arxiv: v2 [cs.cv] 18 Aug 2015](/thumbs/91/105403407.jpg "arxiv: v2 [cs.cv] 18 Aug 2015") Multimodal Deep Learning for Robust RGB-D Object Recognition Andreas Eitel Jost Tobias Springenberg Luciano Spinello Martin Riedmiller Wolfram Burgard arxiv:57.682v2 [cs.cv] 8 Aug 25 Abstract Robust object
Multimodal Deep Learning for Robust RGB-D Object Recognition Andreas Eitel Jost Tobias Springenberg Luciano Spinello Martin Riedmiller Wolfram Burgard arxiv:57.682v2 [cs.cv] 8 Aug 25 Abstract Robust object
Detecting and Parsing of Visual Objects: Humans and Animals. Alan Yuille (UCLA)
") Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
arxiv: v1 [cs.cv] 29 Sep 2016
![arxiv: v1 [cs.cv] 29 Sep 2016](/thumbs/76/73787064.jpg "arxiv: v1 [cs.cv] 29 Sep 2016") arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK
 TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
Introduction to Deep Learning for Facial Understanding Part III: Regional CNNs
 Introduction to Deep Learning for Facial Understanding Part III: Regional CNNs Raymond Ptucha, Rochester Institute of Technology, USA Tutorial-9 May 19, 218 www.nvidia.com/dli R. Ptucha 18 1 Fair Use Agreement
Introduction to Deep Learning for Facial Understanding Part III: Regional CNNs Raymond Ptucha, Rochester Institute of Technology, USA Tutorial-9 May 19, 218 www.nvidia.com/dli R. Ptucha 18 1 Fair Use Agreement
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Reconstructive Sparse Code Transfer for Contour Detection and Semantic Labeling
 Reconstructive Sparse Code Transfer for Contour Detection and Semantic Labeling Michael Maire 1,2 Stella X. Yu 3 Pietro Perona 2 1 TTI Chicago 2 California Institute of Technology 3 University of California
Reconstructive Sparse Code Transfer for Contour Detection and Semantic Labeling Michael Maire 1,2 Stella X. Yu 3 Pietro Perona 2 1 TTI Chicago 2 California Institute of Technology 3 University of California
Previously. Part-based and local feature models for generic object recognition. Bag-of-words model 4/20/2011
 Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Detecting Object Instances Without Discriminative Features
 Detecting Object Instances Without Discriminative Features Edward Hsiao June 19, 2013 Thesis Committee: Martial Hebert, Chair Alexei Efros Takeo Kanade Andrew Zisserman, University of Oxford 1 Object Instance
Detecting Object Instances Without Discriminative Features Edward Hsiao June 19, 2013 Thesis Committee: Martial Hebert, Chair Alexei Efros Takeo Kanade Andrew Zisserman, University of Oxford 1 Object Instance
Convolutional-Recursive Deep Learning for 3D Object Classification
 Convolutional-Recursive Deep Learning for 3D Object Classification Richard Socher, Brody Huval, Bharath Bhat, Christopher D. Manning, Andrew Y. Ng NIPS 2012 Iro Armeni, Manik Dhar Motivation Hand-designed
Convolutional-Recursive Deep Learning for 3D Object Classification Richard Socher, Brody Huval, Bharath Bhat, Christopher D. Manning, Andrew Y. Ng NIPS 2012 Iro Armeni, Manik Dhar Motivation Hand-designed
Seeing the unseen. Data-driven 3D Understanding from Single Images. Hao Su
 Seeing the unseen Data-driven 3D Understanding from Single Images Hao Su Image world Shape world 3D perception from a single image Monocular vision a typical prey a typical predator Cited from https://en.wikipedia.org/wiki/binocular_vision
Seeing the unseen Data-driven 3D Understanding from Single Images Hao Su Image world Shape world 3D perception from a single image Monocular vision a typical prey a typical predator Cited from https://en.wikipedia.org/wiki/binocular_vision
RGB-D Object Discovery via Multi-Scene Analysis
 RGB-D Object Discovery via Multi-Scene Analysis Evan Herbst Xiaofeng Ren Dieter Fox Abstract We introduce an algorithm for object discovery from RGB-D (color plus depth) data, building on recent progress
RGB-D Object Discovery via Multi-Scene Analysis Evan Herbst Xiaofeng Ren Dieter Fox Abstract We introduce an algorithm for object discovery from RGB-D (color plus depth) data, building on recent progress
Deep Learning for Virtual Shopping. Dr. Jürgen Sturm Group Leader RGB-D
 Deep Learning for Virtual Shopping Dr. Jürgen Sturm Group Leader RGB-D metaio GmbH Augmented Reality with the Metaio SDK: IKEA Catalogue App Metaio: Augmented Reality Metaio SDK for ios, Android and Windows
Deep Learning for Virtual Shopping Dr. Jürgen Sturm Group Leader RGB-D metaio GmbH Augmented Reality with the Metaio SDK: IKEA Catalogue App Metaio: Augmented Reality Metaio SDK for ios, Android and Windows
arxiv: v1 [cs.cv] 20 Dec 2016
![arxiv: v1 [cs.cv] 20 Dec 2016](/thumbs/73/68905842.jpg "arxiv: v1 [cs.cv] 20 Dec 2016") End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
Depth-aware CNN for RGB-D Segmentation
 Depth-aware CNN for RGB-D Segmentation Weiyue Wang [0000 0002 8114 8271] and Ulrich Neumann University of Southern California, Los Angeles, California {weiyuewa,uneumann}@usc.edu Abstract. Convolutional
Depth-aware CNN for RGB-D Segmentation Weiyue Wang [0000 0002 8114 8271] and Ulrich Neumann University of Southern California, Los Angeles, California {weiyuewa,uneumann}@usc.edu Abstract. Convolutional
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Flow-Based Video Recognition
 Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
DEPTH SENSOR BASED OBJECT DETECTION USING SURFACE CURVATURE. A Thesis presented to. the Faculty of the Graduate School
 DEPTH SENSOR BASED OBJECT DETECTION USING SURFACE CURVATURE A Thesis presented to the Faculty of the Graduate School at the University of Missouri-Columbia In Partial Fulfillment of the Requirements for
DEPTH SENSOR BASED OBJECT DETECTION USING SURFACE CURVATURE A Thesis presented to the Faculty of the Graduate School at the University of Missouri-Columbia In Partial Fulfillment of the Requirements for
A MULTI-RESOLUTION FUSION MODEL INCORPORATING COLOR AND ELEVATION FOR SEMANTIC SEGMENTATION
 A MULTI-RESOLUTION FUSION MODEL INCORPORATING COLOR AND ELEVATION FOR SEMANTIC SEGMENTATION Wenkai Zhang a, b, Hai Huang c, *, Matthias Schmitz c, Xian Sun a, Hongqi Wang a, Helmut Mayer c a Key Laboratory
A MULTI-RESOLUTION FUSION MODEL INCORPORATING COLOR AND ELEVATION FOR SEMANTIC SEGMENTATION Wenkai Zhang a, b, Hai Huang c, *, Matthias Schmitz c, Xian Sun a, Hongqi Wang a, Helmut Mayer c a Key Laboratory
Depth Estimation from Single Image Using CNN-Residual Network
 Depth Estimation from Single Image Using CNN-Residual Network Xiaobai Ma maxiaoba@stanford.edu Zhenglin Geng zhenglin@stanford.edu Zhi Bie zhib@stanford.edu Abstract In this project, we tackle the problem
Depth Estimation from Single Image Using CNN-Residual Network Xiaobai Ma maxiaoba@stanford.edu Zhenglin Geng zhenglin@stanford.edu Zhi Bie zhib@stanford.edu Abstract In this project, we tackle the problem
HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION
 HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION Chien-Yao Wang, Jyun-Hong Li, Seksan Mathulaprangsan, Chin-Chin Chiang, and Jia-Ching Wang Department of Computer Science and Information
HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION Chien-Yao Wang, Jyun-Hong Li, Seksan Mathulaprangsan, Chin-Chin Chiang, and Jia-Ching Wang Department of Computer Science and Information
Contexts and 3D Scenes
 Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Dec 1 st 3:30 PM 4:45 PM Goodwin Hall Atrium Grading Three
Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Dec 1 st 3:30 PM 4:45 PM Goodwin Hall Atrium Grading Three
LEARNING RIGIDITY IN DYNAMIC SCENES FOR SCENE FLOW ESTIMATION
 LEARNING RIGIDITY IN DYNAMIC SCENES FOR SCENE FLOW ESTIMATION Kihwan Kim, Senior Research Scientist Zhaoyang Lv, Kihwan Kim, Alejandro Troccoli, Deqing Sun, James M. Rehg, Jan Kautz CORRESPENDECES IN COMPUTER
LEARNING RIGIDITY IN DYNAMIC SCENES FOR SCENE FLOW ESTIMATION Kihwan Kim, Senior Research Scientist Zhaoyang Lv, Kihwan Kim, Alejandro Troccoli, Deqing Sun, James M. Rehg, Jan Kautz CORRESPENDECES IN COMPUTER
Martian lava field, NASA, Wikipedia
 Martian lava field, NASA, Wikipedia Old Man of the Mountain, Franconia, New Hampshire Pareidolia http://smrt.ccel.ca/203/2/6/pareidolia/ Reddit for more : ) https://www.reddit.com/r/pareidolia/top/ Pareidolia
Martian lava field, NASA, Wikipedia Old Man of the Mountain, Franconia, New Hampshire Pareidolia http://smrt.ccel.ca/203/2/6/pareidolia/ Reddit for more : ) https://www.reddit.com/r/pareidolia/top/ Pareidolia
arxiv: v1 [cs.cv] 30 Sep 2018
![arxiv: v1 [cs.cv] 30 Sep 2018](/thumbs/89/99613806.jpg "arxiv: v1 [cs.cv] 30 Sep 2018") 3D-PSRNet: Part Segmented 3D Point Cloud Reconstruction From a Single Image Priyanka Mandikal, Navaneet K L, and R. Venkatesh Babu arxiv:1810.00461v1 [cs.cv] 30 Sep 2018 Indian Institute of Science, Bangalore,
3D-PSRNet: Part Segmented 3D Point Cloud Reconstruction From a Single Image Priyanka Mandikal, Navaneet K L, and R. Venkatesh Babu arxiv:1810.00461v1 [cs.cv] 30 Sep 2018 Indian Institute of Science, Bangalore,
SSD: Single Shot MultiBox Detector. Author: Wei Liu et al. Presenter: Siyu Jiang
 SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
Cross-domain Deep Encoding for 3D Voxels and 2D Images
 Cross-domain Deep Encoding for 3D Voxels and 2D Images Jingwei Ji Stanford University jingweij@stanford.edu Danyang Wang Stanford University danyangw@stanford.edu 1. Introduction 3D reconstruction is one
Cross-domain Deep Encoding for 3D Voxels and 2D Images Jingwei Ji Stanford University jingweij@stanford.edu Danyang Wang Stanford University danyangw@stanford.edu 1. Introduction 3D reconstruction is one
arxiv: v1 [cs.cv] 1 Apr 2018
![arxiv: v1 [cs.cv] 1 Apr 2018](/thumbs/86/93806298.jpg "arxiv: v1 [cs.cv] 1 Apr 2018") arxiv:1804.00257v1 [cs.cv] 1 Apr 2018 Real-time Progressive 3D Semantic Segmentation for Indoor Scenes Quang-Hieu Pham 1 Binh-Son Hua 2 Duc Thanh Nguyen 3 Sai-Kit Yeung 1 1 Singapore University of Technology
arxiv:1804.00257v1 [cs.cv] 1 Apr 2018 Real-time Progressive 3D Semantic Segmentation for Indoor Scenes Quang-Hieu Pham 1 Binh-Son Hua 2 Duc Thanh Nguyen 3 Sai-Kit Yeung 1 1 Singapore University of Technology
Multiframe Scene Flow with Piecewise Rigid Motion. Vladislav Golyanik,, Kihwan Kim, Robert Maier, Mathias Nießner, Didier Stricker and Jan Kautz
 Multiframe Scene Flow with Piecewise Rigid Motion Vladislav Golyanik,, Kihwan Kim, Robert Maier, Mathias Nießner, Didier Stricker and Jan Kautz Scene Flow. 2 Scene Flow. 3 Scene Flow. Scene Flow Estimation:
Multiframe Scene Flow with Piecewise Rigid Motion Vladislav Golyanik,, Kihwan Kim, Robert Maier, Mathias Nießner, Didier Stricker and Jan Kautz Scene Flow. 2 Scene Flow. 3 Scene Flow. Scene Flow Estimation:
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Near Real-time Object Detection in RGBD Data
 Near Real-time Object Detection in RGBD Data Ronny Hänsch, Stefan Kaiser and Olaf Helwich Computer Vision & Remote Sensing, Technische Universität Berlin, Berlin, Germany Keywords: Abstract: Object Detection,
Near Real-time Object Detection in RGBD Data Ronny Hänsch, Stefan Kaiser and Olaf Helwich Computer Vision & Remote Sensing, Technische Universität Berlin, Berlin, Germany Keywords: Abstract: Object Detection,
MOTION ESTIMATION USING CONVOLUTIONAL NEURAL NETWORKS. Mustafa Ozan Tezcan
 MOTION ESTIMATION USING CONVOLUTIONAL NEURAL NETWORKS Mustafa Ozan Tezcan Boston University Department of Electrical and Computer Engineering 8 Saint Mary s Street Boston, MA 2215 www.bu.edu/ece Dec. 19,
MOTION ESTIMATION USING CONVOLUTIONAL NEURAL NETWORKS Mustafa Ozan Tezcan Boston University Department of Electrical and Computer Engineering 8 Saint Mary s Street Boston, MA 2215 www.bu.edu/ece Dec. 19,
Feature-Fused SSD: Fast Detection for Small Objects
 Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Joint Object Detection and Viewpoint Estimation using CNN features
 Joint Object Detection and Viewpoint Estimation using CNN features Carlos Guindel, David Martín and José M. Armingol cguindel@ing.uc3m.es Intelligent Systems Laboratory Universidad Carlos III de Madrid
Joint Object Detection and Viewpoint Estimation using CNN features Carlos Guindel, David Martín and José M. Armingol cguindel@ing.uc3m.es Intelligent Systems Laboratory Universidad Carlos III de Madrid
Towards Spatio-Temporally Consistent Semantic Mapping
 Towards Spatio-Temporally Consistent Semantic Mapping Zhe Zhao, Xiaoping Chen University of Science and Technology of China, zhaozhe@mail.ustc.edu.cn,xpchen@ustc.edu.cn Abstract. Intelligent robots require
Towards Spatio-Temporally Consistent Semantic Mapping Zhe Zhao, Xiaoping Chen University of Science and Technology of China, zhaozhe@mail.ustc.edu.cn,xpchen@ustc.edu.cn Abstract. Intelligent robots require
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Geometric Reconstruction Dense reconstruction of scene geometry
 Lecture 5. Dense Reconstruction and Tracking with Real-Time Applications Part 2: Geometric Reconstruction Dr Richard Newcombe and Dr Steven Lovegrove Slide content developed from: [Newcombe, Dense Visual
Lecture 5. Dense Reconstruction and Tracking with Real-Time Applications Part 2: Geometric Reconstruction Dr Richard Newcombe and Dr Steven Lovegrove Slide content developed from: [Newcombe, Dense Visual
Unsupervised Deep Learning. James Hays slides from Carl Doersch and Richard Zhang
 Unsupervised Deep Learning James Hays slides from Carl Doersch and Richard Zhang Recap from Previous Lecture We saw two strategies to get structured output while using deep learning With object detection,
Unsupervised Deep Learning James Hays slides from Carl Doersch and Richard Zhang Recap from Previous Lecture We saw two strategies to get structured output while using deep learning With object detection,
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS. Zhao Chen Machine Learning Intern, NVIDIA
 JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
arxiv: v2 [cs.cv] 24 Apr 2017
![arxiv: v2 [cs.cv] 24 Apr 2017](/thumbs/74/71202274.jpg "arxiv: v2 [cs.cv] 24 Apr 2017") IM2CAD Hamid Izadinia University of Washington Qi Shan Zillow Group Steven M. Seitz University of Washington arxiv:1608.05137v2 [cs.cv] 24 Apr 2017 Figure 1: IM2CAD takes a single photo of a real scene
IM2CAD Hamid Izadinia University of Washington Qi Shan Zillow Group Steven M. Seitz University of Washington arxiv:1608.05137v2 [cs.cv] 24 Apr 2017 Figure 1: IM2CAD takes a single photo of a real scene